An empirical analysis of dropout in piecewise linear networks
The recently introduced dropout training criterion for neural networks has been the subject of much attention due to its simplicity and remarkable effectiveness as a regularizer, as well as its interpretation as a training procedure for an exponentia…
Authors: David Warde-Farley, Ian J. Goodfellow, Aaron Courville
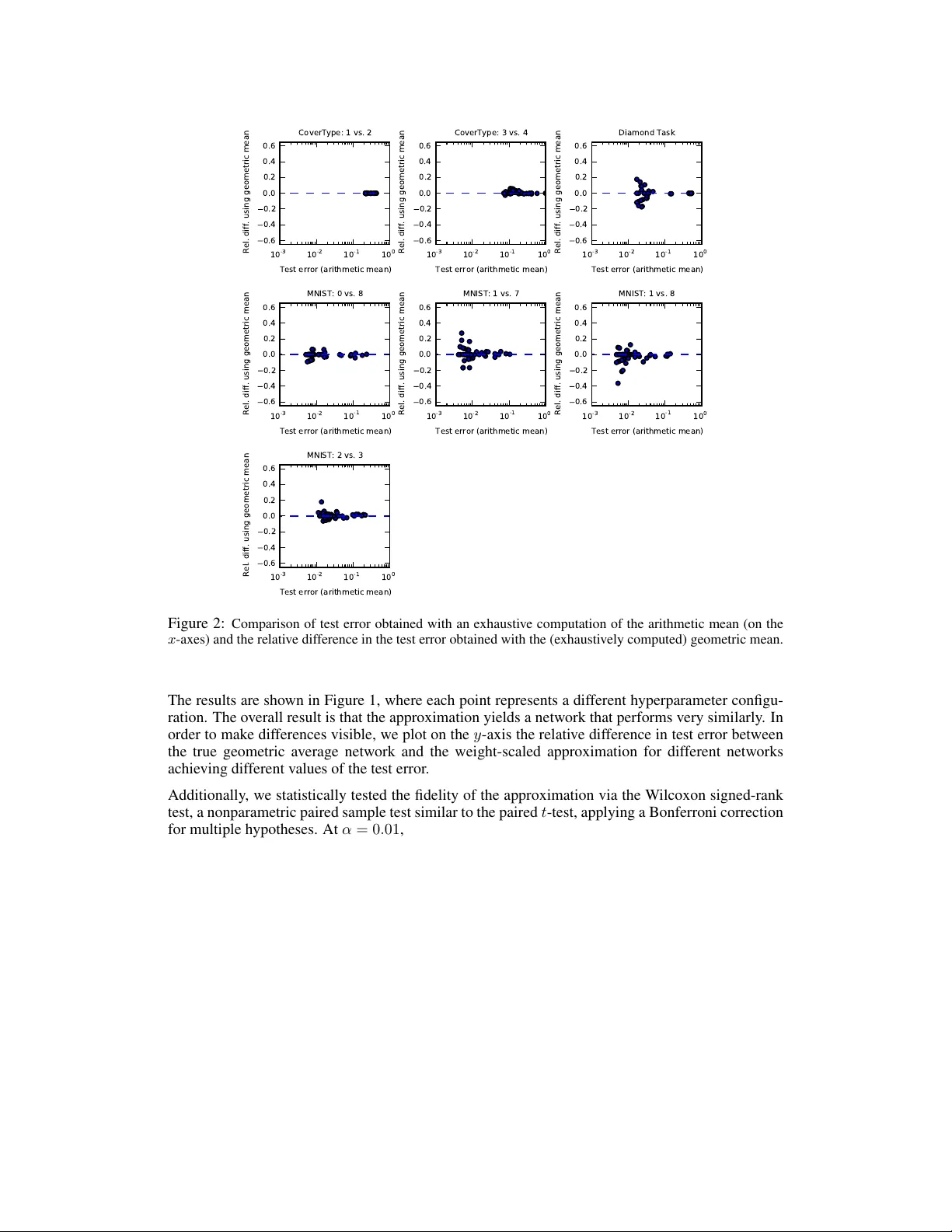
An empirical analysis of dr opout in piecewise linear networks David W arde-Farley , Ian J. Goodfellow , Aaron Courville, Y oshua Bengio D ´ epartement d’informatique et de recherche op ´ erationnelle Univ ersit ´ e de Montr ´ eal Montr ´ eal, QC H3C 3J7 { wardefar,goodfeli } @iro.umontreal.ca , { aaron.courville,yoshua.bengio } @umontreal.ca Abstract The recently introduced dropout training criterion for neural networks has been the subject of much attention due to its simplicity and remarkable ef fectiveness as a regularizer , as well as its interpretation as a training procedure for an exponen- tially large ensemble of networks that share parameters. In this work we empir- ically in vestigate several questions related to the efficacy of dropout, specifically as it concerns networks employing the popular rectified linear acti v ation function. W e inv estigate the quality of the test time weight-scaling inference procedure by ev aluating the geometric av erage exactly in small models, as well as compare the performance of the geometric mean to the arithmetic mean more commonly employed by ensemble techniques. W e explore the effect of tied weights on the ensemble interpretation by training ensembles of masked networks without tied weights. Finally , we inv estigate an alternative criterion based on a biased estima- tor of the maximum likelihood ensemble gradient. 1 Introduction Dropout (Hinton et al. , 2012) has recently garnered much attention as a novel regularization strategy for neural networks in volving the use of structured masking noise during stochastic gradient-based optimization. Dropout training can be viewed as a form of ensemble learning similar to bagging (Breiman, 1994) on an ensemble of size exponential in the number of hidden units and input features, where all members of the ensemble share subsets of their parameters. Combining the predictions of this enormous ensemble would ordinarily be prohibiti vely e xpensive, b ut a scaling of the weights admits an approximate computation of the geometric mean of the ensemble predictions. Dropout has been a crucial ingredient in the winning solution to several high-profile competitions, notably in visual object recognition (Krizhevsky et al. , 2012a) as well as the Merck Molecular Activity Challenge and the Adzuna Job Salary Prediction competition. It has also inspired work on activ ation function design (Goodfello w et al. , 2013a) as well as extensions to the basic dropout tech- nique (W an et al. , 2013; W ang and Manning, 2013) and similar fast approximate model av eraging methods (Zeiler and Fergus, 2013). Sev eral authors have recently in vestigated the mechanism by which dropout achie ves its re gulariza- tion effect in linear models (Baldi and Sadowski, 2013; W ang and Manning, 2013; W ager et al. , 2013), as well as linear and sigmoidal hidden units (Baldi and Sadowski, 2013). Howe ver , many of the recent empirical successes of dropout, and feed forward neural networks more generally , hav e utilised piecewise linear activ ation functions (Jarrett et al. , 2009; Glorot et al. , 2011; Goodfellow et al. , 2013a; Zeiler et al. , 2013). In this work, we empirically study dropout in r ectified linear networks, employing the recently popular hidden unit acti vation function f ( x ) = max(0 , x ) . 1 W e begin by expanding upon previous work which in vestigated the quality of dropout’ s approx- imate ensemble prediction by comparing against Monte Carlo estimates of the correct geometric av erage (Sri vasta v a, 2013; Goodfellow et al. , 2013a). Here, we compare against the true average, in networks of size small enough that the exact computation is tractable. W e find, by exhausti ve enumeration of all sub-networks in these small cases, that the weight scaling approximation is a remarkably and somewhat surprisingly accurate surrog ate for the true geometric mean. Next, we consider the importance of the geometric mean itself. T raditionally , bagged ensembles produce an a veraged prediction via the arithmetic mean, but the weight scaling trick employed with dropout pro vides an efficient approximation only for the geometric mean. While, as noted by (Baldi and Sadowski, 2013), the dif ference between the two can be bounded (Cartwright and Field, 1978), it is not immediately obvious what ef fect this source of error will ha ve on classification performance in practice. W e therefore in vestigate this question empirically and conclude that the geometric mean is indeed a suitable replacement for the arithmetic mean in the context of a dropout-trained ensemble. The questions raised thus far pertain primarily to the approximate model av eraging performed at test time, but dr opout training also raises some important questions. At each update, the dropout learning rule follows the same gradient that true bagging training would follow . Ho wev er , in the case of traditional bagging, all members of the ensemble would hav e independent parameters. In the case of dropout training, all of the models share subsets of their parameters. It is unclear how much this coordination serves to regularize the ev entual ensemble. It is also not clear whether the most important effect is that dropout performs model averaging, or that dropout encourages each individual unit to w ork well in a v ariety of contexts. T o in vestigate this question, we train a set of independent models on resamplings (with replace- ment) of the training data, as in traditional bagging. Each ensemble member is trained with a single randomly sampled dropout mask fixed throughout all steps of training. W e combine these indepen- dently trained networks into ensembles of varying size, and compare the ensembles’ performance with that of a single network of identical size, trained instead with dropout. W e find evidence to support the claim that the weight sharing taking place in the context of dropout (between members of the implicit ensemble) plays an important role in further regularizing the ensemble. Finally , we in vestigate an alternativ e criterion for training the exponentially large shared-parameter ensemble inv oked by dropout. Rather than performing stochastic gradient descent on a randomly selected sub-network in a manner similar to bagging, we consider a biased estimator of the gra- dient of the geometrically av eraged ensemble log likelihood (i.e. the gradient of the model being approximately ev aluated at test-time), with the particular estimator bearing a resemblance to boost- ing (Schapire, 1990). W e find that this ne w criterion, employing masking noise with the exact same distribution as is employed by dropout, yields no discernible rob ustness gains ov er netw orks trained with ordinary stochastic gradient descent. 2 Review of dropout Dropout is an ensemble learning and prediction technique that can be applied to deterministic feed- forward architectures that predict a tar get y given input vector v . These architectures contain a series of hidden layers h = { h (1) , . . . , h ( L ) } . Dropout trains an ensemble of models consisting of the set of all models that contain a subset of the variables in both v and h . The same set of parameters θ is used to parameterize a family of distributions p ( y | v ; θ , µ ) where µ ∈ M is a binary mask vector determining which variables to include in the model, e.g., for a giv en µ , each input unit and each hidden unit is set to zero if the corresponding element of µ is 0. On each presentation of a training example, we train a dif ferent sub-network by following the gradient of log p ( y | v ; θ , µ ) for a dif fer- ent randomly sampled µ . For many parameterizations of p (such as most multilayer perceptrons) the instantiation of different sub-networks p ( y | v ; θ , µ ) can be obtained by element-wise multiplication of v and h with the mask µ . 2.1 Dropout as bagging Dropout training is similar to bagging (Breiman, 1994) and related ensemble methods (Opitz and Maclin, 1999). Bagging is an ensemble learning technique in which a set of models are trained on different subsets of the same dataset. At test time, the predictions of each of the models are a veraged 2 together . The ensemble predictions formed by voting in this manner tend to generalize better than the predictions of the individual models. Dropout training differs from bagging in three w ays: 1. All of the models share parameters. This means that they are no longer really trained on separate subsets of the dataset, and much of what we know about bagging may not apply . 2. T raining stops when the ensemble starts to overfit. There is no guarantee that the individual models will be trained to con vergence. In fact, typically , the vast majority of sub-networks are nev er trained for even one gradient step. 3. Because there are too many models to average together explicitly , dropout averages them together with a fast approximation. This approximation is to the geometric mean, rather than the arithmetic mean. 2.2 Appr oximate model averaging The functional form of the model becomes important when it comes time for the ensemble to make a prediction by av eraging together all the sub-networks’ predictions. When p ( y | v ; θ ) = softmax( v T W + b ) , the predictiv e distribution defined by renormalizing the geometric mean of p ( y | v ; θ , µ ) over M is simply gi ven by softmax( v T W / 2 + b ) . This is also true for sigmoid output units, which are special cases of the softmax. This result holds exactly in the case of a single layer softmax model (Hinton et al. , 2012) or an MLP with no non-linearity applied to each unit (Good- fellow et al. , 2013a). Previous work on dropout applies the same scheme in deep architectures with hidden units that hav e nonlinearities, such as rectified linear units, where the W / 2 method is only an approximation to the geometric mean. The approximation has been characterized mathemati- cally for linear and sigmoid networks (Baldi and Sadowski, 2013; W ager et al. , 2013), but seems to perform especially well in practice for nonlinear networks with piecewise linear activ ation func- tions (Sriv astav a, 2013; Goodfellow et al. , 2013a). 3 Experimental setup Our initial inv estigations employed rectifier networks with 2 hidden layers and 10 hidden units per layer , and a single logistic sigmoid output unit. W e applied this class of networks to six binary classification problems deriv ed from popular multi-class benchmarks, simplified in this fashion in order to allow for much simpler architectures to ef fectiv ely solv e the task, as well as a synthetic task of our own design. Specifically , we chose four binary sub-tasks from the MNIST handwritten digit database (LeCun et al. , 1998). Our training sets consisted of all occurrences of two digit classes (1 vs. 7, 1 vs. 8, 0 vs. 8, and 2 vs. 3) within the first 50,000 examples of the MNIST training set, with the occurrences from the last 10,000 examples held back as a v alidation set. W e used the corresponding occurrences from the official MNIST test set for e valuating test error . W e also chose two binary sub-tasks from the Co verT ype dataset of the UCI Machine Learning Repository , specifically discriminating classes 1 and 2 (Spruce-Fir vs. Lodgepole Pine) and classes 3 and 4 (Ponderosa Pine vs. Cottonwood/W illow). This task represents a very different domain than the first two datasets, but one where neural network approaches have nonetheless seen success (see e.g. Rifai et al. (2011)). 1 The final task is a synthetic task in two dimensions: inputs lie in ( − 1 , 1) × ( − 1 , 1) ⊂ R 2 , and the domain is divided into two regions of equal area: the diamond with corners (1 , 0) , (0 , 1) , ( − 1 , 0) , (0 , − 1) and the union of the outlying triangles. In order to keep the synthetic task moderately challenging, the training set size was restricted to 100 points sampled uniformly at random. An additional 500 points were sampled for a validation set and another 1000 as a test set. In order to keep the mask enumeration tractable in the case of the larger input dimension tasks, we chose to apply dropout in the hidden layers only . This has the added benefit of simplifying the 1 Unlike Rifai et al. (2011), we train and evaluate on the records of each class from the data split advertised in the original dataset description. This makes the task much more challenging and many methods prone to ov erfitting. 3 ensemble computation: though dropout is typically applied in the input layer, inclusion probabil- ities higher than 0.5 are employed (e.g. 0 . 8 in Hinton et al. (2012); Krizhe vsky et al. (2012b)), making it necessary to unev enly weight the terms in the average. W e chose hyperparameters by random search (Bergstra and Bengio, 2012) over learning rate and momentum (initial v alues and de- crease/increase schedules, respecti vely), as well as mini-batch size. W e performed early stopping on the validation set, terminating when a lower validation error had not been observed for 100 epochs; when training with dropout, the figure of merit for early stopping was the validation error using the weight-scaled predictions. 4 W eight scaling versus Monte Carlo or exact model averaging Sriv astav a (2013); Goodfellow et al. (2013a) previously in vestigated the fidelity of the weight scaling approximation in the context of rectifier networks and maxout networks, respectively , through the use of a Monte Carlo approximation to the true model a verage. By concerning ourselves with small networks where exhaustiv e enumeration is possible, we were able to avoid the effect of additional variance due to the Monte-Carlo av erage and compute the exact geometric mean over all possible dropout sub-networks. On each of the 7 tasks, we randomly sampled 50 sets of hyperparameters and trained 50 networks with dropout. W e then computed, for each point in the test set for each task, the activities of the network corresponding to each of the 2 20 possible dropout masks. W e then geometrically averaged their predictions (by arithmetically averaging all values of the input to the sigmoid output unit) and computed the geometric average prediction for each point in the test set. Finally , we compared the misclassification rate using these predictions to that obtained using the approximate, weight-scaled predictions. 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (geometric mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using weight-scaling approx. CoverType: 1 vs. 2 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (geometric mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using weight-scaling approx. CoverType: 3 vs. 4 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (geometric mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using weight-scaling approx. Diamond Task 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (geometric mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using weight-scaling approx. MNIST: 0 vs. 8 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (geometric mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using weight-scaling approx. MNIST: 1 vs. 7 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (geometric mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using weight-scaling approx. MNIST: 1 vs. 8 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (geometric mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using weight-scaling approx. MNIST: 2 vs. 3 Figure 1: Comparison of test error obtained with an exhaustiv e computation of the geometric mean (on the x -axes) and the relati ve dif ference in the test error obtained with the weight-scaling approximation. 4 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (arithmetic mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using geometric mean CoverType: 1 vs. 2 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (arithmetic mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using geometric mean CoverType: 3 vs. 4 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (arithmetic mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using geometric mean Diamond Task 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (arithmetic mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using geometric mean MNIST: 0 vs. 8 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (arithmetic mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using geometric mean MNIST: 1 vs. 7 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (arithmetic mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using geometric mean MNIST: 1 vs. 8 1 0 - 3 1 0 - 2 1 0 - 1 1 0 0 Test error (arithmetic mean) 0.6 0.4 0.2 0.0 0.2 0.4 0.6 Rel. diff. using geometric mean MNIST: 2 vs. 3 Figure 2: Comparison of test error obtained with an exhaustiv e computation of the arithmetic mean (on the x -axes) and the relati ve difference in the test error obtained with the (e xhaustiv ely computed) geometric mean. The results are shown in Figure 1, where each point represents a different hyperparameter configu- ration. The ov erall result is that the approximation yields a network that performs very similarly . In order to make differences visible, we plot on the y -axis the relativ e difference in test error between the true geometric av erage network and the weight-scaled approximation for different networks achieving dif ferent values of the test error . Additionally , we statistically tested the fidelity of the approximation via the W ilcoxon signed-rank test, a nonparametric paired sample test similar to the paired t -test, applying a Bonferroni correction for multiple hypotheses. At α = 0 . 01 , no significant differences were observed for any of the se ven tasks. 5 Geometric mean versus arithmetic mean Though the inexpensiv e computation of an approximate geometric mean was noted in (Hinton et al. , 2012), little has been said of the choice of the geometric mean. Ensemble methods in the literature often employ an arithmetic mean for model av eraging. It is thus natural to pose the question as to whether the choice of the geometric mean has an impact on the generalization capabilities of the ensemble. Using the same networks trained in Section 4, we combined the forward-propagated predictions of all 2 20 models using the arithmetic mean. In Figure 2, we plot the relativ e difference in test error between the arithmetic mean predictions. W e find that across all sev en tasks, the geometric mean is a reasonable proxy for the arithmetic mean, with relative error rarely exceeding 20% except for the synthetic task. In absolute terms, the discrepancy between the test error achieved by the geometric mean and the arithmetic mean nev er exceeded 0.75% for any of the tasks. 5 6 Dropout ensembles versus untied weights W e now turn from our in vestigation of the characteristics of inference in dropout-trained networks to an in vestigation of the training procedure. For the remainder of the experiments, we trained networks of a more realistic size and capacity on the full multiclass MNIST problem. Once again, we employed two layers of rectified linear units. In addition to dropout, we utilised norm constraint regularization on the incoming weights to each hidden unit. W e again performed random search ov er hyperparameter values, now including in our search the initial ranges of weights, the number of hidden units in each of two layers, and the maximum weight vector norms of each layer . Dropout training can be viewed as performing bagging on an ensemble that is of size exponential in the number of hidden units, where each member of the ensemble shares parameters with other members of the ensemble. Because each gradient step is taken on a different mini-batch of training data, each sub-network can be seen to be trained on a different resampling of the training set, as in traditional bagging. Furthermore, while each step is taken with respect to the log likelihood of a single ensemble member, the effect of the weight update is applied to all members of the ensemble simultaneously 2 W e in vestigate the role of this complex weight-sharing scheme by training an ensemble of independent netw orks on resamplings of the training data, each with a single dropout mask fixed in place throughout training. W e first performed a hyperparameter search by sampling 50 hyperparameter configurations and choosing the network with the lowest validation error . The best of these networks obtains a test error of 1.06%, matching results reported by Sriv astava (2013). Using the same hyperparameters, we trained 360 models initialized with different random seeds, on different resamplings (with re- placement) of the training set, as in traditional bagging. Instead of applying dropout during training (and thus applying a dif ferent mask at each gradient step), we sampled one dropout mask per model and held it fix ed throughout training and at test time. The resulting networks thus ha ve architectures sampled from the same distribution as the sub-networks trained during dropout training, but each network’ s parameters are independent of all other networks. W e then ev aluate test error for ensembles of these networks, combining their predictions (with the dropout mask used during training still fixed in place at test time) via the geometric mean, as is approximately done in the context of dropout. Our results for various sizes of ensemble are shown in Figure 3. Our results suggest that there indeed an ef fect; combining all 360 independently trained 0 20 40 60 80 100 120 Number of ensemble members 0.0160 0.0165 0.0170 0.0175 0.0180 0.0185 0.0190 Test error Ensembles of fixed-mask, untied networks Figure 3: A verage test error on MNIST for varying sizes of untied-weight ensembles. 360 networks were trained to con ver gence, each with a single randomly sampled dropout mask fixed in place throughout. These networks pre-softmax activ ations were then averaged to produce predictions for varying sizes of ensembles. For each size n , b 360 /n c disjoint subsets were combined in this fashion, and the test error mean and standard deviation o ver ensembles is sho wn here. models yields a test error of 1.66%, far abov e the e ven the suboptimally tuned netw orks trained with dropout. Aside from the size of the independent ensemble being considerably smaller , one potential 2 At least, all members of the ensemble that share any parameters with the sub-network just updated. There certainly exist pairs of ensemble members whose parameter sets are disjoint. 6 confounding factor is that the non-architectural h yperparameters were selected in the context of their performance when using dropout and used as-is to train the networks with untied weights; although each of these was early-stopped independently , it remains unclear ho w to efficiently optimize hy- perparameters for the indi vidual members of a lar ge ensemble so as to facilitate a fairer comparison (indeed, this highlights a general issue with the high cost of training ensembles of neural networks, that dropout con veniently sidesteps). 7 Dropout bagging versus dropout boosting Other algorithms such as denoising autoencoders (V incent et al. , 2010) are moti vated by the idea that models trained with noise are rob ust to slight transformations of their inputs. Previous work has drawn connections between noise and regularization penalties (Bishop, 1995); similar connections in the case of dropout have recently been noted (Baldi and Sado wski, 2013; W ager et al. , 2013). It is natural to question whether dropout can be wholly characterized in terms of learned noise robustness, and whether the model-a veraging perspectiv e is necessary or fruitful. In order to in vestigate this question we propose an algorithm that injects exactly the same noise as dropout. For this test to be ef fectiv e, we require an algorithm that can successfully minimize training error , and obtain acceptable generalization performance. It needs to perform at least as well as standard maximum likelihood; otherwise all we have done is designed a pathological algorithm that fails to train. W e therefore introduce dr opout boosting . The objective function for each (sub-network, example) pair in dropout boosting is the likelihood of the data according to the ensemble; howe ver , only the parameters of the current sub-network may be updated for each example. Ordinary dropout performs bagging by maximizing the likelihood of the correct tar get for the current example under the curr ent sub-network , whereas dropout boosting takes into account the contributions of other sub-networks, in a manner reminiscent of boosting. The objective function for dropout is 1 2 |M| P µ ∈M log p ( y | v ; θ , µ ) . For dropout boosting, assume each mask µ has a separate set of parameters θ µ (though in reality these parameters are tied, as in con ventional dropout). The dropout boosting objective function is then giv en by log p ensemble ( y | v ; θ ) , where p ensemble ( y | v ; θ ) = 1 Z ˜ p ( y | v ; θ ) Z = X y 0 ˜ p ( y 0 | v ; θ ) ˜ p ( y | v ; θ ) = 2 |M| q Π µ ∈M p ( y | v ; θ µ ) . The boosting learning rule is to select one model and update its parameters giv en all of the other models. In con ventional boosting, these other models hav e already been trained to conv ergence. In dropout boosting, the other models actually share parameters with the network being trained at any giv en step, and initially the other models hav e not been trained at all. The learning rule is to select a sub-network index ed by µ and follow the ensemble gradient ∇ θ µ log p ensemble ( y | v ; θ ) , i.e. ∆ θ µ ∝ 1 2 |M| ∇ θ µ log p ( y | v ; θ µ , µ ) + X y 0 p ensemble ( y 0 | v ) ∇ θ µ log p ( y 0 | v ; θ µ , µ ) . Rather than using the boosting-like algorithm, one could obtain a generic Monte-Carlo procedure for maximizing the log likelihood of the ensemble by av eraging together the gradient for multiple values of µ , and optionally using a dif ferent µ for the term in the left and the term on the right. Empirically , we obtained the best results in the special case of boosting, where the term on the left uses the same µ as the term on the right – that is, both terms of the gradient apply updates only to one member of the ensemble, ev en though the criterion being optimized is global. Note that the intractable p ensemble still appears in the learning rule. T o implement the training algo- rithm ef ficiently , we can approximate the ensemble predictions using the weight scaling approxima- tion. This introduces further bias into the estimator , but our findings in Section 4 suggest that the approximation error is small. 7 Note that dropout boosting employs exactly the same noise as regular dropout uses to perform bag- ging, and thus should perform similarly to con ventional dropout if learned noise robustness is the important ingredient. If we instead take the view that this is a large ensemble of complex learners whose likelihood is being jointly optimized, we would expect that employing a criterion more sim- ilar to boosting than bagging would perform more poorly . As boosting maximizes the likelihood of the ensemble, it would perhaps be prone to overfitting in this setting, as the ensemble is very large and the learners are not particularly weak. 0.012 0.014 0.016 0.018 0.020 0.022 SGD test error 0.2 0.0 0.2 0.4 0.6 0.8 Relative improvement in test error Relative improvement: dropout (MNIST) 0.012 0.014 0.016 0.018 0.020 0.022 SGD test error 0.2 0.0 0.2 0.4 0.6 0.8 Relative improvement in test error Relative improvement: dropout boosting (MNIST) Figure 4: Comparison of dropout (left) and dropout boosting (right) to stochastic gradient descent with matched hyperparameters. Starting with the 50 models trained in Section 6, we employed the same hyperparameters to train a matched set of 50 networks with dropout boosting, and another with plain stochastic gradient de- scent. In Figure 4, we plot the relativ e performance of dropout and dropout boosting compared to a model with the same hyperparameters trained with SGD. While dropout unsurprisingly shows a very consistent edge, dropout boosting performs, on av erage, little better than stochastic gradient descent. The Wilcoxon signed-rank test similarly failed to find a significant difference between dropout boosting and SGD ( p > 0 . 7 ). While sev eral outliers approach very good performance (per - haps owing to the added stochasticity), dropout boosting is, on average, no better and often slightly worse than maximum likelihood training, in stark contrast with dropout’ s systematic advantage in generalization performance. 8 Conclusion W e in vestigated se veral questions related to the efficacy of dropout, focusing on the specific case of the popular rectified linear nonlinearity for hidden units. W e sho wed that the weight-scaling approximation is a remarkably accurate proxy for the usually intractable geometric mean over all possible sub-networks, and that the geometric mean (and thus its weight-scaled surrogate) com- pares fa vourably to the traditionally popular arithmetic mean in terms of classification performance. W e demonstrated that weight-sharing between members of the implicit dropout ensemble appears to have a significant regularization ef fect, by comparing to analogously trained ensembles of the same form that did not share parameters. Finally , we demonstrated that simply adding noise, ev en noise with identical characteristics to the noise applied during dropout training, is not sufficient to obtain the benefits of dropout, by introducing dropout boosting, a training procedure utilising the same masking noise as conv entional dropout, which successfully trains networks but loses dropout’ s benefits, instead performing roughly as well as ordinary stochastic gradient descent. Our results suggest that dropout is an extremely effecti ve ensemble learning method, paired with a clever approximate inference scheme that is remarkably accurate in the case of rectified linear networks. Further research is necessary to shed more light on the model av eraging interpretation of dropout. Hinton et al. (2012) noted that dropout forces each hidden unit to perform computation that is useful in a wide variety of contexts. Our results with a sizeable ensemble of independent bagged models seem to lend support to this view , though our experiments were limited to ensembles of sev eral hundred networks at most, tiny in comparison with the weight-sharing ensemble in voked by dropout. The relativ e importance of the astronomically large ensemble versus the learned “mixabil- ity” of hidden units remains an open question. Another interesting direction inv olves methods that are able to efficiently , approximately average over different classes of model that share parameters in some manner , rather than merely averaging ov er members of the same model class. 8 Acknowledgments The authors would like to acknowledge the ef forts of the many developers of Theano (Bergstra et al. , 2010; Bastien et al. , 2012), pylearn2 (Goodfello w et al. , 2013b) which were utilised in experiments. W e would also lik e to thank NSERC, Compute Canada, and Calcul Qu ´ ebec for providing computa- tional resources. Ian Goodfellow is supported by the 2013 Google Fello wship in Deep Learning. References Baldi, P . and Sadowski, P . J. (2013). Understanding dropout. In Advances in Neural Information Processing Systems 26 , pages 2814–2822. Bastien, F ., Lamblin, P ., Pascanu, R., Bergstra, J., Goodfello w , I. J., Ber geron, A., Bouchard, N., and Bengio, Y . (2012). Theano: new features and speed impro vements. Deep Learning and Unsupervised Feature Learning NIPS 2012 W orkshop. Bergstra, J. and Bengio, Y . (2012). Random search for hyper-parameter optimization. J. Machine Learning Res. , 13 , 281–305. Bergstra, J., Breuleux, O., Bastien, F ., Lamblin, P ., Pascanu, R., Desjardins, G., Turian, J., W arde-Farle y , D., and Bengio, Y . (2010). Theano: a CPU and GPU math expression compiler . In Pr oceedings of the Python for Scientific Computing Confer ence (SciPy) . Oral Presentation. Bishop, C. M. (1995). T raining with noise is equiv alent to T ikhonov regularization. Neural Computation , 7 (1), 108–116. Breiman, L. (1994). Bagging predictors. Machine Learning , 24 (2), 123–140. Cartwright, D. I. and Field, M. J. (1978). A refinement of the arithmetic mean-geometric mean inequality . Pr oceedings of the American Mathematical Society , 71 (1), pp. 36–38. Glorot, X., Bordes, A., and Bengio, Y . (2011). Deep sparse rectifier neural networks. In JMLR W&CP: Pr oceedings of the F ourteenth International Conference on Artificial Intelligence and Statistics (AIST A TS 2011) . Goodfellow , I. J., W arde-Farley , D., Mirza, M., Courville, A., and Bengio, Y . (2013a). Maxout networks. In ICML ’2013 . Goodfellow , I. J., W arde-Farley , D., Lamblin, P ., Dumoulin, V ., Mirza, M., Pascanu, R., Bergstra, J., Bastien, F ., and Bengio, Y . (2013b). Pylearn2: a machine learning research library . arXiv pr eprint arXiv:1308.4214 . Hinton, G. E., Srivasta v a, N., Krizhevsk y , A., Sutske ver , I., and Salakhutdinv , R. (2012). Improving neural networks by pre venting co-adaptation of feature detectors. T echnical report, Jarrett, K., Kavukcuoglu, K., Ranzato, M., and LeCun, Y . (2009). What is the best multi-stage architecture for object recognition? In Pr oc. International Confer ence on Computer V ision (ICCV’09) , pages 2146–2153. IEEE. Krizhevsk y , A., Sutskev er , I., and Hinton, G. (2012a). ImageNet classification with deep con volutional neural networks. In Advances in Neural Information Pr ocessing Systems 25 (NIPS’2012) . Krizhevsk y , A., Sutskev er , I., and Hinton, G. (2012b). ImageNet classification with deep conv olutional neural networks. In NIPS’2012 . LeCun, Y ., Bottou, L., Bengio, Y ., and Haf fner , P . (1998). Gradient-based learning applied to document recog- nition. Proceedings of the IEEE , 86 (11), 2278–2324. Opitz, D. and Maclin, R. (1999). Popular ensemble methods: An empirical study . Journal of Artificial Intelli- gence Resear ch , 11 , 169–198. Rifai, S., Dauphin, Y ., V incent, P ., Bengio, Y ., and Muller , X. (2011). The manifold tangent classifier . In NIPS’2011 . Student paper award. Schapire, R. E. (1990). The strength of weak learnability . Machine Learning , 5 (2), 197–227. Sriv astava, N. (2013). Impro ving Neural Networks W ith Dr opout . Master’ s thesis, U. T oronto. V incent, P ., Larochelle, H., Lajoie, I., Bengio, Y ., and Manzagol, P .-A. (2010). Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. Journal of Machine Learning Resear ch , 11 , 3371–3408. W ager , S., W ang, S., and Liang, P . (2013). Dropout training as adaptive re gularization. In Advances in Neural Information Pr ocessing Systems 26 , pages 351–359. W an, L., Zeiler, M., Zhang, S., LeCun, Y ., and Fergus, R. (2013). Regularization of neural networks using dropconnect. In ICML’2013 . W ang, S. and Manning, C. (2013). Fast dropout training. In ICML’2013 . 9 Zeiler , M. D. and Fergus, R. (2013). Stochastic pooling for regularization of deep con volutional neural net- works. T echnical Report Arxiv 1301.3557. Zeiler , M. D., Ranzato, M., Monga, R., Mao, M., Y ang, K., Le, Q., Nguyen, P ., Senior , A., V anhoucke, V ., Dean, J., and Hinton, G. E. (2013). On rectified linear units for speech processing. In ICASSP 2013 . 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment