Parallelizing MCMC via Weierstrass Sampler
With the rapidly growing scales of statistical problems, subset based communication-free parallel MCMC methods are a promising future for large scale Bayesian analysis. In this article, we propose a new Weierstrass sampler for parallel MCMC based on …
Authors: Xiangyu Wang, David B. Dunson
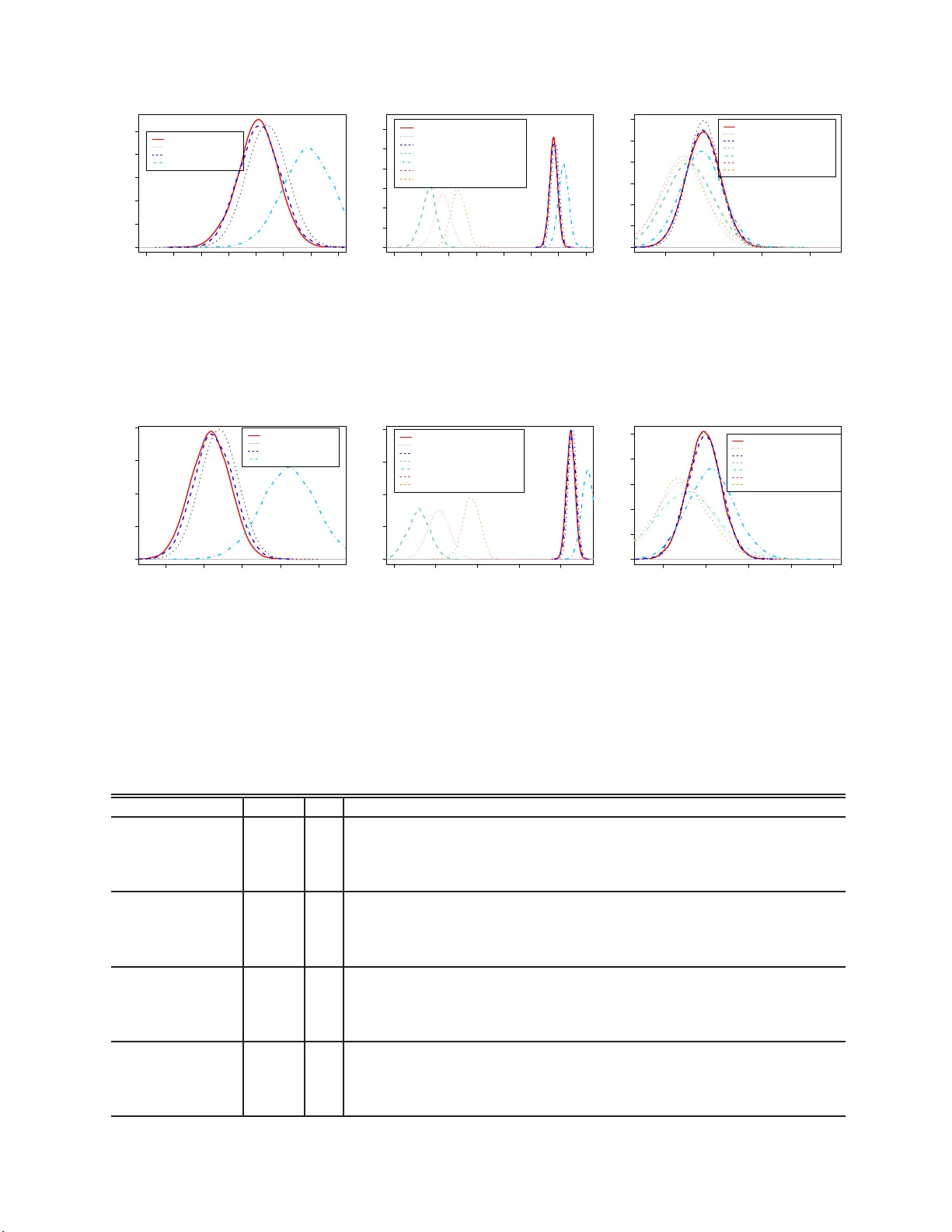
P arallelizing MCMC v ia W eierstrass Sampler Xiangy u W ang and David B. Dunson Ma y 27, 201 4 Abstract With the rapidly gro wing scales of statistica l problems, subset based comm unication- free parallel MCMC metho d s are a promising future for large scale Ba y esian analysis. In this article, w e prop ose a new W eierstrass sampler for parallel MCMC based on indep end en t subsets. The new sampler app ro ximates the f ull d ata p osterior samples via com b in ing the p osterior draws from ind ep endent subs et MCMC chains, and thus enjo ys a h igher computational efficiency . W e sh o w that the appr o ximation error for the W eierstrass sampler is bou n ded b y some tunin g parameters and pro vide su gges- tions for c hoice of the v alues. Simulatio n study sho ws th e W eierstrass sampler is very comp etitiv e compared to other metho d s for com bining MCMC c h ains generated for subsets, including a v eraging and k ernel smo othing. Keywor ds : Big data; Comm unication-free; Em bara ssingly parallel; MCMC ; Scalable Bay es; Subset sampling; W eierstrass transform. 1 In tro ducti o n The explosion in the collection and interest in big data in recen t y ears has brough t new c hallenges to mo dern statistics. Ba y esian a nalysis, whic h has b enefited from the ease and generalit y of sampling-based inference, is no w suffering as a result of the h uge computational demand of p osterior sampling algorithms, suc h as Mark ov c hain Monte Carlo (MCMC), in large scale settings. MCMC f aces sev eral b ottlenec ks in big data problems due to the increasing expense in lik eliho o d calculations, t o the need for up dating laten t v a r ia bles specific to eac h sampling unit, and to increasing mixing problems as the p o sterior b ecomes more concen trated in large samples. T o accelerate computation, efforts hav e b een fo cused in three main directions. The first is to parallelize computation of the lik eliho o d a t eac h MCMC iteration (Agarw al and Duc hi, 2012; Smola and Naray anam urthy, 2010). Under conditional indep endence, calculations can 1 b e conducted separately for mini ba t c hes of data stored on different mac hines, with re- sults fed back to a cen tra l pro cessor. This approach requires comm unication within each iteration, whic h limits o v erall speed. A second strategy fo cuses on accelerating exp en- siv e gradien t calculations in La ng evin and Hamiltonian Mon te Carlo (Neal, 2010) using sto c hastic a ppro ximation based on random mini batches of data (W elling and T eh, 201 1; Ahn et al., 2012). A third direction is motiv ated b y the independen t pro duct equation (1) from Bailer-Jo nes and Smith (2011). The data are par t itioned in to mini batc hes, MCMC is run independen tly for eac h batc h without comm unication, and the c hains are then combine d to mimic dra ws from t he full data po sterior distribution. By running independent MCM C c hains, this approac h byp a sses comm unication costs un til the combining step and increases MCMC mixing rate, as the subset p osteriors are based on smaller sample sizes and hence effectiv ely annealed. The main open question for this approac h is ho w to com bine the c hains to obtain an accurate a pproximation? T o address this qu estion, Scott et a l. (2013) suggested to use a v eraged p osterior draws to appro ximate the true p osterior samples. Neis wanger et al. (2013) a nd White et a l. (2013) instead mak e use of k ernel densit y estimation to approximate the subset p osterior densities, and then approx imate the true p osterior densit y follo wing (1). Based on our experiments , these metho ds hav e adequate p erformance only in sp ecialized settings, and exhibit p o or p erformance in many o ther cases, suc h as when parameter dimensionality increases and large sample Gaussian appro ximations are inadequate. W e prop o se a new com bining me t ho d based on the indep enden t pr o duct equation (1), whic h attempts to address these problems. In Section 2, w e first describ e problems that arise in using (1) in a naive wa y , briefly state the motiv atio n for our metho d, and provide theoretic justification for the appro ximation error. In Section 3 w e then describ e sp ecific algorithms and discuss tuning parameter c hoice. Section 4 assesses the metho d using extensiv e examples. Section 5 con t ains a discussion, and pro ofs a re included in the app endix. 2 Motiv ation The fundamen tal idea for the new metho d is as follow s. F or a parametric mo del p ( X | θ ), assume the data con tain n conditionally indep endent observ ations, whic h are partit io ned in to m non- o ve rla pping subsets, X = { X 1 , · · · , X m } . The following relationship holds b et wee n 2 the p osterior distribution for the full da t a set and p osterior distributions f or each subset, p ( θ | X ) ∝ p ( X | θ ) p ( θ ) = m Y i =1 p ( X i | θ ) p ( θ ) ∝ m Y i =1 p ( θ | X i ) p i ( θ ) p ( θ ) = m Y i =1 p ( θ | X i ) p ( θ ) Q m i =1 p i ( θ ) , where p ( θ ) is the prio r distribution for the full da t a set and p i ( θ ) is that for subset i . As w e will only b e obtaining draw s fr om the subset p osteriors to approximate draw s fr o m p ( θ | X ), w e ha v e flexibilit y in the c hoice of p i ( θ ). If w e further require p ( θ ) = Q m i =1 p i ( θ ), t he ab o ve equation can b e reformulated as p ( θ | X ) ∝ p ( θ | X 1 ) p ( θ | X 2 ) · · · p ( θ | X m ) = m Y i =1 p ( θ | X i ) , (1) whic h we refer to as t he indep enden t pro duct equation. This equation indicates that under the indep endence assumption, the p osterior de nsity of the f ull data can b e repres ented b y the pro duct o f subset p osterior dens ities if the subsets together form a partition of the original s et. Ho w eve r , despite this concise relat io nship, sampling from the pro duct of densities remains a difficult issue. Scott et al. (2013) use a conv olutio n pro duct to appro ximate this equation, resulting in a n a v eraging metho d. This appro ximation is adequate when the subset po steriors are close to Gaussian, as is e xp ected to hold in ma ny parametric models for sufficien tly lar g e subset sample sizes due to the Bernstein-v on Mises theorem (V an der V aart , 1998). Another in tuitiv e w ay to apply (1) is to use k ernel based non-parametric densit y estima- tion (k ernel smo othing). Using ke rnel smo othing, one o btains a closed form appro ximation to each subset p osterior, with these approx imatio ns multiplie d together to appro ximate the full da ta p osterior. This idea has b een implemen ted recen tly b y Neisw anger et al. (201 3), but suffers from sev eral draw backs . 1. Curse of dimensio n ality in the numb er of p ar a meters p . It is w ell known that k ernel densit y estimation breaks do wn a s p increases, with the sample size (n umber of p oste- rior samples in this case) needing to increase exp onen tially in p to maintain the same lev el of a ppro ximation a ccuracy . 2. Subset p osterior disc onne ction . Because of the pro duct form, the p erfo rmance of the appro ximation to the full data p osterior dep ends on the ov erlapping area of t he subset p osteriors, whic h is most lik ely to b e the tail area of a subset p o sterior distribution. Hence, slight deviations in light-tailed appro ximations to the differen t s ubset posteriors migh t lead to p o or approximation of the full dat a p osterior. (See the righ t figure in Fig.2) 3 3. Mo de missp e cific ation . F or a m ultimo dal p osterior, a v erag ing (noticing that the com- p onen t mean of the k ernel smo othing metho d is the av erage of subset dra ws) can collapse differen t mo des, leading to unreliable estimates. T o ameliorate these problems, w e prop ose a differen t metho d for para llelizing MCMC. This new metho d, designated as the Weierstr ass sa m pler , is motiv ated by the W eierstrass transform, whic h is related to k ernel smo othing but from a differen t p ersp ectiv e. Our ap- proac h ha s go o d p erformance including in cases in whic h large sample normalit y of t he p osterior do es not hold. In the rest of the a rticle, w e will us e the term f ( θ ) to denote general p osterior distributions and f i ( θ ) for subset p osteriors, in order to matc h the ty pical no t ation used with W eierstrass transfor m. The k ey of our W eierstrass sampler lies in the W eierstrass tra nsform, W h f ( θ ) = Z ∞ −∞ 1 √ 2 π h e − ( θ − t ) 2 2 h 2 f ( t ) dt, whic h w a s initially introduced by W eierstrass (1885). The origina l pro of show s that W h f ( θ ) con v erges to f ( θ ) point wise as h tends to zero. Our method appro ximates the subset den sities via the W eierstrass transformation. W e a v oid inheriting the problems of the k ernel smo othing metho d b y directly mo difying the targeted sampling distribution instead of estimating it from the subs et p osterior dra ws. In particular, w e attempt to directly sample the a ppro ximated dra ws from the transformed densities instead of the original subset p osterior distributions. Applying the W eierstrass transform to all subset p o steriors and denoting p ( θ | X i ) b y f i ( θ ), the full set p osterior can b e approximated as m Y i =1 f i ( θ ) ≈ m Y i =1 W h i f i ( θ ) = m Y i =1 Z 1 √ 2 π h i e − ( θ − t i ) 2 2 h 2 i f ( t i ) dt i ∝ Z exp − ( θ − ¯ t ) 2 2 h 2 0 exp − ¯ t 2 − ¯ t 2 2 h 2 0 f 1 ( t 1 ) · · · f m ( t m ) dt, where h − 2 0 = P m i =1 h − 2 i , w i = h − 2 i /h − 2 0 , ¯ t 2 = P m i =1 w i t 2 i and ¯ t = P i =1 w i t i . The ab o ve equation can b e view ed as the marginal distribution o f the ra ndom v ariable θ , deriv ed from its jo int distribution with the random v ariables t i , i = 1 , 2 , . . . m with joint densit y exp − ( θ − ¯ t ) 2 2 h 2 0 exp − ¯ t 2 − ¯ t 2 2 h 2 0 · f 1 ( t 1 ) · f 2 ( t 2 ) · · · f m ( t m ) . (2) The or ig inal subset p osteriors app ear a s comp onents of this joint distribution, enabling subset-based p osterior sampling. Moreov er, the conditional dis t r ibutio n of the ta rget random v aria ble θ giv en the subset random v ariables is simply Gaussian. 4 3 Preliminaries The original W eierstrass t r ansformation w a s stated in terms of the Gaussian kernel. F or flexibilit y , w e relax this restriction b y broadening the c hoice of k ernel f unctions, justifying the generalizations throug h Lemma 1 (See app endix). F ollowing f r om the previous se ction, the p osterior densit y can b e approximated as m Y i =1 f i ( θ ) ≈ m Y i =1 W ( K ) h i f i ( θ ) = m Y i =1 Z K h i ( θ − t i ) f i ( t i ) dt i = Z m Y i =1 h − 1 i K h − 1 i ( θ − t i ) f 1 ( t 1 ) f 2 ( t 2 ) · · · f m ( t m ) dt, (3) where the las t term can be view ed as the margina l distribution of random v ariable θ , deriv ed from its joint distribution with the random v ariables t i , i = 1 , 2 , · · · m and a joint densit y Q m i =1 K h i ( θ − t i ) f i ( t i ). If this j o in t densit y is prop er (illustrated in Theorem 1) , one may sample θ from this distribution, utilizing the subset samplers as comp onents . The details will b e discussed in the next section. This section will fo cus on quantifying the approxim a tion error o f (3). The results will b e stated in terms of b oth one-dimensional and multiv ariate mo dels. The detailed deriv ation is only pro vided in the o ne- dimensional case in the App endix, as the multiv ariate deriv atio n pro ceeds along identical lines. A H¨ older α smo oth dens ity function (fo r definition see Lemma 1) is alw ay s b ounded on R p for α ≥ 0. Let M = max i =1 , 2 , ··· ,m { f i ( θ ) , x ∈ R p } denote the maxim um v alue of the subse t p osterior densities. W e ha v e the follow ing result (for the one-dimensional case). Theorem 1. If the p osterior densities and the kernel functions satisfy the c ondition in L em ma 1 w ith α ≥ 2 and k = 2 , i.e., the p osterior de nsity is at le ast se c ond-or der diff e r- entiable and the kernel function has fini te varian c e, then the distribution define d in (3) is pr op er and ther e exists a p os i tive c onstant c 0 such that when h 2 = P m i =1 h 2 i ≤ c − 1 0 , the total variation distanc e b etwe en the p osterior distribution and the appr oximation fol lows k f − ˜ f k = C − 1 m Y i =1 f i ( θ ) − C − 1 W m Y i =1 W ( K ) h i f i ( θ ) ≤ 2 r 0 r − 2 1 h 2 , wher e C and C W ar e the norma lizing c onstants, and r 0 , r 1 ar e define d as r 0 = C − 1 M max i ∈{ 1 , 2 , ··· ,m } Z m Y j 6 = i f j ( θ ) dx r 2 1 = 2 M M 2 R t 2 K ( t ) . F or m ultiv ariate distributions, the k ernel v ariance h i should b e substituted b y the k ernel 5 co v ariance H i and w e hav e a similar result. Corollary 3.1. ( Multivariate c ase) If the p-variate p osterior densities f i ( θ i 1 , · · · , θ ip ) and t h e kernel functions satisfy the c onditions in L emma 2 with α ≥ 2 and k = 2 , then for sufficien tly smal l h 2 , wher e h 2 = P m i =1 tr ( H i ) , the total variation distanc e b etwe en the p osterior and the appr oximate d density fol lows k f − ˜ f k = C − 1 m Y i =1 f i ( θ i 1 , · · · , θ ip ) − C − 1 W m Y i =1 W ( K ) H i f i ( θ i 1 , · · · , θ ip ) ≤ 2 r 0 r − 2 1 h 2 , wher e C , C W ar e normalizing c onstants, and r 0 , r 1 ar e define d in The or em 1. In the erro r b ound in Theorem 1 , the constan ts r 0 and c 0 do not v ary m uc h ev en as the sample size increases to infinit y . In fact, they will con v erge to constan ts in probability (see discussions in the App endix af ter the pro of of Theorem 1). As a result, the choice of the tuning parameters h i is indep enden t of the sample size, whic h is a desirable prop erty . 4 W eierstrass refinemen t sampling As the error c haracterized b y Theorem 1 main tains a r easonable lev el, t he approx ima t io n (3) will b e effectiv e. In this section, a refinemen t sampler is prop osed. F or con venie nce w e will fo cus on the G aussian kerne l if not sp ecified otherwise, but mo difications to other k ernels are straigh tfor w ard. The algorithm is referred to as a Weierstr ass r efinement sampler , b ecause samples from an initial rough a ppro ximation to the p osterior (obtained via Laplace, v a ria- tional a pproximations or o t her methods) are r efi n e d us ing information obta ined from parallel dra ws from the differen t subset p osteriors within a W eierstrass approx imatio n. T ypically , the initial ro ugh approxim a tions can b e obtained using parallel computing algor it hms; f or example, La place and v ariational algorithms a re parallelizable. Equation ( 3 ) can b e used t o obtain a G ibbs sampler. F or the Gaussian k ernel, the densit y in (3) can b e reformu la ted into (2), whic h can then b e used to construct a Gibbs sampler as follo ws (univ a riate case): θ | t i ∼ N ( ¯ t, h 2 0 ) (4) t i | θ ∼ 1 √ 2 π h i e − ( t i − θ ) 2 2 h 2 i f i ( t i ) i = 1 , 2 , . . . , m. (5) This approach t a k es the parameters in eac h subset as latent v ariables, and up dates θ via the av erage of all laten t v ariables. The Gibbs up dating is used as a refinemen t to ol; that is, the parameters θ are initially draw n fro m a rough appro ximatio n (L a place, v ariational) 6 and then plugged into the Gibbs sampler for one step up dating, kno wn as a refinemen t step. Theorem 2 sho ws refinemen t leads to geometric improv emen t. Theorem 2. Assume θ 0 ∼ f 0 ( θ 0 ) wh i c h is an in itial app r ox i m ation to the true p osterior f ( θ ) . By doing one step Gibbs up dating as describ e d in (4) , (5) (wi th gener al kernel K ), we obtain a n e w dr aw θ 1 with de n sity f 1 ( θ ) . Using the notations in The or em 1, if the k e rn el density function K is ful ly supp orte d on R , then fo r any given p 0 ∈ (0 , 1) , ther e exists a me asur able set D such that R D ˜ f ( x ) dx > p 0 and, Z | f 1 ( θ ) − ˜ f ( θ ) | dθ ≤ (1 − η ) Z D | f 0 ( θ ) − ˜ f ( θ ) | dθ + Z D c | f 0 ( θ ) − ˜ f ( θ ) | dθ , wher e η is a p ositive va lue dep ending on p 0 but indep endent o f f 0 . F urthermor e, if the kernel function s a tisfies the fol low ing c ondition, lim θ → ±∞ inf K h ( θ − t ) W ( K ) h f i ( θ ) > 0 (6) for giv en t ∈ R and i ∈ { 1 , 2 , · · · , m } , then the total v ariational distanc e fol lows k f 1 ( θ 1 ) − ˜ f ( θ ) k ≤ (1 − η ) k f 0 ( θ 0 ) − ˜ f ( θ ) k for so m e η > 0 , which is indep endent of f 0 . The pro of of The o rem 2 is pro vided in the appendix. Th o ugh the theorem is stated for univ ariat e distributions, the result is applicable t o multiv ariate distributions as w ell. The concrete refinemen t sampling algorithm is describ ed b elo w as Algo rithm 1. There are a n umber of adv an ta g es of this r efinemen t sampler. F irst, the metho d addresses the dimensionalit y curse (issue 1 in Section 2, whic h app ears as the inefficiency of the Gibbs sampler (5) and ( 4) when h is small), with the la rge sample approximation only used as an initial rough starting p oin t that is then refined. W e find in o ur exp eriments tha t w e hav e go o d p erformance ev en when the true p osterior is high-dimensional, m ultimo dal and very non-Gaussian. Second, as can b e seen from (5), t he subset p o sterior densities are multiplied b y a common conditio nal comp onen t, whic h brings them close to eac h o t her and limits the problem with subset posterior disconne ction (issue 2 of Section 2). In a ddition, step 7-10 can b e fully parallelized, as eac h dra w is an indep enden t op eration. There ma y b e adv a n tages of an iterativ e v ersion of the algorithm, whic h runs more than one step of the Gibbs up date on eac h of the initia l draws (rep eating Algorithm 1 sev eral times). The c hoice of tuning para meters H i and the relationship with n umber of subsets m is an imp ortant issue. The parameter H i on the one hand con trols t he approximation error for eac h subset p o sterior. Apparen tly , tr ( H i ) has to b e reduced a s the n umber of subsets m 7 Algorithm 1 W eierstrass refinemen t sampling Initialization: 1: Input H i (or h i for univ ariate case) for i = 1 , 2 , · · · , m . 2: N = n um b er of samples , M C M C ← {} , T i ← {} , i = 1 , 2 , · · · , m ; 3: for k = 1 t o N do 4: θ k ∼ ˆ f ( θ ); # ˆ f ( θ ) is the r ough appr oximation for the ful l set p osterio r 5: end for Iteration: 6: # On e ach of the m subsets i = 1 , 2 , · · · , m in p ar al lel, 7: for k = 1 t o N do 8: Sample t ( k ) i = ( t ( k ) i 1 , · · · , t ( k ) ip ) T ∼ dN ( t i | θ k , H i ) · f i ( t i ); 9: T i ← T i ∪ { t ( k ) i } ; 10: end for 11: # Col le ct al l T i , i = 1 , 2 , · · · , m to dr aw p osterior samples 12: for k = 1 to N do 13: ˜ θ ∼ N ( m − 1 P m i =1 t ( k ) i , ( P m i =1 H − 1 i ) − 1 ); 14: M C M C ← M C M C ∪ { ˜ θ } ; 15: end for 16: return MCMC increases. On the other hand, H i also determines the efficiency o f the Gibbs sampler (ho w fast can the Gibbs sample r ev olv e the initial appro ximation to w ards the true p osterior), th us, H i migh t nee d to b e c hosen adequately larg e for efficien t refineme nt. Suc h an argumen t leads to the conclusion o f c ha ng ing H i during the refinemen t sampling pro cess if the refinemen t will b e rep eated m ultiple t imes. According to F ukunaga’s (F ukunaga, 1972) a pproac h in choosing the bandwidth, if w e attempt to apply kernel densit y estimation directly to the p osterior distribution obtained from the full data set, the optimal c hoice will b e H 0 = ( p + 2) / 4 − 2 / ( p +4) N − 2 / ( p +4) ˆ Σ , (7) where p is the n um b er of parameters, N is the total num b er of p osterior samples and ˆ Σ is the sample co v ariance of the p osterior distribution (to be appro ximated by the inv erse of the Hessian matr ix at mo de). Based o n this result, the starting v alue fo r H i could b e chos en as mH 0 , of whic h the ma g nitude is comparable to the co v ariance of eac h subset p osterior distribution, admitting efficien t refinemen t in the b eginning. As the r efinemen t pro ceeds, the ending p oint of H i should b e around m − 1 H 0 indicating an accurate approximation. The tuning para meters in the middle of the pro cess should be c hosen in b et we en. F or example, for a 10- step refinemen t pro cedure, one could use mH 0 for the first three steps, H 0 for the next fiv e ste ps a nd m − 1 H 0 for the last t wo steps. 8 5 W eierstrass rejection sampling Algorithm 1 requires an initial appro ximation to the ta rget distribution. T o a void this initial- ization, we pr o p ose an alternativ e self-adaptive algorithm, whic h is designated a s Weierstr ass r ej e ction sampler . Because of the self-adapting feature, the algorithm suffers fr o m certain dra wbac ks, whic h will b e discusse d along with p ossible solutions in the latter part of this section. W e b egin with a description of the algorithm. The formula sho wn in ( 2) immediately ev ok es a rejection sampler for sampling from the joint distribution: assuming t i ∼ f i , i = 1 , 2 , . . . , m . Since exp( − ¯ t 2 − ( ¯ t ) 2 2 h 2 0 ) ≤ 1, w e can accept a dra w of θ ∼ N ( ¯ t, h 2 0 ) with probability exp( − ¯ t 2 − ¯ t 2 2 h 2 0 ). Suc h an approac h mak es use of the av erag e of the dra ws from the subsets to generate further p osterior dra ws, which is similar to the kerne l s mo othing metho d prop osed b y Neisw anger et al. (2013). Ho we ver, with sligh t mo dification, the W eierstrass rejection sampler can use the subset posterior draws as appro ximated samples directly without av erag ing, and th us av oid the mo de missp ecification issue. The result is stated b elow (fo r univ a riate case). Theorem 3. If the subse t p osterior densities f k , k = 1 , 2 , . . . , m satisfy al l the c onditions state d in The or em 1 w ith α ≥ 2 and p osterior dr aws θ k , and the se c ond or der kern e l func- tion K ( · ) (w hich is a density function) satisfie s that max θ ∈R K ( θ ) ≤ c for som e p ositive c onstant c , then for any given i ∈ { 1 , 2 , · · · , m } , the r eje ction samp ler ac c epts θ i with pr ob a- bility c − m +1 Q m k 6 = i K ( θ k − θ i h k ) . R eferring to the density of the ac c epte d dr aws by g ( θ ) , the total variation distanc e of the appr oximation err or fol lo ws k g ( θ ) − f ( θ ) k = 1 2 g ( θ ) − C − 1 m Y k =1 f k ( θ ) L 1 ≤ 2 r 0 r − 2 1 h ′ 2 , wher e h ′ 2 = P m k 6 = i h 2 k . The c onstants r 0 , r 1 ar e define d in The or em 1. The follo wing corollary is the multiv ariate v ersion. Corollary 5.1. (Multivariate c ase) If the p-variate p osterior dens i ties f i ( θ i 1 , · · · , θ ip ) , i = 1 , 2 , · · · , m satisfy the c onditions in Cor ol lary 3.1 with α ≥ 2 and p osterior dr a w s θ k , and the se c ond or der kernels K j , j = 1 , 2 , · · · , p ar e b ounde d b y p ositive c o nstant c , then for any give n i ∈ { 1 , 2 , . . . , m } , the r eje ction sample r ac c epts θ i if c − p ( m − 1) Q m k 6 = i Q p j =1 K j ( θ kj − θ ij r 1 h kj ) ≥ u wher e u ∼ U nif (0 , 1) . R eferring to the density of the ac c epte d dr aws by g ( θ ) , the appr oximation err o r fol l o ws, k g ( θ ) − f ( θ ) k = 1 2 g ( θ ) − C − 1 m Y k =1 f k ( θ ) L 1 ≤ 2 r 0 r − 2 1 h ′ 2 , wher e h ′ 2 = P m k 6 = i tr ( H i ) . The c onstants r 0 , r 1 ar e define d in The or em 1. 9 With the ab ov e theorem, it is easy to construct a rejection sampler as follo ws: f o r each it- eration w e randomly se lect one dra w from the p o ol (or acc o rding to s o me reasonable w eigh ts), and p erform the rejection sampling according to Theorem 3. W e rep eat the pro cedure for all iterat io ns a nd then gather the accepted dra ws. The reason that the rejection op eration is only conducted on one dra w within the same iteratio n is t o a v o id incorp orating extra undesirable corr elat io n b et w een the accepted dra ws. The effectiv eness of a rejection sampler is determined by the acceptance rate. F or a p - v aria te mo del and m subsets, the acceptance rate f or the W eierstrass rejection sampler can b e calculated as (assuming all h k j s are equal to h ∗ ), AR p,m = P c − p ( m − 1) m Y k 6 = i p Y j =1 K j θ k j − θ ij r 1 h k j ≥ u = O r 1 h ∗ c p ( m − 1) , (8) for adequately s mall h ∗ . Clearly , the acceptance rate suffers from the c urse of dimensionalit y in b o th m and p , so t he n um b er of po sterior samples has to increase exp o nentially with m and p . This is the same problem as with the k ernel smo othing metho d discusse d b efore. T o ameliorate the dimensionalit y curse, we provide the follow ing solution. 5.1 Sequen tial rejection sampling The n umber of subsets m is easier to tac kle. It is straig h tforward to bring m dow n to log 2 m b y using a pairwise comb ining strategy : we first com bine the m subsets in t o a pairwise manner to obtain po sterior draw s on m/ 2 subsets. This pro cess is rep eated to obtain m/ 4 subsets and so on until obtaining the complete data set. The whole pro cedure tak es ab out ⌊ log 2 m ⌋ steps, and th us brings the p o wer from m down to ⌊ lo g 2 m ⌋ . The curse of dimensionalit y in t he n umber of par a meter p is less straightforw ard to address. If the p -v ariate p osterior distribution f satisfies that the para meters a r e a ll inde- p enden t, then f ( θ 1 , θ 2 , · · · , θ p ) = p Y j =1 f ( θ j ) and f ( θ j ) ∝ m Y i =1 f i ( θ ij ) , (9) where f ( θ j ) and f i ( θ ij ) ar e the p osterior ma r g inal densities for the j th parameter on the full set and on the i th subset, respective ly . The equation (9) indicates that the p osterior 10 marginal distribution satisfies the indep enden t pro duct equation as well. Therefore, one can obtain the jo int p osterior distribution from the marginal p osterior distributions, whic h a re obtained by com bining t he subset marginal p osterior distributions via W eierstrass r ejection sampling. This appro ac h th us a voids the dimensionality issue (since in this case p is a lwa ys equal to 1). In g eneral, the p osterior marginal distribution do es not satisfy the equation ( 9 ) b ecause, f ( θ j ) = Z f ( θ 1 , θ 2 , · · · , θ p ) Y k 6 = j dθ k ∝ Z m Y i =1 f i ( θ i 1 , · · · , θ ip ) Y k 6 = j dθ ik = m Y i =1 f i ( θ ij ) · Z m Y i =1 p i ( θ ik , k ∈ { 1 , 2 , · · · , p }\{ j }| θ ij ) . The first term in the ab ov e form ula is exactly the indep enden t pro duct equation, while the second term is due to pa r a meter dep endence. Ho we ver, inspired by this marginal combining pro cedure, w e prop ose a (parameter-wise) sequen tial rejection sampling sc heme that decom- p oses the whole sampling pro cedure into p steps, where eac h step is a one-dimensional con- ditional com bining. The intuition is as follo ws: W e first sample θ 1 from its subset marg inal distribution f i ( θ i 1 ) , i = 1 , 2 , · · · , m , and combine the dra ws via the W eierstrass rejection sampler to obtain θ ∗ 1 ∼ Q m i =1 f i ( θ i 1 ) /C 0 . Next, w e plug in θ ∗ 1 in to eac h subset lik eliho o d to sample θ 2 from its subs et conditional dis tr ibution f i ( θ i 2 | θ ∗ 1 ) , i = 1 , 2 , · · · , m and then combine them to obtain the θ ∗ 2 ∼ Q m i =1 f i ( θ 2 | θ ∗ 1 ) /C 1 , where C 1 is the normalizing constan t (Notice that C 1 dep ends on the v alue of θ ∗ 1 ). W e con tin ue the pro cedure until θ ∗ p , obtaining one p osterior dra w θ ∗ = ( θ ∗ i , i = 1 , 2 , · · · , p ) that follow s θ ∗ ∼ Q m i =1 f i ( θ 1 ) f i ( θ 2 | θ 1 ) · · · f i ( θ p | θ j , j < p ) Q p − 1 j =0 C j = Q m i =1 f i ( θ j , j = 1 , · · · , p ) Q p − 1 j =0 C j . (10) The numerator of (10) is exactly the targ et for mula (1), while the denominator serv es as the import a nce w eights. The adv antage o f this new sc heme is that it eliminates the dimensionalit y curse while ke eping the num b er of required sequen tial steps low ( p steps). Moreo v er, the imp ortance w eigh ts can b e calculated easily and accurately as C j = Z m Y i =1 f i ( θ j +1 | θ ∗ k , k ≤ j ) dθ j +1 . (11) Notice that the in tegra ted functions are all one-dimensional. Th us, an estimated (k ernel- based) densit y ˆ f i ( θ j +1 | θ ∗ k , k ≤ j ), com bined with the numeric a l integration tec hnique, is adequate to pro vide an accurate ev aluation fo r C j . An alternativ e approach f or estimating 11 C j is as follows , C j = f ( θ ∗ j +1 | θ ∗ k , k ≤ j ) Q m i =1 f i ( θ ∗ j +1 | θ ∗ k , k ≤ j ) , (12) where f ( θ j +1 | θ ∗ k , k ≤ j ) can b e o btained from ke rnel densit y estimation on the com bined dra ws of θ ∗ j +1 (whic h req uires to sample more than one θ ∗ j +1 at eac h iteration). f i ( θ j +1 | θ ∗ k , k ≤ j ) can b e obtained similarly as before fro m t he subset dra ws. The whole sc heme is describ ed in Algo rithm 2. Algorithm 2 (Sequen tial r ejection sampling Initialization: 1: Input N 0 , h j , j = 1 , 2 , · · · , p . # N 0 is the numb e r of samples dr awn w i thin e ach of the p steps. 2: Set h ij = √ mh j for i = 1 , 2 , · · · , m a nd C j = 0 , j = 0 , · · · , p − 1 . 3: M C M C ← {} , T i ← {} , i = 1 , 2 , · · · , m ; Iteration: 4: for j = 1 t o p do 5: # O n e ach of the m subsets i = 1 , 2 , · · · , m , 6: for t = 1 to N 0 do 7: Sample θ ( t ) ij ∼ f i ( θ j | θ ∗ 1 , · · · , θ ∗ j − 1 ) 8: T i ← T i ∪ { θ ( t ) ij } ; 9: end for 10: # Col le c t al l T i , i = 1 , 2 , · · · , m to c ombine the dr aws 11: Obtain o ne θ ∗ j b y com bining θ ( t ) ij , i = 1 , 2 , · · · , m via W eierstrass rejection sampling. 12: Calculate C j − 1 as C j − 1 = R Q m i =1 ˆ f i ( θ j | θ ∗ 1 , · · · , θ ∗ j − 1 ) dθ j . 13: M C M C ← M C M C ∪ { ( θ ∗ j , C j − 1 ) } . 14: end for 15: return MCMC Algorithm 2 only pro duces one simulated p osterior dra w. Therefore, in order to o btain a certain n um b er of p osterior draws, the alg orithm needs to b e execu t ed in parallel on m ultiple mac hines. F or example, if one aims to acquire N p osterior draws, then N para llel mac hines can b e used, with each mac hine able to run m sub-threads to fulfill the whole pro cedure. It is worth noting that this new sc heme is also applicable to the k ernel smo othing metho d prop osed b y Neisw anger et al. (2013) for o ve rcoming the dimensionalit y curs e: just substituting the step (11) in Algor ithm 2 with the corresp onding k ernel metho d. The ne w algorithm still in v olv es a sequen tial up dating structure, but the n um b er of steps is b ounded b y the num b er of pa r ameters p , whic h is differen t from the usual MCMC updating. A brief interpre t a tion fo r the effe ctiven ess of the new algorithm is that it c ha ng es how error is accum ulated. The o riginal p - dimension f unction with a bandwidth h will accommo date t he error in a manner as h 2 /p , while now with the decomp osed p steps, the error is accum ula t ed linearly as ph 2 whic h reduces the dimensionalit y curse. 12 6 Numerical stu dy In this sec tio n, w e will illustrate the p erformance o f W eierstrass samplers in v arious setups and compare them to o ther part it io n based metho ds, suc h as subset av era g ing and kerne l smo othing. More sp ecifically , w e will compare the p erformance of the following metho ds. • Single c ha in MCM C: running a s ing le Mark ov c hain Mon te Carlo on the total data se t. • Simple a ve ra ging: running indep enden t MCMC on eac h subset, a nd directly a veraging all subset p o sterior draw s within the same iteration. • In v erse v ariance w eigh ted av eraging: running MCMC on all subsets , and carrying out a we ig h ted a v erag e f o r all subset p osterior draws within the same iteration. The w eigh t follo ws w i = ( m X k =1 ˆ Σ − 1 i ) − 1 ˆ Σ − 1 i , where ˆ Σ i is the p osterior v ariance fo r the subset i . • W eierstrass sampler: The detailed algorithms are pro vided in previous section. F or the W eierstrass r ejection sampler, w e do not sp ecify the v a lue o f the tuning parameter h ij , but instead, we sp ecify the acceptance rate. (i.e., w e first determine t he acceptance rate and then calculate the corresp onding h ij ). • Non-parametric densit y estimation (ke r nel smo othing): Using k ernel smo othing to appro ximate the subset p osteriors and obtain the pro duct thereafter. Because this metho d is v ery sensitiv e to the choice of the bandwidth and the cov ariance of the k ernel function when the dimension of the mo del is relativ ely high, in most cases, only the pro cedure of margina l s ubset densities com bining will be considered in this section. • Laplacian a ppro ximation: A Ga ussian distribution with the posterior mo de as the mean and the in ve rse of the Hessian matrix ev aluated at the mo de as the v ariance. The mo dels adopted in this section include logistic regression, binomial mo del and Gaussian mixture mo del. The p erf o rmance of the sev en metho ds will b e ev aluated in terms o f ap- pro ximation accuracy , computational efficiency , and some other sp ecial measures tha t will b e sp ecified later. W e made use of the R pac k age “Ba yes Lo git” (P olson et al., 2013) to fit the log istic mo del and wrote our own JA GS co de for the Ga ussian mixture mo del. 13 6.1 W eierstrass refinemen t sampling W e asse ss the p erformance of the refinemen t sampler in this sec t io n. The first part will b e an ev aluat ion of the refinemen t pro p ert y a s claimed in Theorem 2 a nd in the second part w e will compare the p erformance for v arious metho ds within the logistic regression framew o rk. 6.1.1 Refinemen t prop erty W e ev aluate the refinemen t prop erty under b oth a bi-mo dal p osterior distribution and the real data. F or the bi- mo dal p osterior distribution, the t wo subset p osterior densities are p 1 = 1 2 N ( − 1 . 7 , 0 . 5 2 ) + 1 2 N (0 . 8 , 0 . 5 2 ) p 2 = 1 2 N ( − 1 . 3 , 0 . 5 2 ) + 1 2 N (1 . 2 , 0 . 5 2 ) . Then according to (1), the p osterior on full data set will b e roughly (omitting a tin y p ortion of probability), p 12 = 1 2 N ( − 1 . 5 , 0 . 5 2 / 2) + 1 2 N (1 . 0 , 0 . 5 2 / 2) . The initial appro ximation a dopted for the refinemen t sampling is a normal approximation to p 12 whic h has the same mean a nd v ariance. W e tra ce the c hange of the refined densities for differen t n umbers of iterations a nd illustrated them in Fig 1 ( left) . Because the initial appro ximation is v ery differen t from the true target, the tuning parameter h will start a t a large v alue and then decline at a certain rat e, in particular, h = 0 . 8 iter ation . As sho wn in Fig 1 (left), the appro ximation has ev olve d to a bi-mo da l shap e after the first iteration and it app ears that 10 steps are a dequate to obtain a reasonably go o d result. Fig 1 (right) show s part of the refinemen t results for the real data set (whic h will b e described in more detail in the real data sec t io n), in whic h a logit mo del w as fitted on the 200,000 data set with a par t ition in to 2 0 subsets. W e set the initial approximation a pa rt from the p osterior mo de and monitor the ev olution of the r efinemen t sampler (the tuning parameters are chos en according to (7), a nd H 0 is c hosen to b e the in v erse of the Hessian matrix at the mo de). The refinemen t sampler quick ly mov es from the initial approxim a tion to the truth in just 10 steps. (No p osterior distribution from a full MCMC w as plotted, as the sample size is to o large to run a full MCMC) 6.1.2 Appro ximation accuracy W e adopt the log istic mo del for assessing the appro ximation p erformance. The logistic regression mo del is bro a dly adopted in many scien tific fields for mo deling catego rical data 14 −3 −2 −1 0 1 2 0.0 0.1 0.2 0.3 0.4 0.5 Adaption of the refinement for posterior distribution x density T rue posterior Initial approx One−step Five−step T en−step −40 −20 0 20 0.00 0.01 0.02 0.03 0.04 0.05 Logistic regression on real data: posterior density for β 0 β 0 Density Laplacian approx T en−step refinement Initial approx Figure 1: Refinemen t prop ert y for the W eierstrass sampler and conducting classification, P ( Y = 1 | X ) = l og it − 1 ( X β + β 0 ) = exp( X β + β 0 ) 1 + exp( X β + β 0 ) , where l og it is the corresponding link function and β 0 is the intercept. The predictors X = ( X 1 , X 2 , · · · , X p ) fo llo w a multiv ariate normal distribution N ( 0 , Σ), and t he cov a ri- ance matrix Σ follo ws Σ ii = v ar ( X i ) = 1 , Σ ij = cov ( X i , X j ) = ρ, i = 1 , 2 , · · · , p where ρ will be assigned tw o differen t v alues ( 0 and 0.3) to manipulate tw o differen t corre- lation lev els (independen t to correlated). In this study , the mo del con tains p = 50 predictors and n = 10 , 000 or 3 0 , 000 observ a- tions, b oth of whic h will b e partitioned in to m = 20 subsets. The co efficien ts β f ollo w β i = ( − 1) u i (1 + | N (0 , 1) | ) i ≥ 10 0 1 ≤ i < 10 1 i = 0 where u i is a Bernoulli random v ariable with P ( u i = 1) = 0 . 6 and P ( u i = − 1) = 0 . 4 . The reason to sp ecify the co efficien ts in this w ay is to demonstrate the p erformance of all metho ds in differen t situations (b o th easy and c hallenging) . F or logistic regress ion, the closer the co efficien t is to zero, the lar g er t he effectiv e sample size and the b etter the p erformance of a Gaussian appro ximation. See Fig 2. Because kerne l dens ity estimation is ve ry sensitiv e to the c hoice of the k ernel cov a riance when the dimension of the mo del is mo derately high, w e only demonstrate the p erformance 15 −20 −10 0 10 20 0.0 0.2 0.4 0.6 0.8 1.0 Fullset and subset posterior densities for β 1 = 0 β 1 Density full data posterior subset posterior1 subset posterior2 ... 0 10 20 30 40 0.0 0.2 0.4 0.6 0.8 1.0 Fullset and subset posterior densities for β 2 = 1 β 2 Density full data posterior subset posterior1 subset posterior2 ... Figure 2: Subset p o steriors for zero a nd non-zero co efficien t. ρ = 0 , n = 1 0 , 000. of k ernel smo o t hing for marginally combined p osterior distributions (9) in this section. The W eierstrass rejection sampler is carried o ut in a similar wa y . These tw o metho ds will b e compared more formally in the next section. 50 syn thetic data se t s we re sim ulated for eac h pair of ρ and n . F or po sterior inference, w e drew 20,00 0 samples (thinning to 2,000) after 50,000 burn-in for single MCMC c hain and eac h subset MCMC. F or W eierstrass refinemen t sampling, the Laplacian approximation is adopted as initial appro ximation, and the kerne l v aria nce is c hosen according to (7). W e conduct 10 steps refinemen t to obtain 2,000 refined draws (within eac h refinemen t step, w e run 1 00 MCMC it era t ions on eac h subset to obta in an up dated dra w). The results a re summarized in Fig 3, 4, 5, 6, and T able 1. The p osterior distribution of tw o selected pa r a meters (including b oth zero and nonzero) for differen t ρ ’s and n ’s are illustrated in the fig ures. The nonzero parameter was plotted in t w o differen t scales in order to incorp o rate m ultiple de nsities in one plot. The n umerical c o m- parisons include the difference of the marginal distribution of eac h parameter, the difference of the join t p osterior and the estimation error of the parameters. W e ev alua te the difference of the marginal distribution by the a ve ra ge tota l v ariation difference (upp er b ounded by 1) b et we en the approximated marginal densities and the true p osterior densities . The result will b e se par a tely demonstrated for nonz ero and zero co efficien ts, and denoted b y k ˆ p ( β 1 ) − p ( β 1 ) k (nonzero) and k ˆ p ( β 0 ) − p ( β 0 ) k (zero) resp ectiv ely . Ev aluating the difference b etw een joint distributions is difficult fo r multiv ariate distributions, as one needs to accurately estimate 16 a distance b et w een a true joint distribution and a set of samples fr o m an approximation. Therefore, w e adopted the approxim a ted Kullbac k-Leibler div ergence b etw een t wo densities (appro ximating tw o densities b y G a ussian) for reference, D K L ( ˆ p ( β ) | | p ( β )) = 1 2 ( tr (Σ − 1 ˆ Σ) + ( u − ˆ u ) T Σ − 1 ( u − ˆ u ) − p − log ( | ˆ Σ | / | Σ | )) , where u and Σ are the sample mean and sample v ariance of the true p osterior p ( β ), while ˆ u and ˆ Σ a r e those for ˆ p ( β ). Finally , the error of the parameter estimation w ill b e demonstrated as t he ratio b etw een the estimation erro r of the approximating metho d and that of t he true p osterior mean, whic h is E r r or ( β a | β p ) = k ˆ β appr ox − β k 2 / k ˆ β poster ior − β k 2 . The a v erage results are sho wn in T able.1. 0.8 0.9 1.0 1.1 1.2 1.3 1.4 1.5 0 1 2 3 4 5 6 Logistic regression: posterior density for β = 1.04 (small scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement Weighted av eraging 0 5 10 15 20 25 0 1 2 3 4 5 6 Logistic regression: posterior density for β = 1.04 (large scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) −1.0 −0.5 0.0 0.5 0 1 2 3 4 5 6 7 Logistic regression: posterior density for β = 0 β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) Figure 3: Posterior densities for indep enden t predictors ρ = 0 , n = 10 , 000. −2.0 −1.8 −1.6 −1.4 −1.2 −1.0 0 1 2 3 4 Logistic regression: posterior density for β = −1.24 (small scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement −40 −30 −20 −10 0 0 1 2 3 4 Logistic regression: posterior density for β = −1.24 (large scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) −0.5 0.0 0.5 1.0 1.5 0 1 2 3 4 5 Logistic regression: posterior density for β = 0 β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) Figure 4: Posterior densities for indep enden t predictors ρ = 0 . 3 , n = 10 , 000. 6.2 W eierstrass rejection sampling In this section, we will ev aluate the p erformance f or the W eierstrass rejection sampler. The- orem 3 indicates that the rejection sampler ma y enjo y an adv antage of p osterior mo de searc hing, as this sampler will make use of dra ws from subsets directly , instead of an y form of av eraging (a v eraging migh t mess up modes). This prop ert y will b e inv estigated in the firs t part via the mixture mo del. F or the second part, w e compare the approximation accuracy of the rejection sampler and ot her metho ds through a simple binomial mo del. 17 −4.0 −3.9 −3.8 −3.7 −3.6 −3.5 −3.4 −3.3 0 1 2 3 4 5 Logistic regression: posterior density for β = −3.41 (small scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement Weighted av eraging −6.5 −6.0 −5.5 −5.0 −4.5 −4.0 −3.5 −3.0 0 1 2 3 4 5 6 Logistic regression: posterior density for β = −3.41 (large scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) −0.1 0.0 0.1 0.2 0 2 4 6 8 10 12 Logistic regression: posterior density for β = 0 β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) Figure 5: Posterior densities for indep enden t predictors ρ = 0 , n = 30 , 000. −1.5 −1.4 −1.3 −1.2 −1.1 0 2 4 6 8 Logistic regression: posterior density for β = −1.39 (small scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement Weighted av eraging −3.5 −3.0 −2.5 −2.0 −1.5 0 2 4 6 8 Logistic regression: posterior density for β = −1.39 (large scale) β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) −0.1 0.0 0.1 0.2 0.3 0 2 4 6 8 10 Logistic regression: posterior density for β = 0 β Density Single chain MCMC Laplacian approx Weierstrass refinement Simple averaging Weighted av eraging Kernel smoothing (marginal) Weierstrass rejection (no weights) Figure 6: Posterior densities for indep enden t predictors ρ = 0 . 3 , n = 30 , 000. T able 1: Appro ximatio n accuracy for marginal a nd join t densities. W. Refi. and W. Rej stand for W eierstrass refinemen t sampling and rejection sampling (without w eight correc- tion). n ρ W. Refi. Laplacia n Simple Ave. W eig hted Av e. Kernel W.Rej 10,000 0 0.068 3 0.17 7 0.99 5 0.816 0.997 0.989 k ˆ p ( β 1 ) − p ( β 1 ) k 0.3 0.1 05 0.238 1.00 0.873 1.00 1.00 30,000 0 0.037 7 0.11 2 1.00 0.648 1.00 0.99 0 0.3 0 .0 543 0 .137 1.00 0.738 1.00 0 .995 10,000 0 0.030 6 0.0157 0 .923 0.619 0.9 04 0.826 k ˆ p ( β 0 ) − p ( β 0 ) k 0.3 0 .0 358 0.0235 0.946 0.832 0 .954 0.891 30,000 0 0.023 1 0.0091 0 .268 0.106 0.2 55 0.245 0.3 0 .0 268 0.0114 0.565 0.224 0 .548 0.457 10,000 0 0.487 0.76 6 2 . 38 × 10 5 313.16 — — D K L ( ˆ p ( β ) || p ( β )) 0.3 0.5 51 1.207 2 . 33 × 1 0 5 2 . 32 × 10 4 — — 30,000 0 0.359 0.46 3 478.47 8.997 — — 0.3 0.4 19 0.604 2 . 07 × 1 0 4 51.07 — — 10,000 0 0.867 0.61 9 352.11 9.20 293 .3 0 197.86 E rr or ( β a | β p ) 0.3 0.8 23 0.391 362 .90 144.02 24 9.74 237 .95 30,000 0 0.922 0.89 0 17.9 2 1.34 12.31 11.38 0.3 0.8 39 0.602 151 .13 3.99 102.20 26.04 18 6.2.1 Mo de exploration Finite mixture mo del are widely used for clustering and approx imatio n, but face w ell kno wn c hallenges due to non- iden tifiabilit y and m ulti-mo dalit y . The Gibbs sampler for normal mix- ture mo dels, as pointed out in Ja sra et al. (2005), suffers from the inefficiency of mo de ex plo - ration, whic h has motiv ated metho ds suc h as split-merge and para llel tempering (Earl a nd Deem, 2005; Jasra et a l., 2005; Neisw anger et a l., 2013). In this section, w e implemen t the problem - atic Gibbs sampler for no r ma l mixture mo del without lab el switc hing mov es, as a mimic to more general situations in whic h w e do not ha ve a sp ecific solution fo r handling m ulti-mo des (lab el switc hing is a sp ecific metho d for dealing with mixture mo dels). Then we par a llelize this Gibbs sampler via different subset-based metho ds, and ex a mine the abilities in p osterior mo de exploration. The mixture distribution follows, x ∼ 1 2 N (0 , 0 . 5 2 ) + 1 4 N (2 , 0 . 5 2 ) + 1 4 N (4 , 0 . 5 2 ) . W e sim ulate 10,0 00 data p oin ts from this mo del, divided into 10 subsets, whic h will b e analyzed via single c hain MCMC a s w ell as para llelized a lgorithms. Since the mo del is m ultidimensional, w e drew 2000 samples via the sequen tial rejection sampling describ ed in Algorithm 2. F or other samplers, w e obtained 20,000 p osterior draws after 20,00 0 iterations burn-in on eac h subset. The results a re plo t t ed in F ig 7. It can b e seen from Fig 7 tha t the 0 1 2 3 4 0 2 4 6 8 10 12 P osterior distr ibution f or µ 1 x Density Single chain MCMC Simple aver aging Weighted av eraging Kernel smoothing Weierstrass rejection 0 1 2 3 4 0 2 4 6 8 10 12 P osterior distr ibution f or µ 2 x Density Single chain MCMC Simple aver aging Weighted av eraging Kernel smoothing Weierstrass rejection 0 1 2 3 4 0 2 4 6 8 10 12 P osterior distr ibution f or µ 3 x Density Single chain MCMC Simple aver aging Weighted av eraging Kernel smoothing Weierstrass rejection Figure 7: Posterior distributions for the comp onen t means W eierstrass (sequen tial) rejection sampling correctly recognized the p osterior mo des. There is one false mo de, but is also pick ed b y the single c hain MCMC. 6.2.2 Appro ximation accuracy In this section, the Beta- Bernoulli mo del is emplo y ed for testing the p erformance of the W eierstrass rejection sampler. The dimension of this mo del is low and the t r ue p osterior 19 distribution is av a ilable analytically , whic h mak es the mo del appropriate for comparing re- jection sampling a nd k ernel smo othing metho d. The parameter p will be assigned t w o v a lues in this section: p = 0 . 1 that corresp onds to a common scenario and p = 0 . 001 whic h cor- resp onds t o the ra re ev ent case. W e sim ulated 10,000 samples whic h w ere then par t it io ned in to 20 subsets. T o obtain a conjugate p osterior, w e assign a b eta prior B eta (0 . 01 , 0 . 01 ) and dra w 100 , 0 00 p osterior samples for further ana lysis. The p osterior densities for different v alues of p are sho wn in Fig 8 . 0.08 0.09 0.10 0.11 0.12 0 20 40 60 80 100 120 P osterior density for the parameter p = 0.1 p Density T r ue posterior Simple aver aging Weierstrass sampler (acceptance rate = 0.1) Kernel smoothing (h = 0.002) Weighted a veraging 0.000 0.001 0.002 0.003 0.004 0.005 0.006 0 200 400 600 800 1000 1200 P osterior density for the parameter p = 0.001 p Density T r ue posterior Simple aver aging Weighted a veraging Weierstrass sampler (r ate = 0.001) Kernel smoothing (h = 0.0001) Kernel smoothing (h = 0.002) Figure 8: P osterior densit y for binomial data with p = 0 . 1 a nd p = 0 . 001. T op: the p osterior densities for p = 0 . 1. Botto m: the p osterior densities for p = 0 . 001. It can be seen from F ig 8 that when the data set con tains mo derate amoun t of information (for p = 0 . 1), all metho ds w ork fine. Ho wev er, for the inadeq ua t ely informed case ( p = 0 . 001) , the k ernel smo othing and W eierstrass rejection sampling are the only metho ds that p erform appropriately . T o matc h the scale of the posterior densit y , the rejection sampler adopts an acceptance rate o f 0 . 1%. F or k ernel smo othing, it requires the bandwidth to b e c hosen as h = 0 . 0 0 01 to ac hiev e the same lev el of accuracy (See the result for larger h in Fig .8). 6.3 Computation efficiency Computational efficienc y is a primary motiv ation for parallelization. Reductions in sample size lead to reduction in computational time in mo st cases. W e demonstrate the effects of the total sample size and the num b er o f parameters (or n umber of mixture comp onents ) for logistic regression and the mixture mo del in Fig 9 and Fig 10. The subset num b er is fixed to 20. F or eac h subset and the t otal set w e drew 10,000 samples after 10,000 iterations burn-in. F or W eierstrass refinemen t sampler, we rep eat the pro cedure 10 times with 1 00 iterations within each step. 20 2000 4000 6000 8000 10000 0 100 200 300 400 Time for diff erent sample siz es n time(sec) Single chain MCMC Weierstr ass refinement All other subset methods 50 100 150 200 0 500 1000 1500 2000 Time for diff erent numbers of parameters p time(sec) Single chain MCMC Weierstr ass refinement All other subset methods Figure 9: Computational time for logistic regression. 2000 4000 6000 8000 10000 0 100 200 300 400 500 Time for diff erent sample siz es n time(sec) Single chain MCMC Weierstr ass (sequential) rejection All other subset methods 5 10 15 20 0 100 200 300 400 500 600 Time for diff erent numbers of cluster s p time(sec) Single chain MCMC Weierstr ass (sequential) rejection All other subset methods Figure 10: Computatio nal time for the mixture mo del. 21 7 Real data analysis The real data set used in this section contains w eighted census data extracted from the 19 94 and 199 5 curren t populatio n surv eys conducted b y the U.S. Census Bure a u (Bache a nd Lichman, 2013). The purp ose is to predict whether the indiv idual’s ann ual gross income will be higher than 50,0 00 USD (i.e., whether 50,000+ o r 50,000- ) . The whole set con ta ins around 2 00,000 observ ations, and 40 att r ibutes whic h w ere turned into 17 6 predictors due to the re-coding of the catego rical v aria bles. Because the sample size is to o la rge for fitting a logistic mo del via usual MCMC soft w ares suc h as JAGS or Rstan, w e only illustrate the p osterior inference for parallelized algorithms and the Laplacian appro ximation. In addition, b ecause of the high dimension of t he mo del and the sensitivit y of k ernel smo othing metho d, w e o nly consider the marginal k ernel com bining algorit hm and marginal W eierstrass rejection sampler. The latter will not b e listed in the results as the p erformance is v ery similar to marginal k ernel metho d. F or posterior inference, w e partition the data into 20 subsets , and drew 2 0,000 samples on eac h subset after 50,000 burn-in. F or W eierstrass refinemen t sampler, the initial distribution is c hosen t o b e sligh tly a wa y from Laplacian approx imat io n (See Fig 1, r ig h t figure) to a void the p oten tia l unfair adv an ta g e. W e conduct 10 step refinemen t on 2,000 initial draws , with 50 iterations within each step for prop osing r efined dra ws. The tuning parameter is c hosen according to (7). The T est Set 1 consists of 5,00 0 p ositiv e ( 5 0,000+) and 5,000 negative (50,000-) cases and the T est Set 2 con tains 5,0 0 p ositiv e and 5,000 negative cases. Since the p ositiv e cases a r e rare (8%) in the training set, w e should exp ect differen t b eha viors on the t w o different sets. F or prediction asses sment, t he logistic mo del will predict p ositiv e if lo g it − 1 ( E [ x i β ]) is greater than 0.5, a nd vice - v ersa. The p osterior distribution of selected pa- rameters for differen t metho ds w ere plotted in Fig 11, and the prediction resu lt s fo r differen t categories and the t wo test data sets are listed in T able 2. T able 2: Classification accuracy for test set Correctness on 50,000- (%) 5 0,000+ (%) T est Set 1 (%) T est Set 2 (%) W eierstrass refinemen t 97.0 57.9 77.4 93.0 Laplacian appro x 98.9 39.3 69.1 92.9 Simple a v erag e 98.9 39.4 69.0 92.9 W eighte d a v erage 99.0 39.4 69.2 93.0 Kernel (marg inal) 99.6 15.9 57.8 91.2 Because the p ositiv e category (a nn ual income greater than 50 ,0 00 USD) is rare in t he training set, Laplacian approxim a tion is lik ely to o verfit and the p osterior might not b e appro ximately Gaussian, leading to lo w accuracy in predicting p ositiv eness for most metho ds. On the con trary , it can be seen that all methods p erfo rm w ell on the T est Set 2 (whic h mimics 22 Figure 11: Posterior distribution for selected parameters. the ra t io of the tra ining set). 8 Conclud ing remarks In this article, w e prop osed a new, flexible and efficien t W eierstrass sampler for parallelizing MCMC. The W eierstrass sampler con tains t wo differen t algor ithms, whic h are carefully de- signed for differen t situations. Extensiv e numeric a l evidence show s t ha t, compared to other metho ds in the same direction, W eierstrass sampler enjo ys b etter p erfo rmance in terms of appro ximation accuracy , c hain mixing rate and a p oten tially faster sp eed. F aced with the same difficult issues, suc h as the dimensionalit y curse, W eierstrass sampler attempts to seize the balance in tra ding off b et w een the accuracy and computation efficiency . As illustrated in the num erical study , the rejection sampler can not only we ll a pproximate the original MCMC, but also impro ve its p erformance in the p osterior mo des exploration. In the sim- ulation, the sampler correctly iden tifies all the mixture components , removing problems o f the or ig inal Gibbs sampler. F uture works of W eierstrass samplers m ay lie in the follow ing aspects. First, in v estigating the asymptotic justification for the marginal combining strategy , whic h could help eliminate the dimensionality concern for b oth k ernel density estimation metho d and W eierstrass re- jection sampling. Second, in ves tiga ting the p otential application in parallel temp ering. In parallel temp ering, t here is a temp erature parameter T whic h con trols b oth the appro xi- mation accuracy and the ch a in exploration a bilit y . Here, with the tuning par a meter h , one is able to ach ieve the same thing: small h entails a hig h accuracy , while la r g e h ensures a b etter exploratio n ability . Therefore, o ne could design a set of differen t v alues of h f o r the sampling pro cedure, pro viding a ‘parallel’ w ay of doing parallel tempering, whic h ma y 23 p oten tia lly improv e the p erfor ma nce of the orig ina l metho d. App endix Pro ofs for preliminaries and T heorem 3 Lemma 1. Assume a r e al-value d function f is H¨ older α differ entiable with c onstant C 0 , i.e., for l = ⌊ α ⌋ , the l -th derivative of f fol lows, | f ( l ) ( θ 1 ) − f ( l ) ( θ 2 ) | ≤ C 0 | θ 1 − θ 2 | α − l for some p os i tive c onstant C 0 . L et K ( · ) b e a k -th or der kernel function satisfying that R K ( θ ) dx = 1 , R x t K ( θ ) dx = 0 f o r 1 ≤ t ≤ k − 1 , an d R | x k K ( θ ) | dx < ∞ . Defining the Weierstr as s tr ans form as W ( K ) h f ( θ ) = Z h − 1 K θ − t h f ( t ) dt = Z K h ( θ − t ) f ( t ) dt, we have max θ ∈R | W ( K ) h f ( θ ) − f ( θ ) | ≤ M γ κ γ ( K ) ⌊ γ ⌋ ! h γ , wher e γ = min { α, k } , M k = max θ ∈R | f ( k ) ( θ ) | , M α = C 0 and κ γ ( K ) = R | t γ K ( t ) | dt . Pr o of of L emma 1 . The pro of relies on the higher-order T ay lor expansion on the function. If γ = α , w e hav e f ( θ + th ) = f ( θ ) + f ′ ( θ ) th + · · · + f ( l − 1) ( θ ) ( l − 1)! t l − 1 h l − 1 + f ( l ) ( ˜ θ ) l ! t l h l , where l = ⌊ α ⌋ a nd ˜ θ lies b etw een θ and θ + th . Because l < k , w e thus hav e Z K ( t ) f ( θ + th ) dt = Z K ( t ) f ( θ ) d t + Z K ( t ) t l h l f ( l ) ( ˜ θ ) l ! = f ( θ ) + Z K ( t ) t l h l f ( l ) ( ˜ θ ) l ! and b ecause R K ( t ) t l = 0, Z K ( t ) t l h l f ( l ) ( ˜ θ ) l ! = Z K ( t ) t l h l f ( l ) ( ˜ θ ) l ! − Z K ( t ) t l h l f ( l ) ( θ ) l ! ≤ l ! − 1 Z h l | K ( t ) t l || f ( l ) ( ˜ θ ) − f ( l ) ( θ ) | dt ≤ C 0 l ! − 1 Z | t α K ( t ) | h α . 24 Therefore, | W ( K ) h f ( θ ) − f ( θ ) | = Z K h ( θ − t ) f ( t ) dt − f ( θ ) = Z K ( t ) f ( θ + th ) dt − f ( θ ) ≤ C 0 l ! − 1 Z | t α K ( t ) | h α = M γ ⌊ γ ⌋ ! − 1 Z | t γ K ( t ) | h γ . The case γ = k follows the same argumen t. Just notice tha t the T aylor expansion now b ecomes, f ( θ + th ) = f ( θ ) + f ′ ( θ ) th + · · · + f ( k − 1) ( θ ) ( k − 1)! t k − 1 h k − 1 + f ( k ) ( ˜ θ ) k ! t k h k , whic h en tails tha t | W ( K ) h f ( θ ) − f ( θ ) | ≤ M k k ! − 1 Z | t | k K ( t ) h k = M γ ⌊ γ ⌋ ! − 1 Z | t γ K ( t ) | h γ , where M k = max θ ∈ R | f ( k ) ( θ ) | , a nd thus completes the pr o of. In this article, w e only fo cus on the case when K is chose n to b e a densit y function (second order kerne l function), and thu s γ ≤ 2. The result stated in Lemma 1 can b e naturally generalized to the m ultiv ariate case. Lemma 2. L et f b e a r e al-value d function on R p . D efine the multivariate Weierstr ass tr ansf o rm as W ( K ) h f ( θ 1 , · · · , θ p ) = Z f ( t 1 , · · · , t p ) p Y j =1 h − 1 j K j θ j − t j h j dt j . If f is H¨ older α smo oth with a c onstant C 0 , i.e., for l = ⌊ α ⌋ , f is l -th differ entiabl e an d for al l the l -th derivatives of f , we have | f ( l ) i 1 i 2 ··· i l ( θ 1 , · · · , θ p ) − f ( l ) i 1 i 2 ··· i l ( θ ′ 1 , · · · , x ′ p ) | ≤ p X j =1 C 0 | θ j − x ′ j | α − l ∀ x, x ′ ∈ R p . Assuming K i s ar e al l k -th or der kernels , the appr oximation err or of the Weierstr ass tr ans- form fol low s max θ ∈R p | W ( K ) h f ( θ ) − f ( θ ) | ≤ M γ ⌊ γ ⌋ ! p X j =1 κ γ ( K j ) h γ j , wher e γ , M γ and κ γ ( · ) ar e define d in L emma 1. The pr o of o f Lemma 2 is essen tially an application of Lemma 1 and is omitted. With 25 Lemma 1 w e pro ceed t o prov e Theorem 1. The original Theorem 1 is stated in terms of second-order differen tiable function and second-order k ernels. Here, w e provide a mo r e general vers io n of Theorem 1. The or em 1. I f the p os terior d ensities and the kernel functions satisfy the c ondition in L emma 1 with α a nd k , then the d i s tribution define d in (3) is pr op er an d ther e exists a p ositive c on stant c 0 such that when h γ = P m i =1 h γ i ≤ c − 1 0 for γ = min { α, k } , the total variation distanc e b etwe en the p osterior distribution and the appr oximation fol lows k f − ˜ f k = C − 1 m Y i =1 f i ( θ ) − C − 1 W m Y i =1 W ( K ) h i f i ( θ ) ≤ 2 r 0 r − γ 1 h γ , wher e C and C W ar e the norma lizing c onstants, and r 0 , r 1 ar e define d as r 0 = C − 1 M max i ∈{ 1 , 2 , ··· ,m } Z m Y j 6 = i f j ( θ ) dx r γ 1 = 2 M M 2 κ γ ( K ) . Pr o of of The or em 1 . W e me rg e r 1 in to h i to simplify the notation. With this mo dification the result can b e express ed as, k f − ˜ f k = 1 2 C − 1 m Y i =1 f i ( θ ) − C − 1 W m Y i =1 W ( K ) r 1 h i f i ( θ ) L 1 ≤ 2 r 0 h γ , The deriv ation is divided in t o t w o steps. In the first step, w e obta in an estimate of the difference b etw een the tw o pro ducts k Q f i ( θ ) − Q W ( K ) r 1 h i f i ( θ ) k , and then apply it in the second step to b ound the tota l v ariation distance. A typical w ay to quan tify the difference b et we en t wo pro ducts is to decomp ose it in to sums of relativ e differences, i.e., Z m Y i =1 f i ( θ ) − m Y i =1 W ( K ) r 1 h i f i ( θ ) dx ≤ m X i =1 Z | f i ( θ ) − W ( K ) r 1 h i f i ( θ ) | i − 1 Y j =1 f j ( θ ) m Y j = i +1 W ( K ) r 1 h i f j ( θ ) dx. Define C k = max I ⊂{ 1 , 2 , ··· ,m } , | I | = k R Q j ∈ I f j ( θ ) dx and δ k = max I ′ ⊂ I ⊂{ 1 , 2 , ··· ,m } , | I | = k k Q j ∈ I f j ( θ ) − Q j ∈ I ′ W ( K ) r 1 h j f j ( θ ) Q j ∈ I \ I ′ f j ( θ ) k L 1 , a nd notice that Z i − 1 Y j =1 f j ( θ ) m Y j = i +1 W ( K ) r 1 h j f j ( θ ) dx ≤ Z Y j 6 = i f j ( θ ) + i − 1 Y j =1 f j ( θ ) m Y j = i +1 W ( K ) r 1 h j f j ( θ ) dx − Y j 6 = i f j ( θ ) L 1 ≤ C m − 1 + δ m − 1 . 26 w e can then b ound eac h relativ e difference as Z | f i ( θ ) − W ( K ) r 1 h i f i ( θ ) | i − 1 Y j =1 f j ( θ ) m Y j = i +1 W ( K ) r 1 h i f j ( θ ) dx ≤ max θ ∈R | f i ( θ ) − W ( K ) r 1 h i f i ( θ ) | Z i − 1 Y j =1 f j ( θ ) m Y j = i +1 W ( K ) r 1 h i f j ( θ ) dx ≤ M γ κ γ ( K ) ⌊ γ ⌋ ! r γ 1 h γ i · Z i − 1 Y j =1 f j ( θ ) m Y j = i +1 W ( K ) r 1 h j f j ( θ ) dx ≤ M ( C m − 1 + δ m − 1 ) h γ i . Summing o ve r all i ∈ { 1 , 2 , · , m } , w e hav e Z m Y i =1 f i ( θ ) − m Y i =1 W ( K ) r 1 h i f i ( θ ) dx ≤ M C m − 1 h γ + M δ m − 1 h γ , where h γ = P m i =1 h γ i . Using the same tric k to decomp ose δ k en tails that (no t icing that P i ∈ I ⊂{ 1 , 2 , ··· ,m } h γ i ≤ h γ ), δ k ≤ M C k − 1 h γ + M δ k − 1 h γ ∀ k ∈ { 3 , 4 , · · · , m − 1 } and for δ 2 , a direct computation sho ws tha t δ 2 ≤ M if all h γ i ≤ 1 / 2. Defining c 0 = max { M 2 2 C 3 , M C k 2 C k +1 , 2 ≤ k ≤ m − 1 } , b y mathematical induction, it is easy to ve rif y that for h γ ≤ c − 1 0 and h γ i ≤ 1 / 2, δ k ≤ C k ∀ k ∈ { 3 , · · · , m − 1 } and therefore we hav e Z m Y i =1 f i ( θ ) − m Y i =1 W ( K ) r 1 h i f i ( θ ) dx ≤ 2 M C m − 1 h = 2 C r 0 h γ . (13) An application of (13 ) can help deriving the difference b et w een the tw o normalizing con- stan ts, | C − C W | ≤ Z m Y i =1 f i ( θ ) − m Y i =1 W ( K ) r 1 h i f i ( θ ) dx ≤ 2 C r 0 h γ . 27 W e then b ound the L 1 distance. F o r h γ i ≤ 1 / 2 and h γ ≤ c − 1 0 w e hav e Z C − 1 m Y i =1 f i ( θ ) − C − 1 W m Y i =1 W ( K ) r 1 h i f i ( θ ) dx ≤ C − 1 Z m Y i =1 f i ( θ ) − m Y i =1 W ( K ) r 1 h i f i ( θ ) dx + | C − 1 − C − 1 W | Z m Y i =1 W ( K ) r 1 h i f i ( θ ) dx ≤ 2 r 0 h γ + | C − C W | C W C · C W ≤ 4 r 0 h γ , whic h giv es the error b ound stat ed in the theorem. R emarks : Theorem 1 is a sp ecial case of the ab ov e theorem with α ≥ 2 and k = 2. Though t he features of W eierstrass sampler will not rely on asymptotics (no requiremen t on the sample size), a ro ug h asymptotic analysis on r 0 and r 1 can pro vide a general idea on their mag nitudes a nd b eha vior with t he c ha ng e of sample size. If the like liho o d function satisfies certain regularit y conditions, lo cal asymptotic nor- malit y will ensure the p osterior densit y con v erges to a normal densit y b oth p oint wise and in L 1 . Replacing the p osterior b y its a symptotic distribution, i.e., substituting f i ( θ ) with N ( ˆ θ i , Σ n/m ) = N ( ˆ θ i , mI − 1 /n ), where I is the Fishe r’s infor mation matrix, and ˆ θ i s are lo cally consisten t estimators whic h satisfy that ˆ θ i − θ true ∼ N (0 , Σ n/m ) asymptotically , w e ha ve that C k ≈ Z k Y i =1 dN ( ˆ θ i , mI − 1 /n ) = (2 π ) − ( k − 1) p/ 2 | Σ n/m | − ( k − 1) / 2 k − p/ 2 exp − k 2 k − 1 k X i =1 ( ˆ θ i − ¯ θ ) T Σ − 1 n/m ( ˆ θ i − ¯ θ ) , where ¯ θ = k − 1 P k i =1 ˆ θ i . Since ˆ θ i follo ws N ( θ true , Σ n/m ) roughly , w e can replace k − 1 P k i =1 ( ˆ θ i − ¯ θ ) T Σ − 1 n/m ( ˆ θ i − ¯ θ ) by p f o r large v alues of k and obtain a more concise appro ximatio n as C k ≈ (2 π ) − ( k − 1) p/ 2 | Σ n/m | − ( k − 1) / 2 k − p/ 2 exp − pk 2 . The ab o v e appro ximation suggests that M C k /C k +1 ≈ ( e + e/k ) p/ 2 , where M ≈ (2 π ) − p/ 2 | Σ n/m | − 1 / 2 . Therefore, the following approxim a tions hold asymptotically r 0 ≈ e + e m − 1 p/ 2 and c − 1 0 ≥ 2(2 e ) − p/ 2 . T o quan t if y r 1 requires more elab orate analysis, b ecause the result dep ends on the c hoice of 28 k ernel functions. If the kernel function is a densit y function with γ = 2 (sufficien tly smooth lik eliho o d), r 1 = O ( p M / M 2 ). Pr o of of The or em 3 . By definition we ha ve , Z x −∞ g i ( t ) dt = P θ i ≤ x | c − m +1 m Y k 6 = i K θ k − θ i h k ≥ u = C ′ Z x −∞ f i ( t i ) Z m Y k 6 = i 1 r 1 h k K ( t k − t i h k ) f k ( t k ) m Y k =1 dt k , where C ′ = ( r 1 /c ) m − 1 Q k 6 = i h k . As a result, we hav e, g i ( θ ) = C ′ f i ( θ ) m Y k 6 = i Z 1 h k K t k − x r 1 h k f k ( t k ) dt k = C ′ f i ( θ ) Y k 6 = i W ( K ) h k f k ( θ ) . The right hand side is essen tially the same as the expression Q m i =1 W ( K ) h i f i ( θ ) in Theorem 1 , except for the i th term. Therefore, follow ing the same arg umen t in Theorem 1, w e can pro ve that g i ( θ ) − C − 1 m Y k =1 f k ( θ ) L 1 ≤ 4 r 0 r − 2 1 X k 6 = i h 2 k . Pro of of Theorem 2 T o pro v e Theorem 2 w e first need three lemmas with pro ofs prov ided immediately after the statemen t of lemma. It is w orth no t ing that the Lemma 4 is a common to ol used in sho wing geometric ergo dicit y of MCMC algo r ithms (Johnson, 20 09). The original pro of used the common coupling inequalit y tric k, while here we will adopt a differen t approac h to deriv e a sligh tly differen t conclus ion that is mor e useful for this pap er. Lemma 3. Assume f ( x ) and f 0 ( x ) ar e two c ontinuous density functions. F or any p 0 ∈ (0 , 1) , ther e always exists a b ounde d me asur able set D such that Z D f ( x ) dx = Z D f 0 ( x ) dx and Z D f ( x ) dx > p 0 . Pr o of of L emma 3 . L et A + = { x : f ( x ) > f 0 ( x ) } , A − = { x : f ( x ) < f 0 ( x ) } , A = { x : 29 f ( x ) = f 0 ( x ) } . D efine the follow ing functions H + ( t ) = Z A + ∩{| x |≤ t } f ( x ) , H − ( t ) = Z A − ∩{| x |≤ t } f ( x ) , H ( t ) = Z A ∩{| x |≤ t } f ( x ) and G + ( t ) = Z A + ∩{| x |≤ t } f ( x ) − f 0 ( x ) , G − ( t ) = Z A − ∩{| x |≤ t } f 0 ( x ) − f ( x ) . Because f , f 0 are contin uous, the ab o ve functions are all smo oth and non-decreasing functions for t ≥ 0, and satisfy that H + ( ∞ ) + H − ( ∞ ) + H ( ∞ ) = 1 , G + ( ∞ ) = G − ( ∞ ) = k f − f 0 k . F ro m the assumption that k f − f 0 k > 0 (otherwise the result is trivial), we a r e guaran t eed that H + ( ∞ ) is p ositiv e. The following pro o f is divided in to t wo parts. Case 1: If H − ( ∞ ) > 0. Define ǫ = (1 − p 0 ) / 3. Due to the contin uity and monotonic prop ert y of H + ( · ) , H − ( · ) and H ( · ), w e can alw ays find t 1 and t 2 suc h that H + ( ∞ ) − ǫ < H + ( t 1 ) < H + ( ∞ ) , H − ( ∞ ) − ǫ < H − ( t 2 ) < H − ( ∞ ) and t 3 suc h that H ( ∞ ) − ǫ < H ( t 3 ) ≤ H ( ∞ ) . No w if G + ( t 1 ) = G − ( t 2 ), w e can simply set D = A + ∩ {| x | ≤ t 1 } S A − ∩ {| x | ≤ t 2 } S A ∩ {| x | ≤ t 3 } . Otherwise, without loss of generality , assuming G + ( t 1 ) > G − ( t 2 ), due to the c hoice of t 1 , w e know that H + ( t 1 ) < H + ( ∞ ), whic h ens ures G − ( t 2 ) < G + ( t 1 ) < G + ( ∞ ) = G − ( ∞ ) . Again making use of the contin uit y and the prop erty of limit, w e are able to find t ′ 2 > t 2 suc h that G + ( t 1 ) = G − ( t ′ 2 ) and D is then ta ken to b e D = A + ∩ { | x | ≤ t 1 } S A − ∩ { | x | ≤ t ′ 2 } S A ∩ { | x | ≤ t 3 } Case 2: If H − ( ∞ ) = 0. This case is ev en simple r . Define ǫ = (1 − p 0 ) / 2. Since 30 H + ( ∞ ) > 0, there exist t 1 and t 3 suc h that, H + ( ∞ ) − ǫ < H + ( t 1 ) < H + ( ∞ ) , H ( ∞ ) − ǫ < H ( t 3 ) ≤ H ( ∞ ) , whic h at same time guarantee s tha t G + ( t 1 ) < G + ( ∞ ). Therefore, by a similar argumen t to Case 1 , w e will b e able to find t 2 suc h that G + ( t 1 ) = G − ( t 2 ) . Then D = A + ∩ {| x | ≤ t 1 } S A − ∩ {| x | ≤ t 2 } S A ∩ {| x | ≤ t 3 } . It is easy to v erify tha t the set D defined in the pro of satisfies the prop erties in the lemma. Lemma 4. Assume the Gibbs samp l e r defines a tr ansition kernel κ ( · , x ) , P ( A, x ) = P ( X t ∈ A | X t − 1 = x ) = Z A κ ( t, x ) dt. L et f ( x ) denote the e quilibrium distribution and f 0 ( x ) the app r ox imation to f ( x ) . F or any me asur able set D which sa tisfi e s that Z D f 0 ( x ) dx = Z D f ( x ) dx, if ther e exists a pr ob ability density q and a p osi tive value ǫ s uch that κ ( t, x ) ≥ ǫq ( t ) for an y t ∈ R and x ∈ D , then we have Z | f 1 ( x ) − f ( x ) | dx ≤ (1 − ǫ ) Z D | f 0 ( x ) − f ( x ) | dx + Z D c | f 0 ( x ) − f ( x ) | d x, wher e f 1 ( x ) = R κ ( x, t ) f 0 ( t ) dt . If D = R , the c onclusion b e c omes, k f 1 ( x ) − f ( x ) k ≤ (1 − ǫ ) k f 0 ( x ) − f ( x ) k , wher e k · k denots the total variation distanc e. Pr o of of L emma 4 . Because f ( x ) is the equilibrium distribution of the Gibbs sampler, w e hav e f ( x ) = Z κ ( x, t ) f ( t ) dt. 31 Therefore, Z | f 1 ( x ) − f ( x ) | = Z Z κ ( x, t ) f 0 ( t ) dt − Z κ ( x, t ) f ( t ) dt dx = Z Z κ ( x, t ) f 0 ( t ) − f ( t ) dt dx = Z Z D κ ( x, t ) f 0 ( t ) − f ( t ) dt dx + Z Z D c κ ( x, t ) f 0 ( t ) − f ( t ) dt dx. F or the second term w e hav e Z Z D c κ ( x, t ) f 0 ( t ) − f ( t ) dt dx ≤ Z Z D c κ ( x, t ) | f 0 ( t ) − f ( t ) | dtdx = Z D c | f 0 ( t ) − f ( t ) | dt, where the last equalit y is due to F ubini’s Theorem. F or the first term, notice that κ ( x, t ) = ǫq ( x ) + (1 − ǫ ) κ ( x,t ) − ǫq ( x ) 1 − ǫ , where κ ( x, t ) − ǫq ( x ) 1 − ǫ > 0 and Z κ ( x, t ) − ǫq ( x ) 1 − ǫ dx = 1 for t ∈ D . As a result, we hav e Z Z D κ ( x, t ) f 0 ( t ) − f ( t ) dt dx = Z ǫ Z D q ( x ) f 0 ( t ) − f ( t ) dt + (1 − ǫ ) Z D κ ( x, t ) − ǫq ( x ) 1 − ǫ f 0 ( t ) − f ( t ) dt dx = Z (1 − ǫ ) Z D κ ( x, t ) − ǫq ( x ) 1 − ǫ f 0 ( t ) − f ( t ) dt dx ≤ (1 − ǫ ) Z Z D κ ( x, t ) − ǫq ( x ) 1 − ǫ | f 0 ( t ) − f ( t ) | dtdx = (1 − ǫ ) Z D | f 0 ( t ) − f ( t ) | dt. Consequen t ly , w e hav e, Z | f 1 ( x ) − f ( x ) | ≤ (1 − ǫ ) Z D | f 0 ( x ) − f ( x ) | dx + Z D c | f 0 ( x ) − f ( x ) | dx, whic h completes the pro of. Lemma 5. Conside ring the fol l o wing Gibbs sa mpler, θ | t i ∼ m Y i =1 K h ( θ − t i ) t i | θ ∼ K h ( θ − t i ) f i ( t i ) , 32 which defi n es a tr ansition ke rn e l on θ as κ ( · , θ ) . If the ke rnel K is ful ly supp orte d o n R , then for an y b ounde d m e a s ur able set D , ther e exists an ǫ > 0 a nd a p r ob ability d ensity q ( θ ) such that κ ( θ , θ 0 ) > ǫq ( θ ) for an y θ 0 ∈ D . F urthermor e, if the c ond ition (6 ) is satisfie d, i . e ., lim θ → ∞ inf K ( θ − t ) W ( K ) h f i ( θ ) > 0 for an y t ∈ R and i ∈ { 1 , 2 , · · · , m } , then the set D c an b e taken as R . Pr o of of L emma 5 . Consider the full Gibbs transition kernel g ( θ , t i , i = 1 , 2 , · · · , m | θ 0 ), g ( θ , t | θ 0 ) = Q m i =1 K h ( θ − t i ) R Q m i =1 K h ( θ − t i ) dθ · m Y i =1 K ( θ 0 − t i ) f i ( t i ) R K ( θ 0 − s ) f i ( s ) ds = Q m i =1 K h ( θ − t i ) R Q m i =1 K h ( θ − t i ) dθ m Y i =1 f i ( t i ) · m Y i =1 K ( θ 0 − t i ) R K ( θ 0 − s ) f i ( s ) ds = q ( θ , t ) · m Y i =1 K ( θ 0 − t i ) R K ( θ 0 − s ) f i ( s ) ds , where q ( θ , t ) is a pro babilit y densit y ov er θ , t 1 , · · · , t m , a nd define w D ( t ) = w D ( t 1 , · · · , t m ) = min θ 0 ∈ D m Y i =1 K ( θ 0 − t i ) R K ( θ 0 − s ) f i ( s ) ds , whic h is strictly greater than 0 for an y giv en t 1 , t 2 , · · · , t m b ecause D is bounded and K is strictly p ositiv e on R . Consequen tly , g ( θ , t | θ 0 ) ≥ q ( θ , t ) w D ( t ) . Let ǫ = R R q ( θ , t ) w D ( t ) dtdθ and q ( θ ) = ǫ − 1 R q ( θ , t ) w D ( t ) dt . Because w D ( t ) is strictly p ositiv e on R , thus w e ha v e ǫ > 0 . Apparently q ( θ ) is a probability densit y satisfying that, κ ( θ , θ 0 ) = Z q ( θ , t | θ 0 ) dt ≥ ǫq ( θ ) for any θ 0 ∈ D . 33 No w if the condition (6) is a lso satisfied, w e ha v e that w R ( t ) = min θ ∈R m Y i =1 K ( θ 0 − t i ) R K ( θ 0 − s ) f i ( s ) ds = min θ ∈R m Y i =1 K ( θ 0 − t i ) W ( K ) h f i ( θ 0 ) > 0 for any giv e t 1 , t 2 , · · · , t m , which ensures that D can b e c hosen as R . Theorem 2 is a straigh tforw ar d result of the ab ov e three lemmas, of whic h the pro of is briefly described b elo w, Pr o of of The or em 2 . With Lemma 3 w e are guaranteed the existence o f a set D whic h is b ounded and satisfies that Z D f ( θ ) d θ > p 0 . No w L emma 3 ensures the existence of a densit y q ( θ ) suc h that the transition k ernel defined in (5 ) and (4) (with general k ernel K ) κ ( · , θ ) satisfies that κ ( θ , θ 0 ) ≥ ǫ q ( θ ) for a ny θ 0 ∈ D or for any θ 0 ∈ R if the condition (2) is also satisfied. Com bining these facts with Lemma 4, w e ha ve the result listed in Theorem 2. References Agarw al, A. and Duc hi, J.C. (2012). Distributed dela y ed sto chas t ic optimization, D e cisio n and Contr ol (CD C ), 2012 I EEE 51st A nnual Confer enc e on, I EEE , pp. 5451 -5452. Ahn, S., Korattik ara, A. and W elling, M. (2012). Ba y esian p osterior sampling via stochas- tic gradien t fisher scoring. Pr o c e e dings of the 2 9th I nternational Co n fer enc e on Machine L e arning , pp. 159 1 -1598. Bac he, K. and Lic hman, M. (2013). UCI Machi n e L e arning R ep ository [http://ar chive.ics.uci.e du/ml ] . Irvine, CA: Univ ersity of California , School of Infor- mation and Computer Science. Bailer-Jones, C. and Smith, K. (2011 ). Com bining probabilities. Da ta Pr o c essing and A nal- ysis Consortium (DP AS) , G AIA-C8-TN-MPIA-CBJ-053. Earl, D. J. and Deem, M. W. (200 5) Parallel temp ering: Theory , applicatio ns, and new p ersp ectiv es. Physic al Chemistry Chemic al Physics , 7, 3910 F ukunaga, K. (1972 ) Intro duction to Statistical Pattern Recognitio n. Electrical Science Se- ries. Academic Press, San D iego. 34 Green, P . J. (199 5). Rev ersible jump Mark o v c hain Monte Carlo computation and Ba y esian mo del determination. B i o metrika , 82, 711-7 3 2. Jasra, A., Holmes, C. C. and Stephens , D . A. (2005) Mark ov c hain M o n te C ar lo methods a nd the lab el switc hing problem in Ba ye sian mixture mo delling. Statistal Scienc e , 20, 50-67. Johnson, A. A. (2009 ). Geometric Ergo dicit y of Gibbs Sa mplers PhD thesis, Univ ersit y of Minnesota, Sch o ol of Sta t istics. Liu, Q . and Ihler, A. (2 0 12). Distributed P arameter Estimation via Pseudo-lik eliho o d, In- ternational Confer enc e on Machine le arning (ICML) , June 201 2 Neal, R. M. (1993) Probabilistic inference using Marko v Chain Mon t e Carlo Metho ds. T e chnic al R ep ort . Univ ersity of T oron t o , T or o n to. (Av ailable fro m h ttp://www.cs.toron to.edu/ ∼ radfo r d/review . abstract.h tml.) Neal, R . M. (2010). MCMC using Hamiltonian dynamics. In Handb o ok of Markov Chain Monte Carlo (eds S. Bro oks, A. Gelman, G. Jones and X.-L Meng). Bo ca Raton: Chapman and Hall-CRC Press. Neisw anger, W., W a ng, C. a nd Xing, E. (2013 ) . Asymptotically Exact, Em barrassingly P arallel MCMC, a rXiv:1311.4780. P olson, N. G., Scott, J. G. and Windle, J. (201 3 ). Bay esian inference for log istic mo dels using Poly a-Gamma latent v a r ia bles. Journal of the A m eric an Statistic al Asso ciation , pp. 1339-13 49 Ripley , B. D. (198 7). Sto chastic Sim ulation , Wiley & Sons. Scott, S. L., Blo c k er, A. W., and Bonassi, F. V. ( 2 013). Bay es and big data: The consensus Mon te Carlo algorithm. B ayes 250 . Smola, A. and Naray a na m urthy , S. (20 1 0). An arc hitecture for parallel to pic mo dels, Pr o- c e e dings of the VLDB End o wment , 3, no. 1-2, 703- 710. V an der V aart A. W . (1998). Asymptotic Statistics . Cambridge: Cam bridge Univ ersit y Press . W eierstrass, K. (18 8 5). ¨ Ub er die analytisc he Darstellbark eit sogenann ter willkrlic her F unctio- nen einer reellen V ernderlic hen. Sitzungsb erichte der K¨ oniglich Pr euischen Akademie der Wissenschaften zu Berlin , (I I). Erste Mitteilung (part 1) pp. 633 6 39, Zw eite Mitteilung (part 2) pp. 789-805. W elling, M. and T eh, Y. (201 1 ). Ba yes ian learning via sto chas tic gradien t Langevin dynamics, Pr o c e e di ngs of the 28th International Confer en c e o n Machine L e arning (ICML) , pp. 6 8 1- 688. White, S.R., Kypraios, T., and Preston, S.P . (2013). Piecewis e approximate Ba ye sian com- putation: fast inferenc e fo r discretely observ ed Mark ov mo dels using a factorised p osterior distribution. Statistics and Co mputing , 1-13. 35
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment