Grammars with two-sided contexts
In a recent paper (M. Barash, A. Okhotin, “Defining contexts in context-free grammars”, LATA 2012), the authors introduced an extension of the context-free grammars equipped with an operator for referring to the left context of the substring being defined. This paper proposes a more general model, in which context specifications may be two-sided, that is, both the left and the right contexts can be specified by the corresponding operators. The paper gives the definitions and establishes the basic theory of such grammars, leading to a normal form and a parsing algorithm working in time O(n^4), where n is the length of the input string.
💡 Research Summary
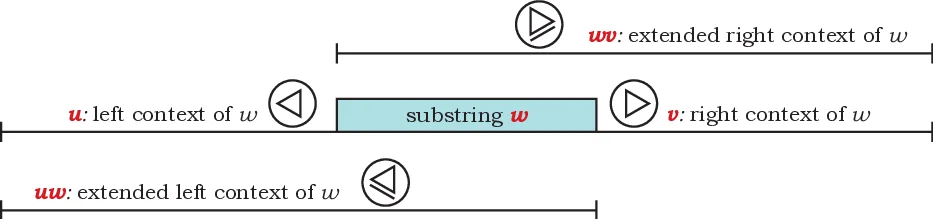
The paper introduces a new class of formal grammars called “grammars with two‑sided contexts”, extending the previously proposed one‑sided context grammars that could only refer to the left context of a substring. A grammar is defined as a quadruple G = (Σ, N, R, S) where each production has three parts: (i) a set of base conjuncts α₁,…,α_k that behave exactly like the right‑hand side of ordinary context‑free productions, (ii) left‑context conjuncts (✁ β) and extended left‑context conjuncts (P γ), and (iii) right‑context conjuncts (✄ δ) and extended right‑context conjuncts (Q κ). The semantics are given by a deduction system over items of the form X ⊢ u⟨w⟩v, meaning that the substring w, occurring between left context u and right context v, has property X. Axioms state that any terminal a has property a in any context; each production becomes a schema of inference rules that combine the premises for the base conjuncts with the premises for the context conjuncts. For example, a rule A → B C & ✁ D requires that B and C cover the target substring while D holds in the left context (the empty string preceding the concatenation of B and C).
The authors provide several illustrative examples: (1) a simple grammar generating the singleton language {abca} using both left and right context operators; (2) a grammar modeling identifier declarations that may appear before or after their use, using extended contexts to enforce the matching; (3) a grammar for function prototypes, bodies, and calls, where prototypes must be followed by a body and calls must be preceded by a matching prototype; (4) a grammar encoding reachability in acyclic graphs via a linear encoding of vertices and edges. These examples demonstrate that many language phenomena that previously required cumbersome constructions with one‑sided contexts or additional logical machinery can be expressed naturally with two‑sided contexts.
A major technical contribution is the transformation of any two‑sided‑context grammar into a normal form that generalises Chomsky normal form. The transformation proceeds in three stages: (a) elimination of ε‑producing rules, (b) removal of explicit empty context specifications (✁ ε, ✄ ε), and (c) breaking of cyclic dependencies of the form A → B & … that could cause non‑termination in the deduction system. After these steps every rule has the shape “one or more base conjuncts ∧ any number of context conjuncts”, where each conjunct is a string of terminals and non‑terminals. This normal form guarantees that the deduction system is well‑founded and that each derivation corresponds to a finite parse tree.
Based on the normal form, the paper presents a parsing algorithm that extends the classic CYK dynamic‑programming approach. For an input string w of length n, the algorithm fills a four‑dimensional table T
Comments & Academic Discussion
Loading comments...
Leave a Comment