Unbiased sampling of network ensembles
Sampling random graphs with given properties is a key step in the analysis of networks, as random ensembles represent basic null models required to identify patterns such as communities and motifs. An important requirement is that the sampling proces…
Authors: Tiziano Squartini, Rossana Mastr, rea
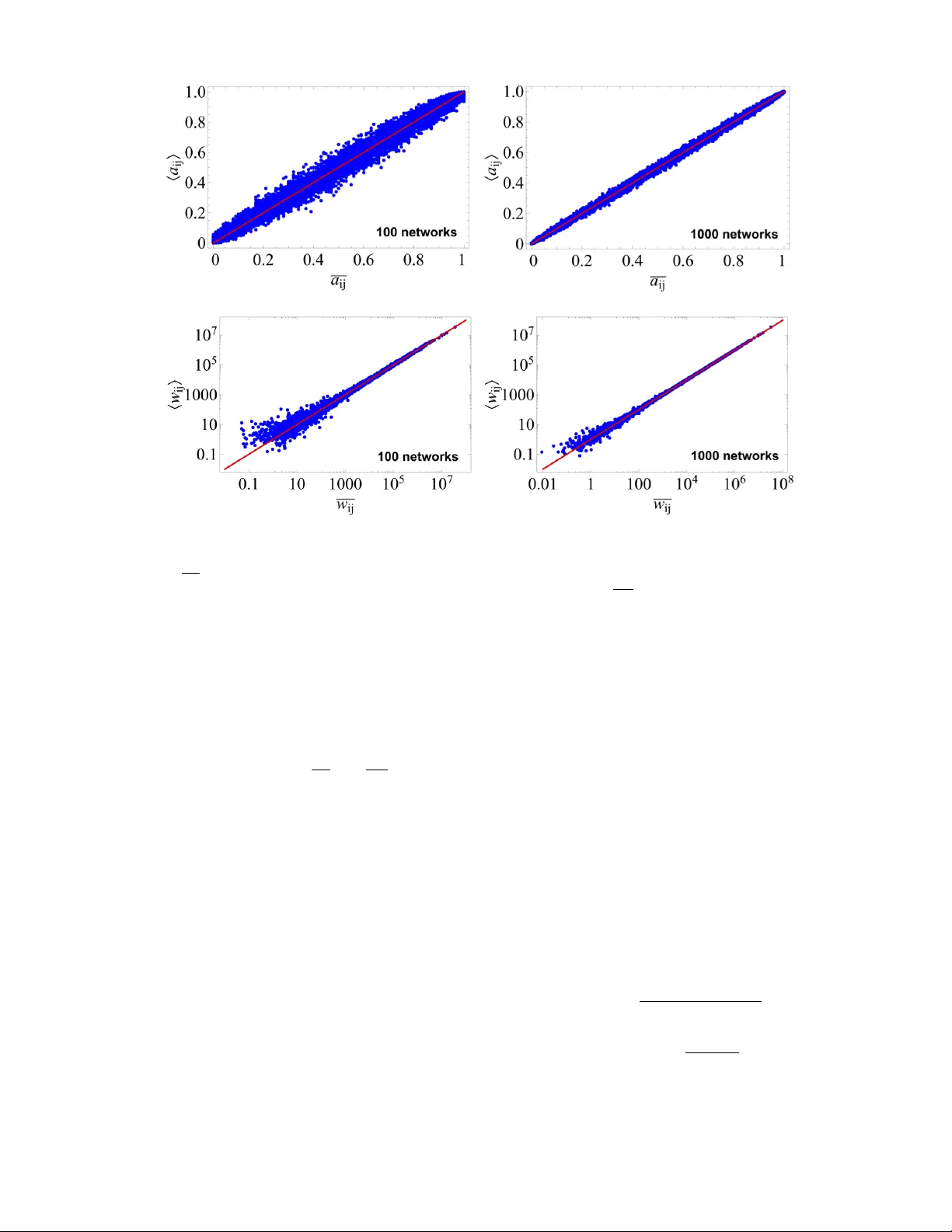
Un biased sampling of net w ork ensem bles Tiziano Squartini Instituut-L or entz for The or etic al Physics, University of L eiden, Niels Bohrwe g 2, 2333 CA L eiden (The Netherlands) Institute for Complex Systems UOS Sapienza, “Sapienza” University of R ome, P.le Aldo Mor o 5, 00185 R ome (Italy) Rossana Mastrandrea Institute of Ec onomics and LEM, Scuola Sup eriore Sant’A nna, 56127 Pisa (Italy) Aix Marseil le Universit ´ e, Universit ´ e de T oulon, CNRS, CPT, UMR 7332, 13288 Marseil le (F r anc e) Diego Garlasc helli Instituut-L or entz for The or etic al Physics, University of L eiden, Niels Bohrwe g 2, 2333 CA L eiden (The Netherlands) (Dated: January 8, 2015) Sampling random graphs with given prop erties is a key step in the analysis of netw orks, as random ensem bles represen t basic n ull mo dels required to iden tify patterns suc h as comm unities and motifs. An imp ortant requiremen t is that the sampling pro cess is unbiased and efficient. The main approac hes are micro canonical, i.e. they sample graphs that match the enforced constraints exactly . Unfortunately , when applied to strongly heterogeneous net works (like most real-w orld examples), the ma jority of these approac hes b ecome biased and/or time-consuming. Moreov er, the algorithms defined in the simplest cases, such as binary graphs with giv en degrees, are not easily generalizable to more complicated ensem bles. Here w e prop ose a solution to the problem via the in tro duction of a “Maximize and Sample” (“Max & Sam” for short) metho d to correctly sample ensembles of netw orks where the constraints are ‘soft’, i.e. realized as ensemble av erages. Our metho d is based on exact maximum-en tropy distributions and is therefore un biased b y construction, even for strongly heterogeneous net works. It is also more computationally efficien t than most micro canonical alternativ es. Finally , it w orks for both binary and weigh ted net w orks with a v ariety of constraints, including com bined degree-strength sequences and full reciprocity structure, for whic h no alternativ e metho d exists. Our canonical approach can in principle b e turned into an un biased microcanonical one, via a restriction to the relev ant subset. Imp ortan tly , the analysis of the fluctuations of the constrain ts suggests that the micro canonical and canonical versions of all the ensembles considered here are not equiv alent. W e sho w v arious real-world applications and provide a co de implemen ting all our algorithms. P ACS n umbers: 05.10.-a,89.75.Hc,02.10.Ox,02.70.Rr I. INTR ODUCTION Net work theory is systematically used to address prob- lems of scientific and societal relev ance [1], from the pre- diction of the spreading of infectious diseases worldwide [2] to the identification of early-warning signals of up- coming financial crises [3]. More in general, several dy- namical and sto chastic pro cesses are strongly affected by the top ology of the underlying netw ork [4]. This results in the need to iden tify the top ological prop erties that are statistically significant in a real netw ork, i.e. to discrimi- nate whic h higher-order properties can b e directly traced bac k to the local features of nodes, and whic h are instead due to additional factors. T o achiev e this goal, one requires (a family of ) ran- domized b enchmarks, i.e. ensembles of graphs where the lo cal heterogeneity is the same as in the real net work, and the top ology is random in any other resp ect: this defines a nul l mo del of the original netw ork. Non triv- ial patterns can then b e detected in the form of empir- ical deviations from the theoretical exp ectations of the n ull mo del [5]. Important examples of such patterns is the presence of motifs (recurring subgraphs of small size, lik e building blo cks of a net work [6]) and c ommunities (groups of no des that are more densely connected in- ternally than with each other [7]). T o detect these and man y other patterns, one needs to correctly sp ecify the n ull model and then calculate e.g. the av erage and stan- dard deviation (or alternatively a confidence in terv al) of an y top ological property of in terest ov er the corresp ond- ing randomized ensemble of graphs. Unfortunately , given the strong heterogeneity of no des (e.g. the p ow er-law distribution of vertex degrees), the solution to the ab ov e problem is not simple. This is most easily explained in the case of binary graphs, even if similar arguments apply to w eighted netw orks as well. F or simple graphs, the most imp ortant null mo del is the (Undirected Binary) Configuration Mo del (UBCM), de- fined as an ensemble of net works where the degree of eac h no de is sp ecified, and the rest of the top ology is maximally random [8 – 10]. Since the degrees of all no des (the so-called de gr e e se quenc e ) act as constraints, “max- imally random” do es not mean “completely random”: in order to realize the degree sequence, interdependencies 2 among vertices necessarily arise. These interdependen- cies affect other top ological prop erties as well. So, even if the degree sequence is the only quantit y that is enforced ‘on purp ose’, other structural prop erties are unav oidably constrained as well. These higher-order effects are called “structural correlations”. In order to disentangle spuri- ous structural correlations from genuine correlations of in terest, it is very imp ortan t to prop erly implement the UBCM in such a wa y that it takes the observed degree sequence as input and generates expectations based on a uniform and efficient sampling of the ensemble. Similar and more challenging considerations apply to other null mo dels, defined e.g. for directed or weigh ted graphs and sp ecified b y more general constraints. Sev eral approaches to the problem hav e b een prop osed and can b e roughly divided in tw o large classes: micr o- c anonic al and c anonic al metho ds. Micro canonical ap- proac hes [11 – 17] aim at artificially generating man y ran- domized v ariants of the observ ed netw ork in suc h a wa y that the constrained prop erties are identical to the em- pirical ones, th us creating a collection of graphs sampling the desired ensemble. In these algorithms the enforced constrain ts are ‘hard’, i.e they are met exactly b y each graph in the resulting ensemble. As we discuss in this pap er, this strong requirement implies that most micro- canonical approaches prop osed so far suffer from v arious problems, including bias, lack of ergo dicity , mathemati- cal in tractability , high computational demands, and po or generalizabilit y . On the other hand, in c anonic al approaches [5, 18– 28] the constraints are ‘soft’, i.e. they can b e violated b y individual graphs in the ensemble, even if the ensem- ble av erage of eac h constraint still matc hes the enforced v alue exactly . Canonical approaches are generally in tro- duced to directly obtain, as a function of the observed constrain ts (e.g. the degree sequence), exact mathemat- ical expressions for the exp ected top ological prop erties, th us a voiding the explicit generation of randomized net- w orks [5]. How ever, this is only p ossible if the mathemat- ical expressions for the top ological prop erties of interest are simple enough to make the analytical calculation of the exp ected v alues feasible. Unfortunately , the most p opular approaches rely on highly appro ximated expres- sions leading to ill-defined or unkno wn probabilities that cannot b e used to sample the ensemble. These approx- imations are in any case av ailable only for the simplest ensem bles (e.g. the UBCM), leaving the problem un- solv ed for more general constraints. This implies that the computational use of c anonical null mo dels has not b een implemen ted systematically so far. In this pap er, by com bining an exact maxim um- lik eliho o d approach with an efficien t computational sam- pling scheme, w e define a rigorously unbiased metho d to sample ensembles of v arious t yp es of netw orks (i.e. directed, undirected, weigh ted, binary) with many p ossi- ble constrain ts (degree sequence, strength sequence, reci- pro cit y structure, mixed binary and weigh ted prop erties, etc.). W e make use of a series of recent analytical results that generate the exact probabilities in all these cases of in terest [5, 21 – 29] and consider v arious examples il- lustrating the usefulness of our metho d when applied to real-w orld net works. W e also analyse the canonical fluctuations of the con- strain ts in each mo del. Previous theoretical analyses of fluctuations in some net w ork ensembles hav e been carried out, for instance, in ref.[37] for graphs with giv en degree sequence and in ref. [38] for graphs with given com m u- nit y structure. Also, a comparison b et ween some mi- cro canonical and canonical netw ork ensem bles has b een carried out in ref. [39]. In this pap er, w e provide a complete analytical c haracterization of the fluctuations of each constraint for all the ensem bles under study . F or the ma jority of these ensembles, the exact analytical ex- pressions characterizing the fluctuations are derived here for the first time. Moreov er, in our maximum-lik eliho o d approac h the knowledge of the hidden v ariables allows us to calculate, for the first time, the exact v alue of the fluctuations explicitly for each no de in the empirical net- w orks considered. Our results suggest that, unlike in most physical systems, the micro canonical and canonical v ersions of the graph ensem bles considered here are sur- prisingly not equiv alent (see ref. [40] for a recent mathe- matical proof of ensem ble nonequiv alence in the UBCM). In an y case, our canonical metho d can in principle b e con verted in to an unbiased microcanonical one, if we dis- card all the sampled net works that violate the sharp con- strain ts. At the end of the paper, we discuss the adv an- tages and disadv an tages of this procedure explicitly , and clarify that canonical ensem bles are more appropriate in presence of missing entries or errors in the data. Finally , we include an appendix with a description of a algorithm that we ha ve explicitly co ded in v arious wa ys [43 – 45]. The algorithm allows the users to sample all the graph ensembles describ ed in this pap er, given an empirically observ ed net work (or ev en only the v alues of the constrain ts). I I. PREVIOUS APPRO ACHES In this section, we briefly discuss the main a v ailable approac hes to the problem of sampling netw ork ensem- bles with given constraints, and highlight the limitations that call for an improv ed solution. W e consider b oth mi- cro canonical and canonical metho ds. In both cases, since the UBCM is the most p opular and most studied ensem- ble, w e will discuss the problem b y fo cusing mainly on the implemen tations of this mo del. The same kind of consid- erations extend to other constraints and other types of net works as well. A. Micro canonical metho ds There hav e b een sev eral attempts to develop mi- cro canonical algorithms that efficiently implemen t the 3 UBCM. One of the earliest algorithm starts with an empt y netw ork having the same num b er of vertices of the original one, where eac h vertex is assigned a n um b er of ‘half edges’ (or ‘edge stubs’) equal to its degree in the real net work. Then, pairs of stubs are randomly matc hed, th us creating the final edges of a random netw ork with the desired degree sequence [10]. Unfortunately , for most empirical net works, the heterogeneity of the degrees is suc h that this algorithm pro duces sev eral multiple edges b et ween v ertices with large degree, and several self-lo ops [11]. If the formation of these undesired edges is forbid- den explicitly , the algorithm gets stuck in configurations where edge stubs hav e no more eligible partners, thus failing to complete any randomized netw ork. T o ov ercome this limitation, a different algorithm (whic h is still widely used) was introduced [11]. This “Lo cal Rewiring Algorithm” (LRA) starts from the orig- inal netw ork, rather than from scratch, and randomizes the top ology through the iteration of an elemen tary mov e that preserves the degrees of all no des. While this al- gorithm alwa ys pro duces random netw orks, it is v ery time consuming since man y iterations of the fundamental mo ve are needed in order to pro duce just one random- ized v ariant, and this entire op eration has to b e rep eated sev eral times (the mixing time b eing still unkno wn [30]) in order to pro duce man y v ariants. Besides these practical problems, the main conceptual limitation of the LRA is the fact that it is biase d , i.e. it does not sample the desired ensem ble uniformly . This has b een rigorously sho wn relativ ely recently [12 – 14]. F or undirected netw orks, uniformity has b een shown to hold, at least approximately , only when the degree sequence is suc h that [12] k max · k 2 / ( k ) 2 N (1) where k max is the largest degree in the netw ork, k is the av erage degree, k 2 is the second moment, and N is the num ber of vertices. Clearly , the abov e condition sets an upp er b ound for the heterogeneity of the degrees of v ertices, and is violated if the heterogeneity is strong. This is a first indication that the a v ailable methods break do wn for ‘strongly heterogeneous’ netw orks. As we dis- cuss later, most real-world netw orks are known to fall precisely within this class. F or directed net w orks, where links are oriented and the constraints to b e met are the n umbers of incoming and outgoing links (in-degree and out-degree) separately , a condition similar to eq.(1) is re- quired to av oid the generation of bias [13]. Again, this condition is strongly violated by most real-w orld net- w orks. Moreov er, the directed v ersion of the LRA is also non-ergo dic, i.e. it is in general not able to explore the en tire ensem ble of net w orks [13]. It has b een shown that ergo dicit y can b e restored by in tro ducing an additional triangular mov e inv erting the direction of closed lo ops of three vertices [13]. How ev er, in order to restore uniformit y (for b oth directed and undi- rected graphs) one needs to introduce an appropriate ac- ceptance probability for the rewiring mov e [12 – 14]. Un- fortunately , the acceptance probabilit y dep ends on some non trivial prop erty of the current net work configuration. Since this prop erty m ust b e recalculated at each step, the resulting algorithm is significantly time consuming. Quan tifying the bias generated b y the LRA when eq.(1) (or its directed counterpart) is violated is difficult, mainly b ecause an exact mathematical c haracterization of mi- cro canonical graph ensembles v alid in such regime is still lac king. Y et, the pro of of the existence of bias pro vided in refs. [12, 13] is an obvious w arning against the use of the LRA on strongly heterogeneous net works. The reader is referred to those pap ers for a discussion. Other recent alternatives [15 – 17] rely on theorems, suc h as the Erd˝ os-Gallai [31] one, that set necessary and sufficien t conditions for a degree sequence to b e gr aphic , i.e. realized by at least one graph. These ‘graphic’ meth- o ds exploit such (or related) conditions to define biased sampling algorithms in conjunction with the estimation of the corresp onding sampling probabilities, thus allow- ing one to statistically rew eight the outcome and sample the ensem ble effectiv ely uniformly [15–17]. Del Genio et al. [15] show that, for netw orks with p ow er-la w degree distribution of the form P ( k ) ∼ k − γ , the computational complexit y of sampling just one graph using their algo- rithm is O ( N 2 ) if γ > 3. Ho w ever, when γ < 3 the computational complexit y increases to O ( N 2 . 5 ) if k max < √ N (2) and to O ( N 3 ) if k max > √ N . The upp er b ound √ N is a particular case of the so-called “structural cut-off ” that w e will discuss in more detail later. F or the moment, it is enough for us to note that eq.(2) is another indication that, for strongly heterogeneous netw orks, the problem of sampling b ecomes more complicated. Unfortunately , most real netw orks violate eq.(2) strongly . So, while ‘graphic’ algorithms do provide a solution for ev ery netw ork, their complexity increases for netw orks of increasing (and more realistic) heterogeneity . A more fundamen tal limitation is that these metho ds can only handle the problem of binary graphs with given degree sequence. The generalization to other types of netw orks and other constrain ts is not straigh tforward, as it would require the pro of of more general ‘graphicality’ theorems, and ad ho c mo difications of the algorithm. B. Canonical metho ds Canonical approaches aim at obtaining, as a function of the observed constrain ts (e.g. the degree sequence), mathematical expressions for the exp ected top ological prop erties, av oiding the explicit generation of random- ized net works. F or canonical metho ds the requirement of uniformit y is replaced b y the requirement that the proa- bilit y distribution ov er the enlarged ensem ble has maxi- m um en tropy [5, 18]. F or binary graphs, since any top ological prop erty X is a function X ( A ) of the adjacency matrix A of the net- 4 w ork (with entries a ij = 1 if the vertices i and j are connected, and a ij = 0 otherwise), the ultimate goal is that of finding a mathematical expression for the proba- bilit y P ( A ) of o ccurrence of each graph. This allows to compute the exp ected v alue of X as P A P ( A ) X ( A ). Im- p ortan tly , for canonical ensem bles with local constraints P ( A ) factorizes to a pro duct ov er pairs of no des, where eac h term in the product inv olves the probability p ij that the vertices i and j are connected in the ensemble. De- termining the mathematical form of p ij is the main goal of canonical approaches. Note that, by contrast, in the micro canonical ensemble all links are dependent on eac h other (the degree sequence must b e repro duced exactly in each realization), which implies that the probabilit y of the entire graph do es not factorize to no de-pair prob- abilities. F or binary undirected netw orks, the most p opular sp ecification for p ij is the factorized one [1, 32, 33]: p ij = k i k j k tot (3) (where k i is the degree of node i and k tot is the total de- gree ov er all no des). F or weigh ted undirected netw orks, where eac h link can hav e a non-negative w eigh t w ij and eac h v ertex i is c haracterized by a giv en strength s i (the total w eight of the links of no de i ), the corresponding assumption is that the exp ected weigh t of the link con- necting the vertices i and j is h w ij i = s i s j s tot (4) (where s tot is the total strength of all vertices). Equations (3) and (4) are routinely used, and ha ve b ecome standard textb ook expressions [1]. The most fre- quen t use of these expressions is p erhaps encoun tered in the empirical analysis of c ommunities , i.e. relatively denser mo dules of vertices in large netw orks [7]. Most comm unity detection algorithms compare different par- titions of vertices in to communities (each partition b eing parametrized by a matrix C suc h that c ij = 1 if the ver- tices i and j b elong to the same comm unit y , and c ij = 0 otherwise) and search for the optimal partition. The lat- ter is the one that maximizes the mo dularity function whic h, for binary netw orks, is defined as Q ( C ) ≡ 1 k tot X i,j h a ij − k i k j k tot i c ij (5) where eq.(3) app ears explicitly as a null mo del for a ij . F or weigh ted netw orks, a similar expression in volving eq.(4) applies. Other imp ortant examples where eq.(3) is used are the characterization of the connected com- p onen ts of net works [33], the a verage distance among v ertices [32], and more in general the theoretical study of p ercolation [1] (characterizing the system’s robustness under the failure of no des and/or links) and other dy- namical processes [4] on net works. Due to the important role that these equations pla y in many applications, it is remark able that the literature puts very little emphasis on the fact that eqs.(3) and (4) are v alid only under strict conditions that, for most real net works, are strongly violated. It is eviden t that eq.(3) represen ts a probability only if the largest degree k max in the net work does not exceed the so-called “structural cut-off ” k c ≡ √ k tot [34], i.e. if k max < p k tot (6) Ob viously , the ab ov e condition sets an upp er b ound for the allo wed heterogeneity of the degrees, since both k max and k tot are determined by the same degree distribution. Unfortunately , as w e discuss b elow, it has b een shown that k max strongly exceeds k c in most real-world net- w orks, making eq.(3) ill-defined. It should b e noted that in principle the knowledge of p ij allo ws one to sample netw orks from the canonical en- sem ble very easily , by running o ver all pairs of no des and connecting them with the appropriate probabilit y . How- ev er, the fact that p ij 1 when k max k c mak es such probabilit y useless for sampling purp oses. This is why , despite their conceptual simplicity , general algorithms to sample canonical ensembles of netw orks hav e not b een implemen ted so far, and the emphasis has remained on micro canonical approac hes. C. The ‘strong heterogeneity regime’ challenging most algorithms Equations (1), (2) and (6), along with our discus- sion ab ov e, show that most metho ds run into problems when the heterogeneit y of the netw ork is to o pronounced: strongly heterogeneous netw orks elude most microcanon- ical and canonical approac hes prop osed so far. Unfortu- nately , net works in this extreme regime are known to be ubiquitous, and represent the rule rather than the excep- tion. A simple wa y to prov e this is by directly chec king whether the largest degree exceeds the structural cut-off k c . As Maslo v et al. first noticed [11], in real net works k c is strongly and systematically exceeded: for instance, for the Internet k max = 1458 and k c ≈ 159, which means that the structural cut-off is exceeded ten-fold. Con- sequen tly , if eq. (3) were applied to the t w o v ertices with largest degree, the resulting connection ‘probabil- it y’ would b e p ij = 43 . 5, i.e. more than 40 times larger than any reasonable estimate for a probability . W e also note that, when inserted in to eq.(5), this v alue of p ij w ould pro duce, in the summation, a single term 40 times larger than any other ‘regular’ (i.e. of order unity) term, th us significantly biasing the communit y detection prob- lem. T o the best of our knowledge, a study of the entit y of this bias has nev er b een performed. The Internet is not a sp ecial case, and similar results are found in the ma jority of real netw orks, making the problem en tirely general. T o see this, it is enough to ex- ploit the fact that most real netw orks hav e a p ow er-law 5 degree distribution of the form P ( k ) ∼ k − γ with exp o- nen t in the range 2 < γ < 3. F or these netw orks, the a verage degree k = k tot / N is finite but the second mo- men t k 2 div erges. Therefore the structural cut-off scales as k c ∼ N 1 / 2 [34], which means that eqs. (2) and (6) coincide. By contrast, Extreme V alue Theory sho ws that the largest degree scales as k max ∼ N 1 / ( γ − 1) [34]. This implies that the ratio k max /k c div erges for large net- w orks, i.e. the largest degree is infinitely larger than the allo wed cut-off v alue. Unfortunately , m an y results and approaches that hav e b een obtained by assuming k max < k c are naively extended to real netw orks where, in most of the cases, k max k c . Therefore, although this might app ear as an exaggerated claim, most analyses of real-world net works (including communit y detection) that hav e b een carried out so far hav e relied on incorrect expressions, and ha ve b een systematically affected by an uncon trolled bias. In theoretical and computational mo dels of netw orks, the problem is normally circumv ented by enforcing the condition k max < k c explicitly , e.g. by considering a truncated p o wer-la w distribution. This pro cedure is usu- ally justified with the exp ectation that the inequality k max < k c should hold for sparse netw orks where the a verage degree does not grow with N , as in most real net- w orks [10, 35]. This in terpretation of the role of sparsit y is how ev er misleading, since in real scale-free netw orks with 2 < γ < 3 the av erage degree is finite irresp ective of the presence of the cut-off. This makes those net- w orks sparse even without assuming a truncation in the degree distribution. As a matter of fact, as clear from the example ab ov e, real netw orks systematically violate the cut-off v alue, and are therefore ‘strongly heterogeneous’, ev en if sparse. By the wa y , the fact that a high density is not the origin of the breakdown of the a v ailable ap- proac hes should b e clear by considering that dense but homogeneous netw orks (including the densest of all, i.e. the complete graph) are such that k max < k c and are therefore correctly describ ed by eq.(3), just lik e sparse homogeneous netw orks. This confirms that the problem is in fact due to str ong heter o geneity and not to high densit y . The ab ov e argumen ts can be extended to other en- sem bles of net w orks with differen t constrain ts. The gen- eral conclusion is that, since real-w orld netw orks are gen- erally strongly heterogeneous, the av ailable approaches either break down or b ecome computationally demand- ing. Moreov er, it is difficult to generalize the av ailable kno wledge to modified constraints and different types of graphs. I I I. THE “MAX & SAM” METHOD In what follows, building on a series of recent results c haracterizing sev eral canonical ensem bles of netw orks [5, 24, 26 – 28], we introduce a unified approach to sam- ple these ensem bles in a fast, unbiased and efficien t wa y . In our approach, the functional form of the probability of each graph in the ensemble is deriv ed by maximizing Shannon’s entrop y [18] (th us ensuring that the sampling is un biased), and the numerical coefficients of this proba- bilit y are derived b y maximizing the probability (i.e. the lik eliho o d) itself [5]. Since this double maximization is the core of our approach, we call our metho d the “Max- imize and Sample” (“Max & Sam” for short) metho d. W e also provide a co de implemen ting all our sampling algorithms (see App endix). W e will consider canonical ensembles of binary graphs with given degree sequence (b oth undirected [5, 21] and directed [5, 21, 23]), of w eighted netw orks with given strength sequence (b oth undirected [5, 22] and directed [5, 22, 23, 26]), of directed net works with giv en reci- pro cit y structure (b oth binary [24, 25] and weigh ted [26]), and of weigh ted netw orks with given combined strength sequence and degree sequence [27 – 29]. In all these cases, that hav e b een treated only separately so far, we imple- men t an explicit sampling proto col based on the exact result that the probability of the en tire netw ork alwa ys factorizes as a product of dyadic probabilities ov er pairs of nodes. This ensures that the computational complex- it y of our sampling metho d is alwa ys O ( N 2 ) in all cases considered here, irresp ective of the level of heterogeneit y of the real-world netw ork b eing randomized. Therefore our metho d do es not suffer from the limitations of the other methods discussed in sec. I I: it is efficient and un- biased ev en for strongly heterogeneous net works. It should b e noted that, while most micro canonical algorithms require as input the entire adjacency ma- trix of the observed graph (see sec. I I A), our canon- ical approac h requires only the empirical v alues of the constrain ts (e.g. the degree sequence). A t a theoreti- cal level, this desirable property restores the exp ectation that such constrain ts should b e the sufficient statistics of the problem. At a practical level, it enormously simpli- fies the data requirements of the sampling pro cess. F or instance, if the sampling is needed in order to reconstruct an unkno wn net work from partial no de-sp ecific informa- tion (e.g. to generate a collection of lik ely graphs consis- ten t with an observed degree and/or strength sequence), then most micro canonical algorithms cannot b e applied, while canonical ones can reconstruct the netw ork to a high degree of accuracy [28]. A. Binary undirected graphs with given degree sequence Let us start b y considering binary , undirected net works (BUNs). A generic BUN is uniquely sp ecified by its bi- nary adjacency matrix A . The particular matrix cor- resp onding to the observed graph that we wan t to ran- domize will b e denoted by A ∗ . As we mentioned, the simplest non-trivial constrain t is the degree sequence, { k i } N i =1 (where k i ≡ P j a ij is the degree of no de i ), defin- ing the UBCM. 6 In our approach, the canonical ensem ble of BUNs is the set of netw orks with the same num b er of no des, N , of the observ ed graph and a n um b er of (undirected) links v arying from zero to the maxim um v alue N ( N − 1) 2 . Appro- priate probability distributions on this ensemble can b e fully determined b y maximizing, in sequence, Shannon’s en tropy (under the chosen constraints) and the likelihoo d function, as already pointed out in [5]. The result of the en tropy maximization [5, 18] is that the graph probabilit y factorizes as P ( A | x ) = Y i Y j 0 1 . A plot of δ [ k i ] as a function of k i for the in terbank netw ork 1 The case k i = 0 also implies σ [ k i ] = 0 and leads to an indeter- minate form for δ [ k i ]. Howev er this case is uninteresting since each isolated no de i remains isolated across the en tire ensem ble ( p ij = 0 ∀ j ) and can be safely remo ved without loss of generality . 8 0 50 100 150 200 0 50 100 150 200 k k 100 120 140 160 180 80 100 120 140 160 180 200 k nn k nn 0.5 0.6 0.7 0.8 0.9 1.0 0.5 0.6 0.7 0.8 0.9 1.0 c c FIG. 2. Sampling binary undirected netw orks with given degree sequence (Undirected Binary Configuration Mo del). The example shown is the binary netw ork of liquidity reserv es exchanges b et ween Italian banks in 1999 [41] (N = 215). The three panels show, for each node in the netw ork, the comparison b etw een the observed v alue and the sample av erage of the (constrained) degree (top), the (unconstrained) ANND (b ottom left) and the (unconstrained) clustering co efficient (b ottom righ t), for 1000 sampled netw orks. The 95% confidence interv als of the distribution of the sampled quantities is sho wn in pink for each node. considered ab ov e is shown in fig. 3. W e find that the relativ e fluctuations v anish for v ertices with large degree, while they are v ery large for vertices with mo derate and small degree. In particular, δ [ k i ] ≈ 1 when k i = 1. In general, we note that the term P j 6 = i p 2 ij / ( P j 6 = i p ij ) 2 in eq.(11) is a p articip ation r atio 2 , measuring the in verse of the effective n umber of equally imp ortant terms in the sum P j 6 = i p ij : in particular, it equals 1 if and only if there is only one nonzero term (complete concentration), while it equals ( N − 1) − 1 if and only if there are N − 1 identical terms (complete homogeneit y), i.e. p ij = k i / ( N − 1) for all j 6 = i . Since these are the tw o extreme bounds for a participation ratio, and since in the case of complete concen tration we also ha ve k i = 1, we conclude that the b ounds for δ [ k i ] are 0 ≤ δ [ k i ] ≤ r 1 k i − 1 N − 1 . (12) The resulting allow ed region for δ [ k i ] is the one comprised b et ween the abscissa and the dashed line in fig.3. W e find 2 Strictly sp eaking, it is the inv erse of a so-called inverse p artici- p ation r atio , but w e av oid the use of ‘in v erse’ t wice. that the realized trend is close to the upper b ound. This suggests that the maximum-en trop y nature of our algo- rithm pro duces almost maximally homogeneous terms in the sum P j 6 = i p ij , i.e. no particular subset of vertices is preferred as canditate partners for i , the only preference b eing ob viously given (as a consequence of the explicit form of p ij in terms of x i and x j ) to vertices with larger degree. Since the degree distribution of most real-world net- w orks is such that the av erage degree remains finite even when the size of the netw ork b ecomes very large, the ab o ve results suggest that, unlike most physical systems, the micro canonical and canonical ensembles defined by the UBCM are not equiv alent in the ‘thermo dynamic’ limit N → ∞ . While eq.(12) sho ws that v alues closer to the low er b ound δ [ k i ] = 0 can b e in principle achiev ed, the maximization of the en tropy app ears to push the ensem ble tow ards the opp osite upp er b ound where the equiv alence of the micro canonical and canonical ensem- bles is maximally violated. On the other hand, one might in principle construct synthetic netw orks with sufficiently large degrees, suc h that the canonical fluctuations are ar- bitrarily small and the t wo ensembles arbitrarily close. 9 10 0 10 1 10 2 10 3 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 k i δ [k i ] FIG. 3. Co efficient of v ariation δ [ k i ] as a function of the degree k i for eac h no de of the binary netw ork of liquidit y reserv es exchanges b etw een Italian banks in 1999 [41] ( N = 215). The blue p oints are the exact v alues in eq.(11), while the dashed curve is the upp er b ound in eq.(12). The low er b ound is the abscissa δ [ k i ] = 0. B. Binary directed graphs with given in-degree and out-degree sequences F or binary directed netw orks (BDNs), the adjacency matrix A is (in general) not symmetric, and each no de i is characterized b y tw o degrees: the out-degree k out i ≡ P j a ij and the in-degree k in i ≡ P j a j i . The Dir e cte d Binary Configur ation Mo del (DBCM), which is the di- rected version of the UBCM, is defined as the ensem ble of BDNs with given out-degree sequence { k out i } N i =1 and in-degree sequence { k in i } N i =1 . A t a canonical level, the DBCM is defined on the en- sem ble of all BDNs with N v ertices and a num b er of links ranging from 0 to N ( N − 1). Equation (7) still applies, but now with “ j < i ” replaced by “ j 6 = i ” and p ij = x i y j 1+ x i y j , where the 2 N parameters x and y are de- termined b y either maximizing the log-likelihoo d func- tion [5] λ ( x , y ) ≡ ln P ( A ∗ | x , y ) = (13) = X i k out i ( A ∗ ) ln x i + k in i ( A ∗ ) ln y i − X i X j 6 = i ln(1 + x i y j ) (where A ∗ is the real netw ork) or, equiv alently , by solving the system of 2 N equations [5] h k out i i = X j 6 = i x i y j 1 + x i y j = k out i ( A ∗ ) ∀ i (14) h k in i i = X j 6 = i x j y i 1 + x j y i = k in i ( A ∗ ) ∀ i. (15) The parameters x and y v ary in the region defined by x i ≥ 0 and y i ≥ 0 for all i respectively [5]. The ensemble can b e efficiently sampled b y consider- ing each pair of vertices twic e , and using (say) p ij and p j i to draw directed links in the tw o directions (these t wo even ts b eing statistically indep endent). Since this is a straightforw ard extension of the UBCM, w e do not consider any sp ecific example to illustrate the DBCM. Ho wev er, the related algorithm has b een implemented in the code (see Appendix). W e conclude the discussion of this ensemble with the calculation of the canonical fluctuations. In analogy with eqs.(10) and (11), the v ariances of k out i and k in i are given b y σ 2 [ k out i ] = X j 6 = i p ij (1 − p ij ) = k out i − X j 6 = i p 2 ij , (16) σ 2 [ k in i ] = X j 6 = i p j i (1 − p j i ) = k in i − X j 6 = i p 2 j i . (17) F or k out i > 0 and k in i > 0, the relative fluctuations are δ [ k out i ] ≡ σ [ k out i ] k out i = s 1 k out i − P j 6 = i p 2 ij ( P j 6 = i p ij ) 2 , (18) δ [ k in i ] ≡ σ [ k in i ] k in i = s 1 k in i − P j 6 = i p 2 j i ( P j 6 = i p j i ) 2 . (19) The ab ov e quantities still inv olve participation ratios de- fined b y the connection probabilities. F or the b ounds of δ [ k out i ] and δ [ k in i ], considerations similar to those leading to eq.(12) apply here. C. Binary directed graphs with given degree sequences and recipro city structure A more constrained null mo del, the R e cipr o c al Binary Configur ation Mo del (RBCM), can b e defined for BDNs b y enforcing, in addition to the tw o directed degree se- quences considered ab ov e, the whole lo cal recipro city structure of the net work [5, 24, 25]. This is equiv alence to the sp ecification of the three degree sequences defined as the vector of the num b ers of non-recipro cated outgo- ing links, { k → i } N i =1 , the vector of the num b ers of non- recipro cated incoming links, { k ← i } N i =1 , and the vector of the n umbers of recipro cated links, { k ↔ i } N i =1 [5, 24, 25]. These n umbers are defined as k → i ≡ P j a ij (1 − a j i ), k ← i ≡ P j a j i (1 − a ij ), and k ↔ i ≡ P j a ij a j i resp ectiv ely [24, 25]. The RBCM is of crucial imp ortance when analysing higher-order patterns that exist b eyond the dy adic level in directed netw orks. The most imp ortant example is that of triadic motifs [3, 6, 25], i.e. patterns of connectiv- it y (inv olving triples of no des) that are statistically ov er- or under-represen ted with respect to a null mo del where the observ ed degree sequences and recipro city structure are preserved (i.e. the RBCM). Note that in this case no 10 appro ximate canonical expression similar to eq.(3) exists, therefore the null mo del is usually implemented micro- canonically using a generalization of the LRA that we ha ve discussed in sec. I I A. Conceptually , this pro cedure suffers from the same problem of bias as the simpler pro- cedures used to implement the UBCM and the DBCM through the LRA [12–14]. T o our knowledge, in this case no correction analogous to that prop osed in ref. [13] has b een dev eloped in order to restore uniformity . In our “Max & Sam” approach, we exploit kno wn an- alytical results [5, 24, 25] showing that the probability of eac h graph A in the RBCM is P ( A | x , y , z ) = Y i Y j 0, k ← i > 0 and k ↔ i > 0, the relative fluctua- tions are δ [ k → i ] ≡ σ [ k → i ] k → i = s 1 k → i − P j 6 = i ( p → ij ) 2 ( P j 6 = i p → ij ) 2 , (28) δ [ k ← i ] ≡ σ [ k ← i ] k ← i = s 1 k ← i − P j 6 = i ( p ← j i ) 2 ( P j 6 = i p ← j i ) 2 , (29) δ [ k ↔ i ] ≡ σ [ k ↔ i ] k ↔ i = s 1 k ↔ i − P j 6 = i ( p ↔ j i ) 2 ( P j 6 = i p ↔ j i ) 2 . (30) Th us, in all the ensem bles considered so far (whic h are defined in terms of pur ely binary constraints), the squared relative fluctuation of each constrain t alwa ys tak es the form of the in verse of the v alue of the constraint itself, minus the participation ratio of the corresp onding probabilities. D. W eighted undirected net works with giv en strength sequence Let us no w consider weigh ted undirected netw orks (WUNs). Differently from the binary case, link weigh ts can now range from zero to infinity by (without loss of generalit y) in teger steps. The num b er of configurations in the canonical ensemble is therefore infinite. Still, en- forcing node-sp ecific constraints implies that a prop er probabilit y measure can b e defined ov er the ensemble, suc h that the av erage v alue of an y netw ork prop erty of in terest is finite [5]. A single graph in the ensemble is no w sp ecified by its (symmetric) w eight matrix W , where the en try w ij represen ts the integer weigh t of the link con- necting no des i and j ( w ij = 0 means that no link is there). W e denote the particular real-world w eighted net- w ork as W ∗ . Each vertex is characterized by its str ength s i = P j w ij represen ting the weigh ted analogue of the degree. The weigh ted, undirected counterpart of the UBCM is the Undir e cte d Weighte d Configur at ion Mo del (UWCM). The constraint defining it is the observed strength se- quence, { s i } N i =1 . Lik e its binary analogue, the UBCM is widely used in order to detect communities and other 11 higher-order patterns in undirected w eighted net works. Ho wev er, most approaches [1] incorrectly assume that this mo del is characterized by eq. (4), which is instead only a highly simplified expression [5]. In the canonical ensemble, the probability of each w eighted netw ork W is [5] P ( W | x ) = Y i Y j 0. A plot of δ [ s i ] as a function of s i for the inter- bank netw ork is shown in fig. 6. Unlike in the UBCM, here the relative fluctuations are found to b e smaller for in termediate v alues of the strength. When comparing eq.(35) with eq.(11), it is interesting to notice that the term P j 6 = i h w ij i 2 / ( P j 6 = i h w ij i ) 2 , while still b eing a participation ratio 3 , is now predeced by a 3 In this case, the participatio ratio measures the inv erse of the ef- 12 FIG. 4. Sampling weigh ted undirected netw orks with given strength sequence (Undirected W eighted Configuration Mo del). The example sho wn is the weigh ted netw ork of liquidity reserves exc hanges betw een Italian banks in 1999 [41] (N = 215). The four panels sho w the con vergence of the sample a v erage w ij of eac h entry of the w eight matrix to its exact canonical expectation h w ij i , for 1 (top left), 10 (top righ t), 100 (bottom left) and 1000 (b ottom right) sampled netw orks. The identit y line is sho wn in red. p ositive sign. This implies that the b ounds for δ [ s i ] are quite differen t from those for δ [ k i ] sho wn in eq.(12): r 1 s i + 1 N − 1 ≤ δ [ s i ] ≤ r 1 s i + 1 . (36) The allow ed region for δ [ s i ] is the one ab ov e the dashed line in fig.6, and extends b eyond 1. W e now find that the realized trend is v ery close to the lower b ound for small and intermediate v alues of the strength (again suggest- ing that in this regime our maximum-en trop y metho d pro duces almost maximally homogeneous terms in the sum P j 6 = i h w ij i ), while it exceeds the low er b ound signif- ican tly for large v alues of the strength. In any case, since eq.(36) implies that δ [ s i ] cannot v anish for any v alue of s i , we find evidence of the fact that for this mo del the micro canonical and canonical ensembles are always not equiv alent. fective num b er of equally important terms in the sum P j 6 = i h w ij i . It equals 1 if and only if there is only one nonzero term (complete concentration, which still implies h k i i = 1 but not s i = 1), while it equals ( N − 1) − 1 if and only if there are N − 1 identical terms (complete homogeneit y), i.e. h w ij i = s i / ( N − 1) for all j 6 = i . E. W eighted directed net works with giv en in-strength and out-strength sequences W e now consider w eighted directed net works (WDNs), defined by a weigh t matrix W which is in general not symmetric. Eac h no de is now characterized by tw o strengths, the out-strength s out i ≡ P j w ij and the in- strength s in i ≡ P j w j i . The Dir e cte d Weighte d Con- figur ation Mo del (DW CM), the directed v ersion of the UW CM, enforces the out- and in-strength sequences, { s out i } N i =1 and { s in i } N i =1 , of a real-world netw ork W ∗ [5, 22, 23]. The mo del is widely used to detect mo dules and comm unities in real WDNs [1]. In its canonical version, the DW CM is still character- ized b y eq.(31) where “ j < i ” is replaced b y “ j 6 = i ” and no w p ij ≡ x i y j . The 2 N unknown parameters x and y can b e fixed by either maximizing the log-lik eliho o d function [5] λ ( x , y ) ≡ ln P ( W ∗ | x , y ) = (37) = X i s out i ( W ∗ ) ln x i + s in i ( W ∗ ) ln y i + X i X j 6 = i ln(1 − x i y j ) 13 100 1000 10 4 10 100 1000 10 4 s s 1760 1780 1800 1820 1840 1000 2000 3000 4000 5000 6000 7000 s nn s nn 10 100 50 20 200 30 10 100 50 20 30 c w c w FIG. 5. Sampling weigh ted undirected netw orks with given strength sequence (Undirected W eighted Configuration Mo del). The example sho wn is the weigh ted netw ork of liquidity reserves exc hanges betw een Italian banks in 1999 [41] (N = 215). The three panels show, for each node in the netw ork, the comparison b etw een the observed v alue and the sample av erage of the (constrained) strength (top), the (unconstrained) ANNS (b ottom left) and the (unconstrained) weigh ted clustering coefficient (b ottom right), for 1000 sampled netw orks. The 95% confidence interv als of the distribution of the sampled quantities is shown in pink for eac h no de. or solving the the 2 N equations [5] h s out i i = X j 6 = i x i y j 1 − x i y j = s out i ( W ∗ ) ∀ i (38) h s in i i = X j 6 = i x j y i 1 − x j y i = s in i ( W ∗ ) ∀ i, (39) where in b oth cases the parameters x and y v ary in the region defined by 0 ≤ x i y j < 1 for all i, j [26]. Once the unknown v ariables are found, we can imple- men t an efficient and unbiased sampling sc heme in the same wa y as for the UWCM, but no w running ov er eac h pair of vertices twic e (i.e. in b oth directions). One can establish the weigh t of a link from v ertex i to v ertex j using the geometric distribution p w ij (1 − p ij ), and the w eight of the rev erse link from j to i using the geometric distribution p w j i (1 − p j i ), these tw o even ts b eing indep en- den t. Alternatively , as for the undirected case, one can construct these random ev ents as a combination of fun- damen tal Bernoulli trials with success probability p ij and p j i . Since this directed generalization of the undirected case is straightforw ard, we do not consider any explicit application. How ever, we hav e explicitly included the D WCM mo del in the code (see Appendix). W e no w come to the canonical fluctuations. In analogy with eq.(34), it is e asy to show that the v ariances of s out i and s in i are giv en b y σ 2 [ s out i ] = X j 6 = i h w ij i (1 + h w ij i ) = s out i + X j 6 = i h w ij i 2 , (40) σ 2 [ s in i ] = X j 6 = i h w j i i (1 + h w j i i ) = s in i + X j 6 = i h w j i i 2 . (41) F or s out i > 0 and s in i > 0, the relative fluctuations are δ [ s out i ] ≡ σ [ s out i ] s out i = s 1 s out i + P j 6 = i h w ij i 2 ( P j 6 = i h w ij i ) 2 , (42) δ [ s in i ] ≡ σ [ s in i ] s in i = s 1 s in i + P j 6 = i h w j i i 2 ( P j 6 = i h w j i i ) 2 . (43) F or the bounds of the ab ov e quan tities, expressions sim- ilar to eq.(36) apply , suggesting that the micro canoni- cal and canonical versions of this ensemble are also not equiv alent. 14 10 100 1000 100000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 s i δ [s i ] FIG. 6. Co efficien t of v ariation δ [ s i ] as a function of the strength s i for each no de of the binary netw ork of liquidity reserv es exchanges b etw een Italian banks in 1999 [41] ( N = 215). The blue p oints are the exact v alues in eq.(35), while the dashed curve is the low er b ound in eq.(36). The upp er b ound exceeds 1 and extends beyond the region sho wn. F. W eighted directed net works with giv en strength sequences and recipro city structure In analogy with the binary case, w e now consider the R e cipr o c al Weighte d Configur ation Mo del (R W CM), whic h is a recently prop osed n ull mo del that for the first time allows one to constrain the recipro cit y structure in w eighted directed netw orks [26]. The R W CM enforces three strengths for each no de: the non-recipro cated in- coming strength, s ← i ≡ P j w ← ij , the non-recipro cated outgoing strength, s → i ≡ P j w → ij , and the recipro cated strength, s ↔ i ≡ P j w ↔ ij [26]. Such quantities are de- fined by means of three pair-sp ecific v ariables: w ↔ ij ≡ min[ w ij , w j i ] (recipro cated weigh t), w → ij ≡ w ij − w ↔ ij and w ← ij ≡ w j i − w ↔ ij (non-recipro cated w eigh ts). Despite its complexit y , the R W CM is analytically solv- able [26] and the graph probabilit y factorizes as: P ( W | x , y , z ) = Y i Y j 0, w ← ij = 0) with probability x i y j (1 − x j y i ) 1 − x i x j y i y j , we establish the existence of a non-recipro cated weigh t from j to i ( w → ij = 0, w ← ij > 0) with probabilit y x j y i (1 − x i y j ) 1 − x i x j y i y j . Third, if a non-recipro cated connection has b een established (i.e. if its w eigh t w is p ositive) we then focus on the v alue to b e assigned to it (i.e. on the extra weigh t w − 1). If w → ij > 0, we draw the weigh t w → ij from a geometric dis- tribution ( x i y j ) w → ij − 1 (1 − x i y j ) (shifted to strictly p ositive in teger v alues of w → ij via the rescaled exponent), while if w ← ij > 0 w e dra w the weigh t w ← ij from the distribution ( x j y i ) w ← ij − 1 (1 − x j y i ). The recip e describ ed abov e is still of complexit y O ( N 2 ) and allows us to sample the canonical ensem ble of the R W CM in an unbiased and efficien t wa y . It should b e noted that the microcanonical analogue of this algorithm has not b een prop osed so far. As for the DW CM, w e sho w no explicit application, ev en if the en tire algorithm is a v ailable in our co de (see App endix). In this model, the canonical fluctuations are somewhat 15 more compicated than in the previous mo dels. The v ari- ances of the constraints are σ 2 [ s → i ] = X j 6 = i x i y j (1 − x j y i )(1 − x 2 i x j y i y 2 j ) (1 − x i y j ) 2 (1 − x i x j y i y j ) 2 , (49) σ 2 [ s ← i ] = X j 6 = i x j y i (1 − x i y j )(1 − x i x 2 j y 2 i y j ) (1 − x j y i ) 2 (1 − x i x j y i y j ) 2 (50) σ 2 [ s ↔ i ] = X j 6 = i z i z j (1 − z i z j ) 2 . (51) While for the v ariance of the recipro cated weigh t we can still write σ 2 [ w ↔ ij ] = h w ↔ ij i (1 + h w ↔ ij i ) in analogy with the UW CM and DW CM, similar relations do not hold for the non-recipro cated w eigh ts. How ever, since x i y j < 1 for all i, j , it is easy to show that σ 2 [ w → ij ] > h w → ij i (1 + h w → ij i ) and σ 2 [ w ← ij ] > h w ← ij i (1 + h w ← ij i ). This still allows us to obtain a lo wer b ound for all quantities as in the other w eighted mo dels, by using σ 2 [ s → i ] > X j 6 = i h w → ij i (1 + h w → ij i ) = s → i + X j 6 = i h w → ij i 2 , (52) σ 2 [ s ← i ] > X j 6 = i h w ← ij i (1 + h w ← ij i ) = s ← i + X j 6 = i h w ← ij i 2 , (53) σ 2 [ s ↔ i ] = X j 6 = i h w ↔ ij i (1 + h w ↔ ij i ) = s ↔ i + X j 6 = i h w ↔ ij i 2 . (54) Then, for s → i > 0, s ← i > 0 and s ↔ i > 0, we get δ [ s → i ] ≡ σ [ s → i ] s → i > s 1 s → i + P j 6 = i h w → ij i 2 ( P j 6 = i h w → ij i ) 2 , (55) δ [ s ← i ] ≡ σ [ s ← i ] s ← i > s 1 s ← i + P j 6 = i h w ← ij i 2 ( P j 6 = i h w ← ij i ) 2 , (56) δ [ s ↔ i ] ≡ σ [ s ↔ i ] s ↔ i = s 1 s ↔ i + P j 6 = i h w ↔ ij i 2 ( P j 6 = i h w ↔ ij i ) 2 . (57) Therefore, for all three quantities, a low er b ound of the form δ [ s i ] ≥ q 1 s i + 1 N − 1 still applies, as in eq.(36). This suggests that, for this mo del as w ell, the micro canonical and canonical ensembles are not equiv alent. G. W eighted undirected net works with giv en strengths and degrees W e finally consider a ‘mixed’ null mo del of weigh ted net works with b oth binary (degree sequence { k i } N i =1 ) and weigh ted (strength sequence { s i } N i =1 ) constraints. W e only consider undirected netw orks for simplicity , but the extension to the directed case is straightfor- w ard. The ensemble of w eighted undirected netw orks with giv en strengths and degrees has b een recently in tro- duced as the (Undir e cte d) Enhanc e d Configur ation Mo del (UECM) [28, 29]. This model, which is based on analytical results de- riv ed in [27], is of great imp ortance for the problem of network r e c onstruction from partial no de-sp ecific infor- mation [28]. As we hav e also illustrated in fig.5, the kno wledge of the strength sequence alone is in general not enough in order to reproduce the higher-order prop- erties of a real-world weigh ted netw ork [22, 23]. Usually , this is due to the fact that the exp ected top ology is m uc h denser than the observed one (often the exp ected netw ork is almost fully connected). By contrast, it turns out that the simultaneous sp ecification of strengths and degrees, b y constraining the lo cal connectivity to b e consistent with the observed one, allows a dramatically improv ed reconstruction of the higher-order structure of the origi- nal w eigh ted net work [28, 29]. This very promising result calls for an efficient imple- men tation of the UECM. W e now describ e an appro- priate sampling pro cedure. The probability distribution c haracterizing the UECM is halfwa y b etw een a Bernoulli (F ermi-like) and a geometric (Bose-lik e) distribution [27], and reads P ( W | x , y ) = Y i Y j 0 The ab ov e expression identifies tw o key steps: the mo del is equiv alent to one where the ‘first link’ (of unit weigh t) is extracted from a Bernoulli distribution with probabil- it y p ij and where the ‘extra weigh t’ ( w ij − 1) is extracted 16 FIG. 7. Sampling weigh ted undirected net works with giv en degree and strength sequences (Undirected Enhanced Configuration Mo del). The example shown is the w eigh ted W orld T rade W eb (N = 162) [42]. The top panels show the con v ergence of the sample av erage a ij of each entry of the adjacency matrix to its exact canonical exp ectation h p ij i , for 100 (left) and 1000 (righ t) sampled matrices. The b ottom panels show the conv ergence of the sample a verage w ij of eac h entry of the weigh t matrix to its exact canonical expectation h w ij i , for 100 (left) and 1000 (right) sampled netw orks. The identit y line is sho wn in red. from a geometric distribution (shifted to the strictly p os- itiv e integers) with parameter y i y j . As all the other ex- amples discussed so far, this algorithm can be easily im- plemen ted. In fig. 7 w e provide an application of this metho d to the W orld T rade W eb [21, 22, 42]. W e show the con- v ergence of the sample av erages ( a ij and w ij ) of the en- tries of b oth binary and weigh ted adjacency matrices to their exact canonical exp ectations ( h a ij i and h w ij i re- sp ectiv ely). As in the previous cases, generating 1000 matrices is enough to guarantee a tight conv ergence of the sample av erages to their exact v alues (in an y case, this accuracy can b e quantified and improv ed b y sam- pling more matrices). F or this sample of 1000 matrices, in the top plots (tw o in this case) of fig. 8 we confirm that b oth the binary and weigh ted constraints are w ell repro duced b y the sam- ple av erages. When we use this null mo del to chec k for higher-order patterns in this netw ork, we find that tw o imp ortan t top ological quantities of in terest (ANND and ANNS, b ottom panels of fig. 8) are w ell replicated by the model. These results are consisten t with what is obtained analytically by using the same canonical null mo del on the same net work [29]. Moreo ver, in this case w e can calculate confidence interv als besides exp ected v alues (for instance, in fig. 8 we can clearly identify outliers that are otherwise undetected), and do this for an y desired top ological prop erty , not only those whose exp ected v alue is analytically computable. Our metho d therefore represents an improv ed algorithm for the un bi- ased reconstruction of weigh ted netw orks from strengths and degrees [28]. The canonical fluctuations in this ensem ble can be also calculated analytically . F or the v ariance of the degrees, w e can still exploit the expression σ 2 [ a ij ] = p ij (1 − p ij ). F or the v ariance of the strengths, we can use the defi- nition σ 2 [ w ij ] = h w 2 ij i − h w ij i 2 , which how ever leads to a more complicated expression in this case. Using the relation h w ij i = p ij / (1 − y i y j ), the end result can b e expressed as follows: σ 2 [ k i ] = X j 6 = i p ij (1 − p ij ) , (62) σ 2 [ s i ] = X j 6 = i p ij (1 + y i y j − p ij ) (1 − y i y j ) 2 = X j 6 = i h w ij i 1 + y i y j 1 − y i y j − h w ij i . (63) Since (1+ y i y j ) / (1 − y i y j ) ≥ 1, w e can obtain the following 17 20 40 60 80 100 120 140 160 20 40 60 80 100 120 140 160 k k 10 4 10 5 10 6 10 7 10 8 10 4 10 5 10 6 10 7 10 8 s s 110 120 130 140 150 110 120 130 140 150 k nn k nn s nn s nn 5∙10 10 2∙10 10 7 2∙10 7 5∙10 6 6 7 7 FIG. 8. Sampling weigh ted undirected net works with giv en degree and strength sequences (Undirected Enhanced Configuration Mo del). The example shown is the w eighted W orld T rade W eb (N = 162) [42]. The four panels show, for each no de in the netw ork, the comparison b etw een the observed v alue and the sample av erage of the (constrained) degree (top left), the (constrained) strength (top right), the (unconstrained) ANND (b ottom left) and the (unconstrained) ANNS (b ottom right), for 1000 sampled netw orks. The 95% confidence interv als of the distribution of the sampled quantities is shown in pink for eac h no de. relations for the relative fluctuations: δ [ k i ] ≡ σ [ k i ] k i = s 1 k i − P j 6 = i p 2 ij ( P j 6 = i p ij ) 2 , (64) δ [ s i ] ≡ σ [ s i ] s i ≥ s 1 s i − P j 6 = i h w ij i 2 ( P j 6 = i h w ij i ) 2 . (65) So δ [ k i ] retains the same expression v alid for the UBCM and all the other ensembles of binary graphs considered previously , whic h in turn leads to the same b ounds as in eq.(12). This is confirmed in fig.9. By con trast, δ [ s i ] has a more complicated form, whic h differs from that v alid for the UWCM and do es not lead to simple expressions for the upp er and low er b ounds. Also note the presence of a minus sign in eq.(65). What can b e concluded relatively easily is that, in the ideal limit y i → 0 (corresp onding to v ery small v alues of s i ), we hav e h w ij i → p ij whic h im- plies s i → k i and δ [ s i ] → δ [ k i ]. This means that, in this extreme (and typically unrealized) limit, δ [ s i ] b ehav es as δ [ k i ], so it has the same upp er b ound q 1 k i − 1 N − 1 . How- ev er, since y i is typically larger than zero, this b ound is systematically exceeded, esp ecially for large v alues of s i . This is also confirmed in fig.9. As in the other mo dels, the non-v anishing of the fluctuations suggests that the micro canonical and canonical ensembles are not equiv a- len t. IV. MICR OCANONICAL CONSIDERA TIONS In this section we come bac k to the difference betw een canonical and micro canonical approaches to the sampling of netw ork ensembles and discuss how, at least in prin- ciple, our method can b e turned in to an un biased micro- canonical one. W e provided evidence that, for all the mo dels con- sidered in this pap er, the canonical and micro canonical ensem bles are not equiv alen t (see also [40] for a recent mathematical pro of of nonequiv alence for the UBCM). This result implies that choosing b et ween micro canoni- cal and canonical approaches to the sampling of netw ork ensem bles is not only a matter of (computational) con- v enience, but also a theoretical issue that should b e ad- dressed more formally . T o this end, we recall that micro canonical ensembles describ e isolated systems that do not interact with an external ‘heat bath’ or ‘reservoir’. In ordinary statisti- cal physics, this means that there is no exc hange of en- ergy with the external w orld. In our setting, this means 18 10 2 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 k i δ [k i ] 10 4 10 6 10 8 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 s i δ [s i ] FIG. 9. Coefficients of v ariation δ [ k i ] (left) and δ [ s i ] (right), plotted as a function of the degree k i and the strength s i resp ectiv ely , for eac h node of the weigh ted W orld T rade W eb ( N = 162) [42]. The blue points indicate the exact v alues, while the dashed curv e (left) and blac k points (righ t) indicate in both cases the v alue q 1 k i − 1 N − 1 , whic h is a strict upper b ound for δ [ k i ] and a reference v alue, typically exceeded, for δ [ s i ]. that micro canonical approac hes do not contemplate the p ossibilit y that the netw ork interacts with some external ‘source of error’, i.e. that the v alue of the enforced con- strain ts migh t b e affected b y errors or missing en tries in the data. When present, such errors (e.g. a missing link, implying a wrong v alue of the degree of tw o no des) are propagated to the entire collection of randomized net- w orks, with the result that the ‘correct’ netw ork is not included in the micro canonical collection of graphs on whic h inference is b eing made. By contrast, b esides b eing unbiased and mathemati- cally tractable, our canonical approach is also the most appropriate choice if one wan ts to accoun t for p ossible er- rors in the data, since canonical ensembles appropriately describ e systems in con tact with an external reserv oir (source of errors) affecting the v alue of the constraints. While in presence of even small errors micro canonical metho ds assign zero probabilit y to the ‘uncorrupted’ con- figuration and to all the configurations with the same v alue of the constraints, our metho d assigns these con- figurations a probability which is only slightly smaller than the (maximum) probability assigned to the set of configurations consistent with the observed (‘corrupted’) one. These considerations suggest that, giv en its sim- plicit y , elegance, and ability to deal with p otential errors in the data, the use of the canonical ensem ble should be preferred to that of the microcanonical one. Nonetheless, it is imp ortant to note that, at least in principle, our canonical method can also be used to pro- vide unbiased micro canonical exp ectations, if theoretical considerations suggest that the micro canonical ensem- ble is more appropriate in some specific cases. In fact, if the sampled configurations that do not satisfy the c hosen constrain ts exactly are discarded, what remains is pre- cisely an unbiased (uniform) sample of the microcanoni- cal ensemble of net works defined b y the same constraints (no w enforced sharply). The sample is uniform b ecause all the micro canonical configurations hav e the same prob- abilit y of o ccurrence in the canonical ensem ble (since all probabilities, as we hav e shown, depend only on the v alue of the realized constraints). The same kind of analysis presen ted in this pap er can then b e rep eated to obtain the micro canonical exp ectations. In the rest of this sec- tion, we discuss some adv an tages and limitations of this approac h. As a guiding principle, one should b ear in mind that, to b e feasible, a micro canonical sampling based on our metho d requires that the num b er R c of canonical re- alizations to b e sampled (among which only a num b er R m < R c of micro canonical ones will b e selected) is not to o large, esp ecially b ecause for each canonical re- alization one m ust (in the worst-case scenario) do O ( N ) c hecks to ensure that eac h constrain t matches the ob- serv ed v alue exactly (the actual n umber is smaller, since all the chec ks after the first unsuccessful one can b e ab orted). W e first discuss the relation betw een R c and R m . Let G denote a generic graph (either binary or w eighted) in the canonical ensemble, and G ∗ the observed netw ork that needs to b e randomized. Let h formally denote a generic vector of c hosen constrain ts, and let h ∗ ≡ h ( G ∗ ) indicate the observed v alues of such constraints. Simi- larly , let θ denote the generic vector of Lagrange multi- pliers (hidden v ariables) asso ciated with h , and let θ ∗ indicate the v ector of their likelihoo d-maximizing v al- ues enforcing the constraints h ∗ . On av erage, out of R c canonical realizations, we will b e left with a num b er R m = Q ( h ∗ ) R c (66) 19 of micro canonical realizations, where Q ( h ∗ ) is the prob- abilit y to pic k a graph in the canonical ensemble that matc hes the constraints h ∗ exactly . This probability reads Q ( h ∗ ) = X G / h ( G )= h ∗ P ( G | θ ∗ ) = N m ( h ∗ ) P ( G ∗ | θ ∗ ) (67) where P ( G | θ ∗ ) is the probability of graph G in the canonical ensemble, and N m ( h ∗ ) is the num b er of micro- canonical netw orks matching the constrain ts h ∗ exactly (i.e. the num b er of graphs with given h ∗ ). Inserting eq. (67) into eq. (66) and inv erting, we find that the v alue of R c required to distill R m micro canonical graphs is R c = R m N m ( h ∗ ) P ( G ∗ | θ ∗ ) (68) Note that P ( G ∗ | θ ∗ ) is nothing but the maximized like- liho o d of the observed netw ork, whic h is automatically measured in our metho d. This is typically an extremely small num b er: for the netw orks in our analysis, it ranges b et ween 3 . 8 · 10 − 36468 (W orld T rade W eb) and 4 . 9 · 10 − 3499 (binary interbank netw ork). On the other hand, the n umber N m ( h ∗ ) is very large (comp ensating the small v alue of the likelihoo d) but unknown in the general case: en umerating all graphs with given (sharp) prop erties is an op en problem in combinatorics, and asymptotic esti- mates are av ailable only under certain assumptions. This means that it is difficult to get a general estimate of the minim um num b er R c of canonical realizations required to distill a desired num b er R m of micro canonical graphs. Another criterion can b e obtained b y estimating the n umber R c of canonical realizations such that the micro- canonical subset samples a desired fr action f m (rather than a desired numb er R m ) of all the N m ( h ∗ ) micro- canonical graphs. In this case, the knowledge of N m ( h ∗ ) b ecomes unnecessary: from the definition of f m w e get f m ≡ R m N m ( h ∗ ) = Q ( h ∗ ) R c N m ( h ∗ ) = P ( G ∗ | θ ∗ ) R c (69) The ab ov e formula shows that, if we wan t to sample a n umber R m of micro canonical realizations that span a fraction f m of the micro canonical ensemble, we need to sample a num b er R c = f m P ( G ∗ | θ ∗ ) (70) of canonical realizations and discard all the non- micro canonical ones. This num b er can b e extremely large, since P ( G ∗ | θ ∗ ) is very small, as we hav e already noticed. On the other hand, f m can b e chosen to b e v ery small as well. T o see this, let us for instance compare f m with the corresp onding fraction f c ≡ R c N c ( h ∗ ) (71) of c anonic al configurations sampled by R c realizations, where N c ( h ∗ ) N m ( h ∗ ) is the n umber of graphs in the canonical ensemble. F or all net works we consid- ered in this pap er, we show ed that R c = 1000 real- izations were enough to generate a go o d sample. This ho wev er corresp onds to an extremely small v alue of f c . F or instance, for the binary interbank netw ork we hav e f c = 1000 / 2 N ( N − 1) / 2 ≈ 1 . 4 · 10 − 6920 . W e might therefore b e tempted to choose the same small v alue also for f m , and find the required n umber R c from eq. (70). How ever, the result is a v alue R c 1 (in the men tioned example, R c = 2 . 8 · 10 − 3422 ), which clearly indicates that setting f m ≡ f c (where f c is an acceptable canonical fraction) is inappropriate. In general, f m should b e muc h larger than f c . Imp ortan tly , we can show that, given a v alue R c 1 that generates a go o d canonical sample, the subset of the R m micro canonical relations contained in the R c canonical ones spans a fraction f m of the micro canon- ical ensem ble that is indeed muc h larger than f c . T o see this, note that P ( G ∗ | θ ∗ ), being obtained with the intro- duction of the constraints h ∗ , is necessarily m uch larger than the completely uniform probability 1 / N c ( h ∗ ) ov er the canonical ensemble (corresponding to the absence of constrain ts). This inequality implies that, if we compare f c with f m (b oth obtained with the same v alue of R c ), w e find that f m = P ( G ∗ | θ ∗ ) R c R c N c ( h ∗ ) = f c (72) The ab ov e expression shows that, even if only R m out of the (many more) R c canonical realizations b elong to the micro canonical ensemble, the resulting micro canon- ical sampled fraction f m is still m uc h larger than the corresp onding canonical fraction f c . This non-obvious result implies that, in order to sample a micro canonical fraction that is muc h larger than the canonical fraction obtained with a given v alue of R c , one do es not need to increase the num b er of canonical realizations b eyond R c . The ab o ve considerations suggest that, under appro- priate conditions, using our “Max & Sam” metho d to sample the micro canonical ensemble might b e compet- itiv e with the av ailable micro canonical algorithms. It should b e noted that the v alue of R c affects neither the preliminary search for the hidden v ariables θ ∗ , nor the calculation of the micro canonical av erages o ver the R m final netw orks. How ever, it do es affect the num ber of c hecks one has to make on the constraints to select the micro canonical netw orks. The w orst-case total n umber of chec ks is O ( R c N ), and p erforming such op eration in a non-optimized wa y might slow do wn the algorithm con- siderably . A go o d strategy would be that of exploit- ing our analysis of the canonical fluctuations to identify the vertices for which it is more unlikely that the lo cal constrain t is matched exactly , and c heck these vertices first. This would allow one to identify , for each of the R c canonical realizations, the constraint-violating nodes at the earliest p ossible stage, and thus to ab ort the fol- lo wing chec ks for that particular netw ork. Implementing suc h an optimized micro canonical algorithm is how ever 20 b ey ond the scope of this pap er. V. CONCLUSIONS The definition and correct implementation of n ull mo d- els is a crucial issue in netw ork analysis. When ap- plied to real-w orld netw orks (that are generally strongly heterogeneous), the existing algorithms to enforce sim- ple constrain ts on binary graphs become biased or time- consuming, and in any case difficult to extend to netw orks of differen t t yp e (e.g. w eighted or directed) and to more general constraints. W e hav e prop osed a fast and unbi- ased “Max & Sam” metho d to sample several canonical ensem bles of net w orks with v arious constraints. While canonical ensembles are b elieved to represen t a mathematically tractable coun terpart of micro canon- ical ones, they ha ve not b een used so far as a to ol to sample netw orks with soft constraints, mainly b ecause of the use of approximated expressions that result in ill- defined sampling probabilities. Here, w e ha ve shown that it is indeed p ossible to use exact expressions to correctly sample a n umber of canonical ensem bles, from the stan- dard case of binary graphs with given degree sequence to the more challenging mo dels of directed and w eigh ted graphs with given reciprocity structure or joint strength- degree sequence. Moreo ver, we hav e provided evidence that micro canonical and canonical ensembles of graphs with lo cal constraints are not equiv alent, and suggested that canonical ones can ac coun t for p ossible errors or missing entries in the data, while micro canonical ones do not. Our algorithms are unbiased and efficient, as their computational complexity is O ( N 2 ) even for strongly heterogeneous net works. Canonical sampling algorithms ma y therefore represent an un biased, fast, and more flexi- ble alternative to their micro canonical coun terparts. W e ha ve also illustrated the p ossibility to obtain an unbi- ased micro canonical metho d by discarding the realiza- tions that do not match the constraints exactly . In our opinion, these findings might suggest new p ossibilities of exploitation of canonical ensembles as a solution to the problem of biased sampling in many other fields b esides net work science. APPENDIX: THE “MAX & SAM” CODE An algorithm has b een co ded in v arious wa ys [43 – 45] in order to implement our sampling pro cedure for all the sev en null mo dels describ ed in sec. I I I. In what follows, w e describ e the Matlab implementation [43]. A more detailed explanation accompanies the co de in the form of a “Read me” file [43]. Here we briefly mention the main features. The co de can b e implemented by typing a command ha ving the typical form of a Matlab function, taking a n umber of different parameters as input. The output of the algorithm is the numerical v alue of the hidden vari- ables , i.e. the vectors x , y and z (where applicable) max- imizing the lik eliho od of the desired n ull mo del (see sec. I I I), plus a sp ecifiable n um b er of sampled matrices. The hidden v ariables alone allo w the user to n umerically com- pute the expected v alues of the adjacency matrix en tries ( h a ij i ≡ p ij and h w ij i ), as well as the exp ected v alue of the constraints (as a c heck of its consistency with the observ ed v alue), according to the sp ecific definition of eac h mo del. Moreo ver, the use r can obtain as output an y n umber of matrices (netw orks) sampled from the desired ensem ble. These matrices are sampled in an unbiased w ay from the canonical ensemble corresp onding to the c hosen n ull mo del, using the relev an t random v ariables as described in sec. I I I. The command to b e typed is the following (more de- tails can b e found in the “Read me” file [43]): output = MAXandSAM(method, Matrix, Par, List, eps, sam, x0new) The first parameter ( method ) can be entered b y t yping the acron ym associated with the selected null mo del: • UBCM for the Undirected Binary Configuration Mo del, preserving the degree sequence ( { k i } N i =1 ) of an undirected binary netw ork A ∗ (see sec. I I I A); • DBCM for the Directed Binary Configuration Mo del, preserving the in- and out-degree sequences ( { k in i } N i =1 and { k out i } N i =1 ) of a directed binary net- w ork A ∗ (see sec. I I I B); • RBCM for the Recipro cal Binary Configuration Mo del, preserving the reciprocated, incoming non- recipro cated and outgoing non-recipro cated degree sequences ( { k ↔ i } N i =1 , { k ← i } N i =1 and { k → i } N i =1 ) of a directed binary netw ork A ∗ (see sec. I I I C); • UW CM for the Undirected W eighted Configu- ration Mo del, preserving the strength sequence ( { s i } N i =1 ) of an undirected weigh ted netw ork W ∗ (see sec. I I I D); • D WCM for the Directed W eighted Configura- tion Mo del, preserving the in- and out-strength sequences ( { s in i } N i =1 and { s out i } N i =1 ) of a directed w eighted netw ork W ∗ (see sec. I I I E); • R W CM for the Recipro cal W eighted Configu- ration Mo del, preserving the the reciprocated, incoming non-recipro cated and outgoing non- recipro cated strength sequences ( { s ↔ i } N i =1 , { s ← i } N i =1 and { s → i } N i =1 ) of a directed weigh ted netw ork W ∗ (see sec. I I I F); • UECM for the Undirected Enhnaced Configu- ration Mo del, preserving both the degree and strength sequences ( { k i } N i =1 and { s i } N i =1 ) of an undirected w eigh ted net work W ∗ (see sec. I I I G). 21 The second, third and fourth parameters ( Matrix , Par and List resp ectively) sp ecify the format of the input data (i.e. of A ∗ or W ∗ ). Differen t data formats can b e tak en as input: • Matrix for a (binary or w eigh ted) matrix repre- sen tation of the data, i.e. if the entire adjacency matrix is av ailable; • List for an edge-list represen tation of the data, i.e. a L × 3 matrix ( L b eing the num b er of links) with the first column listing the starting no de, the sec- ond column listing the ending no de and the third column listing the weigh t (if av ailable) of the cor- resp onding link; • Par when only the constrain ts’ sequences (degrees, strengths, etc.) are a v ailable. In any case, the tw o options that are not selected are left empt y , i.e. their v alue should b e “ [ ] ”. W e stress that the lik eliho o d maximization procedure (or the solution of the corresp onding system of equations making the gra- dien t of the likelihoo d v anish), which is the core of the algorithm, only needs the observed v alues of the chosen constrain ts to b e implemented. How ever, since different represen tations of the system are a v ailable, w e hav e c ho- sen to exploit them all and to let the user choose the most appropriate to the sp ecific case. F or instance, in netw ork reconstruction problems [28] one generally has empiri- cal access only to the lo cal prop erties (degree and/or strength) of each no de, and the full adjacency matrix is unkno wn. The fifth parameter ( eps ) controls for the maxim um allo wed relative error b et ween the observ ed and the ex- p ected v alue of the constrain ts. According to this param- eter, the co de solves the entrop y-maximization problem b y either just maximizing the likelihoo d function or also impro ving this first outcome solution by further solving the asso ciated system. Even if this choice migh t strongly dep end on the observed data, the v alue = 10 − 6 w orks satisfactorily in most cases. The sixth parameter ( sam ) is a bo olean v ariable al- lo wing the user to extract the desired num b er of ma- trices from the c hosen ensemble (using the probabilities p ij ). The v alue “0” corresp onds to no sampling: with this choice, the co de gives only the hidden v ariables as output. If the user en ters “1” as input v alue, the algo- rithm will ask him/her to enter the num b er of desired matrices (after the hidden v ariables hav e b een found). In this case, the co de outputs b oth the hidden v ariables and the sampled matrices, the latter in a .mat file called Sampling.mat . The seven th parameter ( x0new ) is optional and has b een introduced to further refine the solution of the UECM [28] in the very specific case of netw orks ha ving, at the same time, big outliers in the strength distribu- tion and a narrow degree distribution. In this case, the optional argument x0new can b e inputed with the previ- ously obtained output: in so doing, the co de will solv e the system again, by using the previous solution as initial p oin t. This pro cedure can b e iterated un til the desired precision is reached. Note that, since x0new is an op- tional parameter, it is not required to enter “ [ ] ” when the user do es not need it (differently e.g. from the data format case). A CKNOWLEDGMENTS DG ackno wledges supp ort from the Dutch Econo- ph ysics F oundation (Stic hting Econophysics, Leiden, the Netherlands) with funds from b eneficiaries of Duyfken T rading Knowledge BV, Amsterdam, the Netherlands. This work was also supp orted by the EU pro ject MUL- TIPLEX (contract 317532) and the Netherlands Organi- zation for Scientific Researc h (NWO/OCW). [1] M.E.J. Newman, “Netw orks: an introduction”, Oxford Univ ersity Press (2010). [2] V. Colizza, A. Barrat, M. Barthlemy , A. V espignani, Pr o- c e e dings of the National A c ademy of Sciences 103 (7), 2015-2020 (2006). [3] T. Squartini, I. v an Lelyveld, D. Garlaschelli, Sci. R ep. 3 (3357) (2013). [4] A. Barrat, M. Barthlemy , A. V espignani, “Dynamical pro cesses on complex netw orks”, Cambridge Universit y Press (2008). [5] T. Squartini, D. Garlaschelli, New. J. Phys. 13 , 083001 (2011). [6] R. Milo, S. Shen-Orr, S. Itzko vitz, N. Kashtan, D. Chklo vskii, U. Alon, Scienc e 298 (5594), 824-827 (2002). [7] S. F ortunato, Phys. R ep. 486 (3), 75-174 (2010). [8] B. Bollob´ as, Eur op e an Journal of Combinatorics , V olume 1, Issue 4, pp. 311-316 (1980). [9] M. Molloy , B. Reed, R andom structur es & algorithms 6(23), 161-180 (1995). [10] M.E.J. Newman, S.H. Strogatz, D.J. W atts, Phys. R ev. E 64 (2), 026118 (2001). [11] S. Maslov and K. Snepp en, Science 296 , 910 (2002). [12] A.C.C. Co olen, A. De Martino, A. Annibale, J. Stat. Phys. 136 , 1035-1067 (2009). [13] E.S. Rob erts, A.C.C. Co olen, Phys. Rev. E 85 , 046103 (2012). [14] Y. Artzy-Randrup, L. Stone, Phys. R ev. E 72 (5), 056708 (2005). [15] C.I. Del Genio, H. Kim, Z. T oro czk ai, K.E. Bassler, PL oS One 5 (4), e10012 (2010). [16] H. Kim, C.I. Del Genio, K.E. Bassler, Z. T oro czk ai, New J. Phys. 14 , 023012 (2012). [17] J. Blitzstein, P . Diaconis, Internet Mathematics 6 (4), 489-522 (2011). 22 [18] J. Park, M.E.J. Newman, Phys. R ev. E 70 , 066117 (2004). [19] G. Bianconi, Europhys. L ett. 81 (2), 28005 (2007). [20] A. F ronczak, P . F ronczak, J.A. Holyst, Phys. R ev. E 73 , 016108 (2006). [21] T. Squartini, G. F agiolo, D. Garlaschelli, Phys. R ev. E 84 , 046117 (2011). [22] T. Squartini, G. F agiolo, D. Garlaschelli, Phys. R ev. E 84 , 046118 (2011). [23] G. F agiolo, T. Squartini, D. Garlasc helli, J. Ec on. In- ter ac. Co or d. , 8 (1), 75-107 (2013). [24] D. Garlaschelli and M.I. Loffredo, Phys. Rev. E 73 , 015101(R) (2006). [25] T. Squartini, D. Garlaschelli, L e c. Notes Comp. Sci. 7166 , 24 (2012). [26] T. Squartini, F. Picciolo, F. Ruzzenen ti, D. Garlasc helli, Sci. R ep. 3 (2729) (2013). [27] D. Garlasc helli, M.I. Loffredo, Phys. R ev. L ett. 102 , 038701 (2009). [28] R. Mastrandrea, T. Squartini, G. F agiolo, D. Gar- lasc helli, New J. Phys. 16 , 043022 (2014). [29] R. Mastrandrea, T. Squartini, G. F agiolo, D. Gar- lasc helli, http://arxiv.org/abs/1402.4171 (2014). [30] R. Milo, N. Kashtan, S. Itzko vitz, M.E.J. Newman, U. Alon, http://arxiv.org/abs/cond- mat/0312028 (2003). [31] P . Erd˝ os, T. Gallai, Mat L ap ok 11 , 477 (1960). [32] F. Chung, L. Lu, Pr o c e e dings of the National A c ademy of Scienc es 99 (25), 15879-15882 (2002). [33] F. Chung, L. Lu, Annals of Combinatorics 6 (2), 125-145 (2002). [34] M. Bogu˜ na, R. Pastor-Satorras, A. V espignani, The Eu- r op e an Physic al Journal B-Condense d Matter and Com- plex Systems 38 (2), 205-209 (2004). [35] M. Catanzaro, M. Bogu ˜ na, R. P astor-Satorras, Phys. R ev. E 71 (2), 027103 (2005). [36] D. Garlaschelli, New J. Phys. 11 , 073005 (2009). [37] Ginestra Bianconi, Anthon y C. C. Co olen, Conrad J. P erez Vicente, Ph ysical Review E 78 (1), 016114 (2008). [38] Kartik Anand, Ginestra Bianconi, Phys. Rev. E 82, 011116 (2010). [39] Kartik Anand, Ginestra Bianconi, Physical Review E 80 (4), 045102 (2009). [40] Tiziano Squartini, Jo ey de Mol, F rank den Hollander, Diego Garlasc helli, . [41] G. De Masi, G. Iori, G. Caldarelli, Phys. Rev. E 74 , 066112 (2006). [42] UNCOMTRADE database: http://comtrade.un.org/ [43] http://www.mathworks.it/matlabcentral/ fileexchange/46912- max- sam- package- zip [44] https://drive.google.com/open?id=0B_ rBKSwFTur3M0tvd0w4dW45aE0&authuser=0 [45] http://www.lorentz.leidenuniv.nl/ ~ garlaschelli/
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment