Median Selection Subset Aggregation for Parallel Inference
For massive data sets, efficient computation commonly relies on distributed algorithms that store and process subsets of the data on different machines, minimizing communication costs. Our focus is on regression and classification problems involving …
Authors: Xiangyu Wang, Peichao Peng, David Dunson
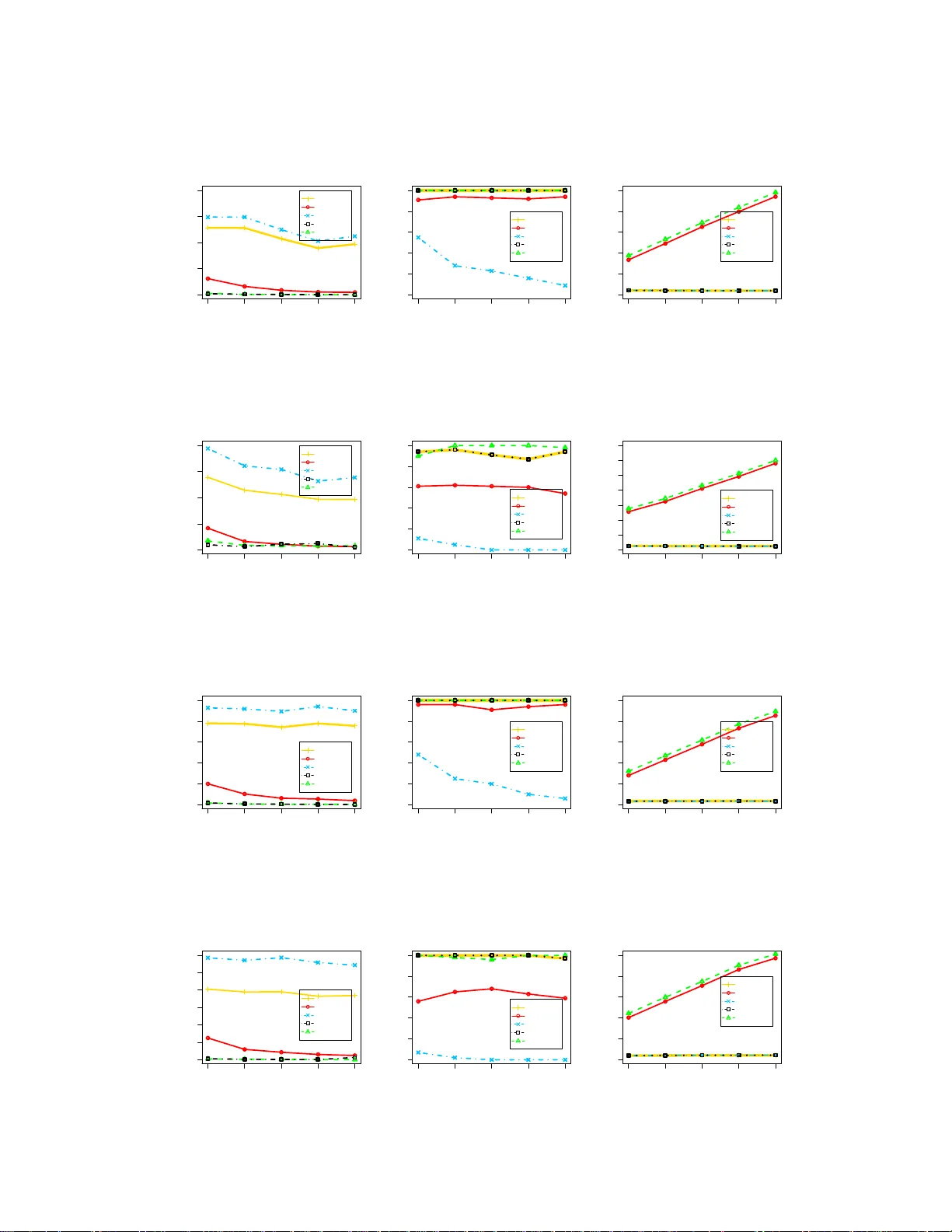
Median Selection Subset Aggregation f or Parallel Inference Xiangyu W ang Departmen t of Statis tical Scien ce Duke Uni versity Durham, NC 2770 8 xw56@stat.du ke.edu Peichao P eng Statistics Department University of Pennsylvania Philadelphia, P A 1910 4 ppeichao@wha rton.upenn. edu David B . Dunson Departmen t of Statis tical Scien ce Duke Uni versity Durham, NC 2770 8 dunson@stat. duke.edu Abstract For massi ve data sets, efficient computation comm only relies on distributed algo- rithms that store and process sub sets o f the data on d ifferent machines, m inimizing commun ication co sts. Our focus is on r egression a nd classification prob lems in- volving many featu res. A variety o f distributed alg orithms have bee n pro posed in this context, but challenges arise in definin g a n algorith m with low co mmuni- cation, theo retical guarante es and excellent practical p erform ance in gene ral set- tings. W e propo se a MEdian Selection Subset A Ggregation Estimator (message) algorithm , which attempts to solve these problems. The algorithm applies fea ture selection in parallel for each subset using Lasso or another metho d, calculates the ‘median’ featur e inclu sion index, estimates coefficients fo r the selected featu res in parallel fo r each subset, and then a verages these estimates. The algorithm is sim- ple, inv olves very minim al communicatio n, scale s efficiently in b oth sample and feature size, and has theoretical g uarantee s. In particular, we show model selection consistency and coefficient estimation ef ficiency . Exten si ve experimen ts show ex- cellent performan ce in variable selection , estimation, prediction, and computation time relativ e to usual competito rs. 1 Intr oduction The exp losion in both size and velocity of data has bro ught new cha llenges to the design of statistical algorithm s. P ar allel inference is a promising appr oach for solving large scale problem s. The typical proced ure for parallelization partitions the full data into multiple s u bsets, stores s ub sets on dif feren t machines, and then pr ocesses subsets simultan eously . Pr ocessing on subsets in parallel can lead to two types of computatio nal gains. The first reduces time for calculatio ns within each iteration of optimization or sampling algorithms via faster oper ations; for example, in conducting linear algebra in volved in calculating likelihoo ds or gr adients [1 – 7]. Although such app roaches can lead to sub- stantial reduction s in compu tational bottlen ecks for b ig da ta, the amo unt of g ain is limited by the need to communicate across com puters at each iteration . It is well kno wn that communication costs are a majo r factor driving the efficiency of distrib uted alg orithms, so that it is o f critical impor tance to limit comm unication . This motiv ates the second type of approach, which conducts comp utations completely ind ependen tly on the d ifferent subsets, and then combin es the results to obtain the final output. This lim its commun ication to the final comb ining step , and may lead to simpler and mu ch 1 faster algor ithms. Howe ver, a major issue is h ow to design algorithms that are close to com muni- cation free, wh ich can preser ve or ev en impr ove the statistical ac curacy r elativ e to (much slower) algorithm s ap plied to the entire data set simultan eously . W e focus on addressing th is challen ge in this article. There is a recen t flurry of research in both Bayesian and frequ entist setti n gs focusing on the second approa ch [8 – 14]. Particularly relev an t to our appro ach is th e literatur e on meth ods for comb ining point estimators ob tained in parallel for d ifferent subsets [8, 9, 13]. Mann et al. [9] sug gest using av erag ing fo r combining subset e stimators, and Zh ang et al. [8] prove th at such estimators will achieve the same err or rate as the o nes obtain ed from the full set if th e number of sub sets m is well chosen. Minsker [1 3] utilizes the geo metric median to combine the estimators, sh owing robustness and sharp con centration ineq ualities. These m ethods fu nction well in certain scenarios, but mig ht not be broadly useful. In practice, infer ence for regre ssion and classification typically contains two importan t compo nents: On e is variable or featur e selection and th e oth er is p arameter e stimation. Current combining methods are not designed to prod uce good results for bo th tasks. T o obtain a simple and computation ally efficient p arallel algo rithm fo r featur e selection and co- efficient estimatio n, we prop ose a ne w co mbining metho d, referred to as messag e . The detailed algorithm will b e fu lly de scribed in the next section. There are related metho ds, which were p ro- posed with the very different goal o f c ombinin g results fro m different imputed data sets in missing data contexts [15]. However , these me thods are primarily motiv ated fo r imputation agg regation, do not im prove compu tational time, an d lack th eoretical guaran tees. Another r elated ap proach is the bootstrap Lasso (Bolasso) [16], which runs Lass o independently f or multiple bootstrap samples, and then intersects the r esults to o btain the final m odel. Asymp totic properties are provide d under fixed number of features ( p fixed) and the comp utational burden is not improved over apply ing Lasso to the full data set. Our message algorithm has strong ju stification in leading to excellen t con vergence proper ties in both feature selection and prediction , wh ile being simp le to implement and computa- tionally highly effi cien t. The article is organ ized as fo llows. In section 2, we describ e message in d etail. In section 3 , we provide theoretical justifications and show that message can produce better results than f ull data in- ferences und er certain scenario s. Sec tion 4 e valuates the pe rforma nce of messag e via extensiv e nu- merical experiments. Section 5 contain s a discussion of possible generalizations of the new metho d to broader families of models and online learning. All pro ofs are provided in the appen dix. 2 Parallelized framework Consider the linear model which has n observations and p featu res, Y = X β + ǫ, where Y is an n × 1 response vector, X is an n × p matrix of features and ǫ is t h e observation erro r , which is assumed to have mean zero an d variance σ 2 . The fundam ental id ea for comm unication efficient parallel inference is to partition the data set into m subsets, e ach of which contains a small portion of the data n/m . Separate analysis on each subset will then be c arried out and the r esult will be aggregated to p roduc e the final outp ut. As mentione d in the previous section, re g ression pr oblems usually consist of two stage s: feature selection a nd par ameter estimation . For linear m odels, there is a ric h litera ture on feature selectio n and we only consider two approaches. The risk inflation criterion (RIC), or more gen erally , the gen- eralized infor mation criterion (GIC) is an l 0 -based feature selection tech nique for high dimen sional data [17–20]. GIC attem pts to solve the following optimization problem , ˆ M λ = arg min M ⊂{ 1 , 2 , ··· ,p } k Y − X M β M k 2 2 + λ | M | σ 2 (1) for some well chosen λ . For λ = 2(log p + log log p ) it corresponds to RIC [18], for λ = (2 log p + log n ) it co rrespon ds to extended BIC [19] and λ = log n reduces to the u sual BIC. K onishi and Kitagawa [18] p rove the consistency o f GI C f or hig h dimen sional data under some regularity conditions. 2 Lasso [21] is an l 1 based feature selection technique, which solves the f ollowing prob lem ˆ β = ar g min β 1 n k Y − X β k 2 2 + λ k β k 1 (2) for some well cho sen λ . Lasso transfers the origina l NP ha rd l 0 -based optimization to a pro blem that can be solved in poly nomial time. Zhao and Y u [ 22] prove th e selection consistency of Lasso under the I rrepresen table condition. Based on the mo del selected b y either GIC or Lasso, we could then apply the ordinary least square (OLS) estimator to find the coefficients. As briefly discu ssed in the in troductio n, a veraging and med ian aggregation approaches possess dif- ferent advantages but also s uffer from certain drawbacks. T o care fully adapt these features to regres- sion and classification, we propo se th e m edian selection subset aggregation ( message ) algorithm , which is motiv ated as follows. A verag ing of sparse regression mod els leads to an inflated number o f features h aving non -zero co- efficients, and hen ce is not appropr iate for model aggregation wh en f eature selection is of interest. When condu cting Bayesian variable selection, the median pro bability mo del h as been r ecommen ded as selecting the single mod el that produ ces the best appro ximation to model-averaged predictions under som e simplify ing a ssumptions [23]. Th e median probab ility mo del includes tho se featur es having inclu sion p robab ilities greater than 1/2. W e ca n apply this no tion to su bset-based inference by in cluding features that are inclu ded in a majority of the subset-specific a nalyses, leading to select- ing the ‘median m odel’. Let γ ( i ) = ( γ ( i ) 1 , · · · , γ ( i ) p ) denote a vecto r o f feature inclusion in dicators for the i th subset, with γ ( i ) j = 1 if featur e j is inc luded so that the coefficient β j on this feature is non-ze ro, with γ ( i ) j = 0 otherwise. The inclu sion indicator vector for the median model M γ can be obtained by γ = arg min γ ∈ { 0 , 1 } p m X i =1 k γ − γ ( i ) k 1 , or equiv alently , γ j = median { γ ( i ) j , i = 1 , 2 , · · · , m } for j = 1 , 2 , · · · , p . If we app ly Lasso or GIC to the fu ll data set, in the presence of heavy-tailed observ ation erro rs, the estimated f eature inclusion ind icator vector will con verge to the tr ue in clusion vector at a p olyno mial rate. It is shown in the next section that the c onv ergence rate of the inclusion vector for th e me dian model can be improved to be expo nential, lea ding to sub stantial gains in no t o nly co mputation al time but also feature selectio n perfo rmance. The intuition for th is gain is tha t in th e heavy-tailed case, a prop ortion of the s ub sets will c ontain outliers having a sizable influen ce on feature s electio n. By taking the median, we obtain a ce ntral m odel that is not so influenced by these outliers, and h ence can concentra te mo re r apidly . As large data sets typically contain outliers and data contamin ation, this is a substantial practical ad vantage in te rms of perfor mance ev en putting aside the compu ta- tional gain . Af ter featur e selection, we obtain estimates of the coefficients for each selected feature by averaging the coefficient e stimates from ea ch subset, fo llowing the spir it of [8]. The message algorithm (described in Algor ithm 1) on ly r equires each machin e to pass the featu re in dicators to a ce ntral co mputer, which (essentially instantaneou sly) calcu lates th e median model, passes back the corr espondin g indicator vector to the individual computer s, which th en pass back coefficient estimates for a verag ing. The commu nication costs are ne glig ible. 3 Theory In this sectio n, we provide th eoretical ju stification for th e message algorithm in th e lin ear mo del case. The th eory is easily generalized to a much w ider r ange of m odels and estimation techniques, as will be discussed in the last section. Throu ghout the pape r we w ill a ssume X = ( x 1 , · · · , x p ) is an n × p featu re matrix, s = | S | is the number of non -zero coefficients and λ ( A ) is the eigenv alue for matrix A . Bef ore we p roceed to the theorems, we enum erate several conditions that are required for establishing the theory . W e assume there exist constants V 1 , V 2 > 0 such that 3 Algorithm 1 Message algorithm Initialization: 1: In put ( Y , X ) , n, p , an d m 2: # n is the sample size, p is the number of featur es and m is the number of subsets 3: Rand omly partition ( Y , X ) into m subsets ( Y ( i ) , X ( i ) ) and distribute them on m machines. Iteration: 4: for i = 1 to m do 5: γ ( i ) = min M γ l oss ( Y ( i ) , X ( i ) ) # γ ( i ) is the estimated model via Lasso or GIC 6: # Gathe r all subset models γ ( i ) to obtain the median model M γ 7: for j = 1 to p do 8: γ j = me dian { γ ( i ) j , i = 1 , 2 , · · · , m } 9: # Redistribute the estimated model M γ to all subsets 10: for i = 1 to m do 11: β ( i ) = ( X ( i ) T γ X ( i ) γ ) − 1 X ( i ) T γ Y ( i ) γ # Estimate the coefficients 12: # Gather all subset estimation s β ( i ) 13: ¯ β = P m i =1 β ( i ) /m 14: 15: return ¯ β , γ A.1 Consistency conditio n f or estimatio n. • 1 n x T i x i ≤ V 1 for i = 1 , 2 , · · · , p • λ min ( 1 n X T S X S ) ≥ V 2 A.2 Conditio ns on ǫ , | S | and β • E ( ǫ 2 k ) < ∞ f or some k > 0 • s = | S | ≤ c 1 n ι for some 0 ≤ ι < 1 • min i ∈ S | β i | ≥ c 2 n − 1 − τ 2 for some 0 < τ ≤ 1 A.3 (Lasso) The strong irrepres enta ble condition. • Assuming X S and X S c are the features having non-z ero and zero coef ficients, respec- ti vely , there exists some positive con stant vector η such that | X T S c X S ( X T S X S ) − 1 sig n ( β S ) | < 1 − η A.4 (Gen eralized information criterion, GIC) The sparse Riesz condition. • Ther e e xist co nstants κ ≥ 0 and c > 0 such that ρ > cn − κ , where ρ = inf | π |≤| S | λ min ( X T π X π ) A.1 is th e usual con sistency c ondition for regression. A. 2 restricts the beh aviors of the three key terms and is crucial for model selection. These are both usual assumptions. See [19 , 20, 22]. A. 3 and A.4 a re specific conditions fo r mod el selection co nsistency for La sso/GIC. As noted in [22], A.3 is almost sufficient and necessary for sign consistency . A.4 could be relaxed sligh tly as s hown in [19], but for simplicity we rely o n th is version . T o amelior ate po ssible concerns o n how realistic these condition s are, we provid e furth er justifications via Theorem 5 and 6 in the appendix. Theorem 1. (GIC) Assume each s ub set satisfies A.1, A.2 and A.4, and p ≤ n α for some α < k ( τ − η ) , w here η = max { ι/k , 2 κ } . If ι < τ , 2 κ < τ an d λ in (1) ar e chosen so that λ = c 0 /σ 2 ( n/m ) τ − κ for some c 0 < cc 2 / 2 , then ther e exists some constant C 0 such that for n ≥ (2 C 0 p ) ( kτ − kη ) − 1 and m = ⌊ (4 C 0 ) − ( kτ − kη ) − 1 · n/p ( kτ − kη ) − 1 ⌋ , the selected model M γ follows, P ( M γ = M S ) ≥ 1 − exp − n 1 − α/ ( kτ − kη ) 24(4 C 0 ) ( kτ − kη ) , and the mean squar e err or of the aggr egated estima tor follows, E k ¯ β − β k 2 2 ≤ σ 2 V − 1 2 s n + exp − n 1 − α/ ( kτ − kη ) 24(4 C 0 ) ( kτ − kη ) (1 + 2 C ′− 1 0 sV 1 ) k β k 2 2 + C ′− 1 0 σ 2 . wher e C ′ 0 = min i λ min ( X ( i ) T γ X ( i ) γ /n i ) . 4 Theorem 2. (Lasso) Assume e ach subset satisfies A.1 , A. 2 and A .3, and p ≤ n α for some α < k ( τ − ι ) . I f ι < τ a nd λ in (2) are chosen so tha t λ = c 0 ( n/m ) ι − τ +1 2 for some c 0 < c 1 V 2 /c 2 , then there e xists some constant C 0 such that for n ≥ (2 C 0 p ) ( kτ − kι ) − 1 and m = ⌊ (4 C 0 ) ( kτ − kι ) − 1 · n/p ( kτ − kι ) − 1 ⌋ , the selected model M γ follows P ( M γ = M S ) ≥ 1 − exp − n 1 − α/ ( kτ − kι ) 24(4 C 0 ) ( kτ − kι ) , and with the same C ′ 0 defined in Theor em 1, we hav e E k ¯ β − β k 2 2 ≤ σ 2 V − 1 2 s n + exp − n 1 − α/ ( kτ − kι ) 24(4 C 0 ) ( kτ − kι ) (1 + 2 C ′− 1 0 sV 1 ) k β k 2 2 + C ′− 1 0 σ 2 . The ab ove two theorems boost th e m odel con sistency prop erty f rom the o riginal po lynomial ra te [20, 22] to an exponential rate f or hea vy -tailed error s. In addition , the mean square error, as shown in the above equ ation, pre serves almost th e same conv ergen ce rate a s if the fu ll data is employed and the true model is known. The refore, we expect a similar or better performance of message with a significantly lower computation load. Detailed comp arisons are demonstrated in Section 4. 4 Experiments This section assesses the perfo rmance of the message algorithm via extensi ve e x amples, comparing the results to • Full data inf erence. (den oted as “full data”) • Subset a verag ing. Partition and average the estimates o btained on all subsets. (denoted as “av era ging”) • Subset med ian. Partition and take the g eometric me dian of the estimates ob tained on a ll subsets (denoted as “median” ) • Bolasso. Run Lasso on multiple boo tstrap samp les and intersect to select model. Then estimate the coefficients based on the selected mod el. (den oted as “Bolasso”) The L asso part o f all algo rithms will be implem ented by the “glmnet” package [ 24]. (W e d id n ot use ADMM [25] for Lasso as its actual performance might suf fer from certain drawbacks [6] and is reported to be slower than “glmnet” [26 ]) 4.1 Synthetic data sets W e use the linear m odel and th e logistic m odel for ( p ; s ) = (10 00; 3 ) or (10 , 0 00; 3) with different sample size n and different partition number m to ev aluate the perfo rmance. Th e feature vector is drawn fro m a multiv ariate norm al distribution with corr elation ρ = 0 or 0 . 5 . Coefficients β are chosen as, β i ∼ ( − 1) ber (0 . 4) (8 log n/ √ n + | N (0 , 1) | ) , i ∈ S Since GIC is intr actable to implemen t (NP h ard), we combine it with Lasso f or variable selectio n: Implemen t Lasso for a set o f different λ ’ s an d determine th e optimal one via GIC. The co ncrete setup of models are as follows, Case 1 L inear model with ǫ ∼ N (0 , 2 2 ) . Case 2 L inear model with ǫ ∼ t (0 , d f = 3) . Case 3 L ogistic model. For p = 1 , 000 , we simulate 200 data sets for e ach case, and vary the samp le size fr om 200 0 to 10 , 000 . For each case, th e subset size is fixed to 4 00, so the number of subsets will be changin g from 5 to 25. I n the exper iment, we record the m ean squa re error for ˆ β , prob ability of selecting the true mod el and co mputation al time, and plot them in Fig 9 - 1 4. F or p = 10 , 000 , we simulate 50 5 2000 4000 6000 8000 10000 0.0 0.1 0.2 0.3 0.4 Mean square error Sample size n value median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.5 1.0 1.5 2.0 2.5 Computational time Sample size n seconds median fullset average message bolasso Figure 1: Results fo r case 1 with ρ = 0 . 2000 4000 6000 8000 10000 0.0 0.2 0.4 0.6 0.8 Mean square error Sample size n value median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 1.0 2.0 3.0 Computational time Sample size n seconds median fullset average message bolasso Figure 2: Results for case 1 with ρ = 0 . 5 . 2000 4000 6000 8000 10000 0.00 0.02 0.04 0.06 0.08 0.10 Mean square error Sample size n value median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.5 1.0 1.5 2.0 2.5 Computational time Sample size n seconds median fullset average message bolasso Figure 3: Results fo r case 2 with ρ = 0 . 2000 4000 6000 8000 10000 0.00 0.10 0.20 0.30 Mean square error Sample size n value median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.5 1.0 1.5 2.0 2.5 Computational time Sample size n seconds median fullset average message bolasso Figure 4: Results for case 2 with ρ = 0 . 5 . 6 2000 4000 6000 8000 10000 0 1 2 3 4 5 6 Mean square error Sample size n value median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message bolasso 2000 4000 6000 8000 10000 0 2 4 6 8 Computational time Sample size n seconds median fullset average message bolasso Figure 5: Results fo r case 3 with ρ = 0 . 2000 4000 6000 8000 10000 0 2 4 6 8 10 Mean square error Sample size n value median fullset average message bolasso 2000 4000 6000 8000 10000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message bolasso 2000 4000 6000 8000 10000 0 2 4 6 8 10 12 Computational time Sample size n seconds median fullset average message bolasso Figure 6: Results for case 3 with ρ = 0 . 5 . data sets for each case, and let t h e sample size range fro m 20 , 000 to 50 , 000 with subset size fixed to 2000 . Results for p = 10 , 000 are provided in appendix. It is clear that message h ad excellent per forman ce in all of the simulation cases, with low MSE, high probab ility of selecting the tru e mo del, and low computatio nal time. The other subset-ba sed methods we con sidered ha d similar com putation al times and also h ad co mputatio nal burdens th at effecti vely did no t incr ease with sample size, while th e full da ta analysis and bootstrap Lasso ap- proach both wer e substantially slower tha n the subset m ethods, with the gap increasing linearly in sample size. In terms of MSE, the averaging and me dian approa ches b oth had dr amatically worse perfor mance than message in e very case, while bootstrap Lasso was competitive (MSEs were same order of magnitu de with messag e ranging from effecti vely identical to having a small b ut significant advantage), with both messa ge and bootstrap Lasso clearly outper forming the full data app roach. In terms of feature selectio n perf ormanc e, averaging had by far the worst perfo rmance, followed b y the full d ata ap proach , which was substantially worse than bootstra p Lasso, median and message , with no c lear win ner among the se th ree m ethods. Overall message clearly had by far the best combin ation of low MSE, accur ate model selection and fas t co mputation . 4.2 Individual household electric power consumption This data set contains measurements o f electric power consump tion for every h ousehold with a one-min ute sampling rate [27]. Th e d ata have been co llected over a per iod of almost 4 year s and contain 2,075, 259 measuremen ts. There are 8 predictors, wh ich ar e con verted to 74 predictors d ue to re-coding o f the categorical v ariab les (d ate and time). W e use the first 2 , 000 , 000 samples as the training set and the remain ing 75 , 259 for testing the predictio n accuracy . The data a re partition ed into 200 subsets f or parallel inference. W e plo t the prediction accu racy (mean square error for test samples) against time for full data, message, averaging and median metho d in Fig 7. Bolasso is excluded as it did not produce meaningful results within the time span. T o illustrate details o f the per forman ce, we split the time line into two parts: the early stage shows how all algorith ms adapt to a low pr ediction err or and a later stage captures mor e subtle perfo rmance of faster algorithms (full set inference excluded due to the scale). It c an be seen that message dominates other algorithms in both speed and accuracy . 7 0.060 0.065 0.070 0.075 0.080 0.0 0.2 0.4 0.6 0.8 Mean prediction error (earlier stage) Time (sec) value message median av erage fullset 0.084 0.086 0.088 0.090 0.092 0.094 0.0016 0.0020 0.0024 Mean prediction error (later stage) Time (sec) value message median av erage Figure 7: Results fo r power con sumption data. 4.3 HIGGS classification The HIGGS data have been pro duced using Monte Carlo simulations from a particle physics model [28]. They conta in 27 predictors that are of interest to physicists wanting to distinguish b etween two classes of particles. The sample size is 11 , 000 , 000 . W e use the first 10 , 000 , 000 samples for training a log istic mod el and the rest to test the classification accuracy . The trainin g set is p artitioned into 1,000 sub sets for par allel inferen ce. The classification accur acy (probability of correctly pr edicting the class of test samples) ag ainst comp utational time is plo tted in Fig 8 (Bolasso excluded for the same reason as above). 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.50 0.55 0.60 0.65 Mean prediction accuracy Time (sec) value message median av erage fullset Figure 8: Results fo r HIGGS classification. Message adapts to the prediction b ound qu ickly . Althou gh the classification r esults are not as g ood as th e b enchmar ks listed in [28] (d ue to the choice of a simp le pa rametric logistic model), ou r n ew algorithm achieves the best perfo rmance s ub ject to the constraints of the model class. 5 Discussion and conclusion In this pap er , we pro posed a flexible a nd efficient messag e alg orithm for regression and classifica- tion with feature selection. Message essentially eliminates the co mputatio nal b urd en attributable to commun ication amo ng machin es, and is as efficient a s other simple subset aggregation method s. By selecting the median mod el, message can achie ve better accuracy e ven than feature selection on th e full data, resulting in an improvement also in MSE perfo rmance. E xtensive simulation experimen ts show outstand ing perform ance relative to competitors in terms of computation , feature selection and prediction . Although the theory described in Section 3 is m ainly concern ed with linear models, the algorith m is applicable in fairly wide situations. Geo metric median is a topolog ical concept, which allo ws the median mod el to be obtained in any n ormed model s p ace. The properties o f t h e median model r esult from indep endenc e of th e subsets an d weak c onsistency on each subset. Once these two cond itions are satisfied, the property shown in Section 3 can be transferred to es sentially any model space. The follow-up averaging s tep has been proven to be consistent for all M estimators with a pro per choice of the partition number [8]. 8 Refer ences [1] Gonzalo Mateos, Juan An dr ´ es Bazerque, and Georgios B Giannakis. Dis tributed sparse linear regression. S ignal Pr ocessing, IEEE T ransactio ns on , 58(10):5 262–5 276, 2010 . [2] Joseph K Bradley , Aapo K yrola, Danny Bickson, and Carlos Guestrin. Parallel coord inate descent for l1-regularized loss minimization. arXiv pr eprint arXiv:1 105.5 379 , 2 011. [3] Chad Scherr er , Ambuj T e wari, Mahantesh Halapp anav ar, a nd David Hag lin. Feature clustering for accelerating parallel coordin ate descent. In NIPS , pag es 28–36, 2012. [4] Alexander Smola and Shravan Nar ayanamu rthy . An ar chitecture for parallel topic m odels. Pr oceedings of the VLDB Endowmen t , 3(1- 2):703 –710 , 2010 . [5] Feng Y an, Ningyi Xu , and Y uan Qi. P ar allel infer ence fo r latent dirichlet allocation on graphics processing units. In NIPS , v olume 9, pag es 2134–214 2, 2009 . [6] Zhimin Peng, Ming Y an, and W otao Y in. Parallel and distrib uted spar se optimization. preprint , 2013. [7] Ofer Dekel, Ran Gilad -Bachrach , Ohad Sham ir , and Lin Xiao. Optimal distributed o nline prediction using mini-ba tches. The J ourna l of Machine Learning Researc h , 13:1 65–20 2, 2012 . [8] Y uchen Zhang, John C Duchi, and Martin J W ainwright. Communicatio n-efficient a lgorithms for statistical optimization . In NIPS , volume 4, pages 5–1, 2012. [9] Gideon Mann, Ryan T McDonald , Mehry ar Mohri, Na than Silberm an, and Dan W a lker . Effi- cient large- scale distrib u ted training of con ditional maximu m entropy mod els. In NIPS , vol- ume 22, pages 1231– 1239 , 20 09. [10] Steven L Scott, Ale xan der W Blocker , Fer nando V Bonassi, Hugh A Chipma n, Edward I George, and Robert E McCulloch. Bayes and big data: Th e consensus monte carlo algo rithm. In EF aBBayes 250 conference , volume 16, 2013. [11] W illie Neiswanger, Chong W ang , and Eric Xing. Asymptotica lly e xa ct, embarrassingly paral- lel MCMC. arXiv preprint arXiv:1311.47 80 , 20 13. [12] Xiang yu W ang a nd David B Dunson. Parallelizing MCMC via weierstrass sampler . arXiv pr eprint arXiv:1 312.4 605 , 2 013. [13] Stanislav Minsker . Geometr ic median and robust estimation in b anach sp aces. arXiv pr eprint arXiv:130 8.133 4 , 20 13. [14] Stanislav Minsker , Sanv esh Sriv astav a, Lizhen Lin, and David B Dunson. Robust and scalable bayes via a median of subset posterior measures. arXiv preprint arXiv:1 403.2 660 , 2014 . [15] Ang ela M W ood, Ian R White, and Patrick Royston. How should variable selection be per- formed with multiply imputed data? Statistics in med icine , 27(17):3 227–3 246, 20 08. [16] Franc is R Bach. Bolasso: model co nsistent lasso e stimation throu gh the bootstrap . I n Pr o- ceedings of the 25th international con fer ence on Machine learnin g , pages 33– 40. A CM, 2008. [17] Dean P Foster and Edward I George. The risk inflation cr iterion fo r m ultiple regression. The Annals of Statistics , pages 1947– 1975 , 19 94. [18] Sadan ori K on ishi and Genshiro Kitag awa. Gener alised informatio n cr iteria in model selection. Biometrika , 83(4):8 75–89 0, 19 96. [19] Jiahua Chen and Zehua Chen . Ex tended bayesian information criteria for model selection with large model s pac es. Bio metrika , 95(3):759 –771 , 2008 . [20] Y ongda i Kim, Sungho on Kwon, and H osik Choi. Consistent model selection criteria o n h igh dimensions. The Journal of Machine Learning Resea r ch , 98888(1) :1037 –1057, 2012. [21] Rober t T ibshir ani. Regression shrink age and selection via the lasso. J ou rnal of the R oyal Statistical Society . Series B (Methodological) , pa ges 267–28 8, 199 6. [22] Peng Zhao and Bin Y u. On mo del selection co nsistency of lasso. The Journal of Machine Learning Resear ch , 7:2541–2 563, 2006 . [23] Maria Madd alena Barbieri and James O Berger . Optimal pr edictive model selection. Anna ls of Statistics , pages 870–89 7, 2004 . 9 [24] Jerom e Fr iedman, T rev or Hastie, and Rob T ibshirani. Regularizatio n path s for gener alized linear models via coordinate descent. Journal of statistical softwar e , 33(1) :1, 20 10. [25] Stephe n Boyd, Neal Parikh, Eric Chu, Borja Peleato, a nd Jonathan Eckstein. Distributed op - timization and statistical learning via the a lternating direction meth od of mu ltipliers. F ounda- tions and T r ends R in Machine Learning , 3(1):1–12 2, 2011 . [26] Xing guo Li, T uo Zhao, Xiaoming Y uan, and Ha n Liu. An R Package flare f or h igh dimensional linear regression and precision matrix estimation, 2013. [27] K. Bache an d M. Lichman. UCI machine learning repositor y , 2013. [28] Pierre Baldi, Peter Sadowski, and Daniel Whiteson . Deep learnin g in high -energy p hysics: Improving the search for e xotic par ticles. arXiv pr eprint arXiv:1 402.4 735 , 2014. [29] A W V an der V aart and J A W e llner . W eak co n vergence and empirica l processes. 1996. [30] Xiang yu W ang and Chenlei Leng. High-dimen sional ordinary least-square projection for vari- able screening. T echnical Report , 2014. 10 Ap pendix A: Proof of Theor em 1 and Theore m 2 In this section, we prove the following stronger version of Theo rem 1 and Theorem 2. Theorem 3. (GIC) A ssume each subset satisfies A.1 , A.2 and A .4, and p ≤ n α for some α < k ( τ − η ) , wher e η = max { ι/k , 2 κ } . If ι < τ , 2 κ < τ and λ are chosen so that λ = c 0 /σ 2 ( n/m ) τ − κ for some c 0 < cc 2 / 2 , then there exists some constant C 0 such th at for n ≥ (2 C 0 p ) ( kτ − kη ) − 1 , an y δ ∈ (0 , 1 / 2) and m = ⌊ ( δ C 0 ) ( kτ − kη ) − 1 n/p ( kτ − kη ) − 1 ⌋ , the selected model M γ follows, P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kη ) − 1 n 1 − α ( kτ − kη ) − 1 , and the mean squar e err or of the aggr egated estima tor follows, E k ¯ β − β k 2 2 ≤ σ 2 V − 1 2 s n + exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kη ) − 1 n 1 − α ( kτ − kη ) − 1 (1 + 2 C ′− 1 0 sV 1 ) k β k 2 2 + C ′− 1 0 σ 2 . wher e C ′ 0 = min i λ min ( X ( i ) T γ X ( i ) γ /n i ) . Theorem 4. (Lasso) Assume e ach subset satisfies A.1 , A. 2 and A .3, and p ≤ n α for some α < k ( τ − ι ) . If ι < τ and λ ar e chosen so that λ = c 0 ( n/m ) ι − τ +1 2 for some c 0 < c 1 V 2 /c 2 , the n ther e e xists some consta nt C 0 such that for n ≥ (2 C 0 p ) ( kτ − kι ) − 1 , any δ ∈ (0 , 1 / 2 ) an d m = ⌊ ( δ C 0 ) ( kτ − kι ) − 1 · n/ p ( kτ − kι ) − 1 ⌋ , the selected model M γ follows P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kι ) − 1 n 1 − α ( kτ − kι ) − 1 , and with the same C ′ 0 defined in Theor em 3, we hav e E k ¯ β − β k 2 2 ≤ σ 2 V − 1 2 s n + exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kι ) − 1 n 1 − α ( kτ − kι ) − 1 (1 + 2 C ′− 1 0 sV 1 ) k β k 2 2 + C ′− 1 0 σ 2 . Fixing δ = 1 / 4 gives e xac tly the Theor em 1 an d Theorem 2 in th e article. The above two theorems can be implied from the following three lemmas. Lemma 1. (Median model fo r Lasso) Assume each subset satisfies A.1, A.2 and A.3. If ι < τ a nd λ is chosen so that λ = c 0 ( n/m ) ι − τ +1 2 for some c 0 < c 1 V 2 /c 2 , then ther e exists some constant C 0 such that for n ≥ (2 C 0 p ) 1 k ( τ − ι ) and any δ ∈ (0 , 1 / 2) , the selected median model M γ satisfies P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kι ) − 1 p − ( kτ − kι ) − 1 n , wher e δ determines the num ber of subsets m m = ⌊ ( δ C 0 ) k − 1 / ( τ − ι ) n/p ( kτ − kι ) − 1 ⌋ and constant C 0 is defined in the pr oof. In particular , if p ≤ n α for some α < k ( τ − ι ) then P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kι ) − 1 · n 1 − α ( kτ − kι ) − 1 . Lemma 2. (Med ian mod el for GIC) Assume ea ch subset s a tisfies A.1 , A.2 and A.4. Let η = max { ι/k , 2 κ } . If ι < τ , 2 κ < τ a nd λ is c h osen so that λ = c 0 /σ 2 ( n/m ) τ − κ for some c 0 < cc 2 / 2 , then there exists some co nstant C 0 such that fo r a ny δ ∈ (0 , 1 / 2 ) a nd n ≥ (2 C 0 p ) ( kτ − kη ) − 1 , the selected median model M γ satisfies P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kη ) − 1 · p ( kτ − kη ) − 1 n , 11 wher e δ determines the num ber of subsets m m = ⌊ ( δ C 0 ) ( kτ − kι ) − 1 n/p ( kτ − kι ) − 1 ⌋ . In particular , when p ≤ n α for some α < k ( τ − η ) we h ave P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kη ) − 1 n 1 − α ( kτ − kη ) − 1 . Recall that the design matrix fo r the true model M S is assumed to be p ositiv e-d efinite (Assump tion A.1) for all sub sets. It is therefore reasonable to en sure th e selected mo del M γ possess the same proper ty , an d thus we have, Lemma 3. (MSE fo r averaging) Assume ˆ β i is the OLS e stimator obtained fr om each subset b ased on the selected model γ , then the averaged estimator ¯ β ha s the mean squar e err or , E k ¯ β − β k 2 2 | M γ = M S ≤ σ 2 V − 1 2 s n . and E k ¯ β − β k 2 2 | M γ 6 = M S ≤ (1 + 2 C ′− 1 0 sV 1 ) k β k 2 2 + C ′− 1 0 σ 2 . wher e C ′ 0 = min i λ min ( X ( i ) T γ X ( i ) γ /n i ) . Proof of L emma 1 Pr oof. Following the pro of of Theorem 3 in [22], we h av e the following r esult: for the i th subset, the selected model M γ ( i ) follows that, P ( M γ ( i ) = M S ) ≥ 1 − C 1 ( 2 c 1 ) 2 k n − kτ + ι i − C 2 4 k pn k i λ 2 k , (3) where C 1 , C 2 are constan ts: C 1 = c 1 (2 k − 1)!! E ( ǫ 2 k ) V 2 , C 2 = (2 k − 1)!! V 1 E ( ǫ 2 k ) and n i = n/m . If λ is cho sen to be c 0 ( n/m ) τ − ι +1 2 , then the above result can be update d as P ( M γ ( i ) = M S ) ≥ 1 − C 1 ( 2 c 1 ) 2 k n − kτ + ι i − C 2 (2 /c 0 ) 2 k pn − kτ + kι i (4) ≥ 1 − C 0 pn − kτ + kι i , (5) where C 0 equals to C 0 = C 1 ( 2 c 1 ) 2 k + C 2 (2 /c 0 ) 2 k . For any fixed m if the sample size n satisfies n ≥ m (2 C 0 p ) 1 k ( τ − ι ) , then we hav e P ( M γ ( i ) = M S ) > 1 / 2 on each subset. Recall the defin ition for the median model, γ = min γ ∈ { 0 , 1 } p m X i =1 k γ − γ ( i ) k 1 . Notice th at as lon g as half su bsets select the correct m odel, i.e., car d ( { i : M γ ( i ) = M S } ) ≥ m/ 2 , we will have M γ = M S . Therefor e, letting S cor = P m i =1 I { M γ ( i ) = M S } , where I A is th e ind ictor function for A , we hav e P ( M γ = M S ) = P ( S cor ≥ ⌈ m/ 2 ⌉ ) . (6) 12 Since all subsets are indep endent and the corr ect selection probability for each subset is greater than 1/2, we can apply the Chernoff i n equality ( [13] or Proposition A.6.1 of [29]) to obtain that, P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − C 0 p ( n/m ) − kτ + kι ) 2 2(1 − C 0 p ( n/m ) − kτ + kι ) · m . (7) Equiv alen tly , fo r any n ≥ (2 C 0 p ) 1 k ( τ − ι ) , if we choo se m = ⌊ ( δ C 0 ) k − 1 / ( τ − ι ) · n/p k − 1 / ( τ − ι ) ⌋ for any δ ∈ (0 , 1 / 2) , we ha ve P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kι ) − 1 p − ( kτ − kι ) − 1 n . In particular, when p ≤ n α for any α < k ( τ − ι ) we ha ve P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kι ) − 1 n 1 − α ( kτ − kι ) − 1 . (8) Proof of L emma 2 Pr oof. Th e proof is essentially the same a s Lemma 1. Following the p roof of Theo rem 2 in [20] , we will hav e the initial result on each subset, P ( M γ ( i ) = M S ) ≥ 1 − C 1 ( 2 c 2 ) 2 k n − kτ + ι i − C 2 ( 2 σ ) 2 k p ( ρλ ) k , (9) where n i = n/m and C 1 = c 1 (2 k − 1)!! E ( ǫ 2 k ) V 2 , C 2 = (2 k − 1)!! V 1 E ( ǫ 2 k ) . Now becau se λ = c 0 σ 2 ( n m ) τ − κ we update the above equation to P ( M γ ( i ) = M S ) ≥ 1 − C 1 ( 2 c 2 ) 2 k n − kτ + ι i − C 2 ( 4 c 0 c 3 ) k pn − k ( τ − 2 κ ) i (10) ≥ 1 − C 0 pn − k ( τ − η ) i , (11) where η = max { ι/k , 2 κ } and C 0 = C 1 ( 2 c 2 ) 2 k + C 2 ( 4 c 0 c 3 ) k . W ith exactly the same argument as in Lem ma 1, once the sample size exceeds (2 C 0 p ) 1 k ( τ − η ) , then for any δ ∈ (0 , 1 / 2) and m = ⌊ ( δ C 0 ) k − 1 / ( τ − η ) · n/ p k − 1 / ( τ − η ) ⌋ , we have P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kη ) − 1 p − ( kτ − kη ) − 1 n . (12) In particular, when p ≤ n α for some α < k ( τ − η ) we have P ( M γ = M S ) ≥ 1 − exp − (1 / 2 − δ ) 2 2(1 − δ ) ( δ C 0 ) ( kτ − kη ) − 1 n 1 − α ( kτ − kη ) − 1 . (13) Proof of L emma 3 Pr oof. T o simplify the n otation, let X den ote the selected feature matrix X γ . Now if the selected model is correct, the error of OLS estimator can be described in the following for m, ˆ β − β = ( X T X ) − 1 X T ǫ. (14) 13 Hence the error of av erag ed estimator is, ¯ β − β = m X i =1 ( X ( i ) T X ( i ) ) T X ( i ) T ǫ ( i ) /m. (15) Because E ǫ 2 = σ 2 we hav e E k ¯ β − β k 2 2 = σ 2 m 2 m X i =1 tr ( X ( i ) T X ( i ) ) − 1 . (16) As the smallest eigenv alue for each subset feature matrix is lo wer bound ed by V 2 , i.e., λ min ( X ( i ) T X ( i ) /n i ) ≥ V 2 , we have E k ¯ β − β k 2 2 = σ 2 m 2 n i m X i =1 tr ( X ( i ) T X ( i ) /n i ) − 1 ≤ σ 2 m 2 n i m X i =1 sV − 1 2 = σ 2 V − 1 2 s n . (17) Howe ver , if the model is incorrect, we can boun d the incorrect estimators in the following w ay . For each subset, k ˆ β − β k 2 2 = k ˆ β γ − β γ k 2 2 + k ˆ β S/γ − β S/γ k 2 2 ≤ k ˆ β γ − β γ k 2 2 + k β S/γ k 2 2 . (18) Now to quan itify the first term, we first notice that ( X ˆ β γ − X β γ ) / √ n i = ( X ( X T X ) − 1 X T Y − X β γ ) / √ n i , ( 19) and therefo re C ′ 0 k ˆ β γ − β γ k 2 2 ≤ k ( X ˆ β γ − X β γ ) / √ n i k 2 2 ≤ n − 1 i ( k Y k 2 2 − 2 β T γ X T Y + k X β γ k 2 2 ) (20) T akin g e x pectation on both sides we hav e, E k ˆ β γ − β γ k 2 2 ≤ C ′− 1 0 ( E k Y k 2 2 /n i + k X S/γ β S/γ k 2 2 ) /n i ≤ C ′− 1 0 ( k X S β S k 2 2 /n i + σ 2 + k X S/γ β S/γ k 2 2 /n i ) ≤ C ′− 1 0 (2 k β k 2 2 λ max ( X T S X S /n i ) + σ 2 ) ≤ C ′− 1 0 (2 sV 1 k β k 2 2 + σ 2 ) (21) Therefo re, we have E k ˆ β − β k 2 2 ≤ (1 + 2 C ′− 1 0 sV 1 ) k β k 2 2 + C ′− 1 0 σ 2 . (22) The above boun d holds for all subset estimtors β ( i ) , it should also hold for their av erag e ¯ β , i.e., E k ¯ β − β k 2 2 ≤ (1 + 2 C ′− 1 0 sV 1 ) k β k 2 2 + C ′− 1 0 σ 2 . (23) Ap pendix B: Assumption justification It is impor tant to caref ully assess whether th e con ditions assumed to obtain th eoretical g uarantees can be satisfied in application s. Ther e is typ ically no com prehen si ve answer to this qu estion, as the answer usually varies acro ss ap plication areas. No netheless, we provide some discussion below to provide some insights, while being limited by the complexity of the que stion. In f ollowing par agraph s, we attempt to justify A.1, A.3 and A.4 with exam ples and theorems. The main reason to leave A.2 alon e is becau se A.2 is an assumption on ba sic model structure that is routine in the high- dimension al literatur e. See Zhao an d Y u (2006) and Kim. et a l. (2 012). The discussion is divided into two parts. In the first p art, we con sider the case wher e features or predictor s are independen t. In the second part, we will ad dress the corr elated case. Because w e can always standardize feature matrix X prior to any analysis, it will be con venient to assume x ij having mean 0 and variance 1. For independen t featur es, we ha ve the following result. 14 Theorem 5. If the entries of the n × p featu r e matrix X are i.id random variables with fi nite 4 w th moments for some inte ger w > 0 , then A.1, A.3 and A.4 will hold for all m subsets with p r obability , P ( A. 1 , A. 3 and A. 4 hold for all subsets ) ≥ 1 − O m 2 w (2 s − 1 ) 2 w p 2 n 2 w − 1 , wher e s is the nu mber of non-zer o coef fic ients. Alternatively , for a given δ 0 > 0 , if the sample size n satisfies that n ≥ m (2 s − 1) 9 w (2 w − 1)!! M 1 (2 s − 1 ) mp 2 δ − 1 0 1 2 w − 1 , wher e M 1 is some constant, then with pr obability a t least 1 − δ 0 , all su bsets satisfy A.1, A.3 and A.4. The pro of will be provided in next section. Theor em 5 requ ires m = o ( n ) , wh ich seems to conflict with Theorem 1 and 2 in the article where m is assumed to be O ( n ) if p is fixed to be constant. This is, howev er, caused by the choice of δ (see the strong er version of Th eorem 1 provided in the first section). δ is fixed at 1 / 4 in the article f or simpicity , leading to the conclu sion of m = O ( n ) . W ith a different choice of δ satisfying δ = o ( n ) , Theorem 3 along with Theo rem 3 and 4 can be satisfied simultaneou sly . The same a rgument can be applied to Theorem 4 intro duced in the next part as well. Next, we consider the case wh en features are cor related. For data sets with cor related features, pre- processing such as precon ditioning might b e req uired to satisfy so me o f th e conditions. Du e to the complexity of the problem, we restrict our a ttention to data sets following ellip tical distributions and under high dim ensional setting ( p > n ). Real world data commo nly follow elliptical distributions approx imately , with den sity propo rtional to g ( x T Σ − 1 x ) for som e non-negative function g ( · ) . The Multiv ariate G aussian is a spec ial case with g ( z ) = exp ( − z / 2 ) . Following the spirit of Jia and Rohe (2012 ), we make use o f ( X X T /p ) − 1 / 2 ( X X T is in vertible whe n p > n ) as precond itioning matrix and then u se results from W ang and Leng (20 14) to show A .1, A.3 and A.4 hold with high probab ility . Thus, we h av e the following result. Theorem 6. Assume p > n and d efine ˜ X = ( X X T /p ) − 1 / 2 X a nd ˜ Y = ( X X T /p ) − 1 / 2 Y . If each r ow o f feature matrix X are i.i.d samples d rawn fr om a n elliptica l distribution with covariance Σ and the condition number of Σ sa tisfies that cond (Σ) < M 2 for some M 2 > 0 , then for any M > 0 ther e exist some M 3 , M 4 > 0 such that, A.1, A.3 and A.4 hold f o r all subsets with pr obability , P ( A. 1 , A. 3 and A. 4 hold for all subsets ) ≥ 1 − O mp 2 exp − M n 2 m log n , if n ≥ exp 4 M 3 M 4 (2 s − 1 ) 2 . Alternatively , for any δ 0 > 0 , if the sample size satisfies that n ≥ max O 2 m (log m + 2 lo g p − log δ 0 ) / M , exp 4 M 3 M 4 (2 s − 1 ) 2 , then with pr obab ility at l ea st 1 − δ 0 , A.1, A.3 and A.4 hold for all subsets. The proof is also provided in next s ection . Proof of T heorem 5 Pr oof. Let C = 1 n X T X . W e di vide the proo f into fo ur p arts. In Part I and II, we examine the magnitud e of C ik and C ii and gi ve the probability that A.3 and the first part of A.1 hold for a single data set. In Part III, we give the probability that A.4 and the second part of A.1 hold on a single data set. W e gener alize the result to multiple data s ets in P ar t IV . P art I . For C ii we hav e E C ii = E k x i k 2 2 /n = 1 n n X j =1 E x 2 ij = 1 , 15 and E | C ii − 1 | 2 w = 1 n 2 w E | n X j =1 ( x 2 ij − 1) | 2 w ≤ (2 w − 1)!! E | x 2 12 − 1 | 2 w n 2 w − 1 , where the last inequality follows the proof of Theorem 3 in [22]. Because E | x 12 | 4 w < ∞ , it is clear that E | x 2 12 − 1 | 2 w = P 2 w j =0 ( − 1) j C j 2 w E | x 12 | 4 w − 2 j is also a finite value, wh ich will be denoted b y M 0 . Now by the Chebyshev’ s inequality we have for any t > 0 , P ( | C ii − 1 | > t ) < (2 w − 1)!! M 0 n 2 w − 1 t 2 w . Therefo re, by taking the unio n bound ov er i = 1 , 2 , · · · , p we have, P ( max i ∈{ 1 , 2 , ··· ,p } | C ii − 1 | > t ) < (2 w − 1)!! M 0 p n 2 w − 1 t 2 w . (24) Recall the definition of C ii , (24) immediately implies that the first part of A.1 will hold with proba- bility at least 1 − O p n 2 w − 1 for a single data set. P art II . Follo wing the same argument, we can establish th e same inequality for C ik where the on ly difference is the m ean, E C ik = E x T i x k /n = 1 n n X j =1 E x ij x j k = 0 . From Chebyshev’ s inequ ality we ha ve for any t > 0 , P ( | C ik | > t ) < (2 w − 1)!! M 1 n 2 w − 1 t 2 w , where M 1 = max { E | x 12 x 23 | 2 w , M 0 } is a constant. T aking union bou nd over all off-diagon al terms we have, P (max i 6 = k | C ik | > t ) < (2 w − 1)!! M 1 p 2 n 2 w − 1 t 2 w . (25) W ith (24) a nd (25), we can quantify the sample correlation be tween x i and x k , which is C ik / √ C ii C kk . T aking t = (6 s − 3 ) − 1 for both inequalities, we have P (max i 6 = k | cor ( x i , x k ) | > 1 4 s − 2 ) < 2(2 w − 1)!!9 w M 1 (2 s − 1 ) 2 w p 2 n 2 w − 1 . W ith Coro llary 2 in [22], the above r esult essentially states that A.3 will h old with p robab ility at least 1 − O (2 s − 1) 2 w p 2 n 2 w − 1 for a single machine. P art III . For the seco nd p art of A.1 and A.4, we might need to qu antify the m inimum v alue of v T C v for any vector k v k 2 = 1 with support | supp { v }| ≤ s . Here sup p { a } stands for all n on-zero coordin ates of vector a . L et S b e index s et f or non-zero coefficients. Noticing that, λ min ( 1 n X T S X S ) = min k v k =1 , supp { v } = S v T C v ≥ min k v k =1 , | supp { v }|≤ s v T C v , and inf | π |≤ s λ min ( 1 n X T π X π ) = inf | π |≤ s min k v k =1 , supp { v } = π v T C v = min k v k =1 , | supp { v }|≤ s v T C v . Thus, ev aluating min k v k =1 , | supp { v }|≤ s v T C v solely is adequ ate. I n fact, for any vector v with | supp { v }| ≤ s we have, v T C v = X i ∈ supp { v } C ii v 2 i + X i 6 = k ∈ supp { v } C ik v i v k ≥ min i ∈{ 1 , 2 , ··· ,p } C ii − ( s 2 − s ) max i 6 = k ∈{ 1 , 2 , ··· ,p } C ( S )2 ik 1 / 2 . (26) 16 The second step is an application of Cauc hy-Schwarz inequ ality and the fact that if k v k 2 = 1 then P i 6 = k v 2 i v 2 k < 1 . Comb ining (26) with (24) and (25), and taking t = (2 s + 2) − 1 we hav e min k v k =1 , | supp { v }|≤ s v T C v ≥ 1 − 1 2 s + 2 − s 2 s + 2 = 1 2 , with probability at least 1 − 2 2 w +1 (2 w − 1)!! M 1 ( s + 1) 2 w p 2 n 2 w − 1 . P art IV . C o nsequently , A.1, A.3 and A.4 will hold for data set on a single machine with pro bability , P ( A. 1 , A. 3 and A. 4) ≥ 1 − O (2 s − 1 ) 2 w p 2 n 2 w − 1 . Now if we hav e m subsets, each with sample size n/m , then the prob ability that all subsets satisfy A.1, A.3 and A.4 follows, P ( A. 1 , A. 3 and A. 4 hold for all ) ≥ 1 − O m 2 w (2 s − 1 ) 2 w p 2 n 2 w − 1 . Alternatively , for a gi ven δ 0 > 0 and the number of subsets m , if the sample size n satisfies that n ≥ m (2 s − 1) 9 w (2 w − 1)!! M 1 (2 s − 1 ) mp 2 δ − 1 0 1 2 w − 1 , then with probab ility at least 1 − δ 0 , all subsets satisfy A.1, A.3 and A.4. Proof of T heorem 6 Pr oof. Th e pr oof p rocedu re is essentially the sam e as The orem 5 . W e begin b y looking at d ata set on a single mach ine. Let C = ˜ X T ˜ X / n = p/n · X T ( X X T ) − 1 X . From Lemma 4 and Lemm a 5 of [30] we have, for any M > 0 there exists some constant M 3 , M 4 > 0 such that, P max i ∈{ 1 , 2 , ··· ,p } C ii > M 3 or min i ∈{ 1 , 2 , ··· ,p } C ii < M − 1 3 < 4 p · e − M n , (27) and P max i 6 = k ∈{ 1 , 2 , ··· ,p } C ik > M 4 √ log n ≤ O p 2 · exp − M n 2 log n . (28) Inequa lity (27) implies the first part o f A.1. For A.3, we can u se (27) and (28) to b ound the sample correlation cor ( x i , x k ) = C ik / √ C ii C kk as follows, P max i 6 = k ∈{ 1 , 2 , ··· ,p } | cor ( x i , x k ) | > M 3 M 4 √ log n ≤ O p 2 · exp − M n 2 log n . Therefo re, to satisfy A.3 on ly requires n ≥ exp 4 M 3 M 4 (2 s − 1 ) 2 . (29) As s is assumed to be small, (29) will not be a big threat to the sample size. For A.4 and the second part of A.1, we continue to ap ply the same strategy in th e proo f of Theorem 3 (Part III ). Using (26) we have, min k v k =1 , | supp { v }|≤ s v T C v ≥ M − 1 3 − M 4 s √ log n with probability 1 − O p 2 · e x p( − M n/ 2 log n ) . T o satisfy A.4 and the second part of A.1, we just need n to be greater than exp( M 3 M 4 s 2 ) , which is already true if (29) holds. 17 Consequently , for a single machine if (29) is satisfi ed , A.1, A.3 and A.4 hold with probability , P ( A. 1 , A. 3 and A. 4) ≥ 1 − O p 2 · exp − M n 2 log n . Now for m subsets, each with sample size n/m , th e prob ability that A.1 , A.3 and A.4 hold fo r all subsets follows, P ( A. 1 , A. 3 and A. 4 hold for all ) ≥ 1 − O mp 2 · exp − M n 2 m log n . Alternatively , for any δ 0 > 0 , if n ≥ max O 2 m (log m + 2 log p − log δ 0 ) / M , ex p 4 M 3 M 4 (2 s − 1) 2 , then A.1, A.3 and A.4 hold for all subsets with prob ability at least 1 − δ 0 . Ap pendix C: Results for p = 10 , 000 we simu late 50 da ta set f or each case, and let the sample size range fr om 20 ,000 to 5 0,000 with subset size fixed to 2,000. Bolasso is not implemen ted as the comp utation cost is too expensive. The results are plotted in Fig 9 - 14. 20000 30000 40000 50000 0.00 0.02 0.04 0.06 Mean square error Sample size n value median fullset average message 20000 30000 40000 50000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message 20000 30000 40000 50000 0 20 40 60 80 100 Computational time Sample size n seconds median fullset average message Figure 9: Results fo r case 1 with ρ = 0 . 20000 30000 40000 50000 0.00 0.05 0.10 0.15 Mean square error Sample size n value median fullset average message 20000 30000 40000 50000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message 20000 30000 40000 50000 0 20 40 60 80 100 Computational time Sample size n seconds median fullset average message Figure 10: Results for case 1 with ρ = 0 . 5 . 18 20000 30000 40000 50000 0.000 0.010 0.020 0.030 Mean square error Sample size n value median fullset average message 20000 30000 40000 50000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message 20000 30000 40000 50000 0 20 40 60 80 100 Computational time Sample size n seconds median fullset average message Figure 11: Results for case 2 with ρ = 0 . 20000 30000 40000 50000 0.00 0.02 0.04 0.06 0.08 0.10 Mean square error Sample size n value median fullset average message 20000 30000 40000 50000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message 20000 30000 40000 50000 0 20 40 60 80 100 Computational time Sample size n seconds median fullset average message Figure 12: Results for case 2 with ρ = 0 . 5 . 20000 30000 40000 50000 0.0 0.2 0.4 0.6 0.8 1.0 1.2 Mean square error Sample size n value median fullset average message 20000 30000 40000 50000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message 20000 30000 40000 50000 0 200 600 1000 Computational time Sample size n seconds median fullset average message Figure 13: Results for case 3 with ρ = 0 . 20000 30000 40000 50000 0.0 0.5 1.0 1.5 Mean square error Sample size n value median fullset average message 20000 30000 40000 50000 0.0 0.2 0.4 0.6 0.8 1.0 Probability to select the true model Sample size n prob median fullset average message 20000 30000 40000 50000 0 200 600 1000 Computational time Sample size n seconds median fullset average message Figure 14: Results for case 3 with ρ = 0 . 5 . 19
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment