Generalized Species Sampling Priors with Latent Beta reinforcements
Many popular Bayesian nonparametric priors can be characterized in terms of exchangeable species sampling sequences. However, in some applications, exchangeability may not be appropriate. We introduce a {novel and probabilistically coherent family of…
Authors: Edoardo M. Airoldi, Thiago Costa, Federico Bassetti
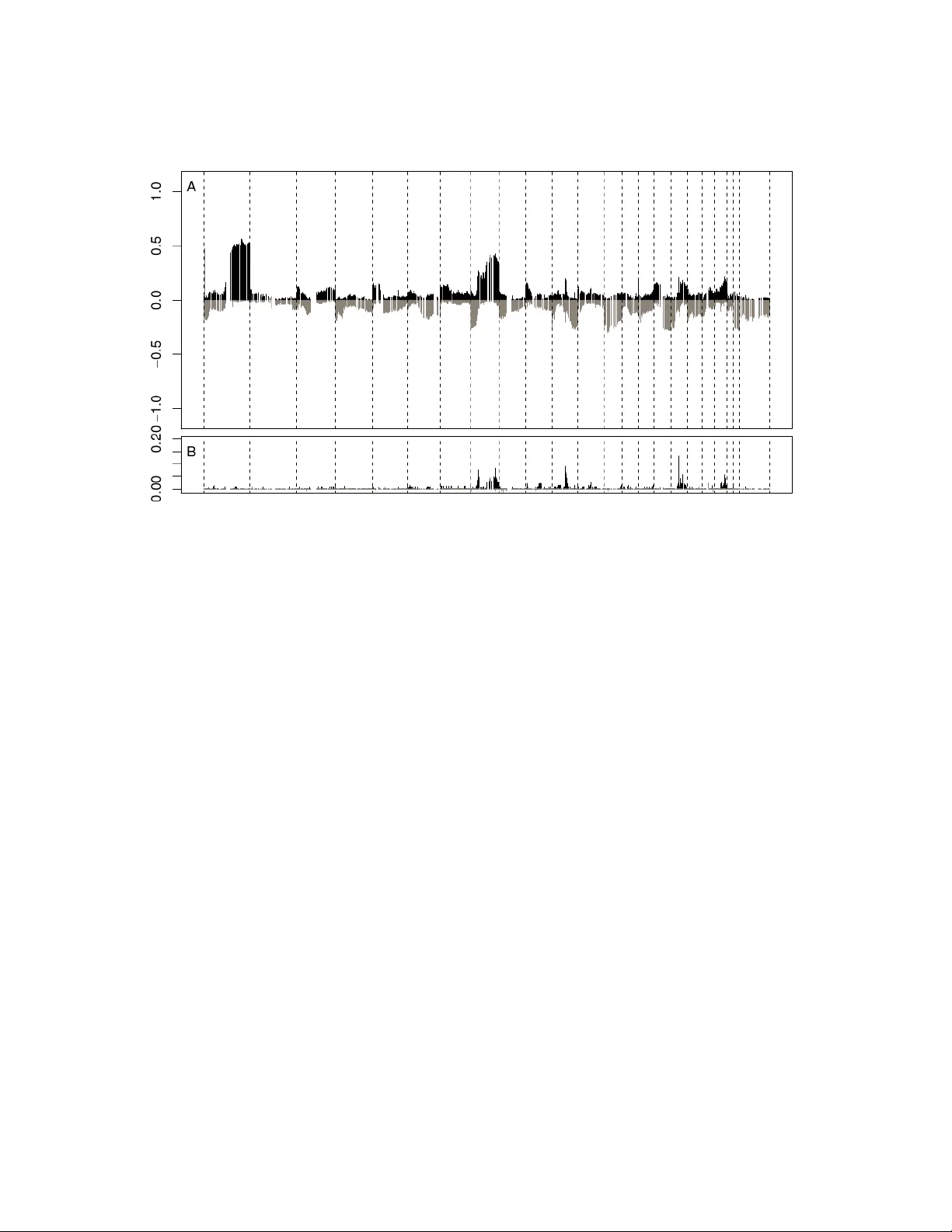
Generalized sp ecies sampling priors with laten t Beta reinforcemen ts Edoardo M. Airoldi Thiago Costa F ederico Bassetti F abrizio Leisen Mic hele Guindani ∗ Abstract Man y p opular Ba y esian nonparametric priors can b e c haracterized in terms of ex- c hangeable sp ecies sampling sequences. Ho w ev er, in some applications, exc hangeability ma y not b e appropriate. W e introduce a nov el and probabilistically coherent family of non-exc hangeable sp ecies sampling sequences characterized b y a tractable predictive probabilit y function with weigh ts driven b y a sequence of indep enden t Beta random v ariables. W e compare their theoretical clustering prop erties with those of the Diric hlet Pro cess and the t wo parameters Poisson-Diric hlet pro cess. The prop osed construction pro vides a complete characterization of the join t pro cess, differently from existing w ork. W e then propose the use of suc h pro cess as prior distribution in a hierarchical Ba yes ∗ Edoardo M. Airoldi is an Asso ciate Professor in the Department of Statistics at Harv ard Universit y and an Alfred P . Sloan Researc h F ellow (airoldi@fas.harv ard.edu), Thiago Costa is a PhD candidate in the Sc ho ol of Engineering and Applied Sciences at Harv ard Univ ersit y (tcosta@fas.harv ard.edu), F ederico Bassetti is an Assistant Professor in the Departmen t of Mathematics at Universita di Pa via, Italy (fed- erico.bassetti@unip v.it), F abrizio Leisen is a Senior Lecturer in the Department of Statistics at Univ ersity of Kent, UK (fabrizio.leisen@gmail.com), Michele Guindani is an Assistant Professor in the Department of Biostatistics at MD Anderson Cancer Center (mguindani@mdanderson.org). All authors hav e equally con tributed to the man uscript. 1 mo deling framew ork, and we describ e a Marko v Chain Monte Carlo sampler for p os- terior inference. W e ev aluate the p erformance of the prior and the robustness of the resulting inference in a sim ulation study , pro viding a comparison with p opular Diric h- let Pro cesses mixtures and Hidden Marko v Mo dels. Finally , we develop an application to the detection of chromosomal ab errations in breast cancer by lev eraging array CGH data. AMS CLASSIFICA TION : Primary 62C10; secondary 62G57 KEYW ORDS : Bay esian non-parametrics, Species Sampling Priors, Predictive Proba- bilit y F unctions, Random Partitions, MCMC, Genomics, Cancer 1. INTR ODUCTION Ba y esian nonparametric priors ha ve b ecome increasingly p opular in applied statistical mo deling in the last few y ears. Examples of their wide area of applications range from v ariable selection in genetics (Kim et al., 2006) to linguistics (T eh, 2006b; W allac h et al., 2008), psyc hology (Nav arro et al., 2006), h uman learning (Griffiths, 2007), image seg- men tation (Sudderth and Jordan, 2009) and applications to the neurosciences (Jbab di et al., 2009). See also Hjort et al. (2010). The increased interest in non-parametric Ba y esian approac hes is motiv ated by a num b er of attractive inferential prop erties. F or example, Bay esian nonparametric priors are often used as flexible mo dels to describ e the heterogeneity of the p opulation of interest, as they implicitly induce a clustering of the observ ations in to homogeneous groups. Suc h a clustering can b e seen as a realiza- tion of a random partition scheme and can often b e characterized in terms of a sp ecies sampling (SS) allo cation rule. More formally , a SS sequence is a sequence of random v ariables X 1 , X 2 , . . . , c haracterized b y the predictiv e probabilit y functions, P { X n +1 ∈ · | X 1 , . . . , X n } = n X j =1 q n,j δ X j ( · ) + q n,n +1 G 0 ( · ) , (1) 2 where δ x ( · ) denotes a p oin t mass at x , q n,j ( j = 1 , . . . , n + 1) are non–negative func- tions of ( X 1 , . . . , X n ), or w eights, suc h that P n +1 j =1 q n,j = 1, and G 0 is a non-atomic probabilit y measure (Pitman, 1996b). Collecting the unique v alues of X j , (1) can b e rewritten as P { X n +1 ∈ · | X 1 , . . . , X n } = K n X j =1 q ∗ j δ X ∗ j ( · ) + q ∗ K n +1 G 0 ( · ) , (2) where K n is the (random) num b er of distinct v alues, sa y ( X ∗ 1 , . . . X ∗ K n ), in the vector X ( n ) = ( X 1 , . . . , X n ) and q ∗ j are suitable non–negative w eights. In particular, an exc hangeable SS sequence is c haracterized b y w eights q ∗ j that dep end only on n n = ( n 1 n , . . . , n K n n ), where n j n is the frequency of X ∗ j in X ( n ) (F ortini et. al, 2000; Hansen and Pitman, 2000; Lee et al., 2008). The most well known example of predictiv e rules of t yp e (1) is the Blac kwell MacQueen sampling rule, whic h implicitly defines a Dirichlet Pro cess (DP , Blac kwell and MacQueen, 1973; Ish waran and Zarep our, 2003). The predictiv e rule c haracterizing a DP with mass parameter θ and base measure G 0 ( · ), D P ( θ , G 0 ), sets q n,j = 1 n + θ and q n,n +1 = θ n + θ in (1). Whenev er the weigh ts q ∗ j ( n n ) and q ∗ K n +1 ( n n ) do not dep end only on n n , the se- quence ( X 1 , X 2 , . . . ) is not exc hangeable. Mo dels with non-exc hangeable random par- titions ha ve recen tly app eared in the literature, e.g. to allo w for partitions that dep end on co v ariates. P ark and Dunson (2007) derive a generalized pro duct partition mo del (GPPM) in which the partition pro cess is predictor–dependent. Their GPPM general- izes the DP clustering mechanism to relax the exchangeabilit y assumption through the incorp oration of predictors, implicitly defining a generalized P´ oly a urn scheme. M ¨ uller and Quintana (2010) define a pro duct partition mo del that includes a regression on co v ariates, allowing units with similar cov ariates to hav e greater probabilit y of b eing clustered together. Arguably , the previous mo dels pro vide an implicit mo dification of the predictiv e rule (1) where the weigh ts can b e seen as function of some external pre- dictor. Alternativ ely , other authors mo del the weigh ts q j ( n n ) explicitly , for instance, 3 b y specifying the w eights as a function of the distance betw een data points (Dahl et al., 2008; Blei and F razier, 2011). Ho wev er, the general properties of the random partitions generated b y suc h pro cesses ha ve not b een specifically addressed. In this pap er, we in tro duce a no v el and probabilistically coherent family of non- exc hangeable sp ecies sampling sequences, where the w eights are sp ecified sequentially and do not dep end on the cluster sizes, but instead they depend on the realizations of a set of laten t v ariables. W orking within this family , w e propose a simple c haracterization of the w eights in the predictive probabilit y function as a pro duct of indep endent Beta random v ariables. This strategy leads to a well-defined random allo cation scheme for the observ ables. The resulting pro cess, which w e call Beta-GOS pro cess, is a sp ecial case of a Generalized Otta w a Sequence (GOS), recently introduced b y Bassetti et al. (2010). In Section 2, we discuss the prop erties of the Beta-GOS pro cess, with particular regard to the clustering induced on the observ ables. In Section 3, we study the asymp- totic distribution of the (random) num b er of distinct v alues in the sequence, K n , for some natural sp ecifications of the weigh ts, and we compare those results with the w ell-kno wn asymptotic results c haracterizing the DP and the t wo-parameters Poisson Diric hlet pro cess. In man y applications, nonparametric pro cesses are often used within hierarc hical mo dels to sp ecify the prior distribution of some parameters of the distri- bution of the observ ables. F or example, this is a popular use for mixtures of Diric hlet Pro cesses. Similarly , the Beta-GOS pro cess can also b e used to define a prior in a hierarc hical mo del. In Section 4, w e outline a basic hierarc hical mo del based on the Beta-GOS pro cess and we outline the basic steps of a MCMC sampler for p osterior inference. In Section 5, we design a set of sim ulations to we compare the b ehavior of the Beta-GOS mo del with that of DP mixtures and hidden Mark ov Mo dels (HMM) in terms of cluster estimation. Our results suggest that the Beta-GOS can b e seen as a robust alternative to the Diric hlet pro cess when exchangeabilit y would b e hardly justified in practice, but still there is a need to describ e the heterogeneity of our ob- 4 serv ations b y virtue of an unsup ervised clustering of the data. The Beta-GOS also pro vides an alternativ e to customary HMM, esp ecially when the num b er of states is unkno wn or the Mark ovian structure is expected to v ary with time. In Section 6, we analyze tw o published data sets of genomic and transcriptional ab errations (Chin et al., 2006; Curtis et al., 2012). Bay esian mo dels for Arra y CGH data hav e b een recently in vestigated b y Guha et al. (2008), DeSantis et al. (2009), Baladanda yuthapani et al. (2010), Du et al (2010), Cardin et al. (2011), and Y au et al. (2011), among others. Guha et al. prop ose a four state homogenous Ba y esian HMM to detect cop y n umber amplifications and deletions and partition tumor DNA into regions (clones) of relatively stable copy num b er. DeSantis et al. extend this approac h and dev elop a sup ervised Bay esian latent class approach for classification of the clones that relies on a heterogenous hidden Marko v mo del to accoun t for local dep endence in the in tensit y ratios. In a heterogeneous hidden Marko v mo del, the transition probabilities b et w een states dep end on eac h single clone or the the distance b etw een adjacent clones (Marioni et al., 2006). Du et al. propose a sticky Hierarchical DP-HMM (F ox et al., 2011; T eh et al., 2006a) to infer the n umber of states in an HMM, while also imp osing state p ersistence. Y au et al. (2011) also prop ose a nonparametric Bay esian HMM, but use instead a DP mixture to mo del the lik eliho o d in eac h state. With resp ect to those prop osals, we also assume that the num b er of states is unknown, as it is typical in a Ba y esian nonparametric setting, but we don’t need a parameter to explicitly account for state p ersistence. This is b ecause the Beta-GOS mo del is “non-homogenous” by design, as the w eights in the sp ecies sampling mec hanisms adapt to tak e into account the lo cal dep endence in the clones’ intensities. W e show that the Beta-GOS is able to iden tify clones that ha v e b een linked to breast cancer pathophysiologies in the medical literature. W e conclude with some final remarks in Section 7. T echnical details and pro ofs of theorems and lemmas are pro vided in the App endix. 5 2. THE BET A-GOS PROCESS. As anticipated, the Beta-GOS pro cess is defined by a modification of the predictive rule that c haracterizes the sp ecies sampling mechanism (1), where the weigh ts are a pro duct of indep enden t Beta random v ariables. More in general, w e start considering a sequence of random v ariables ( X n ) n ≥ 1 c haracterized b y the predictive distributions P { X n +1 ∈ · | X ( n ) , W ( n ) } = n X j =1 p n,j δ X j ( · ) + r n G 0 ( · ) (3) where W ( n ) = ( W 1 , . . . , W n ) is a vector of indep enden t random v ariables W k taking v alues in [0 , 1], and the w eigh ts are defined b y p n,j := (1 − W j ) n Y i = j +1 W i , r n := n Y i =1 W i . (4) The prediction rule (3) defines a sp ecial case of a Generalized Ottaw a Sequence, in- tro duced in Bassetti et al. (2010), a type of Generalized P´ oly a Urn sequences where the reinforcemen t is randomly determined by the realizations of a laten t pro cess (see also Guha, 2010, for an alternativ e prop osal). Except from a few sp ecial cases, the X i ’s in a GOS are not exchangeable. Ho w ev er, it can b e sho wn that these sequences main tain some prop erties t ypical of exc hangeable sequences. Most notably , any GOS is c onditional ly identic al ly distribute d (CID), i.e. for all n > 0, the X n + j ’s, j ≥ 1, are iden tically distributed, conditionally on ( X 1 , . . . , X n , W 1 , . . . , W n ). Hence, the X i ’s are also marginally iden tically distributed. Note that a CID sequence is not necessarily sta- tionary . If a CID sequence is also stationary then it is exc hangeable. Finally , although no representation theorem is known for CID sequences, it can b e shown that given any b ounded and measurable function f , the predictiv e mean E [ f ( X n +1 ) | X 1 , ..., X n ] and the empirical mean 1 n P n i =1 X i con v erge to the same limit as n go es to infinit y . F or details, see Berti et al. (2004), where CID sequences ha v e b e en first introduced. The predictiv e rule (3) reduces to kno wn cases with a suitable c hoice of the latent W n ’s; for 6 instance if W n := ( θ + n − 1) / ( θ + n ), then (3) coincides with the Blackw ell-MacQueen sampling rule characterizing a D P ( θ , G 0 ). In this pap er, w e prop ose ( W n ) n ≥ 1 b e a sequence of indep endent Beta( α n , β n ) random v ariables and we call the resulting ( X 1 , X 2 , . . . ) a Beta-GOS sequence. The c hoice of Beta laten t v ariables allows for a flexible sp ecification of the sp ecies sampling w eigh ts, while retaining a simple and interpretable mo del together with computational simplicit y (see later Sections). The allo cation rule can also b e describ ed in terms of a preferen tial attac hment scheme, where eac h observ ation is attac hed to an y of the pre- ceding by means of a “geometric-type” assignment. In this scheme, every individual X i is characterized by a random weigh t (or “mark”), 1 − W i . W e can interpret each individual mark as an individual sp ecific attractivit y index, as it determines the prob- abilit y that the next observ ation will b e clustered with X i . More precisely , the first individual is assigned a random v alue (or “tag”) X 1 , according to G 0 . No w, supp ose w e ha ve X 1 , . . . , X n together with their marks up to time n , (1 − W 1 , . . . , 1 − W n ). Then, the ( n + 1)-th individual will b e assigned the same tag as X n with probability 1 − W n ; the probability of pairing X n +1 to X n − 1 will be W n (1 − W n − 1 ), and so forth. In general, p n,j will b e the pro duct of the repulsions W i for the latest n − j sub jects and the j th attractivity 1 − W j . Summarizing, X n +1 will result in a new tag (i.e., X n +1 ∼ G 0 ) with probabilit y r n , or will b e clustered together with a previously ob- serv ed tag, say X ∗ k , with probability P j : X j = X ∗ k p n,j . In the next Section, we discuss the clustering behavior induced by different sp ecifications of the Beta weigh ts in more detail. 3. CLUSTERING BEHA VIOR OF THE BET A-GOS. The predictiv e rule (3) implicitly defines a random partition of the set { 1 , . . . , n } in to K n blo c ks. In probability theory , K n is also referred to as the length of the partition. Kno wledge of the b ehavior of K n is useful to understand the clustering structure im- plied b y (3). F or instance, for a D P ( θ , G 0 ), it is well-kno wn that K n / log( n ) conv erges 7 almost surely to a constant, indeed the mass parameter θ . This asymptotic b ehavior is sometimes describ ed as a “self-av eraging” prop ert y of the partition (Aoki, M., 2008). F rom a practical p oint of view, since K n / log( n ) conv erges to a constant, then in the limit K n is essentially θ log( n ); th us, for mo deling purposes it suffices to consider only the first momen t of K n . In the case of the tw o parameter Poisson Diric hlet pro cess the length of the partition K n (suitably rescaled) conv erges instead to a random v ariable. More precisely , for a P D ( α, θ ), with 0 < α < 1, θ > − α , then K n /n α con v erges a.s. to a strictly p ositive random v ariable (see Theorem 3.8 in Pitman, 2006). Therefore, the PD sequence is non self-av eraging. When the limit of K n is essentially a random v ariable, extra care is needed in the prior assessment of the parameters of the non- parametric prior, since the clustering b ehavior is ultimately go v erned by the whole distribution of the limit random v ariable. F or the Beta-GOS process, we fo cus on the follo wing t wo cases: (i) α n = a > 0 and β n = b > 0 for all n ≥ 1; (ii) α n = θ − 1 + n ( θ > 0) and β n ≥ 1 for all n ≥ 1 . Then, w e can prov e the follo wing Prop osition 1. L et K n b e the length of the p artition induc e d by a Beta-GOS, with G 0 non-atomic and W n ∼ Beta ( α n , β n ) ( n ≥ 1 ). (a) If α n = n + θ − 1 , β n = 1 , for given θ > 0 , K n / log( n ) c onver ges in distribution to a Gamma ( θ , 1) r andom variable. (b) If α n = n + θ − 1 , β n = β , ( θ > 0 , β > 1) or if α n = a, β n = b , ( a > 0 , b > 0) , then K n c onver ges almost sur ely to a finite r andom variable K ∞ . In p articular, if α n = a, β n = b , then E [ e − tK ∞ ] = e − t X m ≥ 0 ( e − t − 1) m m Y j =1 ( a ) ( j ) ( a + b ) ( j ) − ( a ) ( j ) 8 wher e ( t ) ( m ) = t ( t + 1) . . . ( t + m − 1) and E [( K ∞ − 1) . . . ( K ∞ − m )] = m ! m Y j =1 ( a ) ( j ) ( a + b ) ( j ) − ( a ) ( j ) . The proof is detailed in the App endix, where w e also provide a general form ula for the probability distribution, the k -th moment and the generating function of K n . The result in Prop osition 1(a) represents a case of a quite natural (non exc hangeable) partition mo del for which the length K n scale as log ( n ) but is not self-a v eraging. When α n = a, β n = b , according to Prop osition 1(b), the conv ergence of K n to a finite random v ariable naturally implies the creation of a few big clusters, as n increases. Instead, for α n = n + θ − 1 , β n = 1, the mean length of the partition dep ends on the v alue of θ , since a bigger n umber of clusters is asso ciated on a verage with greater v alues of θ . Ho wev er, as θ increases so do es the asymptotic v ariabilit y of K n ; therefore, in this case, a Beta-GOS pro cess can b e used to represen t uncertaint y on K n (b y the lac k of the self-av eraging prop ert y of the pro cess. By means of sim ulations, we ha v e also confirmed that, for small v alues of θ , the partition of n elements is skew ed, i.e. it is c haracterized by a small num b er of big clusters as w ell as a few small clusters. As θ increases, the sizes of the clusters decrease accordingly , the observ ations b eing group ed in to clusters of relativ ely fewer elements. This is similar to what happ ens for the DP , and indeed in this case the parameter θ could b e interpreted as a mass parameter for the Beta-GOS. The parameters of the W i ’s can b e chosen to mo del the auto correlation exp ected a priori in the dynamics of the sequence. The probabilit y of a tie ma y decrease with n and atoms that ha v e b een observed at farthest times ma y hav e a greater probability to b e selected if they hav e also b een observ ed more recently . Such considerations ma y b e helpful to guide prior assessmen t of the Beta hyper-parameters. F or giv en n ≥ 1, 9 taking expectations with respect to the weigh ts W i ’s w e obtain E [ r n ] = n Y j =1 α j α j + β j , E [ p n,k ] = β k α k + β k n Y j = k +1 α j α j + β j k = 1 , . . . , n. (5) Under (a), it follows that E [ r n ] = ( a/ ( a + b )) n and E [ p n,k ] = ( a/ ( a + b )) n − k ( b/ ( a + b )); hence, the probabilities of ties depend only on the lag n − k and decrease exp onentially as a function of n − k . Under (b), E [ r n ] = n Y j =1 j + θ − 1 j + θ − 1 + β = Γ( θ + n )Γ( θ + β ) Γ( θ + β + n )Γ( θ ) E [ p n,k ] = β k + θ − 1 + β n Y j = k +1 j + θ − 1 j + θ − 1 + β = β Γ( θ + n )Γ( θ − 1 + β + k ) Γ( θ + β + n )Γ( θ + k ) k = 1 , . . . , n. Th us, for n, k → + ∞ , E [ r n ] ∼ 1 n β and E [ p n,k ] ∼ k β − 1 n β . F or example, if θ = 1 and β = 2, then α j = j and β j = 2 and E [ r n ] = 2 (1+ n )(2+ n ) , E [ p n,k ] = 2( k +1) ( n +1)( n +2) , k = 1 , . . . , n , so that the w eigh ts decrease linearly as a function of the lag n − k . If α j = θ − 1 + j ( θ > 0) and β j = 1 then E [ r n ] = θ θ + n and E [ p n,k ] = 1 θ + n , k = 1 , . . . , n , i.e. any observ ation has the same w eight. This latter specification leads to an expression similar to that in the Blackw ell-McQueen P´ olya Urn c haracterization of the Diric hlet pro cess; how ev er, this identit y is true only in exp ectation, and the clustering behavior of the DP and Beta-GOS pro cess with α j = j + θ − 1 and β j = 1 may b e quite different, as it is eviden t from Prop osition 1. In practice, the determination of the parameters of the Beta distributions is not trivial, and ma y b e problem dep endent, especially giv en the sensitivit y of the clustering b eha vior to the v alues of α j and β j . As a general rule, following what it is usually done with Dirichlet pro cesses priors, one should consider eliciting the parameters on the basis of the exp ected num b er of clusters E ( K n ) = 1 + P n − 1 j =1 E [ r j ]. F or example, one should set α j = a and β j = b to represen t a short memory process, and the v alues of a, b can b e c hosen based on the asymptotic relationship E ( K n ) ≈ a + b b . W e further suggest to choose b = 1, or anyw a y b < a , to encourage a priori low auto correlation 10 of the sequence, since then E ( p n,n ) < 0 . 5. As a matter of fact, w e implemen ted those suggestions in the application to the array CGH data presented in Section 6, where biological considerations lead to further exp ect the true num b er of states to b e around 4. On the other hand, one should set α j = j + θ − 1, β j = 1 to represent a long memory process, and then choose θ based on E ( K n ) = P n − 1 j =0 θ θ + j ∼ θ log( n ), for large n . The latter, single-parameter, formulation should b e the default choice in those applications where prior information on the exp ected num b er of clusters is una v ailable otherwise. Alternative strategies are p ossible. F or example, one could consider second momen ts, or otherwise require further constrain ts on the exp ected auto correlation of the sequence. How ever, w e leav e the exploration of those p ossibilities to future work. See also the discussion at the end of Section 4.2. Finally , we note the functional form of (4) ma y initially suggest a relationship with the stick-breaking characterization of the Dirichlet pro ce ss. How ev er, the stick- breaking construction c haracterizes the represen tation of the DP as a random mea- sure, not the corresp onding predictive probabilit y function. F urthermore, the sequence generated by a DP is exchangeable, whereas a Beta-GOS in general is not and in- cludes the DP as a sp ecial case. As a matter of fact, if one w ould like to stress the “stic k-breaking” analogy anyw a y , one should more prop erly interpret (3) in terms of an inverse stic k-breaking, since eac h p n,j , whic h defines the probability of a tie, say X n +1 = X j , do es not dep end on the W i ’s observed before time j , j = 1 , . . . , n , whereas the probability of c ho osing a new tag dep ends only on the part of the stick that is left at time n . This is evident if we consider the alternative c haracterization of (3) with p n,j = W j Q n i = j +1 (1 − W i ) and r n ( W 1 , . . . , W n ) = Q n i =1 (1 − W i ), W i ∼ Beta( β i , α i ) and c ho ose β i = 1 and α i = θ as in the DP . Then, p n,j = W j Q n i = j +1 (1 − W i ), j = 1 , . . . , n . F or n = 3, p 3 , 1 = W 1 (1 − W 2 )(1 − W 3 ), p 3 , 2 = W 2 (1 − W 3 ), p 3 , 3 = W 3 . By contrast, in a Diric hlet pro cess each piece of the unitary stick is defined from what is left by the previous ones. 11 4. A BET A-GOS HIERARCHICAL MODEL In this Section, we show how the Beta-GOS pro cess could b e used as a prior in a hierarc hical mo del, and we discuss a straightforw ard MCMC sampling algorithm for p osterior inference. 4.1 The hierarchical model. Beta-GOS pro cesses can b e used to mo del dep endencies b etw een non exchangeable observ ations. Let Y = ( Y 1 , . . . , Y m ) T b e a vector of observ ations, e.g. a time series. Then, following a Ba y esian approach, we can assume that the data can b e describ ed b y a hierarchical mo del as Y i | µ i ind. ∼ p ( y i | µ i ) , i = 1 , . . . , m, (6) for some probabilit y density p ( ·| µ i ), where the v ector ( µ 1 , . . . , µ m ) T is a realization of a Beta-GOS pro cess with parameters α i , β i , i = 1 , . . . , m , and base measure G 0 , which w e succinctly denote as µ 1 , . . . , µ m ∼ Beta-GOS( α m , β m , G 0 ) , (7) i.e. is a sample from a random distribution characterized b y the predictive rule (3), for some W i ∼ Beta( α i , β i ), i = 1 , . . . , m . As noted in Section 2, an y Beta-GOS defines a CID sequence. In particular, marginally µ i ∼ G 0 , i = 1 , . . . , m . Therefore, G 0 can b e regarded as a centering distribution, as in DP mixture mo dels: G 0 can represen t a v ague parametric prior assumption on the distribution of the parameters of in terest. The hierarc hical mo del may b e extended by putting hyper-priors on the remaining parameters of the mo del, including the parameters of the Beta-GOS ( α m , β m , G 0 ), although here we fo cus on the characterization of the behavior of the Beta-GOS for fixed c hoices of the Beta parameters. W e conclude this Section by noting that the sequence Y 1 , Y 2 , . . . , defined through 12 (6) and (7), with join t densit y Z m Y i =1 p ( y i | µ i ) π ( dµ 1 , . . . , dµ m ) , m ≥ 0 , and π ( · ) ≡ Beta-GOS( α m , β m , G 0 ), is also a CID sequence. Therefore, although not exc hangeable, the Y n + j ’s, j ≥ 1 are conditionally identically distributed given ( Y 1 , . . . , Y n , µ 1 , . . . , µ n ). F or a proof of this statemen t, see Prop osition 4 in the Ap- p endix. 4.2 MCMC p osterior sampling. P osterior inference for the mo del (6)-(7) entails learning ab out the vector of random effects µ i and their clustering structures. As the p osterior is not a v ailable in closed form, we need to revert to MCMC sampling. In this Section, we describ e a Gibbs Sampler that relies on sampling the subsequen t cluster assignments of the observ a- tions Y 1 , . . . , Y m according to the rule (3). T o do this, the partition structure will b e describ ed b y introducing a sequence of lab els ( C n ) n ≥ 1 recording the pairing of eac h observ ation according to (3), i.e. whic h other data p oint, among those with index j < i , the i th observ ation has b een matched to. Hence, here the lab el C i is not a simple indicator of the cluster mem b ership, as it is t ypical in most MCMC algorithms devised for the Dirichlet pro cess, although cluster mem b ership can b e easily retrieved b y analyzing the sequence of pairings. In what follows, C i will b e sometimes referred to as the i -th pairing lab el. In particular, if the i -th observ ation is not paired to an y of those preceding, C i = i ; in this case, the i -th point consists of a dra w from the base distribution G 0 , and thus generates a new cluster. This sligh tly different representa- tion of data p oints in terms of data-pairing lab els, instead of cluster-assignment lab els, turns useful to develop an MCMC sampling sc heme for non-exc hangeable pro cesses, as it has b een thoroughly discussed in Blei and F razier (2011), who ha ve shown that suc h represen tation allo ws for larger mov es in the state space of the p osterior and faster 13 mixing of the sampler. It is easy to see that the pairing sequence ( C n ) n ≥ 1 assigns C 1 = 1 and has distribution P { C n = i | C 1 , . . . , C n − 1 , W } = P { C n = i | W 1 , . . . , W n − 1 } = r n − 1 I { i = n } + p n − 1 ,i I { i 6 = n } , (8) for i = 1 , . . . , n , where I ( · ) denotes, as usual, the indicator function, such that, given a set A, I ( i ∈ A ) = 1 if i ∈ A and 0 otherwise. As mentioned, the clustering config- uration is a b y-pro duct of the representation in terms of data-pairing lab els. If tw o observ ations are connected b y a sequence of interim pairings, then they are in the same cluster. Given C = ( C 1 , . . . , C m , . . . ), let Π( C ) denote the partition on N gen- erated by C . Accordingly , if ( µ ∗ k ) k ≥ 1 is a sequence of independent random v ariables with common distribution G 0 , we set µ i = µ ∗ k if i b elongs to Π( C ) k , i.e. the k - th blo c k (cluster) of Π( C ). F or any m and an y i ≤ m , let C ( m ) = ( C 1 , . . . , C m ), C − i = ( C 1 , . . . , C i − 1 , C i +1 , . . . , C m ); analogously , let W ( m ) = ( W 1 , . . . , W m ), and W − i = ( W 1 , . . . , W i − 1 , W i +1 , . . . , W m ). Then, the full conditional for the pairing indi- cators C i ’s is P { C i = j | C − i ,Y ( m ) , W ( m ) } ∝ P { C i = j, Y ( m ) | C − i , W ( m ) } = P { Y ( m ) | C i = j, C − i , W ( m ) } P { C i = j | C − i , W ( m ) } . (9) The second term in (9) is the prior predictive rule (8), whereas P { Y ( m ) | C i = j, C − i , W ( m ) } = | Π( C − i ,j ) | Y k =1 Z Y l ∈ Π( C − i ,j ) k p ( Y l | µ ∗ j ) G 0 ( dµ ∗ j ) , where Π( C − i , j ) denotes the partition generated by ( C 1 , . . . , C i − 1 , j, C i +1 , . . . , C m ). If G 0 and p ( y | µ ) are conjugate, the latter integral has a closed form solution. The non- conjugate case could be handled b y appropriately adapting the algorithms of MacEach- ern and M ¨ uller (1998) and Neal (2000). Instead, we believe that split and merge mo v es 14 as the ones considered in Jain and Neal (2007) and Dahl (2005) are more problematic to implemen t giv en the implied exchangeabilit y of the clustering assignmen ts in those algorithms. As far as the full conditional for the laten t v ariables W i ’s, w e can sho w that W i | C ( m ) , W − i , Y ( m ) ∼ Beta( A i , B i ), where A i = α i + P m j = i +1 I { C j < i or C j = j } , and B i = β i + P m j = i +1 I { C j = i } ; hence, they dep end on only on the clustering config- urations and not on the v alues of W − i . Then, consider the set of cluster centroids µ ∗ i ’s. The algorithm describ ed so far allo ws faster mixing of the chain b y integrating o ver the distribution of the µ ∗ i . How ever, in case w e were in terested on inference on the vector ( µ 1 , . . . , µ m ), it is p ossible to sample the unique v alues at each iteration of the Gibbs sampler, from P { µ ∗ j | C ( m ) , W ( m ) , Y ( m ) } ∝ Y i ∈ Π j ( m ) p ( Y i | µ ∗ j ) G 0 ( dµ ∗ j ) , (10) where Π j ( m ) denotes the partition set of the observ ations such that µ i = µ ∗ j , i = 1 , . . . , m . Again, if p ( y | µ ) and G 0 are conjugate, the full conditional of µ ∗ j is a v ailable in closed form, otherwise w e can up date µ ∗ j b y standard Metrop olis Hastings algorithms (Neal, 2000). In addition, we note that if a prior distribution for the Beta h yp er-paramete rs α m and β m , say π ( α m , β m ), were to b e sp ecified, one could implemen t a Metrop olis Hasting sc heme to learn ab out their p osterior distribution, since it can be sho wn that P ( α m , β m | C ( m ) , Y ( m )) ∝ π ( α m , β m ) m Y i =1 B ( A i , B i ) B ( α i , β i ) , (11) where A i and B i are defined as ab ov e and B ( x, y ) = Γ( x )Γ( y ) / Γ( x + y ) denotes the Beta function. Equation (11) is an adaptation of well known results for the Dirichlet Pro cess (Escobar and W est , 1995) to the Beta-GOS pro cess. A thorough study of the efficiency of this algorithm, how ever, as w ell as the c hoice of adequate prop osal distributions is b eyond the scop e of this w ork and will b e pursued elsewhere. 15 5. A SIMULA TION STUDY In this Section, we provide a full sp ecification for mo del (6)–(7) and test the prop- erties of the Beta-GOS prior on a set of simulated examples; more sp ecifically , we dev elop some comparison with the Dirichlet Pro cess and popular hidden Marko v Mo d- els (HMM). 5.1 Mo del sp ecifications Throughout this Section, mo del (6)–(7) will b e sp ecified as follows. First, we assume a Gaussian distribution for the observ ables, Y i ∼ Normal( µ i , τ 2 ). The base measure G 0 is also assumed to b e normal, Normal( µ 0 , σ 2 0 ), and τ 2 ∼ Inv-Gamma( a 0 , b 0 ). The pa- rameters of the latent Beta reinforcements, W i ∼ Beta( α i , β i ), are separately indicated in eac h simulation and are chosen to allow for a range of prior beliefs on the clustering b eha vior of the pro cess (see Section 3). Details of the MCMC algorithm for p osterior inference and parameter estimation in the Beta-GOS mo del are given in Appendix A. 5.2 Mo del fitting and parameter estimation A first sim ulation study considers an ideal setting. W e generate 1000 samples of 101 observ ations each from the Beta-GOS mo del (6)–(7), with (a) α n = n , β n = 1 and (b) α n = 3, β n = 1. The first 100 p oin ts are used for fitting purp ose, whereas the 101 st p oin t is used to assess goo dness of fit. Without muc h loss of generalit y , we fix µ 0 = 0 and σ 0 = 10. W e mimic the t ypical scale observed in the data analyzed in Section 6 and set τ = 0 . 25 to distinguish the sample v ariability from the v ariability of the base mea- sure. W e fit the data using a Beta-GOS hierarc hical mo del, with default Beta hyper- parameters α n = n , β n = 1, and study how well w e can recov er the basic characteristics of the data under such sp ecification. W e assume τ 2 ∼ Inv-Gamma(2 . 004 , 0 . 0063) in the mo del fitting. This c hoice of the Inv erse-Gamma hyper-parameters allo ws τ 2 to ha v e mean around 0 . 25 2 and relatively large v ariance. In addition, we fit a DP mix- ture mo del with concentration parameter θ = 1, which on the basis of Prop osition 1 (a) can b e seen as compatible with the parameters used in our mo del. The mixture 16 of DP mo del is fit to data using the R pack age “DPpack age” (Jara A. , 2007). In this framework, the Dirichlet Pro cess provides a conv enient comparison; ho wev er, we should stress that, in general, the underlying exchangeabilit y assumption may not b e appropriate to fully capture the dep endency structure of the data generating pro cess. The results of this simple sim ulation study are summarized in T able 1. T able 1 rep orts summary statistics aimed at providing syn thetic measures of the go o dness of fit, namely the estimated n umber of clusters and the accuracy of cluster assignments, together with a measure of predictiv e bias. F ollowing the mac hine learning terminology for classification p erformance metrics, we call accuracy the ratio of the correct cluster assignmen ts with resp ect to the total of assignments. W e compute the predictive bias as follows: for eac h sample, and eac h MCMC output, we predict a new observ ation on the basis of the estimated parameters and the clustering configurations provided b y the algorithm, say Y pred . The prediction is compared with the original v alue, Y 101 . The predictive bias is simply the av erage of | Y 101 − Y pred | , and can b e regarded as a measure of ho w well the mo del can predict future observ ations. Nearly all data p oin ts w ere assigned to the correct clusters. The Beta-GOS app ears to compare fav orably in terms of predictive bias, esp ecially when the data incorp orate a stronger dep endency structure. Most of the error is intrinsic to the data generating pro cess. As typical of most Bay esian nonparametric mo dels, including the DP , the abilit y of the mo del and estimation algorithms to reco ver the ground truth ma y b e affected by the choice of the relativ e magnitudes of the hyper-parameters σ 2 0 and τ 2 . The Supplemen tal Materials con tain additional results for several sp ecifications of the data generating mechanism as well as several choices of the hyper-parameters for mo del fitting, confirming the ab o v e remarks. 5.3 Fitting mixture of Gaussians A second sim ulation study is designed to as sess the robustness of the Beta-GOS framew ork to mo del mis-sp ecifications: i.e., w e fit the prop osed non-exchangeable 17 mo del to exchangeable data. The DP pro cess provides a sensible baseline for this study . More in detail, we first generate 1,000 data sets (101 observ ations eac h) from a Normal mixture mo del with five comp onents. The comp onents’ means are sam- pled from a Normal( µ 0 = 0 , σ 0 = 10), whereas their standard deviation is set either to τ = 0 . 25 or τ = 0 . 5 to provide some insigh t in to the robustness of the results to different levels of noise. The v ector of mixture comp onents’ weigh ts is chosen as π = (0 . 2 , 0 . 35 , 0 . 15 , 0 . 1 , 0 . 2) T . W e fit the data with a Diric hlet Pro cess ( θ = 1), and a Beta-GOS pro cess, with a) α n = β n = 1, and b) α n = n , β n = 1. Case (a) corresp onds to a process with short auto correlation exp ected a priori and, asymptotically , a finite n um b er of clusters, whereas case (b) assumes that the rescaled num b er of clusters, K n / log( n ), conv erges to a Gamma (1 , 1), and E [ K n ] ∼ log( n ). The choice of hyper- parameters for the In v erse-Gamma on τ 2 sets the mean around the true v alue and allo ws for a relatively large v ariance. The results of the sim ulations are shown in T able 2. Ov erall, the Beta-GOS framew ork is quite robust to mo del mis-sp ecifications. F or the mixture of Gaussians data, accuracy of cluster assignments w as high (94%), that is b etter or comparable to that of the DP; corresp ondingly , parameters’ estimates were close to the true parameter v alues. F or all pro cesses, the accuracy decreases slightly with increasing level of noise. In Figure 1, we report the p osterior distribution of the n um b er of clusters for the three pro cesses, for the case τ = 0 . 25. In accordance with the findings of Prop osition 1, w e can see that if α n = β n = 1 the distribution is more concen trated around the mean and fewer clusters are generated in the fit. Finally , we note that in our sim ulations, posterior inference for the Beta-GOS pro cess seemed only minimally affected b y the tw o different sp ecifications of the parameters of the Beta w eights. This consideration confirms the suggestion that using α n = n + θ − 1, β n = 1 represents a default c hoice in many applications, where there is no a priori infor- mation to guide parameter c hoice. In this case, θ can be c hosen or estimated similarly as what is routinely done for mixtures of DPs. The Supplemental Materials con tain additional results for several sp ecifications of the mo del h yp er-parameters, ov erall con- 18 T able 1: Summary statistics for the sim ulation study in Section 5.2. The table compares the Beta-GOS and a Dirichlet Pro cess mo del under different sp ecifications of h yp er-parameters when the data generating pro cess is Beta-GOS. Data Generating Pro cess: Beta-GOS Beta-GOS α n = n, β n = 1 α n = 3 , β n = 1 Mo del Fitting Metho d Beta-GOS Dir. Pro c. Beta-GOS Dir. Pro c. α n = n , β n = 1 θ = 1 α n = n , β n = 1 θ = 1 Num b er of Clusters Ground T ruth 5.24 ± 3.88 4.14 ± 1.81 Estimation 4.30 ± 2.67 4.51 ± 2.62 3.61 ± 1.49 3.96 ± 1.72 Accuracy of Cluster Assignment 0.97 ± 0.06 0.96 ± 0.08 0.99 ± 0.01 0.99 ± 0.02 Predictiv e Bias 4.13 ± 7.18 4.34 ± 7.27 0.67 ± 2.61 1.29 ± 3.93 firming the ab ov e remarks. 5.4 Fitting Hidden Semi-Marko v Mo dels A third simulation study is designed to assess the robustness of the Beta-GOS frame- w ork to a mis-sp ecification of a differen t nature. In many problems (e.g. change p oint detection), hidden Mark ov Mo dels are used as computationally conv enient substitutes for temp oral pro cesses that are known to b e more complex than implied b y first or- der Mark ovian dynamics. Here, w e generate non-exchangeable sequences from a hidden semi-Mark o v process (HSMM; F erguson, 1980; Y u, 2010) and study ho w the Beta-GOS pro cess p erforms in fitting this t yp e of data. Hidden semi-Mark ov pro cesses are an ex- tension of the p opular hidden Marko v mo del where the time sp ent in eac h state (state o ccupancy or so journ time) is given b y an explicit (discrete) distribution. A geometric state o ccupancy distribution characterizes ordinary hidden Mark o v mo dels. Therefore, hidden semi-Marko v pro cess ha v e also b een referred to as “hidden Mark o v Mo dels with explicit duration” (Mitc hell et al., 1995; Dewar et al., 2012) or “v ariable-duration hidden Mark ov Mo dels” (Rabiner, 1989). W e generate 1,000 datasets (1000 observ ations each) using a hidden semi-Marko v pro cess with four states and a negative binomial distribution for the state o ccupancy distribution. More sp ecifically , w e parametrize the negative binomial in terms of its 19 T able 2: Summary statistics for the simulation study in Section 5.3. The table compares the Beta-GOS and a Diric hlet Pro cess mo del under differen t sp ecifications of h yp er-parameters when the data generating pro cess is a mixture of 5 gaussian comp onents. Data Generating Pro cess: Gaussian Mixture - 5 Gaussians T rue Sample V ariability τ = 0 . 25 τ = 0 . 5 Mo del fitting Metho d Beta-GOS Dir. Pro c. Beta-GOS Dir. Pro c. α n = n, β n = 1 α n = β n = 1 θ = 1 α n = n, β n = 1 α n = β n = 1 θ = 1 Estimated Num b er of Clusters 4.95 ± 0.97 4.71 ± 0.76 5.52 ± 1.48 4.70 ± 1.32 4.19 ± 0.99 5.28 ± 1.90 Accuracy of Cluster Assignment 0.94 ± 0.09 0.93 ± 0.09 0.93 ± 0.09 0.86 ± 0.11 0.84 ± 0.12 0.85 ± 0.13 Predictiv e Bias 8.86 ± 9.02 8 . 73 ± 9.02 8.84 ± 8.99 8.53 ± 8.61 8.39 ± 8 . 37 8.55 ± 8.61 Estimated Sample V ariabilit y 0.25 ± 0.01 0.25 ± 0.01 0.27 ± 0.05 0.56 ± 0.68 0 . 69 ± 1 . 19 0.62 ± 0.19 20 T able 3: Summary statistics for the simulation studies describ ed in Section 5.4. The table compares the Beta-GOS and a hidden Marko v mo del under differen t sp ecifications of h yp er-parameters. The data generating pro cess assumes a hidden semi-Mark o v with state o ccupancy distribution NegBin(15 , 0 . 15) and tw o levels of the sampling noise τ = 0 . 25 and τ = 0 . 5. i) Data Generating Pro cess: Hidden Semi Marko v Mo del (HSMM) with 4 states and NegBin(15 , 0 . 15) Mo del Fitting Metho d Beta-GOS HMM α n = n ; β n = 1 α n = 5; β n = 1 α n = 1; β n = 1 3 States 4 States 5 States τ = 0 . 25 Estimated Num b er of Clusters 3 . 89 ± 0 . 53 4 . 04 ± 0 . 59 4 . 09 ± 0 . 63 2 . 98 ± 0 . 13 3 . 94 ± 0 . 29 4 . 87 ± 0 . 55 Accuracy of Cluster Assignment 0 . 95 ± 0 . 10 0 . 97 ± 0 . 07 0 . 96 ± 0 . 08 0 . 72 ± 0 . 09 0 . 84 ± 0 . 13 0 . 90 ± 0 . 13 τ = 0 . 5 Estimated Num b er of Clusters 3 . 69 ± 0 . 81 3 . 89 ± 0 . 96 4 . 06 ± 0 . 97 2 . 99 ± 0 . 12 3 . 96 ± 0 . 25 4 . 90 ± 0 . 48 Accuracy of Cluster Assignment 0 . 86 ± 0 . 14 0 . 90 ± 0 . 12 0 . 90 ± 0 . 12 0 . 71 ± 0 . 11 0 . 83 ± 0 . 12 0 . 88 ± 0 . 13 21 Number of clusters Density 0.0 0.1 0.2 0.3 0.4 0.5 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 (a) Number of clusters Density 0.0 0.1 0.2 0.3 0.4 0.5 2 3 4 5 6 7 8 9 10 11 (b) Number of clusters Density 0.0 0.1 0.2 0.3 2 3 4 5 6 7 8 9 10 12 14 16 18 (c) Figure 1: Posterior distribution of the n um b er of clusters in the simulation of Section 5.3 ( τ = 0 . 25). Case (a) corresp onds to a Beta-GOS( α n = n , β n = 1), case (b) to a Beta- GOS( α n = β n = 1) and case (c) to a Dirichlet Pro cess with parameter θ = 1. mean and an ancillary parameter, which is directly related to the amount of ov erdis- p ersion of the distribution (Hilb e, 2011; Airoldi et al., 2006). If the data are not o v erdisp ersed, the Negativ e Binomial reduces to the Poisson, and the ancillary param- eter is zero. F or the simulations presented here, w e consider a NegBin(15 , 0 . 15), which corresp onds to assuming a large o v erdisp ersion (17.25). W e also consider τ = 0 . 25 and τ = 0 . 5 in order to explore robustness to different levels of noise. W e fit the data by means of a Beta-GOS mo del with Beta hyper-parameters defined b y: a) α n = n, β n = 1; b) α n = 5 , β n = 1; c) α n = 1 , β n = 1. Based on Proposition 1, those c hoices corresp ond to assuming differen t clustering b eha viors; in particular, differen t exp ected n umber of clusters a priori . W e then compare the Beta-GOS with the fit resulting from hidden Mark o v mo dels, assuming 3, 4 and 5 states, resp ectively . Results from the sim ula- tions are rep orted in T able 3, where the HMM w as implemen ted using the R pac k age “RHmm” (T aramasco and Bauer, 2012). T able 3 sho ws that the Beta-GOS is a viable alternativ e to HMM, as it can pro vide more accurate inference than a single hidden Mark o v model where the num b er of states is fixed a priori. As exp ected, higher levels of noise decrease the accuracy of the estimates, but the reduction affects the fit of the Beta-GOS and hidden Marko v Models similarly . F urthermore, the fit obtained with 22 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 800 850 900 950 1000 −4 −2 0 2 4 800 850 900 950 1000 1.0 1.5 2.0 2.5 3.0 3.5 4.0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 800 850 900 950 1000 1.0 1.5 2.0 2.5 3.0 3.5 4.0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 800 850 900 950 1000 −4 −3 −2 −1 0 1 (a) Ground T ruth 800 850 900 950 1000 1.0 1.5 2.0 2.5 3.0 3.5 4.0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● (b) Beta Gos 800 850 900 950 1000 1.0 1.5 2.0 2.5 3.0 3.5 4.0 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● (c) HMM Figure 2: Illustrative segmentation-t yp e plots for the simulation study in Section 5.4. Col- umn (a): subset of data for t wo replicates. Column (b) top : an example of allo cation for a Beta-Gos( α n = 1 , β n = 1) plotted vs the truth (blac k line); column (b) b ottom considers a Beta-Gos( α n = n, β n = 1). Column (c) illustrates the fitting by a HMM with 4 states. the Beta-GOS app ears quite robust to the different choices of the hyper-parameters. Figure 2 illustrates the clustering induced b y the Beta-Gos and a 4-state HMM for a subset of the data generated in tw o sp ecific simulation replicates. The middle col- umn illustrates the allo cation, resp ectively , from a Beta-Gos( α n = 1 , β n = 1) ( top ) and a Beta-Gos( α n = n, β n = 1)( b ottom ), whereas column (c) illustrates the clustering attained by the HMM. Caution is necessary in order to av oid ov er-in terpreting the results in the figure. Ov erall, the segmentation-plots suggest similarity in the allo ca- tions induced by the Beta-GOS and the HMM. In some instances, the Beta-GOS fit seems to allow shorter stretches of con tiguous identical states, as illustrated in the top ro w of Figure 2. On the other hand, when data are characterized b y elev ated intra- claster v ariabilit y , as in the b ottom row of Figure 2, b oth the Beta-Gos and the HMM could fail to attain a fair representation of the true clustering structure of the data. Our practical exp erience suggests that the issue is more prominent for the “default” 23 Beta-Gos( α n = n, β n = 1) than for the “informativ e” Beta-Gos( α n = a, β n = b ) form u- lations. This is in accordance with the discussion in Section 3 and, in particular, with the consideration that a Beta-Gos( α n = n, β n = 1) should represen t a long memory pro cess where all previous observ ations are exp ected to contribute the same weigh t in (3). The Supplementary Materials contain results for a wider range of parameter settings, as w ell as differen t data generating mec hanisms, confirming the results noted ab o v e. 6. QUANTIFYING CHROMOSOMAL ABERRA TIONS IN BREAST CANCER W e first apply the Beta-GOS to a classic dataset that has b een used to link patterns of c hromosomal ab errations to breast cancer pathophysiologies in the medical literature (Chin et al., 2006). The ra w data measure genome cop y n umber gains and losses o ver 145 primary breast tumor samples, across the 23 chromosomes, obtained using B A C arra y Comparativ e Genomic Hybridization (CGH). More precisely , the measurements consist of l og 2 in tensit y ratios obtained from the comparison of cancer and normal female genomic DNA lab eled with distinct fluorescen t dyes and co-hybridized on a microarra y in the presence of Cot-1 DNA to suppress unsp ecific h ybridization of re- p eat sequences (see Redon et al., 2009). The analysis of array CGH data presents some c hallenges, b ecause data are typically very noisy and spatially correlated. More sp ecifically , copy num b ers gains or losses at a region are often asso ciated to an in- creased probabilit y of gains and losses at a neighboring region. W e use the Beta-GOS mo del developed in the previous Sections to analyze and cluster clones with similar lev el of amplification/deletion, for eac h breast tumor sample and each chromosome in the dataset. F or arra y CGH data, it is t ypical to distinguish regions with a normal amoun t of c hromosomal material, from regions with single cop y loss (deletion), single cop y gain and amplifications (multiple cop y gains). Therefore, w e present here the results of the analysis where the latent Beta hyper-parameters are set to α n = 3 and 24 β n = 1, corresp onding to E ( K n ) = 4 states for large n (see Section 3). W e hav e also considered α n = n and β n = 1, with no remark able differences in the results. W e c om- plete the sp ecification of mo del (6)–(7) with a v ague base distribution, Normal(0 , 10), and a v ague inv erse gamma distribution for τ cen tered around τ = 0 . 1. This c hoice of τ is motiv ated by the typical scale of the array CGH data and is in accordance with similar c hoices in the literature (see, for example Guha et al., 2008). Figure 3 exemplifies the fit to c hromosome 8 on tw o tumor samples. The mo del is able to iden tify regions of reduced copy n um b er v ariation and high amplification. Note how contiguous clones tend to b e clustered together, in a pattern typical of these chromosomal ab errations. Figure 4 replicates Figure 1 in Chin et al. (2006) and shows the frequencies of genome copy num b er gains and losses among all 145 samples plotted as a function of genome lo cation. In order to iden tify a cop y n umber ab erration for this plot, for eac h chromosome and sample, at eac h iteration w e consider the cluster with low est absolute mean and order the other clusters accordingly . The lo w est absolute mean is chosen to identify the cop y neutral state. F ollo wing Guha et al. (2008) an y other cluster is identified as a cop y n um b er gain or loss if its mean, say ˆ µ ( j ) , is farther than a specified threshold from the minim um absolute mean, say ˆ µ (1) , i.e. if ˆ µ ( j ) − ˆ µ (1) > . W e exp erimented with a range of c hoices of in the range [0 . 05 , 0 . 15] and used = 0 . 1 for the curren t analysis. F urthermore, if the mean of a cluster is ab o v e the mean of all declared gains plus t wo standard deviations, all genes in that cluster are considered high level amplifications. W e identify a clone with an ab erration (or high level amplification) if it is such in more than 70% of the MCMC iterations; then, w e compute the frequency of ab errations and high level amplifications among all 145 samples, which are rep orted, resp ectively , at the top and b ottom of Figure 4. As exp ected, the clusters iden tified by the mo del tend to b e lo calized in space all o ver the genome. This feature ma y b e facilitated by the increasingly low reinforcement of far aw ay clones embedded in the Beta-GOS, and corresp onds to the understanding that clones that liv e at adjacent lo cations on a c hromosome can b e either amplified or 25 ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 50000 100000 150000 −0.5 0.0 0.5 1.0 1.5 2.0 A ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 0 50000 100000 150000 −0.5 0.0 0.5 1.0 B Figure 3: Mo del fit ov erview: Array CGH gains and losses on chromosome 8 for tw o samples of breast tumors in the dataset in (Chin et al., 2006). Poin ts with different shap es denote differen t clusters. deleted together due to the recombination pro cess. Finally , w e considered some regions of chromosomes 8, 11, 17, and 20 that hav e been iden tified by Chin et al. (2006) and shown to correlate in their analysis to increased gene expression. W e adapt the pro cedure described in Newton et al. (2004) to compute a region-based measure of the false discov ery rate (FDR) and determine the q -v alues for neutral-state and ab erration regions estimated in our analysis. The q -v alue is the FDR analogue of the p -v alue, as it measures the minimum FDR threshold at which w e ma y determine that a region corresp onds to significant cop y n umber gains or losses (Storey, 2003; Storey et al., 2007). More sp ecifically , after conducting a clone based test as describ ed in the previous paragraph, w e identify regions of in terest by taking in to account the strings of consecutiv e calls. These regions then constitute the units of the subsequent cluster based FDR analysis. Alternatively , the regions of interest could b e pre-sp ecified on the basis of the information av ailable in the literature. The optimalit y of the type of pro cedures here describ ed for cluster based FDR is discussed 26 Figure 4: A) F requencies of genome copy num b er gains and losses plotted as a function of genomic lo cation. B) F requency of tumors showing high-level amplification. The dashed v ertical lines separate the 23 c hromosomes. in Sun et. al, 2014. See also Heller et al., 2006, M¨ uller et al., 2007 and Ji et al., 2008). In T able 4 we rep ort the q -v alues from a set of candidate oncogenes in well-kno wn regions of recurren t amplification (notably , 8p12, 8q24, 11q13-14, 12q13-14, 17q21-24, and 20q13). Our findings confirm the previous detections of c hromosomal aberrations in the same lo cations. Next, we apply our methodology to the analysis of a mo dern large-scale CGH arra y dataset (Curtis et al., 2012). More sp ecifically , here we consider one sample from the data published by Curtis et al. (2012). W e fit the Beta-GOS mo del to the entire sequence of 969,700 probes matc hed to genomics locations using a priorit y queue on the Harv ard Odyssey cluster. Mo del fit to ok ab out 24 hours. W e also fit a Hidden Marko v mo del and a Hidden semi-Marko v mo del with Negative-Binomial run lengths times, b oth set to hav e three states (Y au et al., 2011), to the same sample. The parameters of b oth mo dels were estimated using standard techniques (Rabiner, 1989; Guedon, 2003). The estimates for the Negative-Binomial run lengths, shared across states for 27 T able 4: F alse discov ery rate analysis for clones with high-lev el amplification previously iden tified by Chin et al. (2006). The individual amplicons are rep orted together with the lo cations of the flanking clones on the arra y platform. Amplicon Flanking clone Flanking clone Kb Kb FDR (left) (righ t) start end q-v alue 8p11-12 RP11-258M15 RP11-73M19 33579 43001 0.021 8q24 RP11-65D17 RP11-94M13 127186 132829 0.021 11q13-14 CTD-2080I19 RP11-256P19 68482 71659 0.022 11q13-14 RP11-102M18 RP11-215H8 73337 78686 0.024 12q13-14 BAL12B2624 RP11-92P22 67191 74053 0.011 17q11-12 RP11-58O8 RP11-87N6 34027 38681 0.017 17q21-24 RP11-234J24 RP11-84E24 45775 70598 0.017 20q13 RMC20B4135 RP11-278I13 51669 53455 0.021 20q13 GS-32I19 RP11-94A18 55630 59444 0.017 simplicit y , were ˆ r = 10 and ˆ π ≈ 0 . 25, leading to a mean run length of 30 prob es with a standard deviation of 10. F or v alidation purp oses, w e accessed a list of 152 consensus genomic lo cations where c hromosomal ab errations were found in Breast cancer tumor samples. This list is in- cluded in the data files asso ciated with The Genome Cancer Atlas (TCGA) pro ject, partly curated by the Broad Institute and hosted by the NIH. The 152 consensus ge- nomic lo cations range in size from 5 to 49 prob es. This list provides a list of lo cations, whic h hav e b een reported as likely altered in terms of DNA conten t in a num b er of publications, using multiple t yp es of datasets and analyses. Therefore, the list is inde- p enden t of the sp ecifics of any particular tec hnique, and it can b e used as a reference for ev aluating the comparative performance of our Beta-GOS mo del with Hidden Marko v mo dels, and Hidden semi-Mark o v mo dels. F or each method, we declared a success at detecting a chromosomal aberration (either deletion or amplification) at an y of the 152 consensus genomic lo cations if the metho d correctly lab eled at least 80% of the prob es asso ciated with any giv e n consensus genomic lo cation. This choice was necessary since lo cations span multiple prob es. According to this simple measure of p erformance, the Beta-GOS correctly lab eled 133 locations (or 87.50%) of the 152 consensus genomic lo- 28 cations as ha ving a chromosomal ab erration, versus 94 lo cations (or 61.84%) using the Hidden Marko v mo del, and 118 lo cations (or 77.63%) using the Hidden semi-Marko v mo del. Of course, caution should b e should be taken against ov er-in terpreting the re- sults of a single illustrativ e example. Ho wev er, the results from the simu lation studies and data analysis all concur to suggests that the Beta-GOS is a flexible model and that can b e usefully employ ed in detecting chromosomal ab errations in array CGH data, since it can account for long range dep endences in the sequence and ac hieve impro v ed accuracy with resp ect to competing Hidden Mark ov Mo del based approaches. 7. CONCLUDING REMARKS. Starting from the c haracterization of spec ies sampling sequences in terms of their pre- dictiv e probability functions, we hav e considered predictive rules where the w eigh ts are functions of latent Beta random v ariables. The resulting Beta-GOS process de- fines a nov el and probabilistically coherent Ba yesian Nonparametric mo del for non- exc hangeable data. W e ha ve discussed the clustering b eha vior of the Beta-GOS pro- cesses for some sp ecifications of the latent Beta densities and illustrated their use as priors in a hierarc hical mo del setting. Finally , w e ha v e analyzed the p erformance of this mo deling framew ork b y means of a set of simulation studies. The results outlined in Section 6 illustrate how the prop osed Beta-GOS mo del can be a useful tool for the analysis of CGH arra y data. In medical applications, for instance, it might b e used to complemen t tumor sub-type definition, or to suggest candidate genes for follo w-up clinical studies. W e exp ect our approach will b e useful in other applications where Hidden Marko v and semi-Marko v mo del are currently considered as standard, e.g. in text segmen tation and sp eec h processing (e.g., Rabiner, 1989; Blei and Moreno, 2001; Chien and F urui, 2005; Ren et al., 2010; Y au and Holmes, 2013; F ox et al., 2014). Recen tly , T eh et al. (2006a), F ox et al. (2011), and Y au et al. (2011) hav e developed flexible and effective hierarc hical Bay esian nonparametric extensions of hidden Marko v mo dels that allow p osterior inference o ver the n um b er of states. The Beta-GOS mo del 29 pro vides an alternativ e, non-exc hangeable, Ba y esian nonparametric formalism to mo del heterogeneit y across non-exc hangeable observ ations that are sequentially ordered, by enabling clustering in a n um b er of unknown states. Since the Beta-GOS mo del do es not rely on the estimation of a single transition matrix across time p oin ts, as in the HMM, we do not need to consider an explicit parameter to accoun t for state p ersistence, as in F ox et al. (2011), or assume a distribution for the so journ times as in HSMMs. Indeed, since the predictiv e weigh ts depend on the sequence of observ ations itself, the Beta-GOS seems particularly conv enient when the underlying generative pro cess is non-stationary , e.g. as a p ossible alternativ e to more complicated non-homogeneous HMMs. Monteiro et al. (2011) discuss a similar issue in a pro duct partition mo del framew ork and explicitly assume that the observ ations in a cluster ha ve their distri- butions indexed by differen t parameters. Our approach is different, for example we do not need to explicitly model the dependence structure within the clusters. Arguably , the ma jor obstacle we can foresee in the wider applicability of this t yp e of mo dels relies in the sp ecification of the prior hyper-parameters in the latent Beta distributions. Some sp ecific suggestions hav e b een pro vided in Section 3. Ho wev er, in cases where there is not enough prior information to advise differently , our exp eri- ence suggests that the default choice of the hyper-parameters outlined in Prop osition 1(a) not only reduces the problem to the choice of a single parameter as it is usual in DP mixture mo dels, but may also suffice for inferential purp oses. Alternativ ely , one could assume a prior distribution on the parameters of the Beta latent v ariables and conduct p osterior inference b y means of MCMC metho ds, as briefly discussed in Section 4. Nev ertheless, in sp ecific applications the optimal mo deling of the latent Beta densities requires further study and will b e pursued elsewhere. In addition, the prop osed approach inherits the general computational limitations of nonparametric Ba y esian metho ds. F or example, a full MCMC algorithm for p osterior inference may b e unfeasible for genomic sequences with sev eral millions of reads. Scalable algorithms ma y facilitate fast inference in those settings (e.g., Colella et. al., 2007). 30 Finally , we b elieve that the flexibility of the latent sp ecification and the p ossibility to tie the clustering implied by the Generalized P´ olya Urn sc heme directly to a set of latent random v ariables giv es an opp ortunity to further mo deling the complex re- lationships t ypical of heterogenous datasets. F or example, further developmen ts ma y substitute the general latent Beta specification with a probit/logistic sp ecification, and define a Generalized P´ oly a Urn sc heme in the aims of Ro driguez et al. (2010) that allo ws the clustering at eac h observ ation to b e dep enden t on a set of (p ossibly se- quen tially recorded) co v ariates or curv es. Similarly , we can imagine using multiv ariate Generalized P´ olya Urn sc hemes of the sort w e describ e in this pap er to mo del time dep enden t parameters in time series, whic h ma y b e imp ortant to iden tify time-v arying structures or regime c hanges at the base of phenomena like the so called financial con- tagion, i.e. the co-mov ement of asset prices across global markets after large sho cks (see, for example, Liu et. al, 2012). A CKNOWLEDGEMENTS This w ork w as partially supported by the National Science F oundation under grants DMS-1106980, IIS-1017967, and CAREER aw ard IIS-1149662, by the National Institute of Health under gran ts R01 GM-096193 and P30-CA016672, and b y the Arm y Researc h Office Multidisciplinary Universit y Researc h Initiativ e under gran t 58153-MA-MUR all to Harv ard Universit y . F abrizio Leisen’s research is supp orted b y the European Comm unit y’s Sev enth F ramework Programme FP7/2007-2013 under gran t agreemen t n umber 630677. The authors w ould lik e to thank the Associate Editor and tw o anon ymous referees for suggestions that substan tially impro ved the pap er. References Airoldi E. M., Anderson, A., Fienberg, S.E., Skinner, K.K. (2006) Who wrote Ronald Reagan’s radio addresses? Bayesian Analysis , 1, 289–320. 31 Aoki M. (2008) Thermo dynamic limits of macro economic or financial models: One- and t wo-parameter P oisson-Dirichlet mo dels, Journal of Ec onomic Dynamics and Contr ol , Elsevier, vol. 32(1), pages 66–84. Baladanda yuthapani V., Ji Y. Nieto-Bara jas, L.E. and Morris, J.S. (2010) Bay esian random segmentation mo dels to identify shared copy n umber ab errations for array CGH data. Journal of the Americ an Statistic al Asso ciation , 105, 1358–1375. Bassetti F., Crimaldi I. and Leisen F. (2010) Conditionally identically distributed sp ecies sampling sequences. A dv. in Appl. Pr ob ab. 42, 433-459. Berti P ., Pratelli L. and Rigo P . (2004) Limit Theorems for a Class of Identically Distributed Random V ariables. Ann. Pr ob ab. 32 2029–2052. Blac kw ell D. and MacQueen J.B. (1973) F erguson distributions via P´ oly a urn sc hemes. A nn. Statist. 1 , 353–355. Blei D. and F razier P . (2011) Distance dependent Chinese restauran t processes. Journal of Machine L e arning R ese ach , 12:2461–2488. Blei D.M., Moreno P . (2001) T opic segmen tation with an asp ect Hidden Marko v Mo del, Pr o c e e dings of the 24th annual international ACM SIGIR c onfer enc e , 343–348. Cardin N., Holmes, C., The W ellcome T rust Case Con trol Consortium, Donnelly P . and Marc hini J. (2011) Ba y esian Hierarchical Mixture Modeling to Assign Copy Num b er from a T argeted CNV Arra y . Genetic Epidemiolo gy , 35, 536–548. Charalam bides C. A. (2005) Combinatorial metho ds in discrete distributions. Wiley Se- ries in Probability and Statistics. Wiley-Interscience, John Wiley & Sons, Hob ok en, NJ. Chin K., DeV ries S., F ridly and J., Sp ellman P . T., Roydasgupta R., Kuo W. L., Lapuk A., Neve R. M., Qian Z., Ryder T., Chen F., F eiler H., T okuy asu T., Kingsley C., 32 Dairk ee S., Meng Z., Chew K.,Pink el D., Jain A., Ljung B. M., Esserman L., Al- b ertson D. G., W aldman F. M., and Gray J. W. (2006) Genomic and transcriptional ab errations link ed to breast cancer pathoph ysiologies. Canc er Cel l , 10(6):529–541. Chien J.T., F urui S. (2005) Predictiv e hidden Mark ov model selection for speech recog- nition, IEEE T r ansactions on Sp e e ch and Audio Pr o c essing , 13 , 377–387. Colella S., Y au C., T a ylor J.M., Mirza G., Butler H., Clouston P ., Basset A.S., Seller A., Holmes C.C. and Ragoussis J. (2007) Quan tiSNP: an Ob ject Ba yes Hidden-Mark ov Mo del to detect and accurately map copy num b er v ariation using SNP genotyping data Nucleic A cids R ese ar ch 35 , 2013–2025. Curtis C., Shah S.P ., Chin S.-F., T urashvili G., Rueda O.M., Dunning M.J., Sp eed D., Lync h A.G., Samara jiw a S., Y uan Y., Gr¨ af S., Ha G., Haffari G., Bashashati A., Rus- sell R., McKinney S., MET ABRIC Group, Langer ˆ A¿d A., Green A., Prov enzano E., Wishart G., Pinder S., W atson P ., Mark ow etz F., Murphy L., Ellis I., Purushotham A., B ˆ A¿rresen-Dale A.-L., Brenton J.D., T av ar’e S., Caldas C., Aparicio S. (2012) The genomic and transcriptomic architecture of 2,000 breast tumours re-v eals nov el subgroups, Natur e , 486 , 7403, 346–352. Dahl D. B. (2005) Sequen tially-Allo cated Merge-Split Sampler for Conjugate and Non- conjugate Diric hlet Pro cess Mixture Mo dels, T e chnic al R ep ort. Dahl D. B., Da y R. and Tsai J. W. (2008) Distance-Based Probabilit y Distribution on Set P artitions with Applications to Protein Structure Prediction, T e chnic al R ep ort . DeSan tis S. M., Houseman E. A., Coull B.A., Louis D.N., Mohapatra G., Betensky , R.A. (2009) A Latent Class Mo del with Hidden Marko v Dep endence for Arra y CGH Data, Biometrics , 65 , 4, 1296–1305. Dew ar M., Wiggins C., W o o d F. Inference in Hidden Mark o v Mo dels with Explicit State Duration Distributions, Signal Pr o c essing L etters, IEEE , 19, 4, 235–238. 33 Du L., Chen M., Lucas, J. and Carin, L. (2010) Stic ky Hidden Marko v Mo deling of Comparativ e Genomic Hybridization, IEEE T r ansactions on Signal Pr o c essing , 58 , 10, 5353–5368. Escobar M. and W est M. (1995) Ba y esian Density Estimation and Inference Using Mixtures, Journal of the Americ an Statistic al Asso ciation , 90 , 577-588. F erguson J. D. (1980), V ariable duration mo dels for sp eech, Pr o c e e dings of the Symp o- sium on the Applic ations of Hidden Markov Mo dels to T ext and Sp e e ch , 143–179. F ortini S., Ladelli L. and Re gazzini E. (2000) Exchangeabilit y , predictive distributions and parametric mo dels. Sankhya Ser. A, 62 , no. 1, 86–109. F o x E.B., Sudderth E.B., Jordan M.I. and Willsky A.S. (2011) A stic ky HDP-HMM with application to sp eaker diarization, A nnals of Applie d Statistics , 5 , 2A, 1020– 1056. F o x E.B., Hughes M.C., Sudderth E.B., Jordan M.I. (2014) Join t mo deling of multiple time series via the Beta pro cess with application to motion capture segmentation, A nnals of Applie d Statistics . T o app ear. Griffiths T.L., Sanborn A.N., Canini K.R., and Na v arro D.J. (2007) Categorization as nonparametric Bay esian densit y estimation, M. Oaksford and N. Chater (Eds.), The Pr ob abilistic Mind: Pr osp e cts for R ational Mo dels of Co gnition , Oxford: Oxford Univ ersit y Press. Guedon Y. (2011) Estimating hidden semi-Marko v c hains from discrete sequences, Journal of Computational and Gr aphic al Statistics , 12 , 3, 604–639. Guha S., Li Y. and Neub erg D. (2008). Ba y esian Hidden Mark o v Mo deling of Array CGH Data. Journal of the Americ an Statistic al Asso ciation , 103, 485–497. Guha S. (2010) P osterior Simulation in Countable Mixture Mo dels for Large Datasets. Journal of the Americ an Statistic al Asso ciation , 105 , 490, 775–786. 34 Hansen B. and Pitman J. (2000) Prediction rules for exchangeable sequences related to species sampling. Statist. Pr ob ab. L ett. 46 251–256. Heller R., Stanley D., Y ekutieli D., Rubin N., and Benjamini Y. (2006). Cluster-based analysis of fmri data. Neur oimage , 33, 599–608. Hjort N.L., Holmes C., M ¨ uller P . and W alker S.G. (2010) Bayesian Nonp ar ametrics , Cam bridge Univ ersity Press. Hilb e J.M. (2011) Ne gative Binomial R e gr ession , Cambridge Universit y Press. Ish w aran H. and Zarep our M. (2003) Random probability measures via P´ oly a sequences: revisiting the Blackw ell-MacQueen urn scheme. Jain S. and Neal R.M. (2007) Splitting and Merging Comp onents of a Nonconjugate Diric hlet Process Mixture Model, Bayesian Analysis , 3, 445–472. Jara A. (2007) Applied Bay esian Non- and Semi-parametric Inference using DPpac k age, Rnews, 7 , 3, 17–26. Jbab di S., W o olric h M.W. and Behrens T.E.J. (2009) Multiple-sub jects connectivity- based parcellation using hierarchical Dirichlet pro cess mixture mo dels, Neur oImage , 44 , 2, 373–384. Ji Y., Lu Y and Mills G. (2008) Bay esian mo dels based on test statistics for multiple h yp othesis testing problems. Bioinformatics , 24 (7), 943-939. Kim S., T adesse M.G. and V annucci M. (2006) V ariable selection in clustering via Diric hlet process mixture models. Biometrika , 93 (4), 877–893. Kingman J. F. C. (1978) The represen tation of partition structures. J. L ondon Math. So c. (2), 18(2), 374-380. 35 Lee J., Quin tana F., M ¨ uller P . and T rippa L. (2013) Defining Predictiv e Probabilit y F unctions for Sp ecies Sampling Models. Statist.Sci. , 28 , 2, 209–222. Liu Z., Windle J. and Scott J.C. (2012) The partition problem: case studies in Ba y esian screening for time-v arying model structure. T echnical report. Curren tly a v ailable at MacEac hern S. N. and M ¨ uller P . (1998) Estimating Mixture of Dirichlet Pro cess Mo d- els, Journal of Computational and Gr aphic al Statistics , 7, 223–238. Marioni J.C., Thorne N.P ., T a v are S., Radv an yi F. (2006) BioHMM: A heterogeneous hidden Marko v mo del for segmenting array CGH data. Bioinformatics ,22, 1144– 1146. Mitc hell C., Harp er M., Jamieson L. , On the complexity of explicit duration HMMs, IEEE T r ansactions on Sp e e ch and Audio Pr o c essing , 3, 2, 213–217. Mon teiro, J.V., Assun¸ cao and Losc hi, R.H. (2011) Product partition mo dels with cor- related parameter, Bayesian Analyis , 6 , 4, 691–726. M ¨ uller P ., Parmigiani G. and Rice K. (2007) FDR and Bay esian multiple comparisons rules. In Bayesian Statistics 8 (eds. J. Bernardo, M. Bay arri, J. Berger, A. Dawid, Hec k erman, A. D., Smith and M. W est). Oxford, UK: Oxford Univ ersit y Press. M ¨ uller P . and Quin tana F. (2010) Random partition mo dels with regression on cov ari- ates, Journal of Statistic al Planning and Infer enc e , 140 , 10, 2801–2808. Na v arro D.J., Griffiths T.L., Steyvers M. and Lee M.D. (2006) Mo deling individual differences using Diric hlet pro cesses. Journal of Mathematic al Psycholo gy . In Sp ecial Issue on Mo del Selection: Theoretical Developmen ts and Applications, V ol. 50, No. 2., pp. 101–122. Neal R.M. (2000) Marko v Chain Sampling Methods for Dirichlet Pro cess Mixture Mo d- els Journal of Computational and Gr aphic al Statistics , 9, 249–265. 36 Newton M. A., Noueiry A., Sark ar D. and Ahlquist P . (2004) Detecting differen tial gene expression with a semiparametric hierarc hical mixture metho d. Biostatistics , 5 , 2, 155—176. P ark J.H. and Dunson D.B. (2010) Ba y esian generalized pro duct partition mo del. Sta- tistic a Sinic a , 20 , 1203–1226 Pitman J. (1996) Some developmen ts of the Blac kwell-MacQueen urn sc heme. In T.S. F er-guson et al., editor, Statistics, Pr ob ability and Game The ory; Pap ers in honor of David Blackwel l , v olume 30 of Lecture Notes-Monograph Series, pages 245-267. Institute of Mathematical Statistics, Ha yward, California. Pitman J. (2006) Combinatorial Sto chastic Pr o c esses. Ecole d’Et ´ e Probabilit´ es de Sain t-Flour XXXI I 2002, Lecture Notes in Mathematics, Springer:Berlin / Heidel- b erg. Rabiner L. R. (1989) A T utorial on Hidden Marko v Mo dels and Selected Applications in Speech Recognition, Pr o c e e dings of the IEEE , 77, 2, 257–287. Redon R., Fitzgeral T. and Carter, N.P . (2009) Comparative Genomic Hybridization: DNA labeling, h ybridization and detection. Metho ds Mol Biol. 529: 267–278. Ren L., Dunson D., Lindroth S., Carin L. (2010) Dynamic nonparametric Ba y esian mo dels for analysis of music, Journal of the Americ an Statistic al Asso ciation , 105 , 490, 458–472. Ro driguez A., Dunson D.B. (2011) Nonparametric Bay esian mo dels through probit stic k-breaking processes. Bayesian Analysis , 6 , 1, 145–178. Storey J. (2003) The p ositive false disco v ery rate: a Bay esian Interpretation and the q-v alue The Annals of Statistics , 31 , 6, 2013–2035. 37 Storey J., Dai J. and Leek J. (2007) The optimal discov ery pro cedure for large-scale significance testing, with applications to comparativ e microarra y exp erimen ts. Bio- statistics , 8 , 414–432. Sudderth E. B. and Jordan M. I. (2009) Shared segmen tation of natural scenes using dep enden t Pitman-Yor pro cesses. In Neur al Information Pr o c essing Systems 22. Sun W., Reic h B., Cai T., Guindani M., Sc h w artzman A. (2014) F alse Disco very Con- trol in Large Scale Spatial Multiple T esting. Journal of the R oyal Statistic al So ciety (Series B). T o app ear. T aramasco O. and Bauer S. (2012) RHmm: Hidden Marko v Mo dels simulations and estimations. T eh Y. W., Jordan M. I., Beal M. J. and Blei D. M. (2006a) Hierarc hical Diric hlet pro cesses., J. A mer. Statist. Asso c. , 101 , no. 476, 1566–1581. T eh Y. W. (2006b) A Hierarchical Bay esian Language mo del based on Pitman-Yor pro cesses. In A CL-44: Pr o c e e dings of the 21st International Confer enc e on Compu- tational Linguis- tics and the 44th annual me eting of the Asso ciation for Computa- tional Linguistics , pages 985-992, Morristown, NJ, USA. Asso ciation for Computa- tional Linguistics. T eh Y.W. and Jordan M.I., (2009) Hierarchical Ba y esian nonparametric mo dels with applications. In N. Hjort, C. Holmes, P . Mueller and S. W alker (Eds.), Bayesian Nonp ar ametrics: Principles and Pr actic e , Cambridge, UK: Cam bridge Universit y Press, to app ear. W allac h H., Sutton, C. and McCallum, A. (2008) Ba y esian Mo deling of De- p endency Trees Using Hierarchical Pitman-Yor Priors. In Pr o c e e dings of the Workshop on Prior Know le dge for T ext and language (held in c onjunction with ICML/UAI/COL T) , pp. 15–20. Helsinki, Finland, 2008. 38 Y au C., Papaspiliopoulos 0., Rob erts G. O., and Holmes, C. (2011) Bay esian Non- parametric Hidden Mark ov Mo dels with application to the analysis of cop y-n um b er- v ariation in mammalian genomes, J. R. Stat. So c. Series B , 73(1): 37–57. Y au C., Holes C.C. (2013) A decision-theoretic approac h for segmen tal classification, A nnals of Applie d Statistics , 7 , 3, 1814–1835. Y u S-Z. (2010), Hidden semi-Mark ov mo dels. A rtificial Intel ligenc e , 174(2): 215–243. A. APPENDIX: DET AILS OF POSTERIOR MCMC SAMPLING FOR THE BET A-GOS MODEL Here, w e pro vide the details of the MCMC sampling algorithm described in Section 4.2 for the sp ecial case of a Normal sampling distribution and a Normal (or Normal-In v erse-Gamma) base measure. A.1 F ull conditionals for the Gibbs sampler A t eac h iteration of Gibbs sampler we sample from the full conditionals of C n and W n , for n = 1 , . . . , N . He re we derive the analytical form of these distributions, for the Beta-GOS mo del sp ecified in Section 5. Recall that the full conditional distribution for C n is P { C n = i | C − n , W ( N ) , Y ( N ) , τ 2 } ∝ P { Y ( N ) | C n = i, C − n , W ( N ) , τ 2 } · P { C n = i | C − n , W ( N ) } , 39 where the factor on the right is giv en b y (8) and (3), and the left factor is obtained b y in tegration, P { Y ( N ) | C n = i, C − n , W ( N ) , τ 2 } = P { Y ( N ) | C n = i, C − n , τ 2 } = Z P { Y ( N ) , µ | C n = i, C − n , τ 2 } dµ = J Y j =1 Z Y l ∈ Π j p ( Y l | µ ∗ j ) G 0 ( dµ ∗ j ) ∝ J Y j =1 1 √ 2 π 1 ( τ ) | Π j | exp n − P l ∈ Π j y 2 l 2 τ 2 − µ 2 0 2 σ 2 0 + 1 2 ( µ 0 σ 2 0 + P l ∈ Π j y l τ 2 ) 2 1 σ 2 0 + | Π j | τ 2 o 1 q | Π j | σ 2 0 τ 2 + 1 , where Π j is the set of indices of data p oin ts in cluster j , and J is the n umber of clusters at that iteration. Note that the latent reinforcements W ( N ) are used to define the cluster assignmen ts through the data-pairing lab els C ( N ). Conditionally on the data-pairing lab els C ( N ), the data Y ( N ) is indep endent of the latent reinforcemen ts W ( N ). The full conditional for W n , denoted by P ( W n | C ( N ) , W − n , Y ( N )), is Beta distributed with up dated parameters A n , B n , defined as in (8). A.2 Inference on the cluster centroids of the Beta-GOS pro cess. F or the purp ose of computational efficiency , it is generally preferable to sample the random partitions integrating out with resp ect to the parameters of the Beta-GOS pro cess, as described in Section 4.2 and in App endix A.1. If the sampling distribution and the base measure are conjugate, this usually results in improv ed mixing of the c hain. How ever, in man y cases, it may b e required to draw inferences on the cluster cen troids themselv es. As usual with mixtures of DP , inference on the cluster cen troids can b e easily conducted (even ex-p ost) from the clustering configurations at eac h iteration. Therefore, w e do not hav e to sample the cen troids within eac h Gibbs iteration, but if the need b e, we can easily resample them at the end of eac h iteration, or at the end of the sampler from the stored output. 40 A.3 Inference on the cluster and global v ariances Let the v ariance of the sampling distribution b e τ 2 . W e assume τ 2 ∼ I Gamma ( a 0 , b 0 ). The p osterior distribution of the v ariance in eac h cluster j , is giv en b y τ 2 j | µ ∗ j , Y i , i ∈ Π j ∼ I Gamma a 0 + | Π j | 2 , b 0 + 1 2 X i ∈ Π j ( Y i − µ ∗ j ) 2 ) , Note that, in case of need and for computational efficiency , w e could use these also quan tities to obtain a global estimate for the sampling v ariance at eac h iteration, in an MCMC-EM step, as ˆ τ 2 = P J j =1 ( | Π j |− 1) τ 2 j N − J . This may turn useful, for example, for parallelization purposes, as in the sim ulations of Section 5. A.4 Inference on the cluster means In the normal-normal mo del described in Section 5, the posterior distribution of µ ∗ j giv en data Y i in the j -th cluster can b e ev aluated at each iteration as P ( µ ∗ j | τ 2 j , Y i , i ∈ Π j ) ∼ N µ 0 σ 2 0 + | Π j | Y j τ 2 j 1 σ 2 0 + | Π j | τ 2 j , 1 σ 2 0 + | Π j | τ 2 j ! − 1 . for j = 1 , . . . , J , where ¯ Y j is the j -th cluster specific mean. Note that w e ha v e assumed a common sampling v ariance τ 2 ; the mo dification of the previous form ula to tak e in to accoun t a cluster sp ecific v ariance is of course straigh tforward. B. APPENDIX: DET AILS OF THE PROOFS AND ADDITIONAL THEORETICAL RESUL TS B.1 Generalized Ottaw a Sequence and its moments According to Bassetti et al. (2010) a sequence ( X n ) n ≥ 1 of random v ariables taking v alues in a P olish space is a Generalized Otta wa Sequence if there exists a sequence ( W n ) n ≥ 1 (of random v ariables) such that the following conditions are satisfied: (i) the 41 law of X 1 is G 0 ; (ii) for n ≥ 1 , X n +1 and the subse quenc e ( W n + j ) j ≥ 1 ar e c onditional ly indep endent given the filtr ation F n := σ ( X 1 , . . . , X n , W 1 , . . . , W n ) ; (iii) the pr e dictive distribution of X n +1 given F n is given by (3) wher e the r n ’s ar e strictly p ositive functions, r n ( W 1 , . . . , W n ) , of the ve ctor of latent variables, such that r n ( W 1 , . . . , W n ) ≥ r n +1 ( W 1 , . . . , W n , W n +1 ) , (A.1) almost sur ely, with r 0 = 1 , and the weights p n,i = p n,i ( W 1 , . . . , W n ) ar e p n,i = r n ( r i − 1 − r i ) r i − 1 r i i = 1 , . . . , n. (A.2) The predictiv e distribution (3)-(4) corresp onds to choice r n ( W 1 , . . . , W n ) = Q n i =1 W i where ( W n ) n ≥ 1 is a sequence of independent random v ariables. W e conclude this Section b y pro viding a general result for the k -th moment and for the momen t generating function of the length K n of a GOS. Supp ose that the sequence ( X n ) n ≥ 1 is a GOS, with G 0 diffuse, and let U j = K j − K j − 1 with K 0 = 0. Then, K n = P n j =1 U j and the joint distribution of U 1 , . . . , U n conditionally on r 1 , . . . , r n − 1 , is P { U 1 = 1 , . . . , U n = e n | r 1 , . . . , r n − 1 } = n Y i =2 r e i i − 1 (1 − r i − 1 ) 1 − e i , for ev ery v ector ( e 2 , . . . , e n ) in { 0 , 1 } n − 1 , since P ( U 1 = 1) = 1 b y definition. Since K 1 = U 1 = 1, it follows that, for every k ≥ 1, P { K n +1 = k + 1 } = P n n +1 X j =2 U j = k o = X e E h n Y i =1 r e i i − 1 (1 − r i − 1 ) 1 − e i i where the summation is extended ov er all sequences e = ( e 1 , . . . , e n ) in { 0 , 1 } n suc h 42 that P n i =1 e i = k . Moreov er, for ev ery k ≥ 1 and n ≥ 2, it is easy to see that E [( K n +1 − 1) k ] = E h n +1 X j =2 U j k i = k ∧ n X m =1 m ! S ( k , m ) φ n,m (A.3) where k ∧ n = min( k , n ), φ n,m := X 1 ≤ l 1 0: P m i =1 n i = k } 1 n 1 ! ...n m ! is the Stirling n umber of second kind. Hence, E [( K n +1 − 1) k ] depends recursiv ely on functions φ n − 1 ,m , m = 1 , . . . , k . It ma y b e in teresting to note that, using the well known relation betw een factorial momen ts and ordinary moments (see, e.g., Example 2.3 in Charalambides, 2005), from (A.3) one gets, for an y m ≤ n , E [( K n +1 − 1) ( m ) ] = m ! φ n,m (A.5) where ( t ) ( m ) = t ( t − 1) . . . ( t − m + 1) is the falling factorial. Moreov er, since X k ≥ m ( − t ) k S ( k , m ) k ! = ( e − t − 1) m m ! , see e.g. Thm. 2.3 in Charalam bides (2005), it follows that the moment generating 43 function of K n +1 is giv en b y M n +1 ( t ) := E [ e − tK n +1 ] = e − t E [ e − t ( K n +1 − 1) ] = e − t X k ≥ 0 ( − t ) k k ! E [( K n +1 − 1) k ] = e − t + e − t X k ≥ 1 k ∧ n X m =1 ( − t ) k m ! k ! S ( k , m ) φ n,m = e − t + e − t n X m =1 m ! φ n,m X k ≥ m ( − t ) k k ! S ( k , m ) = e − t n X m =0 ( e − t − 1) m φ n,m (A.6) with φ n, 0 := 1. B.2 Pro of of Prop osition 1 If w e consider equation (A.4) with ( W i ) i ≥ 1 indep enden t random v ariables taking v alues in [0 , 1], then φ n,m = X 1 ≤ l 1 0 , then φ n,m = Γ( θ + m ) Γ( θ ) n X j 1 = m j 1 X j 2 = m j 2 X j 3 = m · · · j m − 1 X j m = m 1 ( j 1 + θ )( j 2 + θ ) · · · ( j m + θ ) . (A.8) In p articular, as n go es to + ∞ , E [ K k n ] = Γ( θ + k ) Γ( θ ) log k ( n )[1 + o (1)] . (A.9) Let us start by pro ving (A.8). First, note that since W i is a Beta( i + θ − 1 , 1) random 44 v ariable then, for 1 ≤ j ≤ m , E [ W m +1 − j i ] = i + θ − 1 i + θ + m − j . Hence, by (A.7), φ n,m = X 1 ≤ l 1 0, k ≥ 1, m ≥ 2 and n ≥ k , set Ψ k,θ ( n, m ) := n X j 1 = k j 1 X j 2 = k j 2 X j 3 = k · · · j m − 1 X j m = k m ! ( j 1 + θ )( j 2 + θ ) · · · ( j m + θ ) , Ψ k,θ ( n, 1) := n X j 1 = k 1 ( j 1 + θ ) . Note that m ! φ n,m = Ψ m,θ ( n, m )Γ( θ + m ) / Γ( θ ). F or all k ≥ 1, m ≥ 1 and n ≥ k , set Q k,θ ( m, n ) := Ψ k,θ ( n, m ) − log m ( n + θ ) . Now formula (A.9) in Lemma 2 follo ws easily from (A.3) and the next result. Lemma 3. F or θ > 0 , k ≥ 1 and m ≥ 1 , ther e is a c onstant C k,θ ( m ) such that | Q k,θ ( m, n ) | ≤ C k,θ ( m ) log m − 1 ( n + θ ) for every n ≥ k . (A.11) Let k ≥ 1 and θ > 0. F or m ≥ 1 and n ≥ k set S k,θ ( m, n ) := n X j = k m log m − 1 ( j + θ ) j + θ , and R k,θ ( m, n ) := S k,θ ( m, n ) − log m ( n + θ ) = n X j = k m log m − 1 ( j + θ ) j + θ − log m ( n + θ ) . (A.12) W e claim that, for an y m ≥ 1, there is a constan t C ∗ m = C ∗ m,θ,k suc h that | R k,θ ( m, n ) | ≤ C ∗ m , for all n ≥ k . (A.13) 45 No w observ e that Ψ k,θ ( n, 1) = S k,θ (1 , n ) . Hence, (A.13) pro ves (A.11) for m = 1 and ev ery k ≥ 1 and θ > 0. By induction supp ose that (A.11) is true for m = 1 , . . . , M − 1. Note that, for m ≥ 2, Ψ k,θ ( n, m ) = n X j 1 = k m j 1 + θ Ψ k,θ ( j 1 , m − 1) , hence, b y induction hypothesis, for ev ery θ > 0, k ≥ 1 and n ≥ k , Ψ k,θ ( n, M ) = n X j 1 = k M j 1 + θ h log M − 1 ( j 1 + θ ) + Q k,θ ( M − 1 , j 1 ) i . Using (A.12) one gets Ψ k,θ ( n, M ) = log M ( n + θ ) + R k,θ ( M , n ) + n X j 1 = k M j 1 + θ Q k,θ ( M − 1 , j 1 ) . Hence, using (A.13) and the induction hypothesis, one can write | Q k,θ ( M , n ) | ≤ | R k,θ ( M , n ) | + n X j 1 = k M j 1 + θ | Q k,θ ( M − 1 , j 1 ) | ≤ C ∗ M ,θ ,k + M C k,θ ( M − 1) M − 1 n X j 1 = k M − 1 j 1 + θ log M − 2 ( j 1 + θ ) ≤ C ∗ M ,θ ,k + M C k,θ ( M − 1) M − 1 [log M − 1 ( n + θ ) + | R k,θ ( M − 1 , n ) | ] ≤ C ∗ M ,θ ,k + M C k,θ ( M − 1) M − 1 [log M − 1 ( n + θ ) + C ∗ M − 1 ,θ,k ] whic h pro ves (A.11) for m = M . T o complete the pro of let us prov e (A.13). Observ e that x 7→ log m − 1 ( x + θ ) x + θ is a non-increasing function on [ x 0 , + ∞ ) for a suitable x 0 = x 0 ( k , θ , m ). Assume, without real loss of generality , that k ≥ x 0 + 1. Note that, in this case, Z n +1 k m log m − 1 ( x + θ ) x + θ dx ≤ S k,θ ( m, n ) ≤ Z n k − 1 m log m − 1 ( x + θ ) x + θ dx. 46 Hence, log m ( n + 1 + θ ) − log m ( k + θ ) ≤ S k,θ ( m, n ) ≤ log m ( n + θ ) − log m ( k − 1 + θ ) , whic h giv es log m ( n + θ ) − log m ( k + θ ) ≤ S k,θ ( m, n ) ≤ log m ( n + θ ) , and then | S k,θ ( m, n ) − log m ( n + θ ) | ≤ log m ( k + θ ) . Pr o of of Pr op osition 1 (a) . It follo ws immediately from (A.9) and a classical result concerning the conv ergence in distribution when the moments conv erge. Indeed, E K n log n k con v erges to Γ( θ + k ) Γ( θ ) that is the k -th moment of a Γ( θ , 1) random v ariable. Pr o of of Pr op osition 1 (b) . The first part of the statement of Prop osition 1(b) follows from Proposition 2.1 in Bassetti et al. (2010) if one shows that E [ P ∞ i =1 r i ] < ∞ . F or α n = a and β n = b one gets E [ r n ] = a n / ( a + b ) n and the thesis follo ws. When α n = n + θ − 1 and β n = β , as explained in Section 3, E [ r n ] ∼ n − β and the thesis follo ws since β > 1. It remains to prov e the assertion concerning the moment generating function and the factorial moments of K ∞ . If α n = a and β n = b , (A.7) b ecomes φ n,m = X 1 ≤ l 1 0 L ( Y n + j | H n , µ n + j ) = L ( Y n + j | µ n + j ) = p ( · | µ n + j ) (A.15) and for every j and n L ( µ n + j | H n ) = L ( µ n + j | G n ) (A.16) As already recalled, ( µ n ) n is CID with resp ect to G n = σ ( W ( n ) , µ ( n )). This means that for every real, b ounded and measurable function f E ( f ( µ n + j ) |G n ) = E ( f ( µ n +1 ) |G n ) (A.17) for all j ≥ 1, see Berti et al. (2004). Thanks to (A.16), equalit y (A.17) also holds with resp ect the sigma-field H n . Indeed, E ( f ( µ n + j ) |H n ) = E ( f ( µ n + j ) |G n ) = E ( f ( µ n +1 ) |G n ) = E ( f ( µ n +1 ) |H n ) (A.15) implies that E ( g ( Y n + j ) |H n , µ n + j ) = E ( g ( Y n + j ) | µ n + j ) = Z g ( y ) p ( dy | µ n + j ) (A.18) (A.17) and (A.18) allo w to pro ve the thesis. Indeed, E ( g ( Y n + j ) |H n ) = E ( E ( g ( Y n + j ) |H n , µ n + j |H n ) = E ( Z g ( y ) p ( dy | µ n + j ) |H n ) = E ( Z g ( y ) p ( dy | µ n +1 ) |H n ) = E ( E ( g ( Y n +1 ) |H n , µ n +1 |H n ) = E ( g ( Y n +1 ) |H n ) 49
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment