Active Discovery of Network Roles for Predicting the Classes of Network Nodes
Nodes in real world networks often have class labels, or underlying attributes, that are related to the way in which they connect to other nodes. Sometimes this relationship is simple, for instance nodes of the same class are may be more likely to be…
Authors: Leto Peel
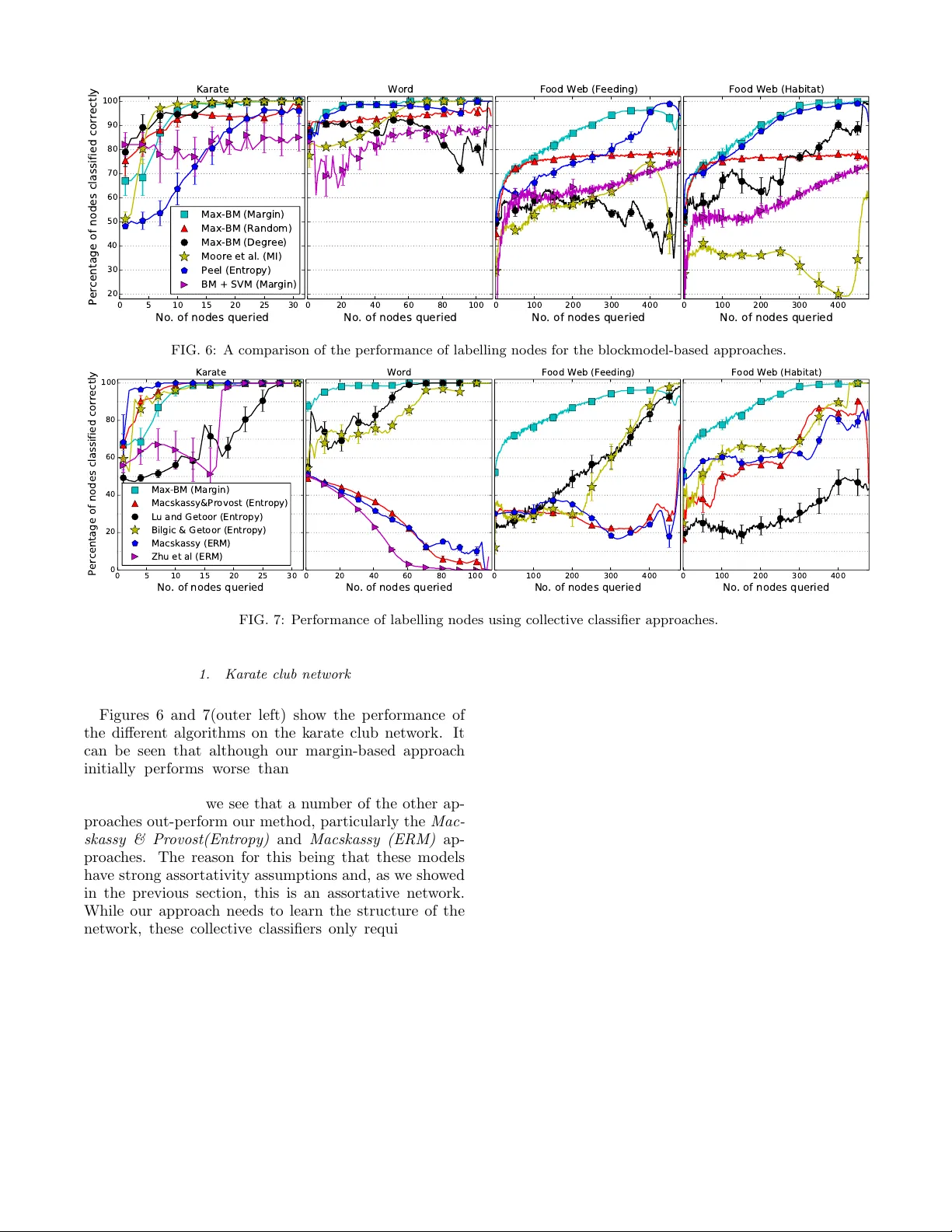
Activ e Disco v ery of Net w ork Roles for Predicting the Classes of Net w ork No des Leto P eel 1 , ∗ 1 Dep artment of Computer Scienc e, University of Color ado, Boulder, CO 80309 No des in real w orld netw orks often ha ve class lab els, or underlying attributes, that are related to the wa y in which they connect to other no des. Sometimes this relationship is simple, for instance no des of the same class are ma y be more likely to b e connected. In other cases, how ever, this is not true, and the wa y that no des link in a netw ork exhibits a different, more complex relationship to their attributes. Here, w e consider netw orks in which we know how the nodes are connected, but w e do not know the class lab els of the no des or how class lab els relate to the netw ork links. W e wish to iden tify the best subset of no des to label in order to learn this relationship betw een no de attributes and netw ork links. W e can then use this discov ered relationship to accurately predict the class lab els of the rest of the netw ork no des. W e present a mo del that iden tifies groups of no des with similar link patterns, whic h we call network r oles , using a generative blockmodel. The mo del then predicts labels by learning the mapping f rom net work roles to class lab els using a maximum margin classifier. W e choose a subset of no des to lab el according to an iterativ e margin-based active learning strategy . By integrating the disco very of netw ork roles with the classifier optimisation, the active learning pro cess can adapt the netw ork roles to better represen t the net w ork for node classification. W e demonstrate the mo del b y exploring a selection of real world net works, including a marine fo od w eb and a netw ork of English words. W e sho w that, in con trast to other netw ork classifiers, this mo del achiev es go o d classification accuracy for a range of netw orks with different relationships b etw een class lab els and netw ork links. I. INTR ODUCTION Man y naturally occurring netw orks can b e decomp osed in to sets of no des that link to the rest of the net w ork in similar wa ys. These sets of equiv alent no des not only share link structure but often share common attributes. F or example, assortative communities in online bidding net works corresp ond to the main user groups according to common interest [27], in blog net works blogs tend to link to others of the same p olitical view [1], and in biolog- ical net w orks proteins tend to link to others that perform similar functions [9]. In addition, there are types of dis- assortativ e link patterns where no des that are dissimilar prefer to link to each other. F or example, in a netw ork of sexual relationships linked entities tend to b e of the opp osite gender [5], sp ecies in a fo o d web tend to eat or- ganisms of a different sp ecies [2], and in an adjacency net- w ork of English words adjectives tend to precede nouns. When we encoun ter a new netw ork, we may not ini- tially know ho w link patterns relate to the attributes of no des. The netw ork could contain relations that are as- sortativ e, disassortative or a mixture therein. If we wish to p erform learning tasks suc h as classification, it is im- p ortan t to understand the relationship b et w een net work links and no de attributes. One wa y w e can analyse the link patterns in netw orks is to iden tify groups of no des that link in equiv alent wa ys. W e call these groups of no des with similar link patterns network r oles . By analysing the pattern of links within and betw een net work roles w e can understand the o v erall net work structure. ∗ leto.peel@colorado.edu Class lab els, on the other hand, represen t attributes or descriptions of the no des. Consider the aforementioned w ord netw ork, in which a link indicates that words are adjacen t in text and the direction of the link indicates the w ord order. Let eac h of the words b e assigned one of tw o p ossible class labels, “noun” or “adjective”. W ords la- b elled adjective are descriptive words and words lab elled noun are naming words. Here the class lab el tells us something ab out the w ord, but without prior knowledge of the language, it does not tell us ho w it links with other w ords. Therefore, class lab els tell us something ab out the no des and netw ork roles tell us about how no des link to eac h other. Our goal is to iden tify the relationship b et w een the tw o. In English we can use netw ork roles to describ e the link pattern that nouns follow adjectives. Ho wev er, in the F renc h language adjectives may come b efore or after a noun so while they hav e the same class labels, they are describ ed by a differen t set of roles. F urthermore, in F renc h certain types of adjectives such as gr and , b e au and b on come before the noun while others suc h as am ´ eric ain , noir , r ond usually come after the noun. In this case, no des of the same class displa y heterogeneity as they do not all link to the netw ork in the same wa y , therefore we can use multiple roles to represen t the heterogeneous link patterns of this class. A graphical representation of some p ossible role and class combinations are sho wn in Figure 1. Each node has a discrete class attribute (indicated by colour). The difference b et w een the netw orks is how the no des link to the rest of the netw ork. No des of the same role (i.e. hav e similar link patterns) are enclosed in a b o x. The top left netw ork illustrates assortative homogeneous classes, while the net w ork in the bottom left shows disassortativ e 2 Homogeneous Heterogeneous Assortative Disassortative FIG. 1: F our examples of classes and roles in netw orks. No de colour indicates class lab el. No des of that hav e similar link patterns are enclosed in a b ox; we call these netw ork roles. A homogeneous class is made up of a single role while a heterogeneous one contains multiple roles. classes. Both of these cases are homogeneous b ecause the links of each class is describ ed by a single role. In con- trast, the link structure of a heterogeneous class cannot b e adequately represented b y a single role and instead m ultiple roles are required to describ e the link patterns of each class (right). In this w ork w e consider the scenario where netw orks links are kno wn but the no de class labels are not. Al- though the lab els of the netw ork no des are not immedi- ately a v ailable, we can query the netw ork for more in- formation (e.g. by conducting field work or lab exp eri- men ts etc.). The task is to query a subset of the lab els to discov er net work roles, which can not only b e used to understand the relationship betw een classes, but can also b e used to predict missing class lab els. Our approac h uses only the link information and is ap- plicable to a range of assortative and disassortative struc- tures with no a priori assumptions ab out the structure t yp e. W e also do not assume that all no des of a par- ticular class link to the rest of the net work in the same w ay . W e achiev e this b y using a v ariant of the sto chastic blo c kmo del [14, 24] to model the probabilities of observ- ing links b etw een a pair of roles. The use of a blo c kmo del giv es us the flexibilit y to mo del a wide range of net work structures, e.g. assortative, disassortative or a mixture of the tw o. It also allows for directed relations. The particular blo ckmodel v arian t we use allows for individual no des to hav e mixed role memberships. This means that a class con tain multiple roles, and also that roles can b e shared across classes. F or example, consider a predator-prey net work where no des represen t sp ecies and directed links represent who-e ats-whom , w e may b e able to lab el no des as carnivores, omnivores, herbivores and plants. While the carniv ore and herbivore classes could b e represen ted by the distinct roles { e ats-animals , N x D X R Y Y R A N x N N x K N x K N x 1 N x 1 In depen den t (ii d) Netw o r k Di m ens i on ali t y R edu c tio n R o le Discovery C l a ss i fi c a tio n C l a ss i fi c a tio n FIG. 2: A comparison of an iid classification pro cess with dimensionalit y reduction (top) and the netw ork classification pro cess of our mo del (b ottom). In the iid case the rows of the input feature matrix, X , are indep enden t while the adjacency matrix, A , of the netw ork is not. e ats-plants } , a no de lab elled as omnivore would take on a mixture of these roles. T o learn the relationship b etw een net work roles and class lab els, we require some alignmen t of the classes and roles, i.e. so we can iden tify a mapping from roles to classes. W e achiev e this with a blo c kmo del that incorp o- rates a maximum margin classifier (e.g. Supp ort V ector Mac hine [11]). This new mo del allows us to use kno wn no de lab els to influence the discov ery of roles to improv e their alignment to the class lab els. Therefore acquiring more no de lab els improv es the correspondence b et ween roles and classe s. T o determine which no des to acquire to efficien tly disco v er net work roles, w e emplo y a margin- based active learning strategy . Once we ha ve trained our mo del, we can use the net- w ork roles w e hav e discov ered to make predictions ab out the node lab els w e do not know. This classification pro- cess is somewhat analogous to p erforming dimensional- it y reduction (e.g. Principal Comp onent Analysis) on iid data b efore p erforming classification. By representing the netw ork with roles, w e ac hieve similar goals to the iid case, i.e. reduce dimensions, remov e linear correla- tions. How ev er, we also gain an additional b enefit of conditional indep endence, since although the no des in the net work are b y nature dep enden t on each other, once w e condition on the net work roles the class lab els become conditionally indep endent of each other. W e test our metho d on a selection of real world net- w orks and show that, in con trast to previous work, it 3 p erforms well for a range of netw ork structures and even when no des with the same class lab el connect to the rest of the net work in different wa ys. I I. RELA TED WORK In this w ork we examine the problem of ho w to explore a netw ork in order to discov er the relationship b etw een no de lab els and netw ork links. Related to this problem are the tasks of collective classification and active learn- ing in net works. These methods make predictions ab out no de lab els, but unlike our work, they do not explicitly try to identify the type of relationship b et ween links and lab els. The problem of classifying no des in netw orks (referred to as collective classification) has received a lot of at- ten tion in recent years (e.g. [8, 15 – 17, 19, 29, 33, 39]). These metho ds consider the hard problem of making a join t, or c ol le ctive , prediction ab out the class lab els of no des. This is hard b ecause for N no des with C p os- sible class lab els, there are C N differen t wa ys to label the no des collectively . In the activ e learning setting, the task is to select a goo d subset of no des to lab el in order to b est predict the remaining no des. Of these collective classification metho ds, the relev ant ones are those that are applicable to the univ ariate setting, i.e. they do not use attributes of the nodes as features for classification. Most collectiv e classifiers mak e assumptions, either ex- plicitly or implicitly , that do not necessarily hold for all net works. The most significant one being assortativity (homophily), the is the assumption that linked nodes are more likely to b e of the same class. This assumption do es not hold in all cases as not all class lab els are re- lated to the netw ork structure in this wa y . The Marko v assumption that node labels are conditionally indep en- den t given the lab els of its neigh b ours (e.g. [17, 20, 22]), is also frequently used. This assumption allows one com- binatorially hard collective problem to b e broken in to man y easier related problems that can b e solved locally at the node level in conjunction with iterativ e algorithms to propagate these predictions around the netw ork. W e mak e a similar, but less restrictive assumption that the lab els of al l no des are conditionally indep enden t of eac h other, given a set of unobserv ed latent v ariables that w e infer from the netw ork structure. I II. ROLE DISCO VER Y IN NETW ORKS W e presen t a mo del for disco vering net work roles (groups of nodes with similar link patterns) to help us understand the relationship b etw een the class labels of no des and the netw ork links. Blo c kmo dels are a t yp e of probabilistic generative net work model and are a natural c hoice for this task since they can mo del a wide range of net work structure types, e.g. assortative, bipartite, core- p eriphery , hierarc hical. Our mo del is based on a mixed membership blo ck- mo del [25] and therefore assumes that each no de a b e- longs to a distribution o ver roles. The nodes’ distribution o ver roles determines the probability of a link existing b et w een an y pair of nodes. This assumption allows us to treat the links in the netw ork as b eing conditionally indep enden t of eac h other given the netw ork roles. Since the blo c kmo del is a type of probabilistic gener- ativ e mo del, we can sp ecify it according to the assumed data generating pro cess: 1. F or a given netw ork dra w a distribution o v er the p ossible K 2 net work role interactions 1 π ∼ Diric hlet( α ) 2. F or each role k ∈ { 1 , 2 , ..., K } : • Draw a distribution ov er no des φ ∼ Diric hlet( β ) 3. F or each interaction i ∈ { 1 , 2 , ..., I } : • Draw a role-role in teraction pair z i = ( z s , z r ) i , z i ∼ Categorical( π ) • Draw a sender no de s i ∼ Categorical( φ z s ) • Draw a receiv er no de r i ∼ Categorical( φ z r ) F or a given netw ork, G = ( V , E ), this blo c kmo del de- fines a likelihoo d function ov er the N = |V | no des and M = |E | links or interactions. The model assigns eac h link, { s i , r i } , in the netw ork a latent v ariable z i represen t- ing a distribution o ver p ossible role pairs. Each no de’s distribution ov er roles, ¯ z v , is then given by a normalised sum o v er the indicator v ectors of length K describing the net work role of the sender ( z s i ) and receiv er ( z r i ) no des: ¯ z v = 1 n v X i : s i = v z s i + X i : r i = v z r i ! . (1) Exact ev aluation of the blo c kmo del likelihoo d, p ( { s, r }| α, β ), is intractable since it requires a sum ov er all possible com binations of the latent v ariables, z . Using a distribution e q and Jensen’s inequalit y , we approximate 1 Conceptually , we can think of π as a matrix with dimensions K × K such that each element π k 1 ,k 2 represents the probability of observing a link from role k 1 to role k 2 . 4 the log lik eliho o d with a more tractable low er b ound 2 : log p ( { s, r }| α, β ) = log Z Z X z p ( π , φ, z , { s, r }| α, β ) d π d φ = log Z Z X z p ( π , φ, z , { s, r }| α, β ) e q ( π , φ, z ) e q ( π , φ, z ) d π d φ ≥ Z Z X z e q ( π , φ, z ) log p ( π , φ, z , { s, r }| α, β ) e q ( π , φ, z ) d π d φ = E e q [log p ( π , φ, z , { s, r }| α , β )] − E e q [log e q ( π , φ, z )] , (2) where E e q is the exp ectation under the e q distribution. Since the Diric hlet and Categorical distributions are con- jugate, we can solve the integration analytically to give us a tigh ter b ound on the log likelihoo d [32]: L ( q ; α, β ) , E q [log p ( z , { s, r }| α, β )] − E q [log q ( z )] (3) ≥ E e q [log p ( π , φ, z , { s, r }| α , β )] − E e q [log e q ( π , φ, z )] . IV. SUPER VISED ROLE DISCO VER Y Our goal is to b etter understand the relationship b e- t ween netw ork link structure and the no de class lab els. In the previous section w e discussed how a blockmodel can b e used to identify net work roles and that netw ork roles can be used to describe how the net w ork links. Therefore to ac hieve our goal we need to find a mapping b et ween the net work roles and the class lab els. T o find this mapping w e use a maximum margin classifier, e.g. supp ort vec- tor machine (SVM) [11]). W e choose maxim um margin classifiers because along with their strong generalisation guaran tees [36], they hav e also demonstrated empirical success on a broad range of iid tasks. Additionally , they ha ve b een effectiv e when used in conjunction with prob- abilistic mo dels to solve problems including optical char- acter recognition [31] and do cumen t classification [38]. Effectiv e metho ds for margin-based active learning in iid data hav e also been established [13, 28, 34]. A classifier is a function F : X → Y that maps a fea- ture v ector x ∈ X to a lab el y ∈ Y . Since the blo ckmodel assigns each no de, v , a vector, ¯ z v , represen ting its distri- bution ov er roles, we can use ¯ z v as a the input feature v ector. The classifier can then learn the relationship b e- t ween roles and class lab els. In this work we restrict F to b e a function of the form: F ( ¯ z v , η ) = arg max y ∈Y η T y ¯ z v , (4) 2 This is true for any choice of distribution, e q , and is an equality when e q is equal to the posterior distribution. corresp onding to a linear classifier in whic h η is a ma- trix of co efficients with dimensions K × C and C = |Y | is the num ber of different class lab els. A classifier with go od generalisation prop erties is one that maximises the margin, i.e. the distance b etw een the training p oin ts and the separating linear decision boundary [36]. In the case when C = 2 the supp ort v ector machine pro vides an ef- fectiv e metho d for learning a binary maxim um margin classifier. Solving the multi-class ( C > 2) case corre- sp onds to the following constrained optimisation [10]: min η ,ξ 1 2 || η || 2 + D N N X v =1 ξ v ∀ v , y s.t. : ( η T y v ¯ z v − η T y ¯ z v ≥ 1 − δ y ,y v − ξ v ξ v ≥ 0 , (5) where D is a p ositiv e regularisation constan t, δ p,q is the Kronec ker delta and 1 − δ y ,y v represen ts our loss func- tion, which equals 0 for the correct prediction and 1 for an y other prediction. T he slack v ariables, { ξ v } are used for classes that cannot b e separated by a linear classifier b y allowing some misclassification in the training data. Since w e minimize ov er the ξ v ’s, when the classes are linearly separable then ξ v = 0 ∀ v . The regularisation pa- rameter, D , controls the scale of the training misclassifi- cation p enalty and can b e set b y using cross-v alidation. Here, the multiclass margin, by which the true class y v is fav oured ov er another class y , is given by: η T y v ¯ z v − η T y ¯ z . (6) The constrain ts in Eq.(5) ensure that all training in- stances lie on the correct side of the decision boundary , if p ossible, and a ξ v > 0 indicates that training instance v is misclassified. Solving Eq.(5) 3 requires the introduction of Lagrange m ultipliers, b µ , and solving the Lagrangian: L ( η , ξ , b µ ) = 1 2 || η || 2 + D N N X v =1 ξ v + N X v =1 X y ∈Y b µ y v [ η T y v ¯ z v − η T y ¯ z v + 1 − δ y ,y v − ξ v ] ∀ v , y s.t. : b µ y v ≥ 0 . (7) Within this framew ork the simplest approach would then b e: first, infer the no de roles using the blo ckmodel, and second, train the SVM classifier using the kno wn class lab els and the inferred roles. Ho wev er, the lik eli- ho od function of blo ckmodels often contains a large n um- b er of lo cal optima p ertaining to go o d but distinct solu- tions [12]. As a result, optimising Eq.(3) migh t not result 3 In practice this inv olves solving an equiv alent dual formulation, which we omit for brevity . 5 ALGORITHM 1: Inference algorithm for Maximum-Margin Blo c kmo del Initialise λ, η randomly . Initialise b µ = 0. while relative improv ement in L > 10 − 6 do for i = 1 to |E | do up date λ i using Eq.(11). end for up date b µ, η by optimising Eq.(8). end while Predict unknown lab els b y v using Eq.(15) in the disco very of roles that relate to the class lab els 4 . Instead, we in tro duce the maximum-margin blo c kmo del (MaxBM), that treats the training of the classifier and the inference of the roles as a joint optimisation problem giv en b y: min q ,η,ξ −L ( q ; α, β ) + 1 2 || η || 2 + D N N X v =1 ξ v ∀ v , y s.t. : ( E q [ η T y v ¯ z v − η T y ¯ z v ] ≥ 1 − δ y ,y v − ξ v ξ v ≥ 0 , (8) The first part of the optimisation corresp onds to the negativ e lo wer b ound on the lik eliho od of the blockmodel (Eq.(3)), while the second part corresp onds to the mar- gin based classifier (Eq.(5)). F orm ulating the problem lik e this means that the mo del will av oid lo cally optimal solutions (i.e. net work roles) if they do not help with the classification task. As with other blo ckmodels, the MaxBM treats the presence or absence of each link as b eing conditionally in- dep enden t given the latent role assignmen t. Additionally , the mo del assumes that giv en the role assignmen t, the class lab els are conditionally indep enden t of each other and the net work structure. V. INFERENCE W e fit the MaxBM mo del to the observed netw ork us- ing an exp ectation-maximisation (EM) style pro cedure (see Algorithm 1). In the exp ectation step, we infer the laten t v ariables (i.e. the netw ork roles z ), and in the max- imisation step, w e learn the mo del parameters (i.e. the classification coefficients η ). Once the algorithm has con- v erged, w e can use the inferred mo del to make predictions ab out the unknown no de lab els. 4 In the worst case the inferred roles could b e orthogonal to the class labels. A. Inferring the netw ork roles W e infer the net work roles, z , using v ariational Ba yesian (VB) inference. VB inference [4] has the ad- v antage o ver sampling-based methods due to con vergence that is faster and easier to diagnose. In VB, a v aria- tional p osterior distribution is used to lo wer b ound the log likelihoo d (see Eq.(2)). This v ariational distribution is restricted to a set of tractable distributions to appro x- imate the true posterior distribution. Most frequen tly this restriction is that the distribution is fully factorised, kno wn as a mean-field approximation. As we ha ve in tegrated out the parameters π and φ , our v ariational p osterior distribution, q , is ov er the latent roles, z , only . This distribution takes the form: q ( z ) = Y i q ( z i | λ i ) , (9) where each λ i is a | K × K | -dimensional v ariational pa- rameter for a categorical distribution o ver pairs of roles for link i . W e optimise ov er q ( z ) by optimising q ( { z i } ) for each edge in the net work until conv ergence. Since our model is comp osed of probabilit y distributions from the conjugate exp onen tial family the up dates take a particular general form [30]: q ( z i ) ∝ exp( E ∼ q z i [log p ( Y , Z )]) (10) where Y represen ts the observed data and E ∼ q z i is the exp ectation under all q z 0 i for all i 0 6 = i . Exact calculation of the exp ectation in (10) is computationally exp ensiv e and therefore we use a first order T aylor expansion to appro ximate the up date equations [3, 30]. The netw ork roles are therefore up dated according to: λ i,k 1 ,k 2 ∝ d ¬ i k 1 ,k 2 + α k 1 ,k 2 ( n ¬ i s i ,k 1 + β )( n ¬ i r i ,k 2 + β ) ( n ¬ i · ,k 1 + N β )( n ¬ i · ,k 2 + N β + δ k 1 ,k 2 ) × exp 1 n s i X y µ y s i E [ η y s i ,k 1 − η y ,k 1 ] + 1 n r i X y µ y r i E [ η y r i ,k 2 − η y ,k 2 ] ! (11) where d k 1 ,k 2 is the count of links from role k 1 to role k 2 , and n v ,k is the num b er of times no de v in teracts as role k . The first line of (11) relates to the unsup ervised part of the up date. This part of the up date is used to fit a blo c kmo del without the use of class lab els and can b e used as an alternative to the Gibbs sampling metho d used in [25]. The last tw o terms are due to the max- margin formulation of Eq.(8) and are non-zero for the no des that lie on the decision b oundary , i.e. the supp ort v ectors. These create a bias in the mo del that encour- ages it to disco ver net work roles that make more accurate predictions on these difficult examples. 6 B. Learning the classification co efficients As a consequence of the conditional indep endence of the class lab els given the netw ork roles, it is p ossible to use standard SVM optimisation algorithms 5 , such as [35], to obtain the optimal µ and η . How ever, different to the standard SVM case the classifier inputs (netw ork roles) are not observed fixed v alues, but are instead la- ten t v ariables represen ted by our p osterior distribution. W e represent our curren t approximation to the p osterior distribution with a series of exp ectations, sp ecifically: E q [ z i ] = λ i , (12) E q [ η T y ¯ z v ] = η y n v T " X i : s i = v λ s i + X i : r i = v λ r i # , (13) where n v is the degree of no de v and λ v is a K -length v ector representing the marginal probability of sender or receiv er positions, i.e.: λ s i = " X k 2 λ i, 1 ,k 2 , X k 2 λ i, 2 ,k 2 , · · · , X k 2 λ i,K,k 2 # T , λ r i = " X k 1 λ i,k 1 , 1 , X k 1 λ i,k 1 , 2 , · · · , X k 1 λ i,k 1 ,K # T . (14) C. Predicting class lab els Once the inference algorithm has con verged and we ha ve an estimate of the netw ork roles and classifier co ef- ficien ts, w e can then p erform classification on the unla- b elled no des in the netw ork according to: b y v = arg max y ∈Y η T y ¯ z v . (15) VI. A CTIVE LEARNING In man y practical scenarios, the lab els of the netw ork no des ma y not be immediately a v ailable at training time. Acquisition of these lab els inv olves some cost; either the cost of consulting an exp ert, conducting an inv estigation or carrying out lab oratory exp eriments. In order to min- imise the cost incurred, w e wish to select the most in- formativ e examples. This is done using activ e learning. Activ e learning is a form of sup ervised learning that in- v olves in teractively selecting the nodes to lab el as part of the learning pro cess. In this setting, netw ork no des start off unlab elled and the active learning algorithm aims to 5 W e use a mo dified version of SVM multiclass : http://svmlight. joachims.org/svm_multiclass.html c ho ose the b est subset of no des to lab el in order to im- pro ve the classification of the remaining no des. This is undertak en in a greedy manner. At eac h stage of the algorithm a single unlab elled no de is selected to explore and is added to the training set. This selection o ccurs based on the output of the classifier and an active learn- ing criterion. As our metho d incorp orates a maximum margin clas- sifier it is p ossible to tak e adv antage of activ e learning criteria developed for supp ort vector machines. This in volv es querying a sample in relation to the decision b oundary . W e employ a simple strategy that chooses no des that hav e the smallest margin [34] as intuitiv ely these represent the examples where the classifier is most uncertain. W e use the multiclass margin [28] as the query function: Q multiclass = arg min v ∈{ 1 ,...,N } η T b y v ¯ z v − η T e y v ¯ z v . (16) where b y v represen ts the predicted class for no de v , as giv en in (15), and e y v = arg max y 6 = b y η T y ¯ z v is the second most likely class label. The query function (16) therefore selects the node that has the smallest margin betw een the top t wo comp eting class lab els. VI I. EXPERIMENT AL RESUL TS F our real world netw orks were used to test our Max- BM approac h to learning the relationship betw een net- w ork links and no de classes: 6 a so cial netw ork, a word net work, a marine fo o d web, and a citation netw ork. The first dataset is Zachary’s Karate Club [37], a social net work of friendships b etw een 34 members of a k arate club. The club split in to tw o factions, one led b y the instructor and the other by the club president. The class lab els corresp ond to the faction each no de b elonged to after the split. The second net work is comprised of 112 frequently o c- curring nouns and adjectives in the no v el David Copp er- field b y Charles Dic kens [23]. It is a directed net w ork where the links indicate adjacent w ords and the order they app ear in the text. The third netw ork is a fo od w eb of consumer-resource in teractions b et w een 488 sp ecies in the W eddell Sea [7]. The directed edges link each predator to its prey . W e p erform tw o classification tasks on this dataset, accord- ing to the attributes feeding type and habitat; these at- tributes partition the netw ork in different wa ys. F eeding t yp e takes one of C = 6 classes: primary pro ducer, car- niv orous, carnivorous/necro v orous, detrivorous, herbivo- rous/detriv orous and omnivorous. Habitat has C = 5 6 A Python implementation of the Max-BM model along with the datasets used are av ailable at http://gdriv.es/letopeel/code. html 7 24 25 26 27 20 21 22 23 28 29 1 3 2 5 4 7 6 9 8 11 10 13 12 15 14 17 16 33 18 31 30 34 19 32 1 2 3 4 6 7 11 5 17 13 4 22 18 8 12 1 2 14 20 3 24 30 26 25 27 23 21 19 15 16 28 33 32 34 29 31 10 9 Inter-faction Instructor President 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 2 3 4 1 2 3 4 log (number of links) 0.0 0.5 1.0 1.5 2.0 2.5 3.0 3.5 4.0 FIG. 3: Left: The k arate club netw ork. The node colour reflects the class lab el, i.e. whic h faction the no de b elongs to, while the link colour reflects the assignment of roles. Midd le: A visual representation of the distribution of inferred roles (columns) for each no de (rows) in the netw ork. Right: The role interaction matrix. The diagonal blo c ks indicate that the netw ork is assortativ e. classes, namely b en thic, b en thop elagic, demersal, land- based, and p elagic. Finally , the fourth net work is the muc h studied Cora citation net w ork [29] containing 2708 machine learning pap ers with directed links indicating citations, and C = 7 class lab els indicating one of 7 sub ject areas. F or each netw ork the algorithm was initialised by ac- quiring the lab el of one randomly chosen no de from each class. It wou ld b e p ossible to learn the num b er of classes as the netw ork is explored by adding a new class when- ev er a new label was encoun tered. It w ould also be p ossi- ble to optimise the num b er of netw ork roles using cross- v alidation at each stage. In this work, ho w ever, the n um- b er of roles was fixed, since w e found in practise that as long as w e had a sufficient n um b er of roles, the exact setting of this parameter did not hav e a substantial ef- fect on the results. The reason for this is that the mo del only uses the roles it needs to represent the link patterns that corresp ond to classes (see Sec. VI I B 1). W e there- fore set the num b er of netw ork roles to twice the num b er of classes, i.e. K = 2 C . Eac h stage of the learning process consisted of carrying out the inference pro cedure in Section V to conv ergence, follo wed b y the selection of a new no de to be lab elled. At eac h stage the margin cost parameter D was optimised using cross-v alidation. The rep orted results are av eraged o ver 50 random initialisations. In the following, we examine the netw ork roles discov- ered and the p erformance of the algorithm in discov ering these roles. A. Role Discov ery When confronted with a new netw ork dataset it is im- p ortan t to understand the patterns of complex interac- tions betw een the nodes. This is useful to further our understanding of how a system works, and also to b etter understand the data so that w e can build better algo- rithms for prediction. In this section w e examine the net work roles found using the MaxBM mo del and how they can b e used to understand the structure of the net- w ork in relation to the attributes of no des. First, we consider the k arate club netw ork. This is a w ell-studied netw ork, largely due to its simple structure and small size. Figure 3 (left) sho ws a visualisation of the net work. The no de colours indicate the factions (which w e use as class lab els) to which the no des b elong to after the split. No de 1 and no de 34 represent the Instructor and club Presiden t resp ectively . In Figure 3 (righ t) we see a visualisation of the logarithm of the n um b er of links that o ccurs b et ween the roles. All the links o ccur on the diagonal so this tells us that the netw ork links are assortativ e. Figure 3 (middle) sho ws the no de mem b erships to roles. In this visualisation, the rows corresp ond to no des in the netw ork and the columns corresp ond to the K = 4 roles. The rows in the top half are the no des in the Presi- den t’s faction, while the ro ws in the b ottom belong to the Instructor’s faction. Notice that the fourth column do es not contain any membership. Although the mo del had 4 roles av ailable, it determined that three were sufficient to represen t the netw ork structure. This visualisation sho ws the relationship b etw een roles and classes. W e can also interpret the roles in terms of the link patterns they represen t. Role 1 and Role 3 represen t interaction within the Instructor and Presiden t factions resp ectiv ely , while 8 Role 2 represen t interactions across factions. The second netw ork is the w ord net work of adjectives and nouns. Figure 4 sho ws the inferred role mem b erships (left) and role interactions (right). This is a net work that has been previously describ ed as being approximately bi- partite [21, 23] due to the tendency for adjectives to pre- cede nouns in the English language. W e observ e this relationship in Roles 1 and 4, which accoun t for the ma- jorit y of the nouns and adjectives resp ectiv ely . Roles 2 and 3 are therefore used by the mo del to account for the w ords that do not follow this simple rule. The third netw ork is the fo o d web of consumer- resource in teractions (i.e. who-eats-whom) and is shown in Figure 5. As there are t wo classification tasks we c ho ose to examine the netw ork roles in relation to the feeding type class lab el. This is b ecause it is the easier of the tw o to interpret without the use of more detailed domain sp ecific knowledge. W e see in Fig. 5(right) that the ma jorit y of the in teractions lie on the off-diagonal, indicating that the netw ork is disassortative. This seems reasonable as it tells us that in general, sp ecies of one t yp e tend to eat sp ecies of a different t yp e. Lo oking closer at the role memberships (Fig. 5(left)), we see ho w the class lab els relate to netw ork roles. W e see that Role 1 is exclusively comp osed of primary producers. Roles 2 to 5 (green ov erlay) corresp ond to herbiv ore species and Roles 6 to 12 (blue o v erlay) corresp ond to carnivore sp ecies. W e might therefore think of these roles as b eing e ats-plant s and e ats-animals resp ectiv ely and the indi- vidual roles b eing another lev el of organisation within these roles. The omniv ore sp ecies are distributed across all of these roles, since we know that omnivores eat b oth plan ts and animals. B. Classification Performance W e sho wed in the previous section that the MaxBM can b e used to disco ver the pattern b etw een net work links and no de attributes. Now we examine the p erformance of the mo del in disco vering this pattern as w e go through the pro cess of acquiring lab els. Each time we acquire the lab el for a new no de, w e quantify the performance according to the accuracy of the mo del predictions on the rest of the net work. W e compare our algorithm (MaxBM+Margin) with t wo baseline strategies: r andom , where no des were queried in a random order, and de gr e e , where no des where queried in order of largest degree. W e also compare against three other blo ckmodel approaches: a standard blo c kmo del using m utual information strategy( Mo or e et al.(MI) ) as describ ed in [21], the blo ckmodel of [26] using entrop y ( Pe el (Entr opy) ), and a SVM using the roles disco vered using an unsupervised blockmodel [25] ( BM+SVM (Entr opy) ). In addition, w e also compare against a selection of uni- v ariate collectiv e classification and net work based active learning methods from the literature. A summary of 1 2 3 4 Adjective Noun 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 2 3 4 1 2 3 4 log (number of links) 0.0 0.8 1.6 2.4 3.2 4.0 4.8 5.6 FIG. 4: L eft: The distribution of inferred roles (columns) for the no des (rows) in the word netw ork. Right: The role in teraction matrix. 1 2 3 4 5 6 7 8 9 10 11 12 Primary Carniv Carn/Nec Detriv Herb/Det Omniv eats-plants eats-animals 0.0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1.0 1 2 3 4 5 6 7 8 9 10 11 12 1 2 3 4 5 6 7 8 9 10 11 12 log (number of links) 0 1 2 3 4 5 6 7 8 FIG. 5: L eft: The distribution of inferred roles (columns) for the no des (rows) in the fo o d web netw ork. R ight: The role in teraction matrix. these classification and active learning selection strate- gies is giv en b elow 7 : • Macskassy & Pr ovost (Entr opy) : The weigh ted v ote relational neigh b our classifier [19] and select- ing the no de that has the highest entrop y predic- tion. • Lu & Geto or (Entr opy) : The netw ork-only version of the count-link logistic regression classifier [17] used with the ab ov e en tropy metho d. • Bilgic & Geto or (Entr opy) : The naiv e Bay es clas- sifier and selecting the no de with the highest sum of entrop y ov er its neighbours and itself [6]. • Zhu et al. (ERM) : The Gaussian harmonic clas- sifier using empirical risk minimisation (ERM) to select the next no de [39]. • Macskassy (ERM) : The same as abov e but using heuristics to select a subset of no des to ev aluate using the ERM metho d [18]. 7 W e use the netkit [20] implementations a v ailable at http:// netkit- srl.sourceforge.net/ 9 0 5 10 15 20 25 30 No. of nodes queried 20 30 40 50 60 70 80 90 100 Percentage of nodes classified correctly Karate Max-BM (Margin) Max-BM (Random) Max-BM (Degree) Moore et al. (MI) Peel (Entropy) BM + SVM (Margin) 0 20 40 60 80 100 No. of nodes queried Word 0 100 200 300 400 No. of nodes queried Food Web (Feeding) 0 100 200 300 400 No. of nodes queried Food Web (Habitat) FIG. 6: A comparison of the p erformance of lab elling no des for the blo c kmo del-based approaches. 0 5 10 15 20 25 30 No. of nodes queried 0 20 40 60 80 100 Percentage of nodes classified correctly Karate Max-BM (Margin) Macskassy&Provost (Entropy) Lu and Getoor (Entropy) Bilgic & Getoor (Entropy) Macskassy (ERM) Zhu et al (ERM) 0 20 40 60 80 100 No. of nodes queried Word 0 100 200 300 400 No. of nodes queried Food Web (Feeding) 0 100 200 300 400 No. of nodes queried Food Web (Habitat) FIG. 7: Performance of lab elling no des using collective classifier approaches. 1. Kar ate club network Figures 6 and 7(outer left) show the performance of the differen t algorithms on the k arate club net work. It can b e seen that although our margin-based approach initially performs worse than random, after exploring ab out 10 no des it has almost p erfect classification ac- curacy . Ho wev er, we see that a num b er of the other ap- proac hes out-p erform our metho d, particularly the Mac- skassy & Pr ovost(Entr opy) and Macskassy (ERM) ap- proac hes. The reason for this b eing that these mo dels ha ve strong assortativity assumptions and, as w e show ed in the previous section, this is an assortativ e netw ork. While our approach needs to learn the structure of the net work, these collective classifiers only require a goo d c hoice of no des to mak e accurate predictions. 2. Wor d network Figures 6 and 7(cen tre left) sho w, at each stage, the prop ortion of unexplored nodes in the w ord net work that are lab elled correctly by eac h of the metho ds. Here it can be seen that the accuracy of the MaxBM (Mar- gin) metho d quickly rises to 90% and after querying just 20 no des is close to 100% accurate. T o start with, the blo c kmo del metho d, Pe el (Entr opy) , performs almost as w ell as the margin approach, but the performance drops sligh tly after exploring about half of the net work. W e can also see that the MaxBM metho d p erforms better than all the other approac hes, since those that ac hiev e 100% accuracy , require the lab els of at least half of the net work b efore they do. In [21] they observe that, b ecause adjectives in the English language tend to precede nouns, no des with high out-degree can b e classified as adjectives and no des with high in-degree as nouns. Consequen tly they find that their mutual information approach, Mo or e et al. (MI) , tends to query no des with almost equal in- and out- de- gree first; these represen t no de labels ab out whic h the mo del is most uncertain. W e p erformed a similar analysis using our MaxBM ap- proac h. W e found that the MaxBM quickly disco vered the main roles represen ting the nouns that follow ed ad- jectiv es, i.e. Roles 1 and 4 in Fig. 4; these no des tended to b e queried last. With Roles 1 and 4 in place, the model c ho oses no des that don’t fit this pattern to determine ho w to b est assign the remaining roles. T o understand why the algorithm chose this ordering, w e considered the degree of each no de not only in terms 10 of its in- and out- degree, but in terms of its in- and out- degree to e ach class . W e found that the ma jority of the adjectives in the netw ork not only had a higher out-degree than in-degree, but also a higher out-degree to nouns than out-degree to adjectives. That is to sa y , these adjectiv es preceded nouns more than they preceded other adjectives. These no des tended to be queried last. In contrast, adjectives that did not link to the rest of the net work in this w ay were queried earlier since the model w as more uncertain ab out their classification. A similar analysis of the nouns sho ws that the subset of nouns ex- plored last nev er follow nouns and hav e a relatively high in-degree. 3. F o o d web In the fo o d web net work w e ha ve t wo classification tasks. The feeding t yp e task is shown in Figures 6 and 7(cen tre right) and the habitat task is in Figures 6 and 7(outer right). W e did not run the Zhu et al. (ERM) metho d on this netw ork due to the long running time. F or b oth tasks the margin strategy with the MaxBM mo del and the Pe el (Entr opy) metho ds outp erform the other algorithms. Again, w e examine the query order under the MaxBM (Mar gin) for b oth classification tasks. F or the classifica- tion of feeding type, the algorithm tends to query primary pro ducers last and the omnivores early on. As we saw in Fig.5, the primary pro ducer is a homogeneous class and is represen ted as a role defined as having no outgoing links (Role 1). Omniv ores, on the other hand, are the hardest to distinguish from the rest of the netw ork as they ha v e the greatest v ariation in link patterns. F or the habitat classification task, the last half of the net work no des to b e explored tend to b e of the b enthic and pelagic classes. In [21] it was suggested that the div ersity of the sp ecies contributed to the misclassifica- tion of more than half of the benthic species. In con- trast to previous work, the evidence suggests that our approac h performs well even when the diversit y is large. The MaxBM mo del can capture this diversit y b ecause it allo ws for class heterogeneity , i.e. the mo del can use mul- tiple roles to mo del the v ariety of link patterns within a class. F urthermore, the fact that the b en thic no des are queried later on suggests that not only do es this mo del predict the b en thic class lab els more accurately , but it do es so with greater confidence. 4. Cor a citation network W e do not run the Mo or e et al.(MI) or the Zhu et al.(ERM) learning algorithms as they do not scale well to netw orks of this size. Figure 8 shows the accuracy of predicting the unlab elled no des as the netw ork is ex- plored. Unlik e for the other netw orks, we do not explore 0 200 400 600 800 1000 1200 No. of nodes queried 0 20 40 60 80 100 Percentage of nodes classified correctly Cora Max-BM (Margin) Macskassy&Provost(Entropy) Lu and Getoor (Entropy) Bilgic & Getoor (Entropy) Macskassy (ERM) Peel (Entropy) FIG. 8: Performance of lab elling no des within the Cora citation netw ork. the entire netw ork and instead terminate the learning pro cess once half of the no des hav e b een queried. W e see that the Pe el (Entr opy) method performs b y far the worst. It can b e seen that the MaxBM (Mar- gin) metho d p erforms b etter, but it is the Macskassy & Pr ovost(Entr opy) and Macskassy (ERM) metho ds that p erform best. By the time half of the netw ork has b een explored all of the methods except Pe el (Entr opy) and Lu & Geto or (Entr opy) reach 90% accuracy . This is a similar pattern to that observed in the k arate club net- w ork. Both the k arate club so cial net work and the Cora citation netw ork are assortativ e and homogeneous [26]. Benefit of sup ervise d r ole disc overy Finally , w e make a general comment on the b enefit gained by allo wing the class lab els to influence the role disco very pro cess. The BM+SVM metho d is similar to our MaxBM metho d, except that it p erforms the role disco very and classifier training as separate steps and the role discov ery do es not use the kno wn class label informa- tion. In all five of the classification tasks we see that the BM+SVM metho d p erformed w orse than the MaxBM mo del. This sho ws that the netw ork roles are adapting as a result of the acquisition of class lab els during the ac- tiv e learning process and that there is measurable b enefit to incorp orating lab els in to the inference pro cess. VI II. DISCUSSION In this work we ha ve considered the problem of identi- fying the b est subset of no des to lab el, in order to discov er net work roles that describ e the relationship b etw een net- w ork links and node lab els. W e constructed an inter- pretable and flexible mo del based on blo c kmo dels and margin-based classification. W e assessed its p erformance at disco vering roles by its abilit y to accurately predict the lab els across the rest of the netw ork. W e build on previous work based on generativ e blo ck- mo dels and active learning to explore an unlab elled net- w ork. In contrast to previous w ork, w e do not assume that no des with the same lab el all connect to the rest of 11 the net work in the same w a y . By allowing for heterogene- it y within classes we can mo del a wider range of netw ork structures, while still attaining go o d classification accu- racy on net works with simple class structures. W e hav e compared our mo del, based on classification accuracy , to the related class of models known as collec- tiv e classifiers. W e see that for simple assortativ e net- w orks, some of these algorithms outp erform ours. If we kno w a priori how classes in a netw ork are distributed relativ e to their link structure and w e kno w that this relationship is assortative, then our metho d is not the metho d to use. How ever, if the relationship b et ween class lab els is y et to be disco vered then, as w e hav e demon- strated, our MaxBM mo del provides a go o d approach to explore the netw ork. F urthermore, if the link patterns are not assortativ e, then our method gives b etter classi- fication p erformance than previous metho ds. IX. A CKNOWLEDGMENTS W e thank Chr is Aicher, Mustafa Bilgic, Aaron Clauset, Abigail Jacobs, Dan Larremore, Sofus Macsk assy and Suzy Moat for helpful comments and Cris Mo ore and Y ao jia Zh u for useful discussions and providing the W ed- dell Sea dataset. The author was supp orted by the UK EPSR C-funded Eng. Do ctorate Centre in Virtual Envi- ronmen ts, Imaging and Visualisation (EP/G037159/1) [1] L. Adamic and N. Glance. The political blogosphere and the 2004 u.s. election: Divided they blog. In In LinkKDD ’05: Pr o c e e dings of the 3r d international workshop on Link Disc overy , pages 36–43, 2005. [2] S. Allesina and M. Pascual. F o o d web mo dels: a plea for groups. Ec olo gy L etters , 12(7):652–662, 2009. [3] A. Asuncion, M. W elling, P . Smyth, and Y. W. T eh. On smo othing and inference for topic mo dels. In Pr o c e e d- ings of the International Confer enc e on Unc ertainty in Artificial Intel ligenc e , 2009. [4] H. A ttias. A v ariational bay esian framew ork for graphical mo dels. In In A dvances in Neur al Information Pr o c essing Systems 12 , pages 209–215. MIT Press, 2000. [5] P . S. Bearman, J. Mo o dy , and K. Sto v el. Chains of Affec- tion: The Structure of Adolescent Romantic and Sexual Net works. Americ an Journal of So ciolo gy , 110(1):44–91, July 2004. [6] M. Bilgic and L. Geto or. Link-based activ e learning. In NIPS Workshop on Analyzing Networks and L e arn- ing with Gr aphs , 2009. [7] U. Brose, L. Cushing, E. L. Berlo w, T. Jonsson, C. Banasek-Rich ter, L.-F. Bersier, J. L. Blanc hard, T. Brey , S. R. Carp enter, M.-F. C. Blandenier, et al. Bo dy sizes of consumers and their resources. Ec olo gy , 86(9):2545, 2005. [8] C. Burfoot, S. Bird, and T. Baldwin. Collective classifi- cation of congressional flo or-debate transcripts. In Pr o- c e e dings of the 49th Annual Me eting of the Asso ciation for Computational Linguistics: Human L anguage T e ch- nolo gies - V olume 1 , pages 1506–1515. Association for Computational Linguistics, 2011. [9] J. Chen and B. Y uan. Detecting functional modules in the yeast protein-protein interaction netw ork. Bioinfor- matics , 22(18):2283–2290, 2006. [10] K. Crammer and Y. Singer. On the algorithmic imple- men tation of multiclass kernel-based vector machines. J. Mach. L e arn. R es. , 2:265–292, Mar. 2002. [11] N. Cristianini and J. Shaw e-T aylor. A n Intr o duction to Supp ort V e ctor Machines and Other Kernel-b ase d L e arn- ing Methods . Cam bridge Universit y Press, 1 edition, 2000. [12] B. H. Go od, Y.-A. de Montjo ye, and A. Clauset. Perfor- mance of mo dularit y maximization in practical contexts. Phys. R ev. E , 81(4):046106, Apr 2010. [13] S. Har-Peled, D. Roth, and D. Zimak. Maximum mar- gin coresets for active and noise tolerant learning. In Pr o c e e dings of the 20th international joint c onfer enc e on Artific al intel ligence , pages 836–841, San F rancisco, CA, USA, 2007. Morgan Kaufmann Publishers Inc. [14] P . W. Holland, K. B. Laskey , and S. Leinhardt. Sto c has- tic blo c kmo dels: First steps. So cial Networks , 5(2):109– 137, 1983. [15] X. Kong, X. Shi, and P . S. Y u. Multi-lab el collectiv e classification. In Pr o c e e dings of the Eleventh SIAM In- ternational Confer enc e on Data Mining , pages 618–629. SIAM / Omnipress, 2011. [16] A. Kuw adek ar and J. Neville. Relational activ e learning for join t collectiv e classification mo dels. In Pr oc e e dings of the 28th International Confer ence on Machine L e arning (ICML-11) , pages 385–392. ACM, June 2011. [17] Q. Lu and L. Geto or. Link-based classification. In Pr o c e e dings of the International Confer enc e on Machine L e arning (ICML) , 2003. [18] S. A. Macsk assy . Using graph-based metrics with empir- ical risk minimization to sp eed up active learning on net- w orked data. In Pr o c e e dings of the 15th ACM SIGKDD International Confer enc e on Know le dge Discovery and Data Mining , pages 597–606. ACM, 2009. [19] S. A. Macsk assy and F. Prov ost. A simple relational classifier. In Pro c e e dings of the Se c ond Workshop on Multi-R elational Data Mining (MRDM-2003) at KDD- 2003 , pages 64–76, 2003. [20] S. A. Macsk assy and F. Prov ost. Classification in net- w orked data: A to olkit and a univ ariate case study . J. Mach. L e arn. R es. , 8:935–983, May 2007. [21] C. Mo ore, X. Y an, Y. Zh u, J.-B. Rouquier, and T. Lane. Activ e learning for no de classification in assortative and disassortativ e netw orks. In Pr oc e e dings of the 17th ACM SIGKDD international c onfer enc e on Know le dge disc ov- ery and data mining , pages 841–849. ACM, 2011. [22] J. Neville and D. Jensen. Iterative classification in rela- tional data. pages 13–20. AAAI Press, 2000. [23] M. E. J. Newman. Finding communit y structure in net- w orks using the eigenv ectors of matrices. Phys. R ev. E , 74(3):036104, Sep 2006. [24] K. Nowic ki and T. A. B. Snijders. Estimation and Pre- diction for Sto chastic Blockstructures. Journal of the Americ an Statistic al Asso ciation , 96(455), 2001. 12 [25] J. Parkkinen, J. Sinkkonen, A. Gyenge, and S. Kaski. A blo c k mo del suitable for sparse graphs. In Pr o c e e dings of the 7th International Workshop on Mining and L e arn- ing with Gr aphs (MLG 2009) , Leuven, Belgium, July 2-4 2009. Extended Abstract. [26] L. Peel. T opological feature based classification. In Pr o- c e e dings of the 14th International Confer enc e on Infor- mation F usion , 2011. [27] J. Reichardt and S. Bornholdt. Clustering of sparse data via netw ork communities—a protot yp e study of a large online mark et. Journal of Statistic al Me chanics: The ory and Exp eriment , 2007(06):P06016, 2007. [28] D. Roth and K. Small. Margin-based active learning for structured output spaces. In J. Frnkranz, T. Scheffer, and M. Spiliop oulou, editors, Machine L e arning: ECML 2006, 17th Eu r op e an Confer enc e on Machine L e arning, Berlin, Germany, Septemb er 18-22, 2006, Pr o c e e dings , v olume 4212, pages 413–424. Springer, 2006. [29] P . Sen, G. M. Namata, M. Bilgic, L. Getoor, B. Gal- lagher, and T. Eliassi-Rad. Collective classification in net work data. AI Magazine , 29(3):93–106, 2008. [30] J. Sung, Z. Ghahramani, and S.-Y. Bang. Latent-space v ariational bay es. IEEE T r ans. Pattern Anal. Mach. In- tel l. , 30(12):2236–2242, 2008. [31] B. T ask ar, C. Guestrin, and D. Koller. Max-margin mark ov netw orks. In S. Thrun, L. Saul, and B. Sch¨ olk opf, editors, A dvanc es in Neural Information Pr o cessing Sys- tems 16 . MIT Press, Cambridge, MA, 2004. [32] Y. W. T eh, D. Newman, and M. W elling. A col- lapsed v ariational Ba y esian inference algorithm for latent Diric hlet allocation. In A dvances in Neur al Information Pr o c essing Systems , volume 19, 2007. [33] Y. Tian, T. Huang, and W. Gao. Robust collective clas- sification with contextual dependency netw ork models. In Pr o c e e dings of the Se c ond international c onfer enc e on A dvanc e d Data Mining and Applic ations , pages 173–180. Springer-V erlag, 2006. [34] S. T ong and D. Koller. Support vector machine active learning with applications to text classification. Journal of Machine L e arning R ese ar ch , 2:45–66, 2001. [35] I. Tso chan taridis, T. Joachims, T. Hofmann, and Y. Al- tun. Large margin methods for structured and interde- p enden t output v ariables. J. Mach. L earn. R es. , 6:1453– 1484, Dec. 2005. [36] V. V apnik. Statistic al le arning the ory . Wiley , 1998. [37] W. W. Zac hary . An Information Flow Mo del for Conflict and Fission in Small Groups. Journal of A nthr op olo gic al R ese ar ch , 33(4):452–473, 1977. [38] J. Zhu, A. Ahmed, and E. P . Xing. MedLDA: Maximum Margin Sup ervised T opic Mo dels. Journal of Machine L e arning Rese ar ch , 13:2237–2278, 2012. [39] X. Zh u, J. Lafferty , and Z. Ghahramani. Com bining ac- tiv e learning and semi-sup ervised learning using gaussian fields and harmonic functions. In ICML 2003 workshop on The Continuum fr om L ab ele d to Unlab ele d Data in Machine L e arning and Data Mining , pages 58–65, 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment