A Game Theoretic Approach to Distributed Opportunistic Scheduling
Distributed Opportunistic Scheduling (DOS) is inherently harder than conventional opportunistic scheduling due to the absence of a central entity that has knowledge of all the channel states. With DOS, stations contend for the channel using random ac…
Authors: Albert Banchs, Andres Garcia-Saavedra, Pablo Serrano
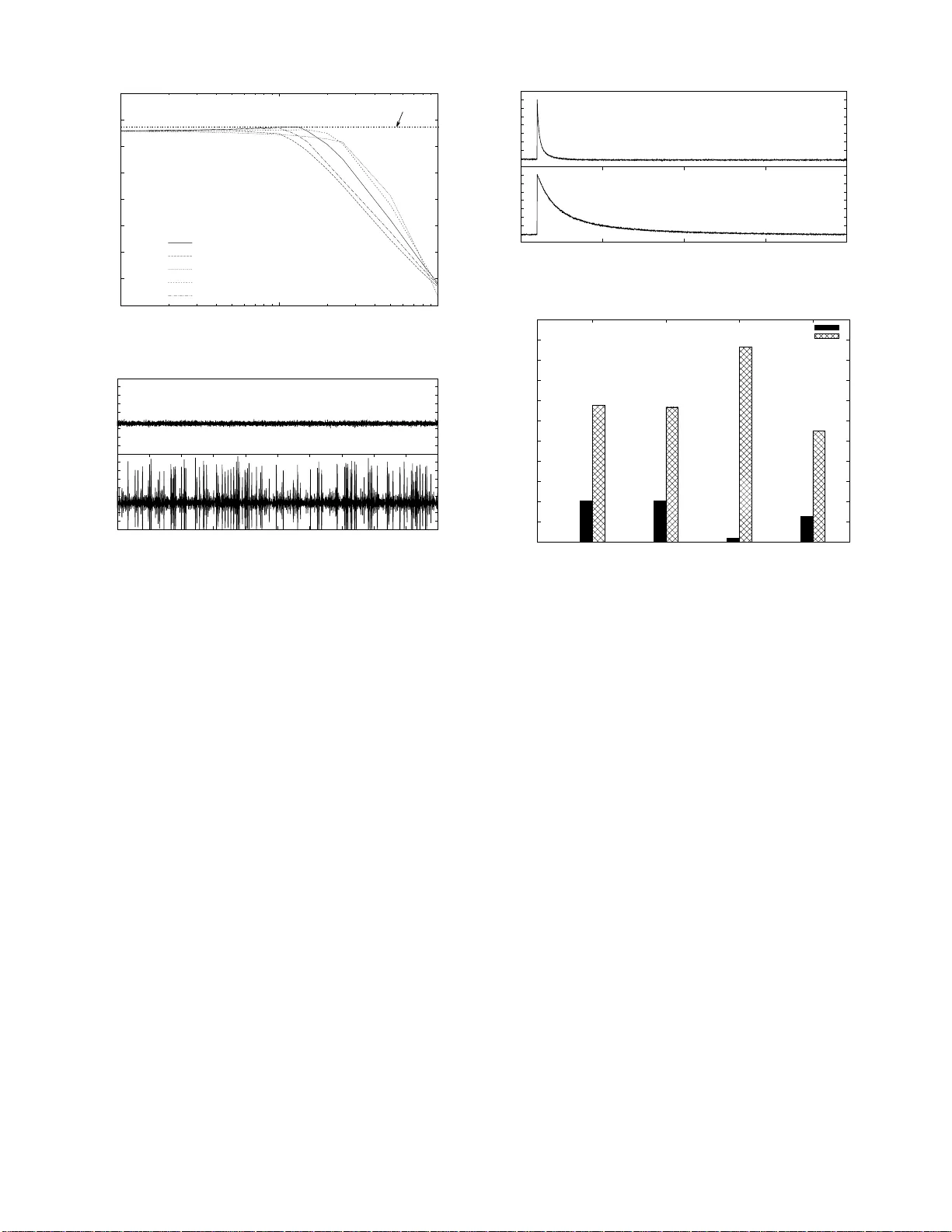
1 A Game Theoretic Approach to Distr ib ute d Opportunistic Scheduling Albert Banchs , Andr ´ es Garc ´ ıa-Saavedra, Pablo Serrano and Jo erg W i dmer Abstract —Distributed Opportun istic S cheduling (DOS ) is in- herently harder than con ventional opportunistic scheduling due to the absence of a central en tity that has knowledge of all the channel states. With DOS, stations contend for the chan nel using random access; after a su ccessful contention, they measure the channel conditions and only transmit in case of a goo d channel, while giving up the transmission opportun ity when the channel conditions are poor . The distributed nature o f DOS systems makes th em vulnerable to selfish users: by deviating from th e protocol and using mor e tra nsmission opportunities, a selfish user can gain a gr eater share of the wir eless resour ces at the expense of the well-behav ed users. In this paper , we addr ess the selfishness problem in DOS from a game th eoretic standpoint. W e propose an algorithm that satisfi es t he following properties: ( i ) when all stations implement the algo rithm, the wireless n etwork is driv en to the optimal point of operation, and ( ii ) one or more selfish stations cannot gain any pr ofit by de viating fr om the algor ithm. The key idea of the algorithm is to react to a selfi sh station by using a more aggressi ve configuration that (indi rectly) punishes this station. W e b uild on multivariable control th eory to design a mechanism for punishment th at on the one hand i s sufficient ly sev ere to pre vent selfish beha vior while on the other hand is light enough to guarantee that, in the absence of selfish behavior , the system is stable and c on verges to the optimum p oint of op eration. W e cond uct a game theoretic analysis based o n repeated games to show the algorithm’ s effectiveness against selfish stations. These results ar e confi rmed by extensive simulations. I . I N T RO D U C T I O N Opportu nistic scheduling te chnique s hav e been shown to provide substantial perfo rmance improvements in wireless networks. These tech niques take adv antage of the fluctuatio ns in the channel conditions of the different wireless stations; by selecting the station with the best instan taneous chan nel for data transmission, opportunistic scheduling can utilize wireless resource mo re efficiently . A key assump tion of most o ppor- tunistic schedulin g techniq ues [1], [2] is that the schedu ler is centralized and ha s kn owledge of the instantaneo us channel condition s of a ll station s. Distributed Opportu nistic Scheduling (DOS) techn iques [3]–[6] have been pr oposed on ly recently . In contrast to centralized schemes, with DOS each station has to make scheduling d ecisions withou t knowledge o f the ch annel co n- ditions o f the other stations. Stations conten d for the chan nel using r andom access with a giv en access pro bability . After successful co ntention, a station measures the chan nel and, in case of p oor channel co nditions (i.e., whe n the instantaneo us transmission r ate is below a given threshold), th e station A. Banchs is with the Uni versity Carlos III of Madrid and with the Institute IMDEA Networks. A. Garc ´ ıa-Saa vedra and P . Serrano are with the Uni versi ty Carlos III of Madrid. J. Widmer is wit h the Institute IMDEA Networks. giv es u p the transmission oppor tunity . This allows a ll stations to recontend for the c hannel, lettin g a station with b etter condition s win the contention, whic h increases the overall throug hput. In this way , DOS techniques exploit both multi- user d iv e rsity across stations and time diversity across slots. The absence of g lobal chann el inf ormation makes DOS systems very vulner able to selfish users. By d eviating fro m the ab ove pr otocol an d u sing a more ag gressive configu ration, a selfish user can easily gain a gr eater share of the wireless resources at the expense of the other, well- behaved user s. In this paper , we addre ss the selfishness problem in DOS from a game theoretic standpoint. In our formulatio n o f the problem, the players are the wir eless stations that implement D OS and stri ve to obtain as much resour ces as p ossible from the wireless network. W e show tha t, in the absence of penalties, the wireless network naturally tends to either great un fairness or network collapse. Following this re sult, we d esign a p enalty mechanism in which any player wh o misbeha ves will be pun- ished b y o ther players in such a way that there is no incenti ve to misbe have. A key challenge when de signing such a p enalty scheme is to carefu lly ad just the punishm ent inflicted upon a misbehaving station. On the one hand side, if the punishmen t is too light, a selfish station may still b enefit from misbehaving. On th e other h and, an ov erreaction may itself be interpreted as misbehavior and co uld trigger punishmen t by other stations, leading to an en dless sp iral of increasing punishmen ts and a th rough put collap se. Addr essing this challenge th rough a combinatio n of ga me theory and m ultiv aria ble co ntrol theory is a key p art o f o ur d esign. The m ost r elev ant p rior work on DOS b y Zh eng et al. [3] sets th e basic foun dations of distributed opp ortunistic sch edul- ing. The authors prop ose a mechanism based on optimal stopping theory and analy ze its p erform ance both with well- behaved an d with selfish users. T he aim of the a lgorithm is to maximize th e total throug hput of the n etwork. [4]–[6] exten d the basic mechanism of [3] by an alyzing the case of im perfect channel information [4], improving channel estimation through two-le vel channel pr obing [ 5], and incor porating delay co n- straints [6]. While our alg orithm deals with the basic DOS mechanism of [3], it co uld be extended with the en hancem ents of [ 4]–[6]. T he key contributions of our work are: 1) W e perfo rm a joint optimization of both the transmission rate thr esholds a nd th e access probab ilities, while [3] only op timizes the th resholds. 2) W e pr ovide a proportio nally fair allocation th at achieves a good tr adeoff between total throu ghput and fairness, while [3] max imizes the total th roug hput of the network, which may lead to starvation of the stations with p oor 2 channel co ndition s. 3) W e pr opose a simple algorith m based on control theory that guaran tees stability and quick convergence to the optimal point of operatio n, in co ntrast to the compa ra- ti vely com plex heuristics o f [ 3]. 4) Our game th eoretic analysis considers that users can selfishly configur e b oth their access probab ility and transmission rate th reshold, while th e analysis o f [3] assumes that selfish users can only maliciously configure the thr esholds. 5) W e use a p enalty mech anism to f orce an op timal Nash equilibriu m, while [3] introduc es a pricing mechanism for th is pu rpose, which may n ot be practica l in many scenarios; additionally , the perfor mance of the pricing mechanism heavily depend s on th e cost par ameter and ev en in the best case is only su boptimal. The remain der o f the pap er is organized as follows . I n Section I I we present an analysis o f our system and d erive the optimal configuratio n o f access probabilities and tra nsmission rate thresholds. In Section III we show that, in the absence of penalties, the wireless network tends to a highly undesirable resource alloca tion; based o n this, we pr opose an algorithm named Distributed Opp ortunistic scheduling with d istrib uted Contr ol ( DOC) that av o ids this situatio n by imp lementing a decentralized p enalty mech anism that c ontrols selfish behavior throug h punishm ents. Section IV shows by means o f control theory , that when all th e stations implement DOC, the system stably con verges to the optima l point of operation o btained in Section II. In Section V we conduct a gam e theo retic an alysis of DOC to show th at station s canno t gain any p rofit fro m behaving selfishly . The perf ormanc e of the pro posed schem e is extensively ev aluated thro ugh simulations in Section VI. Finally , Section VII provid es some co ncludin g remarks. I I . A N A L Y S I S A N D O P T I M A L CO N FI G U R A T I O N In th e fo llowing we presen t our system model a nd analyze the through put as a functio n of the access probab ilities a nd transmission rate thresh olds. W e the n compu te the optim al configur ation of th ese parameters for a p ropor tionally fair throug hput allocation , which is well known to provide a goo d tradeoff between to tal throug hput and fairne ss [7]. A. System Model Our system model follows that of [3] –[6]. W e consider a single-hop wireless network with N stations, where station i c ontends fo r the channel with a n access pro bability p i . A collision model is assumed for the chan nel access, wh ere th e channel conte ntion of a station is successfu l if no other station contend s at the same time. Let τ deno te th e duration of a m ini slot for chann el con tention, which can e ither be empty , o r can contain a succ essful contentio n or a co llision. As in [3]–[6], we assume that a station i o btains its local channel cond itions after a successful con tention. L et R i ( θ ) denote the cor respond ing tran smission ra te at time θ . If R i ( θ ) is small (indicating a poor channel), station i gi ves up on this transmission oppo rtunity and lets all th e stations reconten d. Otherwise, it transmits fo r a duration of T . Fig. 1 d epicts Idle successful contention collision data transmission W W W W i i R R ) ( T i i R R t ) ( T Fig. 1. Channel contention e xample. an example of such chann el co ntention . Our model, like that o f [3]–[6], assumes that R i ( θ ) remains constant f or the duration of a data transmission an d that different o bservations of R i ( θ ) are indepe ndent. 1 From [3], we h ave that the o ptimal transmission policy is a thresh old policy: f or a gi ven threshold ¯ R i , station i only transmits after a successful co ntention if R i ( θ ) ≥ ¯ R i . B. Thr oug hput Analysis The throughp ut r i achieved by station i is a functio n of the parameters p i and ¯ R i . Let l i be the average n umber of bits that station i transmits up on a successful conten tion and T i be the a verage time it holds the ch annel. Th en, the throu ghpu t of station i is r i = p s,i l i P j p s,j T j + (1 − p s ) τ (1) where p s,i is the probability that a min i slot con tains a successful co ntention of statio n i p s,i = p i Y j 6 = i (1 − p j ) (2) and p s is the probab ility th at it contains any successful contention p s = X i p s,i (3) Both l i and T i depend on ¯ R i . Upon a successful con tention, a station hold s the chan nel for a time T + τ in case it tran smits data and τ in case it gives up the transm ission oppor tunity . Thus, T i can b e compu ted as T i = P rob ( R i ( θ ) < ¯ R i ) τ + P rob ( R i ( θ ) ≥ ¯ R i )( T + τ ) (4) In case th e station u ses the transmission oppo rtunity , it transmits a n umber o f b its g iv en by R i ( θ ) T i , which yields l i = Z ∞ ¯ R i rT i f R i ( r ) dr (5) where f R i ( r ) is the pd f o f R i ( θ ) . W ith the abov e, we ca n comp ute r i from p = { p 1 , . . . , p N } and ¯ R = { ¯ R 1 , . . . , ¯ R N } . In the follo wing, we obtain th e op ti- mal configu ration of these parameter s to provide proportion al fairness. 1 The assumption that R i ( θ ) remains constant during a data transmission is a sta ndard assumpti on for t he bloc k-fad ing channel in wirel ess communica - tions [8], [9 ], while the assumption that differe nt observat ions are independent is justified in [3] through numerical ca lculations. 3 C. Optimal p i config uration W e start by c omputin g the optimal co nfiguratio n o f p i . Let us define w i as w i = p s,i p s, 1 (6) where we take station 1 as r eference . From the above equation we have that p s,i = w i p s / P j w j and substituting this in Eq. (1) yields r i = w i p s l i P j w j p s T j + P j w j (1 − p s ) τ (7) In a slotted w ireless system such as the one of this p aper, the o ptimal success prob ability is ap prox imately 1 /e [10]. The problem o f find ing the p config uration th at m aximizes th e propo rtionally fair rate alloca tion is thus equiv alen t to find ing the values w i that maximize P i l og ( r i ) g iv en that p s = 1 / e . T o o btain these w i values, we impose ∂ P i l og ( r i ) ∂ w i = 0 (8) which yields 1 w i − N p s T i + (1 − p s ) τ P i w i p s T i + P j w j (1 − p s ) τ = 0 (9) Combining this expression for w i and w j , we obtain w i w j = p s T j + (1 − p s ) τ p s T i + (1 − p s ) τ (10) From the a bove, the solu tion to the op timization pr oblem is giv en by the values of p resulting fro m solving the following system of equations: X i p i Y j 6 = i (1 − p j ) = 1 e (11) p i Q j 6 = i 1 − p j p 1 Q j 6 =1 1 − p j = T 1 + τ (1 /p s − 1) T i + τ (1 /p s − 1) , i = 2 , . . . , N (12) This system o f equation s h as two solutions, since 1 /e is only an appro ximation to the truly o ptimal success pr obability . For one o f the so lutions, all of the a ccess pro babilities are larger than the c orrespon ding o nes from the othe r . W e select the solutio n with the larger acce ss pro babilities, deno ted by p ∗ = { p ∗ 1 , . . . , p ∗ N } , and ref er to them as the optimal ac cess pr oba bilities . Note that d etermining p ∗ above requ ires com puting T i ∀ i , which depen d on the op timal configur ation of the th resholds ¯ R . In the fo llowing section we address the comp utation of the optimal ¯ R , wh ich we d enote by ¯ R ∗ = { ¯ R ∗ 1 , . . . , ¯ R ∗ N } . D. O ptimal ¯ R i config uration In ord er to ob tain the op timal configuratio n of ¯ R , we need to find the tr ansmission thr eshold of each station that, g i ven the p ∗ computed above, optimizes the overall performance in terms o f propo rtional fairness. This is given by the following theorem. Theorem 1. Let us consider th at station k is alo ne in th e channel and it contend s for the channel with p k = 1 / e . Let ¯ R 1 k be the transmission rate thr e shold that optimizes the thr oug hput of th is statio n under the assumptio n tha t differ ent channel observation s are independe nt. Then, ¯ R ∗ k = ¯ R 1 k . Pr oof: The p roof is b y con tradiction. Assume that there exists a configu ration ¯ R ∗ with ¯ R ∗ k 6 = ¯ R 1 k for som e station k that pr ovides prop ortiona l fairness. Let l 1 k and T 1 k be the values of l k and T k for the th reshold ¯ R 1 k and l ∗ k and T ∗ k the correspon ding values fo r ¯ R ∗ k . Since ¯ R 1 k maximizes r k when station k is alone: l 1 k T 1 k + ( e − 1) τ > l ∗ k T ∗ k + ( e − 1) τ (13) Let us co nsider that th ere are N stations in the network and the configura tion ¯ R ∗ is used. Gi ven ¯ R ∗ , the p ∗ that maximizes P i l og ( r i ) is g iv en by Eqs. (1 1) and (12). T his leads to th e following throug hput for station k : r ∗ k = p ∗ s,k l ∗ k P j p ∗ s,j ( T ∗ j + ( e − 1 ) τ ) = l ∗ k N ( T ∗ k + ( e − 1) τ ) (14) and for the o ther statio ns: r ∗ i = l ∗ i N ( T ∗ i + ( e − 1 ) τ ) , ∀ i 6 = k (15) Let us now con sider the alternative con figuration ¯ R 1 k for station k and ¯ R ∗ i for the o ther stations. Let u s take the p 1 k and p 1 i configur ation that satisfies E qs. (1 1) and (12) with th is alternative config uration. This y ields the following throug hput for station k : r 1 k = l 1 k N ( T 1 k + ( e − 1) τ ) > r ∗ k (16) and for the o ther statio ns: r ∗ i = l ∗ i N ( T ∗ i + ( e − 1 ) τ ) , ∀ i 6 = k (17) W ith the above, we ha ve foun d an alternati ve configur ation that provides a higher th rough put to station k an d th e same throug hput to all other stations. T herefo re, t his altern ativ e con- figuration increases P i l og ( r i ) , wh ich contrad icts the initial assumption that th e configur ation ¯ R ∗ provides pro portion al fairness. Follo wing th e above theore m, th e optim al configur ation of the th resholds ¯ R ∗ can b e comp uted based on optimal stoppin g theory . Th is is d one in [3] wh ich find s that the optimal threshold ¯ R ∗ i can be obta ined b y solving the following fixed point equation : E R i ( θ ) − ¯ R ∗ i + = ¯ R ∗ i τ T /e (18) The ab ove conclu des the search for th e optim al con figura- tion. The key advantage of this configu ration is that it allows each station to com pute its ¯ R ∗ i based o n local informa tion only , which decouples the computation of ¯ R ∗ i from th at of p ∗ i . Based on this finding, we no w present a distributed mechanism to compu te the op timal configu ration where each station uses a fixed ¯ R i = ¯ R ∗ i obtained locally , togeth er with an adap ti ve algorithm to de termine the o ptimal p ∗ i . 4 I I I . D O C A L G O R I T H M In this section we pro pose an adaptive algorithm that satisfies the following p roperties: ( i ) when all stations im- plement the algor ithm, it leads to the o ptimal configur ation computed above, and ( ii ) a selfish station cann ot gain profit b y deviating from the algorith m. W e first m otiv ate our algo rithm by showing tha t, in the absence o f punishm ents, the sy stem will natur ally tend to a highly und esirable point o f op eration. Then, we presen t our algorithm which uses pu nishments to drive the system to the optima l point of operation obtained in the previous section. A. Motivation If n o constrains are imposed on th e wire less n etwork and stations are allowed to configure their { p i , ¯ R i } parameter s to selfishly maximize th eir pr ofit, th e network will not naturally tend to the optimu m configura tion above. I n orde r to show this, we mo del the wireless system as a static g ame in which each station can ch oose its configur ation with out suffering any pena lty . The following theorem characterizes the Nash equilibria o f th is game. Theorem 2 . I n ab sence o f pena lties, there is at least one station th at p lays p i = 1 in any Nash equilibrium. Pr oof: The p roof is b y con tradiction. Assume that there is a Nash equilib rium su ch tha t p j 6 = 1 ∀ j . Now take one player i with through put r i = p i Q j 6 = i (1 − p j ) l i p i ˆ T i + (1 − p i ) ˆ T − i (19) where ˆ T i is the av e rage dur ation the ch annel is occupied when station i tr ansmits and ˆ T − i is the a verage d uration of a transmission or a n empty m ini slot when station i does no t transmit. T akin g th e par tial der iv ative we have ∂ r i ∂ p i = Q j 6 = i (1 − p j ) l i ˆ T − i p i ˆ T i + (1 − p i ) ˆ T − i 2 > 0 (20) It can be seen that the th rough put r i is a strictly increa sing function of p i (given that the ¯ R i configur ation as well as the configur ation of the other station s d oes n ot ch ange). From the above follows th at { p i , ¯ R i } , with p i 6 = 1 , is not the best strategy for player i given the configu ration of the other statio ns, since i would obtain a higher thr ough put for p i = 1 and the sam e ¯ R i . T hus, this solution is no t a Nash equilibriu m, which c ontradicts our in itial a ssumption. Any o f th e a bove Nash equilibria a re highly undesirab le. If station i is the only one that plays p i = 1 , then play er i a chieves no n-zero throu ghpu t while all oth er play ers have zero thro ughpu t. Conv ersely , any other station j also playing p j = 1 results in a network co llapse an d all players obtain zero throug hput. W e conclud e fr om th e ab ove that, in th e absen ce of punish- ments, selfish beh aviors will se verely degra de the p erform ance of the wire less sy stem. In the following, we prop ose an algorithm that ad dresses this p roblem by implem enting a distributed pun ishment mechan ism. B. Rationa le behind the a lgorithm Before presen ting the algorithm, we first d iscuss the ratio- nale th at lies beh ind its d esign. Th is ration ale h eavily relies o n the n otion of channel time that a station obtains ov er a certain interval, defined as t i = n i X j =1 ( T i ( j ) + ( e − 1) τ ) (21) where n i is th e number of successful conten tions of station i in that perio d an d T i ( j ) is the duration o f the j th successful contention of the station. The above definition comprises the aggregated transmission time of the station plus a fixed overhead of ( e − 1) τ that is ad ded every time the station accesses th e channel. An important observation that drives the design of our algorithm is that, with the co nfiguratio n of Section II, all stations recei ve the same channel time, i.e., t i = t j ∀ i, j . Th is can be seen as fo llows. From Eq. (21) we have tha t over a giv en interval, t i t j = n i ( T i + ( e − 1 ) τ ) n j ( T j + ( e − 1) τ ) = p s,i ( T i + ( e − 1 ) τ ) p s,j ( T j + ( e − 1) τ ) (22) since by d efinition n i /n j = p s,i /p s,j . Furthermore, from Eq. (12) we have p s,i ( T i + ( e − 1) τ ) = p s,j ( T j + ( e − 1) τ ) and thus t i = t j . Since the overhead in the definition of channel time, ( e − 1) τ , coin cides with the average time b etween two successes for the optimal configur ation, fro m the ab ove fo llows that, when all stations use the o ptimal configuratio n over a given time interval T total , they all o bserve the same o ptimal channel time t ∗ , t ∗ = T total / N (23) The last o bservation up on which o ur algor ithm relies is that as long as a selfish station does not rec eiv e mo re chann el time than t ∗ , it can not increase its throug hput. Th e throu ghpu t of a station with a giv en chan nel time and ¯ R i is equal to the throug hput it wou ld ob tain if it were alon e in th e chan nel during this time with p i = 1 / e and the same ¯ R i . From Theorem 1, we have that this thro ughp ut is maximize d for the o ptimal transmission rate th reshold ¯ R ∗ i . Th erefore, as long as the statio n do es not receive extra chan nel time, it will not be ab le to ach iev e a higher thro ughpu t. Giv e n these obser vations, we base our alg orithm on the following principles: ( i ) if a given s tation i d etects that ano ther station k is receiving a larger channel time than itself, then station k is con sidered selfish and punishe d b y station i , and ( ii ) when p unishing station k , station i needs to make sure the punishme nt is severe eno ugh so that station k ’ s c hannel time remains below t ∗ and thu s it cann ot benefit f rom misbehaving. C. Alg orithm d esign The DOC algor ithm aim s at driving the system to the optimal co nfigura tion { p ∗ , ¯ R ∗ } obtaine d in Section II. As discussed in Section II -D, th e op timal co nfiguratio n of ¯ R i can be comp uted locally by each station indep enden tly o f the other stations. Th erefore, with DOC each station main tains a fixed 5 PI controller station 1 P 1 Wireless network PI controller station N P N E 1 E N Eq.(25) Eq.(25) p 1 p N Fig. 2. DOC control system. ¯ R i (equal to the optim al value) and implem ents an adaptive algorithm to configu re its access p robab ility p i . T im e is d ivided into intervals in su ch a way that each station updates its a ccess probab ility p i at the beginning of an interval. The centr al idea behin d DOC is that wh en a misbehaving station is detec ted, the oth er stations incr ease their acce ss pro babilities in sub sequent inter vals to p revent the selfish station fr om benefiting f rom the m isbehavior . A key challenge in DOC is to carefully adjust the r eaction against a selfish station . If the re action is not severe en ough , a selfish station may benefit from misbehaving, but if the reaction is too sev ere, the s ystem may turn unstable b y entering an endless loo p wh ere all stations indefinitely increase their p i to punish each other . Control theory is a particularly suitable too l to addr ess this challenge, since it helps to g uarantee th e co n vergence and stability of adaptive algo rithms. W e use techn iques from multi- variable contr ol the ory [11] for th e design of the D OC algo- rithm. The algorith m is based on the class ic sy stem illustrated in Fig. 2 , where each statio n runs an in depend ent controller in order to comp ute its con figuration . Th e controller that we have chosen for this paper is a pr opo rtional-integral (PI) controller, a we ll known con troller from c lassic contro l theory that has been u sed by a numb er o f network ing algor ithms in the literature [ 12]–[14]. As shown in th e figur e, the PI contro ller of station i takes the error signal E i as input an d pr ovides the con trol signal P i as ou tput. T he error signal serves to ev alu ate the state of the system. I f the system is op erating as desired , the erro r signal of all stations is zero. Otherwise, the e rror is non-zero and we n eed to driv e the system from its current state to the desired po int of oper ation. In order to do this, the PI co ntroller adjusts the control signal P i by (appr opriately ) incre asing it when E i > 0 and d ecreasing it oth erwise. I n the following, we address the de sign o f P i and E i . D. Co ntr ol signal P i The goal of the adap tiv e alg orithm imp lemented by the controller of a station is to ad just the access pr obability p i with wh ich th e station contend s. Hence, th ere n eeds to be a one-to- one map ping b etween the con trol signal P i and p i . In addition, we impose th at in the optimal poin t of operation, the P i values of all statio ns are th e same. This latter requ irement is necessary to obtain the cond itions for stability in Section IV. Based on th e ab ove requiremen ts, we design P i as P i = p i 1 − p i ( T i + ( e − 1 ) τ ) (24) Hence, a station can com pute its p i from the contro l signal P i as p i = P i T i + ( e − 1 ) τ + P i (25) E. Err or signal E i The d esign of the error sign al E i has the fo llowing two goals: ( i ) selfish stations should n ot be able to ob tain extra channel time from the wireless n etwork by using a configur a- tion d ifferent from the optim al one , and ( ii ) as long as there are n o selfish stations, p shou ld co n verge to th e op timal p ∗ . T o this en d, each station measures its chan nel time as well as that of the o ther stations at the end of every in terval a nd computes th e error sign al E i = X j 6 = i ( t j − t i ) − F i (26) where F i is a function that we design below . The error signal E i consists of th e two comp onents: • The first compo nent ( P j 6 = i t j − t i ) punishes selfish sta- tions. If a station i rece iv e s le ss chan nel time than the other stations, this component will be positive and hence station i will inc rease its a ccess p robab ility p i . • The second c ompon ent ( F i ) dr iv e s the system to the desired p oint of op eration in the absenc e o f selfish behavior (i.e., when all stations recei ve the same channel time). W e next address the design of the functio n F i . In order to drive the cur rent p to the desired p ∗ when t i = t j ∀ i, j , we need F i > 0 for p i > p ∗ i , such th at in this case p i decreases, and F i < 0 for p i < p ∗ i . Another requir ement when designin g F i is that selfish stations should n ot be able to obtain m ore channel tim e than t ∗ . W e first co nsider the case where all stations are well-be haved and run the DOC algo rithm except one that is selfish. I n this case, the erro r signal allows that the selfish station obtain s an additional chan nel tim e equ al to F i : taking E i = 0 and setting t i = t for all stations but the selfish one, the chann el time t k of th e selfish station is g iv en as t k = t + F i (27) As argu ed befo re, F i needs to be small enoug h such th at t k ≤ t ∗ (28) Combining the two equ ations above yields t k + ( N − 1) t + ( N − 1) F i ≤ N t ∗ (29) Using P j t j = t k + ( N − 1) t we can isolate F i and obtain F i ≤ 1 N − 1 D (30) 6 where D is defin ed a s 2 D = N t ∗ − X j t j (31) W ith this constraint on F i , the additional chan nel time obtained by a selfish station do es not comp ensate for the overall efficiency loss due to su b-optim al access probabilities, and hence a selfish statio n can not benefit from misbe having. In add ition, multiple selfish stations shou ld not be a ble to gain any aggregated ch annel time by play ing a coord inated strategy . W e conside r m selfish station s and again set the t i of th e other station s e qual to t . Fro m E i = 0 we have m X j =1 t j = mt + F i (32) and we require th at m X j =1 t j ≤ mt ∗ (33) Combining the ab ove equations and isolating F i yields F i ≤ m N − m D (34) Eqs. (30) and (34) pr ovide th e maximum value for F i that still pr ev ents one or more selfish stations to benefit from misbehaving. Giv e n all these re quiremen ts, we de sign F i as: F i = min(( N − 1) D , D / N ) , p i > p min i min(( N − 1) D , − D / N , ( N − 1)∆) , p i ≤ p min i (35) where p min = { p min 1 , . . . , p min N } are the acce ss pr obabilities that minimize D subject to t i = t j ∀ i, j and ∆ is the value that D takes at this po int, ∆ = D | p = p min (36) The ab ove desig n satisfies Eqs. (30) and (3 4) and fulfills F i > 0 fo r p i > p ∗ i and F i < 0 fo r p i < p ∗ i (when t i = t j ∀ i, j ). It thus meets all the requ irements set above fo r function F i . No te that the term D / N en sures that Eqs. (30) and (3 4) are satisfied when D > 0 , the term ( N − 1) D ensu res that they are satisfied when D < 0 , and the terms ( N − 1 )∆ and − D / N ensure that F i < 0 wh en t i = t j ∀ i, j and p i < p ∗ i , as illu strated in Fig. 3. Note that we keep F i very close to the u pper bound for p i > p ∗ i , which me ans that the d egree of punishm ent inflicted upon selfish stations is as small as th e above requ irements allow . The rationale for this d esign is that any pun ishment in the form of an increa se in access p robabilities affects selfish stations and well-beh av ed stations alike. Providing just enough punishme nt to prevent any throughpu t gain for selfish stations maintains the highest level of overall throu ghput fo r the system in the presence of maliciou s user s o r in transient condition s. Follo wing a similar rationale, we k eep F i well below the upper bound for p i < p ∗ i . 2 Note tha t D is a funct ion of the ef ficienc y in chan nel conten tion, which depends on p : if channel content ion is more effici ent, we have a lar ger number of data transmissions in the interv al, which results in a larger sum of channel times and therefore a smaller D . p i F i p i * p i min (N-1) Δ (N-1) Δ -D/N (N-1)D D/N Fig. 3. F i as a function of p i when t i = t j ∀ i, j . This co ncludes th e desig n o f the algo rithm. I n th e fo llowing two sections, we analy tically evaluate its p erform ance whe n all stations ar e well-b ehaved (Section IV) and when some of them b ehave selfishly (Section V). I V . D O C A N A L Y S I S W e fir st an alyze the wireless system under steady state condition s and show th at it is driven to th e desired p oint of operation obtained in Section II. W e then conduc t a transien t analysis an d d erive the sufficient con ditions for stability . A. Steady state a nalysis Since the contro ller includes an integrator , there is no steady state er ror [1 5] and the steady solutio n can be o btained f rom E i = 0 ∀ i (37) Using Eqs. (26) and (35), E i can be comp uted from t i and t ∗ , which allows expr essing E q. ( 37) as a system of equations of p . Th e following theore m g uarantees the un iqueness of this system of equations and shows that the un ique stable point in steady state is the desired point of operation from Section II. 3 Theorem 3 . The unique stable point o f operation of the system in stead y state is p = p ∗ . Pr oof: Let us con sider tw o stations i and j . From Eq . (37) we have E i − E j = 0 , which yields N t j + F j − N t i − F i = 0 (38) Note that t j > t i implies F j ≥ F i , an d vice versa. Therefo re, the above requires th at t i = t j ∀ i, j . Su bstituting this into E i = 0 y ields F i = 0 . Giv e n t i = t j , F i is an increasing f unction of p i that crosses 0 at p i = p ∗ i . Hence, the only p i that satisfies F i = 0 is p ∗ i . Since th is holds f or a ll i , the u nique stable p oint o f o peration is p i = p ∗ i ∀ i . B. Stability analysis W e next cond uct a stability an alysis of DOC to con figure the par ameters of th e PI co ntroller . Following the definition of a PI contro ller [15], station i comp utes the value of P i at inter val Θ ′ as a fun ction of the erro r values measured b y 3 While the exist ence of a unique point of operati on can be easily guarante ed in a central ized system where the configurat ion of all stations is imposed by a centra l entity , it is much harder to guarantee in a distrib uted system in which each station chooses its own configurati on. 7 C H P E Controller System z -1 Fig. 4. Control system the station in the cur rent and p revious in tervals based on the following equation : P i (Θ ′ ) = K p E i (Θ ′ ) + K i Θ ′ − 1 X Θ=0 E i (Θ) (39) where K p and K i are the par ameters of the controller that we have to co nfigure . The DOC system sh own in Fig. 2 can b e expressed in the form o f Fig. 4. In this figure, C repr esents the fun ction imple- mented b y the contro llers, wh ich co mputes the control sig nals P i taking as inpu t the er ror signals E i , and H represents the wireless sy stem which provides th e error signals E i measured by the stations based on the control signals P i . The control and error sign als in the fig ure a re g iv en by the following vectors: P = ( P 1 , . . . , P N ) T (40) and E = ( E 1 , . . . , E N ) T (41) Our co ntrol system consists of one PI con troller in each station i that takes E i as inp ut and gives P i as ou tput. Follo wing th is, we can exp ress th e relation ship b etween E and P as fo llows P ( z ) = C · E ( z ) (42) where C = C P I ( z ) 0 0 . . . 0 0 C P I ( z ) 0 . . . 0 0 0 C P I ( z ) . . . 0 . . . . . . . . . . . . . . . 0 0 0 . . . C P I ( z ) (43) with C P I ( z ) b eing the z tran sform o f a PI co ntroller [1 5], C P I ( z ) = K p + K i z − 1 (44) In or der to analyze ou r system fro m a contr ol theoretic standpoin t, we need to ch aracterize the wireless system with a transfer fu nction H that takes P as input and h as E as o utput. Eq. ( 26) giv es a nonlinear relationship betwe en E and P . In order to express this relatio nship as a transfer fu nction, we linearize it when th e system su ffers small pertur bations around its stable point of operatio n. W e then stud y the linearized model and forc e that it is stable. Note th at the stability of the linearized model guarantees that our system is lo cally stable. 4 4 A similar approach was used in [16] to analyze RED from a control theoret ic stan dpoint. W e express the per turbation s aro und the stable point of operation as follows: P = P ∗ + δ P (45) where P ∗ is th e stable point of operation as gi ven b y Eq . (2 4) with p = p ∗ . W ith the ab ove, the pe rturbatio ns suffered by E can be approx imated by δ E = H · δ P (46) where H = ∂ E 1 ∂ P 1 ∂ E 1 ∂ P 2 . . . ∂ E 1 ∂ P N ∂ E 2 ∂ P 1 ∂ E 2 ∂ P 2 . . . ∂ E 2 ∂ P N . . . . . . . . . . . . ∂ E N ∂ P 1 ∂ E N ∂ P 2 . . . ∂ E N ∂ P N (47) In order to com pute these partial deriv atives we proceed as follows. The error sign al E i can be expressed as E i = T total P j 6 = i ( p s,j ( T j +( e − 1) τ ) − p s,i ( T i +( e − 1) τ )) P j p s,j T j +(1 − p s ) τ − F i (48) The a bove can b e rewritten as a fu nction of P g iv e n by E i = T total P j 6 = i ( P j − P i ) P j P j − p s p e ( e − 1 ) τ + 1 − p s p e τ − F i (49) where p e = Q i 1 − p i . W e start by showing that ∂ F i /∂ P i = 0 at the stable p oint of o peration . It f ollows from Eq. (35) th at ∂ F i ∂ P i = 0 ⇐ ⇒ ∂ D ∂ P i = 0 (50) D can be exp ressed as D = N t ∗ − T total P i p s,i T i + p s ( e − 1) τ P i p s,i T i + (1 − p s ) τ (51) The p artial d eriv ative of D can be com puted as ∂ D ∂ P i = ∂ D ∂ p i ∂ p i ∂ P i (52) T akin g the p artial de riv ative of Eq. (51) with respect to p i and ev aluatin g it at the stable p oint of o peration yields ∂ D ∂ p i = T total eτ P i p s,i T i + ( e − 1 ) τ ∂ p s ∂ p i (53) Since p s takes a maxim um at the stable po int of opera tion, we have that ∂ p s /∂ p i = 0 , which yields ∂ D /∂ P i = 0 and hence ∂ F i ∂ P i = 0 (54) The partial derivati ve of E i ev aluated at th e stable point o f operation can then b e com puted f rom Eq . (4 9) as ∂ E i ∂ P i = − ( N − 1) T total 1 P j P j (55) Follo wing a similar reason ing, it can be seen that ∂ E i ∂ P j = T total 1 P j P j (56) 8 Substituting th ese exp ressions in matrix H giv es H = K H − ( N − 1) 1 . . . 1 1 − ( N − 1) . . . 1 . . . . . . . . . . . . 1 1 . . . − ( N − 1) (57) where K H = T total 1 P j P j (58) W ith the above, we h av e the lin earized system f ully char ac- terized by matr ices C an d H . Th e next step is to co nfigure the K p and K i parameters of this system. The followi ng theorem provides the sufficient cond itions of { K p , K i } fo r stability : Theorem 4. The linearized system is gua ranteed to be sta ble as long as K p and K i meet the fo llowing c ondition s: K i < K p + 1 N K H (59) K i > 2 K p − 1 N K H (60) Pr oof: Accord ing to (6. 22) of [1 1], we need to verify that the following transfer function is stable ( I − z − 1 C H ) − 1 C (61) Computing the ab ove matrix y ields ( I − z − 1 C H ) − 1 C = a b b . . . b b a b . . . b b b a . . . b . . . . . . . . . . . . . . . b b b . . . a (62) where a = C P I ( z ) N 1 + N − 1 1 + N z − 1 K H C P I ( z ) (63) b = C P I ( z ) N 1 − 1 1 + N z − 1 K H C P I ( z ) (64) Rearrangin g the terms of the above two equatio ns, we obtain a = P 1 ( z ) z 2 + a 1 z + a 2 (65) b = P 2 ( z ) z 2 + a 1 z + a 2 (66) where P 1 ( z ) an d P 2 ( z ) ar e po lynomials an d a 1 = N K H K p − 1 (67) a 2 = N K H ( K i − K p ) (68) According to Theore m 3.5 of [11], a s ufficient cond ition for the stability of a transfer function is that the zeros of its pole polyno mial (which is the least com mon deno minator of all the minors of the tra nsfer function ma trix) fall within the unit circle. Ap plying this theorem to ( I − z − 1 C H ) − 1 C yie lds that the roots of the polyn omial z 2 + a 1 z + a 2 have to fall inside the unit c ircle. This can be ensur ed b y choo sing co efficients { a 1 , a 2 } that s atisfy the fo llowing thr ee conditions [17]: a 2 < 1 , a 1 < a 2 + 1 and a 1 > − 1 − a 2 . The th ird condition is satisfied as lo ng as K i > 0 , wh ile th e o ther two y ield K i < K p + 1 / ( N K H ) and K i > 2 K p − 1 / ( N K H ) , respectiv e ly . In addition to guaranteeing stability , our goal in the co nfig- uration o f th e { K p , K i } p arameters is to fin d th e rig ht tradeo ff between spee d o f r eaction to ch anges an d o scillations u nder steady conditions. T o this end, we use the Zie gler-Nic h ols rules [18], wh ich h av e b een designed f or th is purp ose. First, we compute the p arameter K u , defin ed as th e K p value that lea ds to instability when K i = 0 , and the para meter T i , d efined as the oscillation period u nder these conditions. Then, K p and K i are co nfigured as follows: K p = 0 . 4 K u (69) and K i = K p 0 . 85 T i (70) In order to compute K u we proceed as follows. From Eq. (59) with K i = 0 we h av e the following co ndition fo r stability K p < 1 2 N K H (71) W e take K u as the value that may turn the system unstable K u = 1 2 N K H (72) and set K p accordin g to Eq. ( 69), K p = 0 . 4 2 N K H (73) W ith the K p value that leads to instability , a g iv en set of input values may chang e th eir sign at most every interval, yielding an oscillation period of two intervals ( T i = 2 ). Thus, from Eq . (7 0), K i = 1 0 . 85 · 2 0 . 4 2 N K H (74) which completes th e configuration of the PI co ntroller param- eters. The stability of this config uration is guar anteed by th e following corollary : Corollary 1. The K p and K i config uration given by Eqs. (73) and (7 4) is stab le. Pr oof: It is easy to see that Eqs. (73) and (7 4) m eet the condition s of T heorem 4. V . G A M E T H E O R E T I C A N A L Y S I S In the p revious section we ha ve seen that, when all stations follow the DOC algorithm , they all pla y w ith p i = p ∗ i and ¯ R i = ¯ R ∗ i . In this section we conduct a gam e the oretic analy sis to show that o ne o r more station s cann ot gain any p rofit by deviating fr om DOC. In what follows, we say that a station is h onest or well-behaved when it implements the DOC algorithm to config ure its p i and ¯ R i parameters, wh ile we say that it is selfish or misbe having when it pla ys a d ifferent strategy from DOC to co nfigure these pa rameters with th e aim of o btaining some g ains. 9 The ga me theoretic analy sis condu cted in this section as- sumes that users are rational a nd want to m aximize their own b enefit or utility , w hich is given by the throug hput. The m odel is based on the the ory of r epea ted games [19]. W ith re peated games, time is di v ided into stages and a player can take new dec isions at each stage based on th e observed behavior of th e other player s in the previous stages. This matches our algorithm, wh ere time is divided into intervals and stations update their configur ation at eac h in terval. 5 Like o ther previous analyses on rep eated g ames [2 0], [ 21], we consider an in finitely rep eated gam e, which is a com mon assumptio n when the p layers d o n ot k now when the g ame will finish . A. Single selfish statio n While the design of the DOC algo rithm in Section III guaran tees that a station cann ot g ain any pr ofit by playin g with a fixed selfish co nfiguratio n, selfish stations might still gain by varyin g their co nfiguratio n over time. As an examp le, let us consider a naive algorithm that on ly takes into a ccount the stations’ behavior in the previous stage . Wh ile this algo- rithm may b e effective ag ainst a fixed selfish configur ation, it co uld ea sily b e defeated by a selfish station tha t alter nates a selfish co nfiguratio n ( p k = 1 , ¯ R k = 0 ) with an honest one ( p k = p ∗ k , ¯ R k = ¯ R ∗ k ) at e very other stage. Since this station would play selfish when a ll the others play honest, it would achieve a significantly high er throug hput e very other inter val, thus b enefiting from its misbehavior . The above example shows that it is imp ortant to make sure that a selfish station c annot gain any pro fit no ma tter how it varies its configura tion over time. Th e following th eorem confirms the effecti veness of DOC against any (fixed or variable) selfish strategy . T he pro of o f the theorem relies o n the integrato r com ponen t of th e PI contro ller , which keep s track of the agg regated chan nel time receiv ed by all station s and can thus be used to g uarantee that th is a ggregate do es not exceed a given amount. Theorem 5. Let u s consider a selfish station that uses a p k (Θ) and ¯ R k (Θ) configu ration th at c an vary over time. If all the other stations implement th e DOC algorithm, the thr ough put r eceived by this station wil l be no la r ger than r ∗ k (wher e r ∗ k is the thr ou ghpu t that station k r eceives wh en all stations pla y DOC). Pr oof: The PI co ntroller co mputes P i at a giv en interval Θ ′ accordin g to the fo llowing expression: P i (Θ ′ ) = P initial i + K p X j 6 = i ( t j (Θ ′ ) − t i (Θ ′ )) − F i (Θ ′ ) + K i Θ ′ X Θ=0 X j 6 = i ( t j (Θ) − t i (Θ)) − F i (Θ) (75) 5 Note that the game theoreti c stud y conducted in Section III-A was based on static games instead of repeated ones. T he reason is that in Section III-A we considered a syste m wit hout pena ltie s and hence we could model it as a static game where all players only make a single mov e at the beginn ing of the game and (a s they are nev er penali zed) do not nee d to m ake any further mov e during the rest of t he game. Note that with th e above, P i will stay between 0 a nd a giv en max imum value P max i . I f at some time P i reaches a P max i value such th at p i = 1 , then we have t j = 0 for j 6 = i and F i > − ( N − 1) t i , which yields E i < 0 and th erefore P i decreases. Similarly , if at som e time P i reaches 0, then t i = 0 and F ≤ 0 , which yields E i > 0 and therefor e P i increases. Considering th at 0 ≤ P i (Θ ′ ) ≤ P max i , the above equation can b e expre ssed as X Θ X j 6 = i ( t j (Θ) − t i (Θ)) − F i (Θ) = K (76) where K is a boun ded value. Let us consider the case in which there is a selfish station that ch anges its con figuration over time an d receives a ch annel time t k (Θ) while the other stations are we ll-behaved and use the same con figuration obtaining the same channel tim e t (Θ) . Then the ab ove can be expr essed as X Θ t k (Θ) = X Θ ( t (Θ) + F i (Θ)) + K (77) Let us co nsider now a giv en interval Θ . From Eq. (30) we have F i (Θ) ≤ 1 N − 1 ( t ∗ − t k (Θ) − ( N − 1) t (Θ)) (78) which yields ( N − 1) t (Θ) + t k (Θ) + ( N − 1) F i (Θ) ≤ N t ∗ (79) Since the a bove equation is satisfied for all Θ , X Θ ( N − 1) t (Θ) + t k (Θ) + ( N − 1) F i (Θ) ≤ X Θ N t ∗ (80) Furthermo re, from E q. ( 77), ( N − 1) X Θ t k (Θ) = ( N − 1) X Θ ( t (Θ) + F i (Θ)) + ( N − 1) K (81) Adding th e ab ove two equa tions yields N X Θ t k (Θ) ≤ N X Θ t ∗ + ( N − 1) K (82) from wh ich X Θ t k (Θ) ≤ X Θ t ∗ + N − 1 N K (83) If we consider a v ery long pe riod of time, the constant term in the ab ove equation ca n be neglected a nd w e obtain X t t k (Θ) ≤ X t t ∗ (84) From the ab ove, we have that the selfish station cann ot receive mor e ch annel time with a selfish stra tegy than by playing DOC and, following the rea soning of Section III-B, therefor e cannot obtain m ore thro ughp ut than it would o btain by playing DOC, i.e. r k ≤ r ∗ k (85) which proves the theo rem. From the ab ove theorem fo llows Corollary 2. 10 Corollary 2. A state in which all stations pla y DOC ( All- DOC ) is a Na sh equilibrium o f th e ga me. Pr oof: According to Theore m 5, if all stations but one play DOC, then the be st response of this station is to play DOC as well since it can not bene fit from playing a different strategy . Thus, All-DOC is a Nash eq uilibrium. This shows that, if all stations start playing with no previous history , then none of them can gain by deviating from DOC. In addition, in r epeated games it is also imp ortant to ensure that, if at som e point th e game has a gi ven history , a selfish station cannot take advantage of this history to gain pr ofit by playing a strategy different fr om DOC . The following theore m co nfirms that All- DOC is a Nash equ ilibrium of any subga me (wher e a subgame is defined as the game resulting from starting to play with a certain history). Therefo re, a selfis h station cannot benefit by deviating fro m DOC independ ently of the previous history of the ga me. Theorem 6. A ll-DOC is a subgame perfect Nash equilibrium of the g ame. Pr oof: Since the proof of Th eorem 5 is ind epende nt of the past history and can therefo re be applied to any s ubgame , All-DOC is a Nash eq uilibrium of any subgame. B. Multiple selfi sh stations The ab ove results show th e effecti veness o f DOC ag ainst a single selfish station. In the f ollowing, we tackle the case when there are mu ltiple selfish stations. The f ollowing theorem shows that, by following a stra tegy different from DOC, multiple stations ca nnot gain any aggr e- gated channel time . Theorem 7 . Let us consider a scenario with m selfish stations. If all o ther station s play DOC, the selfish stations cannot g ain any aggr e gated channel time. Pr oof: Wi thout loss of g enerality , let us consider th at stations i = { 1 , . . . , m } ar e selfish. Applying a reasoning similar to Th eorem 5 leads to m X i =1 X Θ t i (Θ) ≤ m X Θ t ∗ (86) As the lef t hand side of the above equation is the agg regated channel time o btained b y the selfish stations, and the right hand side is the a ggregated chan nel time that they would obtain if the p layed DOC, this p roves the theo rem. The above theo rem shows that, if there is some selfish station that experience s a gain, this is b ecause th ere is some other station th at suffers a loss. Corollary 3 . Let us consider a scena rio with m selfish stations. I f all other stations pla y DOC and a selfish station k r eceives a th r ough put la r ger than r ∗ k , this means that th er e exis ts an other selfish station l that r eceives a thr ough put smaller than r ∗ l (wher e r ∗ k and r ∗ l ar e the thr ou ghpu ts obtained by statio ns k and l if all station s played DOC). Pr oof: If there is some station k ∈ { 1 , . . . , m } for which r k > r ∗ k , then we hav e th at this station r eceiv es mo re channel tim e than it would recei ve if all s tations played DOC. Since, acco rding to Theorem 7 , the selfish station s can not gain any agg regated channel time, this means that th ere must necessarily be some o ther st ation l ∈ { 1 , . . . , m } that recei ves less channel time. This im plies that r l < r ∗ l , which proves the corollary . Based on the a bove, w e ar gue that DOC is ef fectiv e against multiple selfish stations, since two o r mo re selfish stations cannot simulta neously gain pro fit and ther efore d o n ot h av e an incentive to play a coordin ated strategy different fr om DOC. V I . P E R F O R M A N C E E V A L UAT I O N In this section we evaluate DOC by means o f simulatio n to show that ( i ) in the absence of selfish station s, DOC pro - vides optim al per forman ce while beh aving stably and reacting quickly to change s, and ( ii ) selfish stations cann ot benefit b y following a strategy different from DOC. Unless o therwise stated, we assume that different obser- vations of the ch annel condition s ar e inde penden t, and the av ailable tran smission rate fo r a g iv e n SNR is given by the Shannon ch annel capacity: R ( h ) = W log 2 (1 + ρ | h | 2 ) bits/s (87) where W is the cha nnel band width, ρ is the nor malized av erage SNR and h is the rando m gain of Rayleigh fading. W e im plemented the DOC a lgorithm in OMNE T++ 6 . In the simulations, we set W = 1 0 7 , T /τ = 10 and the interval of the controller T total = 1 0 5 τ . For all results, 95% confidenc e intervals are b elow 0.5%. A. Thr oug hput evaluation For the thr ough put ev aluatio n, we co mpare th e per forman ce of DOC to the following approac hes: ( i ) the static op timal configur ation obtained in Section II (‘ static co nfigu ration ’), ( ii ) the config uration proposed in [3] ( ‘ DOS ’ ), and ( ii i ) an app roach that do es not per form oppo rtunistic schedul- ing but always tran smits after suc cessful con tention (‘ n on- opportun istic ’). W e co nsider a scen ario with N = 10 station s, half of them with a n ormalized SNR of ρ 1 = 1 and the other h alf with a normalize d SNR ρ 2 that varies from 1 to 10 . Fig. 5 shows P i l og ( r i ) , the metric that p ropor tional fairn ess aims at m aximizing , as a f unction o f ρ 2 . W e observe that DOC perfor ms at the same level as the b enchmar k given by the static con figuration , while th e other two appr oaches ( DOS an d non-o pportun istic ) pr ovide a su bstantially lo w er perform ance. For above scen ario with ρ 2 = 4 , Fig. 6 depicts th e individual thro ughp ut alloc ation of two stations ( where r 1 is the throu ghpu t of a station with ρ 1 and r 2 that of a station with ρ 2 ). DOC is effecti ve in dr iving the sy stem to the optimal point o f op eration and provides the same through put as the static con figuration . In con trast, the DOS app roach exhibits a high degree of unfairn ess and p rovides the station with hig h SNR with a much higher through put. T he non- oppo rtunistic approa ch provides a g ood level of fairness but has lo wer 6 http://www.omn etpp.org/ 11 134 135 136 137 138 139 140 141 142 143 1 2 3 4 5 6 7 8 9 10 Σ (log(r i )) ρ 2 static configuration DOS non-opportunistic DOC Fig. 5. Proportional fairne ss a s a function of SNR ( ρ 1 = 1 , 1 ≤ ρ 2 ≤ 10 ). 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 2.4 2.6 static configuration DOC DOS non-opportunistic Throughput [Mbps] r 1 r 2 Fig. 6. Throughput for heterogene ous SNRs ( ρ 1 = 1 , ρ 2 = 4 ). throug hput due to the lack of o ppor tunistic sched uling. In conclusion , th e pr oposed DOC algorithm pr ovides a go od tradeoff between overall throug hput and fairn ess. B. Selfish station with fi xed configu ration W e verif y that a station cannot obtain mor e thr oughp ut with a selfish con figuration than by p laying DOC in a scen ario with N = 10 stations, 5 of them with ρ 1 = 1 an d th e o ther half (includin g the selfish station) with ρ 2 = 4 . Th e selfish station uses a fixed configu ration and all other station s implem ent DOC. Fig. 7 shows the thro ughp ut of the selfish station for different { p k , ¯ R k } co nfiguratio ns of the selfish station. This is compare d to the through put that the station would obtain if it played DOC, g i ven by the horizo ntal line. W e o bserve th at none of the selfish configu rations pr ovides more thr ough put than DOC. Further more, r k is far fro m r ∗ k for p k < p ∗ k and c lose to r ∗ k for p k > p ∗ k . T his is a consequ ence of the design o f F i in Section III.E . For p k < p ∗ k , the access probab ilities of the honest stations satisfy p i < p ∗ i . W ith these values of p , F i takes negative values that are large in absolute terms, wh ich m eans that, accor ding to Eq . (2 7), the selfish station re ceiv es m uch less c hannel time than the other stations and hence a throu ghput far from r ∗ k . For p k > p ∗ k , we hav e p i > p ∗ i . These p lead to F i values th at are close to the upper bound an d, as the upp er bound correspo nds to t k = t ∗ , this 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 0.01 0.1 1 Throughput [Mbps] p k Using DOC R - k =R - * k R - k =0 R - k =2·R - * k R - k =1.5·R - * k R - k =0.5·R - * k Fig. 7. T hroughput of a selfish station for fixed configuration s of { p k , ¯ R k } . 0 2 4 6 8 10 12 14 2 4 6 8 10 12 14 16 18 20 Throughput [Mbps] N Selfish configuration ( ρ 2 =4) Selfish configuration ( ρ 2 =2) Selfish configuration ( ρ 2 =8) Selfish configuration ( ρ 2 =1) DOC Fig. 8. Selfish station with fixed configuration for diffe rent N and ρ 2 v alues. giv es a through put close to r ∗ k for the selfish station. In Section VI-E we show that this de sign leads to a robust b ehavior against selfish station s an d tr ansient co ndition s. Fig. 8 analy zes the impact of fixed selfish c onfigur ations for a range of d ifferent N a nd ρ 2 values. It shows the largest throug hput that a selfish station can receive with a fixed configur ation, which is obtained by per forming an exhaustive search over the { p k , ¯ R k } space . Th is throu ghpu t is compare d against the one that the station would receive if it played DOC. Again we observe that the station never benefits from playing selfishly , which validates the desig n of the DOC algorithm . C. S elfish statio n with va riable co nfigu ration According to Th eorem 5 , a selfish station cannot benefit from chang ing its configur ation over time. For verification , we ev aluate the throu ghput obta ined by a selfish station with different a daptive strategies. Th ese strategies are inspir ed by the schemes used in [ 20], [2 2] for a similar pu rpose. The underly ing prin ciple of all of them is that the cheatin g station uses a selfish configu ration to gain thr ough put and, when it realizes that it is not g aining throu ghpu t, it assumes that it has been detected as selfish a nd switches back to the h onest configur ation to avoid being pun ished. In par ticular, we consider the f ollowing strategies. The ‘ adap tive p k strate gy ’ fixes the ¯ R k configur ation of the selfish 12 0 1 2 3 4 5 N=4 N=8 N=12 N=16 N=20 Throughput [Mbps] DOC Adaptive p k strategy Adaptive R - k strategy Adaptive p k and R - k strategy Fig. 9. Throughput of selfish station with differe nt a dapti ve strat egies. station to its o ptimal value, ¯ R k = ¯ R ∗ k , and modifies the p k configur ation as follows: the station uses a selfish co nfigura- tion o f p k = 1 as long as it ob tains some gain, i.e. r k > r ∗ k . When r k drops below r ∗ k , the station switch es to the honest configur ation, p k = p ∗ k , and stays with this configu ration as long as r k stays belo w 0 . 95 r ∗ k . It switches back to p k = 1 when r k grows above 0 . 95 r ∗ k . The ‘ ada ptive ¯ R k strate gy ’ fixes the p k configur ation to the optimal value, p k = p ∗ k , and m odifies the ¯ R k configur ation following a strategy similar to the on e above: the station uses a selfish configuration of ¯ R k = 0 (i. e., it uses all transmission o pportu nities) as long as it obtains some gain and switches to the hon est config uration when it stop s benefiting. Finally , th e ‘ ada ptive p k and ¯ R k strate gy ’ fo llows a similar b ehavior to the previous ones but adapts both the p k and the ¯ R k configur ation. Fig. 9 compare s the through put obtain ed with ea ch of the above strategies against the one with DO C for d ifferent values of N . As expec ted, when all oth er stations play DOC, a g i ven station maximizes its payoff play ing DOC as well, as it obtains a larger th rough put than with any of the other strategies, confirmin g the result o f Theorem 5. D. Mu ltiple selfish statio ns Corollary 3 states that multiple selfish stations cannot si- multaneou sly benefit by deviating from DOC, as it is only possible that on e or mor e of the selfish stations exper ience some thro ughpu t gain s if there are some other selfish stations that suffer some loss. T o validate the result, we consider a network with N = 10 stations including tw o selfis h stations, half of them (inc luding one of the selfish stations) with ρ 1 = 1 and the other half (includ ing the other selfish station) with ρ 2 = 4 . W e perfor m an exhaustiv e search over a wide ran ge of { p i , ¯ R i } configur ations of the two selfish stations. The results of this ex- periment are depicted in Fig. 10, which sho ws the thro ughpu t obtained by the two selfish stations ( r k and r l ) for ea ch o f the configur ations used in the exhaustive searc h. The figure also shows the throug hput o f the two stations when they both play DOC. There is no configuratio n tha t simultaneously improves the throu ghpu t of th e two selfish stations, which co nfirms the result of Corollary 3 . 0 0.5 1 1.5 2 2.5 3 3.5 4 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 r l [Mbps] r k [Mbps] DOC r k > r k * r l > r l * Fig. 10. Throughput obtaine d by multiple selfish stations. W e also observe fr om the figure that the region of feasible allocations has a tring ular shape. T his is a consequ ence of Theorem 7: since the maximu m aggregated channel time that the two stations can obtain is fixed, any through put increase in o ne station leads to a decrease in the oth er station of the same amoun t scaled by a con stant factor that dep ends o n th e respective radio con ditions. E. Robustness to selfish behavio r and transient con ditions For a setting similar to that of Fig. 7 with 10 stations, half of th em with ρ 1 = 1 and half with ρ 2 = 4 , and one selfish station with a fixed config uration and ρ 2 = 4 , we investigate the overall thro ughp ut of th e wir eless system. Again, the thro ughp ut obtain ed w hen all stations play DOC is given by the h orizontal line. From Fig. 11 we see that th e overall throu ghpu t is clo se to optimal for low values of the access probab ility p k of the selfish station and on ly gradually decreases for h igh values of p k . For low values of p k , well- behaved stations contend with a high er access pro bability th an the selfish station which yields an almost o ptimal throug hput. For high values of p k , the selfish station has to be pu nished which un av oid ably results in some th rough put loss. Howe ver , the level of pun ishment is minim ized to av oid d riving the collision prob ability to unn ecessarily hig h levels that harm the overall thro ughpu t. Hence, even fo r very high p k and the subsequen t high rate of co ntention collision s, some thro ughp ut remains fo r th e well-b ehaved stations (no te from Fig. 7 that the max imum throug hput of the selfish station is less than ∼ 1.8 Mb ps). W e conclu de that, as inten ded, the design of F i maintains a lev e l of throu ghpu t as hig h as possible for the well-behaved stations. In addition to robustness against selfish behavior (as seen above), our design of F i also aims at providing robustness in transient conditions. W e in vestigate this through the following experiment: in a wireless ne twork with 10 stations, a new station join s every 100 in tervals, with its p i initially set to 0.5, stays fo r 50 in tervals and then leaves th e system. With our design of F i the total thro ughp ut o btained in this scenario is equal to 9.67 Mbps, while with a d esign of F i 10 times smaller , it is on ly 6.52 Mbp s, confirmin g the robustness of DOC to transient n etwork cond itions. 13 0 2 4 6 8 10 12 14 16 0.01 0.1 1 Total Throughput [Mbps] p k Using DOC R - k =R - * k R - k =0 R - k =2·R - * k R - k =1.5·R - * k R - k =0.5·R - * k Fig. 11. T otal system throughput in the presence of a sel fish station. 0.5 1 1.5 2 2.5 3 3.5 4 Throughput [Mbps] Kp,Ki 0.5 1 1.5 2 2.5 3 3.5 4 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 Interval Kp*10,Ki*10 Fig. 12. Stabil ity ana lysis of the parameters of t he PI controller . F . P arameter setting of the PI contr oller The main objective in the setting of th e K p and K i pa- rameters prop osed in Section IV is to achieve a goo d tr adeoff between stability an d spe ed o f reaction. T o validate that o ur system guar antees a stable be havior , we analyze the e volution over time of the throug hput rec eiv e d b y a station for the chosen { K p , K i } setting and a configur ation of the se p arameters 1 0 times larger, in a wireless network with N = 10 stations. W e observe fr om Fig . 12 that with the p roposed setting (labeled “ K p , K i ”), th e thr ough put shows only m inor deviations aro und its av e rage value, wh ile for a larger setting (labeled “ K p ∗ 1 0 , K i ∗ 1 0 ”), it shows unstab le behavior with drastic oscillations. T o investigate the speed with which th e system reacts against selfish stations, we use a wireless network with N = 10 stations where initially all station s play DOC an d, after 5 0 inter vals, one station tur ns selfish and cha nges its access prob ability to p k = 1 . Fig. 13 shows the ev olution of the thr ough put of the selfish station over time . W e obser ve from the figu re that with our setting (labeled “ K p , K i ”), the system reacts q uickly , and af ter a few tens of in tervals the selfish station no longer b enefits fro m its behavior . In contrast, fo r a setting of these parameter s 10 times smaller (labeled “ K p / 10 , K i / 10 ”), the reaction is very slow and it takes alm ost 20 00 intervals until the station stop s benefiting from its misbehavior . The re sults show th at with a larger settin g of { K p , K i } the system suf fers from instability while with a smaller one it reacts too slowly . Hence, the pro posed setting provides a good 2 4 6 8 10 12 14 16 Throughput [Mbps] Kp,Ki 2 4 6 8 10 12 14 16 0 500 1000 1500 2000 Interval Kp/10,Ki/10 Fig. 13. Speed of reacti on pro vided by the parameters of th e PI controller . 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 2.4 2.6 static configuration DOC DOS non-opportunistic Throughput [Mbps] r 1 r 2 Fig. 14. Performanc e wit h Jak es’ c hannel mod el . tradeoff between stab ility and speed o f r eaction. G. I mpact of chan nel cohe r ence time Our chan nel model is based on th e assumption that different observations of the chan nel condition s ar e in depend ent. I n order to u nderstand the impact of th is assump tion, we rep eat the experiment of Fig. 6 using Jak es’ chan nel mo del [23] to obtain the different channel observations. T he results, fo r a Doppler frequ ency of f D = 2 π / 10 0 τ , are g iv e n in Fig. 14. W e o bserve that the throu ghput ob tained is slightly sma ller than that of Fig. 6. Th is is due to the fact th at wh en the channel is bad, a station do es n ot transmit after a successful contention and therefore it takes (on a vera ge) a sho rter time until the next succ essful conten tion o f this station . As a result, a station a ccesses more often the channel when it is ba d than when it is g ood, which introdu ces a bias that slightly red uces the throug hput. Overall, the results are sufficiently similar to those o f Fig . 6 to conclu de that ou r a ssumption o n th e chann el model only has a min or impact on the r esulting per forman ce. W e further inv e stigate wheth er , in th e above scenar io, a station with ρ 2 = 4 could obtain more throu ghpu t by using a selfish co nfiguratio n. While th e station obtains 1.75 2 Mbps with DOC, it can ob tain up to 1 .757 Mbps with a selfish configur ation. Note that this inc rease is n ot due to the DOC design, as no c onfigur ation gives m ore chan nel time to the selfish station, but rather due to the fact that th e tran smission rate threshold of [ 3] is n ot truly optimal under Jakes ’ c hannel model . In any case, the throu ghput gain o f the selfish station is n egligible. 14 0 1 2 3 4 5 6 7 8 9 2 4 6 8 10 12 14 16 18 20 Throughput [Mbps] N Selfish configuration ( ρ 2 =4) Selfish configuration ( ρ 2 =2) Selfish configuration ( ρ 2 =8) Selfish configuration ( ρ 2 =1) DOC Fig. 15. Throughput comparison for a discrete set of ra tes. H. D iscr ete set of transmission rates While all previous experimen ts assumed contin uous rate s, our analysis as well as th e design of the DOC algorithm does not rely o n any assum ption on the m apping o f SNR to transmission rates and theref ore works for any ( continu ous o r discrete) mapp ing fun ction. T o sh ow that DOC is effecti ve when only a set of discrete rates is allowed, we analyz e a wireless sy stem in w hich the only transmission rates a vailable are { 1 , 2 , 5 . 5 , 12 , 24 , 48 , 54 } Mbps. For a giv e n SNR, we choose the largest av ailable transmission rate that is smaller than the one given by Eq. (87). W e r epeat the exper iment of Fig. 9 with d iscrete rates, and compare the throughput of a selfish station against the t hroug h- put that this station obtains wh en it play s DOC. The results in Fig. 1 5 co nfirm that a station can not b enefit fr om p laying selfish. W e fur ther observe th at, as expected, thro ughpu ts are smaller than tho se o f Fig. 9 since, with the d iscrete mappin g of SNR to r ates, smaller transmission rates are ac hieved on av erage. V I I . C O N C L U S I O N S Recently pr oposed Distributed Oppo rtunistic Schedu ling (DOS) techniques provide thr ough put gains in wireless net- works that do no t have a centr alized scheduler . One of the problem s of these techniq ues is, however , that they ar e vu lner- able to malicio us users which may con figure their param eters to obtain a greater share of th e wireless resources at the expense of other, well-behaved, u sers. In this p aper we add ress the p roblem by pr oposing a novel algorithm that pr ev ents such throug hput gains fr om selfish b ehavior . W ith our appro ach, up on detecting a selfish user , station s react by u sing a more aggressive param eter configuratio n which serves to p unish the selfish station. Such an adaptive algorithm has to carefully adjust the reac tion against a selfish station to av oid that the system turns u nstable by overreacting. A key aspect of the paper is that we use of tools fro m the fields of mu ltivariable co ntr ol theo ry comb ined with g ame theo ry in the design o f our alg orithm. W e conducted a control theo retic analysis of the DOC algorithm that shows that, when all th e stations in the wireless network run DOC, the system behaves stably an d converges to the desired con figuration . W e then used this contro l theo retic analysis to find a setting that provid es a good trad eoff between stability and spe ed of reaction . In addition , we perform ed a game theor etic analysis of DOC based o n repeated games to ev aluate its b ehavior when there are one or m ore selfish sta- tions in the wireless network. The analysis shows that n either a single selfish station no r several co operating selfish station s can be nefit fro m pla ying a strategy d ifferent f rom DOC, and that this hold s for fixed as well as for adaptive strategies. Furthermo re, the DOC strategy represents a sub game per fect Nash eq uilibrium. R E F E R E N C E S [1] M. Andre ws et al. , “Provi ding quality of service ove r a shared wireless link, ” IEEE Communicati ons Magazine , vol. 39, no. 2, February 2001. [2] P . V iswanath, D. N. Tse, and R. Laroia, “Opportuni stic beamforming using dumb antennas, ” IEEE T ransactions on Informati on Theory , vol. 48, no. 6, pp. 1277–1294, June 2002. [3] D. Zheng, W . Ge, and J. Zhang, “Di strib uted opportunisti c scheduling for ad hoc networ ks with random access: an optimal stopping approach, ” IEEE T ransactions on Information Theory , vol. 55, no. 1, January 2009. [4] D. Zheng, , M.-O. P . W . Ge, H. V . Poor , and J . Zhang, “Distrib uted opportuni stic scheduling for ad hoc communications with imperfect channe l information, ” IEE E Tr ansactions on W irele ss Communications , vol. 7, no. 12 , pp. 5450 – 5460, December 2008 . [5] P . Thejaswi, J. Z hang, M.-O. Pun, H. V . Poor , and D. Zheng, “Dis- trib uted opportuni s tic scheduli ng with two-l e vel probing, ” IEEE/ACM T ransacti ons on Ne tworkin g , vo l. 18, no. 5, October 2010. [6] S. T an, D. Z . J. Zhang, and J. R. Z eidler , “Distribut ed opportuni stic scheduli ng for ad-hoc communications under delay constraints, ” in Pr oceed ings of IEE E INFO COM , San Diego, CA, March 2010. [7] F . Kell y , “Charging and rate control for elastic traf fic, ” Euro pean T ransacti ons on T elecommuni cation s , vol. 8, pp. 33–37, 1997. [8] G. Holland, N. V ai dya, and P . Bahl, “ A rate-adapt i ve mac protocol for multi-hop wirele ss netw orks, ” in Pr oceedings of ACM MOBICOM , Rome, Italy , July 2001. [9] B. Sadhegi , V . Kanodia, A. Sabharwal, and E. Knightly , “Opportuni s tic media access for multirate ad hoc networ ks, ” in Procee dings of ACM MOBICOM , Atlant a, GA, September 2002. [10] P . Gupta, Y . Sankarasubr amaniam, and A. Stolyar , “Random-acce s s scheduli ng with service dif ferenti ation in wireless networks, ” in Pro- ceedi ngs of IEEE INFOCOM , Miami, FL, March 2005. [11] T . Glad and L. Ljung, Contr ol theory: multivari able and nonline ar methods . T aylor & Fra ncis, 2000. [12] P . Patras, A. Banchs, P . Serrano, and A. Azcorra, “A Control Theoretic Approach to Distribute d Optimal Configura tion of 802.11 WLANs, ” IEEE T ransaction s on Mobile Computing , v ol. 10, no. 6, June 2011. [13] C. Hollot, V . Misra, D. T owsle y , and W . B. Gong, “On designing improv ed controller s for A QM rou ters support ing TCP flo ws, ” in P r o- ceedi ngs of IEEE INFOCOM , Anchorage, Alaska, April 2001. [14] G. Boggia, P . Camarda, L. A. Grieco, and S. Mascolo, “Feedback- based control for provid ing real-t ime service s with the 802.11e mac, ” IEEE/ACM T ransactions on Networking , vol. 15, no. 2, April 2007. [15] K. As tr ¨ om and R. M. Murray , F eedback Systems . Pri nceton Uni versity Press, 2008. [16] C. V . Hollot, V . Misra, D. T owsle y , and W . B. Gong, “A Control Theoretic Analysis of RED, ” in P r oceedings of IEEE INFOCOM , Anchorage , Al aska, April 2001. [17] K. Astr ¨ om and B. Wit tenmark, Computer-cont r olled systems, theory and design , 2nd ed. Prentic e Ha ll Internat ional Editi ons, 1990. [18] G. F . Franklin, J. D. Po well, and M. L . W orkman, Digital Contr ol of Dynamic Systems , 2nd ed. Addison-W esle y , 1990. [19] D. Fudenber g and J. T irole, Game Theory . MIT Press, 1991. [20] M. Cagalj, S. Ganeriwal , I. Aad, and J .-P . Hubaux, “On selfish behavior in csma/ca networks, ” in Procee dings of IEEE INFOCOM , Miami, Florida, March 2005. [21] J. Konorski , “ A game-theo retic study of csma/ca under a backof f attack, ” IEEE/ACM T ransacti ons on Networking , vol. 16, no. 6, December 2006. [22] L. Buttyan and J.-P . Hubaux, Security and Cooperation in W ireless Network s . Cambridge: Cambridge Univ ersity Press, 2008. [23] W . C. Jake s, Micr owave Mobile Communicati ons . Ne w Y ork: John W iley & Sons Inc., 1975.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment