Generalized Ambiguity Decomposition for Understanding Ensemble Diversity
Diversity or complementarity of experts in ensemble pattern recognition and information processing systems is widely-observed by researchers to be crucial for achieving performance improvement upon fusion. Understanding this link between ensemble div…
Authors: Kartik Audhkhasi, Abhinav Sethy, Bhuvana Ramabhadran
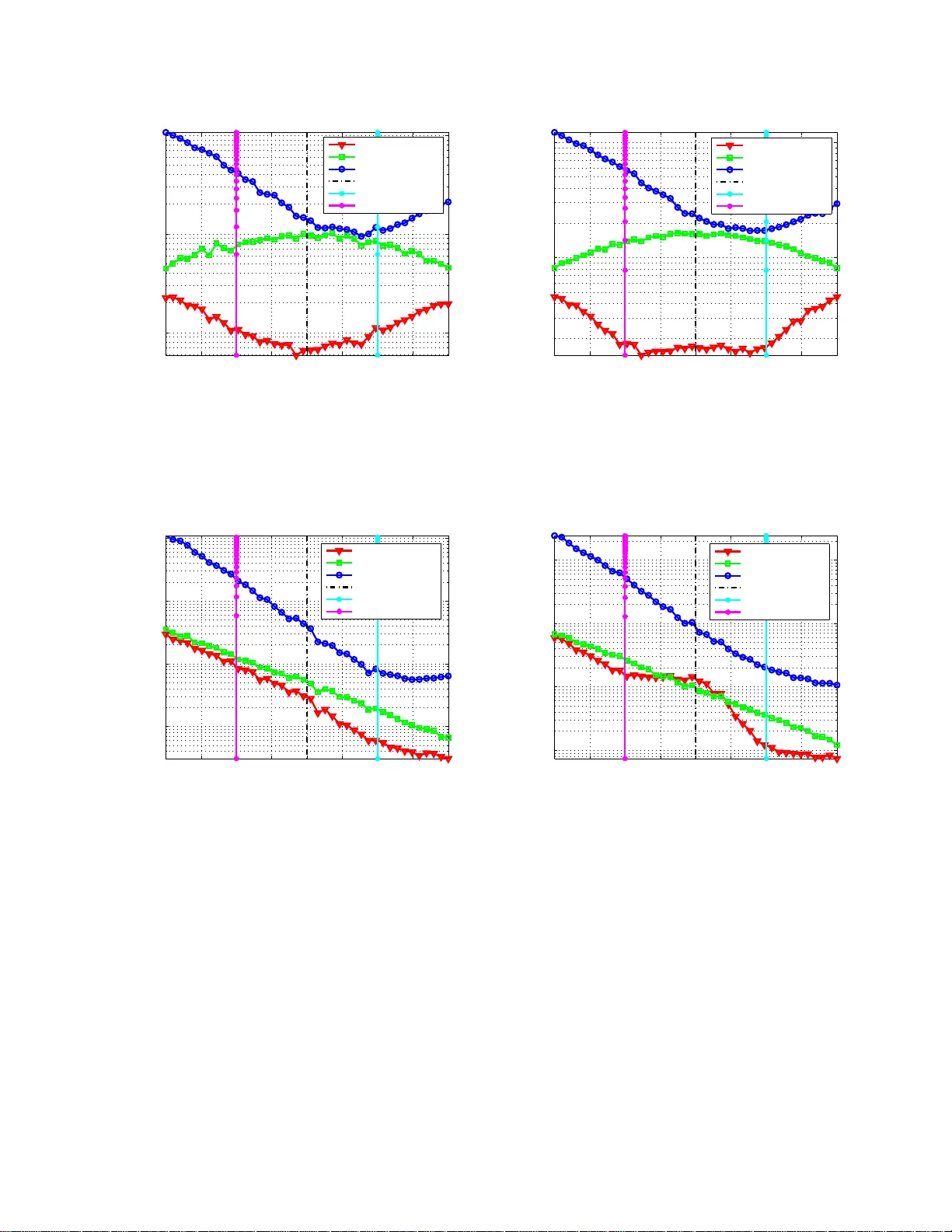
1 Generaliz ed Ambiguity Decomposition for Understanding Ensemble Di v ersity Kartik Audhkhasi 1 , Abhina v Sethy 2 , Bhuv ana Ramabhadran 2 , Shrikanth S. Narayanan 1 1 Signal Analysis and Interpretation Lab (SAIL) Electrical Engineer ing De partment Uni versity of S outhern California, Los Angeles, USA Email: audhkhas@usc.edu, shri@sipi.usc.edu 2 IBM T . J. W atson Re search Ce nter Y orkto wn Heights, New Y ork, USA Email: { asethy , bhuv ana } @us.ibm.com August 24, 2018 DRAFT 2 Abstract Div ersity or com plementar ity of experts in ensem ble p attern recognitio n and informatio n processing systems is widely-o bserved by research ers to b e crucial for achieving per forman ce improvement upo n fusion. Un derstanding this link between ensemble diversity and fusion perform ance is thus an important research question. Howe ver , p rior works have theoretically characte rized ensemb le diversity and have linked it with ensem ble perfor mance in very restricted settings. W e present a gen eralized ambiguity decomp osition ( GAD) the orem as a bro ad framework for answering these qu estions. Th e GAD theorem applies to a generic conve x ensemble of experts for any arbitrary twice-d ifferentiable loss functio n. It shows that the e nsemble p erforma nce app roximately decompo ses into a difference of the average expert perform ance and the div ersity of the e nsemble. It thus pr ovides a theoretica l explanation for the empirically- observed ben efit of fusing o utputs fro m diverse classifiers and regressors. It a lso provid es a loss function -depend ent, ensemble-depen dent, and data-depen dent definition of diversity . W e present extensions of this d ecompo sition to commo n regression and classification loss functio ns, and rep ort a simulation-b ased analysis of the diversity term and the accuracy of the dec omposition . W e finally present experiments o n standard pattern recog nition data sets which indicate the accuracy of the decomposition for real-world classification and r egression prob lems. Index T erms: Multiple Ex perts, Multiple Classifier Systems, En semble M ethods, Div ersity , System Combination , Loss Function, Statistical Learning Theory . I . I N T R O D U C T I O N Researchers across severa l fields have empirically observed that an ensemble of multiple experts (classifiers or regressors) p erforms better th an a singl e expert. W ell-known examples demonstrating this p erformance b enefit s pan a l ar ge va riety of appl ications such as • Automatic speech and language pr ocessi ng : M ost t eams in large-scale projects i n volving automatic speech recognitio n and processing such as the D ARP A GALE [1], CALO [2], RA TS [3] and the IARP A B ABEL [4] programs use a combination o f m ultiple systems for achie ving state-of-the-art performance. Th e use of multiple s ystems is also widespread i n text and natural language processing app lications, wi th examples ranging from parsing [5] to t ext categorization [6]. • R ecommendation systems : Many industri al and academic t eams competing for the N etflix prize [7] used ensembles of di verse systems for the mo vie rating prediction task. The $1 Mil- lion grand prize wi nning system from the team B ellK or’ s Pragmatic Chaos was com posed August 24, 2018 DRAFT 3 of mult iple systems from three independ ent teams ( Bell K or [ 8], Pragmatic Theory [9], and BigChaos [10] ). • W eb information retrie val : Researchers have also used ensembles of div erse system s for information retriev al tasks from the web . For instance, the winning teams [11], [12] in the Y ahoo! Learning t o Rank Challenge [13] used ensem ble methods (such as bagging, boosting, random forests, and lambda-gradient mod els) for improving document ranking performance. The challenge overvie w article [13] also emphasizes the performance b enefits obtained by all teams when using ensem ble methods. • Compu ter vision : Ens emble methods are o ften popular in computer visio n tasks as well, such as tracking [14], object detection [15], and pose estimat ion [16]. • H uman state pattern r ecognition : Systems for multimod al physical acti vity detection [17] often fuse classifiers trained on diffe rent feature sets for achie ving an i mprovement in accu- racy . Sever al teams competin g in the Interspeech challenges have also used ensembles for classification of hu man emotion [18], age and gender [19], intoxication and sleepin ess [20], personality , likabi lity , and pathology [21], and social signals [22]. The above list i s only a small fraction of the large number o f applications which ha ve used ensembles of mul tiple systems. Dietterich [23] offers three main reasons for the observed benefits of an ensemble. First , an ensemble can potentially hav e a lowe r generalization error than a single expert. Second, the parameter estimat ion inv olved in training most s tate of the art exper t systems such as neural networks in volves solvi ng a non-con ve x optimization problem. A single expert can get stuck in local optim a whereas an ensemble of multiple experts can provide parameter estimates closer to th e gl obal opt ima. Finally , the true underlying function for a probl em at hand may b e too comp lex for a single expert and an ensemble may b e better abl e to approxim ate it . Intuition and docum ented research such as the o nes lis ted abov e s uggests that t he experts in the ensemble shou ld be opt imally dive rse. Diversity acts as a hedge agains t uncertainty in the ev aluation d ata set, and the mismatch b etween the l oss functions u sed for training and e valuation. Kunchev a [24] giv es a s imple intui tiv e argument in fav o r of having the right am ount of div ersity i n an ensemble. She says that just one expert su f fices if all experts produce identi cal output, howe ver , if the experts disagree in their outputs very frequently , it indicates that they are individually poor estimato rs of the target v ariable. Ambiguity d ecomposition [25] (AD) explains this tradeoff for the special case of t he s quared error loss function. Let X ∈ X ⊆ R D and August 24, 2018 DRAFT 4 Y ∈ Y ⊆ R denot e th e D -dimensional input and 1 -dimensional target (out put) random variables respectiv ely . Let f k : X → R b e the k th expert which m aps the inp ut space X to the real l ine R . f is a con vex combinat ion of K experts when f ( X ) = K X k =1 w k f k ( X ) where w k ≥ 0 and K X k =1 w k = 1 . (1) AD states t hat th e squared error between the abov e f ( X ) and Y is [ Y − f ( X )] 2 = K X k =1 w k [ Y − f k ( X )] 2 − K X k =1 w k [ f k ( X ) − f ( X )] 2 . (2) The first term on the righ t hand side is the weight ed squared error of the individual experts with respect to Y . The second term qu antifies th e di versity o f the ensemble and i s t he squared error spread of the experts around f ( X ) . For two ensembles with identi cal weighted squared error , one with a greater diversity will have a lo wer overa ll squared error . Th e bias-variance-co va riance decompositio n is an equiv alent result by U eda and Nakano [26] wi th neural network ens embles as t he focus. W e note that an ensemble o f neural networks often consists of almost equally- accurate but d iv erse networks due to t he non -con vex training opti mization problem. AD is also related to the b ias-var iance decomposition (BVD) [27] which says t hat the expected squared error b etween a regressor f D ( X ) trained on dataset D and the target variable Y is E D { [ f D ( X ) − Y ] 2 } = [ Y − E D { f D ( X ) } ] 2 + E D { [ f D ( X ) − E D { f D ( X ) } ] 2 } . (3) The first term on the right hand sid e is the sq uare of the bias, which i s the di f ference between the tar get Y and the expected prediction ov er the dist ribution of D . The second term m easures the var iance of the ensemb le. BVD reduces to A D w hen experts hav e t he same function al form (e.g., linear) and when the training set D is drawn from a con vex mix ture of training sets {D k } K k =1 with mixture w eights { w k } K k =1 . Many existing algorithm s attemp t to promo te diversity while training an ensem ble. Examples include ensembles of decisio n trees [28], support vector machines [29], conditio nal maximum entropy m odels [ 30], ne gative correlation lea rning [31] for neural net works and DECORA TE [32], which is a meta-algorithm based on generation of synthetic data. AdaBoost [33] is another prom i- nent algorithm which incrementally creates a d iv erse ensemble of weak experts by modifying the distri bution from which traini ng instances are sam pled. Howe ver , only few studies ha ve focused on understanding the imp act of d iv ersity o n ensemble p erformance for both classifiers August 24, 2018 DRAFT 5 and regressors. AD provides this link only for l east squares re gression. The analysis presented by Tumer and Ghosh [34 ] assumes class ification as regression ov er class posterior distribution. This paper presents a generalized ambiguity decomposi tion (GAD) t heorem that is applicable to both classification and regression. It does not assu me that the classifier is estimat ing a posterior distribution over the label s et Y in case of class ification. This is often encountered in practice, for example in case of supp ort vector machines. W e note that som e pri or work has been done for deriving a BVD for a singl e expert wi th dif ferent loss functions [35]–[37]. The proposed GAD theorem is differ ent. It focuses on a con vex combin ation of experts rather than a single expert. Even thou gh one can link the BVD to AD b y considering a mixture of trainin g sets as m entioned before, this l ink requires that the individual experts should hav e the same functional form. W e do not make such assumption s. Our result applies pointwis e for any given ( X , Y ) ∈ X × Y rather than relying on an ensemble a verage. W e present the GAD theorem and its proof in the next section. W e deriv e the decom position for some common regression and classification loss functions in Section III. W e present a simulatio n- based analysis in Section IV. W e t hen ev aluate the presented decomposition on m ultiple stand ard classification and regression data sets in Section V. Section VI presents the conclusion and some directions for fut ure work. I I . G E N E R A L I Z E D A M B I G U I T Y D E C O M P O S I T I O N ( G A D ) T H E O R E M The concept of a loss function is central t o statistical learning t heory [38]. It com putes the mismatch between the prediction o f an expert and the true tar get value. Lemma 1 below presents useful bounds on a class of loss functions whi ch are used wid ely in s upervised machine learning. Lemma 1. (T aylor’ s Theorem f or Loss Functions [39]) Let x, Y ∈ R and B ⊆ R be a clo sed and bou nded set containi ng x . Let l : R × R → R be a loss function which is t wice-differ enti able in i ts second a r gument with continuous second deri vative over B . Let M l, B ( Y ) = sup z ∈B l ′′ ( Y , z ) < ∞ and (4) m l, B ( Y ) = inf z ∈B l ′′ ( Y , z ) > −∞ . (5) August 24, 2018 DRAFT 6 Then for any Y 0 ∈ B , we can write t he following qua dratic bounds on the l oss functi on: l ( Y , Y 0 ) ≥ l ( Y , x ) + l ′ ( Y , x )( Y 0 − x ) + m l, B ( Y ) 2 ( Y 0 − x ) 2 and (6) l ( Y , Y 0 ) ≤ l ( Y , x ) + l ′ ( Y , x )( Y 0 − x ) + M l, B ( Y ) 2 ( Y 0 − x ) 2 . (7) Pr oof : Since l ( Y , Y 0 ) is twice-dif ferentiable in its second argument over R × B , by T ayl or’ s theorem [39 ], ∃ a function h 2 : R × B → R such that l ( Y , Y 0 ) = l ( Y , x ) + l ′ ( Y , x )( Y 0 − x ) + h 2 ( Y , Y 0 )( Y 0 − x ) 2 where lim Y 0 → x h 2 ( Y , Y 0 ) = 0 (8) for any giv en x ∈ B . h 2 ( Y , Y 0 )( Y 0 − x ) 2 is called remainder or residu e and has the following form due to th e Mean V alue T heorem [39]: h 2 ( Y , Y 0 )( Y 0 − x ) 2 = l ′′ ( Y , z ) 2 ( Y 0 − x ) 2 where z ∈ ( Y 0 , x ) . (9) The s econd deriv ativ e of the loss functi on is continuous over the clo sed and bounded set B . W eierstrass’ Extreme V alue Theorem [39] giv es: m l, B ( Y ) ≤ l ′′ ( Y , z ) ≤ M l, B ( Y ) ∀ z ∈ B (10) where m l, B ( Y ) = inf z ∈B l ′′ ( Y , z ) > −∞ (11) and M l, B ( Y ) = sup z ∈B l ′′ ( Y , z ) < ∞ . (12) W e note that m l, B ( Y ) = 0 is an obviou s choice if l i s con vex. Using t he bo unds in (10) in T aylor’ s theorem from (8) resul ts in the desired inequalities: l ( Y , Y 0 ) ≥ l ( Y , x ) + l ′ ( Y , x )( Y 0 − x ) + m l, B ( Y ) 2 ( Y 0 − x ) 2 (13) l ( Y , Y 0 ) ≤ l ( Y , x ) + l ′ ( Y , x )( Y 0 − x ) + M l, B ( Y ) 2 ( Y 0 − x ) 2 . (14) The second ar gument of l is alw ays bounded i n practice since it represents the prediction of the expert. Hence, l imiting the domain of twi ce-dif ferentiability and conti nuity of the second deriv ative from R × R to R × B is a reasonable assumption. The next lemma presents ambi guity decompositio n for the squared error los s functi on [25 ]. W e denote f ( X ) as f and f k ( X ) as f k from now on for notational simplicity . August 24, 2018 DRAFT 7 Lemma 2 . (Ambiguity Decomposition (AD) [25]) Consider an ensemble of K experts { f k : X → R , k = 1 , 2 , . . . , K } and let f = P K k =1 w k f k be a con vex combinat ion of these e xperts. Then [ Y − f ] 2 = K X k =1 w k [ Y − f k ] 2 − K X k =1 w k [ f k − f ] 2 ∀ ( X, Y ) ∈ X × R . (15) Pr oof : W e start b y expanding the following term: K X k =1 w k [ Y − f k ] 2 = K X k =1 w k [ Y − f − ( f k − f ) ] 2 (16) = K X k =1 w k [ Y − f ] 2 + K X k =1 w k [ f k − f ] 2 − 2 K X k =1 w k [ Y − f ][ f k − f ] (17) = [ Y − f ] 2 + K X k =1 w k [ f k − f ] 2 − 2[ Y − f ] K X k =1 w k [ f k − f ] (18) = [ Y − f ] 2 + K X k =1 w k [ f k − f ] 2 − 2[ Y − f ][ K X k =1 w k f k − f ] (19) = [ Y − f ] 2 + K X k =1 w k [ f k − f ] 2 . (20) W e arriv e at the Ambig uity Decompositi on by re-arranging terms in the above equation. [ Y − f ] 2 = K X k =1 w k [ Y − f k ] 2 − K X k =1 w k [ f k − f ] 2 . (21) Ambiguity decompositi on describes the tradeoff between t he accuracy of in dividual experts and the dive rsity of t he ensemble. But it applies o nly to the squared error loss function. W e now state and prove th e Generalized Ambiguity Decomp osition (GAD) theorem using Lemmas 1 and 2. Theor em 1 . (Generalized Ambiguity Decomposition (GAD) Theore m) Consider an ensemble of K experts { f k : X → R , k = 1 , 2 , . . . , K } and let f = P K k =1 w k f k be a con vex combination of these e xpert s. Assume that all f k ar e fi nite. Let ( X, Y ) ∈ X × R and August 24, 2018 DRAFT 8 let B ⊆ R be the following closed and boun ded set: B = [ b min , b max ] wher e (22) b min = min { Y , f 1 , . . . , f K } and (23) b max = max { Y , f 1 , . . . , f K } . (24) B is the s mallest closed an d bound ed set which cont ains Y and all f k . Let l : R × R → R be a loss function which is twice-dif fer enti able in its second ar gument with continuous second derivative ove r B . Let: M l, B ( Y ) = sup z ∈B l ′′ ( Y , z ) < ∞ , (25) M l, B ( f ) = sup z ∈B l ′′ ( f , z ) ∈ (0 , ∞ ) , and (26) m l, B ( Y ) = inf z ∈B l ′′ ( Y , z ) > −∞ . (27) Then the ensemble loss is upper-bounded as given below: l ( Y , f ) ≤ K X k =1 w k l ( Y , f k ) − M l, B ( Y ) M l, B ( f ) h K X k =1 w k l ( f , f k ) − l ( f , f ) i + 1 2 M l, B ( Y ) − m l, B ( Y ) K X k =1 w k ( Y − f k ) 2 . (28) Pr oof : B is a closed and bounded s et wh ich i ncludes Y and all f k by definition. Hence w e can write the following lower -bound for l ( Y , f k ) using Lemma 1: l ( Y , f k ) ≥ l ( Y , Y ) + l ′ ( Y , Y )( f k − Y ) + m l, B ( Y ) 2 ( f k − Y ) 2 . (29) T aking a con vex sum on both s ides o f the abov e inequali ty gives K X k =1 w k l ( Y , f k ) ≥ K X k =1 w k l ( Y , Y ) + K X k =1 w k l ′ ( Y , Y )( f k − Y ) + K X k =1 w k m l, B ( Y ) 2 ( f k − Y ) 2 = l ( Y , Y ) + l ′ ( Y , Y )( f − Y ) + m l, B ( Y ) 2 K X k =1 w k ( f k − Y ) 2 . (30) B also includ es f because i t inclu des all f k and f is their con vex combination. Thus, we consi der the following upper-bound on l ( Y , f ) usi ng Lem ma 1: l ( Y , f ) ≤ l ( Y , Y ) + l ′ ( Y , Y )( f − Y ) + M l, B ( Y ) 2 ( f − Y ) 2 (31) ⇐ ⇒ l ( Y , Y ) + l ′ ( Y , Y )( f − Y ) ≥ l ( Y , f ) − M l, B ( Y ) 2 ( f − Y ) 2 . (32) August 24, 2018 DRAFT 9 Substitutin g this inequality in (30) gives K X k =1 w k l ( Y , f k ) ≥ l ( Y , f ) − M l, B ( Y ) 2 ( f − Y ) 2 + m l, B ( Y ) 2 K X k =1 w k ( f k − Y ) 2 . (33) W e use AD in Lemma 2 for ( f − Y ) 2 and write the above bound as: K X k =1 w k l ( Y , f k ) ≥ l ( Y , f ) − 1 2 ( M l, B ( Y ) − m l, B ( Y )) K X k =1 w k ( f k − Y ) 2 + M l, B ( Y ) 2 K X k =1 w k ( f k − f ) 2 . (34) W e finally in v oke the following upper bound on l ( f , f k ) using Lemma 1: l ( f , f k ) ≤ l ( f , f ) + l ′ ( f , f )( f − f k ) + M l, B ( f ) 2 ( f − f k ) 2 (35) ⇐ ⇒ M l, B ( f ) 2 ( f − f k ) 2 ≥ l ( f , f k ) − l ( f , f ) − l ′ ( f , f )( f − f k ) (36) ⇐ ⇒ M l, B ( f ) 2 K X k =1 w k ( f − f k ) 2 ≥ K X k =1 w k l ( f , f k ) − l ( f , f ) . (37) W e get the desi red result by substitut ing t he above inequali ty in (34) and using the fac t that M l ( f ) > 0 : K X k =1 w k l ( Y , f k ) ≥ l ( Y , f ) − 1 2 ( M l, B ( Y ) − m l, B ( Y )) K X k =1 w k ( f k − Y ) 2 + M l, B ( Y ) M l, B ( f ) h K X k =1 w k l ( f , f k ) − l ( f , f ) i (38) ⇐ ⇒ l ( Y , f ) ≤ K X k =1 w k l ( Y , f k ) − M l, B ( Y ) M l, B ( f ) h K X k =1 w k l ( f , f k ) − l ( f , f ) i + 1 2 ( M l, B ( Y ) − m l, B ( Y )) K X k =1 w k ( Y − f k ) 2 . (39) The GAD Theorem is a natural extension of AD in Lemma 2 and reduces to it for the case of squared error loss. W e can gain more intuition about thi s result by defining the fol lowing August 24, 2018 DRAFT 10 quantities: Ensemble loss: l ( Y , f ) (40) W eight ed expert loss: K X k =1 w k l ( Y , f k ) (41) Div ersity: d l ( f 1 , . . . , f K ) = M l, B ( Y ) M l, B ( f ) " K X k =1 w k l ( f , f k ) − l ( f , f ) # (42) Curv ature spread (CS): s l, B ( Y ) = M l, B ( Y ) − m l, B ( Y ) ≥ 0 (43) Ignoring the term in volving curvature sp read, GAD says that the ensemble l oss is upper-bounded by weighted expert loss minus the diversity of the ensemble. Thu s, t he upper -bound in volves a tradeof f between the performance of i ndividual experts (weighted experts lo ss) and the diversity . Div ersity measures t he s pread of the expert p redictions about the ensemble’ s predictio ns and is 0 when f k = f , ∀ k . Diversity is non-negati ve for a con vex loss function due to Jensen’ s inequality [39]. Furthermore, di versity depends on the loss function, the t rue tar get Y and the prediction of the ens emble f at the current data point. Thus, all data points are not equally important from a diver sity p erspectiv e. It is also int eresting to note th at th e GAD theorem provides a decompos ition of the ensemble loss into a su pervised (weighted expert loss) and unsupervised (diversity) term. The l atter term does not require labeled data to compu te. This makes the overall framew ork appl icable to semi -supervised setti ngs. The following corollary of Theorem 1 gives a s imple upper-bound on the error between l ( Y , f ) and its approximation mo tiv ated by the GAD theorem. Corollary 1. (Err or Bound for GAD Loss Function Appr oximatio n) If K X k =1 w k ( Y − f k ) 2 = β ( X , Y ) and (44) max k ∈{ 1 ,...,K } ( Y − f k ) 2 = δ ( X, Y ) , (45) then t he err or between t he true lo ss a nd i ts GA D appr oximat ion is bounded as : l ( Y , f ) − l GAD ( Y , f ) ≤ 1 2 s l, B ( Y , f ) β ( X , Y ) (46) ≤ 1 2 s l, B ( Y , f ) δ ( X, Y ) , (47) August 24, 2018 DRAFT 11 wher e s l, B ( Y , f ) is the curvature spr ead defined pr eviously and l GAD ( Y , f ) = K X k =1 w k l ( Y , f k ) − d l ( f 1 , . . . , f K ) (48) is an a ppr oxim ation for l ( Y , f ) mo tivated by GAD. Pr oof : Theorem 1 giv es: l ( Y , f ) − l GAD ( Y , f ) ≤ 1 2 ( M l, B ( Y ) − m l, B ( Y )) K X k =1 w k ( Y − f k ) 2 = 1 2 ( M l, B ( Y ) − m l, B ( Y )) β ( X , Y ) . (49) W e also note that: K X k =1 w k ( Y − f k ) 2 ≤ max k ∈{ 1 ,...,K } ( Y − f k ) 2 = δ ( X, Y ) . (50) Hence we can also write the following l ess t ight upper b ound on the error: l ( Y , f ) − l GAD ( Y , f ) ≤ 1 2 ( M l, B ( Y ) − m l, B ( Y )) δ ( X, Y ) . (51) Corollary 1 shows that l GAD ( Y , f ) is a good approximation for l ( Y , f ) wh en t he curvature spread is small and all expert predictions are close to the t rue tar get Y . For instances ( X , Y ) where mul tiple experts in the ensemble are far away from t he true tar get, l GAD ( Y , f ) has a high error . T o summarize, the accuracy of l GAD depends on th e data ins tance, los s functi on and the expert predictions. W e note that t he div ersity term in the GAD t heorem computes the loss function between each expert f k and the ensemble prediction f . Ho we ver , it i s som etimes useful to understand div ersity in terms of pairwise lo ss functions between t he expert p redictions t hemselves. The next corollary to the GAD theorem shows that we can indeed re-write the div ersity term in pairwise f ashion for a m etric loss function. Corollary 2 . (Pairwise GAD Theorem for Metric Loss Functions) Consi der a metri c l oss August 24, 2018 DRAFT 12 function l and also let w k = 1 /K ∀ k f or s implicity . Then the GAD theor em becomes l ( Y , f ) ≤ 1 K K X k =1 l ( Y , f k ) − M l, B ( Y ) M l, B ( f ) " 1 K ( K − 1 ) K X k 1 =1 K X k 2 = k 1 +1 l ( f k 1 , f k 2 ) # + 1 2 M l, B ( Y ) − m l, B ( Y ) K X k =1 ( Y − f k ) 2 . (52) Pr oof : The l oss function satisfies t he triangl e inequali ty because it is given to be a metric. W e visualize the output of each expert and the ensemble’ s prediction as poi nts in a m etric space induced by t he m etric loss fun ction. Hence l ( f k 1 , f k 2 ) ≤ l ( f , f k 1 ) + l ( f , f k 2 ) (53) for all k 1 ∈ { 1 , . . . , K } and k 2 ∈ { k 1 + 1 , . . . , K } . W e add these K ( K − 1 ) in equalities to get K X k 1 =1 K X k 2 = k 1 +1 l ( f k 1 , f k 2 ) ≤ ( K − 1) K X k =1 l ( f , f k ) . (54) W e also note that l ( f , f ) = 0 because l is a metric. Hence we g et the following lo wer bound on the div ersity term in GAD M l, B ( Y ) M l, B ( f ) " 1 K K X k =1 l ( f , f k ) − l ( f , f ) # ≥ M l, B ( Y ) M l, B ( f ) " 1 K ( K − 1 ) K X k 1 =1 K X k 2 = k 1 +1 l ( f k 1 , f k 2 ) # (55) Substitutin g this lower -boun d in GAD from Theorem 1 gives the desired decompositi on with pairwise d iv ersity . The squ ared error and absolut e error loss functions u sed for regression are metri c function s and thus permit a decomposition with a pairwise div ersity term as given in Corollary 2 abov e. W e now deriv e the qu antities required for GAD approximation of common loss functions in t he next section. I I I . G A D F O R C O M M O N L O S S F U N C T I O N S W e note that the com putation of M l, B ( Y ) and m l, B ( Y ) i s critical to t he GAD theorem. Hence the following subsections focus on deriving these qu antities for various com mon classification and regression loss functions. August 24, 2018 DRAFT 13 A. Squa r ed Err or Loss Squared error i s the most comm on loss functio n used for regression and is defined as g iv en below: l sqr ( Y , Y 0 ) = ( Y − Y 0 ) 2 where Y , Y 0 ∈ R . (56) Its second deri va tive with respect to Y 0 is l ′′ sqr ( Y , Y 0 ) = 2 . Hence M l, B ( Y ) = m l, B ( Y ) = 2 ∀ Y and CS is 0 . Thus GAD reduces to AD in Lemma 2. B. Abso lute Err or Loss Absolute error lo ss fun ction is more robust than squared error for ou tliers and is defined as: l abs ( Y , Y 0 ) = | Y − Y 0 | where Y , Y 0 ∈ R . (57) This function is not dif ferentiable at Y 0 = Y . W e thus consider two com monly used smooth approximations to the absolute error loss functi on. The first one us es the integral of the in verse tangent function which approximates the sign function. This l eads to the following approxima- tion: l abs, approx1 ( Y , Y 0 ) = 2( Y − Y 0 ) π tan − 1 Y − Y 0 ǫ ! where Y , Y 0 ∈ R and ǫ > 0 . (58) One can g et an arbitarily close approximation b y setting a suitably small positive value o f ǫ . The second deriv ativ e of the l oss function wi th respect to Y 0 is l ′′ abs, approx1 ( Y , Y 0 ) = 4 ǫπ h 1 + Y − Y 0 ǫ 2 i 2 . (59) W e need to com pute the maximum and m inimum of th e above second deri vati ve for Y 0 ∈ B . The above function i s monoton ically increasing for Y 0 < Y , achieves its maxim a at Y 0 = Y , and monoton ically decreases for Y 0 ≥ Y . W e note that Y ∈ B by definition of B . Hence, the maximum of l ′′ abs, approx1 ( Y , Y 0 ) ove r B occurs at Y 0 = Y and is given by: M l, B ( Y ) = l ′′ abs, approx1 ( Y , Y ) = 4 π ǫ . (60) The minimum value depends on the location of B = [ b min , b max ] and is given b elow: m l, B ( Y ) = l ′′ abs, approx1 ( Y , b min ) ; if b max + b min < 2 Y l ′′ abs, approx1 ( Y , b max ) ; otherwise . (61) August 24, 2018 DRAFT 14 W e also consider a second s mooth approx imation of absol ute error: l abs, approx2 ( Y , Y 0 ) = p ( Y − Y 0 ) 2 + ǫ − √ ǫ where Y , Y 0 ∈ R and ǫ > 0 . (62) This approxim ation becomes better with smaller positive values of ǫ . The second deriv ative of the above approximati on with respect to Y 0 is l ′′ abs, approx2 ( Y , Y 0 ) = ǫ [( Y − Y 0 ) 2 + ǫ ] 3 / 2 . (63) The behavior o f the above function with Y 0 is the s ame as l ′′ abs, approx1 ( Y , Y 0 ) . It has a monoton ic increase for Y 0 < Y , achiev es m axima at Y 0 = Y , and has a m onotonic decrea se for Y 0 ≥ Y . This results i n th e following second deriv ative maxima and min ima over B : M l, B ( Y ) = l ′′ abs,approx2 ( Y , Y ) = 1 √ ǫ . (64) m l, B ( Y ) = l ′′ abs, approx2 ( Y , b min ) ; if b max + b min < 2 Y l ′′ abs, approx2 ( Y , b max ) ; otherwise . (65) Both typ es of smooth absolu te error l oss fun ctions give a non-zero curvature spread wh en compared to the squared error loss function. This leads to a non -zero approx imation error for the GAD theorem . C. Logistic Loss Logistic regression i s a popular technique for classification. W e consider the binary classifi- cation case where the label set Y = { -1,1 } . The logistic loss function is l log ( Y , Y 0 ) = log (1 + exp( − Y Y 0 )) where Y ∈ {− 1 , 1 } and Y 0 ∈ R . (66) Y 0 is replaced by the expert’ s prediction for s upervised learning and i s t ypically modeled by an af fine function of X . The ensembl e is thus a con vex com bination of af fine experts. The second deriv ative of the above loss with respect to Y 0 is l ′′ log ( Y , Y 0 ) = Y 2 exp( − Y Y 0 ) (1 + exp( − Y Y 0 )) 2 . (67) l ′′ log ( Y , Y 0 ) is an even function of Y 0 . It is m onotonically increasing for Y 0 ≤ 0 , reaches i ts maximum at Y 0 = 0 , and i s m onotonically decreasing for Y 0 ≥ 0 . Hence we can write m l, B ( Y ) as m l, B ( Y ) = l ′′ log ( Y , b min ) ; if b max < 0 or if b max + b min < 0 l ′′ log ( Y , b max ) ; otherwise . (68) August 24, 2018 DRAFT 15 Similarly , we can write M l, B ( Y ) as M l, B ( Y ) = l ′′ log ( Y , b max ) ; if b max < 0 l ′′ log ( Y , b min ) ; if b min > 0 l ′′ log ( Y , 0) = Y 2 / 4 ; ot herwise . (69) D. Exponent ial Loss AdaBoost.M1 [33] uses the exponential loss function which is d efined as l exp ( Y , Y 0 ) = exp( − Y Y 0 ) where Y ∈ {− 1 , 1 } and Y 0 ∈ R . (70) The second deriv ativ e of the l oss function i s l ′′ exp ( Y , Y 0 ) = Y 2 exp( − Y Y 0 ) . (71) The above function of Y 0 is m onotonically i ncreasing when Y < 0 and m onotonically d ecreasing when Y ≥ 0 . Hence m l, B ( Y ) becomes m l, B ( Y ) = l ′′ exp ( Y , b min ) ; if Y < 0 l ′′ exp ( Y , b max ) ; otherwise . (72) Similarly , M l, B becomes M l, B ( Y ) = l ′′ exp ( Y , b max ) ; if Y < 0 l ′′ exp ( Y , b min ) ; otherwise . (73) E. Hinge Loss The hinge lo ss is anot her p opular loss function which i s used for training s upport vector machines (SVMs) [40] and is defined as l hinge ( Y , Y 0 ) = max( 0 , 1 − Y Y 0 ) where Y ∈ {− 1 , 1 } and Y 0 ∈ R . (74) The above loss function is not differentiable when Y Y 0 = 1 . Hence we u se the following smoot h approximation from Smooth SVM (SSVM) [41]: l hinge, smooth ( Y , Y 0 ) = 1 − Y Y 0 + ǫ log " 1 + exp − 1 − Y Y 0 ǫ !# where ǫ > 0 . (75) August 24, 2018 DRAFT 16 The above approximation is based on the logistic sig moidal approximati on of the sign function which is often used in n eural networks [42]. Picking a small posi tive value of ǫ ensures l ow approximation error . The second deri va tive with respect to Y 0 is l ′′ hinge, smooth ( Y , Y 0 ) = Y 2 exp − 1 − Y Y 0 ǫ ǫ h 1 + exp − 1 − Y Y 0 ǫ i 2 . (76) The abov e functio n of Y 0 is symmetrical abou t Y 0 = 1 / Y , increases for Y 0 < 1 / Y , attains its maximum for Y 0 = 1 / Y , and decreases for Y 0 ≥ 1 / Y . Hence M l, B ( Y ) is M l, B ( Y ) = l ′′ hinge, smooth ( Y , b max ) ; if b max < 1 / Y l ′′ hinge, smooth ( Y , b min ) ; if b min > 1 / Y l ′′ hinge, smooth ( Y , 1 / Y ) or Y 2 / (4 ǫ ) ; oth erwise . (77) Similarly , t he value o f m l, B ( Y ) also d epends on the lo cation of the interval B and is given below: m l, B ( Y ) = l ′′ hinge, smooth ( Y , b min ) ; if b max < 1 / Y or if b max + b min < 2 / Y l ′′ hinge, smooth ( Y , b max ) ; otherwise . (78) The expressions for M l, B ( Y ) and m l, B ( Y ) deri ved in thi s section for various los s functions are used to derive the GAD appro ximation for t he ensemble l oss. Theoretical analys is of t his approximation is not easy for all los s functions. Hence the next sectio n presents simulation experiments for understanding the GAD th eorem. I V . S I M U L A T I O N E X P E R I M E N T S O N T H E G A D T H E O R E M F O R C O M M O N L O S S F U N C T I O N S This section begins by understandi ng the tradeoff between the diversity term and weighted expert l oss in the GAD theorem. W e next analyze the accuracy of the ensembl e l oss approxima- tion motiv ated b y the GAD theorem.W e finally contrast the GAD approximation with t he T aylor series approximation used in gradient boosting. A. Behavior of W eighted Expert Loss and Diversity in GAD Consider t he following prox y for the true loss fun ction implied by GAD: l GAD ( Y , f ) = K X k =1 w k l ( Y , f k ) − d l ( f 1 , . . . , f K ) . (79) August 24, 2018 DRAFT 17 where d l ( f 1 , . . . , f K ) is the diversity . The first term on t he right hand s ide of the above equation is the weighted sum of the individual expert’ s los ses. W e not e that this t erm provides a sim ple upper bound on l ( Y , f ) due to Jensen’ s inequality for con vex lo ss fun ctions: l ( Y , f ) ≤ K X k =1 w k l ( Y , f k ) = l WGT ( Y , f ) . (80) T o understand the tradeoff between the two terms on the right hand side of Eq. 79, we performed Monte Carlo simulations because the analytical forms o f d l ( f 1 , . . . , f K ) for commo n loss fun ctions derive d in the pre vious section are not amenable to direct theoretical analy sis. The K expert predictions were sampled from an independent and identically dis tributed (IID) Gaussian random variable with mean µ f and v ariance σ 2 f . That is f k ∼ N ( µ f , σ 2 f ) for all k ∈ { 1 , . . . , K } . (81) A unimodal distribution was used since it is int uitive to expect most o f the experts to give numerically close predi ctions. W e used a Gaus sian probability density function (PDF) for our simulatio ns since it is the m ost p opular unimodal PDF . Th e con vex nature of the ensemble ensures that µ f is also the expected ensemble predicti on. This is because E { f } = E n K X k =1 w k f k o = K X k =1 w k E { f k } = K X k =1 w k µ f = µ f . (82) The variance σ 2 f governs the spread of the p redictions around the mean. W e varied µ f around the true label Y = 1 . W e picked Y = 1 because the t wo regression loss functi ons d epend only on the distance of the prediction from the tar g et. The analysis also extends easily to Y = − 1 for classification l oss functions . W e generated 1000 M onte Carlo sam ples for K = 3 and 7 experts. W e s et σ 2 f = 2 for t hese simulati ons. Figures 1-5 sh ow the median values of l ( Y , f ) , l GAD ( Y , f ) , and the weigh ted expert los s for va rious los s functions. These figures also plot the median di versity term d l ( f 1 , . . . , f K ) with the expected ensemble predicti on µ f . W e first analyse th e plot s for the two regression loss functio ns. Figure 1 shows the case for the squared error loss fun ction. W e note that l ( Y , f ) and l GAD ( Y , f ) overlap for all v alues of µ f because the G AD theorem reduces t o th e ambiguity decom position. The diversity term also remains nearly constant because it is t he maximum l ikelihood esti mator of the variance σ 2 f . Div ersity corrects for the bi as between the weighted expert los s (green curve) and the actual ensemble loss function (black curve). Figure 2 sh ows the corresponding figure for t he smooth August 24, 2018 DRAFT 18 absolute error loss function with ǫ = 0 . 5 . l GAD ( Y , f ) provides a very accurate approximation of the t rue loss function around the true label Y = 1 and becomes a poorer approxim ation as we m ove away . This is because GAD assumes the experts predictio ns to be close to t he true label. l WGT ( Y , f ) gi ves a much larger approximation error in comparison around Y = 1 . Also, the diversity term is nearly constant because its computation no rmalizes for the value of µ f by subtracting f from each f k . −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2 4 6 8 10 K = 3 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.8 0.9 1 1.1 1.2 Expected ensemble prediction µ f Diversity Term −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2 4 6 8 10 K = 7 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 1.5 1.55 1.6 1.65 Expected ensemble prediction µ f Diversity Term Fig. 1. The top plot i n each figure sho ws t he median actua l ensemble loss, its GAD approx imation and weighted expert loss across 1000 Monte Carlo samples in an ensemble of K = 3 and K = 7 experts for the squared error loss function as a function of e xpected ensemble pred iction µ f . W e used σ 2 f = 2 . Y = 1 is the correct label. W e also sho w the median di versity term for the same setup in the bottom plot. Figures 3-5 show the plo ts for the th ree classi fication loss functions - logi stic, exponential, and smooth hinge ( ǫ = 0 . 5 ) wi th true label Y = 1 . l GAD ( Y , f ) provides an accurate approxi mation to l ( Y , f ) near the true label Y = 1 as was the case for the regression lo ss functions. Howe ver the div ersity term is not constant, but uni modal with a peak around the decision boundary µ f = 0 . This is because the experts di sagree a lot at the decision boundary wh ich causes high diversity . Div ersity reduces as we move away from t he d ecision bound ary in bot h directions. Diversity in GAD is agnostic to the t rue label and on ly quantifies the spread of t he expert predictions with respect to the given loss function. The wei ghted expert loss term captures th e accurac y of the experts wi th respect to the t rue label. Even though all experts agree when they are predicting the incorrect class for µ f < 0 , the ov erall loss rises due to an increase in the weighted expert loss. August 24, 2018 DRAFT 19 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.5 1 1.5 2 K = 3 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.4 0.45 0.5 Expected ensemble prediction µ f Diversity Term −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.5 1 1.5 2 K = 7 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.58 0.6 0.62 0.64 Expected ensemble prediction µ f Diversity Term Fig. 2. The top plot i n each figure sho ws t he median actua l ensemble loss, its GAD approx imation and weighted expert loss across 1000 Monte Carlo samples in an ensemble of K = 3 an d K = 7 exp erts for the smooth absolute error loss fun ction as a function of ex pected ensemble prediction µ f . W e used σ 2 f = 2 and ǫ = 0 . 5 . Y = 1 is the correct l abel. W e also show the median di ve rsity term for the same setup in the bo ttom plot. −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.5 1 1.5 2 K = 3 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0 0.05 0.1 0.15 0.2 Expected ensemble prediction µ f Diversity Term −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.5 1 1.5 2 K = 7 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0 0.05 0.1 0.15 0.2 Expected ensemble prediction µ f Diversity Term Fig. 3. The top plot i n each figure sho ws t he median actua l ensemble loss, its GAD approx imation and weighted expert loss across 1000 Monte Carlo samples in an ensemble of K = 3 and K = 7 exp erts for the logistic loss function as a function of expec ted ensemb le prediction µ f . W e used σ 2 f = 2 . Y = 1 is the correct label. W e also show the median di versity term for the same setup in the bottom plot. B. Accuracy of GA D-Motivated Approximation of Ens emble Loss In t his subsection, we analyze th e error of the approximate GAD ensem ble loss l GAD ( Y , f ) i n terms of absol ute de viation from the true ensemble loss l ( Y , f ) . W e also in vestigate the beha vior August 24, 2018 DRAFT 20 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 2 4 6 8 10 12 K = 3 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0 0.2 0.4 0.6 0.8 Expected ensemble prediction µ f Diversity Term −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0 5 10 15 K = 7 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0 1 2 3 Expected ensemble prediction µ f Diversity Term Fig. 4. The top plot i n each figure sho ws t he median actua l ensemble loss, its GAD approx imation and weighted expert loss across 10 00 Monte Carlo samples in an ensemble of K = 3 and K = 7 experts for the e xponen tial loss fun ction as a function of e xpected ensemble pred iction µ f . W e used σ 2 f = 2 . Y = 1 is the correct label. W e also sho w the median di versity term for the same setup in the bottom plot. −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0.5 1 1.5 2 2.5 K = 3 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0 0.05 0.1 0.15 0.2 Expected ensemble prediction µ f Diversity Term −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 1 2 3 K = 7 experts Expected ensemble prediction µ f Loss Function Ensemble Loss (GAD) Weighted Expert Loss Ensemble Loss (Actual) −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 0 0.1 0.2 0.3 0.4 Expected ensemble prediction µ f Diversity Term Fig. 5. The top plot i n each figure sho ws t he median actua l ensemble loss, its GAD approx imation and weighted expert loss across 1000 Monte Carlo samples in an ensemble of K = 3 and K = 7 experts for the smooth hinge loss function as a function of expected ensemble prediction µ f . W e used σ 2 f = 2 and ǫ = 0 . 5 . Y = 1 is the correct label. W e also show the median di versity term for the same setup in the bottom plot. of t he bound on the approxi mation error | l ( Y , f ) − l GAD ( Y , f ) | presented in Corollary 1 . W e used the same experimental setup for s imulations as in the previous section. Figures 6-9 show the plots of the approximat ion error usi ng l GAD ( Y , f ) and the weigh ted expert loss l WGT ( Y , f ) for August 24, 2018 DRAFT 21 var ious loss function s discussed previously . W e did no t consider the squ ared error loss functio n because GAD reduces to AD and we get 0 absolute error . Figures 6-9 sh ow that the GAD approximation l GAD ( Y , f ) (red curve) always provides signi f- icantly l ower approximation error rate than t he weight ed expert loss l WGT ( Y , f ) (green curve) when µ f is close to the true label Y = 1 . This is because the second order T aylor series expansion used in the GAD theorem’ s proof is accura te wh en the e xpert prediction s are clos e to the true label. W e also note that the bou nd on the approximation error | l ( Y , f ) − l GAD ( Y , f ) | (blue curve) follows t he general t rend of the error but is not very tight . −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −2 10 −1 10 0 Expected ensemble prediction µ f Median absolute error K = 3 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −1 10 0 Expected ensemble prediction µ f Median absolute error K = 7 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label Fig. 6. Median absolute approximation error and error boun d across 1000 Monte Carlo samples in an ensemble of K = 3 and K = 7 ex perts for smooth absolute error loss function as a function of expected ense mble prediction µ f . W e used σ 2 f = 2 , ǫ = 0 . 5 and Y = 1 as the correct label. C. Compariso n with Loss Function Appr oximati on Used in Gradient Boosting Gradient boost ing [43] is a p opular machine learning algorithm whi ch sequ entially trains an ensemble of base learners. Gradient boosting also utili zes a T aylor series expansion for its sequential traini ng. Hence, we de vote th is subsecti on to un derstanding the differences between the loss functio n approxi mation us ed in gradient boo sting and GAD. Consider an ensembl e of K − 1 experts f k , and their linear combination g = K − 1 X k =1 v k f k (83) August 24, 2018 DRAFT 22 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −2 10 −1 10 0 Expected ensemble prediction µ f Median absolute error K = 3 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −1 10 0 Expected ensemble prediction µ f Median absolute error K = 7 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label Fig. 7. Median absolute approximation error and error boun d across 1000 Monte Carlo samples in an ensemble of K = 3 and K = 7 experts for logistic loss function as a function of e xpected ens emble prediction µ f . W e used σ 2 f = 2 an d Y = 1 as the correct labe l. −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −1 10 0 10 1 10 2 Expected ensemble prediction µ f Median absolute error K = 3 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −1 10 0 10 1 10 2 Expected ensemble prediction µ f Median absolute error K = 7 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label Fig. 8. Median absolute app roximation error and error bou nd across 1000 Monte Carlo samples in an ensemble of K = 3 and K = 7 e xperts f or e xponential loss function as a function of expected ensemble prediction µ f . W e used σ 2 f = 2 and Y = 1 as the correct labe l. to generate the ensemble prediction g . Gradient boosting does not require the coefficients { v k } K − 1 k =1 to b e con ve x weights. Now if we add a new expert f K to g with a weight v K , th e loss of t he new ens emble becomes l ( Y , g + v K f K ) . Since gradient boosting est imates v K and f K giv en estimates of { v k , f k } K − 1 k =1 , it assumes t hat v K f K is close to 0 . In oth er words, it assumes that the new b ase learner f K is weak and contributes o nly that informat ion w hich has not been learned August 24, 2018 DRAFT 23 −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −2 10 −1 10 0 Expected ensemble prediction µ f Median absolute error K = 3 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −2 10 −1 10 0 Expected ensemble prediction µ f Median absolute error K = 7 experts Ensemble loss (GAD) Weighted expert loss GAD error bound Decision boundary Correct label Incorrect label Fig. 9. Median absolute app roximation error and error bou nd across 1000 Monte Carlo samples in an ensemble of K = 3 and K = 7 expe rts for smooth hinge loss function as a function of expec ted ensemble prediction µ f . W e used σ 2 f = 2 , ǫ = 0 . 5 , and Y = 1 as the correct label. by t he current ensem ble. T he ne w ensembl e’ s loss is therefore approxi mated b y using a T aylor series expansion around v K f K = 0 . Assuming the los s functi on t o be con ve x, we can write th e following first order T aylor series expansion: l ( Y , g + v K f K ) ≤ l ( Y , g ) + v K f K l ′ ( Y , g ) = l GB ( Y , f ) . (84) Minimizi ng the above upper bou nd with respect to v K and f K is equiv alent to minimi zing v K f K l ′ ( Y , g ) , or maximizin g th e correlation between v K f K and the negative l oss function gra- dient − l ′ ( Y , g ) . This is the central id ea u sed in training an ensemble u sing gradient boo sting. The abov e T aylor series expansion highligh ts the key differences between gradient boosting and GAD. First, the loss function upper b ound used in gradient boosting i s a means to perform sequential trainin g of an ensemble o f w eak experts. Each ne w expert adds only i ncremental information to the ens emble, but is insu f ficiently trained to predict the target variables on its own. This reduces th e utilit y of t he above approx imation in (84) in situati ons wh en the individual experts are themselves strong. This arises when, for e xample, the experts have been trained on diffe rent feature sets, data sets, utili ze diff erent functional forms , or have not been trained usi ng gradient boosti ng. Second, the GAD approximation l GAD ( Y , f ) provides an intui tiv e decompositio n of the ensemble loss i nto the weighted expert loss l WGT ( Y , f ) and t he di versity d ( f 1 , . . . , f K ) which measures the spread of the e xpert predictions about f . Gradient boosting August 24, 2018 DRAFT 24 does n ot off er such an intui tiv e decom position. Figure 10 shows t he median approximati on error for l GAD ( Y , f ) and l GB ( Y , f ) using the expo- nential loss fun ction. W e o bserve t hat g radient boosti ng has m inimum error when the ensemble mean µ f is near the decision boundary because f K ≈ 0 . Howe ver , the approximatio n becomes poor as we move away from the decision boundary . l GAD ( Y , f ) provides a good approximatio n around the true label Y = 1 as noted in the pre vious section. Thus the t wo los s functions l GAD ( Y , f ) and l GB ( Y , f ) provide complementary regions of low approxim ation error . A similar trend is o bserved for the other los s funct ions as well . −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −3 10 −2 10 −1 10 0 Expected ensemble prediction µ f Median absolute error K = 3 experts Ensemble loss (GAD) Ensemble loss (Grad. boost.) Decision boundary Correct label Incorrect label −2 −1.5 −1 −0.5 0 0.5 1 1.5 2 10 −3 10 −2 10 −1 Expected ensemble prediction µ f Median absolute error K = 7 experts Ensemble loss (GAD) Ensemble loss (Grad. boost.) Decision boundary Correct label Incorrect label Fig. 10. Median absolute approximation error for GAD and the gradient boosting upper bound across 1000 Monte Carl o samples in an ensemble of K = 3 and K = 7 experts for smooth hinge loss function as a function of expe cted ensemble prediction µ f . W e used σ 2 f = 0 . 1 and Y = 1 as the co rrect label. V . E X P E R I M E N T S O N G A D W I T H S T A N D A R D M AC H I N E L E A R N I N G T A S K S The previous sections presented empirical analysis of t he GAD theorem based on simulatio ns. This section presents experiments o n some real-world data sets which will revea l the u tility of the GAD theorem to m achine learning problems of in terest. W e used five data sets from t he UCI Machine Learning Repository [44] as listed in T able I for the experiments. W e conducted two sets of experiments u sing the UCI data sets. These experiments mimic common scenarios usually encountered by researchers whi le training systems with mul tiple classifiers or regressors. The first class of experiments tri es to understand diver sity and its impact on ensemble perfor- mance in case the ensembl e consists of dif ferent classifiers and regre ssors trained on the same August 24, 2018 DRAFT 25 data s et. W e trained 3 classifiers and 3 regressors for each data s et. W e used log istic regression, linear support vector machine (SVM) from the Lib-Lin ear toolkit [45], and a homoscedastic linear discriminant analysis (LD A)-based classifier from Matl ab for classification. The three linear regressors were trained by minimi zing least squares, l east absolute de viation, and the Huber loss function. GAD was us ed t o analy se the div ersity of the trained classifiers and regressors for each data set. The second experiment considers the situations where the experts are trained on potentially overlapping subsets of i nstances from a given data set. W e used bagging [46] for creating the mul tiple training subsets b y sampling in stances with replacement. The classifiers and regressors mentioned abov e were used for these experiments one at a ti me. The e v aluation metric of the above experiments is t he relativ e approximation error between the true los s and its approximati on: E x = 1 − l x ( Y , f ( X )) l ( Y , f ( X )) (85) where x is one of GAD, WGT (using weigh ted loss of ensem ble (80)), and GB (using approx- imation used in gradient boosting (84)). W e assigned equal weights { w k } to the experts i n all experiments. T able II shows the relati ve absolut e error for va rious classification data sets and loss functions when dif ferent experts were trained on t he same data set. W e ob serve that the GAD approx imation provides the lo west median absolute error for all cases. This result is statist ically significant at α = 0 . 01 lev el us ing the paired t-test. It is o ften an order of magn itude better than the other two approximations . T able III shows t he relative absolu te error when one expert was trained on three versions o f the same data s et created by samplin g w ith replacement. W e used logis tic regre ssion for t he classification loss functi ons and least squares linear regression for the regression loss functions. T able III shows t hat the GA D approxi mation giv es the lowest error for all cases except for the W ine Quality data s et with s mooth abso lute error loss function. These experiments indicate that l GAD ( Y , f ) provides an accurate approximation of the actual ensemble loss l ( Y , f ) . This adds v alue to the proposed approxi mation for designing supervised machine learning algorithms, in addition to providing an intuitive definition and explanation o f the impact of diversity o n ensemble p erformance. August 24, 2018 DRAFT 26 Data set T arget set No. of instances No. of features Magic Gamma T elescope [47] {− 1 , 1 } 19020 10 Pima Indians Diabetes [48] {− 1 , 1 } 768 8 Abalone [49] { − 1 , 1 } , Z + 4177 7 Parkinson’ s Disease [50] R + 5875 20 W ine Quality [51] { 0 , . . . , 10 } 6497 11 T ABLE I D E S C R I P T I O N O F V A R I O U S U C I M AC H I N E L E A R N I N G R E P O S I T O RY D AT A S E T S U S E D F O R E X P E R I M E N T S O N G A D . A L L DAT A S E T S W I T H {− 1 , 1 } A S T H E TA R G E T S E T W E R E U S E D F O R T R A I N I N G B I N A RY C L A S S I FI E R S . O T H E R S W E R E U S E D F O R T R A I N I N G R E G R E S S O R S . A B A L O N E W A S U S E D F O R B I N A RY C L A S S I FI C A T I O N A S W E L L B Y FI R S T T H R E S H O L D I N G T H E TA R G E T V A R I A B L E A T 10 . V I . C O N C L U S I O N A N D F U T U R E W O R K W e presented the generalized ambiguity decom position (GAD ) t heorem which explains the link between the diversity of experts in an ensemble and the ensembl e’ s overa ll performance. The GAD theorem applies to a con ve x ensemble of arbitrary experts wi th a s econd order differ - entiable loss functi on. It also provides a data-dependent and los s function-dependent definiti on of diversity . W e appl ied this theorem to som e com monly used class ification and regression lo ss functions and provided a simulation-based analysis of div ersity term and accurac y of the resulting loss function app roximation. W e als o presented results on many UCI data sets for two frequentl y encountered situations u sing ensembles of experts. These results demonstrate the utility of the proposed decomposition to ensembl es used in these real-w orld problems. Future work s hould design s upervised learning and ensemble selection algorithms util izing the proposed GAD theorem. Such algorithms m ight extend existing work on t raining diver se ensembles o f neural networks using negative correlation learning [31] and conditional m aximum entropy mod els [30]. The GAD loss funct ion approxim ation is especially attractive because the div ersity term does not require labeled d ata for computation. Thi s opens the possi bility of dev eloping semi -supervised learning algorithms which use large amounts of unlabeled data. Another i nteresting research direction is understanding t he impact of diversity introduced at var ious stages of a conv entional supervised learning algori thm on th e final ens emble performance. The individual experts can be trained on di f ferent data sets and can use different feature sets. August 24, 2018 DRAFT 27 Data set E GAD E WGT E GB Logistic Loss Magic Gamma T elescope [47] 1.3e-2 6.5e-2 6.6e-2 Pima Indians Diabetes [48] 7.0e-3 2.9e-2 2.3e-2 Abalone [49] 9.0e-3 4.4e-1 4.2e-1 Exponential Loss Magic Gamma T elescope [47] 3.5e-2 1.3e-1 1.4e-1 Pima Indians Diabetes [48] 1.5e-2 6.8e-2 6.1e-2 Abalone [49] 2.2e-2 9.2e-2 9.2e-2 Smooth Hinge L oss ( ǫ = 0 . 5 ) Magic Gamma T elescope [47] 2.2e-2 1.6e-1 1.4e-1 Pima Indians Diabetes [48] 7.0e-3 4.9e-2 3.1e-2 Abalone [49] 1.2e-2 8.9e-2 6.8e-2 Squared Error Loss Parkinson’ s Disease [50] 0 1.7e-1 1.7 W ine Quality [51] 0 1.9e-1 1.5e-1 Abalone [49] 0 2.8e-2 1.4e-1 Smooth Absolute Error L oss ( ǫ = 0 . 5 ) Parkinson’ s Disease [50] 1e-2 1.4e-1 1.3 W ine Quality [51] 9.1e-2 9e-2 9.9e-2 Abalone [49] 7e-3 1.9e-2 9.9e-2 T ABLE II T H I S TA B L E S H OW S T H E R E L A T I V E A B S O L U T E E R R O R E X F O R V A R I O U S U C I D AT A S E T S B E T W E E N T H E E N S E M B L E L O S S A N D A P P R O X I M A T I O N X W H I C H I S O N E O F G A D , W G T, A N D G B C O R R E S P O N D I N G T O G A D , W E I G H T E D S U M O F E X P E RT L O S E S , A N D G R A D I E N T B O O S T I N G U P P E R - B O U N D O N T OTA L L O S S . T H E FI R S T T H R E E L O S E S U S E D A N E N S E M B L E O F T H R E E C L A S S I FI E R S - L O G I S T I C R E G R E S S I O N , L I N E A R S U P P O RT V E C TO R M AC H I N E , A N D F I S H E R ’ S L I N E A R D I S C R I M I NA N T A N A L Y S I S C L A S S I FI E R S . T H E T WO L A S T T WO R E G R E S S O R S U S E D T H R E E R E G R E S S O R S O B TA I N E D B Y M I N I M I Z I N G S Q U A R E D E R R O R , A B S O L U T E E R R O R , A N D H U B E R L O S S F U N C T I O N . T H E G A D A P P R O X I M AT I O N H A S S I G N I FI C A N T LY L O W E R E R R O R T H A N T H E O T H E R A P P R O X I M AT I O N S F O R A L L C A S E S E X C E P T T H E W I N E Q U A L I T Y D A TA S E T F O R T H E S M O O T H A B S O L U T E L O S S . August 24, 2018 DRAFT 28 Data set E GAD E WGT E GB Logistic Loss Magic Gamma T elescope [47] 1.76e-4 5.38e-4 1.07e-1 Pima Indians Diabetes [48] 4.02e-3 1.86e-2 3.62e-2 Abalone [49] 1.24e-3 3.91e-3 5.54e-2 Exponential Loss Magic Gamma T elescope [47] 4.03e-4 9.92e-4 1.77e-1 Pima Indians Diabetes [48] 4.22e-3 1.61e-2 7.19e-2 Abalone [49] 1.49e-3 4.09e-3 9.70e-2 Smooth Hinge L oss ( ǫ = 0 . 5 ) Magic Gamma T elescope [47] 8.93e-4 1.89e-3 3.31e-1 Pima Indians Diabetes [48] 1.26e-2 4.93e-2 5.93e-2 Abalone [49] 2.14e-3 6.18e-3 1.46e-1 Squared Error Loss Parkinson’ s Disease [50] 0 5.5e-3 1.6 W ine Quality [51] 0 1.5e-2 8.7e-2 Abalone [49] 0 9.3e-3 1.5e-1 Smooth Absolute Error L oss ( ǫ = 0 . 5 ) Parkinson’ s Disease [50] 5.3e-4 7.4e-3 1.2 W ine Quality [51] 1.2e-2 4.4e-3 6.0e-2 Abalone [49] 1.4e-3 3.4e-3 8.2e-2 T ABLE III T H I S TA B L E S H OW S T H E R E L A T I V E A B S O L U T E E R R O R E X F O R V A R I O U S U C I D AT A S E T S B E T W E E N T H E E N S E M B L E L O S S A N D A P P R O X I M A T I O N X W H I C H I S O N E O F G A D , W G T, A N D G B C O R R E S P O N D I N G T O G A D , W E I G H T E D S U M O F E X P E RT L O S E S , A N D G R A D I E N T B O O S T I N G U P P E R - B O U N D O N T O TA L L O S S . T H E FI R S T T H R E E L O S E S U S E D L O G I S T I C R E G R E S S I O N C L A S S I FI E R S T R A I N E D O N T H R E E D A TA S E T S C R E A T E D B Y S A M P L I N G W I T H R E P L A C E M E N T ( BA G G E D T R A I N I N G S E T S ) . T H E L A S T T WO L O S E S U S E D A L I N E A R R E G R E S S O R O B TA I N E D B Y M I N I M I Z I N G S Q UA R E D E R R O R A N D T R A I N E D O N 3 BA G G E D T R A I N I N G S E T S . T H E G A D A P P R O X I M A T I O N H A S S I G N I FI C A N T LY L OW E R E R R O R T H A N T H E O T H E R A P P RO X I M AT I O N S F O R A L L C A S E S E X C E P T T H E W I N E Q U A L I T Y D A TA S E T F O R T H E S M O O T H A B S O L U T E L O S S . It would be useful to understand the most beneficial ways in whi ch diver sity can be introduced in the ensemble. W e would also l ike to s tudy t he impact of diversity in sequ ential classi fiers such as automatic speech recogniti on (ASR) systems. O ur recent work [52] deve lops a GAD-like frame work for theoretically analyzing the impact of diversity on fusion performance of state-of- the-art A SR system s. Finally , characterizing di versity in an ensembl es of human experts presents August 24, 2018 DRAFT 29 a tougher challenge because it is dif ficult to quantify the underlying loss function. Ho wev er , many real-world problem s inv olv ing crowd-sourcing [53]–[61] and und erstanding human behavior in volve annotation by multiple human experts [62]–[69]. Ex tending the GAD th eorem to such cases will cont ribute significantly t o these dom ains. R E F E R E N C E S [1] G. Saon, H. S oltau, U. Chaudhari, S. Chu, B. Kingsbu ry , H.K. Ku o, L. Mangu, and D. P ov ey , “The IBM 2008 GALE Arabic speech transcription system, ” in Pr oc. , 2010, pp. 4378–43 81. [2] G. Tu r , A. Stolcke, L. V oss, S. Peters, D. Hak kani-T ur , J. Dowd ing, B. Fa vre, R. F ern ´ andez, M. F rampton, M. Frandsen, C. Frederickson, M. Graciarena, D. Kintzing, K. Lev eque, S . Mason, J. Ni ekrasz, M. Purver , K. Riedhammer , E. Shriberg, J. Tien , D. V ergyri, and F . Y ang, “The CAL O meeting assistant system, ” IEEE T ransactions on Audio, Speech , and Langua ge Pro cessing , v ol. 18, no . 6, pp . 1601–161 1, 2010 . [3] L. Mangu, H. Soltau, H. Kuo, B. K ingsbu ry , and G. Saon, “E xploiting diversity for spoken term detection, ” in Pro c. ICASSP . IEEE, 2013 , pp. 8282 –8286. [4] J. Cui, X. Cui, B. R amabhadran , J. Kim, B. Kingsb ury , J. Mamou, L. Mangu, M. Picheny , T . N. Sainath, and A. Set hy , “De veloping speech recog nition systems for corpus indexing under the IARP A B ABEL program, ” in P r oc. ICASSP . 2013, IEEE. [5] K. Sagae and J. Tsujii , “Dependency Parsing and Domain Adaptation with LR Models and Parser Ensembles, ” in Pr oc. EMNLP-CoNLL , 2007, v ol. 200 7, pp. 1044–1 050. [6] F . Sebastiani, “Machine learning in automated text categorization, ” ACM Computing Surve ys , vo l. 34, no. 1, pp. 1–47, 2002. [7] J. Bennett and S. L anning, “The Netflix prize, ” i n Pr oceedings of KDD Cup and W orkshop , 2007, vo l. 2007, p. 35. [8] R. M. Bell, Y . K oren, and C. V olinsky , “The BellKor solution to the Netflix prize, ” Netflix prize documentation , 2007. [9] M. Piotte and M. Chabbert, “The Pragmatic T heory solution t o the Net flix grand prize, ” Netflix prize documentation , 2009. [10] A. T ¨ oscher , M. Jahrer , and R. M. Bell, “The BigChaos solution to the Netflix grand prize, ” Netflix prize documenta tion , 2009. [11] C. J. C. Burges, K. M. S vore, P . N. Bennett, A. Pastusiak, and Q. W u, “Learning to rank using an en semble of lambda- gradient models., ” Jou rnal of Mac hine Learning Resear ch (Pr oceedings Tr ack) , vol. 14 , pp. 25–3 5, 2011. [12] D. Y . Pa vlov , A. Gorodilo v , and C . A. Brunk, “BagBoo: a scalable hybrid bagging-the-boo sting model, ” in Pr oc. CIKM . A CM, 201 0, pp. 1897– 1900. [13] O. Chapelle and Y . Chang, “Y ahoo! l earning t o rank challenge overvie w , ” Journa l of Mac hine Learning Resear ch , vol. 14, pp. 1– 24, 2011. [14] S. A vidan, “Ensemble tracking, ” IE EE T rans actions on P attern Analysis and Machine Intelligence , vol. 29, no. 2, pp. 261–27 1, 2007 . [15] T . Malisiewicz, A. Gupta, and A. A. E fros, “Ensemble of exemplar-SVMs for object detection and beyo nd, ” in P r oc. ICCV . IEEE, 201 1, pp. 89–96 . [16] S. Gutta, J. R. J. Huang, P . Jonathon, and H. W echsler , “Mixture of e xperts for classification of gender , ethnic origin, and pose of huma n faces, ” IEEE T ransactions on Neural Networks , vo l. 11, no . 4, pp. 948– 960, 2000. August 24, 2018 DRAFT 30 [17] M. Li, V . Rozgic, G. Thatte, S. Lee, A. Emken, M. Annav aram, U. Mitra, D. Spruijt-Metz, and S. Narayanan, “Multimodal physical activity recognition by fusing temporal and cepstral information, ” IEEE T ransactions on Neural Systems and Rehabilitation Engineering , v ol. 18, no . 4, pp . 369–380, 2010. [18] B. Schuller , S. St eidl, and A. Batliner , “The INTERSPEECH 2009 emotion challenge, ” in P r oc. Interspeec h , 2009, pp. 312–31 5. [19] B. Schuller, S. Steidl, A. Batliner , F . Burkhardt, L. Devillers, C. A. M ¨ uller , and S. S. Narayanan, “T he INTERSP EECH 2010 paralinguistic challeng e, ” in Pr oc. Interspeec h , 2010, pp. 2794–2797. [20] B. Schuller , S. Steidl, A. Batliner, F . Schiel, and J. Kraje wski, “The INTERS PEECH 2011 speaker state challenge, ” in Pr oc. Inter speec h , 2011, pp. 320 1–3204. [21] B. Schuller, S. Steidl, A. Batliner , E. N ¨ oth, A. V inciarelli, F . Burkhardt, R. V an Son, F . W eninger , F . Eyben, T . Bocklet, G. Mohamm adi, and G. W eiss, “The INTERSPEECH 2012 speaker trait challeng e, ” in Pr oc. Interspeec h , 2012. [22] B. Schuller , S. Steidl, A. Batliner , A. V inciarelli, K. Scherer, F . Ringe v al, M. Chetouani, F . W eninger , F . Eyben, E. Marchi, M. Mortillaro, H. Salamin, A. Polychroniou, F . V alente, and S . Kim, “The INTERSP EECH 2013 computational paralinguistics challenge : social signals, conflict, emo tion, autism, ” i n Pr oc. Interspee ch , 2013. [23] T . Dietterich, “Ensemble methods in machine learning , ” Multiple classifier systems , pp. 1–15, 2000. [24] L. I. Ku nche v a, Combining pattern classifier s: methods and a lgorithms , W iley-Interscience , 2004. [25] A. Krogh and J. V edelsby , “Neural network ensembles, cross v alidation, and activ e learning, ” A dvances i n neural information pr ocessing systems , pp. 231– 238, 1995. [26] N. Ueda and R. N akano, “Generalization error of ensemble estimators, ” in IEEE International Confer ence on Neural Networks , 1996 , vol. 1, pp . 90–95 . [27] S. Geman, E. Bienenstoc k, and R. Doursat, “Neural networks and t he bias/v ariance dilemma, ” Neural Comp utation , vol. 4, no. 1, pp. 1–58, 1992. [28] L. Breiman, “Random forests, ” Machine learning , vol. 45, no . 1, pp. 5–32, 2001. [29] G. V alentini and T .G. Dietterich, “Bias-v ariance analysis of support vector machines for the dev elopment of svm-based ensemble methods, ” The J ournal of Mac hine Learning Resea r ch , v ol. 5, pp. 725–775, 2004. [30] K. Audhkhasi, A. Sethy , B. Ramabhadran , and S.S. Narayanan, “Creating ensemble of div erse maximum entropy models, ” in Pr oceedings of ICASSP , 2012. [31] Y . Li u and X. Y ao, “Ensemble learning via negati ve correlation, ” N eural Networks , vol. 12, no. 10, pp. 139 9–1404, 19 99. [32] P . Melville and R.J. Mooney , “Constructing diverse classifier ensembles using arti ficial tr aining examples, ” in International J oint Confer ence on Artificial Intelligence , 2003, vol. 18, pp . 505–512. [33] Y . Freund and R. Schapire, “ A decision-theoretic generalization of on-line learning and an application to boosting, ” in Computational learning theo ry , 1995, pp. 23– 37. [34] K. T umer and J. Ghosh, “ Analysis of decision bounda ries in linearly combined neural classifiers, ” P attern Reco gnition , vol. 29, no. 2, pp. 34 1–348, 1996. [35] E.B. Kon g and T .G. Dietterich, “Error-co rrecting output coding corrects bias and variance , ” in P r oceedings of International Confer ence on Machine Learning , 1995, vol. 313, p. 321. [36] L. Breiman, “Bias, variance and arcing classifiers (Technical Report 460), ” Statistics Department, University of Cali fornia at Berkele y , Berkele y , CA , 1996. [37] P . Domingo s, “ A unified bias-v ariance decomposition, ” in Proc. ICML , 2000. [38] V . V apnik, The natur e of statistical learning t heory , S pringer , 1999. August 24, 2018 DRAFT 31 [39] G.A. Korn and T . M. Ko rn, Mathematical handbook for scientists and engineers: definitions, theor ems, and f ormulas for r efer ence and r evie w , Dov er Publications, 2000. [40] C. Cortes and V . V apnik, “S upport-v ector networks, ” Machine learn ing , vol. 20, no. 3, pp. 273 –297, 1995. [41] Y .J. Lee and O.L . Mangasarian, “SSVM: A smooth support vector machine for classification, ” Computational optimization and Applications , v ol. 20, no . 1, pp. 5– 22, 2001. [42] B. Kosk o, Neural networks and f uzzy systems: A dynamica l systems appr oach to machine intell igence , Prentice-Hall International Editions, 19 92. [43] J.H. Fri edman, “Greedy function approximation: a gradient boosting machine, ” Annals of Statistics , pp. 1189–12 32, 200 1. [44] A. Frank and A. Asuncion, “UCI machine learning repository , ” 2010. [45] R.E. Fan, K. W . Cha ng, C. J. Hsieh, X.R. W ang, and C .J. Lin, “LIBLINEAR: A library for large linear classifi cation, ” The J ournal of Mac hine Learning Resear ch , vo l. 9, pp. 1871–1874, 2008. [46] L. Breiman, “Bagging predictors, ” Machine learn ing , vol. 24, no. 2, pp. 12 3–140, 1996. [47] D. Heck, J. Knapp , J. Capdev ielle, G. S chatz, and T . T houw , CORSIKA: A Monte Carlo code to simulate extensive air showers , v ol. 601 9, FZKA 6019 F orschungsze ntrum Karl sruhe, 19 98. [48] J.W . Smith, J. E. E verhart, W . C. Dickson, W . C. Knowler , and R.S. Johannes, “Using the AD AP l earning algorithm to forecast the onset of diabetes mellitus, ” in Pr oc. Annual Symposium on Computer A pplication in Medica l Car e , 1988, p. 261. [49] W .J. Nash, The P opulation Biology of Abalone (Haliotis Species) in T asmania. I. Bl acklip Abalone (H Rubra) f r om the North Coast and the Islands of Bass Strait , Sea Fisheries Division, Marine Research Laboratories – T aroona, Dept. of Primary Industry an d Fisheries, T asmania, 1978. [50] A. T anas, M. A. Little, P . E. McSharry , and L. O. Raming, “ Accurate telemonitoring of Parkinson’ s disease progression by nonin va siv e speech tests, ” IEEE T ransa ctions on Biomedical Engineering , vol. 57, no. 4, pp. 884– 893, 2010. [51] P . Cortez, A. Cerdeira, F . Almeida, T . Matos, and J. Reis, “Modeling wine preferences by data mining from physico chemical properties, ” Decision Support Systems , v ol. 47, no. 4, pp. 547–55 3, 2009. [52] K. Audhkhasi, A. Zavou, P . Georgiou, and S. Narayan an, “Theoretical analysis of di versity in an ensemble of automatic speech recognition systems, ” Accepted for pu blication in IEE E Tr ansaction s on Audio, Speec h, and Langu ag e Pr ocessing , 2013. [53] R. Snow , B. O’Connor , D. Jurafsky , and A. Y . Ng, “Cheap and fast—but is it good ?: Ev aluating non-expert annotations for natural lang uage tasks, ” in Pr oc. EMNLP , 20 08, pp. 254–2 63. [54] C. Callison-Burch, “Fast, cheap, and creati ve: Ev aluating translation quality using A mazon’ s Mechanical Turk, ” in Pr oc. EMNLP , 2009, pp . 286–295. [55] V . Ambati and S. V ogel, “Can crowds bu ild parallel corpora for machine translation systems?, ” in Pr oc. HLT -NAA CL , 2010, pp. 62 –65. [56] M. Marge, S . Banerjee, an d A. I. Rudnicky , “Using the Amazon Mechanical Turk for transcription of spok en language, ” in Pr oc. ICASSP , 2010. [57] M. Denk o wski, H. Al -Haj, and A. Lavie, “Turk er-assisted paraphrasing for English-Arabic machin e translation, ” i n Proc. HLT -NAACL , 2010, pp. 66–70. [58] A. Sorokin and D. Forsyth, “Utility d ata annotation with Amazon Mechanical Turk, ” in Pr oc. CVPR , 2008, pp . 1–8. [59] J. Heer and M. Bostock, “Crowdsourcing graphical perception: using Mechan ical Turk to assess visu alization design, ” i n Pr oc. Intl. C onf. on Human F actors in Computing Systems , 2010, pp. 203–21 2. August 24, 2018 DRAFT 32 [60] K Audhkhasi, P . Georgiou, and S. Narayanan, “ Accurate t ranscription of broadc ast ne ws speech using multiple noisy transcribers and unsupervised reliability metrics, ” in Acoustics, Speec h and Signal Pro cessing (ICASSP), 2011 IEEE International Confer ence on . IEEE, 2011, pp . 4980–498 3. [61] K. Audhkhasi, P . Georgiou, and S. Narayanan, “Reliability-weighted acoustic model adaptation using crowd sourced transcriptions, ” Proc. Interspeech , Flor ence , 2011. [62] V . C. Raykar , S. Y u, L. S. Zhao, G. H. V aladez, C. Florin, L. Bogoni, and L. Moy , “Learning from Cro wds, ” Jou rnal of Mach ine Learning Resear ch , vol. 11 , pp. 1297 –1322, Mar . 2010. [63] Y . Y an, R. Rosales, G. Fung, M. Schmidt, G. Hermosillo, L. Bogoni, L. Moy , and G. J. Dy , “Modeling annotator expertise: Learning when e veryone kno ws a bit of something, ” in Proc. AISTA TS , 2010 . [64] P . W elinder , S. Branson , S. Belongie, and P . Perona, “The multidimensional wisdom of crowd s, ” in Pr oc. NIPS , 2010. [65] A. P . Dawid and A. M. Ske ne, “Maximum lik elihood estimation of observer error-rates using the E M algorithm, ” Jo urnal of the Royal Sta tistical Society . Series C (Applied Statistics) , vol. 28 , no. 1, pp. 20–28, 1979. [66] M. W ollmer , F . Ebyen, S. Reiter , B. S chuller , C. Cox, E. Douglas-Co wie, and R. Cowie, “ Abandoning emotional classes - Tow ards continuous emotion recogn ition with modeling of long-range depende ncies, ” in Proc. Interspeech , 2008 , pp. 597–60 0. [67] K. Audhkha si and S. Narayanan, “ A globally-v ariant locally-constant model for fusion of labels from multiple di verse experts withou t using reference labels, ” IEEE T ran sactions on P attern Analysis and Mac hine Intellige nce , vol. 35, no. 4, pp. 769–7 83, 2013. [68] K. Audhk hasi and S. Narayan an, “Emotion classifi cation from speech using ev aluator rel iability-weighted combination of ranked lists, ” in Pr oc. ICASSP . IEEE, 20 11, pp. 4956– 4959. [69] K. Audhkhasi and S. Narayanan, “Data-dependent ev aluator modeling and its application to emotional valence classification from speech, ” in Pr oceedings of InterSpeec h , 2010. August 24, 2018 DRAFT
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment