Pythagoras at the Bat
The Pythagorean formula is one of the most popular ways to measure the true ability of a team. It is very easy to use, estimating a team's winning percentage from the runs they score and allow. This data is readily available on standings pages; no co…
Authors: Steven J. Miller, Taylor Corcoran, Jennifer Gossels
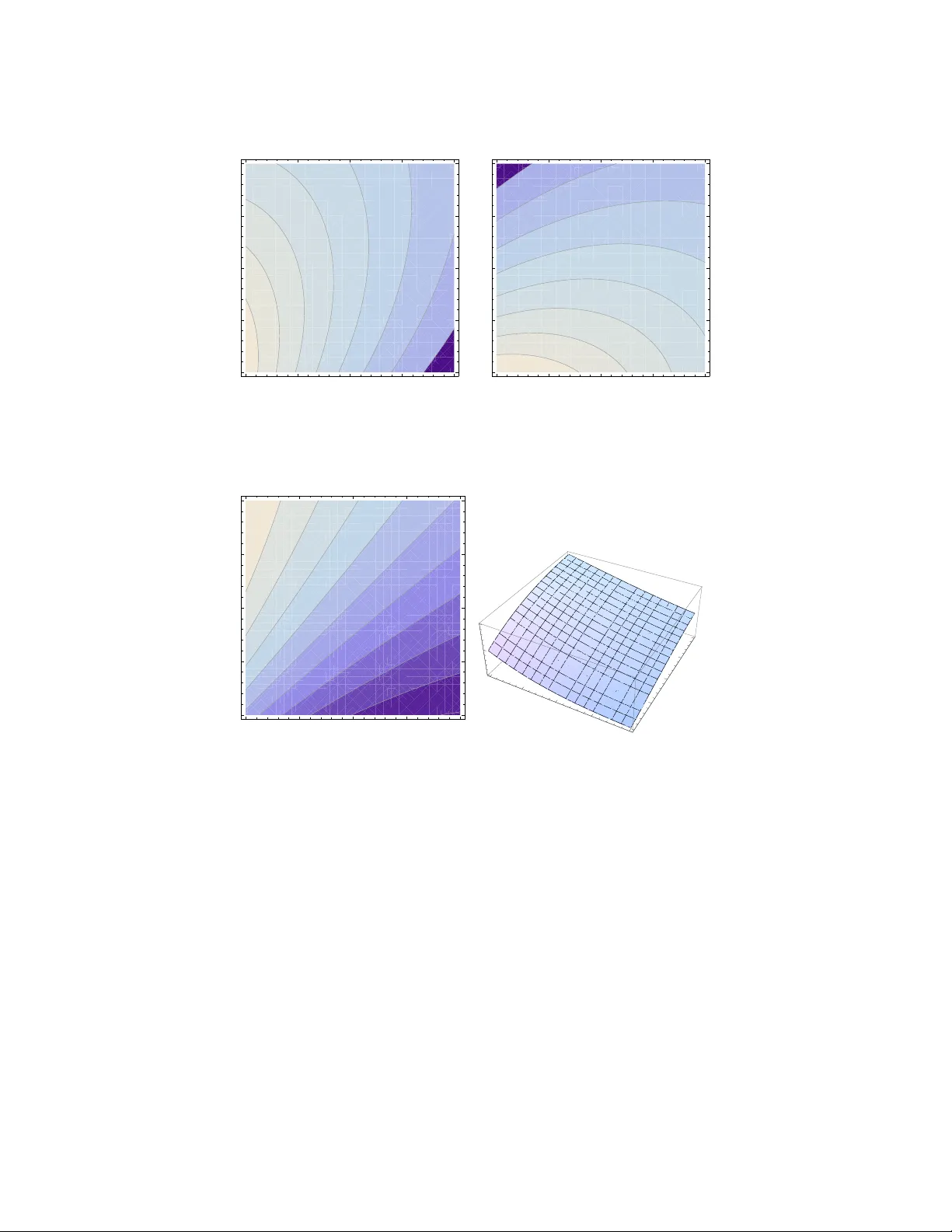
Pythagora s at the Bat Ste ven J Miller , T aylor Corcora n, J ennifer Gossels, V ictor Luo and Jaclyn Porfilio The Pythag orean formula is on e of the mo st popular ways to m easure the true abil- ity of a team. It is very easy to use, estimatin g a team’ s winning percen tage fr om the runs they s core and allow . This data is readily a vailable on standings pages; no computation ally in tensiv e simulations are nee ded. Normally ac curate to within a fe w games per season, it allows teams to determine h ow much a r un is worth in different situations. This determinatio n helps s olve some of the most importan t eco- nomic decisions a team faces: How much i s a player worth, which players should be pursued , and how much should th ey be offered. W e discuss th e formula and these applications in detail, and provide a theoretical justification, both for th e formula as well a s simpler linear estimator s of a team’ s winning percenta ge. T he calc ulations and modeling are discussed in detail, and when possible multiple proo fs are given. W e analyze the 20 12 season in detail, and see that th e data for that and othe r recent years su pport o ur mo deling co njectures. W e co nclude with a discu ssion of work in progr ess to generalize the formula and increase i ts pr edictive power withou t ne eding expensiv e simu lations, thoug h a t the cost of requiring play-by-p lay data . Ste ven J Miller W i lliams Colle ge, W il liamstown , MA 01267, e-mail: sjm1@willi ams.edu , S teven.Miller.MC.96@aya.yale.edu T aylor Corcoran The Uni vers ity of Arizona, T ucson, AZ 85721 Jennifer Gossels Princeton Univ ersity , Princeton, N J 08544 V ictor Luo W i lliams College, W illiamstown, MA 01 267 Jaclyn Porfilio W i lliams College, W illiamstown, MA 01 267 1 2 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio 1 Intr o duction In the classic movie Other P eople’s Money , New En gland W ir e and Cab le is a firm whose parts are worth mor e than th e wh ole. Danny Devito’ s character, Larry the Liquidato r , recog nizes this and tries to take over the c ompany , with th e in tent on breaking it up an d selling it piecemeal. Gregor y Peck p lays Jorgy , the owner of th e firm, who giv es an impassion ed defen se to the stockhold ers at a proxy battle a bout traditional values and the gold en d ays ah ead. In th e climatic conclusion, Larr y the Liquidato r resp onds to Jorgy ’ s speech wh ich painted him a hear tless predato r wh o builds nothing and cares for no one but himself. Larry says Who cares? I’ ll tell you. Me. I’m not your best friend. I’m your only friend. I don’t m ake anything? I’m making you mone y . And lest we forget, that’ s the only reason an y of you became stockholders i n the first place. Y ou want to mak e money! Y ou don’t care if they manuf acture wire and cable, fried chicken, or gro w tangerines! Y ou want to make money! I’m the only friend you’ ve got. I’m making you money . While his speech is significantly long er tha n this snippet, the scen e in g eneral an d the lines above in par ticular h ighlight one of the most impo rtant pr oblems in base- ball, one which is easily fo rgotten. In the twenty -first centur y massi ve computatio n is po ssible. Data is available in gr eater quantities than ever before; it can be ana- lyzed, manipulated, a nd analyzed again thousands of times a second. W e can search for small conn ections b etween unlikely e vents. This is especially true in baseb all, as there has b een an explosion of statistics th at are studied an d quo ted, both among the experts an d practitioners as well as th e e very day fan. The traditional metrics are falling out of fa vor , being replaced by a veritable alp habet soup of acronyms. Ther e are so many statistics now , and so many p ossibilities to analyze, th at go od m etrics are drowned o ut in poor ones. W e need to determine which ones matter most. In this chap ter we assume a team’ s goal is to win as many games as possible giv en a specified amoun t of money to spend on players an d re lated items. This is a reasonable a ssumption fr om the point of vie w of general man agers, thou gh it may not be the owner’ s goal (which could range fr om winning at all costs to crea ting t he most profitable team). In this case, De vito ’ s character has very valuable advice: The goal is to win games. W e d on’t care if it’ s by win ning shoot- outs 1 2-10 in thirtee n innings, or by eking out a win in a 1-0 pitcher’ s duel. W e want to win games. In this lig ht, we see that saber metrics is a d ear friend . Wh ile ther e are many items we could study , we focus on the v alue of a r un (both a run created and a r un sa ved) . W e h av e a two-stage pro cess. W e need to d etermine how much e ach event is worth in terms of creating a run, and then we need to extract how much a run is worth. Obviously these are not constan t v alues; a run is worth far more in a 2-1 gam e than in a 10-1 match. W e focus belo w entirely on the v alue of a run. W e thus completely ignore the first item above, namely how much each e vent contributes to scorin g. Our metric for deter mining th e worth o f a ru n is Bill Jam es’ Pythagor ean W on- Loss fo rmula: If a team scor es RS r uns while allowing RA, then their winning per- centage is appro ximately RS γ RS γ + RA γ . Here γ is an exponen t whose value can vary from sport to sport (as well as from era to era with in that sport). James initially too k γ Pythagora s at the Bat 3 to be 2, which is the source of the name as the formula is reminiscent of the sum of square s fro m the Pythag orean th eorem. Note that instead of u sing th e total runs scor ed and allowed we could use the averag e number per g ame, as such a chan ge r escales th e numerator and the deno minator by the s ame amoun t. In this chapter we discuss p revious w ork p roviding a theoretical ju stification for this for mula, talk a bout future gen eralizations, an d d escribe its imp lications in one of the most importan t econ omics problems confro nted by a baseball team: How much is a gi ven player worth? While much of this chapter has appeared in jou rnals, we h ope that b y co mbining e verything in o ne place an d do ing the ca lculations in full d etail and in as elementary a way as possible that we will increase the visibil- ity o f this method, and p rovide suppo rt for the role of math ematical mo deling in sabermetrics. Before d elving in to the deri vation, it’ s worth rem arking on why such a deriv a tion is importan t, and what it can teach u s. In An Enqu iry Concerning Human Under- standing (1772 ), Da vid Hume wrote: The contrary of ev ery matt er of fact is still possible, because it can ne ver imply a contra- diction, and is conceiv ed by the mind wi th the same facility and distinctness, as i f ever so confor mable t o reality . That the sun wi ll not rise tomorro w is no less i ntelligible a proposi- tion, and impli es no more contradiction, than t he affi rmation, that i t will rise. W e should in v ain, therefore, attempt to demonstrate its fa lsehood. W ere it d emonstrati vely fa lse, it would imply a contradiction, and could ne ver be distinctly conceiv ed by the mind. Hume’ s warning complements o ur earlier quote, and can be summ arized by say- ing that ju st because the sun rose y esterday we cannot conclude that it will rise today . Sabermetrician s f requen tly find quantities that app ear to be we ll correlated with desirable outco mes; h owe ver, there is a real dan ger that the corre lation will not per sist in the futur e as past p erform ance is no gu arantee of futur e perfo rmance. (This lesson has been painfu lly learned by many chartists o n W all Street. ) Thus we must be careful in makin g decisions based o n regressions and o ther calculation s. If we find a relationship, we want some r eason to believe it w ill continue to hold. W e are th erefore led to creating m athematical models with reaso nable assump- tions; thus the po int of this chapter is to develop predictiv e mathematical models to compleme nt inferen tial techn iques. The advantage o f this ap proach is that we now have a reason to believ e the observed pa ttern will continu e, as we can now point to an explanation , a reason. W e will find such a model fo r b aseball, which has the Pythagor ean formula, initially a n umerical o bservation by James th at seemed to d o a good job year after year, as a conseq uence. The Pythagorean formula has a rich history; a lmost any saber metrics book refer- ences it at some point. It is necessary to limit our discussion to just so me o f its aspects. As the economic co nsequence s to a team from better p redictive p ower are clear, we conce ntrate on the mathematical issues. T hus explainin g how math - ematical mo dels can lead to closed-f orm expressions, which can solve re al world problem s, is ou r main goal. W e begin in § 2 with some g eneral comments on the statistic. W e describe a reason able math ematical model in the next section, show the Pythagor ean for mula is a consequen ce, and then give a mathem atical proof in § 4. I n § 5 we examine som e con sequences, in pa rticular how much a run created or 4 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio sa ved is worth at different production le vels, and in § 6 we analyze data f rom se v- eral seasons to s ee ho w well o ur model and the formula d o. Next we examine linear predictor s fo r a team ’ s winnin g percentage , an d show how they fo llow fro m lin- earizing the Pythag orean for mula. W e end b y d iscussing current, ong oing research into generalizin g th e Pythagorea n f ormula. 2 General Comments Before discussing why th e Pythag orean fo rmula should be true , it’ s w orth comm ent- ing on the form it has, both in its present state and its debut ba ck in Bill James’ 1981 Baseball Abstract [6]. Remember it says that a team’ s winning perce ntage sh ould be RS γ RS γ + RA γ , with γ initially taken as 2 but now typically taken to b e arou nd 1.83. One is struck by how easy the formula is to state and to use, espec ially in the origina l incarnation . All we need is to know the a vera ge number o f runs scor ed and allo wed, and the ratio can be found on a simple calculator . Of course, back in th e ’80 s this wou ldn’t be entirely tr ue for someo ne watching at home if γ were not 2, though t he additional alg ebra is slight and not even noticeab le on modern calcu lators, compute rs and even pho nes. One of the great values of this statistic is just how easy it is to calculate, which is on e of the r easons f or its popu- larity . Y ou can ea sily appro ximate how much better you would do if you scored 1 0 more runs, or allowed 10 fe wer, which we do later in Figure 2 . W e can do this as we have a simple, closed form expr e ssion for our winning percentage in ter ms of just three parameter s: a verage runs scored, av e rage runs allo wed , and an exponent γ . This is very different than the mu ltitude of Monte Carlo simulations which tr y to predict a team’ s reco rd. These req uire detailed statistics on batters and pitchers and their interactions. Dependin g on how good and inv o lved th e algorithm is, we may need everything fro m how many pitch es a batter sees per appearan ce to the likelihood of a r unner advancing fro m first to third on a single hit to right field. While this data is available, it takes time to simulate tho usands of games. Fu rther, ev ery small chang e in a team r equires an entirely new batch of simulations. Wit h the Pythagor ean for mula, we can immediately determine the impact of a player if we have a g ood measure of how m any runs they will contribute or save. Of course, as with most things in life there are trade-offs. While the closed-f orm nature of th e Pythago rean formula allows us to readily measur e the impact of p lay- ers, it indicates a m ajor def ect that should be addre ssed. Baseball is a c omplicated game; it is unlikely that all the subtleties an d issues can be distilled into one simple formu la in volving just three inputs. Ad mittedly , it is a majo r ch allenge to der iv e a good formula to predict how many ru ns a player will give a team, and we are ignor - ing th is issue in this chapter; howev er , it is imp robab le that any f ormula as simple as this can capture everything that matters. There are thus sev eral extensions of th e Pythagor ean formula; we d iscuss some o f these in Sections § 7 and § 8, as well as outline a progr am c urrently being pursued to improve its p redictive power . Pythagora s at the Bat 5 3 Pythagore an Formula: Mod el There are many ways to model a baseball game. The more sophisticated the model, the more features can be captured, though added power come s at a cost. The cost varies from incre ased run -time to requiring m assi vely mo re data. W e g i ve a very simple model for a b aseball game, and show th e Pythagor ean f ormula is a conse- quence. Of course, the simp licity of our m odel strongly suggests th at it cannot b e the full story . W e return to that i ssue in § 8, and c ontent ourselves here with the sim- ple case. The hope is that this si mplified mode l of baseball is ne vertheless po werful enoug h to capture th e m ain f eatures and yield a r easonably good pred ictiv e statistic. See the paper of Hammo nd, Johnson and Miller [ 4] for oth er approac hes to model- ing baseball gam es and winning percen tages. Specifically , they look at James’ log5 method, which also appe ared in h is 198 1 abstract [6]. There h e estimates the prob- ability a team with winning percentag e a be ats a team with winning percentage b by a ( 1 − b ) a ( 1 − b )+( 1 − a ) b . I nterestingly , the Pyth agorean form ula with e x ponent 2 follo w s by taking a = RS / ( RS + RA ) and a = RA / ( RS + RA ) , with RS the a vera ge number of runs scored and RA the av erage number of runs allo wed. The following model an d d eriv atio n fir st appea red in work by the first author in [9] , who introdu ced using a W eibull d istribution to mo del run pr oduction . The W eib ull d istribution is extensively used in statistics, arising in m any p roblems in surviv a l an alysis (see [12] for a good descrip tion o f the W eibull’ s properties and applications) . The reaso n a W eibull distribution is able to mod el well so ma ny dif- ferent data sets is that it is a three parame ter distribution, with probability density function f ( x ; α , β , γ ) = γ α (( x − β ) / α ) γ − 1 e − (( x − β ) / α ) γ (1) if x ≥ β and 0 otherw ise. Here α , β and γ are th e three parameter s of the distribu- tion. The effect of β is to shift the en tire distribution along the re al line; essentially it determines the starting point. In our inv estigations β will always be − 1 / 2, fo r reasons that wil l become clear . Next is α , which adjusts th e scale o f the distrib u tion but not the s hape; as α increases the distribution becomes more spread out. The reason that α and β do no t alter the shape of th e distribution is that, for any distribution with finite mean and variance, we can always rescale it to have me an zero and variance 1 (o r , more generally , any mean and any positive v a riance). Thus all α and β do are adjust these two qu antities. It is γ that is th e most importan t, as different values of γ lead to very d ifferent shapes. W e illu strate this in Fig ure 1. For de finiteness, we may rescale a nd assum e α = 1 and β = 0 ; we see how the distribution changes as γ ranges from 1 to 2. W e are n ow r eady to state our model. After listing ou r assump tions we discu ss why these choices were ma de, and their reason ableness. R emember , as remark ed earlier , that in the Pythagorean formu la it makes no differ e nce if we use the total runs or the average per game, as r escaling changes the numerator an d the denomi- nator by the same multiplicative factor , and hence has no effect. 6 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio 0.5 1.0 1.5 2.0 2.5 3.0 x 0.2 0.4 0.6 0.8 1.0 Probability Weibull density as Γ varies, Α = 1 and Β = 0 Fig. 1 The changing p robabilities of a family of W eibulls wit h α = 1, β = 0, and γ ∈ { 1 , 1 . 25 , 1 . 5 , 1 . 75 , 2 } ; γ = 1 corr esponds to the expo nential distribution, and increasing γ results in the bump mo ving rightwar d. Assumptions for modeling a baseball game: T he av erage num ber of runs a team scores per game, denoted RS, and the a verage num ber o f runs al- lowed per game, denote d RA, ar e r andom variables drawn in depend ently from W eibull distributions with β = − 1 / 2 and the same γ . These assum ptions clearly r equire discussion, as they c annot be r ight. T he first issue is tha t we are m odeling run s sco red and allowed by continu ous r andom vari- ables and not d iscrete ran dom variables. While ea rlier work in the field used dis- crete rando m variables ( especially geometric or Poisson), the dif ficulty with th ese approa ches is that it is hard to obtain tractable, closed f orm expressions for th e pro b- ability a team scores mo re ru ns than it allo ws and hen ce wins a game. The reason is th at calculus is un av ailable in this ca se. Ano ther way to put it is that wh ile many people h av e con tinued in m athematics to Calculus II I or IV , n o o ne go es similarly far in classes on summation. In general, we do n ot have goo d fo rmulas for s ums, b ut throug h c alculus we do ha ve nice expressions for integrals. While the mod el allo ws for the Red Sox to be at the Y ankees π to e , we must accep t this if we want to be able to use calculus. The next assumption is that these rando m v ar iables are drawn from W eibull dis- tributions. There are two reason s for th is. One is tha t the W eibull distributions, d ue to their shape parameter γ , are an extremely flexible family and a re cap able o f fit- ting m any one- hump distributions (i.e., distributions that go up and then go down). The second, and far more important, is that calculations with the W eibull are excep- tionally tractable an d lead to clo sed fo rm expressions. T his should be compa red to similar and earlier w ork of Hein Hu ndel [5] , which the autho r learned of from the Pythagora s at the Bat 7 W ikipe dia entry Pythago r ea n e xp ectation [1 1]. In par ticular, the me an µ α , β , γ and the variance σ 2 α , β , γ of the W eibull are readily compu ted: µ α , β , γ = α Γ 1 + γ − 1 + β σ 2 α , β , γ = α 2 Γ 1 + 2 γ − 1 − α 2 Γ 1 + γ − 1 2 . (2) Here Γ ( s ) is the Gamm a function, defined for the real part of s positi ve by Γ ( s ) = Z ∞ 0 e − u u s − 1 d u . (3) The Gamma functio n is th e continuo us generalizatio n o f the factorial function, as for n a non-negative in teger we have Γ ( n + 1 ) = n !. The r eason W eibulls lead to such tractable calculations is that if X is a rando m variable drawn from a W eibull with parame ters α , β and γ , then X 1 / γ is exponen- tially distributed with param eter α γ . Therefo re a simple chang e of variables le ads to simple integrals of expone ntials, which can be done in clo sed form. Due to the importan ce of this calculation , we give full details for the comp utation of the m ean in A ppendix 9.1 (a similar calculatio n determin es the variance). The point is that when ther e ar e sev eral alternatives to use, certain choices are more tractable and should be in corpor ated. W e discuss how to handle mo re general distributions while preserving the all-importan t closed form nature of the solution in § 8. The ne xt issue is our a ssumption that β = − 1 / 2. This ch oice is to facilitate com- parisons to the discrete scoring in baseba ll. Using the above calcu lations f or the mean, if β and γ are fixed we can determin e α so that th e mean o f our W eibull matches the observed average ru ns scored (or allowed) per game. W e can use the Method of L east Squ ares or the Method of Maximum Likelihood to find the b est fit parameters α , β , γ to th e o bserved data. In doing so, we need to deal with th e fact that our d ata is d iscrete. By taking β = − 1 / 2, we are breakin g the da ta into bins [ − 1 2 , 1 2 ) , [ 1 2 , 1 1 2 ) , [ 1 1 2 , 2 1 2 ) an d so on. Notice that the centers of these bins ar e, respectively , 0, 1, 2, . . . . This is no accid ent, and in fact is the reason we ch ose β as we did. By tak ing β = − 1 / 2 the p ossible integer scores are in the middle of each bin. If we too k β = 0, as might s eem more natural, then th ese values would lie at the endpo ints of the bins, which would cau se issues in determining the best fit v a lues. The final issue is that we are assumin g run s scored and r uns allowed are i ndepen - dent. This of course cann ot b e true, for the very simp le reason that baseba ll game s cannot end in a tie! Thus if we kn ow the Orioles scored 5 runs against the Red Sox, then we k now the Sox ended th e game with some number o ther than 5 . There are a pleth ora of oth er obviou s i ssues with this assum ption, rang ing from if you have a large lead late in the gam e you migh t rest yo ur better play ers and take a chance on a weaker pitcher, to b ringing in your closer to p rotect the lead in a tight gam e. That said, an analysis of the data shows that on average these issues can cel each oth er out, and that subject to being different the runs scor ed and allowed be have a s if they are statistically ind epende nt. The interesting feature h ere is tha t we can not use a standard r × c con tingency table analysis a s th ese two values cann ot be eq ual. This 8 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio leads to an iterative procedu re taking into accou nt these structural zer os (v alues o f the table that are inaccessible), which is described in Appendix 9.2. W e end this section by describin g the calculation that yields the Pythag orean formu la, an d remarkin g on why we h av e c hosen to m odel the r uns with W eibull distributions. Le t X be a random variable drawn from a W eibull with parameters α RS , β = − 1 / 2 and γ , representing the number of runs a team scores on a ver- age. Similar ly , let Y be a r andom variable drawn from a W eibull with parameter s α RA , β = − 1 / 2 and γ , representing the num ber of runs a team allows o n a vera ge. Notice we hav e the same γ for X and Y , and we choose α RS and α RA so that the mean of X is the observed a verage numb er of run s scored per g ame, RS, and the mean of Y is the observed a verage number of runs allowed per game, RA. T hus α RS = RS − β Γ ( 1 + γ − 1 ) , α RA = RA − β Γ ( 1 + γ − 1 ) . (4) T o determine our team’ s winning percentag e we just n eed to calculate the probabil- ity that X exceeds Y : Prob ( X > Y ) = Z ∞ x = β Z x y = β f ( x ; α RS , β , γ ) f ( y ; α RA , β , γ ) d y d x . (5) For gen eral probab ility den sities f the above d ouble integral is intractable (as can be seen in Hun del’ s w ork, where he used the log- normal distrib ution). As we’ll see in the n ext s ection, the W eibull distribution lead s to v e ry simple integrals which can be e valuated in c losed form . Th is is no t am acc idental, for tuitous coinciden ce. When first inves tigating this problem, Miller began by choosing f ’ s that led to nice double integrals which could be c omputed in closed fo rm; thu s the cho ice o f the W eibull came no t from looking at the data but from look ing at the integration ! The first f Miller cho se w a s an e xpon ential distribution, which t urns out to be a W eibull with γ = 1. Next, Miller chose a Ray leigh d istribution, which is a W eibull with γ = 2 . (As a numb er theorist working in random matrix theo ry , which is often u sed to model the energy lev els of heavy n uclei, the Rayleigh distrib ution was one Miller encoun tered frequently in his resear ch and read ing, as it appro ximates the spacings between ene rgy levels o f h eavy nu clei.) It was only after comp uting th e answer in both the se cases that Miller realized the two d ensities fit into a n ice family , and d id the calculation for general γ . 4 Pythagore an Formula: Pr oof W e now fina lly pr ove the Pythag orean form ula, which we first state explicitly a s a theorem. For completeness, we restate our assumptions. Theorem 1 (Py thagorean W o n-Loss F o rmula). Let the runs scor ed and runs al- lowed per game be two indep endent rando m variables drawn fr om W eibull distribu- tions with p arameters ( α RS , β , γ ) a nd ( α RA , β , γ ) respectively , wher e α RS and α RA Pythagora s at the Bat 9 ar e chosen so that the means ar e RS and RA ; in application s β = − 1 / 2 . Then W o n-Loss Percentage ( RS , RA , β , γ ) = ( RS − β ) γ ( RS − β ) γ + ( RA − β ) γ . (6) Pr oof. Let X and Y b e independ ent rand om variables with W eibull d istributions ( α RS , β , γ ) and ( α RA , β , γ ) respectively , wh ere X is the n umber of r uns sco red and Y th e numb er of runs allo wed per game. Recall from (4) that α RS = RS − β Γ ( 1 + γ − 1 ) , α RA = RA − β Γ ( 1 + γ − 1 ) . (7) W e need only calculate the prob ability that X exceeds Y . Below we constantly use the integral of a probab ility den sity is 1 (fo r example, in m oving from th e seco nd to last to the final line). W e h av e Prob ( X > Y ) = Z ∞ x = β Z x y = β f ( x ; α RS , β , γ ) f ( y ; α RA , β , γ ) d y d x = Z ∞ x = β Z x y = β γ α RS x − β α RS γ − 1 e − (( x − β ) / α RS ) γ γ α RA y − β α RA γ − 1 e − (( y − β ) / α RA ) γ d y d x = Z ∞ x = 0 γ α RS x α RS γ − 1 e − ( x / α RS ) γ " Z x y = 0 γ α RA y α RA γ − 1 e − ( y / α RA ) γ d y # d x = Z ∞ x = 0 γ α RS x α RS γ − 1 e − ( x / α RS ) γ h 1 − e − ( x / α RA ) γ i d x = 1 − Z ∞ x = 0 γ α RS x α RS γ − 1 e − ( x / α ) γ d x , (8) where we have set 1 α γ = 1 α γ RS + 1 α γ RA = α γ RS + α γ RA α γ RS α γ RA . (9) The above tells us that we ar e essentially integrating a ne w W eibull whose paramete r α is giv en by the above re lation; e x pressions lik e this are co mmon (see f or example center of mass calculations, or adding resistors in parallel). Therefo re Prob ( X > Y ) = 1 − α γ α γ RS Z ∞ 0 γ α x α γ − 1 e ( x / α ) γ d x = 1 − α γ α γ RS = 1 − 1 α γ RS α γ RS α γ RA α γ RS + α γ RA = α γ RS α γ RS + α γ RA . (10) 10 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio Substituting the relations for α RS and α RA of (4) into (10) yields Prob ( X > Y ) = ( RS − β ) γ ( RS − β ) γ + ( RA − β ) γ , (11) which completes the proof of Theore m 1 , the Pythagorean formula. Q.E.D. 5 The Pythagore an Formula: A pplications It is now tim e to apply o ur mathematica l mode ls and results to the ce ntral econo mics issue of this chapter : In ea ch situation, h ow much is a r un worth? W e content ou r- selves with answerin g this f rom the point of view of the season. Th us if we score x runs and allow y , and we have a player who increases our ru n produc tion by s , how much is that worth? Similarly , ho w mu ch would they b e worth if they p rev ented s runs from scoring? W e answer this question n ot in do llars, but in additio nal games won o r lost. Trans- lating the num ber of wins per season into do llar amoun ts is a fascinating and ob- viously impor tant question , which the inter ested rea der is en courag ed to pursue . A good re source is Nate Silver’ s ch apter “Is Alex Rod riguez Overpaid ” in Baseball Between the Numbers: Why Everything Y ou Know About the Ga me Is Wr on g [1 0]. There are also numero us insightful blog posts, such as Phil Birnbaum’ s “Sabermet- ric Research: Saturday , April 24 , 2010” (see [1]). In this chap ter we concern our- selves with deter mining th e number of wins ga ined o r lost, which these and oth er sources can con vert to monetary am ounts. As not all win s are worth the same (going from 65 to 75 wins d oesn’t alter the fact that the season was a bust, but going fr om 85 wins to 95 wins almost sur ely punche s your ticket to the playoffs), it is essential that we can determine chang es from any state. In Figu re 2 we plo t th e add ition wins per seaso n with γ = 1 . 83 an d s = 10. W e plot around a league av erage of 7 00 runs scored per season, wh ich was essentially the av erage in 2012 (see § 7). W e let s = 10 as the common adage is e very 10 additional runs translates to one more win per season. Not surp risingly , the m ore r uns we scor e the more valuable preventing ru ns is to scoring r uns, and vice- versa; what is nice a bout the Py thagorea n formula is that it q uantifies exactly w hat this trade-off is. T o make it easier to see, in Figure 3 we plot th e dif ference in wins g ained fr om scoring 10 mor e ru ns to wins ga ined fro m preventing 1 0 m ore runs. Th e plo t is positive in the upper left region, indicatin g that if our run s scored and allowed p laces us here then it is more valuable to score runs; in the lower r ight region the conclusion is the opposite. Pythagora s at the Bat 11 0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 500 600 700 800 900 500 600 700 800 900 Runs Scored Runs Allowed Additional games won by increasing runs scored by 10 with Γ = 1.83. 0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 500 600 700 800 900 500 600 700 800 900 Runs Scored Runs Allowed Additional games won by increasing runs scored by 10 with Γ = 1.83. Fig. 2 The predicted number of additional wins with γ = 1 . 83: (left) scoring 10 more per season; (right) pre venting 10 more per season. Letting P ( x , y ; γ ) = x γ / ( x γ + y γ ) , the left plot i s P ( x + 10 , y ; 1 . 83 ) − P ( x , y ; 1 . 83 ) , while the right is P ( x , y − 10; 1 . 83 ) − P ( x , y ; 1 . 83 ) . - 0.5 - 0.4 - 0.3 - 0.2 - 0.1 0 0.1 0.2 0.3 0.4 500 600 700 800 900 500 600 700 800 900 Runs Scored Runs Allowed Difference: scoring 10 more vs allowing 10 more runs, Γ = 1.83. Difference: scoring 10 more vs allowing 10 more runs, Γ = 1.83. 500 600 700 800 900 Runs Scored 500 600 700 800 900 Runs Allowed - 0.5 0.0 0.5 Fig. 3 The dif feren ce in the predicted numbe r of additional wins with γ = 1 . 83 from scoring 10 more per season versus pre venting 10 more per season . Letti ng P ( x , y ; γ ) = x γ / ( x γ + y γ ) , the dif ferenc e is P ( x + 10 , y ; γ ) − P ( x , y − 10; γ ) . 6 The Pythagore an Formula: V erification W e have two goals in this section. First, we want to show our assump tion of the runs scored an d allowed being drawn from indepen dent W eibulls is reasonab le. Second, we want to find th e optimal value of γ , and ch eck the conv entional wisdom that the Pythagor ean formula is typically accurate to about four games a season. 12 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio There are many methods available f or su ch analyses. T wo popular o nes are the Method of Lea st Squa res, and the Method o f Maximu m Likelihoo d. As the two g iv e similar results, we u se the Method of Least Squ ares to attack the indep endenc e an d distributional questions, and the Method of Maximum L ikelihood to estimate γ and the error in the formu la. 6.1 Analysis of Independence and Distributional Assumptions W e u se the Metho d of Least Square s to analyze th e 3 0 teams, which are ordered by the number of overall season wins and by league , fro m the 2 012 season to see how closely ou r mo del fits the observed scoring patterns. W e briefly summarize the procedur e. For each team we find α RS , α RA , β and γ that minimize the sum of squared err ors from the ru ns scored d ata plus the sum of sq uared err ors from the runs allowed da ta; instead of the Method of Least Squar es we could also use the Method of Maximum Likelihood (discussed in the next su bsection), which would return similar values. W e alw ay s take β = − 1 / 2 an d let γ vary amo ng team s (thou gh we could also perform the an alysis with the same γ for all). W e partition the runs data into the bins [ − . 5 , . 5 ) , [ . 5 , 1 . 5 ] , [ 1 . 5 , 2 . 5 ] , . . . , [ 8 . 5 , 9 . 5 ) , [ 9 . 5 , 11 . 5 ) , [ 11 . 5 , ∞ ) . (12) Let Bin( k ) be the k th data b in, RS obs ( k ) (resp ectiv ely RA obs ( k ) ) be the observed number of games with runs scored (allo we d) in Bin( k ), and A ( α , β , γ , k ) be the area under the W eibull distribution with p arameters ( α , β , γ ) in Bin( k ) . Then for each team we are searching for the values o f ( α RS , α RA , γ ) that minimize 12 ∑ k = 1 ( RS obs ( k ) − 1 62 · A ( α RS , − . 5 , γ , k )) 2 + 12 ∑ k = 1 ( RA obs ( k ) − 1 62 · A ( α RA , − . 5 , γ , k )) 2 (13) (the 16 2 is because th e teams play 162 games in a season; if a tea m has fe we r games, either due to a can celled game or because w e are analyzing another sp ort, this numb er is tr i vially adjusted). For eac h team we found the best W eibulls with pa rameters ( α RS , − . 5 , γ ) and ( α RA , − . 5 , γ ) and then compared the number of wins, losses, and won-loss percent- age p redicted b y ou r mode l w ith the record ed d ata. Th e resu lts are summarized in T able 1. The mean of γ over the 30 tea ms for the 20 12 season is 1.70 with a stan dard deviation of . 11. This is sligh tly lower than the value in the literature of 1. 82. The difference b etween th e two m ethods is that o ur value of γ is a consequenc e of our model, wher eas th e 1 .82 c omes fro m assuming the P ythago rean f ormula is valid and Pythagora s at the Bat 13 T eam Obs W Pred W Obs % Pred % Diff Ga mes γ W ashington Nationals 98 97.5 0.605 0.602 0.5 1.76 Cincinnati Reds 97 90.7 0.599 0.560 6.3 1.80 Ne w Y ork Y ankees 95 96.0 0.586 0.593 -1.0 1.95 Oakland Athletics 94 89.8 0.580 0.554 4.2 1.54 San Francisco Giants 94 86.1 0.580 0.531 7.9 1.72 Atlanta Brav es 94 89.4 0.580 0.552 4.6 1.51 T exas Rangers 93 91.0 0.574 0.562 2.0 1.69 Baltimore Orioles 93 83.1 0.574 0.513 9.9 1.66 T ampa Bay Rays 90 90.9 0.556 0.561 -0.9 1.75 Los Angeles Angels 89 86.4 0.549 0.533 2.6 1.59 Detroit Tiger s 88 94.7 0.543 0.585 -6.7 1.89 St. Louis Cardinals 88 91.0 0.543 0.562 -3.0 1.66 Los Angeles Dodgers 86 87.9 0.531 0.542 -1.9 1.65 Chicago White Sox 85 87.1 0. 525 0.538 -2.1 1.66 Milwauk ee Brewer s 83 85.0 0.512 0.525 -2.0 1.75 Philadelphia Phillies 81 76.7 0.500 0.474 4.3 1.72 Arizona Diamondbacks 81 84.8 0.500 0.524 -3.8 1.61 Pittsbur gh Pirates 79 80.3 0.488 0.496 -1.3 1.63 San Diego Pa dres 76 74.7 0.469 0.461 1.3 1.65 Seattle Mariners 75 74.6 0.463 0.461 0.4 1.59 Ne w Y ork Met s 74 75.7 0.457 0.467 -1.7 1.63 T oronto Blue Jays 73 73.7 0.451 0.455 -0.7 1.66 Kansas City Royals 7 2 74.8 0.444 0.462 -2.8 1.78 Boston Red Sox 69 73.6 0.426 0.455 -4.6 1.72 Miami Marlins 69 76.1 0.426 0.470 -7.1 1.74 Clev eland Indians 68 65.2 0.420 0.402 2.8 1.76 Minnesota T wins 66 65.8 0.407 0.406 0.2 1.91 Colorado Rockies 64 71.0 0.395 0.438 -7.0 1.79 Chicago Cubs 61 70.6 0.377 0.436 -9.6 1.58 Houston Astros 55 61.3 0.340 0.379 -6.3 1.61 T able 1 Results from best fit values from t he Method of Least Squares, displaying the observed and pr edicted number of wins, winning per centage, and dif ference in games w on and pre dicted for the 2012 season. finding which expo nent gives the best fit to the observed win ning p ercentages. W e discuss ways to improve our mod el in § 8. Comparing the predicted n umber of wins with the o bserved number of wins, we see that the mean difference b etween th ese qu antities is about -.52 with a standard deviation of abou t 4.61. This data is misleading, tho ugh, as the mean d ifference is small as these a re signed quantities. It is thus b etter to examine the ab solute value of the dif ference between ob served an d predic ted win s. Doing so gives an average value of abo ut 3 .65 with a stan dard deviation ar ound 2.79, con sistent with the em - pirical result that the Pythagorean f ormula is usually accurate to a round four wins a season. W e n ext examine each team’ s z -scor e f or the difference between the obser ved and pre dicted r uns scored and runs allowed. A z -test is a pprop riate here bec ause of the large number of gam es pla yed by each team, a cru cial d ifference between baseball an d foo tball. The critical value co rrespond ing to a 95% co nfidence level 14 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio is 1.96, while th e value for the 99% lev el is 2. 575. Th e z -sco re (for r uns score d) for a given team is de fined a s follows. Let RS obs denote the ob served average runs scored, RS pred the predicted a verage runs scored (from the best fit W eibull), σ obs the standard deviation of the o bserved runs scored, and rem ember there are 162 games in a season. Then z RS = RS obs − RS pred σ obs / √ 162 . (14) W e see in T able 2 that b oth the ru ns score d an d ru ns allowed z -statistics almo st always fall well below 1.96 in absolute value, indicating that the p arameters esti- mated by the Metho d of Least Squares pre dict the o bserved data well. W e could do a Bonferro ni ad justment for multiple compar isons as these are n ot in depend ent compariso ns, which allows us to divide the co nfidence levels by 30 (the numb er of compariso ns); this is a very conservativ e statistic. Doing so in creases the thresholds to approx imately 2.92 and 3.38, to the p oint th at all values are in excellen t agr ee- ment with theory . T eam Obs RS Pred RS z -stat Obs RA Pred RA z -stat W ashington Nationals 4.51 4.54 -0.13 3.67 3.49 0.87 Cincinnati Reds 4.13 4.13 0.00 3.63 3.55 0.39 Ne w Y ork Y ankees 4.96 5.02 -0.24 4.12 4.05 0.33 Oakland Athletics 4.40 4.48 -0.30 3.79 3.82 -0.15 San Franc isco Gi ants 4.43 4.36 0.32 4 .01 4.02 -0.05 Atlanta Bra ves 4.32 4.39 -0.27 3.70 3.76 -0.27 T exas Rangers 4.99 4.86 0.48 4.36 4.13 0.88 Baltimore Orioles 4.40 4.41 -0.09 4.35 4.26 0.35 T ampa Bay Rays 4 .30 4.18 0.52 3.56 3.57 -0.04 Los Angeles Angels 4.73 4.84 -0.42 4.31 4.41 -0.38 Detroit T i gers 4.48 4.49 -0.03 4.14 3.66 2.03 St. Louis Cardinals 4.72 4.73 -0.05 4.00 4.01 -0.02 Los Angeles Dodgers 3.93 4.07 -0.67 3.69 3.63 0.29 Chicago White Sox 4.62 4.60 0.09 4 .17 4.15 0.09 Milwauk ee Brewer s 4.79 4.89 -0.41 4.52 4.59 -0.30 Philadelphia Phillies 4.22 4.08 0.61 4 .20 4.37 -0.82 Arizona Diamondbacks 4.53 4.59 -0.24 4.25 4.30 -0.26 Pittsbur gh Pirates 4.02 4.12 -0.45 4.16 4.17 -0.04 San Diego P adres 4 .02 4.09 -0.35 4.38 4.55 -0.76 Seattle Mariners 3.82 3.68 0.60 4 .02 4.11 -0.44 Ne w Y ork Met s 4.01 4.06 -0.24 4.38 4.44 -0.26 T oronto Blue Jays 4.42 4.37 0.19 4.84 4.93 -0.35 Kansas City Royals 4.17 4.21 -0.17 4.60 4.63 -0.09 Boston Red Sox 4.53 4.33 0.79 4 .98 4.87 0.40 Miami Marlins 3.76 3.96 -0.96 4.47 4.29 0.80 Clev eland Indians 4. 12 4.06 0.22 5.22 5.21 0.00 Minnesota T wins 4.33 4.14 0.71 5.14 5.16 -0.12 Colorado Rockies 4.68 4.75 -0.29 5.49 5.53 -0.16 Chicago Cubs 3.78 3.89 -0.50 4.69 4.67 0.05 Houston Astros 3.60 3.57 0.13 4.90 5.04 -0.57 T able 2 M ethod of Least Squar es: z -tests for best fit runs scored and allowed. Pythagora s at the Bat 15 T o f urther d emonstrate th e q uality o f th e fit, in Fig ure 4 we c ompare the b est fit W eibulls with the Pittsburgh Pira tes (who were essentially a .500 team an d thus in the middle of the pack). The fit is excellent . 5 10 15 20 5 10 15 20 25 5 10 15 20 5 10 15 20 Fig. 4 Co mparison of the best fit W eibulls for runs scored (left) and allowed (right) for the 2012 Pittsbur gh Pirates against the observed distribution of sc ores. W e now come to the mo st important part o f the analysis, testing the assump tions that the r uns scored and allowed are giv en b y indep endent W eibulls. W e do this in two stages. W e first see how well the W eibulls do fitting the d ata, an d wheth er or not the runs scored and allo wed are statistically indep endent (oth er th an th e restriction that th ey are n ot equa l). W e describe th e an alysis first, and then present th e results in T able 3. As the independen ce test is complicated by the pr esence of structu ral zeros (unattainab le values), we provide a de tailed description here for the benefit of the reader . The first column in T ab le 3 is a χ 2 goodn ess of fit test to de termine how closely the o bserved data f ollows a W eibull distribution with the estimated parameter s, us- ing the same bins as befor e. O ur test statistic is 12 ∑ k = 1 ( RS obs ( k ) − 1 62 · A ( α RS , − . 5 , γ , k )) 2 162 · A ( α RS , − . 5 , γ , k ) + 12 ∑ k = 1 ( RA obs ( k ) − 1 62 · A ( α RA , − . 5 , γ , k )) 2 162 · A ( α RA , − . 5 , γ , k ) . (15) This test has 20 degrees of freedom , which correspo nds to critical v alues of 31.41 (95% le vel) and 37.5 7 (99% level). Of cour se, as we ha ve multiple comparison s we should again perform a Bonferroni ad justment. W e d i vide the s ignificance lev els by 30, the numb er of comparisons, an d th us th e values increase to 43.67 and 48.75. Al- most all the teams are now in ran ge, with the only major outliers being the Y ankees and the Rays, the two playoff tea ms from the American League East. W e now turn to the final key assumption, the independ ence of run s scored and runs allowed, by doing a χ 2 test for independ ence. This test in volves creating a contingen cy table with the requirement tha t ea ch row and colu mn has at least one non-ze ro entr y . As th e Miami Marlins ha d no games with 10 runs scored, we had to 16 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio slightly modify our choice of bins to [ 0 , 1 ) , [ 1 , 2 ) , . . . , [ 9 , 11 ) , [ 11 , ∞ ) ; (16) as we are using the observed run data fr om g ames, we can have our bins with left endpo ints at th e integers. W e have an 11 × 11 con tingency tab le. As runs scored cannot equal r uns al- lowed in a g ame (g ames cannot end in a tie), we are f orced to hav e zeroe s along the d iagonal. The con straint on the values of runs scor ed and run s allowed leads to an incomplete two-dim ensional contin gency table with ( 11 − 1 ) 2 − 11 = 89 degrees of freed om. W e briefly review the th eory of such tests with stru ctural zero s in Ap- pendix 9.2. The critical values for a χ 2 test with 89 degrees o f fr eedom a re 113. 15 (95% le vel) and 1 24.12 (99% level). T able 3 sho ws that all chi- square v alu es fo r th e teams in the 2012 season fall b elow the 9 9% lev el, indicating that runs scored an d runs allowed are beh aving as if they are statistically ind epende nt. The fits are even better if we use the Bonferr oni adjustments, which ar e 133. 26 and 1 41.56 . 6.2 Analysis of γ and Games Of f Giv e n a dataset and a statis tical model, the me thod of maximum likelihood is a technique that computes the p arameters of the model that ma ke the o bserved d ata most probable. M aximum likelihood estimators have the desirable p roperty of b e- ing a symptotically minimum variance unb iased estimators. Based on the statistical model in question , one constructs the likelihood f unction . For our model, if we have B bins then the likelihood function is gi ven by L ( α RS , α RA , − . 5 , γ ) = 162 RS obs ( 1 ) , . . . , RS obs ( B ) B ∏ k = 1 A ( α RS , − . 5 , γ , k ) RS obs ( k ) · 162 RA obs ( 1 ) , . . . , RA obs ( B ) B ∏ k = 1 A ( α RA , − . 5 , γ , k ) RA obs ( k ) . (17) The maximum likelihood estimators are f ound by determ ining th e values of the parameters α RS , α RA and γ that maximize th e likelihood function . In practice one typically ma ximizes the lo garithm of th e likelihood becau se it is both eq uiv alen t to and compu tationally e asier than maximizing the likelihood function directly . Using ou r mode l, we calculated the m aximum likelihoo d estimators for each team. Figur e 5 d isplays the average v alu es of the param eter γ for each season fro m 2007 to 20 12, with erro r ba rs indicating the stand ard deviation. Note that th e stan- dard deviation of the γ values f or each season are similar to each other, with 2010 having the largest deviation. The mean value of γ is about 1.69 with a standard deviation of .03. Using the maximu m likelihood estimators, we then calculated th e p redicted num- ber of ga mes won for each team and compared this to the observed n umbers. T he Pythagora s at the Bat 17 T eam RS+RA χ 2 : 20 d.f. Indep endence χ 2 : 109 d.f W ashington Nationals 53.80 101.07 Cincinnati Reds 33.69 107.11 Ne w Y ork Y ankees 64.02 82.82 Oakland Athletics 22.34 87.85 San Francisco Giants 14.37 89.57 Atlanta Bra ves 32.34 101.07 T exas Rangers 26.49 93.46 Baltimore Orioles 11.90 98.29 T ampa Bay Rays 66.35 120.25 Los Angeles Angels 28.10 105.73 Detroit Tiger s 38.76 98.96 St. Louis Cardinals 36.32 117.21 Los Angeles Dodgers 31.70 123.33 Chicago White Sox 20.61 121.33 Milwauk ee Brewer s 49.51 98.02 Philadelphia Phillies 19.19 93.78 Arizona Diamondbacks 23.91 78.44 Pittsbur gh Pirates 13.46 103.85 San Diego Pa dres 17.62 92.87 Seattle Mariners 9.79 113.13 Ne w Y ork Met s 42.88 95.66 T oronto Blue Jays 13.09 86.81 Kansas City Royals 22.51 102.39 Boston Red Sox 22.43 99.18 Miami Marlins 43.64 121.32 Clev eland Indians 26.62 83.28 Minnesota T wins 50 .40 115.04 Colorado Rockies 24.30 85.79 Chicago Cubs 40.06 90.72 Houston Astros 41.16 80.48 T able 3 Res ults from best fit values from the Method of Least Squares for 2012, displaying the quality of the fi t of the W eibulls to the obs erv ed scoring data, and testing the inde pendence of ru ns scored and allo wed. av erage absolute value of this difference is shown fo r each year in Figu re 6, with error b ars indicating the standard deviation. The mean of th e abso lute value o f the games off b y is appro ximately 3.81, with a standard deviation of about .94; these number s are in -line with the co n ventional wisdom that the Pythagore an form ula is typically accurate to about 4 games per season. 7 The Pythagore an Formula: L inearization The Pythagorean f ormula is not the only predicto r used, though it is one of the ear li- est and most famous. A popular alterna ti ve is a linear statistic. For example, Michael Jones and Linda T a ppin [7] state that a good estimate for a team’ s winning percent- age is . 500 + B ( RS − RA ) , where RS and RA are runs scor ed and allo wed, and B is 18 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio 2006 2007 2008 2009 2010 2011 2012 2013 1.50 1.55 1.60 1.65 1.70 1.75 1.80 1.85 1.90 Year Best - Fit Gamma Maximum Likelihood Estimates Fig. 5 A verage value of γ from the Method of Maximum Likelihood. 2006 2007 2008 2009 2010 2011 2012 2013 0 2 4 6 8 Year Difference in Games Maximum Likelihood Estimates Fig. 6 A verag e absolute value of the dif ferenc e between the observe d and predicted number of wins from the Method of Maximum Likelihood. a small positi ve co nstant whose average in their studies w as a round 0.000 65. Note her e there is a d iffer ence if we use total runs or average run s p er game, as we no longer have a ratio. W e can of c ourse use average runs per game, but that would require rescaling B; thus, for the rest of this section, we work in total runs. While their formula is simple r to u se, compu ters ar e ha ndling all th e calcula- tions anyway an d thus the sa v ings over the Py thagore an form ula is not significant. Further, by applying a T aylor series exp ansion to the Pythag orean form ula we ob- tain not on ly this line ar predicto r , but also find an interp retation of B in terms of γ Pythagora s at the Bat 19 and the average runs scored by teams. W e giv e a simple pr oof usin g mu lti variable calculus; see Ap pendix 9 .3 f or a n alternativ e proof th at on ly req uires o ne variable calculus. The multivariable argument was first given in [3 ] by Steven J. Miller and Ke vin Dayar atna; the one-dimensiona l argument is from an unpublished appendix. Giv e n a m ultiv ariab le function f ( x , y ) , if ( x , y ) is close to ( a , b ) then f ( x , y ) is approx imately th e first order T ay lor series about the point ( a , b ) : f ( a , b ) + ∂ f ∂ x ( a , b )( x − a ) + ∂ f ∂ y ( a , b )( y − b ) . (18) W e take f ( x , y ) = x γ x γ + y γ , ( a , b ) = ( R total , R total ) , (19) where R total is the a verage of the total run s s cored in the league. After s ome algebra we find ∂ f ∂ x ( x , y ) = γ x γ − 1 y γ ( x γ + y γ ) 2 , ∂ f ∂ x ( R total , R total ) = γ 4R total , (20) which is also − ∂ f ∂ y ( R total , R total ) . T aking ( x , y ) = ( RS , RA ) , the first o rder T aylor series expansion becomes f ( R total , R total ) + γ 4R total ( RS − R total ) − γ 4R total ( RA − R total ) = . 500 + γ 4R total ( RS − RA ) . (21) Thus, not only do we ob tain a linear estimator , but we have a theore tical pre- diction for the all- importan t s lope B, na mely that B = γ / ( 4R total ) . See the pap er by Dayaratna and Miller [3] for a detailed analy sis o f how w ell this ratio fits B . W e c on- tent ourselves her e with remar king that in 20 12 the two leagues comb ined to score 21,01 7 r uns (see http://www.b aseball- almanac .com/hitting/hiruns4.shtml ), for an average of 4.32449 r uns per game per team , or an a verage of 7 00.56 7 runs per team. Using 1.83 f or γ and 700.5 67 for R total , we predict B sho uld be abo ut 0.000 653, agr eeing b eautifully with Jones an d T appin’ s fin dings (see http://www.s ciencedaily. com/release s/2004/03/040330090259.htm ). 8 The Futur e o f the Pythagor ean Formula In the last sectio n we saw how to use calculus to linea rize the Pyth agorean formula and o btain s impler e stimators. Of course, lin earizing the Pythagor ean fo rmula is not the on ly extension (an d, as we are thr owing away infor mation, it is clearly n ot the optimal choice) . In current research, the author and his students are exploring more accurate models fo r teams. The re ar e two disadvantages to this appro ach. The first is that the resulting f ormula will alm ost sur ely be more complicated th an the current 20 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio one, and the second is th at mo re informatio n will be requ ired th an the aggregate scoring. These restrictions, h owe ver, are not severe. As compute rs are doing all the calcu- lations anyway , it is prefer able to h av e a mo re accurate f ormula at the co st of addi- tional computations t hat will ne ver be n oticed. The seco nd item is mo re se vere. The formu las un der de velopment will no t be computable fro m the information av ailable on co mmon standing s pages, but instead will require innin g by inning d ata. Thu s these statistics will not be computab le b y the layper son readin g the sports pag e; howe ver, th is is true about most advanced statistics. F o r e xample, it is imp ossible to calculate the win pr obability ad ded for a player without g oing thro ugh each mo ment of a game. W e ther efore see that th ese a dditional requiremen ts are perfectly fine fo r app li- cations. T eams are concerned with making o ptimal decisions, and the new d ata re- quired is readily available to th em (a nd in m any cases to the average fan who can write a script p rogram to cull it from p ublicly available websites). Th e cur rent ex- panded version o f the Pythagorea n fo rmula, wh ich is work in progress by the first and third authors of this paper [ 8], will include the f ollowing three ingredients, all of which are easily done with readily av ailable data. 1. Write the d istribution for runs scored and allowed as a linear combination s of W eibulls. 2. Adjust the value of a run scored and allowed based on the ballpark. 3. Discount r uns sco red a nd allowed fro m a team’ s statistics based on the g ame state. The r eason r uns sco red a nd a llowed a re mo deled by W eibulls is that these lead to tractable, closed form integration. W e can still p erform the in tegration if instead each distribution is r eplaced with a linear combinatio n of W eibulls; this is similar in spirit to the multitude of weights that occu r in num erous oth er statistics, and will lead to a weighted sum of Pythagorean expressions for the winning p ercentage . An add itional top ic to be explored is allowing fo r depend encies betwe en runs scored and allowed, but this is significan tly har der an d almost surely will lead to non-closed form solution s. It is highly d esirable to have a closed form solution, as then we c an estimate th e value o f a play er by sub stituting their contributions into the formu la and av oid th e need for intense simulations. The second chan ge is tri vial and easily done; c ertain ballpark s fav or pitchers while others fav or h itters. The difficulty in scoring a ru n at Fenway Park is no t the same as scoring one in Y ankee Stadium, and thus ba llpark effects sho uld be used to adjust the values of the runs. Finally , anyone who has tu rned o n the TV du ring election nigh t kn ows that cer- tain states are called quickly after po lls closed; th e pr eliminary p oll d ata is enough to pred ict with incredible accuracy what will hap pen. If a team has a large lead la te in the game, they often rest their starters or use weaker pitch ers, and thus the runs scored and allowed data here is not as ind icativ e of a team ’ s ability as e arlier in th e game. For e xample, in 2005 Mike Remlinger w as trade d to the Red Sox. In his first two games h e allowed 5 runs to sco re ( 2 earned ) while re cording no outs; his ERA Pythagora s at the Bat 21 for the season to date was 5.45 and his win probability added w as sligh tly negati ve. On Au gust 16 the So x and th e Tigers were tied after 9 d ue to an Ortiz home -run in the ninth . 1 Ortiz h ad a three ru n shot the following inning, part of a 7 r un offensi ve at the start of the tenth. Wi th a sev en run lead, th is should not have been a critical situation, and Remling er e ntered th e game to pitch the bo ttom of the tenth. After re- tiring the first two batters, two walks and an infield single later it was bases loa ded. Monroe th en homered to m ake it 10-7, but Remlinger rallied and retir ed Inge. Th ere were two reason s Papelbo n was not b roug ht in for the ten th. T he first is that back then P ap elbon was a starter ( and in fact started that gam e!). Mo re importan tly , h ow- ev er , with a 7 run lead and just one in ning to play , the leverage of the situa tion was low . Thus it is inapp ropriate to treat all runs e qually . This mistake occurs in other sports; for e x ample, when the Pythagorean f ormula is app lied in f ootball practition- ers frequently do not adju st for the fact that at the end of the season certain team s have alr eady locked up their playoff seed and are resting starters. The hope is that inco rporatin g these a nd other mod ifications will result in a more accurate Pythagorean for mula. Th ough it will not b e as easy to use, it will still be computab le w ith known data an d not require any simulations, an d alm ost sure ly provide a better e valuation of a player’ s worth to their team. Acknowled gements The first author was partially supported by NSF Grants DMS0970067 and DMS1265673. He thanks Chris Chiang for suggesting the titl e of this talk, numerous students of his at Brown Uni vers ity and Williams College, as well as Cameron and Kayla Mi ller , for many lively con versa tions on mathematics and sports, Michael Stone f or comments on an ea rlier draft, and Phil Birnbaum, Ke vin Dayaratna, W arren Johnso n and Chris Long for many sabermetrics discussions. This paper i s dedicated to his great uncle Newt Bromberg, who assured him he would live long enough t o see the Red Sox win it all , and the 2004, 2007 and 2013 Red Sox who made i t happen (after the 2013 vict ory his six year old son Cameron turned to hi m and commented t hat he got t o see it at a much younger age!). 9 Ap pendix 9.1 Calculating the Mean of a W eibull Letting µ α , β , γ denote the mean of f ( x ; α , β , γ ) , we h av e µ α , β , γ = Z ∞ β x · γ α x − β α γ − 1 e − (( x − β ) / α ) γ d x = Z ∞ β α x − β α · γ α x − β α γ − 1 e − (( x − β ) / α ) γ d x + β . (22) 1 The data below is from http://www .baseball-refer ence.com/player s/gl. cgi?id=remlimi01&t=p&year=2005 and http://scores.espn.go.com/mlb/boxs core?ga meId=25081610 6 . 22 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio W e change variables by setting u = x − β α γ . Then d u = γ α x − β α γ − 1 d x and we have µ α , β , γ = Z ∞ 0 α u γ − 1 · e − u d u + β = α Z ∞ 0 e − u u 1 + γ − 1 d u u + β = α Γ ( 1 + γ − 1 ) + β . (23) 9.2 Independence test with structural zeros W e describe the iterative pro cedure n eeded to handle the structur al zeros. A good referenc e is B ishop and Fienberg [2]. Let Bin( k ) be the k th bin used in the chi- squared test for ind epende nce. F or each team’ s in complete c ontingen cy table, let O r , c be th e o bserved numb er of games where the numb er o f runs scored is in Bin( r ) an d r uns allowed is in Bin( c ). As games cannot end in a tie, we hav e O r , r = 0 f or all r . W e construc t the expected continge ncy table with e ntries E r , c using an iterative process to find the maximum likeliho od est imators for each entr y . For 1 ≤ r , c ≤ 12, let E ( 0 ) r , c = 1 if r 6 = c 0 if r = c , (24) and let X r , + = ∑ c O r , c , X c , + = ∑ r O r , c . (25 ) W e th en have th at E ( ℓ ) r , c = ( E ( ℓ − 1 ) r , c X r , + / ∑ c E ( ℓ − 1 ) r , c if ℓ is odd E ( ℓ − 1 ) r , c X c , + / ∑ r E ( ℓ − 1 ) r , c if ℓ is ev en . (26) The values of E r , c can be found by taking the limit as ℓ → ∞ of E ( ℓ ) r , c , an d typ ically the con vergence is rapid . The statistic ∑ r , c r 6 = c ( E r , c − O r , c ) 2 E r , c (27) follows a ch i-square distribution with ( 11 − 1 ) 2 − 11 = 89 degrees of freedom. Pythagora s at the Bat 23 9.3 Linearizing Pythagoras Unlike the argumen t in § 7, we do n ot assume kn owledge o f multiv ariable calcu - lus and d eriv e the linearization using just single variable methods. The calculatio ns below are of inter est in the ir own right, as they highlig ht good appr oximation tech- niques. W e a ssume there is some exponent γ such that the winning percentage , WP, is WP = RS γ RS γ + RA γ , (28) with RS and RA the total ru ns scored and allowed. W e m ultiply the rig ht hand side by ( 1 / RS γ ) / ( 1 / RS γ ) and write RA γ as RS γ − ( RS γ − RA γ ) , and find WP = 1 1 + RA γ RS γ = 1 + RA γ RS γ − 1 = 1 + RS γ − ( RS γ − RA γ ) RS γ − 1 = 1 + 1 − RS γ − RA γ RS γ − 1 = 2 · 1 − RS γ − RA γ 2RS γ − 1 = 1 2 1 − RS γ − RA γ 2RS γ − 1 ; (29) notice we manipu lated the alg ebra to p ull out a 1/2, which ind icates an average team; thus the remainin g factor is the fluctuations about a verag e. W e n ow use th e geometric series formula , wh ich says that if | r | < 1 then 1 1 + r = 1 + r + r 2 + r 3 + · · · . (30) W e let r = ( RS γ − RA γ ) / 2RS γ ; since run s scored and runs allo wed should be close to each other, the d ifference of the ir γ powers di vided b y twice the n umber o f r uns scored sho uld be small. Th us r in our geo metric expansion should be clo se to zer o, and we find WP = 1 2 1 + RS γ − RA γ 2RS γ + RS γ − RA γ 2RS γ 2 + RS γ − RA γ 2RS γ 3 + · · · ! ≈ . 500 + RS γ − RA γ 4RS γ . (31) W e now make s ome approximations. W e expect RS γ − RA γ to be small, and thus RS γ − RA γ 2RS should be small. This means we only need to keep the constant an d linear terms in the exp ansion. Note that if we only kept the constant term, there would b e no depend ence o n points scored or allowed! 24 Ste ven J Miller , T aylor Corcoran, Jennifer Gossels, V ictor Luo and Jaclyn Porfilio W e need to do a little m ore an alysis to obtain a formula that is linear in RS − RA. Let R total denote th e average number of ru ns scored per team in the le ague. W e can write RS = R ave + x s and RA = R ave + x a , where it is reasonable to assume x s and x a are small r elativ e to R total . The Mean V alue Theor em from Calculu s says th at if f ( x ) = ( R total + x ) γ , then f ( x s ) − f ( x a ) = f ′ ( x c )( x s − x a ) , (32) where x c is some intermediate point between x s and x a . As f ′ ( x ) = γ ( R total + x ) γ − 1 , we find RS γ − RA γ = f ( x s ) − f ( x a ) = f ′ ( x c )( x s − x a ) = γ ( R total + x c ) γ − 1 ( RS − RA ) , (33) as x s − x a = RS − RA. Substituting this into (31) gi ves WP ≈ . 500 + γ ( R total + x c ) γ − 1 ( RS − RA ) 4RS γ = . 500 + γ ( R total + x c ) γ − 1 4RS γ ( RS − RA ) . (34) W e make on e final a pprox imation. W e replace the factors of R total + x c in the numerato r and RS γ in the denom inator with R γ total , the league av e rage, and reach WP ≈ . 500 + γ 4R total ( RS − RA ) . ( 35) Thus the simple linear approx imation mode l repr oduces the result from mu ltiv ari- able T aylo r series, namely th at the interesting co efficient B should be app roximately γ / ( 4R total ) . 10 Refer ences 1. P . Birnbaum, Sabermetric Resear ch: Saturday , April 24, 2010 , see http://blog. philbirnbaum .com/2010/04/marginal- value- of- win- in- baseball.html . 2. Y . M. M. Bishop an d S. E. Fien berg, Incomplete T wo-Dimensio nal Contingency T ables , Biometrics 25 (19 69), no. 1, 119–128. 3. K. Day aratna and S. J. Miller, F irst Or d er Appr oximations of the Pythago r ean W on- Loss F ormu la for Pr edicting MLB T eams W inning P er centages , By The Numbers – The Newsletter o f the SABR Statistical Analysis Committee 22 (2012 ), no 1, 15 –19. 4. C. N. B. Hammon d, W . P . Joh nson and S. J. Miller , The James Fu nction , 201 3, preprin t. 5. H. Hundel, Derivation of J a mes’ Pythagor ean F ormu la , 2003; see https://grou ps.google.co m/forum/#!topic/rec.puzzles/O- DmrUljHds . Pythagora s at the Bat 25 6. B. James, 1981 Baseball Abstract , self-published, Lawrence, KS, 1981. 7. M. Jones and L. T app in, The Pyth agor e an Theor em of B aseball an d A lternative Models , The UMAP Journal 26.2, 2005. 8. V . Miller an d S. J. Miller , Relieving and Readjusting Pythagoras , p reprint 2014. 9. S. J. Miller , A d erivation o f the Pythagor ea n W on-Loss F o rmula in baseball , Chance Magazine 20 (2 007), no. 1, 40– 48 (an abridged version appeared in The Newsl etter of the SABR Statis tical Analysis Committee 16 (February 2006), no. 1, 17 –22, and an expa nded version is on line at http://arxi v.org/pdf/m ath/0509698 ). 10. N. Silver, Is A lex Rodrigu ez Overpaid , in Baseball Between th e Number s: Why Everything Y ou Know Ab out the Game I s Wrong, b y The Baseball Prospectus T eam of Exp erts, Basic Books, 2006. 11. W ikipedia, Pythagorean E xpectation , http://en.wi kipedia.org/ wiki/Pythagorean\relax$\@@underline{\hbox{\\}}\mathsur r o u n 12. W ikipedia, W eibull , http://en.wi kipedia.org /wiki/Weibul l\relax$\@@underline{\hbox{\\} } \ m a
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment