Network flow-based simultaneous retiming and slack budgeting for low power design
Low power design has become one of the most significant requirements when CMOS technology entered the nanometer era. Therefore, timing budget is often performed to slow down as many components as possible so that timing slacks can be applied to reduce the power consumption while maintaining the performance of the whole design. Retiming is a procedure that involves the relocation of flip-flops (FFs) across logic gates to achieve faster clocking speed. In this paper we show that the retiming and slack budgeting problem can be formulated to a convex cost dual network flow problem. Both the theoretical analysis and experimental results show the efficiency of our approach which can not only reduce power consumption by 8.9%, but also speedup previous work by 500 times.
💡 Research Summary
The paper addresses the increasingly critical problem of low‑power design in the nanometer CMOS era by jointly optimizing retiming and slack budgeting. The authors first model a synchronous sequential circuit as a directed graph G(V,E,d,w), where vertices represent combinational gates, edges represent signal paths, d_i denotes gate delay, and w_{ij} is the number of flip‑flops on edge (i,j). For each vertex i, the latest arrival time a_i, required time γ_i, and slack s_i = γ_i – a_i are defined based on the graph structure. Retiming is expressed as an integer labeling r_i that moves flip‑flops across gates; the new number of flip‑flops on an edge becomes w_{ij}+r_j−r_i.
Each gate is equipped with a discrete power‑slack curve consisting of k slack levels; the relationship between slack and power reduction is assumed to be a convex decreasing function, following the piecewise‑linear model proposed by Qiu et al. The objective is to minimize total power consumption ∑_i P(s_i) while respecting a global clock period T. This leads to an integer linear programming (ILP) formulation (denoted as problem (I) in the paper) that includes constraints for flip‑flop conservation, slack definition, and period limits.
Because solving the ILP directly is computationally prohibitive, the authors transform the problem into a convex‑cost dual network flow formulation. They first simplify the ILP by removing a complex constraint (IIh) and introducing a penalty term P(t_{ij}) to obtain a relaxed problem (III). To compensate for the loss of accuracy, they prove that the optimal solutions of the original and relaxed problems can be related through a simple heuristic that selects the minimum feasible slack for each vertex.
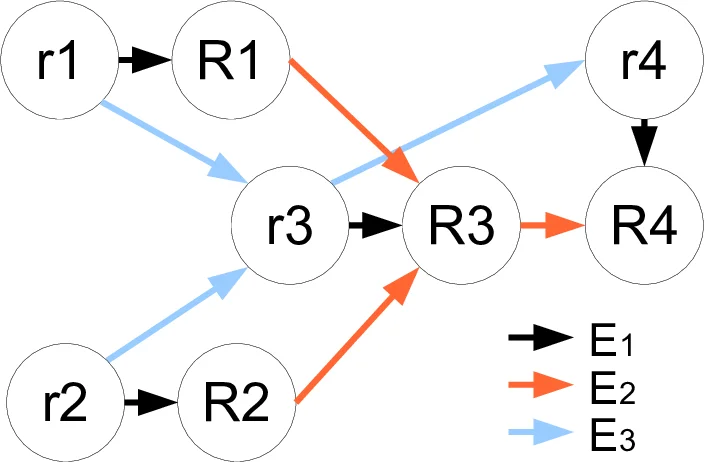
Next, they split each original vertex i into two nodes, \hat r_i and \hat R_i, and construct a transformed graph \bar G(\bar V,\bar E) where edges fall into three categories (E1, E2, E3). Edges in E1 connect \hat r_i to \hat R_i and carry the vertex slack variables; edges in E2 and E3 encode retiming constraints and the effect of moving flip‑flops. By adding large‑M penalty functions to both the slack bounds and node potentials, all explicit bound constraints are eliminated, yielding a pure flow problem (V).
The authors then apply Lagrangian relaxation to eliminate the remaining linear constraints, resulting in a Lagrangian sub‑problem L(·). For each edge (i,j) they define a function H_{ij}(x_{ij}) = min_{s_{ij}}{P_{ij}(s_{ij}) + x_{ij}s_{ij}}, which is piecewise‑linear and concave. By negating H_{ij} they obtain convex cost functions C_{ij}(x_{ij}) and formulate a minimum‑cost flow problem (VI). An expanded network G′ is built by replicating edges according to the discrete slack levels, and a cost‑scaling algorithm is employed to solve the flow efficiently.
Experimental evaluation on ISCAS’89 benchmarks and larger industrial designs demonstrates that the proposed method reduces power consumption by an average of 8.9 % compared with state‑of‑the‑art techniques, while achieving a runtime speed‑up of roughly 500×. Moreover, the total available slack increases, providing designers with additional freedom for downstream optimizations such as gate resizing or multi‑voltage assignment.
The key contributions of the paper are:
- A unified mathematical model that simultaneously captures retiming and discrete slack budgeting.
- A rigorous transformation of the NP‑hard ILP into a convex‑cost dual network flow problem, enabling polynomial‑time solution.
- Theoretical proofs that the simplifications and penalty terms preserve near‑optimality.
- Extensive empirical validation showing significant power savings and massive computational speed‑up.
Overall, the work offers a practical, scalable framework for low‑power sequential circuit optimization and opens avenues for integrating further power‑reduction techniques within a unified flow‑based optimization pipeline.
Comments & Academic Discussion
Loading comments...
Leave a Comment