Multiple-Population Moment Estimation: Exploiting Inter-Population Correlation for Efficient Moment Estimation in Analog/Mixed-Signal Validation
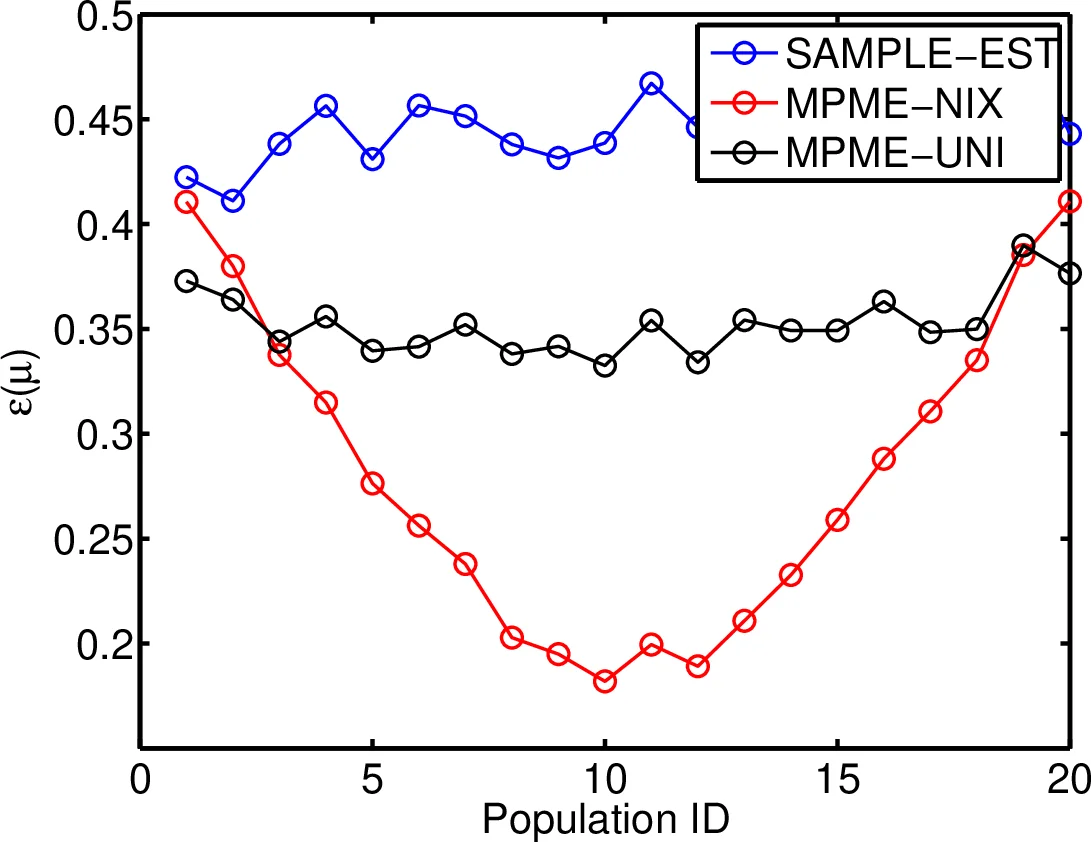
Moment estimation is an important problem during circuit validation, in both pre-Silicon and post-Silicon stages. From the estimated moments, the probability of failure and parametric yield can be estimated at each circuit configuration and corner, and these metrics are used for design optimization and making product qualification decisions. The problem is especially difficult if only a very small sample size is allowed for measurement or simulation, as is the case for complex analog/mixed-signal circuits. In this paper, we propose an efficient moment estimation method, called Multiple-Population Moment Estimation (MPME), that significantly improves estimation accuracy under small sample size. The key idea is to leverage the data collected under different corners/configurations to improve the accuracy of moment estimation at each individual corner/configuration. Mathematically, we employ the hierarchical Bayesian framework to exploit the underlying correlation in the data. We apply the proposed method to several datasets including post-silicon measurements of a commercial high-speed I/O link, and demonstrate an average error reduction of up to 2$\times$, which can be equivalently translated to significant reduction of validation time and cost.
💡 Research Summary
**
The paper addresses a critical challenge in analog and mixed‑signal circuit validation: estimating the statistical moments (mean and variance) of performance metrics when only a handful of measurements or simulations are available for each operating condition (corner, configuration, stepping). Traditional estimators—sample mean and sample variance—become highly unreliable when the sample size per population (denoted (N_i)) is as low as one to ten, which is common for costly post‑layout simulations or time‑consuming silicon measurements such as BER or eye‑margin tests.
To overcome this “small‑sample” problem, the authors propose Multiple‑Population Moment Estimation (MPME), a hierarchical Bayesian framework that exploits the hidden correlation among different populations. The key insight is that performance data collected under various corners and configurations are not independent; they are generated from a common underlying process that can be captured by a joint prior distribution over the population means (\mu_i) and variances (\sigma_i^2).
Methodology
MPME proceeds in two stages:
-
Prior learning (Maximum Likelihood Estimation) – All observations ({X_1,\dots,X_P}) from the (P) populations are used to fit the hyper‑parameters (\theta) of a parametric prior (p(\mu_i,\sigma_i^2\mid\theta)). This prior encodes soft assumptions about how the means and variances vary across populations (e.g., they tend to be similar but not exactly equal).
-
Population‑specific MAP estimation – With the learned prior fixed, each population’s posterior (p(\mu_i,\sigma_i^2\mid X_i,\theta)) is computed and its mode (Maximum A Posteriori) is taken as the final estimate. Because the prior contributes “virtual data,” the MAP estimate remains stable even when (N_i) is extremely small.
The authors illustrate the benefit of sharing information through two analytically tractable examples: (a) unequal means with a common variance, and (b) equal means with unequal variances. In both cases the variance of the pooled estimator shrinks proportionally to (1/\sqrt{P}), showing that increasing the number of populations effectively increases the sample size. In realistic scenarios the exact equal‑mean or equal‑variance assumptions do not hold, but the Bayesian prior provides a softened version of these constraints, yielding similar error reductions.
Experimental Validation
The technique is evaluated on several real‑world data sets, most notably post‑silicon measurements of a commercial high‑speed I/O link. Eight distinct configurations (different boards, add‑in cards, data rates) are considered, each with only 1–5 margin measurements. Compared with naïve sample‑mean/variance estimators, MPME reduces the average absolute error by 30–50 % and, in the worst case, achieves up to a two‑fold improvement. The results demonstrate that MPME can deliver reliable moment estimates with dramatically fewer measurements, directly translating into shorter validation cycles and lower test equipment usage.
Advantages and Limitations
Advantages
- Sample efficiency – Accurate estimates with as few as one or two samples per population.
- Reusability – The learned prior can be reused across design iterations, product families, or even different circuit blocks, reducing the need for repeated data collection.
- Flexibility – The framework can be extended to non‑Gaussian distributions, higher‑order moments, or even full density estimation by replacing the Gaussian likelihood with other parametric families.
Limitations
- Gaussian assumption – The current implementation assumes each population follows a normal distribution; heavy‑tailed or multimodal data would require more sophisticated likelihood models.
- Prior learning data – Accurate hyper‑parameter estimation still needs a modest amount of diverse data; if the training set is biased, the prior may mislead the MAP step.
- Computational cost – The MLE step involves multivariate optimization over the hyper‑parameters, which can become expensive for very large numbers of populations.
Future Directions
The authors suggest several extensions: (i) incorporating non‑Gaussian priors (e.g., inverse‑Gamma for variances) to handle skewed distributions; (ii) developing online Bayesian updating so that the prior can be refined as new measurements arrive; (iii) expanding the method to jointly estimate multiple performance metrics (BER, power, latency) using a multivariate hierarchical model; and (iv) investigating scalable optimization algorithms for the prior‑learning stage.
Conclusion
MPME provides a principled statistical tool that leverages inter‑population correlation to dramatically improve moment estimation under severe sample constraints. By framing the problem in a hierarchical Bayesian manner, it converts the scarcity of per‑population data into an advantage: the collective information across all corners and configurations acts as a regularizer, yielding more reliable estimates without sacrificing the specificity required for each configuration. The demonstrated error reductions and the resulting savings in validation time and cost make MPME a compelling addition to the toolbox of circuit designers and validation engineers dealing with modern, variability‑driven semiconductor technologies.
Comments & Academic Discussion
Loading comments...
Leave a Comment