Learning to Make Predictions In Partially Observable Environments Without a Generative Model
When faced with the problem of learning a model of a high-dimensional environment, a common approach is to limit the model to make only a restricted set of predictions, thereby simplifying the learning problem. These partial models may be directly us…
Authors: Erik Talvitie, Satinder Singh
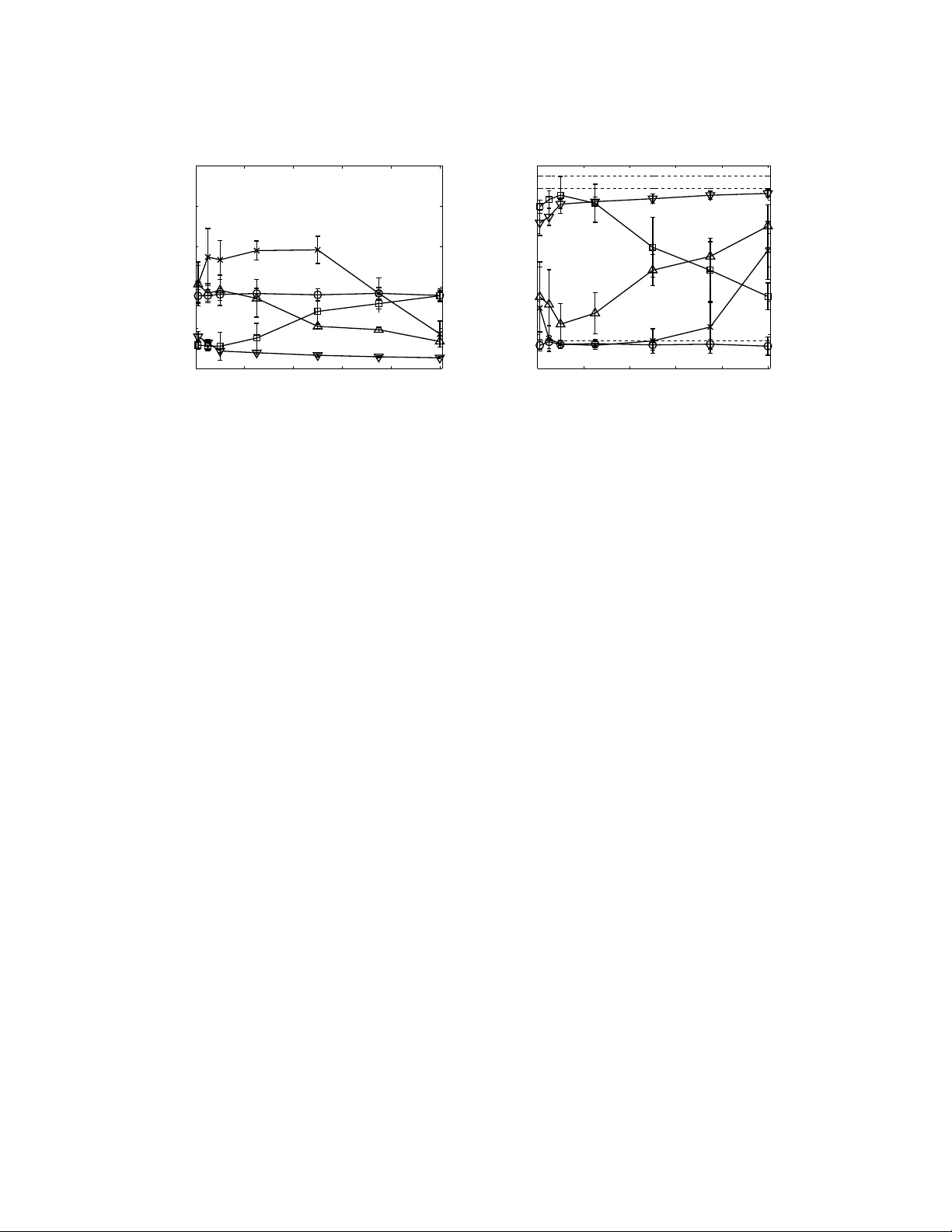
Journal of Artificial Intelligence Researc h 42 (2011) 353-392 Submitted 5/11; published 11/11 Learning to Mak e Predictions In P artially Observ able En vironmen ts Without a Generativ e Mo del Erik T alvitie erik.t al vitie@f andm.edu Mathematics and Computer Scienc e F r anklin and Marshal l Col le ge L anc aster, P A 17604-3003, USA Satinder Singh ba veja@umich.edu Computer Scienc e and Engine ering University of Michigan Ann Arb or, MI 48109-2121, USA Abstract When faced with the problem of learning a mo d e l of a high-dimensional environmen t, a common approach is to limit the mo del to make only a re s tr ic te d set of predictions, thereby simplifying the learning problem. These partial mo dels ma y b e directly useful for making decisions or may b e com bined together to form a more complete, st r uc tu r ed mo del. Ho w- ev er, in partially observ able (non-Marko v) environmen ts, standard mo del-learning method s learn generative mo dels, i.e. mo dels that provide a probabilit y distribution o ver all p os s i- ble futures (such as POMDPs). It is not straightforw ard to restric t suc h mo dels to make only ce r tain predict ions , and doin g so do es not alwa ys simplify the learning problem. In this pap er w e presen t prediction profile models: non-generative partial mo dels for partially observ able systems that mak e only a given set of predictions, and are therefore far simpler than generative mo dels in some cases. W e formalize t he problem of learning a predic ti on profile model as a transformation of the original mo del-learning problem, and show em- pirically that one can learn prediction profile mo dels that make a small set of imp ortant predictions even in systems that are too complex for standard generative models. 1. In tro duction Learning a mo del of the dynamics of an en vironment through exp erience is a critical capa- bilit y for an artificial agen t. Agen ts that can learn to make predictions ab out future even ts and an ticipate the conse q ue nc es of their o wn actions can use the se predictions to plan and mak e b etter decisions. When the agent’s en vironment is v ery complex, ho wev er, this learn- ing problem can p ose serious challenges. One common approach to dealing with complex en vironments is to learn p artial mo dels , fo cusing the mo del-learning problem on making a restricted set of particularly impor t ant predictions. Often when only a few predictions need to b e made, m uch of the compl e x i ty of the dynamics b eing mo deled can b e safely ig- nored. Sometimes a partial mo del can b e di r ec t l y useful for making decisions, for instance if the mo del makes predictions ab out the agen t’s future rewards (e.g., see McCallum, 1995; Mahm ud, 2010). In other cases, many parti al mo dels making restricted predictions are com bined to form a more complete mode l as i n, for instance, factored MDPs (Boutilier, Dean, & Hanks, 1999), factored PSRs (W olfe, James, & Singh, 2008), or “collections of lo cal mo dels” (T alvitie & Singh, 2009b). c 2011 AI Access F oundation. All rights reserved. T al vitie & Singh The most com mon approach to learning a partial model is to apply an abstr action (whether lear ne d or supplied b y a domain exp ert) that filters out detail from the train- ing data that is irrelev an t to making the impor t ant predictions. Mo del-learning metho ds can then b e applied to the abstract data, and t ypically the learni ng problem will be mor e tractable as a result. Ho wev er, esp ecially in the case of partially observ able systems, ab- straction alone ma y not sufficien tly simplify the learning problem, even (as w e will see in subsequen t examples) when the model is b eing asked to make in tuitively simple pre di c t i ons. The counter-in tuitive complexity of learning a partial model in the partially observ able case is a direct result of the fact that standard mo del-learning approaches for partially observ- able systems learn gener ative mo dels that attemp t to mak e ev ery p ossible prediction ab out the future and cannot b e straightforw ardly restricted to mak i ng only a few particularly imp ortan t predictions. In this pap er we present an alternative approach that learns non-gener ative models that mak e only the sp ecified predictions, conditioned on hi st or y . In the follo wing illustrativ e example, w e will see that sometimes a small set of predictions is all that is necessary for go od con trol p erformance but that learning to make these predictions in a hi gh-d i me nsi onal en vironment using standard generat i ve mo dels can p ose serious challenges. By con trast we will see that there exists a simple, non-generative model that can make and maintain these predictions and this will form the learning target of our metho d. 1.1 An Example Consider the simple game of Three Card Mon te. The dealer, p erhaps on a crowded street, has thre e cards, one of whic h is an ace. The dealer sho ws the lo cation of the ace, flips o ver the cards, and then mixes them up by swapping t wo cards at every time step. A pla yer of the game must k eep track of lo cation of the ace. Ev entually the dealer stops mixing up the cards and asks for a guess. If a play er correctly guesses where the ace is, they win some money . If they guess wrong, they lose some money . Consider an artificial agent attempting to learn a mo del of the dynamics of this game from exp erience. It takes a sequence of actions and p erceives a s eq ue nc e of observ ations. The ra w data r e ce i ved b y the agent includes a ric h, high-dimensional scene including the activities of the crowd, the mov ement of cars, the w eather, as well as the game itself (the dealer swapping cards). Clearly , learning a mo del that encompasses all of these complex phenomena is b oth infeasible and unnecessary . In order to win the game, the agent needs only fo cus on making predictions ab out the cards, and nee d not an ticipate the future b e- ha vior of the city scene ar ound it. In particular, the agent need only mak e three predictions: “If I flip o ver card 1, will it b e the ace?” and the corresp onding pr e di c ti ons f or car ds 2 and 3. One can safely ignore muc h of the detail in the agent’s exp erience and still make these imp ortan t predictions accurately . Once one filters out the irrelev an t detail, the agent’s exp erience might lo ok like thi s: bet pos 2 watch sw ap 1 , 2 watch sw ap 2 , 3 . . . , where the agen t takes the bet action, starting the game, and observ es the dealer showing the card in p osition 2. Then the agen t tak es the wa tc h action, observ es t he dealer swapping cards 1 and 2, takes the w atch action again, observes the dealer swapping cards 2 and 3, and 354 Learning to Make Predictions Withou t a Genera tive Model so on until the dealer prompts the agen t for a guess (note that th i s is not an uncontrolled system; w atch is indee d an action th at the agent m ust sel ec t o ver, say , reaching out and flipping the cards itself, whic h in a re al game of Three Card Monte would certainly result in negativ e utility!) Now the data reflects only the mo v ement of the cards. One could learn a mo del using this new data set and the learning problem would b e far simpler than b efore since complex and irrelev ant phenome na like the crowd and the weather hav e b een i gnor ed . In the Marko v case, the agen t directly observ es the en tire state of the environmen t and can therefore learn to make predictions as a direct function of state. Abstraction simplifies the representation of state and thereby simplifies the learning problem. Note, ho w ever, that the Three Card Mon te probl e m is p artial ly observable (non-Marko v). The age nt cannot directly observe the state of the en vironment (th e lo cation of the ace and the state of the dealer’s mind are b oth hidden to the agent). In t he partially observ able case, the age nt m ust le arn to maintain a compact representation of state as well as learn the d y nami c s of that state. The most common metho ds to achiev e this, suc h as e x p ectation-maximization (EM) for learning POMDPs (Baum, P etrie, Soules, & W eiss, 1970), learn gener ative mo dels whic h provide a probability distribution ov er all p ossible futures. In Three Card Mon te, even when all irrelev ant details hav e b een ignored and the data con tains only information ab out the cards’ mo vemen t, a generativ e mo del will stil l b e in- tractably complex! A ge ne r ati ve mo del makes predictions ab out al l future ev en ts. This includes the predictions the mo del is meant to mak e (such as whether flipping o ver card 1 in the next time-step will rev eal the ace) but also many irrele v ant predictions. A generative mo del, will also predict, for instance, whether flipping o ver card 1 in 10 time-steps will rev eal the ace or whether cards 1 and 2 will b e swapped in the n ex t time-step. T o mak e these pre di c t i ons, the mo del must capture not only the dynamics of the cards but also of the de aler’s de cision-making pr o c ess . If the dealer decides which cards to sw ap using some complex pro cess (as a human dealer might) then the problem of learning a generati ve mo del of this abstract system will b e c or re sp ondingly complex. Of course, i n Three Card Mon te, predicting the dealer’s future b eha vior is entirely unnecessary to win. All that is required i s to maintain the ace’s curr ent lo cation o ver time. As such, learni ng a mo del that devotes most of its complexity to an ticipating the dealer’s decisions is counter-in tuitive at b est. A far more reasonable mo del can b e seen in Figure 1. Here the “states” of the mo del are lab eled with predictions ab out the ace’s lo cat i on. The transitions are lab eled with observ ations of the dealer’s b ehavior. As an agen t plays the game, it could use such a mode l to maintain its predictions ab out the lo cation of the ace o ver time, taking the dealer’s b eha vior into account, but not pr e dicting the dealer’s future b eha vior. Note that this is a non-gener ative model. It do es not provide a distribution o ver all p ossible futures and it cannot b e used to “simulate the w orld” b ecause it do es not predict the dealer’s next mov e. It only provides a limited set of conditional predictions ab out the future, given the hi s tor y of past actions and observ ations. On the other hand, it is far simpler than a generative mo del would b e. Because it do es not mo del the dealer’s decision-making pro cess, this mo del has only 3 states, r e gar d less of the underlying pro cess used by the dealer. The mo del in Figure 1 is an example of what w e term a pr e diction pr ofile mo del . This pap er will formalize pre di c ti on profile mo dels and presen t an algorithm for learning them from data, under some assumptions (to b e sp ecified once w e ha ve established some necessary 355 T al vitie & Singh Figure 1: Maintaining predictions ab out the lo cation of the ace in Three Card Monte. T ran- sitions are lab eled with the dealer’s swaps. States are lab eled with the pr e di c te d p osition of the sp ecial card. terminology). W e will empiric al l y demonstrate that in some partially observ able systems that prov e to o complex for standar d generative mo del-learning metho ds, it is p ossible to learn a prediction profile mo del that makes a small set of imp ortan t predictions that allow the agent to mak e go od dec i si on s. The next sections will for mal l y describe the setting and establish some notati on and terminology and formalize the general learning problem b eing addressed. Subsequent sections will formally present prediction profile mo dels and an algorithm for learning them, as w ell as sev eral relev an t theoretical and empirical results. 1.2 Discrete Dynamical Systems W e fo cus on discrete dynamical systems. The agen t has a finite set A of actions that i t can tak e and the environmen t has a finite set O of observ ations that it can pro duce. At every time step i , the agent chooses an action a i ∈ A and the en vironment sto c hastically emits an observ ation o i ∈ O . Definition 1. A t ti me step i , the sequence of past actions and observ ations since the b eginning of time h i = a 1 o 1 a 2 o 2 . . . a i o i is called the history at time i . The h i st ory at time zero, before the agent has taken an y actions or seen any observ ations h 0 , is called the nul l history . 1.2.1 Predictions An agen t uses its mo del to mak e conditional predicti ons ab out future ev ents, giv en the his- tory of actions and observ ations and given its o wn future b eha vior. Because the environmen t is assume d to b e sto c hastic, predictions are probabilities of future even ts. The primitive building blo c k used to describ e future even ts is called a test (after Riv est & Sc hapire, 1994; Littman, Sutton, & Singh, 2002). A test t is simply a sequence of actions and observ ations 356 Learning to Make Predictions Withou t a Genera tive Model that could p ossibly o ccur, t = a 1 o 1 . . . a k o k . If the agen t actually tak es the action sequence in t and observes the observ ation sequence in t , we say that test t suc c e e de d . A pr e diction p ( t | h ) is the probability that test t succeeds after his tor y h , assumi ng the agent takes the actions in the test. Essen tially , the prediction of a test is the answ er to the question “If I were to take this particular sequence of actions, with what probability w ould I see this particular sequence of observ ations, given the history so far?” F ormally , p ( t | h ) def = Pr( o 1 | h, a 1 )Pr( o 2 | ha 1 o 1 , a 2 ) . . . Pr( o k | ha 1 o 1 a 2 o 2 . . . a k − 1 o k − 1 , a k ) . (1) Let T b e the set of all tests (that is, the set of all p ossible action-observ ation sequences of all lengths). Then the set of all p ossible histories H is the set of all action-observ ation sequences that could p ossibly o ccur starting from the n ull history , and the null history itsel f : H def = { t ∈ T | p ( t | h 0 ) > 0 } ∪ { h 0 } . A mo del that can make a prediction p ( t | h ) for al l t ∈ T and h ∈ H can mak e any conditional prediction about the future (Littman et al., 2002). Because it represen ts a probabilit y distribution o ver all futures, such a mo del can b e used to sample from that distribution in order to “simulate the world,” or sample p ossible future tra jectories. As suc h, we c all a mo del that mak es al l predictions a gener ative mo del . Note that the use of the w ord “generative” here is closely related to its broader sense in general density estimation. If one is attempt i ng to represent the conditional probability distribution Pr( A | B ), the gener ative approac h would b e to represen t the full joint distribu- tion Pr( A, B ) from whic h the conditional probabilities can be computed as Pr( A,B ) Pr( B ) . That is to say , a generativ e model in this sense mak es predictions even ab out v ariables we only wish to condition on. The non-gener ative or, in some settings, discriminitive approach would instead directly represen t the conditional distribution, taking the v alue of B as un-mo deled input. The non-generative approach can sometimes result i n significant savings if Pr( B ) is v ery difficult to repre se nt/learn, but Pr( A | B ) is relatively simple (so long as one is truly disin terested in mo deling the join t distribution). In our particular setting, a generative model is one that pro vides a probability distribu- tion ov er all futures (given the agen t’s actions). As such, one w ould use a generativ e mo del to compute p ( t | h ) for some particular t and h as p ( ht | h 0 ) p ( h | h 0 ) . In fact, from Equation 1 one can see that the prediction for an y multi-step test can b e computed from the predictions of one-step tests: p ( a 1 o 1 a 2 o 2 . . . a k o k | h ) = p ( a 1 o 1 | h ) p ( a 2 o 2 | ha 1 o 1 ) . . . p ( a k o k | ha 1 o 1 a 2 o 2 . . . a k o k ) . This leads to a simple definition of a generative mo del: Definition 2. Any mo del that can provide the predictions p ( ao | h ) for al l actions a ∈ A , observ ations o ∈ O and histories h ∈ H is a gener ative mo del . A non-generative mo del, then, w ould not m ake all one-step predictions in all histories and, consequently , would hav e to directly represent the prediction p ( t | h ) with the histor y h as an un-mo deled input. It would condition on a giv en history , but not necessari l y b e capable of computing the probabilit y of that history sequence. As w e sa w in the Three Card Monte example, this can b e b eneficial if making and main taining predictions for t is substan tially simpler than making predicti on s for every p ossible action-observ ation sequence. 357 T al vitie & Singh Note that a test desc r i b es a v ery sp ecific future even t (a sequence of spe ci fi c actions and observ ations). In many cases one might wish to mak e predictions ab out more abstract ev ents. This can b e achiev ed by comp osing the predictions of many tests. F or instance set tests (Wingate, Soni, W olfe, & Singh, 2007) are a sequence of actions and a set of observ ation sequences. A set test succe e ds whe n t he agen t takes the sp ecified action sequence and sees any observ ation sequence contained within the set o ccur. While traditional tests allow an agen t, for instance to express the question “If I go outsi de , what is the probabilit y I will see this exact sequence of images?” a set test can express the far more us ef ul , abstract question “If I go outside, what is the probability that it will b e sunn y?” by gr oupi ng together all observ ations of a sunn y day . Ev en more generally , option tests (W olfe & Singh, 2006; Soni & Singh, 2007) expr e ss future ev ents where the agent’s b eha vior is describ ed abstractly as w ell as the resulting observ ations. These t yp es of abstract pr e di c t i ons can b e computed as the linear combination of a set of concrete predictions . 1.2.2 System D ynamics Ma trix and Linear Dimension It is sometimes useful to desc r i b e a dynamical system using a conceptual ob ject called the system dynamics matri x (Singh, James, & Rudary , 2004). The system dynamics matrix con tains the v alues of al l p ossible pred i ct i ons, and therefore fully enco des the dynamics of the system. Sp e c i fical l y , Definition 3. The system dynamics matrix of a dynamical system is an infinit y-by-infinit y matrix. There is a column correspondi ng to ev ery test t ∈ T . There is a ro w corresp onding to every history h ∈ H . The i j th en try of the system dynamics matrix is the prediction p ( t j | h i ) of the test corresp onding to column j at the history corr es p onding to ro w i and there is an entry for ev ery histor y -t es t pair. Though the system dynamics matrix has infinitely man y en tries, i n many cases it has finite rank. The rank of the system dynamics matrix can b e though t of as a measure of the complexity of the system (Singh et al., 2004). Definition 4. The line ar dimension of a dynamical system is the rank of the corresponding system dynamics matrix. F or some p opular mo deling representations, the linear dimension is a ma jor factor in the complexity of representing and l ear ni ng a generative mo del of the system. F or instance, in POMDPs, the num b er of hidden states required to represent the system is lo wer-bounded b y the linear dimension. In this w ork w e adopt linear dimension as our measure of the complexity of a dynamical system. When w e say a system is “simpler” than another, w e mean it has a low er linear dimension. 1.2.3 The Marko v Proper ty A dynamical system is Markov if all t hat one needs to know ab out history in order to mak e predictions ab out future even ts is the most recent obser v ation. Definition 5. A system is Markov if for any tw o histories h and h ′ (that may b e the null history), any t wo actions a and a ′ , any observ ation o , and any test t , p ( t | hao ) = p ( t | h ′ a ′ o ). 358 Learning to Make Predictions Withou t a Genera tive Model In the Mark ov case we will use the notational shorth and p ( t | o ) to indicate the prediction of t at any history that ends in observ ation o . In the Mark ov case, bec ause observ ations con tain all the information needed to make any prediction ab out the future, they are ofte n called state (b ecause they describ e the state of the world). When a s y st em is not Marko v, it is p artial ly obs e rv ab le . In partially observ able systems predicti ons can dep end arbitrarily on the entire history . W e fo cus on the partially obser v able case. 2. Learning to Mak e Predictions In this work we assume that, as in Three Card Monte, though the agent ma y liv e in a complex en vironment, it has only a small set of important predictions to mak e. These predictions coul d ha ve b een iden tified as imp ortan t b y a designer, or b y some other learning pro cess. W e do not address the problem of iden tifying whic h predictions should b e made, but rather fo cus on the problem of learning to mak e predictions, once they are identified. In general, we imagine that we are given some finite set T I = { t 1 , t 2 , . . . , t m } of tests of inter est for which w e would like our mo de l to make accurate predictions. Here the term “test” should be construed broadly , p ossibly including abstr act tests in addition to raw sequences of actions and observ ations. The tests of interest are the future ev ents the model should predi c t. F or instance, in the Three Card Monte problem, in order to p e rf orm well the agen t m ust predict whether it will see the ace when it flips o ver eac h card. So it will ha ve three one-step tests of in terest: f lip 1 ace , f lip 2 ace , and f l ip 3 ace (representing the future even ts where the agent fli p s o ver car d 1, 2, and 3, resp ectiv ely , and sees the ace). If the agent can learn to maintain the probability of thes e even ts ov er time, it can win th e game. As suc h, the general problem is to learn a function φ : H → [0 , 1] m where φ ( h ) def = h p ( t 1 | h ) , p ( t 2 | h ) , . . . , p ( t m | h ) i , (2) that is, a function from hi st or i es to the predictions for the test of interest (whic h we will refer to as the pr e dictions of inter est ) at that history . Note that the output of φ is not necessarily a probability distri but i on. The tests of interest may b e selected arbitrarily and therefor e need not represen t mutually exclusiv e or exhaustive ev en ts. W e will call a particular v ector of predictions for the tests of interest a pr e diction pr ofile . Definition 6. W e call φ ( h ) the pr e diction pr ofile at history h . W e now describ e t wo existing general approaches to learning φ : learning a direct func- tion from history to predictions (most common in the Mark ov c ase ), and learning a fully generativ e mo del that maintains a finite -di m ens i onal summary of history (com mon in the partially obs er v able case). Both ha ve strengths and weaknesses as approaches to learning φ . Sec t i on 2.3 will contrast these with our approach, whic h combines some of the strengths of b oth approaches. 2.1 Direct F unction Approximation When the system is Marko v, learni ng φ is conceptually straigh tforward; essen tially it is a problem of learning a function from obser v ation (“state”) to predic ti ons . Rather than 359 T al vitie & Singh learning φ which tak es histories as input, one can ins te ad learn a function φ M ar kov : O → [0 , 1] m , whic h maps an observ ation to the predictions for the tests of in terest resulting from al l histories that end in that observ ation. Note t hat, as an immediate consequence, in discrete Mark o v systems there is a finite n um b er of distinct p re di c t i on profiles. In fact, there can b e no more distinct predict i on profiles than there are observ ations. When the n umber of observ ations and the num ber of tests of interest are small e nough, φ M ar kov can b e represented as a |O | × |T I | lo ok-up table, and the entries estimated using sample av erages 1 : ˆ p ( t i | o ) = # times t succeeds from histories ending in o # times acts ( t ) taken from histories ending in o . (3) The main challenge of learning Marko v mo de l s arises when t he num b er of observ ations is v ery large. Then it b ecomes necessary to general i z e across observ ations, using data gathe re d ab out one observ ation to learn ab out many others. Specifically , one may b e able to exploit the fact that some observ ations wil l b e asso ciated wi th v ery similar (or iden tical) prediction profiles (that is, the same predi ctions for the tests of interest) and share data amongst them. Restricting a mo del’s att ention to only a few predictions can afford more generalization, whic h is wh y learnin g a partial mo del can b e b eneficial in t he Marko v sett i ng. Ev en when the system is partially observ able, one can still attempt to learn φ directly , t ypically by p erforming some sort of regression ov er a set of featur es of entir e histori e s . F or instance, U-T ree (McCallum, 1995) tak es a set of history features and learns a decision tree that attempts to distinguish histories that result in differ ent exp ected asymptotic return under optimal b eha vior. W olfe and Barto (2006) apply a U-T ree-like algorithm bu t rather than restricting the mo del to predicting future rew ards, they learn to mak e predictions ab out some pre-selected set of features of the next observ ation (a sp ecial case of the more general concept of tests of in terest). Dinculescu and Precup (2010) learn the exp ected v alue of a given feature of the future as a direct function of a given real-v alued feature of history b y cluster i ng futures and histories that ha ve simil ar asso ciated v alues. Because they directly approximate φ these t yp es of mo dels only mak e predictions for T I and are therefore non-ge ne r ati ve (and therefore able, for instance, to av oid falling in to the trap of predicting the dealer’ s decisions in Th re e Card Mon te). Though this approach has demonstrated promise, it also faces a clear pragmatic challenge, esp ecially in the partially observ able setting: feature selection. Because φ is a function of history , an ever-expanding sequence of actions and observ ations, finding a reasonable set of compactly represen ted fea- tures that collectiv ely capture all of the history information need ed to mak e the predictions of in terest i s a significant c hallenge. In a sense, ev en in the partially observ able setting, this type of approach takes only a smal l step a wa y from the Marko v case. It still requires a go od idea a priori of what information should b e extracted from history (in the form of features) in order to make the predictions of interest. 1. Bowling, McCrack en, James, Neufeld, and Wilkinson (2006) show ed that this estimator is unbiased only in the case where the data is collected using a blind p olicy , in wh ic h action selection do es not dep end on the history of observ ations and provided an alternative estimator that is unbiased for all p olicies. F or simplicity’s sake, how ever, we will as sume throughout that the data gathering p olicy is blind. 360 Learning to Make Predictions Withou t a Genera tive Model 2.2 Generativ e Mo dels If one do es not hav e a go o d idea a priori of what features should b e extracted from history to make accurate predictions, one faces the additional challenge of le arning to summarize the relev an t information from history in a compact sufficien t stati st i c. There exist me tho ds that learn from training data to main tain a finite-dime ns i onal statistic of hi st ory from which any prediction can b e computed. In analogy to the Marko v case, this statistic is called the state ve ctor . Clearly an y mo del that can main tain state can b e used to compute φ (since it can mak e al l predictions). W e briefly mention t w o examples of this approac h that are particularly rel e v ant to the de velopmen t and analysis of our metho d. POMDPs By far the most p opular represen tation for mo dels of partially observ able systems is the partially observ able Marko v decision pro cess (POMDP) (Monahan, 1982). A POMDP p osits an underlying MDP (Puterman, 1994) with a set S of hidd en states that the agen t never observ es. A t any giv en time-step i , the system is in some particular hidden state s i − 1 ∈ S (unkno wn to the agent). The agen t tak es some act i on a i ∈ A and the system transitions to the next state s i according to the transition probability Pr ( s i | s i − 1 , a i ). An observ ation o i ∈ O is then emitted according to a probabi l i ty distribution that in general ma y dep end up on s i − 1 , a i , and s i : Pr( o i | s i − 1 , a i , s i ). Because the agent do es not observ e the hidden states, it cannot know which hidden state the system is in at any giv en momen t. The agent c an ho wev er maintain a probability distribution that represen ts the agent’s cur re nt b eliefs ab out the hi dd en state. This prob- abilit y distribution i s call ed the b elief state . If the b elief state asso ciated with history h is kno wn, then it is straightforw ard to compute the prediction of any test t : p ( t | h ) = X s ∈S Pr( s | h )Pr( t | s ) , where Pr( t | s ) can b e computed using the transition and obse rv ation emission probabili t i e s. The belief state is a finite summary of history f r om which any prediction about the future can b e compute d. So, the b elief state is the state vector for a POMDP . Given the transition probabilities and the observ ation emission probabiliti es , it is p ossible to maintain the b elief state ov er time using Bay es’ r ul e . If at the current history h one knows Pr( s | h ) for all hidden states s and the agen t takes action a and observes observ ation o , t he n one can compute the probability of an y hidden state s at the ne w history: Pr( s | hao ) = P s ′ ∈S Pr( s ′ | h )Pr( s | s ′ , a i )Pr( o i | s ′ , a i , s ) P s ′′ ∈S P s ′ ∈S Pr( s ′ | h )Pr( s ′′ | s ′ , a i )Pr( o i | s ′ , a i , s ′′ ) . (4) The parameters of a POMDP that m ust be learned in order to be able to maintain state are the transition probabilities and the observ ation emission probabilities. Given these parameters, the b elief state correspondi ng to any giv en history can be recursiv ely computed and the mo del can thereby make an y prediction at an y history . POMDP parameter s are t ypically learned using the Exp ectation Maximization (EM) algorithm (Baum et al., 1970). Giv en some training data and the num b er of actions, observ at i ons, and hidden states as input, EM essen tially p erforms gradient ascen t to find transition and emission distributions that (lo cally) maximize the likelihoo d of the provided data. 361 T al vitie & Singh PSRs Another more recently in tro duced mo de l i ng representation is the predictive state represen tation (PSR) (Littman et al., 2002). Instead of hidden states, PSRs are defined more directly in terms of the system dynamics matri x (describ ed in Section 1.2.2). Sp ecifically , PSRs find a set of c or e tests Q whose corr es p onding columns in the system dyn ami cs matrix form a basis. Recall t hat the system dynami cs matrix often has finite rank (for i n stan ce , the matrix asso ciated with an y POMDP with finite hidden states has finite linear dimension) and thus Q is finite for many systems of in terest. Since the predictions of Q are a basi s , the prediction for any other test at some history can b e computed as a linear combination of the predictions of Q at that history . The v ector of predictions for Q is called the pr e dictive state . While the b elief state was the state v ector for POMDPs, the predictive state is the state v ector for PSRs. It can als o b e maintained by application of Ba y es’ rule. Sp ecifically , if at some history h , p ( q | h ) is known for all core tests q and the agent takes some action a ∈ A and observes some observ ation o ∈ O , then one can compute the prediction of an y core test q at the new history: p ( q | hao ) = p ( aoq | h ) p ( ao | h ) = P q ′ ∈ Q p ( q ′ | h ) m aoq ( q ′ ) P q ′ ∈ Q p ( q ′ | h ) m ao ( q ′ ) , (5) where m aoq ( q ′ ) is the co efficient of p ( q ′ | h ) in the linear combination that computes the prediction p ( aoq | h ). So, given a set of core tests, the parameters of a PSR that m ust b e lear ne d in order to main tain state are the co efficien ts m ao for ev ery action a and observ ation o and the co efficien ts m aoq for ev ery action a , observ at i on o , and core tests q . Giv en these parameters the predictiv e state at any given history can be recursiv ely computed and used to mak e an y prediction ab out the future. PSRs are learned by directly estimating the system dynam- ics matrix (James & Singh, 2004; W olfe, James, & Singh, 2005) or, more recently , some sub-matrix or derived matrix thereof (B o ots, Siddiqi , & Gordon, 2010, 2011) using samp l e a verages in the training data. The estimated matrix is used to find a set of core tests and the parameters are then estimated using linear regress i on. Note that b oth of these types of models are inher ently generativ e. They b oth rely up on the main tenance of the stat e v ector in order to make predictions and, as can b e seen in Equations 4 and 5, the state up date equations of these mo dels r ely up on ac c ess to one-step pr e dictions to p erform the Bay esian up date. As such, unlike the direct function appro ximation approach, one cannot si mpl y c ho ose a set of predictions for t he model to mak e. These mo dels b y necessity mak e al l predictions. There are many reasons to desi r e a complete, generative mo d el . Because it makes all p ossible predictions, such a mo del can b e used to sample p ossible future tra jectories which is a useful capability for planning. A ge ne rat i ve mo del is al so, b y definition, very flexible ab out what predictions it can b e used to mak e. On the other hand, in m any cases a compl et e , generativ e model may b e difficult to obtain. B oth PSR and POMDP training methods scale v ery p o orly with the li ne ar dime nsi on of the syste m b eing learned. The linear dimension lo wer-bounds the num b er of hidden stat e s needed to repre se nt a system as a POMDP and is precisely the n um b er of core tests needed to represen t it as a P SR. The learning metho ds for POMDPs and PS Rs are rarely successfull y applied to systems with a linear dimension of 362 Learning to Make Predictions Withou t a Genera tive Model Figure 2: Size 10 1D Ball Bounce more than a few h undred (though the work of Bo ots et al. is pushing these limits further ). Most systems of interest will ha ve several orders of magnitude higher linear dimension. F urthermore, a complete, generativ e mo del is o verkill f or the problem at hand. Recall that w e do not seek to make al l predictions; we are fo cused on making some particularly imp ortan t predictions T I . Ev en in problems where learning to make all predictions might b e intractable, it should still b e p ossible to make some simple but imp ortan t predictions. 2.2.1 Abstract Genera tive Models As discussed earlier, when there is a restricted set of tests of interest, the learning problem can oft en b e simplified b y ignoring irrelev an t details through abstraction. Of course, ha ving an abstraction do es not solve the problem of partial observ ability . What is t ypically done is to apply the abstraction to the training data, discarding the irrelev an t details (as w e did in the Three Card Mon te example) and then to apply mo del learning metho ds like the ones de sc r i b ed ab o ve to the abstr act data set. Just as in the M arko v setting, in some cases observ ation abstraction can greatly simplify the l e ar ni ng problem (certainly learning ab out only the cards in Three Card Monte is easier than learning ab out the cards and the c r owd and w eather and so on). Ignoring details irrelev an t to making the predictions of in terest is intuitiv e and can significan tly simplify the learning problem. On the other hand, bec ause they are generativ e mo dels, an abstract POMDP or PSR will still mak e al l abstr act pr e dictions . Thi s typically includes predictions other than those that are directly of interest. If these extra predictions require a complex mo del, even an abstract gener ati ve mo del can b e intractible to lear n. Thi s is true of the Thre e Card Monte example (where a generative mo del ends up mo deling the dealer as well as the c ar ds) . The following is another simple example of this phenomenon. Example. Consider the uncontrolled system pictured in Figure 2, called the “1D Ball Bounce” system. The agen t observ es a strip of pixels that can b e black or white. The blac k pixel represents the p osition of a ball that mo ves around on the strip. The ball has a curre nt direction and ev ery time-step it mov es one pixel in that di r ec t i on. Whenever it reac hes an edge pixel, its current direction c hanges to mov e aw a y from the edge. In Figure 3(a) a complete PO M D P mo del of a 10 pixel version of this system is pictured. If there are k pixel s, the POMDP has 2 k − 2 hidden states (because the ball can ha ve one of 2 p ossible directi ons in one of k p ossible p ositions, except the tw o ends, where there is only one p ossible direction). No w sa y the agen t wishes onl y to predict whether the ball will be in the p osition marked with the x in the next ti me step. Clearly this prediction can b e made b y only paying atten tion to the immediate neighborho o d of the x . The details of what happ ens to the ball while it is far aw a y do not matter for mak i n g these predictions. So, one could apply 363 T al vitie & Singh (a) (b) Figure 3: POMDP mo del of the size 10 1D Ball Bounce system (a) and of the abstracted 1D Ball Bounce system (b) . an abstraction that lumps together all observ ations in whic h the neigh b orhoo d ab out x lo oks the same. The problem is that an abstract generative mo del of this system mak es predictions not only ab out x , but also about the pixels surrounding x . Sp ecifically , the mo del still makes predi ct i ons about whether the ball wi l l en ter t he neigh b orhoo d in the near future. This of course dep ends on how long it has b een since the ball left the neigh b orho od. So, the POMDP mo del of the abstract sy s te m (pictured in Figure 3(b)) has e xa ct ly the same state diagr am as the original system , though its observ ations hav e changed to reflect the abstraction. The abstract system and the primitiv e system hav e the same linear dimension. In order to mak e predictions about x , one m ust condition on information about the pixels surrounding x . Consequen tly , a generativ e mo del also makes predictions ab out these pixels. Counterin tuitively , the abstract model ’ s complexit y is m ai nl y dev oted to mak i ng predictions other than the predi c ti ons of interest. In general, while learning an abstract mo del can drastically simplify the learning pr obl e m b y ignoring irrelev an t details, an ab- stract generative mo del still learns to make predictions ab out any details that ar e relev ant, ev en if they are not directly of in terest. 2.3 Prediction Profile Mo dels The contribution of this pap er, pr e diction pr ofile mo dels , seek to com bine the main strengths of the tw o mo del-learning approaches discussed ab o ve. As with a direct approximation of φ , a prediction profile mo del will only make the pr edi c t i ons of interest, and no others. As such, it can b e far simpler than a generativ e mo del, which will t ypically mak e man y extraneous predictions. Ho wev er, the learning metho d for prediction profile models will not require a set of history features to b e given a priori . By leveraging exi st i ng generative mo del learning metho ds, prediction profile mo dels learn to main tain the state information necessary for making the predictions of interest. 364 Learning to Make Predictions Withou t a Genera tive Model Figure 4: Prediction profile mo del for the 1D Ball Bounce system A typical mo del learns to make predictions ab out future observ ations emit te d by the system. The main idea b ehind prediction profile mo dels is to instead mo del the values of the pr e dictions themselves as they c hange o ver time, conditioned on b oth the actions c hosen b y the agen t and the observ ations emitted by the system. W e ha ve already seen an example of this i n Three Card Mon te. The prediction profile mo del (sho wn in Figure 1) takes observ ations of the dealer ’ s b eha vior as input and outputs predictions for the tests of in terest. It does not predict the dealer’s b eha vior, but it takes it in to accoun t when updating the p re di c t i ons of in terest. Recal l that, though the Three Card Mon te system can b e arbitrarily complicated (depending on the dealer), this prediction profile system has three states, regardless of the dealer’s decision making pro cess. Another example is shown in Figure 4. This is the prediction profile system for the 1D Ball Bounce system (Figure 2), where the mo del m ust predict whether the ball will enter p osition x in the next time-step . Eac h state of the prediction profile mo del is lab eled wit h a prediction for pixel x (white or blac k). The transitions are lab eled with observ ations of the 3-pixel neigh b orho od centered on p osition x . In this case the transitions capture the ball en tering the neigh b orho od, moving to p osition x , lea ving the neighborho o d, st aying aw a y for some undetermined amount of time, and returning again. Recall that a POMDP mo del of this system has 2 k − 2 hidden states, where k is the n umber of pixels, even after ignoring all pixels irrelev an t to making predictions ab out pixel x . By contrast, the prediction profile mo del alwa ys has three states, regardless of the num b er of pixels. The next section will formally describ e prediction profile mo dels as mo dels of a dynam- ical sy st em that results from a transformation of the original sy st em . Subsequent sections will discuss ho w to learn prediction profile mo dels from data (b y con verting data from the original s y st em into data from the tr ansf or med system and learning a mo del from the con- v erted data set) and present results that help t o c haracterize t he conditions under which prediction profile mo dels are b est applied. 3. The Prediction Profile System W e now formally describ e a theoretical dynamical system, defined in terms of b oth the dynamics of the ori gi nal system and the giv en tests of interest. W e call this constructed system the pr e diction pr ofile system . A pr e diction pr ofile mo del , which it is our goal to 365 T al vitie & Singh construct, is a mo del of the prediction profile system (that is, the system is an ideal, theoretical construct, a mo del may b e imp erfect, approximate, etc.). As such, our analysis of the problem of learning a prediction profile mo del will dep end a great deal on under st andi ng prop erties of the prediction profile sys te m. In this pap er we make the restrictive assumption that, as in the Marko v case, there is a finite num b er of di stinct prediction profiles (that is, the predictions of i nterest take on only a finite num b er of distinct v alues). This is certainly not true of all partially observ able systems and all sets of tests of interest, though it is true in man y in teresting examples. F ormally , this assumption requires that φ map histori e s to a finite set of prediction p r ofil es : Assumption 7. Assume ther e exists a fini t e set of pr e diction pr ofiles P = { ρ 1 , ρ 2 , . . . , ρ k } ⊂ [0 , 1] m such that for every history h , φ ( h ) ∈ P . This assumption allo ws the definition of the pr e diction pr ofile system (or P P for short) as a discrete dynamical system that captures the sequence of prediction profiles ov er time, giv en an action obser v ation sequence. The prediction profile system’s actions, observ ations, and dynamics are defined i n terms of quantities asso ciated with the original system: Definition 8. The pr e diction pr ofile system is defined by a set of obse r v ations, a set of actions, and a rule gov erning its dynamic s. 1. Observ ations: The set of prediction profile observ ations, O P P , is defined to be the set of distinct prediction pr ofil es . That is, O P P def = P = { ρ 1 , . . . , ρ k } . 2. Actions: The set of pre di c t i on profile acti on s, A P P , is defined to b e the set of action- observ ation pairs in the original system. That is, A P P def = A × O . 3. Dynamics: The dynamics of the prediction profile system are deterministically gov- erned b y φ . At any prediction profile history , h a 1 , o 1 i ρ 1 h a 2 , o 2 i ρ 2 . . . h a j , o j i ρ j , and for any next P P -action, h a j +1 , o j +1 i , the prediction profile system deterministically emits the P P -observ ation φ ( a 1 o 1 a 2 o 2 . . . a j o j a j +1 o j +1 ). W e now presen t s ome k ey facts about the prediction profil e system. Sp ecifically , it will be noted that the prediction profile system is alwa ys determini stic. Also, though the prediction profile sy st e m ma y b e Marko v (as it is in the Three Card Monte exampl e ) , in general it is partially observ able. Prop osition 9. Even if the original system is sto chastic, the pr e diction pr ofile system is always deterministic. Pr o of. This follows immediately from the definition: every history corresp onds to exactly one prediction profile. So a P P -history (action-obser v ation-profile sequence) and a P P - action (action-observ ation pair) fully determine the next P P -observ ation (prediction pro- file). The sto c hastic observ ations in the original system hav e b een folded into the un- mo deled actions of the prediction profile system. Prop osition 10. If the original s y s te m is Markov, the pr e diction pr ofile system is Markov. 366 Learning to Make Predictions Withou t a Genera tive Model Pr o of. By definition, i f the original system is Marko v the prediction profile at any time step dep ends only on the most r ec e nt observ ation. So, if at time step t , the current profile is ρ t , the agen t takes action a t +1 and observes observ ation o t +1 , the next profile is simply ρ t +1 = φ M ar kov ( o t +1 ). So, in fact, when the original sy st e m is Marko v, the predict i on profile system satisfies an ev en stronger condition: the next P P -observ ation is ful ly determined b y the P P -action and has no dep endence on history whatso ever (including the most recent P P -observ ation). Prop osition 11. Even if the original system is p artial ly observable, the pr e diction pr ofile system may b e Markov. Pr o of. Consider the Three Car d Mon te example. The original sy st em is clear l y non-Mark o v (the most recen t observ ation, that is t he dealer’s most recent sw ap, tells one very little ab out the lo cation of the ace). How ev er, the prediction profile system for t he tests of in terest regarding the lo cation of the special card (pi c t ur ed in Figure 1) is Marko v. The next profile is fully determined by the current profile and the P P -action. In general, how ev er, the P P system may b e partially observ able. Though in the Three Card Monte example the curr e nt prediction profile and the next action-observ ation pair together fully determine the next predic t i on profile, in general the next predicti on profile is determined by the history of action-observ ation pairs (and prediction profil e s) . Prop osition 12. The pr e diction pr ofile system may b e p artial ly observable. Pr o of. Recall the 1D Ball Bounce example. The corresp onding prediction profile system is sho wn in Figure 4. Note that tw o distinct states in the up date graph are asso ciated with the same prediction profile (pixel x will b e white). Given only the cu r re nt pre di c ti on profile (pixel x will b e white) and the P P -act i on (observ e the ball in a neigh b oring pixel on the left or r i ght), one cannot determine whether the ball is entering or leaving the neigh b orho od, and thus cannot uniquely determine the next profile. This prediction profile system is partially observ able. So, in general, the prediction profile system is a deterministic, partially-observ able dy- namical system. A mo del of t he predict i on profile system can only b e used to make the predictions of interest. As such, if one wishes to use a prediction profile mo del as a gener ative mo del, one m ust select the tests of interest carefully . F or inst ance : Prop osition 13. If the tests of inter est include the s et of one-step primiti v e tests, that is if { ao | a ∈ A , o ∈ O } ⊆ T I , then a mo del of the pr e diction pr ofile sys tem c an b e us e d as a gener ative mo del of the original system. Pr o of. This follows imme di at e l y from the definition of generativ e mo del. While in this s p ecial case a prediction profile mo del can b e a complete, generative mo del of the system, i t will b e shown in Section 5 that if one desires a generati ve mo del, it is es se ntially never preferabl e to learn a prediction profile mo del ov er a more traditional represen tation. A prediction profile mo del is b est applied when it is rel at i vely simple to mak e and maintain the predictions of in terest in comparison to making al l predicti ons . In general, 367 T al vitie & Singh Figure 5: Flo w of the algori t hm . a prediction profile mo d el conditions on the observ ations, but it does not necessarily pr e dict the next observ ation. As suc h, a mo del of the prediction profile system cannot typically b e used for the purp oses of mo del-based planning/control like a generative mo del could. The exp erimen ts in Section 6 will demonstrate that the output of predict i on profile mo dels c an , ho wev er, b e useful for mo del-free con trol metho ds. 4. Learning a Prediction Profile Mo del The definition of the prediction profile system straigh tforwardly suggests a metho d for learning prediction profile mo dels (estimate the prediction profiles, and learn a mo del of their dynamics using a standard mo del-learning tec hnique). This section will present such a learning algorithm, discussin g some of the main practi c al c hallenges that arise. Let S b e a tr ai ni ng data se t of tra jectories of exp erience with the original system (action - observ ation sequences) and let T I = { t 1 , t 2 , . . . , t k } be the set of tests of interest. The algorithm presen ted in this section will learn a mo del of the prediction profile system from the data S . The algorithm has three main steps (pi c tu re d in Figur e 5). First th e trai n i ng data is used to estimate the prediction profil e s (both the num b er of unique profiles and the i r v alues). Next, the learned set of prediction profiles is use d to translate the training data into tra jectories of ex p erience with the predic ti on profile system. Finally , an y applicable mo del learning metho d can b e trained on t he transformed data to le ar n a mo del of the prediction profile system. Ultimately , in our experiments, the l ear n ed prediction profile models will b e ev aluated by h ow useful their predictions are as features for control. 4.1 Estimating the Prediction Profiles Giv en S and T I , the first step of learning a prediction profile mo del is to determine how man y distinct prediction profiles there are, as w ell as their v alues. The estimated prediction for a test of interest t at a history h is: ˆ p ( t | h ) = # times t succeeds from h # times acts ( t ) taken fr om h . (6) One could, at thi s p oin t, directly es ti mat e φ by letting ˆ φ ( h ) def = h ˆ p ( t 1 | h ) , ˆ p ( t 2 | h ) , . . . , ˆ p ( t k | h ) i . Of course, due to sampling error, it is unlikely that any of these est i mate d profiles will b e exactly the same, ev en if the true underlying prediction profiles are identical. So, 368 Learning to Make Predictions Withou t a Genera tive Model to estimate the num b er of distinct underlying profiles, statistical tests will b e used to find histories that hav e signific antly different prediction profiles. T o compare the profiles of t wo histori es , a likelihoo d-ratio test of homogeneit y is p er- formed on the counts for each test of in terest in the t wo his tor i e s. If the statistical te st asso ciated with an y te st of interest rejects the null h yp othesis that the predi c ti on is the same in b oth histories, then the tw o histories hav e different predicti on profiles. In order to find the set of distinct prediction profiles, w e greedily cluster the estimated prediction profiles. Sp ecifically , an initially empty set of exemplar histories is main tained. The algorit hm searc hes o v er all histories in the agen t’s exp erience, comparing each history’s estimated profile to the ex em pl ar histories’ esti mat e d profiles. If the candidate history’s profile is significan tly differen t from the profiles of al l exe mpl ar histories, the candidate is added as a new exemplar. In the end, the estimated profiles corresp onding to the exemplar histories are used as the set of predic ti on profile s. In order to obt ai n the b est estimates p ossible, the searc h is ordered so as to priori t i z e histories with lots of asso ciated data. The prediction profile estimation pro cedure has t wo main sources of complexit y . The first is the sample complexit y of estimating the prediction profiles. It can tak e a great deal of exploration to see each history enough times to obtain go o d statistics, esp ecially if the num b er of actions and observ ations is large. This issue could be addressed b y adding generalization to the estimation pro cedure, so that d ata from one sample tra jectory could impro ve the estimates of man y similar histories. In one of the ex p eriments in Section 6, observ ation abstraction will b e emplo yed as a simple form of generalization. The second b ottlenec k is the computational complexit y of searching for prediction profiles, as this in- v olves exhaustively en umerating all histories in the agent’s exp erience. It w ould b e v aluable to dev elop heuristics to iden tify the histories most likely to pro vide new profiles, in order to av oid searching ov er all histories. In the exp eriments i n Section 6, a simple heuristic of limiting the search to short histories is employ ed. Long histories will tend to hav e less asso ciated data, and will therefore b e less likely to pro vide di s ti ngu i shabl y new profiles. 4.2 Generating Prediction Profile T ra jectories Ha ving generated a finite set of distinct prediction profil es , the next step is to translat e the agen t’s exp erience in to se q ue nc es of action-observ ation pairs and prediction profil e s. These tra jectories will b e us ed to train a mo del of the prediction profile system. The process of translating an act i on-ob se r v ation sequence s in to a prediction profile tra- jectory s ′ is straightforw ard and, apart from a few practical concer ns, follows directly from Definition 8. Recall that, for an action- obse r v ation sequence s = a 1 o 1 a 2 o 2 . . . a k o k , the cor- resp onding P P -action sequence is h a 1 , o 1 ih a 2 , o 2 i . . . h a k , o k i . The corresp onding sequence of profiles is φ ( a 1 o 1 ) φ ( a 1 o 1 a 2 o 2 ) . . . φ ( a 1 o 1 . . . a k o k ). Thus, in principle, ev ery primitive action- observ ation sequ enc e can b e translated into an action-observ ation-profile sequence. Of course φ is not av ail abl e to generate the sequence of prediction profiles. So, it is necessary to use an appro ximation ˆ φ , generated from the traini ng data. Sp ecifically , the estimated predictions for the tests of in terest at each history h (computed using Equation 6) are compared, using statistic al tests, to the set of distinct estimated prediction profiles from Section 4.1. If there is only one estimated profil e ˆ ρ that is not statistically significan tly differen t fr om the estimated predictions at h , then let ˆ φ ( h ) = ˆ ρ . 369 T al vitie & Singh Giv en sufficient data, the statistical tests will uni q uel y identify the correct match with high probability . In practice, how ev er, some histories wil l not ha ve v ery muc h asso ciated data. It is p ossible in suc h a case for the test of homogeneity to fail to reject the null h yp othesis for tw o or more profiles. This indicates that there is not enough data to dis - tinguish b et ween m ultiple p ossible matches. In the exp erimen ts in Section 6, tw o different heuristic strategies for handling this situation are employ ed. The first strategy lets ˆ φ ( h ) b e the matching profile that has the smallest empirical KL-Divergence from the estimated predictions (summed o ver all tests of interest). This is a heuristic c hoice that may lead to noise in the prediction profile lab eling, which could in turn affect the accuracy of the learned mo del. The second strategy is to simply cut off any tra jectory at the p oin t where multiple matc hes o ccur, rather than risk assigning an incorrect lab eling. This ensures that lab els only app ear in the prediction profile tra jectories if there is a reasonable level of confidence in their correctness. Ho wev er, it is wasteful to thro w out training data in this w ay . 4.3 Learning a Prediction Profile Mo del The translation step produces a set S ′ of tra jectories of in teraction with the prediction profile system. Recall that the pr edi c t i on profile system is a deterministic, partially observ- able, discre te dynamical system and these tra jectories can b e used to train a mo del of the prediction profile system us i ng, in principle, any applicabl e mo del-learning metho d. There is an issue face d by mo dels of the predic ti on profile system that is not present in the usual discrete dynamical systems mo deling setting. While the prediction profile lab els are present in the training data, when actually using the mo del they are not av ailable. Sa y the curren t history is h , and an action a 1 is tak en and an observ ation o 1 is emitted. T ogether, this action-observ ation pair cons ti t ut es a P P -action. Being a mo del of the prediction profile system, a prediction profile mo del can identify the next profile, ρ . This pr ofil e can b e used to compute predictions p ( t | ha 1 o 1 ) for the tests of interest at the history ha 1 o 1 . No w another action a 2 and observ ation o 2 o ccur. It is no w necessary to up date the PP-mo del’s state in order to obtain the next prediction profile. A typical dynamical sy s te ms model mak es predictions ab out the next observ ation, but is then able to up date its state with the actual observ ation that o ccurred. A prediction profil e mo del’s observ ations are prediction profiles themselves, which are n ot observ able when in teracting with the world. As s uch, the prediction profile mo del will up date its state with prediction profile it itself pr e dicte d ( ρ ). Once up dated, the prediction profile mo del can obtain the profile that follo ws h a 2 , o 2 i whic h gives the predictions for the te st s of interest at the ne w history ha 1 o 1 a 2 o 2 . If the prediction profile mo del i s a p erfe ct mo del of the predicti on profil e syst e m, this p oses no probl e ms. Because the predic ti on profile system is determini st i c, there is no need to observe the true prediction profile lab el; it is fully determined b y the history . In practice, of course, the mo del will b e imp erfect and different mo deling repre se ntations will require differen t considerations when p erforming the t wo functions of providing predictions for the tests of interest, and pr oviding a profile for the sake of up dating the mo del. 4.3.1 PP-POMDPs Since the prediction profile system is partially observ able it is natural to mo del it us- ing a POMDP . Unfortunately , even when the training data is from a determ i ni st i c sys- 370 Learning to Make Predictions Withou t a Genera tive Model tem, POMDP training using the EM algorithm will generally not provide a deterministic POMDP . Th us, at an y given history , a learned POMD P mo del of the prediction profile system (PP-POMDP) will provide a distribution o ver predict i on p r ofil es instead of deter- ministically pro viding the one profile asso ciated with that hi st ory . The implementation used in Section 6 simply takes the most likely profi l e from th e distribution to b e the profile asso ciated with the history and uses it to make predictions for the tests of interest, as w ell as to up date the POMDP mo del. 4.3.2 PP-LPSTs Another natural choice of represen tation for a prediction profile mo del is a lo oping predictive suffix tree (LPST) (Holmes & I sb ell, 2006). LPSTs are sp ecialized to deterministic, part i al l y observ able systems. As suc h, they could not b e used to mo del the original system (which is assumed to b e sto c hastic in general), but t he y do apply to the prediction pr ofil e system (and they do not hav e to b e determinized like a POMDP). Briefly , an LPST captures the parts of r ec e nt history relev an t to predicting the next observ ation. Every no de in the tree corresp onds to an action-observ ation pair. A node ma y b e a leaf, may hav e children, or it may lo op to one of its ancestors. Every leaf of the tree corresp onds to a history suffix that has a deterministic prediction of an observ ation for every action. In order to predict the next obs er v ation from a particular hist ory , one reads the history in rev erse order, following the corresp onding links on the tree un til a leaf is reac hed, whic h gives the prediction. Holmes and Isb ell provide a learning algorithm that, under certain conditions on the training data, is guaranteed to pro duce an optimal tree. The reader is referred to the work of Holmes and Isb ell (2006) for details. One weakness of LPSTs, how ever, i s that they fail to make a prediction for the next observ ation if the curren t history do es not lead to a leaf node in the tree (or if the leaf no de reached do es not ha v e a prediction for the action b eing queried). This t ypically o cc ur s when som e history suffixe s do not o ccur in the traini ng data but do o ccur while usi ng the mo del. F or a PP-LPST, this can mean that in some historie s the mo del cannot uniquely determine the correspon di ng prediction profile. When this happ ens the implemen tation used in Section 6 simply finds the longest suffix of the c ur r e nt history that do es o ccur in the data. This suffix will b e asso ciated with multiple prediction profiles (otherwise the LPST w ould ha ve pro vided a prediction). T o make predictions for the tests of interest, the mo del pro vides the av erage pre di c ti on o ver this set of p r ofil es . The profile used t o up date the mo del is pic ked out of the set uniformly randomly . 4.3.3 PP-PSRs Applying PSR lear ni ng algorithms to prediction profile data p oses a practical concern. Sp ecifically , metho ds that attempt to estimate the system dynamics matr i x (James & Singh, 2004; W olfe et al., 2005) implicitly presume that every action sequence could in principle b e tak en from ev ery history . If some action sequences can be taken from some histories but not from others, then the matrix will hav e undefined en tries. This p oses challenges to rank estimation (and, indeed, the v ery definition of the mo del representation). Unfortunately , this can b e the case for the prediction profile system since P P -actions (action-observ ation pairs) are not completely under the agen t’s con trol; they are partly sel e ct e d by the en viron- 371 T al vitie & Singh men t itself. The recent sp ectral learning algorithms presen ted b y Boots et al. (2010) ma y b e able to side-step this issue, as they hav e more flexibility in selecting whic h predictions are est i mat ed for use in the mo del-learning process , th ough we hav e not inv estigated this p ossibilit y in this work. Note that, though our metho d for learning a predicti on profile mo del inv olv es standard mo del-learning metho ds for partially observ able environmen ts, the result i s not a generativ e mo del of the original system. A prediction profile mo del is a generativ e mo del of the pr e diction pr ofile system and, as such, cannot b e used to make any predictions ab out the original system, other than the predictions of interest. 5. Complexit y of the Prediction Profile System The learning algorithm we ha ve presen ted will b e ev aluated empirically in Section 6. First, ho wev er, we analyze the complexity of the prediction p rofi l e system in relation to the com- plexit y of the original system. This will give some indication of how difficult it is to learn a prediction profile model and pro vide insight in to when it is appropriate to learn a predict i on profile mo del o ver a more t ypical gener at i ve mo del approach. There are man y factors that affect the complexity of learning a mo del. This section will largely fo cus on linear dimension as the measure of complexity , taking the view that, generally sp eaking, systems with lo wer linear dimension are easier to learn than systems with larger linear dimension. As discussed in Section 1. 2. 2, this is generally true for POMDPs, where the linear dimension lo wer-bounds the num b er of hidden states. So comparing the linear dimen si on of the prediction profile system to that of the original system can give some idea of whether it would b e easie r to le ar n a PP- PO M D P or jus t to learn a standard POMDP of the original system. Of course, there are other model-learning metho ds for whic h other complexit y measures w ould b e more appropriate (for instance it is not known precisely how LPSTs interact with linear dimension). Extending some of these results to other measures of complexity ma y b e an interesting topic of future inv estigation. 5.1 Linear Dimension Comparison This section will discuss ho w the linear dimension of the prediction profile system relates to that of the original s y st em . The first resul t is a “pro of of concept” that simply states that the r e exist problems in whic h the prediction profile system i s v astly more simple than the original system. In fact, such a problem has already b een presented. Prop osition 14. The pr e dicti on pr ofile system c an have line ar dimension that is arbitr arily lower than that of the origi na l system. Pr o of. Recall the Three Card Monte example. Th us f ar the domain has b een describ ed without describi ng the dealer’s b ehavior. Ho wev er, note that the prediction profile system for the tests of interest re l at i ng to the lo cation of the speci al card (pictured in Figure 1) has a linear dimension of 3, r e gar d less of h ow the de aler’s swaps ar e chosen. If a very complex dealer i s c hosen, the original system will hav e high linear dimension, but the prediction profile system’s linear dimen si on will remain constant. F or instance, in t he exp erimen ts in Section 6, the dealer c ho oses which cards to swap sto chastically , but is more likely to choose 372 Learning to Make Predictions Withou t a Genera tive Model the sw ap that has been selected the least often so far. Thus, in orde r to predict the dealer’s next decision, one m ust coun t ho w many times eac h sw ap has b een chosen in history and as a result the system effectively has infinite li n ear dimension. On the other hand, prediction profile mo dels are not a panacea. The fol l owing results indicate that ther e are problems for whic h learning a prediction profil e mo del w ould not b e advisable ov er learning a standard generative mo del, in that the line ar dimension of the prediction profile syste m can b e f ar greater than that of the original system. Later in the section some sp ecial cases will b e c haracterized where prediction profile models are lik ely to b e useful. The nex t result shows that the linear dimens i on of the predict i on p rofi l e mo del can b e infinite when the or i gi nal system has finite li near dimension, via a lo wer b ound on linear dimension that is true of all deterministic dynamical systems. Prop osition 15. F or any deterministic dynamic al system with actions A , and observations O , the line ar dimension, n ≥ log( |A|− 1)+log ( |O| +1) log |A| . Pr o of. See App endix A.1. Because Prop osition 15 applies to all determinist i c dynami c al sy st em s, it cert ai nl y ap- plies to the prediction profile system. Though it is a v ery lo ose bound, the basic implication is that as the num b er of predicti on profiles (th e observ ations of P P ) increases in compari- son to the num ber of action-observ ation pair s (the actions of P P ), the linear dimension of the prediction profile system necessarily increases. This b ound also clearly illustrates the imp ortance of the assumption that there is a finite num b er of distinct prediction profiles. Corollary 16. If ther e ar e infinitely many distinct pr e diction pr ofiles, the pr e diction pr ofile system has infinite line ar dimension. Pr o of. Clearly |A P P | = |A × O| is finite so long as there are finitely many actions and observ ations. So, from the last result it follows immediately that as the num ber of distinct prediction profiles |O P P | approac hes infinity , then so m ust the linear dimension of the prediction profile system. Hence, so long as prediction profi l e models are represen ted using metho ds that rely on a finite linear dimension, it is critical that the r e b e finitely many prediction profiles. Note that t hi s is not a fundamental barrier, but a side e ffec t of the representational c hoice. Mo del learning metho ds that are not as sensitive to linear dimension (suc h as those d es i gned to mo del con tinuous dynamical systems) may b e abl e to effectively captur e systems with infinitely many prediction profi l es . One conclusion to b e drawn from the last few results is that kno wing the linear dimens i on of the original system do es not, in itself, necessarily sa y m uch ab out the complexity of the prediction profil e system. The prediction profile system ma y b e far simpler or far more complex t han the origi nal system. Thus it ma y b e more informative to tur n to other factors when trying to characterize the complexity of the predic t i on profile system. 373 T al vitie & Singh 5.2 Bounding the Complexit y of The Prediction Profile System The results in the previ ous section do not take in to account an obviously imp ortan t asp ect of the prediction profile system: the predictions it is asked to mak e. Some predictions of in terest can b e made v ery simply by k eeping trac k of very little information. Other predictions will rely on a great deal of history information and will therefore require a more complex mo del. The next result identifies the “worst case” set of tests of in terest for any system: the tests of in terest whose corresp onding prediction profile mo del has the highest linear dimension. Ultimately this se ct i on will presen t some (non-exhaustiv e) conditions under which the prediction profile system is likely to b e simpler than the original system. Prop osition 17. F or a given system and set of tests of inter est, the line ar dimension of the c orr esp ondi ng pr e diction p r ofile system is no gr e ater than that of the pr e diction pr ofile system asso ciate d with any set of c or e tests for the s y s t em (as describ e d in Se ction 2.2). Pr o of. See App endix A.2. With this worst case iden tified, one can immediately obtain bounds on how complex an y predict i on profile system can p ossibly b e. Corollary 18. F or any system and any set of tests of inter est, the c orr esp onding pr e diction pr ofile system has line ar dimension no gr e ater than the numb er of distinct pr e dictive states for the original system. Pr o of. The prediction profile system for a set of core tests Q is a deterministic MDP where the observ ations are prediction profiles for Q (that is, predictiv e states). That is, eac h state is ass o ciated with a unique prediction profile. The linear dimension of an MDP is nev er greater than the num b er of observ ations (Singh et al., 2004). Ther e for e, by the previous result the prediction profile system for an y set of tests of in terest can ha ve l i ne ar dimension no greater than the num b er of predictive states. Corollary 19. If the original system is a POMDP, the pr e diction pr ofile sys tem for any set of tests of inter est has line ar dimension no gr e ater than the numb er of distinct b elief states. Pr o of. This follows immediately from the previous result and the fact that the num b er of distinct predictive states is no greater than the num b er of distinct b elief states (Littman et al., 2002). The bounds presen ted so far help explain why t he prediction profile sy stem can be more complex than the original system. How ev er, b ecause they are focuse d on the worst p ossible c hoice of tests of interest, they do little to illuminate when the opp osite is true. A prediction profile mo del is at i ts most complex when it is ask ed t o p erform the same task as a generative mo del: keep trac k of as muc h information from history as is necessary to make al l p ossible pr e dictions (or equiv alen tly , th e predictive state or the b elief state). These results indicate that, gener al l y sp eaking, if one desires a gene r at i ve mo del, standard approac hes would b e preferable to learning a prediction profile mo del. On the other hand, our stated goal is not to learn a generative mo del, but instead to fo cus on some particular predictions that will hop efully be far simpler to mak e than al l predictions. The examples w e hav e seen make it clear that in some cases, some predictions 374 Learning to Make Predictions Withou t a Genera tive Model can b e made by a prediction profile mo del far simp l er than a generati v e mo del of the original system. In general one might exp ect the prediction profile mo del to b e simple when the predictions of i nterest rely on only a smal l amount of the state informat i on required to main tain a generativ e mo del. The next b ound aligns with this intuitiv e reasoning. Essen tially what this r e sul t p oints out is that often muc h of the hidden state information in a POMDP will b e ir r e l ev ant to the predictions of interest. The linear dimension of the prediction profile sy st e m is bounded only b y the n um b er of distinct b eliefs ov er the r elevant parts of the hidden state, rather than the n umber of distinct beliefs states o verall. The idea of the result is that if one can imp ose an abst r ac ti on o ver the hidden states of a POMDP (not the observ ations) that still allows the predict i ons of interest to b e made accuratel y and that all ows abstract b elief states to b e computed accurately , then the prediction profile system’s linear dimension i s b ounded by the n umber of abstr act b elief states. Prop osition 20. Consider a POMDP with hidden states S , actions A , and observations O . L et T I b e the set of test s of inter est. L et a i b e the action taken at time-step i , s i b e the hidden state r e ache d after taking acti o n a i , and o i b e the observation emitt e d by s i . Now, c onsider any surje ction σ : S → S σ mapping hidden s t at es to a set of abstract states with the fol lowing pr op erties: 1. F or any p air of primitive states s 1 , s 2 ∈ S , if σ ( s 1 ) = σ ( s 2 ) , then for any time-step i and any test of inter est t ∈ T I , p ( t | s i = s 1 ) = p ( t | s i = s 2 ) . 2. F or any p air of primitive states s 1 , s 2 ∈ S , if σ ( s 1 ) = σ ( s 2 ) , then for any time-step i , abstr act stat e S ∈ S σ , observation o ∈ O , and a ct i on a ∈ A , Pr ( σ ( s i +1 ) = S | s i = s 1 ,a i +1 = a, o i +1 = o ) = Pr ( σ ( s i +1 ) = S | s i = s 2 , a i +1 = a, o i +1 = o ) . F or any such σ , the pr e diction pr ofile system for T I has line ar dimens i o n no gr e ater than the numb er of distinct b eliefs over abstr act states, S σ . Pr o of. See App endix A.3 There are a few things to note ab out this result. First, a surjection σ always exi st s t hat has prop erties 1 and 2. One can alwa ys define σ : S → S with σ ( s ) def = s . This degenerate case triviall y satisfies the requirements of Pr op osition 20 and reco vers the b ound giv en in Corollary 19. Ho w ever, Prop osition 20 applies to al l surjections that satisfy the c ondi tions. There must b e a surjection that satisfies the conditions and results in the smallest num b er of b eliefs ov er abstract states. Essentially , this is the one that ignores as muc h state information as p ossible while still all owing the predicti ons of in terest to b e made accurately and it is thi s surjection that most tigh tly b ounds the complex i ty of the prediction profil e system (even if σ is not kno wn). Of course, the r e ma y still be a large or ev en infinite num b er of distinct beliefs, even ov er abstract states, so other factors m ust come into play to ensure a simple prediction profile system. F urthermore, this result do es not characterize all settings in whic h the prediction profile system will b e simple. That said, this result does support the in tuition that the 375 T al vitie & Singh prediction profile system will tend to be simple when the predictions it is ask ed to make dep end on s mal l amoun ts of state information. In order to buil d intuition ab out how thi s result relates to earlier examples, recall the Three Card Monte problem. In Three Card Monte there are t wo sources of hidden state: the ace’s unobserved p osition and whatever hi dden me chanism the de al e r uses to make its decisions. Clearly the agen t’s predictions of interest dep end only on the first part of the hidden state. So, in this case one can satis fy Property 1 with a surjection σ that maps t wo hidden states to the same abstract state if the ace is in the same p osition, regardless of the dealer’s state. Under this σ there are only 3 abstrac t st ate s (one for eac h p ossible p osition), e ven though there might b e infinitely man y true hidden states. No w, different states corresponding to the same ace p osition will hav e differen t distributions ov er the ace’s next p osition; this distribution do es, after all, depend up on the dealer’ s state. Ho w ever, Prop ert y 2 is a statement ab out the distribution o v er the next abstract state given the observ ation that is emitted after entering the abstract state. If one kno ws the curren t abstract state and observes what the dealer do es, the next abstrac t state is fully determined. So Prop ert y 2 holds as w ell. In fact, since the ace’s position is known at the b eginning of the game, this me ans the current abstract state is alw ays known with absolute certaint y , even though b eliefs ab out the dealer’s state will in general b e uncertain. Hence, there are only 3 distinct b eliefs ab out the abstract states (one for eac h state). As such, the prediction profile mo del’s linear dimension is upp er-bounded b y 3, regardless of the dealer’s complexity (and in this case the b ound is met). 5.3 Bounding the Num b er of Prediction Profiles The previous sect i on describ es some condi t i ons under which the prediction profile system ma y ha ve a lo wer linear dimension than the original system. Also of concern is the num b er of prediction profiles, and whether that n umber is finite. This secti on will briefly discuss some (non-exhaustive) cases in whic h the n umber of prediction profiles is b ounded. One case that has already been discussed is when the original system is Marko v. In that case t he num b er of prediction profiles is b ounded by the num b er of observ ations (states). Of course, when the original system i s Mark ov, there is l i t t l e need to use prediction profile mo dels. Another, si mi l ar case is when the system i s partially observ able, but completely deterministic (that is, the next observ ation is completely determined b y histor y and the selected action). If the syst e m is a deter m i ni st i c PO MD P th en at any giv en history the curren t hidden state is known. As suc h, the num b er of b elief states is b ounded b y the n umber of hidden states. Since there cannot b e more prediction profiles than b elief states, the num ber of prediction profiles are b ounded as w ell. One can mov e aw a y from determinism in a few different w ays. First, note that the k ey prop ert y of a deterministic POMDP is that the hidden state is fully determined b y history . It is p ossible to sat i sf y this prop ert y ev en in sto chastic systems, as long as one can uniquely determine the hidden state, given the observ ation that w as emitted when arriving there. In that cas e, observ ations can b e emitted sto c hastically , but the num b er of b elief states (and the num ber of prediction profiles) is still b ounded b y the n umber of hidden states. Another step aw a y from determinism i s a class of systems, introduced by Littman (1996), called Det-POMDPs. A Det-POMDP is a POMDP where the transiti on function and 376 Learning to Make Predictions Withou t a Genera tive Model the observ ation function are b oth determini s ti c , but the initi al state distr i but i on may b e sto c hastic. A Det-POMDP is not a deterministic dynamical system, as there is uncertaint y ab out the hidden state. Because of this uncertaint y , the system app ears to emit observ ations sto c hastically . It is only the underlying dynamics that are deterministic. Littman show ed that a Det -P O MD P with n hidden states and an initial state distribution with m states in its supp ort has at most ( n + 1) m − 1 distinct b elief states. So, this b ounds the num b er of prediction profiles as well. Finally , and mos t imp ortan tly , i f the hi dde n state can b e abstracted as in Prop osition 20, then these prop erties only really ne ed to hold for abstr act b eliefs . That is, t he environmen t itself ma y b e complex and stochastic in arbitrary wa ys, but i f the abs t r act hidden state describ ed in Prop osition 20 is fully determined by history , then the n umber of prediction profiles is bounded b y the n um b er of abstract states (as was the cas e in Three Car d Mon te). Similarly , Det-POMDP-like prop erties can b e imagined for abstract hidden states as w ell. These cases b y no means co ver all situations where the num b er of prediction profiles can b e bounded, but they do seem to indicate that the cl ass of problems where the num ber of prediction profiles is finite is quite broad, and ma y contain man y interesting examples. 6. Exp erimen ts This section will empirically ev aluate the prediction profile model learning procedur e devel- op ed in Section 4. In each exp erimen t an agent faces an environmen t for which a generativ e mo del would b e a challenge to learn due to its high linear dimension. Ho w ever, in each problem th e agen t could make go od decisions if it could only hav e the predictions to a small n umber of imp ortan t test s. A prediction profile mo del is learned for these imp ortant te st s and the accuracy of the learned predictions is ev aluated. These exp erimen ts also demonstrate one p ossible use of predic t i on profil e mo dels (and partial mo dels in general) for control. Because they are not generativ e, pr e di c ti on profile mo dels cannot typically b e used directly by offline, mo del-based planning metho ds. Ho w- ev er, their output may b e useful for mo de l -f re e metho ds of control. Sp ecifically , in these exp erimen ts, the predictions made by the learned prediction profile mo dels are provided as features to a p olicy gr adient algorithm. 6.1 Predictiv e F eatures for P olicy Gradient P olicy gradient met ho ds (e.g., Williams, 1992; Bax te r & Bartl e tt , 2000; P eters & Schaal, 2008) ha v e b een very successful as viable options for mo del-free con trol in par ti al l y ob- serv able domains. Though there are differences b et ween v arious algorithms, the common thread is that they assume a parametric form for the agen t’s p olicy and then attempt to alter those parameters in the direction of the gradien t with resp ect to exp ected av erage re- w ard. These exp erimen ts will mak e use of Online GPOMDP wi t h Av erage Re ward Baseline (W ea ver & T ao, 2001), or OLGARB (readers are referred to the original pap er for details ). OLGARB assumes there is some set of features of history , and that the agent’s p olicy tak es the parametric form: Pr( a | h ; ~ w ) = e P i w i,a f i ( h ) P a ′ e P i w i,a ′ f i ( h ) 377 T al vitie & Singh where f i ( h ) is the i t h feature and each parameter w i,a is a w eight sp ecific to the feature and the action b eing considered. T ypically the features used in policy gradient are features that can be directly read from histor y (e.g., featur e s of the most recent few observ ations or the p re se nc e /abse nc e of some even t in history). It can b e difficult to kno w a priori which historical features will b e imp ortan t for making go o d con trol decisions. In con trast, the idea in these exp erimen ts is to provide the v alues of some pr e dictions as features. These pr e dictive fe atur es hav e direct consequences for con trol, as they pro vide infor mat i on about the effects of possible behaviors the agent migh t engage in. As such, it ma y be easier to select a set of predictiv e features that are likely to be informative ab out t he optimal act i on to take (e.g., “Will the agen t reac h the goal state when it takes this action?” or “Will taking this action damage the agen t?”). F urthermore, information ma y b e expressed compactly i n terms of a prediction that w ould b e complex to specify purely in terms of past observ ations. As seen in the discussion of PSRs in Section 2.2, an arbitrary -l e ngth history can b e fully captured b y a finite set of shor t- te r m predic ti on s. F or these reasons it seems reasonable to sp eculate that predi c ti ve features, as main tained by a predicti on profile mo del, may b e particularly v aluable to mo del-free control metho ds like p olicy gradient. 6.2 Exp erimen tal Setup The learning algorithm will b e applied to t wo example problems. In each problem prediction profile mo dels are learned with v arious amounts of training data (using b oth LPSTs and POMDPs as the represen tation and using both str ate gi e s for dealing with multiple matches, as describ ed in Secti on 4.3). The predict i on accuracy of the mo dels is ev aluated, as w ell as ho w useful their predictions are as features for control. The training data is generated by executing a uniform random p olicy in the en vironment. The free parameter of t he learning algorithm is the significance v alue of the statistical tests, α . Given the large num b er of contingency tests that will b e p erformed on the same data set, whic h can comp ound the probabilit y of a false negativ e, α should b e set fairly lo w. In these exp eriments we use α = 0 . 00001, though several reasonable v alues w ere tr i ed with similar results. As discussed in Section 4, there will also be a maximum length of histories to consider duri ng the search for prediction profiles. This cutoff allows the search to a void considering long histories, as there are man y long histories to search o v er and they are unlikely to provide new prediction profiles. After a prediction profile mo del is l e ar ne d, i ts predict i ons are ev aluated as featu re s for the policy gradien t algorithm OLGARB. Sp ecifically , for eac h test of in terest t the unit in terv al i s split up into 10 equally-size d bins b and a binary feature f t,b is provided that is 1 if the prediction of t lies in bin b , and 0 otherwise. Also pro vided are binary features f o , for each p ossible observ ation o . The feature f o = 1 if o is the most recent observ ation and 0, otherwise. The parameters of OLGARB, the l e arn i ng rate and discount factor, are set to 0.01 and 0.95, resp ectively in all e x p eriments. T o ev aluate a prediction profile model OLGARB is run for 1,000,000 steps. The a v erage rew ard obtained and t he root mean squared er r or ( RMS E) of the pre di c t i ons for the test s of interest accrued by the model along the w a y are re p orted. Prediction p erformance is compared to that obtained by learning a POMDP on the training data and using it to 378 Learning to Make Predictions Withou t a Genera tive Model 0 2 4 6 x 10 4 0 0.2 0.4 0.6 0.8 1 # Training Trajectories Avg. RMSE (20 Trials) Prediction Performance Flat POMDP PP−LPST(KLD) PP−LPST(cut) PP−POMDP(KLD) PP−POMDP(cut) 0 2 4 6 x 10 4 −0.06 −0.04 −0.02 0 0.02 0.04 0.06 0.08 0.1 # Training Trajectories Avg. Reward (20 trials) Control Performance Flat POMDP True Expert SOM PP−POMDP(KLD) PP−POMDP(cut) PP−LPST(KLD) PP−LPST(cut) Figure 6: Results in the Three Card Monte domain. mak e the predictions of interest. Because these problems are to o complex to feasibly train a P O MD P with the correct n umber of underlying states, 30-state POMDPs were used (stopping E M after a maxim um of 50 iterati on s) 2 . Control p erformance is compared to that obtained b y OLGARB using the predictions provided b y a learned POMDP mo del as features, as w ell as OLGARB using the true predictions as feature s (the b est the prediction profile mo del could hop e to do), OLGARB using second-order Marko v features (the t wo most recent observ ations, as w ell as the action b et w een them) but no predictive features at all, and a hand-co ded exp ert p olicy . 6.3 Three Card Mon te The firs t domain is the Three Card Mon te example. The agent is presen ted with three cards. Initially , the card in the middle (card 2) is the ace. The agen t has four actions a v ailable to it: w atch , f li p 1, f li p 2, and f lip 3. If the agen t c ho oses a flip action, it observ es whether the card it flipp ed ov er is the sp ecial card. If the agent c ho oses the w atch action, the deale r can swap the p ositions of t wo cards, in which case the agen t observes which t wo cards w ere sw app ed, or the dealer can ask for a guess . If the dealer has not asked for a guess, then w atch results in 0 reward and any flip action resul ts in -1 reward. If the dealer asks for a guess and the agent flips ov er the sp ecial card, the agent gets reward of 1. If the agen t flips ov er one of the other tw o cards, or do esn’t flip a card (by selecting w atch ), it gets rew ard of -1. The agen t has three tests of i nterest, and they tak e the form f lipX ace , for each card X (that is, “If I flip card X , wil l I see the ace?”). As discussed prev i ousl y , the complexity of this system is directly related to the com- plexit y of the dealer’s decision-making pro cess. In this experiment, when the agent c ho oses “w atch” the dealer swaps the pair of cards it has sw app ed the least so far with probability 0.5; with probability 0.4 it c ho oses uniformly amongst the other pairs of cards; ot her wi s e it asks for a guess . Since the dealer is keeping a coun t of how many times each swap was made, the pro cess gov erning its dy nami c s effecti vely has an infinite linear dimension. The 2. Simi lar results w ere obtained with 5, 10, 15, 20, and 25 states. 379 T al vitie & Singh prediction profi l e system, on the ot he r hand, has only 3 states, regardless of the dealer’s complexity (see Figure 1). T raining tra jectories were of length 10. Figure 6 shows the results for v arious amounts of training data, av eraged ov er 20 trials. Both PP-POMDPs and PP-LPSTs learned to make accurate predictions for the tests of interest, ev entually ac hieving zero predic ti on error. In this case, PP-POM D P s did so using less data. This is likely b ecause a POMDP mo del is more readily able to take adv antage of the fact t hat the prediction profile system for Three Card Monte is Marko v. As exp ected, the standard POMDP mo del was unable to accur at el y predict the tests of in terest. Also compared are the t wo different strategies for dealing with multiple matches dis- cussed in Se c ti on 4.3. Recall that the first one (marked “KLD” in the graph) picks the matc hing profile with the smallest empirical KL-Divergence from the estimated predictions. The second (mark ed “cut” in the graph) simply cuts off the tra jectory at the p oin t of a multiple match to a void an y incorrect lab els. In this problem these t wo strategies re- sult in almost exactly the same perf or manc e. This is likely b ecause the profiles in Three Card Monte are deterministic, and are therefore quite easy to distinguis h (making multiple matc hes unli kely). The next ex p eriment will hav e sto c hastic profile s. The predictive features pro vided by the prediction profile mo dels are clearly use ful for con trol, as the control p erformance of OLGARB using their predictions approac hes, and ev entually exact l y matc hes that of OLGARB using the true predict i ons (mark ed “T rue”). The inaccurate predictions provided b y the POMD P were not very useful for control; OL- GARB using the POMDP pro vided predictions do es not even break even, meaning it loses the game more often than it wins. The POMDP features did, ho w ever, seem to con tain some useful information b ey ond that provided by the second-order Marko v features (marked “SOM”) which, as one might exp ect, p erformed very p o orly . 6.4 Sho oting Gallery The second e x ampl e is called the Shooting Gallery , pi ct ur e d in Figure 7(a). The agen t has a gun aimed at a fixed p osi ti on on an 8 × 8 grid (marked by the X ) . A target mo ves diagonally , bouncing off of the b oundaries of the image and 2 × 2 obstacles (an example tra jectory is pictured). The age nt’s task is to sho ot the target. The agent has tw o actions: w atch and shoot . When the agent c ho oses w atch , it gets 0 rew ard. If the agent c ho oses shoot and the target is in the crosshairs in the step after the agent sho ots, the agen t gets rew ard of 10, otherwise it gets a re ward of -5. Whenever the agent hits the target, the sho oting range resets: the agen t receives a special “reset” observ ation, each 2 × 2 square on the range is made an obstacle with probability 0.1, and the target is placed in a random p osition. There is also a 0.01 probability that th e range will reset at every time step. The difficult y is that the target i s “sti cky .” Ev ery time step with probability 0.7 it mov es in its curren t direction, but with probability 0.3 it sticks in place. Th us, lo oking only at recen t history , the agent may not b e able to determine the target’s current direction. The agen t needs to know the probabilit y that the target will b e in its sights in the next step, so clearly the single te st of interest is: w atch tar g et (that is “If I choose the w atch action, will the tar g et en ter the crosshairs?”). When the target is far from the crosshairs, the prediction of this test will be 0. When it target is in the crosshairs, it will b e 0.3. When the target is 380 Learning to Make Predictions Withou t a Genera tive Model (a) (b) Figure 7: The Sho oting Galler y domain. (a) A p ossible arrangement of obst acl es and tra- jectory for the target (ligh ter is further back in time). In this case the target will definitely not en ter the agent’s crosshairs, since it will b ounce off of the obstacle. (b) The abstraction applied to the most recent obser v ation. near t he crosshair s, the mo del m ust determine whether the prediction is 0.7 or 0, based on the target’s previous b ehavior (its directi on) and the configuration of nearb y obstacle s. This problem has sto c hastic predicti on profiles, so it is exp ected that more data will b e required to differen tiate them. Also, due to the n umber of possi bl e configurations of obstacles and p ositions of the target, this system has roughly 4,000,000 obser v ations and ev en more laten t s tat es . This results in a large num ber of p ossible histories, each with only a small probability of o ccurring. As discussed i n Section 4, this can lead to a lar ge sample complexity for obtaining go od estimates of predic ti on profiles. Here this is addressed with a simple form of gen er al i z ati on : observ ation abstraction. Two observ ations are treated as the same if the target is i n the same p osition and if the configuration of obstacles in the immediate vicinit y of the target is the same. In other words, eac h abstract observ ation con tains information only ab out the target’s p osition and the obstacles sur r ound i ng the target, and not the placemen t of obstacles far a wa y from the target (see Figure 7(b)) for an example. Under this abstr act i on, t he abstract observ ations still provide enough detail to mak e accurate predictions. That is, t w o histories do indeed ha ve the same prediction profile if they ha ve the same action se q ue nc e and the i r observ ation sequences corresp ond to the same sequence of aggr egat e observ ations. This enables one sample tra jectory to impro ve the estimates for several histories, though, even with thi s abstraction, there are still ov er 2000 ac t i on-obs er v ation pairs. The same observ ation abstraction was applied when training the POMDP mo del. T raining tra jectories w ere length 4 and the search for profiles was restricted to length 3 histories. Results are sho wn in Figure 8. Perhaps the most ey e-catching feature of the r e sul t s is the upwar d trending curv e in the prediction error graph, corresp onding to the PP-PO M D P with the KL-Divergence based matc hing (lab eled “PP-P OM D P (K L D) ”) . Recall that the danger of the KL-div ergence based matc hing strategy is that it may pro duce incorrect lab els in the training data. Apparently these errors were severe enough in thi s problem to drastically mislead the POMDP mo del. With a small amount of data it obtained 381 T al vitie & Singh 0 2 4 6 8 10 x 10 5 0 0.05 0.1 0.15 0.2 0.25 # Training Trajectories Avg. RMSE (20 Trials) Prediction Performance Flat POMDP PP−POMDP(cut) PP−LPST(cut) PP−LPST(KLD) PP−POMDP(KLD) 0 2 4 6 8 10 x 10 5 −0.005 0 0.005 0.01 0.015 0.02 0.025 # Training Trajectories Avg. Reward (20 Trials) Control Performance PP−LPST(KLD) Expert True PP−POMDP(KLD) PP−LPST(cut) PP−POMDP(cut) SOM Flat POMDP Figure 8: Results in the Sho oting Gallery domain. v ery go od pr e di c ti on error, but with more data came more misleading lab elings, and the p erformance suffered. The PP-POMDP trained with the other matching metho d (“PP- POMDP(cut)”) displays a more typical learning curve (more data results in b etter error), though it takes a great deal of data b efore it b egins to mak e reasonable pr edi c t i ons. This is b ecause cutting off tra jectories that hav e multiple matches thro ws a wa y data that might ha ve b een informative to the mo del. The PP-L PS Ts generally outp erform the PP-POMDPs in this problem. With the tra jectory cutting metho d, the PP-LPST (“PP-L PS T(c ut) ”) quic kly outp erforms the flat POMDP and, with enough data, outp erforms b oth versions of PP-POMDP . The PP-LPST with the KL-divergence based matc hing (“PP-LPST(KLD)”) is by far the b est p erformer, quickly achieving small prediction er r or . Clearly the incorre c t lab els in the training data did not hav e as dramatic an effect on the LPST learning, possibly b ecause, as a suffix tree, an LPST mostly makes its predictions based on recent history , limiting the effects of lab eling errors to a few time-steps. Con trol p erformance essen tially mirrors prediction p erformance, with some interesting exceptions. Note that ev en though PP-POMDP(KLD) obtains roughly the same prediction error as the flat POMDP at 1,000,000 training tra je ct or i e s, the predictive features it pro vides still r es ul t in substantially b etter con trol p erformance. This indicates that, even though the PP-POMDP is making errors in the exact v alues of the predictions, it has still captured more of the imp ortan t dynamics of the pre di c t i ons than the flat POMDP has. The flat POMDP itself pro vides features that are roughly as useful as second-or de r Marko v features, whic h do not result in goo d p e r for manc e . Again, OLGARB using these features do es not break ev en, meaning it is wasting bullets when the target is not likely to en ter the crosshairs. The b est-performing prediction profile mo del, PP-LP ST(K L D ) approaches the p erformance of OLGARB using the true pr ed i ct i ons with sufficient data. 7. Related W ork The idea of modeling only some asp ects of the observ ati ons of a dynamical system has certainly b een raised b efore. F or instance, in a recent example Rudary (2008) learned linear- 382 Learning to Make Predictions Withou t a Genera tive Model Gaussian mo dels of contin uous partially observ able environmen ts where some dimensions of the observ ation w ere treated as unmo deled “exogenous input.” These inputs were assumed to ha ve a line ar effect on state transition. Along somewhat similar lines, but in the context of mo del minimization (taking a given, comple t e model and deriving a simpler, abstract model that preserves the v alue function) W olfe (2010) constructed b oth an abstract mo del and a “shado w mo del” that predicts observ ation details that are ignored by the abst r act i on. The “shado w mo del” tak es the abstract observ ations of the abstract mo del as unmo deled input. Splitting the observ ation in to mo deled and un-modeled components and then learning a generativ e mo del is certainly related to our approac h. In that case, a mo del w ould mak e al l conditional predictions ab out the mo deled p ortion of the observ ation, giv en the exogenous inputs (as well as actual actions and the history). Prediction profile mo dels take this to an extreme, by treati ng the entir e observ ation as input. Instead of predicting future sequences of some piece of the next observ ation conditioned on another piece, predicti on profile mo dels predict the v alues of an arbi t r ary set of predictions of interest at the next time step, given the en tire action and observ ation. This allows significan tly more freedom in choosing whic h predictions the mo del will make (and, more imp ortan tly , will not mak e). One mo deling method cl os el y related to prediction profiles is Causal State Splitting Reconstruction (CSSR) (Shalizi & Klinker, 2004). CSSR is an algorithm for le arn i ng gen- erativ e mo dels of discrete, partially observ able, uncontrolled dynamical systems. The basic idea is to define an equiv alence relation ov er histories where tw o historie s are considered equiv alen t if they are asso ciated with identical distributions o ver p ossible futures. The equiv alence classes under this relation are called c ausal states . The CSSR algorithm lear ns the num b er of causal states, the distr i but i on o ver next observ ations asso ciated with each causal state, and the tr ansi t i ons from one causal state to the next, given an observ ation. It is straigh tforward to see that there is a one-to-one corresp ondance b etw een causal states and the predictiv e states of a PSR. As suc h, a causal state model is precisely the prediction profile mo del where the set of tests of interest is Q , some set of core t e sts . With this corre- sp ondance in hand, the results in Section 5.2 sho w that in many cases the num b er of causal states will gr e atly exceed the linear dimension of the original system and that therefore CSSR may b e inadvisable in man y problems, in comparison to more standard modeling approac hes. It is p ossible that the CSSR algorithm could b e adapted to t he more general setting of arbitrary sets of tests of interest, how ev er the algorithm do es rely hea vily on the fact that a prediction p r ofil e mo del with Q as the tests of i nterest is Marko v, which is not generally the case for othe r sets of tests of i nterest. As mentioned in Section 2, McCallum (1995) pr e se nted UT ree, a suffix-tree-based al- gorithm for learning v alue functions in partially observ able environmen ts. Because UT ree learns only the v alue function (a prediction ab out future rewards), and do es not m ake an y predictions about observ at i ons, UT ree do es learn a non-generati ve partial mo del. W olfe and Barto (2006) exte nd UT ree to make one-step predi c t i ons ab out particular observ ation features rather than limiting predictions to the v alue function. Because it learns a suffix tree, UT ree is able to operate on non-epi so dic domains (whereas our metho d requires seeing histories multiple times) and is not required to explicitly search for distinct predi ct i on pro- files. UT ree also directly i nc or p orates abstr ac ti on learning, learning simultaneously whi c h observ ation features are important, and where in the history suffix to attend to them. That said, the main drawbac k of the suffix tree approach is that the tree only takes in to accoun t 383 T al vitie & Singh information fr om relatively recent his tor y (a suffix of the histor y ) . It can not “remember” imp ortan t information for an arbitr ar y n umber of steps as a recurrent state-based mo del can. In the Three Card Mon te example, for instanc e, having access to a de pt h-l i m i te d suffix of history w ould b e of little help. In order to track the ace, one must take into account ev ery mov e the dealer has made since the b eginning of the game. UT ree w ould essentially forget where the card was if the game’s length surpassed the depth of its memory . McCallum (1993) and Mahmud (2010) b oth provide metho ds for learning state machines that predict the immediate reward resulting from any giv en action-observ ation pair in par - tially observ able con trol tasks (and th us do not suffer from the issue of finite-depth memory that suffix trees do). Th us, their learning problem is a sp ecial case of ours, where they restrict their mo dels to mak e one-step predictions ab out the immediate reward. In b oth cases, a simple mo del is incremen tally and greedily elab orated b y prop osing states to b e split and ev aluating the r es ul ts (via statistical tests in the case of McCallum and via likeliho o d hill-climbing in the case of Mahmud). McCallum expressed concern that his approach had difficult y extracting long-range dep endencies (for instance, learning to attend to an even t that do es not app ear to affect the distribution of rewards until many steps later); it is not clear the exten t to which Mahmud’s approach addresses this issue. These metho ds ha ve some of the adv an tages of UT ree, most not abl y that they can b e applied to non-episo dic domains. That said, our approac h has adv an tages as well. By re-casting the problem of learning a non-generative mo del as a standard gener ative mo del-learning problem, w e ha ve b een able to gain deep er understanding of the complexity and applicabilit y of prediction profile mo dels compared to more standard generativ e models. F urthermore, this has al- lo wed us to incorp orate standard, well-studied generative mo del-learning metho ds into our learning algorithm, thereby leveraging the i r strengths in the non-generative setting. Most sp ecifically , this has resulting in a princ i pl ed (alb eit heuristic) learning algorithm, that do es not rely on guess-and-chec k or sto c hastic lo cal search. The prediction profile system is also similar in spirit to finite state controllers for POMDPs. Sondik (1978) not ed that in some cases, it is possible to represen t the opti- mal p olicy for a POMDP as a finite state mac hine. These finite state c ontrollers are very m uch like prediction pr ofil e mo dels in that they take action-observ ation pairs as i nput s, but instead of outputting predictions asso ciated with the current history , they output the optimal action to take. Multiple authors (e.g., Hansen, 1998; P oupart & Boutilier, 2003) pro vide techniques for learning finite state controllers. How ever, these algorithms typically require access to a complete POMDP mo del of the world to b egin with whic h, in our setting, is assumed to b e impractical. 8. Conclusions and F uture Directions The most standard metho ds for learning mo dels in partially obser v able environmen ts learn generativ e mo dels. If one has only a small set of predictions of in terest to make (and therefore do es not re q ui r e the full p ow er of a generativ e mo del), one can ignore irrelev an t detail via abstraction to simpl i fy the learning problem. Even so, a generative mo del will necessarily mak e predictions ab out an y r elevant details, ev en if they are not directly of in terest. W e ha ve seen b y example that the resulting mo del can b e counter-in tuitively complex, even if the pre di c ti on s the mo del is b eing asked to mak e are quite simple. 384 Learning to Make Predictions Withou t a Genera tive Model W e presented predic ti on profile mo dels, which are non-gener ative mo dels for partially observ able systems that make only the predictions of i nterest and no others. The main idea of prediction profile models is to lear n a mo del of the dynamics of the pr e dictions themselves as they change o v er time, rather than a mo del of the dynamics of the system. The learning metho d for prediction profile mo dels learns a transformation of the training data and then applies standard metho ds to the transformed data (assuming that the pre di c t i ons of interest tak e on only a finite num ber of distinct v alues). As a result, it retains adv antages of metho ds lik e EM for POMDPs that learn what informat i on from hi st or y must b e maintained in order to mak e predictions (rather than requi ring a set of history features a pri o ri ) . W e show ed that a prediction profile mo del can b e far simpler than a generative mo del, though it can also b e far more complex, dep ending on what predictions it is asked to make. Ho w ever, if the pr e di c t i ons of in terest dep end on relatively little state information, prediction profile mo dels can pro vide substantial sa vings o ver standard modeling metho ds suc h as POMDPs. While the exp eriments in Sect i on 6 demonstrate that it is p ossible to learn pre di c t i on profile mo dels in con trived systems to o complex for POMDPs, the sp ecific learning algo- rithm presen ted here i s not likely to scale to more nat ur al domains without mo dification. The most criti cal scaling issues for prediction profile mode l s are the sample complexit y of estimating the prediction profiles, and the computational complexity of sear ching for pre- diction profiles and translatin g the data. In b oth cases, the critical source of com pl ex i ty is essen tially ho w man y distinct histories there are in the tr ain i ng data (more distinct histories means the data is spread thin amongst them and there are more estimated profiles to search through). As such, generalization of prediction estimates across many hi st or i es w ould be a key step tow ard applying these ideas to more realistic domains. W e are curren tly de- v eloping learning algorithms that com bine the ideas b ehind prediction profile mo dels with metho ds for learning abstractions that allo w many esse ntially equiv alen t histories to b e lump ed together for the purp oses of estimating the pr e di c ti on s of interest. Another limitation of the prediction profile mo del learning metho d presen ted here is its reliance on the assumption of a finite num b er of prediction profiles. While this as sump ti on do es hold in man y cases, an ideal method would b e able to deal gracefully with a v ery large or infinite n umber of prediction profiles. One possibi l i ty is to simply cluster the predictions in other w ays. F or instance , one ma y only desire a certain level of predi c t i on accu rac y and ma y therefore b e willing to lump some distinct prediction profiles together i n exc hange for a simpler pre di c t i on profile system. Another idea w ould b e to learn a prediction profile model using contin uous-v alued representations such as Kalman filters (Kalman, 1960) or PLGs (Rudary , Singh , & Wingate, 2005) (or their nonlinear v ariants, e.g., Julier & Uhlmann, 1997; W i ngate , 2008). These representations and le ar ni ng algorithms expli c i tl y deal with systems with an infinite num ber of observ ations (prediction profiles in this case). Even when the r e are finite l y man y prediction profiles, metho ds for learning non-line ar con tinuous mo dels may sti l l b e able to (approximately) capture the discrete dynamics. Additionally , though our results hav e f o cused on discrete syst em s, the main motiv ation b ehind prediction profile models also has purchase in the con tinuous setting. T ypical meth- o ds for learning mo dels of partially observ able sy st e ms in contin uous systems, m uc h like their discrete v al ue d coun terparts, learn gener ative models. As suc h, the non-generative approac h of prediction profile mo dels may provide similar b enefits in the con tinuous setting if not all predictions need b e made. In this setting, prediction profiles migh t b e represen ted 385 T al vitie & Singh in a parametric form (for instance, the mean and v ariance of a Gaussian). The main idea of prediction pr ofil e mo dels (though not t he sp ecific metho d pr es ented here) could sti l l then b e applied: learn a mo del of the dynamics of these distribution parameters, rather than the dynamics of the system i t se l f. Finally , we ha ve not discussed in this w ork how the tests of in terest should b e deter- mined, only ho w to predict them once they are selected. Automatically selecting in ter- esting/imp ortan t predictiv e features as targets for partial mo dels w ould certainly b e an in teresting research c hallenge. Of course, this would dep end on what the predictions will b e used for. If the predictions will b e used as features for control, as w e hav e done in our exp eriments, then it w ould certainly seem in tuitive to start with predictiv e features regarding the reward signal, and p erhaps observ ation fe atu r es that strongly correlate with rew ard (as we ha ve in tuitively done by hand in our exp eriments). It may also b e useful to consider making predi c ti on s ab out those pr e dictions in the style of TD Netw orks (Sutton & T anner, 2005). F or instance, one could imagine learning mo dels t hat make predictions ab out whic h profile another mo del will emit. In this wa y mo dels could b e c hained together to make predictions ab out more extant rewards, rather than fo cusing solely on predicti n g the immediate rew ard signal (which is not alw ays a particularly go od feature for temp oral decision problems). Another common use of parti al mo dels is to decomp ose a large mo deling problem into many small ones, as in, for instance, factored MDPs (Boutilier et al., 1999), factored PSRs (W olfe et al., 2008), or collections of lo cal models ( T al v i t i e & Singh, 2009b). In thi s setting, choosing tests of in terest w ould be an example of the structure learning problem: decomp osing one-step predictions into relativ ely indep enden t comp onents and then assigning them to di fferen t mo dels. Ac kno wledgments Erik T alvitie was supp orted unde r the NSF GRFP . Satinder Singh was su pp orted b y NSF gran t I IS-0905146. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the NSF. The work presented in this pap er is an e x t ens i on of work presented at IJCAI (T alvitie & Singh, 2009a). W e are grateful to the anon ymous review ers whose helpful comments hav e impro ved the presen tation of this work. App endix A. A.1 Pro of of Prop osition 15 This result wil l follow straightforw ardly from a general fact ab out dynamical systems. Let h [ i...j ] b e the sequence of actions and observ ations from h starting with the i th time-step in the sequence and e nd i ng with the j th time-step in the sequence. F or conv enience’s sake, i f i > j let h [ i...j ] = h 0 , the null se q ue nc e. The following tw o results will show that if some test t ever has p ositiv e probability , then it must ha ve p ositive probability at some history with length less than the linear dimension of t he system. 386 Learning to Make Predictions Withou t a Genera tive Model Figure 9: The matrix constructed in Lemma 21 is full rank (a contradiction). Lemma 21. If the line ar dimension of a dynamic al s ystem is n , then for any test t and history h with l eng th ( h ) = k ≥ n and p ( t | h ) > 0 , ∃ i, j with 0 ≤ i < j − 1 ≤ k such that p ( t | h [1 ...i ] h [ j ...k ] ) > 0 . Pr o of. Note that b ecause p ( t | h ) > 0, p ( h [( i +1) ...k ] t | h [1 ...i ] ) = p ( t | h ) p ( h [( i +1) ...k ] | h [1 ...i ] ) > 0 for all 0 ≤ i ≤ k . Now assume for all i, j with 0 ≤ i < j − 1 ≤ k that p ( h [ j ...k ] t | h [1 ...i ] ) = p ( t | h [1 ...i ] h [ j ...k ] ) p ( h [ j ...k ] | h [1 ...i ] ) = 0 and seek a con tradiction. Conside r a submatrix of the system dynamics matrix. The ro ws of this submatrix corresp ond t o prefixes of h : h [1 ...i ] for all 0 ≤ i ≤ k . The columns corresp ond to suffixes of h pre-p ended to the test t : h [ j ...k ] t for all 1 ≤ j ≤ k + 1. This is a k + 1 × k + 1 matrix. Under the abov e assumption, this matrix is tri angul ar with p ositiv e entries along the diagonal (Figure 9 shows this matrix when k = 4). As suc h, this matrix is ful l rank (rank k + 1). This is a contradiction since k ≥ n and a submatrix can never hav e higher rank than the matrix that contains it. The next result follows i mme di at e l y from Lemma 21. Corollary 22. If the system has line ar dimension n and for some test t a nd history h p ( t | h ) > 0 , then ther e exists a (p ossibly non-c onse cutive) subse quenc e h ′ of h s u ch that leng th ( h ′ ) < n with p ( t | h ′ ) > 0 . Pr o of. By Lemma 21, ev ery history h with length k ≥ n such that p ( t | h ) > 0 m ust hav e a subsequence h 1 with length k 1 < k such that p ( t | h ) > 0. If k 1 ≥ n , then h 1 m ust hav e a subsequence h 2 with length k 2 < k 1 . This argumen t can b e rep eated until the subsequence has length less than n . The consequence of Corollary 22 is that ev ery test that ever has p ositiv e probabilit y , m ust hav e p ositive probability foll owing some history of length less than n . With this fact in hand, Prop osition 15 can now b e prov en. Prop osition 15. F or any deterministic dynamic al system with actions A , and observa- tions O , the line ar dimension, n ≥ log( |A|− 1)+log ( |O| +1) log |A| . 387 T al vitie & Singh Pr o of. Since the system is deterministic, eac h h i stor y and action corresp ond to exactly one resulting observ ation. A history is a sequence of actions and observ ations. How ever, since the sequence of observ ations is fully determined by the sequence of actions in a deterministic system, the num ber of distinct histories of length k is simply |A| k . At each history there are |A| action c hoices that could each result in a differen t observ ation. So, the n um b er of observ ations that could p ossibly o ccur after histori e s of length k is simpl y |A| k +1 . By Corollary 22, if the linear dimension is n , al l observ ations must o ccur after some history h with leng th ( h ) ≤ n − 1. Th us, the n um b er of observ ations that can p ossibly follo w histories of length less than n is: |O | ≤ n − 1 X i =0 |A| i +1 = |A| n +1 − 1 |A| − 1 − 1 . Solving for n yields the b ound on linear dimension in terms of the num b er of actions and the num ber of observ ations. A.2 Pro of of Prop osition 17 Prop osition 17. F or a given system and set of tests of inter est, th e line ar dimension of the c orr esp ondi ng pr e diction p r ofile system is no gr e ater than that of the pr e diction pr ofile system asso ciate d with any set of c or e tests for the s y s t em (as describ e d in Se ction 2.2). Pr o of. Recall from the discussion of PSRs in Section 2.2 that a set of core tests, Q , is a set of tests whose corresp onding col umn s in the system dynamics matrix constitute a basis. The predictions for t he core tests at a given history form the pr e dictive state at that history . So, the predictive state is precisely the predic ti on profil e for the core tests Q . The prediction for any other test can b e computed as a linear function of the prediction profile for Q . Note that the pr e di c ti on profile syste m for Q is itself an MDP . It was shown in Section 2.2 how to compute the next predictiv e state given the curren t predict i ve state and an action-observ ation pair. No w consider some other set of tests of in terest T I . Because the predictions for Q can b e used to compute the predicti on for any other test, it must b e that there is some function ζ that maps the prediction profiles for Q to the prediction profiles for T I . In general, multiple predictive states ma y map to the same prediction profile for T I so ζ is a surjection. Now it is easy to see that the prediction profile system for T I is the result of applying the observ ation abstraction ζ to the prediction profile system for Q . Performing observ ation abstraction on an MDP generally pro duces a POMDP , but never increases the linear dimension (T alvitie, 2010). Hence, the prediction profile system for an y set of tests of in terest T I has linear dimension no greater than that of the prediction profile system for an y set of core tests, Q . A.3 Pro of of Prop osition 20 Prop osition 20. Consider a POMDP with hidden states S , actions A , and observations O . L et T I b e the set of test s of inter est. L et a i b e the action taken at time-step i , s i b e the hidden state r e ache d after taking acti o n a i , and o i b e the observation emitt e d by s i . Now, 388 Learning to Make Predictions Withou t a Genera tive Model c onsider any surje ction σ : S → S σ mapping hidden s t at es to a set of abstract states with the fol lowing pr op erties: 1. F or any p air of primitive states s 1 , s 2 ∈ S , if σ ( s 1 ) = σ ( s 2 ) , then for any time-step i and any test of inter est t ∈ T I , p ( t | s i = s 1 ) = p ( t | s i = s 2 ) . 2. F or any p air of primitive states s 1 , s 2 ∈ S , if σ ( s 1 ) = σ ( s 2 ) , then for any time-step i , abstr act stat e S ∈ S σ , observation o ∈ O , and a ct i on a ∈ A , Pr ( σ ( s i +1 ) = S | s i = s 1 ,a i +1 = a, o i +1 = o ) = Pr ( σ ( s i +1 ) = S | s i = s 2 , a i +1 = a, o i +1 = o ) . If such a σ exists, then the pr e diction pr ofile system for T I has line ar dim ens i on no g r e ater than the numb er of distinct b eliefs over abstr act states, S σ . Pr o of. The pro of follo ws similar reasoning to the pro of of Prop osition 17. Not e that, b ecause of Prop erty 1 the b elief ov er abstract states at a given history is sufficient to compute the prediction profile. F or an y hi s tor y h and any test of in terest t ∈ T I : p ( t | h ) = X s ∈S Pr( s | h ) p ( t | s ) = X S ∈S σ X s ∈ S Pr( s | h ) p ( t | s ) = X S ∈S σ p ( t | S ) X s ∈ S Pr( s | h ) = X S ∈S σ p ( t | S )Pr( S | h ) , where the third equality follo ws from prop ert y 1: for an y S ∈ S σ , all hidden states s ∈ S ha ve the sam e asso ciated probabi l i ties for the tests of interest. No w, consider the dynamical system with b eliefs o ver abstract states as “observ ations” and action-observ ation pairs as “act i ons. ” Call this the abstr act b elief syst em . Just as with the predictive state, b ecause it is p ossible to compute the prediction profile from the abstract b eliefs, the prediction profile mo del for T I can be seen as the result of an observ ation aggregation of the abstract b elief system. As a result, the prediction profile system has linear dimension no greater than that of the abstract b elief system. The rest of the pro of sho ws that, b ecause of Prop erty 2, the abstract b elief sy st em i s an MDP , and therefore has linear dimension no greater than the n umber of distinct b eliefs o ver abstract states. Giv en the probability distribution ov er abstract states at a given hi st or y h , and the agent tak es an acti on a and observes and observ ation o , it is p ossible to compute the probability of an abstract state S ∈ S σ at the new history: Pr( S | hao ) = X s ∈S Pr( s | h )Pr( S | s, a, o ) = X S ′ ∈S σ X s ∈ S ′ Pr( s | h )Pr( S | s , a, o ) = X S ′ ∈S σ Pr( S | S ′ , a, o ) X s ∈ S ′ Pr( s | h ) = X S ′ ∈S σ Pr( S | S ′ , a, o )Pr( S ′ | h ) , where the third equalit y foll ows from Prop ert y 2: for an y S ∈ S σ , all hi dde n states s ∈ S ha ve the same associated conditional distribution ov er next abstract states, giv en the action and observ ation. 389 T al vitie & Singh So, b ecause one can compute the next abstract b eliefs from the previous abstract b eliefs, the abstract b elief system is an MDP , and therefore has linear dimension no greater than the num b er of observ ations (the num b er of distinct abstract beli ef s) . Because one can compute the prediction profile from the abstr ac t b eliefs, the prediction profile system can b e constructed by applying an observ ation abstraction to the abstract b elief system. Th us, the prediction profile system has linear dimension no greater th an the num b er of distinct abstract b eliefs. References Baum, L. E., Petrie, T., Soules, G., & W eiss, N. (1970). A maximization technique o ccuring in the statistical anal y si s of probabilistic functions of mark ov chains. The A nnals of Mathematic al Stat i s ti c s , 41 (1), 164–171. Baxter, J., & Bartlett, P . L. (2000). Reinforcemen t learn i ng in POMDPs via di r e ct gra- dien t ascen t. In Pr o c e e dings of the Eigh te enth International Confer enc e on Machine L e arning (ICML) , pp. 41–48. Bo ots, B., Siddiqi, S., & Gordon , G. (2010). Closing the learning-planning lo op with predic- tiv e state represen tations. In Pr o c e e dings of R ob otics: Scienc e and Systems , Zaragoza, Spain. Bo ots, B., Siddiqi, S., & Gordon, G. (2011). An online sp ectral learning algorithm for partially observ able nonlinear dynami c al systems. In Pr o c e e dings of the Twenty-Fifth National Confer enc e on Artificial Intel ligenc e (AAAI) . Boutilier, C., Dean, T., & Hanks, S. (1999). Dec i si on- th eor e ti c planning: Structural as- sumptions and computational lev erage. Journal of Artificial Intel ligenc e R ese ar ch , 11 , 1–94. Bo wling, M., McCrack en, P ., James, M., Neufeld, J., & Wilkinson, D. (2006). Learning predictive state representations us i ng non-blind p olicies. In Pr o c e e dings of the Twenty- Thir d Internati o nal Confer enc e on Mach i ne L e arning ( ICM L) , pp. 129–136. Dinculescu, M., & Precup, D. (2010). Appro ximate predictive representations of partially observ able systems. In Pr o c e e dings of the Twenty-Seventh International Confer enc e on Machine L e arning (ICML) , pp. 895–902. Hansen, E. (1998). Finite-Memory Contr ol of Partial ly Observ ab le Systems . Ph.D . the si s , Univ ersity of Massac hussetts, Amherst, MA. Holmes, M., & Isbell, C. (2006). Lo oping suffix tree-based inference of partially observ- able hidden state. In Pr o c e e dings of the Twenty-Thir d International Confer enc e on Machine L e arning (ICML) , pp. 409–416. James, M., & Singh, S. (2004). Learning and disco very of predictive state represen tations in dynamical systems with reset. In Pr o c e e dings of the Twenty-First International Confer enc e on Machine L e arning (ICML) , pp. 417–424. Julier, S. J., & Uhlmann, J. K. (1997). A new extension of the k alman filter t o nonlinear systems. In Pr o c e e dings of A er oSense: The Eleventh International Symp osium on A er osp ac e/Defense Sensing, Simulat i on and Contr ols , pp. 182–193. 390 Learning to Make Predictions Withou t a Genera tive Model Kalman, R. E. ( 1960). A new approac h to linear filtering and prediction probl e ms. T r ans- actions of the ASME – Jou rna l of Basic Engine ering , 82 , 35–45. Littman, M., Sutton, R., & Singh, S. (2002). Predictive r e pr es entations of state. In A dvanc es in Neur al Information Pr o c essing Systems 14 ( NIPS) , pp. 1555–1561. Littman, M. L. (1996). Algorithms fo r Se quential De cision Making . Ph.D. thesis, Brown Univ ersity , Pro vidence, RI. Mahm ud, M. M. H. (2010). Constructing states for reinforcement lear ni ng. In Pr o c e e dings of the Twenty-Seventh International Confer enc e on Machine L e arning (ICML) , pp. 727–734. McCallum, A. K. (1995). R einfor c ement L e arning with Sele ctive Per c eption and Hidd en State . Ph.D. thesis, Rutgers Universit y . McCallum, R. A. (1993). Overcoming incomplete p erception with utile distinction memory . In Pr o c e e dings of the T enth International Confer enc e on Machine L e arning (ICML) , pp. 190–196. Monahan, G. E. (1982). A surv ey of partiall y observ able mark ov decisions pro cesses: Theory , mo dels, and algorithms. Management Scienc e , 28 (1), 1–16. P eters, J. , & Schaal, S. (2008). Natural actor-critic. Neur o c omputing , 71 , 1180–1190. P oupart, P ., & B out i l i e r, C. (2003). Bounded finite state con trollers. In A dvanc es in Neur al Information Pr o c essing Systems 16 (N IPS) . Puterman, M. L. (1994). Markov De cision Pr o c esses: Discr ete Sto chastic Dynamic Pr o- gr amming . J oh n Wiley and Sons, New Y ork, NY. Riv est, R. L., & Schapire, R. E. (1994). Diversit y-based inference of finit e automata. Journal of the Asso ciation for Computing Machinery , 41 (3), 555–589. Rudary , M. (2008). On Pr e dictive Line ar Gaussian Mo dels . Ph.D. thesis, Univ ersity of Mic higan. Rudary , M., Singh, S., & Wingate, D. (2005). Predictiv e li ne ar -gaus si an mo dels of sto chas- tic dynamical systems. In Unc ertainty in Artificial Intel ligenc e: Pr o c e e dings of the Twenty-First Confer enc e (UA I) , pp. 501–508. Shalizi, C. R., & Klinker, K. L. (2004). Blind construction of optimal nonlinear recursi ve predictors for discrete sequences. In Pr o c e e dings of the Twentieth Confer enc e on Unc ertainty in A rtificial Intel ligenc e (UA I) , pp. 504–511. Singh, S., James, M. R., & Rudary , M. R. (2004). Predictiv e state representations: A new theory for mo deling dynamical systems. In Unc ertainty in Artificial Intel ligenc e: Pr o c e e dings of the Twentieth Confer enc e (UAI) , pp. 512–519. Sondik, E. J. (1978). The optimal control of parti al l y observ able marko v pro cesses o v er the infinite horizon: Discounted c ost s. Op er ations R ese ar ch , 26 , 282–304. Soni, V., & Singh, S. (2007). Abstraction in predictiv e state representations. In Pr o c e e dings of the Twenty-Se c ond National Confer enc e on A rtificial Intel ligenc e (AAAI) , pp. 639– 644. 391 T al vitie & Singh Sutton, R. S., & T anner, B. (2005). T emp or al -di ffe r e nc e ne tw orks. In A dvanc es in Neur al Information Pr o c essing Systems 17 (N IPS) , pp. 1377–1384. T alvitie, E. (2010). Simple Partial Mo dels for Complex Dynamic al Systems . Ph.D. thesis, Univ ersity of Mic higan, Ann Arb or, MI. T alvitie, E., & Singh, S. (2009a). Maintaining predicti ons ov er time without a mo del. In Pr o c e e dings of the Twenty-Fir s t International Joint Confer enc e on A rtificial Intel li- genc e (IJCAI) , pp. 1249–1254. T alvitie, E., & Singh, S. (2009b). Simple lo cal mo dels for complex dynamical systems. In A dvanc es in Neur al Information Pr o c essing Sy s te ms 21 (NIPS) , pp. 1617–1624. W ea ver, L., & T ao, N. (2001). The optimal reward baseline for gradient-based reinforce- men t learning. In Unc ertainty in Artificial Int el ligenc e: Pr o c e e dings of the Sevente enth Confer enc e (UAI) , pp. 538–545. Williams, R. (1992). Simple statistical gradient-follo wing algorithms for conn ec t i oni st rein- forcemen t l ear ni n g. Machine L e arning , 8 , 229–256. Wingate, D. (2008). Exp onential F amily Pr e dictive R epr esentations of State . Ph.D. thesis, Univ ersity of Mic higan. Wingate, D., Soni, V., W olfe , B., & Singh, S. (2007). Relational kno wledge with predictive state representations. In Pr o c e e dings of the Twentieth International Joint Confer enc e on Artificial Intel lige nc e (IJCAI) , p p. 2035–2040. W olfe, A. P . (2010). Paying Attention to What Matters: Observation Abstr action in Partial ly Observable Envir onments . Ph.D. thesis, Universit y of Massac hussetts, Amherst, MA. W olfe, A. P ., & Bart o, A. G. (2006). Decision tree metho ds for finding reusable MDP homomorphisms. In Pr o c e e dings of the Twenty-Firs t National Confer enc e on A rtificial Intel ligenc e (AAAI) . W olfe, B., James, M., & Singh, S. (2008). Appro ximate predictiv e state represen tations. In Pr o c e e dings of the Seventh Confer enc e on Autonomous A gents and Multiagent Systems (AAMAS) . W olfe, B., James, M. R., & Singh, S. (2005). Learning predictive state represen tations in dynamical systems withou t reset. In Pr o c e e dings of t he Twenty-Se c ond International Confer enc e on Machine L e arning (ICML) , pp. 985–992. W olfe, B., & Singh, S. (2006). Predictive state representations with options. In Pr o c e e d- ings of the Twenty-Thir d International Confer enc e on Machine L e arning ( ICM L) , pp. 1025–1032. 392
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment