CPU and/or GPU: Revisiting the GPU Vs. CPU Myth
Parallel computing using accelerators has gained widespread research attention in the past few years. In particular, using GPUs for general purpose computing has brought forth several success stories with respect to time taken, cost, power, and other metrics. However, accelerator based computing has signifi- cantly relegated the role of CPUs in computation. As CPUs evolve and also offer matching computational resources, it is important to also include CPUs in the computation. We call this the hybrid computing model. Indeed, most computer systems of the present age offer a degree of heterogeneity and therefore such a model is quite natural. We reevaluate the claim of a recent paper by Lee et al.(ISCA 2010). We argue that the right question arising out of Lee et al. (ISCA 2010) should be how to use a CPU+GPU platform efficiently, instead of whether one should use a CPU or a GPU exclusively. To this end, we experiment with a set of 13 diverse workloads ranging from databases, image processing, sparse matrix kernels, and graphs. We experiment with two different hybrid platforms: one consisting of a 6-core Intel i7-980X CPU and an NVidia Tesla T10 GPU, and another consisting of an Intel E7400 dual core CPU with an NVidia GT520 GPU. On both these platforms, we show that hybrid solutions offer good advantage over CPU or GPU alone solutions. On both these platforms, we also show that our solutions are 90% resource efficient on average. Our work therefore suggests that hybrid computing can offer tremendous advantages at not only research-scale platforms but also the more realistic scale systems with significant performance gains and resource efficiency to the large scale user community.
💡 Research Summary
The paper revisits the long‑standing “CPU versus GPU” debate by proposing a hybrid computing model that deliberately exploits both processors on a single platform. Rather than asking which device is superior, the authors ask how to use a CPU + GPU system efficiently. To answer this, they evaluate thirteen diverse workloads—including sorting, histogram computation, sparse matrix‑vector and matrix‑matrix multiplication, ray casting, bilateral filtering, convolution, Monte‑Carlo simulation, list ranking, connected‑components detection, Lattice Boltzmann fluid simulation, image dithering, and bundle adjustment—on two representative hybrid platforms. The first, called Hybrid‑High, combines a six‑core Intel i7‑980X (12 logical threads, 130 W TDP) with an NVIDIA Tesla T10 GPU (240 CUDA cores, 1.3 GHz). The second, Hybrid‑Low, pairs an Intel Core 2 Duo E7400 (2 cores, 65 W) with an NVIDIA GT520 (48 cores, 810 MHz).
The authors categorize hybrid algorithm design into two patterns. “Work Sharing” splits the input data statically or dynamically, assigning each partition to the device best suited for its computational characteristics; the algorithms on CPU and GPU may differ, and the split ratio is tuned to balance load and minimize PCI‑e transfer overhead. “Task Parallel” treats the computation as a directed acyclic graph of inter‑dependent tasks, mapping each node to either CPU or GPU so that the critical path (the longest sequence of dependent tasks plus communication time) is minimized. A pipelined variant of task parallelism is also discussed.
For each workload the paper details which pattern was used and why. For example, histogram computation uses GPU atomic operations for partial histograms and CPU aggregation to reduce contention; sparse matrix‑vector multiplication (spmv) assigns index traversal and irregular memory handling to the CPU while the dense multiply kernel runs on the GPU; ray casting exploits the embarrassingly parallel nature of rays on the GPU but offloads ray‑origin generation and final compositing to the CPU; Monte‑Carlo simulations generate random numbers on the CPU and evaluate the stochastic function on the GPU. The authors also note cases where a pure GPU or pure CPU implementation would leave one device idle, wasting resources.
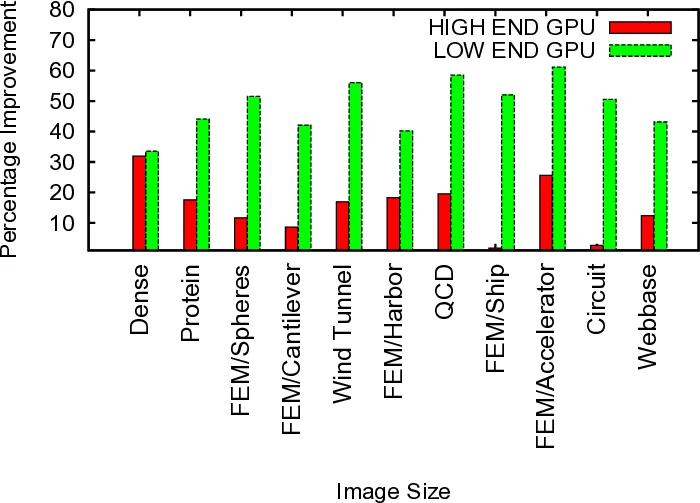
Performance results show that on the high‑end platform the hybrid solutions achieve an average 29 % speed‑up over the best GPU‑only implementation, while on the low‑end platform the average improvement rises to 37 %. In both cases the combined utilization of CPU and GPU resources reaches roughly 90 %, indicating high energy and hardware efficiency. The larger relative gain on the low‑end system is attributed to the smaller performance gap between its CPU and GPU, which makes balanced work distribution more beneficial.
The paper does not claim universal superiority of hybrid approaches. Workloads dominated by data transfer costs or those with highly irregular memory access patterns that cannot be efficiently partitioned may suffer from overhead. Consequently, the authors advocate for quantitative modeling of computation intensity, memory behavior, and data size, coupled with dynamic scheduling mechanisms that can automatically decide the optimal partitioning at runtime. They identify automated scheduler design and more accurate cost models as promising directions for future work.
In summary, this study provides concrete evidence that a well‑designed hybrid CPU‑GPU execution model can deliver significant performance and resource‑efficiency gains on both research‑grade and commodity hardware. By classifying workloads, presenting two generic design patterns, and supplying extensive experimental data, the paper offers a practical roadmap for developers and system architects seeking to harness the complementary strengths of CPUs and GPUs in modern heterogeneous computing environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment