Text Classification Using Association Rules, Dependency Pruning and Hyperonymization
We present new methods for pruning and enhancing item- sets for text classification via association rule mining. Pruning methods are based on dependency syntax and enhancing methods are based on replacing words by their hyperonyms of various orders. We discuss the impact of these methods, compared to pruning based on tfidf rank of words.
💡 Research Summary
The paper proposes a novel pipeline for text classification that combines class‑association‑rule (CAR) mining with two linguistically‑driven preprocessing steps: dependency‑based pruning and hyperonymization. A CAR is a rule of the form “itemset → class” that must satisfy minimum support (σ) and minimum confidence (κ). Because the number of possible itemsets grows exponentially, the authors restrict the mining to the sentence level and apply aggressive pruning to keep the rule set manageable and human‑readable (they fix the final number of rules to about 1,000).
The preprocessing pipeline works as follows. First, each sentence is lemmatized using the Stanford TreeTagger. Then a dependency‑based pruning step selects only those tokens that participate in linguistically salient dependency relations (e.g., nominal subject, direct object, prepositional complement, determiner). This step is motivated by the observation that such tokens carry most of the semantic content, while function words and other low‑information tokens inflate the dimensionality without improving classification. After pruning, a hyperonymization step replaces each retained word with a higher‑level synonym (hypernym) drawn from WordNet. For each word, the most frequent synset in the British National Corpus is identified, and the hypernym chain with the highest logarithmic frequency (lf) is followed; the i‑th hypernym h_i(w) is then used as a replacement. This semantic generalization is intended to increase the support of itemsets (more sentences share the same hypernym) and to reduce sparsity.
The training algorithm (Algorithm 1) processes every sentence through lemmatization, pruning, and hyperonymization, then runs the Apriori algorithm with the given σ and κ to extract CARs. Each rule stores its confidence value. Classification (Algorithm 2) proceeds sentence by sentence: for a new document, the most confident rule whose itemset is fully contained in the sentence is selected; the document’s class is obtained by aggregating the confidences of all selected sentence‑level rules (simple sum per class). Two auxiliary metrics are reported: variety (β) – the number of distinct classes that contributed rules to a document, and dispersion (Δ) – the gap between the highest and lowest summed confidences. Low β and Δ indicate that the rule set is focused and the prediction is stable.
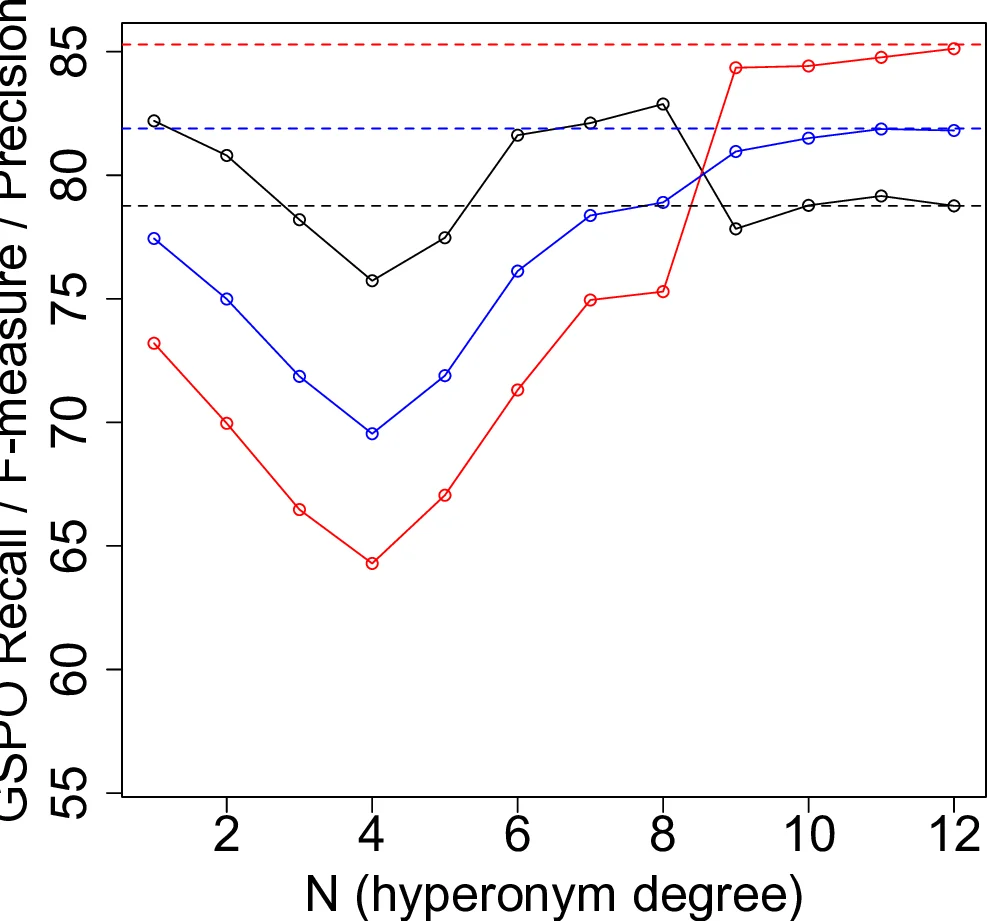
Evaluation is carried out on a subset of the Reuters‑21578 corpus. Seven topics (sports, economics, domestic politics, war, international relations, crime, labor) are selected, and for each the 1,000 longest articles are taken, yielding 7,000 documents (average length ≈ 400 words). Sentences are parsed with the Stanford Dependency Parser (collapsed mode). Three experimental conditions are compared:
- TF‑IDF based pruning – a classic frequency‑based selection of the top N words per sentence (baseline).
- Dependency‑based pruning – only words involved in selected dependency relations are kept.
- Dependency + Hyperonymization – after dependency pruning, each word is replaced by its most significant hypernym (order‑1 hypernym is used in the reported experiments).
For each condition the authors run a 10‑fold cross‑validation, automatically tuning σ and κ so that the number of generated rules stays within the target window
Comments & Academic Discussion
Loading comments...
Leave a Comment