When are Overcomplete Topic Models Identifiable? Uniqueness of Tensor Tucker Decompositions with Structured Sparsity
Overcomplete latent representations have been very popular for unsupervised feature learning in recent years. In this paper, we specify which overcomplete models can be identified given observable moments of a certain order. We consider probabilistic…
Authors: Animashree An, kumar, Daniel Hsu
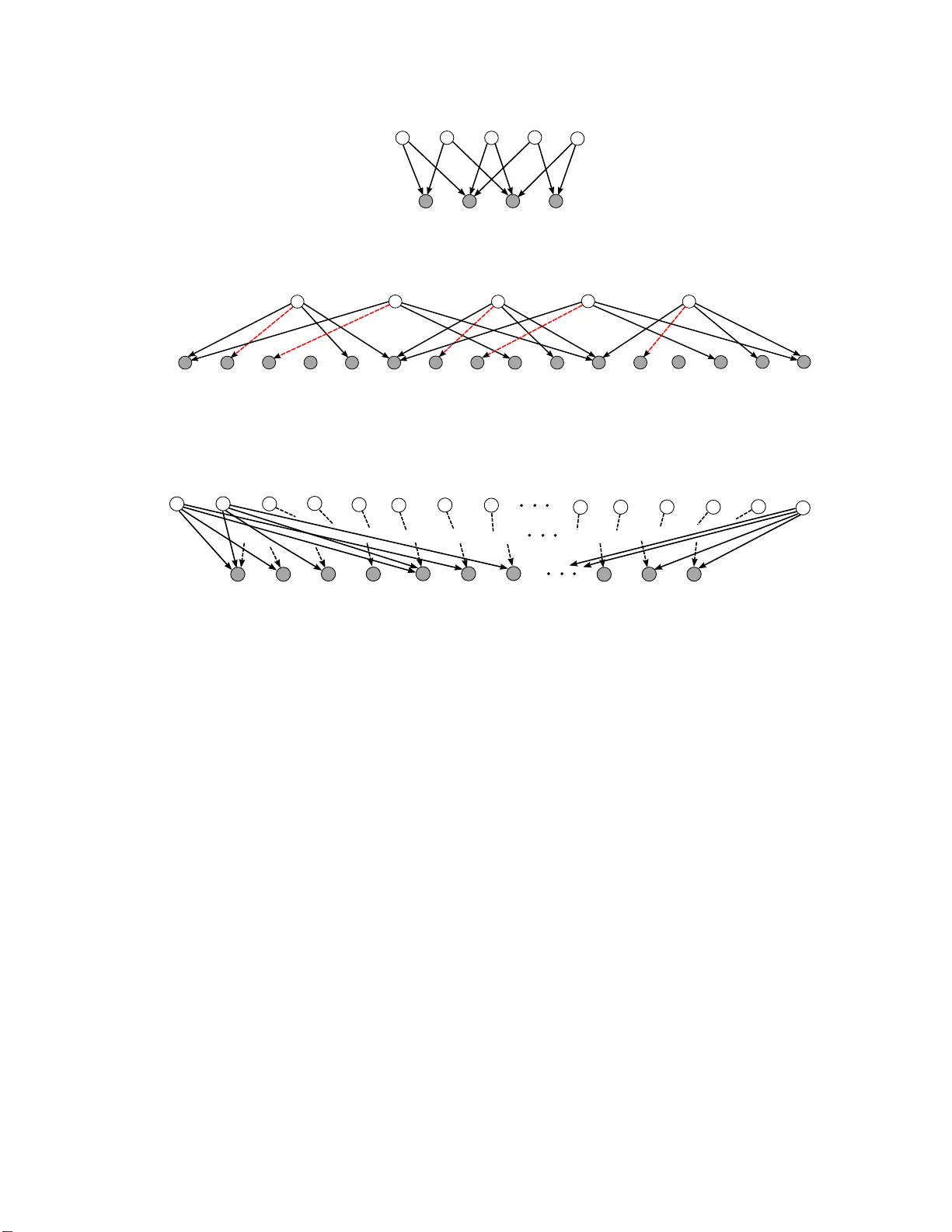
When are Ov ercomplete T opic Mo dels Iden tifiable? Uniqueness of T ensor T uc k er De comp o sitions with Structured Sparsit y Animashree Anandkumar, Daniel Hsu, Ma j id Janzamin and Sham Kak ade ∗ August 13, 2018 Abstract Overcomplete latent representations hav e b een very p o pular for unsupe r vised feature learning in rece nt years. In this pap er, we specify which overcomplete models can b e identified given observ able moments of a certain order. W e consider proba bilistic admixture or topic mo dels in the ov ercomplete regime, where the num b er of latent topics ca n greatly exceed the size of the observed word vocabular y . While general overcomplete topic models ar e not identifiable, w e establish generic iden tifiability under a c o nstrain t, referr e d to as topic p ersistenc e . Our sufficient conditions for iden tifiability in volv e a no vel set of “ higher order ” expansion co nditions on the topic-wor d matrix or the p opulation st ructur e of the model. This set of higher- o rder ex pansion conditions allo w for ov erco mplete mo dels, and require the exis tence of a p erfect matching from latent topics to hig her order observed words. W e establish that ra ndom structured topic mo dels are identifiable w.h.p. in the overcomplete regime. Our identifiabilit y results allows for genera l (non-degenera te) distributions for mo deling the topic pr oportions , and thus, we can handle arbitrar ily correlated topics in our framework. Our identifiabilit y results imply uniqueness o f a class of tensor decompos itions with structured sparsity which is contained in the class of T ucker decomp ositions, but is more g eneral than the Cande c omp/Par afac (CP) decomp o sition. Keyw ords: Ov ercomplete representati ons, topic mo dels, generic identi fi a b ili ty , tensor d e comp osi- tion. 1 In tro duction The p erformance of many m a chine learning metho ds is hugely dep enden t on the c hoice of data represent ations or features. Ov ercomplete repr ese ntatio ns , where the num b er of features can b e greater than the dimensionalit y of the input data, h a ve b een extensiv ely emplo y ed, and are ar- guably critical in a n u m b er of app lic ations such as sp eec h and compu ter vision [1]. O vercomplete ∗ A. Anandku mar and M. Janzamin are with the Cen ter for Perv asive Comm unications and Computing, Electrical Engineering and Computer Science Dept., Universit y of Calif ornia, Irvine, USA 92697. Email: a.anandkumar@uci.edu,mjanzami@uci.edu. Daniel H su and Sham Kak ade are with Microsoft R esea rch New England, 1 Memorial Drive, Cambridge, MA 02142. Email: dahsu@microsoft.com, sk aka de@m icrosoft.com 1 represent ations are known to b e more robust to noise, and can p ro vid e greater flexibilit y in mo d- eling [2]. Unsup ervised estimation of o vercomplete rep r esen tations has b een hugely p opular due to the a v ailabilit y of large-scale u nlab eled samp les in many app lic ations. A p robabilistic framework for incorp orating f ea tur es p osits laten t or hid den v ariables that can pro- vide a goo d explanation to the observ ed data. Overco mp let e pr obabilisti c mo dels can incorp orate a muc h larger num b er of laten t v ariables compared to th e observed dimensionalit y . In this pap er, w e c haracterize the cond itions und er wh ic h o v ercomplete laten t v ariable mo dels can b e identified from their observed momen ts. F or an y p aramet ric statistical mo del, iden tifiabilit y is a fu n damen tal question of whether the mo del parameters can b e un iquely reco ve red giv en the observed statistics. Iden tifiability is crucial in a n umb er of applications where the laten t v ariables are the quan tities of interest, e.g. inferring dis- eases (laten t v ariables) th rough s y m ptoms (observ ations), inf erring comm un iti es (laten t v ariables) via the in teractions among the actors in a so cial net w ork (observ ations), and so on. Moreo v er, iden tifiabilit y can b e relev ant ev en in predictiv e s et tings, where feature learning is emplo y ed for some h ig h er lev el task suc h as classification. F or instance, non-iden tifiability can lead to the pres- ence of non-isolated lo cal optima for optimization-based learning metho ds, and this can affect their con v ergence prop erties, e.g. see [3]. In this pap er, we c haracterize id en tifiability for a p opular class of laten t v ariable mo dels, kn o wn as the admixtur e or topic mo dels [4, 5]. These are hierarc h ical mixture mo dels, which incorp o- rate the p resence of m u lt ip le laten t states (i.e. topics) in eac h do cument consisting of a tup le of obser ved v ariables (i.e. words). Previous w orks ha ve established that th e mo del p arame ters can b e estimated efficien tly using lo w order observ ed momen ts (second and third ord er ) under some n on-dege n er acy assumptions, e.g. [6 – 8]. Ho wev er, these n on-dege n e r a cy conditions imply that the mo del is undercomplete, i.e., the laten t dimensionalit y (num b er of topics) cannot exceed the observ ed dimensionalit y (w ord v o cabulary size). In this pap er, w e remo v e this restriction and consider o v ercomplete topic mo dels, where the num b er of topics can far exceed the w ord v o cabulary size. It is p erhaps not surp rising that general topic mo dels are not iden tifiable in the o v ercomplete regime. T o this end, w e introduce an additional constraint on the mo del, referred to as topic p ersistenc e . Intuitiv ely , this captures the “lo calit y” effect among th e observ ed w ords, and is not present in the usual “bag-of-w ords” or exchange able topic mo del. Suc h lo cal dep endencies among observ ations ab ound in app lications suc h as text, images and sp eec h , and can lead to a more faithful represent ation. In addition, we establish that the presence of topic p ersistence is central to wa rd s obtaining mo del iden tifiabilit y in the o v ercomplete regime, and we pro vide an in -depth analysis of this phenomenon in this pap er. 1.1 Summary of results In this pap er, we pro vide conditions for generic 1 mo del iden tifiabilit y of o v ercomplete topic mo dels giv en observ ab le momen ts of a certain order (i.e., having a certain n u m b er of w ord s in eac h do c- 1 A mo del is generically identifiable, if all the parameters in t h e parameter space are identifiable, almost surely . Refer to D efinition 1 for more discussion. 2 P S f r a g r e p l a c e m e n t s h y 1 y 2 y 2 r x 1 x n x n + 1 x 2 n x ( 2 r − 1 ) n + 1 x 2 rn x 2 A A A A A A Figure 1: Hierarchical structure o f the n -p ersistent topic mo del. 2 rn n umber of words (views ) a re shown for some in tege r r ≥ 1. A single topic y j , j ∈ [2 r ], is chosen for e a c h n succe ssiv e views { x ( j − 1) n +1 , . . . , x ( j − 1) n + n } . Matrix A is the popula tion structure or topic-word matrix. ument ). W e introd uce the notion of topic p ersistenc e , and analyze its effect on id entifiabilit y . W e establish iden tifiability in th e presence of a no ve l com binatorial ob ject, referr ed to as p erfe ct n - gr am matching , in the bipartite graph f rom topics to words. Finally , w e prov e that r an d om stru ctured topic mo dels satisfy these criteria, and are thus identifiable in the ov ercomplete regime. P ersisten t T opic Mo del: W e first introdu ce the n -p ersistent topic mo del, where the parameter n determines the p ersistence level of a common topic in a sequence of n successiv e words. F or instance, in Figure 1, the sequence of successiv e words x 1 , . . . , x n share a common topic y 1 , and similarly , th e words x n +1 , . . . , x 2 n share topic y 2 , and so on. The n -p ersisten t mo del reduces to the p opular “bag-of-w ords” m odel, when n = 1, and to the single topic mo del (i.e. only one topic in eac h do cumen t) when n → ∞ . Intuitiv ely , topic p ersistence aids identifiabilit y since we ha ve m u ltiple views of the common h idden topic generating a sequence of successiv e w ords . W e establish that the bag-of-w ords mo del (with n = 1) is to o non-informativ e ab out the topics in the o v ercomplete regime, and is therefore, not ident ifiab le. On the other hand , n -p ersistent o ve rcomplete topic mo dels with n ≥ 2 can b ecome ident ifiable, and we establish a set of transp a r e nt conditions for iden tifiabilit y . Deterministic C onditions for I den t ifia bilit y: Our sufficient conditions for ident ifi ab ility are in the form of exp an s io n conditions from th e latent topic sp ace to the observ ed word space. In the o v ercomplete regime, there are more topics than words in the v o cabulary , and thus it is imp ossible to hav e expansion on th e bipartite graph from topics to words, i.e., th e graph enco ding the sparsit y pattern of th e topic-w ord m a trix. Ins te ad, w e imp ose an expansion constraint f rom topics to “higher order” words, whic h allo ws us to incorp orate o ve rcomplete mo dels. W e establish that this condition translates to the presence of a nov el com bin at orial ob ject, referred to as the p erfe ct n-gr am matching , on the topic-w ord b ipartite graph. Intuitiv ely , the p erfect n -gram matc hing condition imp lie s “div ersity” among the higher-order w ord supp orts for differen t topics whic h leads to ident ifiab ility . In add it ion, we present trade-offs among the follo wing quan tities: num b er of topics, size of the word v o cabulary , the topic p ersistence level, the order of the observ ed m o ments at h a n d, the m inim u m and maximum degrees of an y topic in the topic-wo rd bipartite graph, and the K rusk al r ank [9] of the topic-wo r d matrix, und e r whic h id en tifiability h olds . T o the b est of our kno wledge, this is th e first wo rk to pro vide cond it ions for characte rizing identifiabilit y of o v ercomplete topic m odels with s tructured sp ars it y . 3 Iden tifiability of Random Structured T opic Mo dels: W e explicitly charac terize the regime of id en tifiability for the random setting, wh ere eac h topic i is randomly supp orted on a set of d i w ords, i.e. the bipartite graph is a rand om graph. F or this rand om mo del with q topics, p - dimensional w ord v o cabulary , and topic p ersistence lev el n , when q = O ( p n ) and Θ(log p ) ≤ d i ≤ Θ( p 1 /n ), for all topics i , the topic-w ord m atrix is ident ifiable fr om 2 n th order observed momen ts with high probabilit y . In tuitive ly , the up p e r b ound on the degrees d i is n ee d ed to limit the o verlap of wo rd supp orts among different topics in the ov ercomplete r e gime: as the num b er of topics q increases (i.e., n in cr eases in the ab o ve d eg r ee b ound), the d egree needs to b e corresp ondin gl y smaller to ens u re identifiabilit y , and we m a ke this dep endence explicit. Intuitiv ely , as the exten t of o v ercompleteness incr eases, we need sp arser conn ec tions from topics to words to ensure su fficie nt div ersity in the w ord supp orts among d ifferent topics. The low er b ound on the degrees is r equired so that there are enough edges in th e topic-w ord bipartite graph so th at v arious topics can b e distinguished from on e another. F urthermore, we establish that the size condition q = O ( p n ) f o r iden tifiabilit y is tigh t. Implications on Uniqueness of Ov ercomplete T uck er and CP T ensor Decompositions: W e establish that identifiabilit y of an o v ercomplete topic mo del is equiv alen t to un iqueness of decomp ositio n of the observe d m o ment tensor (of a certain order). O ur ident ifi ab ility results for p ersisten t topic mo dels imply u niqueness of a stru ct u red class of tensor decomp ositions, wh ic h is con tained in the class of T ucker d ec omp ositions, but is more general than the c ande c omp/p ar afac (CP) decomp osition [10]. Th is sub-class of T uc ker decomp ositions inv olv es stru ctured spars it y and symmetry constraints on the c or e tensor , and sp a r s it y constrain ts on the inverse factors of the T uc ker decomp osit ion. The structural constrain ts on the T uc ker tensor decomp ositio n are r ela ted to the topic mo del as follo ws: the sparsity and s ymmetry constraint s on the core tensor are related to the p ersistence prop ert y of the topic mo del, and the sp a r s it y constrain ts on th e inv erse factors are equiv alent to th e sparsity constraints on the topic-w ord m a trix. F or n -p ersisten t topic mo del with n = 1 (bag-of-w ord s mod el ), the tensor d ecomp osition is a general T u c ker d ec omp osition, wh er e the core tensor is fully dense, while f or n → ∞ (single-topic m odel), the tensor decomp o sition reduces to a CP decomp osition, i.e. the core tensor is a diagonal tensor . F or a fi n ite p ersistence lev el n , in b et wee n these tw o extremes, the core tensor satisfies certain sp arsit y and symmetry constrain ts, whic h b ecomes cru cia l to wards establishing iden tifiabilit y in the ov ercomplete regime. 1.2 Ov erview of T echniqu es W e no w pro vide a sh ort o verview of th e tec hniqu e s emplo ye d in th is pap er. Recap of Ide ntifiabilit y C onditions in Under-complete Sett ing (Expansion Conditions on T opic-W ord Mat rix): Our appr oac h is based on the recen t results of [7 ], where conditions for iden tifiabilit y of topic mo dels are derived, giv en pairwise observ ed m o ments (sp ecifically , co- o cc u rrence of w ord-pairs in d ocuments). Consider a topic mo del with q topics and observ ed wo rd v o cabulary of size p . Let A ∈ R p × q denote the topic-wo rd matrix. E xpansion conditions are imp osed in [7] on the topic-w ord bipartite graph whic h imply that (generically) the sparsest v ectors in the column span of A , d enot ed b y C o l( A ), are the columns of A th ems elves. T h us the topic-w ord matrix 4 A is identifiable fr o m pairwise momen ts un der expansion constraints. Ho wev er, these expansion conditions constrain the mo del to b e u n der-complete , i.e., the num b er of topics q ≤ p , the size of the wo rd v o cabulary . Th erefore, the tec hn iques d eriv ed in [7] are not directly applicable here since w e consider o v ercomplete mo dels. Iden tifiability in Overcomplete Sett ing and Why T opic-P ersistence Helps: P airwise momen ts are th us not sufficient f o r identifiabilit y of ov ercomplete m o dels, and the question is whether higher order moment s can yield iden tifiabilit y . W e can view the higher order momen ts as pairwise momen ts of another equiv alent topic mo del, whic h enables us to apply the tec h niques of [7]. The k ey question is wh ether w e h a ve expansion in the equiv alen t topic mo del, wh ich implies iden tifiabilit y . F or a general topic mo del (without any topic p ersistence constraints), it can b e sho wn that for identi fi a b il ity , w e require expansion of the n th -order Kr one cker pr o duct of th e original topic-w ord matrix A , denoted by A ⊗ n ∈ R p n × q n , when given access to (2 n ) th -order moments, for an y intege r n ≥ 1. I n the o v ercomplete regime wh er e q > p , A ⊗ n cannot expand, and therefore, o v ercomplete mo dels are n ot iden tifiable in general. On th e other h an d , w e sho w that imp osing the constrain t of topic p ersistence can lead to identifiabilit y . F or a n -p ersistent topic mo del, giv en (2 n ) th -order moments, we establish that iden tifiabilit y o ccurs wh en th e n th -order Khatri-R ao pr o duct of A , den o ted by A ⊙ n ∈ R p n × q , expands. Note that the Kh at r i- Rao pro duct A ⊙ n is a sub-matrix of the Kroneck er pr odu c t A ⊗ n , and the Kh at r i-Rao pro duct A ⊙ n can expand as long as q ≤ p n . Thus, the p roperty of topic p ersistence is cent r al tow ard s ac h ieving id entifiabilit y in the o v ercomplete regime. First-Order Approac h for I de ntifiabilit y of Ov ercomplete Mo dels (Expansion of n - gram T opic-W ord Matrix) : W e refer to A ⊙ n ∈ R p n × q as the n -gram topic-w ord matrix, and in tuitive ly , it relates topics to n -t u ple w ord s. Imp osing the expansion conditions d e r iv ed in [7] on A ⊙ n implies that (generically) the sparsest ve ctors in Col( A ⊙ n ), are the columns of A ⊙ n themselv es. Th u s, the topic-w ord matrix A is identifiable from (2 n ) th -order momen ts f or a n -persistent topic mo del. W e refer to this as the “fir s t- ord er ” ap p roac h since we directly imp ose the expansion conditions of [7] on A ⊙ n , without exploiting the additional structure p resen t in A ⊙ n . Wh y t he First-Order Approac h is not E noug h: Note that A ⊙ n ∈ R p n × q matrix r e lates topics to n -tuples of wo r d s. T h us, the en tries of A ⊙ n are highly correlated, ev en if the original topic-w ord matrix A is assumed to b e rand omly generated. It is non-trivial to d eriv e conditions on A , so that A ⊙ n expands. Moreo ver, w e establish that A ⊙ n fails to expand on “small” sets, as required in [7], when the degrees are sufficien tly d ifferen t 2 . Thus, the fir s t- ord er approac h is highly restrictiv e in the o verco mp let e setting. 2 F or A ⊙ n to expand on a set of size s ≥ 2, it is necessary that s · d min + n − 1 n ≥ s + d max + n − 1 n , where d min and d max are the minim um and maximum degrees, and n is the ex ten t of ov ercompleteness: q = Θ( p n ). When the model is highly ov ercomplete (large n ) and we require small set ex pansion (small s ), th e degrees need to b e nearly the same. Thus, it is desirable t o imp ose expansion only on large sets, since it allo ws for more degree d iv ersit y . 5 Incorp orating Rank Criterion: Note that A ⊙ n is highly structured: the columns of A ⊙ n matrix p ossess a tensor 3 rank of 1, when n > 1. This can b e incorp orated in our iden tifiabilit y criteria as follo ws: w e pro vide cond it ions un d er whic h the sparsest vecto rs in C o l( A ⊙ n ), wh ic h also p ossess a tensor r a n k of 1, are the columns of A ⊙ n themselv es. This implies id en tifiability of a n - p ersisten t topic mod el , wh en giv en access to (2 n ) th -order moments. Note that wh en a small num b er of columns of A ⊙ n are com bin ed , th e r esulting ve ctor cannot p ossess a tensor rank of 1, and thus, w e can rule out that suc h sparse com binations of columns using the r a n k criterion. The maxim um suc h n umb er is at least the Kruskal r ank 4 of A . Thus, sparse com b inati ons of columns of A (u p to the Kru s k al rank) can b e ruled out using the rank criterion, and we require expansion on A ⊙ n only on large sets of topics (of size larger than the Kru sk al rank). This agrees with the intuition that when the topic-word matrix A h as a larger Krusk al rank, it s h ould b e easier to iden tify A , since the Kru sk al rank is r ela ted to the mutual inc oher enc e 5 among the column s of A , see [11]. Notion of Perfect n -gram Matc hing and Final I de ntifiabilit y Conditions: Th us, we establish iden tifiability of ov ercomplete topic mo dels su b ject to expansion conditions A ⊙ n on sets of size larger than the K rusk al rank of the topic-w ord matrix A . Ho we ver, it is desirable to imp ose transparent and int erp reta b le conditions d irect ly on A for iden tifiabilit y . W e in tro duce the notion of p erfe c t n -gr am matching on the topic-word bipartite graph , whic h ensures that eac h topic can b e uniquely matc hed to a n -tup le word. Th is combined with a lo we r b oun d on the Krusk al rank pro vides the fin al set of deterministic conditions for identi fi a b ili ty of the o verco mp le te topic mo del. In tuitivel y , w e r equire that the columns of A b e spars e , w hile still main taining a large enough Krusk al rank; in other w ord s, the topics ha ve to b e sparse and h a ve sufficien tly div erse w ord supp orts. Thus, we establish identifiabilit y und er a set of transparent conditions on th e topic-w ord matrix A , consisting of p erfect n -gram matc hing condition and a low er b ound on the K rusk al rank of A . Analysis under Random-Structured T opic-W ord Matrices: Finall y , w e establish that the deriv ed d ete rm inistic conditions are satisfied when the topic-wo rd bipartite graph is r a n domly generated, as long as the d eg rees satisfy certain lo wer and up p er b oun ds. Intuiti vely , a low er b ound on the degrees of the topics is required to ha ve degree concentrat ion on v arious subsets so that expansion can o ccur, while the upp er b ound is required so that the K rusk al rank of the topic-w ord matrix is large enough compared to the sparsit y lev el. Here, the main tec h nica l result is establishin g the presence of a p erfect n -gram matc hing in a random bipartite graph with a wid e range of degrees. W e presen t a greedy and a recursiv e mec hanism for constructing suc h a n -gram matc hing for o vercomplete mo dels, whic h can b e relev an t even in other settings. F or instance, our results imply th e presence of a p erfect matc hing when the ed ges of a b ipartite graph are correlated in a stru ct u r ed manner, as giv en by th e K h at r i- Rao pro duct. 3 When any column of A ⊙ n ∈ R p n × q (of length p n ) is reshaped as a n th -order tensor T ∈ R p × p ×···× p , the tensor T is rank 1. 4 The Krusk al rank is th e maximum n umb er k such that every k -subset of columns of A are linearly ind ependent. Note that th e Krusk al rank is equal to the rank of A , when A has full column rank . But this cannot happ en in th e o vercomplete setting. 5 It is easy to show that krank ≥ (max i 6 = j | a ⊤ i a j | ) − 1 , where a i , a j are an y pair of columns of A . Thus, higher incoherence leads to a larger krusk al rank. 6 1.3 Related w orks W e now summ a r ize some r ec ent related w orks in the area of identifiabilit y and learning of laten t v ariable m odels. Iden tifiability , learning a nd applications of o verco mplete latent represen tations: Many recen t w orks emplo y un sup ervised estimation of o verco mp let e features for higher lev el tasks such classification, e.g. [1, 12 – 14], and record huge gains o ve r other approac hes in a num b er of ap p lica tions suc h as sp eec h recognition and computer vision. Ho w eve r , th eoretical unders ta nd ing regarding learnabilit y or iden tifiabilit y of ov ercomplete representat ions is far more limited. Ov ercomplete laten t representati ons h a ve b een analyzed in the con text of th e indep endent com- p onen ts analysis (IC A), where the sour ce s are assumed to b e indep endent, and the mixing matrix is un kno w n . In the o v ercomplete or under-d etermin ed regime of the ICA, there are more s ou r ce s than sensors. Identifiabilit y and learning of the o v ercomplete ICA redu c es to the problem of findin g an o v ercomplete candecomp/parafac (CP ) tensor decomp osition. The classical result by Krusk al pro vides conditions for u niqueness of a C P decomp osition [9, 15], with recen t extensions to the notion of robust id en tifiability [16]. T hese results provide conditions for strict identifiabilit y of th e mo del, and here, the dimensionalit y of th e laten t space is required to b e of the same ord er as the observ ed space dimens ionalit y . In con trast, a num b er of recent w orks analyze generic id en tifiability of o verco mp let e CP d ec omp osition, whic h is weak er than strict id en tifiability , e.g. [17 – 23]. Th ese w orks assu m e that the factors (i.e. the comp onen ts) of the CP decomp osition are generically drawn and pro vide conditions for uniqueness. They allo w for the laten t d imensionalit y to b e muc h larger (p olynomially larger) than the observ ed dimensionalit y . These resu lts on the uniqueness of CP decomp ositio n s also lead to iden tifiabilit y of other latent v ariable mo dels, such as laten t tr ee mo d- els, e.g. [24, 25], and the sin gle-topic m o del, or more generally latent Diric hlet allocation (LD A). Recen tly Go yal et. al. [26] pr oposed an alternativ e f ramew ork f or o vercomplete ICA mo dels based on the eigen-decomp osit ion of the rew eight ed co v ariance matrix (or higher order momen ts), where the weig hts are the F ourier co efficien ts. How ever, their appr o ac h requires ind epend ence of sou r ce s (i.e. laten t topics in our cont ext), which is n ot imp osed her e. In con trast to the ab o ve w orks dealing with the CP tensor decomp ositi on, w e requ ir e uniqueness for a more general class of tensor decomp ositio n s , in order to establish identifiabilit y of topic m odels with arbitrarily correlated topics. W e establish that our class of tensor decomp osition is con tained in the class of T ucker decomp ositions whic h is more general than CP decomp osition. Moreo v er, we explicitly c h arac terize the effect of the sparsity pattern of the factors (i.e., th e topic-wo rd matrix) on mo del identifiabilit y , while all the pr evious wo rks based on generic identi fi a b ili ty assu m e fully dense f actors (since sparse factors are not generic). F or a general o ve r v iew of tensor decomp ositions, see [10, 27]. Iden tifiability and learning of unde rcomplete/ov er-dete rmined latent represen tations: Muc h of the th e oretical r esults on id en tifiability and learning of the laten t v ariable mo dels are limited to non-singular mo dels, which implies that the laten t space dimensionalit y is at most the observ ed d imensionali ty . W e outline some of the recen t w orks b elo w. 7 The w orks of Anandkumar et. al. [6 , 28, 29] pro vide an efficien t momen t-based app r oa ch f or learning topic mo dels, u n der constrain ts on the d istr ibution of the topic prop ortions, e.g. the sin gl e topic mo del, and more generally laten t Dirichlet allo ca tion (LD A). In add itio n, the app roac h can handle a v ariet y of laten t v ariable mo dels su c h as Gaussian mixtures, hidd en Marko v mo dels (HMM) and comm unity mo dels [30]. The high-lev el id ea is to reduce the problem of learning of the laten t v ariable m odel to finding a CP decomp ositio n of the (suitably adjusted) obser ved momen t tensor. V arious app roac hes can th e n b e employ ed to find the CP decomp osition. In [6], a tensor p o w er metho d ap p roac h is analyzed and is s h o wn to b e an efficien t guarant eed reco ve ry metho d in the n o n - degenerate (i.e. un dercomplete ) setting. P r evio us ly , sim ultaneous diagonaliza tion tec hniques ha ve b een emp loy ed for solving the CP decomp osition, e.g. [28, 31, 32]. Ho wev er, these tec hn iques fail when the mo del is o v ercomplete, as considered h ere. W e note that some recen t tec hniques, e.g. [20], can b e emplo y ed instead, alb eit at a cost of higher computational complexit y for o verco mp le te CP tensor decomp ositio n . Ho w ev er, it is not clear ho w the spars ity constraint s affect th e guaran tees of such metho ds. Moreo v er, these appr oac h e s cann o t handle general topic mo dels, w here the distribution of the topic prop ortions is not limited to these classes (i.e. either single topic or Diric hlet distribution), and w e require tensor decomp o sitions whic h are more general than the CP decomp ositio n . There are man y other works whic h consider learning mixtu re mo dels w hen multiple views are a v ailable. See [28] for a detailed description of these w orks. Recen tly , Rabani et. al. [33] consider learning discrete m ixtures give n a large num b er of “views”, and they refer to the num b er of views as the sampling ap ertur e . They establish imp ro ved r ec ov ery resu lt s (in terms of ℓ 1 b ounds) w hen sufficien t n umb er of views are av ailable (2 k − 1 views for a k -comp onen t mixtur e ). How ever, their results are limited to discrete m ixtures or single-topic mo dels, while our setting can hand le more general topic mo dels. Moreo v er, our approac h is d ifferen t since w e incorp orate sp arsit y constrain ts in the topic-w ord distribution. Another series of recent works b y Arora et. al. [8, 34 ] employ approac hes b ase d on non-negativ e matrix factorization (NMF) to reco ve r the topic-w ord matrix. These w orks allo w mo dels with arbitrarily correlated topics, as considered here. They establish guaran teed learning when ev ery topic has an anchor word, i.e. th e wo r d is uniquely generated from that topic, and do es not o cc u r u nder any other topic. Note that the anc hor-word assumption cannot b e satisfied in the o v ercomplete setting. Our w ork is closely related to the work of Anandkumar et. al. [7 ] wh ic h considers id e ntifiabilit y and learnin g of topic mo dels under expansion conditions on the topic-wo r d m at rix. The work of Spielman et. al [35] considers the p roblem of dictionary learning, whic h is closely r el ated to the setting of [7 ], but in addition assumes that the coefficient matrix is r andom. Ho we ver, these w orks [7, 35] can h andle only the un der-co mp let e setting, wh ere the n umb er of topics is less than the dimensionalit y of the word v o cabulary (or the num b er of dictionary atoms is less than the n umb er of observ ations in [35]). W e extend these results to th e o vercomplete setting b y p roposin g nov el higher order expans io n conditions on the topic-w ord matrix, and also in co rp orate additional rank constrain ts p resen t in higher order momen ts. Dictionary learning/sparse co ding: Ov ercomplete representa tions hav e b een v ery p opular in the con text of dictionary learning or spars e co ding. Here, the task is to j o intly learn a dictionary as we ll as a sparse selection of the dictionary atoms to fit the observed data. T here hav e b een Ba y esian as w ell as frequentist app roac hes for dictionary learning [2, 36, 37]. Ho we ver, the heuristics 8 emplo y ed in these w orks [2 , 36, 37] h a ve n o p erformance guarantee s. The work of S pielman et. al [35] considers learning (un dercomplete ) d ictionaries and provide guarant eed learning u nder the assumption that the coefficient matrix is random (distributed as Bernoulli-Gaussian v ariables). Recen t works [38, 39] pro vide generalization b ounds for predictiv e sparse co ding, where the goal of the learned rep resen tation is to obtain goo d p erformance on some pr edict ive task. This differs from our fr a mework since w e do not consid er pr edict ive tasks here, but the task of reco v ering th e underlying laten t represent ation. Hillar and Sommer [40 ] consider the problem of iden tifiabilit y of sparse cod ing and establish that w hen the dictionary succeeds in reconstru cting a certain set of sparse v ectors, then there exists a unique sparse co ding, up to p erm utation and scaling. Ho wev er, our setting her e is different , since we do not assume that a sparse set of topics o ccur in eac h do cumen t. 2 Mo del Notation: The set { 1 , 2 , . . . , n } is denoted b y [ n ] := { 1 , 2 , . . . , n } . Given a set X = { 1 , . . . , p } , set X ( n ) denotes all ordered n -tuples generated from X . The cardinalit y of a set S is d enot ed b y | S | . F or any v ector u (or matrix U ), the su pp ort is denoted b y S u pp ( u ), and the ℓ 0 norm is denoted b y k u k 0 , whic h corresp onds to the num b er of non-zero en tries of u , i.e., k u k 0 := | S upp( u ) | . F or a v ector u ∈ R q , Diag ( u ) ∈ R q × q is the diagonal matrix with v ector u on its diagonal. The column space of a matrix A is d en o ted b y Col( A ). V ector e i ∈ R q is the i -th basis vec tor, w it h the i -th en try equal to 1 and all the others equal to zero. F or A ∈ R p × q and B ∈ R m × n , the Kr one cker pro duct A ⊗ B ∈ R pm × q n is defined as [41] A ⊗ B = a 11 B a 12 B · · · a 1 q B a 21 B a 22 B · · · a 2 q B . . . . . . . . . . . . a p 1 B a p 2 B · · · a pq B , and for A = [ a 1 | a 2 | · · · | a r ] ∈ R p × r and B = [ b 1 | b 2 | · · · | b r ] ∈ R m × r , the Khatri-R ao pr oduct A ⊙ B ∈ R pm × r is defined as A ⊙ B = [ a 1 ⊗ b 1 | a 2 ⊗ b 2 | · · · | a r ⊗ b r ] . 2.1 P ersistent topic mo del In this section, the n - p ersistent topic mo del is introduced and this imp oses an additional constrain t, kno wn as topic p ersistence on the p opu lar admixture mo del [4, 5, 42]. The n -p ersistent topic mo del reduces to the bag-of-w ord s admixture mo del when n = 1. An admixture mo del sp ecifies a q -dimensional ve ctor of topic prop ortions h ∈ ∆ q − 1 := { u ∈ R q : u i ≥ 0 , P q i =1 u i = 1 } whic h generates th e observ ed v ariables x l ∈ R p through ve ctors a 1 , . . . , a q ∈ R p . This collection of vecto rs a i , i ∈ [ q ], is referred to as the p opulation structur e or the topic-wor d matrix [42]. F or in s ta nce, a i is the conditional distribu tio n of words give n topic i . The laten t v ariable h is a q dimensional rand o m ve ctor h := [ h 1 , . . . , h q ] ⊤ kno wn as prop ortion vec tor. A p r io r 9 distribution P ( h ) ov er the probabilit y simplex ∆ q − 1 c haracterizes the p rior joint distribu ti on o v er the latent v ariables h i , i ∈ [ q ]. In the topic mo deling, this is the prior distribution o v er the q topics. The n -p ersisten t topic mo del h a s a three-lev el m u lt i-view hierarch y in Figure 1. 2 r n n umb er of w ords (views) are sho wn in the mo del for some intege r r ≥ 1. In this mo del, a common hidd e n topic is p ersisten t for a sequence of n wo r d s { x ( j − 1) n +1 , . . . , x ( j − 1) n + n } , j ∈ [2 r ]. Note that th e rand om observ ed v ariables (w ords) are exc hangeable within group s of size n , where n is the p ersistence lev el, b ut are not globally exc hangeable. W e now describ e a linear r epresen tation of the n -persistent topic mo del, on lines of [6 ], bu t with extensions to in corp orate p ersistence. Eac h random v ariable y j , j ∈ [2 r ] , is a discrete v alued r andom v ariable taking one of the q p ossibilities { 1 , . . . , q } , i.e., y j ∈ [ q ] for j ∈ [2 r ]. In the n -p ersistent mo del, a single common topic is chosen for a sequence of n w ords { x ( j − 1) n +1 , . . . , x ( j − 1) n + n } , j ∈ [2 r ], i.e., the topic is p ersisten t for n su cc essive views. F or notational purp oses, we equiv alentl y assume that v ariables y j , j ∈ [2 r ], are encoded b y the b asis v ectors e i , i ∈ [ q ]. Th us, th e v ariable y j , j ∈ [2 r ], is y j = e i ∈ R q ⇐ ⇒ the topic of j -th group of wo r ds is i. Giv en p roportion v ector h , topics y j , j ∈ [2 r ], are indep endently drawn according to the conditional exp ecta tion E y j | h = h, j ∈ [2 r ] , or equiv alent ly Pr y j = e i | h = h i , j ∈ [2 r ] , i ∈ [ q ]. Finally , at the b ottom la yer, eac h observed v ariable x l for l ∈ [2 r n ], is a discrete-v alued p - dimensional random v ariable, where p is the size of wo rd vocabulary . Again, w e assume that v ariables x l , are enco ded b y the basis v ectors e k , k ∈ [ p ], s uc h as x l = e k ∈ R p ⇐ ⇒ the l -th word in the d ocument is k . Giv en the corresp onding topic y j , j ∈ [2 r ], w ords x l , l ∈ [2 r n ], are indep enden tly d ra w n according to the conditional exp ectation E x ( j − 1) n + k | y j = e i = a i , i ∈ [ q ] , j ∈ [2 r ] , k ∈ [ n ] , (1) where v ectors a i ∈ R p , i ∈ [ q ], are the conditional pr obabilit y distr ib ution vecto rs. The matrix A = [ a 1 | a 2 | · · · | a q ] ∈ R p × q collect ing these v ectors is th e p opulation structur e or topic-wor d matrix . The (2 r n )-th order moment of observe d v ariables x l , l ∈ [2 r n ], for some inte ger r ≥ 1, is d efined as (in the matrix form) 6 M 2 rn ( x ) := E h ( x 1 ⊗ x 2 ⊗ · · · ⊗ x r n )( x r n +1 ⊗ x r n +2 ⊗ · · · ⊗ x 2 rn ) ⊤ i ∈ R p r n × p r n . (2) F or the n -persistent topic mo d el with 2 r n n u m b er of observ ations (words) x l , l ∈ [2 rn ], the corre- sp onding momen t is denoted b y M ( n ) 2 rn ( x ). Note that to estimate the (2 r n ) th momen t, we require 6 V ector x is the vector generated by concatenating all vectors x l , l ∈ [2 rn ]. 10 a minim um of 2 r n words in eac h do cumen t. W e can select the first 2 r n w ords in eac h do cumen t, and av erage o v er the different do cumen ts to obtain a consisten t estimate of the moment. I n this pap er, w e consider the problem of id e ntifiabilit y wh en exact momen ts are a v ailable. The momen t characte r ization of the n -p ersisten t topic mo del is pr ovided in Lemma 1 in Section 4.1. Given M ( n ) 2 rn ( x ), what are the sufficient conditions u nder w h ic h the p opulation structure A is iden tifiable? Th is is answered in Section 3. Remark 1. Note that our r esults ar e valid for the mor e gener al line ar mo del x l = Ay j (mor e pr e ci sely, x ( j − 1) n + k = Ay j , j ∈ [2 r ] , k ∈ [ n ] ), i.e., e ach c olumn of matrix A do es not ne e d to b e a valid pr ob ability distribution. F urthermo r e, the observe d r andom variables x l , c an b e c ontinuous while the hidden ones y j ar e assume d to b e discr ete. 3 Sufficien t Conditions for Generic Iden tifiabilit y In th is section, the identi fi a b ili ty result for the n -p ersisten t topic mo del with access to (2 n )-th ord er observ ed moment is provi d ed. First, sufficient deterministic conditions on the p opulation structur e A are p r o vided for identi fi a b il ity in T heorem 1. Next, th e deterministic analysis is sp ecializ ed to a random structur ed mo del in Theorem 2. W e no w mak e the notion of iden tifiabilit y precise. As defi ned in literature, (strict) iden tifiabilit y means that the p opu lation structure A can b e uniquely r ec ov ered up to p erm utation and scaling for all A ∈ R p × q . Instead, w e consid er a m o r e relaxed notion of id e ntifiabilit y , known as generic iden tifiabilit y . Definition 1 (Generic identifiabilit y) . We r efer to a matrix A ∈ R p × q as generic, with a fixe d sp arsity p attern when the nonzer o entries of A ar e dr awn fr om a distribution which is absolutely c ontinuous with r esp e ct to L eb esgu e me asur e 7 . F or a giv en sp arsity p attern, the class of p opulation structur e matric es is said to b e generically identi fi ab le [25] , if al l the non-identifiable matric es form a set of L eb esgue me asur e zer o. The (2 r )-th order moment of hidden v ariables h ∈ R q , denoted by M 2 r ( h ) ∈ R q r × q r , is defin ed as M 2 r ( h ) := E r times z }| { h ⊗ · · · ⊗ h r times z }| { h ⊗ · · · ⊗ h ⊤ ∈ R q r × q r . (3) W e no w provi d e a s et of sufficient cond it ions f o r generic ident ifiab ility of stru ct u red topic mo dels giv en (2 r n )-th ord er observed momen t. W e first start with a n a tur al assumption on the hidden v ariables. Condition 1 (Non-degeneracy) . The (2 r ) -th or der moment of hidden variables h ∈ R q , define d in e quation (3) , is ful l r ank (non-de gener acy of hidden no des). Note that there is no h o p e of distinguishing distinct hidden n odes without this non-degeneracy assumption. W e do n ot imp ose an y other assump tio n on hidden v ariables and can incorp orate arbitrarily correlated topics. 7 As an eq u iv alent definition, if the n on-zero en tries of an arbitrary sparse matrix are ind ependently p erturbed with noise drawn from a contin uous distribution to generate A , then A is called generic. 11 P S f r a g r e p l a c e m e n t s Y X Figure 2: A bipar tite g raph G ( Y , X ; E ) with | X | = 4 and | Y | = 6 wher e the edge set E itself is a p erfect 2-gra m matc hing. F u rthermore, we can only hop e to identify the p opulation structur e A u p to scaling and p erm utation. Therefore, we can iden tify A u p to a canonical form defined as: Definition 2 (Canonical form) . Population structur e A is said to b e in canonical form if al l of its c olumns have unit norm. 3.1 Deterministic conditions for generic iden t ifiability In this section, we consider a fixed sparsity p at tern on the p opulation stru ct u re A and establish generic iden tifiabilit y when n on-z ero entries of A are drawn from some conti nuous distribution. Before providing the m ain result, a generalize d notion of (p erfect) matc hing for bipartite graphs is defin ed. W e subsequ en tly imp ose these conditions on the bipartite graph from topics to words whic h en c o des the sparsit y p at tern of p opulation structure A . Generalized ma t c hing for bipartit e graphs A bipartite graph with t wo disjoint ve rtex sets Y and X and an edge set E b et ween them is denoted by G ( Y , X ; E ). Giv en the bi-adjacency matrix A , th e notation G ( Y , X ; A ) is also used to denote a bipartite graph . Here, the ro ws and columns of matrix A ∈ R | X |×| Y | are r espectiv ely indexed by X an d Y vertex sets. F or an y sub set S ⊆ Y , the set of neighb ors of v ertices in S with resp ect to A is defined as N A ( S ) := { i ∈ X : A ij 6 = 0 for s o me j ∈ S } , or equiv alen tly , N E ( S ) := { i ∈ X : ( j, i ) ∈ E for some j ∈ S } with resp ect to edge set E . Here, w e d efine a generalized n ot ion of matc hing for a bipartite graph and refer to it as n -gram matc hing. Definition 3 ((P erfect) n -gram m a tching) . A n -gram matc hing M f o r a b i p artite gr aph G ( Y , X ; E ) is a subset of e dges M ⊆ E which satisfies the fol lowing c onditions. First, for any j ∈ Y , we have | N M ( j ) | ≤ n . Se c ond, for any j 1 , j 2 ∈ Y , j 1 6 = j 2 , we have min {| N M ( j 1 ) | , | N M ( j 2 ) |} > | N M ( j 1 ) ∩ N M ( j 2 ) | . A p erfect n -g ram matc h ing or Y -saturating n -gram matc hing for the bip artite gr aph G ( Y , X ; E ) i s a n -gr am matching M in which e ach vertex in Y is the end-p oint of exactly n e dges in M . In wo r d s, in a n -g r am matc hing M , eac h vertex j ∈ Y is at m o st the end -point of n edges in M and for an y p ai r of vertic es in Y ( j 1 , j 2 ∈ Y , j 1 6 = j 2 ), there exists at least one non-common neighbor in set X for eac h of them ( j 1 and j 2 ). As an example, a bipartite graph G ( Y , X ; E ) with | X | = 4 and | Y | = 6 is shown in Figure 2 for whic h th e edge set E itself is a p erfect 2-gram m atching. 12 Remark 2 (Relationship to other m a tchings) . The r elationship of n - gr am matching to other typ es of matchings is discusse d b elow. • R e gular matching: F or sp e ci a l c ase n = 1 , the (p erfe ct) n -gr am match ing r e duc es to the usual (p erfe ct) matching for bip artite gr aphs. • b -matching: A b -matching f or a bip artite gr aph G ( Y , X ; E ) (with e qual vertex sizes | X | = | Y | ) is a subset of e dges M b ⊆ E , wher e e ach v ertex is c onne cte d to b e dges. Comp aring with the pr op ose d p erfe ct n - gr am matching, b -matching do es not enfor c e that the set of neighb ors b e dif- fer ent, and furthermor e, it r e quir es that X = Y , which is not p ossible under the over c omplete setting. Remark 3 (Necessary s ize b ound) . Consider a bip artite gr aph G ( Y , X ; E ) with | Y | = q and | X | = p which has a p erfe ct n - gr am matching. Note that ther e ar e p n n -c ombinations on X side and e ach c ombination c an at most have one neighb or (a no de in Y which is c onne cte d to al l no des in the c ombination) thr ough the matching, and ther efor e we ne c essarily have q ≤ p n . Finally , n ote that the existence of p erfect n -gram m a tching resu lt s the existence of p erfect ( n + 1)- gram matc h ing 8 , but the reverse is n ot true. F or example, the bip a r ti te graph G ( Y , X ; E ) with | X | = 4 and | Y | = 4 2 = 6 in Figure 2, has a p erfect 2-gram matc hing, but not a p erfect (1-gram) matc hing (since 6 > 4). Iden tifiability conditions based on existence of p erfect n -gram matc hing in topic-word graph No w, we are ready to p ropose the identifiabilit y conditions and result. Condition 2 (P erfect n -gram matc hing on A ) . The bip artite gr aph G ( V h , V o ; A ) b etwe en hidden and observe d variables, has a p erfe ct n -gr am matching. The ab o v e condition implies that the sp arsit y pattern of matrix A is appropriately scattered in the mapping from hidden to observed v ariables to b e identifiable. Int u it ively , it means that eve ry hidden no de can b e distinguished from another hid den no de by its u nique set of neigh b ors und er the corresp onding n -gram matc hing. F u rthermore, condition 2 is the key to b e able to p r opose identifiabilit y in the o ve rcomplete regime. As stated in the size b oun d in Remark 3, for n ≥ 2, the num b er of h idden v ariables can b e more than the num b er of observ ed v ariables and w e can still ha v e p erfect n -g r am matc hing. Definition 4 (Kr usk al rank, [15]) . The Kru sk al rank or the krank of matrix A is define d as the maximum numb er k such that every sub set of k c olumns of A is line arly indep endent. Note that krank is d ifferent fr om the general notion of matrix rank and it is a lo wer b oun d f o r the matrix rank, i.e., Rank( A ) ≥ krank( A ). Condition 3 (Kr an k condition on A ) . The Kruskal r ank of matrix A satisfies the b ound krank( A ) ≥ d max ( A ) n , wher e d max ( A ) is the maximum no de de gr e e of any c olumn of A . In the o v ercomplete regime, it is not p ossible for A to b e f u ll column rank and krank( A ) < | V h | = q . Ho w eve r , note that a large enough krank ens ures that appropriate sized s u bsets of columns of A are linearly indep endent. F o r instance, when krank( A ) > 1, an y t w o columns cannot b e collinear 8 Note that t h e degree of each node ( o n matching side Y ) in the original bipartite graph should b e at least n + 1. 13 and the ab o ve cond ition rules out the collinea r case for ident ifi ab ility . In the ab o ve condition, w e see that a larger krank can incorp orate denser conn ections b et ween topics and words. The main identifiabilit y result un der a fi xed graph stru ct ur e is stated in the follo win g theorem for n ≥ 2, wh ere n is th e topic p ersistence lev el. Th e iden tifiabilit y result relies on h a ving access to the (2 r n )-th order moment of observ ed v ariables x l , l ∈ [2 r n ], defin ed in equation (2) as M 2 rn ( x ) := E h ( x 1 ⊗ x 2 ⊗ · · · ⊗ x r n )( x r n +1 ⊗ x r n +2 ⊗ · · · ⊗ x 2 rn ) ⊤ i ∈ R p r n × p r n , for some integ er r ≥ 1. Theorem 1 (Generic iden tifiability un d er deterministic topic-w ord graph stru ct u re) . L et M ( n ) 2 rn ( x ) in e quation (2) b e the (2 rn ) -th or der observe d moment of the n -p ersistent topic mo del for some inte ger r ≥ 1 . If the mo del satisfies c onditions 1, 2 and 3, then, for any n ≥ 2 , al l the c olumns of p opulation structur e A ar e generically identifiable fr om M ( n ) 2 rn ( x ) . F urthermor e, the (2 r ) -th or der moment of the hidden v ariables, denote d by M 2 r ( h ) , is also generically identifiable . The theorem is p ro ved in App endix A. It is seen that the p opulation structure A is iden tifiable, giv en an y observ ed moment of ord er at least 2 n . Increasing the order of observ ed momen t results in ident ifyin g h ig h er order momen ts of the hidd e n v ariables. The ab o ve theorem do es not co ver the case when the p ersistence lev el n = 1. This is the usu a l bag-of-w ords adm ixtu re mo d el. Ident ifiab ility of this mo del has b een studied earlier [7] and we recall it b elo w. Remark 4 (Bag-of-w ord s admixtur e m odel, [7]) . Given (2 r ) -th or der observe d moments with r ≥ 1 , the structur e of the p opular b ag-of-wor ds admixtur e mo del and the (2 r ) -th or der moment of hidden variables ar e i dentifiable, when A is ful l c olumn r ank and the fol lowing exp ansion c ondition holds [7] | N A ( S ) | ≥ | S | + d max ( A ) , ∀ S ⊆ V h , | S | ≥ 2 . (4) Our r esult for n ≥ 2 in The or em 1, pr ovides identifiability in the over c omplete r e gi me with we aker matching c ondition 2 and kr ank c ondition 3. The matching c ondition 2 is we aker than the ab ove exp ansion c ondition which is b ase d on the p erfe ct matching and henc e, do es not al low over c omplete mo dels. F urth ermor e, the ab ove r esult for the b ag-of-wor ds admixtur e mo del r e quir es ful l c olumn r ank of A which is mor e stringent than our kr ank c ondition 3. Remark 5 (Kr usk al r a n k and d eg ree diversit y) . Condition 3 r e quir es that the Kruskal r ank of the topic-wor d matrix b e lar ge enough c omp ar e d to the maximum de gr e e of the topics. Intuitively, a lar ger Kruskal r ank ensur e s enough diversity in the wor d supp orts among differ ent topics u nd er a higher level of sp arsity. This Kruskal r ank c ondition also al lows for mor e de gr e e diversity among the topics, when the topic p ersistenc e level n > 1 . On the other hand, for the b ag-of-wor ds mo del ( n = 1 ), u sing (4) implies that 2 d min > d max , wher e d min , d max ar e the minimum and maximum de gr e es of the topics. Thus, we pr ovide identifiability r esults with mor e de gr e e diversity when higher or der moments ar e employe d. Remark 6 (Reco v ery usin g ℓ 1 optimization) . It tu rns out that our c onditions for identifiability imply that the c olumns of the n -gr am matrix A ⊙ n , define d in D efinition 6, ar e the sp arsest ve ctors in Col M ( n ) 2 n ( x ) , having a tensor r ank of one. Se e App endix A. This implies r e c overy of the c olumns of A thr ough exhaustive se ar ch, which is not efficient. Efficient ℓ 1 -b ase d r e c overy algorithms have b e en analyze d in [7, 43 ] for the under c omplete c ase ( n = 1) . They c an b e employe d her e for r e c overy fr om higher or der moments as wel l. Exploiting additional structur e pr esent in A ⊙ n , f o r n > 1 , suc h as r ank-1 test devic es pr op ose d in [20] ar e inter e sting avenues for futu r e investigation. 14 3.2 Analysis under random topic-w ord graph struct ures In this section, we sp ecialize the identifiabilit y resu lt to the random case. This result is based on more tr a n sparen t conditions on the size and the degree of the rand om bipartite graph G ( V h , V o ; A ). W e consider the random mo del where in the bipartite graph G ( V h , V o ; A ), eac h no de i ∈ V h is randomly connected to d i differen t n odes in set V o . Note that th is is a heterogeneous degree mo del. Condition 4 (Size condition) . The r andom bip artite gr aph G ( V h , V o ; A ) with | V h | = q , | V o | = p , and A ∈ R p × q , satisfies the size c ondition q ≤ c p n n for some c onstant 0 < c < 1 . This size condition is r equired to establish th a t the random b ip artit e graph has a p erfect n -gram matc hing (and hence satisfies deterministic condition 2). It is sho wn in Section 5.2.1 that the necessary size constraint q = O ( p n ) stated in Remark 3, is ac h ie ved in the rand om case. Thus, the ab o ve constrain t allo ws for th e ov ercomplete regime, wher e q ≫ p for n ≥ 2, and is tight. Condition 5 (Degree condition) . In the r andom bip artite gr aph G ( V h , V o ; A ) with | V h | = q , | V o | = p , and A ∈ R p × q , the de gr e e d i of no des i ∈ V h satisfies the fol lowing lower and upp e r b ounds ( d i ∈ [ d min , d max ]) : • Lo wer b ound: d min ≥ max { 1+ β log p, α log p } for some c onstants β > n − 1 log 1 /c , α > max 2 n 2 β log 1 c + 1 , 2 β n . • Upp er b ound: d max ≤ ( cp ) 1 n . In tuitivel y , the low er b ound on the degree is required to show that the corresp onding bip a r tite graph G ( V h , V o ; A ) h a s suffi cient num b er of rand om edges to ensu r e that it has p erfect n -gram matc hing w ith high prob ab ility . The upp er b oun d on the degree is mainly required to satisfy the krank condition 3, where d max ( A ) n ≤ krank( A ). It is imp ortan t to see that, for n ≥ 2, the ab o ve condition on d eg r ee co vers a ran ge of mo dels fr om sparse to in termediate regimes and it is reasonable in a num b er of applications that eac h topic do es not generate a very large num b er of w ords. Definition 5 ( whp ) . A se quenc e of events E p o c curs with high probability ( whp ) if Pr ( E p ) = 1 − O ( p − ǫ ) for some ǫ > 0 . The main random iden tifiabilit y result is stated in the follo wing theorem for n ≥ 2, while n = 1 case is add ressed in Remark 8. The iden tifiabilit y result relies on h a ving access to the (2 r n )-th order moment of obs er ved v ariables x l , l ∈ [2 r n ], defin ed in equation (2) as M 2 rn ( x ) := E h ( x 1 ⊗ x 2 ⊗ · · · ⊗ x r n )( x r n +1 ⊗ x r n +2 ⊗ · · · ⊗ x 2 rn ) ⊤ i ∈ R p r n × p r n , for some integ er r ≥ 1. Probabilit y rate constants: The probability rate of su cc ess in the f ollo win g rand o m identifia- bilit y r esult is sp ecified b y constant s β ′ > 0 and γ = γ 1 + γ 2 > 0 as β ′ = − β log c − n + 1 , (5) γ 1 = e n − 1 c n n − 1 + e 2 1 − δ 1 n β ′ +1 , (6) 15 γ 2 = c n − 1 e 2 n n (1 − δ 2 ) , (7) where δ 1 and δ 2 are some constan ts satisfying e 2 p n − β log 1 /c < δ 1 < 1 and c n − 1 e 2 n n p − β ′ < δ 2 < 1. Theorem 2 (Rand o m iden tifiabilit y) . L et M ( n ) 2 rn ( x ) in e quation (2) b e the (2 rn ) -th or der observe d moment of the n - p ersistent topic mo del for some inte ge r r ≥ 1 . If the mo del with r andom p opulation structur e A satisfies c onditions 1 , 4 and 5, then whp (with pr ob ability at le ast 1 − γ p − β ′ for c onstants β ′ > 0 and γ > 0 , sp e cifie d in (5) - (7) ), for any n ≥ 2 , al l the c olumns of p opulation structur e A ar e i dentifiable fr om M ( n ) 2 rn ( x ) . F urthermor e, the (2 r ) - th or der moment of hidden variables, denote d by M 2 r ( h ) , is also identifiable, whp . The theorem is prov ed in Ap pen d ix B. Sim ilar to the d ete rm inistic analysis, it is seen that the p op- ulation structure A is id en tifiable giv en an y observed moment with order at least 2 n . Increasing the order of observed moment results in identifying higher order momen ts of the hidden v ariables. Remark 7 (T rade-o ff b et we en topic-w ord size ratio and degree) . When the numb er of hidden variables incr e ases, i.e. c incr e ases, bu t the or der n is kept fixe d, the b ounds on de gr e e in c ondition 5 also ne e ds to gr ow. Intuitively, a lar ger de gr e e is ne e de d to pr ovide mor e flexibility in c h o osing the subsets of neighb ors for hidden no des to e nsur e the existenc e of a p e rfe ct n -gr am matching in the bip artite gr aph, which in turn ensur es identifiability. Note that as c gr ows, the p ar ameter β , which is the lower b ound on d also gr ows, and the pr ob ability r ate (i.e. , the term − β log c ) r emains c onstant. Henc e, the pr ob ability r ate do es not change as c incr e ases, sinc e the incr e ase in the de gr e e d c omp ensates the additional “difficulty” arising due to a lar ger numb er of hidden variables. The ab o v e identifiabilit y theorem only co v ers for n ≥ 2 and the n = 1 case is addr essed in the follo wing remark. Remark 8 (Bag-of-w ords admixtur e mo del) . The identifiability r esult for the r andom b ag-of- w or ds admixtur e mo del is c omp ar able to the r esult in [ 4 3 ], which c onsiders exact r e c overy of sp arsely-use d dictionaries. They assume that Y = D X is given for some unknown arbitr ary dictionary D ∈ R q × q and unknown r andom sp arse c o effici ent matrix X ∈ R q × p . They establish that if D ∈ R q × q is ful l r ank and the r andom sp arse c o e ffic i ent matrix X ∈ R q × p fol lows the Bernoul li-sub gaussian mo del with size c onstr aint p > C q log q and de gr e e c onstr aint O (lo g q ) < E [ d ] < O ( q log q ) , then the mo del is identifiable, whp. Comp aring the size and de gr e e c onstr aints, our identifiability r esu lt for n ≥ 2 r e quir es mor e stringent upp er b ound on the de g r e e ( d = O ( p 1 /n ) ), while mor e r elaxe d c ondition on the size ( q = O ( p n ) ) which al lows to identifiability in the over c omplete r e gime. Remark 9 (The size condition is tigh t) . The si ze b ound q = O ( p n ) in the ab ove the or em achieves the ne c essary c ondition that q ≤ p n = O ( p n ) (se e R e ma rk 3), and is ther efor e tight. The sufficiency is ar gue d in The or em 3, wher e we show that the matching c ondition 2 holds under the ab ove size and de gr e e c onditions 4 and 5. 4 Iden tifiabilit y v ia Uniqueness of T ensor Decomp ositions In this section, w e c haracterize the moments of the n -p ersisten t topic mo del in terms of the mo del parameters, i.e. th e topic-w ord m a trix A and the momen t of hidden v ariables. W e relate identifia- 16 bilit y of th e topic mo del to uniqueness of a certain class of tensor decomp ositions, which in tu r n, enables us to pro ve Theorems 1 and 2. W e then discuss the sp ecial cases of the p ersisten t topic mo del, viz., the single topic mo del (infinite-p ersisten t topic mo del) and the bag-of-w ords admixture mo del (1-p ersisten t topic mo del). 4.1 Momen t c haracterization of the p ersisten t topic mo del The moment charact erization requ ires the follo win g definition of a n -gram matrix. Definition 6 ( n -gram Matrix) . Given a matrix A ∈ R p × q , its n -gr am matrix A ⊙ n ∈ R p n × q is define d as the matrix whose ( i , j ) -th entry is given by, for i := ( i 1 , i 2 , . . . , i n ) ∈ [ p ] n and j ∈ [ q ] , A ⊙ n ( i , j ) := A i 1 ,j A i 2 ,j · · · A i n ,j , or A ⊙ n := n times z }| { A ⊙ · · · ⊙ A . That is, A ⊙ n is the column-w ise n th order Kronec ker pro duct of n copies of A , and is kno wn as the Khatri-Rao pro duct [41]. In the follo wing lemma, wh ic h is pr o ve d in App end ix A.2, we c haracterize the observed m o ments of a p ersisten t topic mo del. Through ou t this section, the ord er of the observ ed moment is fix ed to 2 m . Lemma 1 ( n -p ersisten t topic m odel momen t c haracterization) . The (2 m ) -th or der moment of observe d variables, define d in e qu ation (2) , for the n -p ersistent topic mo del is char acterize d as 9 : • if m = r n , for some inte ger r ≥ 1 , then M ( n ) 2 m ( x ) = r times z }| { A ⊙ n ⊗ · · · ⊗ A ⊙ n M 2 r ( h ) r times z }| { A ⊙ n ⊗ · · · ⊗ A ⊙ n ⊤ , (8) wher e M 2 r ( h ) ∈ R q r × q r is the (2 r ) -th or der moment of hidden variables h ∈ R q , define d in e quation (3) . • If n ≥ 2 m , then M ( n ) 2 m ( x ) = A ⊙ m M 1 ( h ) A ⊙ m ⊤ , (9) wher e M 1 ( h ) := Diag( E [ h ]) ∈ R q × q is the first or der moment of hidden v ariables h ∈ R q , stacke d in a diagonal matrix. Th u s, w e see that the observed moments can b e expressed in terms of the hidden momen ts M ( h ) and the Kr on eck er pro ducts of the n -gram matrices. In the sp ecial case, when the p ersistence lev el is large enough compared to th e order of the moment ( n ≥ 2 m ), the momen t form reduces to a Khatri-Rao pro duct form in (9). Moreo v er, in (9), we h a ve a diagonal matrix M 1 ( h ) instead of a general (dense) matrix M 2 r ( h ) in (8), w h en n < 2 m = 2 r n . Thus, w e ha ve a more succinct represent ation of the moments in (9) when the p ersistence leve l of the topics is large enough. In the follo wing, we con trast the sp ecial cases when the p ersistence lev el n is n → ∞ (single topic mo del) and n = 1 (bag of w ords admixture mo del), as shown in Fig.3a and Fig.3b. In order to 9 The other cases not cov ered in Lemma 1 are deferred to App endix A.2. See Remark 12. 17 P S f r a g r e p l a c e m e n t s h y x 1 x m x m + 1 x 2 m (a) Single topic mo del (infinite-per sisten t topic mo del) P S f r a g r e p l a c e m e n t s h y 1 y m y m + 1 y 2 m x 1 x m x m + 1 x 2 m (b) Bag-o f-w ords a dmixture mo del (1-p ersisten t topic mo del) Figure 3: Hierarchical str ucture of the single topic mo del and bag -of-w or ds admixture mo del shown for 2 m nu mber o f words (view s ). ha ve a fair comparison, the num b er of observ ed v ariables is fixed to 2 m and the p ersistence leve l is v aried. Single topic model ( n → ∞ ): Th e condition in (9) ( n ≥ 2 m ) is alw ays satisfied for the single- topic mo del, since n → ∞ in this case, and we ha ve M ( ∞ ) 2 m ( x ) = A ⊙ m M 1 ( h ) A ⊙ m ⊤ . (10) Note that M 1 ( h ) is a diagonal matrix. Bag-of-w ords admixture mo del ( n = 1 ): F rom Lemma 1, the (2 m )-th order momen t of observ ed v ariables x l , l ∈ [2 m ], for the bag-of-w ords admixture mo del (1-p ersisten t topic mo del), sho wn in Figure 3b, is giv en b y M (1) 2 m ( x ) = m times z }| { A ⊗ · · · ⊗ A M 2 m ( h ) m times z }| { A ⊗ · · · ⊗ A ⊤ , (11) where M 2 m ( h ) ∈ R q m × q m is the (2 m )-th order momen t of hidden v ariables h ∈ R q , d efined in (3). Note that M 2 m ( h ) is a fu ll matrix in general. Con trasting single topic ( n → ∞ ) and bag of words mo dels ( n = 1) : Comparing equations (10) and (11), it is seen that the m oments u nder the single topic mo del in (10) are more “stru ct u red” compared to the bag of words mo del in (11). I n (11), w e ha ve K ronec ker pro ducts of the topic- w ord matrix A , while (10) inv olv es Khatri-Rao pro ducts of A . T his forms a crucial criterion in determining of w hether ov ercomplete mo dels are identifiable, as discussed b elo w . Wh y p ersistence helps in identifiabilit y of o v ercomplete mo dels? F or simplicit y , let the order of the momen t 2 m = 4. The equ ations (10) and (11) r educe to M ( ∞ ) 4 ( x ) = ( A ⊙ A ) Diag E h ] ( A ⊙ A ) ⊤ , (12) M (1) 4 ( x ) = ( A ⊗ A ) E ( h ⊗ h )( h ⊗ h ) ⊤ ( A ⊗ A ) ⊤ . (13) Note th a t for th e single topic m odel in (12), th e Khatri-Rao pro duct matrix A ⊙ A ∈ R p 2 × q has the same as the num b er of columns (i.e. th e laten t dimensionalit y) of the original matrix A , while the num b er of rows (i.e. the observ ed d imensionalit y) is increased. Th us , th e K hatri-Ra o pro duct 18 P S f r a g r e p l a c e m e n t s X Y 1 1 2 2 3 3 4 4 5 (a) Structure of an ov erco mplete matrix A ∈ R 4 × 5 having a p erfect 2-g ram matching. P S f r a g r e p l a c e m e n t s X (2) Y 1 2 3 4 5 (1 , 1) (1 , 2) (1 , 3) (1 , 4) (2 , 1) (2 , 2) (2 , 3) (2 , 4) (3 , 1) (3 , 2) (3 , 3) (3 , 4) (4 , 1) (4 , 2) (4 , 3) (4 , 4) (b) Structure of A ⊙ A ∈ R 16 × 5 having a pe r fect ( Y -satur ating) matching, hig hligh ted b y dashed red edges. P S f r a g r e p l a c e m e n t s X (2) Y (2) (1 , 1) (1 , 1) (1 , 2) (1 , 2) (1 , 3) (1 , 3) (1 , 4) (1 , 4) (1 , 5) (2 , 1) (2 , 1) (2 , 2) (2 , 2) (2 , 3) (2 , 3) ( 2 , 4 ) ( 3 , 1 ) ( 3 , 2 ) ( 3 , 3 ) ( 3 , 4 ) ( 4 , 1 ) (4 , 2) (4 , 3) (4 , 4) (4 , 5) (5 , 1) (5 , 2) (5 , 3) (5 , 4) (5 , 5) (c) Str ucture of A ⊗ A ∈ R 16 × 25 . F or simplicity , only a few edges and no des a re shown and the dashed edges denote the bunch of edg es connected to each no de, not sp ecifically shown. Figure 4: An example o f an ov ercomplete matrix A and the ma trices A ⊙ A and A ⊗ A . The corr esponding bipartite gra phs enco de the sparsity patter n of ea c h of the matrice s . A ⊙ A expands the effect of hidden v ar iables to second or der observed v ariables which is crucial for ov erco mplete iden tifiability , while in the A ⊗ A , the order of b oth the hidden a nd observed v ariables ar e inc r eased. “expands” the effect of hid den v ariables to higher order obser ved v ariables, which is the k ey to wa rd s iden tifying o verco mp let e mo dels. In other words, the original o vercomplete r e p resen tation b ecomes determined d ue to the ‘expansion effect’ of the K hatri-Ra o p rodu ct stru c tur e of the h igher order observ ed moments. On the other hand, in the b a g-of-w ord s admixtur e mo del in (13), this in teresting ‘expansion prop- ert y’ do es not o cc u r, and we ha ve the Kronec k er pr oduct A ⊗ A ∈ R p 2 × q 2 , in p la ce of th e Khatri-Rao pro ducts. T he Kr o n ec ke r pro duct op eration incr eases b oth the n umb er of the columns (i.e. laten t dimensionalit y) and the num b er of r o ws (i.e. observe d dimensionalit y), whic h implies that higher order moment s do not h elp in iden tifying o vercomplete mo dels. An example is p ro vided in Figure 4 whic h helps to see ho w th e matrices A ⊙ A and A ⊗ A b eha v e differen tly in terms of mapp ing topics to w ord tup le s. 19 Note that for the n -pers istent mo del, for n = 2, the 4 th order moment r e d uces to M (2) 4 ( x ) = ( A ⊙ A ) E hh ⊤ ]( A ⊙ A ) ⊤ . (14) Con trasting the ab o v e equation with (12) and (13), w e fi nd th at the 2-p ersisten t mo del retains the desirable pr operty of p ossessing Kh at ri-Rao pro ducts, wh ile b eing more general than the form f o r single topic m odel in (12). This k ey pr operty enables us to establish id e ntifiabilit y of topic mo dels with finite p ersistence leve ls. 4.2 T ensor algebra of the mo del In Section 4.1, we provided a representa tion of the moment forms in the matrix form. W e n o w pro vide the equiv alent tensor represen tation of the m ome nts. Th e tensor representa tion is more compact and transparent, and allo ws us to compare the topic m odels un der differen t lev els of p er- sistence. W e compare the deriv ed tensor form with the well-kno wn T u c ker and CP decomp ositions. W e first int r oduce some tensor notations and d efinitions. 4.2.1 T ensor nota t ions and definitions A r ea l-v alued order- n tensor A ∈ N n i =1 R p i := R p 1 ×···× p n is a n dimensional arra y A (1 : p 1 , . . . , 1 : p n ), w h ere the i -th mo de is in d exed fr om 1 to p i . In this pap er, we restrict ourselv es to th e case that p 1 = · · · = p n = p , and simply write A ∈ N n R p . A fib er of a tensor A is a v ector obtained b y fixing all ind ices of A except one, e.g., for A ∈ N 4 R 3 , the vec tor f = A (2 , 1 : 3 , 3 , 1) is a fi ber. F or a vect or u ∈ R p , Diag n ( u ) ∈ N n R p is the n -t h ord er diagonal tensor with vecto r u on its diagonal. The tensor A ∈ N n R p , is stac ked as a ve ctor a ∈ R p n b y the vec( · ) op erator, defined as a = v ec( A ) ⇔ a ( i 1 − 1) p n − 1 + ( i 2 − 1) p n − 2 + · · · + ( i n − 1 − 1) p + i n ) = A ( i 1 , i 2 , . . . , i n ) . The inv erse of a = vec( A ) op eration is denoted b y A = ten( a ). F or v ectors a i ∈ R p i , i ∈ [ n ], the tensor outer pro duct op erator “ ◦ ” is defined as [41] A = a 1 ◦ a 2 ◦ · · · ◦ a n ∈ n O i =1 R p i ⇔ A ( i 1 , i 2 , . . . , i n ) := a 1 ( i 1 ) a 2 ( i 2 ) · · · a n ( i n ) . (15) The ab o ve generated tensor is a r a n k-1 tensor. The tensor r ank is the minimal num b er of rank-1 ten- sors into which a tensor can b e decomp osed. Th is type of rank is called CP (Candecomp/Pa r afac) tensor rank in th e literature [41]. According to ab o ve definitions, for an y set of vec tors a i ∈ R p i , i ∈ [ n ], we ha v e the follo wing pair of equalities: v ec( a 1 ◦ a 2 ◦ · · · ◦ a n ) = a 1 ⊗ a 2 ⊗ · · · ⊗ a n , ten( a 1 ⊗ a 2 ⊗ · · · ⊗ a n ) = a 1 ◦ a 2 ◦ · · · ◦ a n . F or an y v ector a ∈ R p , the p o wer notations are also d efi ned as a ⊗ n := n times z }| { a ⊗ a ⊗ · · · ⊗ a ∈ R p n , 20 a ◦ n := n times z }| { a ◦ a ◦ · · · ◦ a ∈ n O R p . The second p o wer is usually called the n -t h order tensor p ower of vecto r a . Finally , the T uc k er and C P (Candecomp/P arafac) representa tions are defined as follo ws [10, 41]. Definition 7 (T uck er repr esentati on) . Given a c or e tensor S ∈ N n i =1 R r i and inverse factors U i ∈ R p i × r i , i ∈ [ n ] , the T ucker r epr esentation of the n -th or der tensor A ∈ N n i =1 R p i is A = r 1 X i 1 =1 r 2 X i 2 =1 · · · r n X i n =1 S ( i 1 , i 2 , . . . , i n ) U 1 (: , i 1 ) ◦ U 2 (: , i 2 ) ◦ · · · ◦ U n (: , i n ) =: [[ S ; U 1 , U 2 , . . . , U n ]] , (16) wher e U j (: , i j ) denotes the i j -th c olumn of matrix U j . The tensor S is r eferr e d to as the c or e tensor. Definition 8 (CP r epresen tation) . Given λ ∈ R r , U i ∈ R p i × r , i ∈ [ n ] , the CP r epr esentation of the n -th or der tensor A ∈ N n i =1 R p i is A = r X i =1 λ i U 1 (: , i ) ◦ U 2 (: , i ) ◦ · · · ◦ U n (: , i ) = : [[Diag n ( λ ); U 1 , U 2 , . . . , U n ]] , (17) wher e U j (: , i ) denotes the i -th c olumn of matrix U j . Note th at the CP r ep resen tation is a sp ecial case of the T uc k er r ep resen tation w h en the core tensor S is squ are and diagonal. 4.2.2 T ensor representation of moments under topic mo del W e no w pro vide a tensor represent ation of the momen ts. F or the n -p ersisten t topic mo del, the 2 m -th observe d momen t is denoted by T ( n ) 2 m ( x ), whic h is th e tensor form of the m o ment matrix M ( n ) 2 m ( x ), c haracterized in Lemma 1. I t is giv en by T 2 m ( x ) ( i 1 ,i 2 ,...,i 2 m ) := E [ x 1 ( i 1 ) x 2 ( i 2 ) · · · x 2 m ( i 2 m )] , i 1 , i 2 , . . . , i 2 m ∈ [ p ] , (18) where T 2 m ( x ) ∈ N 2 m R p . This tensor is charact erized in the follo wing lemma, and is pr o ved in App endix A.2. Lemma 2 ( n -p ersisten t topic mo del momen t charac terization in tensor form) . The (2 m ) -th or der moment of wor ds, define d in e quation (18) , for the n -p e rsistent topic mo del is char acterize d as 10 : • if m = r n for some inte ger r ≥ 1 , then T ( n ) 2 m ( x ) = q X i 1 =1 q X i 2 =1 · · · q X i 2 r =1 E [ h i 1 h i 2 · · · h i 2 r ] a ◦ n i 1 ◦ a ◦ n i 2 ◦ · · · ◦ a ◦ n i 2 r (19) = hh S r ; 2 m times z }| { A, A, . . . , A ii , 10 The other cases not cov ered in Lemma 2 are deferred to App endix A.2. See Remark 12. 21 wher e S r ∈ N 2 rn R q is the c or e tensor in the ab ove T ucker r epr esentation with the sp arsity p attern as S r i = ( M 2 r ( h ) ( i n ,i 2 n ,...,i r n ) , ( i ( r +1) n ,i ( r +2) n ,...,i 2 rn ) , i 1 = i 2 = · · · = i n , i n +1 = i n +2 = · · · = i 2 n , . . . 0 , o . w ., wher e i := ( i 1 , i 2 , . . . , i 2 rn ) . • If n ≥ 2 m , then T ( n ) 2 m ( x ) = X i ∈ [ q ] E [ h i ] a ◦ 2 m i = Diag 2 m ( E [ h ]); 2 m times z }| { A, A, . . . , A . (20) The tensor represen tation in (19) is a sp ecific type of tensor decomp ositio n whic h is a sp ecial case of the T uc k er represen tation (since S r is not fully dens e ), but more general than th e CP rep resen tation. The tensor repr e sentatio n in (20) has a CP form. Comparison with single topic mo del and bag-of-w ords admixture mo del W e n ow pro vid e the tens or form for the sp ecial cases single topic mo del and b ag -of-wo rd s admixture mo del. In order to h a ve a fair comparison, th e num b er of obs e r v ed v ariables is fixed to 2 m and th e p ersistence level is v aried. CP repre sentation of the single topic mo de l: The (2 m )-th order moment of the words for the single topic mo del (infin ite -p ersistent topic mod el) is p ro vided in equation (20) as T ( ∞ ) 2 m ( x ) = X i ∈ [ q ] E [ h i ] a ◦ 2 m i = Diag 2 m ( E [ h ]); 2 m times z }| { A, A, . . . , A . (21) This repr ese ntatio n is the sym m et ric CP representa tion 11 of T ( ∞ ) 2 m ( x ). T uck er represen tation of the bag-of-words admixture mo del: F rom L emm a 2 , the tensor form of the (2 m )-th order momen t of observed v ariables x l , l ∈ [2 m ], for th e bag-of-w ords admixture mo del (1-p ersisten t topic mo del) is giv en b y T (1) 2 m ( x ) = q X i 1 =1 q X i 2 =1 · · · q X i 2 m =1 E [ h i 1 h i 2 · · · h i 2 m ] a i 1 ◦ a i 2 ◦ · · · ◦ a i 2 m = hh E h ◦ (2 m ) ; 2 m times z }| { A, A, . . . , A ii . (22) This represen tation is the T uc k er rep r esen tation (decomp osition) of T (1) 2 m ( x ) w h ere the core tensor S = E h ◦ (2 m ) is the tensor f o r m of the (2 m )-th order hid d en momen t M 2 m ( h ), defined in equation (3), and the in v erse factors corresp ond to the p opulation structure A . 11 In App endix C, we pro vide a more detailed comparison b et ween our approac h and some of the previous identifi- abilit y results for the (ov ercomplete) CP decomp osi tion. 22 P S f r a g r e p l a c e m e n t s Size & degree conditions 4,5 for r ando m case Theorems 3,4 Matc hing & krank conditions 2,3 on A Lemma 5 Rank & expansion conditions 6,7 on A ⊙ n Theorem 5 Non-degeneracy condition 1 on h Iden tifiability Figure 5: Hierarchy a mo ng the pr oposed conditions and results. Comparing the tensor forms for the n -p ersisten t topic mo del (19), single topic m odel (21 ), and bag of words admixtu re mo del (22), we find that all of them inv olv e T uc k er decomp ositions, where the in verse factors corresp ond to the topic-w ord matrix A , and th e only difference is in the sparsit y lev el of the core tensor S . F or th e bag of wo rd s m o del, with n = 1, the core tensor is fully d ense in general, while for the single topic mo del, w it h n → ∞ , the core tens or is d iag onal which reduces to the CP decomp osition. F or a general topic mo del with p ersistence level n , the core tensor is in b et w een these t wo extremes and h as s tructured sp ars it y . This sp arsit y prop ert y of the core tensor is crucial tow ard s establishing identifiabilit y in the o v ercomplete regime. T he bag-of-w ords mo del is n ot id en tifiable in the o v ercomplete regime since the core tensor is fully dense in th is case, while an o verco mp le te n -pers istent topic m odel can b e id entified under certain constrain ts p ro vided in Section 3, since the core tensor has str uctured sparsit y and symmetry . 5 Pro of T ec hniques and Auxiliary Results The m ain identifiabilit y results are given in Th e orems 1 and 2 for deterministic and random cases of topic-w ord graph str uctures. In this sectio n, we provide a p roof sk etc h of these r esults, and then, w e prop ose auxiliary results on the existence of p erfect n -gram matc hing f o r random bipartite graphs and a low er b ound on the Krusk al rank of rand o m matrices. 5.1 Pro of sketc h Summary of relat ions hips among differen t conditions: T o sum marize , there exists a h ier- arc hy among the pr o p osed conditions as follo ws . See Figure 5. First, in the rand o m analysis, th e size and the degree conditions 4 an d 5 are sufficien t for satisfying the p erfect n -gram matc hing and the krank conditions 2 and 3, sh o wn by Theorems 3 and 4 . Then, these conditions 2 and 3 ensu re that the rank and the expansion cond it ions 6 and 7 h old, sho wn by Lemma 5. And fin a lly , these conditions 6 and 7 together with non-degeneracy condition 1 conclude the primary identifiabilit y result in Th eorem 5 . Note that th e genericit y of A is also required for these r esults to hold. Primary deterministic ana lysis in Theorem 5: The deterministic analysis is pr imarily b a sed on conditions on the n -g ram matrix A ⊙ n ; b ut sin ce these conditions are op aqu e (mainly expansion condition on A ⊙ n , provided in condition 7), this analysis is r ela ted to conditions on matrix A itself. See T h eo r em 5 in App endix A.1 for the identifiabilit y r esult based on A ⊙ n . W e briefly d iscuss it b elo w for the case when 2 n num b er of w ords are a v ailable under the n -p ersistent topic mo del. F r om equation (8), th e (2 n )-th order momen t of the observed v ariables u nder the n -p ersisten t topic 23 mo del can b e w r itt en as M ( n ) 2 n ( x ) = A ⊙ n E hh ⊤ A ⊙ n ⊤ . (23) The qu estion is whether w e can r ec ov er A , giv en th e M ( n ) 2 n ( x ). Obviously , the m a trix A is not iden tifiable without any fu rther conditions. First, non-degeneracy and r a n k conditions (conditions 1 and 6) are r equ ired. Assuming these t w o conditions, we hav e from (23) th a t Col M ( n ) 2 n ( x ) = Col A ⊙ n . Therefore, the p roblem of reco vering A from M ( n ) 2 n ( x ) reduces to finding A ⊙ n in Col A ⊙ n . Then, w e show that und er the follo wing expansion condition on A ⊙ n and the genericit y prop ert y , matrix A is identifiable from Col A ⊙ n . The expansion condition (refer to condition 7 for a more de- tailed statemen t), imp oses the follo wing prop ert y on the bipartite graph G V h , V ( n ) o ; A ⊙ n 12 , N A ⊙ n Rest . ( S ) ≥ | S | + d max A ⊙ n , ∀ S ⊆ V h , | S | > krank( A ) , (24) where d max A ⊙ n is the maxim um no de degree in set V h , and the restricted v ersion of n -g r am matrix, denoted by A ⊙ n Rest . , is obtained by remo ving its redu ndan t (iden tical) rows (see Definition 9). Th e iden tifiability claim is p ro ved by sho win g that the columns of A ⊙ n are the spars est and rank-1 ve ctors (in th e tensor form) in Col A ⊙ n under the expansion condition in (24) and gener- icit y conditions. Note that since we only require exp a n sio n on sets larger than Kr u sk al rank, the expansion condition (24) is a more relaxed cond it ion compared to expansion cond iti on prop osed in [7, 43] for identifiabilit y in the undercomplete regime. F or a more d e tailed comparison , refer to Remark 11 in App endix A.1. Deterministic analysis in Theorem 1: Expansion and rank conditions in Theorem 5 are imp osed on the n -gram matrix A ⊙ n . Acco rd ing to the generalized matc h ing notions, defin ed in Section 3.1, sufficien t com bin at orial conditions on matrix A (conditions 2 and 3 ) are in tro duced whic h ensure that the expansion and r ank cond it ions on A ⊙ n are satisfied. Th e follo win g lemma is emp lo ye d to establish these results, w h ere w e s ta te an in teresting pr o p erty whic h relates the existence of a p erfect matc hin g in A ⊙ n to the existence of a p erfect n -gram matc hing in A . Lemma 3. If G ( Y , X ; A ) has a p erfe ct n -g r am matching, then G ( Y , X ( n ) ; A ⊙ n ) has a p erfe ct match- ing. In the other dir e ction, if G ( Y , X ( n ) ; A ⊙ n ) has a p erfe ct matching M ⊙ n , then G ( Y , X ; A ) has a p erfe ct n -gr am matching under the fol lowing c ondition on M ⊙ n . Al l the matching e dges ( j, ( i 1 , . . . , i n )) ∈ M ⊙ n should satisfy i 1 6 = i 2 6 = · · · 6 = i n for al l j ∈ Y . In wor ds, the matching e dges should b e c onne cte d to no des in X ( n ) , which ar e indexe d by tuples of distinct indic es. See App endix A.4 for a p roof. Using th is lemma, condition 2 implies that G ( Y , X ( n ) ; A ⊙ n ) has a p erfect matc h in g. Th en, it is str a ightforw ard to argue that the expansion and r an k conditions on A ⊙ n are satisfied, whic h is sho wn in Lemma 5 in App endix A.3 . Th is leads to th e generic iden tifiabilit y result stated in Theorem 1. 12 V ( n ) o denotes all ordered n -tuples generated from set V o := { 1 , . . . , p } whic h indexes the row s of A ⊙ n . 24 5.2 Analysis of Random St r uctures The iden tifiabilit y result for a random structured matrix A is pro vided in Theorem 2. S u fficien t size and degree conditions 4 an d 5 on the random matrix A are p rop osed suc h that the deterministic com binatorial conditions 2 and 3 on A are satisfied. The details of these auxiliary results are pro vided in the follo wing tw o su bsequen t s e ctions. In Section 5.2.1, it is p ro ved in Th eo rem 3 that a r a n dom bipartite graph satisfying reasonable size and d eg ree constraints, has a p erfect n -gram matc hing (condition 2), w hp . Then, a lo wer b ound on the Kru sk al rank of a random matrix A under size and degree constraints is p ro vid ed in Theorem 4 in Section 5.2.2, whic h implies the krank condition 3. Intuitions on w h y su ch size and degree conditions are required, are mentioned in Section 3.2 where these conditions are prop osed. 5.2.1 Existence of p erfect n -gram matching for random bipartite graphs W e show in the follo w ing theorem that a r a n dom bipartite graph s a tisfyin g r ea sonable size and de- gree constraints, prop osed earlier in conditions 4 an d 5, has a p erfect n -g ram matc hing whp . Theorem 3 (Existence of p erfect n -gram matc h ing for random bipartite graphs) . Consider a r andom bip artite gr aph G ( Y , X ; E ) with | Y | = q no des on the left side and | X | = p no des on the right side, and e ach no de i ∈ Y is r andomly c onne c te d to d i differ ent no des in X . L et d min := min i ∈ Y d i . Assume that it satisfies the size c ondition q ≤ c p n n (c ondition 4) for some c onstant 0 < c < 1 and the de gr e e c ondition d min ≥ max { 1 + β log p , α log p } for some c onstants β > n − 1 log 1 /c , α > max 2 n 2 β log 1 c +1 , 2 β n (lower b ound i n c ondition 5). Then, ther e exists a p e rfe ct ( Y -satur ating) n -gr am matching in the r andom bip artite gr aph G ( Y , X ; E ) , with pr ob ability at le ast 1 − γ 1 p − β ′ for c onstants β ′ > 0 and γ 1 > 0 , sp e cifie d in (5) and (6) . Note th a t the su fficien t size b ound q = O ( p n ) in the ab o ve theorem is also necessary (see Remark 3), and is therefore tigh t. Remark 10 (Insufficiency of the union b ound argumen t) . It is e asier to exploit the union b ound ar guments to pr op ose r andom bip artite gr aphs which have a p erfe ct n -gr am matching whp . It is pr ove d in App endix B.1 that if d ≥ n and the size c onstr aint | Y | = O ( | X | n 2 − δ ) for some δ > 0 is satisfie d, then whp , the r andom bip artite gr aph has a p erfe ct n -gr am matching. Comp aring this r esult with ours i n The or em 3 , our appr o ach has a b etter size sc aling while the uni on b ound appr o ach has a b etter de gr e e sc aling. The size sc aling limitation in the union b ound ar gument makes it unattr active. In or der to identify the p opulation structur e A in the over c omplete r e gime wher e | Y | = O ( | X | n ) , we ne e d ac c ess to at le ast (4 n ) -th or der moment under the uni on b ound ar gument, while only the (2 n ) -th or der moment is r e quir e d under our ar gument. 5.2.2 Lo wer b ound on the Krusk al ra nk of random ma t rices In the follo wing theorem, a lo wer b oun d on th e Krusk al rank of a random matrix A und er dimension and degree constraints is provided, w hic h is pro ve d in App endix B.1. Theorem 4 (Lo we r b ound on the Krusk al rank of ran d om matrices) . Consider a r andom matrix A ∈ R p × q , wher e for any i ∈ [ q ] , ther e ar e d i numb er of r andom non-zer o entries in c olumn i . L et 25 d min := min i ∈ [ q ] d i . Assume that it satisfies the size c ondition q ≤ c p n n (c ondition 4) for some c onstant 0 < c < 1 and the de gr e e c ondition d min ≥ 1 + β log p for some c onstant β > n − 1 log 1 /c (lower b ound in c ondition 5) and in additio n A is generic. Then, kr a n k( A ) ≥ cp , with pr ob ability at le ast 1 − γ 2 p − β ′ for c onstants β ′ > 0 and γ 2 > 0 , sp e cifie d in (5) and (7) . Ac knowled gemen t s The authors ac kn o wledge useful discussions with Sina Jafarp our, Adel Ja v anm a r d, Alex Dimakis, Moses Charik ar, Sanjeev Ar ora, Ankur Moitra and Kamalik a Chaud h uri. A. An andkumar is sup- p orted in part b y Microsoft F acult y F ello wship , NSF C a r ee r a wa rd C CF-1 254106, NSF Aw ard CCF-12192 34, ARO Award W911NF-12- 1-0404, and AR O YIP Award W911NF-13- 1-0084. M. Janzamin is sup p o r ted by NSF Aw ard CCF-121923 4, ARO Aw ard W911NF-12 -1-0404 and AR O YIP Aw ard W911 NF-13-1-00 84. App endi x A Pro of of Deterministic Id en tifiabilit y Result (Theorem 1) First, we sho w the iden tifiabilit y result und er an alternativ e set of conditions on the n -g ram matrix, A ⊙ n , and then, w e s ho w th at the conditions of Theorem 1 are sufficien t f o r th ese conditions to hold. A.1 Deterministic analysis based on A ⊙ n In th is section, the determin istic id en tifiability resu lt based on conditions on the n -gram m a trix, A ⊙ n , is pr o vided. In the n -gram matrix, A ⊙ n ∈ R p n × q , redundant rows exist. If some ro w of A ⊙ n is in dexed b y n -tuple ( i 1 , . . . , i n ) ∈ [ p ] n , then another ro w indexed by an y p ermutat ion of the tuple ( i 1 , . . . , i n ) has the same en tries. Therefore, the num b er of distinct ro ws of A ⊙ n is at most p + n − 1 n . In the follo wing definition, we define a n o n -redundan t ve rsion of n -gram matrix w hic h is restricted to the (p oten tially) distinct r o ws. Definition 9 (Restricted n -gram matrix) . F or any matrix A ∈ R p × q , r estricte d n -gr am matrix A ⊙ n Rest . ∈ R s × q , s = p + n − 1 n , is define d as the r estricte d version of n - gr am matrix A ⊙ n ∈ R p n × q , wher e the r e dundant r ows of A ⊙ n ar e r emove d, as explaine d ab ove. Condition 6 (Rank condition) . The n - gr am matrix A ⊙ n is ful l c olumn r ank. Condition 7 (Graph expansion) . L et G ( V h , V ( n ) o ; A ⊙ n ) denote the bip artite gr aph with vertex se ts V h c orr esp onding to the hidden variables (indexing the c olumns of A ⊙ n ) and V ( n ) o c orr esp onding to the n -th or der observe d variables (indexing the r ows of A ⊙ n ) and e dge matrix A ⊙ n ∈ R | V ( n ) o |×| V h | . The bip artite gr aph G ( V h , V ( n ) o ; A ⊙ n ) satisfies the fol lowing expansion prop ert y on the r estricte d 26 version sp e c i fie d by A ⊙ n Rest . , N A ⊙ n Rest . ( S ) ≥ | S | + d max A ⊙ n , ∀ S ⊆ V h , | S | > krank( A ) , (25) wher e d max A ⊙ n is the maximum no de de g r e e in set V h . Remark 11. The exp ansion c ondition for the b ag-of-wor ds admixtur e mo del is pr ovide d in (4) , intr o duc e d in [7]. The pr op ose d exp ansion c ondition i n (25) is inherite d fr om (4) , with two major mo dific ations. First, the c ondition is appr opriately gener alize d for our mo del which involves a gr aph with e dges sp e cifie d by the n - gr am matrix, A ⊙ n , as state d in (23 ) . Se c ond, the exp ansion pr op erty (4) , pr op ose d in [7], ne e ds to b e satisfie d for al l subse ts S with size | S | ≥ 2 , which is a stricter c ondition than the one pr op ose d her e in (25) , sinc e we c an have kran k( A ) ≫ 2 . The d et ermin istic id entifiabilit y result based on th e conditions on A ⊙ n , is stated in the follo wing theorem for n ≥ 2, while n = 1 case is add r essed in Remarks 4 and 11. The identifiabilit y result relies on access to the (2 n )-th order momen t of observ ed v ariables x l , l ∈ [2 n ], defined in equation (2) as M 2 n ( x ) := E h ( x 1 ⊗ x 2 ⊗ · · · ⊗ x n )( x n +1 ⊗ x n +2 ⊗ · · · ⊗ x 2 n ) ⊤ i ∈ R p n × p n . Theorem 5 (Generic identifiabilit y u nder deterministic conditions on A ⊙ n ) . L et M ( n ) 2 n ( x ) (define d in e quation (2) ) b e the (2 n ) -th or der moment of the n -p ersistent topic mo del describ e d i n Se ction 2. If the mo del satisfies c onditions 1, 6 and 7, then, for any n ≥ 2 , al l the c olumns of p opulation structur e A ar e generically iden tifiable fr om M ( n ) 2 n ( x ) . Pr o of: Define B := A ⊙ n ∈ R p n × q . Then, the momen t c haracterized in equ a tion (23) can b e written as M ( n ) 2 n ( x ) = B E hh ⊤ B ⊤ . Since b oth matrices E hh ⊤ and B ha ve full column rank (from conditions 1 and 6), the rank of B E hh ⊤ B ⊤ is q where q = O ( p n ), and further m o r e Col( B E hh ⊤ B ⊤ ) = Col( B ). Let U := { u 1 , . . . , u q } ∈ R p n b e any basis of Col ( B E hh ⊤ B ⊤ ) satisfying the follo wing t w o prop erties: 1) u i ’s hav e the smallest ℓ 0 norms. 2) u i ’s ha v e q smallest (tensor) ranks in the n -th ord er tensor form, i.e., U i := ten( u i ) , i ∈ [ q ], ha ve q smallest r anks. Let th e columns of matrix B b e b i for i ∈ [ q ]. S ince all the b i ’s (whic h b elong to Col( B E hh ⊤ B ⊤ )) are rank-1 in the n -t h order tensor form (since ten( b i ) = a ◦ n i ) and th e num b er of non-zero ent r ie s in eac h of b i ’s is at m o st d max ( B ) = d max ( A ) n , w e conclude that max i Rank(ten( u i )) = 1 and max i k u i k 0 ≤ d max ( B ) . (26) The ab o v e b ounds are concluded from the fact that b i ∈ Col( B E hh ⊤ B ⊤ ) , i ∈ [ q ] , and ther efore the ℓ 0 norm and the r an k prop erties of b i ’s are upp er b ounds for the corresp onding prop erties of basis v ectors u i ’s (according to the prop osed cond iti ons for u i ’s). No w, exploiting these obs e r v ations and also the genericit y of A and the exp a n sio n condition 7, we sho w that the basis vect ors u i ’s are scaled columns of B . Since u i for i ∈ [ q ] , is a vecto r in the column space of B , it can b e represented as u i = B v i for some ve ctor v i ∈ R q . Equiv alen tly , for 27 an y i ∈ [ q ], u i = P q j =1 v i ( j ) b j where b j = a ⊗ n j is the j -th column of m a trix B and v i ( j ) is a scalar whic h is the j -th en try of vecto r v i . T h en, the tensor form of u i can b e w ritte n as ten( u i ) = q X j =1 v i ( j ) ten( b j ) = q X j =1 v i ( j ) ten ( a ⊗ n j ) = q X j =1 v i ( j ) a ◦ n j = [[Diag n ( v i ); n times z }| { A, . . . , A ]] , (27) where the last equalit y is based on the notation defined in Definition 8. W e defin e e v i := [ v i ( j )] j : v i ( j ) 6 =0 as th e ve ctor w hic h contai n s only the non-zero entries of v i , i.e., e v i is the restriction of v ector v i to its supp ort. Therefore, e v i ∈ R r , w here r := k v i k 0 . F u rthermore, th e matrix e A i := { a j : v i ( j ) 6 = 0 } ∈ R p × r is defin ed as the restriction of A to its columns corresp onding to the supp ort of v i . Let ( e a i ) j denote the j -th column of e A i . According to these definitions, equation (27) r educes to ten( u i ) = [[Diag n ( e v i ); n times z }| { e A i , . . . , e A i ]] = r X j =1 e v i ( j )[( e a i ) j ] ◦ n , (2 8) whic h is deriv ed b y remo ving columns of A corresp ondin g to the zero en tries in v i . Next, we rule out th a t k v i k 0 ≥ 2 under t wo cases (2 ≤ k v i k 0 ≤ krank( A ) and krank( A ) < k v i k 0 ≤ q ), to conclude that u i ’s v ectors are scaled columns of B . Case 1: 2 ≤ k v i k 0 ≤ krank( A ) . Here, the num b er of columns of e A i ∈ R p ×k v i k 0 is less than or equal to krank( A ) and therefore it is f ull column rank. Since, all the comp onen ts of CP representati on in equation (28) are full column rank 13 , for an y 14 n ≥ 2, w e h av e Rank(ten( u i )) = r = k v i k 0 > 1, whic h contradicts the fact that max i Rank(ten( u i )) = 1 in (26). Case 2: krank( A ) < k v i k 0 ≤ q . Here, w e first restrict th e n -gram matrix B to distinct rows, denoted by B Rest . , as defin ed in Definition 9. Let u ′ i = B Rest . v i . Since u ′ i is the restricted version of u i , w e ha v e k u i k 0 ≥ k u ′ i k 0 = k B Rest . v i k 0 > N B Rest . (Supp( v i )) − | S upp( v i ) | ≥ d max ( B ) , where the second inequalit y is from Lemma 4, and th e third inequalit y f o llows from the graph expansion pr o p erty (condition 7). This r esult contradict s th e fact that max i k u i k 0 ≤ d max ( B ) in (26). F r om ab o ve con tradictions, k v i k 0 = 1 and h e n ce , columns of B := A ⊙ n are the scaled ve r s io ns of u i ’s. ✷ 13 Note th at for n ≥ 3, this full rank condition can b e relaxed by Kru sk al’s condition for uniq ueness of CP decomp o- sition [15] and its generaliza tion to higher order tensors [44]. Precisely , instead of sa yin g Rank e A i = k rank e A i = r , it is only requ ired to hav e k rank e A i ≥ ( 2 r + n − 1) /n t o argue the result of case 1. This only impro ves the constan ts inv olved in the fin al result. 14 Note that for n = 1, since the (tensor) rank of any vector is 1, th is analysis do es not work. 28 The follo wing lemma is u seful in the pro of of T heorem 5 . The resu lt p rop o sed in this lemma is similar to the parameter genericit y condition in [7], bu t generalize d for the n -gram matrix, A ⊙ n . The lemma is p ro ved on lines of the pro of of Remark 2.2 in [7]. Lemma 4. If A ∈ R p × q is g e neric, then the n - gr am matrix A ⊙ n ∈ R p n × q satisfies the fol lowing pr op erty with L eb esgue me asur e one. F or any ve ctor v ∈ R q with k v k 0 ≥ 2 , we have A ⊙ n Rest . v 0 > N A ⊙ n Rest . (Supp( v )) − | S upp( v ) | , wher e for a set S ⊆ [ q ] , N A ⊙ n ( S ) := { i ∈ [ p ] n : A ⊙ n ( i, j ) 6 = 0 f or some j ∈ S } . Here, we p r o ve the result for th e case of n = 2. The pro of can b e easily generalized to larger n . Let A := M + Z b e generic, wh er e M is an arbitrary matrix, p erturb ed b y random con tin u ou s p erturbations Z . C o n sider the 2-gram matrix B := A ⊙ A ∈ R p 2 × q . It is shown that the restricted v ersion of B , denoted b y e B := B Rest . ∈ R p ( p +1) 2 × q , satisfies the ab o v e genericit y condition. W e fi rst establish some definitions. Definition 10. We c al l a ve ctor fu lly dense if al l of its entries ar e non-zer o. Definition 11. W e say a matrix has the Null Space Prop ert y (NSP) if its nul l sp ac e do e s not c ontain any ful ly dense ve ctor. Claim 1. Fix any S ⊆ [ q ] with | S | ≥ 2 , and se t R := N M (2 -gram) Rest . ( S ) . L et e C b e a | S | × | S | submatrix of e B R,S . Then Pr( e C has the NSP ) = 1 . Pr o of of Claim 1: First, note that e B can b e exp a n ded as e B := ( A ⊙ A ) Rest . = ( M ⊙ M ) Rest . + ( M ⊙ Z + Z ⊙ M ) Rest . + ( Z ⊙ Z ) Rest . | {z } := U . Let s = | S | and let e C = [˜ c 1 | ˜ c 2 | · · · | ˜ c s ] ⊤ , where ˜ c ⊤ i is the i -th row of e C . Also, let C := [ c 1 | c 2 | · · · | c s ] ⊤ and W := [ w 1 | w 2 | · · · | w s ] ⊤ b e the corresp onding | S | × | S | submatrices of M (2 -gram) Rest . and U , resp ec- tiv ely . F or eac h i ∈ [ s ], denote b y N i the n ull space of the matrix e C i = [˜ c 1 | ˜ c 2 | · · · | ˜ c i ] ⊤ . Finally let N 0 = R s . Then, N 0 ⊇ N 1 ⊇ · · · ⊇ N s . W e need to s h o w th a t, with p robabilit y one, N s do es not con tain an y fully d en se ve ctor. If one of N i , i ∈ [ s ] , d oes n ot conta in any full dense v ector, the result is prov ed. Supp ose that N i con tains some fully dense vecto r v . Since C is a su bmatrix of M (2 -gram) R,S , every row c ⊤ i +1 of C con tains at least one non-zero en try . Th erefore, v ⊤ ˜ c i +1 = X j ∈ [ s ] v ( j )˜ c i +1 ( j ) = X j ∈ [ s ]: c i +1 ( j ) 6 =0 v ( j )( c i +1 ( j ) + w i +1 ( j )) , where { w i +1 ( j ) : j ∈ [ s ] s.t. c i +1 ( j ) 6 = 0 } are ind epend en t r a n dom v ariables, and moreo ve r , they are indep endent of ˜ c 1 , . . . , ˜ c i and thus of v . By assum ption on the distribution of the w i +1 ( j ), Pr " v ∈ N i +1 ˜ c 1 , ˜ c 2 , . . . , ˜ c i # = Pr " X j ∈ [ s ]: c i +1 ( j ) 6 =0 v ( j )( c i +1 ( j ) + w i +1 ( j )) = 0 ˜ c 1 , ˜ c 2 , . . . , ˜ c i # = 0 . (29) 29 Consequent ly , Pr " dim( N i +1 ) < dim( N i ) ˜ c 1 , ˜ c 2 , . . . , ˜ c i = 1 (30) for all i = 0 , . . . , s − 1. As a result, w it h probabilit y one, dim( N s ) = 0. ✷ No w, we are ready to p ro ve Lemma 4. Pr o of of L emma 4 : It follo ws from Claim 1 that, with p r obabilit y one, the follo wing ev en t holds: for ev ery S ⊆ [ q ] , | S | ≥ 2, and ev ery | S | × | S | su b matrix e C of e B R,S where R := N M (2 -gram) Rest . ( S ), then ˜ C h as the NSP . No w fix v ∈ R q with k v k 0 ≥ 2. Let S := Supp( v ) and H := e B R,S . F urthermore, let u ∈ ( R \ { 0 } ) | S | b e the restriction of vec tor v to S ; obs er ve th a t u is fu lly d e n se. It is clear that k e B v k 0 = k H u k 0 , so we need to sho w that k H u k 0 > | R | − | S | . (31) F or the s a ke of contradictio n, supp ose that H u has at most | R | − | S | non-zero en tries. Since H u ∈ R | R | , there is a subset of | S | entries on which H u is zero. Th is corresp onds to a | S | × | S | submatrix of H := e B R,S whic h conta ins u in its n ull space. It means that this submatrix do es not hav e the NSP , whic h is a con tradiction. Therefore w e conclude that H u must ha v e more than | R | − | S | non-zero en tries, w hic h finishes the pr oof. ✷ A.2 Pro of of momen t characterization lemmata Remark 12. In L emmata 1 and 2, a sp e c ific c ase of or der and p ersistenc e ( m = r n ) was c onsider e d. Her e, we pr ovide the moment form for a mor e gener al c ase. Assume that m = r n + s for some inte gers r ≥ 1 , 1 ≤ s ≤ n 2 , then M ( n ) 2 m ( x ) = r times z }| { A ⊙ n ⊗ · · · ⊗ A ⊙ n ⊗ A ( s -gram) f M 2 r ( h ) A (( n − s ) -gram) ⊗ r − 1 times z }| { A ⊙ n ⊗ · · · ⊗ A ⊙ n ⊗ A (2 s -gram) ⊤ , wher e f M 2 r ( h ) ∈ R q r +1 × q r +1 is the hidd en moment as f M 2 r ( h ) ( i 1 ,...,i r +1 ) , ( j 1 ,...,j r +1 ) := E [ h i 1 · · · h i r h 2 i r +1 h j 2 · · · h j r +1 ] if i r +1 = j 1 , 0 o . w . The tensor form is also c h ar acterize d as T ( n ) 2 m ( x ) = hh e S r ; 2 m times z }| { A, A, . . . , A ii , 30 wher e e S r ∈ N 2 m R q is the c or e tensor in the ab ove T ucker r epr esentation with the sp arsity p attern as fol lows. L et i := ( i 1 , i 2 , . . . , i 2 m ) . If i 1 = i 2 = · · · = i n , i n +1 = i n +2 = · · · = i 2 n , · · · , i (2 r − 1) n +1 = i (2 r − 1) n +2 = · · · = i 2 rn , i 2( m − s )+1 = i 2( m − s )+2 = · · · = i 2 m , we have e S r i = f M 2 r ( h ) ( i n ,i 2 n ,...,i r n ,i m ) , ( i ( r +1) n ,i ( r +2) n ,...,i 2 rn ,i 2 m ) . Otherwise, e S r i = 0 . Pr o of of L emma 1: In order to simp lify the notation, similar to tensor p o wers for vect ors, th e tensor p o w er for a matrix U ∈ R p × q is defined as U ⊗ r := r times z }| { U ⊗ U ⊗ · · · ⊗ U ∈ R p r × q r . (32) First, consider the case m = r n for some in teger r ≥ 1. One adv antag e of enco ding y j , j ∈ [2 r ], b y basis v ectors ap p ears in charact erizing the conditional momen ts. The first order conditional momen t of w ords x l , l ∈ [2 m ], in the n -p ersisten t topic mo del can b e written as E x ( j − 1) n + k | y j = Ay j , j ∈ [2 r ] , k ∈ [ n ] , where A = [ a 1 | a 2 | · · · | a q ] ∈ R p × q . Next, the m -th order cond it ional momen t of differen t views x l , l ∈ [ m ], in the n -p ersisten t topic mod el can b e wr itten as E [ x 1 ⊗ x 2 ⊗ · · · ⊗ x m | y 1 = e i 1 , y 2 = e i 2 , . . . , y r = e i r ] = a ⊗ n i 1 ⊗ a ⊗ n i 2 ⊗ · · · ⊗ a ⊗ n i r , whic h is derive d from th e conditional indep endence r el ationships among the observ ations x l , l ∈ [ m ], giv en topics y j , j ∈ [ r ]. Similar to the fi rst order momen ts, since vec tors y j , j ∈ [ r ], are enco ded by the basis vect ors e i ∈ R q , the ab o ve momen t can b e w r itt en as the follo wing matrix m ultiplication E [ x 1 ⊗ x 2 ⊗ · · · ⊗ x m | y 1 , y 2 , . . . , y r ] = A ⊙ n ⊗ r ( y 1 ⊗ y 2 ⊗ · · · ⊗ y r ) , (33) where the ( · ) ⊗ r notation is defined in equation (32). No w for the (2 m )-th order momen t, w e ha ve M ( n ) 2 m ( x ) := E h ( x 1 ⊗ x 2 ⊗ · · · ⊗ x m )( x m +1 ⊗ x m +2 ⊗ · · · ⊗ x 2 m ) ⊤ i = E ( y 1 ,y 2 ,...,y 2 r ) h E h ( x 1 ⊗ · · · ⊗ x m )( x m +1 ⊗ · · · ⊗ x 2 m ) ⊤ | y 1 , y 2 , . . . , y 2 r ii ( a ) = E ( y 1 ,y 2 ,...,y 2 r ) h E ( x 1 ⊗ · · · ⊗ x m ) | y 1 , . . . , y 2 r E ( x m +1 ⊗ · · · ⊗ x 2 m ) ⊤ | y 1 , . . . , y 2 r i ( b ) = E ( y 1 ,y 2 ,...,y 2 r ) h E ( x 1 ⊗ · · · ⊗ x m ) | y 1 , . . . , y r E ( x m +1 ⊗ · · · ⊗ x 2 m ) ⊤ | y r +1 , . . . , y 2 r i ( c ) = E ( y 1 ,y 2 ,...,y 2 r ) " h A ⊙ n i ⊗ r ( y 1 ⊗ · · · ⊗ y r ) ( y r +1 ⊗ · · · ⊗ y 2 r ) ⊤ h A ⊙ n i ⊗ r ⊤ # 31 = h A ⊙ n i ⊗ r E h ( y 1 ⊗ · · · ⊗ y r ) ( y r +1 ⊗ · · · ⊗ y 2 r ) ⊤ i h A ⊙ n i ⊗ r ⊤ ( d ) = h A ⊙ n i ⊗ r M 2 r ( y ) h A ⊙ n i ⊗ r ⊤ , (34) where ( a ) results from the indep endence of ( x 1 , . . . , x m ) and ( x m +1 , . . . , x 2 m ) given ( y 1 , y 2 , . . . , y 2 r ) and ( b ) is concluded f rom the indep endence of ( x 1 , . . . , x m ) and ( y r +1 , . . . , y 2 r ) give n ( y 1 , . . . , y r ) and the ind epend ence of ( x m +1 , . . . , x 2 m ) and ( y 1 , . . . , y r ) giv en ( y r +1 , . . . , y 2 r ). Equ at ion (33 ) is used in ( c ) and finally , the (2 r )-th ord er moment of ( y 1 , . . . , y 2 r ) is d efi ned as M 2 r ( y ) := E h ( y 1 ⊗ · · · ⊗ y r ) ( y r +1 ⊗ · · · ⊗ y 2 r ) ⊤ i in ( d ). F or M 2 r ( y ), w e ha v e by the la w of total exp ectation M 2 r ( y ) := E ( y 1 ⊗ · · · ⊗ y r ) ( y r +1 ⊗ · · · ⊗ y 2 r ) ⊤ = E h h E ( y 1 ⊗ · · · ⊗ y r ) ( y r +1 ⊗ · · · ⊗ y 2 r ) ⊤ | h i = E h r times z }| { h ⊗ · · · ⊗ h r times z }| { h ⊗ · · · ⊗ h ⊤ = M 2 r ( h ) , where th e third equalit y is concluded f rom the cond it ional in d epend ence of v ariables y j , j ∈ [2 r ], giv en h and th e mod el assump tio n that E y j | h = h, j ∈ [2 r ]. Substituting this in equation (34) , finishes the pro of for the n -p ersistent topic mo del. Similarly , the moment of s in gl e topic mo del (infinite p ersistence) can b e also derived. ✷ Pr o of of L emma 2: Defining Λ := M 2 r ( h ) ∈ R q r × q r and B := A ⊙ n ⊗ r ∈ R p r n × q r , the (2 r n )-th order moment M ( n ) 2 rn ( x ) ∈ R p r n × p r n of the n -p ersistent topic mo del prop osed in equation (8) can b e written as M ( n ) 2 rn ( x ) = B Λ B ⊤ . Let b ( i 1 ,...,i r ) ∈ R p r n denote the corresp onding column of B indexed by r -tuple ( i 1 , . . . , i r ) , i k ∈ [ q ] , k ∈ [ r ]. Th en, the ab o ve matrix equation can b e expanded as M ( n ) 2 rn ( x ) = X i 1 ,...,i r ∈ [ q ] j 1 ,...,j r ∈ [ q ] Λ ( i 1 , . . . , i r ) , ( j 1 , . . . , j r ) b ( i 1 ,...,i r ) b ⊤ ( j 1 ,...,j r ) = X i 1 ,...,i r ∈ [ q ] j 1 ,...,j r ∈ [ q ] Λ ( i 1 , . . . , i r ) , ( j 1 , . . . , j r ) [ a ⊗ n i 1 ⊗ · · · ⊗ a ⊗ n i r ][ a ⊗ n j 1 ⊗ · · · ⊗ a ⊗ n j r ] ⊤ , where relation b ( i 1 ,...,i r ) = a ⊗ n i 1 ⊗ · · · ⊗ a ⊗ n i r , i 1 , . . . , i r ∈ [ q ] , is u sed in the last equalit y . Let m ( n ) 2 rn ( x ) ∈ R p 2 rn denote the v ectorized f o r m of (2 r n )-th order moment M ( n ) 2 rn ( x ) ∈ R p r n × p r n . Therefore, w e ha ve m ( n ) 2 rn ( x ) := vec M ( n ) 2 rn ( x ) 32 = X i 1 ,...,i r ∈ [ q ] j 1 ,...,j r ∈ [ q ] Λ ( i 1 , . . . , i r ) , ( j 1 , . . . , j r ) a ⊗ n i 1 ⊗ · · · ⊗ a ⊗ n i r ⊗ a ⊗ n j 1 ⊗ · · · ⊗ a ⊗ n j r . Then, we h a ve the follo wing equiv alen t tensor form f or the original mo del p roposed in equation (8) T ( n ) 2 rn ( x ) := ten m ( n ) 2 rn ( x ) = X i 1 ,...,i r ∈ [ q ] j 1 ,...,j r ∈ [ q ] Λ ( i 1 , . . . , i r ) , ( j 1 , . . . , j r ) a ◦ n i 1 ◦ · · · ◦ a ◦ n i r ◦ a ◦ n j 1 ◦ · · · ◦ a ◦ n j r . ✷ A.3 Sufficien t matchin g prop erties for satisfying rank and graph expansion con- ditions In the f o llo w in g lemma, it is sho wn that und e r a p erfect n -gram matc hing and additional genericit y and krank conditions, the rank and graph expansion conditions 6 and 7 on A ⊙ n , are satisfied. Lemma 5. Assume that the bip artite gr aph G ( V h , V o ; A ) has a p erfe ct n -gr am matching (c ondition 2 is satisfie d). Then, the fol lowing r esults hold for the n -gr am matrix A ⊙ n : 1) If A is generic, A ⊙ n is f ul l c olumn r ank (c ondition 6) with L eb esgue me asur e one (almost sur ely). 2) If kr ank c ondition 3 holds, A ⊙ n satisfies the pr op ose d exp ansion pr op erty in c ondition 7. Pr o of: Let M denote the p erfect n -g ram matc hing of the b ipartite graph G ( V h , V o ; A ). F r o m Lemma 3, there exists a p erfect matc hing M ⊙ n for the bipartite graph G ( V h , V ( n ) o ; A ⊙ n ). Denote the corresp onding bi-adjacency matrix to the edge set M as A M . S imila r ly , B M denotes the corresp onding bi-adjacency matrix to the edge set M ⊙ n . Note that S upp( A M ) ⊆ Supp( A ) and Supp( B M ) ⊆ Su pp ( A ⊙ n ). Since B M is a p erfect matc hin g , it consists of q := | V h | rows, eac h of whic h has only one n on-ze ro en try , and fur thermore, the non-zero en tries are in q differen t columns. Therefore, th ese r o ws form q linearly indep endent v ectors. Since th e row ran k and column rank of a matrix are equal, and th e n umb er of columns of B M is q , the column rank of B M is q or in other w ord s, B M is full column rank. Since A is generic, from Lemma 6 (with a sligh t mo dification in the analysis 15 ), A ⊙ n is also full column r an k w ith Leb esgue measure one (almost sur el y). This completes the pr oof of part 1. Next, the second p art is pro v ed. F rom krank definition, w e ha v e | N A ( S ′ ) | ≥ | S ′ | for S ′ ⊆ V h , | S ′ | ≤ krank( A ) , 15 Lemma 6 result is abou t the column rank of A itself, b ut here it is ab out the column rank of A ⊙ n for which th e same analysis works. Note t h at the supp ort of B M (whic h is full column rank h ere) is within the sup port of A ⊙ n and therefore L emma 6 can still b e applied. 33 whic h is concluded from the fact that the corresp onding su bmatrix of A sp ecified by S ′ should b e full column rank. F rom this in equali ty , w e h a ve | N A ( S ′ ) | ≥ krank( A ) for S ′ ⊆ V h , | S ′ | = kran k( A ) . (35) Then, we hav e | N A ( S ) | ≥ | N A ( S ′ ) | for S ′ ⊂ S ⊆ V h , | S | > krank( A ) , | S ′ | = kran k( A ) , ≥ krank( A ) ≥ d max ( A ) n , (36) where (35) is u sed in the second inequalit y and the last inequalit y is from kr ank condition 3. In th e restricted n -gram matrix A ⊙ n Rest . , th e num b er of neigh b ors for a set S ⊆ V h , | S | > krank( A ), can b e b oun ded as N A ⊙ n Rest . ( S ) ≥ | N A ( S ) | + | S | ≥ d max ( A ) n + | S | for | S | > krank ( A ) , where the fir st inequalit y is due to the fact that the set N A ⊙ n Rest . consists of rows in d exed by the follo wing t wo sub sets: n -t u ples ( i, i, . . . , i ) where all the indices are equal and n -tuples ( i 1 , . . . , i n ) with distinct indices, i.e., i 1 6 = i 2 . . . 6 = i n . The former su bset is exactly N A ( S ) wh ile the size of the latter subset is at least | S | due to the existence of a p erfect n -g ram matc hing in A . The b ound (36) is us ed in the second inequ a lity . S ince d max A ⊙ n = d max ( A ) n , the pro of of part 2 is also completed. ✷ Remark 13. The se c ond r esult of ab ove lemma is similar to the ne c essity ar gument of (Hal l’s) The or em 6 for the existenc e of p erfe ct matching in a bip artite gr aph, but gener alize d to the c ase of p erfe ct n - g r am matching and with additional kr ank c ondition. A.4 (Auxiliary) lemma Pr o of of L emma 3: W e show that if G ( Y , X ; A ) h as a p erfect n -gram matc hing, then G ( Y , X ( n ) ; A ⊙ n ) has a p erfect matc hin g. The rev erse can b e also immediately sho wn by rev ersin g the discussion and exploiting the additional condition stated in the lemma. Let E ⊙ n denote the edge set of the bipartite graph G ( Y , X ( n ) ; A ⊙ n ). Assume G ( Y , X ; A ) has a p erfect n -gram m a tching M ⊆ E . F or an y j ∈ Y , let N M ( j ) denote the set of neigh b ors of ve r te x j according to edge set M . Since M is a p erfect n -gram matc hing, | N M ( j ) | = n for all j ∈ Y . It can b e immed iately concluded fr om Definition 3 that sets N M ( j ) are all distinct, i.e., N M ( j 1 ) 6 = N M ( j 2 ) for an y j 1 , j 2 ∈ Y , j 1 6 = j 2 . F or an y j ∈ Y , let N ′ M ( j ) denote an arbitrary ordered n -tup le generated from the elements of set N M ( j ). F rom the definition of n -gram matrix, we ha v e A ⊙ n ( N ′ M ( j ) , j ) 6 = 0 for all j ∈ Y . Hence, ( j, N ′ M ( j )) ∈ E ⊙ n for all j ∈ Y whic h together with the fact that all N ′ M ( j )’s tuples are d istinct , it results that M ⊙ n := { ( j, N ′ M ( j )) | j ∈ Y } ⊆ E ⊙ n is a p erfect matc h in g for G ( Y , X ( n ) ; A ⊙ n ). ✷ 34 Lemma 6. Consider matrix C ∈ R m × r which is generic. L et e C ∈ R m × r b e such that Supp( e C ) ⊆ Supp( C ) and the non-zer o e ntr ies of e C ar e the same as the c orr esp onding non-zer o entries of C . If e C is ful l c olumn r ank, then C is also ful l c olumn r ank, almost sur ely. Pr o of: Since e C is full column rank, there exists a r × r submatrix of e C , denoted by e C S , with non-zero determinan t, i.e., det ( e C S ) 6 = 0. Let C S denote the corresp onding sub mat r ix of C ind exed b y the same ro ws and columns as e C S . The d et ermin an t of C S is a p olynomial in the en tries of C S . Since e C S can b e deriv ed from C S b y k eeping th e corresp ondin g n on-ze ro en tries, det( C S ) can b e decomp osed in to tw o terms as det( C S ) = det( e C S ) + f ( C S ) , where th e first term corresp onds to the monomials for which all the v ariables (en tries of C S ) are also in e C S and the second term corresp onds to the monomials for whic h at least one v ariable is not in e C S . T h e fir st term is non -zero as stated earlier. S ince C is generic, the p olynomial f ( C S ) is non-trivial and therefore its ro ots ha v e Leb esgue measure zero. It imp lie s that det( C S ) 6 = 0 with Leb esgue measur e one (almost surely), and hence, it is fu ll (column) rank. Thus, C is also full column rank, almost surely . ✷ Finally , Theorem 1 is pro v ed b y combining the resu lt s of T heorem 5 an d Lemma 5. Pr o of of The or em 1: Since conditions 2 and 3 hold and A is generic, Lemma 5 can b e applied whic h results that rank condition 6 is satisfied almost su rely and expans io n condition 7 also h olds. Therefore, all the r equired conditions for Theorem 5 are satisfied almost su r ely and this completes the pr o of. ✷ B Pro of of Random Iden tifiabilit y Result (Theorem 2) W e provi d e detailed p roof of the steps stated in the p roof sk etc h of random result in Section 5.2. B.1 Pro of of existence of p erfect n -gram match ing and Kr usk al results Pr o of of The or em 3: V ertex sets X and Y are partitioned, describ ed as follo ws (see Figure 6). Define J := c p n . P artition set X uniformly at random in to n sets of (almost) equal size 16 , denoted b y X ′ l , l ∈ [ n ]. Defin e sets X l := ∪ l i =1 X ′ i , l ∈ [ n ]. F urthermore, partition set Y uniformly at random, hierarc hically as follo ws. First, p artit ion in to J sets, eac h with size at most c p n n − 1 , and d enote them by Y i , i ∈ [ J ]. Next, p artit ion eac h of th ese new smaller sets Y i further into J sets, eac h w it h size at most c p n n − 2 . Do it iterativ ely u p to n − 1 steps, where at the end, set Y is partitioned in to sets with size at most c p n . The first t wo steps are sho wn in Figur e 6. Pro of by induction: The existence of p erfect n -g r am m a tching from set Y to set X is p ro ved b y an induction argument . Consid e r one of inte rm edia te sets in the hierarchica l partitioning of 16 By almost, w e mean the maximum difference in the size of partitions is 1 which is alwa ys p ossible. 35 P S f r a g r e p l a c e m e n t s X X ′ 1 X ′ 2 X ′ n X 1 X 2 X n Y Y 1 Y 2 Y J Figure 6: Partitioning of sets Y and X , pro posed in the pro of o f Theorem 3. Set X is randomly (uniform) partitioned into n sets of (almost) equal size , denoted by X ′ l , l ∈ [ n ]. Set Y is als o rando mly par titioned in a recursive manner . In each step, it is partitio ne d to J = c p n = O ( p ) num b er o f sets. These smaller sets ar e again partitioned, recurs iv ely . This pa r titioning pro cess is p erformed until rea c hing sets with siz e O ( p ). The first tw o steps a re shown in this figure. Y with size O ( p l ) and its further partitioning in to J := c p n sets, eac h with size O ( p l − 1 ), for an y l ∈ { 2 , . . . , n } . I n the indu ct ion step, it is shown that if there exists a p erfect ( l − 1)-gram m at ching from eac h of these subsets of Y w ith size O ( p l − 1 ) to X l − 1 , then there exists a p erfect l -g ram matc hing from the original set with size O ( p l ) to set X l . Sp ecifically , in the last ind u cti on s te p, it is sh o wn that if there exists a p erfect ( n − 1)-gram m a tching fr om eac h set Y l , l ∈ [ J ] , to set X n − 1 , then there exists a p erfect n -gram matc hing from Y to X n = X . Base case: T he b ase case of induction argumen t holds as follo w s . By app lying Lemma 8 and Lemma 7, there exists a p erfect matc hing fr o m eac h partition in Y w ith size at most c p n = O ( p ) to set X 1 , whp . Induction step: Consider J different bipartite graph s G i ( Y i , X n − 1 ; E i ) , i ∈ [ J ], by considering sets Y i and X n − 1 and the corresp onding subset of edges E i ⊂ E incident to them. See Figure 7a. T h e induction step is to show that if eac h of th e corresp ondin g J bipartite graphs G i ( Y i , X n − 1 ; E i ) , i ∈ [ J ], has a p erfect ( n − 1)-gram matc hing, then whp , th e original bipartite graph G ( Y , X ; E ) has a p erfect n -g ram matc hing. Let us denote the corresp onding p erfect ( n − 1)-gram matc h ing of G i ( Y i , X n − 1 ; E i ) by M i . F ur- thermore, the set of all sub s et s of X n − 1 with cardinalit y n − 1 are denoted by P n − 1 ( X n − 1 ), i.e., P n − 1 ( X n − 1 ) includes the sets w ith ( n − 1) elemen ts in the p ow er s e t 17 of X n − 1 . F or eac h set S ∈ P n − 1 ( X n − 1 ), tak e the set of all n o des in Y which are connected to all members of S according to the union of matc hings ∪ J i =1 M i . C all this s et as the p a r en ts of S , denoted by P a( S ). According to the definition of p erfect ( n − 1)-gram matc hing, there is at most one no de in eac h set Y i whic h is connected to all members of S through the matc hing M i and therefore, | P a( S ) | ≤ J = c p n . In 17 The p o wer set of any set S is the set of all subsets of S . 36 P S f r a g r e p l a c e m e n t s Y Y 1 Y 2 Y J X X n − 1 X ′ n M 1 M 2 M J (a) Partitioning of sets Y and X pro - po sed for the induction step. P S f r a g r e p l a c e m e n t s Y Pa( S 1 ) Pa( S 2 ) Pa( S 3 ) X X n − 1 X ′ n S 1 S 2 S 3 p erfec t matc hi ngs from Pa ( S ) to X ′ n (b) Partitioning of set Y through p erfect ( n − 1)-g ram matchings M i , i ∈ [ J ]. Figure 7: Auxiliar y figures for pro of of induction step. (a) Partitioning of sets Y and X prop osed in the pro of, where set Y is par titioned to J := c p n partitions Y 1 , . . . , Y J with (a lmost) equal size, for so me constant c < 1. In addition, set X is partitio ne d to t wo partitions X n − 1 and X ′ n with sizes | X n − 1 | = n − 1 n p and | X ′ n | = p n . The p erfect ( n − 1 )-gram matchings M i , i ∈ [ J ] , thr ough bipartite gr aphs G i ( Y i , X n − 1 ; E i ) , i ∈ [ J ], a re also highlighted in the figure. (b) Set Y is partitioned to subsets Pa( S ) , S ∈ P n − 1 ( X n − 1 ), which is genera ted through p erfect ( n − 1)-g ram matchings M i , i ∈ [ J ]. S 1 , S 2 and S 3 are three differen t sets in P n − 1 ( X n − 1 ) shown as sa mples. In addition, the p erfect matchings fro m Pa( S ) , S ∈ P n − 1 ( X n − 1 ), to X ′ n , prop osed in the pro of, ar e also highlighted in the figure. addition, note that s e ts P a( S ) imp ose a partitioning on set Y , i.e., eac h no de j ∈ Y is exactly included in one set P a( S ) for some S ∈ P n − 1 ( X n − 1 ). This is b ecause of the p erfect ( n − 1)-gram matc hings consid e r ed for sets Y i , i ∈ [ J ]. No w, a p erfect n -gram matc h in g f or the original bipartite graph is constructed as follo ws. F or an y S ∈ P n − 1 ( X n − 1 ), consider th e set of p a r e nts P a( S ). Create the bipartite graph G S (P a( S ) , X ′ n ; E S ), where E S ⊂ E is the subset of edges in ci d en t to partitions Pa( S ) ⊂ Y and X ′ n ⊂ X . Denote b y d S the min im u m degree of no des in set P a( S ) in the bipartite graph G S (P a( S ) , X ′ n ; E S ). App lying Lemma 8, we h a ve Pr[ d S ≥ 1 + β log( p/n )] ≥ 1 − J exp − 2 n 2 ( d min − β n log( p/n )) 2 d min (37) ≥ 1 − c n p − β log 1 /c = 1 − O ( p − β log 1 /c ) , where β log 1 /c > n − 1, and the last inequalit y is concluded from the d eg ree b ound d min ≥ α log p . F u rthermore, w e ha ve | P a( S ) | ≤ c p n = c | X ′ n | . Now, w e can apply Lemma 7 concluding that there exists a p erfect matc h ing from P a( S ) to X ′ n within the bip a r ti te graph G S (P a( S ) , X ′ n ; E S ), with probabilit y at least 1 − O ( p − β log 1 /c ). Refer to Figure 7b for a sc hematic picture. T he edges of this p erfect matc h in g are com bined with the corresp onding edges of the existing p erfect ( n − 1)-g ram matc hings M i , i ∈ [ J ], to provide n inciden t edges to eac h n ode i ∈ Pa( S ). It is easy to see that this provides a p erfect n -gram m at ching from P a ( S ) to X . W e p erform the same steps for all sets S ∈ P n − 1 ( X n − 1 ) to obtain a p erfect n -g r a m matc h in g from an y Pa( S ) , S ∈ P n − 1 ( X n − 1 ) , to X . Finally , according to this construction, the union of all of these matc hings is a p erfect n -gram matc hing from ∪ S ∈ P n − 1 ( X n − 1 ) P a( S ) = Y to X . This finish es the pro of of indu ct ion step. Note that here w e analyzed the last induction s tep where the existence of p erfect n -gram matc hing is concluded from th e existence of corresp onding p erfect ( n − 1)-gram matc hings. The earlier ind u cti on steps, wher e the existence of p erfect l -gram matc hing is concluded from the existence of corresp onding p erfect ( l − 1)-gram matc hings f o r any l ∈ { 2 , . . . , n } , can b e 37 similarly prov en . Probabilit y rate : W e now p ro vid e th e p robabilit y rate of the ab o v e eve nts. Let N (hp) l , l ∈ [ n ], denote the total num b er of times that p erfect matc h ing resu lt of Lemma 7 is used in step l in ord er to ensure that there exists a p erfect l -gram matc hing from corresp onding partitions of Y to set X l , whp . Let N (hp) = P l ∈ [ n ] N (hp) l . As earlier, let P l − 1 X l − 1 denote the set of all subsets of X l − 1 with cardinalit y l − 1. W e hav e P l − 1 X l − 1 = X l − 1 l − 1 = l − 1 n p l − 1 , l ∈ { 2 , . . . , n } . According to the construction metho d of l -gram matc hing from ( l − 1)-gram matc h ings, prop osed in the induction step, P l − 1 X l − 1 is the num b er of times Lemma 7 is used in order to ensure that there exists a p erfect l -gram matc hing for eac h partition on the Y side. Since at most J n − l n umb er of such l -gram matc h ings are prop osed in step l , the num b er N (hp) l can b e b oun ded as N (hp) l ≤ J n − l P l − 1 X l − 1 = J n − l l − 1 n p l − 1 , l ∈ { 2 , . . . , n } . (38) Since in the first step, N (hp) 1 = J n − 1 n umb er of p erfect matc hings needs to exist in the ab o v e discussion, we h a ve N (hp) = J n − 1 + n X l =2 N (hp) l ≤ J n − 1 + n X l =2 J n − l l − 1 n p l − 1 ≤ c p n n − 1 + n X l =2 c p n n − l e p n l − 1 ≤ n e p n n − 1 = O ( p n − 1 ) , where inequalit y (38) is used in the first inequ a lity and J := c p n and inequalit y n k ≤ e n k k are exploited in the second inequalit y . Since the result of L emma 7 holds with probabilit y at least 1 − O ( p − β log 1 /c ) and it is assumed that β log 1 /c > n − 1, by applying union b ound, we hav e the existence of p erfect n -gram matc hin g with probabilit y at least 1 − O ( p − β ′ ), for β ′ = β log 1 c − ( n − 1) > 0. F u rthermore, note that the degree concent ration b ound in (37) is also u sed O ( p n − 1 ) times. Since the b ound in (37) holds w ith probabilit y at least 1 − O ( p − β log 1 /c ) and it is assumed that β log 1 /c > n − 1, this also r educes to th e same p robabilit y rate. The co efficien t of the ab o ve p olynomial probabilit y rate is also explicitly compu te d , sa ying th a t the p erfect n -g ram matc hing exists with probabilit y at least 1 − γ 1 p − β ′ , with γ 1 = e n − 1 c n n − 1 + e 2 1 − δ 1 n β ′ +1 , 38 where δ 1 is a constan t satisfying e 2 p n − β log 1 /c < δ 1 < 1. ✷ Pr o of of The or em 4: Let G ( Y , X ; A ) denote th e corresp onding b ipartite graph to matrix A w h ere no de sets Y = [ q ] and X = [ p ] in d ex the columns and r o ws of A r esp ectiv ely . Th erefore, | Y | = q and | X | = p . Fix some S ⊆ Y such that | S | ≤ p . Then Pr( | N ( S ) | ≤ | S | ) ≤ X T ⊆ X : | T | = | S | Pr( N ( S ) ⊆ T ) = X T ⊆ X : | T | = | S | Y i ∈ S | S | d i . p d i ≤ X T ⊆ X : | T | = | S | Y i ∈ S | S | p d i ≤ X T ⊆ X : | T | = | S | Y i ∈ S | S | p d min = p | S | | S | p d min | S | , (39) where the b ound | S | d i p d i ≤ | S | p d i is u sed in the second in equalit y , and the last inequalit y is concluded from the fact that | S | p ≤ 1. Let E denote the ev en t that for any subset S ⊆ Y with | S | ≤ r , we h av e | N ( S ) | ≥ | S | , i.e., E := “ ∀ S ⊆ Y ∧ 1 ≤ | S | ≤ r : | N ( S ) | ≥ | S | ” . Then, by the u nion b ound and inequ a lity (39), we ha ve Pr( E c ) = Pr( ∃ S ⊆ Y s . t . 1 ≤ | S | ≤ r ∧ | N ( S ) | < | S | ) ≤ r X s =1 q s p s s p d min s ≤ r X s =1 e q s s e p s s s p d min s ≤ r X s =1 e 2 q r d min − 2 p d min − 1 s , where the b oun d n k ≤ e n k k is used in the second inequalit y . F or r = cp , the ab o ve inequalit y reduces to Pr( E c ) ≤ r X s =1 e 2 c d min − 2 q p s ≤ r X s =1 e 2 c ′ c d min − 1 p n − 1 s 39 ≤ r X s =1 e 2 c ′ c β log p p n − 1 s = r X s =1 e 2 c ′ p n − 1 − β log 1 /c s ≤ e 2 c ′ p β ′ − e 2 c ′ = O ( p − β ′ ) , for β ′ = β log 1 c − ( n − 1) > 0 , where the size condition assumed in the theorem is used in the second inequalit y with c ′ := 1 c c n n , and the d e gree condition is exploited in the third inequalit y . The last inequ a lity is concluded from the geometric series sum form ula for large enough p . Then, Lemma 9 can b e applied concluding that krank( A ) ≥ r = cp , with probabilit y at least 1 − γ 2 p − β ′ for constan ts β ′ = β log 1 c − ( n − 1) > 0 and γ 2 > 0 as γ 2 = c n − 1 e 2 n n (1 − δ 2 ) , where δ 2 is a constan t satisfying c ′ e 2 p − β ′ < δ 2 < 1. ✷ Pr o of of R emark 10 : Consider a random bipartite graph G ( Y , X ; E ) where for eac h no de i ∈ X : 1. Neighbors N ( i ) ⊆ X are pic ked uniformly at rand om among all size d subs et s of X . 2. Matc hin g M ( i ) ⊆ N ( i ) is pic ked un if orm ly at random among all size n sub sets of N ( i ). Note that as long as n ≤ d , the d istribution of M ( i ) is uniform o ve r all size n subsets of X . Fix some p a ir i, i ′ ∈ Y . Th en Pr( M ( i ) = M ( i ′ )) = | X | n − 1 . By the un io n b ound, Pr ∃ i, i ′ ∈ Y , i 6 = i ′ s . t . M ( i ) = M ( i ′ ) ≤ | Y | 2 | X | n − 1 , whic h is Θ( | Y | 2 / | X | n ) w hen n is constant. Therefore, if d ≥ n and the size constraint | Y | = O ( | X | s ) for some s < n 2 is satisfied, then whp , there is n o pair of no des in s et Y with the same rand om n -gram matc hing. This concludes that the rand om bip a r ti te graph h as a p erfect n -gram matc hing whp , und er these size and degree conditions. ✷ B.2 (Auxiliary) lemmata Lemma 7 (Existence of p erfect matc h ing for rand om bipartite graph s) . Consider a r andom bip ar- tite gr aph G ( W , Z ; E ) with | W | = w no des on the left side and | Z | = z on the right side, and e ach no de i ∈ W is r andomly c onne cte d to d i differ ent no des in set Z . L et d w := min i ∈ W d i . A ssume 40 that it satisfies the size c ondition w ≤ cz for some c onstant 0 < c < 1 and the de gr e e c ondition d w ≥ 1 + β log z for some c onstant β > 0 . Then, ther e exists a p e rfe ct matching i n the r andom bip artite gr aph G ( W , Z ; E ) with pr ob ability at le ast 1 − O ( z − β log 1 /c ) wher e β log 1 c > 0 . Pr o of: F rom Hall’s th eo rem (Theorem 6), the existence of p erfect matc hing for a bipartite graph is equiv alent to o ccurrence of the f ollo win g ev ent e E := “ ∀ S ⊆ W : | N ( S ) | ≥ | S | ” . Similar to the analysis in the p roof of Th eo rem 4, it is concluded fr o m union b ound Pr e E c = Pr( ∃ S ⊆ W s . t . | N ( S ) | < | S | ) ≤ w X s =1 w s z s s z d w s ≤ w X s =1 e w s s e z s s s z d w s ≤ w X s =1 e 2 w d w − 1 z d w − 1 s ≤ w X s =1 e 2 c d w − 1 s , where th e b ound n k ≤ e n k k is used in the second inequalit y . F rom the assu med low er b ound on the degree d w and the fact that 0 < c < 1, w e hav e Pr e E c ≤ w X s =1 e 2 c β log z s = w X s =1 e 2 z β log c s ≤ e 2 z β log 1 c − e 2 ≤ e 2 1 − δ 1 z − β log 1 /c , where the second in equali ty is conclud e d from th e geometric s e r ie s sum f ormula for large enough z , and δ 1 is a constan t satisfying e 2 z − β log 1 /c < δ 1 < 1. ✷ Lemma 8 (Degree concen tration b ound) . Consider a r andom bip artite gr aph G ( Y , X ; E ) with | Y | = q and | X | = p , wher e e ach no de i ∈ Y is r andomly c onne cte d to d i differ ent no des in set X . L et Y ′ ⊂ Y b e any subset 18 of no des in Y with size | Y ′ | = q ′ and X ′ ⊂ X b e a r andom (uniformly chosen) subset of no des in X with size | X ′ | = p ′ . Cr e ate the new bip artite gr aph G ( Y ′ , X ′ ; E ′ ) wher e e dge set E ′ ⊂ E is the subset of e dges in E incident to Y ′ and X ′ . Denote the de gr e e of e ach no de i ∈ Y ′ within this new bip artite gr aph by d ′ i . L et d min := min i ∈ Y d i and d ′ min := min i ∈ Y ′ d ′ i . Then, if d min > r p p ′ for a non-ne gative i nte ger r , we have Pr[ d ′ min ≥ r + 1] ≥ 1 − q ′ exp − 2( p ′ /p ) 2 ( d min − ( p/p ′ ) r ) 2 d min . Pr o of: F or an y i ∈ Y ′ , we h a ve Pr[ d ′ i ≤ r ] = r X j =0 p ′ j p − p ′ d i − j . p d i , 18 Note that Y ′ need not to b e uniformly chosen and the result is v alid for any su bset of no des Y ′ ⊂ Y . 41 where the inner term of summ ation is a hyp ergeo metric distribution with parameters p (p opu- lation size), p ′ (n umb er of success states in the p opu lation), d i (n umb er of draws) and j is the h yp ergeometric rand om v ariable denoting num b er of successes. The follo wing tail b ound for the h yp ergeometric distribu tio n is provi d ed [45, 46 ] Pr[ d ′ i ≤ r ] ≤ exp( − 2 t 2 i d i ) , for t i > 0 giv en b y r = p ′ p − t i d i . Note that assumption d min > p p ′ r in the lemma is equiv alent to ha ving t i > 0 , i ∈ Y . Consid e r ing the minimum degree, for any i ∈ Y ′ , w e ha v e Pr[ d ′ i ≤ r ] ≤ exp( − 2 t 2 d min ) , for t > 0 giv en by r = p ′ p − t d min . S ubstituting t from this equ a tion giv es the follo wing b ound Pr[ d ′ i ≤ r ] ≤ exp − 2( p ′ /p ) 2 ( d min − ( p/p ′ ) r ) 2 d min . (40) Finally , applying the union b ound, w e can p r o ve the result as f o llo w s Pr[ d ′ min ≥ r + 1] = Pr[ ∩ q ′ i =1 { d ′ i ≥ r + 1 } ] ≥ 1 − q ′ X i =1 Pr[ d ′ i ≤ r ] ≥ 1 − q ′ X i =1 exp − 2( p ′ /p ) 2 ( d min − ( p/p ′ ) r ) 2 d min =1 − q ′ exp − 2( p ′ /p ) 2 ( d min − ( p/p ′ ) r ) 2 d min , where the union b ound is applied in the first inequalit y and the second inequalit y is concluded from (40). ✷ A lo w er b ound on the Krusk al r ank of matrix A based on a sufficien t relaxed exp a n sio n prop ert y on A is p ro vided in the follo wing lemma. Lemma 9. If A is generic and the bip artite gr aph G ( Y , X ; A ) satisfies the r elaxe d 19 exp ansion pr op erty | N ( S ) | ≥ | S | for any subset S ⊆ Y with | S | ≤ r , then kr ank ( A ) ≥ r , almost sur ely. Before prop osing the pro of, w e state the marriage or Hall’s theorem whic h giv es an equiv alen t condition for having a p erfect matc hing in a bipartite graph. Theorem 6 (Hall’s theorem, [47]) . A b i p artite gr aph G ( Y , X ; E ) has Y -satur ating matching if and only if for every subset S ⊆ Y , the size of the nei ghb ors of S is at le ast as lar ge as S , i.e., | N ( S ) | ≥ | S | . Pr o of of L emma 9: Denote the su bmatrix A N ( S ) ,S b y e A S , i.e., e A S := A N ( S ) ,S . Exploiting marr ia ge or Hall’s theorem, it is concluded that the bipartite graph G ( S, N ( S ); e A S ) has a p erfect matc hin g M S for an y subset S ⊆ Y suc h that | S | ≤ r . Denote by e A M S the corresp ondin g matrix to this p erfect matc hing edge set M S , i.e., e A M S k eeps the non-zero entries of e A S on ed g e set M S and 19 There is no d max term in contrast to the expansion prop ert y prop os ed in condition 7. 42 ev erywhere else, it is zero. Note that the supp ort of e A M S is within the supp ort of e A S . According to the defin ition of p erfect matc h ing, the matrix e A M S is full column rank. F rom L emma 6, it is concluded that e A S is also full column rank almost sur el y . This is true for an y e A S with S ⊆ Y and | S | ≤ r , whic h dir ec tly results that krank( A ) ≥ r , almost surely . ✷ Finally , Theorem 2 is prov ed by exploiting the random results on the existence of p erfect n -gram matc hing and Krusk al rank, provi d ed in T heorems 3 and 4 . Pr o of of The or em 2: W e claim that if random conditions 4 an d 5 are satisfied, then d ete rm inistic conditions 2 and 3 hold whp . Then Th eorem 1 can b e app lie d and the pr oof is done. F r om size and degree conditions, Theorem 3 can b e app lie d , wh ich implies that the p erfect n -gram matc hing condition 2 is satisfied with probabilit y at least 1 − γ 1 p − β ′ for β ′ = β log 1 c − ( n − 1) > 0. The conditions required f o r Th eo rem 4 also hold and b y applying this theorem w e hav e the b ound krank( A ) ≥ cp , with probabilit y at least1 − γ 2 p − β ′ . Combining this inequalit y with the u p p er b ound on degree d in condition 5, we conclude th at krank condition 3 is also satisfied whp . Hence, all the conditions requir ed for Theorem 1 are satisfied with probabilit y at least 1 − γ p − β ′ , where γ = γ 1 + γ 2 = e n − 1 c n n − 1 + e 2 1 − δ 1 n β ′ +1 + c n − 1 e 2 n n (1 − δ 2 ) , and this completes the pro of. ✷ C Relationship to CP Decomp osition Uniqueness Results In this section, we pro vide a m o r e detailed comparison with some un iqueness results of o v ercomplete CP decomp ositio n. Here, the follo wing CP decomp osition f or the third order tensor T ∈ R p × s × q is considered, T = r X i =1 a i ◦ b i ◦ c i , (41) where A = [ a 1 | . . . | a r ] ∈ R p × r , B = [ b 1 | . . . | b r ] ∈ R s × r and C = [ c 1 | . . . | c r ] ∈ R q × r . The most imp ortan t and general un iqueness result of CP , called Krusk al’s cond it ion, is pro vid ed in [15], wh ere it is guaranteed that the ab o ve CP decomp osition is un ique if krank( A ) + kr ank( B ) + krank( C ) ≥ 2 r + 2 . Since th en, sev eral w orks hav e analyzed the uniqueness of CP decomp osition. On e set of wo r k s assume that one of the comp onen ts, say C , is full column rank [17, 18]. it is sho wn in [18], for generic (fully d ense) comp onen ts A, B and C , if r ≤ q and r ( r − 1) ≤ p ( p − 1) s ( s − 1) / 2, then the CP decomp osition in (41) is generically unique. No w, w e demons tr a te h o w this CP uniquen ess result can b e adapted to our setting. First, consider the matrix M ∈ R ps × q whic h is obtained by stac king the entries of T as M ( i − 1) s + j,k = T ij k . 43 Then, we hav e M = ( A ⊙ B ) C ⊤ . (42) On the other han d , for the 2-p ersisten t topic mo d el with 4 words ( n = 2 , m = 2), the moment can b e written as M (2) 4 ( x ) = ( A ⊙ A ) E hh ⊤ ( A ⊙ A ) ⊤ , for A ∈ R p × q . T h e follo wing matrix h a s the same column span of M (2) 4 ( x ), M ′ = ( A ⊙ A ) C ′⊤ , for some full r ank matrix C ′ ∈ R q × q . Our r a n dom iden tifiabilit y r esult in Th eorem 2 p r o vides the uniqueness of A and C ′ , giv en M ′ , und er the size condition q ≤ c p 2 2 and th e add itional d eg ree condition 5. Note that as d iscu ssed in the previous section, this identi fi ab ility argument is the same as the un ique decomp osition of the corresp onding tensor. Th u s, in equation (42), by setting A = B an d a full rank squ are m a trix C , w e obtain the 2-p ersisten t topic mo del, under consideration in this pap er. Thus, the iden tifiabilit y resu lt s of [18] are applicable to our setting, if we assume generic (i.e. fully dense) matrix A . Ho w eve r , we incorp orate a sparse matrix A , and therefore, r equire d ifferen t tec hniques to p ro vid e iden tifiabilit y results. W e n o te that the size b ound sp ecified in [18] is comparable to the size b ound deriv ed in this pap er (for random structured matrices), but we hav e additional degree considerations for id en tifiability . Analyzing the regime wher e the uniqueness conditions of [18] are satisfied under sparsit y constrain ts is an in teresting question for futur e inv estigatio n . References [1] Y o shua Bengio, Aaron Cour ville , and Pa scal Vincen t. Unsup ervised feature learning and deep learning: A review and new p ersp ectiv es. arXiv pr eprint arXiv: 1206.5538 , 2012. [2] Mic hael S . Lewic ki, T errence J. Sejnowski, and Ho ward Hughes. Learning o v ercomplete rep- resen tations. Ne u r al Computation , 12:33 7–365, 1998. [3] Andr´ e Usc hma jew. Lo cal conv ergence of the alternating least sq u ares algorithm for canonical tensor ap p ro ximation. SIAM Journal on M atrix Ana lysis and Applic ations , 33(2):639 –652, 2012. [4] Da vid M. Blei, Andrew Y. Ng, and Mic hael I. Jordan. Laten t Dirichlet Allo ca tion. J ourn al of Machine L e arning R ese ar ch , 3:993–1 022, 2003. [5] J. K. Pr it chard, M. S tephens, and P . Donnelly . Inference of p opulation structure using multi - lo cus genot yp e data. Genetics , 155:945 –959, 2000. [6] A. Anandkumar, R. Ge, D. Hsu , S. M. Kak ade, and M. T e lgarsky . T ensor Metho ds for Learn ing Laten t V ariable Models. Under R eview. J. of Machine L e arning. Available at arXiv:1210.75 59 , Oct. 2012. 44 [7] A. Anandk u mar, D. Hsu , A. Jav anmard, and S . M. Kak ade. Learnin g Linear Ba y esian Net- w orks w ith Laten t V ariables. ArXiv e-prints , S e p te mb er 2012. [8] Sanjeev Arora, Rong Ge, Y o n i Halp ern, Da vid M. Mimno, Ankur Moitra, Da vid S on tag, Yic hen W u , and Mic hael Zhu. A practical algorithm for topic mo deling with pro v able guaran tees. ArXiv 1212.47 77 , 2012. [9] J.B. Krusk al. More factors than sub j ec ts, tests and treatmen ts: an indeterminacy theorem for canonical decomp osition and individual differences scaling. Psychometrika , 41(3):281 –293, 1976. [10] T a mara K olda and Brett Bader. T ensor decomp ositions and applications. SIREV , 51(3):4 55– 500, 2009. [11] Silvia Gandy , Benjamin R ech t, and I s a o Y amada. T ensor completion and low-n-rank tensor reco v ery via conv ex optimization. Inverse Pr oblems , 27(2): 025010, 2011. [12] Adam Coates, Honglak Lee, and And rew Y. Ng. An analysis of single-la ye r net wo rks in unsup ervised feature learning. Journal of Machine L e arning R ese ar ch - Pr o c e e dings T r ack , 15:215 –223, 2011. [13] Quo c V. Le, Alexandre Karp enko , Jiquan Ngiam, and And rew Y. Ng. ICA with Reconstruction Cost for Efficient Ov ercomplete F eature Learning. In NIPS , pages 1017–102 5, 2011. [14] Li Deng and Dong Y u. De ep L e arning for Signal and Informatio n Pr o c essing . NOW Publishers, 2013. [15] J.B. Krusk al. Three-w ay arra ys: Rank and uniqu eness of trilinear decomp ositions, with appli- cation to arithmetic complexit y and statistics. Line ar algebr a and its appl ic ations , 18(2):95– 138, 1977. [16] A. Bhask ara, M. Charik ar, and A. Vijay aragha v an. Uniqueness of T ensor Decomp ositio ns with Applications to Pol yn omia l Identifiabilit y. A rXiv 1304.8087 , Ap ril 2013. [17] T a o Jiang and Nic holas D S idiropoulos. Krusk al’s p ermutatio n lemma and the iden tification of candecomp/parafac and bilinear mo d els with constan t mo dulus constrain ts. Signal Pr o c essing, IEEE T r ansactions on , 52(9):2625 –2636, 2004. [18] Liev en De Lathau wer. A Link b et ween the Canonical Decomp osit ion in Multilinear Alge- bra and Simultaneous Matrix Diagonalizat ion. SIAM J. M atr ix Analysis and A p plic ations , 28(3): 642–666, 2006. [19] Alwin Stegeman, Jos M.F. T en Berge, and Liev en De Lathau wer. Su fficie nt conditions for uniqueness in candecomp/parafac and indscal with rand o m comp onen t matrices. Psychome- trika , 71(2):21 9–229, June 2006. [20] L. De Lathauw er, J . Castaing, and J.-F Cardoso. F ourth-order cumulan t-based blind iden ti- fication of underdetermined mixtures. IEEE T r an. on Si g na l Pr o c essing , 55:296 5–2973, June 2007. [21] Luca Ch ia ntini and Giorgio O ttavia ni. On generic identi fi a b ili ty of 3-tensors of small rank. SIAM Journal on Matrix A nalysis and Applic ations , 33(3):10 18–1037, 2012. 45 [22] Cristiano Bo cci, Luca Chianti n i, and Giorgio Otta viani. Refined metho ds for the iden tifiabilit y of tensors. arXiv pr eprint arXiv: 1303.6915 , 2013. [23] Luca Chian tini, Massimiliano Mella, and Giorgio Otta viani. One example of general uniden- tifiable tensors. arXiv pr eprint arXiv:1303.691 4 , 2013. [24] E.S. Allman, C . Matias, and J.A. Rho des. Id en tifiability of p aramet ers in laten t structure mo dels w it h man y observed v ariables. The Annals of Statistics , 37(6A):3099 –3132, 200 9. [25] Elizab et h S. Allman, John A. Rho des, and Amelia T a ylor. A semialgebraic description of the general mark ov mo del on phylo genetic trees. Arxiv pr eprint arXiv:1212.1200 , Dec. 201 2. [26] Na vin Goy al, Santo sh V empala, and Ying Xiao. F ourier p ca. ArXiv 1306.5 825 , 2013. [27] Joseph M Landsb erg. T ensors: Ge ometry and applic ations , vo lume 128. American Mathemat- ical So c., 2012 . [28] A. Anandkumar, D. Hsu, and S.M. Kak ade. A Metho d of Momen ts for Mixture Mo dels and Hidden Marko v Mo dels. In Pr o c. of Conf. on L e arning The ory , June 2012. [29] A. Anandku mar, D. P . F oster, D. Hsu , S. M. K ak ade, and Y. K. Liu. A Sp ectral Algorithm for Laten t Diric hlet Allocation. In P r o c. of N e ur al Information Pr o c essing (NIPS) , Dec. 2012. [30] A. Anand kumar, R. Ge, D. Hsu, and S . M. Kak ade. A T ensor Sp ectral App roac h to Learning Mixed Mem b ership C omm u nit y Mo dels. In Confer enc e on L e arning The ory (COL T) , Jun e 2013. [31] E. Mossel and S. Roch. Learning nonsingular p h ylogenies and h idden m a r k ov mo dels. The Anna ls of Applie d Pr ob ability , 16(2) :583–614, 2006. [32] J.T. Chang. F u ll reconstruction of marko v mo dels on ev olutionary trees: iden tifiabilit y and consistency . Mathematic al Bi oscienc es , 137(1):51 –73, 1996. [33] Y u v al Rabani, Leonard Sch u lman, and Chaitan ya Swam y . Learning mixtures of arbitrary distributions o ve r large discrete domains. arXiv pr eprint arXiv:1212.1527 , 2012. [34] Saneev Arora, Rong Ge, and Ankur Moitra. Learning topic mo dels—going b ey ond svd. In Symp osium on The ory of Computing , 2012. [35] Daniel A S pielman, Huan W ang, and J ohn W right. Exact reco v ery of sparsely-used dictionaries. In Pr o c. of Conf. on L e arning The ory , 2012. [36] Kenneth Kreutz-Delgado, Joseph F. Murray , Bhask ar D. Rao, Kjersti Engan, T e-W on Lee, and T errence J. S e jn o wski. Dictionary learning algorithms for sp ars e represen tation. Neur al Computation , 15:349–396 , F ebruary 2003. [37] B. Rao and K . K reutz-D elgado. An affin e s c aling method olo gy for b est b a sis selection. IEEE T r an. Signal Pr o c e ssing , 47:187–2 00, Jan u ary 1999 . [38] Nishan t A. Mehta and Alexander G. Gray . S parsit y-b a sed generalizat ion b ounds for predictiv e sparse co ding. In Pr o c. of the Intl. Conf. on Machine L e arning (ICML) , A tlant a, USA, June 2013. 46 [39] Andreas Maurer, Massimiliano P on til, and Bernardin o Romera-P aredes. Sp ars e cod ing for m ultitask and transfer learning. ArxXiv pr eprint , abs/1209.0738 , 2012. [40] Christopher J Hillar and F riedric h T Sommer. Ramsey theory rev eals the conditions when sparse co ding on sub sampled d ata is unique. arXiv pr eprint arXiv:1106.3616 , 2011 . [41] G.H. Golub and C.F. V an Loan. M atrix Computations . Th e Johns Hopkins Univ ersit y Press, Baltimore, Maryland, 2012. [42] XuanLong Nguy en. Poste r io r con traction of th e p opulation p olytop e in fi nite admixture mo d- els. arXiv pr eprint arXiv:1206.0068 , 2012. [43] Daniel A. S pielman, Huan W ang, and John W right. Exact reco ve r y of sparsely-used dictio- naries. ArxXiv pr eprint , abs/1206.5 882, 2012. [44] Nic holas D. Sidir o p oulos and Rasm us Bro. O n th e uniqueness of m ultilinear decomp osition of N-w a y arra ys. Journal of Chemometrics , 14(3):229–2 39, 2000. [45] V. Ch v´ atal. The tail of the hyp erge ometric d istribution. Discr ete Mathematics , 25(3):285 –287, 1979. [46] Matthew S k ala. Hyp ergeometric tail inequalities: ending the insanity . http://a nsuz.sooke.bc.c a /profe s sio n al/hyperge o metric.pdf . [47] Philip Hall. On representati ves of s u bsets. J. L ondon Math. So c. , 10(1):26– 30, 1935. 47
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment