Collective Mind: cleaning up the research and experimentation mess in computer engineering using crowdsourcing, big data and machine learning
Software and hardware co-design and optimization of HPC systems has become intolerably complex, ad-hoc, time consuming and error prone due to enormous number of available design and optimization choices, complex interactions between all software and …
Authors: Grigori Fursin (INRIA Saclay - Ile de France)
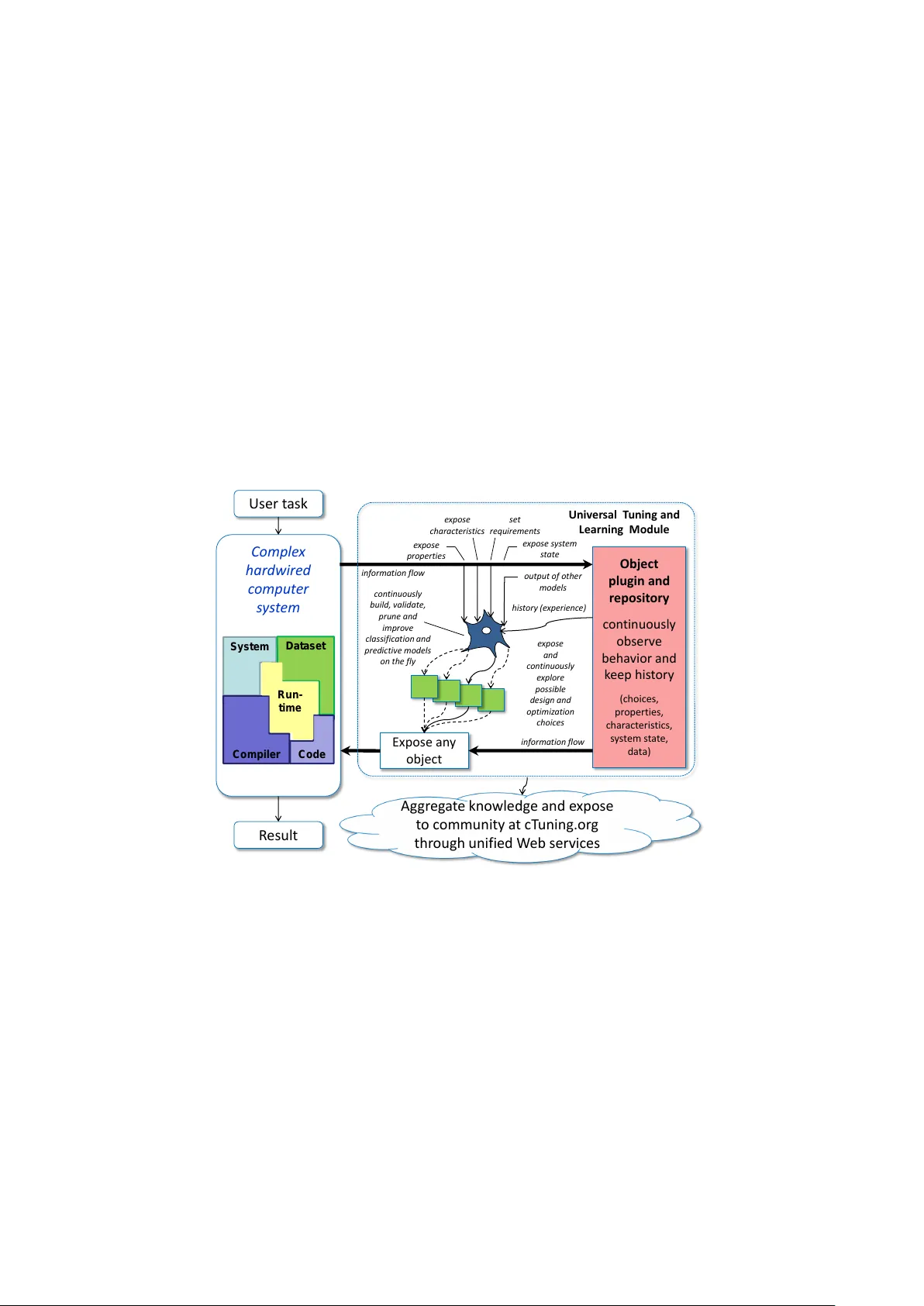
Collecti v e Mind: cleaning up the research and e xperimentation mess in computer engineering using cro wdsourcing, big data and machine learning Grigori Fursin INRIA, F r ance Grigori.Fursin@cT uning.org Abstract Software and hardware co-design and optimization of HPC systems has be- come intolerably complex, ad-hoc, time consuming and error prone due to enor- mous number of av ailable design and optimization choices, complex interactions between all software and hardware components, and multiple strict requirements placed on performance, power consumption, size, reliability and cost. W e present our nov el long-term holistic and practical solution to this problem based on customizable, plugin-based, schema-free, heterogeneous, open-source Collectiv e Mind repository and infrastructure with unified web interfaces and on- line advise system. This collaborativ e frame work distributes analysis and multi- objectiv e off-line and on-line auto-tuning of computer systems among many par- ticipants while utilizing any available smart phone, tablet, laptop, cluster or data center , and continuously observing, classifying and modeling their realistic beha v- ior . Any une xpected behavior is analyzed using shared data mining and predictive modeling plugins or exposed to the community at cTuning.or g for collaborativ e explanation, top-down complexity reduction, incremental problem decomposition and detection of correlating program, architecture or run-time properties (features). Gradually increasing optimization knowledge helps to continuously improve op- timization heuristics of any compiler , predict optimizations for ne w programs or suggest efficient run-time (online) tuning and adaptation strategies depending on end-user requirements. W e decided to share all our past research artifacts includ- ing hundreds of codelets, numerical applications, data sets, models, univ ersal ex- perimental analysis and auto-tuning pipelines, self-tuning machine learning based meta compiler , and unified statistical analysis and machine learning plugins in a public repository to initiate systematic, reproducible and collaborative research, dev elopment and experimentation with a new publication model where experi- ments and techniques are validated, rank ed and improved by the community . Keyw ords Collective Mind, cr owdtuning, cr owdsour cing auto-tuning and co-design, soft- war e and hardwar e co-design and co-optimization, on-line tuning and learning, systematic be- havior modeling, pr edictive modeling, data mining, machine learning, on-line advice system, metadata, top-down optimization, incremental pr oblem decomposition, decremental (differ en- tial) analysis, complexity r eduction, tuning dimension r eduction, customizable plugin-based in- frastructur e, public repository of knowledg e, big data pr ocessing and compaction, agile resear ch and development, cT uning.or g, c-mind.or g , systematic and r epr oducible r esearc h and experi- mentation, validation by community 1 1 Intr oduction, major challenges, and related work 1.1 Motivation Continuing innovation in science and technology is vital for our society and requires ever in- creasing computational resources. Howe ver , deli vering such resources particularly with exascale performance for HPC or ultra lo w po wer for embedded systems is becoming intolerably complex, costly and error prone due to limitations of av ailable technology , enormous number of available design and optimization choices, complex interactions between all software and hardware com- ponents, and growing number of incompatible tools and techniques with ad-hoc, intuition based heuristics. As a result, understanding and modeling of the overall relationship between end- user algorithms, applications, compiler optimizations, hardware designs, data sets and run-time behavior , essential for providing better solutions and computational resources, became simply infeasible as confirmed by numerous recent long-term international research visions about fu- ture computer systems [12, 9, 19, 32, 8, 7]. On the other hand, the research and development methodology for computer systems has hardly changed in the past decades: computer architec- ture is first designed and later compiler is being tuned and adapted to the new architecture using some ad-hoc benchmarks and heuristics. As a result, peak performance of the new systems is often achiev ed only for a few previously optimized and not necessarily representativ e bench- marks such as SPEC for desktops and serv ers or LINP A CK for T OP500 supercomputer ranking, while leaving most of the systems sev erely underperforming and wasting expensiv e resources and power . Automatic off-line and on-line performance tuning techniques were introduced nearly two decades ago in an attempt to solve some of the abo ve problems. These approaches treat computer systems as a black box and explore their optimization parameter space empirically , i.e. compil- ing and ex ecuting a user program multiple times with varying optimizations or designs (compiler flags and passes, fine-grain transformations, frequency adaptation, cache reconfiguration, paral- lelization, etc) to empirically find better solutions that improve ex ecution and compilation time, code size, power consumption and other characteristics [48, 39, 14, 17, 35, 26, 18, 37, 47, 44, 41, 42, 33]. Such techniques require little or no knowledge of the current platform and can adapt programs to any given architecture automatically . W ith time, auto-tuning has been accel- erated with various adaptive exploration techniques including genetic algorithms, hill-climbing and probabilistic focused search. Howe ver , the main disadv antage of these techniques is an ex- cessiv ely long exploration time of lar ge optimization spaces and lack of optimization kno wledge reuse among different programs, data sets and architectures. Moreover , all these exploration steps (compilation and ex ecution) must be performed with exactly the same setup by a giv en user including the same program, generated with the same compiler on the same architecture with the same data set, and repeated a large number of times to become statistically meaningful. Statistical analysis and machine learning hav e been introduced nearly a decade ago to speed up exploration and predict program and architecture behavior , optimizations or system configu- rations by automatically learning correlations between properties of multiple programs, data sets and architectures, av ailable optimizations or design choices, and observed characteristics [48, 39, 14, 17, 35, 26, 18, 37, 47, 44, 41, 42, 33, 46, 29, 30]. Often used by non-specialists, these ap- proaches mainly demonstrate a potential to predict optimizations or adaptation scenario in some limited cases, b ut they do not include deep analysis about machine learning algorithms, their se- lection and scalability for ev er gro wing training sets, optimization choices and a vailable features which are often problem dependent, are the major research challenges in the field of machine learning for sev eral decades, and far from being solved. W e believ e that many of the above challenges and pitfalls are caused by the lack of a com- mon experimental methodology , lack of interdisciplinary background, and lack of unified mech- anisms for knowledge building and exchange apart from numerous similar publications where reproducibility and statistical meaningfulness of results as well as sharing of data and tools is of- ten not ev en considered in contrast with other sciences including physics, biology and artificial intelligence. In f act, it is often impossible due to a lack of common and unified repositories, tools 2 and data sets. At the same time, there is a vicious circle since initiati ves to de velop common tools and repositories to unify , systematize, share knowledge (data sets, tools, benchmarks, statistics, models) and make it widely a vailable to the research and teaching community are practically not funded or re warded academically where a number of publications often matter more than the re- producibility and statistical quality of the research results. As a consequence, students, scientists and engineers are forced to resort to some intuitiv e, non-systematic, non-rigorous and error-prone techniques combined with unnecessary repetition of multiple experiments using ad-hoc tools, benchmarks and data sets. Furthermore, we witness slo wed do wn innov ation, dramatic increase in development costs and time-to-market for the new embedded and HPC systems, enormous waste of e xpensiv e computing resources and ener gy , and diminishing attracti veness of computer engineering often seen as ”hacking” rather than systematic science. 2 Collectiv e Mind approach 2.1 Back to basics W e would like to start with the formalization of the eventual needs of end-users and system dev elopers or providers. End-users generally need to perform some tasks (playing games on a console, watching videos on mobile or tablet, surfing W eb, modeling a new critical vaccine on a supercomputer or predicting a new crash of financial markets using cloud services) either as fast as possible or with some real-time constraints while minimizing or amortizing all associated costs including po wer consumption, soft and hard errors, and de vice or service price. Therefore, end-users or adaptiv e software require a function that can suggest most optimal design or opti- mization choices c based on properties of their tasks and data sets p , set of requirements r , as well as current state of a used computing system s : c = F ( p , r , s ) This function is associated with another one representing beha vior of a user task running on a giv en system depending on properties and choices: b = B ( p , c , s ) This function is of particular importance for hardware and software designers that need to continuously provide and improve choices (solutions) for a broad range of user tasks, data sets and requirements while trying to improve own R OI and reduce time to market. In order to find optimal choices, it should be minimized in presence of possible end-user requirements (con- straints). Howe ver , the fundamental problem is that nowadays this function is highly non-linear with such a multi-dimensional discrete and continuous parameter space which is not anymore possible to model analytically or e valuate empirically using exhausti ve search [10, 48, 21]. For example, b is a behavior vector that can now include execution time, power consumption, com- pilation time, code size, device cost, and any other important characteristic; p is a vector of properties of a task and a system that can include semantic program features [40, 45, 11, 25], dataset properties, hardware counters [15, 34], system configuration, and run-time en vironment parameters among many others; c represents available design and optimization choices includ- ing algorithm selection, compiler and its optimizations, number of threads, scheduling, processor ISA, cache sizes, memory and interconnect bandwidth, frequency , etc; and finally s represents the state of the system during parallel execution of other programs, system or core frequency , cache contentions and so on. 2.2 Interdisciplinary collaborative methodology Current multiple research projects mainly show that it is possible to use some off-the-shelf on- line or of f-line adapti ve exploration (sampling) algorithms combined with some existing models 3 to approximate above function and predict behavior , design and optimization choices for 70- 90% cases but in a very limited experimental setup. In contrast, our ambitious long-term goal is to understand how to continuously build, enhance, systematize and optimize hybrid models that can explain and predict all possible behaviors and choices while selecting minimal set of representativ e properties, benchmarks and data sets for predicti ve modeling [38]. W e reuse our interdisciplinary knowledge in physics, quantum electronics and machine learning to build a new methodology that can effecti vely deal with rising complexity of computer systems through gradual and continuous top-down problem decomposition, analysis and learning. W e also de- velop a modular infrastructure and repository that allo ws to easily interconnect v arious av ailable tools and techniques to distrib ute adapti ve probabilistic exploration, analysis and optimization of computer systems among man y users [3, 1] while exposing une xpected or unexplained beha vior to the community with interdisciplinary backgrounds particularly in machine learning and data mining through unified web interfaces for collaborati ve solving and systematization. 2.3 Collective Mind infrastructur e and repository Comple x hardwi red c omput er s ys t em Us er t ask R esul t Expose an y obje c t in f o rm a t io n f lo w e x p o se s y s t em s t a t e Objec t p lu gin and r e p os it ory c on ti nu ous l y ob se r v e be ha vior and k ee p his t or y ( c h oi c es, p r opert ies, c h ar ac t e ris tic s, s y s t em s t a t e, d a t a) h is t o r y ( e x p erien c e) in f o rm a t io n f lo w e x p o se p ro p ert ies e x p o se c h a ra c t eris t ic s c o n t in u o u sly b u ild , v a lid a t e, p ru n e a n d imp ro v e c la ssif ic a t io n a n d p red ic t iv e mo d els o n t h e f ly e x p o se and c o n t in u o u sly e x p lo re p o ssible d es ig n a n d o p t imiz a t io n c h o ic es se t req u ir eme n t s Univ er sal T u n ing and Learn ing Modu le System D ataset Code C o mp i l er Run - ti me Ag gr eg a t e kno wl edge and e xpose t o c omm un ity a t c T un ing.or g thr ough unifie d W eb se r v ices o u t p u t o f o t h er mo d els Figure 1: Gradual decomposition, parameterization, observation, tuning and learning of complex har dwired computer systems. Collectiv e Mind framework and repository (cM for short) enables continuous, collabora- tiv e and agile top-down decomposition of the whole complex hardwired computer systems into unified and connected s ubcomponents (modules) with gradually e xposed v arious characteristics, tuning choices (optimizations), properties and system state as conceptually shown in Figure 1. At a coarse-grain lev el, modules serve as wrappers around existing command line tools such as compilers, source-to-source transformers, code launchers, profilers, among many others. Such modules are written in python for producti vity and portability reasons, and can be launched from command line in a unified way using Collecti ve Mind front-end cm as following: cm h module name or UID i h command i h unified meta information i – h original cmd i 4 These modules enable transparent monitoring of information flo w , exposure of various char- acteristics and properties in a unified way (meta information), and exploration or prediction of design and optimization choices, while helping researchers to abstract their experimental setups from constant changes in the system. Internally , modules can call each other using just one uni- fied cM access function which uses a schema-free easily extensible nested dictionary that can be directly serialized to JSON as both input and output as following: r=cm_kernel.access({’cm_run_module_uoa’:, ’cm_action’:, parameters}) if r[’cm_return’]>0: print ’Error:’+r[’cm_error’] exit(r[’cm_return’]) where command in each module is directly associated with some function. Since JSON can also be easily transmitted through W eb using standard http post mechanisms, we implemented a simple cM web server that can be used for P2P communication or centralized repository during crowdsourcing and possibly multi-agent based on-line learning and tuning. Each module has an associated storage that can preserve any collections of files (whole benchmark, data set, tool, trace, model, etc) and their meta-description in a JSON file. Thus each module can also be used for any data abstraction and includes various common commands standard to an y repository such as load, save , list, sear ch, etc . W e use our o wn simple directory- based format as following: .cmr// where .cmr is an acronym for Collecti ve Mind Repository . In contrast with using SQL-based database in the first cTuning version that was fast but very complex for data sharing or exten- sions of structure and relations, a new open format allows users to be database and technology- independent with the possibility to modify , add, delete or share entries and whole repositories using standard OS functions and tools like SVN, GIT or Mercury , or easily con vert them to any other format or database when necessary . Furthermore, cM can transparently use open source JSON-based indexing tools such as ElasticSearch [4] to enable fast and powerful queries over schema-free meta information. Now , any research artifact will not be lost and can now be refer- enced and directly found using the so called cID (Collectiv e ID) of the format: h module name or UID i : h data entry or UID i . Such infrastructure allows researchers and engineers to connect existing or new modules into experimental pipelines like ”research LEGO” with exposed characteristics, properties, con- straints and states to quickly and collaboratively prototype and crowdsource their ideas or pro- duction scenarios such as traditional adaptiv e exploration of large experimental spaces, multi- objectiv e program and architecture optimization or continuous on-line learning and run-time adaptation while easily utilizing all available benchmarks, data sets, tools and models provided by the community . Additionally , single and unified access function enables transparent repro- ducibility and validation of any experiment by preserving input and output dictionaries for a giv en e xperimental pipeline module. Furthermore, we decided to keep all modules inside reposi- tory thus substituting various ad-hoc scripts and tools. W ith an additional cM possibility to install various packages and their dependencies automatically (compilers, libraries, profilers, etc) from the repository or keep all produced binaries in the repository , researchers now have an opportu- nity to preserv e and share the whole experimental setup in a priv ate or public repository possibly with a publication. W e started collaborative and gradual decomposition of large, coarse-grain components into simpler sub-modules including decomposition of programs into kernels or codelets [50] as shown in Figure 2 to keep complexity under control and possibly use multi-agent based or brain inspired modeling and adaptation of the behavior of the whole computer system locally or during P2P 5 Gradually expose some characteristics Gradually expose some choices Algorithm selection (time) productivity, variable- accuracy, complexity … Language, MPI, OpenMP, TBB, MapReduce … Compile Program time … compiler flags; pr agmas … Code analysis & Transformations time; memory usage; code size … transformation ordering; polyhedral transformations; transformation parameters; instruction ordering … Process Thread Function Codelet Loop Instruction Run code Run-time environment time; power consumption … pinning/scheduling … System cost; size … CPU/GPU; frequency; memory hierarchy … Data set size; values; description … precision … Run-time analysis time; precision … hardware counters; power meters … Run-time state processor state; cache state … helper threads; hardware counters … Analyze profile time; size … instrumentation; profiling … Figure 2: Gradual top-down decomposition of computer systems to balance coarse- grain vs. fine-grain analysis and tuning depending on user r equir ements and expected R OI crowdsourcing. Such decomposition also allows community to first learn and optimize coarse- grain behavior , and later add more fine-grain effects depending on user requirements, time con- straints and expected return on inv estment (ROI) similar to existing analysis methodologies in physics, electronics or finances. 2.4 Data and parameter description and classification In traditional software engineering, all softw are components and their API are usually defined at the beginning of the project to a void modifications later . Howe ver , in our case, due to ev er e volv- ing tools, APIs and data formats, we decided to use agile methodology together with type-free inputs and outputs for all functions focusing on quick and simple prototyping of research ideas. Only when modules and their inputs and outputs become mature or validated, then (meta)data and interface are defined, systematized and classified. Howe ver , they can still be extended and reclassified at any time later . For e xample, any key in an input or output dictionary of a giv en function and a gi ven module can be described as ”choice”, ”(statistical) characteristic”, ”property” and ”state”, besides a few internal types including ”module UID” or ”data UID” or ”class UID” to provide direct or seman- tic class-based connections between data and modules. Parameters can be discrete or continuous with a given range to enable automatic exploration. Thus, we can easily describe compiler opti- mizations; dataset properties such as image or matrix size, architecture properties such as cache size or frequency , represent execution time, power consumption, code size, hardware counters; categorize benchmarks and codelets in terms of reaction to optimizations or as CPU or memory bound, and so on. 6 ( a ) (b ) Figure 3: Event and plugin-based OpenME interface to ”open up” rigid tools (a) and applications (b) for external fine-grain analysis, tuning and adaptation, and connect them to cM 2.5 OpenME interface for fine-grain analysis, tuning and adapta- tion Most of current compilers, applications and run-time systems are not prepared for easy and straightforward fine-grain analysis and tuning due to associated software engineering complex- ity , sometimes proprietary internals, possible compile or run-time ov erheads, and still occasional disbeliefs in effecti ve run-time adaptation. Some extremes included either fixing, hardwiring and hiding all optimization heuristics from end-users or oppositely exposing all possible opti- mizations, scheduling parameters, hardware counters, etc. Some other available mechanisms to control fine-grain compiler optimization through pragmas can also be v ery misleading since it is not always easy or possible to v alidate whether optimization was actually performed or not. Instead of dev eloping yet another source-to-source tools or binary translators and analyzers that alw ays require enormous resources and ef fort often to reimplement functionality of e xisting and ev olving compilers and support evolving architectures, we dev eloped a simple ev ent and plugin-based interface called Interactiv e Compilation Interface (ICI) to ”open up” previously hardwired tools for external analysis and tuning. ICI was written in plain C originally for Open64 and later for GCC, requires minimal instrumentation of a compiler and helps to e xpose or modify only a subset of program properties or compiler optimization decisions through external dynamic plugins based on researcher needs and usage scenario. This interface can easily evolv e with the compiler itself, has been successfully used in the MILEPOST project to build machine-learning self-tuning compiler [25], and is now a vailable in mainline GCC. Based on this experience, we dev eloped a new version of this interface (OpenME) [3] that is used to ”open up” any available tool such as GCC, LL VM, Open64, architecture simulator , etc in a unified way as shown in Figure 3(a), or any application for example to train predic- tiv e scheduler on heterogeneous many-core architectures [34] as shown in Figure 3(b). It can be connected to cM to monitor application behavior in realistic en vironments or utilize on-line learning modules to quickly prototype research ideas when developing self-tuning applications that can automatically adapt to different datasets, underlying architectures particularly in virtual and cloud en vironments, or react to changes in en vironment and run-time behavior . Since there are some natural ov erheads associated with ev ent in vocation, users can substitute them with hard- wired fast calls after research idea has been validated. W e are developing associated Alchemist plugin [3] for GCC to extract code structure, patterns and various properties to substitute and unify outdated MILEPOST GCC plugin [5] for machine-learning based meta compilers. 7 3 P ossible usage scenarios W e decided first to re-implement various analysis, tuning and learning scenarios from our past research as cM modules combined into univ ersal compilation and ex ecution pipeline to giv e the community a common reproducible base for further research and experimentation. Furthermore, rather than just showing speedups, our main focus is also to use our distributed framew ork sim- ilar to web crawlers to search for unusual or unexpected behavior that can be exposed to the community for further analysis, advise, ranking, commenting, and ev entual improvement of cM to take such beha vior into account. 3.1 Collaborative obser vation and exploration E x e c u ti o n ti me ( s e c . ) Co d e s i z e ( b yte s ) ( a ) (b ) Figure 4: (a) execution time variation of a susan corner codelet with the same dataset on Samsung Galaxy Y for 2 fr equency states; (b) variation in execution time vs code size during GCC 4.7.2 compiler flag auto-tuning for the same codelet on the same mobile phone where yellow rhombus r epr esents -O3 and red cir cles show P areto fr ontier - all data and modules ar e available for r epr oduction at c-mind.or g/repo Having common and portable framew ork with exposed characteristics, properties, choices and state in a unified way allo ws us to collaborativ ely observe, optimize, learn and predict pro- gram behavior on any existing system including mobile phones, tablets, desktops, serv ers, cluster or cloud nodes in realistic environment transparently and on the fly instead of using a few ad- hoc and often non-representati ve benchmarks, data sets and platforms. Furthermore, it elegantly solves a common problem of a lack of experimental data to be able to properly apply machine learning techniques and make statistically meaningful assumptions that slowed down many re- cent projects on applying machine learning to compilation and architecture. For example, Figure 4(a) shows variation of an ex ecution time of an image corner detec- tion codelet with the same dataset (image) on a Samsung Galaxy Y mobile phone with ARM processor using modified Collectiv e Mind Node [2]. Our cM R-based statistical module reports that distribution is not normal that usually results in discarding this experiment in most of the research projects. Ho wever , by e xposing and analyzing this relati vely simple case, we found that processor frequency was responsible for this behavior thus adding it as a new parameter to the ”state” vector of our experimental pipeline to effectiv ely separate such cases. Furthermore, we can use minimal ex ecution time for SW/HW co-design as the best what a gi ven code can achiev e on a given architecture, or expected execution time for realistic end-user program optimization and adaptation. 3.2 Adaptive exploration (sampling) and dimensionality reduction Now , we can easily distribute exploration of any set of choices vs multiple properties and char- acteristics in a computer system among man y users. For e xample, Figure 4(b) sho ws random ex- ploration of Sourcery GCC compiler flags v ersus ex ecution time and binary size on off-the-shelf Samsung mobile phones with ARMv7 processor for image processing codelet while Figure 5 8 shows exploration of dataset parameters for LU-decomposition numerical kernel on GRID5000 machines with Intel Core2 and SandyBridge processors. Since all characteristics are usually dependent, we can apply cM plugin (module) to detect univ ersal Paretto fronter on the fly in multi-dimensional space (currently not optimal) during on-line exploration and filter all other cases. A user can choose to explore any other av ailable characteristic in a similar way such as power consumption, compilation time, etc depending on usage scenario and requirements. In order to speed up random exploration further , we use probabilistic focused search similar to ANO V A and PCA described in [20, 30] that can suggest most important tuning/analysis dimen- sions with likely highest speedup or unusual behavior , and guide further finer-grain exploration in those areas. Collective exploration is critical to build and update a realistic training set for machine-learning based self-tuning meta-compiler cTuning-CC to automatically and continu- ously improve default optimization heuristic of GCC, LL VM, ICC, Open64 or any other com- piler connected to cM [25, 6]. 3.3 On-line learning 0 1000 2000 3000 4000 5000 Dataset size N 0 2 4 6 8 10 12 14 16 CPI Powered by Collective Mind A B C D E F X Figure 5: On-line learning (predictive modeling) of a CPI behavior of ludcmp on 2 differ ent platforms (Intel Core2 vs Intel i5) vs matrix size N and cac he size Crowdtuning has a side effect - generation and processing of huge amount of data that is well-known in other fields as a ”big data” problem. Howe ver , in our past work on online tuning, we showed that it is possible not only to learn behavior and find correlations between character- istics, properties and choices to build models of beha vior on the fly at each client or program, but also to ef fectively compact experimental data keeping only representativ e or unexpected points, and minimize communications between cM nodes thus making cM a giant, distributed learning network to some extent similar to brain [24, 38, 30]. Figure 5 demonstrates how on-line learning is performed in our frame work using LU-decomposition benchmark as an example, CPI characteristic, and 2 Intel-based platforms (Intel Core2 Centrino T7500 Merom 2.2GHz L1=32KB 8-way set-associative, L2=4MB 16-way set associative - red dots vs. Intel Core i5 2540M 2.6GHz Sandy Bridge L1=32KB 8-way set associati ve, L2=256KB 8-way set associativ e, L3=3MB 12-way set associative - blue dots). At the beginning, our sys- tem does not have any kno wledge about behavior of this (or any other) benchmark, so it simply observes and stores av ailable characteristics while collecting as many properties of the whole system as possible (exposed by a researcher or user). At each step, system processes all histor- ical observations using various av ailable predictiv e models such as SVM or MARS in order to find correlations between properties and characteristics. In our example, after sufficient amount 9 of observations, system can build a model that automatically correlated data set size N, cache size and CPI (in our case combination of linear models B-F that reflect memory hierarchy of a particular system) with nearly 100% prediction. Ho wev er, system always continue observing behavior to continuously v alidate it against existing model in order to detect discrepancies (f ailed predictions). In our case, the system e ventually detects outliers A that are due to cache alignment problems. Since off-the-shelf models rarely handle such cases, our frame work allo ws to e xclude such cases from modeling and expose them to the community through the unified W eb services to reproduce and explain this behavior , find relev ant features and improve or optimize existing models. In our case, we managed to fit a hybrid rule-based model that first v alidates cases where data set size is a power of 2, otherwise it uses linear models as functions of a data set and cache size. Systematic characterization (modeling) of a program behavior across many systems and data sets allows researchers or end-users to focus further optimizations (tuning) only on representa- tiv e areas with distinct behavior while collaboratively building an on-line advice system. In the abov e e xample, we e valuated and prepared the follo wing advices for optimizations: points A can be optimized using array padding; area B can profit from parallelization and traditional compiler optimizations tar geting ILP; areas C-E can benefit from loop tiling; area F and points A can ben- efit from reduced processor frequency to reduce po wer consumption using cM online adaptation plugin. Since auto-tuning is continuously performed, we will release final optimization details at cM liv e repository [1] during symposium. Ma chin e l earnin g t ec hni ques t o fi nd mappi ng be t w ee n di f f er en t r un - t i me c on t e x t s an d r epr es en t a ti v e v er si ons Ext r act da t ase t f ea t ur es Moni t or r un - t i me beha vior or ar chite ctur al change s (in vi r t ua l , r ec on f i gu r ab l e or he t er og eneous en vir onme n t s) usi ng t i me r s or per f or m ance c oun t er s Sele ction ( ad a p tio n) plug in op timiz e d ( c ompa ct ed ) f or lo w run - time ov erhe a d … M in imal re p re se n t a tive se t o f version s f o r the f o llo win g o p tim iz a tio n c a se s t o m in imiz e e x e cu tio n tim e , p o wer c o n su m p tio n a n d c o d e - siz e a cro ss a ll a vai la b le d a t a se ts: op timiz a tion s f or di f f er en t da t ase ts op timiz a tion s/ c ompil a tio n f or di f f er en t ar ch it ec tur es (h e t er og en eou s or r ec on fig ur ab le pr oc essor s with di f f er en t IS A suc h as GPGPU , C ELL , e t c or with the same IS A with e xt en sions suc h as 3d no w , S S E, e t c, or as ymm e tric multi - c or e ar ch it ec tur es) op timiz a tion s f or di f f er en t pr ogr am ph ases, di f f er en t ru n - time en vi r on men t beh a vior , or dif f er en t fr equ enc y St a tic al ly - c o mp il ed adap tiv e b inaries and li b r arie s Cr o w dsour cini g au t o - t uni ng wit h mult i pl e da t ase t s P lu gi n fun cti on V er si on N P lug in fun c tion V er sio n 2 P lug in fun c tion V er sio n 1 Or i gi na l hot fu ncti on Ad apt ive prog ram s throug h openME interface Figure 6: Systematizing and unifying split (staged) compilation for statically built adaptive applications using cr owdtuning and machine learning Gradually increasing and systematized knowledge in the repository in form of models can now be used to detect and characterize an abnormal program or system behavior , suggest future architectural improvements, or predict most profitable program optimizations, run-time adap- tation scenarios and architecture configurations depending on user requirements. For example, this knowledge can be effecitv ely used for split (staged) tuning to build static multi-versioning applications with cM plugins for phase-based adaptation [24] or predicti ve scheduling [34] in heterogeneous systems that can automatically adjust their behavior at run-time to varying data sets, en vironments, architectures and system state by selecting appropriate versions or changing 10 frequency to maximize performance and minimize po wer consumption, while av oiding complex recompilation framew orks as conceptually shown in Figure 6. 3.4 Benchmark automatic generation and decremental analysis Projects on applying machine learning to auto-tuning suf fer from yet another well-known prob- lem: lack of benchmarks. Our experience with hundreds of codelets and thousands of data sets [23, 16, 25] sho ws that they are still not enough to co ver all possible properties and behavior of computer systems. Generating numerous synthetic benchmarks and data sets is theoretically possible but will result in additional e xplosion in analysis and tuning dimensions. Instead, we use existing benchmarks, codelets and even data sets as templates, and utilize Alchemist plugin [3] for GCC to randomly or incrementally modify them by removing, modifying or adding various instructions, basic blocks, loops, and thus generating. Naturally , we ignore crashing variants of the code and continue evolving only the working ones. Importantly , we use this approach not only to extend realistic training sets, but also to gradually identify various behavior anomalies and detect code properties to explain these anomalies and improve predicting modeling without any need for slow and possibly imprecise system/architecture simulator or numerous and some- times misleading hardware counters as originally presented in [27, 21]. F or example, we can scalarize memory accesses to characterize code and data set as CPU or memory bound [21] (line X in Figure 5 sho ws ideal codelet beha vior when all floating point memory accesses are NOPed). Additionally , we use Alchemist plugin to extract code structure, patterns and other properties to improv e our cTuning CC machine-learning based meta compiler connected to GCC, LL VM, Open64, Intel and Microsoft compilers, and to guide SW/HW co-design. 4 Conclusions and futur e work W ith the continuously rising number of workshops, conferences, journals, symposiums, consor- tiums, networks of excellence, publications, tools and experimental data, and at the same time de- creasing number of fundamentally new ideas and reproducible research in computer engineering, we strongly believ e that the only way forward now is to start collaborativ e systematization and unification of av ailable knowledge about design and optimization of computer systems. Ho w- ev er , unlike some existing projects that mainly suggest or attempt to share ra w experimental data and related tools, and somehow validate results by the community , or redesign the whole soft- ware and hardware stack from scratch, we use our interdisciplinary background and experience to dev elop the first to our knowledge integrated, extensible and collaborative infrastructure and repository (Collecti ve Mind) that can represent, preserv e and connect directly or semantically all research artifacts including data, ex ecutable code and interfaces in a unified way . W e hope that our collaborative, ev olutionary and agile methodology , and extensible plugin- based Lego-like framework can help to address current fundamental challenges in computer engineering while bringing together interdisciplinary communities similar to W ikipedia to con- tinuously validate, systematize and improve collecti ve knowledge about designing and optimiz- ing whole computer systems, and e xtrapolate it to build faster , more po wer efficient, reliable and adaptiv e devices and software. W e hope that community will continue de veloping more plugins (modules) to plug various third-party tools including T A U [43], Periscope [13], Scalasca [31], In- tel vTune and many others to cM, or continue gradual decomposition of programs into codelets and complex tools into simpler connected self-tuning modules while crowdsourcing learning, tuning and classifying of their behavior . W e started building a large public repository of realis- tic behavior of multiple programs in realistic en vironments with realistic data sets (”big data”) that should allow the community to quickly reproduce and validate existing results, and focus their effort on dev eloping novel tuning techniques combined with data mining, classification and predictiv e modeling rather than wasting time on building individual experimental setups. It can also be used to address the challenge of collaboratively finding minimal representative set of benchmarks, codelets and datasets covering behavior of most of existing computer sys- 11 tems, detecting correlations in a collected data together with combinations of relev ant properties (features), pruning irrelev ant ones, systematizing and compacting existing experimental data, removing or exposing noisy or wrong experimental results. It can also be effecti vely used to validate and compact existing models including roofline [49] or capacity [36] ones, and adap- tation techniques including multi-agent based using cM P2P communication, classify programs by similarities in models, by reactions to optimizations [30] and to semantically non-equiv alent changes [28], or collaborativ ely develop and optimize new complex hybrid predictiv e models that from our past practical experience can not yet be fully automated thus using data mining and machine learning as a helper rather than panacea at least at this stage. Beta proof-of-concept version of a presented infrastructure and its documentation is avail- able for do wnload at [3], while pilot Collecti ve Mind repository is no w li ve at c-mind.or g/r epo [1] and currently being populated with our past research artifacts including hundreds of codelets and benchmarks [25], thousands of data sets [23, 16], univ ersal compilation and execution pipeline with adaptive exploration (tuning), dimension reduction and statistical analysis modules, and classical of f-the-shelf or hybrid predicti ve models. Importantly , presented concepts ha ve already been successfully validated in sev eral academic and industrial projects with IBM, ARC (Syn- opsys), CAPS, CEA and Intel, and we gradually release all our experimental data from these projects including unexplained beha vior of computer systems and misbehaving models. Finally , the example of a Collective Mind Node to crowdsource auto-tuning and learning using Android mobile phones and tables is av ailable at Google Play [2]. W e hope that our approach will help to shift current focus from publishing only good ex- perimental results or speedups, to sharing all research artifacts, validating past techniques, and exposing unexplained behavior or encountered problems to the interdisciplinary community for reproducibility and collaborati ve solving and ranking. W e also hope that Collecti ve Mind frame- work will be of help to a broad range of researchers e ven outside of computer engineering not to drawn in their e xperimentation while processing, systematizing, and sharing their scientific data, code and models. Finally , we hope that Collective Mind methodology will help to restore the attractiv eness of computer engineering making it a more systematic and rigorous discipline [22]. Acknowledgments Grigori Fursin was funded by EU HiPEAC postdoctoral fellowship (2005-2006) and by the EU MILEPOST project (2007-2010) where he originally dev eloped and applied his statistical plugin- based crowdtuning technology to enable realistic and on-line tuning (training) of a machine- learning based meta-compiler cTuning CC together with MILEPOST GCC, and later by French Intel/CEA Exascale Lab (2010-2011) where he extended this concept and de veloped customized codelet repository and auto-tuning infrastructure for software and hardware co-design and co- optimization of Exascale systems together with his team (Y uriy Kashniko v , Franck T albart, and Pablo Oli veira). Grigori is grateful to Francois Bodin and CAPS Entreprise for sharing codelets from the MILEPOST project and for providing an access to the latest Codelet Finder tool, to David Kuck and David W ong from Intel Illinois, and Davide del V ento from NCAR for interest- ing discussions and feedback during dev elopment of cTuning technology . Grigori is also very thankful to cT uning and HiPEAC communities as well as his colleagues from ARM and STMi- croelectronics for motiv ation, many interesting discussions and feedback during dev elopment of Collective Mind repository and infrastructure presented in this paper . Finally he would like to thank GRID5000 project and community for providing an access to powerful computational resources. Refer ences [1] Collectiv e Mind Liv e Repo: public repository of kno wledge about design and optimization of computer systems. http://c-mind.org/repo. 12 [2] Collectiv e Mind Node: Android application connected to Collec- tiv e Mind repository to crowdsource characterization and optimiza- tion of computer systems using off-the-shelf mobile phones and tablets. https://play .google.com/store/apps/details?id=com.collective mind.node. [3] Collectiv e Mind: open-source plugin-based infrastructure and repository for systematic and collaborativ e research, experimentation and management of large scientific data. http://cT uning.org/tools/cm. [4] ElasticSearch: open source distributed real time search and analytics. http://www .elasticsearch.org. [5] MILEPOST GCC: public collaborative R&D website. http://cTuning.org/ milepost- gcc . [6] MILEPOST project archive (MachIne Learning for Embedded PrOgramS opTimization). http://cTuning.org/project- milepost . [7] PRA CE: partnership for advanced computing in europe. http://www .prace-project.eu. [8] Ubiquitous high performance computing (uhpc). T echnical Report D ARP A-BAA-10-37, USA, 2010. [9] The HiPEA C vision on high-performance and embedded architecture and compilation (2012-2020). http://www .hipeac.net/roadmap, 2012. [10] B. Aarts, M. Barreteau, F . Bodin, P . Brinkhaus, Z. Chamski, H.-P . Charles, C. Eisen- beis, J. Gurd, J. Hoogerbrugge, P . Hu, W . Jalby , P . Knijnenbur g, M. O’Boyle, E. Ro- hou, R. Sakellariou, H. Schepers, A. Seznec, E. St ¨ ohr , M. V erhoeven, and H. Wijshof f. OCEANS: Optimizing compilers for embedded applications. In Pr oc. Eur o-P ar 97 , vol- ume 1300 of Lectur e Notes in Computer Science , pages 1351–1356, 1997. [11] F . Agakov , E. Bonilla, J.Cavazos, B.Franke, G. Fursin, M. O’Boyle, J. Thomson, M. T ou- ssaint, and C. Williams. Using machine learning to focus iterativ e optimization. In Pro- ceedings of the International Symposium on Code Generation and Optimization (CGO) , 2006. [12] K. Asano vic, R. Bodik, B. C. Catanzaro, J. J. Gebis, P . Husbands, K. Keutzer , D. A. Patter - son, W . L. Plishker , J. Shalf, S. W . W illiams, and K. A. Y elick. The landscape of parallel computing research: a vie w from Berkeley . T echnical Report UCB/EECS-2006-183, Elec- trical Engineering and Computer Sciences, Uni versity of California at Berkele y , Dec. 2006. [13] S. Benedict, V . Petkov , and M. Gerndt. Periscope: An online-based distributed performance analysis tool. pages 1–16, 2010. [14] F . Bodin, T . Kisuki, P . Knijnenbur g, M. O’Boyle, and E. Rohou. Iterativ e compilation in a non-linear optimisation space. In Pr oceedings of the W orkshop on Pr ofile and F eedback Dir ected Compilation , 1998. [15] J. Cav azos, G. Fursin, F . Agakov , E. Bonilla, M. O’Boyle, and O. T emam. Rapidly se- lecting good compiler optimizations using performance counters. In Pr oceedings of the International Symposium on Code Generation and Optimization (CGO) , March 2007. [16] Y . Chen, L. Eeckhout, G. Fursin, L. Peng, O. T emam, and C. W u. Evaluating iterative optimization across 1000 data sets. In In Pr oceedings of the ACM SIGPLAN Conference on Pr ogramming Langua ge Design and Implementation (PLDI , 2010. [17] K. Cooper , P . Schielke, and D. Subramanian. Optimizing for reduced code space using genetic algorithms. In Pr oceedings of the Confer ence on Langua ges, Compilers, and T ools for Embedded Systems (LCTES) , pages 1–9, 1999. [18] K. Cooper , D. Subramanian, and L. T orczon. Adaptive optimizing compilers for the 21st century . Journal of Super computing , 23(1), 2002. [19] J. Dongarra et.al. The international exascale software project roadmap. Int. J. High P er- form. Comput. Appl. , 25(1):3–60, Feb . 2011. 13 [20] B. Frank e, M. O’Boyle, J. Thomson, and G. Fursin. Probabilistic source-lev el optimisation of embedded programs. In Proceedings of the Confer ence on Languages, Compilers, and T ools for Embedded Systems (LCTES) , 2005. [21] G. Fursin. Iterative Compilation and P erformance Prediction for Numerical Applications . PhD thesis, Univ ersity of Edinbur gh, United Kingdom, 2004. [22] G. Fursin. HiPEAC thematic session at ACM FCRC’13: Making computer engineering a science. http://www .hipeac.net/thematic-session/making-computer-engineering-science, 2013. [23] G. Fursin, J. Cav azos, M. O’Boyle, and O. T emam. MiDataSets: Creating the conditions for a more realistic ev aluation of iterati ve optimization. In Pr oceedings of the International Confer ence on High P erformance Embedded Arc hitectur es & Compilers (HiPEAC 2007) , January 2007. [24] G. Fursin, A. Cohen, M. O’Bo yle, and O. T emam. A practical method for quickly e valuat- ing program optimizations. In Pr oceedings of the International Conference on High P er- formance Embedded Ar chitectur es & Compilers (HiPEAC 2005) , pages 29–46, Nov ember 2005. [25] G. Fursin, Y . Kashnikov , A. W . Memon, Z. Chamski, O. T emam, M. Namolaru, E. Y om- T ov , B. Mendelson, A. Zaks, E. Courtois, F . Bodin, P . Barnard, E. Ashton, E. Bonilla, J. Thomson, C. Williams, and M. F . P . OBoyle. Milepost gcc: Machine learning enabled self-tuning compiler . International Journal of P arallel Pro gramming , 39:296–327, 2011. 10.1007/s10766-010-0161-2. [26] G. Fursin, M. O’Boyle, and P . Knijnenbur g. Evaluating iterativ e compilation. In Proceed- ings of the W orkshop on Languages and Compilers for P arallel Computers (LCPC) , pages 305–315, 2002. [27] G. Fursin, M. O’Bo yle, O. T emam, and G. W atts. Fast and accurate method for determining a lower bound on ex ecution time. Concurr ency: Practice and Experience , 16(2-3):271– 292, 2004. [28] G. Fursin, M. O’Bo yle, O. T emam, and G. W atts. Fast and accurate method for determining a lower bound on ex ecution time. Concurr ency: Practice and Experience , 16(2-3):271– 292, 2004. [29] G. Fursin, M. F . P . O’Boyle, O. T emam, and G. W atts. A fast and accurate method for determining a lower bound on execution time: Research articles. Concurrency: Practice and Experience , 16(2-3):271–292, Jan. 2004. [30] G. Fursin and O. T emam. Collective optimization: A practical collaborative approach. A CM T ransactions on Ar chitectur e and Code Optimization (T A CO) , 7(4):20:1–20:29, Dec. 2010. [31] M. Geimer, F . W olf, B. J. N. W ylie, E. ´ Abrah ´ am, D. Becker , and B. Mohr . The scalasca performance toolset architecture. Concurr . Comput. : Pract. Exper . , 22(6):702–719, Apr . 2010. [32] T . Hey , S. T ansley , and K. M. T olle, editors. The F ourth P aradigm: Data-Intensive Scien- tific Discovery . Microsoft Research, 2009. [33] K. Hoste and L. Eeckhout. Cole: Compiler optimization level e xploration. In Pr oceedings of the International Symposium on Code Generation and Optimization (CGO) , 2008. [34] V . Jimenez, I. Gelado, L. V ilanov a, M. Gil, G. Fursin, and N. Navarro. Predicti ve run- time code scheduling for heterogeneous architectures. In Proceedings of the International Confer ence on High P erformance Embedded Arc hitectur es & Compilers (HiPEAC 2009) , January 2009. [35] T . Kisuki, P . Knijnenbur g, and M. O’Boyle. Combined selection of tile sizes and unroll factors using iterative compilation. In Pr oceedings of the International Confer ence on P arallel Ar chitectur es and Compilation T echniques (P ACT) , pages 237–246, 2000. 14 [36] D. Kuck. Computational capacity-based codesign of computer systems. High-P erformance Scientific Computing , 2013. [37] P . Kulkarni, W . Zhao, H. Moon, K. Cho, D. Whalley , J. Davidson, M. Bailey , Y . Paek, and K. Galliv an. Finding effecti ve optimization phase sequences. In Proceedings of the Confer ence on Languages, Compilers, and T ools for Embedded Systems (LCTES) , pages 12–23, 2003. [38] L. Luo, Y . Chen, C. Wu, S. Long, and G. Fursin. Finding representative sets of opti- mizations for adaptive multiv ersioning applications. In 3rd W orkshop on Statistical and Machine Learning Appr oaches Applied to Arc hitectures and Compilation (SMART’09), colocated with HiPEA C’09 conference , January 2009. [39] F . Matteo and S. Johnson. FFTW: An adaptive software architecture for the FFT. In Pr oceedings of the IEEE International Confer ence on Acoustics, Speech, and Signal Pro- cessing , volume 3, pages 1381–1384, Seattle, W A, May 1998. [40] A. Monsifrot, F . Bodin, and R. Quiniou. A machine learning approach to automatic pro- duction of compiler heuristics. In Pr oceedings of the International Conference on Artificial Intelligence: Methodology , Systems, Applications , LNCS 2443, pages 41–50, 2002. [41] Z. Pan and R. Eigenmann. Rating compiler optimizations for automatic performance tun- ing. In Pr oceedings of the International Conference on Super computing , 2004. [42] Z. Pan and R. Eigenmann. Fast and effecti ve orchestration of compiler optimizations for automatic performance tuning. In Pr oceedings of the International Symposium on Code Generation and Optimization (CGO) , pages 319–332, 2006. [43] S. S. Shende and A. D. Malon y . The tau parallel performance system. Int. J . High P erform. Comput. Appl. , 20(2):287–311, May 2006. [44] B. Singer and M. V eloso. Learning to predict performance from formula modeling and training data. In Pr oceedings of the Conference on Mac hine Learning , 2000. [45] M. Stephenson, S. Amarasinghe, M. Martin, and U.-M. O’Reilly . Meta optimization: Im- proving compiler heuristics with machine learning. In Pr oceedings of the ACM SIGPLAN Confer ence on Pr ogramming Languag e Design and Implementation (PLDI’03) , pages 77– 90, June 2003. [46] M. T artara and S. Crespi-Reghizzi. Continuous learning of compiler heuristics. T ACO , 9(4):46, 2013. [47] S. T riantafyllis, M. V achharajani, N. V achharajani, and D. August. Compiler optimization- space exploration. In Pr oceedings of the International Symposium on Code Generation and Optimization (CGO) , pages 204–215, 2003. [48] R. Whaley and J. Dongarra. Automatically tuned linear algebra software. In Pr oceedings of the Confer ence on High P erformance Networking and Computing , 1998. [49] S. W illiams, A. W aterman, and D. Patterson. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM , 52(4):65–76, Apr . 2009. [50] S. Zuckerman, J. Suetterlein, R. Knauerhase, and G. R. Gao. Using a ”codelet” program ex ecution model for exascale machines: position paper . In Pr oceedings of the 1st In- ternational W orkshop on Adaptive Self-T uning Computing Systems for the Exaflop Era , EXAD APT ’11, pages 64–69, New Y ork, NY , USA, 2011. A CM. 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment