Computational Rationalization: The Inverse Equilibrium Problem
Modeling the purposeful behavior of imperfect agents from a small number of observations is a challenging task. When restricted to the single-agent decision-theoretic setting, inverse optimal control techniques assume that observed behavior is an app…
Authors: Kevin Waugh, Brian D. Ziebart, J. Andrew Bagnell
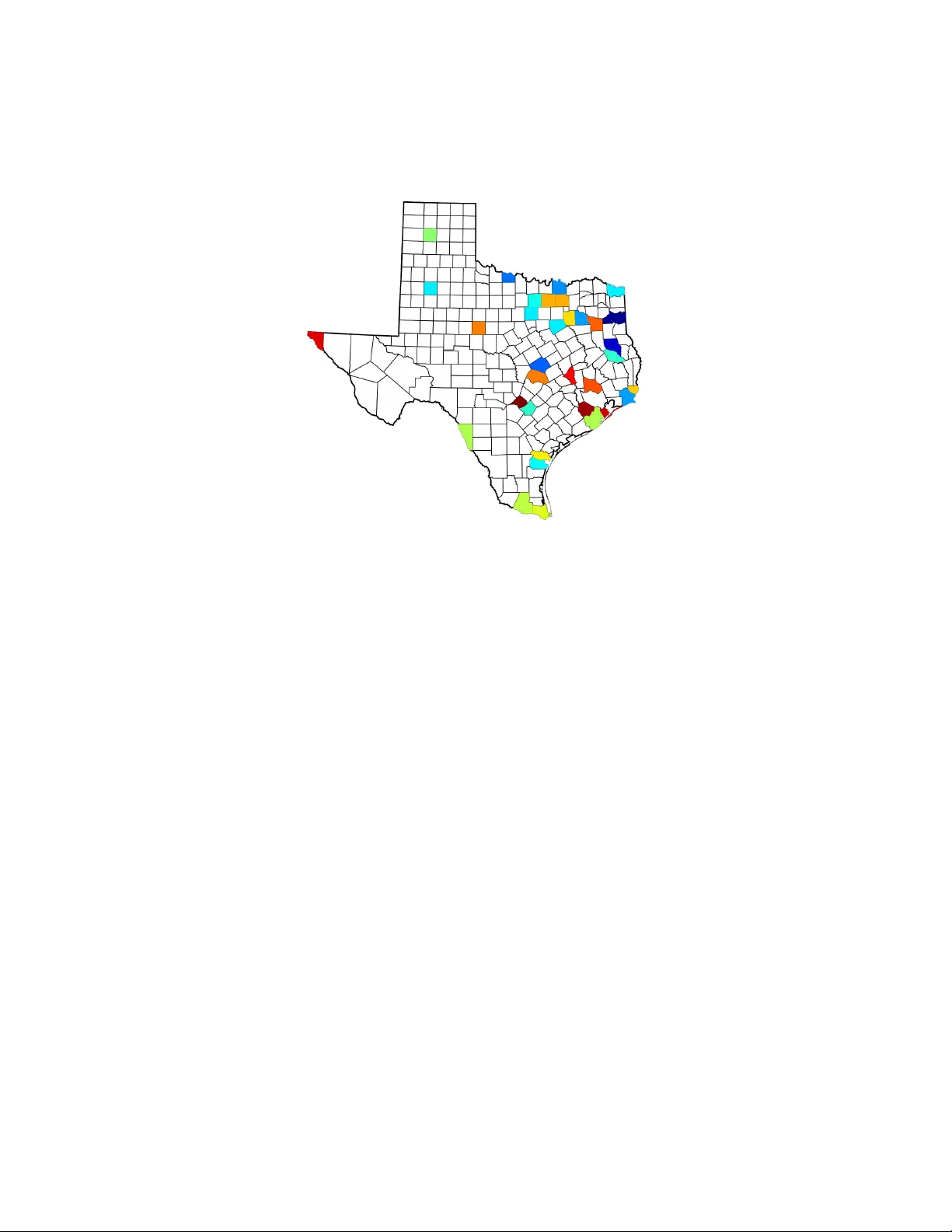
Computational Rationalization: The In v erse Equilibrium Problem Kevin W augh waugh@cs.cmu.edu Departmen t of Computer Science Carnegie Mellon Univ ersity 5000 F orb es Av e Pittsburgh, P A 15213, USA Brian D. Ziebart bziebart@uic.edu Departmen t of Computer Science 851 S. Morgan (M/C 152) Ro om 1120 SEO Chicago, IL 60607, USA J. Andrew Bagnell dbagnell@ri.cmu.edu The Rob otics Institute Carnegie Mellon Univ ersity 5000 F orb es Av e Pittsburgh, P A 15213, USA Jan uary 22, 2018 Abstract Mo deling the purp oseful b eha vior of imp erfect agen ts from a small n umber of observ ations is a c hallenging task. When restricted to the single-agen t decision-theoretic setting, in verse optimal control tec h- niques assume that observed behavior is an appro ximately optimal solution to an unkno wn decision problem. These tec hniques learn a utilit y function that explains the example b eha vior and can then b e used to accurately predict or imitate future b eha vior in similar ob- serv ed or unobserved situations. In this w ork, we consider similar tasks in competitive and coop er- ativ e multi-agen t domains. Here, unlike single-agent settings, a play er cannot my opically maximize its rew ard; it must sp eculate on ho w the other agents may act to influence the game’s outcome. Employing the 1 game-theoretic notion of regret and the principle of maximum en trop y , w e introduce a technique for predicting and ge neralizing b ehavior. 1 In tro duction Predicting the actions of others in complex and strategic settings is an im- p ortan t facet of in telligence that guides our interactions—from w alking in cro wds to negotiating multi-part y deals. Reco vering such b ehavior from merely a few observ ations is an imp ortan t and challenging machine learning task. While mature computational framew orks for decision-making hav e b een dev elop ed to prescrib e the be ha vior that an agent should p erform, suc h framew orks are often ill-suited for predicting the b eha vior that an agen t wil l p erform. F oremost, the standard assumption of decision-making frame- w orks that a criteria for preferring actions ( e.g. , costs, motiv ations and goals) is kno wn a priori often do es not hold. Moreov er, real b ehavior is t ypically not consistently optimal or completely rational; it may b e influenced by fac- tors that are difficult to mo del or sub ject to v arious t yp es of error when executed. Mean while, the standard to ols of statistical mac hine learning ( e.g. , classification and regression) ma y b e equally p oorly matched to mo d- eling purp oseful b ehavior; an agent’s goals often succinctly , but implicitly , enco de a strategy that would require a tremendous num ber of observ ations to learn. A natural approach to mitigate the complexit y of reco vering a full strat- egy for an agen t is to consider iden tifying a compactly expressed utility func- tion that r ationalizes observ ed b ehavior: that is, identify rewards for whic h the demonstrated b ehavior is optimal and then lev erage these rew ards for future prediction. Unfortunately , the problem is fundamentally ill-posed: in general, many rew ard functions can mak e b ehavior seem rational, and in fact, the trivial, everywhere zero rew ard function makes all b eha vior app ear rational [Ng and Russell, 2000]. F urther, after removing suc h trivial reward functions, there ma y b e no rew ard function for which the demonstrated b e- ha vior is optimal as agents may b e imp erfect or the w orld they op erate in ma y only b e approximately represented. In the single-agen t decis ion-theoretic setting, in verse optimal control metho ds ha ve b een used to bridge this gap b etw een the prescriptive frame- w orks and predictive applications [Abb eel and Ng, 2004, Ratliff et al., 2006, Ziebart et al., 2008a, 2010]. Successful applications include learning and pre- diction tasks in p ersonalized v ehicle route planning [Ziebart et al., 2008a], 2 predictiv e cursor control [Ziebart et al., 2012], robotic crowd na vigation [Henry et al., 2010], quadrup ed fo ot placemen t and grasp selection [Ratliff et al., 2009]. A reward function is learned by these techniques that b oth explains demonstrated behavior and appro ximates the optimalit y criteria of decision- theoretic framew orks. As these metho ds only capture a single rew ard function and do not reason ab out comp etitiv e or co op erative motives, inv erse optimal con trol pro ves inadequate for mo deling the strategic in teractions of multiple agen ts. In this article, w e consider the game-theoretic concept of regret as a stand- in for the optimality criteria of the single-agent w ork. As with the inv erse optimal con trol problem, the result is fundamentally ill-p osed. W e address this by requiring that for an y utility function linear in known features, our learned mo del m ust hav e no more regret than that of the observ ed b eha vior. W e demonstrate that this requirement can b e re-cast as a set of equiv alen t con vex constraints that we denote the inverse c orr elate d e quilibrium (ICE) p olytop e. As we are interested in the effective prediction of b ehavior, we will use a maxim um en tropy criteria to select b ehavior from this polytop e. W e demon- strate that optimizing this criteria leads to mini-max optimal prediction of b eha vior sub ject to approximate rationalit y . W e consider the dual of this problem and note that it generalizes the traditional log-linear maximum en- trop y family of problems [Della Pietra et al., 2002]. W e provide a simple and computationally efficien t gradien t-based optimization strategy for this family and sho w that only a small num b er of observ ations are required for accurate prediction and transfer of b ehavior. W e conclude b y considering a v ariet y of exp erimen tal results, ranging from predicting trav el routes in a syn thetic routing game to a market-en try econometric data-analysis explor- ing regulatory effects on hotel chains in T exas. Before we formalize imitation learning in matrix games, motiv ate our assumptions and describ e and analyze our approac h, w e review related work. 2 Related W ork Man y research comm unities are in terested in computational mo deling of h u- man behavior and, in particular, in mo deling rational and strategic behavior with incomplete knowledge of utility . Here w e contrast the contribution s of three comm unities by ov erviewing their interests and approaches. W e con- clude b y describing our contribution in the same ligh t. The econometrics communit y combines micro economics and statistics 3 to inv estigate the empirical prop erties of markets from sales records, census data and other publicly av ailable statistics. McF adden first considered es- timating consumer preferences for transp ortation by assuming them to b e rational utilit y maximizers [McF adden, 1974]. Berry , Levinsohn and Pak es estimate b oth supply and demand-side preferences in settings where the firms must price their go o ds strategically [Berry et al., 1995]. Their initial w ork describ ed a pro cedure for measuring the desirabilit y of certain auto- mobile criteria, such as fuel economy and features like air conditioning, to determine substitution effects. The Berry , Levinsohn and Pak es approac h and its deriv ativ es can b e crudely describ ed as mo del-fitting techniques. First, a parameterized class of utilit y functions are assumed for both the pro ducers and consumers. V ari- ables that are unobserv able to the econometrician, such as internal pro duc- tion costs and certain asp ects of the consumer’s preferences, are kno wn as sho cks and are mo deled as indep endent random v ariables. The dra ws of these random v ariables are kno wn to the market’s participants, but only their distributions are kno wn to the econometrician. Second, an equilibrium pricing mo del is assumed for the pro ducers. The consumers are t ypically assumed to be utility maximizers having no strategic in teractions with in the market. Finally , an estimation tec hnique is optimistically employ ed to determine a set of parameter v alues that are consistent with the observed b eha vior. Ultimately , it is from these parameter v alues that one derives insigh t in to the unobserv able characteristics of the market. Unfortunately , neither efficient sample nor computational complexity b ounds are generally a v ailable using this family of approaches. A v ariet y of questions ha ve b een inv estigated by econometricians using this line of reasoning. Petrin inv estigated the comp etitiv e adv an tage of b eing the first pro ducer in a market b y considering the in tro duction of the miniv an to the North American automotive industry [P etrin, 2002]. Nevo pro vided evidence against price-fixing in the breakfast cereal market b y measuring the effects of adv ertising [Nev o, 2001]. Others ha ve examined the mid-scale hotel mark et to determine the effects of different regulatory practices [Suzuki, 2010] and ho w ov ercapacit y can b e used to deter comp etition [Conlin and Kadiy ali, 2006]. As a general theme, the econometricians are interested in the inten tions that guide b ehavior. That is, the observed b eha vior is considered to b e the truth and the decision-making framew ork used by the pro ducers and consumers is kno wn a priori . The decision theory communit y is interested in human b ehavior on a more individual level. They , to o, note that out-of-the-b ox game theory fails to explain how p eople act in man y scenarios. As opp osed to viewing 4 this as a fla w in the theories, they fo cus on b oth ho w to alter the games that mo del our interactions in addition to devising h uman-like decision- making algorithms. The former can b e ac hieved through mo difications to the pla yers’ utility functions, whic h are known a priori , to incorp orate notions suc h as risk av ersion and spite [Myers and Sadler, 1960, Erev et al., 2008]. latter approaches often t weak learning algorithms b y integrating memory limitations or emphasizing recent or surprising observ ations [Camerer and Ho, 1999, Erev and Barron, 2005]. the Iterative W eigh ting and Sampling algorithm (I-SA W) is more lik ely to choose the action with the highest estimated utility , but recen t observ a- tions are w eighted more highly and, in the absence of a surprising obser- v ation, the algorithm fa vors rep eating previous actions [Erev et al., 2010]. Memory limitations, or more generally b ounded rationality , hav e also led to no vel equilibrium concepts such as the quan tal resp onse equilibrium [McK- elv ey and Palfrey, 1995]. This concept assumes the play ers’ strategies ha ve faults, but that small errors, in terms of forgone utility , are muc h more com- mon than large errors. Contrasting with the econometricians, the decision theory communit y is mainly in terested in the algorithmic pro cess of h uman decision-making. The play ers’ preferences are known and observed behavior serv es only to v alidate or inform an exp erimental hypothesis. Finally , the mac hine learning communit y is interested in predicting and imitating the b eha vior of humans and exp ert systems. Much work in this area fo cuses on the single-agen t setting and in suc h cases it is known as inverse optimal c ontr ol or inverse r einfor c ement le arning [Abb eel and Ng, 2004, Ng and Russell, 2000]. Here, the observed b eha vior is assumed to b e an approximately optimal solution to an unknown decision problem. At a high lev el, known solutions typically summarize the b ehavior as parame- ters to a low dimensional utility function. A num b er of metho ds hav e b een in tro duced to learn these weigh ts, including margin-based metho ds [Ratliff et al., 2006] that can utilize blac k b ox optimal control or planning soft- w are, as w ell as maximum entrop y-based metho ds with desirable predictive guaran tees [Ziebart et al., 2008a]. These utility weigh ts are then used to mimic the behavior in similar situations through a decision-making algo- rithm. Unlik e the other t wo communities, it is the predictive p erformance of the learned model that is most piv otal and noisy observ ations are exp ected and managed b y those techniques. This article extends our prior publication—a nov el maxim um en tropy approac h for predicting b eha vior in strategic multi-agen t domains [W augh et al., 2011a,b]. W e fo cus on the computationally and statistically efficien t reco very of go o d estimates of b ehavior (the only observ able quantit y) b y 5 lev eraging rationalit y assumptions. The work presen ted here further dev el- ops those ideas in tw o key w ays. First, w e consider distributions ov er games and parameterized families of deviations using the notion of conditional en- trop y . Second, this work enables more fine-grained assumptions regarding the play ers’ p ossible preferences. Finally , this work presents the analysis of data-sets from b oth the econometric and decision theory communities, comparing and contrasting the metho ds presented with statistical metho ds that are blind to the strategic asp ects of the domains. Before describing our approac h, we will introduce the necessary notation and bac kground. 3 Preliminaries Notation Let V be a Hilb ert space with an inner pro duct h· , ·i : V × V → R . F or an y set K ⊆ V , let K ∗ = { x | h x, y i ≥ 0 , ∀ y ∈ K } b e its dual cone. W e let k v k 2 = p h v , v i , and, if V is of finite dimension with orthonormal basis { e 1 , . . . , e K } , let k v k 1 = P K k =1 | α k | where v = P K k =1 α k e k . Typically , w e will tak e V = R K and use the standard inner pro duct. Game Theory Matrix games are the canonical to ol of game theorists for representing strategic interactions ranging from illustrative toy problems, suc h as the “Prisoner’s Dilemma” and the “Battle of the Sexes” games, to imp ortant negotiations, collaborations, and auctions. Unlik e the traditional defini- tion [Osb orne and Rubinstein, 1994], in this work w e mo del games where only the features of the pla y ers’ utility are kno wn and not the utilities them- selv es. Definition 1. A ve ctor-value d normal-form game is a tuple Γ = ( N , A , u Γ i ) wher e • N is the finite set of the game’s N players , • A = × i ∈N A i is the set of the game’s outc omes or joint-actions , wher e • A i is the finite set of actions or str ate gies for player i , and • u Γ i : A → V is the utility fe atur e function for player i . 6 We let A = max i ∈N | A i | . Pla yers aim to maximize their utilit y , a quantit y measuring happiness or individual well-being. W e assume that the play ers’ utilit y is a common linear function of the utilit y features. This will allow us to treat the play ers anon ymously should w e so desire. One can expand the utility feature space if separate utilit y functions are desired. W e write the utility for play er i at outcome a under utilit y function w ∈ V as u Γ i ( a | w ) = h u Γ i ( a ) , w i . In contrast to the standard definition of normal-form games, where the utilit y functions for game outcomes are known, in this w ork we assume that the true utilit y function , formed by w ∗ , whic h gov erns observ ed behavior, is unkno wn. This allows us to mo del real-w orld scenarios where a cardinal utilit y is not av ailable or is sub ject to p ersonal taste. Consider, for instance, a scenario where multiple drivers eac h choose a route among shared roads. Eac h outcome, which sp ecifies a trav el plan for all drivers, has a v ariet y of easily measurable quantities that ma y impact the utility of a driver, such as tra vel time, distance, av erage sp eed, n umber of intersections and so on, but ho w these quantities map to utilit y dep ends on the internal preferences of the driv ers. W e mo del the pla yers using a joint strategy , σ Γ ∈ ∆ A , whic h is a dis- tribution o ver the game’s outcomes. Co ordination betw een pla yers can exist, th us, this distribution need not factor into indep endent strategies for each pla yer. Conceptually , a trusted signaling mec hanism, such as a traffic ligh t, can b e though t to sample an outcome from σ Γ and comm unicate to each pla yer a i , its p ortion of the join t-action. Ev en in situations where pla yers are incapable of communication prior to play , correlated pla y is attainable through rep etition. In particular, there are simple learning dynamics that, when emplo yed by each pla yer indep endently , conv erge to a correlated solu- tion [F oster and V ohra, 1996, Hart and Mas-Colell, 2000]. If a play er can b enefit through a unilateral deviation from the prop osed join t strategy , the strategy is unstable. As w e are considering co ordinated strategies, a play er may condition its deviations on the recommended action. That is, a deviation for play er i is a function f i : A i → A i [Blum and Mansour, 2007]. T o ease the notation, w e ov erload f i : A → A to b e the function that mo difies only pla yer i ’s action according to f i . Tw o well-studied classes of deviations are the switc h deviation, switc h x → y i ( a i ) = y if a i = x a i otherwise , 7 whic h substitutes one action for another, and the fixed deviation, fixed → y i ( a i ) = y , whic h do es not condition its change on the prescrib ed action. A deviation set , denoted Φ, is a set of deviation functions. W e call the set of all switch deviations the in ternal deviation set, Φ in t , and the set of all fixed deviations the external deviation set, Φ ext . The set Φ sw ap is the set of all determinis- tic deviations. Giv en that the other play ers indeed play their recommended actions, there is no strategic adv an tage to considering randomized devia- tions. The b enefit of applying deviation f i when the pla yers join tly pla y a is kno wn as instantaneous regret . W e write the instantaneous regret features as r Γ f i ( a ) = u Γ i ( f i ( a )) − u Γ i ( a ) , and the instan taneous regret under utility function w as r Γ f i ( a | w ) = u Γ i ( f i ( a ) | w ) − u Γ i ( a | w ) = h r Γ f i ( a ) , w i . More generally , w e can consider broader classes of deviations than the t wo we ha ve mentioned. Conceptually , a deviation is a strategy modification and its regret is its b enefit to a particular play er. As we will ultimately only w ork with the regret features, we can now suppress the implementation details while b earing in mind that a deviation typically has these prescrib ed seman tics. That is, a deviation f ∈ Φ has asso ciated instantaneous regret features, r Γ f ( · ), and instan taneous regret, r Γ f ( ·| w ). As a play er is only privileged to its o wn p ortion of the co ordinated out- come, it must reason ab out its exp ected regret . W e write the exp ected regret features as r Γ f ( σ Γ ) = E a ∼ σ Γ r Γ f ( a ) , and the exp ected regret under utilit y function w as r Γ f ( σ Γ | w ) = E a ∼ σ Γ r Γ f ( a | w ) = h r Γ f ( σ Γ ) , w i . A joint strategy is in equilibrium or, in a sense, stable if no pla yer can b enefit through a unilateral deviation. W e can quantify this stabilit y using exp ected regret with resp ect to the deviation set Φ, Regret Γ Φ ( σ Γ | w ) = max f ∈ Φ r Γ f ( σ Γ | w ) , 8 and call a join t strategy σ Γ an ε -equilibrium if Regret Γ Φ ( σ Γ | w ) ≤ ε. The most general deviation set, Φ sw ap , corresp onds with the ε -correlated equilibrium solution concept [Osb orne and Rubinstein, 1994, Blum and Mansour, 2007]. Thus, regret can b e thought of as the natural substitute for utility when assessing the optimality of b ehavior in multi-agen t settings. The set Φ sw ap is t ypically intractably large. F ortunately , in ternal re- gret closely approximates swap regret and is p olynomially-sized in b oth the n umber of actions and play ers. Lemma 1. If joint str ate gy σ Γ has ε internal r e gr et, then it is an Aε - c orr elate d e quilibrium under utility function w . That is, ∀ w ∈ V , Regret Γ Φ int ( σ Γ | w ) ≤ Regret Γ Φ swap ( σ Γ | w ) ≤ A · Regret Γ Φ int ( σ Γ | w ) . The pro of is pro vided in the App endix. 4 Beha vior Estimation in a Matrix Game W e are no w equipp ed with the to ols necessary to in tro duce our approach for imitation learning in multi-agen t settings. W e start by assuming a notion of rationalit y on the part of the game’s pla y ers. By leveraging this assumption, w e will then deriv e an estimation pro cedure with muc h b etter statistical prop erties than metho ds that are una ware of the game’s structure. 4.1 Rationalit y and the ICE P olytop e Let { a t } T t =1 b e a sequence of T indep endent observ ations of b eha vior in game Γ distributed according to σ Γ , the play ers’ true b ehavior . W e call the em- pirical distribution of the observ ations, ˜ σ Γ , the demonstrated b eha vior . W e aim to learn a distribution ˆ σ Γ , called the predicted b eha vior , an estimation of the true b eha vior from these demonstrations. Moreov er, w e w ould like our learning pro cedure to extract the motiv es for the b ehavior so that we ma y imitate the play ers in similarly structured, but unobserved games. Initially , let us consider just the estimation problem. While deriving our metho d, w e will assume w e hav e access to the play ers’ true b eha vior. Afterw ards, we will analyze the error introduced by appro ximating from the demonstrations. 9 Imitation appears hard barring further assumptions. In particular, if the agen ts are unmotiv ated or their in tentions are not co erced by the observed game, there is little hop e of reco vering principled behavior in a new game. Th us, we require a form of rationality . Prop osition 1. The players in a game ar e r ational with r esp e ct to devia- tion set Φ if they pr efer joint-str ate gy σ Γ over joint str ate gies ´ σ Γ when Regret Γ Φ ( σ Γ | w ∗ ) < Regret Γ Φ ( ´ σ Γ | w ∗ ) . Our rationalit y assumption states that the play ers are driv en to minimize their regret. It is not necessarily the case that they indeed ha ve lo w or no regret, but simply that they can ev aluate their preferences and that they prefer joint strategies with lo w regret. Through this assumption, w e will b e able to reason about the pla yers’ b eha vior solely through the game’s features; this is what leads to the improv ed statistical properties of our approac h. As agents’ true preferences w ∗ are unknown, we consider an encompass- ing assumption that requires that estimated b eha vior satisfy this prop ert y for all p ossible utilit y weigh ts. A prediction ˆ σ Γ is strongly rational with resp ect to deviation set Φ if ∀ w ∈ V , Regret Γ Φ ( ˆ σ Γ | w ) ≤ Regret Γ Φ ( σ Γ | w ) . This assumption is similar in spirit to the utility matching ass umption emplo yed by inv erse optimal con trol techniques in single-agent settings. As in those settings, we ha ve an if and only if guaran tee relating rationalit y and strong rationalit y [Abb eel and Ng, 2004, Ziebart et al., 2008a]. Theorem 1. If a pr e diction ˆ σ Γ is str ongly r ational with r esp e ct to deviation set Φ and the players ar e r ational with r esp e ct to Φ , then they do not pr efer σ Γ over ˆ σ Γ . This is immediate as w ∗ ∈ V . Phrased another w ay , a strongly rational prediction is no worse than the true b eha vior. Corollary 1. If a pr e diction ˆ σ Γ is str ongly r ational with r esp e ct to deviation set Φ and the true b ehavior is an ε -e quilibrium with r esp e ct to Φ under utility function w ∗ ∈ V , then ˆ σ Γ is also an ε -e quilibrium. Again, the pro of is immediate as Regret Γ Φ ( ˆ σ Γ | w ∗ ) ≤ Regret Γ Φ ( σ Γ | w ∗ ) ≤ ε . Con versely , if w e are uncertain ab out the true utility function we m ust assume strong rationalit y or we risk predicting less desirable b eha vior. 10 Theorem 2. If a pr e diction ˆ σ Γ is not str ongly r ational with r esp e ct to de- viation set Φ and the players ar e r ational, then ther e exists a w ∗ ∈ V such that σ Γ is pr eferr e d to ˆ σ Γ . The pro of follo ws from the negation of the definition of strong rationalit y . By restricting our atten tion to strongly rational behavior, at worst agen ts acting according to their unknown true preferences will b e indifferent b e- t ween our predictiv e distribution and their true behavior. That is, strong rationalit y is necessary and sufficient under the assumption pla yers are ra- tional giv en no knowledge of their true utility function. Unfortunately , a direct translation of the strong rationality requirement in to constrain ts on the distribution ˆ σ Γ leads to a non-con vex optimization problem as it in volv es pro ducts of v arying utilit y vectors with the b ehavior to b e estimated. F ortunately , w e can pro vide an equiv alent concise conv ex description of the constraints on ˆ σ Γ that ensures an y feasible distribution satisfies strong rationality . W e denote this set of equiv alen t constrain ts as the Inverse Corr elate d Equilibria (ICE) p olytop e. Definition 2 (Standard ICE P olytop e) . r Γ f ( ˆ σ Γ ) = E g ∼ η f r Γ g ( σ Γ ) , ∀ f ∈ Φ η f ∈ ∆ Φ f , ∀ f ∈ Φ ˆ σ Γ ∈ ∆ A . Here, we hav e introduced Φ f , the set of deviations that f will b e com- pared against. Our rationality assumption corresponds to when Φ f = Φ, but there are different choices that hav e reasonable in terpretations as alternativ e rationalit y assumptions. F or example, if each switc h deviation is compared only against switches for the same play er—a more restrictive condition— then the quality of the equilibrium is measured b y the sum of all pla yers’ regrets, as opp osed to only the one with the most regret. The follo wing corollary equates strong rationalit y and the standard ICE p olytop e. Corollary 2. A pr e diction ˆ σ Γ is str ongly r ational with r esp e ct to deviation set Φ if and only if for al l f ∈ Φ ther e exists η f ∈ ∆ Φ such that ˆ σ Γ and η satisfy the standar d ICE p olytop e. W e now sho w a more general result that implies Corollary 2. W e s tart b y generalizing the notion of strong rationality by restricting w ∗ to be in 11 a kno wn set K ⊆ V . W e say a prediction ˆ σ Γ is K -strongly rational with resp ect to deviation set Φ if ∀ w ∈ K , Regret Γ Φ ( ˆ σ Γ | w ) ≤ Regret Γ Φ ( σ Γ | w ) . If K is con vex with non-empty relative interior and 0 ∈ K , we derive the K -ICE p olytop e. Definition 3 ( K -ICE Polytope) . r Γ f ( ˆ σ Γ ) − E g ∼ η f r Γ g ( σ Γ ) ∈ −K ∗ , ∀ f ∈ Φ η f ∈ ∆ Φ f , ∀ f ∈ Φ ˆ σ Γ ∈ ∆ A . Note that the ab o ve constrain ts are linear in ˆ σ Γ and η f , and K ∗ , the dual cone, is conv ex. The following theorem shows the equiv alence of the K -ICE p olytop e and K -strong rationalit y . Theorem 3. A pr e diction ˆ σ Γ is K -str ongly r ational with r esp e ct to deviation set Φ if and only if for al l f ∈ Φ ther e exists η f ∈ ∆ Φ such that ˆ σ Γ and η satisfy the K -ICE p olytop e. The pro of is pro vided in the App endix. By choosing K = V , then K ∗ = { 0 } and the p olytope reduces to the standard ICE p olytop e. Thus, Corollary 2 follows directly from Theorem 3. By c ho osing K to b e the p ositiv e orthant, K = K ∗ = R K + , the p olytop e reduces to the following inequalities. Here, we explicitly assume the utility to b e a p ositiv e linear function of the features. Definition 4 (Positiv e ICE Polytope) . r Γ f ( ˆ σ Γ ) ≤ E g ∼ η f r Γ g ( σ Γ ) , ∀ f ∈ Φ η f ∈ ∆ Φ f , ∀ f ∈ Φ ˆ σ Γ ∈ ∆ A . Predictiv e behavior within the ICE polytop e will retain the quality of the demonstrations pro vided. The follo wing corollaries formalize this guaran tee. Corollary 3. If the true b ehavior is an ε -c orr elate d e quilibrium under w ∗ in game Γ , then a pr e diction ˆ σ Γ that satisfies the standar d ICE p olytop e wher e Φ = Φ swap and ∀ f ∈ Φ , Φ f = Φ is also an ε -c orr elate d e quilibrium. 12 This follo ws immediately from the definition of an appro ximate corre- lated equilibrium. Corollary 4. If the true b ehavior is an ε -c orr elate d e quilibrium under w ∗ in game Γ , then a pr e diction ˆ σ Γ that satisfies the standar d ICE p olytop e wher e Φ = Φ int and ∀ f ∈ Φ , Φ f = Φ is also an Aε -c orr elate d e quilibrium. This follo ws immediately from Lemma 1. In tw o-play er constant-sum games, we can make stronger statemen ts ab out our predictive b ehavior. In particular, when these requirements are satisfied we ma y reason ab out games without co ordination. That is, eac h pla yer chooses their action indep enden tly using their strategy , σ Γ i a dis- tribution o ver A i . A strategy profile σ Γ consists of a strategy for each pla yer. It defines a joint-strategy with no co ordination b etw een the play ers. A game is constant-sum if there is a fixed amount of utility divided among the pla yers. That is, if there is a constant C such that ∀ a ∈ A , X i ∈N u Γ i ( a | w ∗ ) = C. In settings where the play ers act indep endently , w e use external regret to measure a profile’s stabilit y , whic h corresp onds with the famous Nash equilibrium solution concept [Osborne and Rubinstein, 1994]. By using the ICE p olytop e with external regret, we can recov er a Nash equilibrium if one is demonstrated in a constant-sum game. Theorem 4. If the true b ehavior is an ε -Nash e quilibrium in a two-player c onstant-sum game Γ , then the mar ginal str ate gies forme d fr om a pr e dic- tion ˆ σ Γ that satisfies the standar d ICE p olytop e wher e Φ = Φ ext and ∀ f ∈ Φ , Φ f = Φ is a 2 ε -Nash e quilibrium. The pro of is pro vided in the App endix. In general, there can b e infinitely many correlated equilibrium with v astly differen t prop erties. One such prop erty that has receiv ed muc h atten- tion is the so cial w elfare of a join t strategy , whic h refers to the total utility o ver all pla yers. Our strong rationality assumption states that the pla yers ha ve no preference on which correlated equilibrium is selec ted, and thus without mo dification cannot capture suc h a concept should it b e demon- strated. W e can easily maintain the so cial welfare of the demonstrations b y additionally preserving the pla yers’ utilities along side the constraints prescrib ed by the ICE p olytop e. A join t strategy is utility-preserving under all utilit y functions if ∀ w ∈ V , i ∈ N , u Γ i ( ˆ σ Γ | w ) = u Γ i ( σ Γ | w ) . 13 As with the corresp ondence b et ween strong rationalit y and the ICE p oly- top e, utilit y preserv ation can b e represented as a set of linear equality con- strain ts. These utility feature matc hing constraints are exactly the basis of man y metho ds of inv erse optimal control [Abb eel and Ng, 2004, Ziebart et al., 2008a]. Theorem 5. A joint str ate gy is utility-pr eserving under al l utility functions if and only if i ∈ N , u Γ i ( ˆ σ Γ ) = u Γ i ( σ Γ ) . The pro of is due to Abb eel and Ng [2004]. A notable c hoice for Φ f is we compare each deviation only to itself. As a consequence this enforces a stronger constraint that the regret under each deviation, and in turn the o verall regret, is the same under our prediction and the demonstrations. That is, ˆ σ Γ is regret-matc hing as for all w ∈ V , Regret Γ Φ ( ˆ σ Γ | w ) = Regret Γ Φ ( σ Γ | w ) . Th us, regret-matching preserves the equilibrium qualities of the demonstra- tions. Unlik e the correspondence b et ween the ICE polytop e and strong ratio- nalit y , matc hing the regret features for eac h deviation is not required for a strategy to matc h the regrets of the demonstrations. That is, the con verse do es not hold. 1 Theorem 6. A pr e diction ˆ σ Γ matches the r e gr et of σ Γ for al l w ∈ V do es not ne c essarily match the r e gr et fe atur es of σ Γ . W e use b oth utility and regret matching in our final set of exp eriments. The former for predictiv e reasons, the latter to allow for the use of smo oth minimization tec hniques. 4.2 The Principle of Maxim um En tropy As w e are interested in the problem of statistical prediction of strategic b eha vior, w e m ust find a mec hanism to resolve the am biguity remaining after accoun ting for the rationalit y constrain ts. The principle of maximum 1 W e may sketc h a simple counterexample. Consider a game with one play er and three actions, x , y and y 0 , where the utility for pla ying x is zero, and the utility for playing either y or y 0 is one. If the true b eha vior alwa ys plays y , then matc hing the regret features will force the prediction to also pla y y . Predicting y 0 also matches the regret, though. 14 en tropy , due to Ja ynes [1957], provides a w ell-justified metho d for c ho osing suc h a distribution. This choice leads to not only statistical guarantees on the resulting predictions, but to efficient optimization. The Shannon en trop y of a joint-strategy σ Γ is H Γ ( σ Γ ) = E a ∼ σ Γ − log σ Γ ( a ) , and the principle of maxim um entrop y advocates c ho osing the distribution with maximum entrop y sub ject to known constraints [Ja ynes, 1957]. That is, σ MaxEnt = argmax σ Γ ∈ ∆ A H Γ ( σ Γ ) , sub ject to: g ( σ Γ ) = 0 and h ( σ Γ ) ≤ 0 . The constrain t functions, g and h , are t ypically c hosen to capture the imp or- tan t or most salient characteristics of the distribution. When those functions are affine and conv ex resp ectively , finding this distribution is a con vex op- timization problem. The resulting log-linear family of distributions ( e.g. , logistic regression, Mark o v random fields, conditional random fields) are widely used within statistical mac hine learning. In the context of multi-agen t b eha vior, the principle of maximum entrop y has been emplo yed to obtain correlated equilibria with predictiv e guaran tees in normal-form games when the utilities are known a priori [Ortiz et al., 2007]. W e will now lev erage its p ow er with our rationality assumption to select predictive distributions in games where the utilities are unknown, but the imp ortan t features that define them are av ailable. F or our problem, the constraints are precisely that the distribution is in the ICE p olytop e, ensuring that whatever we predict has no more regret than the demonstrated b eha vior. Definition 5. The primal maximum entr opy ICE optimization pr oblem is maximize ˆ σ Γ ,η H Γ ( ˆ σ Γ ) subje ct to: r Γ f ( ˆ σ Γ ) − E g ∼ η f r Γ g ( σ Γ ) ∈ −K ∗ , ∀ f ∈ Φ η f ∈ ∆ Φ f , ∀ f ∈ Φ ˆ σ Γ ∈ ∆ A . This program is con vex, feasible, and b ounded. That is, it has a solution and is efficien tly solv able using simple techniques in this form. Imp ortan tly , the maxim um en tropy prediction enjo ys the follo wing guar- an tee: 15 Lemma 2. The maximum entr opy ICE distribution minimizes over al l str ongly r ational distributions the worst-c ase lo g-loss, E a ∼ σ Γ − log 2 ˆ σ Γ ( a ) , when σ Γ is chosen adversarial ly but subje ct to str ong r ationality. The pro of of Lemma 2 follows immediately from the result of Gr ¨ un wald and Da wid [2003]. 4.3 Dual Optimization In this section, w e will deriv e and describ e a pro cedure for optimizing the dual program for solving the MaxEn t ICE optimization problem. W e will see that the dual m ultipliers can b e interpreted as utility vectors and that opti- mization in the dual has computational adv an tages. W e b egin b y presenting the dual program. Theorem 7. The dual maximum entr opy ICE optimization pr oblem is the fol lowing non-smo oth, but c onvex pr o gr am: minimize θ f ∈K ∗∗ X f ∈ Φ Regret Γ Φ f ( σ Γ | θ f ) + log Z Γ ( θ ) , wher e Z Γ ( θ ) = X a ∈A exp − X f ∈ Φ r Γ f ( a | θ f ) . W e derive the dual in the App endix. As the dual’s feasible set has non-empty relativ e in terior, strong duality holds b y Slater’s condition—there is no duality gap. W e can also use a dual solution to reco ver ˆ σ Γ . Lemma 3. Str ong duality holds for the maximum entr opy ICE optimization pr oblem and given optimal dual weights θ ∗ , the maximum entr opy ICE joint- str ate gy ˆ σ Γ is ˆ σ Γ ( a ) ∝ exp − X f ∈ Φ r Γ f ( a | θ ∗ f ) . (1) The dual formulation of our program has imp ortan t inherent computa- tional adv an tages. First, so long as K is simple, the optimization is partic- ularly well-suited for gradient-based optimization, a trait not shared by the primal program. Second, the num b er of dual v ariables, | Φ | dim V , is typ i- cally muc h fewer than the num b er of primal v ariables, |A| + | Φ | 2 . Though 16 Algorithm 1 Dual MaxEnt ICE Gradient Input: Let ˆ σ Γ b e the prediction given the current dual w eights, θ , as from Equation (1). for f ∈ Φ do f ∗ ← argmax f 0 ∈ Φ f r Γ f 0 ( σ Γ | θ f ) g f ← r Γ f ∗ ( σ Γ ) − r Γ f ( ˆ σ Γ ) end for return g the w ork p er iteration is still a function of |A| (to compute the partition function), these tw o adv antages together let us scale to larger problems than if we consider optimizing the primal ob jectiv e. Computing the exp ec- tations necessary to descend the dual gradient can leverage recent adv ances in the structured, compact game representations: in particular, any graphi- cal game with lo w-treewidth or finite horizon Marko v game [Kak ade et al., 2003] enables these computations to b e p erformed in time that scales only p olynomially in the n umber of decision makers. Algorithm 1 describ es the dual gradient computation. This can b e in- corp orated with an y non-smo oth gradient metho d, such as the pro jected subgradien t metho d [Shor, 1985], to approach the optimum dual w eights. 5 Beha vior Estimation in P arameterized Matrix Games T o accoun t for sto chastic, or v arying environmen ts, we now consider distri- butions over games. F or example, rain may affect trav el time along some routes and make certain mo des of transp ortation less desirable, or ev en una v ailable. Op erationally , nature samples a game prior to play from a dis- tribution known to the play ers. The play ers then as a group determine a join t strategy conditioned on the particular game and an outcome is dra wn b y a co ordination device. W e let G denote our class of games. As b efore, w e observ e a sequence of T indep endent observ ations of pla y , but now in addition to an outcome we also observe nature’s choice at each time t . Let { (Γ t , a t ) } T t =1 b e the aforemen tioned sequence of observ ations dra wn from ξ and σ , the true b eha vior . The empirical distribution of the observ ations, ˜ ξ and ˜ σ , together are the demonstrated b ehavior . No w w e aim to learn a predictiv e b eha vior distribution, ˆ σ Γ , for any Γ ∈ G , ev en ones we ha ve not yet observed. Clearly , we must leverage the 17 observ ations across the entire family to ac hieve go o d predictive accuracy . W e con tinue to assume that the play ers’ utility is an unknown linear function, w ∗ , of the games’ features and that this function is fixed across G . Next, we amend our notion of regret and our rationality assumption. 5.1 Beha vior Estimation through Conditional ICE Ultimately , we wish to simply employ an additional exp ectation ov er the game distribution when reasoning ab out the regret and regret features. T o do this, our notion of a deviation needs to account for the fact that it may b e executed in games with different structures. Op erationally , one wa y to ac hieve this is by having a deviation not act when it is applied to such a game, which increases the size of Φ b y a factor of |G | . If the actions, and in turn the deviations, ha ve similar seman tic meanings across our entire family of games, one can simply share the deviations across all games. This allo ws for one to achiev e transfer o ver an infinitely large class. Giv en such a decision, w e write the exp ected regret features under deviation f as r ξ f ( σ ) = E Γ ∼ ξ r Γ f ( σ Γ ) , and the exp ected regret under utilit y function w as r ξ f ( σ | w ) = E Γ ∼ ξ r Γ f ( σ Γ | w ) . Again, w e quan tify the stability of a set of joint strategies using this new notion of exp ected regret with resp ect to the deviation set Φ, Regret ξ Φ ( σ | w ) = max f ∈ Φ r ξ f ( σ | w ) , whic h, in turn, en tails a notion of an ε -equilibrium for a set of joint strategie s, a mo dified rationality assumption, and a slight mo dification to the K -ICE p olytop e, Definition 6 (Conditional K -ICE Polytope) . r ξ f ( ˆ σ ) − E g ∼ η f h r ξ g ( σ ) i ∈ −K ∗ , ∀ f ∈ Φ η f ∈ ∆ Φ f , ∀ f ∈ Φ ˆ σ Γ ∈ ∆ A . ∀ Γ ∈ G All that remains is to adjust our notion of entrop y to tak e into accoun t a distribution ov er games. In particular, we choose to maximize the exp ected en tropy of our prediction, which is conditioned on the game sampled by c hance. 18 Definition 7. The c onditional Shannon entr opy of a set of str ate gies σ when games ar e distribute d ac c or ding to ξ is H ξ ( σ ) = E Γ ∼ ξ H Γ ( σ Γ ) . The mo dified dual optimization problem has a familiar form. W e no w use the new notion of regret and take the expected v alue of the log partition function. Theorem 8. The dual c onditional maximum entr opy ICE optimization pr oblem is minimize θ f ∈K ∗∗ X f ∈ Φ Regret ξ Φ f ( σ | θ f ) + E Γ ∼ ξ log Z Γ ( θ ) . T o reco ver the predicted b eha vior for a particular game, w e use the same exp onen tial family form as b efore. As with any machine learning technique, it is advisable to employ some form of complexity con trol on the resulting predictor to prev ent o ver-fitting. As w e now wish to generalize to unobserved games, w e to o should tak e the appropriate precautions. In our exp erimen ts, w e emplo y L 1 and L 2 regularization terms to the dual ob jectiv e for this purp ose. Regularization of the dual w eights effectiv ely alters the primal constrain ts b y allowing them to hold appro ximately , leading to higher entrop y solutions [Dud ´ ık et al., 2007]. 5.2 Beha vior T ransfer without common deviations A principal justification of in verse optimal control tec hniques that attempt to identify b ehavior in terms of utility functions is the abilit y to consider what b ehavior migh t result if the underlying decision problem w ere changed while the in terpretation of features into utilities remain the same [Ng and Russell, 2000, Ratliff et al., 2006]. This enables prediction of agent b eha vior in a no-regret or agnostic sense in problems such as a rob ot encountering no vel terrain [Silv er et al., 2010] as well as route recommendation for drivers tra veling to unseen destinations [Ziebart et al., 2008b]. Econometricians are interested in similar situations, but for muc h dif- feren t reasons. Typically , they aim to v alidate a mo del of mark et b ehavior from observ ations of product sales. In these models, the firms assume a fixed pricing p olicy given kno wn demand. The econometrician uses this fixed p ol- icy along with pro duct features and sales data to estimate or bound both the consumers’ utilit y functions as well as unkno wn pro duction parameters, 19 lik e markup and pro duction cost [Berry et al., 1995, Nev o, 2001]. In this line of work, the observ ed b ehavior is considered accurate to start with; it is unclear how suitable these metho ds are for settings with limited or noisy observ ations. In our prior work, w e introduced an approach to b eha vior transfer appli- cable b etw een games with differen t action sets [W augh et al., 2011a]. It is based off the assumption of transfer rationalit y , or for tw o games Γ and ´ Γ and some constan t κ > 0, ∀ w ∈ V , Regret ´ Γ Φ ( ˆ σ Γ | w ) ≤ κ Regret Γ Φ ( σ Γ | w ) . Roughly , w e assume that under preferences with lo w regret in the original game, the b eha vior in the unobserv ed game should also hav e low regret. By enforcing this prop ert y , if the agents are p erforming well with resp ect to their true preferences, then the transferred b ehavior will also b e of high qualit y . Assuming transfer rationality is equiv alent to using the conditional ICE estimation program with differing game distributions for the predicted and demonstrated regret features. In such a case, the program is not necessarily feasible and the constraints must be relaxed. F or example, a slac k v ariable ma y b e added to the primal, or through regularization in the dual. W e note that this requires the estimation program to b e run at test time. 6 Sample Complexit y In practice, we do not ha ve full access to the agen ts’ true b ehavior—if we did, prediction would b e straightforw ard and w e would not require our estimation tec hnique. Instead, w e may only approximate the desired exp ectations by a veraging ov er a finite num b er of observ ations, r ˜ ξ f ( ˜ σ | w ) ≈ 1 T T X t =1 r Γ t f ( a t | w ) . In real applications there are costs asso ciated with gathering these obser- v ations and, thus, there are inheren t limitations on the quality of this ap- pro ximation. Next, w e will analyze the sensitivity of our approac h to these t yp es of errors. First, although |A| is exponential in the n umber of pla yers, our tec hnique only accesses ˜ σ through exp ected regret features of the form r ˜ ξ f ( ˜ σ ). That is, we need only approximate these features accurately , not the distribution 20 σ . F or finite-dimensional vector spaces, we can b ound how w ell the regrets matc h in terms of | Φ | and the dimension of the space. Theorem 9. With pr ob ability at le ast 1 − δ , for any w , by observing T ≥ 1 2 2 log 2 | Φ | dim V δ outc omes we have for al l deviations r ˜ ξ f ( ˜ σ | w ) ≤ r ξ f ( σ | w ) + ∆ k w k 1 . where ∆ is the maximum p ossible regret ov er all basis directions. The pro of is an application of the union b ound and Ho effding’s inequality and is pro vided in the App endix. Alternativ ely , we can b ound how well the regrets matc h indep enden tly of the space’s dimension b y considering each utilit y function separately . Theorem 10. With pr ob ability at le ast 1 − δ , for any w , by observing T ≥ 1 2 2 log | Φ | δ outc omes we have for al l deviations r ˜ ξ f ( ˜ σ | w ) ≤ r ξ f ( σ | w ) + ∆( w ) . where ∆( w ) is the maximum p ossible regret under w . Again, the pro of is in the App endix. Both of the ab ov e b ounds imply that, so long as the true utility function is not to o complex, with high probabilit y we need only logarithmic many samples in terms of | Φ | and dim V to closely appro ximate r ξ f ( σ ) and a void a large violation of our rationalit y condition. Theorem 11. If for al l f , r ˜ ξ f ( ˜ σ | w ) ≤ r ξ f ( σ | w ) + γ , then Regret ˜ ξ Φ ( ˜ σ | w ) ≤ Regret ξ Φ ( σ | w ) + γ . Pr o of. F or all deviations, f ∈ Φ, r ˜ ξ f ( ˜ σ | w ) ≤ r ξ f ( σ | w ) + γ ≤ Regret ξ Φ ( σ | w ) + γ . In particular, this holds for the deviation that maximizes the demonstrated regret. 7 Exp erimen tal Results 7.1 Syn thetic Routing Game T o ev aluate our approach exp erimen tally , w e first consider a simple synthetic routing game. Sev en drivers in this game choose how to tra vel home during rush hour after a long day at the office. The differen t road segments hav e v arying capacities that make some of them more or less susceptible to con- gestion. Up on arriv al home, the drivers record the total time and distance they trav eled, the fuel that they used, and the amount of time they sp ent stopp ed at in tersections or in congestion—their utility features. 21 In this game, each of the driv ers chooses from four p ossible routes, yield- ing o ver 16 , 000 p ossible outcomes. W e obtained an ε -so cial welfare maxi- mizing correlated equilibrium for those drivers using a subgradient metho d where the drivers preferred mainly to minimize their trav el time, but were also slightly concerned with fuel cost. The demonstrated b ehavior ˜ σ Γ w as sampled from this true b eha vior distribution σ Γ . In Figure 1 we compare the prediction accuracy of MaxEn t ICE, mea- sured using log loss, E a ∼ σ Γ − log 2 ˆ σ Γ ( a ) , against a num b er of baselines by v arying the num b er of observ ations sampled from the ε -equilibrium. The baseline algorithms are: a smo othed m ultinomial distribution ov er the joint- actions, a logistic regression classifier parameterized with the outcome util- ities, and a maxim um entrop y inv erse optimal con trol approach [Ziebart et al., 2008a] trained individually for each play er. 10 100 1,000 10,000 0 2 4 6 8 10 12 14 16 18 20 22 24 Number of observations Log loss MaxEnt IOC Logistic Regression Multinomial MaxEnt ICE Figure 1: Prediction error (log loss) as a function of num b er of observ ations in the syn thetic routing game. In Figure 1, w e see that MaxEnt ICE predicts b eha vior with higher accuracy than all other algorithms when the n umber of observ ations is lim- ited. In particular, it achiev es close to its b est p erformance with only 16 observ ations. The maximum lik eliho o d estimator even tually o vertak es it, as exp ected since it will ultimately con verge to σ Γ , but only after 10 , 000 obser- v ations, or close to as many observ ations as there are outcomes in the game. MaxEn t ICE cannot learn the true b eha vior exactly in this case without 22 Problem Logistic Regression MaxEnt Ice Add Highw a y 4.177 3.093 Add Driver 4.060 3.477 Gas Shor t age 3.498 3.137 Congestion 3.345 2.965 T able 1: T ransfer error (log loss) on unobserved games. additional constraints due to the so cial welfare criteria the true b ehavior optimizes. That is, our rationality assumption do es not hold in this case. W e note that the logistic regression classifier and the in verse optimal con trol tec hniques p erform b etter than the m ultinomial under low sample sizes, but they fail to outp erform MaxEnt ICE due to their inabilit y to appreciate the strategic nature of the game. Next, we ev aluate b eha vior transfer from this routing game to four sim- ilar games, the results of whic h are display ed in T able 1. The first game, A dd Highway , adds a new route to the game. That is, we sim ulate the city building a new highw ay . The second game, A dd Driver , adds another driv er to the game. The third game, Gas Shortage , k eeps the structure of the game the same, but changes the rew ard function to make gas mileage more imp ortan t to the driv ers. The final game, Congestion , simulates adding con- struction to the ma jor roadwa y , delaying the driv ers. Here, we do not share deviations across the training and test game and we add a slack v ariable in the primal to ensure feasibilit y . These transfer exp erimen ts ev en more directly demonstrate the b enefits of learning utility weigh ts rather than directly learning the join t-action dis- tribution; direct strategy-learning approaches are incapable of being applied to general transfer setting. Thus, w e can only compare against the Logistic Regression. W e see from T able 1 that MaxEn t ICE outp erforms the Logistic Regression in all of our tests. F or reference, in these new games, the uniform strategy has a loss of approximately 6 . 8 in all games, and the true b eha vior has a loss of appro ximately 2 . 7. These exp eriment demonstrates that learning underlying utility func- tions to estimate observed b ehavior can b e muc h more data-efficient for small sample sizes. Additionally , it sho ws that the regret-based assump- tions of MaxEn t ICE are b eneficial in strategic settings, even though our rationalit y assumption do es not hold in this case. 23 7.2 Mark et En try Game W e next ev aluate our approach against a n umber of baselines on data gath- ered for the Market Entry Prediction Comp etition [Erev et al., 2010]. The game has four play ers and is rep eated for fifty trials and is mean t to simu- late a firm’s decision to en ter into a mark et. On each round, all four pla yers sim ultaneous decide whether or not to op en a business. All play ers who en- ter the market receive a sto c hastic pa yoff centered at 10 − k E , where k is a fixed parameter unknown to the pla yers and E is the num b er of play ers who en tered. Pla yers who do not enter the mark et receive a sto c hastic pa yoff with zero mean. After eac h round, each play er is shown their reward, as w ell as the reward they would ha ve received by choosing the alternative. Observ ations of h uman play were gathered by the CLER lab at Har- v ard [Erev et al., 2010]. Eac h studen t in volv ed in the exp eriment play ed ten games lasting fift y rounds each. The students were incentivized to play well through a monetary reward proportional to their cumulativ e utilit y . The parameter k was randomly selected in a fashion so that the Nash equilib- rium had an en try rate of 50% in exp ectation. In total, 30 , 000 observ ations of pla y were recorded. The inten t of the comp etition w as to hav e teams sub- mit programs that w ould play in a similar fashion to the human sub jects. That is, the data w as used at test time to v alidate p erformance. In con trast, our exp eriments use actual observ ations of play at training time to build a predictiv e mo del of the human b eha vior. As we are in terested in stationary b eha vior, we train and test on only the last tw ent y five trials of eac h game. W e compared against tw o baselines. The first baseline, lab eled Multi- nomial in the figures, is a smo othed m ultinomial distribution trained to minimize the leav e-one-out cross v alidation loss. This baseline do es not mak e use of any features of the games. That is, if the pla yers indeed pla y according to the Nash equilibrium we would exp ect this baseline to learn the uniform distribution. The second baseline, lab eled L o gistic R e gr ession in the figures, simply uses regularized logistic regression to learn a linear classification b oundary ov er the outcomes of the game using the same fea- tures presented to our metho d. Op erationally , this is equiv alent to using MaxEn t Inv erse Optimal Con trol in a single-agent setting where the utilit y is summed across all the play ers. This baseline has similar represen tational p o wer to our metho d, but lacks an understanding of the strategic elements of the game. In Figure 2, we see a comparison of our metho d against the baselines when only the game’s true exp ected utility is used as the only feature. W e see that our metho d outp erforms b oth baselines across all sample sizes. W e 24 256 512 1,024 2,048 4,096 8,192 3.7 3.8 3.9 4 Number of observations Log loss Multinomial Logistic Regression MaxEnt ICE Figure 2: T est log loss using only the game’s exp ected utilit y as a feature in the mark et entry exp eriment. also observe the multinomial distribution p erforms slightly b etter than the uniform distribution, whic h attains a log loss of 4, though substantially worse than logistic regression and our metho d, indicating that the human play ers are not particularly well-modeled by the Nash equilibrium. Our metho d substan tially outp erforms logistic regression, indicating that there is indeed a strategic in teraction that is not captured in the utilit y features alone. In Figure 3, we see a comparison of our metho d against the baselines using a v ariety of predictive features. In particular, we summarize a round using the observ ed action frequencies, av erage reward, and reward v ariance up to that p oint in the round. T o w eigh recent observ ations more strongly , w e also emplo y exponentially-w eighted av erages. W e observe that the use of these features substantially improv es the predictive p ow er of the feature- based metho ds. Interestingly , we also note that the addition of these sum- mary features also narro ws the gap b etw een logistic regression and MaxEnt ICE. Under low sample sizes, the logistic mo del p erforms the b est, but our metho d ov ertakes it as more data is made a v ailable for training. It app ears that in this scenario, m uch of the strategic b eha vior demonstrated b y the participan ts can b e captured by these history features. 25 256 512 1,024 2,048 4,096 8,192 2.6 2.62 2.64 2.66 Number of observations Log loss Logistic Regression MaxEnt ICE Figure 3: T est log loss using a num b er of history summary features in the mark et entry exp eriment. 7.3 Mid-scale Hotel Market En try F or our final exp erimental ev aluation, we considered the task of predicting the b eha vior of mid-scale hotel chains, like Holiday Inn and Ramada, in the state of T exas. Giv en demographic and regulatory features of a count y , w e wish to predict if eac h c hain is lik ely to op en a new hotel or to close an existing one. The observ ations of pla y are deriv ed from quarterly tax records ov er a fifteen y ear perio d from forty counties, amoun ting to a total of 2 , 205 observ ations. The particular coun ties selected had records of all of the demographic and regulatory features, had at least four action observ ations, and none was a chain’s flagship coun ty . Figure 4 highligh ts the selected coun ties and visualizes their regulatory practices. The demographic and regulatory features were aggregated from v arious sources and generously pro vided to us by Prof. Junic hi Suzuki (2010). The demographic features for each count y include quan tities such as size of its p opulation and its area, employmen t and household income statistics, as w ell as the presence or absence of an in terstate, airp ort or national park. The regulatory features are indices measuring quan tities such as commercial land zoning restrictions, tax rates and building costs. In addition to these noted features, which are fixed across all time p erio ds, there are time-v arying features suc h as the n umber of hotels and ro oms for each chain and the 26 Figure 4: Regulatory index v alues for select counties in T exas. Blue means little regulation and lo wer costs to enter the market. Red means higher costs. aggregate quarterly income. W e model each quarterly decision as a parameterized sim ultaneous-mov e game with six play ers. Each pla yer, a mid-scale hotel c hain, has the action set { Close , NoAction , Op en } , resulting in 729 total outcomes. F or the game’s utilit y , we allo cated the count y’s features to each pla yer in proportion to ho w man y hotels they o wned. That is, if a pla yer operated 3 out of 10 hotels, the features asso ciated with utility at that outcome would b e the count y’s feature v ector scaled by 0 . 3. W e included bias features asso ciated with each action to accoun t for fixed costs asso ciated with op ening or closing a hotel. In the observ ation data, there are a small num b er of instances where a c hain op ens or closes more than one hotel during a quarter. These even ts are mapp ed to Op en and Close resp ectively . Though the outcome-space is quite large, the outcome distribution is extremely biased and the actions of the c hains are highly correlated. In particular, o ver 80% of time the time no action is taken, around 17% of the time a single chain acts, and less than 3% of the time more than one chain acts. As a result, one exp ects the featureless multinomial estimator to hav e reasonable p erformance despite a large n umber of classes. F or exp erimen tation, we ev aluated four algorithms: a smo othed multi- 27 nomial distribution trained to minimize the lea ve one out cross-v alidation loss, MaxEnt in verse optimal con trol trained once for all pla yers, m ulti-class logistic regression o ver the join t action space, and regret-matching ICE with utilit y matching constrain ts. As the resulting optimizations for the latter t wo algorithms are smooth, we emplo yed the L-BF GS quasi-Newton method with L2-regularization for training [No cedal, 1980]. As a substitute for L1- regularization, w e selected the 23 b est features based on their reduction in training error when using logistic regression. Eac h count y had 63 features a v ailable. Of the top 23 features selected, 11 w ere regulatory indices. F or the logistic regression and ICE predictors, w e only used utility fea- tures on the 13 high probability outcomes (no firms build, and one firm acting). The remaining outcomes had only bias features asso ciated with them to help preven t ov erfitting. W e exp erimented with a n umber of t yp es of bias features, for example, 4 bias features (one for no firms build, one for a single firm builds, one for a single firm closes and one for all remaining outcomes), as w ell as 729 bias features (one for each outcome). W e found that, though on their o wn the differen t bias features had v aried predictiv e p erformance, when combined with utilit y and regret features they w ere quite similar giv en the appropriate regularization. In the b est p erforming mo del, whic h we presen t here, we used 729 bias features resulting in 1 , 028 param- eters to the logistic regression mo del. In the ICE predictor, we tied together the weigh ts for eac h deviation across all the pla yers to reduce the num b er of mo del parameters. F or exam- ple, all play ers shared the same dual parameters for the NoAction → Op en deviation. Effectively , this alters the rationality assumption such that the aver age regret across all play ers is the quantit y of in terest, instead of the maxim um regret. Op erationally , this is implemented as summing each de- viation’s gradient in the dual. This treats the pla yers anonymously , thus w e implicitly and incorrectly assume that conditioned on the count y’s pa- rameters each firm is iden tical. Due to the use parameter tying, the ICE predictor has an additional 156 mo del parameters. The test losses rep orted w ere computed using ten-fold cross v alidation. T o fit the regularization parameters for logistic regression, MaxEnt IOC and MaxEnt ICE, w e held out 10% of the training data and p erformed a parameter sweep. F or logistic regression, a separate parameter sweep and regularization was used for the bias and utility features. F or MaxEnt ICE, an additional regularization parameter was selected for the regret parameters. A sample of the predictions from MaxEnt ICE are shown in Figure 5. In the left of Figure 6, w e present the test errors of the three parameter- ized metho ds in terms of their offset from that of the featureless multino- 28 Figure 5: The marginalized probabilit y that a chain will build a hotel in Spring 1996 predicted by MaxEn t ICE. Brigh ter shades of green denote higher probabilities. mial. This quantit y has low er v ariance than the absolute errors, allowing for more accurate comparisons. W e see that the addition of the regret features more than doubles the improv ement of logistic regression from 2 . 6% to 6 . 3%, where as the inv erse optimal control metho d only sees a 4 . 3% improv ement. In the cen ter of Figure 6, w e show the test log-loss when the methods are only required to predict if any firm acts. Here, the mo dels are still trained o ver their complete outcome spaces and their predictions are marginalized. W e see that all three methods are equal within noise. That is, the differences in the predictiv e p erformances come solely from each method’s ability to predict who acts. W e additionally p erformed this exp eriment without the use of regulatory features and found that the logistic regression metho d ac hieved a relative loss of − 0 . 027300. Using a paired comparison b et ween the tw o metho ds, w e note that this difference of 0 . 004443 is significan t with error 0 . 001886. This ec ho es Suzuki’s conclusions the regulatory en vironmen t in this industry affect firms’ decisions to build new hotels [Suzuki, 2010], measured here b y improv ements in predictive p erformance. In the right of Figure 6, we demonstrate the test log loss conditioned on at least one firm acting—the p ortion of the loss that differentiates the metho ds. The logistic regression metho d with only utilit y features p erforms 29 Figure 6: (Left) T est log loss on the full outcome space relative to the smo othed m ultinomial, which has log loss 1 . 58234 ± 0 . 058088. (Cen ter) T est log loss no build vs. build outcomes only . Loss is relative multinomial, with log loss 0 . 721466 ± 0 . 016539. (Righ t) T est log loss conditioned on build outcomes only . Loss is relative m ultinomial, with log loss 6 . 5911 ± 0 . 116231. the w orst with a 1 . 8% improv ement o ver the m ultinomial base line, the individual inv erse optimal control metho d impro ves by 4 . 1% and MaxEnt ICE p erforms the b est with a 6 . 3% improv emen t. That is, the addition of regret features, and hence accounting for the strategic asp ects of the game, ha ve a significant effect on the predictiv e p erformance in this setting. W e note that replacing the regulatory features in the regret p ortion of the MaxEn t ICE mo del actually slightly improv es p erformance to − 0 . 471763, though not b y a significan t margin. This implies that the regulatory features ha ve little or no b earing on predicting exactly the firm that will act, which suggests the regulatory practices are unbiased. 8 Conclusion In this article, we develop a no vel approac h to b ehavior prediction in strate- gic m ulti-agent domains. W e demonstrate that b y leveraging a rationalit y assumption and the principle of maximum en tropy our metho d can b e effi- cien tly implemented while ac hieving goo d statistical p erformance. Empir- ically , w e display ed the effectiv eness of our approac h on tw o market entry data sets. W e demonstrated b oth the robustness of our approac h to er- rors in our assumption as w ell as the imp ortance of considering strategic in teractions. Our future w ork will consider t wo new directions. First, w e will address classes of games where the action sets and play ers differ. A k ey b enefit of our curren t approac h is that it enables these to differ b et ween training and testing whic h we only leverage mo destly in the transfer exp eriments for route prediction. This will in volv e inv estigating from a statistical p oint of view nov el notions of a deviation and their corresp onding equilibrium 30 concepts Second, we will consider differen t mo dels of interactions, suc h as sto c hastic games and extensive-form games. These mo dels, though no more expressiv e than matrix games, can often represen t in teractions exponentially more succinctly . F rom a practical standp oint, this av enue of research will allo w for the application of our metho ds to a broader class of problems, including, for instance, exploring the time series dep endencies within the T exas Hotel Chain data. Ac kno wledgemen ts This work is supp orted b y the ONR MURI grant N00014-09-1-1052 and by the National Sciences and Engineering Research Council of Canada (NSER C). The authors gratefully ackno wledge Prof. Junichi Suzuki for providing the aggregated mid-scale hotel data and Alex Grubb for the application of den- sit y estimation co de to the data-sets. App endix Pro of of Lemma 1 Pr o of. The low er b ound holds as a consequence of Φ in t ⊆ Φ sw ap . Since max x ∈ A i ,y ∈ A i r Γ i ; x → y ( σ Γ | w ) ≥ r Γ i ; x → x ( σ Γ | w ) = 0 , Regret Γ Φ sw ap ( σ Γ | w ) = max i ∈N X x ∈ A i max y ∈ A i r Γ i ; x → y ( σ Γ | w ) ≤ A · max i ∈N max x ∈ A i max y ∈ A i r Γ i ; x → y ( σ Γ | w ) = A · Regret Γ Φ in t ( σ Γ | w ) . Pro of of Theorem 3 The pro of of Theorem 3 immediately follo ws from the following lemma. Lemma 4. F or any utility function w ∈ K , r Γ f ( ˆ σ Γ | w ) ≤ Regret Γ Φ f ( σ Γ | w ) if and only if ther e exists an η f ∈ ∆ Φ f such that r Γ f ( ˆ σ Γ ) − E g ∼ η f r Γ g ( σ Γ ) ∈ −K ∗ . 31 Pr o of. Assume that for all w ∈ K , r Γ f ( ˆ σ Γ | w ) ≤ Regret Γ Φ f ( σ Γ | w ), ∃ η f ∈ ∆ Φ f suc h that r Γ f ( ˆ σ Γ | w ) ≤ E g ∼ η f r Γ g ( σ Γ | w ) Since 0 ∈ K , max w ∈K r Γ f ( ˆ σ Γ | w ) − E g ∼ η f r Γ g ( σ Γ | w ) ≤ 0 = r Γ f ( ˆ σ Γ | 0) − E g ∼ η f r Γ g ( σ Γ | 0) = max w ∈K ,t r Γ f ( ˆ σ Γ | w ) − t, sub ject to: t ≥ r Γ g ( σ Γ | w ) , ∀ g ∈ Φ f . By Slater’s condition, strong duality holds and the resulting dual is the feasibilit y problem = min η f ∈ ∆ Φ f 0 , sub ject to: r Γ f ( ˆ σ Γ ) − E g ∼ η f r Γ g ( σ Γ ) ∈ −K ∗ . Assume ∃ η f ∈ ∆ Φ f and y ∈ K ∗ suc h that r Γ f ( ˆ σ Γ ) − E g ∼ η f r Γ g ( σ Γ ) + y = 0, then for an y w ∈ K r Γ f ( ˆ σ Γ | w ) − E g ∼ η f r Γ g ( σ Γ | w ) + h y , w i = h 0 , w i = 0 . By the definition of the dual cone h y , w i ≥ 0, therefore r Γ f ( ˆ σ Γ | w ) ≤ E g ∼ η f r Γ g ( σ Γ | w ) ≤ max g ∈ Φ f r Γ g ( σ Γ | w ) = Regret Γ Φ f ( σ Γ | w ) . Pro of of Theorem 4 The pro of of Theorem 4 immediately follo ws from the following lemma. Lemma 5. If joint str ate gy σ Γ has ε external r e gr et, and Γ is 2-player and c onstant-sum with r esp e ct to w , then the mar ginal str ate gies form a 2 ε -Nash e quilibrium under utility function w . Pr o of. Denote one play er x and the other y and their marginal strategies as ¯ σ Γ x and ¯ σ Γ y resp ectiv ely . W e are given ∀ σ Γ x ∈ ∆ A x , u Γ x ( σ Γ x , ¯ σ Γ y | w ) − u Γ x ( σ Γ | w ) ≤ ε and, ∀ σ Γ y ∈ ∆ A y , u Γ y ( σ Γ y , ¯ σ Γ x | w ) − u Γ y ( σ Γ | w ) ≤ ε 32 as when either play er deviates, the other resorts to playing his marginal strategy . Substituting ¯ σ Γ y for σ Γ y and summing, w e get ∀ σ Γ x ∈ ∆ A x u Γ x ( σ Γ x , ¯ σ Γ y | w ) + u Γ y ( ¯ σ Γ y , ¯ σ Γ x | w ) − u Γ y ( σ Γ | w ) + u Γ x ( σ Γ | w ) ≤ 2 ε u Γ x ( σ Γ x , ¯ σ Γ y | w ) + u Γ y ( ¯ σ Γ y , ¯ σ Γ x | w ) − C ≤ 2 ε u Γ x ( σ Γ x , ¯ σ Γ y | w ) + C − u Γ x ( ¯ σ Γ y , ¯ σ Γ x | w ) − C ≤ 2 ε u Γ x ( σ Γ x , ¯ σ Γ y | w ) − u Γ x ( ¯ σ Γ y , ¯ σ Γ x | w ) ≤ 2 ε A symmetric argument shows the equiv alent statement for the opp osing pla yer. Pro of of Theorem 7 Pr o of. The Legrange dual function, L ( θ , α, β , u, v , x ) = max ˆ σ Γ ,η ,y − X a ∈A ˆ σ Γ ( a ) log ˆ σ Γ ( a )+ X f ∈ Φ α f 1 − X g ∈ Φ η f ( g ) + β 1 − X a ∈A ˆ σ Γ ( a ) ! + X f ∈ Φ h r Γ f ( ˆ σ Γ ) − X f ,g ∈ Φ η f ( g ) r Γ g ( σ Γ ) + y f , θ f i + X f ∈ Φ v f · η f + u · ˆ σ Γ + h y f , x f i , is an upp er b ound on the primal ob jectiv e for all u, v ≥ 0 and x ∈ K ∗∗ . W e solv e the unconstrained maximization by setting the deriv atives with resp ect to ˆ σ Γ , η , y to zero, log ˆ σ Γ ( a ) = u ( a ) − 1 − β − X f ∈ Φ h r Γ f ( a ) , θ f i h r Γ g ( σ Γ ) , θ f i − α f + v f ( g ) = 0 ∀ f , g ∈ Φ θ f = − x f . ∀ f ∈ Φ Substituting this solution back in to the Legrangian and minimizing this upp er b ound giv es min θ ∈K ∗∗ ,β exp( − 1 − β ) Z Γ ( θ ) + X f ∈ Φ α f + β sub ject to: h r Γ g ( σ Γ ) , θ f i ≤ α f . ∀ f , g ∈ Φ 33 Solving for β explicitly we get β = log Z Γ ( θ ) − 1, and moving the constraint in to the ob jectiv e gives our result: min θ ∈K ∗∗ X f ∈ Φ Regret Γ Φ ( σ Γ | θ f ) + log Z Γ ( θ ) . Pro of of Theorem 9 Pr o of. Let { e 1 , e 2 , . . . , e K } be an orthonormal basis for V , where K = dim V . W e first b ound how well the regrets match in eac h basis direction. P h max f ∈ Φ ,k ∈ [ K ] | r ˜ ξ f ( ˜ σ | e k ) − r ξ f ( σ | e k ) | ≥ ∆ i ≤ P h [ f ∈ Φ ,k ∈ [ K ] | r ˜ ξ f ( ˜ σ | e k ) − r ξ f ( σ | e k ) | ≥ ∆ i ≤ X f ∈ Φ ,k ∈ [ K ] P h | r ˜ ξ f ( ˜ σ | e k ) − r ξ f ( σ | e k ) | ≥ ∆ i ≤ 2 | Φ | K exp − 2 T 2 ≤ δ. T ≥ 1 2 2 log 2 | Φ | dim V δ . Next, w e b ound ho w well the regrets matc h under w , giv en all regrets are close. | r ˜ ξ f ( ˜ σ | w ) − r ξ f ( σ | w ) | = | K X k =1 α k r ˜ ξ f ( ˜ σ | e k ) − α k r ξ f ( σ | e k ) | ≤ K X k =1 | α k || r ˜ ξ f ( ˜ σ | e k ) − r ξ f ( σ | e k ) | ≤ ∆ K X k =1 | α k | ≤ ∆ k w k 1 . 34 Pro of of Theorem 10 Pr o of. Unlik e Theorem 9, we will b ound the error of regrets directly . P h max f ∈ Φ r ˜ ξ f ( ˜ σ | w ) − r ξ f ( σ | w ) ≥ ∆( w ) i ≤ P h [ f ∈ Φ r ˜ ξ f ( ˜ σ | w ) − r ξ f ( σ | w ) ≥ ∆( w ) i ≤ X f ∈ Φ P h r ˜ ξ f ( ˜ σ | w ) − r ξ f ( σ | w ) ≥ ∆( w ) i ≤ 2 | Φ | exp − 2 T 2 ≤ δ T ≥ 1 2 2 log | Φ | δ . References P . Abb eel and A. Y. Ng. Appren ticeship learning via in verse reinforce- men t learning. In Pr o c e e dings of the International Confer enc e on Machine L e arning , 2004. S. Berry , J. Levinsohn, and A. Pak es. Automobile prices in market equilib- rium. Ec onometric a , 63(4):841–890, July 1995. A. Blum and Y. Mansour. A lgorithmic Game The ory , chapter Learning, Regret Minimization and Equilibria, pages 79–102. Cambridge Univ ersity Press, 2007. C. Camerer and T. H. Ho. Experience w eighted attraction learning in normal form games. Ec onometric a , 67:827–874, 1999. M. Conlin and V. Kadiyali. Entry-deterring capacit y in the texas lodging industry . Journal of Ec onomics and Management Str ate gy , pages 167–185, 2006. S. Della Pietra, V. Della Pietra, and J. Lafferty . Inducing features of random fields. IEEE T r ansactions on Pattern Analysis and Machine Intel ligenc e , 19(4):380–393, 2002. ISSN 0162-8828. 35 M. Dud ´ ık, S. J. Phillips, and R. E. Sc hapire. Maximum en tropy density estimation with generalized regularization and an application to sp ecies distribution mo deling. Journal of Machine L e arning R ese ar ch , 8:1217– 1260, 2007. I. Erev and G. Barron. On adaptation, maximization and reinforcemen t learning among cognitive strategies. Psycholo gic al R eview , 112:912–931, 2005. I. Erev, E. Ert, and E. Y ec hiam. Loss a version, diminishing sensitivit y , and the effect of exp erience on rep eated decisions. Journal of Behavior al De cision Making , 21:575–597, 2008. I. Erev, E. Ert, and A. E. Roth. A choice prediction comp etition for mark et en try games: An introduction. Games , 1:117–136, 2010. D. F oster and R. V ohra. Calibrated learning and correlated equilibrium. Games and Ec onomic Behavior , 21:40–55, 1996. P . D. Gr ¨ un wald and A. P . Dawid. Game theory , maximum entrop y , minimum discrepancy , and robust ba yesian decision theory . A nnals of Statistics , 32: 1367–1433, 2003. S. Hart and A. Mas-Colell. A simple adaptiv e pro cedure leading to correlated equilibrium. Ec onometric a , 68(5):1127–1250, 2000. P . Henry , C. V ollmer, B. F erris, and D. F o x. Learning to na vigate through cro wded environmen ts. In Pr o c e e dings of R ob otics and Automation , 2010. E. T. Ja ynes. Information theory and statistical mechanics. Physic al R eview , 106(4):620–630, Ma y 1957. S. Kak ade, M. Kearns, J. Langford, and L. Ortiz. Correlated equilibria in graphical games. In Pr o c e e dings of Ele ctr onic Commer c e , pages 42–47, 2003. D. McF adden. The measurement of urban trav el demand. Journal of Public Ec onomics , 3(4):303–328, 1974. R. McKelv ey and T. Palfrey . Quantal resp onse equilibria for normal form games. Games and Ec onomic Behavior , 10:6–38, 1995. J. My ers and E. Sadler. Effects of range of pay offs as a v ariable in risk taking. Journal of Exp erimental Psycholo gy , 60:306–309, 1960. 36 A. Nev o. Measuring market p ow er in the ready-to-eat cereal industry . Ec onometric a , 69(2):307–342, March 2001. A. Ng and S. Russell. Algorithms for in verse reinforcement learning. In Pr o c e e dings of the International Confer enc e on Machine L e arning , 2000. J. No cedal. Up dating quasi-newton matrices with limited storage. Mathe- matics of Computation , 35(151):773–782, 1980. L. E. Ortiz, R. E. Shapire, and S. M. Kak ade. Maximum entrop y correlated equilibrium. In Pr o c e e dings of Artificial Intel ligenc e and Statistics , pages 347–354, 2007. M. Osb orne and A. Rubinstein. A c ourse in game the ory . The MIT press, 1994. ISBN 0262650401. A. Petrin. Quantifying the b enefits of new pro ducts: The case of the mini- v an. Journal of Politic al Ec onomy , 110(4), 2002. N. Ratliff, J. A. Bagnell, and M. Zinkevic h. Maximum margin planning. In Pr o c e e dings of the International Confer enc e on Machine L e arning , 2006. N. D. Ratliff, D. Silv er, and J. A. Bagnell. Learning to search: F unctional gradien t tec hniques for imitation learning. Autonomous R ob ots , 27(1): 25–53, 2009. N. Z. Shor. Minimization metho ds for non-differ entiable functions . Springer- V erlag New Y ork, Inc., 1985. ISBN 0-387-12763-1. D. Silver, J. A. Bagnell, and A. Sten tz. Learning from demonstration for autonomous na vigation in complex unstructured terrain. International Journal of R ob otics R ese ar ch , 29(1):1565 – 1592, Octob er 2010. J. Suzuki. Land use regulation as a barrier to en try: Evidence from the texas lo dging industry . International Ec onomic R eview , 2010. K. W augh, B. D. Ziebart, and J. A. Bagnell. Computational rationalization: The inv erse equilibrium problem. In Pr o c e e dings of the 28th International Confer enc e on Machine L e arning , 2011a. K. W augh, B. D. Ziebart, and J. A. Bagnell. Computational rationalization: The in verse equilibrium problem. arXiv , abs/1103.5254, 2011b. 37 B. D. Ziebart, A. Maas, J. A. Bagnell, and A. Dey . Maxim um entrop y in verse reinforcement learning. In Pr o c e e ding of the AAAI Confer enc e on A rtificial Intel ligenc e , 2008a. B. D. Ziebart, A. Maas, A. K. Dey , and J. A. Bagnell. Navigate lik e a cabbie: Probabilistic reasoning from observed context-a ware b ehavior. In Pr o c e e dings of the International Confer enc e on Ubiquitous Computing , 2008b. B. D. Ziebart, J. A. Bagnell, and A. K. Dey . Mo deling in teraction via the principle of maxim um causal entrop y . In Pr o c e e dings of the International Confer enc e on Machine L e arning , 2010. B. D. Ziebart, A. K. Dey , and J. A. Bagnell. Probabilistic p ointing target prediction via inv erse optimal con trol. In Pr o c e e dings of the International Confer enc e on Intel ligent User Interfac es , 2012. 38
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment