An Improved EM algorithm
In this paper, we firstly give a brief introduction of expectation maximization (EM) algorithm, and then discuss the initial value sensitivity of expectation maximization algorithm. Subsequently, we give a short proof of EM's convergence. Then, we im…
Authors: Fuqiang Chen
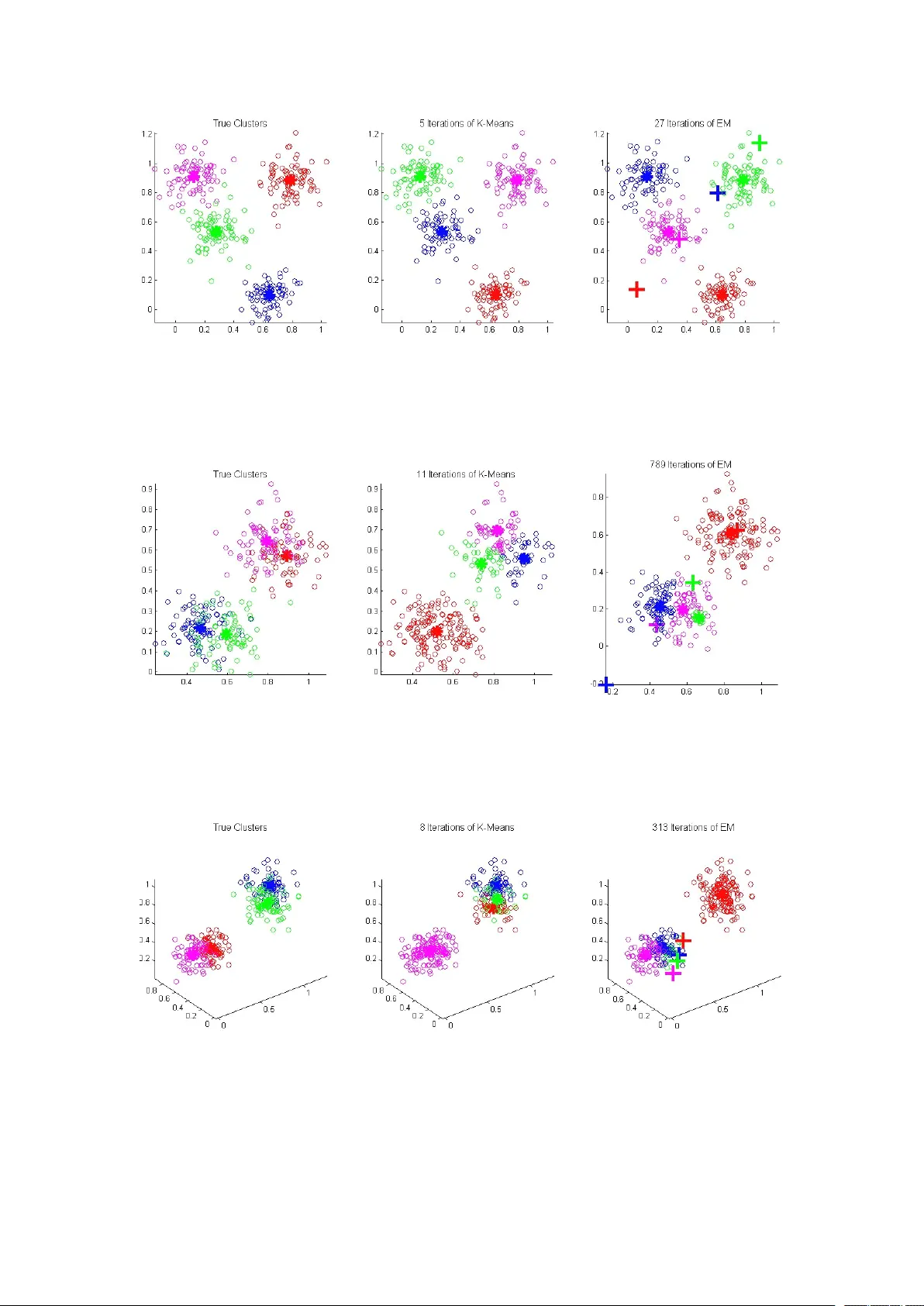
An I mproved E xp ectation M ax imizati on A lgo rith m Chen Fu qiang Dep ar tment of co mpu ter science and technolog y Colleg e of Electronics & I nformatio n Enginee rin g T on gji Univ ersity Sh an ghai, China, 201804 2012f uq iang chen@tongji.edu.c n A bstra ct I n t his pa per , we f irstly giv e a brief introduction of ex pectation max imization (EM) algo rithm, and then discuss the initial v alu e sensitiv ity of ex pectation m aximiza tion algo rithm. Subs equ ently , we giv e a short proof of EM's co nverge nce. T hen , we imple men t ex periments with the ex pectation m axim iz ation algo rithm ( We imple men t all the ex periments on Gaussion m ixtu re model (GMM) ) . Our ex periment with ex pectation m axim iz ation is performed in the f oll owing th ree cas es: ini t ialize rando mly; ini t ialize with result of K-me ans; ini t ialize with result of K-me doid s. T he e xperiment result shows that ex pectation max imization algo rithm depend on its initial state or pa rameters. And we f ou nd th at EM initialized with K -medoid s pe rfor me d be tter than b oth the one initialized with K -means and the one ini t ialized rand om ly . Key word s: S ensitiv ity a n aly sis; C onve rgence analysis; E x pectation M ax imizati on; K -means; K -medoid s 1 I ntroduction M ax imum likelihood estima tion (ML E) is a pa rame te r estimatio n m eth od widely ap plied in statistics [1] . I n max imum likelihood estima tion, the co nd iti on is that we are giv en a set of indepe nd ently identically distributed (i.i. d.) po int s or sam ples , and we k now the spe ci f ic f or m of the distribution where the samples are drawn f rom befo re han d . M aximum likelihood estima tion f ind s the real pa rameters in the d istrib ution by max imizin g the pro bability , whic h is transf ormed to a lo garithmic f o rm , and thus it's much eas ier to co mpu te the deriv ati ve of the ob ject f un ction with resp ect to (w . r . t. ) the unknow n pa rameters. How ever , in m ost c ases , we don't k now th e label of e ach sa mp le we ge t. For ex ample, if we are g ive n two c oins , A and B , and then we ra ndom ly choo se one of them to f lip [ 2 ] . T he upward side o f th e co in m ay be head or tail. S up pose that we don' t know w h ich c oin is chosen in each f lip ping , and o ur ob ject is to estimate the pro bability of head upward f or e ach co in under th e co nd iti on that f or eac h f lippin g we don ’ t k now which co in is chose n. T hi s can be solv ed by expectatio n max imization a lgo rith m, which m ain ly d eals with the p ara met er e stim ati on with latent o r hidden va riables . A n d in th e a bove co in f lip ping pro blem , the hidden variab le is which co in we choos e in each flip p ing , o r rath er , we don ’ t k now the pro bability of choosing one spe c if ic coin, A an d B. EM algorithm has been a pplied in va r ious areas. Sh epp, L . A. et a l. (1 9 82) [3] reso rted to EM algo rithm indirectly to e missio n tomo graphy Im a ge Reco nstru ction. Fede r , M . et al. (1989) [4] ap pl ied EM algo rithm for max imum likelihood Active Noise Cancellation (ANC). Carson, C. et al. (20 02) [5] used E M alg ori thm for imag e segmentation. K riegel, H. P. et al. (2006) [6] f ou nd th at f or multi-instan ce pro blem, EM algo rithm pe rfor me d be tter th an k -medoid alg orithm on th ree re al world data sets. T o our k nowledge, there are n o rese arch ers who in itialize EM alg orithm with k-m edoids. And o ur ex periment result s how t hat EM alg orithm ini t ialized with k -me d oids p erfo rms b etter than that initialized with k-m ean s or initia lized ra ndom ly . T hi s paper is o rganized as f ollows. I n sec tion 2 , we in troduce EM b rief ly . I n section 3 , we analy ze the sensitiv ity o f EM algo rith m on th e ini t ialization. And in section 4, we pres e nt th e co nverg ence of EM algo rithm. I n sec tion 5, we s h ow the ex periment result and gives an analysis. F inally , i n sec tion 6, we co nclu de our w ork a n d po int out the f utu re direc tion o f o ur work . 2 Brie f intro du cti on o f EM I n this section , we introduce the e xpecta tion max imization algo rithm mathema tically and ge nerally . Su pp os e that we are give n n d-dim ensional sam pl es X ={ x 1 , ... , x n } co llected fro m K clusters, g roups or class es, where x i ∈ R d . And f or i =1, .. . , n , we don' t k now which c lu st er x i co mes from, i.e., the lab els of a ll the sam pl es are latent v ariables. Our ob ject is to estima te the p aram e ter θ in the pro bability density fun ction (pdf ) p ( X ; θ ) whi ch max imiz es the probability densit y fun ction . H ere the θ usually re prese nts a parameter se t . F or e xam ple, f o r o ne di mensional norm al distribution , θ = { μ j , σ j ; j = 1 , ... , K }, where μ j rep res ents th e m ean of all the sam ples f rom the j- th cluster , a nd σ j rep resents th e v ariance o f a ll the sam ples f rom the j- th cluster . Generally , f or co nvenience, and also be cau se the f un ction ln (x) incre ases mo notonously , whic h mak es th e e qu iv alence of m ax imizing t he two f un ction, L ( θ ) = p ( X ; θ ) and l ( θ ) = ln p ( X ; θ ), w e chose to max imize the latter o ne instead. I n this pa p er , we discuss ex pectation m aximizatio n algo rithm f or clustering or classif ication, and we u se y to rep resen t th e latent v ariable. Generally , y ca n tak e on so me numb ers m aking u p a s et Y co mposed of sev eral i nteger s , su ch as Y ={1 , 2 , ... , K }. T hen , by th e c omplete pro bability formula, we c an ge t p ( X ; θ ) = 1 k j = ∑ p ( X ; y j , θ ) p ( y j ; θ ) , where p ( y j ; θ ) denotes the s um of all the p rob abilit y of sam pl e x j be longs to the j - th c lu ster . So l ( θ ) = ln 1 k j = ∑ p (X ; y j , ɵ ) p ( y j , θ ), and our o bjec t is to m ax imiz e l ( θ ) . I t' s ob vi ous th at l ( θ ) is a logarithm ic f un ction of a sum mation o f k f un ction, and usu all y it's hard to co mput e the ma ximum of l ( θ ) directly . T hen we c an c hose an initial va lu e θ l f or θ , and then l ( θ )- l ( θ l ) = ln p (X ; θ )- ln p (X ; θ l ) = ln [ p (X ; θ ) / p (X ; θ l ) ] = ln { [ 1 k j = ∑ p ( X ; y j , θ ) p ( y j ; θ ) ] / p ( X ; θ l ) } = ln 1 k j = ∑ [ p ( X ; y j , θ ) p ( y j ; θ ) p ( y j ; X , θ l ) / p ( X ; θ j ) p ( y i ; X , θ l ) ] ≥ 1 k j = ∑ { p ( y j ; X , θ l ) ln [ p ( X ; y j , θ ) p ( y j ; θ ) / p ( X ; θ l ) p ( y j ; X , θ l ) ]}. W e deduce the last step (inequality ) by the f amo us Je nson's inequality , and 1 k j = ∑ p ( y j ; X , θ l ) = 1. T hen we can m ax imiz e 1 k j = ∑ p ( y j ; X , θ l ) ln [ p ( x ; y j , θ ) p ( y j ; θ ) / p ( X ; θ l ) p ( y j ; X , θ l ) ] with res pect to θ to f in d a relative be tter lower bound than genera lized ex pectation m aximiza tion (G EM) algo rithm [ 7 ], which c h os e any θ to mak e l ( θ ) increase i n ea ch iteratio n . I t' s easy to see that in the ab ov e f ormul a, the denom inator has nothing to do with θ , thus we can neglec t it when we ma ximiz e the a bove f ormula. And f inally we can m a xim ize th e following 1 k j = ∑ p ( y j ; X , θ l ) ln p ( X ; y j , θ ) p ( y j ; θ ) , which in f a c t is E { y | X , θ l } [ ln p ( X , y ; θ )] . As yet we ha ve g o t the E- step o f EM a lgo rith m, which is to co mpu te the ab ove exp ectation. T he next step in EM a lgorithm, i.e., M-s tep, is to ma ximize the ex pectation wh ich we ge t in the E- step w ith re spect to (w . r . t.) θ . Form ally , our o bje ct is to ge t the θ l +1 : θ l +1 =arg max θ E{ y | X , θ l } [ ln p ( X , y ; θ )] . We have g iven a n i ntroduction to ex pectation ma ximiz a tion alg orithm in the ab ove. 3 Sensiti vity analysis I n thi s sec tion, we analyze the sensitiv ity o f e xpectation maxim iz ation algo rithm with resp ect to the p ara meters in the p rob abilit y density f un ction, with the numb er o f total clusters clapped, i .e., we m ake the numb er of clusters an inv ariant value. I ntuitive ly , if we initialize the pa rameters with dif fe rent values in each ex periment, the pe rformance of ex pectation maxim iz ation alg orithm dif fer from eac h other . H ere, we analyz e the initial va lu e se n sitiv ity or p erfo rman ce acc ord ing to the ex periment, for that it' s ha rd to a nalyze mathema tically d i rectly . I ntu iti v e ly , if the clusters w e deal with sa tisf y the f oll owing conditions: (1) there a re m an y clusters; (2) the me an v alues o f any two c lu sters/g roups are clo se to eac h other mea sured by a spe c if ic di st ance m etri c ( in o ur p aper we co nsid er the Euclidean di stan ce ); (3) the cov ari ance of any cluster is so larg e that some po int s/sam ples of thi s cluster m ay b e in th e cloud f ormed by a noth er clu ster; For clarity , the rea ders are refe rred to Section 4 (i.e. Ex pe rime nt). H ere we only giv e the analys is int uiti ve ly , if y ou a re intereste d in th e p roof mathema tically , y ou can dev elop th e p roof b y y o u rself. I n co nclu sion, th e f unction l ( θ ) ma y hav e so me loca l max imums bes id es the glo bal m axim u m, thence if w e initia lize th e para meters with dif f erent va lu es, e xpectatio n max imization algo rithm m ay co nverg e to a loc al max imum, unles s the ini tial v alue are initialize d clo se to the true pa rameters, which is generally ve ry hard in prac tice . 4 Co nverg en ce analy sis We talk ab out the c onve rgence of e xpectatio n m a xim ization algorithm in thi s sectio n. I t' s o bv i ous t hat the f ollowing holds: l ( θ l +1 ) ≥ l ( θ l )+ 1 k j = ∑ p ( y j ; X , θ l ) ln [ p ( X ; y j , θ l +1 ) p ( y j , θ l +1 ) / p ( X ; θ l )p(y j ; X , θ l ) ] ≥ l ( θ l )+ 1 k j = ∑ p ( y j ; X , θ l ) ln p ( X ; y j , θ l ) p ( y j , θ j ) p ( X ; θ j ) p ( y j ; X , θ l )} = l ( θ l ) , through which we can see that l ( θ l ) is m on otonously increasing, and it' s ob vious that l ( θ ) is bo un ded. So the co nverg ence of e xpectatio n max imization algorithm ho lds by the theo rem b ound ed se qu enc e will be co nverge d in Mathe matica l Analysis [8] . 5 Ex pe rimen t Befo re present ing the ex periment res u lt, we f irst give a b rief in troductio n to K-mea ns algo rithm which i s usually used in clustering [9] . G iv en n sam pl es in K c lu sters, the K -means alg orithm is an alg orithm which g ive K means f or K c lusters in itially b y a spe c if ic ru le a n d c h ange the K mea ns b y som e ru le to m ake th e m ean s clos e to th e true mea ns . A nd in our e xperiment , we sto p the K -means a lgo rith m if all t he K mea ns don' t change any mo re. Besides the K-m eans algo rith m, there is a nother algo rithm , K-me doid s , which s light ly like K -means algo rithm. And w e also imple men t e xp eri ment with EM alg orithm in it ialized by K-medoids [ 10 ]. I n our experiment, we m ainly deal with the f ollowing ca se s : (1) f our clu sters in 2-dim en sion spa ce; (2) f our clu sters in 3-dim en sion spa ce; We imple men t many ex periments with K-means alg orithm and EM algo rithm resp ecti ve ly on G aussion mixture m od els, and f or th e details of Gaussion mixture mo dels th e rea ders are re f e rred to [ 11 ]. Here we o nl y g ive a brief int rod uction o f h ow to g et the e stimate o f μ a nd Ʃ . T o thi s end, we ca n reg ard Ʃ -1 as a ge neralized rec iprocal f or m atrix of Ʃ and re ga rd | Ʃ | as the genera lized abso lute va lu e f or matrix o f Ʃ , b oth reg ardin g Ʃ as a ge neric varia ble such as x when we ca lculation partial deriv ati ve with re spect to Ʃ . For the p roof in detail the readers a re referre d to [ 1 1 ]. In o ur ex p erime nt , we sto p when th e p ara met ers c h ange sma ller th an a sp eci f ic giv en threshold. T he experime nt results i n the ap pen dix giv e an int uiti ve pro of o f what we analyz e i n sec tion 2. Considering that in expecta tion m ax imiz ation alg orithm if we initialize the p aram ete rs with random v alues, the p erform an ce of ex pectation max imization algo rithm is incline d to p erfo rm po orl y . So we initialize the pa rameters with the re sult of K-mea n s a lgorithm s and K -medoid s algo rithm . We im plement e xperime nt 50 tim es in ea ch ca se ( 2d sp ace EM not initialize d b y K -m e ans; 2d sp ace EM ini t ialized by K-me ans; 3d spa ce EM not in i tialized by K -mea ns; 3d sp ace EM initia lized b y K-me ans; 2d space EM initialized b y K-me d oids; 3d s pac e EM no t ini t ialized by K -m e doids ). T he ex periment result is g iven in th e ap pen dix . From the six tab les, we can c onclud e th at e xpectatio n m aximizatio n algo rithm pe rforms well af ter co mbin ing with K -means alg orithm and K-medoids algo rith m , i.e., if we ini t ialize th e p aram e ters f or expec tation max imization by the res u lt of K-me ans and K -med oids algo rithm resp ecti ve ly , EM p erforms b etter . We f ind tha t EM initialize d with K -means or K-me doid s impro ve the EM' s pe rfor ma n ce , and in lowe r dim ensions m ore ob vious. 6 Co nclusion I n th i s pap er, we f irst giv e a brief introd uction of ex pectation max imization algo rithm, which is a me th od diff e rent from max imum likelihood estimatio n , dealing with p rob lems with latent o r h i dden va riables. Then we p rov e the c onve rgence of the EM algo rithm brie fly . On the ba ses abo ve, we im plement experiment with K -mea n s algo rithms and ex pectation max imiz ation a lgo rith m and giv e so me analys is. T h e ex periment result show that bo th K-me ans algo rith m and ex pectation max imization algo rithm are s ensitiv e to the initial va lue, so in f utu re som e adaptiv e or g eneralized alg orithm need to b e propos e d f or imp rov e the c lassificatio n rate or performance. And, in our e xp e riment, we imple men t e xperiment of initializing the p ara met ers ac cord ing to the result of K -m e ans algorithm, the re sul ts show th at EM p erfo rms b etter than rand om ly ini t ializing the pa rameters. Since K-m eans and K -med oids can impro ve EM's p erfo rman ce, it' s eas y to thi nk abo u t how about ap pl ying o th er clustering a lgo rith m to initialize EM a lgorithm. Besides, in this paper , we perfo rmed EM o n artif icial data, in f uture, we will p erform EM o n re al wo rld d atas et to test th e va lid ity o f our algo rithm, Ack nowledgment T he autho r th an k Y i lu Z hao f or helpf ul discussion. Refere nce [1] Myung , I . J. (2003). T u torial o n max i m um likelihoo d estim ation. Jou rn al of M at he mati ca l P sych ology , 47 (1), 90- 10 0. [2] Do, C. B., & Batz oglou, S. (2 008). What is the e xp ect ation max imization alg orithm?. Natur e biotechno logy , 26(8), 8 97- 89 9. [3] Shep p, L . A., & V a rdi, Y. (1982). Maximum likelihoo d rec onstruction f or emiss ion tom ograph y . Me di cal Imaging, IEEE T r ansactions on , 1(2), 11 3- 122 . [4] Feder , M., O pp enh eim, A. V., & W e instein, E. (1989). M ax imum likelihood noise c ancellation using the EM algo rith m. Acoustics, Speec h and Si gnal P ro ces sing , IEEE T r a nsactions on , 37(2), 204 - 21 6. [5] Carso n, C., Belo ngie, S. , Gree n sp an, H., & Malik, J. (2 002). Blob world : Im age seg men tation using ex pectation-ma xi miza tion and its ap pl ication to image querying. P at tern Analysis and M achi ne Intelligence, IEEE T r ansa ctio ns on , 24(8), 1 026-1038. [6] Krieg el, H. P., Pryak hin , A., & Sch ubert, M. (2 006). An EM- ap proach f or clustering multi-instan ce ob jects. I n Advances in Know ledg e Discover y and Data Mining (pp . 139- 1 48). Springer Berlin H eid elbe rg. [7] Borm an, S. (2009). The e xpecta tion m axim iz ation algorithm-a short tut orial. [8] Chen ji xiu, Y u chonghua, Jinlu, Math ema tic A n aly sis 2 nd e d, Higher Education P re ss , 2004 [9] T e k nomo, K . (2006). K -Means Clustering T uto rial. Me di cine , 100(4), 3. [10] Park , H. S ., & Jun, C. H. (2 009). A simp le and f a st alg orithm f or K-me doid s clustering . Expert Systems w ith Ap plica tions , 36(2), 3336- 33 41. [11 ] Bilm es, J. A . (1 998). A ge nt le tut oria l of th e EM a lgo rith m an d its ap pl ication to pa rameter estimation f or Gaussian mixture and hidden Marko v mo dels. Inter na tional Computer Scienc e Institute , 4(510), 126. App en dix T ab le 1: Re sult of EM not initialize d b y K-me ans: 2d s pac e none w ell K-m e ans well / N K E M we ll / N E N K /N E 11 3 1 27 1.15 T ab le 2: Re sult of EM not initialize d b y K-me ans: 2d s pac e none w ell K-m e ans well / N K E M we ll / N E N K /N E 16 2 7 33 0.82 T ab le 3: Re sult of EM not initialize d b y K-me ans: 3 d spa ce none w ell K-m e ans well / N K E M we ll / N E N K /N E 6 3 6 33 1 . 09 T ab le 4: Re sult of EM not initialize d b y K-me ans: 3 d spa ce none w ell K-m e ans well / N K E M we ll / N E N K /N E 9 4 1 41 1 T ab le 5: Re sult of EM not initialize d b y K-me ans: 3 d spa ce none w ell K-m e ans well / N K E M we ll / N E N K /N E 6 3 6 28 1 . 28 T ab le 6: Re sult of EM not initialize d b y K-me ans: 2d s pac e none w ell K-m e ans well / N K M well / N E N K /N E 12 2 7 31 0.87 Figure 1: Case of f our clusters in 2- dim e nsion s pac e and the *' s re present the mea n f o r e very c lu ster , and the +' s represent the initial mea n for EM. I n this ca se, the K -means pe rform s we ll, while EM p erforms po orly . Figure 2: Case o f f o ur clusters in 2- di m en sion space a nd th e * ' s rep res ent the me an fo r ev ery cluster , and the +' s re present the initial me an f or EM. I n this ca se, the K -means pe rform s p oorly , while EM pe rforms well. Figure 3: Case o f f o ur clusters in 2- di m en sion space a nd th e * ' s rep res ent the me an fo r ev ery cluster , and the +' s re present the initial me an f or EM. I n this ca se , bo th K- means and EM p erfo rms well. Figure 4: Case o f th ree c lu sters in 2- dimension spa ce and the * ' s repre s ent the me an fo r ev ery cluster , and the +' s re present the initial me an f or EM. I n this ca se, none o f EM a nd K -means perfo rm well. Figure 5: Cas e o f f o ur clusters i n 3-dim ension and the * ' s repre s ent th e mea n for e very c lu ster , and th e +' s re pre s ent the initial mea n for EM. I n thi s case , none of EM and K -means pe rform we ll. Figure 6: Cas e o f f o ur clusters i n 3-dim ension and the * ' s repre s ent th e mea n for e very c lu ster , and th e +' s re pre s ent the initial mea n for EM. I n thi s case , b oth EM and K-m eans p erform we ll. Figure 7: Cas e o f f o ur clusters i n 3-dim ension and the * ' s repre s ent th e mea n for e very c lu ster , and th e +' s re pre s ent the initial mea n for EM. I n thi s case , the K-m eans p erfo rms well, while EM pe rfo rms po orly . Figure 8: Cas e o f f o ur clusters i n 3-dim ension and the * ' s repre s ent th e mea n for e very c lu ster , and th e +' s re pre s ent the initial mea n for EM. I n thi s case , the EM p erfo rms w ell, while K-me ans pe rfo rms po orl y .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment