Inner Product Similarity Search using Compositional Codes
This paper addresses the nearest neighbor search problem under inner product similarity and introduces a compact code-based approach. The idea is to approximate a vector using the composition of several elements selected from a source dictionary and …
Authors: Chao Du, Jingdong Wang
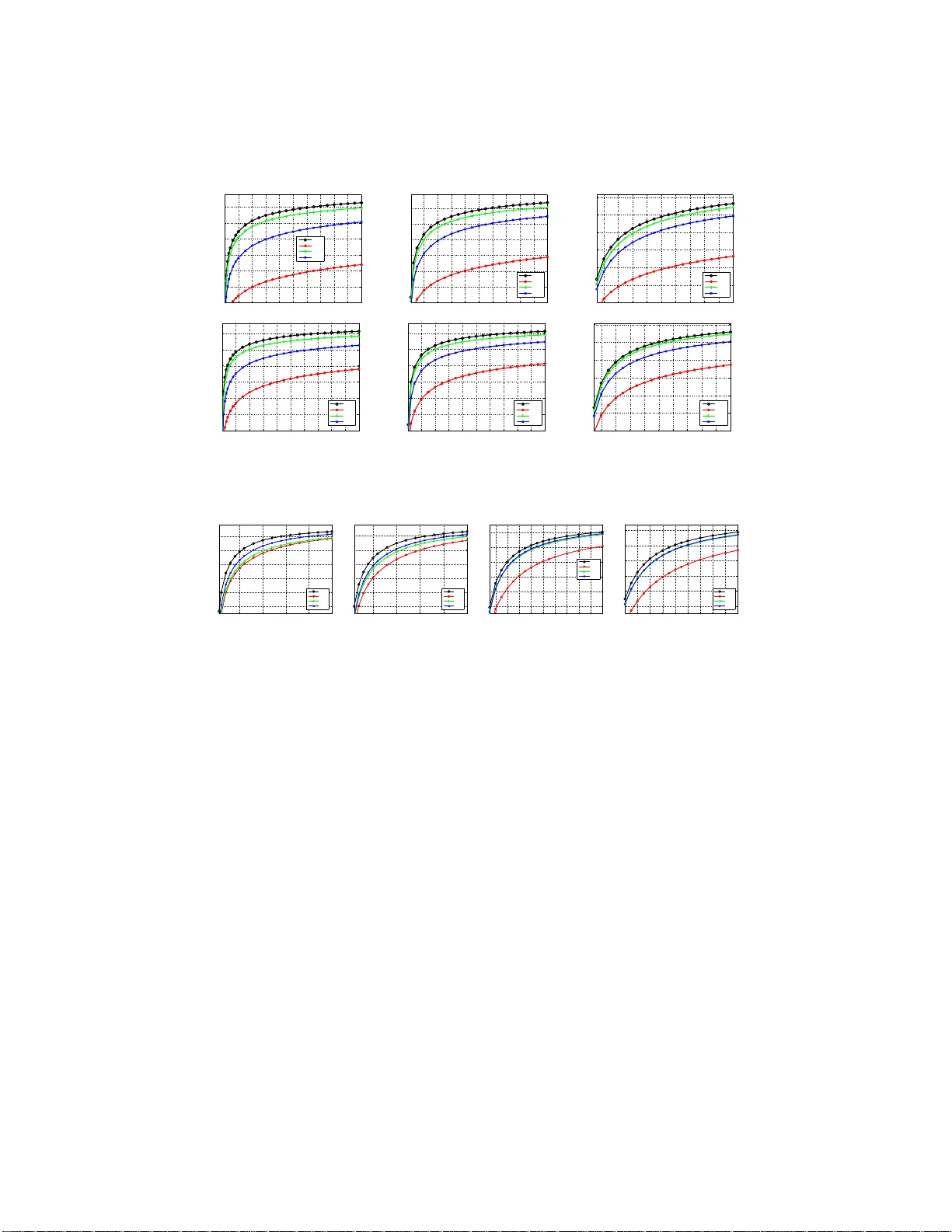
Inner Pro duct Similarit y Searc h using Comp ositio nal Co des Chao Du 1 Jingdong W ang 2 1 Tsingh ua Univ ersity , Beijing, P .R. China 2 Microsoft Researc h, Beijing, P .R. China June 23, 2014 Abstract This pap er addresses the nearest neighbor searc h problem un der inner prod uct similarit y and introduces a co mpact cod e-based approach. The idea is to approximate a vector using th e comp osition of several elements selected from a source dictionary and to represent this vector by a short code comp osed of the indices of the selected elemen ts. The inn er pro duct b etw een a q uery vecto r and a d atabase vector is efficiently estimated from the q uery vector and th e short co de of th e database vector. W e show the sup erior p erformance of the p rop osed group M -selection algorithm that selects M elemen ts from M source d ictionaries for vector app ro ximation in terms of searc h accuracy and efficiency for compact codes of the same length via th eoretical and empirical analysis. Exp erimental results on large-scale datasets (1 M and 1 B SIFT features, 1 M linear mo dels and Netflix) demonstrate the sup eriority of th e p rop osed app roac h. 1 In tro duction Similarity search [1] is a fundamental resea rch t opic in the area of computational geometry and machine learning. It has attracted a lot of interests [2] in computer vision and pattern recog nition b ecause o f the po pularity of larg e scale and high- dimensional multimedia data. V a r ious technologies, such as index structures [3, 4] and compa c t co des [5, 6], ha ve b een developed to so lve the similar ity search problem under differe nt similarity metrics [7]. In this pap er, we are interested in desig ning a compact co de approach with a fo cus on inner pro duct similarity . I nner pro duct similar it y sear ch is an impo r- tant task in many vision applications. In la rge sca le r e tr iev al of imag es from text queries and multi-class catego r ization, the P AMIR (Passive-Aggressive Mo del for Ima ge Retr iev al) approach [8] trains a lar g e num b er of linear mo dels (each corres p o nds to a tex t query), and ranks the querie s for a new ima g e a c cording to the scores ev a lua ted over the linear mo dels, which is an inner pro duct similarity search problem. In the ob ject detection task with a large num b er o f ob ject 1 classes [9 ], it consists o f a step finding the top-r esp onded filters by p erfor ming the conv olution op era tion ov er sliding image windo ws and filters, which is a ls o an inner pro duct similar ity search pr oblem. The laten t factor models widely used in reco mmendation systems [10] a nd do cumen t matching [11], such a s ma - trix fac to rization [1 0], la tent semantic index [12], and s o on, also r ely o n inner pro duct s imilarity search to find the b est matches. W e prop ose a compa ct co de appro a ch to appr oximate inner pro duct similar - it y search. Our approa ch is based on a v ector a pproximation alg orithm, us ing the comp osition of several v ectors selected fr o m a small set (sourc e dictionar y) as the a pproximation, which is not studied for co mpa ct co des and similarity search befo re. Then we use the indices of the se lected vectors to for m a co mpa ct co de, which we call comp o s itional co des, to describ e the data vector. Finally , inner pro duct b etw e e n the query vector a nd the database vector can b e efficiently estimated fro m the query vector and the code o f the data ba se vector. The comp ositional way to vector approximation can be v iewed as a quantiza- tion algo rithm, finding the nea rest element fr o m a lar ger dictiona ry (called c om- po sitional dictionary) that is pr o duced from a sour ce dictionar y . W e study the wa y of using M - selection ( M -combination with rep etitions) 1 to form the com- po sitional dictionar y , and show that it is equiv alent to p er forming 1-selectio n from M identical s o urce dictionar ies r esp ectively . This equiv alence motiv ates us to generalize M -selection by using M differen t sour ce dictionarie s, yield- ing a so-called g roup M -selection a lgorithm that simultaneously learns so ur ce dictionaries and p er fo rms joint M 1-selections from sour ce dictionaries. The adv antage o f gr oup M -selec tio n lies in more a c curate vector approximation b e- cause of a lar ger comp ositional dictionar y but with the co mpact co de o f the same length. Exp erimental results on finding similar SIFT featur es, sear ching for users with simila r int erests and discov ering mo st relev a nt liner mo dels show excellent search a ccuracy . 1.1 Related W ork Similarity sear ch (or near est neig hbo r search) has b een studied in ma ny resear ch areas, including computational geometry , computer vision, mac hine learning , data mining a nd so on. A lot of alg orithms hav e bee n developed for approximate nearest neighbor sear ch, under the Euclidea n distance [3, 1], the ear th mover distance [7, 13], and so on. In this pape r, we are interested in the nearest neighbor se arch pr oblem, instead under the inner pro duct similarity . The challenges, compared with the well-studied s imilarity search under Eu- clidean dista nce, ar e ana lyzed in [1 4]. The main difficulty that inner pr o duct do es not satisfy the tria ngle equa lity makes algor ithms dep ending o n it not suit- able for inner pro duct sear ch. A co ne tr ee based index structure [14] is desig ned for exact inner pro duct similarity search. The fact that exact s e arch under Eu- clidean distance in high-dimensional cases is even slower tha n the naive linear 1 In mathematics, an M -combination of a set S is a subset of M distinct elemen ts of S . An M -selection of a set S is a s ubset of M not necessarily distinct elements of S . 2 scan algo rithm is also obser ved under inner pro duct similarity . Thus, we fo c us on approximate inner pro duct similarity search and study the compact co de approach. There are many algorithms based on compact co des for similar it y sea rch with the Euclidea n distance, including tw o main categ ories: hashing and compressio n- based so ur ce co ding. The hashing categ ory consis ts of r andom alg orithms, such as lo cality s ensitive ha s hing [5], and learning ba sed algo rithms such as sp ec- tral hashing [15], itera tive quantization [16] and so on. These a lg orithms show promising pe r formance for sea rching with Euclidean distance, but most of them cannot b e directly applied for inner pro duct similar ity . The compress ion-based source co ding ca teg ory includes k - means, product quantization [6], and Ca r te- sian k -mea ns [17], which ar e shown to achiev e sup e rior p er formance over hashing co des with a little hig her but still acceptable query time cost. The prop osed approach b elo ngs to the co mpression-ba sed category , with a sp ecific adapta - tion to inner pro duct. The closely rela ted approa ches, pro duct quantization and Cartesia n k -means , we w ill sho w, ar e co nstrained versions of our pro po sed approach. Recent resear ch on hyper plane hashing [18, 19, 2 0] s tudies the problem of finding the p oints that ar e nearest to the hyper plane, which is related to inner pro duct. Different fr om the ma x imu m inner pro duct pr oblem our approach addresses, it is equiv alent to finding the data vector that has the minimum inner pro duct with the q uery vector. Concomitan t hashing [20] is also able to solve the abso lute maximum inner pro duct problem. A pproximate near est subspace sear ch [21], under the simila rity based on the principal angles b etw een subspaces, is related to the co sine similarity search. Those approaches address different pr o blems a nd are no t comparable to o ur a pproach. 2 Inner Pro duc t Similarit y Searc h Given a s et of N d -dimensional da tabase vectors X = { x 1 , x 2 , · · · , x N } and a query q , inner pro duct simila rity search aims to find a databa se vector x ∗ so that x ∗ = arg max x ∈X < q , x > . In this pa p er , we study the approximate inner pro duct similarity sea rch problem with a fo c us on the compa ct co ding approa ch, i.e., finding short co des to represent the da tabase vectors. The ob jectiv e includes three asp ects: the c o de representing the databa s e vector is compact; the similarity b etw een a query q and a vector can b e accur ately approximated using the query a nd the compac t co de; a nd the ev aluation ov er the query and the compact co de can b e q uickly conducted. The basic idea of our appr oach is to appr oximate a database vector x n us- ing a comp os itional vector, the summatio n P M m =1 c n m of M exemplar vectors { c n 1 , c n 2 , · · · , c n M } , where the exemplar vectors a re selected from a collection of exemplars C . The main work of this pap er is to inv es tigate its a pplica tion to compact co des and effective and efficient inner pro duct similarity approxima- tion. Suppo s e that each example in C can b e repr esented by a co de of leng th 3 log K , where K is the size of C . Then the comp ositional vector and thus the database vector ca n be re pr esented by a sho rt co de of length M log K . The prop osed appro ach also exploits the distributive pr o p erty with r esp ect to the inner pr o duct o p e ration ( < · , · > ) ov er the addition op eration: < q , c 1 + c 2 > = < q , c 1 > + < q , c 2 > . With the distribution pr op erty , ev aluating inner product betw een a query and the comp ositio na l vector takes O ( M ) a dditio n op er a tion if the inner pr o duct v alues of q with all vectors in C are co mputed, whose time cost is neg le c table when ha ndling la rge scale da ta. The vector approximation scheme us ing M vectors is exp ected to hav e a better approximation, th us yielding a more accur ate inner pr o duct approxima- tion. This is g ua ranteed by the prop erty that the inner pr o duct appr oximation error is upp e r -b ounded if vector appr oximation is with an uppe r -b ounded err or (Euclidean distance with vector a pproximation has a similar pr op erty derived from the tr iangle inequality). Prop ert y 1 . Given a data ve ctor p and a query ve ctor q , if the distanc e b etwe en p and its appr oximation ¯ p is not lar ger than r , k p − ¯ p k 2 6 r , then t he absolute differ enc e b etwe en the true inner pr o du ct and the appr oximate inner pr o duct is upp er-b ounde d: | < q , p > − < q , ¯ p > | 6 r k q k 2 . (1) The uppe r bo und r k q k 2 is related to the L 2 norms of q , meaning that the bo und dep ends on the quer y q (in contrast, the upp er b ound for Euclidean distance do es not depe nd on the query). How ever, the solution in inner pr o d- uct similar ity search do es not dep end on the L 2 norm of the query as queries with different L 2 norm hav e the same solution, i.e., x ∗ = a rg max x ∈X < q , x > = arg max x ∈X < s q , x > , wher e s is an ar bitrary po sitive num b er. In this sense, it also holds that mor e acc urate vector appr oximation is p otential to lead to b e tter inner pr o duct similarity search. 3 Our A pproac h In this sectio n, we firs t in tro duce the basic vector a pproximation approach, k - means cluster ing , a nd co nnect it with the manner of using a 1 -combination of a source dictiona ry to approximate the da ta vector. W e then present the prop osed comp ositional co de approach, ba s ed o n M -combination, M -selection and group M -s e lection. Finally , we give the analys is. 3.1 K -mea ns K -means cluster ing is a metho d of vector quantization. It aims to pa rtition the da tabase p oints into K clusters whose cen ters form a set C , in which each database po int b elo ng s to the cluster with the nearest center. In its application to data approximation, eac h data base p oint is approximated by the nearest center, eq uiv alently using the b est 1 -combination of C to approximate a database 4 vector. The K -means clus ter ing algorithm provides a way of jointly optimizing the center set C a nd the 1- combination for ea ch da ta vector. 3.2 Comp ositional Co des W e present the basic comp ositional c o de appro ach that uses M -combination ov e r a s et of s amples deno ted by C , i.e., using the comp os itional P M m =1 c n m with c n m ∈ C , to a ppr oximate the data vector x n . This manner c ould b e viewed as a t wo-step scheme: fir st pro ducing a c omp ositional dictionary formed by the M -co mbinations of C that we ca ll sour c e dictio nary and then finding the b est element fro m the comp osite dictionary as the approximation of a data vector. Instead of separately learning the so urce dictionary (e.g., using k -means clustering) and finding the optimal M -combinations, we use the wa y similar to spa rse co ding and k -mea ns to jointly learn the sour ce dictionar y and M - combinations. W e use a K -dimensional bina ry vector b n to repr esent an M - combination, where only M entries in b ar e v a lued a s 1 and all o thers a re 0 , a nd a matrix C of size d × K to repres e nt the sour ce dictiona ry with each column corres p o nding to a n item of the so ur ce dictionary . The ob jective function is written as follows, min C , b 1 , ··· , b N X N n =1 k x n − Cb n k 2 2 . (2) W e r elax the constra int in M -combination that the M elements in M - combination are dis tinct and use M -s election in which the elements are not nec- essarily differe nt . T o mathematically fo rmulate this case, we use a long er binary vector b n whose dimensionality is K × M to represent an M - selection for the data vector x n . b n is a conca tenation of M subv ectors, b n = b T n 1 b T n 2 · · · b T nM T . In each subv ecto r only one entry b nm is v a lued by 1 and all others ar e 0. The ob jective function can b e formulated as follows, min C , b 1 , ··· , b N X N n =1 k x n − [ CC · · · C ] b n k 2 2 . (3) F ur ther more, w e extend the M -selectio n scheme to a so -called gr oup M - selection scheme. Gr oup M -selection is a combination o f the elements fro m M sets { C 1 , · · · , C M } each of which is a matrix of size d × K , tak en 1 at a time from ea ch of the M sets. The whole formulation is then given as the following, min C 1 , ··· , C M , b 1 , ··· , b N X N n =1 k x n − [ C 1 C 2 · · · C M ] b n k 2 2 s . t . b n = b T n 1 b T n 2 · · · b T nM T b nm ∈ { 0 , 1 } K k b nm k 1 = 1 . (4) The group M -selection case , similar to the M -selection case, also pro duces an approximation using the comp os ition of M elements, but differently M s ource 5 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 (a) −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 (b) −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 (c) −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 1 (d) Figure 1: The illustra tions of the comp o sitional dictionaries learnt with (a) k - means, (b) M -co mbin ation, (c) M -s election, and (d) g roup M -selection, from a set of 150 0 random 2 D p oints. K = 5, M = 3 . Each par titio n corres p o nds to a dictionary ele ment dictionaries with e a ch containing K elements ar e used to form the comp osi- tional dictionar y . It, how ever, do es not inc r ease the co de length and keeps the same length M log K , where each b nm is r epresented b y a co de of le ng th log K , denoted by y nm which is the index of the non- zero entry in b nm in our im- plement ation. Note that in this case, the time consumption for computing the similarity table b ecomes to O ( M K d ). How ever, in the la rge sca le similarity search case, the increase of suc h co mputation cost brought due to the increase of the num b er of elemen ts in the so ur ce dictionaries (from K to K M ) is ne- glectable becaus e M in practice is chosen to be small so that the approximate inner pr o duct similarity ev aluation cost O ( M ) is not larg e. Figure 1 illustrates the co mpo sitional dictionaries from K -means, M -combination, M -selection a nd group M -selection. 3.3 Optimization W e adopt alterna ting optimization, which is used in the Lloyd a nd sparse dictio- nary learning algorithms, to so lve the optimization problem in Equa tion 4. T o be clear, we deno te D = [ C 1 · · · C M ]. Our optimiza tion algo r ithm alternatively optimizes the source dictiona ries D and optimizes the gr oup M -s e lection b n for each data vector x n . Up date the dictionary . The o b jective function can b e transfor med as f ( D , B ) = k X − DB k 2 F , wher e X = [ x 1 · · · x N ] is the da ta matrix and B = [ b 1 · · · b N ] is the group M - selection matr ix. This is a quadr atic o ptimization pr oblem w.r.t. the v ariable D . Many a lgorithms have b e e n desig ned to s olve this problem. In this pap er, we solve this pro blem using the clos ed-form solution. Let the der iv ative of f ( D , B ) with resp ect to D b e zero : ∂ f ( D , B ) ∂ D = 2( DBB T − XB T ) = 0 . Then we hav e the clo s ed-form solution: D = XB T ( BB T ) − 1 . The online learning algorithm [2 2] c an b e a lso b e b orrowed for a cceleratio n. Up date the group M -sel ection b n . Optimizing { b 1 , · · · , b N } giv en the source dictionaries D can b e decomp os ed into N indepe ndent subproblems { min b n ( f n ( b n ) = k x n − Db n k 2 2 ) } N n =1 with the asso c ia ted cons traints, each of which o ptimizes the gr oup M -selection b n separately . Int uitively , each subproblem selects one element from each so urce dictio nary so tha t the co mp o s ition o f these elemen ts is the closest to the data vector. 6 The s ubproblem of minimizing f n ( b n ) is a combinatorial pro blem a nd genera lly NP-hard. W e prop ose to adopt a gr eedy algorithm, p er fo rming M 1-selection optimizations over the M s ource dictionaries in the best-fir st manner . The m - th iteration of the greedy alg o rithm consists of determining ov er which source dictionary 1-selection is per formed from the remaining ( M − m − 1) source dictionaries that have no t b een selected and finding the b es t 1 -selection ov er the selected sourc e dictionary . The former issue is solved by selecting the b est source dictionary ov er which the reconstructio n err or given the pr evious selected ( m − 1) 1-selections is the minimal. The latter is s ue is s olved by selecting the element in the s o urce dictionar y that is the neares t to the residual (the difference of the data vector from the current approximate vector using the prev ious ( m − 1) 1-selections). 3.4 Searc h wit h Comp ositional Codes Given that the database { x n } N n =1 is r epresented b y the co mpact co des { y n } N n =1 with y b eing M co des y n 1 , y n 2 , · · · , y nM , we p erform the linear s can search to find neare s t neighbors, by computing the a ppr oximate simila r ity o f a query q with each databas e vector. The inner product s imilarity b etw een q and x n is approximated using the compact co de, < q , x n > ≈ < q , P M m =1 c y nm > . The distributive pr op erty shows that < q , P M m =1 c y nm > = P M m =1 < q , c y nm > , which takes O ( M ) time if the inner pro ducts betw een the q uery and the dictionary elements have b een a lr eady computed. As aforementioned, before linear sca n, the sear ch pro cess first constructs the similarity table, storing inner pr o ducts betw een the query q and all the dictionary elements in C , who se time complexity is O ( M K d ). In summary , the ov erall se arch time complexity is O ( M K d + N M ). When handling lar ge s cale data, the cost of co mputing the similarity table is relatively small and neglecta ble compar e d with the linear sca n cost. In the case of sea rching o ver SIFT1 M with M = 8 a nd K = 25 6, the time of co mputing the s imilarity table is a b out only 2% of the total search time a nd in the c ase of searching over SIFT1 B with M = 8 and K = 256, the r atio for the cost o f similarity table computation is even muc h s maller. 3.5 Analysis Let’s see how to transfor m the group M - s election ca se for mulated in Eq uation 4 to other ca s es. W e intro duce three cons tr aints: c 1: C 1 = C 2 = · · · = C M ; c 2: b ni 6 = b nj , ∀ i 6 = j, ∀ n ; c 3: M = 1. It is ea s y to show that the for mulation in Equation 4 with an extra cons traint c 1 is equiv alent to the M -selection cas e, that it with tw o extra constr aints c 1 and c 2 is reduced to the M -co mbination case, and that it together with all the three ex tra constr aints, c 1, c 2 and c 3, is reduced to the k -means ca se. The r eduction relatio ns are summar ized as the following pr op erty . Prop ert y 2. The c omp ositional c o de appr o ach with gr oup M -sele ction c an b e tr ansforme d to the ones with M - sele ction and M -c ombination and k -me ans by 7 suc c essively adding extr a c onstr aints: Gr oup M - s ele ction + c 1 − − → M -sele ction + c 2 − − → M -c ombination + c 3 − − → k -me ans. With rega rd to the optimal ob jective function v alues of k -mea ns, M - combination, M -s e lection, and group M -s election that a re denoted b y f ∗ km , f ∗ mc , f ∗ ms , and f ∗ gms , resp ectively , we hav e the following prop er ty . Prop ert y 3. Given the same datab ase X and t he s ame variable s of K and M , we have ( 1) f ∗ gms 6 f ∗ ms ; (2) f ∗ ms 6 f ∗ mc ; (3) f ∗ ms 6 f ∗ km . Ther e is no guar ante e for f ∗ mc 6 f ∗ km . The pro ofs of the first three ineq ualities in the ab ove pro p erty is obvious and it is easily v alida ted that the optimal s o lution of the M - selection ( M - combination, k -mea ns) cas e is (or forms) a feasible solution of the gro up M - selection ( M -selection, M -selectio n) case. In co nt ra s t, we can find an ex ample that the o ptimal so lution of the k -means ca se cannot for m a feasible solution of the M -co mbination cas e (e.g., in the ca s e K = M ). W e co mpute the ca rdinalities o f the co mpo sitional dictiona ries (the s ource dictionary in k - means is equiv ale nt ly re garded as the comp os itional dictionary) in the four cases to s how the difference of the four algorithms in another way . Generally , the ob jective v a lue would b e sma ller if the car dinality of the c o mp o - sitional dictionary is larger. The cardinalities ar e summar ized a s follows. Prop ert y 4. The c ar dinalates of the gr oup M -sele ction c ase, t he M - sele ction c ase, the M - c ombination c ase, and the k -me ans c ase ar e K M , K M = K + M − 1 M = ( K + M − 1)! M !( K − 1)! , K M = K ! M !( K − M )! , and K , r esp e ctively. We have K M > K M > K M , and K M > K M > K . Prop erty 3 shows that the g roup M -selection scheme pro duces the smalles t ob jective v alues. In other words, the group M -selection scheme leads to the most accurate appr oximation o n average. Bas ed on the b ound analy sis in Prop er ty 5, it can b e c oncluded that gro up M -selection ca n a chiev e the most accur a te inner pro duct a pproximation as given in the following corolla ry . Corollary 1. On aver age, the gr oup M -sele ction scheme r esu lts in mor e ac- cur ate inner pr o duct app r oximation (smal ler err or upp er-b ound) t han k -m e ans, M -c ombination, and M -sele ction given t he same variables M and K . Time Co mplexity . Section 3 .4 has des c rib ed the search pro cess and its time complexity . The following presents the time complexity for the training pr o cess. The training pr o cess is a n iterative pro cedure and ea ch iteration consists of t wo steps : dictionary learning and code up dating. The dictionary learning step updates the dictionaries as a clo sed-form so lution: D = XB T ( BB T ) − 1 , which includes (sparse) matrix multiplication and ma trix inv ersio n, and its time complexity is O ( N M d + d ( M K ) 2 + N M 2 + ( M K ) 3 ). The co de up dating step inv olves computing the co de for each vector, taking O ( M 2 K d ), and thus takes O ( N M 2 K d ) for all da tabase v ector s . In a word, the time complexity o f the whole itera tion pro cess is O ( T ( N M 2 K d + d ( M K ) 2 + ( M K ) 3 )) with T b eing the 8 T a ble 1: The des c riptions of the four da tasets. #(database) = #(database vectors). #(queries ) = #(quer y vectors) SIFT1M SIFT1B Netflix LM1 M dimension 128 128 17 , 770 2 , 048 #(database) 1 , 000 , 000 1 , 000 , 000 , 000 480 , 189 890 , 912 #(queries) 10 , 000 10 , 000 480 , 189 100 , 000 nu mber of iter ations and one can see that it is linea r with resp ect to the num b er of vectors N and the dimension d . when training the co de s for the SIFT1 M dataset, the algorithm reaches conv ergence in 15 iter ations and takes a bo ut 250 × 1 5 se c onds (with a single In tel i7-26 00 CPU (3 . 40 G Hz)) Our algo rithm also b enefits fr o m pa rallel computing, and thus the practica l time co ns umption is accepta ble, fo r exa mple, c o mputing the co des from the 100 M le a rning vectors for SIFT1 B is completed within 5 hour s . Connections and Di scussions . W e summarize the relations with se veral closely-r elated algorithms. Detailed ana lysis is given in the supplementary ma- terial. Pr o duct qua ntization [6] and Cartesia n k -means [17] can b e viewed as a constrained version of the gro up M -selection algor ithm: ea ch sub quantizer co r- resp onds to a source dictionar y in our approach and each source dictionar y lie s in a different subspac e w ith the same dimension (in the case that each subspa ce is full-ra nked). In compariso n with order p er mutation [23] in which the simi- larity b e t ween p ermutation orders is used as a predicto r of the c loseness, our approach uses the co mp osition of selec ted dictionary elements to approximate the vector a nd thus use s it for inner pro duct similar it y approximation. The pro po sed M -selection and group M -selection s chemes ca n b e regarded as a spa r se co ding appro a ch with group spars ity [24] in which the co e fficie nts are divided into several g roups and the s parsity cons tr aints are impo sed in each group separa tely . In par ticular, the co efficients in o ur approa ch that can b e only v alued by 0 or 1 ar e divided into M groups and fo r ea ch gr oup the non-s parsity degree is 1. 4 Exp erimen ts W e conduct the inner pro duct similarity search ex pe r iments ov er four da ta sets: SIFT1 M [6], SIFT1 B [25], linea r mo dels (LM1 M ), and Netflix. The SIFT1 M dataset consists of 1 M 1 28-dimensio nal SIFT desc riptors as the database vec- tors and 10 K SIFT descriptors as the quer y vectors, which a re extra cted from the I NRIA holidays images [26]. The SIFT1 B datas e t c ontains 1 billion SIFT features as the database vectors, 1 00 M SIFT features as the lear n vectors and 10 K SIFT fea tur es a s the quer y vectors, which are ex tracted from approxi- mately 1 million ima ges. The LM1 M dataset consists of a round 1 M (890 , 9 12) linear models with the weight vector as the database vectors, which are lea r nt from 89 0 , 912 textual queries with the ima ges fr equently click ed in a co mmercial search engine for ea ch textual q uery as the training samples using the P AMIR approach [8] and 100 K 2 048-dimensio nal ima ge featur es as the quer ies. Net- 9 (1,32) (1,64) (1,128) (10,32) (10,64) (10,128) (100,32) (100,64)(100,128) 0 0.2 0.4 0.6 0.8 1 M−combination M−selection group M−selection Figure 2: Performance co mparison o f M - c o mbination, M -s election, and group M -s e lection. ( x, y ) = (#(NNs) , #(bits)) flix [27] co ntains a rating matr ix that 4 80 , 18 9 user s gav e to 17 , 7 70 movies and aims to predict use r r atings for films. It is shown that inner pro duct b etw ee n the ra ting vectors that tw o users gav e to 17 , 770 movies can b e us e d to ev aluate the similarity of user s ’ interest which can help reco mmend films to users. In our exp eriments, the dimension o f the rating vector is r educed to 51 2 with PCA. The descr iptions of the datasets a re summarized in T able 1. The search quality is mea sured with reca ll@ P , which is de fined as the frac- tion of relev ant instances that are retrieved among the firs t P positio ns. Rele- v ant insta nc e s in our ca se are R - nearest neighbors under the inner pr o duct sim- ilarity . This measure is equiv alent to the precisio n meas ur e if R = P , or when ev aluating the r eturned top R re sults after p erfor ming a subsequent rer anking scheme using the exact inner pr o duct similarity ov er the retrieved P items, fol- lowing a n a pproximate search step. The true neares t neighbo rs under the inner pro duct similarity ar e computed by comparing each quer y with all the databa se vectors using the r aw feature s. 4.1 Empirical A nalysis W e rep ort the p erformance of comp o s itional code using the prop osed three schemes: M - combination, M -selection, a nd g roup M - selection. The results of searching different num b er s of nea rest neighbors with different num b ers of bits at the same po sition 100 a r e shown in Fig ur e 2. This result and all the following results are obta ined b y fixing K = 256 (i.e., each source dictionary is encoded with a byte) a nd tuning M to v ar y the n umber of bits. W e can see tha t g roup M -s e lection p er fo rms the b est, which is consistent to the analysis that g r oup M -s e lection is the bes t on av erag e in vector approximation and inner pro duct approximation. In addition, from the results in Figur e 2, it can b e observed that mor e bits r esult in b etter p erformanc e when sear ching the same num b e r of nearest neighbors and the p erfor mance whe n searching mor e nea rest neighbors with the same nu mber of bits decre ases. 4.2 Comparison W e co mpare o ur appro a ch, comp ositio nal co de with gro up M -selection (a bbr e- viated as CC), with several compa ct co ding algo r ithms, including pro duct qua n- 10 100 200 300 400 500 600 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing 200 400 600 800 1000 1200 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing 500 1000 1500 2000 2500 3000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing 100 200 300 400 500 600 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing (a) 200 400 600 800 1000 1200 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing (b) 500 1000 1500 2000 2500 3000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing (c) Figure 3: Performa nc e compariso n ov er SIFT1 M with 64 (top) and 128 (b ot- tom) bits for searching (a) 1 -NN, (b) 10-NNs, and (c) 1 00-NNs tization (PQ) [6 ], the eigenv alue allo cation sc heme of optimized pro duct qua n- tization (abbrev iated as OPQ for convenience) [28], and Cartesian k -means [17] (CKM, equiv alent to optimized pr o duct quan tization [28]). All the results are achiev ed using the same v a riables of M and K (= 256) fro m the co mpared a lgo- rithms. W e a lso repo rt the r andom pro jection ba sed lo cality sensitive hashing (LSH) [5 ] that is designed for cosine similar ity s e arch for co mparison. The exp erimental results ov er SIFT1 M are shown in Fig ure 3 . One can see that our approa ch (CC) is sup er ior over o ther algo rithms. Recall@500 with 64 bits for 1-NN, 10- NN and 100 -NN is 20% lar ger than thos e from other a l- gorithms. One can also obser ve tha t the improv ement with 1 28 bits b ecomes smaller than with 64 bits. This is b ecaus e all the algorithms with mor e bits result in s maller approximation e r ror a nd thus the inner pro duct approximation quality b eco mes clo s er. Figure 4 shows the results ov er a very larg e dataset, SIFT1 B . W e can see that there are consistent improvemen ts a nd our appr oach achiev es ab ove 2 0 % improv ement for Recall@ 500 with 6 4 bits for 1- NN. In co m- parison with the hashing algo r ithm, our algo rithm is muc h b etter in the case of using the same co de length. Our exp eriment indica tes that the quer y time co st of our algor ithm is a b o ut 1 . 8 times o f that of the hashing a lgorithm. How ever, our algor ithm using the co de of a half leng th still o utpe r forms the hashing algo - rithm. F or ex ample, o ne ca n obs e rved fro m Figure 4(b) that o ur metho d using 64 bits achieves ab out 1 . 5 sear ch a ccuracy at p = 10 00 compared with ha shing using 1 28 bits a nd in this ca se the time c ost is ev en smaller than hashing. The exp er imental results over LM1 M are s hown in Fig ure 5. In this cas e , the inner pr o duct simila rity sear ch aims to find the linear mo dels which the query image fits the b es t, eq uiv alently meaning that the query image is most relev ant to the tex tua l queries ass o ciated with the linear mo dels . The retrieved linear mo dels can b e viewed as so ft attributes that can b e applied to image search ranker. F rom the respe c t of large scale classificatio n, our approach ca n 11 100 200 300 400 500 600 700 800 900 1000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing 200 400 600 800 1000 1200 1400 1600 1800 2000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing 100 200 300 400 500 600 700 800 900 1000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing (a) 200 400 600 800 1000 1200 1400 1600 1800 2000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing (b) 1000 2000 3000 4000 5000 6000 7000 8000 9000 10000 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 recall @p CC PQ OPQ CKM Hashing (c) Figure 4: Performance compar ison ov er SIFT1 B with 64 (top) and 128 (b ottom) bits for searching (a) 1 -NN, (b) 10-NNs, and (c) 1 00-NNs provide fast prediction for a larg e num be r of catego ries, which is a flat approa ch rather than hierarchical lab el trees rece nt ly studied (e.g. [29]). W e pres ent the per formance to s how how the approximate sea rch algorithms are c lo se to the exact sear ch algorithm. F rom the r esults shown in Figure 5, we can see that the re c all improv ement @300 with 64 bits for 1 -NN is ab ov e 3% ov er the second bes t, 14% ov er the other s , and our appr o ach p erforms the b est. W e also show the p e rformance ov er the Netflix da taset in Figure 6. The task in this exp eriment is that we re tr ieves the similar user s by viewing the r ating vector as the feature of one user, which can b e applied to mine the films that the que r y user might b e int eres ted from the films rated by the similar users. One can se e that o ur approach p erfo r ms muc h b etter with 32 bits, showing the adv antage of approa ch under very small co des, and the improv ement with 64 bits is a little sma ll, which might come from that the c o de of 6 4 bits is a lready able to well characterize the differences. One p oint observed from all the four compariso ns is that o ur approach consistently p erfor ms the b est while no other algorithm a lwa ys p erforms the seco nd b est. Last, we s how the a dv antage in the p otential applica tion of lea rning lar ge scale image classifiers, b eyond similarity search. Ima ge cla ssification with a large scale is sho wn to a chiev e state-of-the- a rt p er formance with the use of high-dimensional s ignatures [3 0, 31]. [30, 31] show that da ta co mpression is necessary to suppo rt efficient in-RAM tr aining with stochastic gra dient decent (SGD) as the raw training features ar e to o la r ge to b e loade d into the memory in normal P Cs. The training pr o cess [30, 3 1] nee ds to decompre ss the compact co de and pass the decompressed version to the SGD iteratio n. It is exp ected that the decompressed version is a s clo se as the raw feature a s p o s sible. Thus, we first use the clos e ne s s, i.e., the av erage feature appr oximation err or (E i [ k x i − ¯ x i k 2 2 ] with ¯ x b eing the deco mpr essed vector), as a criterion. The per formance is rep orted 12 100 200 300 400 500 600 700 800 900 1000 0.2 0.3 0.4 0.5 0.6 0.7 0.8 recall @p CC PQ OPQ CKM 200 400 600 800 1000 1200 1400 1600 1800 2000 0.2 0.3 0.4 0.5 0.6 0.7 0.8 recall @p CC PQ OPQ CKM 200 400 600 800 1000 1200 1400 1600 1800 2000 0.2 0.3 0.4 0.5 0.6 0.7 0.8 recall @p CC PQ OPQ CKM 100 200 300 400 500 600 700 800 900 1000 0.3 0.4 0.5 0.6 0.7 0.8 0.9 recall @p CC PQ OPQ CKM (a) 200 400 600 800 1000 1200 1400 1600 1800 2000 0.3 0.4 0.5 0.6 0.7 0.8 0.9 recall @p CC PQ OPQ CKM (b) 200 400 600 800 1000 1200 1400 1600 1800 2000 0.3 0.4 0.5 0.6 0.7 0.8 0.9 recall @p CC PQ OPQ CKM (c) Figure 5: Performance compar is on over LM1 M with 64 (top) a nd 128 (b ottom) bits for searching (a) 1 , (b) 10, and (c) 100 most rele v ant linear mo dels 500 1000 1500 2000 2500 0.4 0.5 0.6 0.7 0.8 0.9 recall @p CC PQ OPQ CKM (a) 500 1000 1500 2000 2500 0.4 0.5 0.6 0.7 0.8 0.9 recall @p CC PQ OPQ CKM (b) 100 200 300 400 500 600 700 800 900 1000 0.4 0.5 0.6 0.7 0.8 0.9 recall @p CC PQ OPQ CKM (c) 100 200 300 400 500 600 700 800 900 1000 0.4 0.5 0.6 0.7 0.8 0.9 recall @p CC PQ OPQ CKM (d) Figure 6 : Performance comparis on over Netflix with 3 2 ((a) and (b)) and 64 ((c) and (d)) bits for searching top 50 ((a) and (c)) and 100 ((b) and (d)) users with similar interest ov e r the 409 6-dimensiona l fisher vectors [3 1] extr acted from the INRIA ho lidays dataset [26] that contains 50 0 quer y and 9 91 corres p o nding re lev ant images , and the UK b e nch Recognition Benchmark images [3 2] that contains 10 200 ima g es. The conclusio ns fro m such tw o datasets ho ld for larg er s c ale datasets. F rom the results shown in T ables 2 and 3, one c an s e e that o ur appro ach can achieve the bes t vector approximation. One po pular ca tegory of class ific a tion algor ithms in la rge-sca le imag e class i- fication is linear SVM or its v ar iants, e.g., used in [3 0, 31], in which the training equiv alently dep ends on the inner pro duct a pproximation as the dual fo r mula- tion is bas ed on the kernel matrix formed by the inner pro ducts of the train- ing features. So we a lso compar e the inner pr o duct a ppr oximation ac curacy (E ij [( x T i x j − ¯ x T i ¯ x j ) 2 ]) a s shown in T ables 2 and 3 . Here the inner pro duct is ev aluated in a s ymmetric way as the training algorithm can only use the decom- pressed features. Note that the computation cost o f symmetric inner pr o duct, O ( M 2 ), do es not matter b e c ause the SGD algor ithm do es not really compute the inner pro duct. In addition, we also show that such a pproximate (symmetric) inner pro duct similarities is a lso sup erior in pres erving the s emantic similar - 13 T a ble 2: Performance compar ison in the application o f data compre ssion using short co des ov er the holidays datas e t. V AE = vector approximate erro r. IP AE = inner pro duct approximation erro r 32 bits 64 bits V AE IP AE MAP V AE IP AE MAP PQ 0 . 4326 0 . 0057 0 . 4179 0 . 3775 0 . 0044 0 . 4740 OPQ 0 . 4014 0 . 0049 0 . 4339 0 . 3221 0 . 0030 0 . 4787 CKM 0 . 3081 0 . 0054 0 . 4843 0 . 2279 0 . 0039 0 . 5251 CC 0 . 1462 0 . 0020 0 . 5245 0 . 0139 . 00002 0 . 6360 it y by ev aluating the search p erforma nc e in terms of mea n av erag e precision (MAP) [26] for the holiday da taset a nd score [32] for the UKBench dataset. T a ble 3: Performance compar ison in the application o f data compre ssion using short co des ov er the UKBench datas et 32 bits 64 bits V AE IP AE score V AE IP AE score PQ 0 . 4629 0 . 0075 1 . 871 0 . 4120 0 . 0054 2 . 180 OPQ 0 . 3982 0 . 0050 1 . 790 0 . 3232 0 . 0025 2 . 193 CKM 0 . 3767 0 . 0059 2 . 064 0 . 3079 0 . 0037 2 . 382 CC 0 . 3076 0 . 0038 2 . 152 0 . 2261 0 . 0021 2 . 551 5 Conclusion This pap er studies the approximate inner pr o duct simila rity search pr oblem and introduces a compa ct co de appro ach, comp ositio nal co de using group M - selection. V ector a pproximation of our approa ch is more accura te, witho ut increasing the co de leng th. The similarity search is efficient as ev alua ting the approximate inner pro duct b etw een a query and a co mpa ct co de is computa- tionally cheap. In the future, we will gener alize our appr oach for sear ch with Euclidean distance and o ther s imilarity measures. 6 App endix: Pro of W e rewrite P rop erty 5 presented in the ma in pap er in the following and then give the pro of 2 . Prop ert y 5 . Given a data ve ctor p and a query ve ctor q , if the distanc e b etwe en p and its appr oximation ¯ p is not lar ger than r , k p − ¯ p k 2 6 r , then t he absolute differ enc e b etwe en the true inner pr o du ct and the appr oximate inner pr o duct is 2 There i s a similar theorem (Theorem 3 . 1) in [14] showing the maximum v alue of the appro ximate inner pr oduct i n the same condition. Differently , we provide the upper- b ound of the approximation error (including b oth maximum and mini mum v alues of the approximate inner pr oduct) and pr esen t a m ore succinct proof . 14 upp er-b ounde d: | < q , p > − < q , ¯ p > | 6 r k q k 2 . (5) Pr o of. The pro of is simple and given as follows. Let ¯ p = p + δ . By definition, we hav e k δ k 2 ≤ r . Loo k a t the absolute v a lue of the inner pro duct appr oximation error , k < q , ¯ p > − < q , p > k (6) = k < q , p + δ > − < q , p > k (7) = k ( < q , p > + < q , δ > ) − < q , p > k (by the distributive pr op erty) (8) = k < q , δ > k (9) ≤ k δ k 2 k q k 2 (10) ≤ r k q k 2 . (11) Thu s, the approximation err or is upp er-b ounded by r k q k 2 . 7 App endix: Analysis 7.1 Connection t o Pro duct Quan tization and Cartesian K -mea ns The idea of pro duct quantization [6 ] is to decomp ose the space into a Cartesian pro duct of M low dimensio nal subspaces and to quantize e ach subspace sepa- rately . A vector x is then dec o mp osed int o M subv ector s , x 1 , · · · , x M . Let the quantization dictionar ies over the M subspaces b e C 1 , C 2 , · · · , C M with C m being a set o f centers { c m 1 , · · · , c mK } . A vector x is r epresented b y the concatena - tion of M centers, [ c T 1 k ∗ 1 c T 2 k ∗ 2 · · · c T mk ∗ m · · · c T M k ∗ M ] T each of which c mk ∗ m is the o ne nearest to x m in the m -th qua ntization dictionary , res pe ctively . Rewrite each cen ter c mk as a d -dimensiona l vector ˜ c mk so that ˜ c mk = [ 0 T , · · · , ( c mk ) T , · · · , 0 T ] T , i.e., a ll entries a re zero exc e pt that the par t cor - resp onding to the m th subspace is equal to c mk . The approximation o f a vector x using the concatena tio n ¯ x = [ c T 1 k ∗ 1 c T 2 k ∗ 2 · · · c T M k ∗ M ] T is equiv alent to the com- po sition ¯ x = P M m =1 ˜ c mk ∗ m . Cartesian k -means [17] extends the subspace decomp o sition by p erfor ming a rotation R ( R T x ) and then the pro duct quantization in the rotated space , wher e the r otation and the sub quantizers ar e jointly optimized. Similar to pro duct quantization, the vector approximation in Car tesian k -means is equiv a le nt to ¯ x = P M m =1 R ˜ c mk ∗ m = P M m =1 ˜ c ′ mk m ∗ . F r om the ab ov e analysis, the vector approximation appr oach using pro duct quantization and Cartesian k - means can b e viewed as a constrained version of our a pproach, e a ch sub quantizer c o rresp o nds to a source dictiona ry in o ur approach and ea ch source dictiona ry lies in a different subspace with the same dimension in the case that each subspace is full-r anked. If so me subspaces are not full-ra nked, the equiv alence still holds. 15 7.2 Relation to Or der Perm utation Order per mutation [23] is an index alg orithm for approximate neares t neig hbo r search. It a ims to predict clo seness b etw een data vectors accor ding to how they order their distanc e s towards a distinguished set of anchor vectors (such a s the k -means cent ers C ). Each da ta v ector sorts the anchor ob jects from closest to farthest to it, i.e., a p ermutation of a nchor ob jects, { c i ∗ 1 , c i ∗ 2 , · · · , c i ∗ t } ( t 6 K ), and the simila rity b etw een or ders is used as a predictor of the closeness b etw e e n the corres po nding element s. In contrast, our approa ch finds a pa rtial p ermutation of the source dictiona ry and uses their c omp osition (rather than the or der) to appr oximate the data vector, yielding a compact co de repre s entation. In the query stag e, the distance of the query to the approximated data vector, in a fast wa y by the efficient ta ble- lo okup and a ddition op eratio ns, is computed to approximate the clos eness. 7.3 Connection to Sparse Co ding The aim of sparse co ding is to find a set of K (over-complete) basis vectors { φ k } such that a data vector x a s a linear co m bination o f these basis vectors: x = P K k =1 α k φ k , where ther e ar e few no n- zero co efficient s in the co efficient vector α = [ α 1 α 2 · · · α K ] T , i.e., k α k 0 is sma ll. The pr op osed M -combination scheme can b e viewed as a s p ecia l spa rse co ding approa ch in which the co efficients can be only v a lued as 0 or 1 and the spars ity is fixed, k α k 0 = M . Co ding with gro up s parsity [24] is an extens io n of s pa rse co ding , in which the co efficients { φ k } ar e divided int o several gro ups and the sparsity constra int s are imp osed in each group sepa r ately . The prop osed M -selectio n a nd gro up M - selection sch emes can be rega rded as a specia l coding appr oach with gro up sparsity , where the co efficients that can be only v alued by 0 o r 1 ar e divided int o M gr oups and for ea ch g roup the non- s parsity degree is 1 . 7.4 Time Complexity In the main pap er, we hav e shown that the time complexity o f dictionary up- dating is O ( N M d + d ( M K ) 2 + N M 2 + ( M K ) 3 ) and the time complexity of co de computation (g roup M -selection up dating) is O ( N M 2 K d ). The following gives deta ile d analysis on the time complexity . The dictionar y is up dated in our algo rithm by computing the clo sed-form solution: D = XB T ( BB T ) − 1 . The computation consists of (1) the matrix m ultiplication op era tio n: XB T (= E ), (2) the matrix multiplication op er ation: BB T (= Q ), (3) the inv e r se op eration: Q − 1 (= R ), and (4 ) the multiplication op eration: ER . Note tha t X is a matr ix of d × N , B = [ b 1 · · · b N ] and each b n is a M K -dimensional vector with only M entries b eing 1 and all the others being 0. It can b e easily shown that E is of size d × M K , Q is of size M K × M K , and R is o f size M K × M K . Step (1) takes O ( N M d ) due to the sparse matrix B . Step (2) can be transformed to BB T = P N n =1 b n b T n . Because b n is a spars e vector, b n b T n takes O ( M 2 ) instead o f O ( M 2 K 2 ). Step (3 ) takes O (( M K ) 3 ) 16 T a ble 4 : The av era g e vector a pproximation error for the data base vectors, and the average inner pro duct approximation erro r b etw een the q uery vector and the nearest 10 0 database vectors using 64 bits. V AE = vector approximate er ror. IP AE = inner pr o duct approximation err or. SIFT1M SIFT1B Netflix LinerMo dels V AE (10 4 ) IP AE (10 2 ) V AE (10 4 ) IP AE (10 3 ) V AE (10 2 ) IP AE V AE (10 − 3 ) IP AE (10 − 3 ) PQ 2 . 319 8 . 915 2 . 540 1 . 707 8 . 588 166 . 03 4 . 99 9 4 . 755 OPQ 2 . 842 8 . 238 3 . 282 2 . 154 7 . 091 52 . 58 4 . 364 1 . 957 CKM 2 . 134 6 . 835 2 . 346 1 . 318 6 . 273 68 . 78 4 . 278 2 . 312 CC 1 . 626 2 . 148 1 . 773 0 . 460 6 . 014 48 . 31 3 . 797 1 . 724 T a ble 5 : The av era g e vector a pproximation error for the data base vectors, and the av erag e inner pr o duct appr oximation er ror b etw een the query v ector a nd the nearest 1 00 database vectors using 1 28 bits. SIFT1M SIFT1B Netflix LinerMo dels V AE (10 4 ) IP AE (10 2 ) V AE (10 4 ) IP AE (10 2 ) V AE (10 2 ) IP AE V AE (10 − 3 ) IP AE (10 − 3 ) PQ 1 . 038 3 . 191 1 . 070 5 . 075 7 . 945 157 . 02 3 . 235 2 . 956 OPQ 1 . 468 2 . 398 1 . 620 5 . 610 6 . 031 60 . 24 2 . 760 0 . 984 CKM 0 . 992 2 . 768 1 . 047 4 . 269 4 . 908 49 . 25 2 . 775 1 . 336 CC 0 . 797 0 . 868 0 . 850 1 . 252 4 . 707 75 . 23 2 . 534 0 . 926 , and step (4) takes O ( d ( M K ) 2 ). In summa r y , the whole time co mplexity is O ( N M d + d ( M K ) 2 + N M 2 + ( M K ) 3 ). The co de (g r oup M -selection) is upda ted by optimizing b n separately . Ea ch b n is computed as min b n = k x n − Db n k 2 2 . W e s olve it by a greedy algorithm, per forming M 1-selectio n optimizations ov er the M s ource dictiona ries in the bes t-first manner . The m -th o ptimization inv olves selecting the b est 1 -selection ov e r ( M − m − 1) source dictionarie s , each of which contains K d -dimensional exemplar vectors. It co sts O (( M − m − 1)( K d )) to s elect the b est e xemplar vector. There ar e M optimizatio ns to b e p er formed, thus the co st o f up dating b n is P M m =1 O (( M − m − 1)( K d )) = O ( M 2 K d ). In summary , the time co mplexity of up dating a ll b n is O ( N M 2 K d ). 8 App endix: More Exp erimen tal Results In the ma in pap er, we show the inner pro duct similarity search p er fo rmance over four da tasets. Here we rep ort the average approximation err o r using the com- po sition of the selected vectors a s the vector approximation over the databa se vectors, and the average inner pro duction a pproximation err or using the a pprox- imated vector b etw een the query vector and the near e st 100 database vector a s shown in T ables 4 and 5. One c an observe that the average vector appr oxima- tion er ror of our approa ch is the smallest a nd the inner pro duct approximation error is a ls o the smallest. This gives a nother evidence that o ur a ppr oach can achiev e the b est similarity sea rch p erfor mance. 17 9 App endix: F uture W ork Adaptation to cosine si milarity searc h . Inner pro duct is equiv ale nt to co- sine similarity in the case that the databa se vectors are of the same L 2 norm. Our a pproach finds the optimal comp osition, how ever, without making the com- po sition vector keep the same nor m. In the future, we will study the wa y of approximating the vector with maintaining the L 2 norm, e.g. ex tending spher- ical k -means clustering. Extension to sim ilarity searc h under E uclidean distance. The exp eri- men ts show that using the co mpact co des learnt from our appr oach for Euclidean distance ba sed simila rity search achiev es b etter sea rch a ccuracy than pro duct quantization and Ca rtesian k -means. Because the distr ibutive prop er ty with resp ect to the Euclidean dis ta nce op e r ation ov er the addition op era tion do es not hold ( d 2 ( q , P M m =1 c mk m ) 6 = P M m =1 d 2 ( q , c mk m )), the g eneral time cost o f ev aluating the a pproximate E uclidean distance using the co des pro duced fr om our a pproach is Θ( M 2 ), which is a little lar ge. If the M sour ce dictiona ries (i.e., the M subspaces spanned by the M source dictionaries) a re m utually orthog- onal ( < c si , c r j > = 0 , ∀ s 6 = r, ∀ i, j .), the time cost is re duce d to Θ( M ) with the constant co efficient 2 b ecause k q − P M m =1 c mk m ) k 2 2 = k q k 2 2 + P M m =1 c 2 mk m − 2 × q T ( P M m =1 c mk m ). How ever, we hav e the following equa tio n: k q − M X m =1 c mk m k 2 2 (12) = ( q − M X m =1 c mk m ) T ( q − M X m =1 c mk m ) (13) (fr om ortho gonality c onst ra ints b etwe en the items of differ ent dictionaries) (14) = q T q − 2 q T ( M X m =1 c mk m ) + M X m =1 c T mk m c mk m (15) = q T q − 2 q T ( M X m =1 c mk m ) + M X m =1 c T mk m c mk m + ( M − 1) q T q − ( M − 1) q T q (16) = M X m =1 ( q T q − 2 q T c mk m + c T mk m c mk m ) − ( M − 1) q T q (17) = M X m =1 k q − c mk m k 2 2 − ( M − 1) k q k 2 2 . (18) The a bove eq ua tions show that, g iven a quer y , it is enough to compute the first part, P M m =1 k q − c mk m k 2 2 , to find the near est neighbors as the s econd part, ( M − 1) k q k 2 2 , is the sa me for all the database vectors. Thus, it can b e c o ncluded tha t 18 ( M − 1) addition op era tions a re enough, if we hav e pre computed the distance table fro m the query to dictionary items as PQ a nd Car tes ian k -means do . References [1] Samet, H.: F oundations of multidimensional and metric data structures. Elsevier, Amsterdam ( 2006) [2] Shakhn aro vich, G., Darrell, T., Indyk , P .: Nearest-Neighbor Metho ds in Learning and V ision: Theory and Practice. The MIT press (2006) [3] Bentley , J.L.: Multidimensional binary searc h trees u sed for associative searching. Comm un. ACM 18 (9) (1975) 509–517 [4] Muja, M., Low e, D.G.: F ast approximate nearest neighbors with automatic algo- rithm confi guration. In : VISS APP (1). (2009) 331–340 [5] Datar, M., Immorlica, N ., Ind y k, P ., Mirrokni, V.S.: Lo cality-sensitiv e hash- ing scheme based on p- stable distributions. In: Symp osium on Computational Geometry . (2004) 253–262 [6] J´ egou, H., Douze, M., Schmid, C.: Produ ct quantiza tion for nearest n eigh b or searc h. IEEE T rans. Pattern An al. Mach. Intell. 33 (1) (2011) 117–128 [7] Andoni, A.: Nearest Neighbor Search: the Old, the New, and the I mp ossible. PhD thesis, MIT (2009) [8] Grangier, D., Bengio, S.: A discriminative kernel-based approach to rank images from text queries. IEEE T rans. P attern Anal. Mach. Intell. 30 (8) (2008) 1371– 1384 [9] Dean, T., Ruzon, M., Segal, M., S hlens, J., Vijay anarasimhan, S., Y agnik, J.: F ast, accurate detection of 100,000 ob ject classes on a single machine. In: CVPR. (2013) 1814–182 1 [10] Koren, Y., Bell, R.M., V olinsky , C.: Matrix factorization tec hniqu es for recom- mender systems. IEEE Computer 42 (8) (2009) 30–37 [11] Ba yardo, R .J., Ma, Y., S rik ant, R .: Scaling up all pairs similarit y searc h. In: WWW. (2007) 131–140 [12] Deerw ester, S.C., Dumais, S.T., Landauer, T.K., F urnas, G.W., Harshman, R.A.: Indexing by latent semantic analysis. JASIS 41 (6) (1990) 391–407 [13] Grauman, K., Darrell, T.: F ast contour matc hing using appro ximate earth mo ver’s distance. In: CVPR (1). (2004) 220–227 [14] Ram, P ., Gray , A.G.: Maximum inner-pro duct search using cone trees. I n: KD D . (2012) 931–939 [15] W eiss, Y., T orralba, A.B., F ergus, R .: Sp ectral h ashing. In: NIPS. (2008) 1753– 1760 [16] Gong, Y., Lazebn ik, S .: Iterative quantization: A pro crustean approach to learn- ing binary cod es. In: CV PR . (2011) 817–824 [17] Norouzi, M., Fleet, D.J.: Cartesian k -means. In: CVPR. (2013) 3017–3024 [18] Jain, P ., V ija yanarasi mhan, S ., Grauman, K.: Hashing hyp erplane q ueries to near p oints with ap p lications to large-scale active learning. In : NIPS. (2010) 928–936 19 [19] Liu, W., W ang, J., Mu, Y., Kumar, S., Chang, S.F.: Compact hyperplane hashing with bilinear functions. In : ICML. (2012) [20] Mu, Y., W right, J., Chang, S.F.: Accelerated large scale optimization by con- comitan t hashing. In: ECCV (1). (2012) 414–427 [21] Basri, R., Hassner, T., Zelnik-Manor, L.: Approximate n earest subspace searc h. IEEE T rans. Pattern An al. Mach. I ntell. 33 (2) (2011) 266–278 [22] Mairal, J., Bach, F., Ponce, J., S apiro, G.: Online dictionary learning for sp arse codin g. In: ICML. (2009) 87 [23] Ch´ avez, E., Figueroa, K., Nav arro, G.: Effective proximit y retriev al by ordering p ermutations. IEEE T rans. Pattern An al. Mach. Intell. 30 (9) ( 2008) 1647–165 8 [24] Y uan, M., Lin, Y.: Model selection and estimation in regression with group ed v ariables. Journal of t he R oy al St atistical S ociety , Series B 68 (2006) 49–67 [25] Jegou, H., T a venard, R., Douze, M., Amsaleg, L.: Searching in one billion vectors: Re-rank with source coding. In : ICASSP . (2011) 861–864 [26] Jegou, H., Douze, M., Schmid, C.: Hamming embedding and weak geometric consistency for large scale image searc h. In: ECCV (1). (2008) 304–317 [27] Bennett, J., Lann ing, S.: The netflix p rize. In: KDD Cup and W orkshop. (2007) [28] Ge, T., He, K., Ke, Q., Sun, J.: Optimized pro duct qu antiza tion for approximate nearest neighbor searc h. In: CVPR. (2013) 2946–2953 [29] Deng, J., Sath eesh, S ., Berg, A .C., Li, F.F.: F ast and balanced: Efficient lab el tree learning for large scale ob ject recognition. In: NIPS. (2011) 567–575 [30] Perr onnin, F., Ak ata, Z., Harchaoui, Z., S chmid, C.: T o w ards goo d practice in large-scale learning for image classification. In: CVPR. (2012) 3482–3489 [31] S´ anchez, J., P erronnin, F.: High-dimensional signature compression for large- scale image classification. In: CVPR. (2011) 1665–1672 [32] Nist´ er, D., Stew´ enius, H .: Scalable recognition with a vocabulary tree. In: CVPR (2). (2006) 2161–216 8 20
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment