Learning a Factor Model via Regularized PCA
We consider the problem of learning a linear factor model. We propose a regularized form of principal component analysis (PCA) and demonstrate through experiments with synthetic and real data the superiority of resulting estimates to those produced b…
Authors: Yi-Hao Kao, Benjamin Van Roy
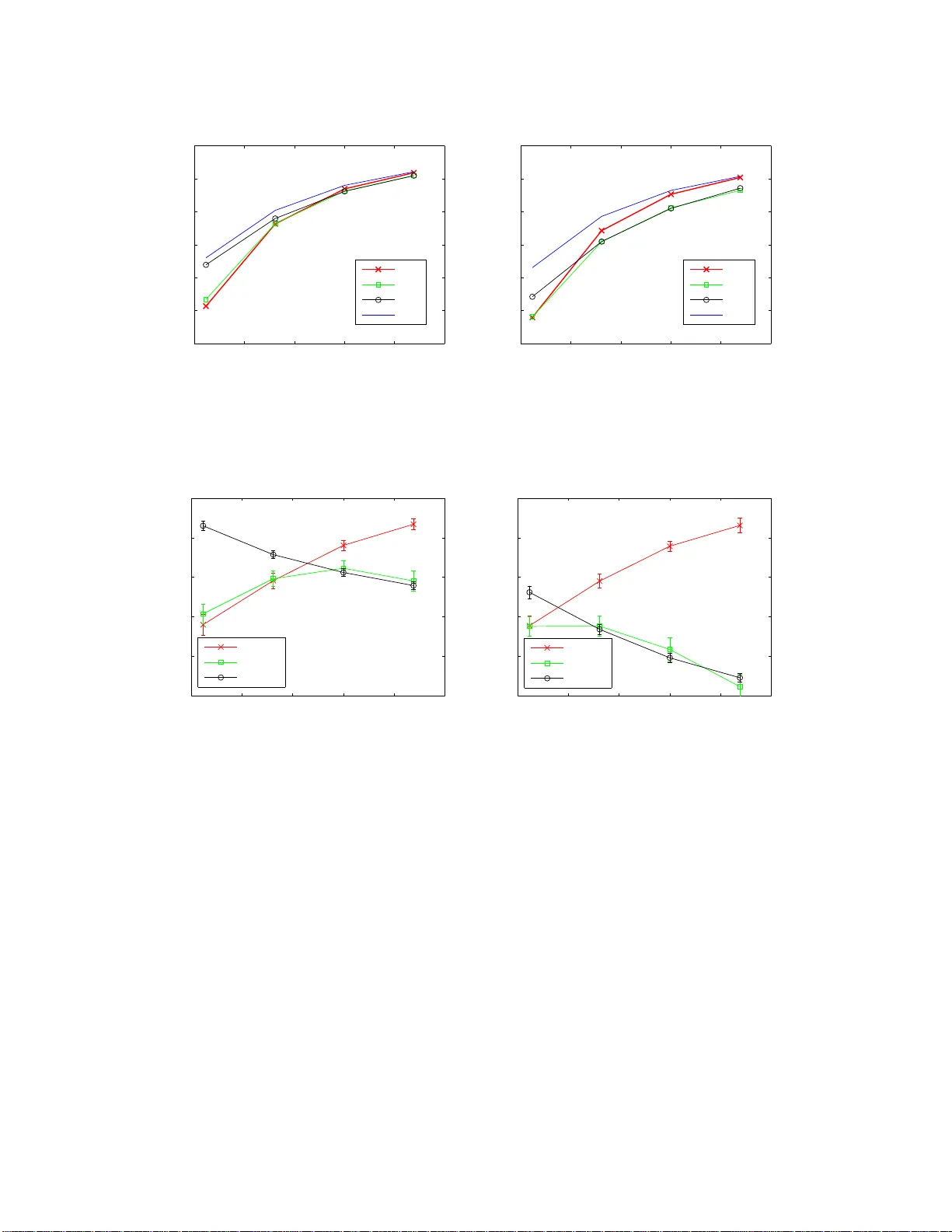
Learning a F actor Mo del via Regularized PCA Yi-Hao Kao Stanford Univ ersit y yhk ao@alumni.stanford.edu Benjamin V an Ro y Stanford Univ ersit y b vr@stanford.edu Abstract W e consider the problem of learning a linear factor mod el . W e prop os e a regularized form of p rin ci - pal comp onent analysis (PCA) and demonstrate through exp erimen ts with synthetic and real data the sup erio rity of resulting estimates to t hose produced by pre-existing factor analysis approaches. W e also establish theoretical results that explain h o w our algorithm corrects the biases induced by con ven tional approac hes. An imp ortant feature of our algorithm is that its computational requ i rements are similar to those of PCA, which en j oys wide use in large part due to its efficiency . 1 In tro duction Linear factor mode ls hav e be en widely used for a long time and with notable success in economics, finance , medicine, psychology , and v arious other natura l a nd so cial scie nc e s (Har man, 197 6 ). In such a mo del, each observed v ariable is a linear combination of unobserved common facto rs plus idiosyncra tic noise, and the collection of ra ndom v ar iables is jointly Ga us sian. W e consider in this pap er the proble m of learning a factor mo del from a tra ining set of vector obser v ations. In particula r, our lear ning problem e n ta ils s im ultane o usly estimating the loa ding s of eac h factor and the r esidual v ar iance of each v ariable. W e s eek an estimate o f these parameters that b est explains out-of-s ample data. F or this purp ose, we consider the likelihoo d of test data that is indep enden t o f the training da ta. As s uch, our go al is to design a lear ning algor it hm that max imizes the likeliho od of a test set that is no t used in the learning pro cess. A common approach to factor mo del learning inv olves application of principa l component ana lysis (PCA). If the num b er o f factors is known and r e sidual v ariances are ass umed to b e uniform, P CA ca n b e applied to efficiently compute mo del par a meters that maximize likeliho o d of the training data (Tipping and Bishop, 1999). In or de r to simplify analys is, we be g in o ur study with a context for whic h PCA is ideally s uit ed. In particular, b efore treating more general mo dels, we will restrict attention to mo dels in which res idua l v ar iances are uniform. As a baseline a mong le a rning algo rithms, we cons ide r a pplying PCA tog e t her with cross- v alidatio n, computing likelihoo d-maximizing pa rameters for different num b ers of facto rs and sele c t ing the n umber of factors that maximizes lik eliho od of a po r tion of the training data that is reserved for v alidation. W e will refer to this base line a s u nif orm-r esidual r ank-c onstr aine d maximum-likeliho o d (URM) estimation. T o improv e on URM, we pr o pose uniform-r esidual tr ac e-p enalize d max i mum -li keliho o d (UTM) estimation. Rather than estima ting par ameters of a mo del with a fixed num b er of factors a nd iter ating ov er the num b er of factors, this a pproac h ma ximizes likelihoo d acr oss mo dels without restr icting the num b er of factors but instead pena lizing the tra ce o f a matrix derived fro m the mo del’s cov a riance ma trix. This tra ce pena lt y serves to regula rize the mo del and naturally se le c t s a pa rsimonious set of factor s. The co efficien t of this pena lt y is chosen via cross- v a lidation, similarly with the wa y in which the num b er of factors is s elected by URM. Thr ough a c omputational study using synthetic data, we demo nstrate that UTM r esults in b etter estimates than URM. In par t icula r , we find that UTM req uir es as little as tw o-thirds of the quantit y of data used by URM to match its p erformance. F urther, leveraging recent w or k on r andom matrix theory , we establish theo retical results that explain how UTM corr ects the biases induced by URM. W e then extend UTM to address the more genera l a nd pr actically relev ant lear ning pro blem in which residual v ariance s are not assumed to b e uniform. T o ev aluate the resulting alg orithm, which we refer to as sc ale d tra c e-p enalize d maximum-likeliho o d (STM) estimation, we carr y out ex periments using b oth synthetic data and r e al sto c k price data. The co mp utationa l r esults demons tr ate that STM leads to more ac curate 1 estimates than a lternativ es av a ila ble from pr io r art. W e als o provide an analysis to illustra te how these alternatives can suffer fro m bia ses in this nonuniform residual v a riance setting. Aside from the afo remen tioned empirical and theore tica l analyses, an imp ortant contribution o f this pap er is in the design of algorithms that make UTM and STM efficient. The UTM a pproac h is formulated as a conv ex semidefinite progr am (SDP), which can be so lv ed b y existing algor ithm s such as interior-p oint metho ds or alternating direction metho d of multipliers (see, e.g ., B oyd et al. (201 1 )). How ever, when the data dimension is lar ge, a s is the case in many relev ant contexts, such algor ith ms can take to o long to be practically useful. This exemplifies a recur ring obstacle that arises in the use of SDP formulations to study large data sets. W e prop ose a n algo rithm ba sed on PCA that solves the UTM formulation efficiently . In particular, we found this metho d to typically require three or ders o f magnitude les s co mput e time than the alternating direction metho d o f m ultipliers. V ariations of PCA s uch a s URM hav e enjoyed wide use to a larg e extent b ecause of their efficiency , and the computation time require d for UTM is essentially the sa me as that of URM. STM r equires additional computation but remains in r eac h for pr o blems where the co mp utationa l costs of URM ar e acceptable. Our for m ula tion is r elated to that of Chandr a sek aran et al. (2012), which estimates a factor mo del using a similar tra ce p enalt y . There are so me imp ortant differences , howev er, that distinguish our work. Fir st, the analysis of Chandras ek a ran et al. (2012) fo cuses on establishing p erfect recov er y of structur e in a n as ymptotic regime, wherea s our work makes the p oint that this trace p enalt y reduces nona symptotic bia s. Second, our approach to dealing with nonuniform res idual v ariances is distinctiv e and w e demonstrate through computational and theoretical analysis that this difference reduces bias. Third, Chandrasek ara n et al. (20 12) treats the problem as a se midefinite progra m, whose so lut ion is often co mput atio nally demanding when data dimension is large . W e provide an a lgorithm bas ed on P CA that efficiently s o lv es our pro blem. The algor ithm can a lso b e adapted to solve the for m ula tion of Chandrasek aran et al. (2012), thoug h that is not the aim of our pape r . In addition, there is a no ther thread o f r esearc h on r egularized ma xim um-likelihoo d estimation for c o v ar i- ance matr ic e s that relates lo osely to this pap er. Along this line, Baner jee et al. (20 08) r egularizes maximum- likelihoo d estimation by the ℓ 1 norm o f the in verse cov ar iance matrix in order to recov er a spa r se graphical mo del. An efficient alg o rithm called gra phical Lass o w as then pro p osed by F r iedman et a l. (200 8 ) for solv- ing this for m ula tion. Simila r for m ulations ca n also b e found in Y uan and Lin (200 7 ) and Ravikumar et al. (2011), who ins tea d p enalize the ℓ 1 norm of off-diagona l elements of the inverse cov ariance ma trix when computing maximum-lik eliho o d estimates . F or a detailed survey , s ee Pourahmadi (201 1 ). Although our approach shares some of the spir it represented by this line of resear c h in that w e also reg ularize ma xim um- likelihoo d estima t ion by an ℓ 1 -like p enalt y , the settings a re fundamentally different: while o urs fo cuses on a factor mo del, theirs are based on spar se g raphical mo dels. W e pro pose an approa c h that cor rects the bias induced by conv entional factor analysis , whereas their res ult s are mainly concerned with acc ur ate recovery of the top ology o f an underlying graph. As such, their work do es not addr e ss bias e s in cov aria nce estimates. On the alg orithmic front, we develop a simple and efficient solution metho d that builds o n PCA. On the contrary , their algor ithms are more complicated and computatio nally demanding. 1 2 Problem F orm ulation W e consider the problem of lear ning a factor mo del without knowledge of the num b er of factors. Spe cifically , we wan t to es tima te a M × M c o v ar iance matrix Σ ∗ from samples x (1) , . . . , x ( N ) ∼ N (0 , Σ ∗ ), wher e Σ ∗ is the sum of a symmetric ma tr ix F ∗ 0 a nd a diag onal matrix R ∗ 0. These s a mples can b e thought of as ge ner ated by a factor mo del of the form x ( n ) = F 1 2 ∗ z ( n ) + w ( n ) , wher e z ( n ) ∼ N (0 , I ) repr esen ts a set o f common factors and w ( n ) ∼ N (0 , R ∗ ) repr e s en ts re sidual noise. The num b er o f facto r s is repres en ted by rank( F ∗ ), and it is usually assumed to b e much smalle r than the dimension M . Our go a l is to pro duce based o n the obser v ed s a mples a factor loadings matrix F 0 and a r esidual v ar iance matrix R 0 such that the resulting factor mo del b est explains out-of-s ample data. In particular , we s eek a pair of ( F , R ) such that the cov ar iance ma t r ix Σ = F + R maximizes the average log-likeliho od of 1 The code of our algorithms can b e do wnloaded at: http://www .yhkao.com/RPCA-code.zip . 2 out-of-sample da ta: L ( Σ , Σ ∗ ) , E x ∼N (0 , Σ ∗ ) [log p ( x | Σ )] = − 1 2 M log (2 π ) + log det( Σ ) + tr( Σ − 1 Σ ∗ ) . This is als o equiv alent to minimizing the Kullback-Leibler divergence b et ween N (0 , Σ ∗ ) a nd N (0 , Σ ). 3 Learning Algorithms Given our ob jectiv e, one simple appr oac h is to cho ose an estimate Σ that ma ximizes in-sample log -lik eliho od: log p ( X | Σ ) = − N 2 M log(2 π ) + log det( Σ ) + tr( Σ − 1 Σ SAM ) , (1) where X = { x (1) , . . . , x ( N ) } , a nd we use Σ SAM = P N n =1 x ( n ) x T ( n ) / N to deno te the s ample cov ariance matrix. Here, the maximum likeliho od es t imate is simply given by Σ = Σ SAM . The pr oblem w ith maximum likelihoo d estimatio n in this context is that in-sample log- lik eliho od do es not accurately predict out-of-s ample log -lik eliho od unless the num b er of samples N far exc e e ds the dimension M . In fact, when the num b er of samples N is smaller than the dimension M , Σ SAM is ill-conditio ne d and the out-of-sample lo g-lik eliho od is negative infinity . One remedy to such p o or generaliz a tion inv olves ex plo iting factor structure, a s w e discuss in this se c tio n. 3.1 Uniform Residual V ariances W e b egin with a s imp lified scenario in which the residual v ar iances are assumed to be identical. As we will later see, such simplification facilitates theoretical analys is. This as sumpt ion will b e relaxed in the nex t subsection. 3.1.1 Constraining the Num b er o f F actors Given a belie f that the data is genera ted b y a factor model with few factors, one natural approach is to employ maximum likeliho od es tim atio n with a constraint on the n umber of factors. Now supp ose the residual v a r iances in the generative mo del are identical, and as a result we imp ose an a ddit iona l a ssumption that R is a multip le σ 2 I o f the identit y matrix. This lea ds to an optimization problem max F ∈ S M + ,σ 2 ∈ R + log p ( X | Σ ) (2) s.t. Σ = F + σ 2 I rank( F ) ≤ K where S M + denote the s et of a ll M × M pos itive semidefinite symmetric ma t r ic e s, a nd K is the exogeno usly sp ecified n umber of factors. In this case, we ca n efficiently compute a n ana lytical s olution v ia principal comp onen t analys is (PCA), a s e s tablished in Tipping and Bisho p (19 99 ). This inv olves firs t computing an eigendeco mposition of the sample cov ar iance matrix Σ SAM = BSB T , where B = [ b 1 . . . b M ] is orthonor m a l and S = diag( s 1 , . . . , s M ) with s 1 ≥ . . . ≥ s M . The solution to (2) is then given by ˆ σ 2 = 1 M − K M X i = K +1 s i ˆ F = K X k =1 ( s k − ˆ σ 2 ) b k b T k . (3) In other words, the e stimate for re s idual v aria nce equals the average o f the last M − K sample eigenv alues, whereas the estimate for factor lo ading ma trix is spa nned by the top K s ample eigenvectors with co efficien ts s k − ˆ σ 2 . W e will refer to this metho d as uniform-r esidual r ank-c onstr aine d maximum- li keliho o d estimation, 3 and use Σ K URM = ˆ F + ˆ σ 2 I to denote the c o v ar iance matrix resulting fro m this pro cedure. It is easy to see that the eig en v alues o f Σ K URM are s 1 , . . . , s K , ˆ σ 2 , . . . , ˆ σ 2 , as illustr a ted in Figur e 1 (a). A num b er of metho ds hav e be e n pr oposed for estimating the nu mber of factors K (Ak aike, 1987; B ishop , 1998; Mink a, 2000; Hiro se et al., 2011). Cross- v alidatio n provides a conceptually simple appr oac h that in practice works a t lea s t ab out a s well as any other. T o o btain b est p erformance from such a pro cedure, one would make us e o f so-called n -fold cross -v a lidation. T o keep things simple in o ur study and compar ison of estimation metho ds, for all metho ds we will cons ide r , we employ a version o f c r oss-v alidatio n that reserves a single subset of data for v a lidation and selection of K . Details of the pr o cedure we used ca n b e found in the app endix. Through se lection of K , this pro cedure arr iv es at a cov ariance matrix which we will deno te by Σ URM . 3.1.2 P enalizing the T race Although (2) can b e ele gan tly solved via P CA, it is unclea r that imp osing a har d co nstrain t on the num b er of factors will lea d to an optimal estimate. In particula r, one might susp ect a “softer” regula rization could improv e estimation accur a cy . Motiv ated by this idea, we prop ose p enalizing the trace instead of constraining the rank of the factor loa ding matrix. As we shall s ee in the e x periment results a nd theoretica l ana ly sis, such a n approa ch indeed improves estimatio n ac curacy significantly . Nevertheless, naively replacing the ra nk constra in t of (2) by a tr ace constraint tr( F ) ≤ t will result in a non-conv ex optimizatio n pr oblem, and it is not clear to us whether it can b e solved efficiently . Let us explore a r elated alter nativ e. Some stra igh tforward matrix a lgebra shows that if Σ = F + σ 2 I with F ∈ S M + and σ 2 > 0 , then the matrix defined by G = σ − 2 I − Σ − 1 is in S M + , with ra nk( G ) = r ank( F ). This obser v atio n, together with the well-known fact that the log- likeliho od o f X is concav e in the inverse cov a riance matrix Σ − 1 , motiv ates the following conv ex pro g ram: max G ∈ S M + ,v ∈ R + log p ( X | Σ ) s . t . Σ − 1 = v I − G tr( G ) ≤ t. Here, the v aria ble v repres en ts the recipro cal o f residual v ar iance. Pricing out the trace constra in t leads to a clo sely related problem in which the trace is pena lized r ather than co nstrained: max G ∈ S M + ,v ∈ R + log p ( X | Σ ) − λ tr( G ) (4) s . t . Σ − 1 = v I − G . W e will co ns ider the trace p enalized pro blem instead of the trace constr a ined problem bec a use it is mor e conv enient to design alg orithms that addre s s the p enalt y ra ther than the constraint. Let ( ˆ G , ˆ v ) b e an o ptima l solution to (4), and let Σ λ UTM = ( ˆ v I − ˆ G ) − 1 denote the cov ariance matrix estima t e derived fr o m it. Her e , the “U” indicates that residual v aria nces are as sumed to be uniform acro s s v ar ia bles and “ T” stands for tr ac e-p enalize d . It is e a sy to see that (4) is a semidefinite progr am. As s uc h, the problem ca n b e solved in p olynomial time by existing algor ithms such as in terior -point metho ds or alternating direction metho d o f mult ipliers (ADMM). How ever, when the num b er of v aria bles M is large, as is the cas e in many contexts of pra ctical impo rt, such algor ithm s can ta k e too long to b e pra c tica lly us efu l. One contribution of this pap er is an efficient metho d for solving (4), which we now descr ibe. The following result motiv ates the alg orithm we will prop ose fo r computing Σ λ UTM : Theorem 1 Σ SAM and Σ λ UTM shar e the same tr ac e and eigenve ctors, and let t ing t he eigenvalues of the two matric es, sorte d in de cr e asing or der, b e denote d by s 1 , . . . , s M and h 1 , . . . , h M , r esp e ct i vely, we have h m = max s m − 2 λ N , 1 ˆ v , for m = 1 , . . . , M . (5) 4 This theorem suggests an algor ithm for computing Σ λ UTM . First, we compute the eigendecomp osition of Σ SAM = BSB T , where B a nd S ar e as defined in Section 3.1 .1 . This pr o vides the e ig en vectors and tra ce of Σ λ UTM . T o obtain its eigenv a lues, we only need to determine the v alue of ˆ v such that the eigenv alues given by (5) sum to the desired tr a ce. This is equiv alent to deter mining the larges t integer K such that s K − 2 λ N > 1 M − K K · 2 λ N + M X m = K +1 s m ! . T o see this, no te that setting ˆ v − 1 = 1 M − K K · 2 λ N + M X m = K +1 s m ! h m = s m − 2 λ N , m = 1 , . . . , K ˆ v − 1 , m = K + 1 , . . . , M uniquely satisfies (5) and ens ures P M m =1 h m = P M m =1 s m . Algorithm 1 presents this metho d in greater detail. In our ex p eriments, we found this metho d to typically r equire three order s of magnitude less compute time than ADMM. F o r exa mple, it can solve a pro blem of dimension M = 1000 within seco nds on a workstation, whereas ADMM r equires ho urs to atta in the same level of ac curacy . Also note that for reasonably lar ge λ , this algo rithm will flatten most sample eige nv alues and allow only the larg est eigenv alues to rema in outstanding, effectively pr oducing a fa ctor mo del estimate. Figure 1(b) illustrates this effect. Compar ing Fig ure 1(a) and Figure 1 ( b), it is easy to see that URM and UTM primar ily differ in the lar gest eigenv alues they pr oduce: while URM simply retains the larges t sa mple eigenv alues, UTM subtracts a constant 2 λ/ N fr om them. As we sha ll see in the theor etical analysis, this subtr a ction indeed corrects the bia s incurr e d in sample eigenv a lues. 0 1 2 3 4 5 6 0 2 4 6 8 10 12 eigenvalues position sample URM (a) (b) Figure 1 : (a) An example o f s ample eig en v alues and the corr esponding eigenv alues of URM estimate, with M = 5 and K = 2. URM essentially pr e serv es the top eigenv alues and av era ges the remaining ones as residual v ar iance. (b) An exa mple of sample eigenv a lues and the corresp onding eigenv alues of UTM e stimate. With a particular choice o f λ , this estimate has tw o o utsta nding e igen v alues , but their magnitudes are 2 λ/ N b elo w the sa mple ones . Its residual v aria nce 1 / ˆ v is deter mined in a wa y that ensures the summation of UTM eigenv alues equal to the sample o ne . Like URM, the most computationally exp ensiv e step o f UTM lies in the eigendecomp osition. 2 Beyond that, the ev aluation o f UTM eigenv a lues for a n y given λ takes O ( M ), a nd is g enerally negligible. In our implemen tation, this regular ization parameter λ is c hos e n by cros s-v alidation from a r ange around M ˆ σ 2 , 2 In fact, a full eigendecomposition is not required, as we only need the top K eigenv ectors to compute the estimate. 5 whose rea sons will b ecome appar e nt in Section 5.1. W e denote by Σ UTM the cov aria nce matrix resulting from this cro ss-v alidation pro cedure. Algorithm 1 Pro cedure for computing Σ λ UTM Input: X , λ Output: Σ λ UTM Compute eigendecomp osition Σ SAM = BSB T v − 1 k ← 1 M − k k · 2 λ N + P M m = k +1 s m , ∀ k = 0 , 1 , . . . , M − 1 K ← max k : s k − 2 λ N > v − 1 k // define s 0 = ∞ ˆ v ← v K h m ← s m − 2 λ N if m ≤ K ˆ v − 1 otherwise , ∀ m = 1 , . . . , M Σ λ UTM ← P K k =1 ( h k − ˆ v − 1 ) b k b T k + ˆ v − 1 I 3.2 Non uniform Residual V ariances W e now relax the assumption o f unifor m residua l v ariance s and discuss several metho ds for the genera l case. As in the prev io us subsectio n, the hyper- parameters o f these metho ds will b e se le cted by cr oss-v alidatio n. 3.2.1 Constraining the Num b er o f F actors Without the a s sumption of uniform residual v aria nces, the ra nk ed-constraine d maximum-lik eliho o d formu- lation ca n b e wr itten as max F ∈ S M + , R ∈ D M + log p ( X | Σ ) (6) s.t. Σ = F + R rank( F ) ≤ K where D M + denote the set of all M × M p ositiv e semidefinite diagonal matrices . Unlike (2 ) , this for mulation is gene r ally hard to so lve, and therefore we consider tw o widely-used approximate solutions. The exp e ctation-maximization (EM) algorithm (Rubin and Thay er, 1982) is argua bly the most conven- tional appr o ac h to solving (6), though there is no guarantee that this will result in a globa l optimal solution. The algo rithm g enerates a s equence of iterates F 1 2 ∈ R M × K and R ∈ D M + , such that the cov ariance matrix Σ = F 1 2 F T 2 + R increases the log-likeliho od of X with each itera tio n. Each itera t ion in volves an es t imatio n step in which we assume the da ta are gener a ted according to the cov ariance matrix Σ = F 1 2 F T 2 + R , and compute exp ectations E[ z ( n ) | x ( n ) ] and E[ z ( n ) z T ( n ) | x ( n ) ] for n = 1 , . . . , N . A maximiza tion step then up dates F and R based o n these exp ectations. In our implemen tation, the initial F and R ar e selected by the MRH algorithm describ ed in the next par a graph. W e will denote the estimate pro duced by the EM a lgorithm by Σ K EM and that res ulting from further selection of K through cross- v a lida tion by Σ EM . A common heuristic for approximately solving (6) without ent ailing iterative computation is to first compute Σ K URM by P CA and then take the fa ctor matrix estimate to b e the ˆ F defined in (3) and the residual v ar iances to b e ˆ R m,m = Σ SAM − ˆ F m,m , for m = 1 , . . . , M . In other words, ˆ R m,m is selected so that the diagonal elements of the estimated cov aria nce matrix ˆ Σ = ˆ F + ˆ R are equal to those o f the sample cov ar iance matrix. W e will refer to this metho d a s mar ginal-varianc e-pr eserving r ank-c onstra ine d heuristic and de no te the r esulting estimates by Σ K MRH and Σ MRH . 6 3.2.2 P enalizing the T race W e now dev elo p an extensio n of Algor it hm 1 that applies when r esidual v ar iances ar e no n uniform. One formulation that may seem natura l involv es replacing v I in (4) with a diag onal ma tr ix V ∈ D M + . That is, max G ∈ S M + , V ∈ D M + log p ( X | Σ ) − λ tr( G ) (7) s . t . Σ − 1 = V − G . Indeed, a clos e ly related for m ula tion is prop osed in Chandrasek ara n e t al. (2012). How ever, a s we will se e in Sections 4 and 5 , solutions to this formulation s uff er from bias and do not comp ete well ag ainst the metho d we will prop ose next. That said, let us denote the es tima tes res ultin g from solving this for m ula tion by Σ λ TM and Σ TM , where “ T” sta nds for t ra c e-p enalize d . Also note that this formulation ca n b e efficiently solved by a str aigh tforward g eneralization o f Theorem 1, though we will not e laborate o n this. Our approa c h inv olves comp onen twise scaling of the da ta. Consider a n es tima t e ˆ Σ of Σ ∗ . Recall that we ev aluate the quality of the estimate using the exp ected log -lik eliho od L ( ˆ Σ , Σ ∗ ) of out-of-sample data. If we multiply e ac h da t a sample by a matrix T ∈ R M × M , the data set b ecomes T X , { Tx (1) , . . . , Tx ( N ) } , where Tx ( n ) ∼ N ( 0 , TΣ ∗ T T ). If we als o change o ur estimate a ccordingly to T ˆ ΣT T then the new ex p ected log-likeliho o d b ecomes L ( T ˆ ΣT T , TΣ ∗ T T ) = L ( ˆ Σ , Σ ∗ ) − log det T . Therefore, as lo ng as we constrain T to have unit determinant, L ( T ˆ ΣT T , TΣ ∗ T T ) will b e equal to L ( ˆ Σ , Σ ∗ ), suggesting that if ˆ Σ is a go od estimate of Σ ∗ then T ˆ ΣT T is a g oo d es t imate of TΣ ∗ T T . This motiv ates the following optimization problem: max G ∈ S M + ,v ∈ R + , T ∈ D M + log p ( T X | Σ ) − λ tr( G ) (8) s . t . Σ − 1 = v I − G . log det T ≥ 0 . The solution to this pr oblem identifies a comp onen twise-scaling matrix T ∈ D M + that allows the data to b e bes t-explained by a factor mo del with uniform r esidual v ariance s . Given an optimal solution, 1 / T 2 i,i should b e approximately pr oportiona l to the r esidual v a riance of the i th v ar iable, so that sc aling by T i,i makes r esidual v ar iances uniform. Note tha t the optimiza t io n pro blem constrains log det T to b e nonnegative rather than zero. This makes the feasible regio n co n vex, a nd this co nstrain t is binding at the optimal solution. Denote the o ptimal s olution to (8) by ( ˆ G , ˆ v , ˆ T ). Our estimate is thus given by ˆ T − 1 ( ˆ v I − ˆ G ) − 1 ˆ T − T . The o b jectiv e function o f (8) is not concav e in ( G , v , T ), but is biconcav e in ( G , v ) a nd T . W e solve it by co ordinate as c en t, a lternating b et ween optimizing ( G , v ) and T . This pr ocedure is g uaran teed c on vergence. In o ur implementation, we initialize T by I . W e will denote the r e sulting estima tes by Σ STM , wher e “ST” stands for sc ale d and tr ac e-p enalize d . 4 Exp erimen ts W e car ried o ut tw o sets of exp eriments to co mpa re the p erformance of aforementioned algorithms. The first is ba s ed o n s yn thetic data, whereas the second uses histor ical pr ices of sto cks that make up the S&P 50 0 index. 4.1 Syn thetic Data W e ge nerated tw o kinds of sy nthetic data. The first was generated by a mo del in which ea c h re sidual has unit v ar iance. This data was sampled acco r ding to the fo llowing pr ocedure, which takes as input the n umber of factors K ∗ , the dimension M , the facto r v aria nces σ 2 f , and the num be r of samples N : 1. Sample K ∗ orthonor m a l vectors φ 1 , φ 2 , . . . , φ K ∗ ∈ R M isotropica lly . 2. Sample f 1 , f 2 , . . . , f K ∗ ∼ N (0 , σ 2 f ). 7 3. Let F 1 2 ∗ = [ f 1 φ 1 f 2 φ 2 . . . f K ∗ φ K ∗ ]. 4. Let Σ ∗ = F 1 2 ∗ F T 2 ∗ + I . 5. Sample x (1) , . . . , x ( N ) iid fr om N (0 , Σ ∗ ). W e rep eated this pro cedure one hundred times for ea c h N ∈ { 50 , 1 00 , 200 , 400 } , with M = 200 , K ∗ = 10, a nd σ f = 5. W e applied to this data URM and UTM, since they are metho ds desig ned to treat such a scenario with uniform residual v ariance s. Regula rization parameters K and λ were s elected v ia cross- v alidatio n, where ab out 70 % of ea c h data set was used for training and 30% for v alidatio n. Figure 2(a) plots out-of- sample log-likeliho od delivered b y the tw o algor ithms. Performance is plotted a s a function of the log- ratio of the num b er o f s amples to the n umber of v aria bles, which represe nts the av aila bility of da ta relative to the n umber of v ar ia bles. W e expe ct this mea sure to drive pe r formance differences . UTM o utperforms URM in all sc enarios. The difference is larges t when data is scarce. When data is abundant, b oth metho ds work ab out as well. This should b e exp ected since bo th estimation metho ds ar e consistent. T o interpret this result in a more tangible way , we also plot the e quivalent data r e quir ement of UTM in Figur e 2(b). This metr ic is defined as the portio n o f training data required by UTM to match the per formance of URM. As we ca n s e e , UTM needs as little as 67% of the data used by the URM to reach the same es tim atio n a c curacy . −1.5 −1 −0.5 0 0.5 1 −315 −310 −305 −300 −295 log(N/M) average log likelihood URM UTM (a) −1.5 −1 −0.5 0 0.5 1 60 65 70 75 80 85 90 95 100 Equivalent Data Requirement of UTM (%) log(N/M) (b) Figure 2: (a) The average out-o f-sample lo g-lik eliho od delivered by URM and UTM, when residua l v ar iances are identical. (b) The av era ge p ortion of da ta re q uired by UTM to match the p erformance of URM. The error bars denote 95 % co nfidence interv al. Our sec ond t yp e of synthet ic data was genera ted using an ent ire ly similar pro cedure exc ept step 4 was replaced b y Σ ∗ = F 1 2 ∗ F T 2 ∗ + dia g( e r 1 , e r 2 , . . . , e r M ) , where r 1 , . . . , r M were sampled iid from N (0 , σ 2 r ). Note that σ r effectively co n tr ols the v ariatio n amo ng residual v ariances. Since these r esidual v ar ia nces are no n unifor m, EM, MRH, TM, and STM were applied. Figure 3 plots the results for the ca ses σ r = 0 . 5 and σ r = 0 . 8, co rresponding to mo derate and larg e v ar iation among r esidual v aria nces, r espectively . In either case, STM outpe rforms the a lter nativ es. Figure 4 further gives the equiv alent data req uiremen t of STM with res pect to each alter nativ e. It is worth p oin ting o ut that the per formance of MRH and TM deg rades significantly as the v a riation among re s idual v ar ia nces g r o ws, while EM is less susceptible to such change. W e will e laborate o n this phenomeno n in Section 5.2. 4.2 S&P 500 Data An impor tan t application area of factor analysis is finance, where return cov a r iances ar e us ed to assess risks and guide diversification (Markowit z, 1 952 ). The exp erimen ts w e will no w desc ribe involv e estimation of 8 −1.5 −1 −0.5 0 0.5 1 −325 −320 −315 −310 −305 −300 −295 log(N/M) average log likelihood EM MRH TM STM (a) −1.5 −1 −0.5 0 0.5 1 −325 −320 −315 −310 −305 −300 −295 log(N/M) average log likelihood EM MRH TM STM (b) Figure 3 : The average out-of-sample log -lik eliho od delivered b y EM, MRH, TM, and STM, when residuals hav e indep enden t random v a riances with (a) σ r = 0 . 5 and (b) σ r = 0 . 8. −1.5 −1 −0.5 0 0.5 1 50 60 70 80 90 100 Equivalent Data Requirement of STM (%) log(N/M) vs. EM vs. MRH vs. TM (a) −1.5 −1 −0.5 0 0.5 1 50 60 70 80 90 100 Equivalent Data Requirement of STM (%) log(N/M) vs. EM vs. MRH vs. TM (b) Figure 4: The equiv a len t data requir emen t o f STM with resp ect to EM, MRH, a nd TM when (a) σ r = 0 . 5 and (b) σ r = 0 . 8. The error bars denote 9 5 % co nfidence interv al. such c o v ar iances fr om historical daily returns of sto c ks represented in the S&P 50 0 index a s of March, 201 1. W e use price data collected from the p erio d starting Nov ember 2, 2001, and ending Augus t 9, 2007 . This per iod was chosen to av oid the erratic market behavior obser ved during the bursting o f the dot- c om bubble in 2000 and the financia l cr isis that beg an in 200 8. Norma lized daily log-r e t urns were computed from clos ing prices thro ugh a pro cess describ ed in detail in the app endix. Over this duration, there were 14 00 trading days and 4 53 of the sto cks under co nsideration were active. This pro duced a data set Y = { y (1) , . . . , y (1400) } , in w hich the i th comp onen t o f y ( t ) ∈ R 453 represents the no rmalized log-daily -return of sto c k i o n day t . W e generated estimates corres ponding to e ac h among a subset o f the 140 0 days. As would b e done in real-time application, for each such day t we used N data p oin ts { y ( t − N +1) , . . . , y ( t ) } tha t would hav e be e n av a ilable o n that day to compute the estimate and subs e quen t data to asses s p erformance. In particular, w e generated estimates every ten days b eginning o n day 1 2 00 a nd ending on day 1 290. F or each of these days, we ev a lua ted av erag e log-likeliho o d of log -daily-returns ov er the next ten days. Alg o rithm 2 formalize s this pro cedure. These tests served the pur pose of sliding- window cross-v alidatio n, as we tried a rang e of r egularization parameters over this time p eriod and used test results to select a regular ization par ameter for each algorithm. 9 Algorithm 2 T es ting Pro cedure T Input: lea rning a lgorithm U , r e g ularization pa rameter θ , window size N , time p oint t Output: test-set log - lik eliho od X ← { y ( t − N +1) , . . . , y ( t ) } (training set) X ′ ← { y ( t +1) , . . . , y ( t +10) } (test set) ˆ Σ ← U ( X , θ ) return log p ( X ′ | ˆ Σ) More spe c ifically , for each algor ithm U , its re gularization pa rameter w as selected by ˆ θ = a r gmax θ 9 X j =0 T ( U , θ , N , 1200 + 1 0 j ) . On days 1300 , 1 310 , . . . , 13 90, we g enerated o ne estimate p er day p e r algor it hm, in ea c h case using the regular iz ation pa rameter selected ear lier and ev a luating av era g e log-likeliho od over the next ten days. F or each alg orithm U , we to ok the average of these ten ten-day av erag es to b e its out-of-sample p erformance, defined as 1 100 9 X j =0 T ( U , ˆ θ , N , 13 00 + 10 j ) . Figure 5 plots the p erformance delivered EM, MRH, TM, and STM with N ∈ { 20 0 , 300 , . . . , 12 00 } . STM is the dominant so lutio n. It is natur a l to ask why the p erformance of ea c h a lgorithm improves then degrades as N grows. If the time s e r ies were stationary , one would exp ect p erformance to monoto nic a lly improve with N . How ever, this is a re a l time s e r ies and is not necessa rily stationar y . W e b eliev e that the distribution changes enough ov e r ab out a thousand trading days so that using historical da ta collected further back worsens estimates. This observ ation p oin ts o ut that in rea l applications STM is likely to gener ate sup erior results even when all aforementioned alg o rithms are allow ed to use all av aila ble da ta. This is in contrast with the exp eriments o f Section 4.1 inv olving synthetic data, which may have led to a n impre ssion that the per formance difference could b e ma de sma ll by using mor e data. 200 400 600 800 1000 1200 −615 −610 −605 −600 −595 −590 −585 N average log likelihood EM MRH TM STM Figure 5: The av erage lo g -lik eliho od of test s e t , delivered b y EM, MRH, TM, and STM, ov er different training-window sizes N . 5 Analysis In this sectio n, we e x plain why UTM and STM are ex p ected to outp erform a lternativ es as we hav e seen in our expe r imen tal re s ults. 10 5.1 Uniform Residual V ariances Let us sta r t with the simpler context in which residual v aria nc e s ar e ident ica l. In other words, let Σ ∗ = F ∗ + σ 2 I for a low rank matrix F ∗ and unifor m residual v aria nce σ 2 . W e will b egin our ana lysis with tw o desirable prop erties of UTM, a nd then mov e on to the compariso n b et ween UTM and URM. It is easy to see that Σ λ UTM is a consistent estimator of Σ ∗ for any λ > 0, since lim N →∞ 2 λ N = 0 and by Theorem 1 we hav e lim N →∞ Σ λ UTM = lim N →∞ Σ SAM a.s. − → Σ ∗ . Another imp ortant prop ert y of UTM is the fact that the tra ce of UTM es tima t e is the s ame as tha t of sa mple cov ariance matr ix. This preser v ation is des ir able as s uggested by the following res ult. Prop osition 1 F or any fixe d N , K , sc alars ℓ 1 ≥ ℓ 2 ≥ · · · ≥ ℓ K ≥ σ 2 > 0 , and any se quenc e of c ovarianc e matric es Σ ( M ) ∗ ∈ S M + with eigenvalues ℓ 1 , . . . , ℓ K , σ 2 , . . . , σ 2 , we have tr Σ SAM tr Σ ∗ a.s. − → 1 , as M → ∞ and Pr tr Σ SAM tr Σ ∗ − 1 ≥ ǫ ≤ 2 exp − N ǫ 2 Ω( M ) . (9) Note that, for any fix ed fixed num b er of sa mples N , the r igh t-hand-side of (9) diminishes tow ar ds 0 as data dimension M grows. In other words, as long as the data dimension is large compared to the num b er of factors K , the sample tra ce is usually a go o d e s tim ate of the true one, even when w e have very limited data samples. Now we would like to understand w hy UTM outp erforms URM. Recall that, given an eigendecomp osition Σ SAM = BSB T of the sa mple cov ariance matr ix, estimates genera ted b y URM and UTM admit eigendecom- po sitions Σ URM = B H URM B T and Σ UTM = B H UTM B T , devia ting from the sample eig en v alues S but not the e ig en vectors B . Hence, URM and UTM differ only in the way they s elect e ig en v alues : URM takes each eigenv alue to b e either a co nstan t or the c orrespo nding sample eigenv alue, while UTM takes each eigenv alue to b e either a c onstan t or the corres ponding sample eigenv a lue less another constant. Thus, lar ge eigenv alues pro duced by UTM are a constant offset less than those pro duced by URM, as illustrated in Figure 1. W e now e x plain wh y such subtraction lends UTM an a dv antage ov er URM in hig h-dimensional cases. Given the eig en vectors B = [ b 1 · · · b M ], let us consider the optimal eig en v alues that maximize out-of- sample lo g-lik eliho od o f the estimate. Sp ecifically , let us define H ∗ , argmax H ∈ D M + L ( BHB T , Σ ∗ ) . With some straightforw ar d algebra, we can show that H ∗ = dia g( h ∗ 1 , . . . , h ∗ M ), where h ∗ i = b T i Σ ∗ b i , for i = 1 , . . . , M . Let each i th sample e igen v alue b e denoted b y s i = S i,i , and let the i th larg est eigenv alue of Σ ∗ be denoted by ℓ i . The following theorem, whose pro of relies on tw o results fro m ra ndom matrix theor y found in Ba ik and Silverstein (2006) and Paul (2 007), relates sample eig en v alues s i to optimal eig en v alues h ∗ i . Theorem 2 F or al l K , sc alars ℓ 1 > ℓ 2 > · · · > ℓ K > σ 2 > 0 , ρ ∈ (0 , 1 ) , se quenc es N ( M ) such that | M / N ( M ) − ρ | = o (1 / p N ( M ) ) , c ovarianc e matric es Σ ( M ) ∗ ∈ S M + with eigenvalues ℓ 1 , . . . , ℓ K , σ 2 , . . . , σ 2 , and i su c h that ℓ i > (1 + √ ρ ) σ 2 , t h er e exists ǫ i ∈ (0 , 2 σ 2 / ( ℓ i − σ 2 )) su ch that h ∗ i p − → s i − (2 + ǫ i ) ρσ 2 as M → ∞ . Consider eig en v alues ℓ i that ar e la r ge rela tiv e to σ 2 so that ǫ i is negligible. In suc h ca ses, when in the asymptotic r egime iden tified by Theor em 2, we have h ∗ i ≈ s i − 2 ρσ 2 . This o bs erv ation sugges ts tha t , when the nu mber of factors K is r elativ ely sma ll compared to data dimension M , a nd when M and num b er of samples N s cale pro portionally to large num b ers, the wa y in whic h UTM subtra cts a constant from large sample eigenv alues s ho uld improve p erformance relative to URM, which do es no t mo dify lar ge sample eigenv alues. F urthermo re, comparing Theor em 1 and 2, we can see that the corr e ction term sho uld satisfy 2 λ N ≃ 2 ρσ 2 , or equiv ale ntly λ ≃ M σ 2 . This relation can help us narr o w the search r ange of λ in cros s-v alidation. It is w or th p oin ting o ut that the ov er- shooting e ffect of sample eigenv alues is well k no wn in statistics literature (see, e.g, Jo hnstone (2 001) ). Our contribution, howev er, is to quantify this effect for factor mo dels, and show that the larg e eigenv a lues are not only biased high, but bias ed hig h by the sa me a m o unt. 11 5.2 Non uniform Residual V ariances Comparing Figure 2, 3, and 4, we can se e that the relatio n betw een URM a nd UTM is ana lo gous to tha t betw een EM and STM. Specifica lly , the eq uiv a le nt data req uiremen t of UTM versus URM b eha ves v er y similarly as tha t of STM versus EM. This should not b e surpr ising, a s we now explain. T o develop an int uitive understanding of this phenomenon, let us co nsider an idealiz ed, analytica lly tractable context in whic h b oth EM a nd STM successfully estimate the re la tiv e magnitudes of res idual v ar iances. In particular , supp ose we impo se an additiona l constra in t R ∝ R ∗ int o (6) and an a dditional constraint T ∝ R − 1 2 ∗ int o (8). 3 In this c ase, it is straightforward to show that EM is equiv a len t to URM with data sc aled by R − 1 2 ∗ , and STM is equiv alent to UTM with the same scaled da ta. Therefore, by the argument given in Section 5.1, it is na tu r a l to exp ect STM outp erforms E M. A question that remains, how ever, is why MRH and TM are not as effective as STM. W e b eliev e the rea s on to be that they tend to s elect factor loadings that assign larger v alue s than appro priate to v ariables with lar ge residual v ariance s . Indeed, such dis a dv a n ta ge has b een observed in our synthetic data exp e r imen t: when the v ar iation among re s idual v ar iances increa ses, the p erformances of MRH a nd TM degr ade significantly , as s ho wn in Figure 3. Again, let us illustrate this phenomenon thro ugh an idealized co n tex t . Sp ecifically , co nsider a ca se in which the sample cov aria nce matrix Σ SAM turns out to be iden tical to Σ ∗ = F ∗ + R ∗ , with R ∗ = diag( r , 1 , 1 , . . . , 1) a nd F ∗ = 11 T , where 1 is a vector with every comp onen t equal to 1. Recall that MRH uses the eigenvectors of Σ SAM corres p onding to the la rgest eigenv alues as factor loading vectors. O ne would hop e that factor lo ading estimates ar e insensitive to under lying residual v ariances . Howev er, the following prop osition sugge sts that, a s r grows, the firs t comp onent of the fir st eig en vector o f Σ SAM dominates other comp onen ts by an unbounded ratio . Prop osition 2 Supp ose R ∗ = diag ( r, 1 , 1 , . . . , 1) and F ∗ = 11 T , r > 1 . L et f = [ f 1 . . . f M ] T b e the top eigenve ctor of Σ ∗ . Then we have f 1 /f i = Ω( r ) , ∀ i > 1 . As such, the factor estimated by this top e ig en vector ca n be gross ly mis r epresen ted, implying MRH is not preferable when res idual v aria nces differ significa n tly from each other. TM suffers from a similar problem, thoug h p ossibly to a lesser degr ee. The matrix V in the TM for m u- lation (7) represents an estimate o f R − 1 ∗ . F or simplicity , let us co nsider an idealized T M for m ula tion w hich further incorp orates a co nstrain t V = R − 1 ∗ . That is, max V ∈ D M + , G ∈ S M + log p ( X | Σ ) − λ tr( G ) (10) s . t . Σ − 1 = V − G Σ SAM = Σ ∗ V = R − 1 ∗ . Using the same setting as in Prop osition 2, we ca n show that when this idealized TM a lgorithm pro duces an es tim ate o f ex actly one factor as desired, the fir st c o mponent of the estimated factor loading vector is strictly la rger than the o ther comp onen ts, as formally describ ed in the following pr oposition. Prop osition 3 Supp ose R ∗ and F ∗ ar e given as in Pr op osition 2, and let the estimate r esulting fr om ( 1 0 ) b e ˆ Σ = R ∗ + ˆ F . Then for al l λ > 0 we have 1. r ank ( ˆ F ) = 1 if and only if λ < M N / 2 . 2. In that c ase, if we r ewrite ˆ F as ff T , wher e f = [ f 1 . . . f M ] T , t he n ∀ i > 1 , f 1 /f i is gr e ater than 1 and monotonic al ly incr e asing with r . F urthermor e, if λ > ( M − 1) N / 2 , then f 1 /f i = Ω( r ) . Again, this repr e s en ts a bias that ov eremphasize s the v ar iable with lar ge residual v aria nce, even when we incorp orate additional infor mation into the formulation. O n the co n tr ary , it is eas y to see that STM can accurately recov er all ma jor factors if s imilar favorable co ns train ts ar e incor p orated into its formulation (ie., if we set Σ SAM = Σ ∗ and T ∝ R − 1 2 ∗ in (8 ) ). 3 Here we use the notation A ∝ B to mean that there exists γ ≥ 0 such that A = γ B . 12 6 Conclusion W e prop osed facto r mo del estimates UTM and STM, b oth of which are r egularized versions of those that would be pro duced via PCA. UTM dea ls with contexts wher e res idual v ar iances a re a ssumed to b e uniform, whereas STM handles v a riation a mong residual v aria nces. O ur algorithm for computing the UTM estimate is as efficient as conv entional PCA. F or STM, we pr o vide an iterative algo rithm with guaranteed conv ergence. Computational e x periments inv olving bo th s yn thetic and real data demonstr ate that the estimates pr oduced by our appro ac h are sig nifican tly mor e accura te than those pr oduced by pre-exis tin g metho ds. F ur th er , we provide a theo retical analys is that elucida t es the wa y in which UTM and STM cor rects biases induced by alternative a pproach es. Let us clo se by mentioning a few p ossible directions for further resea rc h. O ur analysis has relied on data being generated by a Gaus s ian distribution. It w ould b e useful to understand how things change if this assumption is relaxed. F urther, in practice estimates are often used to guide subsequent decisio ns. It would be interesting to study the impact of STM on decisio n qua lit y and whether there ar e other a pproac hes that fare b etter in this dimensio n. Our recent pap er on directed principle comp onen t ana lysis (Kao and V an Roy, 2012) re la tes to this. In so me applications, P C A is used to identify a subspace for dimension reductio n. It would b e interesting to under stand if and when the subs pa ce identified by STM is more suitable. Finally , there is a g ro wing b ody of resear c h on robust v aria tions of factor analy s is a nd PCA. These include the pursuit of sparse factor loa dings (Jolliffe et al., 200 3 ; Zou et a l., 200 4 ; D’Aspremont et al., 2004; Jo hnstone and Lu, 2007; Amini and W ainwright , 200 9 ), a nd the metho ds that are res is tan t to corr upted data (Pison et al., 2003; Cand` es et al., 2009; Xu et al., 201 0 ). It would b e in tere sting to explore connec tio ns to this b ody of work. A Pro ofs W e first prov e a main lemma that will b e used in the pro of of Theo rem 1 a nd P r oposition 3. Lemma 1 Fixing V ∈ D M ++ , c onsider the optimization pr oblem max G ∈ S M + log p ( X | Σ ) − λ tr( G ) (11) s . t . Σ − 1 = V − G . L et G V b e the solution to (11), λ ′ = 2 λ/ N , and UDU T b e an eigende c omp osition of matrix V 1 2 ( Σ SAM − λ ′ I ) V 1 2 with U orthonormal. Then we have ( V − G V ) − 1 = V − 1 2 ULU T V − 1 2 , wher e L is a diagonal m atrix with entries L i,i = max { D i,i , 1 } , ∀ i = 1 , . . . , M . Pro of W e ca n rewrite (11 ) as min G − log det ( V − G ) + tr(( V − G ) Σ SAM ) + λ ′ tr( G ) s.t. G ∈ S M + Now as sociate a Lag r ange multiplier Ω ∈ S M + with the G ∈ S M + constraint and write down the La grangian as L ( G , Ω ) = − lo g det ( V − G ) + tr(( V − G ) Σ SAM ) + λ ′ tr( G ) − tr( ΩG ) . Let Ω ∗ denote the dual solution. By KK T co ndit io ns we hav e: ∇ G L G V , Ω ∗ = ( V − G V ) − 1 − Σ SAM + λ ′ I − Ω ∗ = 0 (12) Ω ∗ , G V ∈ S M + (13) tr( Ω ∗ G V ) = 0 . (14) Recall that ( V − G V ) − 1 = ( V 1 2 V 1 2 − G V ) − 1 = V − 1 2 ( I − V − 1 2 G V V − 1 2 ) − 1 V − 1 2 . (15) 13 Plugging this into (12) we get V − 1 2 ( I − V − 1 2 G V V − 1 2 ) − 1 V − 1 2 = Σ SAM − λ ′ I + Ω ∗ and so I − V − 1 2 G V V − 1 2 − 1 = V 1 2 ( Σ SAM − λ ′ I + Ω ∗ ) V 1 2 (16) = V 1 2 ( Σ SAM − λ ′ I ) V 1 2 + V 1 2 Ω ∗ V 1 2 . By (13 ), b o th V − 1 2 G V V − 1 2 and V 1 2 Ω ∗ V 1 2 are in S M + . Let an eigendecomp osition of V − 1 2 G V V − 1 2 be A QA T for which A = [ a 1 . . . a M ] is orthonorma l and Q i,i ≥ 0 , i = 1 , . . . , M . Using (14) a nd the fa ct that trac e is inv aria n t under cyclic p erm utations , we hav e 0 = tr( Ω ∗ G V ) = tr( Ω ∗ V 1 2 V − 1 2 G V V − 1 2 V 1 2 ) = tr ( V 1 2 Ω ∗ V 1 2 )( V − 1 2 G V V − 1 2 ) = tr ( V 1 2 Ω ∗ V 1 2 ) A QA T = tr A T ( V 1 2 Ω ∗ V 1 2 ) A Q = M X i =1 Q i,i a T i ( V 1 2 Ω ∗ V 1 2 ) a i . Since Q i,i ≥ 0 a nd V 1 2 Ω ∗ V 1 2 ∈ S M + , we ca n deduce a T i ( V 1 2 Ω ∗ V 1 2 ) a i = 0 if Q i,i > 0 , ∀ i = 1 , . . . , M . Let I + = { i : Q i,i > 0 } . Becaus e V 1 2 Ω ∗ V 1 2 is p ositiv e semidefinite, for all i 0 ∈ I + we also have V 1 2 Ω ∗ V 1 2 a i 0 = 0. F urthermore, since ( I − V − 1 2 G V V − 1 2 ) − 1 = A diag 1 1 − Q 1 , 1 , . . . , 1 1 − Q M ,M A T m ultiplying b oth sides of (16) by a i 0 leads to a i 0 1 − Q i 0 ,i 0 = V 1 2 ( Σ SAM − λ ′ I ) V 1 2 a i 0 which shows a i 0 is an eigenv ector of V 1 2 ( Σ SAM − λ ′ I ) V 1 2 . Rec all that V 1 2 ( Σ SAM − λ ′ I ) V 1 2 = UDU T . Without lo ss of generality , we can ta ke a i = u i for a ll i ∈ I + . Indeed, since I + = { i : Q i,i > 0 } , w e hav e A QA T = M X i =1 Q i,i a i a T i = X i ∈I + Q i,i a i a T i + X j / ∈ I + 0 · a j a T j = X i ∈I + Q i,i u i u T i + X j / ∈ I + 0 · u j u T j which implies we ca n further take A = U . This gives ( I − V − 1 2 G V V − 1 2 ) − 1 = ULU T , (17) where L is a diagona l matrix with en tries L i,i = 1 1 − Q i,i , for i = 1 , . . . , M . Plugg ing this in to (16) we hav e ULU T = UDU T + V 1 2 Ω ∗ V 1 2 . (18) F or any i 0 ∈ I + , m ultiplying the b oth sides of the a bov e equatio n by u i 0 results in L i 0 ,i 0 u i 0 = D i 0 ,i 0 u i 0 + 0 which implies L i 0 ,i 0 = D i 0 ,i 0 , or more genera lly L i,i = D i,i if Q i,i > 0 1 otherwise , i = 1 , . . . , M . 14 Since L i,i = 1 1 − Q i,i ≥ 1, to see L i,i = max { D i,i , 1 } , it remains to show L i,i ≥ D i,i for all i . This follows by rearr anging (18) ULU T − UDU T = V 1 2 Ω ∗ V 1 2 0 ⇒ L − D 0 ⇒ L i,i ≥ D i,i , ∀ i = 1 , . . . , M . Finally , plugg ing (17) into (15) completes the pro of. Theorem 1 Σ SAM and Σ λ UTM shar e the same tr ac e and eigenve ctors, and let t ing t he eigenvalues of the two matric es, sorte d in de cr e asing or der, b e denote d by s 1 , . . . , s M and h 1 , . . . , h M , r esp e ct i vely, we have h m = max s m − 2 λ N , 1 ˆ v , for m = 1 , . . . , M . Pro of Let U diag( s 1 , . . . , s M ) U T be an eigendeco mposition of Σ SAM such that U is orthonorma l. Define V = ˆ v I , and note that an eigendecomp osition o f matrix V 1 2 Σ SAM − 2 λ N I V 1 2 = ˆ v Σ SAM − 2 λ N I can b e wr itt en as UDU T , where D i,i = ˆ v ( s i − 2 λ / N ) , i = 1 , . . . , M . By Lemma 1 we hav e Σ λ UTM = ( ˆ v I − ˆ G ) − 1 = V − 1 2 ULU T V − 1 2 = 1 ˆ v ULU T where L ∈ D M + , and L i,i = max { D i,i , 1 } = max { ˆ v ( s i − 2 λ/ N ) , 1 } = ˆ v max { s i − 2 λ/ N , 1 / ˆ v } = ˆ v h i , ∀ i = 1 , . . . , M . Therefor e , Σ λ UTM = 1 ˆ v ULU T = UHU T . where H = diag( h 1 , . . . , h M ), a s desired. F urthermo re, recall that we imp ose no constraint on v w he n solving UTM, and as a result the partial deriv a tiv e of the o b jectiv e function with res p ect to v should v a nis h at ˆ v . That is, ∂ ∂ v (log p ( X | Σ ) − λ tr( G )) ˆ G , ˆ v = − N 2 tr( Σ SAM ) − tr ( ˆ v I − ˆ G ) − 1 = 0 which implies tr( Σ SAM ) = tr ( ˆ v I − ˆ G ) − 1 = tr Σ λ UTM . Theorem 2 F or al l K , sc alars ℓ 1 > ℓ 2 > · · · > ℓ K > σ 2 > 0 , ρ ∈ (0 , 1 ) , se quenc es N ( M ) such that | M / N ( M ) − ρ | = o (1 / p N ( M ) ) , c ovarianc e matric es Σ ( M ) ∗ ∈ S M + with eigenvalues ℓ 1 , . . . , ℓ K , σ 2 , . . . , σ 2 , and i such that ℓ i > (1 + √ ρ ) σ 2 , ther e exists ǫ i ∈ (0 , 2 σ 2 / ( ℓ i − σ 2 )) such that h ∗ i p − → s i − (2 + ǫ i ) ρσ 2 . Pro of Let ALA T be an eigendecomp osition of Σ ∗ , where A = [ a 1 . . . a M ] is orthono rmal a nd L = diag( ℓ 1 , . . . , ℓ K , σ 2 , . . . , σ 2 ). Recall that h ∗ i = b T i Σ ∗ b i = b T i K X j =1 a j ℓ j a T j + M X j = K +1 a j σ 2 a T j b i = K X j =1 ℓ j ( b T i a j ) 2 + σ 2 M X j = K +1 ( b T i a j ) 2 . (19) Using Theo rem 4 in Paul (200 7 ), we have ( b T i a i ) 2 a . s . − → 1 − ρσ 4 ( ℓ i − σ 2 ) 2 1 + ρσ 2 ℓ i − σ 2 . (20) 15 F urthermo re, deco mposing b i int o ˜ b i + ˜ b ⊥ i , where ˜ b i ∈ spa n( a 1 , . . . , a K ) and ˜ b ⊥ i ∈ spa n( a K +1 , . . . , a M ), by Theo rem 5 in Paul (200 7 ) we have ˜ b i k ˜ b i k p − → a i . This implies if 1 ≤ j ≤ K, j 6 = i , b T i a j = ˜ b T i a j p − → k ˜ b i k a T i a j = 0 (21) and for K < j ≤ M , M X j = K +1 ( b T i a j ) 2 = 1 − K X j =1 b T i a j 2 p − → 1 − ( b T i a i ) 2 . (22) Plugging (2 0 ), (21), and (22) into (19) we arr iv e at h ∗ i p − → ℓ i 1 − ρσ 4 ( ℓ i − σ 2 ) 2 1 + ρσ 2 ℓ i − σ 2 + σ 2 1 − 1 − ρσ 4 ( ℓ i − σ 2 ) 2 1 + ρσ 2 ℓ i − σ 2 = ℓ i 1 + ρσ 2 / ( ℓ i − σ 2 ) = ℓ i − 1 + (1 − ρ ) σ 2 ℓ i − (1 − ρ ) σ 2 ρσ 2 . (23) By Theo rem 1.1 in Baik and Silverstein (20 06) we have s i a . s − → ℓ i + ρℓ i σ 2 ℓ i − σ 2 = ℓ i + 1 + σ 2 ℓ i − σ 2 ρσ 2 . (24) Finally , combining (23) and (2 4) yields h ∗ i p − → s i − (2 + ǫ i ) ρσ 2 where ǫ i = (1 − ρ ) σ 2 ℓ i − (1 − ρ ) σ 2 + σ 2 ℓ i − σ 2 . It is easy to see 0 < ǫ i < σ 2 ℓ i − σ 2 + σ 2 ℓ i − σ 2 , as desired. Prop osition 1 F or any fixe d N , K , sc alars ℓ 1 ≥ ℓ 2 ≥ · · · ≥ ℓ K ≥ σ 2 > 0 , and any se quenc e of c ovarianc e matric es Σ ( M ) ∗ ∈ S M + with eigenvalues ℓ 1 , . . . , ℓ K , σ 2 , . . . , σ 2 , we have tr Σ SAM tr Σ ∗ a.s. − → 1 as M → ∞ and Pr tr Σ SAM tr Σ ∗ − 1 ≥ ǫ ≤ 2 exp − N ǫ 2 Ω( M ) . Pro of Let ALA T be an eigendecomp osition of Σ ∗ , where A = [ a 1 . . . a M ] is orthono rmal a nd L = diag( ℓ 1 , . . . , ℓ K , σ 2 , . . . , σ 2 ). Thus, tr Σ ∗ = tr L = P K k =1 ℓ k + ( M − K ) σ 2 . Note that tr Σ SAM = tr( AA T Σ SAM ) = tr( A T Σ SAM A ) = M X i =1 a T i Σ SAM a i = M X i =1 1 N N X n =1 a T i x ( n ) 2 . Since x ( n ) ∼ N (0 , Σ ∗ ), we can think of each x ( n ) as generated by x ( n ) = Az ( n ) , where z ( n ) is s ampled iid from N (0 , L ). This lea ds to tr Σ SAM = M X i =1 1 N N X n =1 z 2 ( n ) ,i = M X i =1 L i,i N w 2 i , where w 2 i ’s ar e i.i.d. samples from χ 2 N . Therefore , lim M →∞ tr Σ SAM tr Σ ∗ = lim M →∞ P M i =1 L i,i N w 2 i P K k =1 ℓ k + ( M − K ) σ 2 = lim M →∞ P K k =1 ℓ k w 2 i N + P M i = K +1 σ 2 w 2 i N P K k =1 ℓ k + ( M − K ) σ 2 . 16 Since the first terms in the denominator and the numerator a r e b ounded and do not scale with K , we can drop them in the limit and rewrite lim M →∞ tr Σ SAM tr Σ ∗ = lim M →∞ P M i = K +1 σ 2 w 2 i N ( M − K ) σ 2 = lim M →∞ 1 M − K M X i = K +1 w 2 i N = 1 (w. p. 1) due to the strong law of la rge num b ers and the fact that E [ w 2 i ] = N . T o pr o ve the second part of the prop osition, let us rewr ite w 2 i = P N n =1 ˜ w 2 i,n , where ˜ w i,n are i.i.d samples from N (0 , 1). Therefore, tr Σ SAM − tr Σ ∗ = M X i =1 N X n =1 L i,i N ˜ w 2 i,n − M X i =1 L i,i = M X i =1 N X n =1 L i,i N ˜ w 2 i,n − 1 . By the exp onen tial inequality for chi-square distributions (Laurent and Ma ssart, 2000), we have Pr( | tr Σ SAM − tr Σ ∗ | ≥ 2 ξ √ τ ) ≤ 2 exp( − τ ) , ∀ τ > 0 , where ξ = r P M i =1 P N n =1 L i,i N 2 = q 1 N P M i =1 L 2 i,i . T a king τ = ǫ tr Σ ∗ 2 ξ 2 , we can r ewrite the a bov e inequal- it y as Pr tr Σ SAM tr Σ ∗ − 1 ≥ ǫ ≤ 2 ex p − ǫ tr Σ ∗ 2 ξ 2 ! = 2 exp − N ǫ 2 P M i =1 L i,i 2 4 P M i =1 L 2 i,i . The desired r esult then follows str aigh tforwardly from the fact tha t P M i =1 L i,i 2 P M i =1 L 2 i,i = M σ 2 + κ 1 2 M σ 4 + κ 2 = Ω( M ) , since κ 1 = P K i =1 ( ℓ i − σ 2 ) a nd κ 2 = P K i =1 ( ℓ 2 i − σ 4 ) a re b oth constants. Prop osition 2 Supp ose R ∗ = diag ( r, 1 , 1 , . . . , 1) and F ∗ = 11 T , r > 1 . L et f = [ f 1 . . . f M ] T b e the top eigenve ctor of Σ ∗ . Then we have f 1 /f i = Ω( r ) , ∀ i > 1 . Pro of Note that f is the solution to the following o pt imizatio n pro blem max u ∈ R M u T ( R ∗ + F ∗ ) u s.t. k u k 2 = 1 and the ob jectiv e function can wr itt en b e as rf 2 1 + P M i =2 f 2 i + P M i =1 f i 2 . By symmetry , we hav e f 2 = f 3 = . . . = f M . T o simplify notation, let us r epresen t f as [ x y y . . . y ] T . Supp o se the la rgest eigenv alue is q . By definitio n we have ( R ∗ + F ∗ ) f = q f , o r equiv alently ( r + 1) x + ( M − 1) y = qx x + M y = qy . Solving the a bov e equations leads to q = 1 2 M + r + 1 + p ( M + r + 1) 2 − 4 ( M r + 1 ) = Ω( r ) , and plugg ing this ba c k to the ab o ve equa tio ns y ields x/y = q − M = Ω( r ) . 17 Prop osition 3 Supp ose R ∗ and F ∗ ar e given as in Pr op osition 2, and let the estimate r esulting fr om ( 1 0 ) b e ˆ Σ = R ∗ + ˆ F . Then for al l λ > 0 we have 1. r ank ( ˆ F ) = 1 if and only if λ < M N / 2 . 2. In that c ase, if we r ewrite ˆ F as ff T , wher e f = [ f 1 . . . f M ] T , t he n ∀ i > 1 , f 1 /f i is gr e ater than 1 and monotonic al ly incr e asing with r . F urthermor e, if λ > ( M − 1) N / 2 , then f 1 /f i = Ω( r ) . Pro of Let λ ′ = 2 λ/ N , C = R − 1 2 ∗ ( Σ ∗ − λ ′ I ) R − 1 2 ∗ , UDU T be an e igendecompositio n of C , and L b e the diagonal matrix with entries L i,i = max { D i,i , 1 } , ∀ i = 1 , . . . , M . Applying Lemma 1 with Σ SAM = Σ ∗ and V = R − 1 ∗ we have ˆ Σ = R 1 2 ∗ ULU T R 1 2 ∗ = R 1 2 ∗ UIU T R 1 2 ∗ + R 1 2 ∗ U ( L − I ) U T R 1 2 ∗ = R ∗ + R 1 2 ∗ U ( L − I ) U T R 1 2 ∗ and therefo r e ˆ F = R 1 2 ∗ U ( L − I ) U T R 1 2 ∗ . Since L i,i = max { D i,i , 1 } , we further hav e rank( ˆ F ) = r a nk ( L − I ) = | { i : D i,i > 1 } | . Recall that D denotes the e ig en v alues of matrix C , which can be wr itt en as R − 1 2 ∗ ( Σ ∗ − λ ′ I ) R − 1 2 ∗ = R − 1 2 ∗ Σ ∗ R − 1 2 ∗ − λ ′ R − 1 ∗ = R − 1 2 ∗ ( R ∗ + F ∗ ) R − 1 2 ∗ − λ ′ I − 1 − 1 r e 1 e T 1 = I + aa T − λ ′ I + λ ′ 1 − 1 r e 1 e T 1 = (1 − λ ′ ) I + aa T + λ ′ 1 − 1 r e 1 e T 1 where a = h 1 √ r 1 . . . 1 i T and e 1 = [1 0 . . . 0] T . Let A = aa T + λ ′ 1 − 1 r e 1 e T 1 . Since C = (1 − λ ′ ) I + A , we know C and A share the same eige nvectors, and the corr e s ponding eigenv alues differ by (1 − λ ′ ). Thus, the num b er of the eigenv a lues o f C tha t are g reater than 1 is equal to the num b er of the eigenv alues of A that are gr eater than λ ′ . How ever, ra nk ( A ) = r ank ( aa T + λ ′ 1 − 1 r e 1 e T 1 ) = 2, which implies A has only 2 no n-zero eigenv alues. Let q be one of them. By s ymmetry , we can denote the corres p onding eigenv ector by u = [ x y . . . y ] T . Then we hav e Au = q u , which lea ds to x r + ( M − 1 ) y √ r + λ ′ − λ ′ r x = q x x √ r + ( M − 1) y = q y. (25) After e limina ting x and y we ar riv e at the fo llo wing equation rq 2 − (( M − 1) r + ( r − 1) λ ′ + 1 ) q + λ ′ ( M − 1 )( r − 1) = 0 . Let s ( q ) denote the left-hand-side of the ab ov e equation. It is ea sy to see that its discriminant ∆ > 0, and therefore the eq uation s ( q ) = 0 ha s tw o distinct rea l ro ots, e a c h co rrespo nding to one of the non-zer o eigenv alues of A . Reca ll that r ank( ˆ F ) equals the num b er of the eigenv alues of A that ar e g r eater than λ ′ , which is equal to the num b er o f the ro ots o f s ( q ) = 0 that are g reater than λ ′ . Thus, rank( ˆ F ) = 1 if and only if one ro ot of s ( q ) = 0 is greater than λ ′ and the other is less than λ ′ . This is equiv a len t to s ( λ ′ ) < 0 ⇐ ⇒ λ ′ ( λ ′ − M ) < 0 ⇐ ⇒ λ ′ < M ⇐ ⇒ λ < M N 2 . T o prove the second part of this prop osition, let q + be the gre atest eigenv a lue of A , o r equiv alently the greater ro ot of s ( q ) = 0 , and u + be the cor responding eigenv ector. That is, q + = 1 2 r ( M − 1) r + ( r − 1) λ ′ + 1 + √ ∆ 18 and u + = [ x + y + . . . y + ] T , where ( x + , y + ) is a solution of ( x, y ) in (25) given q = q + . Recall that ˆ F = R 1 2 ∗ U ( L − I ) U T R 1 2 ∗ = R 1 2 ∗ ( q + − λ ′ ) u + u T + R 1 2 ∗ , which leads to f = ( q + − λ ′ ) 1 2 R 1 2 ∗ u + = ( q + − λ ′ ) 1 2 [ √ rx + y + . . . y + ], and f 1 f i = √ r x + y + = r ( q + + 1 − M ) , ∀ i > 1 . It is eas y to show lim λ ′ → 0 + q + = 1 r + M − 1 a nd as a result lim λ ′ → 0 + f 1 f i = 1. Therefore, to show f 1 f i is grea ter than 1 and monotonically increa sing with r , it is sufficient to show that d f 1 f i dr > 0 , ∀ r > 1 , λ ′ ∈ (0 , M ) . By str aigh t for w ard alge bra we hav e d f 1 f i dr = ( λ ′ − M + 1) + 1 √ ∆ (( λ ′ r − λ ′ − M r + r ) ( λ ′ − M + 1) + ( M − 1 + λ ′ )) . Now co nsider three c a ses: 1. 0 < λ < ( M − 1) N 2 : In this case 0 < λ ′ < M − 1 and d f 1 f i dr > 0 ⇐ ⇒ (( λ ′ r − λ ′ − M r + r ) ( λ ′ − M + 1) + ( M − 1 + λ ′ )) > ( M − 1 − λ ′ ) √ ∆ ⇐ ⇒ − λ ′ r + λ ′ + M r − r + M − 1 + λ ′ M − 1 − λ ′ 2 > ∆ . Expanding the b oth sides of the last inequa lit y yields the desired result. 2. λ = ( M − 1) N 2 : In this case λ ′ = M − 1 and d f 1 f i dr = 2( M − 1) √ ∆ > 0, a s desired. 3. ( M − 1) N 2 < λ < M N 2 : In this case λ ′ − M + 1 ∈ (0 , 1 ), a nd we have ( λ ′ r − λ ′ − M r + r ) ( λ ′ − M + 1) + ( M − 1 + λ ′ ) = r ( λ ′ − M + 1) 2 − λ ′ ( λ ′ − M + 1) + ( λ ′ + M − 1) > − λ ′ + ( λ ′ + M − 1) > 0 which implies d f 1 f i dr > ( λ ′ − M + 1). Since the deriv ative is b ounded b elo w b y a p ositiv e constant, we conclude f 1 f i = Ω( r ). B Exp erimen t Detai ls B.1 Co ordinate Ascent Algorithm for STM Algorithm 3 descr ib es our co ordinate a scen t metho d for solving STM. 19 Algorithm 3 Pro cedure for solving STM Input: X , λ Output: Σ λ STM T ← I . rep eat Σ ← UTM( T X , λ ) T ← a rgmax ¯ T ∈ D M + log p ( ¯ T X | Σ ) , s.t. log det ¯ T ≥ 0 un til conv erge Σ λ STM ← T − 1 ΣT − T B.2 Cross V alidation for Syn thetic Data E xperimen t F or the synthetic data exp erimen t, we select the regular ization para meter via the following cr oss-v alidatio n pro cedure. Let θ b e the regular ization par ameter to b e determined and U ( X , θ ) b e the lea rning algorithm that takes as input ( X , θ ) and r eturns a cov aria nce ma trix estimate. W e ra ndo mly split X int o a partial training set X T and a v alida tion s et X V , whose sizes are roughly 70% a nd 30% of X , resp ectiv ely . F or ea ch candidate v alue of θ , ˆ Σ θ T = U ( X T , θ ) is c o mput ed and the likelihoo d p ( X V | ˆ Σ θ T ) of the v alida tion se t X V conditioned on the s olution ˆ Σ θ T is ev alua t ed. The v alue of θ that maximizes this likelihoo d is then s elected and fed into U ( X , θ ) along with the full training set X , r esulting in our es t imate ˆ Σ θ . In our synthetic data exp erimen t, the K for URM/EM/MRH ar e selected from { 0 , 1 , . . . , 15 } , a nd the λ fo r UTM/TM/STM are selec t ed fro m { 100 , 120 , . . . , 4 00 } . These rang es ar e chosen so that the selected v alues rar ely fall on the e x tremes. B.3 T ermination Crit e ria for Iterativ e Algorithms In our implementation, the EM alg orithm terminates when max i R New i,i − R Curren t i,i R Curren t i,i < 0 . 001 . Similarly , the STM algorithm ter mina tes when ma x i T New i,i − T Curren t i,i T Curren t i,i < 0 . 001 . B.4 Equiv alen t Data Requiremen t Consider t wo learning algor ithm s U 1 and U 2 , and N da ta samples X = { x (1) , . . . , x ( N ) } . Deno te the out-o f - sample log-likelihoo d delivered by U with X by L ( U , X ). Suppo se U 2 generally has better per formance than U 1 . Algorithm 4 ev aluates the equiv alent data requirement o f U 2 with resp ect to U 1 . In o ur implementation, we se t step size α = 2% for unifor m-residual exp erimen t and α = 1 0% fo r nonuniform-residual ones. Algorithm 4 Pro cedure for ev alua ting e q uiv a le nt da ta r equiremen t Input: X , U 1 , U 2 Output: γ i ← 0 while 1 do γ ← 1 − iα X i ← { x (1) , . . . , x ( γ N ) } if L ( U 2 , X i ) < L ( U 1 , X ) then if i > 0 then γ ← γ + L ( U 1 , X ) − L ( U 2 , X i ) L ( U 2 , X i − 1 ) − L ( U 2 , X i ) α (in terp olation) end if return γ end if i ← i + 1 end while 20 B.5 S&P500 Dat a Prepro cessing Define Nov ember 2, 2001 as trading day 1 and August 9, 20 07 as trading day 1 451. After deleting 4 7 constituent sto c ks that are not fully defined ov er this p erio d, we compute for ea c h sto c k the normalized log daily r eturns as follows: 1. Let y ′ i,j be the adjusted close price of sto ck i on day j , i = 1 , . . . , 453 and j = 1 , . . . , 1 451 . 2. Compute the r a w lo g-daily-return of sto c k i on day j by y ′′ i,j = log y ′ i,j +1 y ′ i,j , i = 1 , . . . , 453 , j = 1 , . . . , 1 450 . 3. Let ¯ y b e the smalle s t num b er such that at least 99.5% of all y ′′ i,j are less than or equal to ¯ y . Let y be the larg est num b er such that at le ast 99 .5% of all y ′′ i,j ’s ar e gre ater than or equa l to y . Clip all y ′′ i,j by the interv al [ y , ¯ y ]. 4. Let the volatility of sto c k i on day j > 50 b e the 10 -w eek rms ˆ σ i,j = s 1 50 50 P t =1 y ′′ 2 i,j − t . 5. Set y ( n ) = h y ′′ 1 ,n +50 ˆ σ 1 ,n +50 . . . y ′′ 453 ,n +50 ˆ σ 453 ,n +50 i T for n = 1 , . . . , 1400. B.6 Candidates for Regularization Parameter in Real Dat a Exp erimen t In o ur rea l da ta exp erimen t, the K fo r EM/MRH are s elected from { 0 , 1 , . . . , 40 } , and the λ for TM/STM are sele cted from { 2 00 , 21 0 , . . . , 6 00 } . These ra nges are chosen so tha t the selected v alues never fall on the extremes. References Ak aike, H. (1987). F actor analysis and AIC. Psychometrika , 52(3). Amini, A. A. and W ainwright, M. J. (200 9). High-dimensio nal ana lysis of semidefinite relaxa t ions for spars e principal c omponents. Ann. Statist. , 3 7:2877–29 2 1. Baik, J. and Silverstein, J. W. (2006). Eigenv alues of lar ge sample cov aria nce matrices of s piked p opulation mo dels. Journal of Multivariate Analy sis , 9 7:2006. Banerjee, O ., Ghao ui, L. E ., a nd d’Aspremont, A. (200 8). Mo del s e lection thro ugh spars e maximum likeli- ho od estimation for multiv ariate gaussian or binary data. Jour n a l of Machine L e arning Rese ar ch , 9:485 – 516. Bishop, C. M. (1 9 98). Bay esian PCA. In Kearns , M. J ., Solla , S. A., and Cohn, D. A., editors, A dvanc es in Neur al Information Pr o c essing Systems 11 , pages 38 2–388. MIT Pre ss. Boyd, S., Parikh, N., Chu, E., Peleato, B., and E ckstein, J. (2011). Distributed o ptim iza t io n and statistical learning via the alter nating direction metho d of m ultipliers . F oundations and T r ends in Machine L e arning , 3(1):1–12 2. Cand` es, E. J ., Li, X., Ma, Y., and W right, J . (20 09). Robust principal comp onent ana lysis? J o urn a l of the ACM , 58(1 ) :1– 37. Chandrasek ara n, V., Parrilo , P . A., and Willsky , A. S. (2 012). Latent v ariable gra phical mo del selection via conv ex optimization. Annals of Statistics , 40(4):1 935–2013 . D’Aspremont, A., Ghaoui, L. E., Jo rdan, M. I., and Lanckriet, G. R. G. (200 4). A direct formulation for sparse P CA using s emidefinit e pro gramming. S IAM R eview , 49(3):434 . F riedman, J., Hastie, T., a nd Tibshirani, R. (200 8). Sparse inv ers e cov aria nce estimation w ith the graphica l lasso. Biostatistics , 9 (3):432–441. 21 Harman, H. H. (197 6). Mo dern F actor Analysis . Universit y of Chicag o Pr ess, third edition. Hirose, K ., Kawano, S., Konishi, S., a nd Ichik awa, M. (201 1). Bayesian information criterion and selection of the num b er of factors in fac to r analysis mo dels. J o urn a l of Data Scienc e , 9(2). Johnstone, I. M. (2001). On the dis t r ibutio n of the la r gest eigenv alue in principal comp onent s ana ly sis. Annals of Statist i cs , 29:295 –327. Johnstone, I. M. and Lu, A. Y. (20 0 7). Spars e Principal Comp onen ts Analysis. Journal of the Americ an Statistic al Asso ciation . Jolliffe, I . T., T rendafilov, N. T., and Uddin, M. (2003). A mo dified principal comp onent technique base d on the lass o . Jou rn a l of Computational and Gr aphic al Stat ist ics , 12:53 1–547. Kao, Y.-H. and V an Roy , B. (2012). Directed principle comp onen t analysis. Laurent, B. and Massa rt, P . (200 0). Adaptive estimatio n of a quadra t ic functional by model se lection. Annals of S tatistics , 2 8(5):1302–13 3 8. Marko witz, H. M. (1952 ). Portfolio selection. J ou r n a l of Financ e , 7:7 7–91. Mink a, T. P . (200 0). Automatic choice o f dimensionality for P CA. In Leen, T. K., Dietterich, T. G., and T res p, V., editors , Ad vanc es in Neu ra l In f ormation Pr o c essing S y st ems 13 , pa ges 598– 6 04. MIT Press. Paul, D. (2 007). Asymptotics of s ample eigens tr utu r e for a large dimensional spiked cov a riance mo del. Statistic a Sinic a , 17(4):161 7–1642. Pison, G., Rousseeuw, P . J ., Filzmoser, P ., a nd Cro ux, C. (2003). Robust factor analysis . Journal of Multivariate Analysis , 84(1):145 – 172 . Pourahmadi, M. (2011). Cov a riance e s tim atio n: The GLM and regular ization p ersp ectiv es. Statistic al Scienc e , 26 (3 ):369–387. Ravikumar, P ., Raskutti, G., W a in wright, M. J ., and Y u, B. (20 11). High-dimensiona l c ov a riance estimation by minimizing L1 - penalized log-determinant. Ele ctr onic Journal of Statistics . Rubin, D. B. and Thayer, D. T. (1 982). EM algorithm for ML fa ctor analysis. Psychometrika , 47(1):69 – 76. Tipping, M. E. and Bis hop, C . M. (1999 ). Pr obabilistic pr incipal comp onen t ana ly sis. Journal of the Roy al Statistic al So ciety, Series B , 61:6 11–622. Xu, H., Ca ramanis, C., and Mannor, S. (2 010). Principa l comp onen t ana lysis with co n ta minated da ta: The high dimensional case. In COL T , pag es 490–5 02. Y uan, M. and Lin, Y. (200 7). Mo del selection a nd estimation in the ga ussian g raphical mo del. Biometrika , 94(1):19– 35. Zou, H., Has t ie, T., and Tibshira ni, R. (2004 ). Spar se Principal Comp onen t Analysis . Jou r n a l of Computa- tional and Gr aphic al St a tistics , 15. 22
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment