Mapping and Matching Algorithms: Data Mining by Adaptive Graphs
Assume we have two bijective functions $U(x)$ and $M(x)$ with $M(x)\neq U(x)$ for all $x$ and $M,N: \N \rightarrow \N$ . Every day and in different locations, we see the different results of $U$ and $M$ without seeing $x$. We are not assured about the time stamp nor the order within the day but at least the location is fully defined. We want to find the matching between $U(x)$ and $M(x)$ (i.e., we will not know $x$). We formulate this problem as an adaptive graph mining: we develop the theory, the solution, and the implementation. This work stems from a practical problem thus our definitions. The solution is simple, clear, and the implementation parallel and efficient. In our experience, the problem and the solution are novel and we want to share our finding.
💡 Research Summary
**
The paper tackles a practical privacy‑preserving identification problem: given only the daily, location‑specific observations of two deterministic but unknown functions U(x) (UUID) and M(x) (MAC address) for an unknown device x, can we recover the hidden mapping between the two identifiers? The authors formalize the setting by defining, for each airport Lᵢ and day t, a set S_{Lᵢt} of users observed within a one‑mile radius and a set M_{Lᵢt} of MAC addresses seen at the Wi‑Fi access point. Each pair (Lᵢ, t) yields a fully‑connected bipartite graph h S_{Lᵢt} : M_{Lᵢt}, which represents all possible UUID‑MAC pairings for that day and location.
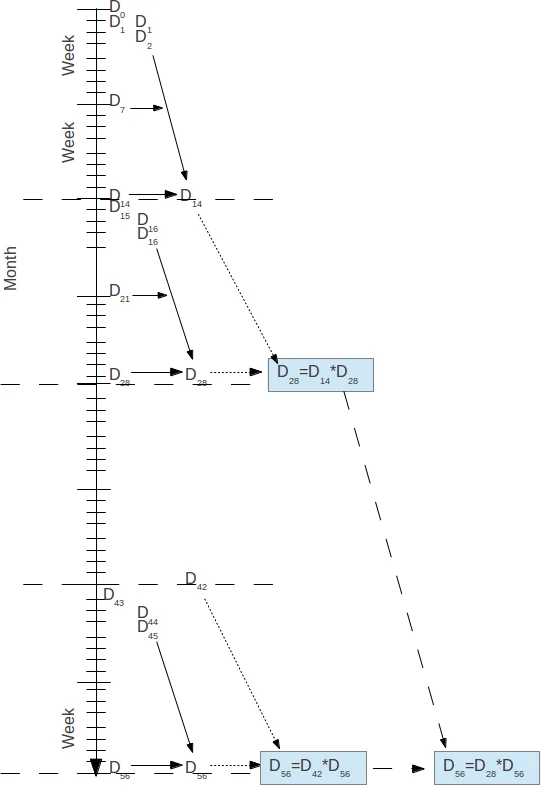
The core contribution is an “adaptive graph mining” algorithm that progressively refines these graphs by intersecting them across days and locations. Two algebraic operators are introduced: “+” simply unions two mappings when no overlap exists, while “” computes the intersection of both user and MAC sets whenever the address sets overlap, thereby producing a smaller, more precise mapping. The authors present a series of set‑theoretic equations (2.5‑2.8) that describe how repeated application of “” across successive days yields a sequence D_{t+1}=D_{t+1} * D_t. The algorithm thus builds a daily mapping D_t consisting of (i) disjoint user‑MAC pairs and (ii) cross‑airport departure‑arrival relationships, and then repeatedly multiplies these structures to converge toward a one‑to‑one matching.
Parallelism is addressed on two levels. First, the six‑month observation window is split into independent two‑week intervals; each interval is processed in parallel (“embarrassingly parallel”). Second, the results of these intervals are combined in a binary‑tree fashion, where each node performs the costly “*” operation. Although the tree’s height reduces the number of sequential steps, each node still requires a Cartesian product of its operand graphs, leading to O(N²) work. To mitigate this, the authors implement the algorithm in R using the parallel package’s mclapply function, distributing the pairwise intersection work across P cores.
A case study uses data from six airports over six months. Approximately 500 000 distinct MAC addresses appear more than once, and nine million UUIDs appear at least twice. On a typical day there are about 2.5 million users and 10 000 MACs. The authors construct graphs using both two‑week and four‑week windows. The four‑week graphs finish about two hours faster (given the same 16‑core resources) and produce more matches but with slightly higher redundancy; the two‑week graphs yield fewer matches but more refined, less overlapping mappings. Distribution statistics of the user‑to‑MAC ratio are reported, showing that longer windows tend to increase coverage at the cost of precision.
Critically, the paper lacks rigorous proofs of correctness or convergence for the “*” operator, and it does not quantify the probability of false matches when multiple devices share similar observation patterns. The O(N²) complexity, even with parallelism, becomes prohibitive for truly large‑scale deployments, and the R implementation suffers from high memory consumption. Moreover, the authors do not compare their approach to existing record‑linkage or bipartite‑matching techniques, leaving the claimed novelty insufficiently substantiated.
In conclusion, the work introduces a formally described, algebraic framework for refining ambiguous identifier mappings via adaptive graph intersections and demonstrates a parallel R prototype on real‑world airport data. While the methodology is clear and the parallel execution strategy is thoughtfully designed, the lack of theoretical guarantees, scalability concerns, and limited comparison to prior art suggest that further research is needed before the approach can be considered a robust solution for large‑scale device‑identifier reconciliation.
Comments & Academic Discussion
Loading comments...
Leave a Comment