Why does Deep Learning work? - A perspective from Group Theory
Why does Deep Learning work? What representations does it capture? How do higher-order representations emerge? We study these questions from the perspective of group theory, thereby opening a new approach towards a theory of Deep learning. One fact…
Authors: Arnab Paul, Suresh Venkatasubramanian
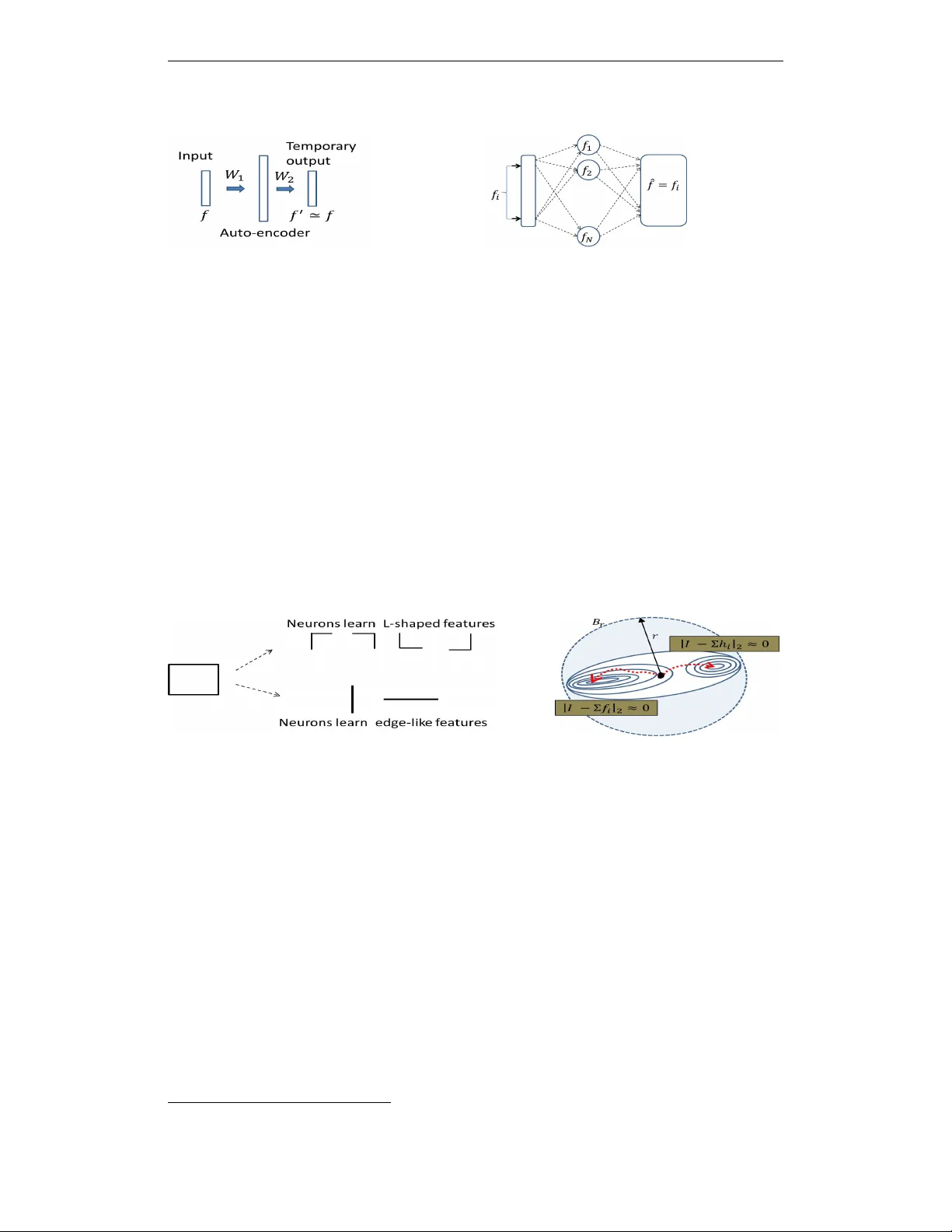
Under revie w as a conference paper at ICLR 2015 W H Y D O E S U N S U P E R V I S E D D E E P L E A R N I N G W O R K ? - A P E R S P E C T I V E F RO M G R O U P T H E O RY Arnab Paul ∗ 1 and Suresh V enkatasubramanian † 2 1 Intel Labs, Hillsboro, OR 97124 2 School of Computing, Univ ersity of Utah, Salt Lake City , UT 84112. A B S T R AC T Why does Deep Learning work? What representations does it capture? How do higher-order representations emerge? W e study these questions from the perspec- tiv e of group theory , thereby opening a new approach towards a theory of Deep learning. One factor behind the recent resurgence of the subject is a key algorithmic step called pr etraining : first search for a good generati ve model for the input samples, and repeat the process one layer at a time. W e show deeper implications of this simple principle, by establishing a connection with the interplay of orbits and stabilizers of group actions. Although the neural networks themselves may not form groups, we show the existence of shadow groups whose elements serve as close approximations. Over the shadow groups, the pretraining step, originally introduced as a mech- anism to better initialize a network, becomes equi valent to a search for features with minimal orbits. Intuitively , these features are in a way the simplest . Which explains why a deep learning network learns simple features first. Next, we show how the same principle, when repeated in the deeper layers, can capture higher order representations, and why representation complexity increases as the layers get deeper . 1 I N T RO D U C T I O N The modern incarnation of neural networks, no w popularly kno wn as Deep Learning (DL), accom- plished record-breaking success in processing di verse kinds of signals - vision, audio, and text. In parallel, strong interest has ensued to wards constructing a theory of DL. This paper opens up a group theory based approach, tow ards a theoretical understanding of DL. W e focus on two ke y principles that (amongst others) influenced the modern DL resurgence. ( P1 ) Geof f Hinton summed this up as follo ws. “In order to do computer vision, first learn ho w to do computer graphics”. Hinton (2007). In other words, if a network learns a good generativ e model of its training set, then it could use the same model for classification. ( P2 ) Instead of learning an entire netw ork all at once, learn it one layer at a time . In each round, the training layer is connected to a temporary output layer and trained to learn the weights needed to reproduce its input (i.e to solve P1 ). This step – ex ecuted layer -wise, starting with the first hidden layer and sequentially moving deeper – is often referred to as pre-training (see Hinton et al. (2006); Hinton (2007); Salakhutdino v & Hinton (2009); Bengio et al. (in preparation)) and the resulting layer is called an autoencoder . Figure 1(a) shows a schematic autoencoder . Its weight set W 1 is learnt by the network. Subsequently when presented with an input f , the network will produce an output f 0 ≈ f . At this point the output units as well as the weight set W 2 are discarded. There is an alternate characterization of P1 . An autoencoder unit, such as the above, maps an input space to itself. Moreover , after learning, it is by definition, a stabilizer 1 of the input f . Now , input ∗ arnab .paul@intel.com † suresh@cs.utah.edu 1 A transformation T is called a stabilizer of an input f , if f 0 = T ( f ) = f . 1 Under revie w as a conference paper at ICLR 2015 (a) General auto-encoder schematic (b) post-learning behavior of an auto-encoder Figure 1: (a) W 1 is preserved, W 2 discarded (b) Post-learning, each feature is stabilized signals are often decomposable into features, and an autoencoder attempts to find a succinct set of features that all inputs can be decomposed into. Satisfying P1 means that the learned configurations can reproduce these features. Figure 1(b) illustrates this post-training behavior . If the hidden units learned features f 1 , f 2 , . . . , and one of then, say f i , comes back as input, the output must be f i . In other words learning a featur e is equivalent to sear ching for a transformation that stabilizes it . The idea of stabilizers in vites an analogy reminiscent of the orbit-stabilizer relationship studied in the theory of group actions. Suppose G is a group that acts on a set X by moving its points around (e.g groups of 2 × 2 in vertible matrices acting o ver the Euclidean plane). Consider x ∈ X , and let O x be the set of all points reachable from x via the group action. O x is called an orbit 2 . A subset of the group elements may leave x unchanged. This subset S x (which is also a subgroup), is the stabilizer of x . If it is possible to define a notion of volume for a group, then there is an in verse relationship between the volumes of S x and O x , which holds ev en if x is actually a subset (as opposed to being a point). For example, for finite groups, the product of | O x | and | S x | is the order of the group. (a) Alternate Decomposition of a Signal (b) Possible ways of feature stabiliza- tion Figure 2: (a) Alternate ways of decomposing a signal into simpler features. The neurons could potentially learn features in the top ro w , or the bottom ro w . Almost surely , the simpler ones (bottom row) are learned. (b) Gradient-descent on error landscape. T wo alternate classes of features (denoted by f i and h i ) can reconstruct the input I - reconstructed signal denoted by Σ f i and Σ h i for simplicity . Note that the error function is unbiased between these two classes, and the learning will select whichev er set is encountered earlier . The inver se relationship between the volumes of orbits and stabilizers takes on a central role as we connect this back to DL. There are many possible ways to decompose signals into smaller features. Figure 2(a) illustrates this point: a rectangle can be decomposed into L-shaped features or straight- line edges. All experiments to date suggest that a neural network is likely to learn the edges. But why? T o answer this, imagine that the space of the autoencoders (viewed as transformations of the input) form a group. A batch of learning iterations stops whenever a stabilizer is found. Roughly speaking, if the search is a Markov chain (or a guided chain such as MCMC), then the bigger a stabilizer , the earlier it will be hit. The group structure implies that this big stabilizer corresponds to a small orbit. No w intuition suggests that the simpler a feature, the smaller is its orbit. F or example, a 2 Mathematically , the orbit O x of an element x ∈ X under the action of a group G , is defined as the set O x = { g ( x ) ∈ X | g ∈ G } . 2 Under revie w as a conference paper at ICLR 2015 line-segment generates many fewer possible shapes 3 under linear deformations than a flower -like shape. An autoencoder then should learn these simpler features first, which falls in line with most experiments (see Lee et al. (2009)). The intuition naturally extends to a many-layer scenario. Each hidden layer finding a feature with a big stabilizer . But beyond the first le vel, the inputs no longer inhabit the same space as the training samples. A “simple” feature over this new space actually corresponds to a more complex shape in the space of input samples. This process repeats as the number of layers increases. In effect, each layer learns “edge-like features” with respect to the previous layer , and from these locally simple representations we obtain the learned higher-order representation. 1 . 1 O U R C O N T R I B U T I O N S Our main contribution in this work is a formal substantiation of the abov e intuition connecting autoencoders and stabilizers. First we build a case for the idea that a random search process will find large stabilizers (section 2), and construct e vidential examples (section 2.3). Neural networks incorporate highly nonlinear transformations and so our analogy to group transfor - mations does not directly map to actual networks. Howe ver , it turns out that we can define (Section 3) and construct (Section 4) shadow groups that approximate the actual transformation in the net- work, and reason about these instead. Finally , we examine what happens when we compose layers in a multilayer network. Our analysis highlights the critical role of the sigmoid and sho w how it enables the emergence of higher-order representations within the framew ork of this theory (Section 5) 2 R A N D O M W A L K A N D S TA B I L I Z E R V O L U M E S 2 . 1 R A N D O M W A L K S OV E R T H E P A R A M E T E R S PAC E A N D S T A B I L I Z E R V O L U M E S The learning process resembles a random walk, or more accurately , a Marko v-Chain-Monte-Carlo type sampling. This is already known, e.g. see (Salakhutdinov & Hinton (2009); Bengio et al. (in preparation)). A newly arriving training sample has no prior correlation with the current state. The order of computing the partial deri vati ves is also randomized. Effecti vely then, the subsequent min- imization step takes off in an almost random direction , guided by the gradient, to wards a minimal point that stabilizes the signal. Figure 2(b) shows this schematically . Consider the current network configuration, and its neighbourhood B r of radius r . Let the input signal be I , and suppose that there are two possible decompositions into features: f = { f 1 , f 2 . . . } and h = { h 1 , h 2 . . . } . W e denote the reconstructed signal by Σ i f i (and in the other case, Σ j h j ). Note that these features are also signals (just like the input signal, only simpler). The reconstruction error is usually given by an error term, such as the l 2 distance ( k I − Σ f i k 2 ). If the collection f really enables a good reconstruction of the input - i.e. k I − Σ f i k 2 ≈ 0 - then it is a stabilizer of the input by definition . If there are competing feature-sets, gradient descent will ev entually move the configuration to one of these stabilizers. Let P f be the probability that the network discovers stabilizers for the signals f i (and similar defini- tion for P h ), in a neighbourhood B r of radius r . S f i would denote the stabilizer set of a signal f i . Let µ be a volume measure o ver the space of transformation. Then one can roughly say that P f P h ∝ ∏ i µ ( B r ∩ S f i ) ∏ j µ ( B r ∩ S h j ) Clearly then, the most likely chosen features are the ones with the bigger stabilizer v olumes. 2 . 2 E X P O S I N G T H E S T R U C T U R E O F F E A T U R E S - F RO M S TA B I L I Z E R S T O O R B I T S If our parameter space was actually a finite group, we could use the follo wing theorem. Orbit-Stabilizer Theorem Let G be a group acting on a set X , and S f be the stabilizer subgroup of an element f ∈ X . Denote the corresponding orbit of f by O f . Then | O f | . | S f | = | G | . 3 In fact, one only gets line segments back 3 Under revie w as a conference paper at ICLR 2015 𝑺 𝒆 ≃ { 𝑺𝑶 𝟐 × ℝ + } \ℝ + : An Infinite Cylinder with a puncture Dim( 𝑺 𝒆 ) = 2 𝑺 𝒄 ≃ O(n) for n=2, the two dimensional Orthogonal group Dim( 𝑺 𝒄 ) = 𝒏−𝟏 𝒏 𝟐 = 𝟏 𝑻 𝒑 : 𝐩 → 𝐜 (deforms p to c) For every symmetry 𝝓 of the circle 𝑻 𝒑 −𝟏 𝝓𝑻 𝒑 is a symmetry of the ellipse Dim ( 𝑺 𝒑 ) = Dim( 𝑺 𝒄 ) = 𝟏 An Edge ( 𝑒 ) A circle ( 𝑐 ) An Ellipse ( 𝑝 ) Figure 3: Stabilizer subgroups of GL 2 (( R )) . The stabilizer subgroup is of dimension 2, as it is isomorphic to an infinite cylinder sans the real line. The circle and ellipse on the other hand hav e stabilizer subgroups that are one dimensional. For finite groups, the in verse relationship of their volumes (cardinality) is direct; but it does not extend v erbatim for continuous groups. Nev ertheless, the following similar result holds: dim ( G ) − dim ( S f ) = dim ( O f ) (1) The dimension takes the role of the cardinality . In fact, under a suitable measure ( e.g. the Haar measure), a stabilizer of higher dimension has a larger volume, and therefore, an orbit of smaller volume. Assuming group actions - to be substantiated later - this explains the emergence of simple signal blocks as the learned features in the first layer . W e provide some evidential examples by analytically computing their dimensions. 2 . 3 S I M P L E I L L U S T R AT I V E E X A M P L E S A N D E M E R G E N C E O F G A B O R - L I K E FI L T E R S Consider the action of the group GL 2 ( R ) , the set of in vertible 2D linear transforms, on various 2D shapes. Figure 3 illustrates three example cases by estimating the stabilizer sizes. An edge(e): F or an edge e (passing through the origin), its stabilizer (in GL 2 ( R ) ) must fix the direc- tion of the edge, i.e. it must have an eigen vector in that direction with an eigenv alue 1. The second eigenv ector can be in any other direction, giving rise to a set isomorphic to S O ( 2 ) 4 , sans the direction of the first eigen vector , which in turn is isomorphic to the unit circle punctured at one point. Note that isomorphism here refers to topological isomorphism be- tween sets. The second eigenv alue can be anything, but considering that the entire circle already accounts for every pair ( λ , − λ ) , the effecti ve set is isomorphic to the positive half of the real-axis only . In summary , this stabilizer subgroup is: S e ' SO ( 2 ) × R + \ R + . This space looks like a cylinder extended infinitely to one direction (Figure 3). More importantly dim ( S e ) = 2, and it is actually a non-compact set. The dimension of the corresponding orbit, dim ( O e ) = 2, as re vealed by Equation 1. A circle: A circle is stabilized by all rigid rotations in the plane, as well as the reflections about all possible lines through the centre. T ogether , they form the orthogonal group ( O ( 2 ) ) ov er R 2 . From the theory of Lie groups it is known that the dim ( S c ) = 1. An ellipse: The stabilizer of the ellipse is isomorphic to that of a circle. An ellipse can be deformed into a circle, then be transformed by any t ∈ S c , and then transformed back. By this isomorphism dim ( S p ) = 1. In summary , for a random walk inside GL 2 ( R ) , the likelihood of hitting an edge-stabilizer is very high, compared to shapes such as a circle or ellipse, which are not only compact, b ut also hav e one dimension less. The first layer of a deep learning network, when trying to learn images, almost always discov ers Gabor-filter like shapes. Essentially these are edges of different orientation inside those images. W ith the stabilizer view in the background, perhaps it is not all that surprising after all. 4 SO ( 2 ) is the subgroup of all 2 dimensional rotations, which is isomorphic to the unit circle 4 Under revie w as a conference paper at ICLR 2015 3 F R O M D E E P L E A R N I N G T O G R O U P A C T I O N - T H E M A T H E M A T I C A L F O R M U L A T I O N 3 . 1 I N S E A R C H O F D I M E N S I O N R E D U C T I O N ; T H E I N T R I N S I C S PAC E Reasoning ov er symmetry groups is con venient. No w we shall show that it is possible to continue this reasoning over a deep learning network, even if it employs non-linearity . But first, we discuss the notion of an intrinsic space. Consider a N × N binary image; it’ s typically represented as a vector in R N 2 , or more simply in { 0 , 1 } N 2 , yet, it is intrinsically a two dimensional object. Its resolution determines N , which may change, but that’ s not intrinsic to the image itself. Similarly , a gray-scale image has three intrinsic dimensions - the first two accounts for the euclidean plane, and the third for its gray-scales. Other signals have similar intrinsic spaces. W e start with a few definitions. Input Space (X) : It is the original space that the signal inhabits. Most signals of interest are com- pactly supported bounded real functions ov er a vector space X . The function space is denoted by C 0 ( X , R ) = { φ | φ : X → R } . W e define Intrinsic space as: S = X × R . Every φ ∈ C 0 ( X , R ) is a subset of S . A neural network maps a point in C 0 ( X , R ) to another point in C 0 ( X , R ) ; Inside S , this induces a deformation between subsets. An example. A binary image, which is a function φ : R 2 → { 0 , 1 } naturally corresponds to a subset f φ = { x ∈ R 2 such that φ ( x ) = 1 } . Therefore, the intrinsic space is the plane itself. This w as implicit in section 2.3. Similarly , for a monochrome gray-scale image, the intrinsic space is S = R 2 × R = R 3 . In both cases, the input space X = R 2 . F igure A subset of the intrinsic space is called a figure, i.e., f ⊆ S . Note that a point φ ∈ C 0 ( X , R ) is actually a figure ov er S . Moduli space of F igures One can imagine a space that parametrizes various figures over S . W e denote this by F ( S ) and call the moduli space of figures. Each point in F ( S ) corresponds to a figure ov er S . A group G that acts on S , consistently extends over F ( S ) , i.e., for g ∈ G , f ∈ S , we get another figure g ( f ) = f 0 ∈ F ( S ) . Symmetry-group of the intrinsic space For an intrinsic space S , it is the collection of all in vertible mapping S → S . In the event S is finite, this is the permutation group. When S is a vector space (such as R 2 or R 3 ), it is the set GL ( S ) , of all linear in vertible transformations. The Sigmoid function will refer to any standard sigmoid function, and be denoted as σ () . 3 . 2 T H E C O N VO L U T I O N V I E W O F A N E U RO N W e start with the con ventional view of a neuron’ s operation. Let r x be the vector representation of an input x . For a giv en set of weights w , a neuron performs the following function (we ommit the bias term here for simplicity) - Z w ( r x ) = σ ( < w , r x > ) Equiv alently , the neuron performs a con volution of the input signal I ( X ) ∈ C 0 ( X , R ) . First, the weights transform the input signal to a coefficient in a F ourier -like space. τ w ( I ) = Z θ ∈ X w ( θ ) I ( θ ) d θ (2) And then, the sigmoid function thresholds the coefficient ζ w ( I ) = σ ( τ w ( I )) (3) A decon volution then brings the signal back to the original domain. Let the outgoing set of weights are defined by S ( w , x ) . The two arguments, w and x , indicate that its domain is the fr equency space index ed by w , and range is a set of coefficients in the space index ed by x . For the dummy output layer of an auto-encoder, this space is essentially identical to the input layer . The decon v olution then looks like: ˆ I ( x ) = R w S ( w , x ) ζ w ( I ) d w . In short, a signal I ( X ) is transformed into another signal ˆ I ( X ) . Let’ s denote this composite map I → ˆ I by the symbol ψ , and the set of such composite maps by Ω , i.e., Ω = { ψ | ψ : C 0 ( X , R ) → C 0 ( X , R ) } . 5 Under revie w as a conference paper at ICLR 2015 W e already observ ed that a point in C 0 ( X , R ) is a figure in the intrinsic space S = X × R . Hence any map ψ ∈ Ω naturally induces the follo wing map from the space F ( S ) on to itself: ψ ( f ) = f 0 ⊆ S . Let Γ be the space of all deformations of this intrinsic space S , i.e., Γ = { γ | γ : S → S } . Although ψ deforms a figure f ⊆ S into another figure f 0 ⊆ S , this action does not necessarily extend uniformly ov er the entire set S . By definition, ψ is a map C 0 ( X , R ) → C 0 ( X , R ) and not X × R → X × R . One trouble in realizing ψ as a consistent S → S map is as follows. Let f , g ⊆ S so that h = f ∩ g 6 = / 0. The restriction of ψ to h needs to be consistent both ways; i.e., the restriction maps ψ ( f ) | h and ψ ( g ) | h should agree ov er h . But that’ s not guaranteed for randomly selected ψ , f and g . If we can naturally extend the map to all of S , then we can translate the questions asked ov er Ω to questions ov er Γ . The intrinsic space being of lo w dimension, we can hope for easier analyses. In particular , we can examine the stabilizer subgroups ov er Γ that are more tractable. So, we now examine if a map between figures of S can be effecti vely captured by group actions ov er S . It suf fices to consider the action of ψ , one input at a time. This eliminates the conflicts arising from different inputs. Y et, ψ ( f ) - i.e. the action of ψ over a specific f ∈ C 0 ( X , R ) - is still incomplete with respect to being an automorphism of S = X × R (being only defined over f ). Can we then extend this action to the entire set S consistently? It turns out - yes. Theorem 3.1. Let ψ be a neural network, and f ∈ C 0 ( X , R ) an input to this network. The action ψ ( f ) can be consistely extended to an automorphism γ ( ψ , f ) : S → S, i.e. γ ( ψ , f ) ∈ Γ . The proof is giv en in the Appendix. A couple of notes. First, the input f appears as a parameter for the automorphism (in addition to ψ ), as ψ alone cannot define a consistent self-map o ver S . Second, this correspondence is not necessarily unique. There’ s a family of automorphisms that can correspond to the action ψ ( f ) , but we’ re interested in the existence of at least one of them. 4 G R O U P A C T I O N S U N D E R L Y I N G D E E P N E T W O R K S 4 . 1 S H A D O W S TA B I L I Z E R - S U B G R O U P S W e now search for group actions that approximate the automorphisms we established. Since such a group action is not exactly a neural network, yet can be closely mimics the latter , we will refer to these groups as Shadow gr oups . The existence of an underlying group action asserts that corre- sponding to a set of stabilizers for a figure f in Ω , there is a stabilizer subgroup, and lets us argue that the learnt figures actually correspond to minimal orbits, with high probability - and thus the simplest possible. The following theorem asserts this fact. Theorem 4.1. Let ψ ∈ Ω be a neural network working over a figure f ⊆ S, and the corr esponding self-map γ ( ψ , f ) : S → S, then in fact γ ( ψ , f ) ∈ Homeo ( S ) , the homeomorphism gr oup of S. The above theorem (see Appendix, for a proof) shows that although neural networks may not e xactly define a group, they can be approximated well by a set of group actions - that of the homeomorphism group of the intrinsic space. One can go further , and inspect the action of ψ locally - i.e. in the small vicinity of each point. Our next result shows that locally , they can be approximated further by elements of GL ( S ) , which is a much simpler group to study; in fact our results from section 2.3 were really in light of the action of this group for the 2 dimensional case. L O C A L R E S E M B L A N C E T O GL ( S ) Theorem 4.2. F or any γ ( ψ , f ) ∈ Homeo ( S ) , there is a local appr oximation g ( ψ , f ) ∈ GL ( S ) that ap- pr oximates γ ( ψ , f ) . In particular , if γ ( ψ , f ) is a stabilizer for f , so is g ( ψ , f ) . The abov e theorem (proof in Appendix) guarantees an underlying group action. But what if some large stabilizers in Ω are mapped to very small stabilizers in GL ( S ) , and vice versa? The next theorem (proof in Appendix) asserts that there is a bottom-up correspondence as well - every group symmetry over the intrinsic space has a counter-part over the set of mapping from C 0 ( S , R ) onto itself. Theorem 4.3. Let S be an intrinsic space, and f ⊆ S . Let g f ∈ GL ( S ) be a gr oup element that stabilizes f . Then ther e is a map U : GL ( S ) → Ω , such that the corr esponding element U ( g f ) = τ f ∈ Ω that stabilizes f . Mor eover , for g 1 , g 2 ∈ GL ( S ) , U ( g 1 ) = U ( g 2 ) ⇒ g 1 = g 2 . 6 Under revie w as a conference paper at ICLR 2015 Summary Argument : W e showed via Theorem 4.1 that any neural network action has a counter - part in the group of homeomorphisms over the intrinsic space. The presence of this shadow group lets one carry over the orbit/stabilizer principle discussed in section 2.1 to the actual neural net- work transforms. Which asserts that the simple features are the ones to be learned first. T o analyse how these features look like, we can examine them locally with the lens of GL ( S ) , an e ven simpler group. The Theorems 4.2 and 4.3 collectiv ely establish this. Theorem 4.2 shows that for every neural network element there’ s a nearby group element. For a large stabilizer set then, the corre- sponding stabilizer subgroup ought to be large, else it will be impossible to find a nearby group element e verywhere. Also note that this doesn’t require a strict one-to-one correspondence; exis- tence of some group element is enough to assert this. T o see ho w Theorem 4.3 pushes the argument in re verse, imagine a suf ficiently discrete v ersion of GL ( S ) . In this coarse-grained picture, an y small ε -neighbourhood of an element g can be represented by g itself (similar to how integrals are built up with small regions taking on uniform values) . There is a corresponding neural network U ( g ) , and furthermore, for another element f which is outside this neighbourhood (and thus not equal to g ) U ( f ) is another different network. This implies that a large volume cannot be mapped to a small volume in general - and hence true for stabilizer v olumes as well. 5 D E E P E R L A Y E R S A N D M O D U L I - S P A C E Now we discuss ho w the orbit/stabilizer interplay extends to multiple layers. At its root, lies the principle of layer-wise pre-training for the identity function. In particular , we show that this succinct step, as an algorithmic principle, is quite po werful. The principle stays the same across layers; hence ev ery layer only learns the simplest possible objects from its own input space. Y et, a simple objects at a deeper layer can represent a comple x object at the input space. T o understand this precisely , we first examine the critical role of the sigmoid function. 5 . 1 T H E R O L E O F T H E S I G M O I D F U N C T I O N Let’ s re visit the the transfer functions from section 3.2 (conv olution view of a neuron): τ w ( I ) = Z θ ∈ X w ( θ ) I ( θ ) d θ (2) ζ w ( I ) = σ ( τ w ( I )) (3) Let F R ( A ) denote the space of real functions on an y space A . Now , imagine a (hypothetical) space of infinite number of neurons index ed by the weight-functions w . Note that w can also be vie wed as an element of C 0 ( X , R ) . Plus τ w ( I ) ∈ R . So the family τ = { τ w } induces a mapping from C 0 ( X , R ) to real functions ov er C 0 ( X , R ) , i.e. τ : C 0 ( X , R ) → F R ( C 0 ( X , R )) (4) Now , the sigmoid can be thought of composed of tw o steps. σ 1 turning its input to number between zero and one. And then, for most cases, an automatic thresholding happens (due to discretized representation in computer systems) creating a binarization to 0 or 1. W e denote this final step by σ 2 , which reduces to the output to an element of the figure space F ( C 0 ( X , R )) . These three steps, applying τ , and then σ = σ 1 σ 2 can be viewed as C 0 ( X , R ) τ → F R ( C 0 ( X , R )) σ 1 → F [ 0 , 1 ] ( C 0 ( X , R )) σ 2 → F ( C 0 ( X , R )) (5) This construction is recursi ve over layers, so one can envision a neural net building representations of moduli spaces ov er moduli spaces, hierarchically , one after another . F or example, at the end of layer-1 learning, each layer-1 neuron actually learns a figure ov er the intrinsic space X × R (ref. equation 2). And the collective output of this layer can be thought of as a figure over C 0 ( X , R ) (ref. equation 5). These second order figures then become inputs to layer-2 neurons, which collectiv ely end up learning a minimal-orbit figure ov er the space of these second-order figures, and so on. What does all this mean physically ? W e now show that it is the power to capture figures over moduli spaces, that giv es us the ability to capture representation of features of increasing complexity . 5 . 2 L E A R N I N G H I G H E R O R D E R R E P R E S E N TA T I O N S Let’ s recap. A layer of neurons collectively learn a set of figures ov er its own intrinsic space. This is true for any depth, and the learnt figures correspond to the largest stabilizer subgroups. In other 7 Under revie w as a conference paper at ICLR 2015 Ev ery point over the space ( ) learnt by the -th la yer corresponds t o a figure over the space ( ) learnt b y the pr evious lay er . Learning a simple shape ov er theref ore, corresponds t o learning a more complex s tructure over (a) Moduli spaces at subsequent layers ( ( ( ( ( ( ( V arious Shapes genera ted i n (b) Moduli space of line segments Figure 4: A deep network constructs higher order moduli spaces. It learns figures having increas- ingly smaller symmetry groups; which corresponds to increasing complexity words, these figures enjoy highest possible symmetry . The set of simple examples in section 2.3 rev ealed that for S = R 2 , the emerging figures are the edges. For a layer at an arbitrary depth, and working over a very dif ferent space, the corresponding figures are clearly not physical edges. Nev ertheless, we’ll refer to them as Generalized Edges . Figure 4(a) captures a generic multi-layer setting. Let’ s consider the neuron-layer at the i -th level, and let’ s denote the embedding space of the features that it learns as M i - i.e., this layer learns figures ov er the space M i . One such figure, now refereed to as a generalized edge , is schematically sho wn by the geodesic se gment P 1 P 2 in the picture. Thinking do wn recursively , this space M i is clearly a moduli-space of figures ov er the space M i − 1 , so each point in M i corresponds to a generalized edge ov er M i − 1 . The whole segment P 1 P 2 therefore corresponds to a collection of generalized edges o ver M i − 1 ; such a collection in general can clearly hav e lesser symmetry than a generalized edge itself. In other words, a simple object P 1 P 2 ov er M i actually corresponds to a much more complex object ov er M i − 1 . These moduli-spaces are determined by the underlying input-space, and the nature of training. So, doing precise calculations ov er them, such as defining the space of all automorphisms, or computing volumes over corresponding stabilizer sets, may be very difficult, and we are unaw are of any work in this context. Ho wever , the follo wing simple example illustrates the idea quite clearly . 5 . 2 . 1 E X A M P L E S O F H I G H E R O R D E R R E P R E S E N T AT I O N Consider again the intrinsic space R 2 . An edge on this plane is a line segment - [( x 1 , y 1 ) , ( x 2 , y 2 )] . The moduli-space of all such edges therefore is the entire 4-dimensional real Euclidean space sans the origin - R 4 / { 0 } . Figure 4(b) captures this. Each point in this space ( R 4 ) corresponds to an edge over the plane ( R 2 ). A generalized-edge ov er R 4 / { 0 } , which is a standard line-segment in a 4-dimensional euclidean space, then corresponds to a collection of edges over the real plane. Depending on the orientation of this generalized edge upstairs, one can obtain man y dif ferent shapes downstairs. 8 Under revie w as a conference paper at ICLR 2015 The T rapezoid The figure in the leftmost column of figure 4(b) shows a schematic trapezoid. This is obtained from two points P 1 , P 2 ∈ R 4 that correspond to two non-intersecting line-segments in R 2 . A T riangle The middle column sho ws an example where the starting point of the tw o line segments are the same - the connecting gener alized edge between the two points in R 4 is a line parallel to tw o coordinate axes (and perpendicular to the other two). A middle point P m maps to a line-segment that’ s intermediate between the starting lines (see the coordinate values in the figure). Stabilizing P 1 P 2 upstairs effecti vely stabilizes the the triangular area o ver the plane. A Butterfly The third column shows yet another pattern, drawn by two edges that intersect with each other . Plotting the intermediate points of the generalized edge over the plane as lines, a butterfly- like area is swept out. Again, stabilizing the generalized edge P 1 P 2 effecti vely stabilizes the butterfly ov er the plane, that would otherwise take a long time to be found and stabilized by the first layer . More general constructions W e can also imagine e ven more generic shapes that can be learnt this way . Consider a polygon in R 2 . This can be thought of as a collection of triangles (via triangulation), and each composing triangle would correspond to a generalized edge in layer-2. As a result, the whole polygon can be effecti vely learnt by a network with tw o hidden layers. In a nutshell - the mechanism of finding out maximal stabilizers ov er the moduli-space of figures works uniformly across layers. At each layer, the figures with the largest stabilizers are learnt as the candidate features. These figures correspond to more complex shapes over the space learnt by the earlier layers. By adding deeper layers, it then becomes possible to make a network learn increasingly complex objects o ver its originial input-space. 6 R E L A T E D W O R K This starting influence for this paper were the ke y steps described by Hinton & Salakhutdinov (2006), where the authors first introduced the idea of layer-by-layer pre-training through autoen- coders. The same principles, but ov er Restricted Boltzmann machines (RBM), were applied for image recognition in a later work (see Salakhutdinov & Hinton (2009)). Lee et al. (2009) sho wed, perhaps for the first time, ho w a deep network builds up increasingly complex representations across its depth. Since then, several v ariants of autoencoders, as well as RBMs have taken the center stage of the deep learning research. Bengio et al. (in preparation) and Bengio (2013) provide a comprehen- siv e cov erage on almost e very aspect of DL techniques. Although we chose to analyse auto-encoders in this paper, we believ e that the same principle should extend to RBMs as well, especially in the context of a recent work by Kamyshanska & Memisevic (2014), that rev eals seemingly an equiv- alence between autoencoders and RBMs. The y define an energy function for autoencoders that corresponds to the free energy of an RBM. They also point out ho w the energy function imposes a regularization in the space. The hypothesis about an implicit re gularization mechanism was also made earlier by Erhan et al. (2010). Although we haven’ t in vestigated any direct connection between symmetry-stabilization and regularization, there are evidences that they may be connected in subtle ways (for example, see Shah & Chandrasekaran (2012)). Recently Anselmi et al. (2013) proposed a theory for visual-cortex that’ s heavily inspired by the principles of group actions; although there is do direct connection with layer-wise pre-training in that context. Bouvrie et al. (2009) studied inv ariance properties of layered network in a group the- oretic framew ork and showed how to deri ve precise conditions that must be met in order to achieve in variance - this is very close to our w ork in terms of the machineries used, but not about how a un- supervised learning algorithm learns representations. Mehta & Schwab (2014) recently showed an intriguing connection between Renormalization group flow 5 and deep-learning. They constructed an explicit mapping from a renormalization group over a block-spin Ising model (as proposed by Kadanoff et al. (1976)), to a DL architecture. On the face of it, this result is complementary to ours, albeit in a slightly dif ferent settings. Renormalization is a process of coarse-graining a system by first throwing away small details from its model, and then e xamining the new system under the simplified model (see Cardy (1996)). In that sense the orbit-stabilizer principle is a re-normalizable theory - it allo ws for the e xact same coarse-graining operation at e very layer - namely , keeping only minimal orbit shapes and then passing them as new parameters for the next layer - and the theory remains unchanged at ev ery scale. 5 This subject is widely studied in many areas of physics, such as quantum field theory , statistical mechanics and so on 9 Under revie w as a conference paper at ICLR 2015 While generally good at many recognition tasks, DL networks hav e been sho wn to fail in surprising ways. Szegedy et al. (2013) showed that the mapping that a DL network learns could have sudden discontinuities. F or example, sometimes it can misclassify an image that is deri ved by applying only a tiny perturbation to an image that it actually classifies correctly . Even the rev erse was also reported (see Nguyen et al. (2014)) - here, a DL network was tested on grossly perturbed versions of already learnt images - perturbed to the extent that humans cannot recognize them for the original any more - and they were still classified as their originals. Szegedy et al. (2013) made a related observation: random linear combination of high-lev el units in a deep network also serve as good representations. They concluded - it is the space, rather than the individual units, that contain the semantic information in the high layers of a DL network. W e don’t see any specific conflicts of any of these observations with the orbit-stabilizer principle, and view the possible explanations of these phenomena in the clear scope a future work. 7 C O N C L U S I O N S A N D F U T U R E W O R K In a nutshell, this paper b uilds a theoretical framework for unsupervised DL that is primarily inspired by the key principle of finding a generati ve model of the input samples first. The framework is based on orbit-stabilizer interplay in group actions. W e assumed layer-wise pre-training, since it is conceptually clean, yet, in theory , ev en if many layers were being learnt simultaneously (in an unsupervised way , and still based on reconstructing the input signal) the orbit-stabilizer phenomena should still apply . W e also analysed how higher order representations emerge as the networks get deeper . T oday , DL e xpanded well beyond the principles P1 and P2 (ref. introduction). Several factors such as the size of the datasets, increased computational po wer, impro ved optimization methods, domain specific tuning, all contribute to its success. Clearly , this theory is not all-encompassing. In par- ticular , when large enough labeled datasets are av ailable, training them in fullly supervised mode yielded great results. The orbit-stabilizer principle cannot be readily e xtended to a supervised case; in the absence of a self-map (input reconstruction) it is hard to establish a underlying group action. But we believ e and hope that a principled study of how representations form will e ventually put the two under a single theory . 8 A P P E N D I X This section in volv es elementary concepts from dif ferent areas of mathematics. For functional anal- ysis see Bollob ´ as. F or elementary ideas on groups, Lie groups, and representation theory , we rec- ommend Artin; Fulton & Harris. The relev ant ideas in topology can be looked up in Munkres or Hatcher. Lemma 8.1. The gr oup of invertible squar e matrices ar e dense in the set of squar e matrices. Proof - This is a well known result, but we provide a proof for the sake of completeness. Let A be n × n matrix, that is square, and not necessarily in vertible. W e show that there is a non-singular matrix nearby . T o see this, consider an arbitrary non-singular matrix B , i.e. det ( B ) 6 = 0, and consider the following polynomial parametrized by a real number t , r ( t ) = det (( 1 − t ) A + t B )) Since r is finite degree polynomial, and it is certainly not identically zero, as r ( 1 ) = d et ( B ) 6 = 0, it can only v anish at a finite number of points. So, e ven if p ( 0 ) = 0, there must be a t 0 arbitrarily close to 0 such that r ( t 0 ) 6 = 0. So the corresponding ne w matrix M = ( 1 − t 0 ) A + t 0 B is arbitrarily close to A , yet non-singular , as det ( M ) = r ( t 0 ) does not identically vanish. Lemma 8.2. The action of a neural network can be appr oximated by a network that’s completely in vertible. Proof - A three layer neural network can be represented as W 2 σ W 1 , where σ is the sigmoid function, and W 1 and W 2 are linear transforms. σ is already inv ertible, so we only need to show existence of in vertible approximations of the linear components. Let W 1 be a R m × n matrix. Then W 2 is a matrix of dimension R n × m . Consider first the case where m > n . The map W 1 howe ver can be lifted to a R m × m transform, with additional ( m − n ) columns set to zeros. Let’ s call this map W 0 1 . But then, by Lemma 8.1, it is possible to obtain a square inv ertible 10 Under revie w as a conference paper at ICLR 2015 Diff( )) )) Homotopy Lifting from a figure to the entire space Figure 5: Homotopy Extension over the intrinsic space S . An imaginary curve (geodesic) η ov er the diffeomorphisms induces a family of continuous maps from f to f 0 in S . This homotopy can be extended to the entire space S by the homotopy e xtension theorem. transform W 1 that serves as a good approximation for W 0 1 , and hence for W 1 . One can obtain a similar inv ertible approximation W 2 of W 2 in the same way , and thus the composite map W 2 σ W 1 is the required approximation that’ s completely inv ertible. The other case where m < n is easier; it follows from the same logic without the need for adding columns. Lemma 8.3. Let the action of a neur al network ψ over a figur e f be ψ ( f ) = f 0 wher e f , f 0 ⊆ S , the intrinsic space. The action then induces a continuous mapping of the sets f ψ − → f 0 . Proof Let’ s consider an infinitely small subset ε a ⊂ f . Let f a = f \ ε a . The map ψ ( f ) can be described as ψ ( f ) = ψ ( { f a ∪ ε a } ) = f 0 . Now let’ s imagine an infinitesimal deformation of the figure f - by continuously deforming ε a to a new set ε b . Since the change is infinitesimal, and ψ is continuous, the new output, let’ s call it f 00 , dif fers from f 0 only infinitesimally . That means there’ s a subset ε 0 a ⊂ f 0 that got deformed into a ne w subset ε 0 b ⊂ f 00 to gi ve rise to f 00 . This must be true as Lemma 8.2 allo ws us to assume an in vertible mapping ψ - so that a change in the input is detectable at the output. Thus ψ induces a mapping between the infinitesimal sets ε a ψ − → ε 0 a . Now , we can split an input figure into infinitesimal parts and thereby obtain a set-correspondence between the input and output. P RO O F O F T H E O R E M 3 . 1 W e assume that a neural network implements a differentiable map ψ between its input and output. That means the set Ω ⊆ Diff ( C 0 ( X , R )) - i.e. the set of diffeomorphisms of C 0 ( X , R ) . This set admits a smooth structure (see Ajayi (1997)). Moreov er, being parametrized by the neural-network parameters, the set is connected as well, so it makes sense to think of a curve over this space. Let’ s denote the identity transform in this space by 1 . Consider a curve η ( t ) : [ 0 , 1 ] → Diff ( C 0 ( X , R )) , such that η ( 0 ) = 1 and η ( 1 ) = ψ . By Lemma 8.3, η ( t ) defines a continuous map between f and η ( t )( f ) . In other words, η ( t ) induces a partial homotopy on S = X × R . Mathematically , η ( 0 ) = 1 ( f ) = f and η ( 1 ) = ψ ( f ) = f 0 . In other words, the curve η induces a continuous family of deformations of f to f 0 . Refer to figure 5 for a visual representation of this correspondence. In the language of topology such a family of deformations is known as a homotopy . Let us denote this homotopy by φ t : f → f 0 . Now , it is easy to check (and we state without proof) that for a f ∈ C 0 ( X , R ) , the pair ( X × R , f ) satisfies Homotopy Extension property . In addition, there exists an initial mapping Φ 0 : S → S such that Φ 0 | f = φ 0 . This is nothing but the identity mapping. The well known Homotopy Extension Theorem (see Hatcher) then asserts that it is possible to lift the 11 Under revie w as a conference paper at ICLR 2015 same homotopy defined by η from f to the entire set X × R . In other words, there exists a map Φ t : X × R → X × R , such that the restriction Φ t | f = φ t for all t . Clearly then, Φ t = 1 is our intended automorphism on S = X × R , that agrees with the action ψ ( f ) . W e denote this automorphism by γ ( ψ , f ) , and this is an element of Γ , the set of all automorphisms of S . P RO O F O F T H E O R E M 4 . 1 Note that lemma 8.2 already guarantees in vertible mapping beteen f and f 0 = ψ ( f ) . Which means in the context of theorem 3.1, there is an in verse homotopy , that can be extended in the opposite direction. This means γ ( ψ , f ) is actually a homeomorphism, i.e . a continuous in vertible mapping from S to itself. The set Homeo ( S ) is a group by definition. P RO O F O F T H E O R E M 4 . 2 Let ψ ( f ) be the neural network action under consideration. By Theorem 3.1, there is a correspond- ing homeomorphism γ ( ψ , f ) ∈ Γ ( S ) . This is an operator acting S → S , and although not necessarily differentiable everywhere, the operator (by its construction) is differentiable on f . This means it can be locally (in small vicinity of points near f ) approximated by its Fr ´ echet deriv ative (analogue of deriv ativ es ov er Banach space ) near f ; ho wever , in finite dimension this is nothing b ut the Jacobian of the transformation, which can be represented by a finite dimensional matrix. So we have a linear approximation of this deformation γ ( ψ , f ) = J ( γ ( ψ , f ) ) = ˆ γ . But then since this is a homeomorphism, by the inv erse function theorem, ˆ γ − 1 exists. Therefore ˆ γ really represents an element g ψ ∈ GL ( S ) . P RO O F O F T H E O R E M 4 . 3 Let S be the intrinsic space ov er an input vector space X , i.e.S = X × R , and g f ∈ GL ( S ) a stabilizer of a figure f ∈ C 0 ( X , R ) . Define a function χ f : F ( S ) → F ( S ) χ f ( h ) = [ s ∈ h g f ( s ) = h 0 It is easy to see that χ f so defined stabilizes f . Howe ver there is the possibility that - h 0 / ∈ C 0 ( X , R ) ; although h 0 is a figure in S , it may not be a well-defined function o ver X . T o av oid such a pathological case, we make one more assumption - that the set of functions under considerations are all bounded. That means - there exists an upper bound B , such that ev ery f ∈ C 0 ( X , R ) under consideration is bounded in supremum norm - | f | su p p < B 6 . Define an auxiliary function ˆ ζ f : X → R as follows. ˆ ζ f ( x ) = B ∀ x ∈ su p port ( f ) ˆ ζ f ( x ) = 0 otherwise Now , one can always construct a continuous approximation of ˆ ζ f - let ζ f ∈ C 0 ( X , R ) be such an approximation. W e are now ready to define the neural network U ( g f ) = τ f . Essentially it is the collection of mappings between figures (in C 0 ( X , R ) ) defined as follo ws: τ f ( h ) = χ f ( h ) whenev er χ f ( h ) ∈ C 0 ( X , R ) τ f ( h ) = ζ f otherwise T o see why the second part of the theorem holds, observe that since U ( g 1 ) and U ( g 2 ) essentially reflect group actions over the intrinsic space, their action is really defined point-wise. In other words, if p , q ⊆ S are figures, and r = p ∩ q , then the follo wing restriction map holds. U ( g 1 )( p ) | r = U ( g 1 )( q ) | r Now , further observe that given a group element g 1 , and a point x ∈ S , one can always construct a family of figures containing x all of which are v alid functions in C 0 ( X , R ) , and that under the action 6 This is not a restricti ve assumption, in f act it is quite common to assume that all signals have finite energy , which implies that the signals are bounded in supremum norms 12 Under revie w as a conference paper at ICLR 2015 of g 1 they remain valid functions in C 0 ( X , R ) . Let f 1 , f 2 be two such figures such that f 1 ∩ f 2 = x . Now consider x 0 = U ( g 1 )( f 1 ) ∩ U ( g 1 )( f 2 ) . Ho wever , the collection of mapping { x → x 0 } uniquely defines the action of g 1 . So, if g 2 is another group element for which U ( g 2 ) agrees with U ( g 1 ) on ev ery figure, that agreement can be translated to point-wise equality over S , asserting g 1 = g 2 . 8 . 1 A N O T E O N T H E T H R E S H O L D I N G F U N C T I O N In section 5.1 we primarily based our discussion around the sigmoid function that can be thought of as a mechanism for binarization, and thereby produces figures over a moduli space. This moduli space then becomes an intrinsic space for the next layer . Howe ver , the theory extends to other types of thresholding functions as well, only the intrinsic spaces would vary based on the nature of thresholding. For example, using a linear rectification unit, one would get a mapping into the space F [ 0 , ∞ ] ( C 0 ( X , R )) . The elements of this set are functions ov er C 0 ( X , R ) taking values in the range [ 0 , ∞ ] . So, the new intrinsic space for the next le vel will then be S = [ 0 , ∞ ] × C 0 ( X , R )] , and the output can be thought of as a figure in this intrinsic space allowing the rest of the theory to carry ov er . R E F E R E N C E S Ajayi, Deborah. The structure of classical dif feomorphism groups. In The Structure of Classical Diffeomorphism Gr oups . Springer, 1997. Anselmi, Fabio, Leibo, Joel Z., Rosasco, Lorenzo, Mutch, Jim, T acchetti, Andrea, and Poggio, T omaso. Unsupervised learning of in variant representations in hierarchical architectures. CoRR , abs/1311.4158, 2013. URL . Artin, M. Algebra . ISBN 9780130047632. Bengio, Y oshua. Deep learning of representations: Looking forward. CoRR , abs/1305.0445, 2013. URL . Bengio, Y oshua, Goodfellow , Ian, and Courville, Aaron. Deep learning. In Deep Learning . MIT Press, in preparation. URL http://www.iro.umontreal.ca/ ~ bengioy/dlbook/ . Bollob ´ as, B. Linear Analysis: An Intr oductory Course . Cambridge mathematical textbooks. ISBN 9780521655774. Bouvrie, Jake, Rosasco, Lorenzo, and Poggio, T omaso. On in variance in hierar- chical models. In Bengio, Y ., Schuurmans, D., Laf ferty , J.D., Williams, C.K.I., and Culotta, A. (eds.), Advances in Neural Information Pr ocessing Systems 22 , pp. 162–170. Curran Associates, Inc., 2009. URL http://papers.nips.cc/paper/ 3732- on- invariance- in- hierarchical- models.pdf . Cardy , J. Scaling and Renormalization in Statistical Physics . Cambridge Lecture Notes in Physics. Cambridge Uni versity Press, 1996. ISBN 9780521499590. URL http://books.google.com/ books?id=Wt804S9FjyAC . Erhan, Dumitru, Bengio, Y oshua, Courville, Aaron, Manzagol, Pierre-Antoine, V incent, Pascal, and Bengio, Samy . Why does unsupervised pre-training help deep learning? The Journal of Machine Learning Resear ch , 11:625–660, 2010. Fulton, W . and Harris, J. Repr esentation Theory: A Fir st Course . Graduate T exts in Mathematics / Readings in Mathematics. ISBN 9780387974958. Hatcher , A. Algebraic T opolo gy . ISBN 9780521795401. Hinton, Geof frey E. T o recognize shapes, first learn to generate images. Pro gress in br ain r esearc h , 165:535–547, 2007. Hinton, Geoffrey E and Salakhutdino v , Ruslan R. Reducing the dimensionality of data with neural networks. Science , 313(5786):504–507, 2006. 13 Under revie w as a conference paper at ICLR 2015 Hinton, Geof frey E., Osindero, Simon, and T eh, Y ee Whye. A f ast learning algorithm for deep belief nets. Neural Computation , 18:1527–1554, 2006. Kadanoff, Leo P , Houghton, Anthony , and Y alabik, Mehmet C. V ariational approximations for renormalization group transformations. Journal of Statistical Physics , 14(2):171–203, 1976. Kamyshanska, Hannah and Memisevic, Roland. The potential energy of an autoencoder . IEEE T ransactions on P attern Analysis and Mac hine Intelligence (P AMI) , T o Appear , 2014. Lee, Honglak, Grosse, Roger , Ranganath, Rajesh, and Ng, Andrew Y . Conv olutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Pr oceedings of the 26th Annual International Confer ence on Machine Learning , pp. 609–616. A CM, 2009. Mehta, Pankaj and Schwab, David J. An exact mapping between the variational renormalization group and deep learning. arXiv pr eprint arXiv:1410.3831 , 2014. Munkres, J.R. T opology; a F irst Cour se . ISBN 9780139254956. Nguyen, Anh, Y osinski, Jason, and Clune, Jeff. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. arXiv pr eprint arXiv:1412.1897 , 2014. Salakhutdinov , Ruslan and Hinton, Geoffre y E. Deep boltzmann machines. In International Con- fer ence on Artificial Intelligence and Statistics , pp. 448–455, 2009. Shah, Parikshit and Chandrasekaran, V enkat. Group symmetry and covariance regularization. In Information Sciences and Systems (CISS), 2012 46th Annual Confer ence on , pp. 1–6. IEEE, 2012. Szegedy , Christian, Zaremba, W ojciech, Sutskev er, Ilya, Bruna, Joan, Erhan, Dumitru, Goodfellow , Ian, and Fergus, Rob. Intriguing properties of neural networks. arXiv pr eprint arXiv:1312.6199 , 2013. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment