Ensemble approaches for improving community detection methods
Statistical estimates can often be improved by fusion of data from several different sources. One example is so-called ensemble methods which have been successfully applied in areas such as machine learning for classification and clustering. In this …
Authors: Johan Dahlin, Pontus Svenson
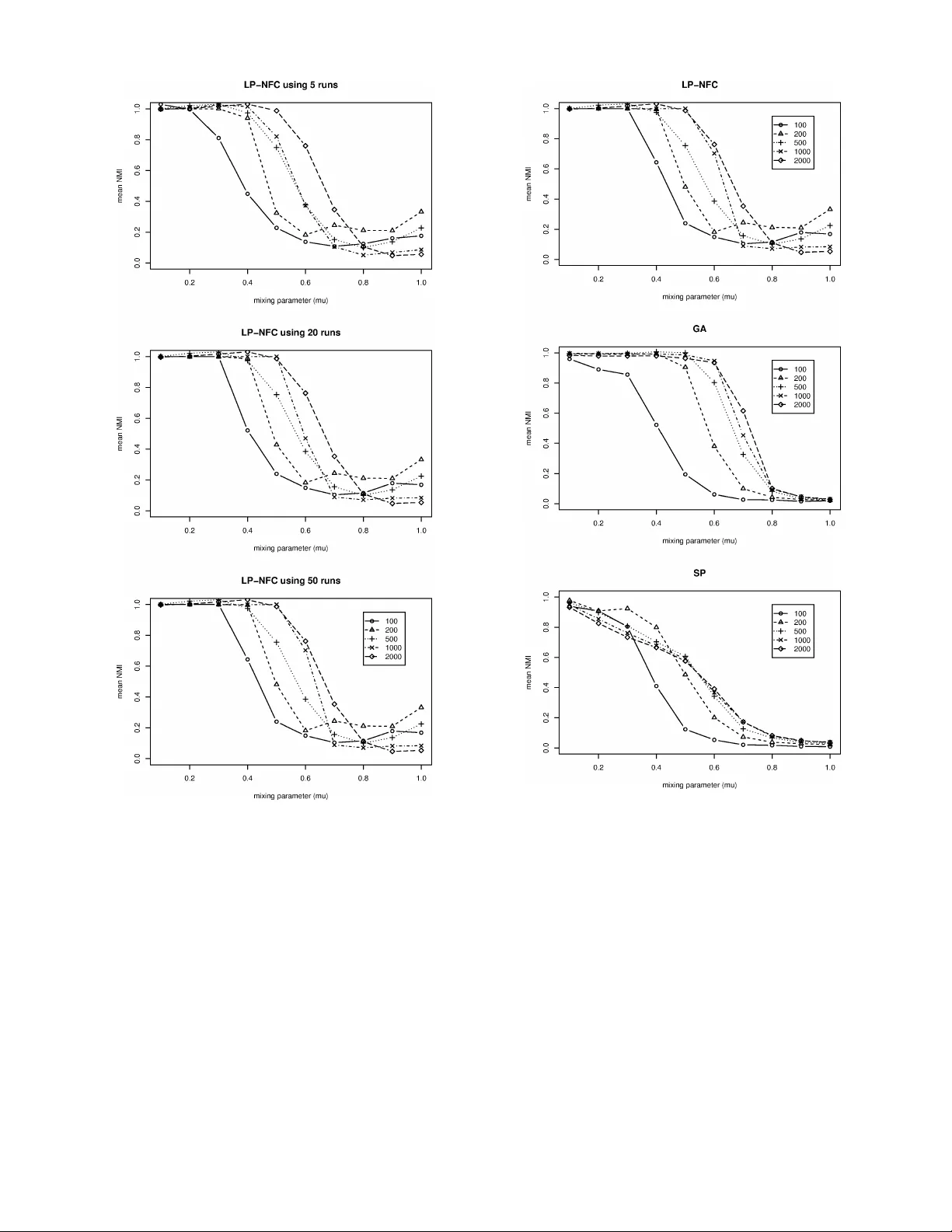
Ensem ble approac hes for impro ving comm unit y detection metho ds Johan Dahlin ∗ Dep artment of Physics, Ume ˚ a University and Division of Information and A er onautics Systems, Swe dish Defenc e R ese arch A gency P ontus Sv enson † Division of Information and A eronautics Systems, Swe dish Defenc e Rese ar ch Agency (Dated: Sep 1, 2013) Statistical estimates can often be improv ed by fusion of data from several different sources. One example is so-called ensem ble methods whic h ha ve been successfully applied in areas suc h as mac hine learning for classification and clustering. In this pap er, we present an ensemble metho d to improv e comm unity detection b y aggregating the information found in an ensem ble of comm unity structures. This ensemble can found by re-sampling metho ds, m ultiple runs of a sto chastic communit y detec- tion metho d, or b y several different communit y detection algorithms applied to the same netw ork. The prop osed metho d is ev aluated using random netw orks with communit y structures and com- pared with t wo commonly used communit y detection methods. The proposed metho d when applied on a sto c hastic communit y detection algorithm p erforms well with low computational complexity , th us offering b oth a new approach to communit y detection and an additional communit y detection metho d. P ACS num b ers: 02.50.-r,05.90.+m I. INTR ODUCTION Net works are ubiquitous in nature and pro vide v er- satile mo dels for many-bo dy systems with non-regular in teractions. F or these reasons, they hav e b ecome an im- p ortan t topic of current research. Net work science has pro vided no vel application areas for metho ds from sta- tistical ph ysics, and has in turn developed new metho ds that can b e used to study physical systems. The study of netw orks is often concerned with quantifying differ- en t microscopic asp ects of the structure, such as central- it y measures, degree distributions, information flow in net works, and robustness. Concepts and metho ds from net work analysis hav e been applied to a large range of differen t t yp es of netw orks. Some examples of the most imp ortan t applications include analysis of energy grids, epidemiology , metab olic netw orks, protein-protein inter- action netw orks, so cial netw orks, etc. [1] . Netw orks of- ten arise as a consequence of strongly interacting agents or many-bo dy systems with weak interactions but where the complex netw ork structure leads to emergent b eha v- ior that has in teresting ph ysical prop erties. Other imp ortan t topics in net work research include higher-lev el structures called comm unities. Communities are commonly defined as groups of no des more densely connected with each other than with no des outside the group. These comm unities, or partitions, are commonly found in e.g. our ev eryday so cial netw orks as colleagues, high-sc ho ol friends, neigh b ors, family , etc. Muc h effort ∗ johan.dahlin@gmail.com; Current address: Department of Elec- trical Engineering, Division of Automatic Con trol, Link oping Universit y † ponsve@foi.se has been devoted to defining communit y structures and finding algorithms to detect partitions with low compu- tational complexity and high accuracy . Despite this, no accepted general definition of what a communit y struc- ture is has b een prop osed. In order to clarify the prop er (if an y) definition of comm unit y structures, there is a need for new approaches. In this pap er, w e present a new approac h to the communit y detection problem by considering an ensemble of communit y clustering meth- o ds working on the same net w ork. The results of the differen t communit y detection algorithms are then fused in to a, hopefully more accurate, represen tation of the comm unity structure of the net work. It is our hop e that the w ork presen ted here will con- tribute b oth to more efficien t algorithms for comm unity detection and to a conceptual discussion ab out what a comm unity structure is. By considering an ensemble of clustering metho ds, it is p ossible to consider different definitions of communit y structure. More effectiv e al- gorithms can be found by merging (aggregating) many runs of fast sto chastic algorithms as well as several runs of the same algorithm using different settings. In addi- tion the latter metho d can b e used to analyze the com- m unity structure of the netw ork at many differen t scales, pro viding insight into the relations b etw een communit y structure at different levels. The merging metho d is also applicable in aggregation of comm unities generated by b ootstrap replicates of the netw ork data, whic h is neces- sary in cases where there is missing or incomplete infor- mation av ailable ab out the net work. Previous and related work includes work in the areas of comm unity detection and in ensem ble metho ds developed for data clustering and classification metho ds. In recent y ears a large n umber of methods for detecting comm unit y structures ha v e been dev elop ed, drawing on kno wledge 2 from many differen t fields, e.g. statistical mechanics, dis- crete mathematics, computer science, statistics, and so ci- ology . These methods hav e also been improv ed to handle w eighted, directed, and m ulti graphs. A thorough review of the current state in communit y detection is given in Ref.[1]; we provide some background in Section I I. Ensem ble clustering is a technique used in e.g. bioin- formatics applications and is useful in merging sev eral clustering results in to one. T o our knowledge, no work has b een devoted to applying these metho ds in comm u- nit y detection problems. Ho wev er other metho ds ha ve b een used to merge sev eral comm unity structures, e.g. v oting in Refs. [2, 3]. As data clustering and commu- nit y detection are quite similar, it should b e p ossible to merge communities in the same manner as ensem bles of data with goo d results. Ensem ble clustering metho ds w ere first introduced in Ref. [4] and further developed by e.g. Refs. [5, 6]. This pap er con tinues with a presentation of the back- ground in comm unity detection (Section I I) and ensem- ble methods (Section I I I) previously used in classification and clustering, where w e discuss some common comm u- nit y detection metho ds and the p erformance of ensem- ble metho ds The ensem ble-based communit y clustering metho d is introduced in Section I II C, where its com- putational complexit y is discussed and suggestions for ho w to estimate the certaint y of the obtained solution giv en. Finally , Section IV offers some simulation exp eri- men ts which compare the prop osed metho d to tw o well- kno wn comm unit y detection algorithms: greedy mo du- larit y maximizing agglomerative algorithm [7], and a q- P otts based spin glass mo del [8]. The pap er is concluded with a summary with some remarks concerning implications and future work. I I. COMMUNITY DETECTION Net works consist of no des, representing e.g. individu- als, computers, or proteins, that are connected by edges represen ting e.g. friendships, netw ork connections, or other types of in teractions. F ormally , net works are de- fined using graph structures, G = ( V , E ), where V de- notes the set of no des and E the set of edges. W e denote the num b er of edges in a graph n = | V | and the num b er of edges by m = | E | . Net works often con tain some form of communit y struc- ture, i.e. groups of nodes that are more densely connected to each other than to no des outside of the group. In essence, this resembles the similar problem in data clus- tering, where similar data p oints are group ed together in to clusters. In the same manner, no des inside com- m unities are often thought of as sharing some common feature. The interpretation of this feature naturally de- p ends on the nature of the netw ork data, e.g. communi- ties in so cial netw orks are often thought of as constituting some so cial group sharing family ties, emplo y er, a sp e- cific interest, etc. Detection of comm unities is therefore an imp ortan t to ol in so ciology and other related areas, but is also used in fields including ecology and biology where fo o d webs, protein-protein interaction, metab olic net works and natural resource exploittation netw orks are of interest[9]. Comm unity detection is a widely studied sub ject and m uch w ork has b een devoted to developing faster and more accurate automatic metho ds for detection and ver- ification of comm unities in complex netw orks. This sec- tion serv es only as a short review of the field and some of the proposed metho ds for iden tifying communities in net works. F or a comprehensive review of the field as a whole, we refer the reader to Refs. [1] and [10]. A. Existence and uniqueness There is no formal generally accepted definition of what a comm unity , despite large efforts in the study of comm unity detection and complex netw orks. In this pa- p er, we adopt the practical viewpoint of Definition 1 and use the definition due to Ref. [11] for what a communit y structure is. Definition 1 (Communit y) A c ommunity (in qualita- tive terms) is a subset of no des within a network such that c onne ctions b etwe en no des in the subset ar e denser than c onne ctions with the r est of the network. The main problem with this definition is questions like: ho w large a subset must b e (can a comm unity consist of only a few nodes?) and what exactly denser means in terms of num b er of edges inside the communit y versus b et w een communities. W e return to the latter question in connection with the discussion of algorithms for generat- ing synthetic (random) netw orks with communit y struc- tures in b elo w. Another issue with the definition is that in real netw orks, there are often edges of different kinds. F or example, a so cial netw ork contains edges that denote friendship, whic h are separate from those that represent colleagues. When lo oking for work-related communities, only work-related edge t yp es should b e considered. The lack of a general definition raises problems related to uniqueness and existence of communities in netw orks. A netw ork may con tain many differen t communit y struc- tures dep ending on the scale considered, from just one comm unity containing all no des to comm unities only con- taining one no de eac h. This is kno wn from previous w ork as the r esolution limit , when discussing mo dularit y (see next subsection) as a quality measure for communit y structures. Problems with existence includes questions regarding if the communities are the result of the data or by the underlying pro cess generating this data. With this it is mean t that obse rv ations seldom identifies the en tire netw ork and therefore it is difficult to verify if the resulting communities exist or only is an artifact of some missing or erroneous data. Assume that we ha ve studied a dense social netw ork and ha v e iden tified some of the ties betw een v aries in- 3 FIG. 1. F our communities found using the q-Potts spin glass metho d (see b elow) in the famous k arate netw ork from Ref. [12], indicating the friendships in a k arate club at an U.S. univ ersity during the 1970’s. dividuals. As previously discussed, it is often difficult to iden tify all ties in the netw ork and therefore we may only find a subset of all the edges in the real net work. Applying standard comm unity detection methods on this net work will probably return some communit y structure with a certain n umber of comm unities. But as only a subset of the edges hav e b een used, the real unobserved net work may only con tain one communit y . Therefore, the existence of the identified comm unities are in question, do they really exist or not? The previous example discusses the well-kno wn prob- lem of the r obustness of comm unities. This has b een studied by e.g. using bo otstrap metho ds to generate sub- sets of edges and study how the comm unity structure app ear as a mean of a large num b er of b ootstrapp ed net- w orks. Later, we will see ho w the methods prop osed in this paper offer another solution to the problem of esti- mating the robustness of a communit y structure. Additional problems with the definition of communit y structure arises b ecause of the multi-modal nature of most netw orks of in terest. If we for instance are in ter- ested in clustering a so cial net w ork of individuals and their relations, we m ust distinguish b etw een many differ- en t kinds of in terp ersonal relations: friendship, colleague, co-author and citation net works. B. Qualit y of comm unit y structures Comparing the qualit y of a obtained communit y struc- ture is usually done b y a measure called mo dularity . This measure compares the netw ork structure with the struc- ture of a null model in whic h edges are randomly re- distributed k eeping the degree of all no des fixed. The concept of mo dularit y was in tro duced in Ref. [13] and is usually denoted Q ( c ), where c = ( c i ) is the v ector of comm unities to which each no de i b elongs. The measure is calculated using the expression Q ( c ) = 1 2 m n X i,j =1 ( A ij − N ij ) δ ( c i , c j ) = 1 2 m n X i,j =1 A ij − k i k j 2 m δ ( c i , c j ) , (1) where c i is the communit y of whic h no de i is a mem b er, k i is the degree of no de i , A = [ A ij ] is the adjacency matrix[14] m is the num b er of edges, n is the num b er of no des, and δ is the Kroneck er delta function[15]. Mo dularit y is often used to compare different commu- nit y structures in the same or similar net works. Due to the null mo del used, mo dularit y can not b e used to com- pare the comm unity structures of different netw orks, as its maxim um v alue is determined by the netw ork struc- ture. Often higher modularity is tak en as an indication of a b etter comm unity structure as it is more differen t com- pared to the random n ull mo del. As such, the modularity can only be used as a comparative measure and has dra w- bac ks including difficulties in in terpretation, that random net works usually hav e higher maximum mo dularit y than real-w orld netw orks, and the previously discussed resolu- tion limit. It can b e shown that mo dularity optimization, i.e. find- ing the optimal communit y structure, is an NP-complete problem [16]. Th us the problem of comm unity detection is time consuming for large netw orks and go o d approx- imations are necessary for detecting communities with reasonable computational effort. In the following sec- tion, three different metho ds are introduced for detect- ing communities in netw orks. These metho ds are exam- ples of heuristic and sto chastic metho ds for relaxing the NP-complete problem. It is also possible to show that the mo dularity has man y local maxima [17] making the iden tification of a global maxim um v ery difficult. C. Algorithmic communit y detection As previously discussed, large efforts hav e b een giv en the problem of automatically iden tifying communities in net works. W e refer to these methods as algorithmic com- m unity detection metho ds, in contrast to earlier manual metho ds pioneered by Refs. [18, 19]. A large n um b er of metho ds ha ve b een prop osed based on concepts from e.g. the fields of computer science, discrete mathemat- ics, statistical physics, and statistics. In this pap er, we consider three differen t metho ds: the q-Potts based spin glass algorithm (SP) introduced in Ref. [8], the greedy agglomerativ e metho d (GA) prop osed in Ref. [7], and the fast sto c hastic metho d of propagation of lab els (LP) presen ted in Ref. [2]. The SP-algorithm is based on a q-Potts spin glass and comm unities are detected by minimizing the energy of 4 the following Hamiltonian H = − J n X i =1 n X j =1 A ij δ ( c i , c j ) + γ q X k =1 s k 2 , (2) where J and γ are c oupling p ar ameters , δ ( · ) is the Kro- nec ker delta function, and s k is the num b er of spins in state k . The size of the detected communities is deter- mined by the ratio[20] b et w een the tw o coupling param- eters. This is due to the fact that the first term with coupling factor J fav ors many edges inside communities and few b et ween comm unities, The second term whic h is scaled by γ fa vors a uniform distribution of no des in comm unities. [8] The configuration of spins (communities) that mini- mizes the Hamiltonian in (2) is found using simulated annealing [21]. The system is initialized at the temp era- ture T 0 = 1 and co oled using the cooling factor 0 . 99 until the final temp erature T t = 0 . 1 is obtained. As simulated annealing is quite computer intensiv e, this algorithm has a high complexity of at least O ( n 2+ θ ) with θ = 1 . 2 on a sparse netw ork. The adv antage of this metho d is that it is known to often find go o d approximations of the global minim um of the Hamiltonian and therefore also goo d ap- pro ximations of the communit y structure. The GA-metho d greedily merges pairs of no des/clusters using agglomerativ e hierarc hical cluster- ing. The order in whic h no des are merged is go v erned b y the mo dularity measure, which is calculated for all p ossible merges and the resulting merge is determined b y the pair that yield the highest increase. This greedy metho d is quite computation intensiv e as many p ossible merges must b e ev aluated and it is not certain that the optimal solution yielding the maximum mo dularit y is found. The complexit y for this algorithm is estimated to b e O ( nl og 2 n ), which is quite low in comparison with the SP-algorithm. [7] FIG. 2. A simple situation in the label propagation algorithm. A node is voted to change its label to B instead of A, as this lab el is in the ma jority of the neighboring no des. cm is a function returning the most common lab el breaking ties randomly . The LP-algorithm is an example of a sto chastic metho d for detecting communities in net works. The metho d uses lab els for each no de to decide to which communit y the sp ecific no de b elongs. LP is an iterative algorithms that initializes by assigning eac h no de an unique lab el. The iterativ e step b egins by selecting a no de at random and then assigning it a new lab el using voting (breaking ties randomly) by the lab els of the neighboring no des. The iterativ e pro cedure is rep eated until no no de changes la- b el and thereby an equilibrium is obtained. As comm u- nities are groups of no des more densely connected than with other communities, the labels should propagate and spread in each comm unity . [2] The sto chastic part of this algorithm is tw o-fold: firstly the order in which no des are selected and secondly the random breaking of ties. These tw o factors are re- sp onsible for that the algorithm pro duces random out- comes. The adv antage of this metho d is that it is very fast, O ( m ), where m is the n um b er of edges whic h is n ≤ m ≤ n 2 . Several runs of the LP-algorithm are often com bined to counter the stochastic nature of the method. This combination is the essential topic of this pap er and it is further discussed in the next section. [2] I II. ENSEMBLE METHODS Comm unity detection is a form of clustering of net work data, in which nodes are similar by sharing many com- mon neighbors. Clustering in turn is a form of classifica- tion, which is extensively used in machine learning and other related areas. In this section, w e discuss the im- p ortan t concept of b o osting used in classification to com- bine several weak er classifiers into a b etter classifier using (w eighted) v oting schemes. Another imp ortant concept in classification is b agging in whic h a large num ber of b ootstrap replicated are aggregated to form a robust av- erage. This metho d has b een successfully applied using net work data in Ref. [3] and it is therefore lik ely that b oosting will also b e applicable to netw ork data. Bo osting has previously b een used on clustering meth- o ds in e.g. bioinformatics to impro ve the result of clus- tering analysis. As clustering is similar to communit y detection, it is fruitful to discuss the ensemble cluster- ing metho ds previously used in data clustering and gen- eralize these for net work data. This is the aim of this section which also contains a prop osed metho d for com- bining several runs of a sto chastic communit y detection algorithm, as the LP method previously discussed, or the structures found by differen t comm unity detection meth- o ds and b y b ootstrap re-sampled net works. A. Bo osting classifiers The idea b ehind bo osting classifiers is to arrange a large num b er of simple (w eak) classifiers into an ensemble (committee), which by a wisdom-of-cro wd-effect creates a b etter classifier. In man y cases, the resulting classifier p erforms m uch better than a simple more complex classi- 5 fier. This makes b o osting a p o werful, yet simple metho d to greatly improv e the classification accuracy . Another related metho d to b o osting is ensemble learn- ing, in which a num b er of differen t w eak classifiers are com bined into an ensem ble without any re-sampling or re-w eighting. This family of metho ds suits our setting b etter and is the basis for the following discussion on en- sem ble clustering. It is how ev er imp ortant to put some effort in to trying to explain wh y a group of simpler classi- fiers may perform m uch b etter than single more adv anced classifier. Muc h effort has b een devoted to answer this question and some answers hav e b een found for indep en- den t classifiers. The ensemble metho d is discussed in Ref. [22] for use with neural netw orks, which are trained using some data set. It is p ossible to show that the training problem is an optimization problem with man y lo cal minimum (as in the case with mo dularit y maximization). Therefore the w eightings found can differ largely for solutions with almost the same error rate. By com bining many of these w eightings, the authors could show large improv ements in ov erall accuracy . Assume that each classifier has some probabilit y of classification error, p , therefore the proba- bilit y of finding exactly k classification errors in N clas- sifiers is given b y N k p k (1 − p ) N − k , (3) and b y applying a simple ma jority v oting rule, the cor- resp onding probability of k mis-classifications in an en- sem ble with N classifiers is N X k>N / 2 N k p k (1 − p ) N − k . (4) It is further stated in Ref. [22], that it is p ossible by in- duction to prov e that this probability is decreasing with increasing N when p < 1 2 . This means that when each classifier is b etter than a random classification and inde- p enden t of other classifiers, an arbitrarily error rate can b e selected by v arying the num b er of classifiers used in the ensem ble. The assumption of indep endence is seldom v alid in practical applications but the metho d still works when each classifier p erform b etter than chance. The error rate of an ensemble is further discussed and calculated for dep enden t classifiers in Ref. [23], where the ensemble gener alization err or , , is expressed as = X k w k h ( y ( x ) − f k ( x )) 2 − f k ( x ) − ¯ f ( x ) 2 i , (5) where y ( x ) is the label of observ ation x , f k ( x ) is the lab el giv en by classifier k and ¯ f ( x ) is the weigh ted ensemble a verage, ¯ f = X k w k f k ( x ) , (6) for some weigh ts w k for classifiers k = 1 , 2 , . . . , n . The first term in Eq. (5) is the (weigh ted) av erage of the generalization errors of the individual predictors and the second is the weigh ted av erage of ambiguities. The latter contains all correlations b etw een the different clas- sifiers. Finally the relation shows that the more predic- tors differ, the b etter is the p erformance of the ensem ble. This explains why an ensem ble of classifiers p erforms b et- ter than a more adv anced single classifiers, as the error rate can b e decreased by increasing the n umber of clas- sifiers included in the ensemble. [23] B. Ensem ble clustering As classification is related to clustering, it is reason- able that these ensemble metho ds are useful in cluster- ing as well. In ensemble clustering, the problem is often to combine an ensemble of clusterings generated by e.g. some re-sampling metho d (b ootstrap) [24]. The combi- nation should return the av erage or aggregated prop erties of the clusterings found in the ensemble. A metho d for finding ensem ble clusterings is prop osed b y Ref. [4] called Instanc e-b ase d Ensemble Clustering (IBEC). Other im- p ortan t examples of ensemble clustering metho ds are found in Refs. [6], but are not used in this pap er. Definition 2 (IBEC) Given an ensemble of clusters, x = { x (1) , . . . , x ( r ) } , IBEC c onstructs a ful ly c onne cte d (c omplete) gr aph, G = ( V , F ) , wher e V is a set of n no des and F = [ F ij ] is a fr e quency matrix with F ij as the fr e- quency of instanc es that no des i and j ar e plac e d in the same cluster. The IBEC method aggregates the clusterings by con- structing a graph where eac h no de represen ts a data point and each edge indicates that the t wo connected no des ha ve b een clustered together. The frequency with whic h the tw o no des hav e b een clustered together acts as a w eight or similarit y for the resulting edge, see Defini- tion 2 for details. The no des are finally partitioned into clusters using agglomerative hierarc hical clustering with some link age rule, or b y a graph partitioning metho d as the Kernighan-Lin algorithm [25]. C. No de-based F usion of Communities In this pap er, w e prop ose a generalization of IBEC for net work data and for fusing different comm unity struc- tures (subgraphs) in to a final represen tation. This final comm unity structure should indicate the most probable structure as it is the aggregated information from many candidates. No de-b ase d F usion of Communities (NF C) is similar to the previously discussed IBEC but use a special link age rule to accoun t for the sp ecial nature of netw ork data, i.e. nodes can not b e placed in the same communit y if they are not connected by a sufficiently short path. The NF C-metho d is outlined in Figur e 3 . Firstly , a complete graph, G = ( V , F ), is constructed using the 6 data from candidate communities, which are the output from some communit y detection algorithm(s). The set of nodes, V , is the original set of no des in the netw ork, and the set of edges F now indicate that tw o no des hav e b een found in the same comm unit y . The matrix, F = [ F ij ], where the element in ro w i and column j , F ij is the frequency of the even t that no des i and j has b een found in the same candidate communit y . This new graph is clustered using agglomerative hier- arc hical clustering using a sp ecial link age rule. This is necessary as recalculating is needed for determining the frequency of that the nodes ha ve been placed in the same comm unity as the meta-cluster, i.e. a cluster of some merged no des. FIG. 3. No de-based F usion using agglomerative hierarchical clustering. The frequency betw een the merged nodes (cluster) l and the other no des or clusters, v 1 , v 2 , . . . , v n l , is found b y F k,l = \ k M kl , (7) where the memb ership matrix , M = [ M ik ], where M ik is the communit y in which no de i is a member in candidate net work k = { j, i 1 , . . . , i n l } . That is, F k,l is the n umber of o ccurrences where all no des (in b oth clusters) are in the same candidate cluster. Using this link age rule incur some information loss as information of individual no des is lost in the meta-cluster. The result of the hierarc hical clustering algorithm is a dendrogram and a list of merges. The clustering cor- resp onding to the maximum mo dularity is tak en as the comm unities found in the merged candidate netw orks. The complexity of NFC is determined by the hierarc hi- cal clustering algorithm and therefore is O ( n 2 ). D. Estimating certaint y in communit y structures By using the output from the NF C-method, it is p ossi- ble to estimate the certaint y of the hypothesis that a no de b elongs to a certain comm unit y . This is especially impor- tan t for no des lying in the b orderland b et w een commu- nities. Perhaps it is equally lik ely that the no de b elongs to another neighboring comm unit y . It is also imp ortan t in structures similar to chains and tree in the netw ork. These nodes are naturally quite sensitive to uncertain edges b ecause they ha ve few neigh bors. No des having an uncertain communit y membership can b e found using the candidate comm unities. If a node is found quite often in t wo different communities, the confidence that it has b een classified correctly is low as it is very sensitiv e to the netw ork structure. F or the no de-b ase d metho d , the nodes are merged in a hierarchical manner, the tw o first no des are the most similar and for eac h merge the nodes get more dissimilar. If a no de was merged early in to a communit y , it is less lik ely that it w ould belong to another comm unity . There- fore a qualitativ e measure of the certaint y that a no de i b elongs to a communit y is found as b i = t − 1 i where t i is the num b er of merges needed b efore the no de i is added to the communit y . A larger v alue of this score indicates an early merge and therefore a more certain merge. IV. SIMULA TION EXPERIMENTS This section con tains details regarding the conducted sim ulation exp eriments using the prop osed metho d for merging communit y structures, the NF C metho d. W e prop ose to use this metho d in combination with the sto c hastic LP-algorithm and call this combination Lab el Propagation-No de-based F usion of Comm unities (LP- NF C). This section discuss some preliminary methods including the generation of synthetic netw orks and p er- formance measures. Comparativ e studies of the prop osed LP-NF C algorithm with the SP and GA-algorithms are presen ted and the comm unity detection metho ds are ev aluated by p erformance and computational complex- it y . A. Syn thetic netw orks with communit y structure The prop osed metho d is demonstrated using syn thetic (random netw ork with communit y structures) netw orks with a communit y structure. The synthetic network mo del used in this paper is adopted from Refs. [26, 27]. The authors hav e constructed algorithms to generate ar- tificial netw orks with communit y structures, which has b ecome a standard b enc hmark for comm unit y detection using synthetic netw orks. The net works are generated using six differen t input parameters, sho wn in T able I , to- gether with the v alues used in the following exp erimen ts. These parameters allo w for the generation of families of net works with desired prop erties. The mixing parameter, µ , is the fraction of edges b e- t ween the different communities and 1 − µ is the fraction of in tra-communit y edges. A small mixing parameter cor- resp onds to w ell-separated comm unities, the extreme is when µ = 0 and only disjoin t comm unities exist. As µ in- creases, the comm unities become more difficult to detect, un til µ = 0 . 5 when no communities exist in the netw ork according to the adopted definition of a comm unity in Definition 1 . 7 V ariable V alue Description n - n umber of no des in the netw ork ¯ k 15 mean degree of each no de k max 50 maximum degree µ - mixing parameter c min 20 minimum size of a communit y c max 50 maximum size of a communit y β 1 exponent of communit y size distribution (t ypically 1 ≤ β ≤ 2 in real-world net works) γ 2 exp onen t of degree distribution (t ypically 2 ≤ γ ≤ 3 in real-world netw orks) T ABLE I. The parameters used for generating synthetic net- w orks in the simulation studies using the algorithm f rom Ref. [26]. These parameters create net works similar to Newman- Girv an benchmarks. The mixing parameter, µ , and num b er of no des n are v aried during the exp eriments. [28] The algorithm to generate the synthetic netw orks con- sists of fiv e different steps. A simplified v ersion, see Ref. [26] for the full version, is as follo ws: Firstly , generate the degree of eac h no de by sampling from a pow er-la w distribution with parameter, γ , satisfying, ¯ k and k max . Secondly , generate the size of eac h comm unit y from a p o w er-law distribution with parameter, β , such that all no des are members of a comm unity and the communit y sizes are consistent with the parameters, c min and c max . 1. using the configuration mo del, assign edges b e- t ween all nodes suc h that the degree of all no des are satisfied, 2. randomly distribute the no des to the communities in the netw ork, 3. rewire the edges betw een nodes un til the mixing parameter, µ is satisfied. The drawbac k of this algorithm is the lack of triangles observ ed in real-world so cial netw orks, which result in a sparser net work than in empirically found netw orks. The adv antage is that synthetic netw orks enable the study of ho w the mixing parameter is correlated with the effective- ness in finding communities in uncertain net works. The algorithm has a linear complexit y , O ( n ), and can there- fore b e used to simulate large netw orks with communit y structures that are consistent with real-world so cial net- w orks. [26] B. Comparing communit y structures Sup ervised measures are used to ev aluate the p erfor- mance of the communit y detections metho ds used in the sim ulation exp erimen ts. This is p ossible due to that the c orr e ct communit y structured is returned b y the syn- thetic netw orks algorithm, thus external information is a v ailable for supervised metho ds. T raditionally , sup er- vised metho ds hav e included precision and recall which are commonly used in classification and clustering to ev aluate metho ds and algorithms. The drawbac k with these traditional metho ds are that it is difficult to find the matc hing pair of lab els from the obtained solution and the externally provided lab els. F or example, a single comm unity detected by the communit y detection algo- rithms ma y corresp ond to tw o differen t lab els in the ex- ternal information. The problem is to select the external lab el to match this obtained comm unit y with. Previously the corresp onding lab el has b een taken as the set with the largest o verlap, therefore only obtaining approximate p erformance measures. In this pap er, the Normalize d Mutual Information (NMI) is instead used to measure the p erformance of the differen t communit y detection algorithm. An additional metho d using correlation is prop osed, as it is a simpler measure and later discussed also yields result similar to the former measure. 1. Normalize d Mutual Information The NMI-measure originates in information theory and can b e interpreted as how m uch is kno wn ab out the ex- ternal lab eling given the obtained solution and vice v ersa. W e follow Ref. [29] to defined the NMI-measure. Let ˆ I ( C , L ) denote the NMI-measure where C is the obtained comm unity structure and L is the external la- b eling. Assume that L = { l i } where l i is the label of no de i and the same for C with the obtained communit y mem b ership of no de i . F urther assume that l and c are the realizations of some random v ariables, L and C , with some (joint) probability distributions as P ( l, c ) = P ( L = l , C = c ) = |L ∩ C | n , (8) P ( l ) = P ( L = l ) = |{ l i ∈ L : l i = l }| n , (9) P ( c ) = P ( C = c ) = |{ c i ∈ C : c i = c }| n , (10) where |{ l i ∈ L : l i = l }| is the num b er of elements in L which equals the lab el l with the corresp onding for c , and n is the total num b er of no des, n = |L| = |C | . The mutual information , I ( C, L ), is defined by I ( C, L ) = X l X c P ( c, l ) log P ( c, l ) P ( c ) P ( l ) , (11) where the sums are taken o v er all assumed v alues of l and c , and log( · ) is the logarithm (with base 2). The NMI-measure, ˆ I ( C , L ), b etw een the obtained comm unity structure, C , and the externally given lab els, L , is ˆ I ( C , L ) = 2 I ( C , L ) H ( C ) + H ( L ) , (12) 8 whic h equals zero if the comm unity structures are inde- p enden t and unity if they are equiv alen t. The entr opy , H ( X ), of a random v ariable X defined as H ( X ) = − X x P ( x ) log ( P ( x )) . (13) 2. Corr elation The correlation is used to calculate a measure of how the ro ws in the matrices tend to be similar [30]. This t yp e of measure has previously b een used in comparing clustering and classification metho ds. Let N = [ N ij ] de- note the neighb orho o d matrix where N ij = 1 if no des i and j are found in the same cluster and 0 otherwise. The mean correlation ¯ ρ ( N , ˆ N ), b etw een the tw o matrices, N and ˆ N , is found as the mean of the Pe arson c orr elations , ρ i , for each ro w ¯ ρ ( N , ˆ N ) = 1 n n X i =1 ρ i ( N i , ˆ N i ) = 1 n n X i =1 Cov ( N i , ˆ N i ) V [ N i ] V [ ˆ N i ] , (14) where V ( · ) denotes the v ariance. Using the cov ariance b et w een eac h elemen t in each ro w and the expected v alue (mean) of the that sp ecific row Cov ( N i , ˆ N i ) = 1 n n X j =1 ( N ij − E [ N i ])( ˆ N ij − E [ ˆ N i ]) , (15) where E ( · ) denotes the expected v alue. By letting N b e the ide al neighb orho o d matrix , N ∗ = [ N ∗ ij ], with N ∗ ij = 1 when l i = l j (equal external lab els) but zero otherwise and N ∗ ii = 0. Finally letting ˆ N denote the neighborho o d matrix from the obtain solution, results in another sup er- vised metho d for comparing the p erformance of commu- nit y detection metho ds. As the NMI, this measure scales to unity when a perfect match is found and if the measure assumes the v alue zero then no matches are found. Both the NMI and correlation measures ha ve the ad- v antage ov er metho ds lik e precision and recall, that no iden tification/link age of lab els are needed. This there- fore remo v es the need of using appro ximate methods as largest ov erlap to iden tify whic h lab el that is external giv en b est matches the obatined lab els from the commu- nit y detection metho d. C. Con vergence prop erties A first imp ortan t question to answer is ho w many runs of the LP algorithm need to b e merged by the NFC metho d to obtain stable solutions. This is the question whic h is to b e answ ered in this section, b efore an y p er- formance comparisons can b e made. In Figur e 4 , we present the NMI measures for several differen t runs of the prop osed LP-NF C metho d. In eac h run, the num b er of nodes n is v aried betw een 100 and 2000 no des, the mixing parameter is v aried b etw een 0 and 1, and finally the num b er of merged runs n r is v aried b et w een 5 and 50. As the num ber of samplings increase some of the curv es shift right w ards, which indicates b etter p erformance in finding the correct structures in net w ork with more dif- fuse communit y structures. Remem b er, that higher mix- ing parameter indicate more diffuse communit y struc- ture, that are more difficult to detect. The largest mov e- men t is found in the curve corresp onding to n = 1000 no des. The conclusion is that more samplings are needed in net w orks with more no des than in netw orks with fewer no des. This as the NMI for the smaller net works are more or less constan t with resp ect to the num b er of samplings. This corresp onds to what is known from standard Mon te Carlo-metho ds, that it is p ossible to decrease the statistical error by increasing the num b er of samples. This is only p ossible up to a certain lev el, b efore the sys- tematic errors dominates the statistical error. W e con- clude that 50 samplings are a goo d choice due to this result as well as required computational time. D. Comparisons with GA and SP Con tinuing with comparing the prop osed metho d to merge (aggregate) a n umber of runs by the LP-algorithm with the commonly used SP and GA-algorithms. The algorithms hav e b een ev aluated using the previously dis- cussed syn thetic netw orks with v arying num ber of no des, n ∈ { 100 , 200 , 500 , 1000 , 2000 } , and mixing parameter, µ ∈ { 0 . 1 , 0 . 2 , . . . , 1 . 0 } . The obtained communit y struc- ture is compared with the lab eling outputted by the syn- thetic netw ork algorithm using, the previously discussed. NMI and correlation measures. The most imp ortant feature in the follo wing figures are the shift from high v alues of NMI and correlation to lo wer. The critical v alue of the mixing parameter, µ c , clearly dep ends on the size of the netw ork, n , and differ b et w een the compared algorithms. In Figur e 5 , the metho ds are compared using the mean NMI from 100 runs at each v alue of the num ber of no des and mixing parameter. The profiles of the LP-NFC and GA-algorithms are quite similar in appearance compared with the SP-algorithm. The latter is previously known to p erform w orse on syn thetic netw orks than on real- w orld net works. This is clearly visible b y that the NMI v alues quickly fall of in comparison with the other t wo algorithms, that seems to hav e more or less constant NMI un til the critical mixing parameter. Another feature worth noting is the tail b eha vior for the LP-NFC-algorithm at high mixing parameters. The NMI v alue for the other t wo algorithms quickly drops to zero after the shift in p erformance, but the LP-NFC algorithm con tinues to hav e non-zero NMI. This is par- 9 FIG. 4. The NMI for the LP-NFC metho d with three dif- feren t num ber of samplings used on synthetic netw orks with comm unity structures. The graphs are found as an av erage of 100 runs on net works with n ∈ { 100 , 200 , 500 , 1000 , 2000 } no des and mixing parameter, µ ∈ { 0 . 1 , 0 . 2 , . . . , 1 . 0 } . ticularly visible for the smaller netw orks with 100, 200, and 500 no des and is probably some artifact from the sto c hastic nature of the LP-algorithm. Comparing the LP-NF C and GA-algorithms, we con- clude that the p erformance is similar b etw een these t w o metho ds and are sup erior to the SP-algorithm. Con- tin uing, with another comparison using the correlation and the computational complexity to find the preferred metho d. In Figur e 6 , methods are compared using the mean cor- FIG. 5. The NMI for three different communit y detection metho ds used on synthetic netw orks with communit y struc- tures. The graphs are found as an av erage of 100 runs on net works with n ∈ { 100 , 200 , 500 , 1000 , 2000 } nodes and mix- ing parameter, µ ∈ { 0 . 1 , 0 . 2 , . . . , 1 . 0 } . relation from 100 runs at each p ossible num b er of no des and mixing parameter. This figure is quite similar to the previous but with some differences in the LP-NFC algo- rithm, where the mean correlation drops to zero (as for the other t wo algorithms). The artifacts at high mixing parameters hav e therefore v anished and seems to b e to b e related with the use of the NMI-measure. Most of the analysis from the NMI-measure remains with the correlation measure as w ell. It is perhaps ev en more apparent that the GA-algorithm is less sensitive to the num b er of no des than the LP-NFC-algorithm. This is 10 FIG. 6. The correlation for three differen t comm unit y de- tection metho ds used on synthetic netw orks with communit y structures. The graphs are found as an a v erage of 100 runs on netw orks with n ∈ { 100 , 200 , 500 , 1000 , 2000 } no des and mixing parameter, µ ∈ { 0 . 1 , 0 . 2 , . . . , 1 . 0 } . seen by the densely pack ed correlation curves in the GA- algorithm that is not visible in the LP-NFC-algorithm. The SP-algorithm contin ues to under-p erform in com- parison with the t wo other methods. As previously dis- cussed, this is probably the result of using the synthetic net works, as the metho d p erform well for real-world net- w orks. These tw o types of net works differ in some im- p ortan t aspects, as for example the n um b er of triangles whic h could explain the p o or p erformance of the SP- algorithm. Concluding this analysis, we suggest an improv ement FIG. 7. The NMI of the mo dularity-w eigh ted LP-NFC metho d. The graph are found as an av erage of 100 runs on net works with n ∈ { 100 , 200 , 500 , 1000 , 2000 } nodes and mix- ing parameter, µ ∈ { 0 . 1 , 0 . 2 , . . . , 1 . 0 } . to the LP-NF C-algorithm by weigh ting eac h frequency b y the normalized mo dularity . F or each candidate com- m unity structure, the mo dularity is calculated and nor- malized with the maximal v alue of the mo dularit y . This generates a set of weigh ts, w i ∈ [0 , 1], for each candidate comm unity structure and the elemen ts in the frequency matrix is w eigh ted b y w i . This gives more w eigh t to no des that ha ve b een placed in the same communit y in structures with higher mo dularity than in situations with lo wer mo dularity . As the mo dularity indicates the qual- it y of the comm unit y structure found, this could generate b etter results. This mo dification has b een ev aluated in the same man- ner as the previous v ersion and the results from ev alua- tion by the NMI and correlation measures are shown in Figur e 7 . E. Time complexity Imp ortan t aspects of communit y detection algorithms are p erformance and computational complexity . A go o d algorithm should hav e a lo w computational complexity , whic h is equiv alent to scalabilit y to larger netw orks. P er- formance and accuracy are also desirable prop erties of 11 comm unity detection metho ds. LP has a lo w complexity and p erformance, it is therefore interesting to determine the complexity of the LP-NF C. This especially as the LP- NF C method has p erformed well in comparison with SP and GA-algorithms. It is previously known that the GA-algorithm has a rather low computational complexity , O ( nl og 2 n ), for most netw orks. This is esp ecially true with the mo difica- tions describ ed in Ref. [31]. The sim ulation exp erimen ts in this pap er are done in the softw are R using the imple- men tations offered by the igraph -pac k age, which are not optimized for lo w computational complexity . The follow- ing comparison is therefore just preliminary and a b etter implemen tation of LP-NFC is needed for making b etter comparisons. The LP-NF C-algorithm is based on t wo different steps, the first is p runs of the LP-algorithm which then is merged using agglomerativ e hierarc hical clustering. Us- ing the link age rule considered in this paper, the complex- it y of the latter algorithms is O ( n 2 log n ) or O ( n 2 ). The total complexit y of the method is then, O ( pm + n 2 log n ), where m is the num ber of edges with m < n 2 and p is some suitable num b er of merged runs e.g. p = n . This giv es a theoretical computational complexity of appro xi- mately O ( n 2 log( n )). The running time of the LP-NFC and GA-algorithms is shown in Figur e 8 for different num b ers of nodes, n , and mixing parameters, µ . The LP-NF C-algorithm hav e a rather high complexit y in its curren t implemen tation as previously discussed. It is approximately O ( n 3 ), which is higher than the theoretical v alue. The GA-algorithm has about linear computational complexit y , as previously discussed by Ref. [31]. Some other interesting asp ects is that the LP-NFC-algorithm is a lot faster for smaller net works (ha ve a smaller constan t term than the GA- algorithm) and the impact of the mixing parameter. In the GA-algorithm the mixing parameter has a rather high influence on the running time of the comm unit y detec- tion metho d. This effect is not visible for the prop osed metho d in this pap er. The SP-algorithm is neglected in this comparison b e- cause of implementation differences, making this algo- rithm a lot faster than the other tw o. This making the comparison difficult but the theoretical complexit y of the SP-algorithm is approximately O ( n 3 . 2 ) for sparse net- w orks where m << n 2 . W e conclude by that the computational complexity of the current implementation of LP-NFC can b e improv ed but the theoretical limit is still higher than for the GA- algorithm. The adv antage of the LP-NFC-algorithm is that the running time is not an increasing function of the mixing parameter and is faster for netw orks smaller than 1000 no des. 2.0 2.4 2.8 3.2 −1 0 1 2 3 LP−NFC number of nodes (n) mean time 2.0 2.4 2.8 3.2 −1 0 1 2 3 GA number of nodes (n) mean time mu: 0.1 mu: 0.5 mu: 1 FIG. 8. The running time of the LP-NF C and GA-algorithms. The graph are found as an av erage of 30 runs on net works with n ∈ { 100 , 200 , 500 , 1000 , 2000 } no des and mixing parameter, µ ∈ { 0 . 1 , 0 . 2 , . . . , 1 . 0 } . The dotted lines are reference curv es for O ( n 3 ) for the LP-NF C algorithm and O ( n ) for the GA- algorithm. V. CONCLUDING REMARKS In this pap er, we hav e presented a metho d for combin- ing communit y structures detected in netw orks, named No de-based F usion of Communities (NFC). This method has applications including combining several different comm unity detection metho d, for enhancing the p erfor- mance of stochastic metho ds, and for merging comm u- nities detected at different scales. The metho d has b een used in com bination with the Label Propagation (LP) algorithm and ev aluated using simulation studies with syn thetic net works. A CKNOWLEDGMENTS JD would esp ecially like to thank Sang Ho on Lee, Jari Saramki, P etter Holme, and Martin Rosv all for helpful discussions, comments, and suggestions during the work underlying this paper. This paper is part of the pro ject T o ols for information management and analysis , whic h is funded by the R&D programme of the Swedish Armed F orces. [1] S. F ortunato, Ph ysics Rep orts, 486 , 75 (2010), ISSN 03701573. [2] U. N. Raghav an, R. Alb ert, and S. Kumara, Physical Review E, 76 , 036106+ (2007). [3] M. Rosv all and C. T. Bergstrom, PLoS ONE, 5 , e8694+ (2010), ISSN 1932-6203. [4] A. Strehl and J. Ghosh, Journal of Machine Learning Researc h, 3 , 583 (2003), ISSN 1532-4435. [5] S. Mon ti, P . T amay o, J. Mesirov, and T. Golub, Mac hine Learning, 52 , 91 (2003), ISSN 08856125. [6] X. Z. F ern and C. E. Bro dley , in ICML ’04: Pr o c ee dings of the twenty-first international confer enc e on Machine le arning (ACM, New Y ork, NY, USA, 2004) pp. 36+, 12 ISBN 1-58113-828-5. [7] A. Clauset, M. E. J. Newman, and C. Mo ore, Physical Review E, 70 , 066111+ (2004). [8] J. Reichardt and S. Bornholdt, Ph ys Rev E Stat Non- lin Soft Matter Phys, 74 (2006), ISSN 1539-3755, doi: 10.1103/Ph ysRevE.74.016110. [9] ¨ O. Bo din and C. Prell, eds., So cial networks and natur al r esourc e management : unc overing the so cial fabric of envir onmental governanc e (Cam bridge Univ ersity Press, 2011). [10] M. A. P orter, J.-P . Onnela, and P . J. Mucha, (2009), [11] F. Radicc hi, C. Castellano, F. Cecconi, V. Loreto, and D. Parisi, (2004), arXiv:cond-mat/0309488. [12] W. W. Zachary , Journal of Anthropological Researc h, 33 , 452 (1977). [13] M. E. J. Newman, Pro ceedings of the National Academ y of Sciences, 103 , 8577 (2006), ISSN 0027-8424, arXiv:ph ysics/0602124. [14] The elements of the adjacency matrix, A ij , are equal to 1 if an edge exist b et ween no des i and j , and 0 otherwise. [15] The Kroneck er delta function, δ ( · ), takes the v alue 1 if the elements are equal and 0 otherwise. [16] U. Brandes, D. Delling, M. Gaertler, R. Go erk e, M. Ho efer, Z. Nikoloski, and D. W agner, (2006), arXiv:ph ysics/0608255. [17] B. H. Go o d, Y. A. de Montjo ye, and A. Clauset, Physical Review E, 81 , 046106+ (2010), [18] R. S. W eiss and E. Jacobson, American So ciological Re- view, 20 (1955). [19] S. A. Rice, The American Political Science Review, 21 (1927). [20] In the following simulation exp eriments, this ratio is set as unit y and therefore only communities with sizes larger than √ m where m is the num b er of edges can be detected. [8]. [21] S. Kirkpatrick, C. D. Gelatt, and M. P . V ecchi, Science, Num b er 4598, 13 May 1983, 220, 4598 , 671 (1983). [22] L. K. Hansen and P . Salamon, IEEE T ransactions on Pat- tern Analysis and Mac hine Intelligence, 12 , 993 (1990), ISSN 0162-8828. [23] P . Sollich and A. Krogh, Adv ances in Neural Information Pro cessing Systems, 8 , 190 (1996). [24] S. Dudoit and J. F ridlyand, Bioinformatics (Oxford, Eng- land), 19 , 1090 (2003), ISSN 1367-4803. [25] M. Newman, Networks: An Intr o duction , 1st ed. (Oxford Univ ersity Press, USA, 2010) ISBN 0199206651. [26] A. Lancichinetti and S. F ortunato, Ph ysical Review E (Statistical, Nonlinear, and Soft Matter Ph ysics), 80 , 016118+ (2009). [27] A. Lancic hinetti, S. F ortunato, and F. Radicchi, Phys- ical Review E (Statistical, Nonlinear, and Soft Matter Ph ysics), 78 (2008). [28] M. E. J. Newman and M. Girv an, Ph ysical Review E, 69 , 026113+ (2004). [29] A. Lancichinetti and S. F ortunato, Physical Review E, 80 , 056117+ (2009). [30] A. K. Jain and R. C. Dub es, Algorithms for clustering data (Prentice-Hall, Inc., Upp er Saddle River, NJ, USA, 1988) ISBN 0-13-022278-X. [31] K. W akita and T. Tsurumi, “Finding Communit y Structure in Mega-scale So cial Net works,” (2007), arXiv:cs/0702048.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment