A testing based extraction algorithm for identifying significant communities in networks
A common and important problem arising in the study of networks is how to divide the vertices of a given network into one or more groups, called communities, in such a way that vertices of the same community are more interconnected than vertices belo…
Authors: James D. Wilson, Simi Wang, Peter J. Mucha
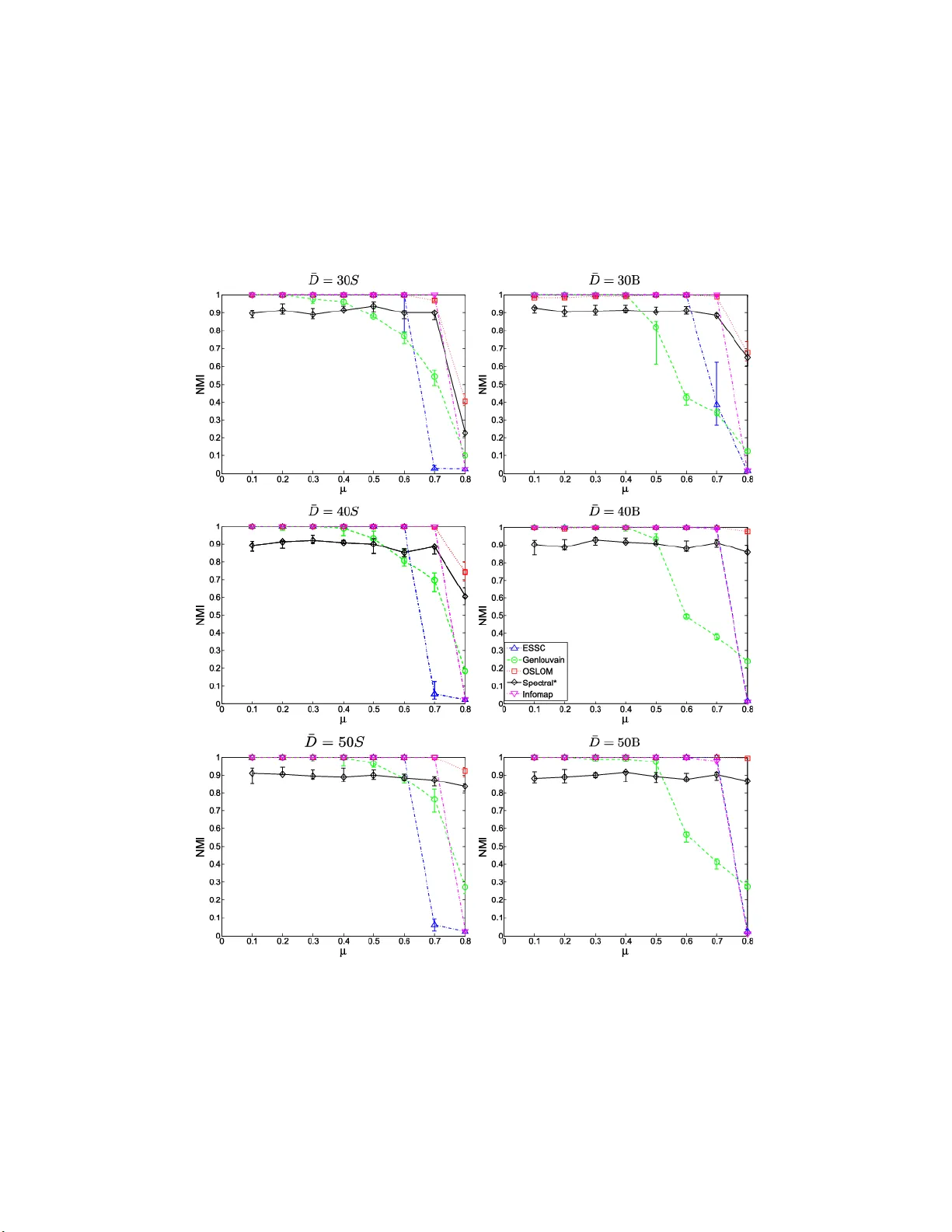
The Annals of Applie d Statistics 2014, V ol. 8, No. 3, 1853–189 1 DOI: 10.1214 /14-A OAS760 c Institute of Mathematical Statistics , 2 014 A TESTING BASE D EXTRACTION ALGORITHM F OR IDENTIFYING SIGNIFICANT COMMUNITIES IN NETWORKS 1 By James D. Wilso n , Simi W ang, Peter J. Mucha 2 , Shankar Bhamidi and Andr e w B. Nobel University of North Car olina at Chap el Hil l A common and i mp ortant problem arising in th e stud y of net- w ork s is how to d ivide the vertices of a given netw ork into one or more g roups, called comm unities, in such a w a y that vertices of th e same comm unity are more interconnected than vertices b elonging to different ones. W e prop ose and inve stigate a testing based commu- nity detection pro cedure called Extraction of Statistically Significant Comm u nities (ESSC). The ESSC procedu re is based on p -val ues for the strength of connection b etw een a single vertex and a set of ver- tices und er a reference distribution derived from a conditional con- figuration netw ork model. The pro cedure automatically selects b oth the number of communities in t he n etw ork and their size. Moreov er, ESSC can han d le ove rlapping communities and, unlike th e ma jor- it y of existing metho ds, identifies “background” vertices that do not b elong to a w ell-defined communit y . The metho d has only one p a- rameter, which controls the stringency of the hyp othesis tests. W e in- vestig ate th e p erformance and p otential use of ES S C and compare it with a number of existing metho ds, through a v alidation study using four real netw ork data sets. In add ition, we carry out a sim ulation study to assess the effectiveness of ESSC in n etw orks with vari ous types of comm u n ity structu re, including netw orks with ov erlapping comm unities and those with bac kground vertices. These results sug- gest that ESSC is an effective exploratory to ol for the discov ery of relev ant comm unity stru cture in complex n etw ork systems. D ata and soft ware are av ailable at http://www.unc.edu/ ~ jameswd/resear ch. html . Received Sep tember 2013; revised May 2014. 1 Supp orted in part by NSF Gran ts DMS-09-07177, DMS-13-10002, DMS- 06-45369, DMS-11-05581 and SES- 1357622 . 2 Supp orted in part by th e James S. McDonnell F o undation 21st Century Science Initiative—Co mplex Systems S cholar Award Grant 220020315. Key wor ds and phr ases. Comm un it y detection, netw orks, extraction, background, mul- tiple testing. This is an ele c tronic reprint of the orig ina l a rticle published by the Institute of Ma thematical Statistics in The Annals of Applie d St atistics , 2014, V ol. 8, No . 3, 18 5 3–18 91 . This reprint differs from the or iginal in paginatio n and typogra phic detail. 1 2 WILSON ET AL. 1. In tro d uction. The study of net works has b een motiv ated by , and made significan t contributions to, the mo deling an d und erstanding of com- plex systems. Net works are used to mo d el the relational stru cture b et w een individual u nits of an observed system. In the net work setting, v ertices rep- resen t the units of the system and ed ges are placed b etw een v ertices th at are related in some wa y . Net w ork-b ased mo dels ha ve b een used in a v ariet y of disciplines: in biology to mo del p rotein-protein and gene–gene in teractions; in so ciology to mo del friendsh ip and information flow among a group of in- dividuals; and in neur oscience to mo d el the relationship b et w een the organi- zation and fun ction of the brain. In many of th ese applications, the vertice s of the n et work und er stud y can natur ally b e sub d ivided into comm un ities. Informally , a communit y is a group of vertices that are m ore connected to eac h other than they are to the remainder of the net work. More rigorous definitions quanti fy this notion of differential connection in different wa ys. Figure 1 illustrates a net work with three disjoint communities. The problem of dividin g the v ertices of a give n net w ork into well-defined comm un ities is kno w n as comm unity detect ion. Communit y detection has b ecome increasingly p opular, as comm un ities ha v e b een foun d to identify imp ortant and useful features of man y complex systems. Comm u nit y detec- tion has b een stu d ied by r esearc hers in a v ariet y of fields, includin g statistic s, the so cial sciences, computer science, physics and applied mathematics, and a div erse set of comm unit y detection algo r ithms ha ve b een d ev elop ed [see F ortunato ( 2010 ), P orter, Onnela and Muc ha ( 2009 ) for reviews]. Existing comm u nit y detection metho ds capture different t yp es of comm u - nit y structure. The simplest communit y structure, and the one most com- monly studied, is a hard partitioning, in which eac h v ertex of the net wo rk is assigned to one and only one comm u nit y , and the collection of comm u n ities together form a partition of the netw ork [e.g., Newman and Girv an ( 2004 ), Ng, Jordan and W eiss ( 2002 ), Snijd ers and No wicki ( 1997 )]. Another class of comm u nit y structure allo ws o verlapping comm un ities [see Xie, K elley and Szymanski ( 2011 ) for a recen t r eview], in wh ic h the collection of comm u nities together form a cov er of the net w ork. Broadly sp eaking, most comm unit y detection metho d s pro duce one of these types of stru ctures. Fig. 1. A simple network wi th thr e e distinct c ommunities. IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 3 Comm u nit y detectio n has b een successful in un derstanding a wide v a- riet y of complex systems. In addition to the numerous examples cited in the aforemen tioned revie ws, comm unit y d etectio n metho ds ha v e recen tly b een profitably applied to pr otein interacti on netw orks [Lewis et al. ( 2010 )], functional brain activit y [Bassett et al. ( 2011 )], so cial media [P apadop ou- los et al. ( 2012 )] and mobile p hone data [Muhammad and V an Laerho ve n ( 2013 )], as w ell as social groups [Greene, Do yle and Cun ningham ( 2010 ), Miritello, Moro and Lara ( 2011 ), On nela et al. ( 2011 )]. The ma jorit y of existing comm u nit y detection metho d s make the assump- tion that eve ry vertex within an observ ed net wo r k b elongs to at least one comm un it y . T hough many net works can b e appropriately d ivided into a par- tition (or co ve r) of communities, some large and heterogeneous net works do not fit in to this framewo rk. F or example, consider the Enr on email net w ork from Lesko v ec et al. ( 2009 ) w here edges r epresen t the email corresp ondence (sen t or receiv ed) b et w een email accoun ts in 2001. T h e net wo rk con tains man y (on the order of 10K) email accoun ts outsid e of Enron and relativ ely few (on the ord er of 1K) email accoun ts fr om emplo y ees at E nron. The outside email accoun ts, man y of which are sp am email accoun ts, are not preferent ially attac hed to an y group of employ ees and thereb y do not b e- long to a well-defined communit y . F rom this example and several others that w e inv estigate in Section 4 , we w ill see that man y r eal n et wo rks conta in v er - tices that do not h a ve strong connections to any comm un it y . Informally , we call vertic es that are not p referen tially connected to an y communit y b ack- gr ound v ertices, as they act as a bac kground against which more standard comm un it y stru ctur es m a y b e d etecte d. In net works wh ere bac kground vertic es are p resen t, partitioning and co v- ering metho ds t yp ically assign them to more tightl y conn ected communities. T o illustrate this, we generated a 500 no de to y n et wo rk with a single comm u - nit y of size 50, w hose v ertices are link ed ind ep endently with probabilit y 0.5; the r emaining vertices are b ac kground and are link ed to all vertice s in the net work indep enden tly with p r obabilit y 0.05. W e ran t w o p opular detection metho ds—the mo dularit y based algorithm of Newman and Girv an ( 2004 ) and the normalized Sp ectral algorithm of Ng, Jordan and W eiss ( 2002 )— and found t wo disjoint comm unities. W e considered th e comm unity that most closely m atc hed the true em b edded comm un it y and found, as sh o wn in Figure 2 , that b oth metho d s included many bac kgroun d vertic es. Also s h o wn in Figure 2 is the result of applyin g the ESSC metho d in- tro duced in this p ap er. ESSC accurately iden tifies th e em b edded commu- nit y and the backg round, and separates one from the other. Although there are metho ds in m ultiv ariate clustering to capture bac kground [Ester et al. ( 1996 ), Hinnebu r g and Keim ( 1998 )], only a few recen t pap er s , for example, Zhao, Levina and Z h u ( 2011 ), Lancic hinetti et al. ( 2011 ), consider bac k- ground in the con text of comm un it y detection. 4 WILSON ET AL. Fig. 2. (A) A toy network that c ontains one si gnific antly c onne cte d c ommunity—c olor e d in black—and many sp arsely c onne cte d b ackgr ound vertic es. (B) The p artition given by the GenL ouvain mo dularity optimization metho d. (C) The p artition given by normalize d Sp e ctr al clustering. (D) The extr acte d c ommunity found by the pr op ose d metho d ESSC, which sep ar ates and distinguishes the emb e dde d c ommunity f r om the b ackgr ound. In this pap er w e prop ose and study a testing based comm u nit y detec- tion algorithm, called Extraction of Statistically S ignifican t Comm u nities (ESSC), that is capable of identifying b oth backg round v ertices and ov erlap- ping comm un ities. The core of the algorithm is an iterativ e search pr o cedure that identifies statistically stable communities. I n particular, the searc h pro- cedure u ses tail probab ilities deriv ed from a s to c hastic configur ation mo del based on the observ ed netw ork in ord er to assess th e strength of the conn ec- tion b et w een a single v ertex and a candidate comm unit y . Up dating of the candidate comm un it y is carried out using ideas f rom multiple testing and false disco v ery r ate con trol. The only free parameter in the ESS C algorithm is a false discov ery r ate threshold that is u sed in the up d ate step of the iterativ e search pro cedure. The n u m b er of detected comm un ities, th eir ov erlap (if an y) and the size of the backg round are handled automatically , without user input. In practice, the ou tp ut of E S SC is not o verly sensitiv e to the thresh old parameter; see the App endix D for more details. 1.1. Notation. F or ease of discussion th r oughout th e remainder of this pap er, we first in tro duce some notation. Let G = ( V , E ) b e an undirected m u ltigraph with verte x s et V = [ n ] = { 1 , . . . , n } and edge multise t E cont ain- ing all (u nordered) pairs { i, j } su c h that there is an edge b et w een vertice s i and j in G , allo wing rep etitions for m ultiple edges. Let d ( u ) denote the degree of a vertex u , and let d = { d (1) , . . . , d ( n ) } denote th e degree sequen ce of G . Let B ⊂ [ n ] d enote a s ubset of ve rtices in G . Indices on B are simply used for sp ecification th roughout. W rite Π for a partition of the v ertex set [ n ] (Π = B 1 ∪ B 2 ∪ · · · ∪ B k , k ≥ 1). In m an y cases, d etectio n metho ds seek a partition (or co v er) through optimizing a sp ecified qualit y or score function, whic h we will d enote as S ( · ). It is imp ortan t to note that the score may b e global, in wh ich case S ( · ) measures the qualit y of an en tire partition, or lo cal, in whic h case S ( · ) measures the qualit y of a p ote n tial comm u nit y . W e IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 5 will u s e G o to denote an observed graph and b G for a sto chastic mo d el on the vertex set [ n ] . 1.2. R e late d work. Th ere is an extensive literature on the develo p men t and analysis of comm unity detection metho ds. In this section w e giv e an o ve rview of this literature. F or recen t sur veys describing communit y detec- tion metho ds, see F ortunato ( 2010 ), P orter, Onnela and Muc ha ( 2009 ) or Golden b erg et al. ( 2010 ). In Section 3 we describ e in more detail the metho ds to which w e compare ES SC. Man y of the earliest comm unit y detection metho ds approac h net work clustering from a graph-theoretic standp oint. Relying on a presp ecified inte- ger k , these metho ds seek the p artition of k comm u nities that minimize the n u m b er of edges b etw een comm unities. Th e optimal partition of this crite- rion is known as the partition of min-cut and max-flo w [Goldb erg and T arjan ( 1988 )], wh ere the cut of a communit y sp ecifies the num b er of ed ges from the communit y to the rest of the netw ork. Unfortunately , min-cut metho ds often resu lt in many s in gleton comm u nities. T o address this issue, the cut of a comm un it y can b e n ormalized by either the communit y size, resulting in the ratio-cut criterion [W ei and Chen g ( 1989 )], or b y the total degree of the comm un it y , giving th e normalized-cut criterion [Shi and Malik ( 2000 )]. When k > 2, the task of findin g the partition th at satisfies any of th ese cut criterions is NP-hard. Sp ectral clustering metho ds [Krzak ala et al. ( 2013 ), Ng, Jordan and W eiss ( 2002 )] find an appr o ximate solution to the norm-cut criterion by app ealing to sp ectral pr op erties of th e graph Laplacian. Sp ectral clustering metho ds can b e applied to either nonnetw ork multiv ariate data or d ir ectly to relational net work data. Another class of comm un ity d etection metho ds seek comm unity structure b y comparing th e observed net work G o = ([ n ] , E o ) with an u nstructured sto c hastic net work on the same v er tex set b G n ull = ([ n ] , ˆ E n ull ). A s to c hastic net work b G n ull describ es the prob ab ilities of edge connection b et w een all pairs of vertice s in [ n ] giv en th at eac h pair wa s connected at random. Detecti on metho ds of this class seek the partition of G o whose clustering most deviates from what is exp ected und er b G n ull . Mo d ularit y method s [see, e.g., Blondel et al. ( 2008 ), Clauset, Newman and Mo ore ( 2004 ), Newman ( 2006 ), Muc h a et al. ( 2010 )] are a p opular subs et of this class. Mo d ularit y metho ds seek the partition whose communities’ f r action of observ ed edges are furthest f r om the fraction of ed ges exp ected un d er b G n ull , that is, th e partition Π th at maximizes S mod (Π) = 1 2 | E o | k X ℓ =1 X i,j ∈ B ℓ I ( { i, j } ∈ E o ) − γ E X i,j ∈ B ℓ I ( { i, j } ∈ ˆ E n ull ) , where γ > 0 is a r esolution parameter that cont rols the size of disco v er ed comm un ities. In man y cases, γ is treated as one, ho we v er, this parameter 6 WILSON ET AL. can b e tun ed in a d ata-driv en fash ion. There are many c hoices for a refer- ence sto c hastic net w ork. F or instance, in the case of the Newman –Girv an mo dularity [Newman and Girv an ( 2004 )], b G n ull is sp eci fied as th e configu- ration mo del [Mollo y and Reed ( 1995 )] under which th e degree sequence of G o is m aintained. In this case E ( P i,j ∈ B ℓ I ( { i, j } ∈ ˆ E n ull )) is d o ( i ) d o ( j ) / 2 | E o | . Our pr op osed metho d ESS C also relies u p on the configur ation mo del as a reference sto chastic net work. An alternativ e class of communit y detection metho ds estimate the com- m u nit y structure of a netw ork by fitting a structured sto chasti c net wo rk b G struct = ([ n ] , ˆ E struct ) to th e observed data G o . Here, b G struct describ es ran- dom assignmen ts of edges conditional on sto c hastic communit y (or block) structure on the vertex set [ n ]. F ormally , b G struct is a parametric mo del w hose parameters describ e the comm unity lab els of eac h v ertex and p oten tially the top ological prop erties of the net w ork (e.g., the degree distribution of the net work). Given an observ ed net work G o and a p resp ecified inte ger k , a structured net w ork (with parameters Θ) is fit to G o b y maximizing the lik eliho o d function d escribing Θ: L (Θ | G o , k ). A recen t review of structured net work mo dels is pr o vided b y Goldenb erg et al. ( 2010 ). One of the most p opular n et wo rk mo dels of this type is the sto c h astic b lo c k mo d el [Holland, Lask ey and Leinhardt ( 1983 ), S n ijders and Nowic ki ( 1997 ), No wic ki and Sni- jders ( 2001 )]. Under this mo del, ve rtices are assigned lab els taking v alues in { 1 , . . . , k } according to pr obabilities π = ( π 1 , . . . , π k ). Conditional on the ver- tex lab els, ed ge probabilities are giv en by a k × k s y m metric matrix P wh ere the i , j th entry of P give s the pr obabilit y of an edge b etw een comm un it y i and j . Blo c k mo d els are fit to G o b y maximizing the corresp ondin g likeli - ho o d L (Θ = ( P , π ) | G o , k ). O ther examples of structured sto c h astic n et wo rks include laten t v ariable m o dels [Hoff, Raftery and Handco c k ( 2002 ), Hand- co c k, Raftery and T an trum ( 2007 )] and mixed mem b ership mo dels which are flexible to o ve rlapping comm u nities [Airoldi et al. ( 2008 ), Ball, Karrer and Newman ( 2011 )]. Recen tly , there has b een significan t progress in the deve lopmen t of f ast and efficient algorithms for fitting sto c hastic blo c k mo dels. Th e authors of Decelle et al. ( 2011 ) describ e an algorithm that estimates blo c k structure of a degree-corrected blo c k mo del in time lin ear in the num b er of v ertices. Their algorithm is based on a p o werful h euristic of b elief propagation f r om statistica l p h ys ics. See, for example, M ´ ezard and Mon tanari ( 2009 ) for a surve y lev el treatment of b elief propagation and a v ariet y of applications. In the cont ext of sparse sto c hastic blo c k mo dels, th ese tec h niques ha v e b een sho w n to b e near optimal in estimating the underlying communities [Kr za- k ala et al. ( 2013 )], at least in th e balanced regime where b oth communities are of equal size. A sublinear algorithm based on the pseud o-lik eliho o d of the sparse blo c k mo del is d escrib ed in Amini et al. ( 2013 ) wherein b lo c k lab els IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 7 are sho wn to b e consisten t in the size of net work. Finally , r ecent nonp ara- metric represent ations of the b lo c k m o del through dense graph limits, or graphons [Airoldi, Costa and Ch an ( 2013 )] and netw ork histograms [Olhede and W olfe ( 2013 )] pr o vide p romising new dir ections for th e understanding and estimation of b lo c k mo dels. Another s ub class of comm unity detection method s are the so-called ex- traction tec hniques where comm un ities are extracte d one at a time [Zhao, Levina and Zhu ( 2011 ), Lancic hinetti et al. ( 2011 )]. Rather than searc h for an optimal partition or co v er, these extraction metho ds seek the strongest connected comm u n it y sequen tially . Extraction metho d s d o not force all v er- tices to b e placed in a communit y and thereby are flexible to loosely con- nected bac kgroun d vertic es. ES S C is an extraction metho d that utilizes the reference distribu tion of th e connectivit y of a comm u nit y based on the con- ditional confi guration mo del. There are tw o main app roac hes currently used to assess the statistical sig- nificance of comm unities in net w orks . The first approac h , lik e E SSC, builds up on statistical p rinciples based on features of the observed n etw ork itself. The second approac h is p ermutation based in that the significance of com- m u nit y stru cture is determined based on the r esults of a p rescrib ed m etho d on many b o otstrapp ed samples of the observ ed netw ork [see, e.g., Clauset, Mo ore and Newman ( 2008 ), Rosv all and Bergstrom ( 2010 )]. Many theoreti- cal qu estions remain op en for these typ es of metho d s, includin g conv ergence of b ootstrapp ed samples of netw orks. 1.3. Or ganization of the p ap er. The remainder of this pap er is organized as follo ws. Section 2 is dev oted to a d etailed description of our prop osed algorithm for extraction of statistically s ignifican t comm un ities (ESSC), in - cluding motiv ation and a description of the reference distribution gener- ated from the confi guration mo del. In Section 1.2 we discuss the comp eting metho ds that w e use to v alidate our algorithm in b oth n u merical and real net work studies. In S ection 4 w e apply the ESSC algorithm to four real- w orld net w orks. These resu lts pro vide solid evidence that ESSC p erf orms w ell in practice, is comp etit iv e with (and in some cases arguably sup erior to) sev eral leading comm un it y detection metho d s , and is effectiv e in captur- ing bac kgroun d v ertices. In Section 5 we p rop ose a test b ed of b enc hmark net works f or assessin g the p erformance of detection metho d s sp ecificall y on net works w ith bac kground vertic es. T o the b est of our kno wledge, this is the first set of b enc hmarks prop osed for net works of this t yp e. W e s h o w that ESSC outp erf orms existing metho d s on these b ac kground b enchmarks. W e also sh o w that ESSC p erforms comp etit iv ely on standard (n onbac kground) b enchmark net w orks with b oth nono verlapping and o v erlapp in g comm u nit y structures. W e end with a d iscussion of our w ork and a v en u es for future researc h. 8 WILSON ET AL. 2. The ESS C algorithm. 2.1. Conditional c onfigur ation mo del. Let G o b e an obser ved, un d irected net work ha ving n v ertices. Though man y net w orks of int erest will b e simple, G o ma y contai n self-loops or m ultiple edges. Assume without loss of gen- eralit y that G o has v ertex set V = [ n ] = { 1 , 2 , . . . , n } . T he edge m u ltiset E o of G o con tains all (u n ordered) pairs { i, j } suc h that i, j ∈ [ n ] and there is a link b et w een v ertices i and j in G o , with rep etitions for m u ltiple edges. Let d o ( u ) denote the d egree of a v ertex u , that is, the n umber of edges incident on u , and let d o = { d o (1) , . . . , d o ( n ) } d enote the degree sequence of G o . The starting p oint for our analysis is a stochastic net work mo del that is derive d from the d egree sequence d o of G o , sp ecifically , the configuration mo del asso ciated with d o , which w e denote b y C M( d o ) [Bender and Canfield ( 1978 ), Bollob´ as ( 1979 ), Mollo y and Reed ( 1995 )]. Th e configur ation mo d el CM( d o ) is a probability measure on the family of m u ltigraphs with vertex set [ n ] and degree sequence d o that reflects, within the constrain ts of the degree sequence, a rand om assignmen t of edges b et we en vertice s. The configuration mo d el CM( d o ) has a simp le generativ e form . In itially , eac h v ertex u ∈ [ n ] is assigned d o ( u ) “stubs,” whic h act as half-edges. A t the next stage, t w o stubs are chosen u niformly at random and connected to form an edge; this pro cedur e is r ep eated in d ep endently u n til all stubs hav e b een connected. Let b G = ([ n ] , ˆ E ) denote the rand om n etw ork generated b y this pro cedur e. Note that b G ma y con tain self lo ops and m u ltiple ed ges b et w een v ertices, even if the giv en net work G is simp le. The configuration mo del CM( d o ) is capable of capturing and preservin g strongly heterogeneous degree distributions often encoun tered in real n et- w ork d ata sets. Imp ortan tly , all edge p robabilities in the configu r ation null mo del are determined solely by the degree sequ ence d o of an observed graph. As a result, fi tting a configuration mo del do es not rely on sim u lation, r ather, estimation only requires th e degree sequence of a sin gle observe d graph. Under the configuration mo d el CM( d o ) there are n o preferenti al connec- tions b et w een v ertices, b ey ond what is dictated by their degrees. As suc h, CM( d o ) pro vid es a referen ce measure against wh ic h w e ma y assess the sta- tistical signifi cance of the connections b et w een tw o s ets of v ertices in the observ ed net work G o : the more the observ ed num b er of cross-edges deviates from the exp ecte d num b er un d er th e mo del, the greater the significance of the connection b et w een the v ertex sets. Let the observ ed net w ork G o and the r an d om net work b G b e as ab o ve. Give n a vertex u ∈ [ n ] and v ertex set B ⊆ [ n ], let d o ( u : B ) = X v ∈ B X e ∈ E o I ( e = { u, v } ) IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 9 denote the num b er of edges b etw een u and some vertex in B in G o . Define ˆ d ( u : B ) as the corresp onding n umber of ed ges in b G . Note that ˆ d ( u : B ) is a random v ariable taking v alues in the set { 0 , 1 , . . . , d o ( u ) } , and that d o ( u : B ) = ˆ d ( u : B ) = d o ( u ) when B = [ n ] is th e full verte x set. W e n o w state a theorem describ ing asymptotics for the random v ariable ˆ d ( u : B ) in the configuration mo del wh ic h will form the basis of the algorithm. Recall th at the total v ariation distance b etw een tw o prob ab ility mass functions p := { p ( i ) } i ≥ 0 and q := { q ( i ) } i ≥ 0 on the sp ace of natural num b ers N is defined by d TV ( p , q ) := 1 2 ∞ X i =0 | p ( i ) − q ( i ) | . Theorem 1. L et { d o,n } n ≥ 1 b e the de gr e e se quenc es of an observe d se- quenc e of gr aphs { G n o } n ≥ 1 , wher e G n o is a gr aph with vertex set [ n ] and e dge set E o,n . L et { b G n } n ≥ 1 b e the c orr esp onding r andom gr aphs on [ n ] c onstructe d via the c onfigur ation mo del. L et F n b e the empiric al distribution of d o,n . As- sume that ther e exists a c umulative distribution function F on [0 , ∞ ) with 0 < µ := R R + x dF ( x ) < ∞ such that F n w − → F (2.1) and Z R + x dF n ( x ) → µ. (2.2) Fix k ≥ 1 . F or e ach n ≥ 1 , let u = u n ∈ [ n ] b e a vertex with de gr e e d o,n ( u ) = k and let B = B ( n ) ⊆ [ n ] b e a set of vertic es. Then the r andom variable ˆ d n ( u : B ) is appr oximately Binomial( k , p n ( B )) in the sense that d TV ( ˆ d n ( u : B ) , Bin( k , p n ( B ))) → 0 , as n → ∞ . Her e p n ( B ) = P v ∈ B d o,n ( v ) P w ∈ [ n ] d o,n ( w ) = 1 2 | E o,n | X v ∈ B d o,n ( v ) , (2.3) wher e | E o,n | i s the total numb er of e dges in the gr aph. A pr ecise pro of of this fact is give n in the App endix A . In ligh t of the fact that the configuration mo del CM( d o ) do es not con tain pr eferen tial connec- tions b et w een v ertices, the probabilities p ( u : B ) = P ( ˆ d ( u : B ) ≥ d o ( u : B )) (2.4) can b e used to assess the strength of conn ection b etw een a ve rtex u and a set of v ertices B ⊆ [ n ]. In particular, small v alues of p ( u : B ) indicate that there 10 WILSON ET AL. are more edges b etw een u and B than exp ected under the configuration mo del. If we regard d o ( u : B ) as th e observed v alue of a test statistic that is distributed as ˆ d ( u : B ) under the n u ll mo d el CM( d o ), then p ( u : B ) has the form of a p -v alue for testing the h yp othesis that u is not strongly associated with B . This testing interpretation of p ( u : B ) pla ys a r ole in the iterativ e search pro cedur e that u nderlies the ESSC m etho d (see b elo w). Ho wev er, w e note that the testing p oin t of view is inform al, as the n ull mo d el CM( d o ) itself dep end s on the obser ved net work G o through its degree distr ib ution. In general, the exact v alue of the probabilit y p ( u : B ) in ( 2.4 ) ma y b e difficult to obtain. In p ractice, the ES SC pro cedu re appro xim ates p ( u : B ) b y P ( X B ≥ d o ( u : B )), where X B has a Binomial( d ( u ) , p ( B )) distr ib ution app ealing to the r esult of Theorem 1 . 2.2. Description of the ESSC algorithm. Th e core of the ESSC algorithm is an iterati v e deterministic pro cedure ( Community-Se ar ch ) that searc hes for robust, statisti cally significan t comm unities. Beginning with an in itial set B 0 of vertice s that acts as a seed, the pro ce dure successiv ely refi n es and up d ates B 0 using (the binomial appro ximation of ) the probabilities ( 2.4 ) unt il it reac hes a fi x ed p oint , that is, a vertex set that is unchanged under up d ating. The final vertex set identified by the searc h pr o cedure is a detected comm un it y . The Community-Se ar ch pr o cedure is applied rep eatedly , using an adap- tiv ely chosen sequence of seed v ertices, until it returns an empt y comm unit y with no no d es. The r esulting collection C of detected comm u nities (omitting rep etitions) constitutes the output of the algorithm. Th e seed set B 0 for th e initial r u n of th e searc h pro cedur e is the v ertex of h ighest degree and all of the v ertices adjacen t to it. In sub sequen t r uns of the searc h pro cedure the seed set B 0 is the ve rtex of highest d egree not con tained in an y previously detected comm u nit y and all the ve rtices adjacen t to it, regardless of whether the latter lie in a previously detected comm u nit y or not. T o simplify what follo ws, let C 1 , . . . , C K b e th e distinct detected commu- nities of G o in C . The bac kgroun d of G o is defined to b e the set of vertices that do not b elong to any detected comm u n ities: C ∗ = Bac kgroun d ( G o : C ) = [ n ] / K [ k =1 C k . (2.5) In pr inciple, the num b er K of detecte d comm unities can range fr om zero to n . Imp ortan tly , K is not fixed in adv ance, but is adaptively determined b y the ES SC algorithm. Th e identifica tion of detected communities by the Community-Se ar ch pro cedure allo ws comm unities to o v erlap. As with the IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 11 n u m b er of disco vered comm unities, K , the presence and extent of o v er lap is automatic; n o pr ior sp ec ification of o ve r lap sp ecific parameters are required. The up dates of the Community-Se ar ch pro cedu re b ear further discussion. Consider an id eal setting in which, for eac h vertex u and v ertex s et B we can determine, in an un am biguous w a y , wh ether or not u is strongly connected to B in G o . Informally , a set of v ertices B is a comm unity if the v ertices u ∈ B h a ve a strong connection with v ertices in B , while the ve rtices u ∈ B c do not. Equ iv alen tly , B is a communit y if and only if it is a fixed p oint of the up date ru le S ( A ) = { u ∈ [ n ] such that u is strongly connected with A } that identifies the v ertices ha ving a str on g connection with a set of v ertices A ⊆ [ n ] . F ormally , we may regard S ( · ) as a map fr om th e p ow er set of [ n ] to itself. A v ertex set B is a fix ed p oin t of S ( · ) if S ( B ) = B . In order to find a fixed p oint of the up date ru le S ( · ), we apply the rule rep eatedly , starting from a seed set of v ertices B 0 , until a fi x ed p oint is obtained. The eve n tual termination (and su ccess) of this simp le pr o cedure is assur ed, as th e p o w er set of [ n ] is fi nite. By the exhaustiv e or selectiv e considering of approp r iate seed sets we can effectiv ely explore the space of fixed p oin ts of S ( · ), and thereb y identify comm un ities in G o . The c hoice of a seed set B o for th e Community-Se ar ch pro cedu re requires further discus s ion. As current ly implemen ted, w e choose B o as the neigh- b orho od of the h ighest d egree v ertex among the vertice s lying outside cur- ren tly extracted communities. Consider the f ollo wing situation, as p oin ted out b y a referee, where one h as t wo disconn ected clusters C , C ′ suc h that C conta ins n o inherent comm un it y structure, for example, an Erd ˝ os–R ´ en yi random graph, and C ′ con tains strong comm unit y structure, for examp le, a w ell-differen tiated sto c h astic blo ck mo del. If the maximal d egree of C is larger than C ′ , then ESSC could f ail to find the comm unity str u cture in C ′ . T o address the ab o v e s itu ation, one can run the Community-Se ar ch p ro- cedure in parallel across all vertex neigh b orho ods. In this case, the fin al comm un ities are the collect ion of uniqu ely extracted verte x sets. W e found that the situation ab o ve did not arise in an y of the app lications or sim ula- tions that w e inv estigat e in this pap er. In practice, w e make use of the pr obabilities { p ( u : B ) : u ∈ [ n ] } to measure the strength of the connection b et w een u ∈ [ n ] and B relativ e to the reference distribution C M( d ). In particular, we r egard p ( u : B ) inf ormally as a p -v alue for testing the n u ll hyp othesis H B u that u is not preferent ially connected to B . Then the task of identifying the v ertices u pr eferentially connected to B amounts to rejecting a subset of the h yp otheses { H B u : u ∈ [ n ] } . This is accomplished in steps 4 and 5 of the Community-Se ar ch pro cedure, where we mak e use of an adaptiv e metho d of Benjamini and Ho ch b erg [Benjamini and 12 WILSON ET AL. Ho c hb erg ( 1995 )] to reject a subset of the h yp otheses. The rejection metho d ensures that the exp ected n um b er of falsely r ejected hyp otheses divided b y the total n um b er of rejected h yp otheses (the so-called false disco very rate) is at m ost α [see Benjamini and Ho c h b erg ( 1995 ) for more details]. A default false discov ery r ate threshold α of 5% is common in man y applications, and w e adopt this v alue her e. Pseudo-co de for th e Community-Se ar ch pro cedur e and ESS C algorithm is sho w n b elo w . Community-Se ar ch Pr o c e dur e Given : Graph G o = ([ n ] , E o ); significance lev el α ∈ (0 , 1). Input : Seed set B 0 ⊆ [ n ]. Initialize : t := − 1, B − 1 = ∅ . L o op (Up date) : Until B t +1 = B t 1. t := t + 1. 2. Compute p ( u : B t ) for eac h u ∈ [ n ] . 3. Order the n v ertices of G o so that p ( u 1 : B t ) ≤ · · · ≤ p ( u n : B t ). 4. Let k ≥ 0 b e the largest int eger such th at p ( u k : B ) ≤ ( k /n ) α . 5. Up d ate B t +1 := { u 1 , . . . , u k } . R e turn : Fixed p oint comm u nit y B t . ESSC Algorith m Input : Graph G o = ([ n ] , E o ); significance lev el α ∈ (0 , 1). Initialize : V = [ n ] , C := ∅ . L o op : Let u ∈ V b e the smallest (in case of ties) vertex with maximal degree. Define seed set B 0 := { u } ∪ { v ∈ [ n ] : { u, v } ∈ E o } . Obtain detected comm unity C := Community-Se ar ch ( B 0 ) from searc h pro cedu re. If C 6 = ∅ th en Up date C := C ∪ { C } . Up date V := V \ C . Rep eat Lo op. Otherwise (if C = ∅ ), terminate the pr o cedure. R e turn : F amily C of detected communities. 3. Comp eting method s. Here w e describ e the set of comm u n it y detec- tion metho ds that we us e for v alidation and comparison w ith ESSC . W e implemen t a v ariet y of established detection metho ds all of which ha v e pu b- IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 13 licly av ailable co de. W e n ote that we do n ot compare ES SC with the r ecen tly dev elop ed fast b lo c k mo d el alg orithms from Decel le et al. ( 2011 ), Airoldi, Costa and C han ( 2013 ) and Krzak ala et al. ( 2013 ); suc h comparison s wo uld b e interesting for future work. The parameter settings for eac h algorithm are describ ed in the App endix C . GenL ouvain : Th e GenLouv ain method of Jutla, Jeub and Mu c ha ( 2011 /2012 ) is a mo dularity- based metho d th at emplo ys an agglomerativ e optimization algorithm to searc h for the partition that maximizes the s core in ( 1.2 ). Th e algorithm is comp osed of tw o stages that are rep eated itera- tiv ely until a lo cal optimum is reac h ed. In the firs t, eac h vertex is assigned to its o wn distinct communit y . Then for eac h vertex u (of comm u n it y B u ), the neigh b ors of u are sequential ly added to B u if the addition results in a p ositiv e c h ange in mo dularity . This pr o cedure is r ep eated for all v ertices in the n etw ork until no p ositiv e c hange in mo d u larit y is p ossible. In the second stage of the algorithm, the comm u n ities found in the firs t stage are treated as the n ew v ertex set and passed b ac k to th e first stage of the algorithm where tw o communities are treated as neigh b oring if they sh are at least one edge b et w een them. Thr oughout the remainder of th is pap er, w e sp ecify b G n ull as the configuration mo del so that GenL ou v ain is set to optimize the Newman–Girv an mo du larit y [Newman and Girv an ( 2004 )]. As a result, the Louv ain metho ds of Blondel et al. ( 2008 ) and GenLouv ain can b e used in- terc hangeably (notably , ho wev er, the GenLouv ain co de do es not exploit all p ossible efficiencies for this null mo d el). Infomap : The Inf omap metho d of Rosv all and Bergstrom ( 2008 ) is a flow- based metho d that seeks the p artition that optimally compresses the infor- mation of a random w alk through the n et work. In particular, the optimal partition minimizes the qualit y fu nction kn o wn as the Map Equ ation [Ros- v all, Axelsson and Bergstrom ( 2009 )], whic h measures the description length of the rand om walk. The metho d emplo ys the same greedy searc h algorithm as Louv ain [Blondel et al. ( 2008 )], refin ing the results th r ough sim u lated annealing. Sp e ctr al : Giv en a p resp ecified in teger k , the Sp ectral metho d of Ng, Jor- dan and W eiss ( 2002 ) seeks the partition that b est separates the k smallest eigen v ectors of the graph Laplacian. Sp ecifically , th e k smallest eigen v ectors of the graph Laplacian are stac ked to form the n × k eigen vect or matrix X and k -means clustering is app lied to th e normalized ro ws of X . V ertice s are then assigned to comm unities according to the results of k -means. W e note that there are prop osed h euristics for c ho osing k . F or example, the algo - rithm in Kr zak ala et al. ( 2013 ) do es n ot require one to sp ecify the num b er of comm unities in adv ance and us es the n u m b er of real eigen v alues out- side a certain disk in the complex plane as a starting estimate. Th r oughout the manuscript, ho w ever, w e c h o ose k based on c haracteristics of the data in vestig ated. 14 WILSON ET AL. ZLZ : The metho d of Zhao, Levina and Zhu ( 2011 ), whic h we informally call ZL Z , is an extraction metho d that searc hes for comm u nities one at a time based on a lo cal graph-theoretic criterion. In eac h extraction, ZLZ emplo ys the T abu searc h algorithm [Glo v er ( 1989 )] to fin d the comm unity B that maximizes the d ifference of within -communit y edge density and outer edge density: | B || B c | X i,j ∈ [ n ] A i,j I ( i ∈ B , j ∈ B ) | B | 2 − A i,j I ( i ∈ B , j ∈ B c ) | B k B c | , (3.1) where | B | denotes the num b er of ve rtices in B and A i,j is th e i , j th entry of the adjacency matrix asso ciated with th e observed graph . On ce a communit y is extracted, the v ertices of the comm unit y are remo v ed from th e net work and the pr o cedure is r ep eated un til a presp ecified n um b er of disjoint com- m u nities are f ound. By follo w ing a similar technique d escrib ed in Bic k el and Chen ( 2009 ), the authors sh o w that u nder a degree-corrected b lo c k mo del, the estimated lab els resulting from maximizing ( 3.1 ) are consisten t as the size of the n et work tends to infinity [see Zhao, Levina and Z h u ( 2012 ) for more details]. OSLOM : The OS LOM metho d [Lancic h inetti et al. ( 2011 )] is an inferen- tial extraction metho d that compares the lo cal conn ectivit y of a comm un it y with what is exp ected un der the configuration mo del. Giv en a fixed collec- tion of ve rtices B , the metho d first calculate s th e probabilit y of all external v ertices ha vin g at least as man y edges as it has sh ared with the collection. These probab ilities are then r esampled from the observ ed distribution. Th e order statistics of the r esampled probabilities are used to decide wh ic h ver- tices should b e added to B ; a v ertex is added wh enev er the cumulativ e distribution fun ction of its order statistic falls b elo w a p reset threshold α . V ertices are iterativ ely add ed and tak en aw a y from B in a stepwise fashion according to the ab ov e pr o cedure. This extraction pro cedure is run across a random set of initializing comm un ities and the fin al set of comm un ities are prun ed b ased on a pairwise comparison of o verlap. There are a few similarities b et w een ESSC and these describ ed comp eting metho ds. F or instance OSLOM and GenLouv ain b oth sp ecify the configura- tion mo del as a reference n et wo rk mo d el to whic h candidate comm u n ities are compared. Both ZLZ and OS LOM are extraction metho ds, like ES SC, that do not require all vertic es to b elong to a comm u nit y . The ESSC metho d uses the p arametric distribution that appro xim ates lo cal connectivit y of v ertices and a candidate communit y . S in ce the confi guration mo del can b e estimated using only th e observe d graph, the pr obabilities in ( 2.3 ) hav e a closed form whic h can b e computed analytically . On the other h an d , OSLOM relies up on a b o otstrapp ed sample of n et wo rks for d etermining the significance of a com- m u nit y . Whereas b ot h OSLO M and E S SC are b ased on inferentia l statistical IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 15 T able 1 A summary of the dete ction metho ds we c onsider in our simulation and appli c ation study. F r om left to right, we list the typ e of c ommunity structur e that e ach metho d c an hand le and the p ar ameters r e quir e d as i nput for e ach al gorithm. Liste d f r e e p ar ameters include the fol lowing: k , the numb er of c om m unities; α , the signific anc e level; N , the numb er of iter ations; and γ , a r esolution p ar ameter Comm u nity structure F ree p arameters Metho d Disjoint Ov e rlapping Bac kground k α N γ ESSC X X X X OSLOM X X X X X ZLZ X X X X GenLouv ain X X Infomap X X X Sp ectral X X X tec hniques, Infomap, Sp ectral, Z L Z and GenLouv ain use net work s u mmaries directly . Unlik e seve r al of th ese men tioned metho d s, ESSC requires no sp ec- ification of the num b er of communities and only relies up on one parameter whic h guides the false disco v ery rate. W e summ arize the features of ESS C and these comp eting metho ds in T able 1 . 4. Real net wo rk analysis study . Existing communit y detection metho ds differ widely in their und erlying criteria, as we ll as the algorithms they use to iden tify comm unities that satisfy these criteria. As suc h , we assess the p er- formance of ESS C b y comparing it with seve r al existing metho ds—OSLO M, ZLZ, GenLouv ain, In fomap, Sp ectral and k -means—on b oth a collection of real-w orld net works as w ell as an extensive collection of sim ulation b enc h- marks. W e fir s t applied ESSC to four real n etw orks of v arious size an d density: the Caltec h F aceb o ok net work [T raud et al. ( 2011 )], the p oliti cal blog net work [Adamic and Glance ( 2005 )], the p ersonal F acebo ok net w ork of the first author an d the Enron email net wo rk [Lesk ov ec et al. ( 2009 )]. W e summarize the netw ork s tr uctures in T able 2 and visualize them in Figure 3 . T able 2 Summary statistics of the four networks that we analyze Netw ork Number of vertices Number of ed ges Caltec h 762 16,651 P olitical b log 1222 16,714 P ersonal F acebo ok 561 8375 Enron email 36,691 293 ,307 16 WILSON ET AL. Fig. 3. R e al networks analyze d i n the p ap er. (A) The Calte ch F ac eb o ok network of 2005 c olor e d by dormitory r esidenc e. (B) The 2005 p olitic al blo g network c olor e d by p oli tic al affiliation. (C) The p ersonal F ac eb o ok network of the first author c olor e d by lo c ation in which he met e ach indivi dual. (D) The Enr on email network. Each gr aph is dr awn wi th the F or c e Atlas 2 layout using Gephi softwar e. On the fir st tw o net w ork s , we compare quan titativ e f eatures of the com- m u nities of eac h metho d, including size, num b er of comm un ities, exten t of o ve rlap and exten t of b ac kground. Moreo v er, w e ev aluate th e abilit y of eac h metho d to capture sp ecific f eatures of these t w o complex net works through a f ormal classificati on study . W e d escrib e the p recise s ettings of all tu n- ing parameters for eac h of the detection algorithms in the App endix C . All metho ds we re run on a 4 GB RAM, 2.8 GHz dual pro cessor p ersonal computer. 4.1. Calte ch F ac eb o ok network. The Caltec h F acebo ok net work of T raud et al. ( 2011 ) r epresen ts the friendsh ip relations of a group of un dergraduate student s at the California Institute of T ec hnology on a single d a y in S eptem- b er, 2005. An edge is presen t b etw een t wo ind ividuals if they are f riends on F ace b o ok. In add ition to friendship relations, several d emograph ic features are a v ailable for eac h s tudent , including dormitory residence, college ma- jor, year of ent ry , high sc ho ol and gender. A summary of these features is giv en in T able 3 . This d ata set pro vides a natural b enc h mark for communit y detection metho d s du e to the p ossible asso ciation of comm unity structur e with one or m ore demographic f eatures. Previous studies ha ve foun d that this netw ork disp la ys comm un it y structure closely matc hing the dormitory residence of the individ uals [T raud et al. ( 2011 )]. W e illustrate the net work according to residence in Figure 3 (A). 4.1.1. Quantitative c omp arison. W e fir st compare the comm unities de- tected b y eac h metho d based on quantita tiv e su mmaries of the comm unities themselv es: the n u m b er and size of the communities; th e o v erlap pr esen t; and the num b er of b ac kground vertice s found. A summ ary of the find ings is giv en in T able 4 . ESS C to ok 1.584 seconds to run on this net work. IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 17 T able 3 A summary of the f e atur es asso ciate d with the individuals in the C alte ch F ac eb o ok network. F r om left to right, k is the numb er of unique c ate gories, p m is the pr op ortion of missing data, m is the minimum size of any uni que c ate gory, and M is the maxim um size of any unique c ate gory F eature k p m m M Dormitory 8 0.2205 44 98 Y ear 15 0.1457 1 173 Ma jor 30 0.0984 1 88 High school 498 0.1693 1 3 Gender 2 0 .0827 22 7 472 W e note that the ZLZ, k -means and Sp ectral metho ds requ ire prior sp ec- ification of the num b er of discov ered comm un ities. Based on the ES S C and GenLouv ain results, w e ran eac h of these metho ds with sev en and eigh t detected comm un ities. W e sho w the size d istributions of the detected com- m u nities for eac h metho d in Figure 4 , and fin d that the size d istribution is broadly similar across the E S SC, ZLZ , GenLouv ain and Sp ectral metho ds . Infomap found many ( N C = 18) sm all comm un ities, includ ing sev eral com- m u nities of size three or fewer. At b oth k = 7 and 8, k -means foun d one large comm unity as w ell as man y small similarly sized comm un ities. Inter- T able 4 A summary of the dete ction metho ds run on the Calte ch F ac eb o ok network. F r om left to right, N C is the numb er of c ommunities dete cte d, S is the aver age size of the c ommunities, ˆ σ S is the standar d deviation of the c omm uni ty size, M is the aver age numb er of c ommunities to which nonb ackgr ound vertic es b elong, D sig is the aver age de gr e e of the vertic es i n a c ommunity, D B is the aver age de gr e e of the b ackgr ound vertic es, P B is the pr op ortion of b ackgr ound vertic es, and ˆ E is the me an classific ation err or asso ciate d with the dormi tory fe atur e of the individuals. *Metho ds wer e set to find 7 and 8 c ommunities, b ase d on the numb er of c ommunities dete cte d by ESSC and GenL ouvain. —: r epr esents r ep e ate d values Metho d N C S ˆ σ S M D sig D B P B ˆ E ESSC 7 78 . 57 16 . 03 1.034 55.75 15.81 0.3018 0.0925 OSLOM 18 86 . 78 63 . 25 1.085 50.30 6.18 0.1496 0.2011 ZLZ* 7 62 . 14 41 . 97 1 64.08 16.60 0.429 1 0.5346 ZLZ* 8 58 40 . 58 – 62 .44 14.53 0.3911 0.5323 GenLouv ain 8 95 . 25 35 . 75 – 43. 70 NA NA 0.2576 Infomap 18 42 . 33 46 . 23 – – – – 0.8132 Sp ectral* 7 108 . 86 72 . 77 – – – – 0.4865 Sp ectral* 8 95 . 25 61 . 52 – – – – 0.4512 k - means* 7 1 08 . 86 126 . 51 – – – – 0.4242 k - means* 8 95 . 25 118 . 35 – – – – 0.4327 18 WILSON ET AL. Fig. 4. The size distributions of c ommunities fr om e ach dete ction metho d when run on the Calte ch network. estingly , GenLouv ain also pro d uced an eigh th comm unit y of size tw en ty-o ne, all of whose vertices w ere part of the b ackg round vertex set d etermined by ESSC. No m etho d found significan t ov erlap among the detected comm u- nities. Th e av erage num b er of comm u nities to wh ic h eac h v ertex b elonged ranged fr om 1 to 1.085 . Eac h of the metho ds capable of d etecting bac k- ground (ESSC , OSLOM and ZLZ) designated more than 15% of the total net work as bac kground , and v ertices con tained within comm un ities had a v- erage degree nearly three times that of bac kground v ertices. This suggests, as exp ected, that the b ac kground v ertices are less connected to other vertice s in the net work. 4.1.2. Community fe atur es. One motiv ation for communit y detection metho ds is their abilit y to find communities of v er tices that represen t inte r - esting, bu t p ossibly un a v ailable, features of the system u nder study . Here, w e explore the abilit y of eac h metho d to capture the d emographic features of the Caltec h net wo r k. T o do this, w e measure the exten t to whic h the demographic f eatures “cluster” within comm unities. T ypical pair coun tin g measures do not work well here, as the detected comm un ities ma y ov erlap and ma y not co v er the ent ire net work. Also, pair coun ting measures treat the features as a “ground truth” partition of the net work, whereas the true structure of a net w ork is often more complex [Y ang and Lesk ov ec ( 2012 ), Lee and Cunn ingham ( 2013 )]. As an alternativ e, w e address the connection b et w een communities and features through the problem of classification [see, e.g., Shabalin et al. ( 2009 ), Hastie, Tibshirani and F riedman ( 2001 )]: for eac h IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 19 v ertex, we treat its communit y iden tification as a predictor and its demo- graphic f eatures as a discrete resp onse that w e wish to pr edict. W e d escrib e our appr oac h in more detail. Supp ose that a detection metho d divides the vertice s of the net work into K comm unities plus bac kground . Then the n × K matrix X = [ x i,j ] de- fined by x i,j = 1 , if v er tex i b elongs to comm un it y j , 0 , otherwise , represent s the detected comm u nit y structure of the net work. F or a giv en demographic feature α taking L -v alues, let y α i ∈ [ L ] b e the v alue of α in sample i . W e ignore samp les for wh ic h the v alue of feature α is not a v ailable. T reating the i th r ow of the matrix X as a K -v ariate p redictor for y α i , w e use the Adab o ost classification metho d [F r eund and Schapire ( 1997 )] with tree classifiers to construct a pr ediction rule φ : { 0 , 1 } K → [ L ] . T o ev aluate eac h metho d, w e fi r st randomly divide the n s amples into ten equally sized sub grou p s. Then b y setting aside one s ubgroup as a test set, w e train the classifier on the remaining subgroup s and p r edict the features of the test set. By sub sequen tly treating eac h su bgroup as a test set in this w ay , w e calc ulate the misclassification error associated with eac h test. W e rep ort the a v erage misclassification er r or ˆ E for eac h metho d as a m eans of comparison and rep ort the r esu lts in T able 4 . Th e d istribution of errors is sho w n in Figure 5 . V alues of ˆ E near zero suggest that the d etecte d comm u - Fig. 5. The misclassific ation err or of e ach metho d b ase d on the ten-fold classific ation study p erforme d on the Cal te ch network. The c ommuni ty c ontainment of e ach individual was use d to cl assif y his/her dormitory r esidenc e. F or e ach test, an A dab o ost cl assifier was use d f or c omp arison. 20 WILSON ET AL. nit y structure captur es the clus terin g of the selec ted feature. W e consider the d ormitory r esidence of th e net work, as this feature has b een shown to b e most represent ativ e of th e communit y stru cture in past s tu dies [T raud, Muc ha and P orter ( 2012 )]. F rom Figure 5 , we see that ESSC has the low est misclassification err or among comp eting m etho ds in this classification s tu dy . These results suggest that the detected comm unities of ESSC b est matc h the dorm itory residence of the Caltec h net work. 4.2. Politic al blo g network. The p olit ical blog net work of Ad amic and Glance ( 2005 ) represents the h yp erlink stru cture of 1222 p olitical blogs in 2005 near the time of the 2004 U.S. election. Undir ected edges connect tw o blogs that ha ve at least one hyperlink b et w een them. The blogs were pre- classified according to p olitical affiliation by th e authors in Adamic and Glance ( 2005 ). These authors , as wel l as those of Newman ( 2006 ), observ ed that blogs of a similar p olitical affiliation tend to link to one another m u ch more often th an to blogs of the opp osite affiliation. W e sho w a force d irected la yo u t of this net work colored by p olitical affiliation in Figure 3 (B). 4.2.1. Quantitative c omp arison. W e fir st compare the comm unities de- tected by eac h metho d based on their quantita tiv e c haracteristics. The re- sults are su m marized in T able 5 . ESSC to ok 2.012 seconds to run on this net work. Both the ES SC algorithm and GenLouv ain foun d t wo large communities of similar size. Interestingly , Infomap found thirty-six comm un ities, thirty- four of whic h con tained fewer than 25 v ertices. Roughly 95% of the vertic es in these smaller comm un ities of In fomap w ere conta ined in the bac kground v er- tices of ESS C. Neither ESSC nor OSLOM fou n d significan t o ve rlap among T able 5 A summary of the dete ction metho ds run on the Politic al blo g network. The statistics shown her e ar e the same as those in T able 4 . *We set k to 2 to m atch the r esults of GenL ouvain and ESSC. **We chose k as 10 so that at le ast 50 p er c ent of the vertic es wer e plac e d i n a c ommunity Metho d N C S ˆ σ S M D sig D B P B ˆ E ESSC 2 448 . 50 75 . 66 1 36 . 322 2 . 577 0 . 2651 0 . 0201 OSLOM 11 87 . 58 79 . 48 1.110 33 . 749 5 . 342 0 . 225 0 . 0306 ZLZ** 10 60 . 00 37 . 69 1 35 . 50 2 . 50 0 . 506 0 . 1341 GenLouv ain 2 611 . 00 72 . 12 – 2 7 . 36 NA 0 0 . 0475 Infomap 36 33 . 94 125 . 74 – – – – 0 . 0532 Sp ectral* 2 611 . 00 858 . 43 – – – – 0 . 3821 k - means* 2 611 . 00 613 . 77 – – – – 0 . 2856 IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 21 the comm u nities, reflecting the tend ency of the p olit ical bloggers to com- m u nicate with lik e-minded in dividuals: as noted by the authors of Adamic and Glance ( 2005 ), “divided they blog.” ESSC, OSLOM and ZLZ eac h assigned o v er t wen t y p ercent of the v er- tices to b ac kground. Th e p airwise J accard score of these bac kgrou n d sets is greater than 0.67 in eac h case. The b ackg round ve r tices of all three extrac- tion metho ds h ad m ean degree six times smaller than ve rtices within com- m u nities, suggesting the presence of sparsely connected bac kgroun d v ertices in this net work. 4.2.2. Politic al affiliation. W e no w ev aluate the extent to wh ic h the p o- litical affiliatio n of the blogs “cluster” by conducting the same classification study detailed in S ection 4.1.2 . W e r ep ort the mean prop ortion of m isclas- sified lab els ˆ E in T able 5 . ESS C , OSLOM, GenLou v ain and Inf omap all main tained classification errors b elo w 10% , suggesting that p olitical affili- ation is captured b y the net work’s comm un it y stru cture q u ite w ell. ES SC had the lo we st misclassification error in this study , k eeping an err or b e- lo w 4% across all tests. W e lo ok d eep er into th e strength of connection of the bac kgroun d vertice s to the true p olit ical affiliations. Inte restingly , these v ertices were still preferentiall y attac hed to their true affiliation, ho wev er, their asso cia ted p -v alues w ere t ypically greater than 0.10, indicating wea k affiliation. 4.3. Personal F ac eb o ok network. The p ersonal F aceb ook netw ork giv es friendship structure of the fi r st auth or’s fr iends on F acebo ok. In addition, eac h ind ividual is lab eled according to the time p erio d during wh ic h he or she m et th e fir s t author. This data set, as well as the lab els, is pro vided in th e sup plemen tal file [Wilson ( 2014 )]. This netw ork is sh o wn, colored by lab el, in Figure 3 (C). The un d erstanding of h uman so cial in teractions has b een improv ed throu gh the analysis of large a v ailable so cia l n et works lik e F acebo ok [Lee and Cun- ningham ( 2013 ), T raud et al. ( 2011 ), T raud, Muc ha and Porter ( 2012 )]. T yp ically , these net works capture th e so cial activit y of ind ividuals of a sin- gle lo cation. F or example, the F ace b o ok net work analyzed in Section 4.1 reflects the friend ships of individ uals sp ecifically from the California Insti- tute of T ec h nology . The p ersonal F aceb o ok net w ork pro vides one view of ho w individu als fr om different s c ho ols and lo cations int eract given that they all h a ve one friend in common. W e ran ESSC on the n et wo rk (ru nning time ab out 1 second) and f ou n d 7 comm un ities with sizes v arying f rom 10 to 157; see T able 6 . Appro ximately 18% of the no d es in the netw ork were distinguished as bac kground . The mean degree of th e v ertices b elo nging to a comm unity ( D sig ≈ 33) was ab out sev en times that of the bac kground ( D B ≈ 5). O f the v ertices that were con tained 22 WILSON ET AL. T able 6 F e atur es of the p ersonal F ac eb o ok network as wel l as the r esults of ESSC. On the l eft, we list the lab els of the i ndi viduals ac c or ding to lo c ation and the size of e ach gr oup. On the right, we list the dete cte d c ommunities and b ackgr ound as wel l as their c orr esp onding size T ru e f eatures ESSC results Lab el Size Communit y Size Acquaintance 80 1 43 A 62 2 107 B 94 3 75 C 150 4 157 D 147 5 53 E 3 6 26 F 3 7 10 G 22 Bac k ground 101 (18.0%) in a comm un it y , the a v erage mem b ership w as ve ry close to 1, suggesting little o v erlap b et w een communities. T o und erstand h o w the lo cation feature of the in dividuals cluster, we in- v estigate th e comp ositi on of eac h lab el according to detected comm unity in Figure 6 and find sev eral in teresting results. The ind ivid uals f rom lo cations A, B, C, D and G all tend to cluster according to the d etected communi- ties. F or instance, 79% of the individ uals from lo cation A w ere conta ined in comm un it y 5. Similarly , 60% or more of the individu als fr om lo cations B, C, D and G also b elong to a single comm un ity in eac h case. Groups A, B, C and D rep resen t the sc ho ols th at the author attended f rom high sc h o ol to final graduate school and m ak e up nearly 81% of the total netw ork. Groups Fig. 6. A b ar plot showing the clustering of lo c ations A–G and A c quaintanc es of the p ersonal F ac eb o ok network. F or e ach lo c ation l ab el, we show the p er c entage of individu- als fr om that lo c ation that wer e c ontaine d in e ach dete cte d c ommunity. Communi ties ar e lab ele d 1–7 and Back. r epr esents the b ackgr ound vertic es. IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 23 E and F are not captured w ell by the comm unities, h ow ev er, this is ex- p ected due to the small size of these lo ca tions ( n = 3 in b oth cases). Finally , the most highly represented group among the bac kgroun d d istinguished by ESSC we r e acquain tances—ind ividuals met through other fr iends, ev ents or conferences. These results suggest that friendship s in th is net wo rk cluster are based on lo cation and that the acquain tances of the author are not we ll connected to his remainin g friends. 4.4. Enr on email network. The En ron email n et wo rk from Lesko v ec et al. ( 2009 ) is a large (36,691 vertices) , sparse net work in which eac h vertex repre- sen ts a uniqu e email addr ess. An undirected edge connects an y t w o addr esses if at least one email message has b ee n sent f rom one add ress to the other. A t least one v ertex of eac h edge corresp onds to the email addr ess of an emplo yee of the Enron corp oratio n . The netw ork is sh o wn in Figure 3 (D). W e r an ESSC on the net work with α = 0 . 05. ESSC to ok approximate ly 10 min utes to run on th is net work. Imp ortantly , the netw ork includes Enron emplo ye es as we ll as ad vertising agencies and spam sites outside Enron. As su c h, we exp ect there to b e many bac kground vertic es represen ting spam and adv er tisement email addresses. On applying ESSC to th e net work, we ind eed find an abu n dance of bac k- ground vertic es—nearly 83 % (30,454 v ertices) of th e net w ork. The a v erage degree of the vertice s within a communit y is nearly t wel v e times that of the bac kground v ertices. ESSC foun d 8 comm u nities with a v erage size of 1239 and standard deviation 450. The a v erage membersh ip of the v ertices that were con tained within a comm u nit y was 1.409, indicating a mo d er ate amoun t of o v erlap of comm u nities. 5. Sim u lation study . In this section w e ev aluate th e p erformance of ES SC on s imulated n et wo rks with three primary t yp es of comm u nit y stru cture: (1) comm un ities that partition the net work; (2) communities that ov erlap and co v er the n et wo rk; an d (3) disjoin t comm un ities plu s b ac kground . Net wo r ks of the first tw o t yp es ha v e b een we ll studied, and there are sev- eral existing sim ulation b enc hmarks for these s tr uctures [Girv an and New- man ( 2002 ), Lancic hin etti and F ortunato ( 2009a , 2009b )]. W e mak e use of the Lancic hin etti, F ortunato and Radicc h i (LFR) ben c hmark fr om Lancic hinetti and F ortunato ( 200 9a , 2009 b ) in ord er to assess th e p erfor- mance of ESSC and other metho ds on n etw orks of the fi rst t wo types. Our principal reason for using th e LFR sim ulation b enc hmark is its fl exibilit y , as w ell as the fact that the p ow er-la w d egree distribution it employs is represen- tativ e of the d egree of h eterogeneit y pr esen t in many real net w orks [Barab´ asi and Alb ert ( 1999 )]. ES S C p er f orms w ell on these standard nono verlapping and o verlapping b enc hmarks, and is in fact comp etitiv e w ith the other detec- tion metho d s in th ese settings. W e ev aluate the results on these b enc hmarks in the App end ix B . 24 WILSON ET AL. Relativ ely little attenti on h as b een p aid to net works with backg round v ertices, and w e are not a ware of a sim u lation b enc hmark for netw orks of this sort. W e therefore pr op ose a flexible simulat ion b en c hmark for n et wo rks with b ackg round that extends the LFR b enc hmark, and use it to compare ESSC with comp eting metho d s. In the remainder of the section, we first describ e the LFR b enc h marks of Lancic hinetti and F ortunato ( 2009a , 2009b ) and then show ho w these b enchmarks can b e extend ed to net works with b ackg round. W e assess the p erformance of ES SC and other comp eting metho ds on n et works with bac k- ground u sing our prop osed b enc hmark. 5.1. The LFR b enc hmark. Th e LFR b enc hmarks of L ancic hinetti and F ortunato ( 2009a , 2009b ) include a num b er of p arameters that gov ern th e comm un it y structure of the simulated net work; a list is giv en in T able 7 . The edge density of the sim ulated net work is con trolled through the size n of the netw ork and the mean degree D . F or example, sparse n et works are represent ed by b enchmarks with large n and small D . T he degree d istribu- tion of simulate d net works follo ws a p o w er la w with exp onen t τ 1 . Lo wer and upp er limits of th e degree distribution are set to maint ain an av erage degree D among ve rtices in the net w ork. The distrib ution of communit y sizes in the LFR b enc hmark follo ws a p o we r la w with exp onent τ 2 . The size range [ s 1 , s 2 ] sets low er and up p er limits on th e size of communities in the net work. Con- sider a vertex u and its comm u nit y C . Then u sh ares a fraction µ of its edges with ve rtices outside of C while the remainin g 1 − µ of its edges are s h ared with v ertices within C . Th u s, the mixing p arameter µ con trols the extent to wh ich comm un ities mix, with comm un ities b ec oming less distinguishable as µ increases. Fin ally , in the LFR b enc hmark with o v er lap, the parame- ter ρ ∈ (0 , 1) is the p rop ortion of v ertices that are con tained in exactly t w o T able 7 Description of the fr e e p ar ameters available wi th the LFR b enchmark networks Pa rameter Description n S ize of the n etw ork µ ∈ (0 , 1) Mixing parameter: the p roportion of external comm unity d egree for eac h vertex τ 1 P o w er-la w exp on ent for degree distribu tion of netw ork τ 2 P o w er-la w exp on ent for size distribution of communities in netw ork D Mean degree [ s 1 , s 2 ] Size range of each communit y: s 1 = low er limit s 2 = up p er limit ρ ∈ (0 , 1 ) Proportion of ve rtices contained in tw o communities (used in ov erlapping b enchmark only) IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 25 comm un ities, and therefore con trols the exten t of o verlap. If u b elo n gs to t wo comm unities in the o verlapping L FR b en chmark, then µ repr esen ts the prop ortion of edges of u that fall outside all these comm unities. 5.2. Backgr ound b enchmarks. T o assess detection metho d s on net w orks with bac kground , we pr op ose three principled test b ed sim u lations: (1) a net work with no comm unities (and therefore all v ertices are b ackg round); (2) a netw ork with a single embedd ed communit y; and (3) a net work with disjoin t communities and bac kgroun d. In what follo ws, we fir st d escrib e h ow to sim u late eac h t yp e of net work and then discuss the r esults for eac h type. Networks with no c ommunity structur e : I t is imp orta n t to measure th e exten t to whic h a detection metho d correctly iden tifies the lack of communit y structure w hen n one is present. W e construct suc h b ac kground net w orks by using t wo random net wo r k mo dels: the Erd˝ os–R ´ en yi mo d el of Er d ˝ os and R ´ enyi ( 1960 ) where all v ertices are link ed with equal probabilit y , and the configuration mo del of Mollo y and Reed ( 1995 ) where v ertices are linke d according to a pr escrib ed degree sequence as discus s ed in Section 2 . F or eac h of these mo dels, w e v ary the size n and mean degree D in order to con trol the edge d en sit y of the generated net work. In particular, f or con- figuration rand om n etw orks, we sp ecify that the degree sequ en ce follo ws a p o w er la w with degree τ 1 and a v erage d egree D . Single emb e dde d c ommunity : W e consider netw orks that con tain a single em b edded comm unity and many bac kground v ertices. T o constr u ct suc h net works, w e use a v ariant of the sto c h astic t wo blo ck mo del of Snijders and No wic ki ( 1997 ), that has a simple generativ e pro cedure. First, vertic es are placed randomly and indep enden tly in t wo blo c ks, C 1 and C 2 , according to the probabilities π 1 and π 2 = 1 − π 1 . An edge is included b et ween a pair of distinct v ertices u ∈ C i and v ∈ C j with pr ob ab ility P i,j , ind ep endently fr om pair to pair. T o constru ct a netw ork of size n with a single em b edded comm u nit y C 1 and bac kground C 2 , w e generate a sto c hastic t wo blo c k mo d el using π = { π , 1 − π } with π ∈ (0 , 1) and P = { P i,j : 1 ≤ i, j ≤ 2 } giv en by P = θ κ 1 1 1 . Here κ > 1 controls the inner communit y edge probability , and θ < 1 con trols the a verage d egree of the net work. Mo difying π con trols for the size of the em b edded comm un it y . The parameters θ and n can b e mo dified to con trol the edge den sit y of the n et wo rk. By generating a n et wo rk of fixed size and mean d egree, one can assess the sensitivit y of a d etectio n metho d by runnin g the m etho d across a range of π . W e note that Z hao, Levina and Zhu ( 2011 ) used a similar b enchmark net work to assess the p erformance of their o wn detection algorithm. 26 WILSON ET AL. Disjoint c ommunities and b ackgr ound : As a thir d b enchmark test set, we sim u late a net w ork with b ac kground and degree heterogeneities. T o do so, w e p rop ose com bining the LFR b enc hmark describ ed in Section 5.1 with the blo c k structure describ ed ab ov e. W e construct this netw ork in t wo s teps using the same parameters as the L FR b enc hmark describ ed in T able 7 . First, w e in dep end ently and randomly assign vertice s to on e of t w o blo c ks C 1 and C 2 according to probabilities π = { π , 1 − π } . W e place edges b et w een v ertices in blo c k C 1 according to the disj oin t LFR b enc hmark with parame- ters Θ = ( τ 1 , τ 2 , n · π , µ, D · π , [ s 1 , s 2 ]). The remaining v ertices, corresp onding to C 2 , are connected to all vertice s w ith equ al probabilit y P 2 := D (1 − π ). Th us, our b enc hmark is constructed as a sto c hastic 2 blo c k m o del describ ed b y π and P = P LFR P 2 P 2 P 2 , where P LFR denotes the edge pr ob ab ilities b etw een vertic es in C 1 deriv ed from the LFR random net w ork. Th e resulting net work has av erage degree D . On a verage , a fraction π of the vertic es exhib it comm unity structure follo w- ing the LFR disjoint b enchmark, while th e remaining vertic es are connected to eac h other and to v ertices in the fir st blo c k in an Er d˝ os–R ´ en yi lik e fashion. This n ew b enchmark is flexible and can b e u sed to assess the p erformance of any comm un it y detection m etho d for net w orks with bac kground . 5.3. R e sults. Networks with no c ommunity structur e : W e generated b oth Erd˝ os–R´ enyi and configuration mo del random graph s with 1000 vertice s , with av erage degree D ranging from 10 to 100 in in cr ements of 10. Th e degree sequence of the vertic es in the configuration n et wo rk follo w a p o w er- la w d istribution with degree τ 1 = 2. F or eac h v alue of D , w e generate 30 random graph s , with edge pr obabilities determined by the v alue of D . In eac h of the simulations, ES SC assigned all no des to b ackg round, as d esired. Single emb e dde d c ommunity : W e generated net works of size 2000, and set κ to 10, so that the edge probabilit y within the s ingle communit y is ten times that of the b ac kground. W e selected v alues of θ to generate net w ork s with av erage degree D of 30, 40 and 50. F or eac h v alue of D , w e generated net works with em b edded comm unities of size π ∗ 2000 for π ranging from 0.01 to 0.3. F or eac h set of parameters, we generated 30 netw ork r ealizat ions and ga v e these as inp ut to E S SC, Sp ectral, Z L Z and OSLOM. W e set Sp ectral to partition th e net work into t w o comm unities and set ZLZ to extract one comm un it y , thereb y giving b oth of the metho ds an adv an tage o ver the other metho ds consider ed . In order to measure the abilit y of eac h metho d to find the tr ue single em- b edded comm un it y , we used th e maxim um Jaccard Matc h score of the de- tected comm u nities. In detail, w e m easured the J accard score b et w een eac h IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 27 Fig. 7. The r esults for networks with a single emb e dde d c ommunity. Shown ar e the first, se c ond and thir d quartile of the m axi m um Jac c ar d Match of e ach metho d over 30 r e ali za- tions acr oss values of π . *Sp e ctr al and ZLZ wer e given the true numb er of c ommuniti es: Sp e ctr al was set to p artition the network into two c omm uni ties, while ZLZ was set to extr act 1 c ommunity. detected comm unity and the true em b edded comm u nit y and r ep orted the maxim um of these v alues for eac h sim u lation. Results are s h o wn in Figure 7 . F rom Figure 7 , we see that ESS C is able to find, w ith Matc h ≈ 1, single em b edded comm u nities ev en w hen the comm un it y is as small as 4% of the to- tal net work. As the size of emb edded communit y in cr eases, the p erformance of eac h metho d imp ro ves, eve ntually reac hing near optimal p erformance. In the case of small embedd ed comm unities ( π < 0 . 05), ESS C and ZLZ p erform similarly , with ES S C ha ving a sligh t adv an tage. Finally , ES SC and all other metho ds imp ro ve as the av erage degree of the net work increases. Across all sim u lations, we note that OS L OM did n ot fin d more than tw o n on trivial comm un ities. Disjoint c ommunities and b ackgr ound : W e simulated netw orks of size n = 2000 with π = 1 / 2, so that half of the v ertices we re bac kgroun d and the other h alf b elonged to disjoint comm un ities generated according to the LFR 28 WILSON ET AL. b enchmark. Net works were generated with av erage degree D = 30, 40 and 50, with comm unit y sizes in th e range [ s 1 , s 2 ] = [20 , 100 ]. Degree d istr ibutions w ere generate d according to a p o w er la w w ith degree exp onent τ 1 = 2 and comm un it y size d istr ibutions were generated according to a p ow er la w with degree exp on ent τ 2 = 1. F or eac h v alue of D , n et works w ere generated with mixing parameter µ ranging b et w een 0.1 and 0.8 in increments of 0.1. F or eac h set of parameters 30 netw ork realizations w ere generated and then passed as inp ut to ESSC, Sp ectral , ZLZ, OSLOM and Infomap. As b efore, the Sp ect ral and ZLZ were ru n u sing the true num b er of communities. T he generalized normalized mutual inform ation (NMI) was u sed to measure th e concordance of the detected comm unities and the tru e comm unities with bac kground v ertices treated as a single comm unity . NMI is an in formation theoretic to ol that can measure the similarit y b et w een t wo partitions as well as b et w een t wo cov ers of a n et wo rk. F or more in formation on th is similarit y measure, refer to Lancic hinetti, F ortu nato and K ert ´ esz ( 2009 ). Results are sho w n in Figure 8 . Figure 8 tells us several inte resting things ab out the p erformance of ESS C and other detection metho ds on complex netw orks with bac kground. First, w e see that ESSC p erforms we ll (NMI ≈ 1) across a range of mixin g param- eters µ from 0.1 to 0.5. After µ = 0 . 6, ES SC finds no significan t comm u nities and, hence, the p erformance falls at this p oint. Infomap comp ete s fav orably with ESSC u p until µ = 0 . 3, at w hic h p oin t Infomap p laces all ve r tices in the same comm unity . Interestingly , OSLOM has a p eak of p erformance around µ = 0 . 6. Th is app ears to hinge on the fact that the metho d m easures the strength of a comm u nit y thr ough assu ming th at vertice s outside a commu- nit y are close to the connectivit y of the ve rtex of the communit y that h as the lo west connectivit y for the sp ecified comm u nit y . Highly mixed comm u - nities tend to f a vo r this similarit y , giving OS LOM an adv an tage in these cases. Imp ortant ly , ES SC p erforms nearly as w ell on net works of disjoint comm un ities with bac kground ve rtices as it do es on these typ es of n etw orks without bac kgroun d (see the App end ix B for nonbac kground sim ulations). On the other hand, the remaining metho ds tend to, on av erage, p erform m u c h wo rse w hen bac kgroun d ve rtices are introduced. 6. Discussion. The iden tification of comm un ities of tigh tly connected v ertices in net w orks has pr o ve n to b e an imp ortan t to ol in the exploratory analysis and study of a v ariet y of complex connected systems. In this p ap er w e int ro duced a means to measure th e statistical significance of conn ection b et w een a single vertex and an y collection of ve rtices in undirected net works through a reference distrib u tion deriv ed from the p rop erties of the condi- tional configuration mo d el. W e introd uced and ev aluated a testing based comm un it y d etectio n metho d, ESSC, whic h iden tifies statistically signifi- can t communities through the u se of p -v alues derived from this reference IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 29 Fig. 8. The r esults for networks with LFR and b ackgr ound fe atur es. Shown ar e the first, se c ond and thir d quartile match of e ach metho d over 30 r e alizations acr oss values of µ . The de gr e e distribution of the signific ant c ommunity structur e fol lows a p ower law with exp onent τ 1 = 2 wi th aver age de gr e e D sp e cifie d in e ach figur e. *Her e, Sp e ctr al and ZLZ wer e given the true numb er of c ommunities. distribution. This method automatically c ho oses the n umb er of comm u ni- ties and relies only up on one parameter wh ic h guides the false d iscov ery r ate of discov ered communities. The ES S C extractio n tec h nique directly ad d resses the imp ortance of iden- tifying bac kground v ertices within a net work that need not necessarily b e assigned to iden tified comm un ities. Give n the heterogeneities of ve rtex r oles in most real-w orld net wo r k d ata, iden tifying bac kgroun d no d es is an im- p ortant asp ect of comm un ity detection. Metho d s which ident ify bac k grou n d v ertices can help preven t the noise asso ciated with their connections from p olluting the otherwise significant features among and b et w een comm uni- ties. W e ev aluated ESSC and a n u m b er of comp eti ng communit y detectio n metho ds u sing a v ariet y of qu antitat iv e and net work-sp ecific v alidation mea- sures. W e hav e sho wn that ESS C is able to capture features of net wo rk data 30 WILSON ET AL. that are relev ant to the mo deled complex sy s tem. F or instance, in the Caltec h net work study w e found that ESS C identified communities closely m atc h- ing th e dormitory r esidence of its individu als; similarly , in the p olitical blog study ESS C identified comm un ities matc hing the p olit ical affiliation of the bloggers in the n et wo rk. Imp ortan tly , ES SC ident ified a mo derate amoun t of bac kgrou n d for eac h analyzed net work in this pap er, su ggesting p oten tial b enefits to distinguishin g bac kground in a net work. Finally , through a series of simula tions we ha v e sho w n that ESSC is able to su ccessfully captur e b oth ov erlapping and disjoint communit y structure, as well as communit y structure in netw orks with backg round. In th e former scenario, ESSC is comp etit iv e with many mo dern d etection metho ds, while in the latter we find that ES S C outp erforms comp eting metho ds. The dev elopment of ES SC relied on u ndirected, unw eigh ted net works, ho wev er, this can b e extended to n et works of d ifferen t stru ctur es, in clud ing directed, multila y er and time-v arying n et wo rks. Und er s tanding the statisti- cal signifi cance of comm unities in eac h of these m ore complex n et wo rk stru c- tures requir es b oth theoretical and metho dological work, p ro vid ing a ven ues for futu r e r esearc h. T h is includes comparing ESSC to the v arious stochas- tic blo c k mo d el fitting algorithms and other p ermutatio n-based statistical metho ds that ha v e b een recen tly d evelo p ed o ve r the past few y ears. F ur- thermore, unders tand ing the consistency pr op erties of the ESSC algorithm is an in teresting question of indep enden t interest whic h w ill requ ire recen tly dev elop ed pr obabilistic to ols. APPENDIX A: APPRO XIMA TE DIST RIBUTION OF ˆ D ( U : B ) Here we state and pro ve Theorem 1 wh ic h giv es the approximat e law of ˆ d n ( u : B ) on whic h our algo rithm is based in the large net work limit. The result is sp ecific to the conditional configuration mo del, whic h we use as a n u ll netw ork m o del in ord er to fi n d significan t communit y str ucture. Pr oof of Theore m 1 . Equation ( 2.2 ) imp lies that for the n u m b er of edges E o,n one has Z R x dF n ( x ) = ∞ X k =0 k N k ( n ) n = 2 | E o,n | n ∼ µ, where N k ( n ) is the num b er of v ertices of degree k . Thus, | E o,n | ∼ nµ / 2 . No w to understand the d istribution of ˆ d n ( u : B ), namely , the n umber of connections of v ertex u to the s u bset B in C M( d o,n ), we use the fact that for constructing the configuration mo del, one can s tart at an y v ertex and start sequen tially attac hing the half-edges of that v ertex at r andom to av ailable IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 31 half-edges. W e start w ith the fixed ve rtex u and decide the h alf-edges paired to th e d o,n ( u ) := k half-edges of ve r tex u . W rite A 1 for the ev en t that the first half-edge of v er tex v connects to the s et B and w rite r 1 ( B ) for the probabilit y of this ev ent. Th en, r 1 ( B ) = P v ∈ B d o,n ( v ) [ P v ∈ [ n ] d o,n ( v )] − 1 = P v ∈ B d o,n ( v ) 2 | E o,n | − 1 . (A.1) No w if eac h half-stub sampled with replacemen t from the stu b s corresp ond- ing to set B , then ˆ d n ( u : B ) wo uld exactly corresp ond to a Binomial dis- tribution. The main issue to und erstand is th e effect of sampling without replacemen t from the half-stubs of B , namely , once a h alf-stub of B is used b y u , it cannot b e reused . In general, for 1 ≤ i ≤ k , let A i denote the even t that half-edge i connects to the set B and w rite r i ( B ) for the conditional probabilit y of A i conditional on th e outcomes of the first i − 1 c h oices. F or i = 2, we claim that uniformly on all outcomes for the fir s t edge, this condi- tional p r obabilit y can b e b ounded as [ P v ∈ B d o,n ( v )] − 1 2 | E o,n | − 2 ≤ r 2 ( B ) ≤ P v ∈ B d o,n ( v ) 2 | E o,n | − 2 . (A.2) The lo w er b ound arises if the firs t half-edge of v connected to a half-edge of B , w h ile the u pp er b ound arises if th e fir st half-edge do es not connect to a half-edge emanating f r om B . Arguin g analogously for 1 ≤ i ≤ k , w e fi nd th at the conditional probab ility r i ( B ) that the i th half-edge of vertex v conn ects to B is b ounded (uniformly on all c h oices of the first i − 1 edges) as [ P v ∈ B d o,n ( v )] − ( i − 1) 2 | E o,n | − i ≤ r i ( B ) ≤ P v ∈ B d o,n ( v ) 2 | E o,n | − i . (A.3) Recall that p n ( B ) = P v ∈ B d o,n ( v ) / 2 | E o,n | . Since | E o,n | ∼ nµ / 2 , using ( A.3 ), w e ha v e sup 1 ≤ i ≤ k | r i ( B ) − p n ( B ) | ≤ 3 k 2 | E o,n | + O k 2 | E o,n | 2 → 0 (A.4) as n → ∞ . No w note that the ran d om v ariable of inte r est ˆ d n ( u : B ) can b e expressed as ˆ d n ( u : B ) = k X i =1 1 { A i } . Equation ( A.4 ) imp lies that d TV ( ˆ d n ( u : B ) , Bin( k , p n ( B ))) → 0 as n → ∞ . This completes the pr o of. 32 WILSON ET AL. APPENDIX B: SIMULA TIONS ON DISJOI NT AND O VERLAPPING COMMUNITY BENCHMARKS Disjoint c ommunities : LFR b enc hmarks of size 2000 were sim ulated w ith t wo ranges of comm un it y size, [10 , 50] (small, S) and [20 , 100] (big, B), where the communit y sizes w ere d eriv ed fr om a p ow er-la w distribu tion w ith exp o- nen t τ 2 = 1 and with av erage degree D equal to 30, 40 or 50 with d egrees deriving from a p o w er-law d istribution with exp onen t τ 1 = 2. F or eac h v alue of D , netw orks we re generated with v alues of µ r anging fr om 0.1 to 0.8 in incremen ts of 0.1. Th ir t y realizations we re generated from eac h set of pa- rameters, and the resulting net w ork s w ere input to the ES S C, GenLouv ain, Infomap, OSLOM and Sp ectral metho ds. F or Sp ect ral, the parameter k w as set to the true n u m b er of comm u nities, thereb y p ro vid ing Sp ectral with an adv an tage o ver the other metho ds considered. Normalized mutual informa- tion (NMI) [Lancic hinetti an d F ortunato ( 2009b )] w as u sed as a measure of p erformance f or all metho ds . The results are summ arized in Figure 9 . ESSC p erforms well (NMI ≈ 1) for all simulatio ns with mixing parameter µ ≤ 0 . 6. In net works with small communities ([10 , 50]), E SSC finds no signif- ican t comm u nities for extreme v alues of µ ( ≥ 0 . 7). In net w ork s with larger comm un ities ([20 , 100]), ES S C identifies un d erlying stru ctur e w h en µ = 0 . 7, and p erforms particularly well for dense net works ( D = 40 , 50). These re- sults suggests that, when comm u n ities are we akly defined, ES SC p erforms b etter when the u n derlying comm u nities are large. Overall, ESS C, OSLOM and Inf omap p erf orm ed ideally when µ ≤ 0 . 6. Overlapping c ommunities : LFR b en chmarks of size 2000 we re sim u lated with tw o ranges of communit y size, [10 , 50] (small, S) and [20 , 100] (big, B), w ith size d istribution follo wing a p o wer law with exp onen t τ 2 = 1 and with a verag e degree D equal to 30, 40 or 50 w h ere the degree distribu tion follo ws a p ow er law with exp onen t τ 1 = 2. F or eac h v alue of D , n et works w ere generated w ith v alues of ρ ranging fr om 0.1 to 0.8 in increments of 0.1. The mixing parameter µ wa s set to 0.3. Thir t y realizatio ns were generated from eac h set of parameters and then input to ESS C and OSLOM. Once again, the generalized NMI was u sed to ev aluate the similarit y b et w een the detected comm u nities and the true co v er. The results are summarized in Figure 10 . F rom Figure 10 , we fi rst notice that ESSC p erforms comp etiti v ely with OSLOM in detecting o v erlapp in g comm unity stru cture across all ρ . In net- w orks with small comm un ities (size in [10 , 50]), the p erformance of ESSC impro v es as the density of the net wo rk increases. W e also see that ES SC impro v es w hen the size of the communities increases as observ ed by com- paring the left and right panels of the ESSC results in Figure 10 . T h is agrees IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 33 Fig. 9. The r esults on the LFR disj oint b enchmarks. Shown ar e the first, se c ond and thir d quartile match of e ach metho d over 30 r e alizations acr oss values of µ . The de gr e e distribution f ol lows a p ower law with exp onent τ 1 = 2 with aver age de gr e e sp e cifie d in e ach plot. *Her e, Sp e ctr al was given the true numb er of c ommuni ties. 34 WILSON ET AL. Fig. 10. The r esults on the LFR overlapping b enchmarks. Shown ar e the first, se c ond and thir d quartile match of e ach metho d over 30 r e alizations acr oss values of ρ at fixe d µ = 0 . 3 for b oth smal l [ 30–50] and big [50–100] c omm unities. The de gr e e distribution f ol lows a p ower law wi th exp onent τ 1 = 2 w i th aver age de gr e e sp e cifie d by the c olor of e ach line. with our observ ation in the disjoint comm unit y study suggesting that ESSC prefers n et wo rks with larger communities. APPENDIX C: P ARAMETER SETTINGS OF DETECTION METHODS W e now d escrib e the exact parameter s ettings as well as the co de used for all detection metho ds throughout our real n et work analysis and simulation studies in Sections 4 – 5 : • ESSC : W e use the MA TLAB implemen tation of the algorithm provided b y the authors at http://www.unc.edu/ ~ jameswd/researc h. h tml . W e set α to b e 0.05 for all real d ata sets and sim ulated n et wo rks except for the Caltec h F ace b o ok net work w here w e set α to b e 0.01. • OSLOM : W e use the C ++ implementat ion a v ailable at http://www. oslom.org/software.htm . F or eac h s tu dy we use the default settings IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 35 under an unw eigh ted undir ected net work with no hierarc hy . The p -v alue threshold is by default set at 0.1. A r an d om seed is u sed for its r andom n u m b er generator. • Infomap : W e use the C++ imp lemen tation a v ailable at h ttp://www. map equation.org/cod e.h tml . F or eac h study we use the d efault settings of the algorithm for an u ndirected net work. W e u s e a random p ositiv e in teger as the seed and r u n 500 attempts of the algorithm to partition th e net work. • k -me ans : W e use the MA TLAB im p lemen tation of the algorithm that is av ailable for current MA TLAB soft ware. I n eac h stud y w e c ho ose k according to th e netw ork as describ ed throughout the text. W e ran the algorithm ov er 500 iterations and used a random seed f or initializatio n. • Sp e ctr al clustering : W e u se th e MA TLAB imp lemen tation of the norm al- ized Sp ectral Clustering algorithm. W e c h o ose k according to the net work as describ ed in the text. Again, we ran the algorithm o ver 500 iterations and used a random seed for in itializa tion. • GenL ouvain : W e use the MA TLAB implemen tation of the generalized v er- sion of Louv ain (GenLouv ain) from J u tla, Jeub and Muc ha ( 2011/ 2012 ). F or th e r eal net work analysis, we run th e algorithm across a range of res- olution parameters, γ ranging fr om 0.1 to 1.0 (in increment s of 0.1). F or eac h γ , we lo ok at the num b er of comm u nities of the resulting partition and c ho ose γ to b e the first v alue for w hic h the size is stable in terms of b eing constant across neigh b oring v alues of γ . In doing so, w e c hose γ = 0 . 8 for the Caltec h F aceb o ok netw ork and γ = 0 . 3 for the p olitical blog n etw ork. In the simulation study , we use the rand omized version of GenLouv ain (a v ailable on the same website ) and c ho ose th e partition of the highest mo dularity across 30 rep etit ions. In eac h r un, we use the de- fault r esolution parameter γ = 1. W e use a random seed for eac h run of the algorithm. • ZLZ : W e use the R implement ation pro v id ed to us by th e author Y unp en g Zhao. W e run th e tabu searc h part of the algorithm 1000 iteratio n s for eac h run. W e c ho ose k according to the net w ork as describ ed in our rep ort. The normalized default score from Z hao, Levina and Zh u ( 2011 ) was us ed as the ob jectiv e fun ction to wh ic h the algorithm was run to optimize. A rand om s eed was set for in itializa tion. APPENDIX D: ON T HE EFFECTS OF α As discussed in th e main pap er, α is the only tunable parameter of the ESSC algorithm. The v alue of α control s the lev el for w h ic h comm u nities are declared statistically signficant. T o get an idea of ho w sensitiv e the algorithm is to this parameter, we ru n the algorithm on the fi rst t w o analyzed data 36 WILSON ET AL. T able 8 A summary of the c om m unities dete cte d by ESSC acr oss a r ange of values of α when run on the Cal te ch F ac eb o ok network. T hese statistics ar e the same as those pr esente d in Se ction 4 α N C S ˆ σ S M D in D out P B 0.01 7 78 . 57 16.03 1. 03 55. 76 15 . 81 0.30 0.02 7 80 . 29 15.52 1. 04 55. 52 14 . 97 0.29 0.03 7 82 . 43 15.05 1. 05 55. 14 14 . 41 0.28 0.04 6 86 . 67 12.40 1. 02 56. 34 17 . 98 0.33 0.05 6 94 . 33 14.02 1. 07 55. 25 17 . 33 0.30 0.06 6 95 . 67 14.12 1. 07 54. 92 17 . 26 0.30 0.07 6 97 . 33 14.99 1. 07 54. 58 16 . 04 0.28 0.08 6 98 . 17 14.93 1. 07 54. 16 16 . 93 0.28 0.09 8 110 . 63 22.61 1 .28 5 2.38 7 . 42 0.19 0.10 8 117 . 13 31.02 1 .36 5 1.95 9 . 50 0.19 sets—the Caltec h F acebo ok net w ork and the p olitic al blog net work—with v alues of α b etw een 0.01 and 0.10. W e summarize the detecte d communities using the statistics of S ection 4 . A su mmary of results are p ro vid ed in T ables 8 and 10 . The matc h of the iden tified communities w ith those d iscussed in the main text are give n in T ables 9 and 11 . F urther, we assess the similarit y of the bac kground v ertices from eac h setting usin g the Jaccard score. The matc h and statistics are sho wn b elo w . In general, these statistics suggest T able 9 The Jac c ar d sc or e of the b ackgr ound vertic es distinguishe d at e ach value of α when c omp ar e d to the b ackgr ound vertic es found with α = 0 . 01 . These analyses ar e done on the Calte ch F ac eb o ok pr esente d in Se ction 4 α Jaccard score 0.01 1.00 0.02 0.9652 0.03 0.9304 0.04 0.8015 0.05 0.7303 0.06 0.7116 0.07 0.6985 0.08 0.7011 0.09 0.5907 0.10 0.6085 IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 37 T able 10 A summary of the c om m unities dete cte d by ESSC acr oss a r ange of values of α when run on the p olitic al blo g network. These statistics ar e the same as those pr esente d in Se ction 4 α N C S ˆ σ S M D in D out P B 0.01 2 394 . 5 54 . 45 1.00 40.51 3 . 40 0.35 0.02 2 406 . 5 67 . 18 1.00 39.47 3 . 27 0.33 0.03 2 420 . 0 53 . 74 1.00 38.40 3 . 07 0.31 0.04 2 423 . 5 57 . 28 1.00 38.14 3 . 00 0.31 0.05 2 448 . 5 75 . 66 1.00 36.30 2 . 58 0.27 0.06 2 449 . 5 75 . 66 1.00 36.27 2 . 45 0.26 0.07 2 431 . 0 46 . 67 1.00 37.60 2 . 84 0.29 0.08 3 528 . 3 146 . 92 1.30 27. 37 24 0.01 0.09 2 449 . 5 72 . 83 1.00 36.24 2 . 54 0.26 0.10 3 323 . 67 249 . 93 1.02 34.39 2 . 56 0.22 that the comm unities detected b y the ESSC algorithm are robu st in the sense that they are not sensitive to the choic e of α . Ac kn o wledgment s. W e would lik e to thank the referees, Ass o cia te Ed itor and the Editor for their constructiv e suggestions which led to a significant impro v ement of the pap er. W e w ould lik e to thank Mason P orter for sharin g the Caltec h F aceb o ok data s et that w e analyzed in Section 4.1 . W e w ould also lik e to than k Y unp eng Zhao f or con tribu ting his co de for the ZLZ extraction algorithm. T able 11 The Jac c ar d sc or e of the b ackgr ound vertic es distinguishe d at e ach value of α when c omp ar e d to the b ackgr ound vertic es f ound with α = 0 . 05 . These analyses ar e done on the p oli tic al blo g network of Se ction 4 α Jaccard score 0.01 0.7483 0.02 0.7922 0.03 0.8433 0.04 0.8590 0.05 1.00 0.06 0.9938 0.07 0.8843 0.08 0.0062 0.09 0.9877 0.10 0.8277 38 WILSON ET AL. SUPPLEMENT AR Y MA TERIAL Supp lemen tal p ersonal F aceb o ok data set (DOI: 10.121 4/14-A OAS760 S UPP ; .zip). W e pr ovide the p ersonal F aceb o ok data set as w ell as an onymized lab els used in the analysis in Section 4.3 of the manuscript. REFERENCES Adamic, L. A. and G lance, N. (2005). The political blogosphere and th e 2004 U S election: Divided th ey blog. In Pr o c e e dings of the 3r d International Workshop on Link Disc overy 36–43. ACM, New Y ork. Airoldi, E. M. , Cost a, T. B. and Chan, S. H. (2013). Sto chastic blockmo d el ap- proximati on of a graph on : Theory and consistent estimation. In A dvanc es in Neur al Information Pr o c essing Systems 692–70 0. Airoldi, E. M. , Blei, D. M . , Fienberg, S. E. and Xi ng, E. P. (2008). Mixed mem- b ership sto chastic blo ckmodels. J. Mach. L e arn. R es. 9 1981–2014. Amini, A. A. , Chen, A. , B ickel, P. J. and Levina, E. (2013). Pseudo-likelihood meth- ods for comm unity detection in large sparse netw orks. Ann. Statist. 41 2097–2122 . MR3127859 Ball, B. , Karrer, B. an d Newman, M. E. J. ( 2011). Efficien t and principled metho d for d etecting communities in n etw orks. Phys. Re v. E (3) 84 036103. Barab ´ asi, A.-L. and Alber t, R. (1999). Emergence of scaling in random n etw orks. Scienc e 286 509–512. MR2091634 Bassett, D. S. , Wymbs, N . F. , Por ter, M. A. , Mucha, P. J. , Carlson, J. M. and Grafton, S . T. (2011). Dyn amic reconfiguration of human brain netw orks during learning. Pr o c. Natl. A c ad. Sci. USA 108 7641–764 6. Bender, E. A. and Canfie ld, E. R. ( 1978). The asymptotic num b er of lab eled graphs with given degree sequences. J. C om bin. The ory Ser. A 24 296–30 7. MR0505796 Benjami ni, Y. and Hochberg, Y. (1995). Controlling the false disco very rate: A practical and p ow erful approach to multiple testing. J. R. Stat. So c. Ser. B Stat. Metho dol. 57 289–300 . MR1325392 Bickel, P. J. and C hen, A. (2009). A nonparametric view of netw ork models and Newman–Girv an an d other mo dularities. Pr o c. Natl. A c ad. Sci. USA 106 21068–2 1073. Blondel, Vi. D. , Guillaume, J. L. , Lambiotte, R. and Lefebvre , E. (2008). F ast unfolding of communities in large netw orks. J. Stat. Me ch. T he ory Exp. 2008 P10008. Bollob ´ as, B. ( 1979). A probab ilistic pro of of an asymptotic formula for the number of labelled regular graphs. A arhus Universitet. Clauset, A. , Moore, C . and Newman, M . E. (2008). Hierarchical structure and the prediction of missing link s in netw orks. Natur e 453 98–101 . Clauset, A. , Newman, M. E. J. and Moore, C . (2004). Finding communit y structu re in very large n etw orks. Phys. R ev. E (3) 70 066111. Decelle, A. , Krzakala, F. , Moore, C. and Zdeboro v ´ a, L. (2011). Inference and phase transitions in th e detection of modu les in sparse netw orks. Phys. R ev. L ett. 107 065701. Erd ˝ os, P. and R ´ enyi, A. (1960). On t he evolution of random graphs. Magyar T ud. Akad. Mat. Kutat´ o I nt. K¨ ozl. 5 17–61. MR0125031 Ester, M. , Krie gel, H.-P. , Sa nder, J. and Xu, X. (1996). A densit y-based algorithm for d isco vering clusters in large spatial databases with noise. In KDD 96 226–231 . IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 39 F or tun a to, S. (2010). Communit y detection in g rap h s. Phys. R ep. 48 6 75–174. MR2580414 Freund, Y. and Schapire, R. E. (1997). A decision-theoretic generalizatio n of on- line learning and an app lication to b o osting. J. Com put. System Sci. 55 119–13 9. MR1473055 Gir v an , M. and Newman, M. E. J. (2002). Community structure in so cial and biologica l netw orks. Pr o c. Natl. A c ad. Sci. USA 99 7821–7826 ( electronic). MR1908073 Glo ver, F. (1989). T abu searc h— part I . ORSA Journal on Computing 1 190–206. Goldberg, A. V. and T arjan, R. E. (1988). A n ew approach to the maximum-flo w problem. J. Asso c. Comput. Mach. 35 921–940. MR1072405 Goldenberg, A. , Zheng, A. X. , Fienberg, S. E. and Airoldi, E. M. (2010). A survey of statistical netw ork mo dels. F oundations and T r ends in Machine L e arning 2 129–233. Greene, D. , Do yle, D. and Cunning ham, P. (2010). T racking the evolution of comm u - nities in dyn amic social netw orks. In International Confer enc e on A dvanc es i n So ci al Networks Analysis and Mining (ASONAM) 176–1 83. Springer, New Y ork. Handcock, M. S. , Raf te r y, A. E. and T antrum, J. M. (2007). Model-based clustering for so cial netw orks. J. R oy. Statist. So c. Ser. A 170 301–354. MR2364300 Hastie, T . , Ti bshi rani, R. and Friedman, J. (2001). The Elements of Statistic al L e arn- ing: Data Mini ng, Infer enc e, and Pr e diction . Springer, N ew Y ork . MR1851606 Hinneburg, A. and Kei m, D. A. (1998). An efficien t approach to clustering in large multimedia databases with noise. In KDD, 1998 58–65 . Hoff, P. D. , Rafter y, A. E. and Handcock, M . S. (2002). Latent space approac hes to so cial netw ork analysis. J. A mer. Statist. Asso c. 97 1090–1098. MR1951262 Holland, P. W. , Laskey, K. B . and Le inhardt, S. (1983). S tochastic blo ckmodels: First steps. So cial Networks 5 109–1 37. MR0718088 Jutla, I. S. , Jeu b, L. G . S . and Mucha, P. J. (2011/2012). A generalized Lou- v ain meth od for communit y detection implemented in Ma tlab . Avai lable at http:// netwiki.amath.unc.edu/GenLouvain . Krzakala, F. , Moore, C. , Mossel, E. , Nee m an, J. , S l y , A. , Zd e bor ov ´ a, L. and Zhang, P. ( 2013). Sp ectral redemp tion: Clustering sparse netw orks. Preprint. Av ailable at arXiv:1306.55 50 . Lancichinetti, A . and For tuna to, S. ( 2009a). Benchmarks for testing comm u nity d e- tection algorithms on directed and w eighted graphs with ov erlapping communities. Phys. R ev. E (3) 80 016118. Lancichinetti, A. and For tuna to, S. (2009b). Comm unity detection algorithms: A comparativ e analysis. Phys. R ev. E (3) 80 056117. Lancichinetti, A. , F or tuna to, S. and Ker t ´ esz, J. (2009). Detecting the o verla pping and hierarc hical communit y structure in complex netw orks. New J. Phys. 11 033015 . Lancichinetti, A. , R adicchi, F. , Ramasco, J. J. and For tuna to, S. (2011). Finding statistically significan t communities in n etw orks. PloS One 6 e18961. Lee, C. and Cunni ngham, P. (2013). Benchmarking communit y detection metho ds on social media data. Preprint. Ava ilable at arXiv:1302.07 39 . Lesk o vec, J. , Lang, K. J. , Dasgupt a, A. and Mahoney, M. W. (2009). Comm unity structure in large netw orks: Natural clu ster sizes and the absence of large well-defined clusters. I nternet Math. 6 29–123. MR2736090 Lewis, A. C. , Jones, N. S. , Por ter, M. A. and De ane, C. M. (2010). The function of comm unities in protein interaction netw orks at multiple scales. B M C Systems Biol o gy 4 1–14. M ´ ezard, M. and Mont anari, A. (2009). I nformation, Physics, and Computation . Oxford Univ. Press, Oxford. MR2518205 40 WILSON ET AL. Miritello, G. , Mor o, E. and Lara, R. (2011). Dynamical strength of social t ies in information spreading. Phys. Re v. E (3) 83 045102. Mollo y, M. and Reed, B. (1995). A critical p oint for random graphs with a given degree sequence. Ra ndom Structur es Algorithms 6 161–179. Mucha, P. J. , Ri cha rdson, T. , Mac on, K. , Por te r, M. A. and Onnela, J.-P. (2010). Comm u nity structure in time-dep endent, multiscale, and multiplex netw orks. Scienc e 328 876–878. MR2662590 Muhammad, S. A. and V an Laerh o v en, K. (2013). Quantitative analysis of community detection meth od s for longitudinal mobile data. I n International Confer enc e on So cial Intel l igenc e and T e chnolo gy (SOCIET Y) 47–56. Springer, New Y ork. Newman, M. E. J. ( 2006). Mod u larit y and communit y structure in netw orks. Pr o c. Natl. A c ad. Sci . USA 103 8577–8 582. Newman, M. E. J. and Gir v an, M. (2004). Finding and ev aluating comm unity structure in n etw orks. Phys. R ev. E (3) 69 026113. Ng, A. Y. , Jord a n, M. I. and W eiss, Y. (2002). On sp ectral clustering: Analysis and an algorithm. A dv. Neur al Inf. Pr o c ess. Syst. 2 849–856. No wicki, K. and Snijde rs, T. A. B. (2001). Estimation and prediction for sto chastic blockstructures. J. Amer . Statist. Asso c. 96 1077–1 087. MR1947255 Olhede, S. C. and Wolfe, P. J. ( 2013). Netw ork histograms and un ivers alit y of blo ck- mod el approximation. Preprint. Av ailable at arXiv:1312.53 06 . Onnela, J.-P. , Arbesman, S. , Gonz ´ alez, M. C. , Barab ´ asi, A.-L. an d Chris- t akis, N . A. (2011). Geographic constraints on social netw ork groups. PLo S ONE 6 e16939. P ap adopoulos, S. , Komp a tsiaris, Y. , V akali, A. and S pyridonos, P. (2012). Com- munit y detection in social media. Data Min. Know l. Disc ov. 24 515–554. Por ter, M. A. , Onn e la, J.-P. and M ucha, P. J. (2009). Comm u nities in netw orks. Notic es Amer. Math. So c. 56 1082–1097. MR2568495 Ro sv all, M. , Axelsson, D. and Bergstr om, C. T . (2009). The map eq u ation. The Eur op e an Physic al Journal Sp e cial T opics 178 13–23. Ro sv all, M . and Bergstr om, C. T. (2008). Maps of random wa lks on comp lex netw orks revea l community structu re. Pr o c. Natl. A c ad. Sci. USA 105 1118–11 23. Ro sv all, M. and Bergstr om, C. T. (2010). Mapping change in large netw orks. PL oS ONE 5 e8694. Shabalin, A. A. , Weigma n, V. J. , Perou, C . M. and Nobel, A. B. ( 2009). Find- ing large a verag e submatrices in high dimensional d ata. Ann. Appl. Stat. 3 985–1012. MR2750383 Shi, J. and Malik, J. (2000). Normalized cuts and image segmen tation. I EEE T r ansac- tions on Pattern Ana lysis and Machine Intel ligenc e 22 888–905. Snijders, T. A. B. and No wicki, K. (1997). Estimation and prediction for stochas- tic blo ckmo dels for graphs with latent block structure. J. Classific ation 14 75–100 . MR1449742 Traud, A. L. , Mucha, P. J. and Por ter, M. A. (2012). So cial structu re of F aceb ook netw orks. Phys. A: Statistic al Me chanics and Its Appli c ations 391 4165–418 0. Traud, A. L. , Ke lsic, E. D. , Mucha, P. J. and Por ter, M. A. ( 2011). Comparing comm unity structure to chara cteristics in online collegiate so cial n etw orks. SIAM R ev. 53 526–543. MR2834086 Wei, Y. C. and Cheng, C. K. (1989). T ow ards efficient hierarchica l designs by ratio cut partitioning. In IEEE I nternational Confer enc e on Computer-A ide d Design (ICCAD- 89). Digest of T e chnic al p ap ers 298–301 . IEEE, New Y ork. IDENTIFYING SI GNIFICANT COMMUNI TIES IN NETW O RKS 41 Wilson, J. , W ang, S. , Mucha, P. , Bh amidi, S. and Nobel, A. (2014). Supplement to “A testing based extraction algorithm for identifying significant comm u nities in netw orks.” DOI: 10.1214 /14-AO AS760SUPP . Xie, J. , Kelley, S. and Szym anski, B. K. (2011). Overlapping communit y detec- tion in n etw orks: The state of the art and comparative study . Preprint. Av ailable at arXiv:1110.58 13 . Y ang, J. and Lesko vec, J. (2012). Defi n ing and Ev aluating Netw ork Comm un ities based on Ground -truth. In Pr o c e e di ngs of the ACM SIGKDD Workshop on Data Semantics, 2012 . ACM, New Y ork. Zhao, Y. , Levina, E. and Zhu , J. (2011). Communit y extraction for so cial netw orks. Pr o c. Natl. A c ad. Sci. USA 108 7321–7326 . Zhao, Y. , Levi na, E. and Zhu, J. (2012). Consistency of communit y detection in n et- w ork s under degree-corrected stochastic blo ck mo dels. Ann. Statist . 40 2266–2292. MR3059083 J. D. Wilson S. Bhamidi A. B. Nob el Dep ar tment of St a tistics and Opera tions Research University of Nor th Carolina a t Chapel Hill Chapel Hill, Nor th Carolina 2 7599 USA E-mail: jameswd@email.unc.edu bhamidi@email.unc.edu nobel@email. unc.edu S. W ang Dep ar tment of Ma thema tics University of Nor th Carolina at Chapel Hill Chapel Hill, Nor th Carolina 2 5799 USA E-mail: wa ngsimi@email.unc.edu P. J. Mucha Dep ar tment of Applied Physical Sciences University of Nor th Carolina a t Chapel Hill Chapel Hill, Nor th Carolina 2579 9 USA E-mail: muc ha@email.unc.edu
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment