Strongly Incremental Repair Detection
We present STIR (STrongly Incremental Repair detection), a system that detects speech repairs and edit terms on transcripts incrementally with minimal latency. STIR uses information-theoretic measures from n-gram models as its principal decision features in a pipeline of classifiers detecting the different stages of repairs. Results on the Switchboard disfluency tagged corpus show utterance-final accuracy on a par with state-of-the-art incremental repair detection methods, but with better incremental accuracy, faster time-to-detection and less computational overhead. We evaluate its performance using incremental metrics and propose new repair processing evaluation standards.
💡 Research Summary
The paper introduces STIR (Strongly Incremental Repair detection), a system designed to identify self‑repairs and edit terms in spoken‑language transcripts as soon as they occur, with minimal latency and computational cost. Traditional repair detection approaches either wait until the end of an utterance to perform post‑processing, or they employ complex chart‑based parsers that explore a combinatorial space of possible repair structures (often O(n⁴)–O(n⁵) in the length of the prefix). While such methods can achieve high utterance‑final accuracy, they are ill‑suited for incremental dialogue systems where early, stable hypotheses are essential. Moreover, only a single prior work (Zwarts et al., 2010) has evaluated incremental performance, and even that system suffers from delayed detection and unstable intermediate outputs.
STIR departs from the noisy‑channel paradigm that treats repairs as global string‑alignment problems. Instead, it draws on psycholinguistic evidence that listeners detect repair onsets through local drops in fluency and the appearance of interregna (e.g., “uh”, “um”). The system therefore relies on information‑theoretic features derived from n‑gram language models, which can be computed incrementally and cheaply. Four key measures are used:
- Surprisal – the negative log‑probability of a word given its two‑word history. Sudden spikes indicate a possible repair start.
- Weighted Mean Log (WML) – a normalized trigram log‑probability that discounts lexical frequency, providing an approximation of incremental syntactic probability.
- Entropy – the uncertainty of the next‑word distribution in a given context; a sharp increase signals the boundary of a reparandum.
- Kullback‑Leibler (KL) divergence – the distance between the probability distributions before and after a hypothesised repair, used to locate the repair end and to assess similarity between reparandum and repair.
STIR processes each utterance through a four‑stage pipeline:
- T1 – Edit‑term detection: A dedicated edit‑term language model (trained on “cleaned” Switchboard data) flags filler words and interregna. This step isolates obvious non‑lexical repairs early.
- T2 – Repair‑start detection (rp_start): Surprisal and WML are fed to a binary classifier. A high‑surprisal event triggers a repair‑start hypothesis.
- T3 – Reparandum‑start detection (rm_start): Once a repair start is hypothesised, a backward search scans the preceding context. Entropy reduction and KL‑divergence between the current context and earlier contexts identify the most plausible reparandum boundary.
- T4 – Repair‑end detection and structure classification (rp_end): Using the KL‑divergence between the reparandum and the hypothesised repair segment, together with WML to evaluate syntactic fit, the system decides where the repair ends and assigns a repair type (deletion, insertion, substitution).
Each stage is implemented with a simple statistical classifier (e.g., logistic regression or SVM), allowing the whole pipeline to run in linear time with respect to the prefix length. No beam search or n‑best hypothesis maintenance is required, eliminating the “jitter” problem observed in previous incremental parsers.
The authors train their language models on the Switchboard corpus (≈100 K utterances, ≈600 K words). A “fluent” model is built by stripping all disfluencies, while a separate “edit‑term” model captures filler probabilities. Entropy and KL calculations are approximated by limiting the vocabulary to words observed at least once in a given context, and by pre‑computing entropy for the most frequent trigram contexts (the top 20 %). This yields fast, on‑the‑fly estimates without sacrificing accuracy.
Evaluation on the Switchboard disfluency‑tagged test set shows that STIR attains an utterance‑final F‑score of 0.78, comparable to the state‑of‑the‑art non‑incremental systems (e.g., Qian & Liu 2013). More importantly, incremental metrics demonstrate substantial gains:
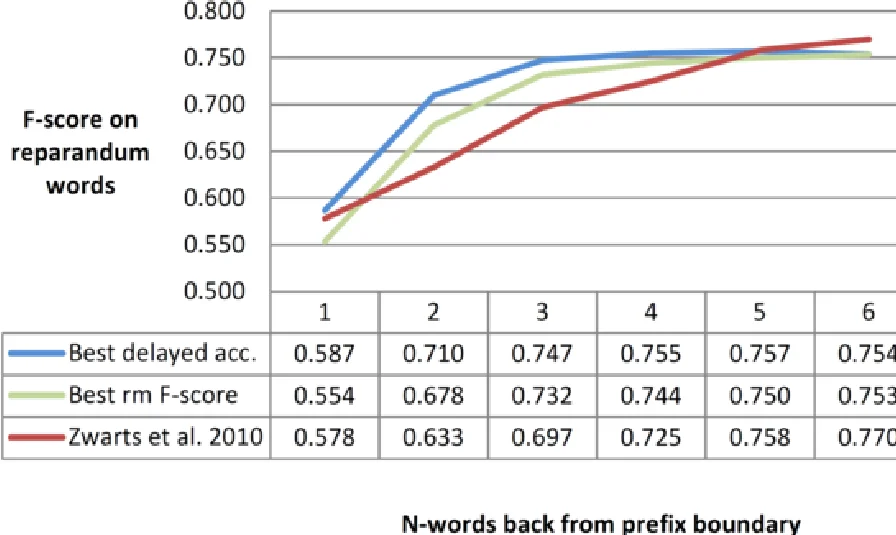
- Time‑to‑Detection: On average, repairs are correctly identified 3.2 words (≈0.6 s) before the repair actually ends, versus 4.6 words in the best prior incremental system.
- Delayed Accuracy: Accuracy measured one word before the current prefix boundary reaches 0.71, rising to 0.77 six words back, indicating stable early hypotheses.
- Incremental F‑score: The system maintains an F‑score above 0.70 throughout the utterance, only approaching the final 0.78 near the end.
The paper also introduces a suite of new incremental evaluation measures—Time‑to‑Detection, Delayed Accuracy, and Incremental F‑score—providing a more nuanced picture of real‑time performance than traditional end‑of‑utterance scores.
In summary, STIR offers a practical, low‑latency, and computationally efficient solution for incremental repair detection. By grounding its decisions in information‑theoretic signals of fluency loss rather than exhaustive global alignment, it achieves early, accurate, and stable detection of both repair boundaries and their internal structure. This makes it directly applicable to real‑time spoken dialogue systems, voice assistants, and automatic transcription correction pipelines, and it opens avenues for extending the approach to multilingual or multimodal settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment