Simultaneous Source for non-uniform data variance and missing data
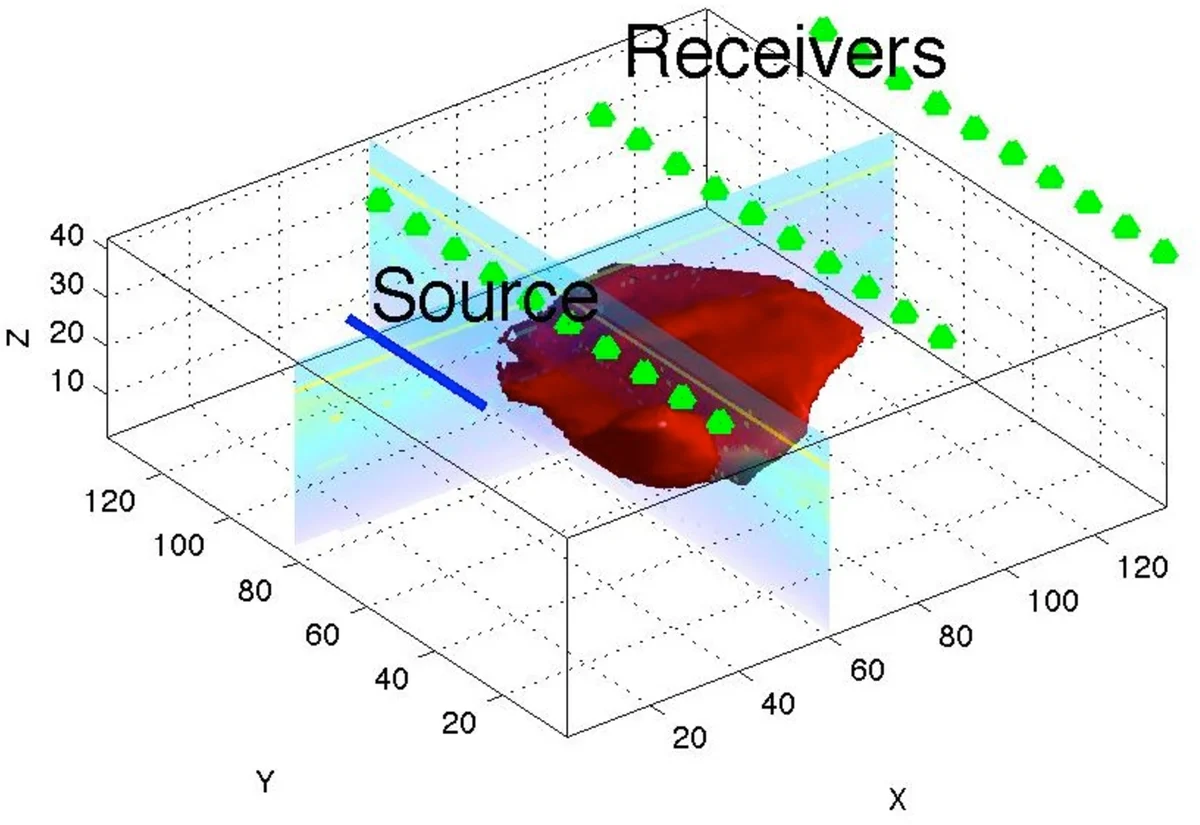
The use of simultaneous sources in geophysical inverse problems has revolutionized the ability to deal with large scale data sets that are obtained from multiple source experiments. However, the technique breaks when the data has non-uniform standard deviation or when some data are missing. In this paper we develop, study, and compare a number of techniques that enable to utilize advantages of the simultaneous source framework for these cases. We show that the inverse problem can still be solved efficiently by using these new techniques. We demonstrate our new approaches on the Direct Current Resistivity inverse problem.
💡 Research Summary
The paper addresses a fundamental limitation of simultaneous‑source (SS) techniques in large‑scale geophysical inverse problems: they break down when the data variance matrix C is not a simple scalar multiple of an all‑ones matrix (i.e., when the standard deviations are non‑uniform) or when some source‑receiver pairs are missing. In the standard SS setting, the misfit ‖C⊙(PᵀA(u)⁻¹Q−D)‖_F² can be rewritten as an expectation over a single random vector w, allowing each stochastic sample to require only one forward solve of the PDE. This property is lost for a general C because the Hadamard product does not commute with matrix‑vector multiplication, preventing the linear combination of sources that underlies the SS advantage.
The authors propose four distinct strategies to restore computational efficiency for three typical forms of C: (a) a binary mask (0/1) representing missing data, (b) a low‑rank matrix, (c) a full‑rank matrix with widely varying variances, and (d) a situation where only a subset of sources is used at each iteration.
-
Data Completion – When C contains only 0 and σ⁻¹ entries (i.e., missing data), the authors treat the problem as a matrix‑completion task. They generate a reduced‑dimensional forward model (1‑D or 2‑D) that is cheap to solve, compute its synthetic data D_red, and fill the missing entries of the observed data D_obs with the corresponding entries from D_red. The completed data D_all = C⊙D_obs + (σ⁻¹E−C)⊙D_red is then fed into the standard SS stochastic program. This approach acts as a regularizer that pulls the solution toward a physically plausible low‑dimensional model, but it can introduce bias if the interpolated values are far from the true measurements.
-
Low‑Rank Approximation – If C can be expressed (or approximated) as X Zᵀ with rank k ≪ min(n_r,n_s), the Hadamard product can be rewritten as a sum of k independent terms: (C⊙R)w = ∑_{j=1}^k X_j⊙R (Z_j⊙w). Consequently, the expected misfit becomes an average over k independent forward solves, each involving a modified source vector Z_j⊙w. When k is small, the computational cost is essentially identical to the original SS method, while still accounting for non‑uniform variances. If C is not exactly low‑rank, a low‑rank approximation can be used, trading off accuracy for speed.
-
Stochastic Approximation of the Data Matrix – For full‑rank, highly heterogeneous C, the authors propose moving the expectation inside the Frobenius norm: ‖C⊙(PᵀA⁻¹Q−D)‖_F² = E_w‖C⊙((PᵀA⁻¹Qw−Dw)wᵀ)‖_F². This yields a new stochastic program where each sample requires forming the product (PᵀA⁻¹Qw−Dw)wᵀ before applying C. Although each sample is more expensive, the formulation remains valid for any C and does not rely on low‑rank structure. Convergence follows from standard stochastic programming theory under mild assumptions.
-
Source Subset Sampling (Randomized Kaczmarz) – Instead of combining all sources, a single source index j is drawn uniformly at each iteration, and the misfit for that source alone, weighted by its corresponding column C_j, is minimized. This reduces memory and compute requirements by a factor of n_s, at the cost of potentially slower convergence, especially when individual sources illuminate only limited parts of the domain.
All four reformulations share the same stochastic‑optimization backbone: the expected‑value objective is approximated by a Sample Average Approximation (SAA). The authors replace the expectation with an empirical average over N independent draws of w (or j for the subset method), yielding the finite‑sample objective J_N(u)=½∑_{i=1}^N‖f(u,w_i)‖₂²+αS(u). They employ a Gauss‑Newton scheme, which leverages second‑order information for rapid convergence, and a continuation strategy on the regularization parameter α to avoid over‑regularization early on.
The methods are tested on a 2‑D Direct Current (DC) resistivity inverse problem. Experiments vary the structure of C (e.g., uniform, low‑rank, high‑rank, and missing‑data masks) and the number of sources/receivers. Key findings include:
- Data Completion works well when the missing‑data fraction is modest (<30 %) and the reduced model captures the dominant physics; it provides a strong regularizing effect but can bias the solution if the interpolated entries are inaccurate.
- Low‑Rank Approximation achieves near‑identical reconstruction quality to the ideal SS case when rank(C)≤5, while cutting the number of forward solves by an order of magnitude. Its performance degrades gracefully as the rank increases.
- Full‑Rank Stochastic Approximation converges with a modest increase in sample size (≈3 × n_s) but requires substantially more memory because each sample stores a full n_r × n_s matrix.
- Source Subset Sampling minimizes memory usage and is trivial to implement; however, it often needs 2–3 times more iterations to reach comparable misfit levels, and fine‑scale features may be lost.
Overall, the paper demonstrates that the SS paradigm can be extended to realistic geophysical data scenarios with non‑uniform noise and incomplete acquisition geometries. By selecting the appropriate strategy based on the structure of C, practitioners can retain the dramatic computational savings of SS methods while preserving inversion accuracy. The work opens avenues for adaptive C updates, integration with more complex PDEs, and large‑scale parallel implementations aimed at real‑time subsurface imaging.
Comments & Academic Discussion
Loading comments...
Leave a Comment