KL-based Control of the Learning Schedule for Surrogate Black-Box Optimization
This paper investigates the control of an ML component within the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) devoted to black-box optimization. The known CMA-ES weakness is its sample complexity, the number of evaluations of the objecti…
Authors: Ilya Loshchilov (LIS), Marc Schoenauer (INRIA Saclay - Ile de France, LRI)
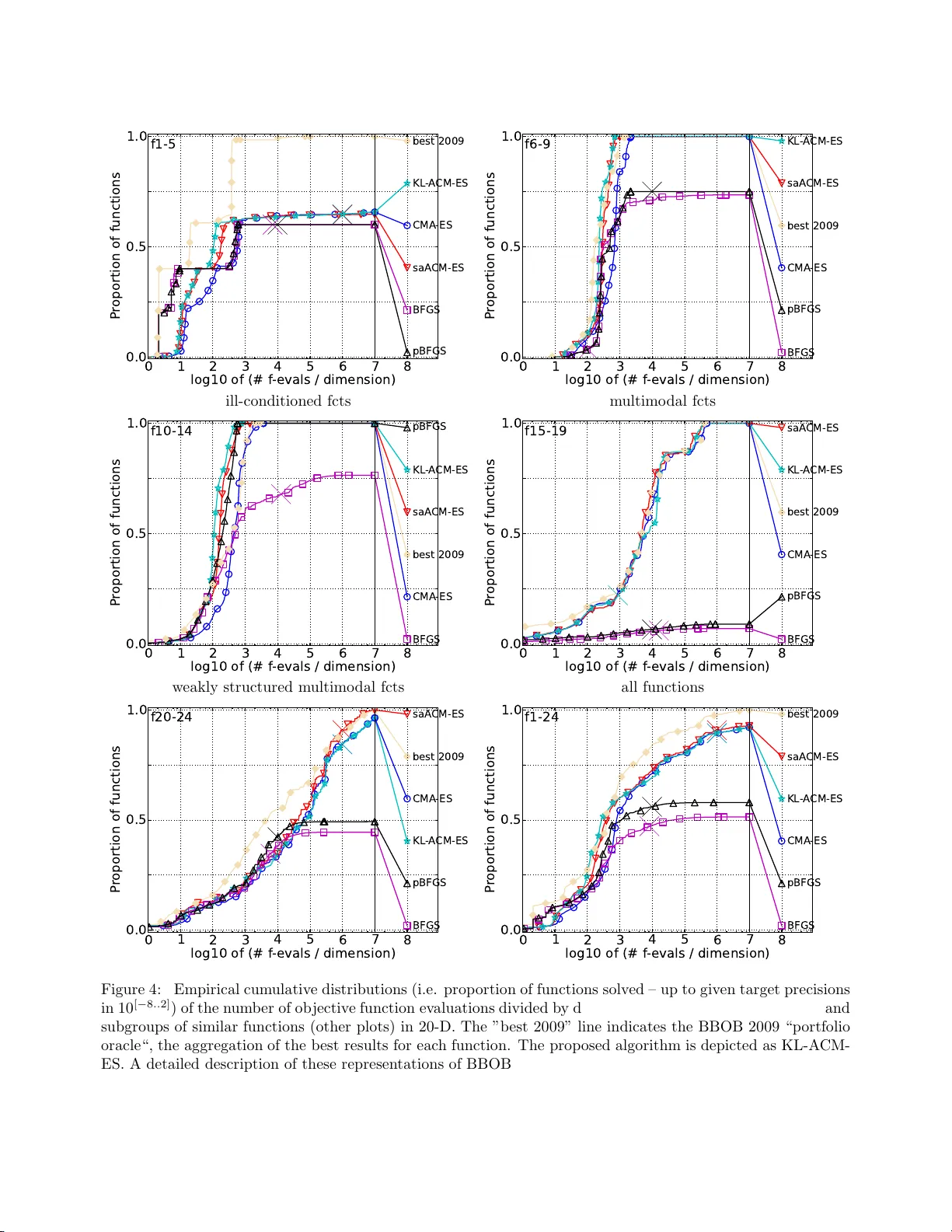
KL-based Con trol of the Learning Sc hedule for Surroga te Blac k-Box Optimization Ily a Loshc hilo v 1 , Marc Sc hoenauer 2 , and Mic h ` ele Sebag 3 1 LIS, EPFL, Switzerland. ilya.loshc hilo v@epfl.c h 2 T A O, INRIA Sacla y , F rance. marc.sc ho enauer@inria.fr 3 CNRS, LRI UMR 8623, F rance. mic hele.sebag@lri.fr Abstract This pap er inv estigates the control of an ML comp o- nent within the Cov ariance Ma trix Ada pta tion Evo- lution Strategy (CMA-ES) devoted to black-b ox opti- mization. The kno wn CMA-ES w eakness is its sample complexity , the num be r o f ev a luations of the ob jective function needed to approximate the global optim um. This weakness is co mmonly addresse d thr ough s urro- gate optimization, lear ning an estimate of the ob jective function a.k.a . surrog ate model, and replacing most ev alua tions of the true ob jective function with the (in- exp ensive) ev aluation of the surrogate mo del. This pa- per presents a principled c o ntrol of the lea rning sched- ule (when to relearn the sur roga te mode l), based on the Kullback-Leibler divergence of the cur r ent search dis- tribution a nd the training distr ibutio n of the for mer surrog ate mo del. The ex pe r imental v alidation of the prop osed approach shows significant perfor mance ga ins on a comprehensive s et of ill-co nditioned b enchmark problems, compar ed to the be st state of the ar t includ- ing the q uasi-Newton high- precision BFGS metho d. Mots-clef : exp ensive bla ck-box o ptimiza tion, ev olu- tionary algo rithms, surog ate mo dels, Kullback-Leibler divergence, CMA-E S. 1 In tro duc tion As noted in [HCO12], the r equirements on machine learning algor ithms (ML) might b e rather different de- pending on whether these a lgorithms are used in isola- tion, or as c o mp o nents in computationa l systems. Be- yond the usual ML criteria of consistency and conv er- gence sp eed, ML comp onents should enfor ce so me sta- bilit y and controllabilit y prop er ties. Spec ific a lly , a n ML comp one nt should never c ause any c atastrophic even t (b e it r elated to exceedingly high computational cost or exceedingly bad p erfor ma nce), over all s ystem calls to this comp onent. As a co ncrete example o f controllabilit y-enfor cing strateg y and co ntrarily to the ML usage, the stopping criterion of a Supp ort V e c- tor Mac hine algorithm sho uld be defined in terms of nu mber of qua dr atic prog ramming iterations , rather than in terms of a ccuracy , since the conv erge nce to the g lobal optimum might b e very slow under some circumstances [LS0 9]. In counterpart, such a s trategy might r educe the predictive p er formance of the learned mo del in s ome cases, thus hindering the perfor mance of the whole computational system. It thus b e comes advisable that the ML comp onent ta kes in charge the control of its hyper-par a meters and even the schedule of its ca lls (when and how the pr edictive model should most a ppropriately b e r e built). The automatic hyper- parameter tuning o f a n ML algorithm in the general case howev er shows to b e a cr itical tas k , r equiring suf- ficient empirical evidence. This pap er fo cuses on the embedding o f a learning comp onent within a distribution-based optimization al- gorithm [RK04, HMK03]. The v isibility of s uch algo- rithms, particular ly for industrial applications, is ex- plained from their ro bustness w.r.t. (modera te) noise and multi-moda lit y o f the o b jectiv e function [Han13], in contrast to classic al optimization metho ds such a s quasi-Newton metho ds (e.g. BFGS [Sha70]). One pric e to pay for this robustness is that the lack of any reg- ularity assumption on the ob jective function leads to a la rge empirical s a mple complexity , i.e. nu mber of ev alua tions of the ob jective function needed to a pprox- imate the global optima. Another drawbac k is the usu- ally large num b er of hyper-pa rameters to be tuned for such algor ithms to reach go o d p erfor mances. W e shall how ever restrict ourse lves in the r emainder of the pa- per to the Cov aria nce Matrix Adaptation E volution 1 Strategy (CMA-ES) [HMK03], known as an almost pa- rameterless distribution-based black-box optimization algorithm. This prop erty is co mmonly attributed to CMA-ES inv aria nce prop er ties w.r.t. b oth mo notonous transformatio ns of the ob jectiv e function, and linear transformatio ns o f the initial representation of the in- stance space (section 2.1). The high sample complexity co mmonly preven ts distribution-based optimization alg orithms fro m b eing used on exp ensive optimization problems, wher e a sin- gle ob jective ev alua tion might requir e up to s everal hours (e.g. for optimal desig n in numerical eng ine e r- ing). The so-called surrog ate o ptimization algo r ithms (see [Jin11] for a survey) addres s this limitation b y cou- pling black-box optimization with lea rning o f surrog ate mo dels, that is, lo ca l approximations o f the o b jectiv e function, and replacing mos t ev aluations of the true ob jectiv e function w ith the (inexp ensive) ev aluation of the surr ogate function (section 2.2). The key issue of sur r ogate- based optimization is the control of the learning mo dule (hyper- parameters tuning and up date schedule). In this paper , an in tegra ted coupling of distribution- based optimization and r ank-base d learning alg o- rithms, calle d KL- ACM-ES, is presented. The contri- bution compar ed to the sta te of the art [LSS12] is to an- alyze the learning schedule with resp ect to the drift of the s ample distribution: F or mally , after the s ur roga te mo del is trained from a given sample distr ibution, this distribution is iter a tively modified along optimization. When to relear n the surro gate mo del dep ends on how fast the error rate o f the surrog ate mo del increases as the sample dis tribution moves aw ay fro m the tra ining distribution. Under mild a ssumptions, it is shown that the e rror ra te increase can b e b ounded with resp ect to the Kullback-Leibler divergence b etw een the train- ing a nd the curre nt distribution, yielding a principled learning schedule. The mer it of the approach is empiri- cally demonstra ted a s it shows significant p erfo rmance gains on a co mprehensive set of ill- conditioned b ench- mark problems [HFRA09a, HFRA09b], compar ed to the be s t state of the ar t including the quasi- Newton high-precisio n BFGS metho d. The pap er is o rganize d as follows. F or the sake of self-containedness, section 2 presents the Cov ari- ance Matrix Adaptatio n E S, and briefly r eviews r elated work. Section 3 gives an overview of the prop os ed KL- A CM-E S algorithm a nd discusses the notion of drifting error rate. The exp erimental v alidation o f the pro po sed approach is rep or ted and discussed in section 4 a nd sec- tion 5 concludes the pap er. 2 State of the art This section summarizes Cov ar iance Matrix Adapta- tion Evolution Stra tegy (CMA-ES ), b efore discussing work rela ted to surr ogate-a ssisted optimization. 2.1 CMA-ES Let f deno te the o b jectiv e function to b e minimized on I R n : f : I R n 7→ I R The so-called ( µ/µ w , λ )-CMA-ES [HMK03] maintains a Gaus sian distribution on I R n , iteratively used to gen- erate λ samples, and up dated based on the be s t (in the sense of f ) µ samples out of the λ ones. F ormally , samples x t +1 at time t + 1 are drawn from the current Gaussian distribution P θ t , with θ t = ( m t , σ t , C t ): x t +1 ∼ N m t , σ t 2 C t (1) where m t ∈ I R n , σ t ∈ I R, and C t ∈ I R n × n resp ec- tively are the center of the Gaussian distr ibution (cur - rent b est estimate of the optimum), the p erturbation step size a nd the co v ariance matrix. The next distribu- tion center m t +1 is set to the weigh ted sum of the b est µ samples , denoting x ( i : λ ) t +1 the i -th b est sa mple out o f the λ ones: m t +1 = µ X i =1 w i x ( i : λ ) t +1 with µ X i =1 w i = 1 (2) The next cov ar iance matrix C t +1 is up dated from C t using b oth the lo ca l information ab out the search di- rection, given by 1 σ t ( x ( i : λ ) t +1 − m t ), and the global infor- mation stored in the so -called evolution path p t +1 of the dis tribution center m . F or p os itive learning rates c 1 and c µ ( c 1 + c µ ≤ 1) the upda te of the cov aria nc e matrix rea ds: C t +1 = (1 − c 1 − c µ ) C t + c 1 p t +1 · p t +1 T | {z } rank − one up d ate + c µ µ X i =1 w i σ t 2 ( x ( i : λ ) t +1 − m t ) · ( x ( i : λ ) t +1 − m t ) T | {z } rank − µ u p date (3) The step-size σ t +1 is likewise upda ted to bes t align the distribution o f the a ctual evolution pa th of σ , a nd an evolution path under rando m selection. As mentioned, the CMA-ES r obustness and p er - formances [HAR + 10] are explained fro m its in v ari- ance prop erties. On the one hand, CMA-ES only considers the s ample ranks after f ; it thus do es no t 2 make a ny difference betw een optimizing f a nd g ◦ f , for any strictly increasing scalar function g . On the other ha nd, the self-adapta tion of the cov aria nce ma - trix C makes CMA-ES inv ariant w.r.t. orthogo nal transformatio ns of the sea rch space (rotatio n, symme- tries, translation). Int ere stingly , CMA-E S can b e in- terpreted in the Informa tion-Geometric Optimiza tio n (IGO) framework [AAHO11]. IGO achiev es a natu- r al gr adient asc ent o n the spa ce of para metric distri- butions on the sample space X , using the Kullback- Leibler divergence as distance among distributio ns. It has b een shown tha t the basic ( µ, λ )-CMA-ES v ari- ant is a pa rticular ca se of IGO when the pa ramet- ric distribution space is that of Gaussian distributions [AAHO11]. 2.2 Surrogate-based CMA-ES Since the late 90s, many lea rning algor ithms hav e bee n used within surr ogate-ba sed o ptimization, ra ng- ing from neural nets to Ga ussian P ro cesses (a.k.a . krig- ing) [USZ03, BSK05], using in particular the exp ected improv ement [JSW98] as selection criterio n. The s ur- rogate CMA-ES algor ithm most similar to o ur ap- proach, s ∗ A CM-E S [LSS12], interlea ves tw o o ptimiza- tion pro cedures (Fig. 1): The first one (noted CMA-ES #1) rega rds the op- timization of the ob jective function f , ass is ted by the surroga te mo del b f ; the second one (CMA-ES #2) rega r ds the optimization o f the learning hyper- parameters α used to learn b f . More pr ecisely , s ∗ A CM-E S fir st la unches CMA-ES o n the tr ue ob jectiv e function f for a n umber of itera tions n start , and gather s the computed samples in a tr aining set E θ = { ( x i , f ( x i )) , i = 1 , . . . q } ; the first sur r ogate mo del b f is learned from E θ . s ∗ A CM-E S then iterates the following pro cess , r eferred to as ep o ch: i) b f is optimized by CMA-ES for a given num be r of steps ˆ n , leading fro m distribution P θ to P θ ′ ; ii) CMA-ES is launc hed with distribution P θ ′ on the true ob jective function, thereby building a new tra in- ing set E θ ′ ; iii) the previous a nd current training sets E θ and E θ ′ are used to adjust ˆ n and the other lear ning hyper - parameters α , a nd a new sur roga te mo del b f is lea rned from E θ ′ . Surrogate mo del l earning Surroga te mo del b f is lear ned fro m the current train- ing set E θ , using Ranking-SVM [Joa 05] toge ther with the learning hyper- parameter vector α . F o r the sake Figure 1: s ∗ A CM-E S: interlea ved optimization lo op. of computational efficiency , a linear num b er of ra nk ing constraints ( x i ≺ x i +1 , i = 1 . . . q − 1) is used (assum- ing wlog that the samples in E θ are ordered by increas - ing v a lue of f ). B y construction, the surr ogate mo del th us is in v ariant under monotonous tr ansformatio ns of f . The inv ariance o f b f w.r.t. orthogo nal transfor- mations o f the s earch space is enforced by using a Radia l B a sis F unction (RBF) k erne l, which in- volv es the inv erse o f the cov ar iance matrix adapted b y CMA-ES. F ormally , the rank -based surrog ate model is learned using the kernel K C defined as: K C ( x i , x j ) = e − ( x i − x j ) T C − 1 ( x i − x j ) 2 s 2 , which corresp onds to resca ling datasets E θ and E θ ′ using the tr ansformation x → C − 1 / 2 ( x − m ), where C is the cov ar iance matrix adapted by CMA-ES (and s is a learning hyper- parameter). Thro ugh this kernel, b f b enefits fro m the CMA-ES efforts in ident ifying the lo ca l curv ature of the optimization landscap e. Learning hy p er-parameters As mentioned, the cont ro l of the learning module (e.g. whe n to refresh the surrog ate mo del; how many ranking constr a ints to use; which p enaliza tion weigh t) has a dr amatic impact on the p erformance of the surrog ate optimization alg o rithm. Both issues are settled in s ∗ A CM-E S through exploiting the e r ror of 3 the surrogate mo del b f trained fro m E θ , measur ed on E θ ′ . F o rmally , let ℓ ( b f , x, x ′ ) b e 1 iff b f misranks x and x ′ compared to f , 1/2 if f ( x ) = f ( x ′ ) a nd 0 otherwise. The empirica l r anking er ror of b f on E θ ′ , refer red to as empirical drift erro r rate, is de fined as d E rr = 1 |E θ ′ | ( |E θ ′ | − 1) X x,x ′ ∈ E θ ′ x 6 = x ′ ℓ ( b f , x, x ′ ) It is used to linearly adjust ˆ n : clo se to 50 %, it in- dicates tha t b f is no b etter than ra ndo m guessing and that the sur rogate mo de l s ho uld hav e be e n rebuilt ear- lier ( ˆ n = 0); close to 0%, it inv ersely suggests that b f could hav e b een used for a longer epo ch ( ˆ n is set to n max , user-sp ecified parameter of s ∗ A CM-E S). In the same spirit, E θ and E θ ′ are us ed to adjust the learning hyper-par ameter v ector, thro ugh a 1-iteration CMA-ES on the hyper- parameter spa c e , minimizing the dr ift er ror rate of the surroga te mo del learned from E θ with h yp er-pa rameters α ′ . T he learning hype r- parameter vector α to be us ed in the next ep o ch is set to the cen ter of the CMA-ES distribution on the hyper-para meter spa ce. 2.3 Discussion The main strength of s ∗ A CM-E S is to ac hieve the si- m ultaneo us optimization of the ob jectiv e function f to- gether with the learning hype r -para meters (considering ˆ n as one a mong the learning hype r -para meters), thus only requiring the use r to initially define their range of v alues and a djusting them online to minimize the drift error rate. It is worth noting that the automatic tuning of ML hype r-para meters is critical in ge neral, particu- larly so when dealing with small sample sizes. The fact that the h yp er- parameter tuning w as found to b e effec- tive in the considered setting seems to b e explained as the ML comp onent in s ∗ A CM-E S i) actually considers a sequence of learning pr oblems defined by the succes- sive distributions P θ , ii) r eceives some feedbac k in each epo c h ab out the α choice made in the previous ep o ch. A significant weakness how ever is that the s ∗ A CM- ES lear ning schedule is defined in terms of the num b er ˆ n of CMA-E S itera tions in each ep o ch. How ever, the drift e r ror rate s hould ra ther dep end on how fast the optimization distribution P θ is mo dified. This remark is a t the cor e of the prop osed algor ithm. 3 Kullbac k-Leibler Div ergence for Surrogate M o del Con trol The prop osed KL-ACM-ES algorithm presented in this section differs fr o m s ∗ A CM-E S regarding the co ntrol o f the learning schedule, that is, the decisio n of rele a rning the s urrog ate mo del. The prop o sed criterion is bas e d on the Kullba ck-Leibler divergence betw een the distri- bution P θ that w as us ed to gener ate the training set of the c urrent surr ogate mo del b f , refer red to as training distribution, and the cur rent w or k ing distribution P θ ′ of CMA-ES. It is worth noting that since the Kullba ck- Leibler divergence dep ends only on P θ and no t o n the parameteriza tion of θ , this criterion is intrinsic a nd could b e used for other distr ibutio n-based blac k-b ox optimization alg orithms. 3.1 Analysis Letting P θ and P θ ′ denote tw o distributions o n the sample s pace, their K ullback-Leibler divergence noted K L ( P θ ′ || P θ ) is defined as: K L ( P θ ′ || P θ ) = Z x ln P θ ′ ( x ) P θ ( x ) P θ ′ ( dx ) . (4) Let b f deno te in the following the surro gate model learned from E θ , sampled after distribution P θ . The idea is to retrain the surrog ate mo del b f whenever it is estimated that its ra nk ing error on P θ ′ might be greater than a (user- s pe cified) a dmissible erro r E rr admissible . Let us show that the difference b etw een the gener aliza- tion err or of b f wrt P θ and P θ ′ is bo unded dep ending on the K L divergence of P θ and P θ ′ : Prop ositi on 1 The difference b etw e en the exp ectation o f the ranking error of b f w.r.t. P θ and w.r .t. P θ ′ , resp ectively no ted E rr P θ ( b f ) and E rr P θ ′ ( b f ), is bounded b y the square ro ot of the KL divergence of P θ and P θ ′ : | E rr P θ ( b f ) − E rr P θ ′ ( b f ) | ≤ c k p K L ( P θ ′ || P θ ) (5) with c k = 2 √ 2 ln 2 Pr o of | E rr P θ ( b f ) − E rr P θ ′ ( b f ) | = | s ℓ ( b f , x, x ′ )[ P θ ( x ) P θ ( x ′ ) − P θ ′ ( x ) P θ ′ ( x ′ )] dxdx ′ | ≤ | s ( P θ ( x ) P θ ( x ′ ) − P θ ′ ( x ) P θ ′ ( x ′ )) dxdx ′ | ≤ 2 || P θ − P θ ′ || 1 ≤ c k p K L ( P θ ′ || P θ ) where the first inequality follows fro m the fact that ℓ is p ositive a nd b ounded by 1, and the second fro m 4 applying the us ua l trick ( ab − cd ) = a ( b − d ) + d ( a − c ), and separately integrating w.r.t. x and x ′ . The last inequality follows from the result that for any t wo distributions P a nd Q , K L ( P || Q ) ≥ 1 2 ln 2 || P − Q || 2 1 See, e.g., Cov er and Thomas (199 1, Lemma 12 .6.1, pp. 300–3 01). 2 The second step, bo unding the difference betw een the empirical a nd the genera lization r anking error of b f θ , follows fr om the statistical lear ning theory applied to r anking [CL V08, AN09, Rej1 2]. Let us first re call the prop erty of uniform loss st abil- ity . A r a nking algo rithm has the unifor m lo s s stability prop erty iff for any t wo q -size sa mples E and E ′ drawn after the s ame distribution and differing b y a single sample, if b f a nd ˆ f ′ are the ranking functions learned from resp ectively E and E ′ , the fo llowing ho lds for any ( x, x ′ ) pair, for some β q that only dep ends o n q : | ℓ ( b f , x, x ′ ) − ℓ ( ˆ f ′ , x, x ′ ) | < β q Prop ositi on 2 [AN09] If the ra nking algo rithm has the unifor m los s stability prop erty , then for any 0 < δ < 1, with proba bilit y a t least 1 − δ (ov er the draw of the q -size test set E θ drawn according to P θ ), the genera liz a tion ra nking er ror of b f is bounded by its empirica l error on E θ , plus a term that only dep ends o n q : | E rr P θ ( b f ) − \ E rr P θ ,q ( b f ) | < 2 β q + ( q β q + 1) s 2 ln 1 /δ q (6) F ro m E qs. (5) a nd (6), it is straightforward to show that with probability at lea st 1 − δ / 2 the empirical error of b f on E θ ′ is b ounded by a term tha t only dep ends on q , plus the square ro o t of the KL divergence b etw een P θ and P θ ′ : \ E rr P θ ′ ,q ( b f ) < 4 β q + 2( q β q + 1) q 2 ln 1 /δ q + \ E rr P θ ,q ( b f ) + c k p K L ( P θ || P θ ′ ) (7) In the context of this work, Ranking -SVM have the uniform loss s tability pro pe r ty [AN09]. Hence, if the q -dep endent terms o f Eq. (7) a re small eno ugh, it is po ssible, giv en a par ameter E rr admissible , to define a threshold K L thr esh such that, provided that the KL di- vergence betw een P θ and P θ ′ remains b elow K L thr esh , the empirical error of b f θ on E θ ′ remains bounded by −2 −1 0 1 2 −2 −1 0 1 2 x 1 x 2 Figure 2: Ellipsoidal 9 5% confidence re g ions of the Gaussian distributio n P θ (black thin line) a nd three other Gaussian distributions P θ ′ (color marked lines) with same K L ( P θ ′ || P θ ). E rr admissible with high probability . In pr actice how- ever, a s noted by [CL V08], it is w ell kno wn that the ab ov e b ound is often quite lo ose , ev en in the case where ℓ is co nv ex and σ -a dmissible [AN09]. F or instance, us- ing the hinge los s function prop os e d in [AN09], the constant β q of Eq . (7) is inv ers e ly prop ortiona l to q , and the q -dependent terms of Eq. (7) v anish for large q . How ever, as discus s ed in section 1, the con- text of application of ML algo rithms is dr iven her e by the o ptimization goal. In pa r ticular, the num ber o f training samples q ha s to b e kept as small as p ossible. This is why an empirical alternative for the up da te of K L thr esh has b een inv estigated, inspired by the trust- region para digm from classic a l optimization. 3.2 Adaptiv e adjustmen t of K L thr e sh Let us remind that, for P θ and P θ ′ (resp ectively defined by θ = ( m , C ) and θ ′ = ( m ′ , C’ )) the Kullback-Leibler divergence of P θ and P θ ′ has a closed form expressio n, K L ( P θ ′ || P θ ) = 1 2 [ tr ( C − 1 C’ )+ ( m − m ′ ) T C − 1 ( m − m ′ ) − n − ln( det C’ det C )] . (8) Note that increasing v alues o f K L ( P θ ′ || P θ ) mig ht re - flect different phenomenons; they can b e due to either differences in the distributio n center or in the s caling of the cov a riance ma trix (see the examples on Fig. 2 ). 5 The soug ht threshold K L thr esh finally is int erpr eted in terms of trust reg ions [MS83]. Cla ssical heuristic op- timization metho ds often pro ceed by asso ciating to a region o f the search space the (usually) quadratic sur- rogate mo del appr oximating the ob jective function in this region. Such a r egion, refer red to a s trust region, is assessed from the ra tio of exp ected improvemen t mea- sured o n the surrog a te mo del, and the improv ement o n the tr ue ob jective. Depending on this r atio, the tr ust region is expanded or restr ic ted. The prop os ed KL-based control of the lear ning schedule can be view ed as a principled way to adap- tively control the dynamics of the trust region, with three differences. Firstly , the trust r egion is here de- fined in terms of distributions on the search space: the trust region is defined as the set o f all dis tributions P θ ′ such that K L ( P θ ′ || P θ ) < K L thr esh . Seco ndly , this trust regio n is assess ed a p osterio r i from the empirical error of the surr ogate mo del, on the first distribution P θ ′ outside the trust region. Thirdly , this assessment is exploited to adjust the KL “radius” of the next trust region, K L thr esh . Finally , K L thr esh is set such that log K L thr esh is in- versely prop ortional to the r e laxed surro gate error E r r : ln( K L thr esh ) ← τ err − E rr τ err ln( K L M ax ) , (9) where τ err is an erro r thr eshold (exp erimentally s et to .45), K L M ax is the maximal allow ed K L div erg ence when b f is ideal, and the re laxed surro gate error E rr is computed as E rr = (1 − α ) E rr + α \ E rr P θ ′ ,q ( b f ) , in order to mo derate the effects o f \ E rr P θ ′ ,q ( b f ) hig h v aria nce. The log-scaling is chosen o n the ba sis of pr eliminary exp eriments; its adjustment online is left for further work. Finally , KL-ACM-ES differ s from s ∗ A CM-E S in tw o po ints: • The seco nd step of the a lgorithm (Fig. 1) thus b e- comes ”O ptimize b f while K L ( P θ ′ || P θ ) ≤ K L thr esh ; • The fifth step of the alg orithm (Fig. 1) b ecomes ”Adjust K L thr esh ” from E q. (9). 4 Exp erimen tal v alidation This section pres ent s the exp erimental v alida tion of the prop osed KL- A CM-E S alg o rithm co mpa red to v ar- ious CMA-ES alg orithms including s ∗ A CM-E S, and the quasi Newton BFGS algor ithm [Sha70] o n the BBOB noiseless a nd noisy b enchmark suite [HAFR12]. 4.1 Exp erimen tal Set ting F or r epro ducibility , the Ma tlab sour c e co de of KL- A CM-E S is made av a ilable together with its default pa- rameters 1 . After preliminary exp er imen ts, ln( K L M ax ) is se t to 6; the CMA-ES λ pa rameter us ed when o pti- mizing b f θ is multiplied by 100 when the empiric al er ror rate of b f θ on E θ ′ is less than .35. The compar ative v al- idation firstly inv olves s ∗ A CM-E S with its default pa- rameters 2 . The CMA-ES v ariant use d within s ∗ A CM- ES and KL-ACM-ES is the state of the ar t BIPOP- active CMA-ES algorithm [HR10]. The compara- tive v alida tion als o inv olves the Q uasi-Newton BFGS metho d. I ndee d, B FG S suffers from known numerical problems on ill- conditioned pr oblems (see [Po w87] for an extensive discussio n). This limitation is ov ercome by co nsidering instead the 32-decimal digit precision arithmetic version o f BFGS, referred to as pBFGS 3 and included in the high-precisio n arithmetic pack age ARPREC [BYL T02]. The alg orithms hav e b een compa red o n the tw ent y- four 20-dimensio nal noiseless and thirt y no is y b ench- mark problems of the BBO B suite [HFRA09a, HFRA09b] with different known character istics: sep- arable, non-separa ble, unimodal, multi-modal, ill- conditioned, deceptive, functions with and without weak globa l structure. F or ea ch problem, 50 uniformly generated orthog onal transfor mations of f are co nsid- ered. F or each pro blem and each algo rithm, 15 indep en- dent runs (each one with a randomly chosen p os itio n for the optim um) are launched. The p erfor mance of each algo rithm is rep or ted as the median optimum v alue (in log sca le) vs the num b er of ev aluations of f (Fig. 3), or a s the empirical cumulative distribution of success for so lving sets of similar functions (Fig . 4, see ca ption there). All algor ithms are initialized with samples uniformly drawn in [ − 5 , 5] 20 . 4.2 Case st udy: the Rosenbrock func- tion A first study is conducted on the 20-dimens io nal Rosenbrock function and its second and fourth p ow er. Rosenbrock function is defined as: f Ros ( x ) = n − 1 X i =1 100( x 2 i − x i +1 ) 2 + ( x i − 1) 2 1 h ttps://sites.go ogle.com/site/acmesKL/ 2 h ttps://sites.go ogle.com/site/acmesge cco/ 3 h ttps://sites.go ogle.com/site/highprecision bfgs/. F or gradient appro ximations by finite differences ǫ = 10 − 20 is used in pBFGS i nstead of ǫ = 10 − 8 in BFG S. 6 0.5 1 1.5 2 2.5 x 10 4 10 −8 10 −6 10 −4 10 −2 10 0 10 2 10 4 n um b er of f unction ev al uations ob jec tive fun ction F8 R osen brock 20-D KL−ACM−ES saACM−ES CMA−ES pBFGS pBFGS**2 pBFGS**4 Figure 3: Co mparative p erfor mance of KL- A CM-E S compa red to high- pr ecision BFGS a nd CMA-ES v ariants (see text) o n the 20- dimens io nal Rosenbro ck function f Ros , f 2 Ros and f 4 Ros . The medium num b er of function ev alua tions (out of 15 runs) to reach the target o b jectiv e v alue 10 − 8 was co mputed and the corr esp onding run is shown. Markers show the ob jective v alue re a ched in ea ch run after a given num b er o f function ev a luations. The empirical r esults (Fig. 3) show that b oth surrog ate-based optimization a lg orithms s ∗ A CM-E S and KL- ACM-ES improv e on the CMA-E S v ariant baseline by a facto r ranging from 2.5 to 3. KL-ACM-ES outper fo rms s ∗ A CM-E S and pBFGS on the Ro senbrock function (BFGS, omitted for clar- it y , b ehav es like pBF GS as the Rosenbro ck function is not ill-conditio ne d). The merits o f the inv arianc e w.r.t. monotono us transformatio ns of the ob jective function s hine as the pBFGS b ehavior is significantly degraded on f 2 Ros (legend pBF GS**2) and f 4 Ros (leg- end pB F GS** 4) compa red to f Ros , slowing down the conv ergence by a factor of ab out 4 for f 4 Ros . Quite the contrary , all CMA-ES v a riants including s ∗ A CM- ES and KL-ACM-ES be have exactly the sa me on all three functions, by construction. The perfo rmance improv ement of KL-ACM-ES on s ∗ A CM-E S and pBFGS is ov er 20 %. 4.3 Results on BBOB problems Fig. 4 displays the ov era ll results o n BBO B b ench- mark. Similar functions ar e gr oup ed, thus distin- guishing the cases of separa ble, mo der ately difficult, ill-conditioned, mu lti-mo da l, weakly structured multi- mo dal ob jective functions (last plot aggr egates all func- tions). T he Best 2009 re fer ence corr esp onds to the (virtual) best p er formance reached ov er the por tfolio of all alg orithms participating in the BBOB 2009 contest (po rtfolio or a cle; note that the high-precisio n pBFGS was not included in the p or tfolio). On separable ob jectiv e functions, pBFGS dominates all CMA-ES v a riants for small num b er s of ev aluations. Then KL- ACM-ES ca tch es up, follow ed by s ∗ A CM-E S and the o ther CMA-E S v aria nts. On mo dera te and ill-conditioned functions, KL-ACM-ES dominates all other algor ithms a nd it even improv es ov er Best 2009 . On multi-modal and weakly structured multi-moda l functions, KL-ACM-ES is do mina ted by s ∗ A CM-E S; in the meanwhile BFGS and pBFGS alik e yield p o or p er- formance. Finally , on the ov erall plot, KL-ACM-ES shows go o d per formances c o mpared to the state of the art, prod- ding the Best 2009 cur ve in the median regio n due to the significant progr ess ma de on ill-conditioned func- tions. Besides the merits of r ank-based optimization, these results demonstra te the relev ance of using high- precision BFGS instead of BFGS for solving ill- conditioned optimization pro blems. A cav eat is that high-precisio n computations requir e the sour ce code to be rewritten (not only in the optimization a lgorithm, 7 but also in the ob jective function), which is hardly fea- sible in standar d black-b ox sce na rios − even when the ob jectiv e s ource co de is av ailable. Albeit pBF GS sig nificantly dominates BF GS, its b e- havior is shown to b e significa nt ly deg raded when the scaling of the ob jective function differs from the ”de- sirable” quadr atic BFGS sc a ling. 5 Discussion and future w ork This pap er inv estigates the control of an ML comp o- nent within a comp ound computatio na l system. In or- der to pr ovide a steady and robust contribution to the whole system, it is emphasized that an ML comp o- nent m ust take in c har ge the adjustmen t of its lea rning hyper-para meters, and also when and how fr e quently this ML c omp onent should b e c al le d . In the mean- while and a s could have b een expected, s uch a n au- tonomous ML co mp o nent must accommo date applica- tive priorities and exp erimental conditions whic h differ from thos e commonly fac ed by ML alg orithms in iso- lation. A first attempt tow ard building such an au- tonomous ML comp onent in the context of black-b ox distribution-based o ptimization has b een present ed. In this context, the ML co mpo nent is meant to supply an estimate of the ob jective optimization function; it faces a sequence of lear ning problems, drawn fro m moving distributions on the instance space. The first contri- bution is to show how the KL div erg ence b etw een s uc - cessive distributions can yield a principled control of the lea rning schedule, that is, the decision to relearn an estimate of the ob jectiv e optimization function. The second contribution is that the KL-ACM-ES algo- rithm implementin g this learning schedule control im- prov es o n the b es t s tate-of-the-ar t distribution-ba sed optimization algo rithms and qua s i-Newton metho ds , on a comprehensive suite of ill-c onditioned b enchmark problems. F urther work will examine how to further enhance the a utonomy of the ML comp onent, e.g. when facing mult i-mo da l ob jective functions. Alternativ e compariso n-based surrog ate models will also b e c o n- sidered, s uch as Gaussian Pro ces ses for ordina l r e- gressio n [CG05]. Fina lly , as shown by [HK12], qua si- Newton methods can be interpreted as approximations of Bayesian linea r reg ression under v ary ing prior as- sumptions; a pr osp ective res earch direction is to re- place the linea r reg ression by ordinal regres s ion-based Ranking SVM or Gaussian Pro cesses in order to de- rive a version of BFGS in v a riant w.r.t. mono tonous transformatio ns of the o b jectiv e function f . References [AAHO11] L . Arnold, A. Auge r , N. Hans e n, and Y. O llivier. Information- Geometric Opti- mization Alg o rithms: A Unifying P icture via Inv a r iance Pr inciples. ArXiv e-prints , June 2 011. [AN09] S. Ag a rwal and P . Niyogi. Genera liz ation Bounds for Ranking Algo r ithms via Algo- rithmic Stability . J. of Machine L e arning R ese ar ch , 1 0:441– 474, 200 9 . [BSK05] D. Buche, N. N . Schraudolph, and P . Koumoutsakos. Accelerating Evolu- tionary Algorithms with Gaussian Pro cess Fitness Fn Mo dels. IEEE T r ans. Sys- tems, Man and Cyb ernetics , 35(2):183 – 194, 200 5. [BYL T02 ] D.H. Bailey , H. Y ozo, X.S. Li, and B. Thompson. ARPREC: An Arbitr ary Precisio n Computation Pack age. T ech- nical rep ort, Ernest Orlando Lawrence Berkeley Nationa l Lab ora tory , CA, 200 2. [CG05] W. Chu and Z. Ghahr amani. P reference learning with Gaussian pro ces ses. In Pr o c. 22nd ICML , pa ges 13 7–14 4. ACM, 2 005. [CL V08] S. Clemen¸ con, G. Lugosi, and N. V ay- atis. Ranking and Empirica l Minimization of U-s tatistics. The A nnals of Statistics , 36(2):844 –874 , 2008. [HAFR12] N. Hansen, A. Auger, S. Finck, and R. Ros. Real-Parameter Bla ck-Box Op- timization Benchmarking 2012 : E xp eri- men tal Setup. T echnical repo r t, INRIA, 2012. [Han13] N. Hansen. References to CMA- ES Applications. W ebsite, Jan- uary 20 1 3. Av ailable online at ht tp://www .lr i.fr/ hansen/cmaapplica tions.p df. [HAR + 10] N. Hansen, A. Auger, R. Ros, S. Finc k, and P . Po ˇ s ´ ık. Compar ing results of 3 1 al- gorithms from the black-box optimization benchmarking BBOB- 2009. In GECCO Comp anion , pages 1689 –1696 , 2010. 8 [HCO12] P . Hennig, J. P . Cunningham, and M. A. Osb orne, editors. Pr ob abilistic N umerics Workshop, NIPS , 2 012. [HFRA09a] N. Hansen, S. Finck, R. Ros, and A. Auger. Real-Parameter B la ck-Bo x Op- timization Benchmarking 2009 : Noiseless F unctions Definitions. Research Rep or t RR-6829 , INRIA, 2009. [HFRA09b] N. Hansen, S. Finc k, R. Ros, and A. Auger . Real-Parameter Black-Box Optimization Benchmarking 2009 : Noisy F unctions Definitions. Research Rep or t RR-6869 , INRIA, 2009. [HK12] P . Hennig and M. Kiefel. Quasi-Newto n Metho ds: A New Direction. Pr eprint arXiv:120 6.4602 , 201 2. [HMK03] N. Hansen, S.D. M¨ uller, and P . Koumout- sakos. Reducing the Time Complexity of the Derandomized E volution Str a tegy with Cov a riance Matrix Adaptation. Evo- lutionary Computation , 11(1):1– 18, 2003. [HR10] N. Hansen a nd R. Ros. Benchmarking a weigh ted nega tive cov a riance matrix up- date on the BBOB-20 10 nois e less testbed. In GECCO Comp anion , page s 1673–16 80, New Y ork, NY, USA, 20 10. ACM. [Jin11] Y. Jin. Surroga te-Assisted Evolutionary Computation: Recent Adv ances and F u- ture Challenges. Swarm and Evolutionary Computation , pages 61–7 0, 20 11. [Joa05 ] T. Joachims. A Supp ort V ector Metho d for Multiv aria te Performance Measur es. In Pr o c. 22nd ICML , pages 377– 3 84. A CM, 2005 . [JSW98] Donald R. Jo nes, Ma tthias Schonlau, and William J. W elch. Efficient Global Optimization of Exp ensive Blac k-Box F unctions. J . of Glob al Optimization , 13(4):455 –492 , Decem b er 1998. [LS09] N. List and H.U. Simon. SVM- optimization and s teep e st-descent line search. In Pr o c e e dings of t he 22nd COL T , 2009. [LSS12] I. Loshchilo v, M. Schoenauer , a nd M. Se- bag. Self-Adaptive Surro gate-Assisted CMA-ES. In T. Soule a nd J.H. Mo or e, ed- itors, Pr o c. GECCO , pag es 321– 328. A CM Press, July 201 2. [MS83] J. J. Mor´ e and D. C. Sorensen. Com- puting a tr ust region step. SIAM Jour- nal on Scientific and Statistic al Comput- ing , 4(3):5 5 3–57 2, 1983 . [Po w87] M.J.D. Pow ell. Up dating Conjugate Di- rections b y the BF GS F o rmula. Mathe- matic al Pr o gr amming , 38(1):29 –46, 1987. [Rej12] W o jciech Rejc hel. On r anking a nd gen- eralization b ounds. The Journal of Machine L e arning R ese ar ch , 9888 8:137 3– 1392, 20 12. [RK04] R. Y. Rubinstein and D. P . Kro ese. The Cr oss-Entr opy Metho d: A Uni- fie d Appr o ach to Combinatorial Optimiza- tion, Monte-Carlo Simulation and Ma- chine L e arning . Springer, 200 4. [Sha70] D. F. Shanno . Conditio ning of Quas i- Newton Metho ds fo r F unction Minimiza- tion. Mathematics of Computation , 24(111 ):647–6 56, 1970. [USZ03] H. Ulmer, F. Streic hert, and A. Zell. Evolution Strateg ies as sisted b y Ga ussian Pro cess es with Improved Pre-Selection Criterion. In IEEE Congr ess on Evo- lutionary Computation , pag es 692– 699, 2003. 9 separable fcts mo derate fcts 0 1 2 3 4 5 6 7 8 l o g 1 0 o f ( # f - e v a l s / d i m e n si o n ) 0 . 0 0 . 5 1 . 0 P r o p o r t i o n o f fu n c t i o n s p BF G S BF G S sa A C M - E S C M A - E S K L - A C M - E S b e st 2 0 0 9 f1 - 5 0 1 2 3 4 5 6 7 8 l o g 1 0 o f ( # f - e v a l s / d i m e n si o n ) 0 . 0 0 . 5 1 . 0 P r o p o r t i o n o f fu n c t i o n s BF GS p BF GS C M A - E S b e st 2 0 0 9 sa A C M - E S K L - A C M - E S f 6 - 9 ill-conditioned fcts m ultimo dal fcts 0 1 2 3 4 5 6 7 8 l o g 1 0 o f ( # f - e v a l s / d i m e n si o n ) 0 . 0 0 . 5 1 . 0 P r o p o r t i o n o f f u n c t i o n s BF G S C M A - E S b e st 2 0 0 9 sa A C M - E S K L - A C M - E S p BF G S f1 0 - 1 4 0 1 2 3 4 5 6 7 8 l o g 1 0 o f ( # f - e v a l s / d i m e n si o n ) 0 . 0 0 . 5 1 . 0 P r o p o r t i o n o f f u n c t i o n s BF GS p BF GS C M A - E S b e st 2 0 0 9 K L - A C M - E S sa A C M - E S f 1 5 - 1 9 weakly structured mult imo dal fcts all functions 0 1 2 3 4 5 6 7 8 l o g 1 0 o f ( # f - e v a l s / d i m e n si o n ) 0 . 0 0 . 5 1 . 0 P r o p o r t i o n o f f u n c t i o n s BF G S p BF G S K L - A C M - E S C M A - E S b e st 2 0 0 9 sa A C M - E S f2 0 - 2 4 0 1 2 3 4 5 6 7 8 l o g 1 0 o f ( # f - e v a l s / d i m e n si o n ) 0 . 0 0 . 5 1 . 0 P r o p o r t i o n o f f u n c t i o n s BF GS p BF GS C M A - E S K L - A C M - E S sa A C M - E S b e st 2 0 0 9 f 1 - 2 4 Figure 4: Empirical cum ulative distributions (i.e. propo rtion o f functions solved – up to given tar get pre cisions in 10 [ − 8 .. 2] ) of the n umber of ob jective function ev a lua tions divided b y dimensio n for all functions (last plot) a nd subgroups of simila r functions (other plots) in 20- D. The ” bes t 20 09” line indicates the BBO B 200 9 “p ortfolio oracle“ , the ag g regatio n of the b est res ults fo r e a ch function. The prop osed algorithm is depicted as KL-ACM- ES. A deta iled descr iption of these repre sentations of BBO B results can b e found in [HAR + 10]. 10 0 1 2 3 4 5 6 7 8 l o g 1 0 o f ( # f - e v a l s / d i m e n si o n ) 0 . 0 0 . 5 1 . 0 P r o p o r t i o n o f f u n c t i o n s BF G S p BF G S p o w 4 p BF G S p o w 2 p BF G S BI PO P - a C M A BI PO P - sa A C M b e st 2 0 0 9 f 1 - 2 4
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment