On the Estimation of Nonrandom Signal Coefficients from Jittered Samples
This paper examines the problem of estimating the parameters of a bandlimited signal from samples corrupted by random jitter (timing noise) and additive iid Gaussian noise, where the signal lies in the span of a finite basis. For the presented classi…
Authors: Daniel S. Weller, Vivek K Goyal
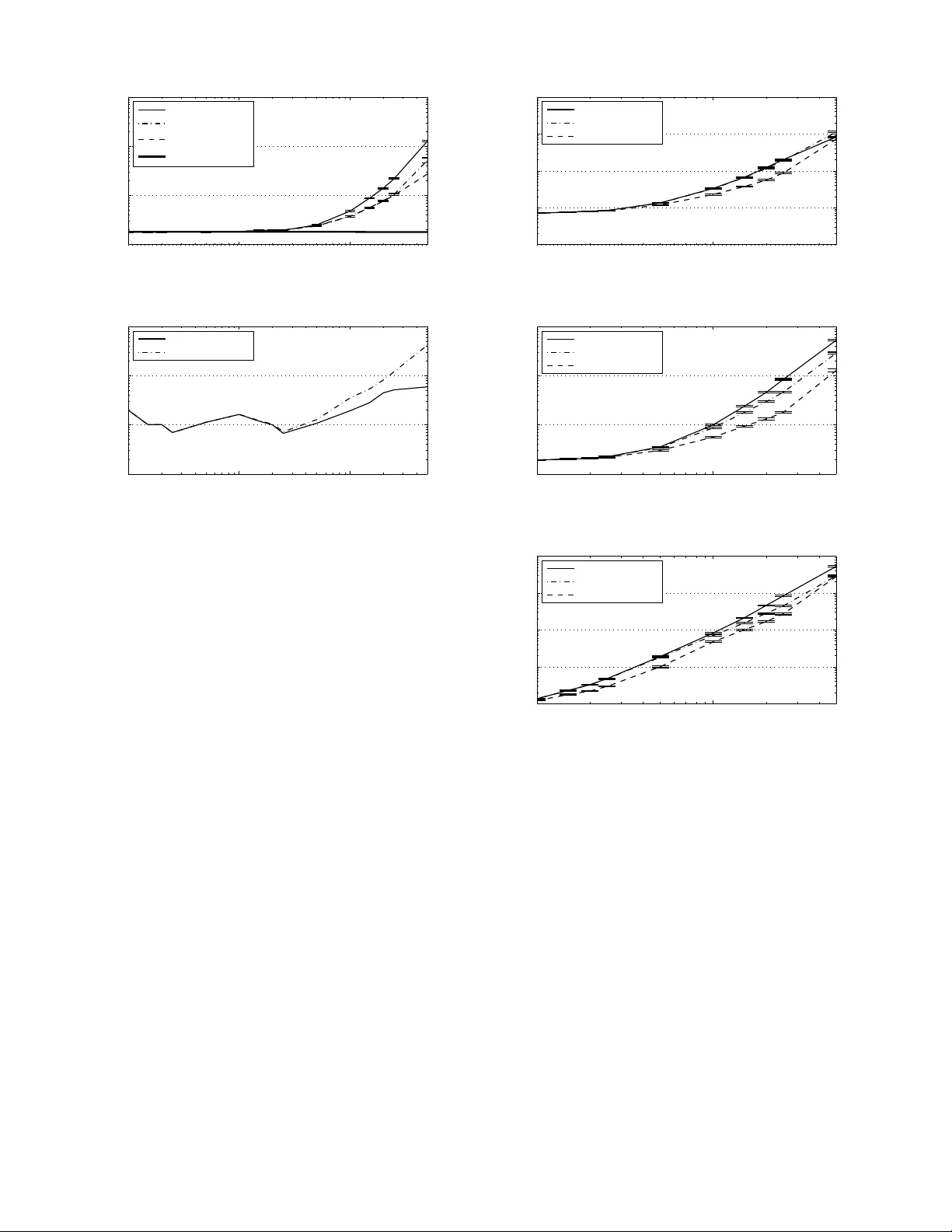
DRAFT 1 On the Estimation of Nonrandom Signal Coef ficients from Jittered Samples Daniel S. W eller*, Student Member , IEEE, and V iv ek K Goyal, Senior Member , IEEE Abstract —This paper examines the pro blem of estimating the parameters of a ban dlimited signal fr om samples corrupted by random jitter (timing noise) and additiv e iid G aussian noise, where the signal lies in the sp an of a finite basis. Fo r t he presented classical estimation problem, the Cram ´ er –Rao lower bound (CRB) is computed, and an E xpectation-Maximization (EM) algorithm approxima ting the maximum likelihood (ML) estimator is dev eloped. Simulations ar e perfo rmed to study the conv ergence properties of the EM algorithm and compare the perf ormance both against th e CRB and a b asic linear estimator . These simulations d emonstrate that by post-processing the jit tered samples with th e proposed EM algorithm, greater jitter can be tolera ted, potentially reducing on-chip ADC p ower consumption substantially . Index T erms —analog -to-digital con verters , Cram ´ er –Rao bound, EM algorithm, jitter , maximum likelihood esti mator , sampling, timing noise. I . I N T RO D U C T I O N An analog-to-dig ital conv erter ( ADC) processes a real signal x ( t ) to gener ate a sequen ce of observations (sam ples) { y n } a t times { t n } : y n = [ s ( t ) ∗ x ( t )] t = t n + w n , (1) where s ( t ) is the sampling prefilter and w n is an additive noise term that lumps together quantization, thermal noise, and other effects. For standard sampling applicatio ns, it is assumed that th e samp le times ar e un iformly spac ed by some perio d T s ( t n = nT s , n ∈ Z ), wh ere the period is small enou gh that the total b andwidth of x ( t ) is less than the sampling rate F s = 1 /T s . Jitter { z n } , a lso known as timing noise, perturbs the sam ple times: t n = nT s + z n . (2) This pape r focu ses on the mitiga tion of ran dom jitter in a non- Bayesian estima tion fram ew ork. A simplified block diagram for the ov erall system is illustrated in Figu re 1. The gen erally-accep ted prac tice is to design clocks with low en ough phase noise that the ef fect of jitter is negligible. The max imum allowable jitter is set such th at the effect of jitter on a sinusoid of maximum freq uency and maximum amplitude is at most o ne-half th e least sign ificant bit lev el [ 1]. While m aking jitter negligible obviates th e mitigation of This material is based upon work supported in part by the Of fice of Nav al Researc h through a National Defense Science and E ngineeri ng Graduate (NDSEG) fellowshi p, the National Scie nce Foundat ion under CAREER Grant No. 0643836, T exas Instruments through its Leader Uni versi ty program, and Analog Devi ces, Inc. D. S. W eller and V . K. Goyal are with the Massac husetts Insti- tute of T echnology , Room 36-680, 77 Massachusetts A venue, Cambridge, MA 02139 US A (phone: +1.617.324.5862 ; fax: +1.617.324.4290; email: { dwelle r ,vgoya l } @mit.edu). P S f r a g r e p l a c e m e n t s x ( t ) t n s ( t ) w n ADC y estimator off-chip ˆ x Fig. 1. Abstract block diagram of an ADC with off-ch ip post-processing. The s ignal x ( t ) is filtered by the sampling prefilter s ( t ) and sampled at time t n . These samples are corrupted by additi ve noise w n to yield y n . The post- processor estimate s the parameters x of x ( t ) using the vec tor of N sample s y from the ADC. jitter , this may n ot be possible or de sirable f rom an overall system design perspective, b ecause requirin g jitter to have a negligible effect may mandate h igh power c onsump tion in the clock circ uitry . (A mode l relating jitter and power is giv en below .) T echnolog ical trends sug gest that eventually it will be worthwhile to a llow nontrivial jitter and compen sate throug h digital po st-processing : the dig ital por tions of mixed- signal systems like sensors and wireless transceiv ers co ntinue to shrink , so the a nalog por tions of such systems, in cluding the ADC and its clock gen erator, d ominate the size an d power consu mption of th ese chip s. The ab ility to u se mo re power -efficient analog circu itry would enab le substantial n ew capabilities in diverse ap plications like im plantable medica l devices an d r emote sensor s. One mo tiv atio n of our stud y is to contr ibute to und erstanding the trade-off betwee n accuracy in analog circu itry vs. comp lexity of of f-chip digital po st- processing of samples. The power consumed b y a typica l ADC design is appro x- imately propo rtional to the d esired accuracy and samplin g rate [2], so lower - power circuitry would produce clock signals with more jitter . Specifically , it is shown in [3] that Power ∝ Speed × ( Accuracy (rms) ) 2 . (3) Furthermo re, the ana lyses in [4] and [5] sugge st that in the large-jitter dom ain, every dou bling of the stand ard d eviation of the jitter redu ces th e effecti ve n umber of bits (E NOB = log 2 accuracy (rms)) by o ne. Th us, pre- compen sating for the expected jitter in th e d esign r equires in creasing th e power consump tion o f the ADC by a factor of four for e very doub ling of the jitter stand ard deviation (e.g. by addin g an a dditional lev el of comp arators). In th is paper, we instead prop ose b lock post-pro cessing the jittered sam ples using classical estimation technique s off-chip. In ad dition to mitigating r andom jitter, this work may also b e a dapted to comp ensate for frequ ency modulated and spre ad-spectru m clocks, which p rodu ce lower EMI and radiation [6]. No te that this bloc k post-p rocessing 2 DRAFT method is intend ed to be performed off-chip, where power consump tion o f an implemen tation of the algorithm is not importan t. A. Pr o blem F o rmulation While more sophisticated signal mod els m ay be more approp riate f or some app lications, we con cern ourselves with a signa l that lies in the span of a finite basis { h k ( t ) } , with K b asis function s. W e further r estrict th e basis to be unif orm shifts of a single smoo th ban dlimited functio n h ( t ) : h k ( t ) = h ( t − k T ) . (4) Denote the unknown we ighting parameters x k ; there are K of them. Th e signal x ( t ) then equals x ( t ) = K − 1 X k =0 x k h ( t − k T ) . (5) W ith out loss of gener ality , assume that T eq uals th e critical sampling pe riod of x ( t ) , and assume th is perio d is un ity . In th is work , the signal p arameters { x k } K − 1 k =0 are u nknown deterministic q uantities. While there are many possible ch oices o f h ( t ) , when in need of a specific example in this work, we choose the sinc interpolatin g fun ction sinc( t ) = sin( π t ) π t . This b asis satisfies x ( k ) = x k , for all k = 0 , . . . , K − 1 . In g eneral, we choo se h ( t ) to be ap propr iate for the class of inpu t sign als we wish to sample; we choose th e sinc f unction because bandlimited ness is a common assumption in the context of sign al processing. It is sufficient, but n ot n ecessary , in this work th at h ( t ) be analytic an d bou nded. When sampling the sign al x ( t ) , we will assume that the sampling prefilter is an ideal anti-aliasing filter wit h ban dwidth F s , so [ s ( t ) ∗ x ( t )] t = t n = x ( t n ) for approp riately ban dlimited inputs. The sign al’ s critical samp ling period is assumed to be one , b ut to acco mmod ate oversamplin g b y a factor of M into our mod el, th e ideal samp le tim es are spaced 1 / M time units ap art. W e acquir e N jittered samp les with add itiv e noise, y 0 , . . . , y N − 1 , at this rate: y n = x ( n/ M + z n ) + w n . (6) In this paper, we will assume that the jitter an d additive n oise are iid ze ro-mean Gaussian, with known variances equ al to σ 2 z and σ 2 w , respectively . W e assume that these v ariances can be measured reasonab ly accurately thro ugh in-factory calib ration, although we e xpect the v ariances to v ary n aturally over time due to en vironmen tal effects. Combining the signal and observation models yield s y n = K − 1 X k =0 h ( n/ M + z n − k ) x k + w n . (7) This relationship can be e xpressed as a semilinear system of equations: y = H ( z ) x + w , (8) where y = [ y 0 , . . . , y N − 1 ] T , x = [ x 0 , . . . , x K − 1 ] T , z = [ z 0 , . . . , z N − 1 ] T , and w = [ w 0 , . . . , w N − 1 ] T . For no tational conv enience, denote the n th (zero -indexed) row of H ( z ) by h T n ( z n ) . T o keep n otation compa ct, deno te the pro bability density function (pdf ) of a by p ( a ) , the pdf o f a parameterized by the n onran dom vector b by p ( a ; b ) , and th e pdf o f a condition ed o n the random variable c by p ( a | c ) . The pdf is made explicit using subscripts only when ne cessary to av oid ambiguity . Expectations are written similarly . Also, de note the d -dimension al multiv a riate normal distribution by N ( a ; µ , Λ ) ∆ = | 2 π Λ | − 1 / 2 exp − 1 2 ( a − µ ) T Λ − 1 ( a − µ ) . (9) The prim ary objective of classical (non -Bayesian) estima- tion is to derive an estimator ˆ x that minimizes a desired cost function C ( ˆ x ; x ) of unknown nonrandom p arameters x . One such cost function is the mean squared error ( MSE): C ( ˆ x ; x ) = E y k ˆ x ( y ) − x k 2 2 , (10) where E y [ · ] is the expectatio n with respect to y , ˆ x ( y ) is the estimate of the unkn own para meters x based on the samples y , and the observations y are implicitly a function of x . Howe ver , except in cer tain cases, co mputing the estimate that m inimizes this cost fun ction, which is called the minimum MSE (MMSE) estimator, is impossible with out prio r knowledge about x . Instead, it is e ssential to der iv e an estimator that relies only on the observation model and the actu al o bservations y . One such estimator is the maximum likelihood (ML ) estimator , which max imizes the likelihood fun ction ℓ ( x ; y ) ∆ = p ( y ; x ) . The likelihood function correspo nding to the signal param eter observation mo del in ( 8) is ℓ ( x ; y ) = Z N ( y ; H ( z ) x , σ 2 w I ) N ( z ; 0 , σ 2 z I ) d z . (11) Using th e assump tions that the jitter and ad ditiv e noise are iid, an d the fact that th e n th row of H ( z ) only depends on one z n , the multivariate norm al distributions in (11) are separable over z . Thus, p ( y ; x ) is also separable, with p ( y ; x ) = Q n p ( y n ; x ) , and the likelihood fu nction is the produ ct of N univariate integrals ℓ ( x ; y ) = N − 1 Y n =0 Z N ( y n ; h T n ( z n ) x , σ 2 w ) N ( z n ; 0 , σ 2 z ) dz n . (12) Giv en the likelihood fun ction, parameters M , σ 2 z , and σ 2 w , MSE cost function , and observations y , the go al of this work is use ML estimation to toler ate more jitter wh en estimating x . Thus, the bulk of this pap er is concerned with the ev aluation of this likelihood fun ction and th e pro blem o f maxim izing it. B. Related W ork The problem of mitigating jitter has been invest igated since the early days of sign al processing . T he effects o f jitter on the statistics of samples of a dete rministic ( nonra ndom) bandlimited signal are briefly discussed in [7]; this work also is concerned with stochastic signals an d proposes an optimal linear r econstructio n filter f or th e stochastic case. Much more work on analyzing the e rror and re constructing stochastic signals from jittered samples can be f ound in [8] and [9]. ON THE E STIMA TION OF NONRANDOM SIGN AL COEFFICIENTS FROM JITTERE D SAMPLES 3 Howe ver , the ana lysis of jittered samp les of d eterministic signals ap pears to b e mu ch mo re limited in th e early literatur e. When the sample times ar e irregularly spaced, but k nown, the prob lem greatly simplifies. Efficient tec hnique s, as well as a mentio n of prior work, can be found in [10]. When the sample times are u nknown, but belong to a known fin ite set, the jitter mitigation p roblem becomes a combinator ial one; [11] describes geome tric and alg ebraic solution s to this p rob- lem of reco nstructing discrete-time signals. T wo block-based reconstruc tion meth ods for this finite location -set prob lem a re described in [12]. Howe ver , when the set is in finitely large, or when th e jitter is describ ed by a continuo us ran dom distribution as seen here, a different approa ch is necessary . On e contr ibution of this work is an Ex pectation-M aximization (EM) algorithm; in a similar context, [13] develops a similar EM algo rithm for the relate d pro blem of m itigating unk nown phase offsets between co mpon ent ADCs in a time- interleaved ADC system. Some of the results summarized in this paper are describ ed in greater de tail in [14], which also provides fu rther backg roun d material. C. Outline In Sectio n II, numerical in tegration using Gauss quad rature and iteration u sing the EM algor ithm are discussed. Section II I presents and derives the Cram ´ er–Rao lower bou nd (CRB) on the MSE for this e stimation pro blem. Sections IV a nd V derive lin ear an d ML estimators for the jitter mitigation problem ; simu lations compar ing the se estimators are discussed in Section VI. In conc lusion, the results and co ntributions are summarized , and futu re research directio ns are in troduce d. I I . B A C K G R O U N D Except for certain limited choices for h ( t ) , th e expression for the likelihood functio n in (12) has no closed form ; how- ev er , various tech niques exist to app roxim ate it. One such powerful an d general tec hnique is that of qua drature, wh ich refers to th e method of approx imating a n in tegral with a finite weighted sum mation. The trapezoid al and Simpson’ s rules are elemen tary examp les of qu adratur e. In particu lar , due to the norm al distribution assum ption on the jitter z n , Gauss– Hermite quadratu re is a natur al choice o f quadratu re rule. Gauss–Legendre quadr ature and Rom berg’ s me thod are also discussed below . Computation al problems a lso oc cur when deriving the ML estimator, du e to the nonco ncave and high-d imensional natu re of the likelihoo d f unction . On e local app roximatio n tech nique called the EM alg orithm can be used to locate loc al maxima in a compu tationally- feasible manner . Th e EM algorith m is also introdu ced in this section. A. Numerical Inte g ration Consider appro ximating the in tegral R f ( x ) w ( x ) dx using the summation P J j =1 w j f ( x j ) , w here x j and w j are fixed abscissas (sampling loca tions) an d weights. T his type of approx imation is known gene rally as q uadratu re. When the abscissas ar e unifo rmly spaced, the summa tion is k nown as interpolato ry quadra ture; the tra pezoidal an d Simpson’ s rules, as we ll as Romberg’ s m ethod [ 15], are of this typ e. Gau ss quadra ture seeks greater accuracy fo r a given num ber o f function ev aluations by allowing the ab scissas to b e spaced nonun iformly . An appro priate choice of abscissas an d weights (called a rule) can b e pr ecompu ted f or a choice of w ( x ) and J using a variety of metho ds, includ ing a very efficient eigenv a lue-based metho d derived in [16]. Or thogon al po ly- nomials satisfy a three- term recu rsiv e re lationship, which is used to form a tri-diago nal matrix, who se eigen values are the abscissas, and whose eigen vectors yield the weights. The eigendeco mposition of a tri-d iagonal matrix is very e fficient, so qu adrature rules are very in expensive to com pute, even fo r very large J . Quadr ature is pa rticularly attracti ve when f ( x ) is smooth and has b ounde d deriv ativ es. This meth od can be applied to multi variate integration a s w ell, altho ugh in the absence of separability , the com plexity scales exponentially with the number of variables. One weightin g fu nction o f particu lar interest in this work is the p df of the normal distribution. For a standard nor mal distribution, the associated for m of qu adratur e is known as Gauss–Hermite quadratu re, since the abscissas and weig hts derive from Hermite polyn omials. Using eleme ntary changes of variables, this meth od can be generalized to normal distri- butions with arbitrar y mean µ and variance σ 2 : Z ∞ −∞ f ( x ) N ( x ; µ, σ 2 ) dx ≈ J X j =1 w j f ( σ x j + µ ) , (13) where w j and x j are the weig hts and abscissas fo r Gauss– Hermite quadrature with a standard normal weigh ting f unction . As mentio ned in [17], the a pprox imation err or fo r Gauss– Hermite qu adrature is bo unded by the function ’ s deriv ativ es: Z ∞ −∞ f ( x ) N ( x ; µ, σ 2 ) dx − J X j =1 w i f ( σ x j + µ ) ≤ J ! σ 2 J (2 J )! max x f (2 J ) ( x ) . (14) As long as f ( x ) is sufficiently smooth, the (2 J )! ter m in the denomin ator domina tes th e above expression for large J , and the approximatio n error goes to zero superexp onentially fast. While gen eral con ditions fo r convergence are dif ficult to iso- late for arbitrary f ( x ) , a su fficient conditio n for con vergen ce mentioned in [17] is th at lim x →∞ | f ( x ) || x | 1+ ρ e x 2 ≤ 1 , for some ρ > 0 . (15) Many o ther Gauss q uadratu re rules exist; on e simple ru le also consider ed is called Gau ss–Legendre q uadratu re and is defined fo r integrating over a finite interval [ a, b ] , with the weighting fu nction w ( x ) ≡ 1 : Z b a f ( x ) dx ≈ J X j =1 w j f ( x j ) . (16) The abscissas and weights for Gauss–Legend re quadrature can be comp uted using the eig env alu e-based metho d m entioned above. Gauss–Legen dre qu adratur e an d other rules de fined 4 DRAFT over a fin ite interval, in cluding interpolato ry quad rature meth- ods like Simpson’ s rule and Romberg’ s me thod, c an be ex- tended to the infinite supp ort case by re-mapp ing the variable of integration : Z ∞ −∞ f ( x ) w ( x ) dx = Z π / 2 − π / 2 f (tan( y )) w (tan( y )) s ec 2 ( y ) dy . (17) When a pplied to the Ga uss–Legendre qu adrature ru le, the n ew rule beco mes Z ∞ −∞ f ( x ) w ( x ) dx ≈ J X j =1 w ′ j f ( x ′ j ) , (18) where x ′ j = tan( x j ) , and w ′ j = w ( x ′ j )(1 + ( x ′ j ) 2 ) w j . T o compare the ef fectiveness o f these dif ferent quad rature- based methods for n umerical integration, Gau ss–Hermite quadra ture and Gauss–Legendre quadra ture are contrasted against two mo re gener al m ethods, Simp son’ s ru le and Romberg’ s meth od, by co mparin g each metho d against the marginal likeliho od function p ( y n ; x ) , for a fixed, but ran - domly chosen, value o f x . The marginal likelihoo d fu nction is calculated from the em pirical distrib ution of sam ples generated by the o bservation model in (7). As shown in Figure 2, Gau ss– Legendre quadrature approximates t he likelihood function well when σ z is relati vely large, b u t when σ z and σ w are both sm all, Gauss–Hermite quadra ture is mu ch more ef fective. Howe ver, other quadr ature rules may be more accur ate for different choices of signal basis f unction s { h k ( t ) } . B. EM Algorithm The E M algo rithm was introduced in [18]; a classic ap- plication of this algo rithm is ML estimation in the p resence of incomplete data. Consider the problem of m aximizing the likelihood function ℓ ( x ; y ) , where y d epends on some latent random variables z . The observations y are described as the incom plete d ata. W e au gment this inco mplete data with some sub set o f latent (h idden) variables to form the com plete data. The und erlying assumption of the EM algo rithm is that knowledge o f the co mplete data makes the M L estimation problem easier to solve. The EM alg orithm consists of repeatedly maximizin g th e function Q x ; ˆ x ( i − 1) = E h log p ( y , z ; x ) | y ; ˆ x ( i − 1) i (19) with respect to the desired p arameters x ; the maximizin g value becom es ˆ x ( i ) , which is used in th e next iter ation. As long as the orig inal likelihood function is bo unded ab ove, and some other mild conditions are satisfied, this alg orithm is guaran teed to con verge to a local m aximum of the likelihood function [1 8]. Much has been written about the conv ergence rate of EM al- gorithms. In [19], the r ate of convergence of the EM algo rithm is related to the difference in the CRB using the inc omplete data and the CRB using th e complete data (in complete data + latent variables). Th e supplem ented EM alg orithm in [20] also obtains Fisher inform ation estimates, condition ed on the −1 −0.5 0 0.5 1 1.5 2 0 500 1000 1500 y n # of samples −1 −0.5 0 0.5 1 1.5 2 0 0.5 1 1.5 p(y n ; x ) ≈ Σ j=1 J w j N (y n ; h n T (z j ) x , σ w 2 ) Gauss−Hermite quad. Romberg’s method Simpson’s rule Gauss−Legendre quad. (a) K = 10 , M = 4 , σ z = 0 . 75 , σ w = 0 . 1 , J = 129 , n = 32 . 0.48 0.5 0.52 0.54 0.56 0.58 0.6 0.62 0.64 0.66 0 500 1000 1500 2000 2500 y n # of samples 0.48 0.5 0.52 0.54 0.56 0.58 0.6 0.62 0.64 0.66 0 10 20 30 40 p(y n ; x ) ≈ Σ j=1 J w j N (y n ; h n T (z j ) x , σ w 2 ) Gauss−Hermite quad. Romberg’s method Simpson’s rule Gauss−Legendre quad. (b) K = 10 , M = 4 , σ z = 0 . 01 , σ w = 0 . 01 , J = 129 , n = 34 . Fig. 2. T he quadrature approximat ion to p ( y n ; x ) is computed for a fixed, but randomly chosen, x on a dense grid of y n and is compa red aga inst a histogram of 100 000 samples y n generat ed using (7). T wo ca ses are shown to illustra te the approximation qualit y of (a) Gauss-Legendre quadrature and (b) Gauss-Hermite quadrat ure; the worst-case n is chosen for each of these approximat ions. N ote: the choice of J = 129 is used instead of J = 100 because Romberg’ s method ev aluates the fun ction J = 2 j + 1 times for j iterat ions. observations y , which can be used to ev aluate the quality of the resulting approximation to the ML estimate. Since the likelihood function in (11) is not in general strictly concave, the pre sence of m any critical p oints is a po tential problem fo r any local algorithm . Simulated ann ealing [21] an d other meth ods can be combined with the EM algo rithm to improve ro bustness to getting trapped in local extrema. I I I . A P P RO X I M AT I N G T H E C R B Minimizing the MSE without access to p rior in formatio n about th e un known parame ters x may be impo ssible in th e general ca se. Howe ver , ev en in situation s when the M MSE estimator cannot be co mputed, the Cram ´ er – Rao lower bound on the minimu m a chiev able MSE by an u nbiased estimator may be straig htforward to compute . The CRB y ( x ) , where x is the v ariable to estimate from observations y , is d efined to be th e trac e of the in verse of the Fishe r in formatio n m atrix I y ( x ) , wh ich is defined as I y ( x ) ∆ = E " ∂ log ℓ ( x ; y ) ∂ x ∂ log ℓ ( x ; y ) ∂ x T # . (20) Assuming the likelihood fu nction satisfies the regular ity con- dition E 1 ℓ ( x ; y ) ∂ 2 ℓ ( x ; y ) ∂ x ∂ x T = Z ∞ −∞ ∂ 2 ℓ ( x ; y ) ∂ x ∂ x T d y = 0 , (21) ON THE E STIMA TION OF NONRANDOM SIGN AL COEFFICIENTS FROM JITTERE D SAMPLES 5 the Fisher in formatio n matrix can be expressed in term s of th e Hessian of the log-likeliho od: [ I y ( x )] j,k = E ∂ lo g ℓ ( x ; y ) ∂ x j ∂ log ℓ ( x ; y ) ∂ x k (22) = E 1 ℓ ( x ; y ) 2 ∂ ℓ ( x ; y ) ∂ x j ∂ ℓ ( x ; y ) ∂ x k (23) = E 1 ℓ ( x ; y ) 2 ∂ ℓ ( x ; y ) ∂ x j ∂ ℓ ( x ; y ) ∂ x k − 1 ℓ ( x ; y ) ∂ 2 ℓ ( x ; y ) ∂ x j ∂ x k (24) = E ∂ ∂ x k − 1 ℓ ( x ; y ) ∂ ℓ ( x ; y ) ∂ x j (25) I y ( x ) = − E ∂ 2 log ℓ ( x ; y ) ∂ x ∂ x T . (26) A sufficient co ndition for the regularity co ndition in (21) is that d ifferentiation an d integration interch ange, since Z ∞ −∞ ∂ 2 ℓ ( x ; y ) ∂ x ∂ x T d y = ∂ 2 ∂ x ∂ x T Z ∞ −∞ ℓ ( x ; y ) d y = ∂ 2 ∂ x ∂ x T (1) = 0 . (27) By basic analy sis, u niform convergence of the integra l in likelihood fu nction in (11) implies that the above regular ity condition h olds. Since the likelihoo d function is separable, the log- likelihood function can be expressed as the su mmation of marginal log- likelihood func tions; i.e. log ℓ ( x ; y ) = N − 1 X n =0 log p ( y n ; x ) , (28) which mean s tha t (2 6) can be rewritten as ( again, a ssuming regularity cond itions are satisfied) I y ( x ) = N − 1 X n =0 E " ∂ log p ( y n ; x ) ∂ x ∂ log p ( y n ; x ) ∂ x T # . (29) The m arginal p df p ( y n ; x ) can be co mputed numerically using qu adratur e: p ( y n ; x ) ≈ J X j =1 w j N ( y n ; h T n ( z j ) x , σ 2 w ) , (30) where z j and w j are the abscissas and weights for the chosen quadra ture rule. As depicted in Figure 2, Gauss–Her mite quadra ture is a g ood choice for small σ z , an d Gauss–Legend re quadra ture is m ore accurate for larger σ z ( > 0 . 1 ). For all simulations in this paper, we use J = 100 un less otherwise specified. The deriv ativ e of the m arginal pd f can be ap prox imated similarly: ∂ p ( y n ; x ) ∂ x = Z ( y n − h T n ( z n ) x ) h n ( z n ) σ 2 w N ( y n ; h T n ( z n ) x , σ 2 w ) N ( z n ; 0 , σ 2 z ) dz n ≈ J X j =1 w j ( y n − h T n ( z j ) x ) h n ( z j ) σ 2 w N ( y n ; h T n ( z j ) x , σ 2 w ) . (31) Since ∂ ∂ x [log p ( y n ; x )] is equ al to 1 p ( y n ; x ) ∂ p ( y n ; x ) ∂ x , combin - ing (3 0) and ( 31) yields a complica ted approx imation to the expression inside the expectation in (29): ∂ lo g p ( y n ; x ) ∂ x ∂ lo g p ( y n ; x ) ∂ x T ≈ P J j =1 w j ( y n − h T n ( z j ) x ) h n ( z j ) N ( y n ; h T n ( z j ) x , σ 2 w ) σ 2 w P J j =1 w j N ( y n ; h T n ( z j ) x , σ 2 w ) ! · P J j =1 w j ( y n − h T n ( z j ) x ) h n ( z j ) N ( y n ; h T n ( z j ) x , σ 2 w ) σ 2 w P J j =1 w j N ( y n ; h T n ( z j ) x , σ 2 w ) ! T . (32) For conv enience, d enote the above appro ximation F n ( y n ; x ) . Now , consider compu ting the Fisher info rmation m atrix from this approximation : I y ( x ) ≈ N − 1 X n =0 E [ F n ( y n ; x )] . (33) T o com pute this expe ctation, a n umerical m ethod is need ed again. T he expectation is with respect to the distrib ution p ( y n ; x ) , which is ap proxim ated in (30) with a Gaussian mixture, so Mo nte Carlo sampling is a convenient meth od to ap proxim ate this expe ctation. Generatin g S samples y n,s from the Gaussian mixtu re P J j =1 w j N ( y n ; h T n ( z j ) x , σ 2 w ) an d av eraging the correspondin g fun ction v alues F n ( y n,s ; x ) , the Fisher infor mation matrix can be comp uted as I y ( x ) ≈ 1 S N − 1 X n =0 S X s =1 F n ( y n,s ; x ) . (34) Once this matrix is comp uted an d in verted, the trace gives th e Cram ´ er –Rao lower boun d for that choic e o f p arameter x . Due to matrix inv ersion, to ensure an accu rate CRB estimate, we use J = 10 00 for th e q uadratu res in (32). How much do es the CRB d ecrease when z is assumed giv en? Comp aring th e CRB y ( x ) against th e CRB y , z ( x ) of the jitter-augmented data will be impo rtant later when ana lyzing the EM algorithm de sign. The Fisher infor mation m atrix in this case is equal to I y , z ( x ) = − N − 1 X n =0 E ∂ 2 log p ( y n , z n ; x ) ∂ x ∂ x T . (35) Of cour se, since − log p ( y n , z n ; x ) = 1 2 σ 2 w ( y n − h T n ( z n ) x ) 2 + 1 2 σ 2 z z 2 n + constant , (36) and the Hessian matrix with respect to x is ∂ 2 ∂ x ∂ x T log p ( y n , z n ; x ) = − 1 σ 2 w h n ( z n ) h T n ( z n ) , (37) the jitter-augmented Fisher information matrix is I y , z ( x ) = 1 σ 2 w N − 1 X n =0 E h n ( z n ) h T n ( z n ) , (38) where the exp ectation can be approx imated nume rically us- ing quadrature or Monte Carlo approximation . Th e jitter- augmen ted CRB y , z ( x ) is the trace of the in verse o f this m atrix. 6 DRAFT W e will return to the question of the difference o f the two CRBs later in Sectio n VI, after we discuss ML estimation using an EM algorithm . I V . L I N E A R E S T I M A T I O N In this paper, an estimator is said to be lin ear if it is a lin ear function o f the o bservations; suc h an estimator has th e form ˆ x L ( y ) = Ay , (39) where the matrix A is fixed. 1 For the semilinear observation model in ( 8), a linear estima- tor is unbiased if and only if A E [ H ( z )] = I . Since E [ H ( z )] is a tall ma trix, assuming it has f ull colu mn ran k, o ne po ssible linear un biased estimator is ˆ x L ( y ) = E [ H ( z )] † y , (40) where E [ H ( z )] † ∆ = E [ H ( z )] T E [ H ( z )] − 1 E [ H ( z )] T is the left pseudoinverse. This estimator is only o ne such linear unbiased estimator; more gen erally , any matrix that lies in the nullspace of E [ H ( z )] can b e added to th e pseudoinv erse and yield an unbiased estimator . The qu estion then remains o f how to obtain the b est linear unbiased estimato r (BLUE ), in th e MMSE sense. In the context o f a simple line ar observation mo del y = H x + w , with Gaussian noise w , th e BLUE is eleme ntary to find (see [22]), and it is also the ML and efficient m inimum variance unb iased estimator (MVUE) . If we choo se z = 0 to be deter ministic ( no jitter) in the observation mode l, the correspo nding BLUE /efficient estima tor would b e ˆ x eff | z = 0 ( y ) = H ( 0 ) T H ( 0 ) − 1 H ( 0 ) T y . (41) The p erform ance o f this estimator when applied to the pro per (jittered) obser vation mod el will be u sed as on e baseline for MSE imp rovement for the p ropo sed estimators. As d erived p reviously in [14], the BLUE for the semilinear model ( 8) is ˆ x BLUE ( y ) = E [ H ( z )] T Λ − 1 y E [ H ( z )] − 1 E [ H ( z )] T Λ − 1 y y , (42) where the covariance matrix of the data Λ y depend s on the value of the parameters: Λ y = E [ H ( z ) xx T H ( z ) T ] − E [ H ( z )] xx T E [ H ( z )] T + σ 2 w I . (43) The BLUE estimator, in gener al, is n ot a valid estimator, since it depen ds on the true value of the unkn own x . T w o sufficient condition s fo r the estimator to be valid ar e: Λ y is a scalar matrix, in which case, the cov ariance matrix com mutes across multiplication, or Λ y does not d epend on x . Since z m and z n are indepen dent for m 6 = n , off-diagon al elements of Λ y are z ero. For the cov ariance matrix to be a scalar m atrix that commutes over matrix mu ltiplication f or all x , cov( h n ( z n )) must be equ al for all n . Howev er, this equ ality generally does not ho ld due to oversampling. Also , the covariance matrix 1 Sometimes, af fine estimators ˆ x ( y ) = Ay + b are considered to be line ar as well. Howe ver , as we will concern ourselves with unbiased estimators, b would turn out to be necessaril y zero. 0 1 2 0.2 0.25 0.3 0.35 0.4 0.45 k Estimate of x k Fig. 3. The best linear unbiased estimat or (BLUE) is computed for dif ferent choice s of x (holdin g y fixed ), using (42). In this exampl e, K = 3 , M = 2 , and σ z = σ w = 0 . 25 . clearly depen ds on x when cov( h n ( z n )) is non zero for some n . When the covariance matrix Λ y is a scalar m atrix, the BLUE estimato r is eq ual to ˆ x L ( y ) . T o conclusively demonstrate that the BLUE is not a valid estimator, the estimator is comp uted for a fixed value of y and varying x ; the results ar e shown in Figure 3. Clearly , since the estimates of x k vary depe nding on the value of x used in (42), the estimato r is not valid. Th us, an MSE-op timal linear estimator does no t exist for this prob lem, a nd we will utilize the estimator in ( 40). V . M L E S T I M AT I O N Giv en a semilinear mod el as in (8), we would no t expect the optima l MMSE estimator to have a linear fo rm. In deed, as shown in the pr evious section , for mo st signal mod els a nd priors o n the jitter , the BLUE do es n ot even exist. T o improve upon linear estimation, and re duce the M SE, we move to maximum likelihoo d estimation. Consider the pr oblem of maxim izing the likelihood functio n in (12); since the logarith m is an increasing func tion, we can perfor m the optimization by maximizing th e log -likelihood: ˆ x ML ( y ) = arg ma x x N − 1 X n =0 log p ( y n ; x ) . (44) Howe ver , since the ma rginal pdf does no t h av e a closed form, and neither do its derivati ves, p erform ing the necessary optimization is d ifficult. Numerical techn iques may be ap plied directly to ( 44), an d various general-p urpose m ethods have been studied extensi vely throu ghou t the liter ature. An iter ativ e joint maximization metho d p ropo sed in [2 3] attem pts to ap- proxim ate th e ML estimate by alter nating between maximizing p ( z | y ; x ) with r espect to z and p ( y | z ; x ) w ith r espect to x . One me thod that explicitly takes advantage of the special structure in (44) is th e EM algorithm. A. ML Estima tion using the EM Algo rithm Consider the function Q x ; ˆ x ( i − 1) in (19). The expression for log p ( y n , z n ; x ) is in (3 6), and summin g the se to gether (without the minus sign) g iv es log p ( y , z ; x ) = − 1 2 σ 2 w k y − H ( z ) x k 2 2 − 1 2 σ 2 z k z k 2 2 + constants . (45) ON THE E STIMA TION OF NONRANDOM SIGN AL COEFFICIENTS FROM JITTERE D SAMPLES 7 Expand ing an d sub stituting into th e expectation in (19) y ields Q ( x ; ˆ x ( i − 1) ) = − 1 2 σ 2 w y T y − 2 y T E h H ( z ) | y ; ˆ x ( i − 1) i x + x T E h H ( z ) T H ( z ) | y ; ˆ x ( i − 1) i x − 1 2 σ 2 z E h z T z | y ; ˆ x ( i − 1) i + constants . (46) W e w ant to find the value of x that maximizes this expres- sion. Noticing that ( 46) is quad ratic in x , the candidate value x satisfies the linear system E h H ( z ) T H ( z ) | y ; ˆ x ( i − 1) i x = E h H ( z ) | y ; ˆ x ( i − 1) i T y . (47) Also, the Hessian matrix is n egati ve-definite, so (46) is strictly concave, an d the can didate p oint x is the u nique maxim um ˆ x ( i ) . All th at remain s to specify the EM alg orithm is to approx imate th e expecta tions in (47). Using Bayes’ rule and the separability of both p ( y , z ; x ) and p ( y ; x ) , the p osterior distribution of the jitter is also separ able: p z | y ; ˆ x ( i − 1) = N − 1 Y n =0 p y n | z n ; ˆ x ( i − 1) p ( z n ) p y n ; ˆ x ( i − 1) (48) = N − 1 Y n =0 p z n | y n ; ˆ x ( i − 1) . (49) Thus, the expectations are also separab le in to u niv ariate ex- pectations: E h H ( z ) T H ( z ) | y ; ˆ x ( i − 1) i = N − 1 X n =0 E h h n ( z n ) h T n ( z n ) | y n ; ˆ x ( i − 1) i ; (50) E h H ( z ) | y ; ˆ x ( i − 1) i n, : = E h h T n ( z n ) | y n ; ˆ x ( i − 1) i . (51) The su bscript after the lef t-side exp ectation in ( 51) d enotes the n th (zer o-indexed) row o f the matr ix. T he d istribution p y n ; ˆ x ( i − 1) is constant with re spect to z n , and can be ev a luated u sing quadratu re, a s in (30). Approx imating each of the u niv ariate expectations in (50) and (51) with quadra ture yields E h H ( z ) T H ( z ) | y ; ˆ x ( i − 1) i ≈ N − 1 X n =0 1 p y n ; ˆ x ( i − 1) J X j =1 w j h n ( z j ) h T n ( z j ) p y n | z j ; ˆ x ( i − 1) , and (52) E h H ( z ) | y ; ˆ x ( i − 1) i n, : ≈ 1 p y n ; ˆ x ( i − 1) J X j =1 w j h T n ( z j ) p y n | z j ; ˆ x ( i − 1) . (53) The complexity of each iteration of this algorithm appears to be linear in the n umber of samples, althoug h the rate of conv ergence (and thu s, the nu mber of iterations re quired) may also vary with the num ber of samples, or other factors. The conv ergence rate, a s well as suscep tibility to initial con ditions (since the EM algorithm only guarantees local c onv ergence), are the subject of simulatio ns in this work and in [1 4]. The EM algorith m for ML estimation is summarized in Algorithm 1. Algorithm 1 Pseudocod e for the EM algo rithm for co mputing ML estimates for the u nknown sign al parame ters x . Require: p ( y , z ; x ) , y , ˆ x (0) , I , J , δ , ǫ i ← 0 Compute J -term quad rature rule (usin g e.g., the eigen de- composition metho d in [16]) fo r use in below approx ima- tions (use J = 10 0 ). repeat i ← i + 1 for n = 0 to N − 1 do Approx imate p ( y n ; ˆ x ( i − 1) ) using (30). Compute E h n ( z n ) h T n ( z n ) | y n ; ˆ x ( i − 1) using (5 2). Approx imate E H ( z ) | y ; ˆ x ( i − 1) n, : using (5 3). end for Solve for ˆ x ( i ) using (4 7) and th e above approx imations. until i = I or k ˆ x ( i ) − ˆ x ( i − 1) k 2 < δ or | log ℓ ( ˆ x ( i ) ; y ) − log ℓ ( ˆ x ( i − 1) ; y ) | < ǫ return ˆ x ( i ) V I . S I M U L A T I O N R E S U LT S The o bjectives of the simulations p resented h ere are to (a) analy ze the behavior of th e pr oposed EM algorith m f or approx imating the ML e stimator, and to (b) compare the perfor mance of this estimator to both the Cram ´ er – Rao bound and that of linear pa rameter estimation. The c onv ergence behavior is studied in de tail in [14] fo r periodic band limited signals. In this work, experime nts to determine co n vergence behavior and sensitivity to initial cond itions are conducted for the sinc basis signal model described in Section I. In all expe riments, we utilize MA TL AB to g enerate sign als with pseudo- random parameters and n oise and apply the algorith ms described to the samples of these signals. For a f actor of M oversampling, we generate N = K M samples. A. Conver gence Analysis While guaranteed to conver ge, the E M algorithm would be of little u se if it did n ot con verge qu ickly . Th e rate of conv ergence of the EM algo rithm is studied for se veral choices of M , σ z , an d σ w , an d trend s are presented in Figu re 4. T he rate of convergence is expone ntial, and the rate decr eases with increasing M , in creasing σ z , an d decr easing σ w . As mentioned in Sectio n I I, the rate of conver gence of the EM algorithm is related to the difference b etween the CRBs of the c omplete and the incom plete data. As shown late r in Figure 6, the difference between the CRBs for th e co mplete data and incomp lete data increa ses exponentially with σ z . This relation ship coincides w ith the con vergence behavior observed in Figure 4b. Altho ugh these experiments e valuated 500 iterations of th e EM algo rithm, the results suggest that 100 iteratio ns would suffice as lon g as the jitter stand ard deviation σ z is not to o large. Also, 10 − 8 is chosen as a reasonable stopping criterion for chang e in x ( i ) and change in log-likelihood b etween iterations ( δ and ǫ in Algorithm 1 , respectively). 8 DRAFT 0 100 200 300 400 500 10 −20 10 −15 10 −10 10 −5 10 0 # of iterations || x (i) − x (i−1) || 2 M = 4 M = 8 M = 16 (a) K = 10 , σ z = 0 . 25 , σ w = 0 . 1 , M v aries. 0 100 200 300 400 500 10 −20 10 −15 10 −10 10 −5 10 0 # of iterations || x (i) − x (i−1) || 2 σ z = 0.1 σ z = 0.25 σ z = 0.5 (b) K = 10 , M = 4 , σ w = 0 . 1 , σ z v aries. 0 100 200 300 400 500 10 −20 10 −15 10 −10 10 −5 10 0 # of iterations || x (i) − x (i−1) || 2 σ w = 0.5 σ w = 0.25 σ w = 0.1 (c) K = 10 , M = 4 , σ z = 0 . 25 , σ w v aries. Fig. 4. The conv er gence of the EM algo rithm depends on the choice of paramete rs M , σ z , and σ w , as demonstrated in the above plots. B. Sensitivity to Initial Cond itions The likelihood functio n described in (11) is gen erally nonco ncave, so max imizing th e func tion via a h ill-climbing method like the EM algo rithm is only gua ranteed to yield a local m aximum . Th e ability of the a lgorithm to co n verge to the glo bal maximum depen ds on the nonco ncavity of the likelihood func tion. T o demonstrate the sensitivity of the EM algorithm , as a function of M , σ z , an d σ w , the empirical distribution of the log -likelihood of the op timal values reached from multiple in itial con ditions is ev aluated over num erous trials for d ifferent choices of th ese parameters. In this exper - iment, the true value of x , the no-jitter linear estimator ( 41), x = 0 , a nd ten ran dom choices, are used as initial conditions for each tr ial. As suggested b y the spre ad of the samples sho wn in Figu re 5 , th e variability of the EM alg orithm in creases with σ z and decreasing σ w . Even when the EM algorithm appears sensitive to initial conditions, usin g th e no-jitter line ar 0 2 4 6 8 10 12 14 16 18 −150 −100 −50 0 50 log−likelihood (rel. to x (0) = H ( 0 )\ y ) M (a) K = 10 , σ z = 0 . 25 , σ w = 0 . 25 , and varyin g M . −0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 −80 −60 −40 −20 0 20 log−likelihood (rel. to x (0) = H ( 0 )\ y ) σ z (b) K = 10 , M = 8 , σ w = 0 . 25 , and varyin g σ z . 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 −400 −300 −200 −100 0 100 log−likelihood (rel. to x (0) = H ( 0 )\ y ) σ w (c) K = 10 , M = 8 , σ z = 0 . 25 , and varyin g σ w . Fig. 5. The effe cts of varyi ng initia l c onditions of the EM algori thm as a functio n of (a) ov ersampling factor , (b) jitter varia nce, and (c) additi ve noise v ariance are studied by computing the log-like lihoods of the EM algorit hm results, for multiple initia l conditions, across 50 trials. The log-lik elihoo d of the EM algorit hm results are displayed relati ve to th e result for zero-ji tter initia lizat ion, so that the log-lik eliho od of the result for ˆ x (0) = H ( 0 ) † y is zero. estimate ( 41) results in a re lativ ely small deviation from the best observed log-likeliho od value. I n situations when such initialization does fail to prod uce consistent results, m ethods such as the determ inistic annealin g EM alg orithm describ ed in [24] may improve co nsistency . C. P erformance of the EM Algorithm In th e first p erfor mance expe riment, the Cra m ´ er –Rao lower bound is comp ared to the unbiased linear estimator (4 0) and the EM algo rithm of the ML estimato r to measur e the efficiency o f th e algorithm s. The Cram ´ er –Rao lower bo und for the co mplete data is also presented f or ref erence. Althou gh computatio nal dif ficulties prev ent a complete comp arison for ev ery po ssible value of x , ca rrying out a com parison fo r ON THE E STIMA TION OF NONRANDOM SIGN AL COEFFICIENTS FROM JITTERE D SAMPLES 9 10 −3 10 −2 10 −1 10 −3 10 −2 10 −1 10 0 σ z x −MSE (1000 trials) Linear (unbiased) ML (EM) CRB y ( x) CRB y , z ( x) (a) 10 −3 10 −2 10 −1 10 −4 10 −3 10 −2 10 −1 σ z x −bias (RMS) (1000 trials) Linear (unbiased) ML (EM) (b) Fig. 6. The approximate performanc es of the linear unbiased estimator and ML estimator (E M algorith m) are plotted i n (a) against the CRB y ( x ) and the complete data CRB y , z ( x ) , as a function of σ z for K = 10 , M = 16 , σ w = 0 . 05 , and a fixed random choice of x . The linear and ML estimator biases are plotted in (b), using the root-mean-squ ared (RMS) values of the bias vect ors. T he bars abo ve and belo w each data point for the linear and ML estimato rs in (a) delineat e the 95% confidence interva ls for those data points. a few rando mly ch osen values of x provide a measure o f the q uality of the algorith ms. As the curves in Figure 6 demonstra te for o ne su ch rand om ch oice of x , b oth algo rithms are ap prox imately ef ficient f or small σ z , but the EM algor ithm continues to be efficient f or larger values o f σ z than the lin ear estimator . I n addition , the bias shown for the linear and ML estimators is approx imately the same for σ z < σ w ; this b ias may be d ue to the small error in th e num erical in tegration. Note how this er ror b ecomes larger with σ z . In Figure 7, the EM alg orithm is comp ared again st two linear estimators. First, to demo nstrate the MSE improvement attainable throu gh nonlinear estimation, the EM algo rithm is pitted against the line ar u nbiased estimato r . Sinc e a major mo- ti vating factor for developing these algorithm s is to reduce the power consump tion d ue to clock accu racy , th e E M alg orithm also can achieve the same MSE as the line ar estimator for a substantially larger jitter variance, reduc ing the clock’ s power consump tion. When the add iti ve noise do minates the jitter ( σ z ≪ σ w ), th e improvement can be expected to be minimal, since the sy stem is nearly linear, an d the jitter is statistically insignificant. As the amo unt of jitter increases, th e density f unction p ( z | y ; x ) used in each iteration of the EM algor ithm beco mes more nonlinear in z , and th e qua drature become s less accurate for a giv en n umber of te rms. Th erefor e, the EM algorithm generally takes long er to conver ge, and the result sho uld be 10 −2 10 −1 10 −3 10 −2 10 −1 10 0 10 1 σ z Approximate x −MSE (1000 trials) Linear ( z = 0 ) Linear (unbiased) ML (EM) (a) K = 10 , M = 4 , 0 . 01 ≤ σ z ≤ 0 . 5 , σ w = 0 . 05 . 10 −2 10 −1 10 −3 10 −2 10 −1 10 0 σ z Approximate x −MSE (1000 trials) Linear ( z = 0 ) Linear (unbiased) ML (EM) (b) K = 10 , M = 16 , 0 . 01 ≤ σ z ≤ 0 . 5 , σ w = 0 . 05 . 10 −2 10 −1 10 −4 10 −3 10 −2 10 −1 10 0 σ z Approximate x −MSE (1000 trials) Linear ( z = 0 ) Linear (unbiased) ML (EM) (c) K = 10 , M = 16 , 0 . 01 ≤ σ z ≤ 0 . 5 , σ w = 0 . 01 . Fig. 7. The MSE performance of the ML estimator (EM algorit hm) is compared ag ainst both the unbia sed linear estima tor (40) and the no-j itter BLUE (41), as a functio n of σ z . T he bars above and belo w each data point for the linear and ML estimator s deline ate the 95% confidence interv als for those data points. a less accurate app roxima tion to the true ML estimator . This behavior is observed in Figur e 7, where the EM algor ithm is comp ared against both the linear un biased estimator and the no -jitter linear estimator . Th e EM algorith m genera lly h as lower MSE than either linear estimator, an d the per forman ce gap is more p rono unced f or hig her oversampling factor M . T o answer the que stion o f how m uch mor e jitter can b e tolerated for the same desired MSE using the EM algorithm , the maximu m propor tional increase is plotted as a function of M and σ w in Figure 8. Th e maximum pro portion al incr ease for a choice of M and σ w is comp uted by ap proxim ating log - log domain MSE curves, like th ose in Fig ure 7, with piece- wise lin ear cu rves and interpo lating the maximum d istance between them over the range of σ z ≥ σ w . The range of σ z < σ w is ign ored sinc e the linear and non linear reco nstruc- tions perfo rm similarly when th e add itiv e n oise do minates (as 10 DRAFT 2 4 8 16 32 1 1.5 2 2.5 3 Oversampling factor (M) Max. σ z improvement 2 4 8 16 32 0.1 0.2 0.3 0.4 0.5 σ z * Max. σ z improvement σ z * (a) K = 10 , M v aries, 0 . 01 ≤ σ z ≤ 0 . 5 , σ w = 0 . 1 . 0.01 0.025 0.05 0.1 0.25 0.5 1 1.2 1.4 1.6 1.8 w n std. dev. ( σ w ) Max. σ z improvement 0.01 0.025 0.05 0.1 0.25 0.5 0.1 0.2 0.3 0.4 0.5 σ z * Max. σ z improvement σ z * (b) K = 10 , M = 8 , 0 . 01 ≤ σ z ≤ 0 . 5 , σ w v aries. Fig. 8. These graphs sho w the maximum factor of improvement in jit ter tolera nce, m easured by σ z , achie va ble by the EM alg orithm (relati ve to linea r reconstru ction). Holding σ w fixed, (a) sho ws the trend in maximum improve- ment as M increases, and (b) sho ws the trend in maxi mum improv ement as σ w increa ses while holding M fixed. The jitter standard devi ation σ ∗ z correspond ing to this maximum improve ment for the ML estimator is plotted on the same axe s. expected). The pro portio n of imp rovement increases linearly as M increases. As σ w increases, the level o f improvement stays app roximate ly the same fo r σ w < σ z . Howe ver , when σ w increases beyond σ z , the le vel of improvement d ecreases substantially as expe cted, since the additive noise dominates, and the op timal estimator is appr oximately linear . A max imum σ z improvement factor of two corr esponds to p ower sa v ings of up to 75 p ercent. V I I . C O N C L U S I O N The results pr esented in Section VI ar e very encou raging from a power-consumption standpoin t. A maxim um im prove- ment of between 1 . 4 to 2 time s the jitter translates to a two-to-four fold dec rease in power consumptio n by the clo ck, accordin g to (3). T o p ut the m agnitud e of such an improvement in co ntext, consider the digital baseband p rocessor for ultra- wideband commu nication in [2 5]. This proce ssor in corpo rates an ADC and a PLL , which co nsume 86 mW and 45 mW , respectively , ou t of a 271 mW budget for the chip. Reducing by a factor o f two the power consumed by th e ADC alon e would decrea se the to tal power consump tion o f th e ch ip by almost sixteen percent. While effecti ve, the EM algorithm is compu tationally ex- pensive. One benefit of digital po st-processing is that these algorithm s can be p erfor med off-chip , o n a compu ter o r o ther system with less limited com putation al resou rces. For r eal- time on-ch ip app lications, Kalman filter-like version s of the EM algorith m would be more pr actical; this extension is a topic for furthe r investigation. Related to r eal-time pro cessing is de veloping streaming algorithms for the infinite-dimensiona l case, e xtending this work f or general real-time sampling systems. Anothe r future direction inv olves m odifyin g th ese algorithm s fo r cor related or p eriodic jitter . Sampling jitter m itigation is actu ally just o ne ap plication of these new alg orithms. In the frequ ency dom ain, jitter maps to uncerta inty in fr equency; usin g alg orithms such as these should produ ce more reliable Fourier transfor ms for systems like spec trum analyzer s. In higher dim ensions, timing n oise becomes location jitter in images or v ideo. Greater tolerance of the location s o f pixels in images would allow scan ning electron microsco pe users to acquire higher resolu tion image s without sacrificin g MSE. Th is pap er shows that significan t im- provements over the best linear p ost-pro cessing a re possible; thus, fur ther work may impact these an d other a pplications. A C K N O W L E D G M E N T The author s thank J. Kusuma for asking stimulating ques- tions abou t samp ling and applications of jitter mitig ation. T he authors also th ank Z. Zvonar at Analog Devices and G. Frantz at T exas Instru ments for the ir insights and suppor t. R E F E R E N C E S [1] I. King, “Understa nding high-speed signals, clocks, and data capture, ” Nationa l Semicondutor Signal Path Designer , vol. 103, Apr . 2005. [2] T . H. Lee and A. Hajimiri, “Oscill ator phase noise: A tutorial, ” IEEE J. Solid-St ate Circu its , vol. 35, no. 3, pp. 326–336, Mar . 2000. [3] K. Uyttenho ve and M. S. J. Steyaer t, “Speed-po wer-a ccurac y tradeof f in high-spee d CMOS ADCs, ” IEEE T rans. Circ uits Syst. II , vol. 49, no. 4, pp. 280–287, Apr . 2002. [4] B. Brannon, “ Aperture uncert ainty and ADC s ystem performance, ” Analog Devi ces, T ech. Rep. AN-501, Sep. 2000. [5] R. H. W alden , “ Analog-to-di gital con verter survey and analysis, ” IE EE J . Sel. Areas Commun. , vol. 17, no. 4, pp. 539–550, Apr . 1999. [6] Y . Lee and R. Mittra , “Electromagneti c interference mitigation by using a spread-spectrum approach, ” IEEE T rans. Elect r omagn. Compat. , vol. 44, no. 2, pp. 380–385, May 2002. [7] A. V . Balakrish nan, “On the problem of time jitte r in sampling, ” IRE T rans. Inform. Th. , vol. 8, no. 3, pp. 226–236, Apr . 1962. [8] W . M. Brown, “Sampling with random jitter , ” J. Soc. Industri al and Appl. Math. , vol. 11, no. 2, pp. 460–473, Jun. 1963. [9] B. Liu and T . P . Stanley , “Error bounds for jittered samplin g, ” IEEE T rans. Autom. Contr ol , vol. 10, no. 4, pp. 449–454, Oct. 1965. [10] H. G. Feichtin ger , K. Gr ¨ ochenig , and T . Strohmer , “Efficient numerical methods in non-unifo rm sampling theory , ” Numer . Math. , vol. 69, no. 4, pp. 423–440, Feb. 1995. [11] P . Marzil iano and M. V etterli , “Reconst ruction of irregul arly sampled discrete -time bandlimite d signals with unknown sampling locati ons, ” IEEE T rans. Signal Pr ocess. , vol. 48, no. 12, pp. 3462–3 471, Dec. 2000. [12] T . E. T uncer , “Block-based methods for the reconstructi on of finite- length signals from nonuniform samples, ” IEEE T rans. Signal P r ocess. , vol. 55, no. 2, pp. 530–541, Feb . 2007. [13] V . Di vi and G. W ornell, “Signal reco ver y in time-inte rlea ved analog-to- digita l con vert ers, ” in Pr oc. IEEE Int. Conf. Acoustics, Speec h, Signal Pr ocess. , vol. 2, May 2004, pp. 593–596. [14] D. S. W eller , “ Mitigat ing timing noise in ADCs through dig ital post- processing, ” SM Thesis, Massachuset ts Institute of T echnology , Depart - ment of E lectri cal Engineeri ng and Computer S cienc e, Jun. 2008. [15] P . K. Ky the and M. R. Sch ¨ aferk otter , Handbook of Computati onal Methods for Inte grati on . Boca Raton, FL: CRC, 2005. [16] G. H. Golub and J. H. W elsch, “Cal culati on of Gauss quadrature rules, ” Math. Comp. , vol. 23, no. 106, pp. 221–230, Apr . 1969. [17] P . J. Davis and P . Rabino witz, Methods of Numerical Inte grati on . Orlando: Academic Press, 1984. ON THE E STIMA TION OF NONRANDOM SIGN AL COEFFICIENTS FROM JITTERE D SAMPLES 11 [18] A. P . Dempster , N. M. Laird, and D. B. Rubin, “Maximum likelih ood from incomple te data via the E M algorithm, ” J . Roy . Statist. Soc., Ser . B , vol. 39, no. 1, pp. 1–38, 1977. [19] C. Herzet and L . V andendorpe, “Predicti on of the EM-algorithm s peed of con verge nce with Cramer-Ra o bounds, ” in Pro c. IEE E Int. Conf. Acoustics, Speech, Signal P r ocess. , vo l. 3, Apr . 2007, pp. 805–808. [20] X.-L. Meng and D. B. Rubi n, “Using EM to obtain asymptotic va riance- cov ariance matrice s: The SEM algorithm, ” J . Amer . Statist. Assoc. , vol. 86, no. 416, pp. 899–909, Dec. 1991. [21] S. K irkpatri ck, C. D. Gelatt , and M. P . V ecc hi, “Optimiz ation by simulate d annea ling, ” Science , vol. 220, no. 4598, pp. 671 –680, May 1983. [22] S. M. Kay , Fundamentals of Stati stical Signal Proce ssing: Estimation Theory , ser . Prenti ce-Hall Signal Processing Ser ies. Upper Saddle Ri ver , NJ: Prentice Hall, 1993, vol. 1. [23] J. Kusuma and V . K. Goyal, “Delay estimation in the presence of timing noise, ” IEEE T rans. Cir cuits Syst. II , vol. 55, no. 9, pp. 848–852, Sep. 2008. [24] N. Ueda and R. Nakano , “Deterministic anneal ing EM algorithm, ” Neural Network s , vol. 11, no. 2, pp. 271–282, Mar . 1998. [25] R. Bl ´ azquez , P . P . Newa skar , F . S. Lee, and A. P . Cha ndrakasan , “ A baseband processor for impulse ultra-wide band communications, ” IEEE J . Solid-State Circuit s , vol. 40, no. 9, pp. 1821–1828, Sep. 2005.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment