Optimal Reinforcement Learning for Gaussian Systems
The exploration-exploitation trade-off is among the central challenges of reinforcement learning. The optimal Bayesian solution is intractable in general. This paper studies to what extent analytic statements about optimal learning are possible if al…
Authors: Philipp Hennig
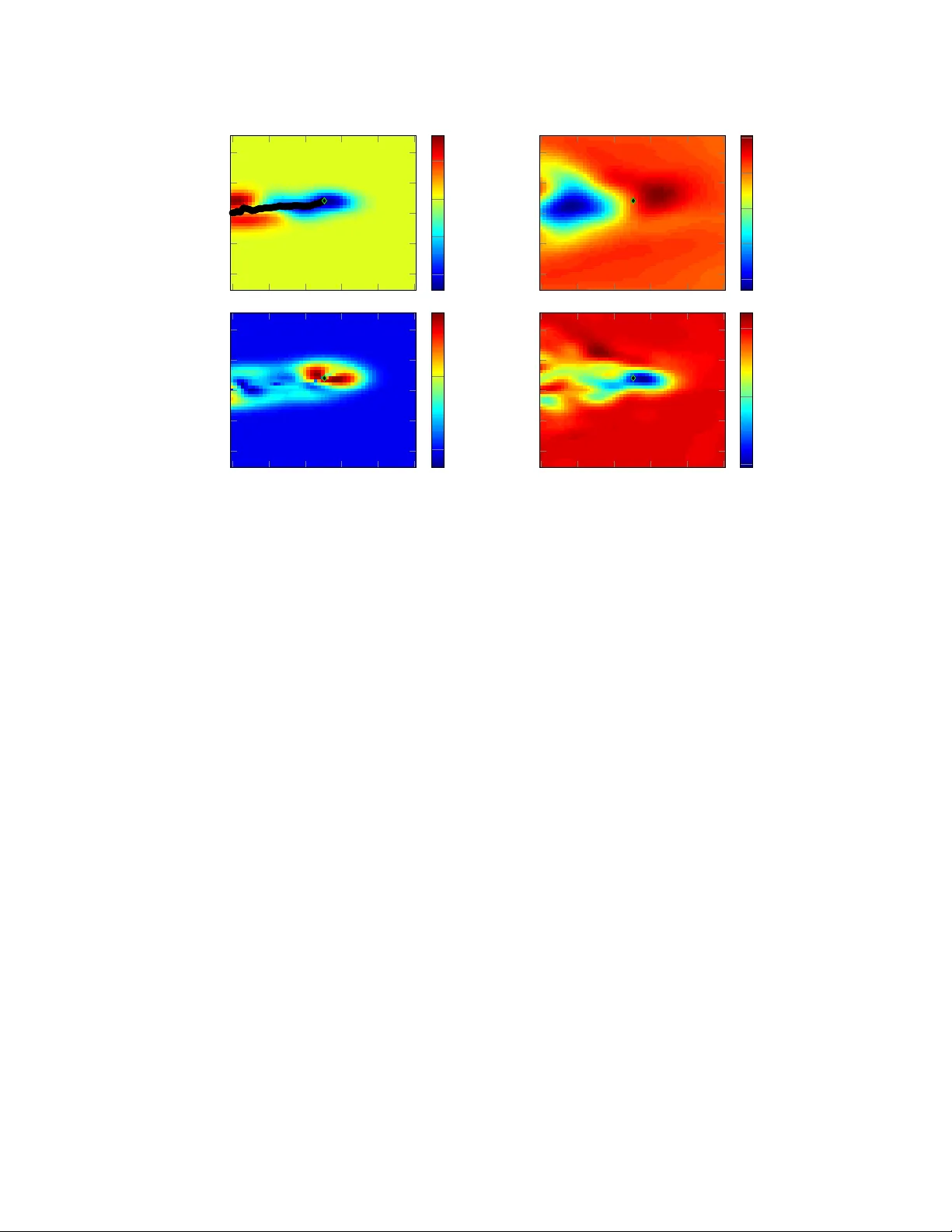
Optimal Reinf or cement Learning f or Gaussian Systems Philipp Hennig Max Planck Institute for Intelligent Systems Department of Empirical Inference Spemannstraße 38, 72070 T ¨ ubingen, Germany phennig@tuebingen.mpg.de Abstract The exploration-e xploitation trade-off is among the central challenges of rein- forcement learning. The optimal Bayesian solution is intractable in general. This paper studies to what e xtent analytic statements about optimal learning are possible if all beliefs are Gaussian processes. A first order approximation of learning of both loss and dynamics, for nonlinear , time-varying systems in continuous time and space, subject to a relativ ely weak restriction on the dynamics, is described by an infinite-dimensional partial differential equation. An approximate finite- dimensional projection giv es an impression for how this result may be helpful. 1 Introduction – Optimal Reinf or cement Learning Reinforcement learning is about doing two things at once: Optimizing a function while learning about it. These two objectiv es must be balanced: Ignorance precludes efficient optimization; time spent hunting after irrelev ant kno wledge incurs unnecessary loss. This dilemma is famously kno wn as the explor ation exploitation tr ade-off . Classic reinforcement learning often considers time cheap; the trade-of f then plays a subordinate role to the desire for learning a “correct” model or policy . Many classic reinforcement learning algorithms thus rely on ad-hoc methods to control exploration, such as “ -greedy” [ 1 ], or “Thompson sampling” [ 2 ]. Howe ver , at least since a thesis by Duff [ 3 ] it has been known that Bayesian inference allo ws optimal balance between exploration and exploitation. It requires integration o ver e very possible future trajectory under the current belief about the system’ s dynamics, all possible new data acquired along those trajectories, and their ef fect on decisions taken along the way . This amounts to optimization and inte gration over a tree, of exponential cost in the size of the state space [ 4 ]. The situation is particularly dire for continuous space-times, where both depth and branching factor of the “tree” are uncountably infinite. Sev eral authors have proposed approximating this lookahead through samples [ 5 , 6 , 7 , 8 ], or ad-hoc estimators that can be shown to be in some sense close to the Bayes-optimal policy [9]. In a parallel de velopment, recent work by T odorov [ 10 ], Kappen [ 11 ] and others introduced an idea to reinforcement learning long commonplace in other areas of machine learning: Structural assumptions, while restricti ve, can greatly simplify inference problems. In particular, a recent paper by Simpkins et al. [ 12 ] sho wed that it is actually possible to solv e the exploration e xploitation trade-off locally , by constructing a linear approximation using a Kalman filter . Simpkins and colleagues further assumed to know the loss function, and the dynamics up to Bro wnian drift. Here, I use their work as inspiration for a study of general optimal reinforcement learning of dynamics and loss functions of an unkno wn, nonlinear , time-varying system (note that most reinforcement learning algorithms are restricted to time-in v ariant systems). The core assumption is that all uncertain variables are known up to Gaussian process uncertainty . The main result is a first-order description of optimal reinforcement learning in form of infinite-dimensional dif ferential statements. This kind of description opens up new approaches to reinforcement learning. As an only initial example of such treatments, Section 4 1 presents an approximate Ansatz that af fords an explicit reinforcement learning algorithm; tested in some simple but instructi ve e xperiments (Section 5). An intuiti ve description of the paper’ s results is this: From prior and corresponding choice of learning machinery (Section 2), we construct statements about the dynamics of the learning pr ocess (Section 3). The learning machine itself provides a probabilistic description of the dynamics of the physical system. Combining both dynamics yields a joint system, which we aim to control optimally . Doing so amounts to simultaneously controlling exploration (controlling the learning system) and exploitation (controlling the physical system). Because large parts of the analysis rely on concepts from optimal control theory , this paper will use notation from that field. Readers more familiar with the reinforcement learning literature may wish to mentally replace coordinates x with states s , controls u with actions a , dynamics with transitions p ( s 0 | s, a ) and utilities q with losses (negati ve re wards) − r . The latter is potentially confusing, so note that optimal control in this paper will attempt to minimize values, rather than to maximize them, as usual in reinforcement learning (these two descriptions are, of course, equi valent). 2 A Class of Learning Pr oblems W e consider the task of optimally controlling an uncertain system whose states s ≡ ( x, t ) ∈ K ≡ R D × R lie in a D + 1 dimensional Euclidean phase space-time: A cost Q (cumulated loss) is acquired at ( x, t ) with rate d Q/ d t = q ( x, t ) , and the first inference problem is to learn this analytic function q . A second, independent learning problem concerns the dynamics of the system. W e assume the dynamics separate into fr ee and contr olled terms affine to the control: d x ( t ) = [ f ( x, t ) + g ( x, t ) u ( x, t )] d t (1) where u ( x, t ) is the control function we seek to optimize, and f , g are analytic functions. T o simplify our analysis, we will assume that either f or g are known, while the other may be uncertain (or, alternativ ely , that it is possible to obtain independent samples from both functions). See Section 3 for a note on how this assumption may be relaxed. W .l.o.g., let f be uncertain and g known. Information about both q ( x, t ) and f ( x, t ) = [ f 1 , . . . , f D ] is acquired stochastically: A Poisson process of constant rate λ produces mutually independent samples y q ( x, t ) = q ( x, t ) + q and y f d ( x, t ) = f d ( x, t ) + f d where q ∼ N (0 , σ 2 q ); f d ∼ N (0 , σ 2 f d ) . (2) The noise levels σ q and σ f are presumed known. Let our initial beliefs about q and f be giv en by Gaussian processes G P k q ( q ; µ q , Σ q ); and independent Gaussian processes Q D d G P k f d ( f d ; µ f d , Σ f d ) , respectiv ely , with k ernels k r , k f 1 , . . . , k f D ov er K , and mean / cov ariance functions µ / Σ . In other words, samples ov er the belief can be drawn using an infinite vector Ω of i.i.d. Gaussian variables, as ˜ f d ([ x, t ]) = µ f d ([ x, t ]) + Z Σ 1 / 2 f d ([ x, t ] , [ x 0 , t 0 ])Ω( x 0 , t 0 ) d x 0 d t = µ f d ([ x, t ]) + (Σ 1 / 2 f d Ω)([ x, t ]) (3) the second equation demonstrates a compact notation for inner products that will be used throughout. It is important to note that f , q are unknown, b ut deterministic. At any point during learning, we can use the same samples Ω to describe uncertainty , while µ, Σ change during the learning process. T o ensure continuous trajectories, we also need to regularize the control. Follo wing control custom, we introduce a quadratic control cost ρ ( u ) = 1 2 u | R − 1 u with control cost scaling matrix R . Its units [ R ] = [ x/t ] / [ Q/x ] relate the cost of changing location to the utility g ained by doing so. The ov erall task is to find the optimal discounted horizon value v ( x, t ) = min u Z ∞ t e − ( τ − t ) /γ q [ χ [ τ , u ( χ, τ )] , τ ] + 1 2 u ( χ, τ ) | R − 1 u ( χ, τ ) d τ (4) where χ ( τ , u ) is the trajectory generated by the dynamics defined in Equation (1) , using the control law (polic y) u ( x, t ) . The exponential definition of the discount γ > 0 gi ves the unit of time to γ . Before beginning the analysis, consider the relativ e generality of this definition: W e allow for a continuous phase space. Both loss and dynamics may be uncertain, of rather general nonlinear form, and may change over time. The specific choice of a Poisson process for the generation of samples is 2 somewhat ad-hoc, but some measure is required to quantify the flow of information through time. The Poisson process is in some sense the simplest such measure, assigning uniform probability density . An alternati ve is to assume that datapoints are acquired at regular interv als of width λ . This results in a quite similar model but, since the system’ s dynamics still proceed in continuous time, can complicate notation. A downside is that we had to restrict the form of the dynamics. Howe ver , Eq. (1) still cov ers numerous physical systems studied in control, for example many mechanical systems, from classics like cart-and-pole to realistic models for helicopters [13]. 3 Optimal Control f or the Lear ning Process The optimal solution to the exploration exploitation trade-of f is formed by the dual contr ol [ 14 ] of a joint representation of the physical system and the beliefs over it. In reinforcement learning, this idea is known as a belief-augmented POMDP [ 3 , 4 ], but is not usually construed as a control problem. This section constructs the Hamilton-Jacobi-Bellman (HJB) equation of the joint control problem for the system described in Sec. 2, and analytically solves the equation for the optimal control. This necessitates a description of the learning algorithm’ s dynamics: At time t = τ , let the system be at phase space-time s τ = ( x ( τ ) , τ ) and hav e the Gaussian process belief G P ( q ; µ τ ( s ) , Σ τ ( s, s 0 )) ov er the function q (all deriv ations in this section will focus on q , and we will drop the sub-script q from many quantities for readability . The forms for f , or g , are entirely analogous, with independent Gaussian processes for each dimension d = 1 , . . . , D ). This belief stems from a finite number N of samples y 0 = [ y 1 , . . . , y N ] | ∈ R N collected at space-times S 0 = [( x 1 , t 1 ) , . . . , ( x N , t N )] | ≡ [ s 1 , . . . , s N ] | ∈ K N (note that t 1 to t N need not be equally spaced, ordered, or < τ ). For arbitrary points s ∗ = ( x ∗ , t ∗ ) ∈ K , the belief over q ( s ∗ ) is a Gaussian with mean function µ τ , and co-variance function Σ τ [15] µ τ ( s ∗ i ) = k ( s ∗ i , S 0 )[ K ( S 0 , S 0 ) + σ 2 q I ] − 1 y 0 Σ τ ( s ∗ i , s ∗ j ) = k ( s ∗ i , s ∗ j ) − k ( s ∗ i , S 0 )[ K ( S 0 , S 0 ) + σ 2 q I ] − 1 k ( S 0 , s ∗ j ) (5) where K ( S 0 , S 0 ) is the Gram matrix with elements K ab = k ( s a , s b ) . W e will abbreviate K 0 ≡ [ K ( S 0 , S 0 ) + σ 2 y I ] from here on. The co-vector k ( s ∗ , S 0 ) has elements k i = k ( s ∗ , s i ) and will be shortened to k 0 . How does this belief chang e as time moves from τ to τ + d t ? If d t _ 0 , the chance of acquiring a datapoint y τ in this time is λ d t . Marginalising o ver this Poisson stochasticity , we expect one sample with probability λ d t , two samples with ( λ d t ) 2 and so on. So the mean after d t is expected to be µ τ + d t = λ d t ( k 0 , k τ ) K 0 ξ τ ξ | τ κ τ − 1 y 0 y τ + (1 − λ d t − O ( λ d t ) 2 ) · k 0 K − 1 0 y 0 + O ( λ d t ) 2 (6) where we hav e defined the map k τ = k ( s ∗ , s τ ) , the vector ξ τ with elements ξ τ ,i = k ( s i , s τ ) , and the scalar κ τ = k ( s τ , s τ ) + σ 2 q . Algebraic re-formulation yields µ τ + d t = k 0 K − 1 0 y 0 + λ ( k t − k 0 | K − 1 0 ξ t )( κ t − ξ | t K − 1 0 ξ t ) − 1 ( y t − ξ | t K − 1 0 y 0 ) d t. (7) Note that ξ | τ K − 1 0 y 0 = µ ( s τ ) , the mean prediction at s τ and ( κ τ − ξ | τ K − 1 0 ξ τ ) = σ 2 q + Σ( s τ , s τ ) , the marginal v ariance there. Hence, we can define scalars ¯ Σ , ¯ σ and write ( y τ − ξ | τ K − 1 0 y 0 ) ( κ τ − ξ | τ K − 1 0 ξ τ ) 1 / 2 = [Σ 1 / 2 Ω]( s τ ) + σ ω [Σ( s τ , s τ ) + σ 2 ] 1 / 2 ≡ ¯ Σ 1 / 2 τ Ω + ¯ σ τ ω with ω ∼ N (0 , 1) . (8) So the change to the mean consists of a deterministic but uncertain change whose effects accumulate linearly in time, and a stochastic change, caused by the independent noise process, whose variance accumulates linearly in time (in truth, these tw o points are considerably subtler , a detailed proof is left out for lack of space). W e use the W iener [16] measure d ω to write d µ s τ ( s ∗ ) = λ k τ − k 0 | K − 1 0 ξ τ ( κ τ − ξ | τ K − 1 0 ξ τ ) − 1 / 2 [Σ 1 / 2 Ω]( s τ ) + σ ω [Σ( s τ , s τ ) + σ 2 ] 1 / 2 d t ≡ λL s τ ( s ∗ )[ ¯ Σ 1 / 2 τ Ω d t + ¯ σ τ d ω ] (9) where we hav e implicitly defined the innovation function L . Note that L is a function of both s ∗ and s τ . A similar argument finds the change of the co variance function to be the deterministic rate dΣ s τ ( s ∗ i , s ∗ j ) = − λL s τ ( s ∗ i ) L | s τ ( s ∗ j ) d t. (10) 3 So the dynamics of learning consist of a deterministic change to the co variance, and both deterministic and stochastic changes to the mean, both of which are samples a Gaussian processes with cov ariance function proportional to LL | . This separation is a fundamental characteristic of GPs (it is the nonparametric version of a more straightforw ard notion for finite-dimensional Gaussian beliefs, for data with known noise magnitude). W e introduce the belief-augmented space H containing states z ( τ ) ≡ [ x ( τ ) , τ , µ τ q ( s ) , µ τ f 1 , . . . , µ τ f D , Σ τ q ( s, s 0 ) , Σ τ f 1 , . . . , Σ τ f D ] . Since the means and cov ariances are functions, H is infinite-dimensional. Under our beliefs, z ( τ ) obe ys a stochastic differential equation of the form d z = [ A ( z ) + B ( z ) u + C ( z )Ω] d t + D ( z ) d ω (11) with fr ee dynamics A , contr olled dynamics B u , uncertainty operator C , and noise operator D A = h µ τ f ( z x , z t ) , 1 , 0 , 0 , . . . , 0 , − λL q L | q , − λL f 1 L | f 1 , . . . , − λL f D L | f D i ; (12) B = [ g ( s ∗ ) , 0 , 0 , 0 , . . . ]; C = diag(Σ 1 / 2 f τ , 0 , λL q ¯ Σ 1 / 2 q , λL f 1 ¯ Σ 1 / 2 f 1 , . . . , λL f D ¯ Σ 1 / 2 f d , 0 , . . . , 0); D = diag(0 , 0 , λL q ¯ σ q , λL f 1 ¯ σ f 1 , . . . , λL f D ¯ σ f D , 0 , . . . , 0) (13) The value – the expected cost to go – of any state s ∗ is gi ven by the Hamilton-Jacobi-Bellman equation, which follows from Bellman’ s principle and a first-order expansion, using Eq. (4): v ( z τ ) = min u Z Z µ q ( s τ ) + Σ 1 / 2 q τ Ω q + σ q ω q + 1 2 u | R − 1 u d t + v ( z τ + d t ) d ω dΩ = min u Z µ τ q +Σ 1 / 2 q τ Ω q + 1 2 u | R − 1 u + v ( z τ ) d t + ∂ v ∂ t +[ A + B u + C Ω] | ∇ v + 1 2 tr[ D | ( ∇ 2 v ) D ]dΩ d t (14) Integration o ver ω can be performed with ease, and removes the stoc hasticity from the problem; The uncertainty over Ω is a lot more challenging. Because the distribution o ver future losses is correlated through space and time, ∇ v , ∇ 2 v are functions of Ω , and the inte gral is nontri vial. But there are some obvious approximate approaches. For example, if we (inexactly) sw ap integration and minimisation, draw samples Ω i and solve for the value for each sample, we get an “average optimal controller”. This ov er-estimates the actual sum of future re wards by assuming the controller has access to the true system. It has the potential advantage of considering the actual optimal controller for ev ery possible system, the disadv antage that the average of optima need not be optimal for an y actual solution. On the other hand, if we ignore the correlation between Ω and ∇ v , we can inte grate (17) locally , all terms in Ω drop out and we are left with an “optimal a verage controller”, which assumes that the system locally follows its average (mean) dynamics. This cheaper strategy was adopted in the follo wing. Note that it is myopic, b ut not greedy in a simplistic sense – it does take the effect of learning into account. It amounts to a “global one-step look-ahead”. One could imagine extensions that consider the influence of Ω on ∇ v to a higher order , but these will be left for future work. Under this first-order approximation, analytic minimisation ov er u can be performed in closed form, and bears u ( z ) = − R B ( z ) | ∇ v ( z ) = − Rg ( x, t ) | ∇ x v ( z ) . (15) The optimal Hamilton-Jacobi-Bellman equation is then γ − 1 v ( z ) = µ τ q + A | ∇ v − 1 2 [ ∇ v ] | B R B | ∇ v + 1 2 tr D | ( ∇ 2 v ) D . (16) A more explicit form emer ges upon re-inserting the definitions of Eq. (12) into Eq. (16): γ − 1 v ( z ) = [ µ τ q + µ τ f ( z x , z t ) ∇ x + ∇ t v ( z ) | {z } free drift cost − 1 2 [ ∇ x v ( z )] | g | ( z x , z t ) Rg ( z x , z t ) ∇ x v ( z ) | {z } control benefit + X c = q ,f 1 ,...,f D − λ L c L | c ∇ Σ c v ( z ) | {z } exploration bonus + 1 2 λ 2 ¯ σ 2 c L | f d ( ∇ 2 µ f d v ( z )) L f d | {z } diffusion cost (17) Equation (17) is the central result: Given Gaussian priors on nonlinear control-affine dynamic systems, up to a first order approximation, optimal reinforcement learning is described by an infinite- dimensional second-order partial dif ferential equation. It can be interpreted as follows (labels in the 4 equation, note the negati ve signs of “beneficial” terms): The value of a state comprises the immediate utility rate; the effect of the free drift through space-time and the benefit of optimal control; an explor ation bonus of learning, and a diffusion cost engendered by the measurement noise. The first two lines of the right hand side describe effects from the phase space-time subspace of the augmented space, while the last line describes ef fects from the belief part of the augmented space. The former will be called exploitation terms , the latter exploration terms , for the follo wing reason: If the first two lines line dominate the right hand side of Equation (17) in absolute size, then future losses are gov erned by the physical sub-space – caused by exploiting knowledge to control the physical system. On the other hand, if the last line dominates the v alue function, exploration is more important than exploitation – the algorithm controls the physical space to increase knowledge. T o my knowledge, this is the first differential statement about reinforcement learning’ s two objectiv es. Finally , note the role of the sampling rate λ : If λ is very lo w , e xploration is useless over the discount horizon. Even after these approximations, solving Equation (17) for v remains nontrivial for two reasons: First, although the vector product notation is pleasingly compact, the mean and cov ariance functions are of course infinite-dimensional, and what looks lik e straightforward inner v ector products are in fact integrals. For e xample, the average e xploration bonus for the loss, writ large, reads − λL q L | q ∇ Σ q v ( z ) = − Z Z K λL ( q ) s τ ( s ∗ i ) L ( q ) s τ ( s ∗ j ) ∂ v ( z ) ∂ Σ( s ∗ i , s ∗ j ) d s ∗ i d s ∗ j . (18) (note that this object remains a function of the state s τ ). For general k ernels k , these integrals may only be solved numerically . Howe ver , for at least one specific choice of kernel (square-exponentials) and parametric Ansatz, the required inte grals can be solved in closed form. This analytic structure is so interesting, and the square-e xponential kernel so widely used that the “numerical” part of the paper (Section 4) will restrict the choice of kernel to this class. The other problem, of course, is that Equation (17) is a nontrivial dif ferential Equation. Section 4 presents one , initial attempt at a numerical solution that should not be mistaken for a definiti ve answer . Despite all this, Eq. (17) arguably constitutes a useful gain for Bayesian reinforcement learning: It replaces the intractable definition of the value in terms of future trajectories with a differential equation. This raises hope for ne w approaches to reinforcement learning, based on numerical analysis rather than sampling. Digression: Relaxing Some Assumptions This paper only applies to the specific problem class of Section 2. Any generalisations and e xtensions are future work, and I do not claim to solv e them. But it is instructiv e to consider some easier extensions, and some harder ones: For example, it is intractable to simultaneously learn both g and f nonparametrically , if only the actual transitions are observed, because the beliefs ov er the two functions become infinitely dependent when conditioned on data. But if the belief on either g or f is parametric (e.g. a general linear model), a joint belief on g and f is tractable [see 15 , § 2.7], in fact straightforward. Both the quadratic control cost ∝ u | Ru and the control-af fine form ( g ( x, t ) u ) are relaxable assumptions – other parametric forms are possible, as long as they allo w for analytic optimization of Eq. (14) . On the question of learning the kernels for Gaussian process regression on q and f or g , it is clear that standard ways of inferring kernels [ 15 , 17 ] can be used without complication, but that the y are not covered by the notion of optimal learning as addressed here. 4 Numerically Solving the Hamilton-Jacobi-Bellman Equation Solving Equation (16) is principally a problem of numerical analysis, and a battery of numeri- cal methods may be considered. This section reports on one specific Ansatz, a Galerkin-type projection analogous to the one used in [ 12 ]. For this we break with the generality of previous sections and assume that the kernels k are gi ven by square exponentials k ( a, b ) = k SE ( a, b ; θ , S ) = θ 2 exp( − 1 2 ( a − b ) | S − 1 ( a − b )) with parameters θ , S . As discussed abov e, we approximate by setting Ω = 0 . W e find an approximate solution through a factorizing parametric Ansatz: Let the value of any point z ∈ H in the belief space be gi ven through a set of parameters w and some nonlinear functionals φ , such that their contributions separate o ver phase space, mean, and cov ariance functions: v ( z ) = X e = x, Σ q ,µ q , Σ f ,µ f φ e ( z e ) | w e with φ e , w e ∈ R N e (19) 5 This projection is obviously restricti ve, but it should be compared to the use of radial basis functions for function approximation, a similarly restrictiv e framew ork widely used in reinforcement learning. The functionals φ hav e to be chosen conducive to the form of Eq. (17) . F or square exponential kernels, one con venient choice is φ a s ( z s ) = k ( s z , s a ; θ a , S a ) (20) φ b Σ ( z Σ ) = Z Z K [Σ z ( s ∗ i , s ∗ j ) − k ( s ∗ i , s ∗ j )] k ( s ∗ i , s b ; θ b , S b ) k ( s ∗ j , s b ; θ b , S b ) d s ∗ i d s ∗ j and (21) φ c µ ( z µ ) = Z Z K µ z ( s ∗ i ) µ z ( s ∗ j ) k ( s ∗ i , s c , θ c , S c ) k ( s ∗ j , s c , θ c , S c ) d s ∗ i d s ∗ j (22) (the subtracted term in the first inte gral serves only numerical purposes). W ith this choice, the integrals of Equation (17) can be solved analytically (solutions left out due to space constraints). The approximate Ansatz turns Eq. (17) into an algebraic equation quadratic in w x , linear in all other w e : 1 2 w | x Ψ ( z x ) w x − q ( z x ) + X e = x,µ q , Σ q ,µ f , Σ f Ξ e ( z e ) w e = 0 (23) using co-vectors Ξ and a matrix Ψ with elements Ξ x a ( z s ) = γ − 1 φ a s ( z s ) − f ( z x ) | ∇ x φ a s ( z s ) − ∇ t φ a s ( z s ) Ξ Σ a ( z Σ ) = γ − 1 φ a Σ ( z Σ ) + λ Z Z K L s τ ( s ∗ i ) L s τ ( s ∗ j ) ∂ φ Σ ( z Σ ) ∂ Σ z ( s ∗ i , s ∗ j ) d s ∗ i d s ∗ j Ξ µ a ( z µ ) = γ − 1 φ a µ ( z µ ) − λ 2 ¯ σ 2 s τ 2 Z Z K L s τ ( s ∗ i ) L s τ ( s ∗ j ) ∂ 2 φ a µ ( z µ ) ∂ µ z ( s ∗ i ) ∂ µ z ( s ∗ j ) d s ∗ i d s ∗ j Ψ( z ) k` = [ ∇ x φ k s ( z )] | g ( z x ) Rg ( z x ) | [ ∇ x φ ` s ( z )] (24) Note that Ξ µ and Ξ Σ are both functions of the physical state, through s τ . It is through this functional dependency that the v alue of information is associated with the physical phase space-time. T o solve for w , we simply choose a number of ev aluation points z ev al sufficient to constrain the resulting system of quadratic equations, and then find the least-squares solution w opt by function minimisation, using standard methods, such as Lev enberg-Marquardt [ 18 ]. A disadv antage of this approach is that is has a number of degrees of freedom Θ , such as the kernel parameters, and the number and locations x a of the feature functionals. Our experiments (Section 5) suggest that it is ne vertheless possible to get interesting results simply by choosing these parameters heuristically . 5 Experiments 5.1 Illustrative Experiment on an Artificial En vir onment As a simple example system with a one-dimensional state space, f , q were sampled from the model described in Section 2, and g set to the unit function. The state space w as tiled regularly , in a bounded region, with 231 square exponential (“radial”) basis functions (Equation 20), initially all with weight w i x = 0 . For the information terms, only a single basis function was used for each term (i.e. one single φ Σ q , one single φ µq , and equally for f , all with very large length scales S , cov ering the entire region of interest). As pointed out abov e, this does not imply a trivial structure for these terms, because of the functional dependency on L s τ . Fiv e times the number of parameters, i.e. N ev al = 1175 ev aluation points z ev al were sampled, at each time step, uniformly over the same region. It is not intuitiv ely clear whether each z e should hav e its o wn belief (i.e. whether the points must co ver the belief space as well as the phase space), but anecdotal e vidence from the experiments suggests that it suffices to use the current beliefs for all ev aluation points. A more comprehensiv e ev aluation of such aspects will be the subject of a future paper . The discount factor was set to γ = 50s , the sampling rate at λ = 2 / s , the control cost at 10m 2 / ($s) . V alue and optimal control were ev aluated at time steps of δ t = 1 /λ = 0 . 5s . Figure 1 shows the situation 50s after initialisation. The most notew orthy aspect is the nontri vial structure of exploration and exploitation terms. Despite the simplistic parameterisation of the corresponding functionals, their functional dependence on s τ induces a complex shape. The system 6 0 20 40 60 80 100 − 40 − 20 0 20 40 x − 1 − 0 . 5 0 0 . 5 0 20 40 60 80 100 − 40 − 20 0 20 40 − 8 − 6 − 4 − 2 0 0 20 40 60 80 100 − 40 − 20 0 20 40 t x 0 0 . 5 0 20 40 60 80 100 − 40 − 20 0 20 40 t − 1 − 0 . 5 0 Figure 1: State after 50 time steps, plotted over phase space-time. top left: µ q (blue is good). The belief over f is not shown, but has similar structure. top right: value estimate v at current belief: compare to next two panels to note that the approximation is relati vely coarse. bottom left: exploration terms. bottom right: exploitation terms. At its current state (black diamond), the system is in the process of switching from exploitation to e xploration (blue region in bottom right panel is roughly cancelled by red, forward cone in bottom left one). constantly balances exploration and e xploitation, and the optimal balance depends nontri vially on location, time, and the actual value (as opposed to only uncertainty) of accumulated kno wledge. This is an important insight that casts doubt on the usefulness of simple, local exploration boni, used in many reinforcement learning algorithms. Secondly , note that the system’ s trajectory does not necessarily follo w what would be the optimal path under full information. The value estimate reflects this, by assigning lo w (good) value to re gions behind the system’ s trajectory . This amounts to a sense of “remorse”: If the learner would have known about these regions earlier, it would have striv ed to reach them. But this is not a sign of sub-optimality: Remember that the v alue is defined on the augmented space. The plots in Figure 1 are merely a slice through that space at some lev el set in the belief space. 5.2 Comparative Experiment – The Furuta P endulum The cart-and-pole system is an under-actuated problem widely studied in reinforcement learning. For variation, this experiment uses a cylindrical version, the pendulum on the rotating arm [ 19 ]. The task is to swing up the pendulum from the lower resting point. The table in Figure 2 compares the av erage loss of a controller with access to the true f , g , q , but otherwise using Algorithm 1, to that of an -greedy TD ( λ ) learner with linear function approximation, Simpkins’ et al. ’ s [ 12 ] Kalman method and the Gaussian process learning controller (Fig. 2). The linear function approximation of TD ( λ ) used the same radial basis functions as the three other methods. None of these methods is free of assumptions: Note that the sampling frequency influences TD in nontri vial ways rarely studied (for example through the coarseness of the -greedy policy). The parameters were set to γ = 5s , λ = 50 / s . Note that reinforcement learning experiments often quote total accumulated loss, which differs from t he discounted task posed to the learner . Figure 2 reports actual discounted losses. The GP method clearly outperforms the other two learners, which barely explore. Interestingly , none of the tested methods, not e ven the informed controller , achie ve a stable controlled balance, although 7 ` 1 θ 1 u ` 2 θ 2 Method cumulativ e loss Full Information (baseline) 4 . 4 ± 0 . 3 TD( λ ) 6 . 401 ± 0 . 001 Kalman filter Optimal Learner 6 . 408 ± 0 . 001 Gaussian process optimal lear ner 4 . 6 ± 1 . 4 Figure 2: The Furuta pendulum system: A pendulum of length ` 2 is attached to a rotatable arm of length ` 1 . The control input is the torque applied to the arm. Right: cost to go achiev ed by different methods. Lower is better . Error measures are one standard deviation ov er fiv e experiments. the GP learner does swing up the pendulum. This is due to the random, non-optimal location of basis functions, which means resolution is not necessarily av ailable where it is needed (in regions of high curvature of the v alue function), and demonstrates a need for better solution methods for Eq. (17). There is of course a lar ge number of other algorithms methods to potentially compare to, and these results are anything but exhausti ve. They should not be misunderstood as a critique of any other method. But they highlight the need for units of measure on every quantity , and show how hard optimal exploration and exploitation truly is. Note that, for time-varying or discounted problems, there is no “conservati ve” option that cold be adopted in place of the Bayesian answer . 6 Conclusion Gaussian process priors provide a nontrivial class of reinforcement learning problems for which optimal reinforcement learning reduces to solving differential equations. Of course, this fact alone does not make the problem easier , as solving nonlinear differential equations is in general intractable. Howe ver , the ubiquity of differential des criptions in other fields raises hope that this insight opens new approaches to reinforcement learning. For intuition on how such solutions might work, one specific approximation was presented, using functionals to reduce the problem to finite least-squares parameter estimation. The critical reader will have noted how central the prior is for the arguments in Section 3: The dynamics of the learning process are predictions of future data, thus inherently determined e xclusiv ely by prior assumptions. One may find this unappealing, but there is no escape from it. Minimizing future loss requires predicting future loss, and predictions are always in danger of falling victim to incorrect assumptions. A finite initial identification phase may mitigate this problem by replacing prior with posterior uncertainty – but e ven then, predictions and decisions will depend on the model. The results of this paper raise new questions, theoretical and applied. The most pressing questions concern better solution methods for Eq. (14) , in particular better means for taking the expectation ov er the uncertain dynamics to more than first order . There are also obvious probabilistic issues: Are there other classes of priors that allo w similar treatments? (Note some conceptual similarities between this work and the BEETLE algorithm [ 4 ]). T o what extent can approximate inference methods – widely studied in combination with Gaussian process re gression – be used to broaden the utility of these results? Acknowledgments The author wishes to express his gratitude to Carl Rasmussen, Jan Peters, Zoubin Ghahramani, Peter Dayan, and an anonymous re viewer , whose thoughtful comments uncov ered sev eral errors and crucially improv ed this paper . 8 References [1] R.S. Sutton and A.G. Barto. Reinforcement Learning . MIT Press, 1998. [2] W .R. Thompson. On the likelihood that one unknown probability e xceeds another in view of two samples. Biometrika , 25:275–294, 1933. [3] M.O.G. Duff. Optimal Learning: Computational pr ocedur es for Bayes-adaptive Markov decision pr ocesses . PhD thesis, U of Massachusetts, Amherst, 2002. [4] P . Poupart, N. Vlassis, J. Hoey , and K. Regan. An analytic solution to discrete Bayesian reinforcement learning. In Pr oceedings of the 23r d International Confer ence on Mac hine Learning , pages 697–704, 2006. [5] Richard Dearden, Nir Friedman, and David Andre. Model based Bayesian exploration. In Uncertainty in Artificial Intelligence , pages 150–159, 1999. [6] Malcolm Strens. A Bayesian framew ork for reinforcement learning. In International Confer ence on Machine Learning , pages 943–950, 2000. [7] T . W ang, D. Lizotte, M. Bowling, and D. Schuurmans. Bayesian sparse sampling for on-line rew ard optimization. In International Conference on Mac hine Learning , pages 956–963, 2005. [8] J. Asmuth, L. Li, M.L. Littman, A. Nouri, and D. W ingate. A Bayesian sampling approach to exploration in reinforcement learning. In Uncertainty in Artificial Intelligence , 2009. [9] J.Z. K olter and A.Y . Ng. Near -Bayesian exploration in polynomial time. In Pr oceedings of the 26th International Confer ence on Machine Learning . Morgan Kaufmann, 2009. [10] E. T odorov . Linearly-solvable Mark ov decision problems. Advances in Neural Information Pr ocessing Systems , 19, 2007. [11] H. J. Kappen. An introduction to stochastic control theory , path inte grals and reinforcement learning. In 9th Granada seminar on Computational Physics: Computational and Mathematical Modeling of Cooperative Behavior in Neural Systems. , pages 149–181, 2007. [12] A. Simpkins, R. De Callafon, and E. T odoro v . Optimal trade-off between exploration and exploitation. In American Contr ol Confer ence, 2008 , pages 33–38, 2008. [13] I. Fantoni and L. Rogelio. Non-linear Contr ol for Underactuated Mechanical Systems . Springer, 1973. [14] A.A. Feldbaum. Dual control theory . Automation and Remote Contr ol , 21(9):874–880, April 1961. [15] C.E. Rasmussen and C.K.I. W illiams. Gaussian Processes for Mac hine Learning . MIT Press, 2006. [16] N. W iener . Differential space. Journal of Mathematical Physics , 2:131–174, 1923. [17] I. Murray and R.P . Adams. Slice sampling covariance hyperparameters of latent Gaussian models. arXiv:1006.0868 , 2010. [18] D. W . Marquardt. An algorithm for least-squares estimation of nonlinear parameters. Journal of the Society for Industrial and Applied Mathematics , 11(2):431–441, 1963. [19] K. Furuta, M. Y amakita, and S. Kobayashi. Swing-up control of in verted pendulum using pseudo-state feedback. Journal of Systems and Contr ol Engineering , 206(6):263–269, 1992. 9
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment