Learning Reputation in an Authorship Network
The problem of searching for experts in a given academic field is hugely important in both industry and academia. We study exactly this issue with respect to a database of authors and their publications. The idea is to use Latent Semantic Indexing (L…
Authors: Charanpal Dhanjal (LTCI), Stephan Clemenc{c}on (LTCI)
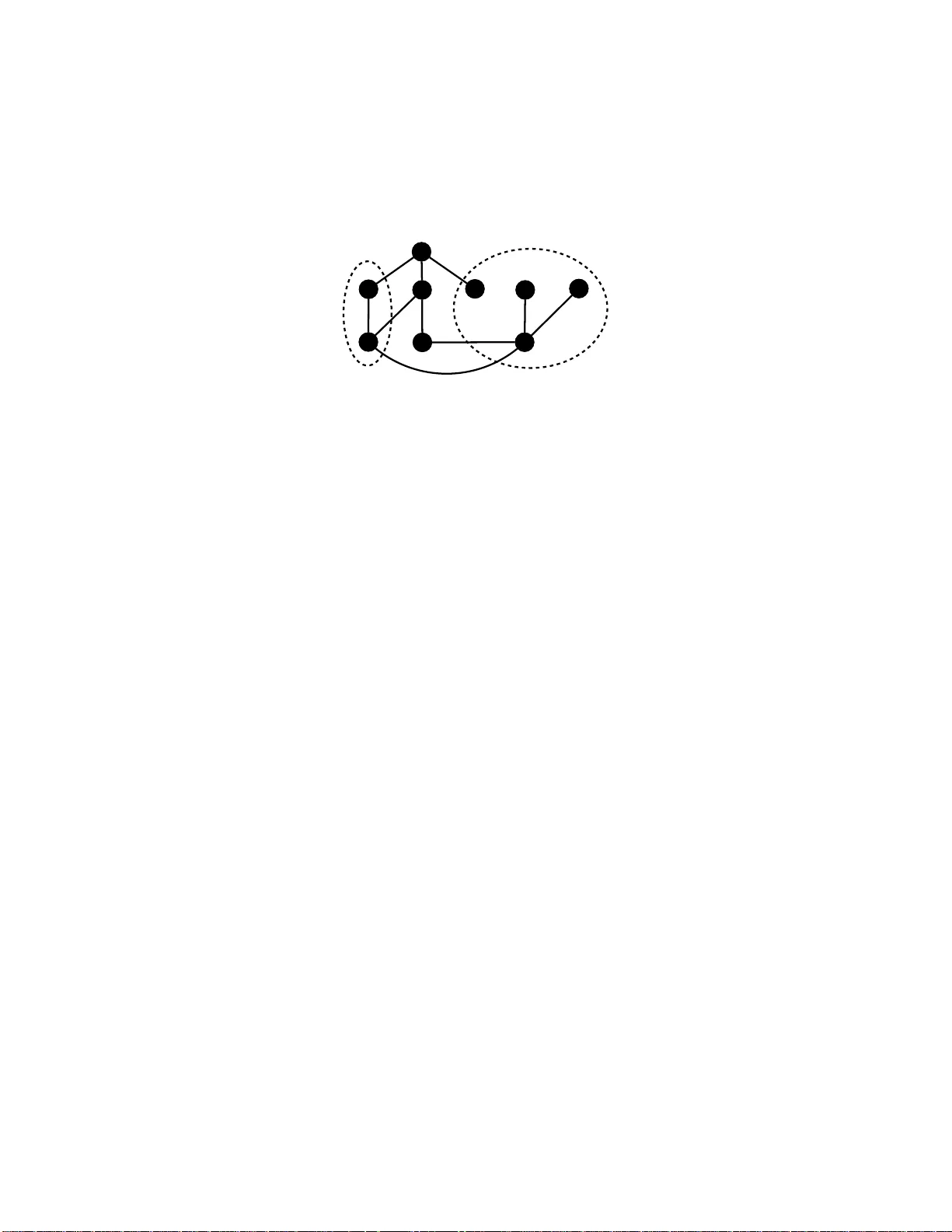
LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK CHARANP AL DHANJAL AND ST ´ EPHAN CL ´ EMENC ¸ ON T ´ el ´ ec om ParisT e ch, 46 rue Barr ault, 75634 Paris Ce dex 13, F r anc e Abstract. The problem of searching for exp erts in a give n academic field i s h ugely imp ortant in b oth i ndustry and academia. W e study exactly this issue with respect to a database of authors and their pub li cations. The idea is to use Laten t Seman tic Indexing (LSI) and Latent Dirichlet Allo cation (LD A) to perf orm topic mo delling in or der to find authors who hav e work ed in a query field. W e then construct a coauth orship graph and motiv ate the use of influence maximisation and a v ariet y of graph cen tralit y measures to obtain a rank ed list of exp erts. The ranked l ists are further improv ed using a Marko v Chain- based rank aggregation approac h. The complete method is r eadily scalable to large datasets. T o demonstrate the efficacy of the approac h we rep ort on an extensiv e set of computational simulations using the Ar netminer dataset . An improv emen t in mean av erage precision is demonstrated o ver the baseline case of simply using the order of authors found by the topic mo dels. 1. Introduction Ident ifying exp erts is a v aluable task for finding coauthors for a new research pro ject or grant , as signing reviewers for the p eer- review of an article or employing consultants. In so - called Reputation Systems [23] one has explicit ra tings of reputa- tion such seller feedback provided o n the eBay online auction site. Her e we addr ess the more challenging problem of estimating the r eputation of authors in a netw or k of authors and their publicatio ns. In a g e ne r al sense, one must fir st ev alua te the domain(s) of author s and then grade their exp ertise b y the num b e r and quality o f publications in p eer-reviewed journal and conferences. The particular problem under study is stated in a more forma l setting as fo l- lows. An undirected g r aph G = ( V , E ) is comp osed o f vertices { v 1 , . . . , v n } = V and edges E ⊆ V × V in which vertices re pr esent authors and edges repres en t connections betw een the authors , for example common mediums of influence such as co authorship o r citation. Each vertex has a list of articles ass ocia ted with it, representing an author’s publications. The first questio n is ho w can o ne find all authors who hav e worked in a given domain D i ⊂ V based on their publications . Next, consider a class of scoring functions ov er the vertices in D i , f ∈ F , and an unordered set o f top k vertices S i = { v x 1 , u v 2 , . . . u v k } ⊂ D i . Our ta sk is to find a ranking function clos e to the or acle f ∗ for which the top k ranked elemen ts are E-mail addr ess : { charan pal.dhanjal, stephan.cl emencon } @tele com-pariste ch.fr . Date : October 7, 2018. Key wor ds and phr ases. reputation assessmen t, exp ert finding, graph centralit y , rank aggregation. 1 2 LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK ident ical to S i . Thu s, the lea rning problem is to identify the c hara cteristics of a reputable author in do main D i in the space o f functions F . 1 2 3 4 5 6 Figure 1. A graph o f authors and co nnections, with the authors in the domain of interest circled. If w e take the num ber of edges incident to a v ertex as a measure of its exp ertise then we can see that author 3 has the most exper tise as he/she has 3 edg e s to other authors in the same doma in. T o tackle this proble m we first study the titles and abstr acts corr esp o nding to the ar ticles written by e a c h author using Latent Sema n tic Indexing (LSI, [6]) and Latent Dir c hlet Allo cation (LDA , [4 ]). These are tw o popula r a nd effectiv e topic modelling algorithms, and readily s calable to the large datas et typically in use. This step identifies author s within the field of interest. W e then cons truct a coauthorship graph using the author s found in this step (see Fig ure 1), and use a v ar iet y o f centrality measures to scor e and rank vertices in that pa rticular domain. F urthermo re, to leverage the rankings we ex amine rank ag gregation fo r the task of exper t pre dic tio n. The chief novelt y o f this pa per is the use of e fficie n t topic mo delling appr oaches and state-of-the-a r t graph-based algo rithms in co m bination with rank a ggrega tion to study this problem. W e start by des c r ibing our appro ach to the domain ident ificatio n of the authors in Section 2. F ollowing, we outline a n umber of centrality measure s in g raphs and how the r anking of vertices of these measures c a n b e a ggrega ted in Sectio ns 3 a nd 4 r espectively . Section 5 reviews related work in this area, and then w e present computationa l r esults on a la rge author- publication dataset in Section 6. A summary a nd so me p ersp ectives are g iv en in the final section. 2. Domain I dentifica tion It is a common problem in info r mation r e triev al to r ecov er do cumen ts corre- sp onding to a par ticular sub ject and here we briefly review LSI and LD A and their online v ariants for this purp ose. Imagine that one has a set T = { d 1 , . . . , d m } of doc umen ts and we wish to discov er the subset o f those do cumen ts in a particular domain. The first step is to prepro c ess the words using a P orter Stemmer [28] to amalgamate w ords with the same bas e such as “learning” and “ learned”. One then finds a b ag of ℓ -gr ams representation of the do cuments whic h is essentially a count of eac h sequence of ℓ consecutive w or ds in the do cuments. This enables the identification of imp ortant word co ncurrences such a s “s ing ular v alues” whic h would b e lost if a bag of w ords (1-gra m) repr esen tation was used. This representation can be impro ved by remov- ing sto p w or ds such as “ a nd” and “ the” which are common and do not conv ey LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK 3 information useful for discr imination. At the end o f this pro cess we hav e a set of terms ( n - grams) and do cumen ts, and o ccurr e nc e s of terms within the do cuments. Rather than use this data directly it is often useful to re present do cument s us - ing the term fr e qu ency/inverse do cument fr e quency (TF-IDF, [2 4]) repr esentation. Assume that there are m do cuments and k j app ears in n i of them so that F ij is the num ber of times k i app ears in do cument d j . The no rmalised term frequency is defined as: TF i,j = F ij max z F z j , where the maximum is computed over all frequencies F z j for do cument d j . F requent keyw ords may not b e us eful and hence o ne also uses inv ers e do cumen t frequency , defined for a k eyword k i as IDF i = log | T | n i . The TF-IDF weigh t for a keyword k i in do cument d i is then X j i = TF i,j × IDF i and each do cument can be repr e sen ted using a v ector of keyw or d w eights. In this wa y similar v ectors corresp ond to similar do cuments. In LSI, a pa rtial Singular V alue Decompo sition (SVD, [11]) is perfo r med on the TF-IDF matrix X to determine relationships betw een the terms and sema n tic concepts represen ted in the tex t. The SVD of X ∈ R m × ℓ is the decomp osition X = PΣQ T , where P = [ p 1 , . . . , p r ], Q = [ q 1 , . . . , q r ] a re respective matrices who se co lumns are left and r igh t sing ula r vectors, and Σ = diag( σ 1 , . . . , σ r ) is a diago nal matrix of singular v a lues σ 1 ≥ σ 2 ≥ , . . . , ≥ σ r , with r = min( m, n ). The matrix P can be thought of a mapping from do cuments to a sema n tic concept, Q is a mapping from terms to concepts and Σ is a sca ling of the columns and ro ws respectively of these matrices. By taking the par tial SVD one chooses the singula r v alues and vectors cor r esp o nding to the lar gest k singular v alues, denoted b y P k , Σ k and Q k resp ectively . This truncatio n has the effect of retaining the imp orta n t co ncepts whilst removing nois e in the concept space of X . Notice that X is t ypically a sparse matrix and hence one can use efficient metho ds for computing the SVD such as Lanczo s or Arno ldi (e.g. PROP ACK [17]) or randomised metho ds [12]. In the later exp eriment s we use the multipass sto chastic online L SI a lgorithm pr esent ed in [20 ]. LD A is a gener ative model that explains a se t of do cument s using a small set of topics . It assumes a set o f k topics ab out the set of do cuments T . E ach topic is drawn from a Dirichlet distribution β ℓ ∈ Dir ic hlet( η ). F or each do cumen t d j one dra ws a distribution ov er topics θ d j ∈ Diric hlet( α ). F or each word t i in the do cumen t one draws a to pic index z d j ,t i ∈ { 1 , . . . , k } with weigh ts z d j ,t i ∈ θ d j . The observed word is then dr a wn from t j i ∈ β z d j ,t i . T o infer the distributions in this mo del, one uses a v ariational Bayes approximation of the p osterior distr ibution. In our later computational w ork, we us e the online v aria nt of LD A g iv en in [14]. One a pproach to ev a luate the similarit y of a query to the tra ining do cumen ts is to map the query and do cumen ts to the LSI o r LDA s pa ce and find the highest cosine of the ang le b etw een them, kno wn as c osine simila rity . Note that the cosine of the angle b et ween t wo vectors a a nd b is given b y c o s( θ ) = a T b / ( k a kk b k ). If we 4 LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK fix a threshold γ and find all do cuments with cos( θ ) > γ a nd then the corresp onding authors, we have tw o e ffectiv e metho ds of identifying autho r s in the quer y do ma in. 3. Ranking Exper ts Once we hav e a collection of authors who hav e published under a particular domain, we can extract the cor resp onding coauthorship graph and use this graph to rank author s by their exp ertise. T o do so we draw up on state-of-the-art results in gr aph structure analysis a nd r ank aggr egation. The key idea is to construct F in suc h a way that we encaps ulate the main characteristics of reputatio n. F o r that re ason, we consider six measures : influ enc e maximisatio n [15], PageR ank , hub sc or e , closeness c entra lity , de gr e es , and b etwe enness , and motiv ate their use. 3.1. Influence M axim isation. Influence maximisation is a n in tuitive way to mea- sure the r eputation in an a utho rship graph. T o find the most influential vertices we firs t introduce the conce pt of gr aph p er c olation in which v ertices within a g raph hav e a binary state: either active or inactive. A p ercolation pro cess decides how activ a tion spreads within the gr aph. The pr oblem of influence max imisation is to find the k vertices which result in the lar gest total spread of activ ation a t the end of the pro cess 1 . In epidemic spread, for example, finding the most influential v ertices may help to devise effective control strateg ie s . A binary p ercola tion pro cess P computes in an iterative manner which vertices will b e active in the next iteration base d on the edg e s and thos e that ar e curr en tly active, and contin ues until no mo re activ ations o ccur. Let σ P ( G, A ) b e the num b er of ac tive vertices at the end of a p erco lation pro ces s defined b y P , over graph G and with an initial s et of active vertices A . Figure 2 demonstrates a pe r colation pro cess within a simple g raph. A commonly studied p erco lation pro cess is the Indep endent Casc ade mo del . F or this model, there is a probability p ij on an edg e from v i to v j which allows a random decision to b e taken for the activity of v j given that v i is active. The p ercolation then pro ceeds as follows: at time step t when a vertex v i first b ecomes active it is given a single c hance to activ ate eac h of its neighbours n ( v i ) according to the edge pro babilities. If v i succeeds then the corresp onding vertices become active in the next time step. If not then no further attempts ar e made in subsequent rounds. 1 1 1 Figure 2 . Percolation within a graph. V ertices in black are active and activ ation spreads to o ther vertices in an iter ative manner . The initial activ e set is A = { 1 } and σ P ( G, A ) = 6 in this case. 1 A percolation pro cess can b e said to be concluded when there are no additional activ ations/disactiv ations. LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK 5 The problem of computing the maximal influence is: giv en a graph G and pro- cess P which subse t A ⊆ V of k = | A | < n vertices should b e c hosen to ensur e maximal activ a tion σ P ( G, A ) at the end o f the pro cess? This optimisa tio n corr e- sp onds to a combinatorial problem that is NP-hard in g eneral. The authors of [1 5] tackle this problem for the Line a r Thr eshold and the Independent Cascade mo d- els, and provide greedy alg orithms to max imise influence. The key obse r v ation is that the influence function σ P ( G, A ) is submo dular for these p ercolation mo dels. A submo dular function is o ne in whic h th ere ar e diminishing r eturns. P rovided that σ P ( G, A ) is submo dular and mo notone, a simple O ( nk ) gr e edy algor ithm exists for choosing th e most influen tial v ertices, see [15] for more details. A faster v ariant of this algor ithm, known as Cost Effective Lazy F orward s election (CELF), is given in [18] in which computational savings are made by using the submo dularity prop erty and the previous influences of each vertex at each stage. 3.2. Graph Centra li t y M easures. Closely related to the influence of v ertices within a graph is the idea of g raph centrality , and he r e we outline several useful measures. W e beg in with PageRank whic h was desig ned to r a nk W eb pages using the graph of hyperlinks, ho wev er since then has been applied to ma n y other t yp es of gr aph. The k ey intuition of P ageRa nk is that a h yp erlink to a pa ge co unts as a vote of suppo rt, and h yp erlinks from “importa nt” pag es are weigh ted higher than unim- po rtant ones. In this sense Pagerank is defined r ecursively and dep e nds on the PageRank metric of a ll pag e s that link to it (incoming links). A page that is linked to by many pa ges with high PageRank rece iv es a high ra nk itself. The idea is link ed closely to the concept of p erfor ming a ra ndom walk o n a gra ph. F o r a directed graph G P ageRank is defined as follows: P ( u ) = 1 − | V | D + D X n in ( u ) P ( v ) | n out ( v ) | , where n in ( u ) is the set of all vertices with edg es directed tow ards u , n out ( u ) is a set of v ertices with edges directed from u and D is a damping factor betw een 0 and 1 which is used to enable the rando m walk er to jump out of cycles. A precur sor to PageRank is the hu b score (HS, [16]) of the vertices in a graph. In short, a h ub is a catalog ue of infor mation that p oints to authority pages. A highly rated h ub p o in ts to many authority page s , and a go o d a uthority is r e fer enced by many hubs. T o compute the h ub score we initialise tw o scor es h ( v ) = 1 a nd a ( v ) = 1 for a ll v ∈ V . T o update these sc o res one per forms mutual rec ur sion as follo ws: a ( v ) = X u ∈ n in ( v ) h ( u ) , and h ( v ) = X u ∈ n out ( v ) a ( u ) , and one norma lises uses the 2- no rm of the corr espo nding scores after each iter ation to a llow c o n vergence. Another use ful measure which we s hall use for our analysis is b etw eenness, which is the num be r of times a sho r test path pa ssed through a certa in vertex. In tuitiv ely , 6 LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK this quantifies the importance of the v ertex in terms of linking other v ertices. It is defined more fo r mally a s B ( u ) = X v, w ∈ V \ u σ vw ( u ) σ vw , where σ vw ( u ) is the num ber of s hortest paths fro m v to w that pass through u and σ vw is the total n umber o f paths betw een v and w . Next w e loo k at closeness cen trality [10] whic h is a measur e of how close all other vertices are to the current one. One way o f consider ing this type o f centralit y is how long it would tak e for information to sprea d to other vertices in the net work, and hence it makes sense for the type of netw or k considered. The closeness centralit y is defined as f ollows: C ( u ) = 1 P v ∈ V \ u d ( u, v ) , where d ( u, v ) is the dis tance betw een u and v . Hence closeness cen trality is the inv erse o f the average length o f the shortest paths to a ll o ther v ertices in the graph. Finally w e also use the degree of vertices as a meas ure of their cen trality where the degree is simply the n um b er of edges inciden t to a v ertex. 4. Aggre ga ting Rankings In this section we show how to combine the ra nk ings given by the a bove central- it y measures. Rank aggrega tion has been studied using Borda count [1], median rank aggr egation [9] and Ma rko v Cha ins [8 ]. Her e w e detail the p opular Mar ko v chain metho d of [8]. T he principal adv antages of Mark ov Chain based ra nk aggre- gation metho ds is that they c a n work with partial lis ts , are efficient, and s ho wn to outp e rform o ther metho ds in [22]. The setup for rank aggr egation is describ ed as follows. Consider a set o f elements D and an order e d list τ w ho se elements a re a subset of the elements o f D , τ = [ x 1 ≥ x 2 ≥ . . . ≥ x | τ | ] with x i ∈ D , whe r e ≥ is an order ing relation on D . If τ contains all the elements in D it is c alled a ful l list otherwise it is a p artial or top - k list for which only the first k elements a re present. In the cas e of r a nk ag gregation we hav e a n umber of ranked lists τ 1 , . . . τ n and w e also hav e an ideal ranking τ ∗ . The goa l is to find an ag gregation function φ : τ 1 , . . . , τ ℓ 7→ x , where x is a s core v ector for all entries, s uc h that the ordering acco rding to x is as clo se to τ ∗ as p ossible. In the MC 2 mo del of [8] we construct a Ma r ko v c hain which is a state transitio n machine in which a transition to a new state is dep endent only on the cur rent one. Each item x i ∈ D is represented b y a state a nd then a ranking list τ j is selected rando mly suc h that x i is an element of τ j . O ne then selects a r andom state unifor mly fr om the elements in τ j which ar e not ranked lower than x i . Mor e formally , define the k th tr ansition matrix as P ( k ) such that P ( k ) ij is the conditional probability o f sta te x j given state x i and ranking list τ k . W e ha ve P ( k ) ij = 1 q x j ≥ x i 0 otherwise , where q = |{ x j | x j ≥ τ k x i }| . The final transition matrix is given by the mean of the individual matrices for eac h ranked list, R = 1 ℓ P ℓ i =1 P ( i ) . The score v ector is LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK 7 then computed a s the stationary distribution x = R T x such that P | D | i =1 x i = 1 and x i > 0 for i = 1 , . . . , | D | . 5. Rela ted Work A k ey driver of exp ert recommenda tion in recent years ha s b een the exper t finding task in the TREC En terprise tra c k in 200 5 [5]. The data presen t in this task includes email o n public mailing lists, c ode and web pa g es extr acted fro m the W orld Wide W eb Consortium (W3C) sites in June 2004 . The task co nsisted of ranking 1 092 exp erts from the 33 1,037 do cuments av ailable. Two types of mo del app eared from this task [2, 3]: candidate a nd do cumen t models. In candida te mo dels, o ne builds a textual representation of the exper ts and ranks them based on a quer y . In do cument based mo dels, one first finds do cuments relev an t to the query and then lo cates asso ciated exp erts. In o ur w ork we use a mixture of these t wo ideas. F or aca demic netw orks, the topic of dis c o vering exp erts using gr aphs has b een studied in co njunction with th e Arnetminer [27] academic databas e and so cial net- work in [25]. Unlike our work which incor por ates topic lea rning a s part of the pro cess, the author s lab el ea ch member of the so cial netw ork with a pre-a ssigned topic vector, and then try to mea s ure influence in the net w or k. A T opical Affin- it y Propag ation (T AP) mo del is prop osed which optimises the topic-level so cial influence on a net w ork . In [7] which fo cuses on the exp ert seeking task on the Digital Bibliography and Library Pro ject (DBLP) dataset, three mo dels are propo sed, namely a Bayesian statistical language mo de l, a topic-based mo del and a h ybrid one. One of the key parts of the mo del is computing pr ior proba bilities of a utho rs using cita tio n data which is used in conjunction with the la nguage-base d ra nking of a uthors. Note that each ar ticle is augmented with similar do cumen ts e x tracted from Goo g le Scholar which we do not use in o ur exp eriments. The exp erts are manually g raded on a sc ale from 0 − 3 and the lea rning system is tested aga inst these ratings with fa vourable results to rela ted a lgorithms in [19, 29]. In [19], the authors aug men t the DBLP data w ith Go ogle sea r c h results as w ell as publication rankings from Citeseer. A mor e scientometric a ppr oach is g iv en in [13] which uses meas ures such as bibliographic coupling (t wo authors A1 and A2 are linked if they cite the sa me references) and a uthor co citation to r ecommend similar author s. In this pap er there is not a f o cus o n finding the most influen tial author s . Alo ng the same lines, there ar e a num b er o f other metrics one could use to rate the reputation o f authors in a particular domain such a s h -index and impact fac to r. The h -index is the largest nu mber h such that h publications hav e at lea st h citations and impact factor 2 of a jour nal is the average num b er o f citations in the t wo preceding years. 6. Simula tions In this se c tio n we ev aluate the exp ertise ra nking a lgorithms by compar ing them to the bas eline ca se o f using the author order giv en solely using topic mo delling and not any g raph-based r anking scheme. The Arnetminer dataset [26] which is based on DBLP , is used. This dataset is a list of a rticles in co mputer s cience, alo ng with their a uthors, the publication ven ue, year and pap er a bstracts and citations for 2 Note that altho ugh this is the generally ac cepted definition of impact f actor, alternative definitions exist. 8 LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK Abbreviation Category Exp erts BS Bo osting 57 CV Computer Visio n 215 CR Y Cryptogra ph y 174 DM Data Mining 351 IE Information Extraction 91 IA Int elligent Agents 30 ML Machine Learning 76 NLP Natural Language P ro cessing 54 NN Neural Net w orks 122 OA Ontology Alignment 56 PL Planning 26 SW Semantic W eb 412 SVM Suppo rt V ector Machines 111 T able 1. Summary of the information ab out exp erts ov er the Ar- netminer dataset. some a rticles. W e use v ers ion 5 of the da taset which contains 1,57 2,277 pap ers with 529,49 9 abstracts and is generated on 21 /2/201 1. W e wan t to observe the a ccuracy of our exper t finding approach on this datas et in conjunction with exper ts in 13 fields sugges ted on the Arnetminer web site. The exp ert lis ts are ge ne r ated using the Pr ogram Committee mem b ers of well know confere nces/workshops and the mem b ers on sites specific to a pa rticular field, for example on www.bo osting. org . The lists a re unordered and “noisy ” due to their nature, how ever still useful for the purp oses of ev aluation. W e us e the exp erts in the fields listed in T able 1. All exp eriment al co de is written in Python and we use the Gensim library [2 1] for topic mo delling. Before pre dicting a set of exp erts, we p erform mo del s e lection for our learning algorithm a nd hence split the exp erts into a 50:5 0 training/tes t set. The w or d vectoriser is set up as describ ed ab ov e on the title a nd abstra c ts o f articles for 1 and 2-gra ms with term counts included if the ter m fr e q uency is in at least a prop ortio n ρ ∈ { 10 − 3 , 10 − 4 } of the total num b er of do cuments. Since the do cuments b eing pro cessed are typically small we use binary indicators for ter ms. F or LSI we take the SVD of this ma trix using the randomised SVD metho d of [12] with an exp onent of q = 2 a nd ov ersampling of p = 100 and take k ∈ { 100 , 200 , . . . , 600 } . After this stage, we find similar do cuments to a quer y term (the field) using the method outlined ab ov e and a cosine similarity threshold of γ ∈ { 0 . 0 , 0 . 1 , . . . , 0 . 9 } . Each author in this set is then scored b y summing the co sine similarit y of their articles and we take the first x author s acc o rding to their score (denote this set of authors as U ). In this case x is 10 times the n umber of tr aining experts. F or LD A w e c ho ose the num b er of topics in k ∈ { 100 , 20 0 , . . . , 600 } and otherwise use an ide ntical pro cess. The o ptimal mo del is s elected by cho osing parameters which result in the largest n um b er o f tra ining exp erts across the complete set of 1 3 fields. After model selection, the a uthors in U ar e po sitioned in a coa uthorship g raph in which an edge exists only if tw o authors u, v ∈ U ha ve colla b or a ted. Edges in this graph a re weigh ted a ccording to the num ber of articles written by the c orresp onding pair of a utho r s. W e compute each centrality metric over the weighted graph and LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK 9 use the in verse of the w eights for the computation of betw eenness and closenes s centralit y . Th is implies for example that t wo authors who hav e collab or ated 5 times hav e an edg e w eight betw een them of 1 / 5 and thus ar e more likely to be on a sho rtest path than adjacent authors who have co lla bo r ated less frequently . F or influence max imisation we obtain the 10 0 most influen tial authors using 100 rep etition of the indep endent cascade mo del with transitio n probability p = 0 . 05. W e also r ecord the order of autho r s given b y the topic mo delling appro aches a nd that given b y sor ting a uthors acco rding to the total num b er of citations for ar ticles in U . The rankings are ev aluated using the test s et with the Mean Av erag e Precision (MAP) at N metric. The pr e cision at N is the num b er of exp erts in the first N items of the rank ed list of authors divided b y N or equiv alently p @ N = tp tp + f p , where tp is the num b er o f true p ositives and f p is the num ber of false positives. Precisio n falls within the range [0 , 1] with 1 signifying that a ll items at the top of the list a re exp erts. The aver age pr e cision is the a verage of all precisions for all of the experts: ap @ N = P N i =1 p @ i × rel( i ) R , where rel( i ) is an indicator function whic h is 1 for relev ant exp e rts and R is the nu mber of exp erts. MAP is simply the average pr ecision ov er all the queries. W e lo ok at MAP for N ∈ { 5 , 10 , . . . , 50 } . Note that to compute these precisio ns fo r the test exp erts we remov e the training exp erts from the rankings, and vice versa. After computing the gr aph and topic-ba sed rankings , we use the MC2 a lgorithm of [8] to aggre g ate ra nkings from each field in a gr eedy fashion: using the tr aining expe r ts we pick the ranking with the b est ap @20 score then cho ose additional rankings that give the best marginal gain until no improv ement is o btained. The pro por tion of training exp erts cov ered by LSA topic mo delling is a ppr oxi- mately 0.381 using k = 500 , ρ = 10 − 4 and γ = 0 . 3 . This indicates the difficult y of finding relev a n t a uthors using this data set. It is worth noting that among st the complete set of exp erts, a mean prop ortion of 0.4 of their articles also hav e abstracts and we b elieve results could b e improv ed with a higher propor tion of ab- stracts. LD A was less effectiv e than LSI at recov ering the tr a ining experts during mo del selection with a mean cov era ge of 0 .318 ov er all the fields, using k = 400, ρ = 10 − 3 and γ = 0 . 4. T able 2 shows the MAP v a lues on the test exp erts in conjunction with the au- thors re tur ned using LSI. In this table we see that the strong est single metho d is betw eenness follow ed by the citation and topic or ders. A possible reason for the efficacy of b etw eenness is that r eputable authors a re a lso so cial and attract c o llab- orations and hence pa rticipate in ma n y shortest paths in the coauthorship gr aph. Citation is a go o d indicatio n of r eputation since citations ar e o ften p ositive v otes ab out the v a lue a nd qua lit y of a pap er. W e obse rved that the relative p erformances of the r ankings v aried b etw een fields. In Ontology Alignment for example the ap @ 50 score for the citation r anking was 0.0 8 versus 0.163 for b etw eenness. A pa rticularly challenging field was Neural Net works which w as ranked b est using influence with ap @5 = 0 . 05 and ap @ 5 0 = 0 . 058. A p oss ible reason is that Neural Netw orks cov- ers a la rge ra nge of to pics bo th in biology and machine learning. In contrast, we 10 LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK N T opic Cit. Bet. Cls PR D gr Inf. HS MC 2 5 0.152 0.170 0.196 0.130 0.129 0 .065 0.1 12 0.0 00 0.250 10 0 .109 0.133 0 .122 0.09 4 0.098 0.046 0.07 7 0.00 4 0.176 15 0.092 0.138 0.108 0.0 95 0.090 0.038 0.0 75 0.0 07 0.165 20 0 .087 0.141 0 .110 0.09 2 0.086 0.036 0.07 7 0.00 8 0.161 25 0 .088 0.139 0 .107 0.09 3 0.084 0.033 0.08 0 0.00 9 0.157 30 0.087 0.143 0.109 0.0 92 0.086 0.032 0.0 83 0.0 13 0.162 35 0 .086 0.146 0 .118 0.09 6 0.085 0.033 0.08 5 0.01 3 0.165 40 0.088 0.147 0.122 0.0 98 0.086 0.033 0.0 85 0.0 18 0.163 45 0 .087 0.150 0 .124 0.09 8 0.088 0.034 0.08 5 0.01 9 0.166 50 0 .089 0.152 0 .126 0.09 9 0.089 0.034 0.08 5 0.02 2 0.168 T able 2. MAP v alues at e ach v a lue of N for the rankings using LSI for topic mo delling. Abbreviations: T o pic (LDA o rder), Cit. (citation order ), Bet. (b e t weenness), Cls (closeness), PR (PageR- ank), Dgr (degree), Inf. (influence), HS (h ub sc o re) and MC 2 is the Mark ov chain mo del of [8]. obtained ap @5 = 0 . 7 6 with Data Mining using b etw eenness a nd a p @5 = 0 . 76 for Information Extraction using the citatio n ra nking. A significant improvemen t is gained by agg regating the rankings of the topic mo delling or de r , citation ranking and b etw eenness ranking. W e see that ap @5 improv es fr om 0.1 9 6 using b et weenness to 0 .2 50 with MC 2 and ap @ 50 improves from 0.152 with citations to 0.168 . T able 3 shows the corresp onding results using LD A for topic mo delling. The bes t p erfor ming ra nk metho ds were closeness a nd PageRank with ap @5 score s of 0.137 and 0 .134 resp ectively . They improve significant ly ov er the baseline topic order score (denoted “T opic” in the table) of 0.11 1. Interestingly , the citation-base d ranking do es not per form well in this case b ecause mor e irrelev ant, but highly cited, authors a re found in U relative to LSI. The r ank aggr egate of our greedy MC 2 algorithm g iv es a slight improv ement ov er the using clo seness centrality . When considering individua l fields, the compa rison to LSI is more complicated. In the case of Semantic W eb for example, PageRank gives a p @5 of 0.483 using LSI and 0.8 using L DA. As with LSI how ever, LDA scores p o o rly when the domain is Neur al Net works. 7. Conclusions W e prop osed a n appro ach for finding exp erts in a set of authors and their publi- cations. The metho d uses w ell-known topic modelling algorithms LSI and LD A to ident ify authors within the query domain, and then c onstruct a co authorship g raph using these a uthors. In turn, the g raph is used for the ex traction o f exp ert ra nk ings using a num b er of cen trality meas ures. F urthermo re, w e explore the use of a rank aggre g ation approach to leverage the o rderings a nd impr o ve rank ings. Co mputa- tional results on the large Arnetminer dataset show that the citation ranking and betw eenness in co njunction with LSI for topic mo delling provide the most precise single-ra nk estimates of exp erts, ho wev er these rankings are improved significantly using a ggrega tions. LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK 11 N T opic Cit. Bet. Cls PR D gr Inf. HS MC 2 5 0.111 0.065 0.108 0.1 37 0.134 0.033 0.0 82 0.0 00 0.142 10 0 .076 0.060 0 .086 0.10 1 0.084 0.028 0.06 6 0.00 6 0.109 15 0.074 0.058 0.075 0.0 98 0.083 0.027 0.0 61 0.0 09 0.108 20 0 .070 0.057 0 .070 0.10 5 0.081 0.026 0.05 7 0.01 4 0.108 25 0 .074 0.057 0 .072 0.10 2 0.077 0.028 0.05 7 0.01 6 0.104 30 0.076 0.061 0.071 0.1 04 0.077 0.028 0.0 58 0.0 21 0.107 35 0 .078 0.061 0 .074 0.10 6 0.076 0.030 0.05 7 0.02 3 0.111 40 0.080 0.061 0.077 0.1 10 0.075 0.033 0.0 59 0.0 25 0.111 45 0 .078 0.062 0 .076 0.11 1 0.075 0.033 0.05 9 0.02 8 0.111 50 0 .080 0.065 0 .077 0.11 1 0.077 0.034 0.06 0 0.03 2 0.110 T able 3. MAP v alues at e ach v a lue of N for the rankings using LD A for topic modelling. Abbreviations: T opic (LD A o rder), Cit. (citation order ), Bet. (b e t weenness), Cls (closeness), PR (PageR- ank), Dgr (degree), Inf. (influence), HS (h ub sc o re) and MC 2 is the Mark ov chain mo del of [8]. Ackno wledgements This w ork is funded b y the Eurostar s ERASM pro ject. References [1] J. A. Aslam and M. Mon tague. Mo dels for met asearch. In Pr o c e e dings of the 24th annual international ACM SIGIR c onfer e nc e on R ese ar ch and development in information r etrieval , pages 276–284 . ACM, 2001. [2] P . B ai ley , N. Craswe ll, A. P . de V r ies, and I. Sob oroff. Overview of the trec 2007 ent erpris e trac k. 2007. [3] K. Balog, I. Sob oroff, P . Thomas, P . Bail ey , N. Craswell, and A. P . de V ries. Ov erview of the trec 2008 en terprise track. 2008. [4] D. M. Blei, A. Y. N g, and M. I. Jordan. Laten t dir ic hlet allo cation. the Journal of machine L e arning r ese ar ch , 3:993–1022, 2003. [5] N. Cr asw ell, A. P . de V ri es, and I. Soboroff. Overview of th e trec-2005 enterprise track. In TREC 2005 con fer enc e notebo ok , pages 199–205, 2005. [6] S. C. Deerwester, S. T. Dumais, T. K. Landauer, G. W. F ur nas, and R. A. Harshman. Indexing by latent seman tic analysis. JASIS , 41(6):391–407 , 1990. [7] H. Deng, I. K i ng, and M. R. Lyu. F ormal mo dels f or exp ert finding on dblp bibli ograph y data. In Data Mining, 2008. ICDM’08. Eighth IEEE International Confer enc e on , pages 163–172. IEEE, 2008. [8] C. D w ork, R. Kumar, M. Naor, and D. Siv akumar. Rank aggregation metho ds for the web. In Pr o c e e dings of the 10th international c onfer enc e on World Wide Web , pages 613–622. ACM, 2001. [9] R. F agin, R. Kumar, and D. Siv akumar. Efficien t similarity search and classification via rank aggregation. In Pr o ce e dings of the 2003 A CM SIGMOD international c onfer enc e on Management of data , pages 301–312. ACM, 2003. [10] L. C. F reeman. Cen trality in s ocial net works conceptual clarification. So cial net works , 1(3):215–2 39, 1979. [11] G. H . Golub and C. F. V an Loan. Matrix c omputations , volume 3. JHUP , 2012. [12] N. Halko, P .-G. Martinsson, and J. A. T ropp. Finding structure with randomness: Probabilis- tic algorithms for constructing approximate matrix decompositions. SIAM r eview , 53(2):217– 288, 2011. [13] T. Heck , O. Hanraths, and W. G. Stock. Exp ert r ecommendat ion for knowledg e managemen t in academia. Pr o c e e dings of the A meric an So ciety for Information Scienc e a nd T e chnolo gy , 48(1):1–4, 2011. 12 LEARNING REPUT A TION IN AN A UTHORSHIP NETWORK [14] M. Hoffman, F. R. Bach, and D. M . Blei. Online learning for l aten t diric hlet allo cation. In advanc es i n neur al inf ormation pr o cessing sy stems , pages 856–864, 2010. [15] D. Kemp e, J. Kleinberg, and ´ E. T ar dos. Maximizing the spread of influence through a so cial net work. In Pr o ce e dings of the 9th A CM SIGKDD international c onfer enc e o n Know le dge disc overy and data mining , pages 137–146, 2003. [16] J. M. Kleinberg. Hubs, authorities, and communities. ACM Comp uting Surveys (CSUR) , 31(4es):5, 1999. [17] R. M. Larsen. Lancz os bidiagonalization with partial reorthogonalization. D AIMI R ep ort Series , 27(537), 1998. [18] J. Lesko v ec, A. Krause, C. Gu estrin, C. F aloutsos, J. V anBriesen, and N. Glance. Cost- effectiv e outbreak detec tion in net works. In Pr o c e e dings of the 13th ACM SIGKDD interna- tional co nfer enc e on Know le dge disc overy and data mining , pages 420–429. ACM, 2007. [19] J. Li, J. T ang, J. Zhang, Q. Luo, Y. Liu, and M. Hong. Eos: expertise oriented searc h using social netw orks. In Pr o ce e dings of the 16th international c onfer enc e on World Wide Web , pages 1271–12 72. ACM, 2007. [20] R. ˇ Reh u ˇ rek. Subspace trac king for late nt seman tic analysis. In A dvanc es in Information R etrieval , pages 289–300 . Springer, 2011. [21] R. ˇ Reh ˚ u ˇ r ek and P . So j k a. Softw are F ramework for T opic Mo delling with Large Corp ora. In Pr o c e e dings of the LREC 2010 Workshop on New Chal lenges fo r NLP F r ameworks , pages 45–50, V alletta, Malta, May 2010. ELR A. http:/ /is.muni.cz/p ublication/884893/en . [22] M. E. Renda and U. Straccia. W eb metasearc h: rank vs. score based rank aggregation meth- ods. In Pr o c e e dings of t he 2003 ACM symp osium on Applie d co mputing , pages 84 1–846. ACM, 2003. [23] P . Resnick, K. Kuw abara, R. Zec khauser, and E. F riedman. Reputation systems. Communi- c ations of t he ACM , 43(12):45–48, 2000. [24] G. Salton. Automa tic T ext Pr o cessing: The T r ansformation, Analysis, and R e trieval of . Addison-W esley , 1989. [25] J. T ang, J. Sun, C. W ang, and Z. Y ang. So cial i nfluence analysis i n large-scale net works. In Pr o c e ed ings of the 15th ACM SIGKDD i nternational c onfer enc e on K now le dge disc overy and data mining , pages 807–816. ACM, 2009. [26] J. T ang, J. Zhang, L. Y ao, J. Li, L. Zhang, and Z. Su. Arnetminer: extraction and m ining of academic so cial netw orks. In Pr o ce e dings of the 14th ACM SIGKDD international c onfer enc e on Know le dge disc overy and data mining , pages 990–998. ACM, 2008. [27] J. T ang, J. Zhang, D. Zhang, L. Y ao, C. Zhu, J.-Z. Li, et al. Arnetminer: An exp ertise orient ed search system f or w eb communit y . In Semantic Web Chal lenge , 2007. [28] C. J. V an R i jsb er gen, S. E. R obertson, and M. F. Porte r. New mo dels in p r ob abilistic inf or- mation retrieval . Computer Lab oratory , University of Cambridge, 1980. [29] J. Zhang, J. T ang, and J. Li. Exp ert finding in a so cial netw ork. In Ad vanc es i n Datab ases: Conc e pts, Sy stems and Applic ations , pages 1066–1069. Springer, 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment