Active Learning of Halfspaces under a Margin Assumption
We derive and analyze a new, efficient, pool-based active learning algorithm for halfspaces, called ALuMA. Most previous algorithms show exponential improvement in the label complexity assuming that the distribution over the instance space is close t…
Authors: Alon Gonen, Sivan Sabato, Shai Shalev-Shwartz
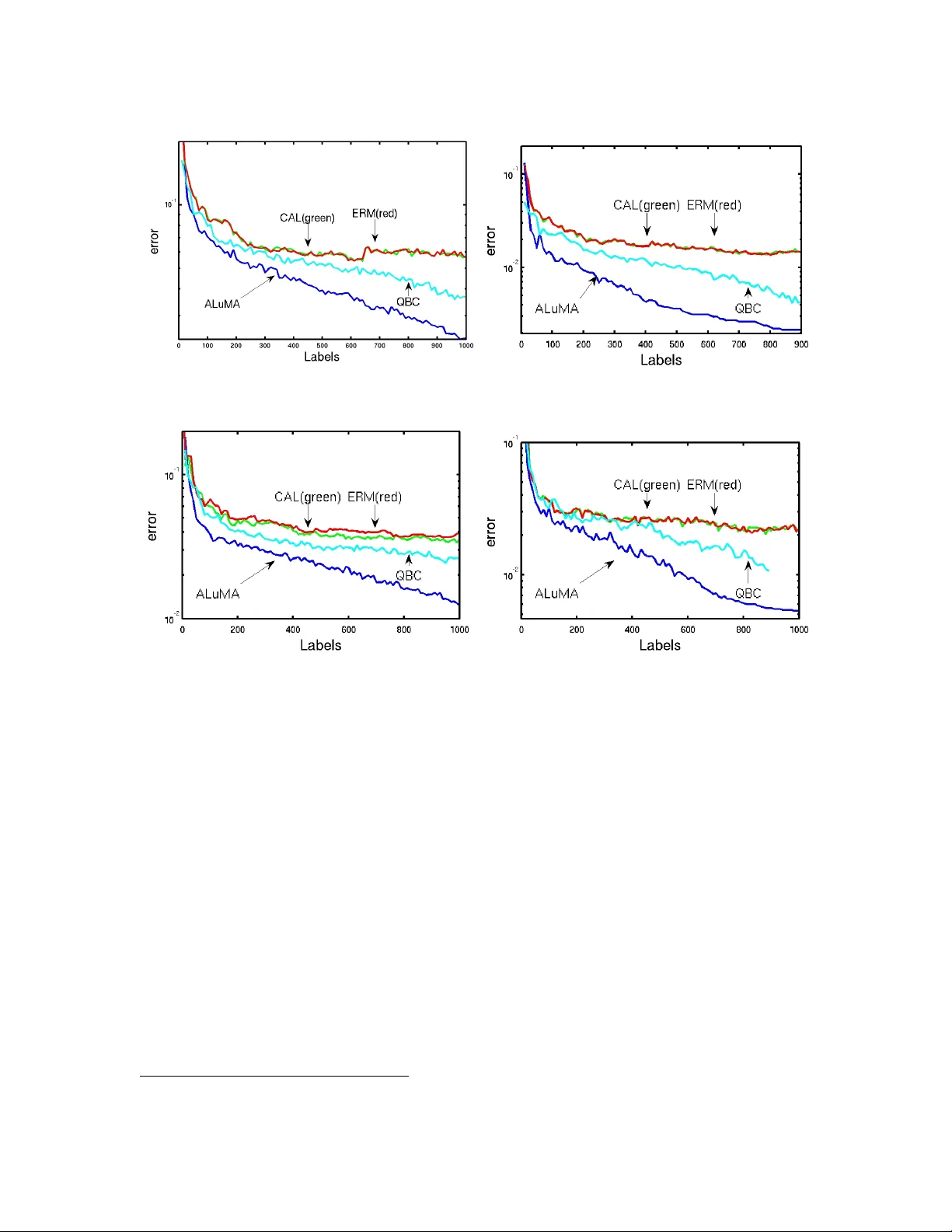
A ctive Learning of Halfsp aces under a Mar gin Assumption Activ e Learning of Halfspaces under a Margin Assumption Alon Gonen alongnn@cs.huji.ac.il Siv an Sabato saba to@cs.huji.ac.il Shai Shalev-Sh w artz shais@cs.huji.ac.il Benin scho ol of Computer Scienc e and Engine ering The Hebr ew University Givat R am, Jerusalem 91904, Isr ael Abstract W e deriv e and analyze a new, efficien t, p o ol-based activ e learning algorithm for halfspaces, called ALuMA. Most previous algorithms sho w exponential improv ement in the lab el com- plexit y assuming that the distribution ov er the instance space is close to uniform. This assumption rarely holds in practical applications. Instead, we study the label complexit y under a large-margin assumption—a muc h more realistic condition, as evident by the suc- cess of margin-based algorithms suc h as SVM. Our algorithm is computationally efficient and comes with formal guarantees on its label complexity . It also naturally extends to the non-separable case and to non-linear kernels. Exp erimen ts illustrate the clear adv antage of ALuMA o v er other active learning algorithms. 1. Introduction W e consider the c hallenge of p ool-based active learning (McCallum and Nigam, 1998), in whic h a learner receiv es a p o ol of unlab eled examples, and can iteratively query a teacher for the lab els of examples from the p o ol. The goal of the learner is to return a low-error prediction rule using a small n umber of queries. The num b er of queries used by the learner is termed its lab el c omplexity . This setting is most useful when unlab eled data is abundan t but labeling is expensive, a common case in many data-laden applications. In some cases, p o ol-based active learning can provide an exp onen tial improv emen t in lab el complexit y ov er standard ‘passiv e’ learning. F or instance, suppose the examples are p oin ts in [0 , 1] and there exists some unknown threshold suc h that p oin ts b elo w the threshold are classified as negative and p oints ab ov e the threshold are classified as p ositiv e. The sample complexity of learning a prediction rule with error less than using an i.i.d. lab eled sample is ˜ Θ(1 / ). In comparison, an activ e learner can select its queries to follow a binary searc h, and thus can achiev e the same accuracy with a lab el complexity of only O (ln(1 / )). This result holds for an y distribution ov er [0 , 1]. The example abov e is a sp ecial and v ery simple case of the imp ortant and highly com- mon setting of activ e learning of halfspaces in R d . Much research has been devoted to this c hallenge, and sev eral algorithms hav e b een prop osed. F or instance, the Query By Com- mittee (QBC) algorithm (Seung et al., 1992; F reund et al., 1997) and the CAL algorithm (Cohn et al., 1994) both examine the unlab eled examples sequentially , and main tain a ver- sion space that is shrunk with each receiv ed lab el. QBC requests the lab el of an example 1 Gonen, Saba to and Shalev-Shw ar tz if t w o hypotheses randomly sampled from the curren t version space disagree on its lab el. CAL simply requests the lab el of an y example whose lab el is not determined by the current v ersion space. Another example is an activ e v ariant of the P erceptron algorithm, prop osed in Dasgupta et al. (2005). If the marginal distribution of the data is uniform ov er a sphere cen tered at the origin, then all of these algorithms ac hiev e an exp onen tial improv ement in the lab el complexity compared to passiv e learning, similarly to the single-dimensional case of thresholds on the line. F or CAL, a more general result has b een sho wn: a lab el complexity of O (ln(1 / )) is ac hiev ed whenever the joint distribution of data and lab els has a b ounded disagreemen t co efficien t (Hanneke, 2007, 2009). This holds, for instance, for an y “smo oth” distribution (F riedman, 2009). Ho w ev er, the “O notation” here hides a dep endency on the disagreement co efficien t, whic h for some data distributions can be v ery large, making this upp er b ound similar to the sample complexit y required b y a passive learner. This makes the exp onential impro v emen t with resp ect to meaningless in these cases. T o illustrate this p oint, w e consider the following example, due to Dasgupta (2006), sho wing a simple distribution in R 3 for whic h no significan t improv ement ov er passiv e learning can b e ac hiev ed with any active learning algorithm. Example 1 Consider a distribution in R d for any d ≥ 3 . Supp ose that the supp ort of the distribution is a set of evenly-distribute d p oints on a two-dimensional spher e that do es not cir cumscrib e the origin, as il lustr ate d in the fol lowing figur e. As c an b e se en, e ach p oint c an b e sep ar ate d fr om the r est of the p oints with a halfsp ac e. In this example, to distinguish b et w een the case in whic h all points hav e a negativ e label and the case in whic h one of the p oin ts has a p ositive label while the rest hav e a negativ e lab el, an y active learning algorithm will hav e to query ev ery point at least once. It follo ws that for any > 0, if the num ber of p oin ts is 1 / , then the lab el complexit y to achiev e an error of at most is 1 / . On the other hand, the sample complexity of passiv e learning in this case is order of 1 log 1 , hence no activ e learner can b e significantly b etter than a passiv e learner on this distribution. 1 This pro ves the following claim: Claim 1 L et C b e a universal c onstant. F or al l ∈ (0 , 1 2 ) and d ≥ 3 , ther e exists a distribution over R d , such that no active le arner c an have lab el c omplexity smal ler than 1 / for le arning the hyp othesis class of origin-c enter e d halfsp ac es on this distribution. On the 1. The disagreement co efficien t for this example is equal to the num ber of p oints. In addition, while the distribution in this example is not smo oth, and th us the results of F riedman (2009) do not hold here, we can easily slightly change the distribution to make it smo oth, while still having the same phenomenon. This do es not con tradict the result of F riedman (2009), as the exponential improv emen t from 1 / to ln(1 / ) kicks in only when 1 / is larger than the num ber of p oin ts. 2 A ctive Learning of Halfsp aces under a Margin Assumption other hand, the sample c omplexity of the vanil la ERM p assive le arner for this distribution is C log 1 . W e see that there cannot b e a true exp onen tial improv ement with resp ect to which is uniform ov er all distributions and target h yp otheses. Moreo ver, the only kno wn case where a non-trivial label complexit y bound can b e ac hiev ed for active learning is when the distribution is uniform (or nearly uniform) o v er a sphere centered at the origin. This is a serious limitation, since real applications rarely exhibit an ything similar to a uniform distribution of their data. A second limitation of the result for CAL is that despite the logarithmic dep endence on 1 / , the absolute label complexity of CAL can b e muc h worse than that of the optimal algorithm. This is illustrated in the follo wing example and the theorem following it. Example 2 Consider a distribution in R d that is supp orte d by two typ es of p oints on an o ctahe dr on (se e an il lustr ation for R 3 b elow). 1. V ertic es: { e 1 , . . . , e d } . 2. F ac e c enters: z /d for z ∈ {− 1 , +1 } d . Consider the hyp othesis class W = { x 7→ sgn( h x, w i − 1 + 1 d ) | w ∈ {− 1 , +1 } d } . Each hyp othesis in W , define d by some w ∈ {− 1 , +1 } d , classifies at most d + 1 data p oints as p ositive: these ar e the vertic es e i for i such that w [ i ] = +1 , and the fac e c enter w /d . Theorem 1 Consider Example 2 for d ≥ 3 , and assume that the p o ol of examples includes the entir e supp ort of the distribution. Ther e is an efficient algorithm that finds the c orr e ct hyp othesis fr om W with at most d lab els. On the other hand, with pr ob ability at le ast 1 e over the r andomization of the sample, CAL uses at le ast 2 d + d 2 d +3 lab els to find the c orr e ct sep ar ator. Pro of First, it is easy to see that if h ∗ ∈ W is the correct hypothesis, then w = ( h ∗ ( e 1 ) , . . . , h ∗ ( e d )) . Th us, it suffices to query the d v ertices to discov er the true w . W e now sho w that the n um ber of queries CAL asks un til finding the correct separator is exp onential in d . Consider some run of CAL (determined by the random ordering of the sample). Assume w.l.o.g. that eac h data p oin t app ears once in the sample. Let S be the set that includes the p ositive face center and all the vertices. Note that CAL cannot terminate b efore either querying all the 2 d − 1 negative face centers, or querying at least one example from S . Moreov er, CAL will query all the face centers it encoun ters b efore encoun tering 3 Gonen, Saba to and Shalev-Shw ar tz the first example from S . At each iteration t b efore encountering an example from S , there is a probability of d +1 2 d + d − t that the next example is from S . Therefore, the probability that the first T = 2 d + d 2 d +3 examples are not from S is T − 1 Y t =0 1 − d + 1 2 d + d − t ≥ 1 − d + 1 2 d + d − T T ≥ e − 2 T d +1 2 d + d − T = e − 2( d +1) 2 d + d T − 1 = 1 e , where in the second equality w e used 1 − a ≥ exp( − 2 a ) which holds for all a ∈ [0 , 1 2 ]. Therefore, with probability at least 1 e the n umber of queries is at least 2 d + d 2 d +3 . In this paper we present a new efficient po ol-based activ e learning algorithm for learning high dimensional halfspaces. As Example 1 abov e shows, it is not p ossible to guarantee a significan t impro v emen t in label complexity that holds uniformly for all distributions. How- ev er, for any giv en p o ol of unlab eled examples, there exists some optimal lab el complexit y— the one that would b e ac hieved by an optimal activ e learning algorithm for this p o ol. By “optimal” we mean an algorithm which queries the minimal num b er of lab els in the worst- case sense, where w orst-case here is with resp ect to the target h yp othesis. Unfortunately , it is unknown whether there exists a p olynomial-time optimal algorithm for the class of halfspaces. W e therefore present an efficien t approximation algorithm. That is, w e will an- alyze the label complexit y of our algorithm with a r e gr et-typ e analysis: we b ound the label complexit y of our algorithm relative to the optimal label complexit y that can be ac hiev ed for the given unlab eled p o ol. Therefore, if for a given p o ol of examples activ e learning can outperform passive learning, then our algorithm will enjoy a similar impro v emen t. On the other hand, if the p o ol is inheren tly “difficult”, as in Example 1, our algorithm might require the same num b er of labels as a passive learner. As in QBC and CAL, w e maintain a v ersion space and up date it whenev er we receive a lab el. Unlik e QBC and CAL, we do not restrict ourselves to examining the unlab eled examples sequentially . Instead, w e examine the entire p o ol at each iteration and select the next example to query in a greedy manner—we select an example that approximately maximizes the worst-case reduction in the v ersion space. 2 Deriving active learning algorithms by greedily maximizing reductions in the version space has b een recently prop osed b y Golovin and Krause (2010). In particular, they pro- p osed the notion of adaptiv e sub-mo dular optimization, and show ed that in the case of a finite hypothesis class, a greedy selection rule can b e comp etitive with the optimal al- gorithm, where the comp etitiv eness factor depends on the logarithm of the size of the h yp othesis class. How ever, in the case of halfspaces the hypothesis class is of infinite size, hence this analysis is not directly applicable. 3 F urthermore, a generic implementation of their algorithm yields a run time that dep ends linearly on the size of the hypothesis class. T o tac kle these issues, we will rely on the familiar notion of mar gin . W e will assume that the negative and p ositiv e examples can b e separated (or approximately separated) with a 2. The efficient algorithm shown in the pro of of Theorem 1 is in fact an instance of this strategy . 3. By Sauer’s lemma, the effective size of the h ypothesis class of halfspaces on a set of m unlab eled examples is only m d . One can th us apply the algorithm of Golovin and Krause (2010) to this finite h ypothesis class, how ever the runtime of the resulting algorithm will b e exponential in d . 4 A ctive Learning of Halfsp aces under a Margin Assumption p ositiv e margin. Under this assumption, w e are able to deriv e an efficient algorithm with a lab el-complexit y comp etitiveness guarantee that depends on the margin. A larger margin will result in b etter regret guaran tees for our algorithm. Some of the most p opular learning algorithms (e.g. SVM, Perceptron, and AdaBo ost) rely on a large margin assumption, and their practical success indicates that margin is a reasonable requirement for man y real world problems. The margin assumption is b eneficial in tw o additional asp ects. First, our algorithm can handle high-dimensional data by p erforming a pre-pro cessing step of dimensionality reduction. In particular, this can b e p erformed when the data is represented by a kernel matrix. Kernels hav e had tremendous impact on mac hine learning theory and algorithms o v er the past decade (Cristianini and Sha w e-T a ylor, 2004; Sc h¨ olk opf and Smola, 2002), so the ability to apply our algorithm with k ernels is a clear adv an tage. W e note that an efficient implemen tation of QBC with k ernels has b een prop osed in Gilad-Bac hrac h et al. (2005), but no formal lab el complexit y guarantees hav e b een provided for the resulting algorithm. Second, our algorithm can handle samples with a small lab el error via a simple transfor- mation, that transforms any lab eled sample to a sample whic h is separable with a margin. This margin dep ends on the optimal hinge-loss of the sample. This transformation can be applied for any algorithm, including CAL or QBC. How ev er, the transformation leads to a data distribution which migh t be far from uniform, hence the lab el complexity guaran tees of these algorithms do not apply . In con trast, since our analysis only assumes margin, the theoretical guaran tees still hold for our algorithm. W e note that sev eral algorithms hav e b een prop osed for active learning in the agnostic case, for instance A 2 (Balcan et al., 2006a) and IW AL (Beygelzimer et al., 2009). These algorithms pro vide similar exp onential sp eedups for the uniform distribution without re- quiring separabilit y . How ever, unlik e the algorithms for the separable case, these algorithms are computationally in tractable when learning the class of halfspaces with the zero-one loss. T o summarize, the prop osed algorithm is computationally efficien t, toleran t to some la- b el error, applicable for learning in high dimensional spaces, and comes equipp ed with lab el complexit y guarantees that hold for an y distribution in R d that (approximately) satisfies a margin assumption. T ong and Koller (2002) also addressed active learning of halfspaces under the assumption of separabilit y with a margin. They prop osed the principle of choosing the example that splits the version space as ev enly as p ossible. They show that if at every round the c hosen example splits the version space exactly in half, then the algorithm ac hiev es the minimal p ossible lab el complexit y (in a certain Ba y esian sense). They implement sev eral heuristics that attempt to follo w this selection principle using an efficient algorithm. F or instance, they suggest to choose the vector x which is closest to the max-margin solution of the data lab eled so far. How ever, no formal guarantees are provided for these heuristics relative to the prop osed principle. Moreov er, for eac h of these heuristics there are cases where the split induced b y the example selected b y the heuristic is m uc h less balanced than the one induced b y the most balanced example. In Balcan et al. (2007), an active learning algorithm with guaran tees under a margin assumption is prop osed. How ev er, these guaran tees hold only if the data distribution is uniform ov er an ellipsoid. One ma y wonder if a large margin assumption alone can guaran tee a uniform improv e- men t in lab el complexit y . This is not the case, as eviden t by the follo wing example. 5 Gonen, Saba to and Shalev-Shw ar tz Example 3 L et γ ∈ (0 , 1 2 ) b e a mar gin p ar ameter. Consider the uniform distribution supp orte d by N p oints in R d , such that al l the p oints ar e on the unit spher e, and for e ach p air of p oints x 1 and x 2 in the supp ort, h x 1 , x 2 i ≤ 1 − 2 γ . It was shown in Shannon (1959) that for any N ≤ O ((1 /γ ) d ) , ther e exists a set of p oints that satisfy the c onditions ab ove. Now, for any p oint x in the supp ort, ther e exists a (biase d) line ar sep ar ator that sep ar ates x fr om the r est of the p oints with a mar gin of γ . This c an b e se en by letting w = x and b = 1 − γ . Then h w , x i − b = γ while for any z 6 = x in the set, h w , z i − b = h x, z i − 1 + γ ≤ − γ . By adding a single dimension, this example c an b e tr ansforme d to one with origin-c enter e d halfsp ac es. Just as in Example 1, here to o any activ e learner must query all N points in the worst case. W e ha v e thus pro ved: Claim 2 L et C b e a universal c onstant. F or al l d ≥ 2 , γ ∈ (0 , 1 2 ) , N = Ω((1 /γ ) d − 1 ) and ∈ ( 1 N , 1 2 ) , ther e exists a distribution over R d , such that no active le arning algorithm c an have lab el c omplexity smal ler than 1 / for le arning the hyp othesis class of origin-c enter e d halfsp ac es on this distribution, even if the le arner knows that the data is sep ar able with mar gin of γ . On the other hand, the sample c omplexity of the vanil la ERM p assive le arner for this distribution is C ln( 1 ) . W e pro vide a formal problem statement in Section 2, and state our main results in Section 3. Section 4 describ es the ALuMA algorithm, and Section 5 outlines the pro of of the prop erties of ALuMA. Section 6 provides the transformation that allows ALuMA to handle kernel represen tations and lab eling errors. In Section 7 we describ e a simpler implemen tation of ALuMA, whic h is useful for running the algorithm in practice. W e rep ort exp erimen ts on real and syn thetic datasets in Section 8. The detailed pro ofs of our main results are disclosed in Appendix A and App endix B. 2. F ormal Problem Statemen t In p o ol-based activ e learning, the learner receives as input a set of instances, denoted X = { x 1 , . . . , x m } . Eac h instance is asso ciated with a lab el (which is initially unknown to the learner). The goal of the active learner is to lab el all x ∈ X correctly using as few lab el queries as p ossible. If X is a sample dra wn i.i.d. from a fixed distribution, then the lab els the active learning algorithm outputs can then b e used to train a classifier with lo w error on the distribution, using an y passiv e learning algorithm that receives the lab eled sample as input. Therefore, from no w on w e fo cus on the problem of determining the labels of the examples in X . The learner has access to a teacher, represen ted b y an oracle L : [ m ] → {− 1 , 1 } . The goal of the learner is to find the v alues L (1) , . . . , L ( m ) using as few calls to L as p ossible. W e study activ e learning of the hypothesis class of halfspaces. Let B d 1 b e the unit ball in R d . W e assume that X ⊆ B d 1 , and that there exists some w ∗ ∈ B d 1 suc h that L ( i ) = sgn( h w ∗ , x i i ) for all i ∈ [ m ]. The lab el complexit y of an activ e learning algorithm is the maximal num b er of calls to L that it makes before determining the labels of all instances in X , where the maximum is o v er all the p ossible functions L determined b y a w ∗ ∈ B d 1 . F ormally , an active learning algorithm A can call L several times, and then 6 A ctive Learning of Halfsp aces under a Margin Assumption should output ( L ( x 1 ) , . . . , L ( x m )). Let N ( A, w ∗ ) b e the n um b er of calls to L that A mak es b efore outputting ( L ( x 1 ) , . . . , L ( x m )) if L is determined by w ∗ . The (w orst-case) cost of A is defined as c wc ( A ) = max w ∗ ∈ B d 1 N ( A, w ∗ ). W e define the worst-case cost of the optimal algorithm b y OPT = min A c wc ( A ) , (1) where the minimum is ov er all activ e learning algorithms. As mentioned in the in troduction, our lab el complexity guarantees will b e relative to the optimal label complexity that can be achiev ed for the giv en sample X . W e refer to OPT as a measure of the difficulty of the activ e learning problem and exp ect our algorithm to succeed if OPT is “small”. When analyzing the lab el complexity of our algorithm we mak e t w o relaxations. First, we further assume that ( X , L ) is separated with a mar gin γ , that is that there exists a w ∗ suc h that min i ∈ [ m ] L ( i ) h w ∗ , x i i ≥ γ . The lab el complexity guarantees of our algorithm dep end on γ . W e describ e a relaxation of this assumption of separabilit y with a margin in Section 3. Second, we allow our algorithm to mak e randomized decisions, and require it to output ( y 1 , . . . , y m ) such that with high probability y i = L ( i ) for all i . That is, the algorithm is allow ed to fail with small probability . W e will show that the num b er of calls to L our algorithm mak es is not m uch larger than OPT. 4 3. Main results It is easy to see that the problem of finding a p olicy that implements OPT for a general h yp othesis class is at least as hard as the problem of finding a decision tree of minimal height. Unfortunately , this problem is NP-hard in the general case (Arkin et al., 1993). Using the additional assumption of separabilit y with a margin, we pro vide an efficient algorithm that finds the correct lab eling of the sample with high probabilit y , using a n um b er of queries whic h is comparable to OPT. Sp ecifically , w e prov e the following theorem: Theorem 2 L et X = { x 1 , . . . , x m } ⊆ B d 1 . Assume that ( X , L ) is sep ar able with a mar gin γ . L et δ ∈ (0 , 1) b e a c onfidenc e p ar ameter. Ther e exists a p o ol-b ase d active le arning algorithm with the fol lowing guar ante es: 1. With pr ob ability at le ast 1 − δ , it r eturns L (1) , . . . , L ( m ) . 2. It r e quests at most OPT · 4(2 d ln(2 /γ ) + ln(2)) lab els, wher e OPT is define d in Equa- tion (1). 3. Its running time is p olynomial in m , d and ln(1 /δ ) . The guaran tees of the theorem ab o v e depend linearly on d , the dimension of the repre- sen tation of the examples. This may b e an issue in very high dimensions, and is prohibitive 4. Note that the requirements of our algorithm are easier than those of the optimal algorithm via the definition of OPT, since in the definition of c wc (and therefore of OPT) w e do not maximize only ov er those w ∗ that achiev e margin γ , and we do not allow A to fail with small probability . It is easy to derive cases in whic h OPT is large, but under the margin assumption there exists an algorithm that makes few calls to L . Nev ertheless, OPT is a reasonable measure of the “difficulty” of the activ e learning problem. W e lea ve further research on relaxed definitions of OPT to future work. 7 Gonen, Saba to and Shalev-Shw ar tz in the case of a k ernel represen tation of X . In addition, this theorem holds only for fully separable data. These limitations can b e circumv ented b y applying a fairly simple transfor- mation on the p oints in X as a preprocessing step. This transformation maps the points of X to a set of p oints in a lo w er dimension, such that the new set is separable with resp ect to the same oracle L . The input p oin ts X can be represented either directly as p oin ts in R d , or via a kernel matrix k ( x, x 0 ) for x, x 0 ∈ X . The dimension of the new representation dep ends on the hinge-loss of { ( x 1 , L (1)) , . . . , ( x m , L ( m )) } with resp ect to the margin. Our algorithm can then b e applied to the low-dimension p oints to retrieve the lab els of X , with time com- plexit y and lab el complexit y appro ximation guarantees that do not dep end on the original dimension d . As a final step, the labeled sample { ( x 1 , L (1)) , . . . , ( x m , L ( m )) } can b e used as input to a passive learner. Note that in this scheme the generalization b ounds depend only on the prop erties of X and not on the prop erties of the low-dimensional mapping. The follo wing theorem formalizes the properties of the transformation. Theorem 3 L et X = { x 1 , . . . , x m } ⊆ B , wher e B is the unit b al l in some Hilb ert sp ac e. L et H ≥ 0 and γ > 0 , and assume ther e exists a w ∗ ∈ B such that H ≥ m X i =1 max(0 , γ − L ( i ) h w ∗ , x i i ) 2 . L et δ ∈ (0 , 1) b e a c onfidenc e p ar ameter. Ther e exists an algorithm that r e c eives X as ve ctors in R d or as a kernel matrix K ∈ R m × m , and input p ar ameters γ and H , and outputs a set ¯ X = { ¯ x 1 , . . . , ¯ x m } ⊆ R k , such that 1. k = O ( H +1) ln( m/δ ) γ 2 , 2. With pr ob ability 1 − δ , ¯ X ⊆ B k 1 and ( ¯ X , L ) is sep ar able with a mar gin γ 2+2 √ H . 3. The run-time of the algorithm is p olynomial in d, m, 1 /γ , ln(1 /δ ) if x i ar e r epr esente d as ve ctors in d , and is p olynomial in m, 1 /γ , ln(1 /δ ) if x i ar e r epr esente d by a kernel matrix. Finally , consider the common learning setting in whic h there is some distribution D ov er (instance,lab el) pairs, and { ( x 1 , L (1)) , . . . , ( x m , L ( m )) } are i.i.d. pairs drawn from D . If D is separable with a margin γ , then it suffices to ha v e a labeled sample of size m = O ( 1 γ 2 ) to allo w passive learning to accuracy . The transformation ab ov e thus maps the sample to dimension O ( 1 γ 2 ln( 1 γ 2 δ )). Executing our algorithm on the resulting sample we get an activ e learning algorithm that runs in time polynomial in 1 γ , 1 and ln(1 /δ ), and has a label complexit y which is guaranteed to b e no more than OPT · O ( 1 γ 2 ln( 1 γ 2 δ )), where OPT is the num b er of queries required by an optimal active learning algorithm on the transformed sample. 4. The ALuMA algorithm In this section w e describ e our algorithm. W e name it Active Learning under a Margin Assumption or ALuMA for short. 8 A ctive Learning of Halfsp aces under a Margin Assumption T o explain our approach, it is conv enient to think ab out the active learning process as a search pro cedure for the vector w ∗ that determines the lab els L (1) , . . . , L ( m ). Supp ose our first t calls to L are for the lab els L ( i 1 ) , . . . , L ( i t ), and denote P t = { ( x i 1 , L ( i 1 )) , . . . , ( x i t , L ( i t )) } . Then, w e know that w ∗ m ust be in the set V ( P t ) = { w ∈ B d 1 : ∀ ( x, y ) ∈ P t , y h w , x i > 0 } . The set V ( P t ) is called the version sp ac e induced b y P t . In tuitiv ely , w e would lik e to query lab els that will mak e V ( P t ) “small”. There are many w a ys to define the “size” of V ( P t ). One wa y , whic h is con v enien t for our analysis, is to define the size of a v ersion space b y its volume, denoted V ol( V ( P t )). Therefore, ideally , w e w ould lik e to query the labels L ( i 1 ) , . . . , L ( i t ) for which V ol( V ( P t )) is minimal. Naturally , the size of V ( P t ) dep ends on the actual lab els we will receiv e from L , which are unknown to us prior to querying them. W e therefore w ould lik e to query the lab els for whic h V ol( V ( P t )) is minimal in the worst-case, where the worst-case is ov er all p ossible v ectors w ∗ that ma y determine L (1) , . . . , L ( m ). The n umber of all possible sequences of t queries gro ws exponentially with t , whic h poses a computational challenge. W e th us follo w a simple greedy approac h: At each iteration, query the example whose lab el will lead to a version space of minimal size. Again, since w e do not know the lab el prior to querying, w e would lik e to choose the example whic h leads to the minimal size in the w orst-case, where the worst-case is o ver all possible v ectors w in the curren t v ersion space. F ormally , given the current version space V ( P t ), the next query should be for the lab el of the example in argmin x ∈ X max w ∈ V ( P t ) V ol( V ( P t ∪ { ( x, sgn( h w , x i )) } )) . (2) Denoting V 1 t,x = V ( P t ∪ { ( x, 1) } ) and V − 1 t,x = V ( P t ∪ { ( x, − 1) } ), an equiv alen t wa y to write Equation (2) is 5 argmax x ∈ X V ol( V 1 t,x ) · V ol( V − 1 t,x ) . (3) T o implement Equation (3), w e need to b e able to calculate the v olumes of the sets V 1 t,x and V − 1 t,x . Both of these sets are conv ex sets obtained by intersecting the unit ball with halfspaces. The problem of calculating the volume of suc h con v ex sets in R d is #P-hard if d is not fixed (Brigh t w ell and Winkler, 1991). Moreov er, deterministically approximating the v olume is NP-hard in the general case (Matou ˇ sek, 2002). Luckily , it is p ossible to appro xi- mate this v olume using randomization. Sp ecifically , in Kannan et al. (1997) a randomized algorithm with the following guarantees is pro vided: Lemma 4 L et K ⊆ R d b e a c onvex b o dy with an efficient sep ar ation or acle. Ther e exists a r andomize d algorithm, such that given , δ > 0 , with pr ob ability at le ast 1 − δ the algorithm 5. T o see the equiv alence, denote α ( x ) = max w ∈ V ( P t ) V ol( V sgn( h w,x i ) t,x ) / V ol( V ( P t )). Clearly , Equation (2) can b e written as argmin x α ( x ). Note that α ( x ) ∈ [1 / 2 , 1] and 1 − α ( x ) = V ol( V − sgn( h w,x i ) t,x ) / V ol( V ( P t )). Therefore, Equation (3) can b e written as argmax x α ( x )(1 − α ( x )) = argmax x min { α ( x ) , 1 − α ( x ) } = argmin x max { 1 − α ( x ) , α ( x ) } . Since α ( x ) ∈ [1 / 2 , 1] we conclude that the abov e equals argmin x α ( x ) as required. 9 Gonen, Saba to and Shalev-Shw ar tz r eturns a non-ne gative numb er Γ such that (1 − )Γ < P ( K ) < (1 + )Γ . The running time of the algorithm is p olynomial in d, 1 /, ln(1 /δ ) . ALuMA uses this algorithm to estimate V ol( V 1 t,x ) and V ol( V − 1 t,x ) with sufficien t accuracy . W e denote an execution of this algorithm on a con v ex b o dy K b y Γ ← V olEst( K , , δ ). The con v ex bo dy K is represented in the algorithm by the set of the constraints that define it. ALuMA terminates when it exhausts its budget of queries, whic h is provided as a pa- rameter to the algorithm. If the final version space V do es not determine the lab eling of X , ALuMA randomly dra ws sev eral h ypotheses from V and lab els X according to a ma jorit y v ote ov er these h yp otheses. Our analysis will sho w that if the budget is large enough and the draw of the hypotheses is appro ximately uniform from V , then this strategy leads to the correct lab eling of X with high probabilit y . T o draw a hypothesis approximately uniformly from V , we use the hit-and-run algo- rithm (Lo v´ asz, 1999), whic h dra ws a random sample from a con v ex bo dy K according to a distribution which is close in total v ariation distance to the uniform distribution ov er K . F ormally , The follo wing definition parametrizes the closeness of a distribution to the uniform distribution: Definition 5 L et K ⊆ R d b e a c onvex b o dy with an efficient sep ar ation or acle, and let τ b e a distribution over K . τ is λ -uniform if sup A | τ ( A ) − P ( A ) / P ( K ) | ≤ λ, wher e the supr emum is over al l me asur able subsets of K . The hit-and-run algorithm draws a sample from a λ -uniform distribution in time ˜ O ( d 3 /λ 2 ). ALuMA is listed below as Alg. 1. Its inputs are the unlab eled sample X , the lab eling oracle L , the maximal allow ed n um b er of lab el queries N , and the desired confidence δ ∈ (0 , 1). It returns the labels of all the examples in X . Algorithm 1 The ALuMA algorithm 1: Input: X = { x 1 , . . . , x m } , L : [ m ] → {− 1 , 1 } , N , δ 2: I 1 ← [ m ] 3: V 1 ← B d 1 4: for t = 1 to N do 5: ∀ i ∈ I t , j ∈ {± 1 } , do ˆ v x i ,j ← V olEst( V j t,x i , 1 3 , δ 4 mN ) 6: Select i t ∈ argmax i ∈ I t ( ˆ v x i , 1 · ˆ v x i , − 1 ) 7: I t +1 ← I t \ { i t } 8: Request y = L ( i t ) 9: V t +1 ← V t ∩ { w : y h w, x i t i > 0 } 10: end for 11: M ← d 72 ln(2 /δ ) e . 12: Dra w w 1 , . . . , w M 1 12 -uniformly from V N +1 . 13: F or eac h x i return the lab el y i = sgn P M j =1 sgn( h w j , x i i ) . 10 A ctive Learning of Halfsp aces under a Margin Assumption 5. Pro of outline In this section we describ e the outline of the pro of of Theorem 2. The detailed pro of is giv en in App endix A. Giv en S ⊆ X and w , w e define the partial realization of w on S as w | S = { ( x, sgn( h w , x i )) : x ∈ S } . An y activ e learning algorithm works as follo ws. Let w b e a vector that determines L , whic h is unknown to the learner. The algorithm starts with S 1 = ∅ . At iteration t , the algorithm kno ws w | S t , and based on this information, it selects a new example x ∈ X and sets S t +1 = S t ∪ { x } . W e can therefore represen t any algorithm b y a p olicy function π which maps each partial realization to an element from X . 6 W e denote by S ( π, w , k ) the v alue of w | S k if policy π is applied for k iterations, and the received lab els are consisten t w ith w . W e define a utilit y function ov er partial realizations as follows. Let U be the uniform distribution o v er B d 1 . That is, a measurable subset Z ⊆ B d 1 has probabilit y mass U ( Z ) = V ol( Z ) / V ol( B d 1 ). Giv en a partial realization w | S for some S ⊆ X and w ∈ B d 1 , we define the utilit y of the partial realization to b e f ( w | S ) = 1 − U ( V ( w | S )) = P v ∼ U [ v / ∈ V ( w | S )] . (4) That is, f measures the probabilit y mass of all v ectors in B d 1 whic h are not in the version space corresp onds to the partial realization. In tuitiv ely , a go o d p olicy should yield partial realizations of high utility . Giv en a budget of k calls to the lab eling oracle, w e would like to construct a p olicy π for which f ( S ( π , w ∗ , k )) is as large as possible, in the w orst-case o v er the c hoice of w ∗ . F or tec hnical reasons, we prefer to deriv e a p olicy aiming to maximize the exp ected v alue of f ( S ( π, w ∗ , k )), where expectation is with respect to w ∗ ∼ U . That is, w e define f avg ( π , k ) = E w ∗ ∼ U [ f ( S ( π, w ∗ , k ))] . With this definition at hand, a non-efficient approac h for deriving a goo d p olicy function is to p erform exhaustiv e searc h ov er all p olicies, and then c hoose the one for whic h f avg ( π , k ) is maximal. On the other hand we sho w that ALuMA, whic h is an efficien t algorithm, implemen ts an appro ximated greedy p olicy for increasing f avg ( π , k ). Indeed, let P t b e the partial realization ac hiev ed b y ALuMA b y the b eginning of iteration t . At this point the algorithm “kno ws” that the correct separator is in V ( P t ). Therefore, to mak e f avg ( ALuMA , k ) larger, w e perform an appro ximately greedy step, b y querying the lab el of an example whic h appro ximately maximizes E w ∗ ∼ U [ f ( P t ∪ { ( x, sgn( h w ∗ , x i )) } ) | w ∗ ∈ V ( P t )] . Standard algebraic manipulations can sho w that the ab o v e is equiv alent to Equation (3). W e see that ALuMA p erforms an approximated greedy p olicy for maximizing f avg . But, ho w go o d is this greedy p olicy? Recently , Golovin and Krause (2010) show ed that if f satisfies certain conditions then an approximately greedy p olicy achiev es an approximately- optimal exp ected utilit y . These conditions are called adaptive submo dularity and adaptive 6. F or randomized algorithms, w e can define a p olicy function for any realization of their random bits. 11 Gonen, Saba to and Shalev-Shw ar tz monotonicity , and it can b e shown that our utilit y function adheres to these conditions. W e use this to show (see Section A.1) that for any p olicy π and in teger k , if we run ALuMA for n iterations then f avg ( ALuMA , n ) ≥ f avg ( π , k ) − e − n 4 k . (5) In particular, this holds for the p olicy π ∗ that implements the optimal algorithm in the definition of OPT, and for k = OPT. Since for an y w , S ( π ∗ , w , OPT) determines the predic- tions of w on all the examples in X , it follows that V ( S ( π ∗ , w , OPT)) ⊆ V ( S ( ALuMA , w , n )). This fact can b e used to show (see Lemma 12) that for an y w , f avg ( π ∗ , OPT) − f avg ( ALuMA , n ) ≥ U ( V ( w | X )) ( U ( V ( S ( ALuMA , w , n ))) − U ( V ( w | X ))) . Com bining the ab ov e with Equation (5) and rearranging terms yields ∀ w , U ( V ( w | X )) U ( V ( S ( ALuMA , w , n ))) ≥ U ( V ( w | X )) 2 e − n 4 k + U ( V ( w | X )) 2 . (6) Our final step is to use the assumption that that w separates X with margin γ , whic h implies that U ( V ( w | X )) ≥ ( γ / 2) d (Lemma 13). Plugging this into Equation (6) yields that, for n large enough, at least 2 / 3 of the vectors in V ( S ( ALuMA , w , n )) are also in V ( w | X ). Hence, an (appro ximate) ma jorit y vote ov er V ( S ( ALuMA , w , n )) will correctly determine the lab els of all the examples in X (Corollary 15). 6. Handling inseparable data, high-dimensions, or kernels If the data X = { x 1 , . . . , x m } is in a v ery high dimension, or it is not guaranteed to b e separable, or it is represen ted only using a k ernel matrix, then ALuMA still can b e used, after a prepro cessing step. This preprocessing step maps the points in X to a set of p oints in a lo w er dimension, which are separable using the original lab els of X . W e describ e the pro cedure b elo w, and pro ve that it satisfies the requiremen ts of Theorem 3 in App endix B. The prepro cessing step is comp osed of tw o simple transformations. In the first trans- formation, whic h can b e skipp ed if the data is kno wn to b e separable, eac h example x i ∈ X is mapped to an example in dimension d + m , defined by x 0 i = ( ax i ; √ 1 − a 2 · e i ), where e i is the i ’th vector of the natural basis of R m and a > 0 is a scalar that will b e defined b elo w. Thus the first d coordinates of x 0 i hold the original v ector times a , the rest of the co ordinates are zero,except for x 0 i [ d + i ] = √ 1 − a 2 . This mapping guaran tees that the set X 0 = ( x 0 1 , . . . , x 0 m ) is separable with the same labels as those of X , and with a margin that dep ends on the cum ulativ e squared-hinge-loss of the data. In the second transformation, a Johnson-Lindenstrauss random pro jection (Johnson and Lindenstrauss, 1984; Bourgain, 1985) is applied to X 0 , thus pro ducing a new set of points ¯ X = ( ¯ x 1 , . . . , ¯ x m ) in a low er dimension R k , where k dep ends on the original margin and on the amoun t of margin error. With high probabilit y , the new set of p oin ts will b e separable with a margin that also dep ends on the original margin and on the amount of margin error. If the input data is provided not as vectors in R d but via a kernel matrix, then a simple decomp osition is performed b efore the prepro cessing b egins. The full prepro cessing pro ce- dure is listed b elo w as Alg. 2. The first input to the algorithm is the data for prepro cessing, 12 A ctive Learning of Halfsp aces under a Margin Assumption giv en as X ⊆ R d or as a kernel matrix K ∈ R m × m . The other inputs are γ —a margin pa- rameter, H —an upper b ound on the margin error relative to γ , and δ , which is the required confidence. Algorithm 2 Prepro cessing 1: Input: X = { x 1 , . . . , x m } or K ∈ R m × m , γ , H , δ 2: if input data is a kernel matrix K then 3: Find U ∈ R m × m suc h that K = U U T 4: ∀ i ∈ [ m ] , x i ← ro w i of U 5: d ← m 6: end if 7: a ← q 1 1+ √ H 8: ∀ i ∈ [ m ] , x 0 i ← ( ax i ; √ 1 − a 2 · e i ) 9: k ← O ( H +1) ln( m/δ ) γ 2 10: M ← a random {± 1 } matrix of dimension k × ( d + m ) 11: for i ∈ [ m ] do 12: ¯ x i ← M x 0 i 13: end for 14: Return ( ¯ x 1 , . . . , ¯ x m ) . After the prepro cessing step, ¯ X is used as input to ALuMA, which then returns a set of lab els for the examples in ¯ X . These are also the lab els of the examples in the original X . T o retriev e a halfspace for X with the least margin error, any passive learning algorithm can b e applied to the resulting labeled sample. The full active learning pro cedure is describ ed in Alg. 3. Note that if ALuMA returns the correct lab els for the sample, the usual generalization b ounds for passiv e supervised learning can be used to b ound the true error of the returned separator w . In particular, we can apply the support vector machine algorithm (SVM) and rely on generalization b ounds for SVM. Algorithm 3 Active Learning 1: Input: X = { x 1 , . . . , x m } or K ∈ R m × m , L : [ m ] → {− 1 , 1 } , N , γ , H , δ 2: if input has X then 3: Get ¯ X b y running Alg. 2 with input X , γ , H , δ / 2. 4: else 5: Get ¯ X b y running Alg. 2 with input K , γ , H , δ / 2. 6: end if 7: Get ( y 1 , . . . , y m ) b y running ALuMA with input ¯ X , L , N , δ / 2. 8: Get w ∈ R d b y running SVM on the lab eled sample { ( x 1 , y 1 ) , . . . , ( x m , y m ) } . 9: Return w . 13 Gonen, Saba to and Shalev-Shw ar tz 7. A Simpler Implementation of ALuMA The ALuMA algorithm describ ed in Alg. 1 uses O ( N m ) volume estimations as a black-box pro cedure, where N is the budget of labels and m is the po ol size. The complexit y of eac h application of the volume estimation pro cedure is ˜ O ( d 5 ) where d is the dimension. Th us the ov erall complexit y of the algorithm is ˜ O ( N md 5 ). This complexity can b e somewhat impro v ed under some “luc kiness” conditions. The volume estimation procedure uses λ -uniform sampling based on hit-and-run as its core procedure. Instead, we can use hit-and-run directly as follo ws: At each iteration of ALuMA, instead of step 5, perform the follo wing pro cedure: Algorithm 4 Estimation Pro cedure 1: Input: λ ∈ (0 , 1 24 ) , V t , I t 2: k ← ln(2 N m/δ ) 2 λ 2 3: Sample h 1 , . . . , h k ∈ V t λ -uniformly . 4: ∀ i ∈ I t , j ∈ {− 1 , +1 } , ˆ v x i ,j ← 1 k |{ i | h i ( x i ) = j }| . The complexit y of ALuMA when using this pro cedure is ˜ O ( N ( d 3 /λ 4 + m/λ 2 )), which is b etter than the complexit y of the full Alg. 1 for a constant λ . An additional practical b enefit of this alternativ e estimation pro cedure is that when implementing, it is easy to limit the actual computation time used in the implementation by running the pro cedure with a smaller num ber k and a smaller num ber of hit-and-run mixing iterations. 7 This pro vides a natural trade-off betw een computation time and labeling costs. Theorem 20 in App endix C shows that letting ALuMA use Alg. 4 as the estimation pro cedure results in similar guaran tees to those of the original implemen tation of ALuMA (Alg. 1). The only condition is that the b est example in each iteration induces a fairly balanced partition of the current v ersion space. In our exp eriments we noticed that this is generally the case in practice. Moreov er, the theorem sho ws that it is p ossible to v erify that the condition holds while running the algorithm. Thus, the estimation procedure can easily b e augmen ted with an additional v erification step at the b eginning of eac h iteration. On iterations that fail the verification, the algorithm will use the original black-box volume estimation procedure. 8. Exp erimen ts W e ev aluated ALuMA ov er syn thetic and real data sets and compared its label complexit y p erformance to that of a passive ERM (that is, one that uses random lab eled examples), as w ell as to that of QBC and CAL. Our implementation of ALuMA uses hit-and-run samples instead of full-blo wn v olume estimation, as detailed in Section 7 abov e. QBC is also implemen ted using hit-and-run as in Gilad-Bac hrac h et al. (2005). F or both ALuMA and QBC, we used a fixed n umber of mixing iterations for hit-and-run, which w e set to 1000. W e also fixed the n um ber of sampled h yp otheses at each iteration of ALuMA to 1000, and used the same set of hypotheses 7. Gilad-Bac hrac h et al. (2005) report that the actual mixing time of hit-and-run is m uch faster than the one guaran teed by the theoretical b ounds, and we hav e observed a similar phenomenon in our exp eriments. 14 A ctive Learning of Halfsp aces under a Margin Assumption d ALuMA QBC CAL ERM 10 29 50 308 1008 12 38 113 862 3958 15 55 150 2401 > 20000 T able 1: Octahedron: Number of iterations to achiev e zero error to calculate the ma jority v ote for classification. CAL and QBC examine the examples sequen tially , thus the input provided to them was a random ordering of the example p o ol. Since the activ e learners op erate b y reducing the training error, the graphs w e show compare the training errors of the different algorithms. The test errors show a similar trend. In eac h of the algorithms, the classification of the training examples is done using the v ersion space defined b y the queried labels. The theory for CAL and ERM allo ws selecting an arbitrary predictor out of the version space. In QBC, the h yp othesis should b e dra wn uniformly at random from the v ersion space. How ever, we ha v e found that all the algorithms sho w a significan t improv ement in classification error if they classify using the ma jorit y vote classification prop osed for ALuMA. Therefore, in all of our exp eriments, the results for all the algorithms are based on a ma jorit y v ote classification. The first exp eriment is synthetic: the po ol of examples is taken to b e the support of the distribution describ ed in Example 2 (the o ctahedron example), with an additional dimension to account for halfspaces with a bias. W e also added the negative vertices − e i to the p ool. Similarly to the pro of of Theorem 1, it suffices to query the vertices of the o ctahedron to reac h zero error. T able 1 lists the n um b er of iterations required in practice to ac hiev e zero error b y each of the algorithms. ALuMA is clearly muc h b etter than QBC and CAL. F urthermore, the num b er of queries ALuMA requires is indeed close to the n um ber of v ertices. The second batc h of exp eriments is with the MNIST dataset. 8 The examples in this dataset are gray-scale images of handwritten digits in dimension 784. Each digit has ab out 6 , 000 training examples. W e performed binary active learning by pre-selecting pairs of digits. Figure 1 and Figure 2 depict the training error as a function of the lab el budget when learning to distinguish the digits 3 and 5, and b etw een the digits 4 and 7. Both these digits pairs are linearly separable in this dataset. Figure 1 depicts the error as a function of the lab el budget. It is striking to observe that CAL provides no impro vemen t ov er passiv e ERM in the first 1000 examples, while this budget suffices to reach zero training error for ALuMA. W e also tested the effectiveness of our approach for data with lab eling errors (see Sec- tion 6). T o this end w e applied the prepro cessing algorithm listed in Alg. 2 to the linear represen tation of the digits 2 and 3, whic h are not separable in the original represen tation. Applying the Johnson-Lindenstrauss pro jection to the enhanced represen tation resulted in a separable represen tation in dimension 800. Figure 3 depicts the p erformance of ALuMA, CAL, QBC and ERM, all on the transformed separable representation. Finally , to test the use of k ernel representations, w e generated a dataset in whic h t wo digits (4 and 7) are lab eled as p ositive, and tw o other digits (3 and 5) are lab eled as negativ e, and used a kernel 8. h ttp://y ann.lecun.com/exdb/mnist/ 15 Gonen, Saba to and Shalev-Shw ar tz Figure 1: MNIST 3 vs. 5 Figure 2: MNIST 4 vs. 7 Figure 3: MNIST 2 vs. 3 (non-separable). Figure 4: MNIST 4,7 vs. 3,5 with kernel RBF. RBF representation so that the data is separable. The prepro cessing step resulted in a separable represen tation in dimension 700. The results of running each of the algorithms on this representation are depicted in Figure 4. Note that QBC do es not use the entire budget of lab els in this experiment. This is b ecause the mec hanism b y whic h QBC selects an example takes a v ery long time when the training error is small, thus w e w ere not able to run it long enough so that it uses its full label budget. W e also tested the algorithms on the PCMAC dataset. 9 This is a real-w orld data set, whic h represents a tw o-class categorization of the 20-Newsgroup collection. The examples are w eb-p osts represen ted using bag-of-words. The original dimension of examples is 7511. W e used the Johnson-Lindenstrauss pro jection to reduce the dimension to 300, whic h kept the data still separable. W e used a training set of 1000 examples. Figure 5 depicts the results. Here to o w e w ere not able to run QBC long enough to use its en tire budget. The exp erimen ts on MNIST and PCMAC sho w that ALuMA is sup erior to CAL and QBC for real-w orld distributions, in which CAL and QBC hav e no theoretical analysis. The next exp eriment sho ws that ALuMA outperforms CAL and QBC ev en on a data sampled 9. h ttp://vik as.sindhw ani.org/datasets/lskm/matlab/pcmac.mat 16 A ctive Learning of Halfsp aces under a Margin Assumption Figure 5: PCMAC Figure 6: Uniform distribution ( d = 10). Figure 7: Uniform distribution ( d = 100). from the uniform distribution on a sphere, whic h is the distribution with the best guaran tees for b oth CAL and QBC. Figure 6 and Figure 7 depict the training error as a function of the lab el budget when learning a random halfspace ov er the uniform distribution in R 10 and in R 100 . Here to o, CAL requires many more lab els than ALuMA requires. F or R 100 , it impro v es ov er passiv e learning only long after ALuMA has reached zero training error. The difference b et w een the p erformance of the different algorithms is less marked for d = 10 than for d = 100, suggesting that the difference gro ws with the dimension. 9. Discussion W e studied active learning of halfspaces under a margin assumption. W e hav e shown that a large margin assumption alone cannot guarantee a uniform improv emen t in label complexit y o v er passiv e learning. Ho w ev er, the margin assumption enables us to deriv e an algorithm with regret-t ype guarantees: it will not query man y more labels than OPT, where OPT is the minimal n um ber of queries required to ac hiev e zero training error on the given po ol of examples, in the worst-case ov er the target hypotheses. An op en problem, which we leav e for future w ork, is whether one can b e efficien tly comp etitiv e with respect to a relaxed definition of OPT, one which only requires ac hieving zero training error with high probability , and only if the target hypothesis separates the training set with a margin γ . 17 Gonen, Saba to and Shalev-Shw ar tz References E.M. Arkin, H. Meijer, J.S.B. Mitchell, D. Rappaport, and S.S. Skiena. Decision trees for geometric mo dels. In Pr o c e e dings of the ninth annual symp osium on Computational ge ometry , pages 369–378. ACM, 1993. M.F. Balcan, A. Beygelzimer, and J. Langford. Agnostic activ e learning. In Pr o c e e dings of the 23r d international c onfer enc e on Machine le arning , pages 65–72. A CM, 2006a. M.F. Balcan, A. Blum, and S. V empala. Kernels as features: On kernels, margins, and lo w-dimensional mappings. Machine L e arning , 65(1):79–94, 2006b. M.F. Balcan, A. Bro der, and T. Zhang. Margin based activ e learning. L e arning The ory , pages 35–50, 2007. A. Beygelzimer, S. Dasgupta, and J. Langford. Imp ortance w eigh ted activ e learning. In Pr o c e e dings of the 26th A nnual International Confer enc e on Machine L e arning , pages 49–56. A CM, 2009. J. Bourgain. On lipschitz embedding of finite metric spaces in hilb ert space. Isr ael Journal of Mathematics , 52(1):46–52, 1985. G. Bright w ell and P . Winkler. Counting linear extensions is #p-complete. In Pr o c e e dings of the twenty-thir d annual ACM symp osium on The ory of c omputing , STOC ’91, pages 175–181, 1991. D. Cohn, L. Atlas, and R. Ladner. Improving generalization with activ e learning. Machine L e arning , 15(2):201–221, 1994. N. Cristianini and J. Sha w e-T a ylor. Kernel Metho ds for Pattern Analysis . Cambridge Univ ersit y Press, 2004. S. Dasgupta. Coarse sample complexity b ounds for active learning. A dvanc es in neur al information pr o c essing systems , 18:235, 2006. S. Dasgupta, A. Kalai, and C. Monteleoni. Analysis of p erceptron-based active learning. L e arning The ory , pages 889–905, 2005. Y. F reund, H.S. Seung, E. Shamir, and N. Tishb y . Selective sampling using the query by committee algorithm. Machine le arning , 28(2):133–168, 1997. E. F riedman. Active learning for smo oth problems. In Pr o c e e dings of the 22nd Confer enc e on L e arning The ory , volume 1, pages 3–2, 2009. R. Gilad-Bachrac h, A. Nav ot, and N. Tish by . Query b y committee made real. A dvanc es in Neur al Information Pr o c essing Systems (NIPS) , 19, 2005. D. Golo vin and A. Krause. Adaptiv e submodularity: A new approac h to active learning and sto c hastic optimization. In Pr o c e e dings of International Confer enc e on L e arning The ory (COL T) , 2010. 18 A ctive Learning of Halfsp aces under a Margin Assumption S. Hannek e. T eac hing dimension and the complexit y of active learning. In COL T , 2007. S. Hannek e. Adaptiv e rates of con v ergence in active learning. In COL T , 2009. W. Johnson and J. Lindenstrauss. Extensions of lipsc hitz mapping in to hilb ert space. Contemp or ary Mathematics , 26:189–206, 1984. R. Kannan, L. Lov´ asz, and M. Simonovits. Random w alks and an o ∗ ( n 5 ) v olume algorithm for con vex b o dies. R andom structur es and algorithms , 11(1):1–50, 1997. L. Lo v´ asz. Hit-and-run mixes fast. Mathematic al Pr o gr amming , 86(3):443–461, 1999. J. Matou ˇ sek. L e ctur es on discr ete ge ometry , volume 212. Springer V erlag, 2002. A. McCallum and K. Nigam. Emplo ying em in po ol-based active learning for text classifi- cation. In Pr o c e e dings of ICML-98, 15th International Confer enc e on Machine L e arning , pages 350–358, 1998. Siv an Sabato, Nathan Srebro, and Naftali Tishb y . Tight sample complexity of large-margin learning. In A dvanc es in Neur al Information Pr o c essing Systems 23 (NIPS) , pages 2038– 2046, 2010. B. Sch¨ olkopf and A. J. Smola. L e arning with Kernels: Supp ort V e ctor Machines, R e gular- ization, Optimization and Beyond . MIT Press, 2002. H.S. Seung, M. Opp er, and H. Somp olinsky . Query by committee. In Pr o c e e dings of the fifth annual workshop on Computational le arning the ory , pages 287–294. A CM, 1992. C.E. Shannon. Probabilit y of error for optimal co des in a gaussian c hannel. Bel l System T e chnic al Journal , 38:611–656, 1959. S. T ong and D. Koller. Supp ort v ector machine activ e learning with applications to text classification. The Journal of Machine L e arning R ese ar ch , 2:45–66, 2002. App endix A. Analysis of ALuMA In this section w e pro v e Theorem 2 by showing that ALuMA satisfies the conditions of the theorem. First, note that eac h step in Alg. 1 runs in polynomial time in N , m, d and ln(1 /δ ). Since eac h step is rep eated at most N ≤ m times, ALuMA is p olynomial in m, d and ln(1 /δ ). This pro v es item (3) of Theorem 2. In the following we prov e items (1) and (2), follo wing the pro of outline describ ed in Section 5. The result will b e stated formally as Corollary 15. A.1 ALuMA Increases the Utilit y F unction F ast Recall that in Equation (4) we defined a utility function f , that measures the progress of our algorithm. In this section we redefine f using a slightly differen t notation. Let H b e 19 Gonen, Saba to and Shalev-Shw ar tz the hypothesis class induced b y homogeneous halfspaces in R d . W e define a version space of a partial realization as a subset of H as follows: V ( P t ) = { h ∈ H : ∀ ( x, y ) ∈ P t , h ( x ) = y } . W e further define the probabilit y mass of a set G ⊆ H b y P ( G ) = P w ∼ U ( { w ∈ B d 1 | ∃ h ∈ G, ∀ x ∈ R d , h ( x ) = sgn( h w , x i ) } ) , where U is the uniform distribution o v er B d 1 . Consequently , the exp ected v alue of a random v ariable, g : H → R , is defined as E h [ g ( h )] = Z h ∈H g ( h ) P ( dh ) . The utilit y function f for h ∈ H and S ⊆ X is thus f ( h | S ) = 1 − P ( V ( h | S )) = P ( H \ V ( h | S )) . (7) Let L X, H = { h | X 0 : X 0 ⊆ X , h ∈ H} b e the set of all p ossible partial lab elings of X by a h yp othesis in H . A p olicy is any function π : L X, H → X . F or a p olicy π , an in teger k , and a h ypothesis h ∈ H , we denote by S ( π , h, k ) the first k (example,label) pairs queried b y π , under the assumption that L = h | X . That is, S ( π , h, 1) = { ( π ( ∅ ) , h ( π ( ∅ ))) } , and S ( π , h, k ) = S ( π , h, k − 1) ∪ { ( π ( S ( π , h, k − 1)) , h ( π ( S ( π , h, k − 1)))) } . The expected utilit y of applying p olicy π for k steps is f avg ( π , k ) = E h [ f ( S ( π, h, k ))] . In this section w e show that ALuMA increases f avg almost as fast as any other p olicy , including the optimal one. W e pro v e that with probability at least 1 − δ / 2, for any policy π and any n, k > 0, f avg ( ALuMA , n ) ≥ f avg ( π , k ) − e − n 4 k . (8) T o prov e this inequalit y we present the notion of an adaptive sub-mo dular function, first defined in Golovin and Krause (2010). Let f : L X, H → R + b e any utility function from the set of p ossible partial lab elings of X to the non-negative reals. W e define the notions of adaptive monotonicity and adaptive submo dularity of a utilit y function using the follo wing notation: F or an element x ∈ X , a subset Z ⊆ X and a h ypothesis h ∈ H , w e define the conditional exp ected marginal benefit of x , conditioned on having observed the partial lab eling h | Z , b y ∆( h | Z , x ) = E g f ( g | Z ∪{ x } ) − f ( g | Z ) g | Z = h | Z . Put another wa y , ∆( h | Z , x ) is the exp ected impro v emen t of f if we add to Z the element x , where exp ectation is o v er a choice of a hypothesis g tak en uniformly at random from the set of hypotheses that agree with h on Z . 20 A ctive Learning of Halfsp aces under a Margin Assumption Definition 6 (Adaptiv e Monotonicit y) A utility function f : L X, H → R + is adaptiv e monotone if the c onditional exp e cte d mar ginal b enefit is always non-ne gative. That is, if for al l h ∈ H , Z ⊆ X and x ∈ X , ∆( h | Z , x ) ≥ 0 . Definition 7 (Adaptiv e Submo dularit y) A function f : L X, H → R + is adaptiv e sub- mo dular if the c onditional exp e cte d mar ginal b enefit of a given item do es not incr e ase if the p artial lab eling is extende d. That is, if for al l h ∈ H , for al l Z 1 ⊆ Z 2 ⊆ X ,and for al l x ∈ X , ∆( h | Z 1 , x ) ≥ ∆( h | Z 2 , x ) . The cen tral theorem of adaptiv e submodularity , stated b elo w as Theorem 9, links the exp ected utilit y of the optimal p olicy for maximizing f avg with the exp ected utilit y of an appro ximately-greedy policy . Definition 8 (Appro ximate Greedy) L et α ≥ 1 . A p olicy π : L X, H → X is α -appro ximately greedy with r esp e ct to a utility function f if for every h and for every Z ⊆ X ∆( h | Z , π ( h | Z )) ≥ 1 α max x ∈ X ∆( h | Z , x ) . (9) Theorem 9 (Golo vin and Krause (2010)) L et f : L X, H → R + b e a utility function, and let π : L X, H → X b e a p olicy. If f is adaptive monotone and adaptive submo dular, and π is α -appr oximately gr e e dy, then for any p olicy π ∗ and for al l p ositive inte gers n, k , f avg ( π , n ) ≥ (1 − e − n αk ) f avg ( π ∗ , k ) . (10) In the activ e learning setting, w e define the utilit y function f as in Equation (7) and ha v e the follo wing result: Lemma 10 (Golo vin and Krause (2010)) The function f define d in Equation (7) is adaptive monotone and adaptive submo dular. Therefore Theorem 9 holds for this utility function. It follows that for an y α -appro ximate greedy policy π , an y policy π ∗ and an y integers n, k > 0, f avg ( π , n ) ≥ (1 − e − n αk ) f avg ( π ∗ , k ) ≥ f avg ( π ∗ , k ) − e − n αk . (11) In order to prov e that Equation (8) holds, w e now sho w that the p olicy implemen ted by ALuMA is approximately greedy relativ e to f , with high probabilit y o ver the randomization of ALuMA. Theorem 11 With pr ob ability at le ast 1 − δ / 2 , the p olicy applie d by ALuMA is a 4 - appr oximately gr e e dy p olicy with r esp e ct to the utility function f define d in Equation (7). Pro of Define λ = 1 / 3 and α = 1+ λ 1 − λ 2 = 4. W e need to show that for any Z ⊆ X , our p olicy selects an elemen t x that approximately maximizes ∆( h | Z , x ) = E g ∼ U f ( g | Z ∪{ x } ) − f ( g | Z ) g | Z = h | Z = P ( V 1 t,x ) · ( P ( V ( h | Z )) − P ( V ( h | Z ∪ { ( x, 1) } )))+ P ( V − 1 t,x ) · ( P ( V ( h | Z ) − P ( V ( h | Z ∪ { ( x, − 1) } )))) = 2 P ( V 1 t,x ) P ( V − 1 t,x ) . 21 Gonen, Saba to and Shalev-Shw ar tz Therefore it suffices to sho w that for all x ∈ X and for all iterations t , P ( V 1 t,x t ) P ( V − 1 t,x t ) ≥ 1 α P ( V 1 t,x ) P ( V − 1 t,x ) . where x t is the element chosen by ALuMA at iteration t . By line 6 of Alg. 1, we select x t ∈ X t that maximizes ˆ v x, 1 · ˆ v x, − 1 , where ˆ v x,j ← V olEst( V j t,x , λ, δ 4 mN ) , j ∈ {± 1 } . Since ALuMA calls V olEst at most 2 mN times in total, b y Lemma 4 with probabilit y 1 − δ / 2, for all x ∈ X , j ∈ {± 1 } , t ∈ [ N ], P ( V j t,x ) 1 + λ < ˆ v x,j < P ( V j t,x ) 1 − λ . (12) Therefore, for all x ∈ X , j ∈ {± 1 } , t ∈ [ N ], P ( V 1 t,x ) P ( V − 1 t,x ) (1 + λ ) 2 < ˆ v x, 1 · ˆ v x, − 1 < P ( V 1 t,x ) P ( V − 1 t,x ) (1 − λ ) 2 . Let x ∗ t = argmax x ∈ X ∆( h | X , x ) = argmax x ∈ X ( P ( V 1 t,x ) P ( V − 1 t,x )). Then P ( V 1 t,x ∗ t ) P ( V − 1 t,x ∗ t ) (1 + λ ) 2 < ˆ v x ∗ t , 1 · ˆ v x ∗ t , − 1 < ˆ v x t , 1 · ˆ v x t , − 1 < P ( V 1 t,x t ) P ( V − 1 t,x t ) (1 − λ ) 2 Therefore P ( V 1 t,x t ) P ( V − 1 t,x t ) ≥ (1 − λ ) 2 (1 + λ ) 2 P ( V 1 t,x ∗ t ) P ( V − 1 t,x ∗ t ) . Since 4 = α = (1+ λ ) 2 (1 − λ ) 2 this pro ves that our p olicy is 4-approximately greedy . A.2 Comparing to OPT By Theorem 11, ALuMA implemen ts an approximately greedy p olicy . In addition, b y Equation (11), any approximately greedy p olicy reduces the version space almost as fast as an y other policy , including the optimal one. While these results seem promising, they are not enough for our needs. Recall that our true ob jectiv e is not to ha v e a small v ersion space but rather to be able to correctly lab el all the examples in X . Therefore, w e m ust quan tify ho w the size of the version space corresp onds to this ob jectiv e. The first issue with Equation (11) is that it do es not provide a worst-case guaran tee, since f avg a v erages ov er all h ∈ H . It should b e noted that Golovin and Krause (2010) deriv e a w orst-case guaran tee as well, but their approach requires that the utility function receiv e discrete v alues, whic h clearly do es not hold in our case. The follo wing lemma helps solv e this issue, b y pro viding a guarantee which holds individually for any h ∈ H . 22 A ctive Learning of Halfsp aces under a Margin Assumption Lemma 12 L et π ∗ b e a p olicy that achieves OPT , that is c wc ( π ∗ ) = OPT . F or any h ∈ H , any α -appr oximate gr e e dy p olicy π , and any n , f avg ( π ∗ , OPT) − f avg ( π , n ) ≥ P ( V ( h | X )) ( P ( V ( S ( π , h, n ))) − P ( V ( h | X ))) . Pro of Since π ∗ is an optimal p olicy , the version space induced b y the lab els π ∗ queried within OPT iterations is exactly the set of hypotheses which are consistent with the true lab els of the sample. Therefore, for an y h ∈ H . P ( V ( S ( π ∗ , h, OPT))) = P ( V ( h | X )) . By definition of f avg , f avg ( π ∗ , OPT) − f avg ( π , n ) = E h ∼ U [ P ( V ( S ( π , h, n ))) − P ( V ( S ( π ∗ , h, OPT)))] = E h ∼ U [ P ( V ( S ( π , h, n ))) − P ( V ( h | X ))] . Since S ( π , h, n ) does not dep end on the v alue of h outside of X , w e can sum o v er the possible lab elings of X to ha v e f avg ( π ∗ , OPT) − f avg ( π , n ) = X h | X : h ∈H P ( V ( h | X ))( P ( V ( S ( π , h | X , n ))) − P ( V ( h | X ))) . No w, it is easy to see that for an y h ∈ H , V ( S ( π , h | X , n ))) ⊇ V ( h | X ), th us P ( V ( S ( π , h | X , n ))) − P ( V ( h | X )) ≥ 0 . It follo ws that for an y h ∈ H f avg ( π ∗ , OPT) − f avg ( π , n ) ≥ P ( V ( h | X ))( P ( V ( S ( π , h | X , n ))) − P ( V ( h | X ))) . Com bining Equation (11) and Lemma 12 we conclude that for any α -appro ximate greedy p olicy π , ∀ h ∈ H , P ( V ( h | X ))( P ( V ( S ( π , h | X , n ))) − P ( V ( h | X ))) ≤ e − n α OPT , whic h yields ∀ h ∈ H , P ( V ( h | X )) P ( V ( S ( π , h, n ))) ≥ P ( V ( h | X )) 2 e − n α OPT + P ( V ( h | X )) 2 . (13) This means that if P ( V ( h | X )) is large enough and w e run an appro ximate greedy p olicy , then after a sufficient n um b er of iterations, most of the remaining version space induces the correct lab eling of the sample. W e no w sho w that under the margin assumption, P ( V ( h | X )) is indeed b ounded from below. 23 Gonen, Saba to and Shalev-Shw ar tz A.3 Using the Margin Assumption Denote b y H γ the subset of H whic h has margin γ on the unlabeled sample X , that is H γ = { h ∈ H | ∃ w ∈ B d 1 s.t. ∀ x ∈ X , h ( x ) h w , x i ≥ γ } . Our b ound on the num b er of queries for a h yp othesis with a margin hinges on the fact that P ( V ( h | X )) is large enough if h has a margin on X . This is quan tified in the following lemma. Lemma 13 F or al l h ∈ H γ , P ( V ( h | X )) ≥ γ 2 d . Pro of Fix some h ∈ H γ . Let w ∈ B d 1 suc h that ∀ x ∈ X , h ( x ) h w, x i ≥ γ . F or a given v ∈ B d 1 , denote b y h v ∈ H the mapping x 7→ sgn( h v , x i ). Note that for all v ∈ B d 1 suc h that k w − v k < γ , h v ∈ V ( h | X ). This is because for all x ∈ X , h ( x ) h v , x i = h v − w , h ( x ) · x i + h ( x ) h w , x i ≥ −k w − v k · k h ( x ) · x k + γ > − γ + γ = 0 , whic h implies sgn( h v , x i ) = h ( x ). It follows that { v | h v ∈ V ( h | X ) } ⊇ B d 1 ∩ B ( w, γ ), where B ( z , r ) denotes the ball of radius r with center at z . Let u = (1 − γ / 2) w . Then for any z ∈ B ( u, γ / 2), w e hav e z ∈ B d 1 , since k z k = k z − u + u k ≤ k z − u k + k u k ≤ γ / 2 + 1 − γ / 2 = 1 . In addition, z ∈ B ( w , γ ) since k z − w k = k z − u + u − w k ≤ k z − u k + k u − w k ≤ γ / 2 + γ / 2 = γ . Therefore B ( u, γ / 2) ⊆ B d 1 ∩ B ( w, γ ) . W e conclude that { v | h v ∈ V ( h | X ) } ⊇ B ( u, γ / 2). Th us, P ( V ( h | X )) ≥ V ol( B ( u, γ / 2)) / V ol( B d 1 ) ≥ γ 2 d . W e can now ensure that most of the remaining v ersion space induces the correct lab eling. The follo wing theorem is a direct consequence of combining Lemma 13 with Equation (13). Theorem 14 F or any h ∈ H γ , any α -appr oximate gr e e dy p olicy π , and any n ≥ α · OPT · (2 d ln(2 /γ ) + ln(2)) , we have P ( V ( h | X )) P ( V ( S ( π , h, n ))) > 2 3 . (14) W e are no w ready to pro ve items (1) and (2) of Theorem 2. 24 A ctive Learning of Halfsp aces under a Margin Assumption Corollary 15 If ALuMA is exe cute d for n ≥ 4 · OPT · (2 d ln(2 /γ ) + ln(2)) iter ations, then with pr ob ability at le ast 1 − δ ALuMA r eturns the c orr e ct lab eling of al l the elements of X . Pro of By Theorem 11, with probability at least 1 − δ / 2 ALuMA runs a 4-approximately greedy p olicy . Therefore, if n satisfies our assumption, then Equation (14) holds. Since V ( h | X ) ⊆ V ( S ( π , h, n )) = V n , it follows that the probability of dra wing a hypothesis from V ( h | X ) when dra wing uniformly from V n is at least 2 3 . In step 12 of ALuMA, M ≥ 72 ln(2 /δ ) h yp otheses are dra wn 1 12 -uniformly at random from V n . Therefore each h yp othesis h i is from V ( h | X ) with probability at least 7 12 . By Ho effding’s inequalit y , P ( 1 M M X i =1 I [ h i ∈ V ( h | X )) ≤ 1 2 ] ≤ exp( − M / 72) = δ 2 . Therefore, with probabilit y 1 − δ / 2 the ma jority vote ov er the drawn hypotheses pro vides the correct label for all x ∈ X . In total, the correct lab eling is returned with probabilit y 1 − δ . App endix B. Analysis of the Prepro cessing Pro cedure W e now pro v e Theorem 3 by sho wing that Alg. 2 satisfies the claims of the theorem. It is clear that Alg. 2 is p olynomial as required in item (3). In addition, item (1) holds from the definition of Alg. 2. W e hav e left to prov e item (2). W e first pro v e that it holds for the case where the input is represen ted directly as X ⊆ R d . W e start b y showing that under the assumption of Theorem 3, the set { x 0 1 , . . . , x 0 m } , whic h is generated in step 8, is separated with a b ounded margin b y the original lab els of x i . Fix γ > 0 and w ∗ ∈ B d 1 . F or each i ∈ [ m ], define ` i = max(0 , γ − L ( i ) h w ∗ , x i i ) . Th us, ` i quan tifies the margin violation of example x i b y w ∗ , relative to its true lab el L ( i ). Lemma 16 If H ≥ P m i =1 ` 2 i , wher e H is the input to A lg. 2, then ther e is a w ∈ B d + m 1 such that for al l i ∈ [ m ] , L ( i ) h w, x 0 i i ≥ γ 1+ √ H . Pro of By step 8 in Alg. 2, x 0 i = ( a · x i ; √ 1 − a 2 · e i ), where a = q 1 1+ √ H . Define w 0 = ( w ∗ ; a √ 1 − a 2 ( L (1) ` 1 , . . . , L ( m ) ` m )) . Then L ( i ) h w 0 , x 0 i i = aL ( i ) h w ∗ , x i i + a` i ≥ a ( γ − ` i ) + a` i = aγ . Let w = w 0 k w 0 k . Then w ∈ B d + m 1 , and L ( i ) h w , x 0 i i = L ( i ) h w 0 , x 0 i i k w 0 k ≥ aγ q 1 + a 2 1 − a 2 P m i =1 ` 2 i = γ q 1 a 2 + 1 1 − a 2 P m i =1 ` 2 i . 25 Gonen, Saba to and Shalev-Shw ar tz Set a 2 = 1 1+ √ H , and assume H ≥ P m i =1 ` 2 i . Then L ( i ) h w , x 0 i i ≥ γ 1 + √ H . The set { ¯ x 1 , . . . , ¯ x m } returned by Alg. 2 is a Johnson-Lindenstrauss pro jection of { x 0 1 , . . . , x 0 m } on R k . It is known (see e.g. Balcan et al. (2006b)) that if a set of m p oin ts is separable with margin η and k ≥ O ln( m/δ ) η 2 , then with probabilit y 1 − δ , the pro jected p oin ts are separable with margin η / 2. Setting η = γ 1+ √ H , it is easy to see that step 12 in Alg. 2 indeed main tains the desired margin. This completes the pro of of item (2) of Theorem 3 for the case where the input is X ⊆ R m . W e now show that if the input is a kernel matrix K , then the decomp osition step 3 preserv es the separation prop erties of the input data, th us showing that item (2) holds in this case as well. T o sho w that our decomp osition step does not c hange the properties of the original data, w e first use the following lemma, which indicates that separation properties are conserv ed under differen t decompositions of the same kernel matrix. Lemma 17 (Sabato et al. (2010), Lemma 6.3) L et K ∈ R m × m b e an invertible PSD matrix and let V ∈ R m × n , U ∈ R m × k b e matric es such that K = V V T = U U T . F or any ve ctor w ∈ R n ther e exists a ve ctor u ∈ R k such that V w = U u and k u k ≤ k w k . The next lemma extends the ab ov e result, sho wing that the property holds even if K is not in vertible. Lemma 18 L et K ∈ R m × m b e a PSD matrix and let V ∈ R m × n , U ∈ R m × k b e matric es such that K = V V T = U U T . F or any ve ctor w ∈ R n ther e exists a ve ctor u ∈ R k such that V w = U u and k u k ≤ k w k . Pro of F or a matrix A and sets of indexes I , J let A [ I ] b e the sub-matrix of A whose ro ws are the rows of A with an index in I . Let A [ I , I ] b e the sub-matrix of A whose rows and columns are those that ha v e index I in A . If K is in v ertible, the claim holds b y Lemma 17. Thus, assume K is singular. Let I ⊆ [ m ] b e a maximal subset such that the matrix K [ I ; I ] is inv ertible—If no such subset exists then K , V , U are all zero and the claim is trivial. By Lemma 17, K [ I ; I ] = V [ I ]( V [ I ]) T = U [ I ]( U [ I ]) T , and there exists a v ector u suc h that V [ I ] w = U [ I ] u , and k u k ≤ k w k . W e will sho w that for an y i / ∈ I , V [ i ] w = U [ i ] u as well. F or any i / ∈ I , K [ I ∪ { i } ; I ∪ { i } ] is singular. Therefore V [ I ∪ { i } ] is singular, while V [ I ] is not. Th us there is some vector λ ∈ R | I | suc h that V [ i ] T = V [ I ] T λ . By a similar argumen t there is some vector η ∈ R | I | suc h that U [ i ] T = U [ I ] T η . W e hav e K [ I , i ] = V [ I ] V [ i ] T = V [ I ] V [ I ] T λ = K [ I , I ] λ . Similarly for U , K [ I , i ] = K [ I , I ] η . There- fore K [ I , I ]( λ − η ) = 0. Since K [ I , I ] is in v ertible, it follo ws that λ = η . Therefore, U [ i ] u = η T U [ I ] u = λ T V [ I ] w = V [ i ] w . W e no w use this lemma to show that the decomp osition step do es not change the upp er b ound on the margin loss which is assumed in Theorem 3. 26 A ctive Learning of Halfsp aces under a Margin Assumption Theorem 19 L et ψ 1 , . . . , ψ m b e a set of ve ctors in a Hilb ert sp ac e S , and let K ∈ R m × m such that for al l i, j ∈ [ m ] , K i,j = h ψ i , ψ j i . supp ose ther e exists a w ∈ S with k w k ≤ 1 such that H ≥ m X i =1 max(0 , γ − y i h w , ψ i i ) 2 . (15) L et U ∈ R m × k such that K = U U T and let x i b e r ow i of U . Then ther e exists a u ∈ B k 1 such that H ≥ m X i =1 max(0 , γ − y i h u, x i i ) 2 . (16) Pro of Let α 1 , . . . , α n ∈ S b e an orthogonal basis for the span of ψ 1 , . . . , ψ m and w , and let v 1 , . . . , v m , v w ∈ R n suc h that P n l =1 v i [ l ] α l = ψ i and P n l =1 v w [ l ] α l = w . Let V ∈ R m × n b e a matrix suc h that row i of the matrix is v i . Then K = V V T , and V v w = r , where r [ i ] = h v w , v i i = h w , ψ i i . By Lemma 18, there exists a u ∈ R k suc h that U u = r . Then w e ha v e h u, x i i = r [ i ]. Therefore for all i ∈ [ m ], h w , ψ i i = h u, x i i , th us Equation (15) implies Equation (16). In addition, k u k ≤ k v w k = k w k ≤ 1, therefore u ∈ B k 1 . App endix C. Analysis of the Simpler Implementation The follo wing theorem sho ws that using the estimation pro cedure listed in Alg. 4 also results in an appro ximately greedy p olicy , as do es the original implemen tation of ALuMA. Similarly to the pro of of Corollary 15, it follows that Theorem 2 holds for this implemen tation as w ell. Theorem 20 If for e ach iter ation t of the algorithm, the gr e e dy choic e x ∗ satisfies ∀ j ∈ {− 1 , +1 } , P [ h ( x ∗ ) = j | h ∈ V t ] ≥ 4 √ λ then ALuMA with the estimation pr o c e dur e implements a 2 -appr oximate gr e e dy p olicy. Mor e over, it is p ossible to efficiently verify that this c ondition holds while running the algo- rithm. Pro of Fix the iteration t , and denote p x, 1 = P ( V 1 t,x ) / P ( V t ) and p x, − 1 = P ( V 1 t,x ) / P ( V t ). Note that p x, 1 + p x, − 1 = 1. Since h 1 , . . . , h k are sampled λ -uniformly from the v ersion space, w e hav e ∀ i ∈ [ k ] , | P [ h i ∈ V j t,x ] − p x,j | ≤ λ. (17) In addition, by Hoeffding’s inequality and a union b ound ov er the examples in the p o ol and the iterations of the algorithm, P [ ∃ x, | ˆ v x i ,j − P [ h i ∈ V j t,x ] | ≥ λ ] ≤ 2 m exp( − 2 k λ 2 ) . (18) F rom Alg. 4 we hav e k = ln(2 m/δ ) 2 λ 2 . Combining this with Equation (17) and Equation (18) w e get that P [ ∃ x, | ˆ v x i ,j − p x i ,j ] | ≥ 2 λ ] ≤ δ. 27 Gonen, Saba to and Shalev-Shw ar tz The greedy choice for this iteration is x ∗ ∈ argmax x ∈ X ∆( h | X , x ) = argmax x ∈ X ( P ( p x, 1 ) P ( p x, − 1 )) . By the assumption in the theorem, p x ∗ ,j ≥ 4 √ λ for j ∈ {− 1 , +1 } . Since λ ∈ (0 , 1 64 ), w e ha v e λ ≤ √ λ/ 8. Therefore p x ∗ ,j − 2 λ ≥ 4 √ λ − √ λ/ 4 ≥ √ 10 λ . Therefore ˆ v x ∗ , 1 ˆ v x ∗ , − 1 ≥ ( p x ∗ , 1 − 2 λ )( p x ∗ , − 1 − 2 λ ) ≥ 10 λ. (19) Let ˜ x = argmax( ˆ v x, − 1 ˆ v x, +1 ) be the query selected by ALuMA using Alg. 4. Then ˆ v x ∗ , − 1 ˆ v x ∗ , +1 ≤ ˆ v ˜ x, − 1 ˆ v ˜ x, +1 ≤ ( p ˜ x, 1 + 2 λ )( p ˜ x, − 1 + 2 λ ) ≤ p ˜ x, 1 p ˜ x, − 1 + 4 λ. Where in the last inequality w e used the facts that p ˜ x, 1 + p ˜ x, − 1 = 1 and 4 λ 2 ≤ 2 λ . On the other hand, by Equation (19) ˆ v x ∗ , − 1 ˆ v x ∗ , +1 ≥ 5 λ + 1 2 ˆ v x ∗ , − 1 ˆ v x ∗ , +1 ≥ 5 λ + 1 2 ( p x ∗ , − 1 − 2 λ )( p x ∗ , − 1 − 2 λ ) ≥ 4 λ + 1 2 p x ∗ , − 1 p x ∗ , − 1 . Com bining the t w o inequalities for ˆ v x ∗ , − 1 ˆ v x ∗ , +1 it follo ws that p ˜ x, 1 p ˜ x, − 1 ≥ 1 2 p x ∗ , − 1 p x ∗ , − 1 , Th us this is a 2-appro ximately greedy p olicy . T o v erify that the assumption holds at eac h iteration of the algorithm, note that for all x = x i suc h that i ∈ I t p x, − 1 p x, +1 ≥ ( ˆ v x, − 1 − 2 λ )( ˆ v x, +1 − 2 λ ) ≥ ˆ v x, − 1 ˆ v x, +1 − 2 λ. therefore it suffices to c hec k that for all x = x i suc h that i ∈ I t ˆ v x, − 1 ˆ v x, +1 ≥ 4 √ λ + 2 λ. 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment