Why approximate Bayesian computational (ABC) methods cannot handle model choice problems
Approximate Bayesian computation (ABC), also known as likelihood-free methods, have become a favourite tool for the analysis of complex stochastic models, primarily in population genetics but also in financial analyses. We advocated in Grelaud et al.…
Authors: Christian Robert (Universite Paris Dauphine), Jean-Michel Marin (Universite de Montpellier 2), Natesh S. Pillai (Harvard University)
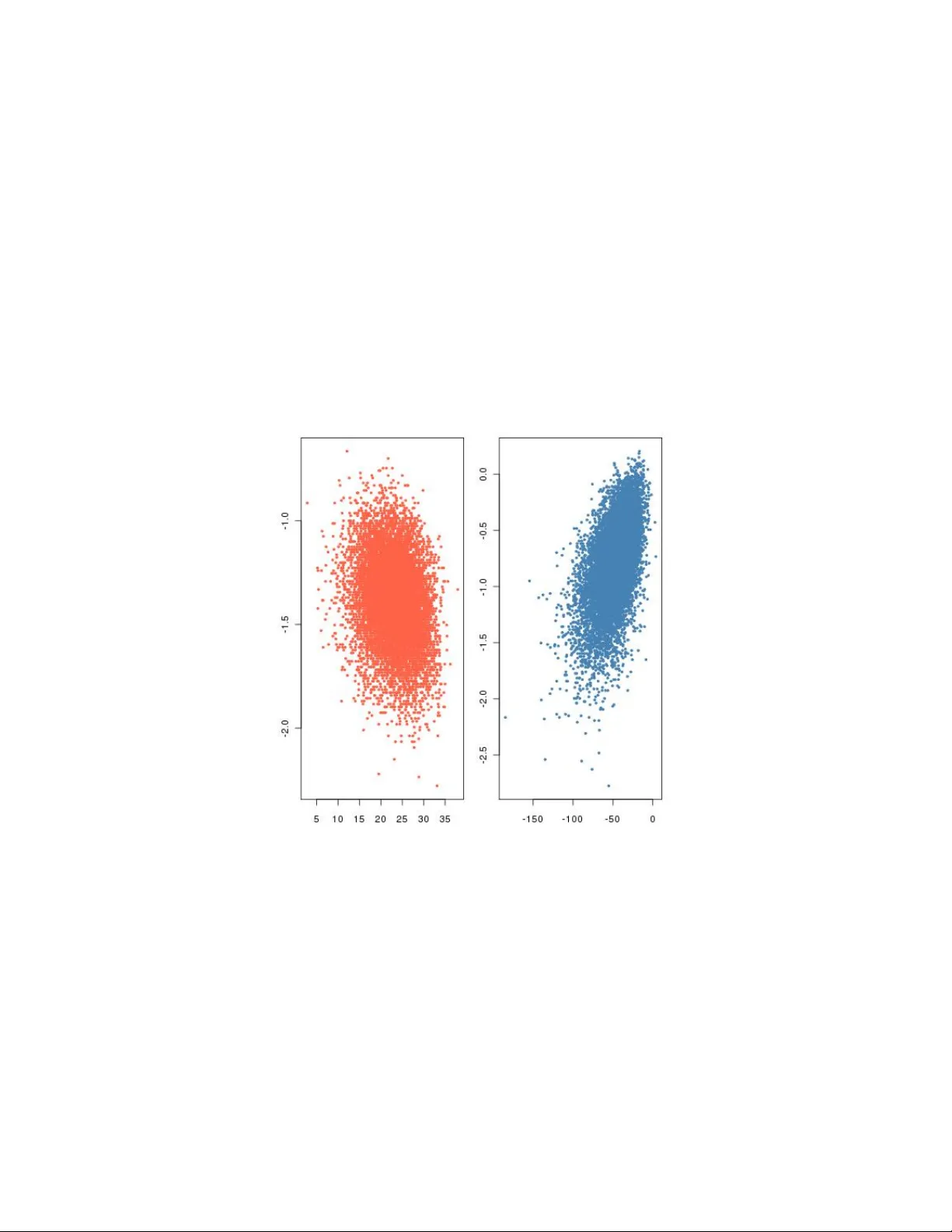
Wh y appro ximate Ba y esian computational (ABC) metho ds cannot handle mo del c hoice problems Christian P. R ober t Univ ersit´ e P aris Dauphine, CEREMADE, IUF, and CREST Jean-Michel Marin I3M, UMR CNRS 5149 Univ ersit´ e Mon tp ellier 2 Na tesh S. Pillai Departmen t of Statistics, Harv ard Universit y Abstract Appro ximate Ba yesian computation (ABC), also kno wn as likelihoo d-free metho ds, ha ve b ecome a fav ourite to ol for the analysis of complex sto c hastic mo dels, primarily in p opulation genetics but also in financial analyses. W e advocated in Grelaud et al. (2009) the use of ABC for Ba yesian mo del choice in the sp ecific case of Gibbs random fields (GRF), relying on a sufficiency prop ert y mainly enjo yed b y G RFs to show that the approac h was legitimate. Despite ha ving previously suggested the use of ABC for mo del c hoice in a wider range of mo dels in the DIY ABC softw are (Cornuet et al., 2008), we presen t theoretical evidence that the general use of ABC for mo del choice is fraugh t with danger in the sense that no amount of computation, how ever large, can guaran tee a prop er approximation of the p osterior probabilities of the mo dels under comparison. Keyw ords : likelihoo d-free metho ds, Ba yes factor, DIY ABC, Bay esian model choice, sufficiency . 1 In tro duction Inference on p opulation genetic mo dels suc h as coalescent trees is one represen tative ex- ample of cases when statistical analyses like Bay esian inference cannot operate b ecause the likelihoo d function asso ciated with the data is not completely known, i.e. cannot b e computed in a manageable time (T a v ar´ e et al., 1997, Beaumont et al., 2002, Cornuet et al., 2008). The fundamental reason for this imp ossibility is that the statistical mo del asso ciated with coalescen t data needs to integrate o ver trees of extreme complexity . In such settings, traditional approximation to ols based on Monte Carlo simulation (Rob ert and Casella, 2004) from the Bay esian p osterior distribution are unav ailable for all practical purp oses. Indeed, due to the complexity of the latent structures defining the 1 lik eliho o d (suc h as the coalescent tree), simulation of those structures is to o unstable to b e trusted to bring a reliable approximation in a manageable time. Suc h complex mo dels call for a practical if cruder approximation method, the ABC metho dology b eing a serious con tender, where ABC stands for appr oximate Bayesian c omputation . T a v ar´ e et al. (1997) and Pritchard et al. (1999) introduced ABC metho ds as a rejection technique b ypassing the computation of the likelihoo d function via a simulation from the corresp onding dis- tribution. F or recent reviews on ABC, see Beaumon t (2010) and Lop es and Beaumont (2010). The wide and successful array of applications based on implemen tations of ABC in genomics and ecology is co vered b y Csill ` ery et al. (2010a), while the num b er of publications relying on this technique runs in the hundreds. Pritc hard et al. (1999) describ e the use of mo del choice based on ABC for distin- guishing b et ween differen t m utation mo dels. The in tuition b ehind the method is that the av erage ABC acceptance rate asso ciated with a giv en model is prop ortional to the marginal lik eliho od corresp onding to this approximativ e mo del, when identical summary statistics, distance, and tolerance level are used for all mo dels. In practice, an estimate of the ratio of marginal likelihoo ds is given b y the ratio of observed acceptance rates. Us- ing Bay es formula, estimates of the p osterior probabilities are straightforw ard to derive. This approac h has b een widely used in the literature (see, e.g., Estoup et al., 2004, Miller et al., 2005, and Pascual et al., 2007, Sainudiin et al., 2011). Note that Miller et al. (2005) is particularly influencial for the conclusion it derives from the ABC analysis: the fo cus of this Scienc e pap er is the Europ ean in v asion of the w estern corn ro ot worm, whic h is North America’s most destructiv e corn pest. Because this p est w as initially introduced in Cen tral Europe, it w as believed that subsequen t outbreaks in W estern Europ e originated from this area. Based on this ABC mo del choice analysis of the genetic v ariability of the ro ot w orm, the authors conclude that this b elief is false: There ha ve b een at least three indep enden t introductions from North America during the past tw o decades. An improv ement to the ab o ve estimate is due to F agundes et al. (2007), thanks to a regression regularisation. In this approach. model indices are pro cessed as categorical v ari- ables in a formal m ultinomial (p olyc hotomous) regression. F or instance, when comparing t wo mo dels, this leads to a standard logistic regression. Rejection-based approac hes w ere lately introduced b y Corn uet et al. (2008), Grelaud et al. (2009) and T oni et al. (2009), in a Mon te Carlo p erspective sim ulating mo del indices as w ell as mo del parameters. Those more recen t extensions are already widely in use b y the population genetics comm unity , as exemplified b y Belle et al. (2008), Corn uet et al. (2010), Excoffier et al. (2009), Ghirotto et al. (2010), Guillemaud et al. (2009), Leuen b erger and W egmann (2010), P atin et al. (2009), Ramakrishnan and Hadly (2009), V erdu et al. (2009), or W egmann and Excoffier (2010). Another illustration of the p opularity of this approach is given b y the av ailability of three three softw ares implemen ting an ABC mo del c hoice metho dology: 2 • ABC-SysBio 1 , dev elopp ed by the Theoretical Systems Biology Group at Imp erial College London, whic h implemen ts a SMC-based ABC for inference in system biol- ogy , including mo del-c hoice (T oni et al., 2009). • DIY ABC 2 , dev elopp ed b y the Cen tre de Biologie et de Gestion des Populations, at INRA Mon tp ellier, whic h implemen ts a regularised ABC-MC algorithm on popula- tion history using molecular mark ers (Cornuet et al., 2008). • P opABC 3 , dev elopp ed b y the School of Biological Sciences at the Universit y of Reading, whic h implemen ts a regular ABC-MC algorithm for genealogical simulation (Lop es et al., 2009). Grelaud et al. (2009) pro cess via ABC the sp ecific case of Gibbs random fields with missing normalising constan ts. They establish that exact Ba y esian mo del selection can b e implemented in this setting, deriving this result from the prop erty that the concate- nation of the sufficien t statistics across mo dels is also sufficient for mo del comparison. In a subsequent pap er, Didelot et al. (2010) advocate the role of ABC appro ximations in general Bay esian mo del c hoice. The issue of sufficiency is co vered in this pap er, with a generic cross-mo del sufficiency completion leading the authors to v alidate the metho d in full generality , including in-sufficien t cases. In this pap er, we argue that ABC is a v alid appro ximation metho d for conducting Ba yesian inference in complex sto c hastic mo dels, barring the limitation that it cannot discriminate b et ween those complex sto c hastic mo dels when based on summary statistics. In essence, w e highligh t the fact that, since ABC is conducting mo del choice based on in-sufficien t statistics, the resulting inference is flaw ed in that the loss of information is sev ere to the p oin t of inconsistency , namely that the ABC mo del selection cannot recov er the prop er mo del, even with an infinite amount of observ ation and computation. W e demonstrate this inconsistency in the limiting (and more fav ourable) case of sufficien t statistics. The conclusion of the current paper are thus quite negativ e in that we consider that conducting testing or mo del comparison using ABC do es not carry an y reliable w eigh t of evidence and therefore should not b e trusted. More empirical measures such as those pro- p osed in Ratmann et al. (2009) and Dro v andi et al. (2011) seem to b e the only p ossibilit y at the current time for conducting model comparison. W e are therefore at o dds with the p ositiv e conclusion found in Didelot et al. (2010), as discussed b elo w. W e stress here that, while T empleton (2008, 2010) rep eatedly expressed reserv ations ab out the formal v alidit y of the ABC approac h in statistical testing, those criticisms were addressed at the Ba yesian paradigm p er se rather than at the appro ximation metho d. 1 http://ab c-sysbio.sourceforge.net 2 http://www1.montp ellier.inra.fr/CBGP/diyabc 3 http://co de.go ogle.com/p/p opab 3 Quite clearly , T empleton’s criticisms got rebutted in Beaumont et al. (2010), Csill` ery et al. (2010b), Berger et al. (2010) and are not relev ant for the current pap er. The plan of the paper is as follo ws: in Section 2, w e recall the basics of ABC as w ell as its justification; Section 4 exp oses why a Bay es factor based on an ABC appro ximation is not conv erging to the true Ba yes factor as the computational effort increases; Section 5 explains the sp ecificit y of MRFs in this regard, while Section 6 illustrates the p oten tial for divergence in examples. Sectoion 7 concludes the pap er. 2 The ABC approac h and its justifications The se tting in whic h ABC operates is the appro ximation of the sim ulation from the p os- terior distribution π ( θ | y ) ∝ π ( θ ) f ( y | θ ) when b oth distributions asso ciated with π and f can be simulated. The first ABC algorithm w as introduced b y Pritchard et al. (1999) in a genetic setting, as follo ws: giv en a sample y from a sample space D , Algorithm 1 ABC sampler for i = 1 to N do rep eat Generate θ 0 from the prior distribution π ( · ) Generate z from the lik eliho od f ( ·| θ 0 ) un til ρ { η ( z ) , η ( y ) } ≤ set θ i = θ 0 , end for The parameters of the ABC algorithm are the statistic η , the distance ρ {· , ·} ≥ 0, and the tolerance lev el > 0. The approximation of the p osterior distribution pro vided by the algorithm is that it samples from the marginal in θ of the join t distribution π ( θ , z | y ) = π ( θ ) f ( z | θ ) I A , y ( z ) R A , y × Θ π ( θ ) f ( z | θ )d z d θ , (1) where I B ( · ) denotes the indicator function of the set B and where A , y = { z ∈ D | ρ { η ( z ) , η ( y ) } ≤ } . The basic justification of the ABC appro ximation is that, when using a sufficient statistic η and a small (enough) tolerance , w e ha ve π ( θ | y ) = Z π ( θ , z | y )d z ≈ π ( θ | y ) , the (correct) posterior distribution π ( θ | y ) b eing the limit as goes to zero of π ( θ | y ). 4 In practice, the statistic η is not sufficien t and the appro ximation then con v erges to π ( θ | η ( y )). This fact is appreciated b y users in the field who see this loss of information as an unv oidable price to pay for the access to computable quantities. While ackno wledging the gain brought by ABC in handling Bay esian inference in complex mo dels, w e will demonstrate below that the loss due to the ABC approximation may be arbitrary in the sp ecific setting of Ba yesian mo del choice and testing, whether or not η is sufficien t. 3 ABC and mo del c hoice T esting and mo del choice constitute a highly sp ecific domain of Bay esian analysis that in volv es conceptual and computational complexification since sev eral models are sim ulta- neously considered (Rob ert, 2001, Marin and Rob ert, 2010). Given that both inferential problems are processed the same w ay in a Bay esian p ersp ectiv e, w e will only men tion mo del choice in the remainder of the pap er, but the reader must b ear in mind that we co ver testing as a particular case. The standard to ol on which a Ba yesian approac h relies is the evidence (Jeffreys, 1939), also called the marginal lik eliho o d, w ( y ) = Z Θ π ( θ ) f ( y | θ ) d θ , that leads to the Ba yes factor for comparing the evidences brought by the data on mo dels with likelihoo ds f 1 ( z | θ 1 ) and f 2 ( z | θ 2 ), B 12 ( y ) = w 1 ( y ) w 2 ( y ) = R Θ 1 π 1 ( θ 1 ) f 1 ( y | θ 1 ) d θ 1 R Θ 2 π 2 ( θ 2 ) f 2 ( y | θ 2 ) d θ 2 . As detailed in the Bay esian literature (Berger, 1985, Rob ert, 2001, MacKa y, 2002, Marin and Robert, 2010), this ratio provides an absolute criterion for model comparison that is naturally penalised for mo del complexity (B eaumon t et al., 2010, Berger et al., 2010) and whose first order approximation is the Ba yesian information criterion (BIC). Giv en that this issue is fundamen tal to our p oin t, we recall that Ba yesian model choice pro ceeds by creating a probability structure across mo dels (or likelihoo ds). Namely , in addition to the parameters associated with each mo del, a Ba yesian inference in tro duces the mo del index M as an extra parameter. It is asso ciated with its o wn prior distribution, π ( M = m ) ( m = 1 , . . . , M ), while the prior distribution on the parameter is conditional on the v alue m of the mo del index, denoted by π m ( θ m ) and defined on the parameter space Θ m . The choice betw een those mo dels is then driv en by the posterior distribution of M , P ( M| y ) = π ( M = m ) w m ( y ) P k π ( M = k ) w k ( y ) where w k ( y ) denotes the marginal lik eliho o d of y for mo del k . 5 While this distribution is well-defined and straightf orward to in terpret, it offers a c hallenging computational conundrum in Ba yesian analysis. Moreov er, the solutions found in the literature (Chen et al., 2000, Marin and Rob ert, 2010) do not handle the case when the likelihoo d is not av ailable and ABC represents the almost unique alternative. As exposed in e.g. Grelaud et al. (2009), T oni and Stumpf (2010), and Didelot et al. (2010), once M is incorp orated within the parameters, the ABC appro ximation to the p osterior follo ws from the same principles as regular ABC. The corresp onding implemen- tation is as follo ws, using for the tolerance region a statistic η ( z ) = ( η 1 ( z ) , . . . , η M ( z )) that is the concatenation of the summary statistics used for all models (with an obvious elimination of duplicates). Algorithm 2 ABC mo del c hoice sampler (ABC-MC) for i = 1 to N do rep eat Generate m from the prior π ( M = m ) Generate θ m from the prior π m ( θ m ) Generate z from the model f m ( z | θ m ) un til ρ { η ( z ) , η ( y ) } ≤ Set m ( i ) = m and θ ( i ) = θ m end for The ABC estimate of the p osterior probabilit y π ( M = m | y ) is then the frequency of acceptances from model m in the ab o ve sim ulation \ P ( M| y ) = 1 N N X i =1 I m ( i ) = m . This also corresp onds to the frequency of simulated pseudo-dataset from mo del m that are closer to the data y than the tolerance . In order to improv e the estimation by smo othing, Cornuet et al. (2008) follow the rationale that motiv ated the use of a lo cal linear regression in Beaumont et al. (2002) and rely on a w eighted p olyc hotomous logistic regression to estimate π ( M = m | y ). This mo delling is implemen ted in the DIY ABC soft ware. 4 The difficult y with ABC-MC Most p erspectives on ABC do not question the role of the ABC distance nor of the statistic η in mo del choice settings. There is ho wev er a m uc h stronger discrepancy b et ween the gen uine Bay es factor / p osterior probabilit y and the appro ximations resulting from ABC. 6 The ABC appro ximation to a Bay es factor, B 12 sa y , resulting from Algorithm 2 is d B 12 ( y ) = π ( M = 2) π ( M = 1 P N i =1 I m ( i ) =1) P N i =1 I m ( i ) =2 An alternative representation is given by d B 12 ( y ) = π ( M = 2) π ( M = 1) P T t =1 I m t =1 I ρ { η ( z t ) , η ( y ) }≤ P T t =1 I m t =2 I ρ { η ( z t ) , η ( y ) }≤ , where the pairs ( m t , z t ) are simulated from the (join t) prior and T is the total num b er of sim ulations that are necessary for N acceptances in Algorithm 2. In order to study the limiting behaviour of this appro ximation, w e first let T go to infinit y . (F or simplification purp oses and without loss of generality , we c ho ose a uniform prior on the mo del index.) The limit of d B 12 ( y ) is then B 12 ( y ) = P [ M = 1 , ρ { η ( z ) , η ( y ) } ≤ ] P [ M = 2 , ρ { η ( z ) , η ( y ) } ≤ ] = R I ρ { η ( z ) , η ( y ) }≤ π 1 ( θ 1 ) f 1 ( z | θ 1 ) d z d θ 1 R I ρ { η ( z ) , η ( y ) }≤ π 2 ( θ 2 ) f 2 ( z | θ 2 ) d z d θ 2 = R I ρ { η , η ( y ) }≤ π 1 ( θ 1 ) f η 1 ( η | θ 1 ) d η d θ 1 R I ρ { η , η ( y ) }≤ π 2 ( θ 2 ) f η 2 ( η | θ 2 ) d η d θ 2 , where f η 1 ( η | θ 1 ) and f η 2 ( η | θ 2 ) denote the distributions of η ( z ) when z ∼ f 1 ( z | θ 1 ) and z ∼ f 2 ( z | θ 2 ), resp ectiv ely . By L’Hospital formula, if we let go to zero, the ab o ve con verges to B η 12 ( y ) = R π 1 ( θ 1 ) f η 1 ( η ( y ) | θ 1 ) d θ 1 R π 2 ( θ 2 ) f η 2 ( η ( y ) | θ 2 ) d θ 2 , whic h is precisely and exactly the Bay es factor for testing model 1 versus mo del 2 based on the sole observ ation of η ( y ). This result is completely coherent with the current p erspective on ABC, namely that the inference deriv ed from the ideal ABC output when = 0 only uses the information con tained in η ( y ). Thus, in the limiting case, i.e. when the ABC algorithm uses an infinite computing pow er, the ABC odds ratio does not tak e in to accoun t the features of the data b esides the v alue of η ( y ), whic h is wh y the limiting Ba yes factor only dep ends on the distributions of η under both models. In contrast with p oin t estimation—where using a sufficient statistic has no impact on the inference in the limiting case—, the loss of information resulting from considering solely η seriously impacts the resulting inference on which model is b est supp orted by the data. Indeed, as exhibited in a sp ecial case b y Grelaud et al. (2009), the information con tained in η ( y ) is almost alwa ys smaller than the information con tained in y and this 7 ev en in the case η ( y ) is a sufficient statistic for b oth mo dels . In other words, η ( y ) b eing sufficient for b oth f 1 ( y | θ 1 ) and f 2 ( y | θ 2 ) do es not usual ly imply that η ( y ) is sufficient for { m, f m ( y | θ m ) } . T o see why this is the case, consider the most fav ourable case, namely when η ( y ) is a sufficien t statistic for b oth mo dels. W e then hav e b y the factorisation theorem (Lehmann and Casella, 1998) that f i ( y | θ i ) = g i ( y ) f η i ( η ( y ) | θ i ), therefore that B 12 ( y ) = w 1 ( y ) w 2 ( y ) = R Θ 1 π ( θ 1 ) g 1 ( y ) f η 1 ( η ( y ) | θ 1 ) d θ 1 R Θ 2 π ( θ 2 ) g 2 ( y ) f η 2 ( η ( y ) | θ 2 ) d θ 2 = g 1 ( y ) R π 1 ( θ 1 ) f η 1 ( η ( y ) | θ 1 ) d θ 1 g 2 ( y ) R π 2 ( θ 2 ) f η 2 ( η ( y ) | θ 2 ) d θ 2 = g 1 ( y ) g 2 ( y ) B η 12 ( y ) . (2) Therefore, unless g 1 ( y ) = g 2 ( y ), the tw o Bay es factors differ b y this ratio, g 1 ( y ) /g 2 ( y ), whic h is only equal to one in a v ery small n umber of kno wn cases. This decomposition is a straightforw ard pro of that a model-wise sufficient statistic is usually not sufficien t across mo dels, i.e. for mo del comparison. An immediate corollary is that the ABC-MC appro ximation does not conv erge to the exact Bay es factor. The discrepancy b et ween the limiting ABC inference and the gen uine Ba yesian infer- ence do es not completely come as a surprise, b ecause ABC is indeed an appro ximation metho d. Users of ABC algorithms are therefore prepared for some degree of imprecision in their final answer, a p oin t stressed by Wilkinson (2008) or F earnhead and Prangle (2010) when they qualify ABC as exact inference on a wrong model. Ho wev er, the magnitude of the difference betw een B 12 ( y ) and B η 12 ( y ) expressed b y (2) is suc h that there is no direct connection b et ween b oth answ ers. In a general setting, if η has the same dimension as one comp onen t of the n comp onents of y , the ratio g 1 ( y ) /g 2 ( y ) is equiv alen t to a densit y ratio for a sample of size O( n ), hence it can b e arbitrarily small or arbitrarily large when n grows. On the opp osite, the Bay es factor B η 12 ( y ) is based on what is equiv alent to a single observ ation, hence do es not necessarily conv erge with n , as shown by the Poisson and normal examples b elo w. The conclusion derived from one Bay es factor may therefore completely differ from the conclusion derived from other one and there is no possibility of a generic agreemen t betw een both, or even of a manageable correction factor. F or this reason, w e conclude that the ABC approach cannot b e used for testing nor for mo del c hoice, with the exception of Gibbs random fields as explained in the next section. In all cases when g 1 ( y ) /g 2 ( y ) is differen t from one and imp ossible to approximate, no inference on the true Bay es factor can b e made based on the ABC-MC approximation without further information on the ratio g 1 ( y ) /g 2 ( y ), whic h is most often una v ailable. W e note that Didelot et al. (2010) also deriv ed this relation betw een b oth Bay es factors 8 in their formula (18) but surprisingly concluded on advocating the use of ABC in complex mo dels, where there are no sufficient statistics. W e disagree with this p ersp ectiv e for reasons that will b e made clear in the following sections. 5 The sp ecial case of Gibbs random fields Grelaud et al. (2009) sho wed that, for Gibbs random fields and in particular for P otts mo dels, when the goal is to compare several neigh b ourho o d structures, the computation of the p osterior probabilities of the mo dels/structures under comp etition can b e op erated b y likelihoo d-free simulation techniques, in the sense that there exists a conv erging ap- pro ximation to the true Ba yes factor. The reason for this prop ert y is that, in the ab ov e ratio, g 1 ( y ) = g 2 ( y ) in this special model. Indeed, if w e consider a Gibbs random field giv en by the lik eliho od function f ( y | θ ) = 1 Z θ exp { θ T η ( y ) } , where y is a vector of dimension n taking v alues ov er the finite set X (p ossibly a lattice), η ( · ) is the p oten tial function defining the random field, taking v alues in R p , θ ∈ R p is the asso ciated parameter, and Z θ is the corresp onding normalising constant, the p oten tial function η is a sufficien t statistic for the mo del. F or instance, in Potts mo dels, the sufficien t statistic is the num b er of neigh b ours, η ( y ) = X i 0 ∼ i I { y i = y i 0 } , asso ciated with a neighbourho o d structure denoted by i ∼ i 0 (meaning that i and i 0 are neigh b ours). The prop ert y that v alidates an ABC resolution for the comparison of Gibbs random fields is that, due to their sp ecific structure, there exists a sufficient statistic v ector that runs across mo dels and which allo ws for an exact (when = 0) sim ulation from the p osterior probabilities of the mo dels. More sp ecifically , consider M Gibbs random fields in comp etition, each one b eing asso ciated with a p otential function η m (1 ≤ m ≤ M ), i.e. with corresponding lik eliho o d f m ( y | θ m ) = exp θ T m η m ( y ) Z θ m ,m , where θ m ∈ Θ m and Z θ m ,m is the unknown normalising constant. A Bay esian analysis op erates on the extended parameter space Θ = ∪ M m =1 { m } × Θ m that includes b oth the mo del index M and the corresp onding parameter space Θ m . The inferential target is th us the mo del posterior probabilit y P ( M = m | y ) ∝ Z Θ m f m ( y | θ m ) π m ( θ m ) d θ m π ( M = m ) , 9 i.e. the marginal in M of the p osterior distribution on ( M , θ 1 , . . . , θ M ) giv en y . Each mo del has its own sufficient statistic η m ( · ). Then, for e ach model, the v ector of statistics η ( · ) = ( η 1 ( · ) , . . . , η M ( · )) is clearly sufficien t; furthermore Grelaud et al. (2009) exp osed the fact that η is also sufficient for the joint parameter ( M , θ 1 , . . . , θ M ). That this con- catenation of sufficient statistics is jointly sufficien t across mo dels is a prop ert y that is rather sp ecific to Gibbs random field mo dels, at least from a practical p erspective (see b elo w). Figure 1 sho ws an exp erimen t from Grelaud et al. (2009) concluding rightly at the agreement b et ween the exact Ba yes factor and an ABC appro ximation. Figure 1: Comparison betw een the true Ba yes factor and the ABC approximation in a Mark ov mo del selection of Grelaud et al. (2009), based on 2 , 000 simulated sequences and 4 × 10 6 prop osals from the prior. The solid/red line is the diagonal. (Sour c e: Gr elaud et al., 2009.) Didelot et al. (2010) p oin t out that this sp ecific prop ert y of Gibbs random fields can b e extended to an y exponential family (hence to an y setting enjo ying sufficien t statistics, see e.g. Casella and Berger, 2001). Their argumen t is an encompassing prop erty: by including all sufficient statistics and all dominating measure statistics in an encompassing mo del, mo dels under comparison become submo dels of the encompassing mo del. They then conclude that the concatenation of those statistics is jointly sufficient across mo dels. While this encompassing principle holds in full generality , in particular when comparing 10 mo dels that are already embedded, we think it leads to a biased p ersp ectiv e ab out the merits of ABC for mo del choice: in practice, complex mo dels do not enjoy sufficient statistics (if only b ecause they are not exp onen tial families). As demonstrated in the next section, there is more than a mere loss of information due to the use of insufficient statistics and lo oking at what happ ens in the limiting case when one is relying on a common sufficien t statistic is a formal study that brings ligh t on the p oten tially huge discrepancy betw een the ABC-based Ba yes factor and the true Ba yes factor. T o study a solution to the problem in the formal case of the exp onen tial families do es not help in the understanding of the discrepancy in non-exp onen tial models. 6 Arbitrary ratios The difficulty with the arbitrary discrepancy b et ween B 12 ( y ) and B η 12 ( y ) is that it is imp ossible to ev aluate in a general setting, while there is no reason to exp ect a reasonable agreemen t b et ween b oth quan tities. A first illustration was produced b y Marin et al. (2011) in the setting of M A ( q ) time series: a simulation exp erimen t show ed that, when comparing an M A (2) with an M A (1) mo del, the ABC appro ximation to the Bay es factor w as stable (around 2 . 3) as decreases, remaining far from the true Bay es factor 17 . 7 for an M A (2) simulated sample, while the appro ximation was 0 . 25 against a true v alue of 0 . 004 in the case of a sim ulated M A (1) sample. 6.1 A P oisson-negativ e binomial illustration As a first illustration of the discrepancy due to the use of a sufficien t statistic, consider the simple case when a sample y = ( y 1 , . . . , y n ) could come from either a Poisson P ( λ ) distribution or from a geometric G ( p ) distribution, already in tro duced in Grelaud et al. (2009) as a coun ter-example to Gibbs random fields and later repro cessed in Didelot et al. (2010) to supp ort their sufficiency argumen t. In this setting, the sum S = P n i =1 y i = η ( y ) is a sufficien t statistic for b oth mo dels but not across mo dels. The distribution of the sample giv en S is a m ultinomial M ( S, 1 /n, . . . , 1 /n ) distribution when the data is P oisson, since S is then a Poisson P ( nλ ) v ariable, while it is the uniform distribution with constan t probabilit y 1 n + S − 1 S I P i y i = S = S !( n − 1)! ( n + S − 1)! I P i y i = S in the geometric case, since S is then a negativ e binomial N eg ( n, p ) v ariable. The dis- crepancy ratio is therefore g 1 ( y ) g 2 ( y ) = S ! n − S / Q i y i ! 1 n + S − 1 S 11 When simulating n P oisson or geometric v ariables and using prior distributions λ ∼ E (1) , p ∼ U (0 , 1) , on the resp ective models, the exact Ba yes factor can b e ev aluated and the range and distribution of the discrepancy are therefore av ailable. Figure 2 giv es the range of B 12 ( y ) v ersus B η 12 ( y ), showing that B η 12 ( y ) is in this case absolutely un-related with B 12 ( y ): The v alues pro duced b y b oth approaches simply hav e nothing in common. As noted ab o v e, the appro ximation B η 12 ( y ) based on the sufficient statistic S is pro ducing figures of the magnitude of a single observ ation, while the true Bay es factor is of the order of the sample size. Figure 2: Comparison b et ween the true log-Bay es factor (first axis) for the comparison of a P oisson mo del v ersus a negative binomial mo del and of the log-Ba yes factor based on the sufficient statistic P i y i (se c ond axis) , for P oisson (left) and negative binomial (left) samples of size n = 50, based on T = 10 4 replications. The discrepancy b et w een b oth Bay es factors is in fact increasing with the sample size, as shown by the following result: Lemma 1. Consider p erforming mo del sele ction b etwe en mo del 1: P ( λ ) with prior dis- tribution π 1 ( λ ) e qual to an E (1) distribution and mo del 2: G ( p ) with a uniform prior 12 distribution π 2 when the observe d data y c onsists of iid observations with E [ y i ] = θ 0 > 0 . Then S ( y ) = P n i =1 y i is the minimal sufficient statistic for b oth mo dels and the Bayes factor b ase d on the sufficient statistic S ( y ) , B η 12 ( y ) , satisfies lim n →∞ B η 12 ( y ) = ( θ 0 + 1) 2 θ 0 e − θ 0 a.s. Therefore, the Bay es factor based on the sufficient statistic S ( y ) is not consistent; it con verges to a non-zero, finite v alue almost surely . Pr o of. Under mo del 1, w e ha v e S ∼ P ( nλ ), with corresp onding likelihoo d f S 1 ( S | λ ) = 1 Γ( S + 1) ( nλ ) S e − nλ . The marginal lik eliho od of S under the prior π 1 is then Z ∞ 0 λ S e − nλ Γ( S + 1) n − S e − λ d λ = 1 S Z ∞ 0 λ S e − ( n +1) λ Γ( S ) n − S d λ = 1 S n S ( n + 1) S = 1 S 1 + 1 n − S . (3) Under mo del 2, the sufficient statistic has a negativ e binomial distribution, S ∼ Neg ( n, p ) and thus f S 2 ( S | p ) = n + S − 1 S p S (1 − p ) n = Γ( S + n ) Γ( S + 1) Γ( n ) p S (1 − p ) n . The corresp onding marginal lik eliho o d under the prior π 2 is Γ( S + n ) Γ( S + 1) Γ( n ) Z 1 0 p S (1 − p ) n d p = Γ( S + n ) Γ( S + 1) Γ( n ) Beta( S + 1 , n + 1) = n ( S + n + 1)( S + n ) . (4) Therefore from (3) and (4), the Ba yes factor based on the sufficien t statistic is giv en b y B η 12 ( y ) = 1 + 1 n − S × ( S + n ) ( S + n + 1) S n (5) Since the y i ’s are iid with mean θ 0 , the Law of Large Num b ers implies that S/n → θ 0 almost surely , thus lim n →∞ ( S + n ) ( S + n + 1) S n = ( θ 0 + 1) 2 θ 0 13 since θ 0 > 0. F urthermore, lim n →∞ 1 + 1 n − S = lim n →∞ e − S log (1+1 /n ) = e − θ 0 . Th us from (3)–(5) w e deduce that lim n →∞ B η 12 ( y ) = e − θ 0 ( θ 0 + 1) 2 θ 0 pro ving the result. In this sp ecific setting, Didelot et al. (2010) show that adding P = Q i y i ! to the suffi- cien t statistic S induces a statistic ( S, P ) that is sufficient across b oth mo dels. While this is a mathematically correct observ ation, we think it is not helpful for the understanding of the b eha viour of ABC-mo del choice in realistic settings: outside to y examples as the one ab o ve and w ell-structured although complex exp onen tial families lik e Gibbs random fields, it is not p ossible to come up with completion mechanisms that ensure sufficiency across models and it is therefore more fruitful to consider the diverging b ehaviour of the ABC approximation as giv en, rather than attempting at solving the problem. 6.2 A normal illustration First, note that, giv en a one-dimensional sufficient statistic S = η ( y ), the functions g 1 ( y ) and g 2 ( y ) can on principle b e anything. F or instance, g 1 ( y ) = n Y i =1 ϕ ( y i − S | σ 2 1 ) I P i y i = nS and g 2 ( y ) = n Y i =1 ϕ ( y i − S | σ 2 2 ) I P i y i = nS is a p ossible model. In other words, by a reparameterisation of the models, we could observ e y = ( y 1 , . . . , y n − 1 , S ) with y 1 , . . . , y n − 1 | S iid ∼ N ( S, σ 2 1 ) and y 1 , . . . , y n − 1 | S iid ∼ N ( S, σ 2 2 ) , this indep enden tly of the distributions of S under b oth mo dels. (This means that we can find tw o comp eting mo dels where the distributions of S are not connected with σ 1 nor with σ 2 .) Because they dep end on the choice of those distributions, the true Bay es factor and the ABC-Bay es factor are unrelated and may as well div erge from one another. Admitedly , this construct is artificial in that there is no clear statistical setting when this 14 could o ccur, but the construct is b oth mathematically v alid and informativ e ab out the lac k of control o ver the diverging factor g 1 ( y ) /g 2 ( y ). If we lo ok at a fully normal N ( µ, σ 2 ) setting, w e ha ve f ( y | µ ) ∝ exp ( − nσ − 2 ( ¯ y − µ ) 2 / 2 − σ − 2 n X i =1 ( y i − ¯ y ) 2 / 2 ) σ − n hence f ( y | ¯ y ) ∝ exp ( − σ − 2 n X i =1 ( y i − ¯ y ) 2 / 2 ) σ − n I P y i = n ¯ y . If we reparameterise the observ ations in to u = ( y 1 − ¯ y , . . . , y n − 1 − ¯ y , ¯ y ), w e do get f ( u | µ ) ∝ σ − n exp − nσ − 2 ( ¯ y − µ ) 2 / 2 × exp − σ − 2 n − 1 X i =1 u 2 i / 2 − σ − 2 " n − 1 X i =1 u i # 2 2 since the Jacobian is 1. Hence f ( u | ¯ y ) ∝ exp − σ − 2 n − 1 X i =1 u 2 i / 2 − σ − 2 " n − 1 X i =1 u i # 2 / 2 σ − n Considering b oth models y 1 , . . . , y n iid ∼ N ( µ, σ 2 1 ) and y 1 , . . . , y n iid ∼ N ( µ, σ 2 2 ) , the discrepancy ratio is then given b y g 1 ( y ) g 2 ( y ) = exp − σ − 2 1 P n − 1 i =1 ( y i − ¯ y ) 2 / 2 − σ − 2 1 h P n − 1 i =1 ( y i − ¯ y ) i 2 / 2 σ − n +1 1 exp − σ − 2 2 P n − 1 i =1 ( y i − ¯ y ) 2 / 2 − σ − 2 2 h P n − 1 i =1 ( y i − ¯ y ) i 2 / 2 σ − n +1 2 = σ n − 1 2 σ n − 1 1 exp σ − 2 2 − σ − 2 1 2 n − 1 X i =1 ( y i − ¯ y ) 2 + " n − 1 X i =1 ( y i − ¯ y ) # 2 and is connected with the lack of consistency of the Ba yes factor: Lemma 2. Consider p erforming mo del sele ction b etwe en mo del 1: N ( µ, σ 2 1 ) and mo del 2: N ( µ, σ 2 2 ) , σ 1 and σ 2 b eing given, with prior distributions π 1 ( µ ) = π 2 ( µ ) e qual to a N (0 , a 2 ) distribution and when the observe d data y c onsists of iid observations with finite me an and 15 varianc e. Then S ( y ) = P n i =1 y i is the minimal sufficient statistic for b oth mo dels and the Bayes factor b ase d on the sufficient statistic S ( y ) , B η 12 ( y ) , satisfies lim n →∞ B η 12 ( y ) = 1 a.s. Pr o of. The marginal lik eliho o d asso ciated with S ( y ) and the prior µ ∼ N (0 , a 2 ) is m η ( S ) ∝ √ nσ − 1 1 Z e − n ( ¯ y − µ ) 2 / 2 σ 2 1 e − µ 2 / 2 a 2 d µ = √ nσ − 1 1 exp − ¯ y 2 2( a 2 + σ 2 1 /n ) q nσ − 1 1 + a − 2 , hence leading to the Ba y es factor B η 12 ( y ) = σ 2 σ 1 exp − ¯ y 2 2( a 2 + σ 2 1 /n ) exp − ¯ y 2 2( a 2 + σ 2 2 /n ) q nσ − 1 2 + a − 2 q nσ − 1 1 + a − 2 , whic h indeeds conv erges to 1 as n go es to infinity . Figure 3 illustrates the b eha viour of the discrepancy ratio when σ 1 = 0 . 1 and σ 2 = 10, for datasets of size n = 15 sim ulated according to b oth mo dels. The discrepancy (expressed on a log scale) is once again dramatic, in concordance with the ab o ve lemma. If w e no w turn to an alternativ e c hoice of sufficien t statistic, using the pair ( ¯ y, S 2 ) with S 2 = n X i =1 ( y i − ¯ y ) 2 , w e follo w the solution of Didelot et al. (2010). Using a conjugate prior µ ∼ N (0 , a 2 ), the true Bay es factor is given by B 12 ( y ) = σ − n 1 σ − n 2 exp {− S 2 / 2 σ 2 1 } exp {− S 2 / 2 σ 2 1 } exp {− ¯ y 2 / 2( a 2 + σ 2 1 /n ) } exp {− ¯ y 2 / 2( a 2 + σ 2 2 /n ) } q a − 2 + σ − 2 2 n q a − 2 + σ − 2 1 n . and it is equal to the Bay es factor based on the corresp onding distributions of the pair ( ¯ y , S 2 ) in the resp ectiv e models. Again, w e do not think this coincidence brings the prop er ligh t on the behaviour of the ABC approximations in realistic settings. 16 Figure 3: Empirical distributions of the log discrepancy log g 1 ( y ) /g 2 ( y ) for datasets of size n = 15 simulated from N ( µ, σ 2 1 ) (left) and N ( µ, σ 2 2 ) (right) distributions when σ 1 = 0 . 1 and σ 2 = 10, based on 10 4 replications and a flat prior. 17 7 Conclusion Since its introduction by T av ar ´ e et al. (1997) and Pritc hard et al. (1999), ABC has b een extensiv ely used in sev eral areas inv olving complex lik eliho o ds, primarily in p opulation genetics. In those domains, ABC has b een used both for p oin t estimation and testing of h yp otheses. In realistic settings, with the exception of Gibbs random fields that satisfy a resilience prop erty with respect to their sufficient statistics, the conclusions dra wn on mo del comparison cannot alas b e trusted p er se but require further analyses as to the p ertinence of the (ABC) Bay es factor based on the summary statistics. This pap er has only examined in details the case when the summary statistics are sufficient for b oth mo dels, while practical situations imply the use of in-sufficien t statistics, and further re- searc h is needed for the latter case. Ho wev er, this practical situation implies a wider loss of information compared with the exact inferential approach , hence a wider discrepancy b et w een the exact Ba yes factor and the quantit y pro duced by an ABC approximation. It thus app ears to us an urgent duty to w arn the comm unity ab out the dangers of this appro ximation, esp ecially when considering the rapidly increasing n umber of applications using ABC for conducting mo del choice and h yp othesis testing. As a final (and negative) p oin t, we unfortunately do not see an immediate and generic alternative for the approx- imation of Bay es factors b ecause imp ortance sampling techniques are suffering from the same difficulty , namely they only depend on the summary statistics. As a final remark, w e note that Sousa et al. (2009) adv o cate the use of full allelic distributions in an ABC framework, instead of resorting to summary statistics. They sho w that it is p ossible to apply ABC using allele frequencies to draw inferences in cases where it is difficult to select a set of suitable summary statistics (and when the complexity of the mo del or the size of dataset makes it computationally prohibitive to use full-lik eliho o d metho ds). In such settings, were w e to consider a mo del choice problem, the divergence exhibited in the curren t paper w ould not occur because the measure of distance do es not rely on a reduction of the sample. Ac kno wledgemen ts The first t w o authors’ work has b een partly supp orted b y the Agence Nationale de la Rec herche (ANR, 212, rue de Bercy 75012 Paris) through the 2009-2012 pro ject Emile , directed by Jean-Marie Corn uet. References Beaumon t, M. (2010). Approximate Bay esian computation in evolution and ecology. A nnual R eview of Ec olo gy, Evolution, and Systematics , 41:379–406. Beaumon t, M., Nielsen, R., Rob ert, C., Hey , J., Gaggiotti, O., Kno wles, L., Estoup, A., Mahesh, 18 P ., Coranders, J., Hic kerson, M., Sisson, S., F agundes, N., Chikhi, L., Beerli, P ., Vitalis, R., Corn uet, J.-M., Huelsen b eck, J., F oll, M., Y ang, Z., Rousset, F., Balding, D., and Excoffier, L. (2010). In defense of model-based inference in phylogeograph y . Mole cular Ec olo gy , 19(3):436– 446. Beaumon t, M., Zhang, W., and Balding, D. (2002). Approximate Ba yesian computation in p opu- lation genetics. Genetics , 162:2025–2035. Belle, E., Benazzo, A., Ghirotto, S., Colonna, V., and Barbujani, G. (2008). Comparing models on the genealogical relationships among Neandertal, Cro-Magnoid and mo dern Europ eans b y serial coalescent simulations. Her e dity , 102(3):218–225. Berger, J. (1985). Statistic al De cision The ory and Bayesian Analysis . Springer-V erlag, New Y ork, second edition. Berger, J., Fienberg, S., Raftery , A., and Rob ert, C. (2010). Incoherent ph ylogeographic inference. Pr o c. Nat. A c ad. Sci. USA , 107(41):E57. Casella, G. and Berger, R. (2001). Statistic al Infer enc e . W adsworth, Belmont, CA, second edition. Chen, M., Shao, Q., and Ibrahim, J. (2000). Monte Carlo Metho ds in Bayesian Computation . Springer-V erlag, New Y ork. Corn uet, J.-M., Ra vign´ e, V., and Estoup, A. (2010). Inference on population history and mo del c hecking using DNA sequence and microsatellite data with the softw are DIY ABC (v1.0). BMC Bioinformatics , 11:401. Corn uet, J.-M., Santos, F., Beaumon t, M. A., Rob ert, C. P ., Marin, J.-M., Balding, D. J., Guille- maud, T., and Estoup, A. (2008). Inferring population history with DIY ABC: a user-friendly approac h to Appro ximate Ba yesian Computation. Bioinformatics , 24(23):2713–2719. Csill ` ery , K., Blum, M., Gaggiotti, O., and F ran¸ cois, O. (2010a). Appro ximate Bay esian computa- tion (ABC) in practice. T r ends in Ec olo gy and Evolution , 25:410–418. Csill ` ery , K., Blum, M., Gaggiotti, O., and F ran¸ cois, O. (2010b). In v alid arguments against ABC: A reply to A.R. Templeton. T r ends in Ec olo gy and Evolution , 25:490–491. Didelot, X., Ev eritt, R., Johansen, A., and Lawson, D. (2010). Lik eliho od-free estimation of mo del evidence. T echnical Rep ort 10-12, CRiSM, Universit y of W arwick. Dro v andi, C., P ettitt, A., and F addy , M. (2011). Approximate Bay esian computation using indirect inference. J. R oyal Statist. So ciety Series A , 60(3):503–524. Estoup, A., Beaumont, M., Sennedot, F., Moritz, C., and Cornuet, J. (2004). Genetic analysis of complex demographic scenarios: spatially expanding p opulations of the cane toad, Bufo Marinus. Evolution , 58(9):2021–2036. Excoffier, C., D., L., and L., W. (2009). Ba yesian computation and mo del selection in p opulation genetics. 19 F agundes, N., Ra y , N., Beaumon t, M., Neuensch wander, S., Salzano, F., Bonatto, S., and Excoffier, L. (2007). Statistical ev aluation of alternative models of h uman evolution. Pr o c. Nat. A c ad. Sci. USA , 104(45):17614–17619. F earnhead, P . and Prangle, D. (2010). Semi-automatic approximate Bay esian computation. Ghirotto, S., Mona, S., Benazzo, A., P aparazzo, F., Caramelli, D., and Barbujani, G. (2010). Infer- ring genealogical processes from patterns of bronze-age and mo dern DNA v ariation in Sardinia. Mol. Biol. Evol. , 27(4):875–886. Grelaud, A., Marin, J.-M., Robert, C., Ro dolphe, F., and T ally , F. (2009). Likelihoo d-free methods for mo del c hoice in Gibbs random fields. Bayesian Analysis , 3(2):427–442. Guillemaud, T., Beaumont, M., Ciosi, M., Cornuet, J.-M., and Estoup, A. (2009). Inferring in tro duction routes of inv asive sp ecies using approximate Bay esian computation on microsatellite data. Her e dity , 104(1):88–99. Jeffreys, H. (1939). The ory of Pr ob ability . The Clarendon Press, Oxford, first edition. Lehmann, E. and Casella, G. (1998). The ory of Point Estimation (r evise d e dition) . Springer-V erlag, New Y ork. Leuen b erger, C. and W egmann, D. (2010). Bay esian computation and mo del selection without lik eliho o ds. Genetics , 184(1):243–252. Lop es, J. and Beaumon t, M. (2010). ABC: a useful Bay esian tool for the analysis of population data. Infe ction, Genetics and Evolution , 10(6):825–832. Lop es, J. S., Balding, D., and Beaumont, M. A. (2009). P opABC: a program to infer historical demographic parameters. Bioinformatics , 25(20):2747–2749. MacKa y , D. J. C. (2002). Information The ory, Infer enc e & L e arning A lgorithms . Cam bridge Univ ersity Press, Cam bridge, UK. Marin, J., Pudlo, P ., Rob ert, C., and Ryder, R. (2011). Approximate Bay esian computational metho ds. arXiv:1011:0955. Marin, J. and Rob ert, C. (2010). Importance sampling metho ds for Bay esian discrimination b e- t ween embedded mo dels. In Chen, M.-H., Dey , D., M¨ uller, P ., Sun, D., and Y e, K., editors, F r ontiers of Statistic al De cision Making and Bayesian Analysis . Springer-V erlag, New Y ork. to app ear. Miller, N., Estoup, A., T o epfer, S., Bourguet, D., Lapchin, L., Derridj, S., Kim, K. S., Reynaud, P ., F urlan, L., and Guillemaud, T. (2005). Multiple transatlantic introductions of the W estern corn ro otw orm. Scienc e , 310(5750):992. P ascual, M., Chapuis, M., Balan y` a, J., Huey , R., Gilchrist, G., Serra, L., and Estoup, A. (2007). In tro duction history of Drosophila subobscura in the New World: a microsatellite-based survey using ABC metho ds. Mole cular Ec olo gy , 16:3069–3083. 20 P atin, E., Lav al, G., Barreiro, L., Salas, A., Semino, O., Santac hiara-Benerecetti, S., Kidd, K., Kidd, J., V an Der V een, L., Hombert, J., et al. (2009). Inferring the demographic history of African farmers and pygm y hun ter-gatherers using a mu ltilo cus resequencing data set. PL oS Genetics , 5(4):e1000448. Pritc hard, J., Seielstad, M., P erez-Lezaun, A., and F eldman, M. (1999). Population growth of h uman Y chromosomes: a study of Y c hromosome microsatellites. Mole cular Biolo gy and Evo- lution , 16:1791–1798. Ramakrishnan, U. and Hadly , E. (2009). Using phylochronology to rev eal cryptic population histories: review and synthesis of 29 ancien t DNA studies. Mole cular Ec olo gy , 18(7):1310–1330. Ratmann, O., Andrieu, C., Wiujf, C., and Richardson, S. (2009). Mo del criticism based on lik eliho o d-free inference, with an application to protein netw ork ev olution. Pr o c. Nat. A c ad. Sci. USA , 106:1–6. Rob ert, C. (2001). The Bayesian Choic e . Springer-V erlag, New Y ork, second edition. Rob ert, C. and Casella, G. (2004). Monte Carlo Statistic al Metho ds . Springer-V erlag, New Y ork, second edition. Sain udiin, R., Thornton, K., Harlow, J., Bo oth, J., Stillman, M., Y oshida, R., Griffiths, R., McV ean, G., and Donnelly , P . (2011). Exp erimen ts with the site frequency spectrum. Bul- letin of Mathematic al Biolo gy . (T o app ear.). Sousa, V., F ritz, M., Beaumon t, M., and Chikhi, L. (2009). Appro ximate Ba yesian computation without summary statistics: the case of admixture. Genetics , 181(4):1507–1519. T av ar´ e, S., Balding, D., Griffith, R., and Donnelly , P . (1997). Inferring coalescence times from DNA sequence data. Genetics , 145:505–518. T empleton, A. (2008). Statistical hypothesis testing in intraspecific phylogeograph y: nested clade ph ylogeographical analysis vs. approximate Bay esian computation. Mole cular Ec olo gy , 18(2):319–331. T empleton, A. (2010). Coheren t and incoherent inference in ph ylogeograph y and human ev olution. Pr o c. Nat. A c ad. Sci. USA , 107(14):6376–6381. T oni, T. and Stumpf, M. (2010). Sim ulation-based mo del selection for dynamical systems in systems and p opulation biology. Bioinformatics , 26(1):104–110. T oni, T., W elc h, D., Strelko wa, N., Ipsen, A., and Stumpf, M. (2009). Approximate Bay esian computation scheme for parameter inference and mo del selection in dynamical systems. Journal of the R oyal So ciety Interfac e , 6(31):187–202. V erdu, P ., Austerlitz, F., Estoup, A., Vitalis, R., Georges, M., Th´ ery , S., F roment, A., Le Bomin, S., Gessain, A., Hom b ert, J.-M., V an der V een, L., Quin tana-Murci, L., Bah uchet, S., and Heyer, E. (2009). Origins and genetic diversit y of pygm y hun ter-gatherers from western central africa. Curr ent Biolo gy , 19(4):312–318. 21 W egmann, D. and Excoffier, L. (2010). Bay esian inference of the demographic history of chim- panzees. Mole cular Biolo gy and Evolution , 27(6):1425–1435. Wilkinson, R. D. (2008). Appro ximate Bay esian computation (ABC) gives exact results under the assumption of mo del error. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment