Network Inference Using Steady State Data and Goldbeter-Koshland Kinetics
Network inference approaches are widely used to shed light on regulatory interplay between molecular players such as genes and proteins. Biochemical processes underlying networks of interest (e.g. gene regulatory or protein signalling networks) are g…
Authors: Chris J Oates, Bryan T Hennessy, Yiling Lu
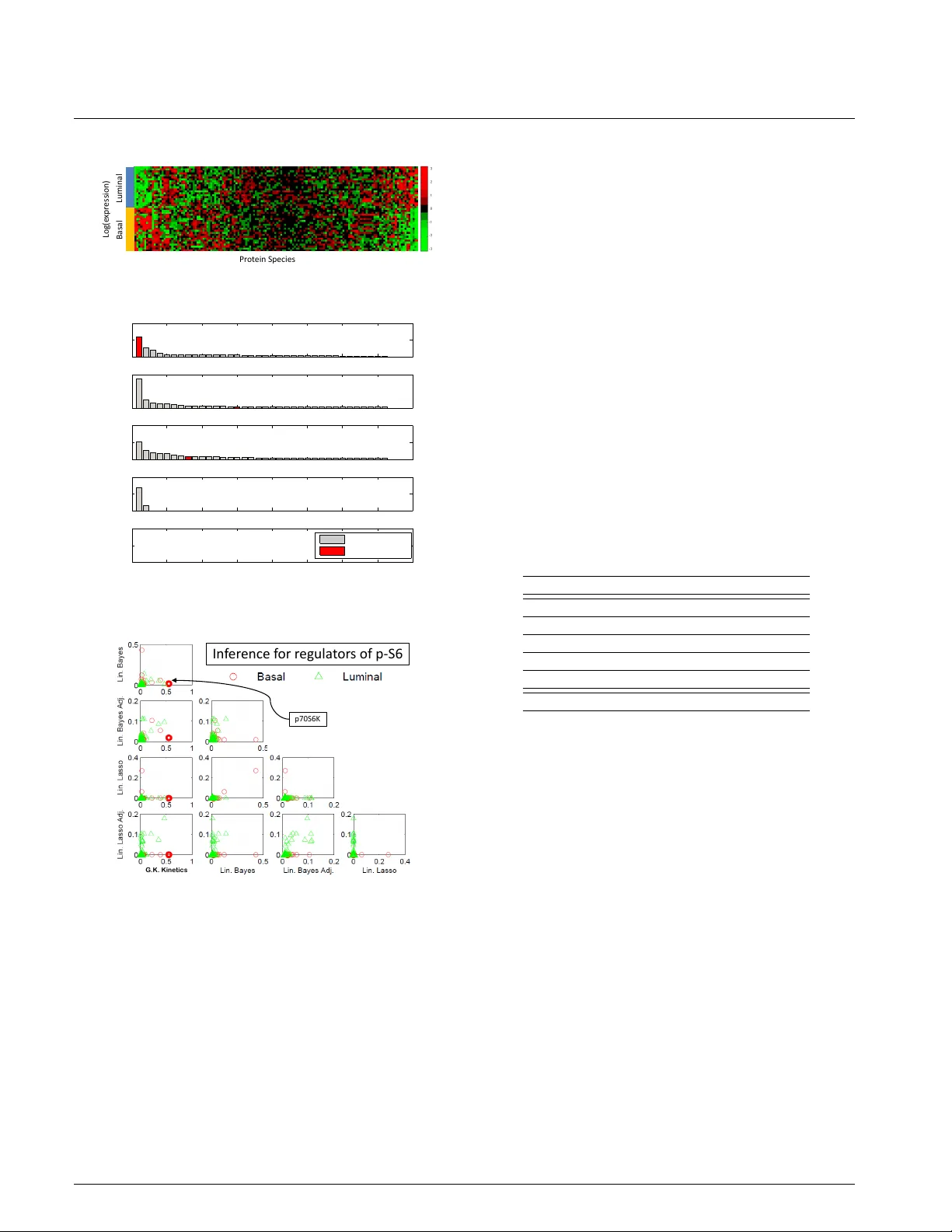
Doc-Start BIOINFORMA TICS V ol. 00 no . 00 2005 P ages 1–7 Netw ork Inference Using Stead y-State Data and Goldbeter -K oshland Kinetics Chris J Oates 1 , 2 , 3 , Br y an T Hennessy 4 , Y iling Lu 5 , Gordon B Mills 5 and Sach Mukherjee 3 1 Centre f or Comple xity Science, Univ ersity of W arwick, CV4 7AL, UK. 2 Depar tment of Statistics, Univ ersity of W arwick, CV4 7AL, UK. 3 Depar tment of Biochemistr y , Netherlands Cancer Institute, 1066CX Amsterdam, The Netherlands. 4 Depar tment of Medical Oncology , Beaumont Hospital, Dublin, Ireland. 5 Depar tment of Systems Biology , The University of T e xas M. D . Anderson Cancer Center , Houston, TX 77030, USA. Received on XXXXX; re vised on XXXXX; accepted on XXXXX Associate Editor : XXXXXXX ABSTRA CT Motivation: Network inf erence approaches are widely used to shed light on regulatory interplay betw een molecular play ers such as genes and proteins . Biochemical processes underlying netw orks of interest (e.g. gene regulatory or protein signalling networks) are generally nonlinear . In many settings, knowledge is a vailab le concerning relev ant chemical kinetics. Howe v er , e xisting networ k inference methods for continuous data are typically rooted in conv enient statistical f ormulations which do not e xploit chemical kinetics to guide inference . Results: Here we present an approach to networ k inference for steady-state data that is rooted in nonlinear descr iptions of biochemical mechanism. W e use equilibr ium analysis of chemical kinetics to obtain functional forms that are in tur n used to infer networks using steady-state data. The approach we propose is directly applicable to conventional steady-state gene e xpression or proteomic data and does not require knowledge of either networ k topology or any kinetic par ameters; both are sim ultaneously learned from data. W e illustrate the approach in the context of protein phosphorylation networks, using data simulated from a recent mechanistic model and proteomic data from cancer cell lines . In the former , the tr ue network is known and used for assessment, whilst in the latter results are compared against known biochemistr y . We find that the proposed methodology is more effectiv e at estimating network topology than methods based on linear models. A vailability: MA TLAB R2009b code used to produce these results is provided in the Supplemental Inf ormation. Contact: c.j.oates@warwic k.ac.uk, s.mukherjee@nki.nl 1 INTRODUCTION Networks of molecular components play a prominent role in molecular and systems biology . A graph G = ( V , E ) can be used to describe a biological network, with verte x set V ( G ) identified with molecular components (e.g. genes or proteins) and edge set E ( G ) with regulatory interplay between the components. Edges in a biological network are often associated with the causal notion that interv ention on a parent node influences its child node(s). Data- driv en characterisation of the graph structure E ( G ) (often referred to as the topology ) is known as network inference and has emerged as an important problem class in bioinformatics and systems biology (Chou and V oit, 2009). Network inference can aid in ef ficient generation of biological hypotheses from high-throughput data. Further , network inference can aid in exploring molecular interplay that is associated with specific phenotypes, such as disease states. From a statistical perspecti ve, network inference entails re verse- engineering a graph G using biochemical data D and, where av ailable, prior kno wledge reg arding aspects of the topology . Over the last decade many methods for network inference have been proposed, with popular approaches are reviewed in Bansal et al. (2007); Hecker et al. (2009); Lee and Tzou (2009); Markovetz and Spang (2007). T o date, most methods for network inference hav e been rooted in discrete or linear formulations (Bender et al. , 2010; Sachs et al. , 2005; Morrissey et al. , 2010; Opgen-Rhein and Strimmer, 2007; Hill, 2012; Kim et al. , 2003). As discussed in Oates and Mukherjee (2012a), a wide range of existing approaches can be viewed as variants of the linear regression model in statistics. (In this paper “linear” refers to linearity in parameters, so that nonlinear basis functions may be used within a “linear” framework.) Moreov er , a number of approaches based on ordinary differential equations (ODEs; Bansal et al. (2007); Li and Chen (2010); Nam et al. (2007)) are ultimately reducible to linear statistical models, as described in Oates and Mukherjee (2012c). Howe ver , the biochemical processes underlying biological networks are often highly nonlinear . When the data-generating process is nonlinear , use of linear models may produce inef ficient or inconsistent estimation, attributing causal status to artifacts resulting from model misspecification (Heagerty and Kurland, 2001; Lv and Liu, 2010). Indeed, such bias can prevent recovery of the correct network even in fav ourable asymptotic limits of large sample size and low noise (Oates and Mukherjee, 2012a). On the other hand, in many settings nonlinear dynamical models of relev ant biochemical processes are av ailable. For example gene regulation may be modelled using Michaelis-Menten functionals (Cantone et al. , 2009), and metabolism may be modelled using c Oxford University Press 2005. 1 Oates and Mukherjee mass action chemical kinetics (Min Lee et al. , 2008). Here, we describe an approach by which kinetic models can be used to inform network inference from steady-state data. As we show below , such information can be valuable in guiding exploration of network topologies. Kinetic formulations hav e been widely studied in the systems biology literature (Bintu et al. , 2005) and recently there has been much interest in statistical inference for such systems, with examples including Chen et al. (2009); Xu et al. (2010). Our work is in a similar vein, but focuses on network inference per se and on the steady-state rather than time-course setting. While biochemical assays hav e become cheaper, it remains the case that experimental designs must often negotiate a trade off between more conditions (e.g. perturbations, biological samples, technical replicates) and temporal resolution (e.g. number of time points). Methodologies which can exploit knowledge concerning relev ant dynamical systems in the steady-state setting are therefore potentially valuable. In brief, we proceed as follows. W e consider a class of nonlinear biochemical dynamical systems that are rele vant to the biological process of interest (we focus on protein signalling, discussed in detail belo w). Steady-state analysis leads to a class of functional relationships between parent and child. These functional relationships are used to formulate a statistical model for network inference from steady-state data. In this way , network inference is rooted in functional relationships deriv ed from nonlinear kinetics. Importantly , we do not assume detailed knowledge of the dynamical system, but only the broad class to which dynamics and associated equilibria may belong. Indeed, the approach we describe does not require any kinetic parameters to be kno wn a priori , nor kno wledge of the network topology , and is in that sense directly comparable to con ventional network inference methods. Its potential advantage stems from then rich yet constrained nature of the class of functional relationships that are considered. As recently discussed in Peters et al. (2011), nonlinear functional forms can aid in identification of underlying causal relationships. W e dev elop these ideas in the context of protein signalling mediated by phosphorylation. Enzyme kinetics hav e been extensi vely studied, and dynamical formulations are widely av ailable in the literature (see e.g. Leskov ac, 2003). For some proteins and pathways, regulation has been studied in considerable causal and mechanistic detail. Indeed, there exist detailed computational models for canonical protein signalling pathways, which have been v alidated against experimental data (e.g. Schoeberl et al. , 2002; Xu et al. , 2010). Further , proteomic technologies no w allow multiv ariate, data-dri ven study of phosphorylation, f acilitating biological v alidation of proposed methodology . W e take advantage of these factors to examine the performance of our methodology using both simulated and real data. In the phosphorylation setting, Goldbeter-K oshland kinetics (Goldbeter and Koshland, 1981) form the functional class that underlies our network inference approach. Goldbeter -K oshland kinetics are well known to be capable of highly nonlinear behaviour including e xquisite sensitivity . It has been experimentally demonstrated that this so-called ultrasensitivity is biologically relev ant to signalling network dynamics, facilitating abrupt and precise decision making (e.g. Kim and Ferrell (2007)). W e carry out statistical inference in a Bayesian framework, using re versible- jump Markov chain Monte Carlo (RJMCMC) to explore the joint model and parameter space. This yields posterior probability scores for edges in the network that are analogous to scores obtained in existing statistical network inference approaches for steady-state data Hill (2012). The remainder of this paper is or ganised as follo ws. In Section 2 our approach is laid out, follo wed by a detailed e xposition of the associated computational statistics. In Section 3 we present results on data simulated from a recently developed dynamical model of the mitogen-activ ated protein kinase (MAPK) signalling, that has been validated against experimental data (Xu et al. , 2010). W e then show results on real proteomic data from breast cancer cell lines. Finally , Section 4 closes with a discussion of practical implications and opportunities for netw ork inference based on functional models, along with associated technical challenges. 2 METHODS W e begin in Section 2.1 by describing our approach in general terms. Section 2.2 then introduces rele v ant concepts in the application area of protein phosphorylation. In particular we describe a class of nonlinear equations deriv ed from Goldbeter-Koshland kinetics. Next, in Section 2.3 this model class is embedded into a Bayesian statistical framework for observations obtained at equilibrium. Inference over model space is facilitated by RJMCMC, with Section 2.4 dedicated to a presentation of our sampling scheme and a discussion of key implementational details. 2.1 General F ormulation W e consider a state vector X = ( X 1 , . . . , X p ) containing concentrations of p proteins. Equilibrium analysis of phosphorylation dynamics, as described below , leads to a system of p equations X i = f i ( X , U i ; θ i ) where i indexes proteins, U i are external input variables and θ i unknown parameters. The component function f i depends on a subset π i of the state variables, such that we may write X i = f i ( X π i , U i ; θ i ) , where X π i indicates selection of components of the vector X whose indices are members of the set π i . V ariables j ∈ π i are the parents of node i in graph G ; the parent sets π i specify the (unknown) topology of interest since ( j, i ) ∈ E ( G ) ⇐ ⇒ j ∈ π i . Our inference scheme seeks to infer the π i ’ s from steady-state data. Since the dynamical system is not usually known in detail a priori , we consider the practically applicable case in which the f i ’ s are known only to belong to a certain class F (derived from Goldbeter -Koshland kinetics, as described below) with parent sets π i and all parameters θ i remaining unknown. 2.2 Protein Phosphorylation W e consider proteins i ∈ V = { 1 , . . . , p } , each of which has an unphosphorylated form X 0 i and a phosphorylated form X i ( i ∈ V ). Phosphorylated proteins are referred to as phosphopr oteins . The chemical reaction that giv es product X i from substrate X 0 i is known as phosphorylation and is catalysed by kinases X E ( E ∈ E i ). W e consider the case in which the kinases themselv es are phosphoproteins (if phosphorylation is not driven by a kinase in V , we set E i = ∅ ). The ability of a kinase E ∈ E i to catalyse phosphorylation of X i may be tempered by inhibitors X I ( I ∈ I i,E ⊂ V ; the double subscript indicates that inhibition is specific to both substrate and kinase). Thus the parents π i of X i comprise both the kinases and their inhibitors: π i = E i ∪ {I i,E } E ∈E i . Due to specificity of phosphorylation reactions, the underlying netw ork G is typically sparse, such that the number of parents π i for v ariate X i is usually low . An example is sho wn, using a standard graphical representation, in Fig. 1a. In what follows we use X 0 i , X i to denote the concentrations of proteins X 0 i , X i respectiv ely; U i = X 0 i + X i is then the total concentration of protein i , which is taken to be approximately inv ariant over the timescale of phosphorylation dynamics. 2 Network Inference Using Goldbeter-Koshland Kinetics X 0 1 X 1 X 0 2 X 2 X 3 X 0 3 X 0 4 X 4 1 (a) X 1 X 2 X 3 X 4 . . . X p X i X 0 i inhibitor kinase kinase f i ( X π i , U i ; θ i ) = V 2 X 2 X 0 i X 0 i + K 2 (1+ X 4 /K 4 ) + V p X p X 0 i X 0 i + K p − V 0 X i ( U i = X 0 i + X i ) 1 (b) E ∈ E i X E I ∈ I i,E X I X 0 i X i σ V 0 V E K E V I K I (c) Fig. 1: Overvie w of approach. (a) An example of a phosphorylation network. (b) Our approach couples automatic generation of chemical models with Bayesian model selection to infer re gulators π i of species i . (c) A statistical formulation (graphical model) for equilibrium phosphorylation of species i is characterised by specifying kinases ( E ∈ E i ) and inhibitors ( I ∈ I i,E ) of kinases. [Bounding boxes in this case are used to indicate multiplicity of variables, shaded nodes are observ ed with noise.] For network inference, model selection will take place over parent sets π i . Accordingly , we require functional equations for any such subset (Fig. 1b). Following the biochemical literature (Kholodenko, 2006; Steijaert et al. , 2010), we use ODEs of the Michaelis-Menten type to provide a suitable class of analytic approximations for phosphorylation dynamics. The rate of phosphorylation X 0 i → X i due to kinase X j is giv en by V X j X 0 i / ( X 0 i + K ) , which explicitly acknowledges v ariation of kinase concentration X j and permits kinase-specific response profiles (parameterised by K ) with maximum reaction rate V . Equilibrium analysis of the foregoing kinetic model yields functional relationships between nodes that we use to inform analysis of steady-state data. The famous example of Goldbeter and K oshland (1981) considered phosphorylation by a single enzyme ( X E ) and dephosphorylation by a single phosphatase ( X P ), which at equilibrium satisfy the balance equation V E X E X 0 i X 0 i + K E = V P X P X i X i + K P (1) whose solution X i = f i (( X E , X P ) , X 0 i ; θ i ) is capable of expressing a range of biologically relev ant nonlinearities. In this work we extend the class of molecular regulatory mechanisms by entertaining multiple (independent) kinases along with competitiv e inhibition, where substrate ( X 0 i ) and inhibitor ( X I ) compete for the same binding site on the enzyme ( X E ): X E X I X E X E X 0 i → X E + X i (2) When multiple inhibitors ( I , I 0 ) are present, they are assumed to act exclusi vely , competing for the same binding site on the enzyme: X E X I 0 X E X E X I 0 (3) Mathematically , competitive inhibition by exclusi ve inhibitors corresponds to rescaling of the Michaelis-Menten parameter K E 7→ K E 1 + X I ∈I i,E X I K I ! . (4) where the sum ranges over inhibitors I of the kinase E . Phosphatase specificity is currently poorly characterised compared with kinase specificity , so our analysis does not attempt to co ver this le vel of regulation. In particular dephosphorylation is assumed to occur at a rate V 0 X i proportional to the amount of phosphoprotein. Collecting together our modelling assumptions and solving the resulting balance equation produces a functional model class F , with member functions f i ∈ F given by f i ( X π i , U i ; θ i ) = X E ∈E i V E /V 0 X E X 0 i X 0 i + K E 1 + P I ∈I i,E X I K I . (5) Here the parameter vector θ i contains the maximum rates ( V ) and Michaelis-Menten constants ( K ) specific to phosphorylation of species i (dependence of V , K on i is notationally suppressed for clarity). When E i = ∅ we instead define f i = µ i , equal to the average phosphoprotein concentration. 2.3 Statistical F ormulation The Goldbeter -K oshland model (5) giv es a general form for the functional relationship between nodes at steady-state. Inference proceeds based on a Bayesian formulation of this model (Fig. 1c). Consider independent observations of protein expression obtained at equilibrium with respect to phosphorylation dynamics. T o fix a characteristic scale, all data are scale-normalised prior to inference such that each species has unit mean. For a given protein i , a model M i for phosphorylation describes putativ e kinases E i and associated inhibitors I i,E ( E ∈ E i ) for protein i (note that M i contains more information than the subset π i , namely the specific mechanistic roles played by each variable in π i ). Then, conditional on M i and parameters θ i we hav e the following statistical model log( X i ) = log( f i ( X π i , U i ; θ i )) + i (6) where i ∼ N (0 , σ 2 i ) . The logarithm of both predictor and response is taken in order to improve the normality assumption on the error i . In the Bayesian setting, prior probability distributions are required for parameters θ i and models M i . For the parameters θ i = ( V , K , σ ) , which we hav e augmented with σ (as with the other parameters, we drop the subscript i on σ for clarity), physical considerations require that V j , K j , σ > 0 . Following Xu et al. (2010) we postulate that all biological processes must occur on an observable timescale, moti vating, in the shape, scale parametrisation, the gamma priors V ∼ Γ(2 , 1 / 2) , K ∼ Γ(2 , 1 / 2) , each of unit mean and variance 1 / 2 . The noise parameter σ is in verse- gamma distributed a priori as σ ∼ Γ − 1 (6 , 1) , with prior mean 1 / 5 and variance 1 / 100 chosen to correspond to the magnitude of measurement noise in current proteomic technologies (Hennessey et al. , 2010). When expert opinion is available, rich subjective model priors may be elicited (see e.g., for graphical models, Mukherjee and Speed, 2008), b ut for this work we employed an objective prior , depending on a (possibly empty) prior model M 0 i . Prior specification should account for the distinct roles of kinases and inhibitors; a mathematical formulation for the objective model prior is described in the Supplemental Information. 2.4 Reversible Jump Markov Chain Monte Carlo The dimensionality of the parameter vector θ M depends on the model M ; dim( θ M ) = dim( V M ) + dim( K M ) + 1 where the former quantities are 3 Oates and Mukherjee functions of the numbers of kinases and inhibitors according to M . Since we seek models with high posterior probability , and noting that most models will provide insuf ficient explanatory po wer , we implement RJMCMC (Green, 1995) to reduce the effecti ve size of model space. Following Green and Hastie (2009) we enumerate all possible models as { M ( k ) } k ∈K and define the acr oss-model state space S = [ k ∈K ( { k } × Θ k ) , k = O E ∈E M ( k ) ( { E } × I M ( k ) E ) (7) where parameters θ M ( k ) for model M ( k ) belong to Θ k and ⊗ denotes the Cartesian product. The re versible jump sampler constructs an ergodic Markov chain on S which has, as its stationary distribution, the posterior probability distribution p ( s |D ) , s ∈ S . In particular the marginal p ( k |D ) over the model index k ∈ K corresponds exactly to the posterior model probabilities p ( M ( k ) |D ) . Construction of an efficient RJMCMC sampler requires an intuition for the across model state space. W e adopt a deliberately transparent Metropolis-within-Gibbs approach (Roberts and Rosenthal, 2006), updating one coordinate of S at a time using a Metropolis-Hastings accept/reject probability of the form α ( s, s 0 ) = min(1 , A ( s, s 0 ) p ( D| s 0 ) /p ( D| s )) . A number of distinct proposal mechanisms were employed in order to ensure ergodicity and provide rapid mixing. Precise details of the proposals used, along with their associated ratios A ( s, s 0 ) may be found in the Supplemental Information. For applications, 30,000 iterations of the Gibbs sampler were performed, with 5,000 discarded as burn-in. Conv ergence was assessed using repeated runs from dispersed initial conditions. 3 RESUL TS In this Section we empirically assess our methodology and compare its performance against network inference based on the linear model. In Section 3.1 we show results using a recently published dynamical model of the MAPK signalling pathway due to Xu et al. (2010), where the underlying network is known exactly . In Section 3.2 we apply our approach to a real proteomic dataset, which has an unknown and presumably more complex noise structure. In both cases, for fair comparison between different methods, no informativ e model priors were used (i.e. we set ∀ i, M 0 i = ∅ ). 3.1 Simulation Study Data were generated from a computational model of the MAPK signaling pathway due to Xu et al. (2010), specified by a system of 25 nonlinear ODEs (Fig. 2a). The simulation gives covariates that are highly correlated at equilibrium, as would be expected in practice, whilst providing a kno wn network G for ev aluation purposes. Further details regarding the computational model are described in the Supplemental Information. W e introduced independent Gaussian measurement noise, additive on the log scale, of magnitude σ = 0 . 2 , similar to technical error incurred by current proteomic technologies (Hennessey et al. , 2010). W e benchmarked our approach against the linear -additiv e- Gaussian formulation log ( X i ) ∼ N ( 1 β 0 + D M β M , σ 2 I ) with design matrix D M = [ . . . log( X j ) . . . ] j ∈ π M and intercept β 0 ; the logarithm of a vector is taken component-wise. All variables were mean-variance standardised prior to inference. W e consider two standard approaches to inference for the linear model, namely (1) the LASSO with penalty parameter set according to cross validation (“Lin. Lasso”), and (2) a conjugate Bayesian formulation (“Lin. Bayes”; Hill (2012)), based on the g -prior β M ∼ N ( 0 , nσ 2 ( D 0 M D M ) − 1 ) , with a flat prior over the intercept p ( β 0 ) ∝ 1 and reference prior over the noise p ( σ ) ∝ 1 /σ . For the Bayesian approach we took a model prior p ( M ) to be uniform ov er in-degree d = dim( β M ) with the restriction d ≤ 3 . Model av eraging w as then used to obtain posterior inclusion probabilities. For each of the linear approaches (1) and (2) we also considered adjusted v ariants (“Lin. Lasso Adj. ” and “Lin. Bayes Adj. ”) where log-phospho-ratios log ( X i /U i ) constitute the response; this can be motiv ated as a simple first order correction for variation in total protein lev els. For each phosphorylated or activ e species i in the computational model, we sought to infer the parents π i . For a fair comparison with the linear approaches, which do not ascribe functional roles to variables, we did not distinguish between kinases and inhibitors during assessment. The resulting receiv er operating characteristic (R OC) curves are shown in Fig. 2b. Overall performance was quantified using area under the R OC curve (A UR), aggregated ov er all i ∈ V . Results are sho wn ov er 10 datasets D for each of various combinations of sample size n and noise le vel σ (Fig. 2c). In all regimes our approach outperformed linear approaches; the latter did not perform well ev en in this low dimensional example. W e note also that e ven in the least challenging regime ( n = 24 , σ = 0 ), none of the approaches were able to perfectly reco ver the entire network G . The adjusted regressions, which model the log-phospho-ratio as the response, did not outperform the standard linear regressions. 3.2 Cancer Pr oteomic Data Data were obtained using reverse-phase protein arrays (RPP A; Hennessey et al. (2010)) applied to a panel of breast cancer cell lines (Neve et al. , 2006). Data D comprised equilibrium observations for p = 38 phosphorylated proteins, in addition to their unphosphoryated counterparts (Fig. 3a). Cell lines belong to two biologically distinct subtypes known as basal ( n = 22 ) and luminal ( n = 21 ), with each member cell line comprising one sample. The true data-generating network is not known for biological samples, but for certain nodes the relev ant kinase-substrate relationships ha ve been described in considerable mechanistic detail in the literature. T o minimize the risk of comparing results of inference against an incorrect literature model, we focused attention on selected nodes in the data for each of whom the key kinase is well established. For e xample, the protein S6 is kno wn to be phosphorylated via the kinase acti vity of p70 S6 Kinase (p70S6K); both proteins are included in our assay . Treating S6 as the target (i.e. the network child), we scored each of the remaining 37 proteins as a candidate regulator (i.e. for inclusion in the parent set π S6 ) using each method. Fig. 3b displays the result of inference for the parents of S6 (S6 is phosphorylated on amino acid residues Serine 235,236; results for basal subtype sho wn; measurements of S6 phosphorylation on residues Serine 240,244 were excluded since this correlates closely with phosphorylation on Serine 235,236). Despite the known well established re gulatory role for p70S6K, it is striking that only our approach ranks p70S6K highly . The LASSO approaches ascribe no weight to the correct kinase in this case. T o gain more insight into the assignment of weights by the competing methodologies we constructed scatter plots comparing weight distrib utions (Fig. 3c). It is immediately clear that the weight assignments v ary mark edly between basal and luminal subtypes. In addition, it is noticeable that there is little agreement between the apparently similar linear formulations. W e extended this in vestigation to sev eral other key signalling players whose regulation is well understood (T able 1). 4 Network Inference Using Goldbeter-Koshland Kinetics EGFR EGFR SOS SOS SOS C3G C3G EP AC EPA C RAS RAS RAP1 RAP1 RAF RAF RAF BRAF BRAF PKA PKA MEK MEK ERK ERK GAP PKAA EP ACA Cilostamide 1 (a) 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 False Positive Rate True Positive Rate Averaged Receiver Operating Characteristic Curves G.K. Kinetics Lin.Bayes Adj.Lin.Bayes Lin.LASSO Adj.Lin.LASSO n=8, σ = 0.2 (b) 0.4 0.5 0.6 0.7 0.8 0.9 1 Lin. Lasso Adj. Lin. Lasso Lin. Bayes Adj. Lin. Bayes G.K. Kinetics n = 8, σ = 0.2 n = 16, σ = 0.2 n = 24, σ = 0.2 n = 24, σ = 0 Area Under ROC Curve (c) Fig. 2: Simulation study . (a) Computational model of the MAPK signalling pathway (due to Xu et al. , 2010). Circles represent proteins, rectangles represent interventions (drug treatments) used to perturb the system. For proteins, one strike-through represents inactivity , two strikes represent degradation. (b) A verage recei ver operating characteristic (R OC) curves (sample size n = 24 , noise σ = 0 . 2 , see text for details) using data generated from model (a). (c) Area under ROC curv e (A UR) for each of the sample size ( n ) and noise ( σ ) regimes shown (boxplots ov er 10 datasets for each n, σ regime). [Legend: “G.K. Kinetics”: network inference using Goldbeter -K oshland kinetics as described in text; “Lin. Bayes”: Bayesian v ariable selection using linear model; “Lin. Lasso”: variable selection using LASSO and linear model; “Lin. Bayes Adj. ” and “Lin. Lasso Adj. ”: as previous b ut corrected for total protein le vels as described in text.] Overall, we find that the proposed approach outperforms the linear methods. 4 DISCUSSION AND CONCLUSIONS In this work we inv estigated integration of biochemical mechanisms into network inference for steady-state data. W e focused on protein phosphorylation, a key biochemical process where the av ailability of relativ ely sophisticated simulation models, extent of existing mechanistic insight and av ailability of relev ant proteomic data combine to facilitate assessment of network inference approaches. Our results, on simulated and real data, demonstrated that protein signalling network topology may be estimated much more successfully under our approach than by con ventional linear formulations. The linear approaches we used were outperformed on simulated data and failed to identify known regulation in real data. Further , we saw that apparently similar linear formulations can return very dif ferent recommendations for which v ariables ought to be included in the model; one possible explanation for such disagreement may be model misspecification. In addition to superior performance, a chemical formulation benefits from increased interpretability , ascribing mechanistic roles to variables and relating parameters to scientifically interpretable rates. Although we focussed on network inference, the methodology presented here simultaneously learns values for these rate parameters, providing a fitted predictiv e model of signalling dynamics. Up to this point we have not discussed identifiability of either parameters or structure. P arameter identifiability does not present challenges within our Bayesian formulation when the objective is structural inference. (The interested reader is referred to Craciun and Pantea (2008); Calderhead and Girolami (2011) for discussions of parameter identifiability in chemical systems.) It terms of structural identifiability , Peters et al. (2011) recently discussed the limitations that arise from symmetry inherent in the the linear-additi ve- Gaussian model and showed that within an identifiable functional model class (IFMOC) it is possible to estimate causal relationships with statistical consistency . Howe ver , in order to formally show that a given functional class constitutes an IFMOC, the theory at present requires strong assumptions, including acyclicity of the causal graph, that do not hold in many real systems, including protein signalling networks. When faced with such challenging circumstances, empirical in vestigations naturally ha ve a k ey role to play . In this sense, our contribution demonstrates that the theoretical results of Peters et al. (2011) have substantive implications for biological network inference in practice. Further work will be required to better understand these implications and to extend the ideas presented here to further application domains, including gene regulation. In complementary work, (Oates and Mukherjee, 2012b) considered the use of nonlinear chemical kinetics for network inference using time-course data, reporting that a chemical formulaion outperformed a number of mechanism-free approaches, including nonparametric models. Network inference is naturally facilitated by interv entional experiments (Lu et al. , 2011), howe ver adequate modelling of the effects of intervention is important to ameliorate statistical confounding (Pearl, 2009). W ithin a chemical kinetic frame work such factors may be easily accounted for; for instance a perfect intervention simply corresponds to remov al of the tar geted species from the chemical model. In testing, not presented here, we extended our methodology to incorporate imperfect certain intervention , where the interventional targets are assumed kno wn, but the interventions may not completely block catalytic acti vity of their targets (see Eaton and Murphy, 2007, for a general discussion of interventions in graphical models). In the context of protein 5 Oates and Mukherjee P r ot ein Spe c ies Log( e xpr essio n ) B asal Lu m ina l (a) Phosphoproteomic data obtained from breast cancer cell lines 0 5 10 15 20 25 30 35 40 0 0.5 1 G.K. Kinetics 0 5 10 15 20 25 30 35 40 0 0.5 Lin. Bayes 0 5 10 15 20 25 30 35 40 0 0.1 0.2 Lin. Bayes Adj. 0 5 10 15 20 25 30 35 40 0 0.2 0.4 Lin. Lasso 0 5 10 15 20 25 30 35 40 0 0.5 1 Lin. Lasso Adj. Phosphorylated Proteins (ranked by scores) incorrect proteins p70S6K (b) Inferred parents (ranked) for S6, based on basal cell line data p70S6K In f er ence f or r egula t or s of p - S6 G . K . K in e t ic s (c) Comparison of competing methodologies Fig. 3: Cancer protein data. (a) Heatmap of rev erse-phase protein array data from a panel of breast cancer cell lines. (b) Proteins were ranked as potential regulators of the node S6 under each methodology . The protein p70 S6 Kinase (p70S6K) is kno wn to be a ke y kinase for the node S6; this kno wn regulator is shown in red in the bar plots. (c) Comparison of methodologies: Each point in the scatter plots represents one phosphoprotein, with the kno wn kinase p70S6K highlighted in bold. [(b) and (c) display weights (posterior probabilities or absolute re gression coefficients) assigned to each protein by each method. phosphorylation, kinases and their inhibitors can be intervened upon using agents (such as monoclonal antibodies or small molecule inhibitors). W e modelled these effects by rescaling the ef fectiv e concentration of interventional targets, in the presence of the treatment, as X j 7→ α j X j where 0 ≤ α j ≤ 1 is an unknown parameter capturing interventional efficacy of the agent. Using this extended methodology we observed that interv entional experiments were more informativ e than the global perturbation experiments considered here, leading to improv ed A UR scores. Network inference based on nonlinear models is computationally challenging. W e considered low-to-moderate dimensional settings ( p = 12 , 38 ), for which the RJMCMC prov ed to be ef fectiv e. The computations in this paper are parallelisable by population Monte Carlo techniques (Laske y and Myers, 2003), and it may therefore be possible to also e xtend this work to the high-dimensional setting (Lee et al. , 2010). In general, nonlinear approaches are clearly more burdensome than their linear counterparts, where highly efficient approaches, including those based on LASSO and related penalised likelihood schemes, allow rapid estimation even in high dimensions (Meinshausen and B ¨ uhlmann, 2006). W e therefore vie w the methods presented here as complementary to variable selection based on linear models, allo wing more refined exploration in settings where some insight into underlying dynamics is av ailable. T arget: Akt p70S6K S6 p53 G.K. Kinetics 4 3 1 8 Lin. Bayes 10 9 15 32 Lin. Bayes Adj. 14 8 8 14 Lin. Lasso N A 8 N A N A Lin. Lasso Adj. N A 12 N A N A T otal # Candidates: 36 37 36 37 T able 1. Cancer protein data, comparison of methods. The proposed method was compared with linear approaches using re verse-phase protein array data for nodes whose regulation has been extensiv ely studied in the literature. Each method ranked potential regulators among candidate proteins; here we display the rank assigned to the known kinase, using each of the 5 methods. For e xample, Fig 3b sho ws such an analysis for the target node (i.e. netw ork child) S6, where G.K. Kinetics ranked the known kinase p70S6K 1st out of a total of 36 candidates. High rank indicates that the known kinase is correctly highlighted in the analysis; the highest-ranked result is highlighted in bold for each target node. Here we show the rank assigned to the known kinase for each of the target nodes Akt, p70S6k, S6 and p53. [“N A ” indicates that the known kinase recei ved zero weight. Alternative phospho-forms of the tar get were excluded as candidates for Akt and S6, so that there were 36 candidates rather than 37. Here we present results obt ained using data from cell lines of basal subtype; luminal results are shown in Supplementary Information.] On real proteomic data we observed that network inference was challenging. In particular , inference based on data obtained from luminal cell lines encouraged poor performance from all approaches (see Supplemental Information). Whilst the genomic background (in our example breast cancer) may be a factor - illustrated by the luminal f ailure case - we suspect that the real difficulties result from a complex noise process. At present, network inference can aid in hypothesis generation, but care must be taken in interpreting results. Further experimental and methodological advances will be required 6 Network Inference Using Goldbeter-Koshland Kinetics before network inference methods can be regarded as truly robust tools for biological discov ery . In this work we in vestigated integration of biochemical mechanisms into network inference. Whilst the Goldbeter- K oshland formulae are inv alid at the single-cell level, which is intrinsically stochastic, the e vidence presented here suggests that these deterministic nonlinear equations represent a better approximation than the corresponding linear equations. In particular a chemical kinetic formulation is able to account, in a principled way , for variation in total protein le vels between samples. Consequently , inferred edges cannot be interpreted as indicators of direct biochemical interaction; rather an edge corresponds to the prediction that intervention on the parent will result in a change in expression of the child, possibly indirectly via unobserved variables. In our real data example we therefore allo wed for candidate species which are not themselves kinases, such as S6 and p53. For simplicity , in specifying the class F of functional forms, we did not consider post-translational modifications such as ubiquitin ylation, nor spatial ef fects such as translocation, nor did we explicitly distinguish between phosphorylation on different residues. The methodology which we presented may be generalised to other molecular mechanisms. In particular alternativ e mechanisms of enzyme interaction such as noncompetiti ve, uncompetitiv e, hyperbolic and parabolic inhibition could be readily integrated into our frame work. A CKNO WLEDGEMENT Funding : Financial support was provided by NCI CCSG support grant CA016672, NIH U54 CA112970, UK EPSRC EP/E501311/1 and the Cancer Systems Biology Center grant from the Netherlands Organisation for Scientific Research. REFERENCES Bansal, M. et al. (2007) How to infer gene networks from expression profiles, Mol. Sys. Bio. , 3 , 78. Bender , C. et al (2010) Dynamic deterministic effects propagation networks: learning signalling pathways from longitudinal protein array data, Bioinformatics , 26 (ECCB 2010), i596-i602. Bintu, L. et al. (2005) T ranscriptional regulation by the numbers: models, Curr . Opin. Genet. Dev . , 15 (2), 116-124. Calderhead, B., Girolami, M. (2011) Statistical analysis of nonlinear dynamical systems using differential geometric sampling methods, J. Roy . Soc. Interface F ocus , 1 (6), 821-835. Cantone, I. et al. (2009) A yeast synthetic network for in vi vo assessment of reverse- engineering and modeling approaches, Cell , 137 (1), 172-81. Chen, W . et al. (2009) Input-output behavior of ErbB signaling pathways as revealed by a mass action model trained against dynamic data, Mol. Sys. Bio. , 5 , 239 Chou, I.C., V oit, E.O. (2009) Recent Dev elopments in Parameter Estimation and Structure Identification of Biochemical and Genomic Systems, Math. Biosci. , 219 (2), 5783. Craciun, G., P antea, C. (2008) Identifiability of chemical reaction networks, J. Math. Chem. , 44 , 244-59. Eaton D, Murphy K (2007) Exact Bayesian structure learning from uncertain interventions, Pr oc. 11th Conf. Artificial Intelligence and Statistics (AIST ATS-07) . Goldbeter , A., Koshland, D.E. (1981) An amplified sensiti vity arising from covalent modification in biological systems, Pr oc. Nati Acad. Sci. , 78 (11), 6840-6844. Green, P .J. (1995) Reversible jump Markov chain Monte Carlo computation and Bayesian model determination, Biometrika , 82 (4), 711-732. Green, P ., Hastie, D. (2009) Reversible jump MCMC, technical report (http://www .maths.bris.ac.uk/mapjg/Papers.html). Heagerty , P .J., Kurland, B.F . (2001) Misspecified Maximum Likelihood Estimates and Generalised Linear Mixed Models, Biometrika , 88 (4), 973-985. Hecker , M. et al. (2009) Gene regulatory network inference: Data integration in dynamic models - A revie w , Biosystems , 96 (1), 86-103. Hennessey , B.T . et al. (2010) A T echnical Assessment of the Utility of Re verse Phase Protein Arrays for the Study of the Functional Proteome in Nonmicrodissected Human Breast Cancer , Clin. Pr oteom. , 6 , 129-151. Hill, S. (2012) Sparse Graphical Models for Cancer Signalling, PhD Thesis, University of W arwick, U.K. Kholodenko, B.N. (2006) Cell-signalling dynamics in time and space, Nat. Rev . Mol. Cell Bio. , 7 (3), 165-176. Kim, S.Y ., Imoto, S., Miyano, S. (2003) Inferring gene networks from time series microarray data using dynamic Bayesian networks, Briefings in Bioinformatics , 4 (3), 228-35. Kim, S.Y ., Ferrell, J.E. (2007) Substrate Competition as a Source of Ultrasensitivity in the Inactiv ation of W ee1, Cell , 128 , 11331145. Laskey , K.B., Myers, J. (2003) Population Markov Chain Monte Carlo, Mach. Learn. , 50 (12), 175196. Lee, A. et al. (2010) On the Utility of Graphics Cards to Perform Massi vely Parallel Simulation of Adv anced Monte Carlo Methods, J . Comp. and Graph. Stat. , 19 (4), 769-789. Lee, W .P ., Tzou, W .S. (2009) Computational methods for discov ering gene networks from expression data, Brief. Bioinform. , 10 (4), 408-423. Leskov ac, V . (2003) Comprehensive enzyme kinetics, Springer . Li, C-W ., Chen, B-S. (2010) Identifying Functional Mechanisms of Gene and Protein Regulatory Networks in Response to a Broader Range of En vironmental Stresses, Comp. and Func. Genomics , 408705. Lu, Y . et al. (2011) Kinome siRNA-phosphoproteomic screen identifies networks regulating Akt signaling, Oncogene , 30 , 4567-77. Lv , J., Liu, J.S. (2010) Model Selection Principles in Misspecified Models, T echnical Report, Markowetz, F ., Spang, R. (2007) Inferring cellular networks - A re view , BMC Bioinformatics , 8 (Suppl. 6), S5. Meinshausen, N., B ¨ uhlmann, P . (2006) High-dimensional graphs and variable selection with the lasso, The Annals of Statistics , 34 (3), 1436-62. Min Lee, J. et al. (2008) Dynamic Analysis of Integrated Signaling, Metabolic, and Regulatory Networks, PLoS Comput. Biol. , 4 (5), e1000086. Morrissey , E.R. et al. (2010) On re verse engineering of gene interaction networks using time course data with repeated measurements, Bioinformatics , 26 (18), 2305-2312. Mukherjee, S., Speed, T .P . (2008) Network inference using informati ve priors, Pr oc. Nat. Acad. Sci. , 105 (38), 14313-14318. Nam, D., Y oon, S.H., Kim, J.F . (2007) Ensemble learning of genetic networks from time-series expression data, Bioinformatics , 23 (23), 3225-3231. Nev e, R. et al. (2006) A collection of breast cancer cell lines for the study of functionally distinct cancer subtypes, Cancer Cell , 10 (6), 515-527. Oates, C., Mukherjee, S. (2012a) Network Inference and Biological Dynamics, T o Appear in the Annals of Applied Statistics . Oates, C., Mukherjee, S. (2012b) Structural inference using nonlinear dynamics, CRiSM W orking Paper Series, No. 12-07. Oates, C., Mukherjee, S. (2012c) On the relationship between ODEs and DBNs, T echnical Report, Opgen-Rhein, R., Strimmer, K. (2007) Learning causal networks from systems biology time course data: an effecti ve model selection procedure for the vector autoregressi ve process, BMC Bioinformatics , 8 , (Suppl. 2), S3. Pearl, J. (2009) Causal inference in statistics: An overvie w , Stat. Surveys , 3 , 96-146. Peters, J. et al. (2011) Identifiability of Causal Graphs using Functional Models, Proc. 27th Ann. Conf. Uncertainty in Artificial Intelligence (U AI-11) , 589-598. Roberts, G.O., Rosenthal, J.S. (2006) Harris Recurrence of Metropolis-within-Gibbs and Trans-Dimensional Mark ov Chains, Ann. App. Pr ob. , 16 (4), 2123-2139. Sachs, K. et al (2005) Causal protein-signaling networks deriv ed from multiparameter single-cell data, Science , 308 , 5239. Schoeberl, B. et al. (2002) Computational modeling of the dynamics of the MAP kinase cascade activ ated by surface and internalized EGF receptors, Nat. Biotech. , 20 (4), 370-375. Steijaert, M.N. et al. (2010) Computing the Stochastic Dynamics of Phosphorylation Networks, J. Comp. Bio. , 17 (2), 189-199. Xu, T . et al. (2010) Inferring signaling pathway topologies from multiple perturbation measurements of specific biochemical species, Sci. Sig. , 3 (113), ra20. 7
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment