Non-parametric Power-law Data Clustering
It has always been a great challenge for clustering algorithms to automatically determine the cluster numbers according to the distribution of datasets. Several approaches have been proposed to address this issue, including the recent promising work …
Authors: Xuhui Fan, Yiling Zeng, Longbing Cao
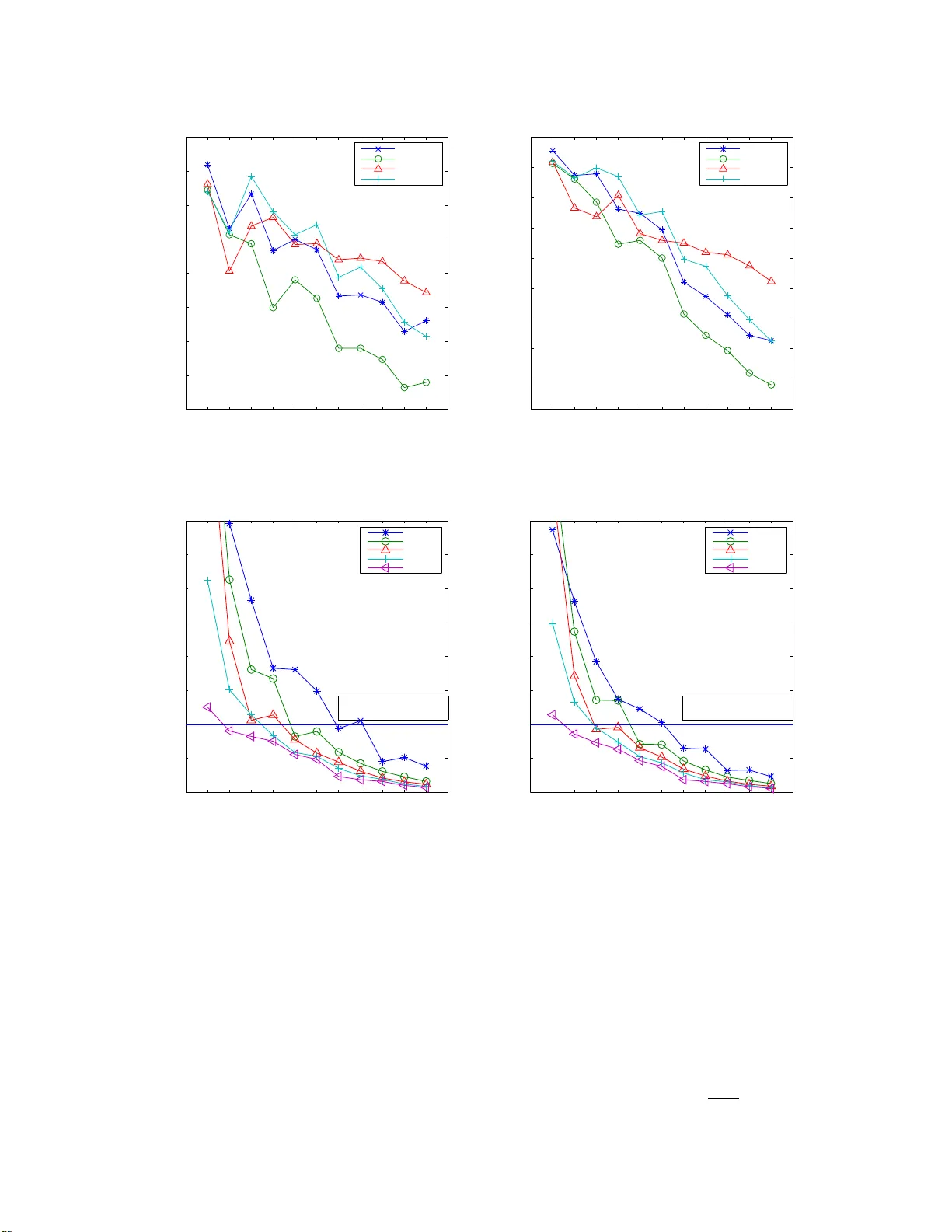
Non-parametr ic Po wer -law Data Clust e ring Xuhui Fan 1 , Y iling Zeng 2 , Longbing Cao 3 Advance d An alytics Institute University of T echnology Sydn ey , Australia 1 Xuhui.Fan@stu dent.uts.edu.a u 2 , 3 { Yiling.Zeng,Lon gBing.Cao } @uts.ed u.au Abstract —It has always been a gr eat challenge f or clustering algorithms to automatically determine the cluster numbers according to th e distribution of datasets. Several approaches hav e been proposed to address this issue, includi n g the recent promising work which incorporate Bayesian Nonp arametrics into th e k - means clu stering procedure. T his approach shows simplicity in implementation and solidity i n th eory , while it also pro vides a feasible way to inference in large scale d atasets. Howe ver , several problems remains unsolved i n this pioneering work, in cluding the power -law data applicability , mechanism to merge centers to a void the over -fittin g problem, clustering order problem, e.t.c.. T o address th ese issues, the Pitman-Y or Process based k-means (namely pyp-means ) is proposed in this paper . T ak ing adv antage of the Pi tman-Y or Process, pyp-means treats clusters differently by dynamically and adaptively chang- ing th e threshold to guarantee th e generation of power - law clustering results. Also, one center agglomeration proc edure is integrated into the implementation to be able to merg e small but close clusters and then adaptively determine the cluster nu mb er . With more discussi on on the clusterin g order , the con verg ence proof , complexity analysis and extension to spectral clustering, our approach is compared with traditional clustering algorithm and var iational inference methods. The advantages and properties of pyp- means are va lidated by experiments on b oth syntheti c d atasets and real wor ld datasets. Key words -Bay esian Non-parametrics; Pit man-Y or P rocess ; power -law data structu re; k -means clustering. I . I N T RO D U C T I O N Power -law data is ub iquitous in r eal world. Ex amples include social n etworks on Facebook, topics in web forum s and c itations amo ng pub lished papers. T his kind of da ta differs from the traditional on es by the large fluctuations that occur in the tails of th e distributions. In creased attentions have been received in recen t ye ars for detection the power - law phenome na an d characterization the structur e of such kind o f d ata. Clusterin g is one essential techn ique for data structure lear ning owing to its capability of grouping d ata collections automa tically . Ho w e ver, the key challenge of em- ploying clusterin g on power -law data lies on the difficulties of inferring the cluster number, as well as determining the cluster sizes. In th e p revious de cades, various clustering method s h a ve been propo sed in dealin g with different kin ds of data. Howe ver , most o f th em, in cluding cla ssic k-m eans [ 1][2][3], Mixture Models [4][5], Spectral Clustering[6][7], Mean Shift[8][9] , etc., assume the clu ster number to be a kin d of prio r information which should be pr ovided b y users, the value of which is usually unk nown f or the u ser . A f ew initial approa ches[10 ][11][12][1 3] have be en p roposed to h andle this unknown cluster num ber pro blem. However , most o f them a ddress th is pr oblem fro m th e m odel selection criteria, and th is lead s to a dilemma in the selection of criteria. Bayesian non -parametr ic learn ing, a fast growing research topic in r ecent years, can be u tilized as an effective ap proach to a ddress the parameter selection issue. Its core idea is to treat the req uired par ameters, e.g., the c luster nu mber, under a h yper-distribution and employ inferen ce method s to learn the po sterior probab ility of the latent variables giv en the observations. It demonstrates its significance contributions in p arameter inf erence. However , it often suffers fro m the difficulty o f design ing learning schemes ba sed on c onjugate assumption, as well as computatio nal complexity induce d by infer ence and sam pling . T o ad dress this problem , a new method called ”DP-m eans”[14] [15] has been proposed to bridge the cla ssic k-mean s clustering and the n on-para metric Dirichlet Process Gaussian M ixture Model (DPGMM). T ak- ing advantage of the asymp totic zero -covariance property o f Gaussian Mixtu re Models, dp-mea ns natu rally introdu ces a fixed threshold to d etermine whether a data point should belong to an existing clu ster or a new clu ster should be created for it. It provides a unified view to combine B ayesian non-p arametric meth ods and th e hard clustering algorithm s to address scale learn ing in large datasets. Howe ver , several issues remain unsolved in th is promising pioneerin g work. (i) The method is no t designed fo r power- law data. A glob al thresho ld for all cluster s may result in cluster s with similar sizes. (ii) Mechanism to merge closed ce nters is n eeded. Th e algo rithm may r esult in many small clu sters. Some of them should be merged if they are closed enoug h. (iii) The cluster ing ord er influences the result. Strategies shou ld be discu ssed more to address this issue. This paper p roposes a novel clustering approach , Pitman- Y or Process-means ( pyp-mean s ), for clustering power-law data. A modified Pitman-Y or Proce ss [16] [17] is first pro- posed to approxim ate the power -law data structur e in hard partition. Unlike the fixed thresho ld pro posed in dp - means , the mod ified Pitman-Y or Pr ocess introdu ces a deregulated threshold wh ose value cha nges in acco rdance to the cluster number du ring clusterin g. The larger the cluster nu mber, the smaller the thresho ld would be . In this way , pyp -means establishes a pro per connectio n between the cluster n umber and th reshold setting . A center agg lomeration procedu re is also propo sed to adaptively determine the cluster n umber . T o address the issue that th e clusterin g pro cedure may result in isolated sm all clusters in which are are n ot far fro m each other, we ch eck the inter-distance between e ach pair of cluster centers and combine them if the d istance of the two clusters ar e smaller than a value. Th is will prevent the clustering result from over fitting the power-law distribution while taking n o acco unt of the real da ta distribution. The heu ristic ”furthe st first” strategy is more discussed here to address th e data or der issue. W e f urther prove that once the cluster n umber stop s increasing , arbitrary ord er of the remained data points will result in the same clu stering result. The conv ergence of pyp-mean s is proved an d the com- plexity of the alg orithm is an alyzed. W e further extend our method to spectral clusterin g to prove the ef fectiveness o f our work. The co ntribution of o ur work is summarised as follows: • we extend the ne wly propo sed d p-means to th e mo d- ified Pitman-Y or process based k-means algorithm to address the power-law data, which is a g eneralization and being able to cluster both the power - law dataset and n ormal dataset. • we integrate a cen ter agglom eration procedur e into the m ain implementation to overcome the overfitting problem . • we introdu ce a heuristic ”fu rthest first” stra tegy to ad- dress the data orde r issue durin g clustering p rocedur e. • we p rove the co n vergence of p yp-mean s and calculate the co mplexity of the algorithm. W e also e xtend the method to fit spe ctral clustering to expa nd our approach to multiple clusterin g algo rithms. The rem aining part of th e paper is organized as fo llows . Section II introduces related work on Gaussian M ixture Models with its ne w der i vati ves and the Pitman- Y or Process. The modified Pitman-Y or Process towards power-law data is represented in Section III. Th en followed b y Sectio n IV detail discusses our pro posed ap proach pyp-means , inclu ding the main imp lementation, the strategy f or data or der issue, and the cen ter agglomeratio n p rocedur e to avoid overfitting. Further discussion on pyp- means’ convergence proof, com- plexity analysis a nd its extension to spectral clustering can be fou nd in Section V. Sec tion VI intro duces experimental results on different da tasets to prove th e ef fectiveness of o ur work. Follo wed by the last section which d raws a conclusion of th is pap er . I I . B AC K G R O U N D W e briefly introdu ce the relations between Gau ssian M ix- ture Mod els with its der i vati ves to k -m eans clsutering [4], and th e pitman -yor proce ss. A. Gau ssian Mixture Mod els with its n ew derivatives to k - means Gaussian Mix ture Models(G MM) treats a dataset as a set containing the samp les from several Gaussian distributions. The likelihood of a data point x in the dataset can be calculated as:: p ( x ) = c X k =1 π k N ( x | µ k , Σ k ) (1) Here c is the c ompon ents’ number, π k denotes the p roportio n of com ponent k , a nd N ( x | µ k , Σ k ) is x ’ s Gaussian likeli- hood in co mponen t k . The local maximum of a Gaussian Mix ture Mod el can be achie ved by ap plying Exp ectation Maximization with iteration of the following equatio ns: µ k = 1 N k N X n =1 γ ( z nk ) x n N k = N X n =1 γ ( z nk ) Σ k = 1 N k N X n =1 γ ( z nk )( x n − µ k )( x n − µ k ) T (2) Here γ ( z nk ) = π k N ( x | µ k , Σ k ) P c k =1 π k N ( x | µ k , Σ k ) denotes the probability of assigning data poin t x n to cluster k . As a result, it is regarded as a kind of soft clustering [14] wh ich is different from traditional har d cluster ing (e .g. k -means) in the way of assigning single point to multiple clusters with pro babilities. Actually , the “asymptotic” link (i.e. zero-variance limit) between the GMM and k -m eans clusterin g is a well-known result as in [4][15]. More specifically , the covariance matri- ces of all m ixture comp onent in GMM a re assumed to be ǫI d × d , and p ( x ) bec omes p ( x | µ k , Σ k ) = 1 (2 π ǫ ) d/ 2 exp ( − 1 2 ǫ k x − µ k k 2 ) (3) with γ ( z nk ) ’ s calculation is change d as: γ ( z nk ) = π k exp {−k x n − µ k k 2 / 2 ǫ } P j π j exp {−k x n − µ j k 2 / 2 ǫ } (4) Consider the case ǫ → 0 , th e sm allest term of {k x n − µ j k 2 } c j =1 will do minate the de nominator of Eq . (4). Th us, γ ( z n,k ) b ecomes: γ ( z n,k ) = 1 k = arg min j {k x n − µ j k 2 } c j =1 0 otherwise (5) In this case, GMM degenerates into k -m eans which a s- signs each poin ts to its nearest clustering with probability of 1 . Both GMM an d k-mea ns are suffering from the selectio n of cluster numbers. T o address th e p roblem, Dirichlet Pro - cess [16][17] is in troduced into k-means recently . T aking advantage of the Dirichlet Process, a distance thresho ld can be g enerated to prevent data points fro m be ing assign ed to a cluster if the d istances exceed the thresho ld. If a d ata poin t fails to be assigned to all clusters, a ne w clu ster will be created by tak ing it as the clu ster c enter . More specifically , a dirich let p rocess can be denoted as D P ( α, H ) , with the hy per-parameter α and basem ent distribution H . The hyper-parame ter a lfa can be further written in the form o f α = e xp ( − λ 2 ǫ ) f or some λ , and the base measurem ent H is used to gener ate Gaussian distribution N (0 , ρI ) . Gibbs sampling is take to addre ss the the above p rocess. The probability used in Gibbs sampling can b e wr itten as γ z nk = n − i,k · exp ( − 1 2 ǫ k x i − µ k k 2 ) / Z k -th c luster exp ( − 1 2 ǫ λ − 1 2( ǫ + ρ ) k x i k 2 ) / Z new clu ster (6) Where k (1 ≤ k ≤ c ) den otes the existing k -th cluster , n − i,k represents the size of the k -th cluster excluding data point x i and Z is the normalizin g con stant. While ǫ → 0 , the allocated label for data point x n becomes: l n = k o k 0 = ar g min j { λ, k x n − µ j k 2 } c j =1 c + 1 λ = arg min j { λ, k x n − µ j k 2 } c j =1 (7) Once Gibbs sampling a ssigns a ne w label c + 1 to x n , a ne w cluster will be generated with Gau ssian d istribu- tion N (0 , ρI ) . W ithin finite steps, local minimum can be achieved. All data p oints are assign ed to co rrespon ding clusters with distances to the centers smaller than th e g iv en threshold. T akin g advantage o f Dirichlet Pro cess, this work, known as dp-means , succe ssfully comb ines the prior in formation (hyper parameter α = exp ( − λ 2 ǫ ) ) and local info rmation of each co mponen t (the gaussian distribution N ( µ , ǫI ) ). Dp-means treat each componen t equally . On e u niv ersal threshold is set fo r all clusters. I n this way , clu stering result tends to contain clu ster with similar sizes. Howe ver , clusters in real world dataset u sually vary a lot. They typically ob ey power -law distributions. T herefor e, it would be con venient if the m ethod is able to generate mor e r easonable clustering results which satisfy power-law distribution. Thoug h a wonderful work, a system atic learning on the unsolved prob lems, including a n in creasing clu ster numb er problem , the clustering ord er pr oblem, co mplexity analysis, e.t.c., should be focused. Other practical issues including power -law data appro ximating, parame ter λ ’ s ad justment also needs to b e furth er in vestigated. B. Pitma n -Y or Pr ocess Pitman-Y or p rocess ( py-pr ocess )[18][19] is a gene raliza- tion of Dirichlet Process. In py - pr o c e ss , a disco unt parameter d is added to increa se the pro bability of new class gen- eration. Due to the discou nt par ameter d ’ s tunin g effect, it becomes a suitable mode l to d epict power -law data. py pr o c ess degenerate to classic d irichlet proc ess when d is set to 0. A P ´ o lya urn scheme is u sed here to explain the py- process’ gen erative p aradigm in the techn ical per spectiv e. In this schem e, o bjects of interests ar e rep resented as colored balls con tained in an u rn. At the b eginning, the u rn is em pty . All b alls a re un colored. W e pick the first ball, pain t it with a certain c olor and put it into the ur n. In the following steps, we pick one b all each time, color it and put it into th e urn . The color of the ball is allocated ac cording to the following probab ility . π i,k = ( n − i,k − d λ + n − i existing k -th (1 ≤ k ≤ c ) co lor λ + c · d λ + n − i k = c + 1 new color (8) Where i denotes the i -th b all picked, k denote s the color assigned to i , n − i,k denote the numbe r of balls in co lor k exclude ball i , n − i denotes the whole numb er of balls without ball i . The pr ocess co ntinues until all balls are p ainted and put into the ur n. While the size of each cluster is fixed, the joint probab ility is unchan ged, which refers as “excha ngeability”. Py-pr ocess preserves Dirichlet Process’ ’rich get richer’ proper ty du ring the pro cess o f assigning co lors to balls. The larger size of balls in a cer tain colo r , the greater p robability that the new ball will be painted in this color . Tha nks to the discoun t p arameter d, the p robability of gener ating a new color in py-p rocess is greater than that of DP . It can be easily p roven th at py-process draws colo rs to data p oints in a power-la w scheme. T herefore , it would be p romising if py-process in incorpo rated into clusterin g algo rithms to help address th e p ower -law d ata. I I I . M O D I FI E D P I T M A N - YO R P RO C E S S F O R H A R D C L U S T E R I N G Power -law da ta[20], also named as h eavy-tailed beh a vior data, represents the ca se that th e frequency or the size of some data cluster obey the expo nential distribution, i.e., more small sized subsets o f cluster data are coming up. In reality life, a wide range of the data obeys power -law data, including the f requencies o f word s in languages, the populatio ns of cities, the intensities of earthqu akes. Under most situations, these kind of findin gs in power-la w data would be considered as n oisy or defective. Howev er, these are at the same time some of the most interesting part from the whole obser vations. In our scenarios, one cluster’ s data are denoted as the same, and we d efine the clu ster size fo llows accord ing to the power -law distribution. In contrast to th e o rdinary data, its clustering encounters mo re d iffi culties, such as the trivial cluster discovery , the cluster nu mber determinatio n and the related im balanced p roblem. A gen eral form of the den sity function of power-law da ta is stated as: p ( x ) ∝ L ( x ) x − α (9) where L ( x ) is a slowly varying function, wh ich is any function that satisfies lim x →∞ L ( tx ) /L ( x ) = 1 w ith t constant, and α ( α > 1) is on e decre asing parame ter . Regarding to th ese d ifficulties in power-law data cluster- ing, tradition al clustering methods tend to gro up the small size clusters into major clusters or simply treat them as noisy data points. It is un-p roper while these trivial clusters may still be impo rtant to the whole data structure. Many soft clustering methods including the py-pr o cess ha ve been put forward to ef fectively mining this kind of data. They ha ve received g ood results, howev er, most of them still suffer the complexity pr oblem in implem entation and high cond itions required . T o the best of our knowledge, little work has been done on the h ard clustering scenario, nor an equiv alence connected with the classic k -mean s clustering . W ith the core idea in py-pr ocess of increasing the new cluster ge neration’ s pro bability , we r e vise the con centration parameter f rom λ to λ · ( θ ) ln c in dp-mean s . More specifically , during each ball’ s color painting in the P ´ o lya urn scheme, the co lor allocated ac cording to the paradigm below: π i,k = n − i,k · exp ( 1 2 ǫ θ ) / Z k -th (1 ≤ k ≤ c ) cluster λ · exp ( ln c 2 ǫ θ ) / Z the new cluster (10) It is quite straightforward to see that th e balls are e x- changeab le, which is qu ite basic for th e power-law approx - imating. Proposition 1. The r evised allocation paradigm in Eq. (10) still keeps the exchangeability pr o perty , i.e., the joint pr o b ability of a d ata set is not affected b y their or d ers given each cluster size fixed. Pr oo f: Assume the cluster number is c , each cluster’ s number is { c i } c i =1 . Thus, the jo int probability o f the data points is P ( X ) = λ c · c Y i =1 ( c i ! c i Y j =1 exp ( − ln j 2 ǫ )) /Z n (11) The equation is d etermined o nly these variables, which is exchangeab ility preserved . In our revision, while θ is fixed at 1, th en it is the norm al dp-mean s . I V . P Y - P RO C E S S M E A N S Benefit from the revised co lor allocation para digm (Eq . (10)), we extend the existed d p-mean s algorithm to do a further generalizatio n, which name d as “ rpy-means ”. The induction strategy i s also quite similar as dp-means . Emp loy- ing th e sam e settin g on b oth o f the fin ite an d infin ite Gau s- sian Mixture Model ( p ( x ) = P k π k N ( x | µ k , ǫ I ) ), th e pa- rameters ar e mo dified as { λ = exp ( − λ 2 ǫ ) , θ = ex p ( − θ 2 ǫ ) } in our revised pitm an-yor pro cess appro ximating m ethod. This lead s to th e related probab ility of data point i assigning to an existed cluster k as: p i,k = n − i,k · exp ( − 1 2 ǫ θ − 1 2 ǫ k x i − µ k k 2 ) Z (12) following the pr obability to the new cluster as: p i,new = exp ( − 1 2 ǫ ( λ − ln c · θ ) − 1 ǫ + ρ k x i k 2 ) Z (13) While ǫ → 0 , the do minating term in p i,k , p i,new is th e minimal value of { λ − ln c · θ , { θ + k x i − µ k k 2 } c k =1 } , lea ding to the cluster allo cation parad igm as: l n = k o k x n − µ k o k 2 = arg min { λ − ln c · θ , k x n − µ j k 2 } c j =1 new λ − ln c · θ = arg min { λ − ln c · θ , k x n − µ j k 2 } c j =1 (14) Here cluster nu mber c is co nstrained to c < exp ( λ/θ ) to avoid the min imal distance problem. By shorten the threshold value in acco rdance to th e cluster nu mber, more hidden clusters could b e discovered an d the clusters would also be mo re com pact than a la rger th reshold. A. main implemen tation One stage of ou r main implem entations in the pyp- means clustering is q uite similar a s in dp- means . However , differences come up in the flu ctuated thr eshold during the clustering procedure and an stepwise/adaptive density check- ing p rocedur e. One d efinition on the r each of cluster ce nters is first mad e to clarify the no tation. Definition 1 . Any da ta point x that lies within the ball b ( µ k , λ ) is said that x is λ -in of µ k ( λ -in data ), while being outside fr om the ball b ( µ k , λ ) is said to be λ -out o f µ k ( λ -out data). Under D ef. ( 1), the dp -means g ets r esults that all of the data p oints are λ -in of centers { µ k } c k =1 . Figure 1. dep icts the pro cess of o ur im plementation . Figure 1. Main implementat ion illustrati on The who le implemen tation c onsists of three procedu res: data partition , center recalculation an d center agglo meration. Data par tition pr ocedure sh ares similarities with the existed dp-mean s , which divides the data into λ -in data and λ -o ut data. For th e λ -in data, its clustering method is ac cording to the usual way as k -mean s, while the λ -out data’ s clustering employs an adaptive w ay to determine the cluster , wh ich would be detail d iscussed later . The c enter-recalculation proced ure is the same as the correspo nding step in k -means. The center agg lomeration procedure is one that to avoid too many trivial clusters. Details would be discussed later . The detail implemen tation of ou r pro posed pyp -means is shown in Algo rithm 1. Algorithm 1 p y p -means Input: x 1 , · · · , x n ; λ, θ , py-pr ocess ’ s para meter Output: clu sters l 1 , · · · , l c and th e n umber of clusters c Initialize c = 1 ; initialize cluster center µ 1 repeat for e ach po int { x i , i = 1 , · · · , n } do compute d ik = k x i − µ k k 2 for c = 1 , . . . , c . if min k d ik − θ > λ − ln c · θ then put i in to un- clustered set D r else set z i = arg min k d ik end if end for re-clustering the rem ained un- clustered data set D r employ the agglo meration pro cedure ch eck update c , µ k until co n verge The objec ti ve functio n is identified as the co st o f all inter - cluster distan ce ( k m -cost) add ing one penalty ter m: arg min l 1 ,...,l n c X j =1 X i ∈ l i k x i − µ j k 2 + ( λ − ln c · θ ) c where µ k = 1 | l k | X x ∈ l k x (15) While km - cost tend s to seek a larger c value and the c - penalty term’ s value increases with c value increases, the minimum value we are seeking is a trade- off in co nsidering both of th e cases. B. re-clustering on D r The clustering or der on the data will affect its performance in our pyp-mean s , suf ferin g fr om the same problem as in [16]. W e discuss this prob lem here in accordan ce with the two stages of our main impleme ntation: λ -in da ta clustering and r e-clustering o n λ -ou t data. On clu stering λ -in data points, arbitr ary ord er of th ese data p oints would result in the same clustering p erforman ce. This assertion ap plies for the classic k -means clustering. On the co ntrary , the clustering ord er o f λ -o ut data poin ts would a ffect the cen ter’ s determination in a sequence. T he new generated different centers would be su rely affect the data belongin g. T o explore this complex situation, a heuristic search metho d called “f urthest fir st” is employed her e. From the start of the re-clustering, we choose the data point i 0 whose shortest distance to all the existed centers are the largest, i.e ., i 0 = arg max i { d i | d i = min c k d ik } and set it as the new cluster center . Then we remove data poin t i 0 from D r and recu rsi vely do re-clusterin g. One benefit o f ou r “fu rthest first” is that we can av oid the generating of new clusters o nce th e cluster nu mber stopped increasing. Th en arbitrary orde r of remain ed data points would not affect th e clustering perfor mance. This saves the computatio nal co st in defin ing the c enters. Proposition 2. During each iter ation of our method, on ce no r emain ing λ -out data po int becomin g new cluster , the following data po in ts wou ld not be n ew centers eith er . Pr oo f: Assume that th e shortest distances of the re- maining D r are d (1) < d (2) < · · · < d ( r ) , correspon ding to the variables x (1) , · · · , x ( r ) . While the x ( k ) (1 ≤ k ≤ r ) does not come to be one ne w center , d ( k ) < λ − ln c · θ , then th e thresh old becom es fixed. Similar as the Aprior i rules, then all the remaining data points { x ( l ) } r l>k with { d ( l ) < λ − ln c · θ } r l>k will b elong to the existed clusters. Thus, ou r selection o rder will no t gen erate the new cluster centers. W e formalize o ur re-clusterin g proced ure on the remain- ing d ataset D r as Algorithm 2. Algorithm 2 re -clustering on D r Input: r emain dataset D r ; λ, θ , p y-pr o cess ’ s parame ter; generated centers { µ k } c 0 k =1 Output: clu sters l 1 , · · · , l c and th e n umber of clusters c for e ach data p oint in D r do compute d ik = k x i − µ k k 2 for k = 1 , . . . , c , select th e shortest on e for each data po int in D r , denoted a s { d k } r k =1 order { d k } r k =1 from largest to sm allest if d 1 − θ > λ − ln c · θ then c = c+ 1; set x (1) as one new cen ter µ c +1 else put x (1) into th e existed nearest clu ster end if end for C. ce n ter agglomeration p r oced ur e In dp- means , new clu ster generated while n ew λ -out data encoun tered, however , it n ev er disappeared e ven if it gets much closer to another cluster . This co uld result in an overfitting pro blem on dividing one dense c lusters into two parts. On the othe r han d, th is spe cial overfitting results in an unpro per smaller thresh old on deter mining the valid clu ster number . Thus, we ne ed to adaptively d etermine th e cluster number . From the following p roposition , we can evaluate the k m - cost value’ s ch ange while tw o clusters com bine into on e. Then the cond ition of clustering co mbining could be well established. Assuming that λ, θ are the pre -defined param eter , c is the current cluster number, { µ i } 2 i =1 and { n i } 2 i =1 are the correspo nding cluster center and cluster size, we have the following propo sition: Proposition 3. If two clusters satisfy k µ 1 − µ 2 k 2 < n 1 + n 2 n 1 n 2 ( λ − θ · ln ( c +1) ( c +1) c c ) , then combinin g th ese two clusters could r ed uce the value of the ob jective function (Eq. (15)). Pr oo f: Assume { x (1) i } n 1 i =1 and { x (2) i } n 2 i =1 are the tw o closed clu ster , with { y i } n 1 + n 2 i =1 denoting their comb ined clusters. Then th e two cluster center satisfy the condition with the new comb ined cluster center µ : n 1 µ 1 + n 2 µ 2 = ( n 1 + n 2 ) µ (16) W e first sh ow that the combin ation of two cluster would result an inc rease in the k m -cost value, n 1 + n 2 X k =1 k y k − µ k 2 − ( n 1 X i =1 k x (1) i − µ 1 k 2 + n 2 X i =1 k x (1) 2 − µ 2 k 2 ) = n 1 + n 2 X k =1 k y k k 2 − ( n 1 + n 2 ) k µ k 2 − ( n 1 X i =1 k x (1) i k 2 + n 2 X j =1 k x (2) j k 2 − n 1 k µ 1 k 2 − n 2 k µ 2 k 2 ) = n 1 k µ 1 k 2 + n 2 k µ 2 k 2 − k n 1 µ 1 + n 2 µ 2 k 2 n 1 + n 2 = n 1 n 2 k µ 1 − µ 2 k 2 n 1 + n 2 ≥ 0 (17) Due to the c luster nu mber redu cement, the cluster num ber c -penalty term jumps from ( λ − ln( c + 1) · θ )( c + 1) to ( λ − ln c · θ ) c . T hus, if the co ndition satisfied n 1 n 2 k µ 1 − µ 2 k 2 n 1 + n 2 ≤ ( λ − ln( c + 1) · θ )( c + 1) − ( λ − ln c · θ ) c ⇔ k µ 1 − µ 2 k 2 < n 1 + n 2 n 1 n 2 ( λ − θ · ln ( c + 1) ( c +1) c c ) (18) Our objectiv e fu nction is decreasing with the two c lusters’ combinatio n. The following simple p rototype illustrates our idea mo re clearly . A, B , C, D are fo ur data poin ts to be clusterd. Assume the threshold is r and we have pr e viou sly clustered A, B and C , D being individual clusters. Accor ding to the agglomer ation pro cedure, we combine these two c lusters since the d istance o f th e two centers are 0 . 8 r , satisfies the condition 0 . 8 r ≤ 2+2 2 · 2 r = r . If we d o not employ this proced ure, th en these two clu sters would remain the same, leading to a un satisfied result. U ' & % $ U U Figure 2. Agglomeration procedure illustra tion In our detail implementation , each time after the cluster centers re-calcu lated, we run this agglom eration proced ure. By checking if any pair of cluster cen ters satisfies the condition , we can effectiv ely prevent the above situations. V . F U RT H E R D I S C U S S I O N The work is exten ded here for fur ther discussion, in- cluding the co n vergence analysis, the com plex analy sis, and possible extension to spectral clu stering. A. co nver genc e ana lysis Guaranteein g a local min imum value within finite steps is vital in our pyp -means . W e appr oach this goal by first show- ing that the objective fu nction ( Eq. (15)) strictly decreases during each iteratio n. Proposition 4. The objec tive fun ction (Eq. ( 15)) is to be strictly dec reasing d uring each iteration we ha ve applied in Algorithm 1, un til a local optimal point r e ached. Pr oo f: The iteratio n is divided into three stages: parti- tioning data p oints; up dating cluster cen ters; agglo meration proced ure. In Partitioning data po ints stage , th e distance between λ - in data and its newly belo nging cluster center would n ot increased, this is confirmed by [ 21]. The λ -o ut data are set as new cluster center s, this shrink age the cost from to th e c penalty value λ − c · θ . Wh at is more, as c in creases, the c penalty value λ − c · θ d ecreases, wh ich r educes the objective function more. In the up dating clu ster center s stage, the mean re presenta- tion is alw ays the optim al selection with the least cost value. In agg lomeration proced ure, the objective fu nction is strictly decreasing as provid ed in Section IV -C. Thus, the ob jecti ve functio n is strictly d ecreasing. Employing the similar idea of [21], the co n vergence proper ty of o ur pyp-me ans could be e asily o btained. Theorem 1. p yp-mean s conver ges to a p artial optimal solution of th e ob jec tive functio n (E q . 15) in a fi nite nu mber of iterations. Pr oo f: As finite number of data points, we get finite partitions of d ata poin ts in the m aximum. Assume o ur de claim is not true, wh ich means that th ere exist r 1 6 = r 2 , such that J r 1 = J r 2 . W ithou t loss of generality , we set r 1 > r 2 . According to Pr oposition 4, ou r objective functio n J r strictly decre ase while r incre ases. Thus, f or any n 1 > n 2 , we get J n 1 < J n 2 . Th e inequality also ap plies to r 1 , r 2 . This leads to the fact th at J r 1 < J r 2 , wh ich is contradict to ou r assumptions. Thus, the assump tion d oes not success and we get our con clusion. Under Th eorem 1, we can ensu re the our procedur e could reach a lo cal minim um within finite step s. B. co mp lexity an alysis Our pro posed pyp-m e ans is scalable to the nu mber of da ta points n and the final cluster nu mber c . T he computatio nal complexity can b e analyzed as follows. All th e three major computatio nal step s d uring one iteration are c onsidered as follows. • Partitioning t he data points . After initialization of the center s, th is steps main ly consists of two d ifferent proced ures. – For λ -in d ata with da ta size n 1 , this pro cess is the same as k -means clu stering in simply compar ing the distances of data in all c cluster centers. Thus, the complexity for this step is O ( n 1 c ) – For λ -out data with d ata size n 2 , the re -clustering process in volves a sort o peration, which the quick- est complexity is n 2 log n 2 . Under the worst case of each λ -o ut data bein g n ew centers, the co m- plexity cost would be O ( n 2 · n 2 log n 2 ) . Wi th an label assigning pr ocess, the co mplexity would b e O ( n 2 2 log n 2 + c n 2 ) . • Updating cluster c e nters . Given th e par tition matrix, updating the cluster cen ters is to find the me ans o f the data points in the same cluster . Thus, for c clu sters, the computatio nal co st com plexity fo r this step is O ( nc ) . • Agglomera tion procedure . This proced ure needs to check all the possible p airs of the clusters, thus a complexity of O ( c 2 ) is n eeded. Assume the clusterin g pro cess n eeds h iter ations to con- verge, the to tal compu tational co mplexity o f this algo rithm is O ( hn 2 2 log n 2 + hnc + hc 2 ) . While n 2 is u sually set to be s small subset of the algor ithm, the algorithm is compu tational feasible. However , while we set th e th reshold λ, θ small values, lead ing to a larger n 2 , then the computatio nal cost would be heavy . C. p itman-yor spectral clu stering Our work can also be transplan ted in to the spectral clustering framework. W e have first shown that our objective function (Eq. (15)) in pyp-means is equiv ale nt to the trace optimization problem: max { Y | Y T Y = I } tr ( Y T ( K − ( λ − ln c · θ ) I ) Y ) (19) Where K is th e n × n kernel matrix. Detail pro of is quite similar as the on e in [16], we do not provide the detail h ere du e to the dup licate. The class ical determination of the o rthonor mal m atrices Y in spe ctral theo ry states that while Y selects to be the top c eigenvectors, the o bjectiv e function in (Eq. 1 9) reaches its maximum for a fixed c clusters. For flexible c v alue in our problem , the ob jecti ve function (Eq. 19) r eaches its maxi- mum while Y selected to be the matrices of eigen vectors with the no n-negative eig en values, correspo nding to the c - adjusted matrix K − ( λ − ln c · θ ) I . Particularly , we d etermine c , the integer num ber of clus- ters, through an adaptive measure on the c value’ s connection to the thre shold chan ging of the eigenv alues of th e similarity matrix, i.e.: c = arg max c ∈{ 1 , ··· ,n } { c | λ c > λ − ln c · θ , λ c +1 < λ − ln( c + 1) · θ } (20) Where { λ, θ } are the pre-defined param eter , { λ i } n i =1 are the decr easing eig en values of the kern el Matr ix K , an d λ k denotes the k - th larger eigenvalue, k = 1 , · · · , n . After getting the re laxed c luster ind icator matrices Y , we can c luster the r ows of Y as d ata poin ts using k -means clu s- tering, acco rding to the stan dard spectra l clustering m ethod and take the corresp onding result as the final clustering result. V I . E X P E R I M E N T S The experim ental ev aluation is c onducted on three ty pes of datasets, which are gr ouped into synthetic dataset, UCI benchm arking d ataset [22] and US comm unities’ criminal dataset [23]. All datasets are p reprocessed by norm alizing each feature on each dimension into th e interval [0, 1]. Furthermo re, the clu stering process of the algorithms is repeated for 50 times at each setting and the average value is taken as the final result. All experiments were r un on a comp uter with Intel Xeno (R) CPU 2.53-GHz, Microsof t W indows 7 with algor ithms coded in Ma tlab . A. Exp erimental Setting For su fficient comparison , our propo sed pyp-m e a ns are compare d with three b aseline algor ithms: k -means cluster- ing, dp-mea ns an d Dirich let Process variational learnin g (V .L.). Parameters in th ese algorith ms are set accordingly . In k - means clustering, the pre-d efined cluster number is set as the tr ue numb er in Syn thetic data an d we use the rand om initialization strategy as the starting partition; dp-mea ns and pyp-mea n s are using the same pa rameter setting, which will be de scribed later; in V . L., we u se the variational inference [24] procedu re to do th e learning and the related parameters are using cross validation technique to de termine. B. P erformance Metrics V alid ating clustering results is always a non- trivial task. Under th e presence of true labels in synthetic data, we employ the accu racy to measu re the effecti veness of ou r propo sed meth ods, wh ich is defined as follows: AC C = P n i =1 δ ( y i , m ap ( c i )) n × 1 00 (21) Where n is the data size, y i and c i denote the true label and the obtained label; δ ( · ) is the dirac func tion as δ ( y , c ) = 1 y = c ; 0 y 6 = c. ; map ( · ) is a perm utation function tha t map s each cluster label to a category labe l, an d the op timal matching ca n be fo und by the Hungarian algo rithm[25]. Besides ACC , the NMI ( normalized mutual infor mation) is also used in the synthetic d ata le arning, i.e. , N M I = P c i =1 P c j =1 log( N · n ij n i n j ) q P c i =1 n i log ( n i N ) P c i =1 n j log ( n j N ) (22) where n ij is the num ber of agreements between clusters i and j , n i is the number of data p oints in cluster i , n j is the n umber of data points in cluster j , and N is the total number of d ata poin ts in the d ataset. C. S ynthetic Dataset T o be more focu sed, the synthe tic dataset is m anually set to contain po wer-law behavior in our learnin g proc edure. Here we would like to inv estigate multiple aspects of our method, includin g the clustering accuracy and NMI score perfor mance, the relationsh ips between thresho ld and dis- covered cluster nu mber, running time, e.t.c .. 1) syn th etic data generation: T he synthetic data is de- riv ed from the same ge neration algorithm as that in [2 6]. The power -law p roperty is reflected by specially assignin g more data p oints to the first few clu sters (to the size of about 200) while remaining others as about 30. Also, the cluster number varies fro m 3 to 15 0 to cov er la rger cases. Each cluster is distributed accord ing to the 3-dimen sional Gaussian Distribution N ( µ , I ) , where µ is one un iform distributed rand om cen ters. 2) Practical par ameter setting: W e employ the method in [16] to set λ ’ s value. W e first r oughly estimate the cluster number c and initialize the center with th e cluster mean. From k = 1 to c , we iterati vely select the data po int that has the largest distance (the d istance is d efined as the smallest distance to all the existed cen ters) as the new gener ated center . The maximum value of distance while k = c is identified as the value of λ in ou r experime nt. For θ ’ s value, we experimentally set it as θ = λ/ 6 . Detail discussions of the θ d etermination will be discussed later . 3 5 8 10 15 20 35 50 75 100 150 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 actual cluster numbers Discovery rate pyp−means dp−means V.L. Figure 5. Discov ery rate 3) simula tion results: Figure 3 . shows the run ning result on the syn thetic d ataset. Th e experim ents are runnin g on cases with cluster nu mber from 3 to 15 0 and the corre- sponding NMI score and accur acy sco re are reco rded. Fro m Figure 3., it is easy to see that bo th dp-means and pyp- means get satisfied results while the cluster nu mber is sm all ( c < 10) . Howe ver , when more clusters are generated , d p- means falls below 0 .8 in NMI an d 7 0 in accur acy while pyp-mea n s receives a much better perfor mance bo th in NMI and accu racy . W e shou ld also note that wh en c ≤ 0 , our pyp - means r eceiv es a better p erforman ce than k -m eans clustering in mo st cases, even if the later ha s the true cluster nu mber . 4) p arameter lea rning: In th is part, the p arameter λ ’ s value is taken from 0 . 05 to 0 . 2 . The “discovery rate” (discovery rate = number of resulted clusters number of actual clusters ) is employed to de- note th e cluster numb er we have unc overed. By default, we set θ = λ/ 10 in pyp-means . Th e d etail result sh ows in Figure 4. Fro m this figure, we can find th at smaller threshold would in a larger discovered clu ster num ber . This is quite reasonable as the smaller threshold w ould lead to smaller cluster size and then the larger cluster number . Also, ou r propo sed p yp-means can discovery a relati ve accurate cluster number while it is less than 75; h owe ver , the dp-me a ns can only discov er perform well under the 10 cluster number case. 5) clu ster numbe r learning : W e shows th e cor respondin g cluster number discovered by using the parameter setting in previous in this experim ent. Since k -m eans alw ays take the true cluster number as a prio r informatio n. W e che ck the other three methods’ d iscovery rate in comparison. W e can see that due to the cluster numb er’ s in crease, all of the discovery rate slo wly decrease. Howe ver , we c an see that our pyp-mean s receives a better perfor mance th an the e xisted dp-mean s wh ile facing large cluster number situation. 6) run ning time te st: The ru nning time o f our methods is tested to validate ou r comp lexity analysis, with m ethods compara ble test an d self-parameter comparable test. From Figure 6., w e can see that our pyp -means runs app roximate the same time as dp-mea n s . Even if in large scale case, the 3 5 8 10 15 20 35 50 75 100 150 0.65 0.7 0.75 0.8 0.85 0.9 0.95 1 actual cluster numbers NMI score pyp−means dp−means k−means V.L. 3 5 8 10 15 20 35 50 75 100 150 10 20 30 40 50 60 70 80 90 100 actual cluster numbers Accuracy score pyp−means dp−means k−means V.L. Figure 3. Syntheti c dataset running result 3 5 8 10 15 20 35 50 75 100 150 0 0.5 1 1.5 2 2.5 3 3.5 4 Pyp- me ans ’ act ual cl u st er n u m b ers Discovery rate θ =0. 05 θ =0. 09 θ =0. 13 θ =0. 17 θ =0. 20 3 5 8 10 15 20 35 50 75 100 150 0 0.5 1 1.5 2 2.5 3 3.5 4 Dp-me ans ’ act ual cl u st er n u m b er s Discovery rate θ =0. 05 θ =0. 09 θ =0. 13 θ =0. 17 θ =0. 20 discovery rate =1 discovery rate =1 Figure 4. Parame ter learning result runnin g time is still to lerated; wh ile in variational lear ning, the runnin g time incr eases in expo nential. D. Rea l W orld Dataset T wo k inds of real world d ataset ar e used he re to fur- ther validate our p yp-means ’ s perform ance, including the UCI bench marking dataset and the US c ommunities Crime dataset. 1) UCI benchma rkin g dataset: In the UCI benc hmarking dataset study , two types of th e d atasets are selected for o ur study: the power-law dataset and “normal” d ataset wit h a fe w clusters or equal sized clu sters, in con trast to the power -law dataset. W e do this to sho w that our m ethods not on ly could receive better perform ance on the p ower law dataset but also could obtain a satisfied result on the “n ormal” dataset. Since th e power-law d ataset is limited , we ma nually make up so me by rem oving some data points in certain clusters in some datasets. One maximum likelihoo d estimation of the power -law density fu nction parameter α is u sed to curve its detail power -law behavior , d enoted as: ˆ α = 1 + c " c X i =1 ln x i x min # − 1 (23) 6 7 8 9 10 11 12 13 −6 −5 −4 −3 −2 −1 0 1 2 3 4 logrithm of the whole datasize ln(n) logrithm of the running time ln(t) pyp−means dp−means k−means V. L. Figure 6. Histogram of communiti es distrib ution Here x i denotes the cluster size in our study , wh ile c represents the cluster n umber . The smaller ˆ α , the larger p ower -law be havior ten dency . W ith the following tab le, the detail of UCI benchm arking datasets w e ar e using is shown: T able I U C I B E N C H M A R K I N G D AT A S E T type data size dimension cluster s ˆ α normal wine 178 13 3 6.02 satell ite 6435 36 7 3.15 statlog 231 0 19 7 ∞ P . L. yeast 1484 8 10 1.38 vo w el 349 10 11 1.33 shape 160 17 9 1.49 pendigi ts 7494 16 10 1.63 page-bl ock 5473 11 5 1.49 glass 21 4 9 6 1.94 W e tu ne the parameter λ ’ s value experimentally to r e- ceiv e a better per formance , an d the θ ’ s value is default as θ = λ/ 10 . T able II is the detail outcome s of the UCI benchmark ing data experiments. Here C.N. denotes the Cluster N umber the me thod has produ ced. From the results given, we can see that on the normal datasets, our method p yp-means performan ces better or at least as good as the dp-means and k -m eans clustering on most ca ses. T his usually because the cluster number c is usually small un der this kin d of d ataset, leadin g the discou nt parameter θ functio n little in th e p rocess. On the power -law dataset in UCI, our pyp-means can receive better result than dp-mean s . The ab ility to automat- ically learn the thresho ld play s a vital role in this learning. Although o ur method s loses at some datasets, it cou ld still be validated valued. 2) co mmunities crime da taset: W e also conduct experi- ments on the com munities crime rate dataset. The commun ities crim e dataset is o ne collection combines socio-econ omic data from the 1990 US Census, law enforce - ment data f rom the 199 0 US L EMAS survey , and crim e data T able II U C I B E N C H M A R K I N G D AT A S E T R E S U L T S dataset criter ion p y p -means dp -means k -means V . L. wine NMI 0.8126 0.7815 0.8349 0.4288 A CC 82.04 80.12 94.94 62.92 C.N. 2.90 2.82 3 3 satell ite NMI 0.5953 0.5683 0.6125 0.3122 A CC 66.74 66.58 67.19 34.93 C.N. 5.96 5.26 6 4 statlog NMI 0.6537 0.6570 0.6128 0.4823 A CC 55.69 55.97 59.91 31.17 C.N. 6.82 6.62 7 6 yeast NMI 0.2476 0.1768 0.2711 0.1063 A CC 41.3329 36.2278 36.8706 33.6927 C.N. 9 6.04 10 8 vo w el NMI 0.4479 0.4125 0.4357 0.3938 A CC 28.9914 27.5645 29.5645 31.2321 C.N. 11.90 9.04 11 11 shape NMI 0.7405 0.7204 0.6593 0.4279 A CC 64.00 61.36 63.05 32.50 C.N. 15.90 14.90 9 9 pendigi ts NMI 0.6903 0.6622 0.6834 0.7024 A CC 66.86 64.65 69.96 62.57 C.N. 10.76 8.88 10 10 page-bl ock NMI 0.1817 0.1807 0.1484 0.2622 A CC 67.70 66.90 44.23 73.91 C.N. 6.02 5.32 5 5 glass NMI 0.3875 0.3784 0.3077 0.2865 A CC 49.50 48.37 42.88 45.37 C.N. 5.94 5.00 6 6 0 0.2 0.4 0.6 0.8 1 0 50 100 150 200 250 300 350 400 violent crimine rate communities’ frequency Figure 7. Histogram of communiti es distrib ution from the 1 995 FBI UCR. The dataset co nstitute o f ne arly 1 00 attrib utes. The at- tributes varies in many aspects of the com munity , excludin g the clearly unrelated attributes. The class label is the total number of violent crimes per 100 , 00 0 populatio n. In this experiment, as the crime rate is one contin uous variable ranges in [0, 1], we manu ally discrete the values in to a certain n umber o f intervals and gets the related lab els. Figure 7 . de picts the histogram of the each inter val’ s number under the case of 16 inter vals. The figure above clearly shows the data distributed acco rding to power -law behavior . T o av o id the “ curse of dimensiona lity ” pro blem, we apply the f eature selection tech nique [ 27] an d select first 10 features as the mo st corre lated ones in ad vance. The p arameter are also tu ned so as to better d escribe th e true cluster labels. The tu ned par ameter and related resu lts are shown in T able I II.. T able III U S C O M M U N I T I E S ’ C R I M I NA L DAT A S E T R E S U LTS θ cri terion pyp-means dp-means k -means V . L. 6.57 NMI 0.2291 0.2075 0.2284 0.0862 A CC 11.10 12.14 9.92 10.34 C. N. 53.8 34.9 51.0 13.0 11.01 NMI 0.1794 0.1680 0.1721 0.0639 A CC 16.52 22.23 15 .27 18.66 C. N. 23.5 10.6 21.0 11.0 12.51 NMI 0.1800 0.1715 0.1746 0.0896 A CC 24.30 27.17 22 .60 34.32 C. N. 11.7 7.7 11.0 9.0 17.11 NMI 0.1737 0.1536 0.1706 0.1119 A CC 40.06 48.13 35 .33 59.46 C. N. 5.7 3. 6 6.0 6.0 From the result, we can see that ou r pyp-means can receive a better per formanc e in both the NM I score an d cluster nu mber pr ediction. V I I . C O N C L U S I O N One n ovel m odified Pitman- Y o r Process based metho d is propo sed he re to address the power-law data clustering problem . W ith the discoun t p arameter in py- p r ocess slightly adjusted, the power -law data is to b e perfectly dep icted. W e also introduce one center agg lomeration pro cedure, lead ing to an adap ti vely way in d etermining the n umber of clusters. Further, we extend our work to the sp ectral clustering case to address m ore sophisticated situations. Some other issues ar e also well discussed here, inclu ding the con vergence and complexity analysis, the practical issues including one reliab le data clustering order . All these ha ve greatly strengthen the solidness and rea lity ap plicability of the method. R E F E R E N C E S [1] S . Ll oyd , “Least squares quan tization i n pcm, ” Information Theory , IE E E T ransactions on , vol. 28, no. 2, pp. 129–137, 1982. [2] J. Hartigan and M. W ong, “ Algorithm as 136: A k-means clustering algorithm, ” Jou rnal of the Royal Statisti cal Society . Series C (Applied Statistics) , v ol. 28, no. 1, pp. 100 –108, 1979. [3] J. Bezdek, “ A con ver gence theorem f or the fuzzy isodata clus- tering algorithms, ” P attern Analysis and Machin e Intelligence, IEEE T ransactions on , no. 1, pp. 1–8, 1980. [4] C. Bishop and S. S . en ligne), P attern r ecognition and machine learning . springer New Y ork, 2006, vol. 4. [5] M. Figueiredo and A. Jain, “Unsupervised learning of finite mixture models, ” P attern Analysis and Machine I ntell igenc e, IEEE T ransactions on , vol. 24, no. 3, pp. 381–396, 2002. [6] J. Shi and J. Malik, “No rmalized cuts and image segmen- tation, ” P attern A nalysis and Mach ine Intelligence , IE EE T ransactions on , vol. 22, no. 8, pp. 888–905 , 2000. [7] U. V on Luxbur g, “ A tutorial on spectral clustering, ” Statistics and Computing , vol. 17, no. 4, pp. 395–416, 2007. [8] Y . Cheng, “Mean shift, mode seeking, and clu stering, ” P attern Analysis and Machine Intelligence , IEEE T ransactions on , vol. 17, no. 8, pp. 790–799, 1995. [9] D. Comaniciu and P . Meer , “Mean shift: A r obu st approach to ward feature space analysis, ” P attern Analysis and Mach ine Intelligence , IEEE T ransa ctions on , vol. 24, no. 5, pp. 603– 619, 2002. [10] H. Bischo f, A. Leonardis, and A. Selb, “Mdl principle for robust vector quantisation, ” P attern Analysis & Applications , vol. 2, no. 1, pp. 59–72, 1999. [11] C. F raley and A. Raftery , “How many clusters? which cluster- ing method? answers via model-based cluster analysis, ” T he computer journal , vol. 41, no. 8, pp. 578–588, 1998. [12] G. Hamerly and C. Elkan, “Learning the k i n k-means, ” in In Neural Information Pro cessing Systems . MIT Press, 2003, p. 2003. [13] C. Sugar and G. James, “Finding the number of clusters in a dataset, ” Journa l of the A m erican Statistical Association , vol. 98, no. 463, pp. 750–763, 2003. [14] R. Nock and F . Nielsen, “On weighting clustering, ” P attern Analysis and Machine Intelligence , IEEE T ransactions on , vol. 28, no. 8, pp. 1223–123 5, 2006. [15] S. Ro weis and Z. Ghahramani, “ A unifying revie w of linear gaussian models, ” Neural computation , vol. 11, no. 2, pp. 305–34 5, 1999. [16] M. Jordan and B. Kulis, “Re visit ing k-means: New algorithms via bayesian nonparametrics. ” [17] B. Kulis and M. Jordan, “Rev isiting k-means: New al- gorithms via bayesian nonparametrics, ” Arxiv prep rint arXiv:1111.035 2 , 2011. [18] J. Pitman and M. Y or , “The two-parameter poisson-dirichlet distribution deriv ed from a stable subordinator , ” T he Annals of Pro bability , vol. 25, no. 2, pp. 855–900 , 1997. [19] H. Ishwaran and L. James, “Gibbs sampling methods for stick-breaking priors, ” Jou rnal of the A m erican Statist ical Association , vol. 96, no. 453, pp. 161–173, 2001. [20] A. Clauset, C. R. Shalizi, and M. E. J. Newman, “Powe r-law distributions in empirical data, ” SIAM Rev . , vol. 51, no. 4, pp. 661–703, Nov . 2009. [Online]. A va ilable: http://dx.doi.org/10 .1137/070710 111 [21] S. Seli m and M. Ismail, “K-means-type algorithms: a gen- eralized con verg ence theorem and ch aracterization of local optimality , ” P attern Analysis and Machine Intelli gence, IEEE T ransactions on , no. 1, pp. 81–87, 1984. [22] A. Frank and A. Asuncion, “UCI machine learning reposi- tory , ” 2010. [Online]. A v ailable: http://archiv e.ics.uci.edu/ml [23] M. Redmond and A. Ba veja, “ A data-driv en software tool for en abling cooperati ve informa tion sharing amo ng police departments, ” Eur opean J ournal of Operational R esear ch , vol. 141, no. 3, pp. 660 – 678, 2002. [24] D. Blei and M. Jordan, “V ari ational inference for dirichlet process mixtures, ” Bayesian Analysis , vol. 1, no. 1, pp. 121– 144, 2006. [25] C. Papadimitriou and K. Steiglit z, Combinatorial optimiza- tion: algorithms and complexity . Dover Pubns, 1998. [26] J.-S . Zhang and Y .-W . Leung, “Improved possibilistic c- means clustering algorithms, ” Fuzzy Systems, IEE E T rans- actions on , vol. 12, no. 2, pp. 209 – 217, april 2004. [27] G. Bro wn, A. Pocock , M.-J. Zhao, an d M. Luj ´ an, “Condi- tional likelihood maximisation: A unifying f rame work for information theoretic feature selection, ” J. Mach. Learn. Res. , vol. 13, pp. 27–66, Mar . 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment