Reinforcement Learning for Matrix Computations: PageRank as an Example
Reinforcement learning has gained wide popularity as a technique for simulation-driven approximate dynamic programming. A less known aspect is that the very reasons that make it effective in dynamic programming can also be leveraged for using it for …
Authors: Vivek S. Borkar, Adwaitvedant S. Mathkar
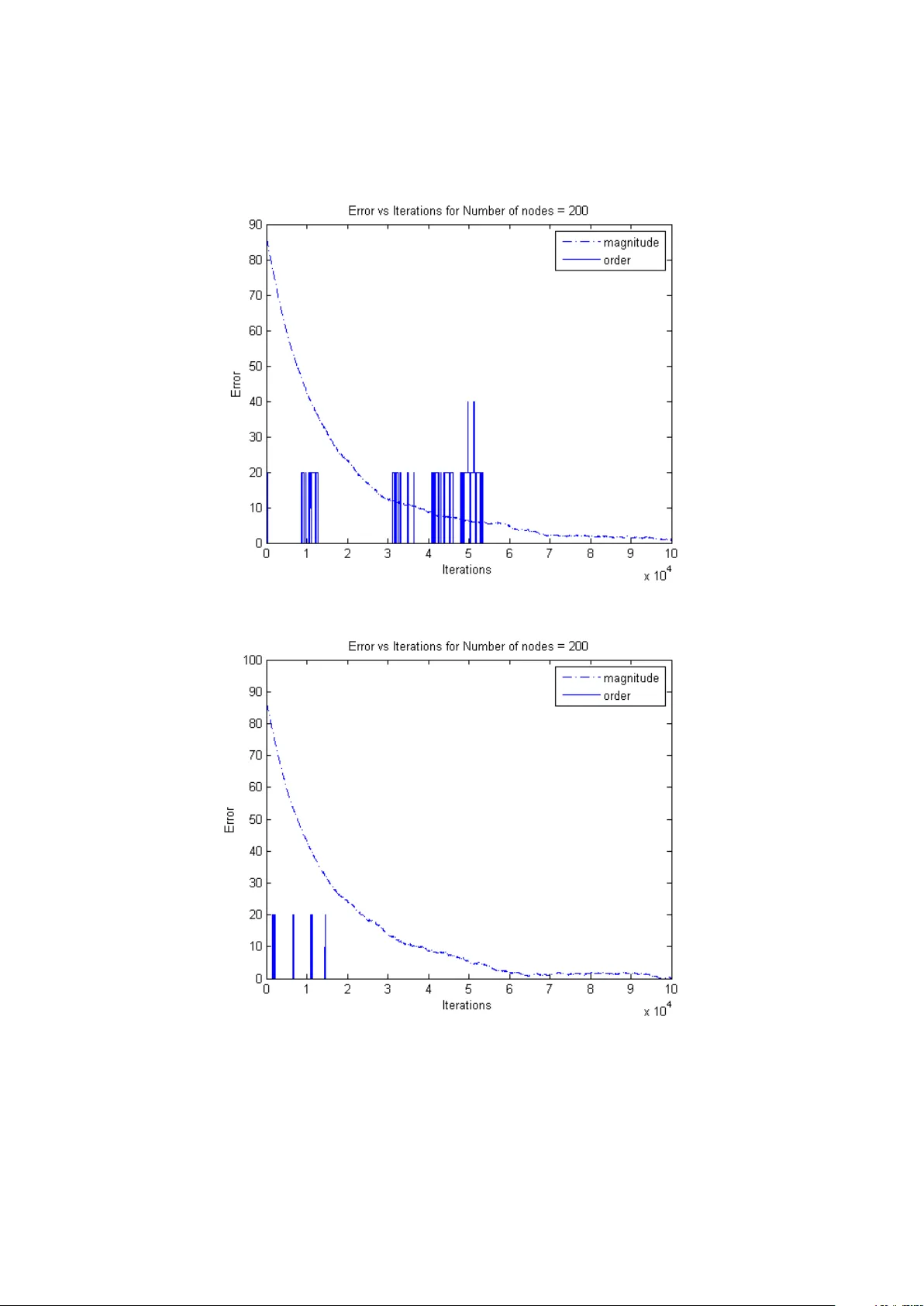
Reinforcemen t Learning for Matrix Computations: P ageRank as an Example Viv ek S. Bork ar and Adw aitvedan t S. Mathk ar Departmen t of Electrical Engineering, Indian Institute of T echnology , P ow ai, Mumbai 400076, India. { b ork ar.vs, mathk ar.adwaitv edant } @gmail.com Abstract. Reinforcemen t learning has gained wide p opularity as a tec hnique for sim ulation-driven approximate dynamic programming. A less known aspect is that the very reasons that make it effective in dynamic programming can also b e leveraged for using it for distributed schemes for certain matrix computa- tions in volving non-negativ e matrices. In this spirit, w e propose a reinforcement learning algorithm for PageRank computation that is fashioned after analogous sc hemes for approximate dynamic programming. The algorithm has the ad- v antage of ease of distributed implementation and more importantly , of b eing mo del-free, i.e., not dep endent on any specific assumptions ab out the transition probabilities in the random web-surfer mo del. W e analyze its conv ergence and finite time b eha vior and present some supp orting numerical experiments. Key w ords: Reinforcemen t Learning, PageRank, Stochastic Appro ximation, Sample Complexity 1 In tro duction Reinforcemen t learning has its ro ots in mo dels of animal b ehavior [1] and math- ematical psyc hology [2], [3]. The recen t resurgence of interest in the field, ho wev er, is prop elled b y applications to artificial in telligence and control en- gineering. By now there are several textb o ok accounts of this dev elopment [4] (Chapter 16), [5], [6], [7], [8], [9]. T o put things in con text, recall that metho d- ologically , reinforcemen t learning sits somewhere in b etw een sup ervised learning, whic h w orks with a reasonably accurate information regarding the p erformance gradien t or something analogous (e.g., parameter tuning of neural netw orks), and unsup ervised learning, which w orks without suc h explicit information (e.g., clustering). T o b e sp ecific, sup ervised learning is usually based up on an op- timization formulation such as minimizing an error measure, whic h calls for a higher quantum of information p er iterate. Reinforcemen t learning on the other hand has to manage with signals somehow correlated with performance, 1 but whic h fall short of the kind of information required for a typical supervised learning scheme. It then makes simple incremen tal corrections based on these ‘suggestiv e though inexact’ signals, usually with low per iterate computation. The latter asp ect has also made it a popular framew ork for mo dels of bounded rationalit y in economics [10]. Our interest is in its recen t a v atar as a sc heme for simulation-based metho dology for appro ximate dynamic programming for Mark ov decision processes which has found applications, among other things, in rob otics [11]. These can b e view ed as sto chastic appro ximation coun terparts of the classical iterative metho ds for solving dynamic programming equations, such as v alue and p olicy iteration. Sto c hastic appro ximation, introduced b y Robbins and Monro [12] as an itera- tiv e scheme for finding the ro ots of a nonlinear function giv en its noisy measure- men ts, is the basis of most adaptiv e sc hemes in control and signal processing. What it do es in the present context is to replace a conditional av erage app ear- ing on the right hand side of the classical iterative schemes (or their v ariants) b y an actual ev aluation at a simulated transition according to the conditional distribution in question. It then makes an incremen tal mov e tow ards the re- sulting random quantit y . That is, it takes a con vex combination of the current v alue and the random righ t hand side, with a slo wly decreasing w eight on the latter. The a v eraging properties of stochastic approximation then ensure that asymptotically you see the same limiting b ehavior as the original scheme. But there are other situations wherein one encoun ters iterations in volving condi- tional a verages. In fact, by pulling out ro w sums of a non-negativ e matrix in to a diagonal matrix pre-m ultiplier, we can write it as a pro duct of a diagonal matrix and a stochastic matrix. This allo ws us to cast iterations inv olving non-negativ e matrices as iterations in volving a veraging with resp ect to sto chastic matrices, making them amenable to the abov e methodology . This opens up the p ossibilit y of using reinforcement learning schemes for distributed matrix computations of certain kind. Important instances are plain v anilla av eraging and estimation of the P erron-F rob enius eigenv ectors [13]. Reinforcemen t learning literature is replete with means of curtailing the curse of dimensionality , a hazard only to o common in dynamic programming applications. This mac hinery then b ecomes a v ailable for suc h matrix computations. An imp ortant sp ecial case is the case of linear function approximation, wherein one appro ximates the desired v ector b y a weigh ted combination of a mo derate num ber of basis vectors, and then up dates these w eights instead of the entire vector [14]. In the present article, we illustrate this metho dology in the context of Go ogle’s P ageRank, an eigenv ector-based ranking scheme. It is primarily based on the stationary distribution π of the ‘random w eb-surfer’ Marko v c hain, equiv alently , the normalized left Perron-F rob enius eigenv ector of its transition probability matrix. This chain is defined on a directed graph wherein eac h node i is a web page. Let N ( i ) := the set of nodes to whic h i p oin ts. Let d ( i ) := |N ( i ) | and N := the total num b er of no des. The chain mo v es from i to j ∈ N ( i ) with a probabilit y (1 − c ) 1 d ( i ) + c N , and to any other no de in the graph with probability c N where c > 0 is the ‘Go ogle constan t’. The latter renders it irreducible, en- suring a unique stationary distribution. An excellent accoun t of the numerical 2 tec hniques for computing π , essentially based on the ‘p ow er metho d’ and its v ariants, app ears in [15], along with a brief historical accoun t. See also [16]. While a bulk of the work in this direction has been on efficient computations for the p ow er metho d, there hav e also b een alternative approac hes, such as Mark ov Chain Monte Carlo [17], [18], optimization based metho ds [19], and schemes based on sto c hastic appro ximation and/or gossip [20], [21], [22]. Suc h ‘sp ectral ranking’ techniques, made p opular by the success of PageRank, are in fact quite old. See [23] for a historical survey . Ev aluativ e exercises of this kind o ccur in other applications as well, such as reputation systems or p op- ularit y measures on social netw orks. In such applications (for that matter, in searc h), it is unclear whether the assumption that each j ∈ N ( i ) is equally im- p ortan t to i is reasonable. Motiv ated by this, we prop ose a mo del-free sc heme based on ideas from reinforcement learning. This idea has also b een discussed in [13]. The present sc heme, ho wev er, differs in an essen tial wa y from [13] in that whereas [13] views PageRank as a special instance of the general problem of eigenv ector estimation, we exploit the special structure of the random web- surfer mo del to simplify the problem to a simple linear sc heme. This is very m uch in tune with some of the works cited ab ov e (notably [20], [22]), but with a non-standard sample and up date rule. The outcome is an algorithm that can run on accumulated traces of no de-to-no de interactions without requiring us to explicitly estimate the probabilities asso ciated with these. The next section describ es our algorithm and its conv ergence analysis. Section 3 describ es finite time analysis and a v arian t of the basic sc heme. Section 4 presen ts some numerical exp erimen ts. Section 5 concludes with some general observ ations. 2 The Algorithm Let P be an N × N sto chastic matrix. Define ˆ P := cP + 1 − c N 1 · · · 1 . . . . . . . . . 1 · · · 1 . Let π denote the unique stationary probability distribution of ˆ P . That is, for 1 := [1 , 1 , · · · , 1] T , π = π ˆ P = π cP + π 1 − c N 1 · · · 1 . . . . . . . . . 1 · · · 1 = cπ P + 1 − c N 1 T ⇒ π ( I − cP ) = 1 − c N 1 T ⇒ π = 1 − c N 1 T ( I − cP ) − 1 . 3 Here π is a row v ector and every other vector is a column v ector. Since we are only interested in ranking we can neglect the factor 1 − c N . Thus by abuse of terminology , π T = 1 + cP T π T . T o estimate π , we run the following N dimensional sto chastic iteration. Sample ( X n , Y n ) as follows: Sample X n uniformly and indep endently from { 1 , 2 , ..., N } . Sample Y n with P ( Y n = j | X n = i ) = p ( i, j ), indep endent of all other random v ariables realized b efore n . Up date z n as follows: z n +1 ( i ) = z n ( i ) + a ( n )( I { X n +1 = i } (1 − z ( n )) + cz n ( X n +1 ) I { Y n +1 = i } ) , (1) where the step-sizes a ( n ) > 0 s atisfy P ∞ n =0 a ( n ) = ∞ and P ∞ n =0 a ( n ) 2 < ∞ . Hence z n ( i ) is updated only if X n +1 , Y n +1 or b oth are i. W e can write (1) as follo ws: z n +1 ( i ) = z n ( i ) + a ( n )( I { X n +1 = i } (1 − z ( n )) + cz n ( X n +1 ) p ( X n +1 , i ) + M n +1 ( i )) , where M n +1 := cz n ( X n +1 ) I { Y n +1 = i } − cz n ( X n +1 ) p ( X n +1 , i ) is a martingale difference sequence w.r.t. σ ( X m , Y m , m ≤ n ; X n +1 ). By Theorem 2, p. 81, [24], the ODE corresp onding to the iteration is ˙ z ( i ) = 1 N (1 + N X j =1 cz ( j ) p ( j, i ) − z ( i )) . In vector form, ˙ z = 1 N ( 1 + cP T z − z ) . Since the constan t 1 / N do esn’t affect the asymptotic b ehavior, w e consider ˙ z = ( 1 + cP T z − z ) =: h ( z ) . (2) Define h ∞ ( z ) := lim a ↑∞ h ( az ) a = cP T z − z . It is easy to see that h ( az ) a → h ∞ ( z ) uniformly on R N . Theorem 1: Under the ab ov e assumptions, z ( t ) → z ∗ a.s., where z ∗ is the unique solution to h ( z ∗ ) = 0. Pro of: Define V p ( z ( t )) := k z ( t ) − z ∗ k p , p ∈ [1 , ∞ ). As in the pro of of Theorem 2, p. 126, [24], for 1 < p < ∞ , ˙ V p ( z ( t )) ≤ k cP T ( z ( t ) − z ∗ ) k p − k z ( t ) − z ∗ k p . In tegrating, V p ( z ( t )) − V p ( z ( s )) ≤ Z t s k cP T ( z ( r ) − z ∗ ) k p − k z ( r ) − z ∗ k p dr . 4 Letting p ↓ 1, V 1 ( z ( t )) − V 1 ( z ( s )) ≤ Z t s k cP T ( z ( r ) − z ∗ ) k 1 − k z ( r ) − z ∗ k 1 dr , ≤ − Z t s (1 − c ) k z ( r ) − z ∗ k 1 dr , ≤ 0 , with equality iff z ( t ) = z ∗ . W e similarly get that V 1 ( z ( t )) := k z ( t ) k 1 is a Ly apunov function for the scaled o.d.e ˙ z ( t ) = h ∞ ( z ( t )) which has the origin as its globally asymptotically stable asymptotic equilibrium. By Theorem 9, p. 75, [24] , sup n k z ( n ) k < ∞ a.s. In turn (2) has z ∗ as its globally stable asymptotic equilibrium with V ( z ( t )) = k z ( t ) − z ∗ k 1 as its Ly apuno v function. The claim follo ws from Theorem 7 and Corollary 8, p. 74, [24]. 2 3 Remarks 1. W e first lo ok at sample complexity of the sto chastic iteration. W e mainly use section 4.2 of [24] to deriv e sample complexity estimates. Let 1 ≤ m < M < N . Let z ∗ denote the stationary distribution. Without loss of generality (by relab eling if necessary), let z ∗ 1 ≥ z ∗ 2 ≥ .... ≥ z ∗ N , i.e., the comp onents of z ∗ are num b ered in accordance with their ranking. W e shall consider as our ob jective the even t that the top m ranks of z ∗ fall within the top M ranks of the output of our algorithm when stopp ed, for a prescrib ed pair m < M . This is a natural criterion for ranking problems, which are an instance of ‘ordinal optimization’ [25]. T o a void pathologies, we assume that z ∗ m > z ∗ M . W e shall deriv e an estimate for the n umber of iterates needed to ac hieve our aim with ‘high’ probabilit y . Let C := { z ∈ ∆ N : if z l 1 ≥ z l 2 ≥ .... ≥ z l N then z i ≥ z l M , 1 ≤ i ≤ m } , where ∆ N is the N-dimensional probabilit y simplex. Thus C consists of all distributions such that the top m indices of z ∗ are in the top M indices of the giv en distribution. Let Φ T b e the time- T flo w-map asso ciated with the differential equation, where T > 0. Thus, Φ T ( z ) = e cP T − I N T ( z − ( cP T − I ) − 1 1 ) − ( cP T − I ) − 1 1 , with Φ T ( z ∗ ) = z ∗ . Define C ∗ := { z ∈ C : k z − z ∗ k 1 ≤ min z 0 ∈ ∂ C k z 0 − z ∗ k 1 } , and for > 0, C := { x : inf y ∈ C k x − y k 1 < } . 5 Then min z ∈ ∆ N − C h k z − z ∗ k 1 − k Φ T ( z ) − z ∗ k 1 i = min z ∈ ∆ N − C h k z − z ∗ k 1 − k e cP T − I N T ( z − z ∗ ) k 1 i ≥ min z ∈ ∆ N − C h k z − z ∗ k 1 − k e cP T − I N T k 1 k ( z − z ∗ ) k 1 i = (1 − k e cP T − I N T k 1 ) min z ∈ ∆ N − C k z − z ∗ k 1 = (1 − k e cP T − I N T k 1 ) κ where κ := min z ∈ ∆ N − C k z − z ∗ k 1 and k A k 1 for a matrix A is its induced matrix norm. W e argue that k e cP T − I N T k 1 < 1. T o see this, view Q = cP − I as the rate matrix of a con tinuous time Marko v chain killed at rate 1 − c . Then e cP − I N T is its transition probabilit y matrix after time T N , whose row sums will b e uniformly b ounded aw a y from 1. The claim follows. Let γ > 0 and pick T > 0 such that γ ≥ min z ∈ ∆ N − C [ k z − z ∗ k 1 − k Φ T ( z ) − z ∗ k 1 ] . Since max z ∈ ∆ N k z − z ∗ k 1 = 2, max z ∈ ∆ N k z − z ∗ k 1 γ / 2 × ( T + 1) ≤ τ := 4 (1 − k e cP T − I N T k 1 ) κ × ( T + 1) . Let n 0 := min { n ≥ 0 : P n m =0 a ( m ) ≥ τ } . Also, let N η ( S ) := { z : inf y ∈ S k z − y k 2 ≤ η } denote the op en η -neighborho o d w.r.t. k · k 2 norm of a generic set S . Set δ := γ 2 √ N . Then k x − y k 2 < δ = ⇒ k x − y k 1 < γ 2 . Arguing as in Corollary 14, p. 43 of [24], we hav e P ( z n ∈ N δ ( C γ 2 ) ∀ n ≥ n 0 + k ) ≥ 1 − 2 N e − K δ 2 N P ∞ m = k a ( m ) 2 = 1 − o ( ∞ X m = k a ( m ) 2 ) , where K > 0 is a suitable constant. (In ibid. , replace H b y C ∗ and ∆ by γ .) 2. Note that at each time n , we can generate more than one, say m pairs ( X i n , Y i n ) , 1 ≤ i ≤ m , whic h are indep endent, each distributed as ( X n , Y n ) ab o ve, and change the iteration to: z n +1 ( i ) = z n ( i ) + a ( n )( I { i ∈ { X j n +1 , 1 ≤ j ≤ m }} (1 − z ( n )) + c m X j =1 z n ( X j n +1 ) I { Y j n +1 = i } ) . That is, w e update sev eral comp onents at once. This will speed up con- v ergence at the exp ense of increased p er iterate computation. 6 4 Numerical Exp erimen ts In this section we sim ulate the algorithm for different n umber of no des. The results for the cases when the num b er of no des are 50, 200 and 500 are plotted in Figure 1, Figure 2 and Figure 3 resectively . The dotted line indicates the distance betw een z ∗ and z n w.r.t. n . The solid line indicates the p ercentage of top 5 indices of z ∗ that do not feature in the top 10 indices of z n . Figure 4, Figure 5 and Figure 6 further show (for 200 nodes) that the num ber of iterations required to ac hieve this ob jective v aries inv ersely with v ariance of z ∗ . Figure 1: v araince of z ∗ =47.1641 7 Figure 2: v ariance of z ∗ =277.3392 Figure 3: v ariance of z ∗ = 743.4651 8 Figure 4: v araince of z ∗ =259.6187 Figure 5: v ariance of z ∗ =335.6385 9 Figure 6: v ariance of z ∗ = 365.0774 5 Conclusions In conclusion, we highligh t some of the imp ortant features of the ab ov e scheme, whic h are facilitated b y the reinforcement learning framework. 1. As already mentioned, the sc heme do es not dep end on an a priori mo del for transition probabilities, but is completely data-driv en in this aspec t. 2. W e use ‘split sampling’ introduced in [14] for reinforcement learning, sam- pling pairs ( X n , Y n ) with the desired conditional law for Y n giv en X n , but with uniform sampling for { X n } . This is a departure from classical rein- forcemen t learning, where one runs a single Marko v chain { X n } according to ˆ P and Y n = X n +1 . 3. Since we are iterating ov er probability vectors as they evolv e under a transition matrix, the scheme requires left-multiplic ation by ro w vectors thereof. This is differen t from usual reinforcement learning sc hemes, whic h in volv e av eraging with resp ect to the transition probabilities, i.e., right- multiplic ation b y a column v ector. W e hav e w orked around this difficult y b y mo difying the up date rule. In classical reinforcemen t learning algo- rithms based on a sim ulated Marko v chain { X n } , one up dates the X n th comp onen t at time n , i.e., the i th comp onent gets up dated only when X n = i . In the ab o ve scheme, the i th comp onen t gets up dated b oth when X n +1 = i and when Y n +1 = i , alb eit in different w ays. This is another no vel feature of the present scheme. 10 References [1] Thorndike, E. L., “ Animal in telligence: an exp erimental study of the as- so ciativ e pro cesses in animals”, Psycholo gic al R eview , Monograph Supple- men t 2, No. 8, 1898. [2] Bush, R. R. and Mosteller, F., “A mathematical mo del of simple learning”, Psycholo gic al R eview 58, 313-323. [3] Estes, K. W., “T o wards a statistical theory of learning”, Psycholo gic al R e- view 57, 94-107. [4] Bertsek as, D. P .; Dynamic Pr o gr amming and Optimal Contr ol, V ol. 2 (4th ed.), Athena Scientific, Belmont, Mass., 2007. [5] Bertsek as, D. P . and Tsitsiklis, J. N., Neur o-dynamic Pr o gr amming , A thena Scien tific, Belmon t, Mass., 1996. [6] Gosavi, A., Simulation-b ase d Optimization, Par ametric Optimization T e ch- niques and R einfor c ement L e arning , Springer V erlag, New Y ork, 2003. [7] Po well, W. B., Appr oximate Dynamic Pr o gr amming: Solving the Curses of Dimensionality (2nd Edition), Wiley , New Y ork, 2011. [8] Sutton, R. S. and Barto, A. G., R einfor c ement L e arning: An Intr o duction , MIT Press, Cam bridge, Mass., 1998. [9] Szep esv ari, C., Algorithms for R einfor c ement L e arning , Morgan and Cla y- p o ol Publishers, 2010. [10] Sargent, T. J., Bounde d R ationality in Macr o e c onomics , Oxford Uni. Press, Oxford, UK, 1994. [11] Thrun, S., Burgard, W. and F o x, D., Pr ob abilistic R ob otics , MIT Press, Cam bridge, Mass., 2005. [12] Robbins, H. and Monro, J., “A sto chastic approximation metho d”, Annals of Math. Stat. 22, 1951, 400-407. [13] Bork ar, V. S., Makhijani, R. and Sundaresan, R., “Ho w to gossip if you m ust”, pr eprint , 2013, av ailable at [14] Bork ar, V., S., “Reinforcement Learning - A Bridge b etw een Numerical Metho ds and Marko v Chain Mon te Carlo”, in Persp e ctives in Mathematic al Scienc es , ( Sastry , N. S. N., Ra jeev, B., Delampady , M. and Rao, T. S. S. R. K., eds.), W orld Scientific, 2008. [15] Langville, A. N. and Mey er, C. D.; Go o gle’s PageR ank and Beyond: The Scienc e of Se ar ch Engine R ankings , Princeton Uni. Press, Princeton, NJ, 2006. [16] Langville, A. N. and Meyer, C. D.; “Deep er inside PageRank”, Internet Mathematics 1(3), 2004, 335-380. 11 [17] Avrachenk ov, K.; Litv ak, N.; Nemirovsky , D; and Osip o v a, N.; “Monte Carlo methods in P ageRank computation: when one iteration is sufficien t”, SIAM J. Numer. Anal. 45(2), 2007, 890-904. [18] Avrachenk ov, K.; Litv ak, N.; Nemirovsky , D; Smirnov a, E.; and Sokol, M.; “Quick detection of top-k p ersonalized PageRank lists”, Algorithms and Mo dels for the Web Gr aph, Pr o c. W A W 2011 (A. F rieze, P . Horn and P . Pralat, eds.), Lecture notes in Comp. Sci. No. 6732, Springer V erlag, Berlin-Heidelb erg, 2011, 50-61. [19] Poly ak, B. T. and Timonina, A. V., “PageRank: new regularizations and sim ulation models”, Pr o c. of 11th IF AC World Congr ess, Milano, A ug. 28 - Sep. , 2011, 11202-11207. [20] Ishii, H. and T emp o, R.; “Distributed randomized algorithms for P ageRank computation”, IEEE T r ans. Auto. Contr ol 55(9), 2010, 1987-2002. [21] Nazin, A. V. and Poly ak, B. T.; “The randomized algorithm for finding an eigen vector of the sto chastic matrix with application to PageRank”, Doklady Mathematics , V ol. 79(3), 2009, 424-427. [22] Zhao, W.; Chen, H-F. and F ang, H-T., “Conv ergence of distributed ran- domized PageRank algorithms”, arXiv:1305.3178 [cs.SY], 2013. [23] Vigna, S., “Sp ectral ranking”, [24] Bork ar, V. S.; Sto chastic Appr oximation: A Dynamic al Systems Viewp oint , Hindustan Publ. Agency , New Delhi, and Cam bridge Uni. Press, Cam- bridge, UK, 2008. [25] Ho, Y.-C.; “An explanation of ordinal optimization: Soft computing for hard problems”, Information Scienc es 113(34), 1999, 169-192. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment