Hyperparameter Optimization and Boosting for Classifying Facial Expressions: How good can a "Null" Model be?
One of the goals of the ICML workshop on representation and learning is to establish benchmark scores for a new data set of labeled facial expressions. This paper presents the performance of a "Null" model consisting of convolutions with random weigh…
Authors: James Bergstra, David D. Cox
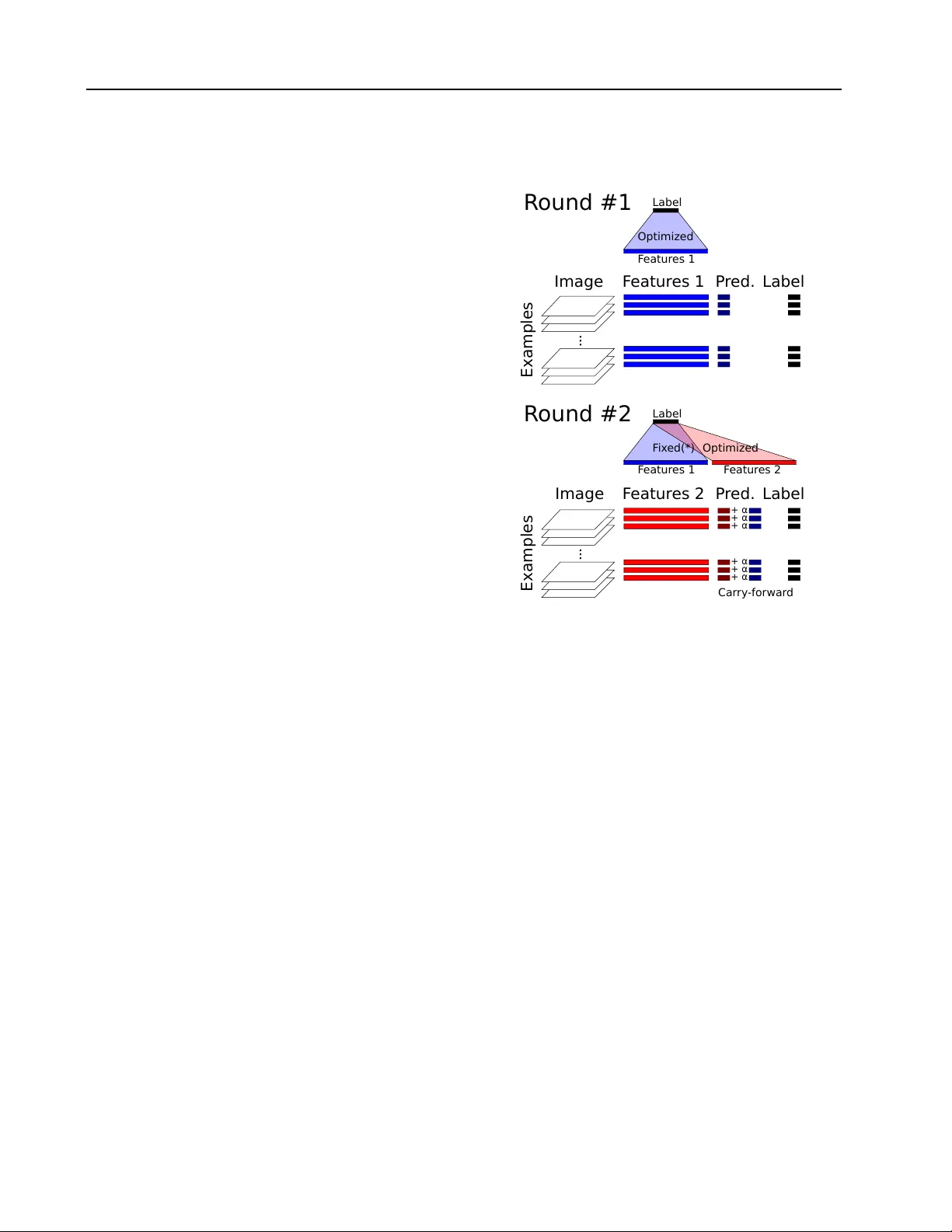
Hyp erparameter Optimization and Bo osting for Classifying F acial Expressions: Ho w go o d can a “Null” Mo del b e? James Bergstra bergstra@uw a terloo.ca Univ ersity of W aterlo o, 200 Universit y Av e., W ateroo, Ont N2L 3G1 CANAD A Da vid D. Cox da vidcox@f as.har v ard.edu Harv ard Univ ersity , 52 Oxford St., Cambridge, MA 02138 USA Abstract One of the goals of the ICML w orkshop on represen tation and learning is to establish b enc hmark scores for a new data set of la- b eled facial expressions. This pap er presents the performance of a “Null model” consisting of conv olutions with random weigh ts, PCA, p ooling, normalization, and a linear readout. Our approac h focused on hyperparameter op- timization rather than nov el mo del comp o- nen ts. On the F acial Expression Recogni- tion Challenge held by the Kaggle website, our hyperparameter optimization approach ac hieved a score of 60% accuracy on the test data. This pap er also introduces a new en- sem ble construction v ariant that combines h yp erparameter optimization with the con- struction of ensembles. This algorithm con- structed an ensemble of four mo dels that scored 65.5% accuracy . These scores rank 12th and 5th respectively among the 56 chal- lenge participan ts. It is w orth noting that our approac h was dev elop ed prior to the release of the data set, and applied without modifi- cation; our strong comp etition p erformance suggests that the TPE hyperparameter opti- mization algorithm and domain expertise en- co ded in our Null mo del can generalize to new image classification data sets. 1. In tro duction The design of an effective machine learning system t yp- ically in volv es making man y design c hoices that reflect the nature of data at hand and the inferences w e wish Presen ted at the ICML Workshop on R epr esentation and L e arning , A tlanta, Georgia, USA, 2013. Copyrigh t 2013 by the author(s). to make. The tec hniques at our disposal, as designers of mac hine learning systems, are intuition : rep eating what work ed in other settings that seem to b e sim- ilar (app ealing to our exp ertise and intuition), and se ar ch : mo del selection by trial and error searc h us- ing e.g. cross-v alidation. In common practice, b oth intuition and search are t yp- ically carried out informally . A practitioner may de- sign a complete system by a semi-automated search pro cess in which small-scale searches (e.g. grid search) up date the practitioner’s own implicit b eliefs regarding what constitutes a go o d mo del for the task at hand. Those beliefs inform the choice of future small-scale searc hes in an iterative pro cess that m ak es progres- siv e improv ements to the system. (W e ma y see many empirical results published in machine learning con- ferences as evidence of this pro cess unfolding on an in ternational scale ov er a course of y ears.) One practical problem that arises from this common practice is that algorithms which hav e b een demon- strated to work on particular data sets are notoriously difficult to adapt to new data sets. The trouble is that the implicit b eliefs of the practitioner pla y a crucial role in the process of mo del selection. This difficulty has b een widely recognized b y domain exp erts, but the status quo remains b ecause so man y exp erts feel that their search is sufficiently efficien t, and the insights gained from the mo del selection pro cess are v aluable. W e hop e that our results, tak en together with other recen t work on hyperparameter optimization suc h as Bergstra et al. ( 2011 ); Snoek et al. ( 2012 ); Thornton et al. ( 2012 ), challenge these b eliefs and induce more researc hers to recognize automatic h yp erparameter op- timization as an imp ortant tec hnique for mo del ev alu- ation. Hyp erparameter Optimization and Bo osting for Classifying Expressions 1.1. Hyp erparameter Optimization and Ensem ble Construction While hyperparameter optimization is imp ortan t, it is not the only standard p erformance-enhancing tech- nique used to improv e the scores of a mo del family on a giv en b enc hmark task. Ensem ble metho ds such as Bagging ( Breiman , 1996a ), Bo osting ( Demiriz et al. , 2002 ), Stac king ( W olp ert , 1992 ; Breiman , 1996b ; Sill et al. , 2009 ), and Bay esian Mo del Averaging ( Ho et- ing et al. , 1999 ) are also commonly employ ed to exact ev ery last drop of accuracy from a giv en set of algo- rithmic tec hnology . One of the goals of automating h yp erparameter optimization is to assess, in an ob- jectiv e wa y , how go od a set of classification system comp onen ts can b e. In pursuit of that goal, the au- tomation of ensemble creation is also critical. This pap er presents a first attempt to provide a fully automated algorithm for mo del selection and ensem- ble construction. It starts from a palette of con- figurable pre-pro cessing strategies, and classification algorithms, and pro ceeds to creates the most accu- rate ensemble of optimized comp onen ts that it can. Our algorithm uses a Bo osting approach to ensem ble construction, in which h yp er-parameter optimization pla ys the role of a base learner. This setting creates unique challenges that motiv ate a new Bo osting algo- rithm, which w e call SVM Hyp erBoost. 2. Null Mo del for Image Classification Our basic approach is describ ed in Bergstra et al. ( 2013a ). W e use Hyp eropt ( Bergstra et al. , 2013b ) to describ e a configuration space that includes one- la yer, tw o-la yer, and three-lay er conv olutional net- w orks. The elements of our image classification mo del are standard scaling (image resolution), affine warp (rigid image deformation), filterbank normalized cross- correlation, lo cal spatial p ooling, di-histogram spatial p ooling, and an L2-SVM classifier. F or each lay er in eac h architecture, h yp erparameters gov ern the size of filters, the volume of p o oling regions, constants that mo dulate lo cal normalization, and so on. The fil- ters themselves are either c hosen randomly from a cen tered Gaussian distribution, or are random pro- jections of PCA comp onen ts of training data (as it app ears as input to each la yer), or are random pro- jections of input patches (again, as input arrives to eac h la yer). F eatures for classification are deriv ed from the output lay er by either signed (di-histogram) or unsigned p o oling ov er some top ographically lo cal partitioning of output features. This configuration space w as chosen to span the mo del space inv esti- gated by Pinto & Cox ( 2011 ) and the random-filter mo dels of Coates & Ng ( 2011 ). Relativ e to Bergstra et al. ( 2013a ) we add the p ossibilit y of affine warping of input images and remo ve the input-cropping step. In total, the configuration space includes 238 hyper- parameters, although no configuration uses all 238 at once. Man y of the hyperparameters are c onditional h y- p erparameters because they are only active in certain conditions; for example, the hyperparameters gov ern- ing the creation of a third la yer are inactiv e for tw o- la yer mo dels. The details of this meta-mo del are de- scrib ed in Bergstra et al. ( 2013a ) and implemented in the hyperopt-convnet softw are a v ailable from http: //github.com/jaberg/hyperopt- convnet . Notable omissions from the mo del space include: bac k- propagation ( Rumelhart et al. , 1986 ), unsup ervised learning for filters such as RBMs ( Hinton , 2002 ; Hin ton et al. , 2006 ), Sparse Co ding ( Coates & Ng , 2011 ), DAAs ( Vincent et al. , 2008 ), and recent high- p erformance regularization strategies such as drop out ( Hin ton et al. , 2012 ) and maxout ( Goo dfellow et al. , 2013 ). Hyp erparameter optimization within this Null mo del w as carried out using the TPE algorithm ( Bergstra & Bengio , 2012 ), as implemented by the hyperopt soft- w are (av ailable from http://jaberg.github.com/ hyperopt ). 3. SVM Hyp erBo osting This section describ es an ensemble construction metho d (SVM Hyp erBoost, or just Hyp erBoost) that is particularly well-suited to the use of a hyperparam- eter optimization algorithm as an inner lo op. This algorithm is presented in the context of models whic h ha ve the form of a feature extractor and a linear clas- sifier. In this context, the ensemble is simply a larger linear function that can b e seen as the concatenation of ensemble members. The Hyp erBo ost algorithm can b e understo od as a piecewise training of this single gian t linear classifier. T o derive the Hyp erBoost algorithm, supp ose that w e commit to using an ensemble of size J . (No such com- mitmen t is necessary in practice, but it makes the de- v elopment clearer.) The ideal ensemble weigh ts w ( ∗ ) and h yp erparameter configuration settings λ ( ∗ ) for a binary classification task w ould optimize generaliza- tion error: w ( ∗ ) , λ ( ∗ ) = argmin w ∈ R ∗ ,λ ∈ H J E x ,y ∼D I { 0 > y ( X j w j · f ( x, λ j ) } . (1) Hyp erparameter Optimization and Bo osting for Classifying Expressions Here D stands for a joint density ov er inputs and labels ( x ∈ R M , y ∈ {− 1 , 1 } ). W e hav e used f ( x, λ j ) to de- note the feature vector associated to input x by h yp er- parameter configuration λ j . The expression I { 0 > a } denotes the indicator function that is one for v alues of a which are negativ e, but zero for v alues of a which are not negative. W e use H to stand for the set of p ossi- ble hyperparameter configurations, so that the argmin means “choose J optimal hyperparameter configura- tions” (one for eac h ensemble member). W e use the notation w ∈ R ∗ in the argmin to indicate that the final set of weigh ts w ( ∗ ) will b e a vector, but it is not kno wn a-priori how man y elements it will hav e. Rather, w will b e logically divided into J pieces corre- sp onding to ensemble elements and each piece w j will ha ve a dimensionality that matches f ( x ; λ j ). The joint optimization of w and λ implied b y Equa- tion 1 is c hallenging because of • the complicated effect of eac h λ j on f , • the exp ectation o ver unkno wn D , and • the non-differen tiable indicator function. Our strategy for dealing with the complicated relation- ship betw een λ j and f is to select the λ j configurations greedily , using the algorithm illustrated in Figure 1 . Our strategy for dealing with the exp ectation is to es- timate it from what is typically called v alidation data, so that each argmin for j < J is what previous work has called hyperparameter optimization. Our strategy for dealing with the non-differen tiability of the indi- cator function is to use a gradient-free optimization metho d, namely TPE ( Bergstra et al. , 2011 ). Normally , Boosting (functional gradient metho ds) on a Hinge loss or Zero-One loss would quic kly run in to trouble b ecause once the training margins are pushed past the decision b oundary , subsequent rounds hav e nothing to do (the training criterion is completely sat- isfied). W e av oid this nonsense using t wo techniques. First, Bo osting on sufficient v alidation data helps b e- cause models fit to training data are seldom p erfect for v alidation data b y random c hance (incidentally , w e are in terested in collaborations that migh t shed ligh t on exactly how muc h v alidation data is necessary). Sec- ond, eac h round of HyperBo ost is free to scale the con- tribution of previous ensemble comp onents (see α in Figure 1 ), so standard SVM regularization techniques (i.e. C ) allo w us to meaningfully add features and impro ve w even if the Hinge loss had b een reduced to 0 at a previous Hyp erBoosting iteration. The reg- ularization parameter go verning the entire SVM is a h yp erparameter that is re-optimized on every round of Hyp erBo ost. This tec hnique mak es Hyp erBoost a partially corrective Boosting algorithm. Image F eatur es 1 P r ed. Examples Label Image F eatur es 2 P r ed. Examples Label R ound #1 R ound #2 Optimized F ix ed(*) Optimized + α + α + α + α + α + α Label F eatur es 1 F eatur es 2 F eatur es 1 Label Car ry -forwar d Figure 1. The SVM Hyp erBo ost algorithm creates a large linear SVM piece-wise. The first round of training is stan- dard SVM training. At the end of the first round, the SVM w eights are fixed (*) up to multiplicativ e scaling. Subse- quen t rounds “carry forward” the total con tribution of pre- vious features and their corresponding fixed w eights tow ard lab el predictions. On Round 2, HyperBo ost optimizes the feature weigh ts (shown in ligh t red) for a candidate feature set (brigh t red) and re-scales (via α ) w eights fit in previous rounds. This approximate, greedy pro cedure makes it p os- sible to fit very large SVMs to large num b ers of examples, when feature computation is also computationally costly . 3.1. W eak Learners vs. Strong Learners Hyp erBoost is suitable for Bo osting str ong base learn- ers. In fact, when Bo osting and mo del fitting are conducted on statistically indep endent example sets, the distinction b et ween distinction b et ween “weak” vs. “strong” learners is no longer imp ortan t. Instead, an y learners (weak or strong) simply provide mo dels, and Hyp erBoosting c ho oses the mo del that most impro ves the v alidation set performance of the ensemble. While strong learners generally require additional regulariza- tion compared with w eak learners in order to general- ize correctly from training data, strong and weak base learners are equally useful for Hyp erBo osting. Hyp erparameter Optimization and Bo osting for Classifying Expressions 4. Results on F acial Expression In support of the ICML2013 w orkshop on rep- resen tation learning, Pierre-Luc Carrier and Aaron Courville released a data set for facial ex- pression recognition as a Kaggle competition ( http://www.kaggle.com/c/challenges-in- representation-learning-facial-expression- recognition-challenge ). The data consist of 48x48 pixel grayscale images of faces, and labels for the expressions of those faces. The faces hav e b een automatically registered so that each face is appro ximately centered and o ccupies ab out the same amoun t of area within each image. The task is to categorize each face as one of sev en categories (anger, disgust, fear, happ y , sad, surprised, neutral). The set distributed b y Kaggle consists of 28,709 training examples examples, and 7,178 test examples. Our proto col for mo del selection was simple cross- v alidation on the training examples. W e partitioned the training data in to 20709 SVM-fitting examples and 8000 v alidation examples, and performed h yp erparam- eter optimization with regard to the p erformance on this v alidation set. The test examples w ere not used for mo del selection. The Kaggle website only pro vided the images for test examples, to prev ent cheating in the con test. The test scores listed for the F acial Expression Recognition Challenge w ere obtained b y uploading our predictions to Kaggle’s website, which computed the test set accuracy on our b ehalf. On each round of Hyp erBoosting, we ev aluated 1000 non-degenerate hyperparameter prop osals in searc h of the b est feature set to add to the ensem ble. These prop osals ranged in accuracy from chance baseline of 20% up to a relatively strong 62%. Exp erimen ts were done using a single computer with four NVidia T esla 2050 GPUs and a slow file system so t ypically 2 or 3 jobs would run simultaneously . Many configura- tions were inv alid (e.g. do wnsampling so muc h that 0 features remain) but these are recognized relatively quic kly . V alid (non-degenerate) trials t ypically took 10 - 25 min utes to complete, so eac h round of HyperBo ost to ok t wo or three days using this one mac hine. The accuracies of the mo dels c hosen b y Hyp erBo ost are shown in Figure 2 . Hyp erBoost creates a small ensem ble whose combined accuracy (65.5%) is signif- ican tly b etter than the b est individual mo del (60%). The ranking relativ e to other mo dels in the Kaggle comp etition is sho wn in T able 1 . The ensem ble of size 4 ranks among the top 5 comp etition en tries. It is w orth noting that the mo del and training pro- grams used for Hyp erBo osting in this mo del space Hyp erBoost for Ensemble Construction 1 2 3 4 HyperBoost Round 0.58 0.59 0.60 0.61 0.62 0.63 0.64 0.65 Classification Accuracy Test Validation (Ensemble) Validation (Round Features) Figure 2. Hyp erBoost impro ves test set generalization with successiv e rounds while the individual feature sets c hosen at each round hold steady just below 60% accuracy . Each round selects the b est of 1000 non-degenerate candidate feature sets. T raining set accuracy (not shown) ranges from 85% for the first round up to 97% on the fourth round. w ere entirely designed prior to the release of the data set. The mo del space was chosen to span the mo d- els of Pinto & Cox ( 2011 ) and Coates & Ng ( 2011 ). Pin to & Cox ( 2011 ) rep orted excellent match verifi- cation p erformance on the Lab eled F aces in the Wild (LFW) data set ( Huang et al. , 2007 )), and Coates & Ng ( 2011 ) adv anced the state of the art at the time on the CIF AR-10 ob ject recognition data set. Our approac h w as dev elop ed prior to the release of the F a- cial Expression Recognition data set, so the goo d per- formance sp eaks directly to the ability of our meta- mo deling approac h to generalize to new image classi- fication tasks. It is also w orth noting that the training accuracy (not sho wn) of all mo dels in the ensemble is m uch higher than the generalization accuracy (from 85% up to 97%). The size of individual feature sets was capp ed at 9000 (to stay within the av ailable memory on the GPU cards), and all of the b est models approached this maximum num b er of features. Although these large feature sets demonstrated significant ov er-fitting of the training data (these feature sets represent str ong base learners for Bo osting), Hyp erBoost selected en- sem ble members that brought steady improv ement on the test set. This is a familiar story for Bo osting algo- rithms based on an exp onen tial loss, but Hyp erBoost pro duces the effect while operating on the more repre- sen tative hinge loss. Hyp erparameter Optimization and Bo osting for Classifying Expressions T able 1. Performance relative to Kaggle submissions. Rank Team A ccuracy (%) 1 “RBM” 71 . 162 2 “Unsuper vised” 69 . 267 3 “Maxim Milakov” 68 . 821 4 “Radu+Marius+Cristi” 67 . 484 - Hyp erBoost Round 4 65 . 450 5 “Lor.V oldy” 65 . 255 . . . 11 “jaberg” 61 . 967 - Hyp erBoost Round 1 61 . 466 12 “bulbugoglu” 59 . 654 . . . 56 “dst arerstor ” 20 . 006 5. Conclusion Hyp erparameter optimization within large model classes is difficult. W e hav e sho wn that h yp erparame- ter optimization within a Null mo del achiev es ov er 60% accuracy in the w orkshop’s F acial Expression Recogni- tion Challenge, whic h ranks 12th of 56 con test submis- sions. F urther use of an ensem ble-construction mec ha- nism raises that accuracy to 65.5%, whic h w ould hav e rank ed 5th / 56 had it b een ready by the con test clos- ing date. These p erformances underscore the imp or- tance and difficulty of fully leveraging kno wn algorith- mic technology for image classification. W e can only conjecture that a future version of our mo del space that includes a wider range of algorithms for feature initialization and refinement (e.g. bac kpropagation, drop out, maxout, sparse co ding, sparsity regulariza- tion, RBMs, D AAs) could p erform b etter yet. By the same tok en, until such a search is carried out, it is difficult to make quantitativ e claims regarding the v alue added by suc h algorithms ov er and ab ov e a well- configured set of simpler comp onen ts. The soft ware used in these exp erimen ts is publicly a v ailable from gith ub: Hyp eropt The TPE h yp erparameter optimiza- tion algorithm and distributed optimization infrastructure. http://jaberg.github.com/ hyperopt Hyp eropt-Con vNet The HyperBo ost algorithm and h yp eropt-searc hable represen tation of the im- age classification mo del. http://github.com/ jaberg/hyperopt- convnet Ac kno wledgments This pro ject has been supported b y the Ro wland Insti- tute of Harv ard, the United States’ National Science F oundation (I IS 0963668), and Canada’s National Sci- ence and Engineering Researc h Council through the Ban ting F ellowship program. References Bergstra, J. and Bengio, Y. Random search for hyper- parameter optimization. Journal of Machine L e arn- ing R ese ar ch , 13:281–305, 2012. Bergstra, J., Bardenet, R., Bengio, Y., and K ´ egl, B. Algorithms for hyper-parameter optimization. In NIPS*24 , pp. 2546–2554, 2011. Bergstra, J., Y amins, D., and Co x, D. D. Making a sci- ence of mo del searc h: Hyperparameter optimization in h undreds of dimensions for vision architectures. In In Pr o c. ICML , 2013a. Bergstra, J., Y amins, D., and Cox, D. D. Hyp eropt: A p ython library for optimizing the hyperparameters of machine learning algorithms. In SciPy’13 , 2013b. Breiman, L. Bagging predictors. Machine L e arning , 24:123–140, 1996a. Breiman, L. Stack ed regressions. Machine L e arning , 24:49–64, 1996b. Coates, A. and Ng, A. Y. The imp ortance of enco d- ing versus training with sparse co ding and vector quan tization. In Pr o c. ICML-28 , 2011. Demiriz, A., Bennett, K.P ., and Sha we-T a ylor, J. Lin- ear programming b oosting via column generation. Machine L e arning , 46:225–254, 2002. Go odfellow, I., W arde-F arley , D., Mirza, M., Courville, A., and Bengio, Y. Maxout net works. CoRR , abs/1302.4398, 2013. Hin ton, G. E. T raining pro ducts of exp erts by mini- mizing con trastive div ergence. Neur al Computation , 14:1771–1800, 2002. Hin ton, G. E., Osindero, S., and T eh, Y. A fast learn- ing algorithm for deep b elief nets. Neur al Computa- tion , 18:1527–1554, 2006. Hin ton, G. E., Sriv asta v a, N., Krizhevsky , A., Sutsk ever, I., and Salakh utdinov, R. R. Impro v- ing neural net works by preven ting co-adaptation of feature detectors. CoRR , abs/1207.0580, 2012. Hyp erparameter Optimization and Bo osting for Classifying Expressions Ho eting, J. A., Madigan, D., Raftery , A. E., and V olin- sky , C. T. Ba y esian mo del av eraging: A tutorial. Statistic al Scienc e , pp. 382–401, 1999. Huang, G . B., Ramesh, M., Berg, T., and Learned- Miller, E. Labeled faces in the wild: A database for studying face recognition in unconstrained en- vironmen ts. T echnical Rep ort 07-49, Universit y of Massac husetts, Amherst, Octob er 2007. Pin to, N. and Co x, D. D. Beyond simple features: A large-scale feature search approach to unconstrained face recognition. In Pr o c. F ac e and Gestur e R e c o g- nition , 2011. Rumelhart, D. E., Hinton, G. E., and Williams, R. J. Learning internal represen tations by error propaga- tion. In Rumelhart, D. E. and McClelland, J. L. (eds.), Par al lel Distribute d Pr o c essing , volume 1, c hapter 8, pp. 318–362. MIT Press, Cam bridge, 1986. Sill, J., T ak´ acs, G., Mack ey , L., and Lin, D. F eature- w eighted linear stacking. CoRR , abs/0911.0460, 2009. Sno ek, J., Laro c helle, H., and Adams, R. P . Practi- cal Ba yesian optimization of machine learning algo- rithms. In Neur al Information Pr o c essing Systems , 2012. Thorn ton, C., Hutter, F., Ho os, H. H., and Leyton- Bro wn, K. Auto-WEKA: Automated selection and h yp er-parameter optimization of classification algo- rithms. CoRR , abs/1208.3719, 2012. Vincen t, P ., Laro c helle, H., Bengio, Y., and Manzagol, P-A. Extracting and composing robust features with denoising auto enco ders. In Pr o c. of the 25th ICML , pp. 1096–1103. ACM, 2008. W olp ert, D. H. Stack ed generalization. Neur al Net- works , 5:241–259, 1992.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment