Metric-Free Natural Gradient for Joint-Training of Boltzmann Machines
This paper introduces the Metric-Free Natural Gradient (MFNG) algorithm for training Boltzmann Machines. Similar in spirit to the Hessian-Free method of Martens [8], our algorithm belongs to the family of truncated Newton methods and exploits an effi…
Authors: Guillaume Desjardins, Razvan Pascanu, Aaron Courville
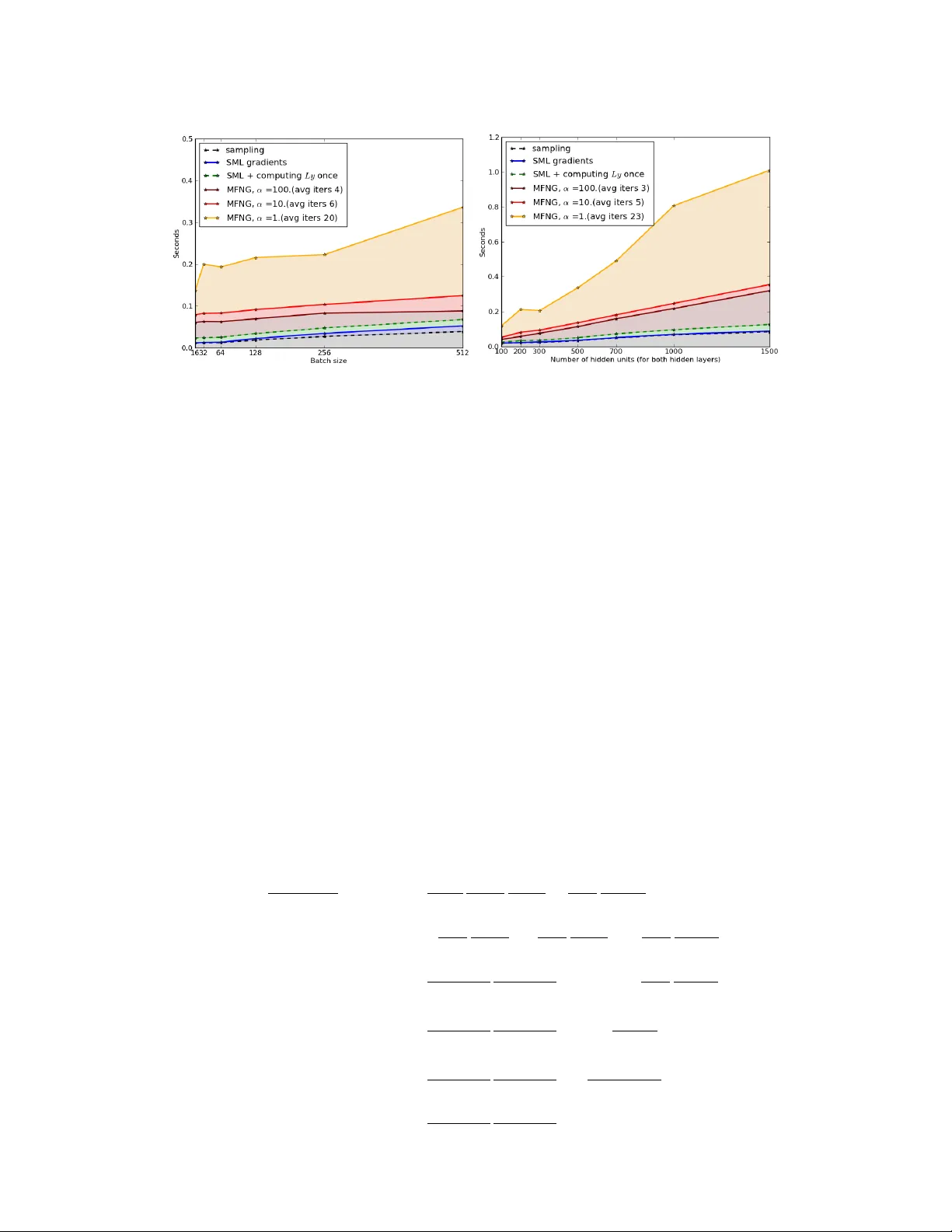
Metric-Fr ee Natural Gradient f or J oint-T raining of Boltzmann Machines Guillaume Desjardins, Razvan Pascanu, Aar on Courville and Y oshua Bengio D ´ epartement d’informatique et de recherche op ´ erationnelle Univ ersit ´ e de Montr ´ eal Abstract This paper introduces the Metric-Free Natural Gradient (MFNG) algorithm for training Boltzmann Machines. Similar in spirit to the Hessian-Free method of Martens [8], our algorithm belongs to the family of truncated Ne wton methods and exploits an efficient matrix-vector product to a v oid explicitly storing the natural gradient metric L . This metric is shown to be the expected second deriv ati ve of the log-partition function (under the model distribution), or equiv alently , the cov ariance of the vector of partial deri vati ves of the energy function. W e e valuate our method on the task of joint-training a 3-layer Deep Boltzmann Machine and show that MFNG does indeed hav e faster per-epoch conv ergence compared to Stochastic Maximum Likelihood with centering, though wall-clock performance is currently not competitiv e. 1 Introduction Boltzmann Machines (BM) have become a popular method in Deep Learning for performing fea- ture extraction and probability modeling. The emergence of these models as practical learning algorithms stems from the dev elopment of ef ficient training algorithms, which estimate the negati ve log-likelihood gradient by either contrastiv e [4] or stochastic [18, 19] approximations. Howe ver , the success of these models has for the most part been limited to the Restricted Boltzmann Machine (RBM) [6], whose architecture allows for ef ficient exact inference. Unfortunately , this comes at the cost of the model’ s representational capacity , which is limited to a single layer of latent v ariables. The Deep Boltzmann Machine (DBM) [15] addresses this by defining a joint energy function ov er multiple disjoint layers of latent variables, where interactions within a layer are prohibited. While this affords the model a rich inference scheme incorporating top-do wn feedback, it also makes train- ing much more difficult, requiring until recently an initial greedy layer-wise pretraining scheme. Since, Montav on and Muller [9] hav e sho wn that this difficulty stems from an ill-conditioning of the Hessian matrix, which can be addressed by a simple reparameterization of the DBM energy function, a trick called centering (an analogue to centering and skip-connections found in the de- terministic neural network literature [17, 14]). As the barrier to joint-training 1 is overcoming a challenging optimization problem, it is apparent that second-order gradient methods might prov e to be more effecti ve than simple stochastic gradient methods. This should prove especially important as we consider models with increasingly complex posteriors or higher-order interactions between latent variables. T o this end, we explore the use of the Natural Gradient [2], which seems ideally suited to the stochas- tic nature of Boltzmann Machines. Our paper is structured as follo ws. Section 2 provides a detailed deriv ation of the natural gradient, including its specific form for BMs. While most of these equations 1 Joint-training refers to the act of jointly optimizing θ (the concatenation of all model parameters, across all layers of the DBM) through maximum likelihood. This is in contrast to [15], where joint-training is preceded by a greedy layer-wise pretraining strate gy . 1 hav e pre viously appeared in [3], our deri vation aims to be more accessible as it attempts to derive the natural gradient from basic principles, while minimizing references to Information Geometry . Sec- tion 3 represents the true contrib ution of the paper: a practical natural gradient algorithm for BMs which exploits the persistent Markov chains of Stochastic Maximum Likelihood (SML) [18], with a Hessian-Free (HF) lik e algorithm [8]. The method, named Metric-Free Natural Gradient (MFNG) (in recognition of the similarities of our method to HF), avoids explicitly storing the natural gradient metric L and uses a linear solver to perform the required matrix-vector product L − 1 E q [ ∇ log p θ ] . Preliminary experimental results on DBMs are presented in Section 4, with the discussion appearing in Section 5. 2 The Natural Gradient 2.1 Motivation and Derivation The main insight behind the natural gradient is that the space of all probability distributions P = { p θ ( x ); θ ∈ Θ , x ∈ χ } forms a Riemannian manifold. Learning, which typically proceeds by iterativ ely adapting the parameters θ to fit an empirical distribution q , thus traces out a path along this manifold. An immediate consequence is that follo wing the direction of steepest descent in the original Euclidean parameter space does not correspond to the direction of steepest descent along P . T o do so, one needs to account for the metric describing the local geometry of the manifold, which is gi ven by the Fisher Information matrix [1], shown in Equation 4. While this metric is typically deriv ed from Information Geometry , a deriv ation more accessible to a machine learning audience can be obtained as follows. The natural gradient aims to find the search direction ∆ θ which minimizes a giv en objectiv e func- tion, such that the Kullback–Leibler div ergence K L ( p θ k p θ +∆ θ ) remains constant throughout optimization. This constraint ensures that we make constant progress regardless of the curvature of the manifold P and enforces an in variance to the parameterization of the model . The natural gradient for maximum likelihood can thus be formalized as: ∇ N := ∆ θ ∗ ← argmin ∆ θ E q [ − log p θ +∆ θ ( x )] (1) s.t. K L ( p θ k p θ +∆ θ ) = const . In order to deriv e a useful parameter update rule, we will consider the KL div ergence under the assumption ∆ θ → 0 . W e also assume we hav e a discrete and bounded domain χ over which we define the probability mass function 2 p θ . T aking the T aylor series expansion of log p θ +∆ θ around θ , and denoting ∇ f as the column vector of partial deriv atives with ∂ f ∂ θ i as the i -th entry , and ∇ 2 f the Hessian matrix with ∂ 2 f ∂ θ i ∂ θ j in position ( i, j ) , we hav e: K L ( p θ k p θ +∆ θ ) ≈ X χ p θ log p θ − X χ p θ log p θ + ( ∇ log p θ ) T ∆ θ + 1 2 ∆ θ T ∇ 2 log p θ ∆ θ = 1 2 ∆ θ T E p θ −∇ 2 log p θ ∆ θ (2) with the transition stemming from the fact that P χ p θ ∂ log p θ ∂ θ i = ∂ ∂ θ i P x ∈ χ p θ ( x ) = 0 . Replacing the objective function of Equation 1 by its first-order T aylor expansion and rewriting the constraint as a Lagrangian, we arrive at the following formulation for L ( θ , ∆ θ ) , the loss function which the natural gradient seeks to minimize. L ( θ , ∆ θ ) = E q [ − log p θ ] + E q [ −∇ log p θ ] T ∆ θ + λ 2 ∆ θ T E p θ −∇ 2 log p θ ∆ θ . Setting ∂ L ∂ ∆ θ to zero yields the natural gradient direction ∇ N : ∇ N = L − 1 E q [ ∇ log p θ ] with L = E p θ −∇ 2 log p θ (3) or equiv alently L = E p θ ∇ log p θ ∇ T log p θ (4) 2 When clear from context, we will drop the ar gument of p θ to sav e space. 2 While its form is reminiscent of the Newton direction, the natural gradient multiplies the estimated gradient by the in verse of the expected Hessian of log p θ (Equation 3) or equiv alently by the Fisher Information matrix (FIM, Equation 4). The equiv alence between both expressions can be shown trivially , with the details appearing in the Appendix. W e stress that both of these expectations are computed with respect to the model distribution , and thus computing the metric L does not in volve the empirical distribution in any way . The FIM for Boltzmann Machines is thus not equal to the uncentered covariance of the maximum likelihood gradients. In the following, we pursue our deriv ation from the form giv en in Equation 4. 2.2 Natural Gradient for Boltzmann Machines Derivation. Boltzmann machines define a joint distribution over a vector of binary random vari- ables x ∈ { 0 , 1 } N by way of an energy function E ( x ) = − P k
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment