Semi-supervised logistic discrimination for functional data
Multi-class classification methods based on both labeled and unlabeled functional data sets are discussed. We present a semi-supervised logistic model for classification in the context of functional data analysis. Unknown parameters in our proposed m…
Authors: ** - **Shuichi Kawano** – Department of Mathematical Sciences, Graduate School of Engineering, Osaka Prefecture University
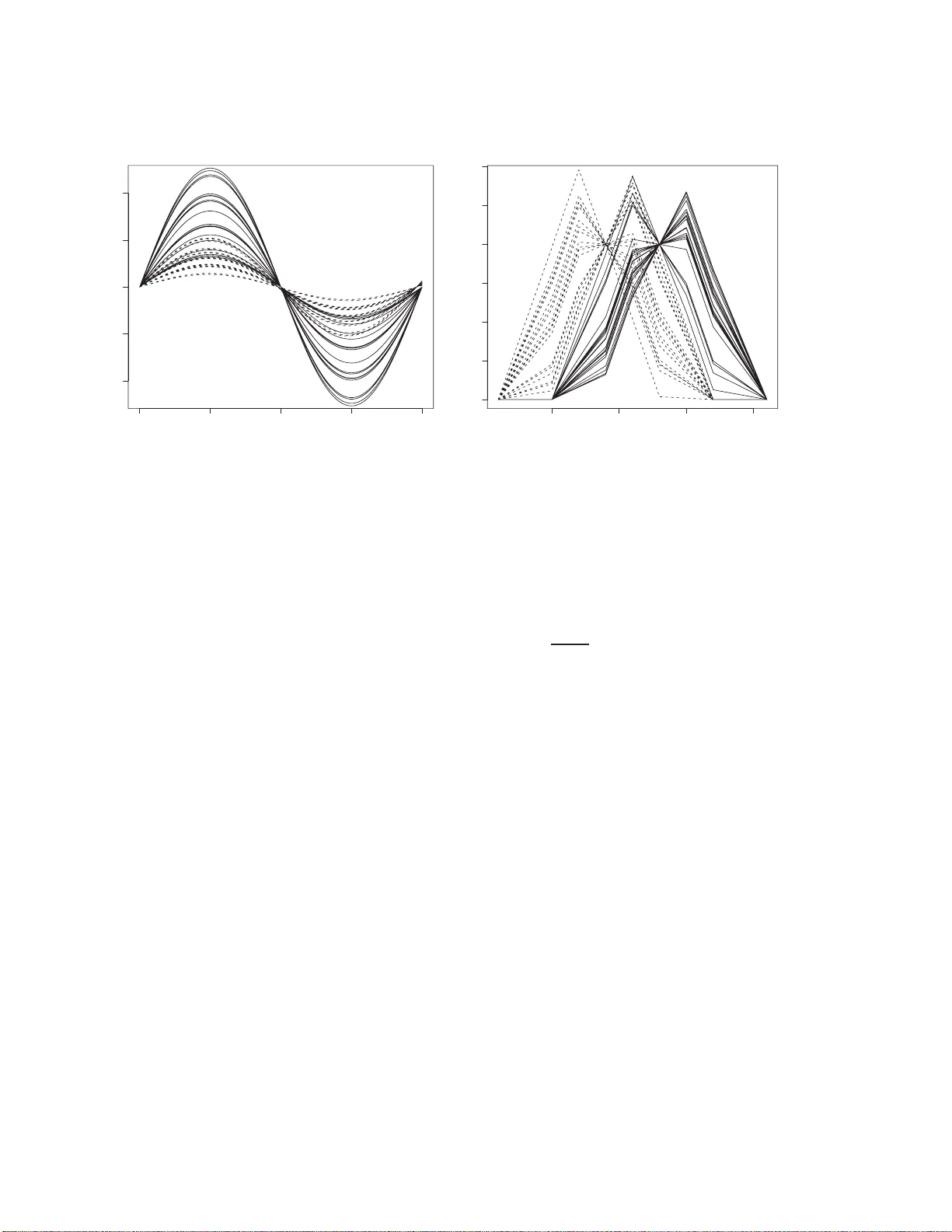
Semi-sup ervised logistic discriminatio n for functional data Sh uic hi Ka w ano 1 and Sadanor i Konishi 2 1 Dep artment of Mathematic al Scienc es, Gr ad uate Scho o l of Engine ering, Osaka Pr ef e ctur e University, 1-1 Gakuen-cho, Sakai, Os aka 599-8531 , Jap an. 2 Dep artment of Mathematics, F aculty of Scienc e and Engine ering, Chuo Un iversity, 1-13-27 Kasuga, Bunkyo-ku, T okyo 112-8551, Jap an. sk a w ano@ms.osak afu-u.ac.jp k onishi@math.c huo-u.ac.jp Abstract: Multi-class classification metho ds based on b oth lab eled and unlab ele d functional data sets are discussed. W e present a semi-sup ervised logistic m o del f or classification in the co nt ext of f unctional data analysis. Unknown parameters in our prop osed mo d el are estimated by regularization with the help of EM algorithm. A crucial p oin t in the mo deling pro cedure is the c hoice of a regularization p arameter in v olv ed in the se mi-sup ervised fun ctional lo gistic mo del. In ord er to select the adjusted parameter, we in tro duce mod el sele ction criteria f rom information-theoretic and Ba y esian viewp oint s. Mon te Carlo sim ulations and a real d ata analysis are giv en to examine the effectiv eness of our prop osed mo deling strategy . Key W ords and Phrases: EM algorithm, F u nctional data analysis, Mo del selec- tion, Regularizatio n, Semi-sup ervised lea rning. 1 In t ro duction In recen t y ears, functional data analysis has been used in v arious fields of study suc h as c hemometrics and meteorology (e.g., w e refer to Ramsa y and Silv erman, 2002; 2 0 05, F erraty and Vieu, 20 0 6). The basic idea b ehind functional data analysis is to express a discrete data set as a smo oth function data set, and then exploit informa t ion obtained from the set of f unctiona l data using the functional a nalogs of classical m ultiv ariate statistical to ols. Till this day , sev eral researc hers ha v e studied a v ariety of functional versions of traditional sup ervised and unsup ervised statistical metho ds; e.g., functional regression 1 analysis ( Ja mes and Silve rman, 2005 ; Y a o et al. , 2005; Araki et al. , 2 009a), functional discriminan t analysis (F erra ty and Vieu, 2 003; Rossi and Villa, 2006; Araki et al. , 2 009b), functional principal compo nen t analysis (Rice a nd Silv erman, 1991; Siverm an, 19 9 6; Y ao and Lee, 2006) and functional clustering (Abraham et al. , 2 003; Rossi et al. , 2004; Chiou and Li, 2007). Mean while, a semi-sup ervised learning, whic h is a mo deling pro cedure based on b oth lab eled and unlab eled da t a , has receiv ed considerable atten tion in the conte mp orar y statistics, mac hine learning and computer science (see, e.g., Chap elle et al ., 2006; Liang et al. , 20 07; Zhu, 2008). In particular, it is kno wn that the semi-sup ervised learning is useful in the application a reas including text mining and bioinformatics, in whic h o b- taining lab eled dat a is difficult while unlab eled da t a can b e easily obtained. Man y of ordinary statistical m ultiv ariate analyses hav e b een extended into the semi-supervised re- sem blances by earlier researc hers; e.g., semi-sup ervised regression analysis (V erbeek and Vlassis, 2006; La ffert y and W asserman, 20 07; Ng et al. , 2 007), semi-sup ervised discrimi- nan t ana lysis (Miller and Uyer, 1997 ; Y u et al. , 2004; Zhou et al ., 20 04; Dean et al. , 2006; Ka w ano and Konishi, 2011) and semi-sup ervised clustering (Basu et al. , 20 04; Zhong, 2006; Kulis et al. , 2009). In this pap er, our aim is to extend the sup ervised mo deling pro cedures for func- tional da t a into semi-supervised counterparts. W e, in par t icular, fo cus on a m ulti-class classification or discriminan t problem, and dev elop a semi-sup ervised log istic mo del f or functional classification problem. Unkno wn parameters in the mo del are es timated b y the regularization metho d along with the tec hnique of EM algorit hm. A crucial issue f or the mo deling pro ce dure is to c ho ose a v alue of a regularization parameter inv olv ed in the semi- sup ervised functional logistic model. In order to select the optimal v alue of the regula r iza- tion parameter, we then introduce mo del selec tion criteria based on information-theoretic and Bay esian approaches that ev aluate semi-sup ervised functional logistic mo dels esti- mated b y the regularization metho d. Some nume rical examples including a microarr ay data analysis ar e illustrat ed to in v estigate the effectiv eness of our mo deling strategy . This pap er is organized as fo llows. In Section 2, w e consider a functionalization metho d 2 that con v erts the discrete data in to the functional form using basis expansions. Section 3 prop oses a functional logistic mo del in the context of the semi-sup ervised m ulti-class classification problem. In this section, w e also presen t an estimation pro cedure based on the regularization metho d with the help of EM algor it hm. Section 4 derive s mo del selection criteria to select a regularization parameter in the functional logistic mo dels. In Section 5, Monte Carlo simulations and a real data a nalysis ar e given to assess the p erformances of the prop o sed semi-sup ervised functional logistic discrimination. Some concluding remarks are given in Section 6. 2 F unction alization Supp ose that w e hav e n indep enden t observ ations x 1 , . . . , x n , where x α consist of the N α observ ed v alues x α 1 , . . . , x αN α at discrete times t α 1 , . . . , t αN α , respective ly . Our aim in this section is to express a data set { ( x αi , t αi ); i = 1 , . . . , N α , t αi ∈ T ⊂ R } ( α = 1 , . . . , n ) a s a set of smo oth functions { x α ( t ); α = 1 , . . . , n, t ∈ T } b y a smo othing techn ique. In this section w e drop the notat ion on the sub ject x α , and hence consider a functionalization pro cedure of the da t a set { ( x i , t i ); i = 1 , . . . , N } . It is assumed that the observ ed v alues { ( x i , t i ); i = 1 , . . . , N } for a sub ject a re drawn from a regression mo del as follow s: x i = u ( t i ) + ε i , i = 1 , . . . , N , (1) where u ( t ) is a smo o th function to b e estimated and the error s ε i are indep enden tly , normally distributed with mean zero a nd v ariance σ 2 . W e also a ssume that the function u ( t ) can b e represen t ed b y a linear com bination of pre-prepared basis functions in the form u ( t ) = m X k =1 ω k φ k ( t ; µ k , η 2 k ) , (2) where ω k are co efficien t parameters, m is the num b er of basis functions and φ k ( t ; µ k , η 2 k ) are Gaussian ba sis functions given by φ k ( t ; µ k , η 2 k ) = ex p − ( t − µ k ) 2 2 η 2 k , k = 1 , . . . , m. (3) 3 Here µ k are the cen ters of the basis functions and η k are the disp ersion parameters. In particular, w e use Gaussian basis functions prop osed by Ka w ano and Konishi (2007), and hence the centers µ k and the disp ersion parameters η k are determined a s follows: for equally spaced knots τ k so that τ 1 < · · · < τ 4 = min( t ) < · · · < τ m +1 = max( t ) < · · · < τ m +4 , we set the centers and the disp ersion parameters as ˆ µ k = τ k +2 and ˆ η ≡ ˆ η k = ( τ k +2 − τ k ) / 3 for k = 1 , . . . , m , resp ectiv ely . F or details of the pro cedure, w e refer to Ka w ano and Konishi (2 007). It fo llows that the nonlinear regression mo del based on the Gaussian basis functions can b e written as f ( x i | t i ; ω , σ 2 ) = 1 √ 2 π σ 2 exp " − x i − ω T φ ( t i ) 2 2 σ 2 # , i = 1 , . . . , N , (4) where ω = ( ω 1 , . . . , ω m ) T and φ ( t ) = ( φ 1 ( t ) , . . . , φ m ( t )) T . The parameters ω and σ 2 are estimated b y maximizing the regula r ized log - lik eliho o d function in the form ℓ ζ ( ω , σ 2 ) = N X i =1 log f ( x i | t i ; ω , σ 2 ) − N ζ 2 ω T K ω = − N 2 log(2 π σ 2 ) − 1 2 σ 2 ( x − Φ ω ) T ( x − Φ ω ) − N ζ 2 ω T K ω , (5) where x = ( x 1 , . . . , x N ) T , Φ = ( φ ( t 1 ) , . . . , φ ( t N )) T , ζ ( > 0) is a smo ot hing para meter and K is a p ositive semi-definite matrix defined by K = D T 2 D 2 , where D 2 is a second-order difference term. The r egula rized maxim um lik eliho o d estimates are given by ˆ ω = (Φ T Φ + N ζ ˆ σ 2 K ) − 1 Φ T x , ˆ σ 2 = 1 N N X i =1 x i − ˆ ω T φ ( t i ) 2 . (6) W e obtain the optimal num b er of basis functions m and the v alue o f the smo othing parameter ζ by using a mo del selection criterion GIC (Ando e t al. , 200 8) for eac h smo ot h curv e as the minimizer of the form GIC( ζ ) = N log(2 π ˆ σ 2 ) + N + 2tr { QR − 1 } , (7) where ˆ σ 2 is give n in Equation (6) and the m × m matrices Q and R are, resp ectiv ely , 4 0.0 0.2 0.4 0.6 0.8 1.0 0.0 0.5 1.0 1.5 2.0 2.5 Figure 1: F unctionalization by Ga ussian basis expansions giv en b y Q = 1 N ˆ σ 2 1 ˆ σ 2 Φ T Λ 2 Φ − ζ K ˆ ω 1 T N ΛΦ 1 2 ˆ σ 4 Φ T Λ 3 1 N − 1 2 ˆ σ 2 Φ T Λ 1 N 1 2 ˆ σ 4 1 T N Λ 3 Φ − 1 2 ˆ σ 2 1 T N ΛΦ 1 4 ˆ σ 6 1 T N Λ 4 1 N − N 4 ˆ σ 2 , (8) R = 1 N ˆ σ 2 Φ T Φ + N ζ ˆ σ 2 K 1 ˆ σ 2 Φ T Λ 1 N 1 ˆ σ 2 1 T N ΛΦ N 2 ˆ σ 2 , (9) where 1 N = (1 , . . . , 1) T and Λ = diag x 1 − ˆ ω T φ ( t 1 ) , . . . , x N − ˆ ω T φ ( t N ) . Hence, the o bserv ed discrete data { ( x αi , t αi ); t αi ∈ T , i = 1 , . . . , N α } ( α = 1 , . . . , n ) are smoo thed b y the metho dology described ab o ve, and w e obtain a functional data set { x α ( t ); α = 1 , . . . , n } giv en b y ˆ u ( t ) = m X k =1 ˆ ω αk φ k ( t ) ≡ x α ( t ) , t ∈ T . (10) Figure 1 sho ws a sk etc h of the functionalization using Gaussian basis functions. Circles represen t o bserv ed discrete da t a, the b elo w solid curv es basis functions pre-prepared and the ab ov e solid line the estimated smo oth curv e. F or details of the functiona lizatio n step in functional data analysis, we refer to Ramsa y and Silv erman (2005) or Araki et al. (2009a). 3 Semi-sup ervised fun ctional logistic discrimination 5 3.1 Semi-sup ervise d logist ic mo del for functional data In the framew ork of semi-supervised functional data analysis, w e are giv en n 1 lab eled functional data { ( x α ( t ) , g α ); α = 1 , . . . , n 1 , t ∈ T } and ( n − n 1 ) unlab eled f unctiona l data { x α ( t ); α = n 1 + 1 , . . . , n, t ∈ T } . Here x α ( t ) are functional predictors given in the previous section and g α ∈ { 1 , . . . , L } ar e group indicator v ariables in whic h g = k implies that the functional predictor x α ( t ) b elongs to g roup k . First, a f unctiona l log istic mo del is constructed b y using only lab eled functional data { ( x α ( t ) , g α ); α = 1 , . . . , n 1 , t ∈ T } . W e cons ider the p osterior probabilities for gro up k ( k = 1 , . . . , L ) giv en in a functional data x α ( t ) a s follow s: Pr ( g α = k | x α ). Under these p osterior probabilities, Araki et al. (2009b) in tro duced a functional logistic mo del in the form log Pr( g α = k | x α ) Pr( g α = L | x α ) = β k f + Z x α ( t ) β k ( t ) dt, k = 1 , . . . , L − 1 . (11) By using the same Gaussian basis function φ j ( t ) as in Equation (2), β k ( t ) is assumed to b e expanded as β k ( t ) = m X j =1 β k j φ j ( t ) . (12) Then w e can rewrite the functional logistic mo del in Equation (11) using the expansion in Equation (12) as follows : log Pr( g α = k | x α ) Pr( g α = L | x α ) = β k f + Z x α ( t ) β k ( t ) dt = β T k z α , (13) where β k = ( β k f , β k 1 , . . . , β k m ) T and z α = (1 , w T α J ) T . Here J is an m × m matrix with the ( i, j )-th elemen t J ij = p π ˆ η 2 exp − ( ˆ µ i − ˆ µ j ) 2 4 ˆ η 2 , i, j = 1 , . . . , m, (14) where ˆ µ i and ˆ η a re estimated cen t ers and width parameters included in Gaussian basis functions in Section 2, resp ectiv ely . 6 Th us the conditional probabilities can b e rewritten as Pr( g α = k | x α ) = exp { β T k z α } 1 + L − 1 X j =1 exp { β T j z α } , k = 1 , . . . , L − 1 , Pr( g α = L | x α ) = 1 1 + L − 1 X j =1 exp { β T j z α } . (15) W e describe Pr( g α = k | x α ) as π k ( x α ; β ), since the probabilities dep end on a parameter v ector β = ( β T 1 , . . . , β T L − 1 ) T . W e in tro duce an ( L − 1)-dimensional resp onse v ariable y α = ( y ( α ) 1 , . . . , y ( α ) L − 1 ) T ( α = 1 , . . . , n 1 ), which indicates that the k - th elemen t of y α is set to 1 if the corresp o nding x α ( t ) b elongs to the k -th class, for n 1 lab eled functional data { ( x α ( t ) , g α ); α = 1 , . . . , n 1 } . Hence we o btain a m ultinomial distribution with t he p osterior pro ba bilities π k ( x α ; β ) a s follo ws: f ( y α | x α ; β ) = L − 1 Y k =1 π k ( x α ; β ) y ( α ) k { π L ( x α ; β ) } 1 − P L − 1 j =1 y ( α ) j . (16) By in tro ducing a dumm y class lab el v ariable t α for unlab eled functional data { x α ( t ); α = n 1 + 1 , . . . , n } giv en b y t α = ( t ( α ) 1 , . . . , t ( α ) L − 1 ) T = (0 , . . . , 0 , 1 ( k ) , 0 , . . . , 0 ) T if x α ( t ) b elongs to k -th class , (0 , . . . , 0) T if x α ( t ) b elongs to L -th class , it is assumed that t α is distributed as the same m ultinomial distribution with the p osterior probabilities π k ( x α ; β ) as in Equation (16). Also, for unlab eled functional data, we assume β k f + R x α ( t ) β k ( t ) = β T k z α ( α = n 1 + 1 , . . . , n ; k = 1 , . . . , L − 1) similar to Equation (13). The lo g -lik eliho o d function based on b o t h lab eled and unlab eled functional da t a is then obtained b y ℓ ( β ) = n 1 X α =1 " L − 1 X k =1 y ( α ) k β T k z α − log 1 + L − 1 X l =1 exp { β T l z α } !# + n X α = n 1 +1 " L − 1 X k =1 t ( α ) k β T k z α − log 1 + L − 1 X l =1 exp { β T l z α } !# . (17) 7 3.2 Estimation via regularization As men t ioned in Araki et al. (20 0 9b), the maxim um likelihoo d metho d often causes some ill-p osed problems fo r a functional logistic mo del; i.e., unstable or infinite par a meter esti- mates. Then w e employ a regularization metho d to obtain the estimator of the pa r a meters included in the functional logistic mo del. A regularization metho d ac hiev es to ma ximize a regularized lo g-lik eliho o d function ℓ λ ( β ) = ℓ ( β ) − n 1 λ 2 L − 1 X k =1 β T k K β k , (18) where λ ( > 0) is a regularizat io n parameter and K is an ( m + 1) × ( m + 1) matrix giv en b y K = 0 0 T 0 K ∗ . (19) Here 0 is an m -dimensional zero v ector and K ∗ is an m × m p o sitiv e semi-definite matrix. In t he section o f n umerical examples, w e use a n iden tity mat r ix a s the matrix K ∗ . In maximizing the regular ized log-lik eliho o d function in Equation (18), it is difficult to obta in the estimator of the parameters, since the v alues of dumm y class lab els t are unkno wn and ∂ ℓ λ ( β ) /∂ β = 0 do es not ha v e an explicit solution with respect to the parameter vec tor β . Hence, we employ a f ollo wing EM-based alg o rithm to obtain the estimator ˆ β . Step1 Initializing the parameter v ector β b y maximizing the regular ized log-lik eliho o d function via only lab eled f unctional data { ( x α ( t ) , g α ); α = 1 , . . . , n 1 } with the help of F isher’s scoring metho d. Step2 Construct a classification rule π k ( x α ; ˆ β ). Step3 By the use of the classification rule in Step2, compute the p osterior pro babilities π k ( x α ; ˆ β ) ( k = 1 , . . . , L ) for unla b eled functional data x α ( t ) ( α = n 1 + 1 , . . . , n ). According to the p osterior probabilities, estimate t α as follo ws: ˆ t α = ( ˆ t ( α ) 1 , . . . , ˆ t ( α ) L − 1 ) T = ( π 1 ( x α ; ˆ β ) , . . . , π L − 1 ( x α ; ˆ β )) T . (20) 8 Step4 Replace t ( α ) k in to ˆ t ( α ) k in the regula r ized log-likelihoo d function. Then estimate the parameter v ector β using Fisher’s scoring metho d. Step5 Repeat the Step2 to the Step4 until the con v ergence condition | ℓ λ ( ˆ β ( k +1) ) − ℓ λ ( ˆ β ( k ) ) | < 10 − 5 (21) is satisfied, where ˆ β ( k ) is the v alue o f β after the k -th EM iterat io n. Therefore, we deriv e a statistical mo del f ( y | x ; ˆ β ) whic h is constructed b y using b oth lab eled and unlab ele d functional da t a . The statistical mo del includes a t uning parameter; i.e., the regularization parameter λ . Since the selection of this parameter is r ega rded as the selection of candidate mo dels, w e in tro duce mo del selection criteria to choose the constructed mo dels. 4 Mo del sel ection cr iteria In this section, w e deriv e t w o t yp es of mo del selection criteria to ev aluat e semi-sup ervised functional logistic mo dels f r o m the viewp oints of information-t heoretic a nd Ba y esian ap- proac hes. 4.1 Generalized information criterion Ak aik e (1974) prop osed t he Ak aik e inf o rmation criterion (AIC), whic h enables us to ev al- uate statistical mo dels estimated by the maximum lik eliho o d metho d. While the AIC is v ery useful for v arious fields of researc h, the criterio n cannot b e directly applied in to mo dels constructed b y other estimation pro cedures. Konishi and Kitagaw a (1996 ) in tro duced an information criterion, whic h can ev alu- ate mo dels constructed by v arious estimation pro cedure s including r o bust, Ba y esian and regularization metho ds. Using the result o f Konishi and Kita g a w a (1996), w e prop ose a generalized information criterion (GIC) in the conte xt of the semi-supervised functional logistic mo del. The mo del selection criterion is given as follows : GIC = − 2 n 1 X α =1 log f ( y α | x α ; ˆ β ) + 2tr n Q ( ˆ β ) R − 1 ( ˆ β ) o , (22) 9 where the matrices Q ( ˆ β ) and R ( ˆ β ) are Q ( ˆ β ) = 1 n 1 h { ( B − C ) ⊙ A } T − λE ˆ β 1 T n 1 i { ( B − C ) ⊙ A } , (23) R ( ˆ β ) = − 1 n 1 ( C ⊙ A ) T ( C ⊙ A ) + 1 n 1 D + λE , (24) with A = ( Z, . . . , Z ) , n 1 × ( m + 1)( L − 1) , B = ( y (1) 1 T m +1 , . . . , y ( L − 1) 1 T m +1 ) T , C = ( π (1) 1 T m +1 , . . . , π ( L − 1) 1 T m +1 ) T , D = blo c k diag { Z T diag ( π (1) ) Z , . . . , Z T diag( π ( L − 1) ) Z } , E = blo c k diag ( K, . . . , K ) , ( m + 1)( L − 1) × ( m + 1 )( L − 1) , Z = ( z 1 , . . . , z n 1 ) T , y ( k ) = ( y (1) k , . . . , y ( n 1 ) k ) T , π ( k ) = ( π k ( x 1 ; ˆ β ) , . . . , π k ( x n 1 ; ˆ β )) T . Here t he o p erator ⊙ denotes the Hadamard pro duct, whic h means the elemen t wise pro d- uct o f matrices; that is, A ij ⊙ B ij = ( a ij b ij ) for matrices A ij = ( a ij ) and B ij = ( b ij ). 4.2 Generalized B a y esian informatio n criterion In Ba y esian inference, Sc h w arz (1978) presen ted the Ba y esian information criterion (BIC) from the viewp oint of maximizing a marginal lik eliho od. How ev er, the BIC cov ers o nly mo dels estimated b y the maximum lik eliho o d metho d. By extending the Sch w arz’s (1978) idea, Konishi et al. (2004) de riv ed a nov el Ba y esian information criterion to ev aluate mo dels estimated by regularization in the fra mework of generalized linear mo dels. Hence, b y using the result giv en in Konishi et al. (2004), w e presen t a generalized Bay esian information criterion (G BIC) for ev aluat ing the statistical mo del constructed b y the semi-supervised f unctiona l logistic mo deling pro cedure in the 10 form GBIC = − 2 n 1 X α =1 log f ( y α | x α ; ˆ β ) + n 1 λ L − 1 X k =1 ˆ β T k K ˆ β k − ( L − 1) log | K | + + log | R ( ˆ β ) | − ( L − 1)( m + 1 − d ) log λ − ( L − 1) d log 2 π n 1 , (25) where R ( ˆ β ) is given b y Equation (24) and | K | + is the pro duct of the p o sitive eigen v alues of K with the ra nk d . W e thus select a t uning parameter λ b y minimiz ing either the model selec tion criterion GIC or GBIC. F or more details of deriv ations ab o ut the mo del selection criteria, w e refer to Konishi and Kitagaw a (200 8). 5 Numerical studies W e conducted some n umerical examples to inv estigate the effectiv eness o f the prop osed mo deling pro cedure. Mon te Carlo sim ulations and a real data analysis are giv en to illus- trate our prop osed semi-sup ervised functional mo deling strategy . 5.1 Mon te Carlo sim ulations W e demonstrated the efficiency of the pro p osed functional mo deling pro cedure through Mon te Carlo sim ulations. In the sim ulation study , w e generated n discrete samples { ( x αt i , g α ); α = 1 , . . . , n, i = 1 , . . . , l } , where predictors x αt i are assumed to b e obta ined b y x αt i = h α ( t i ) + ε αt i and the class lab el g α indicates 1 or 2 whic h is the group n um b er. W e considered t w o settings a s follows: Case 1 h α ( t i ) = sin( c α t i π ) u α , ε αt i ∼ N (0 , 0 . 1) , t i = 2 i − 2 49 , n = 600 , l = 50 , g α = 1 : c α = 1 , u α ∼ U [0 . 3 , 1 . 3] , g α = 2 : c α = 1 . 02 , u α ∼ U [0 . 1 , 0 . 6] , 11 0.0 0.5 1.0 1.5 2.0 −1.0 −0.5 0.0 0.5 1.0 5 10 15 20 0 1 2 3 4 5 6 (a) (b) Figure 2: T rue functions for (a) Case 1 and (b) Case 2. In eac h case, there are 10 sub jects. Solid lines represen t the group 1, while da shed lines represen t the group 2. Case 2 h α ( t i ) = u α w ( t i ) + (1 − u α ) v ( t i ) , ε αt i ∼ N (0 , 1) , t i = i + 4 5 , n = 600 , l = 101 , g α = 1 : u α ∼ U [0 , 1 ] , w ( t i ) = max(6 − | t i − 11 | , 0) , v ( t i ) = max(6 − | t i − 11 | , 0) − 4 , g α = 2 : u α ∼ U [0 , 1 ] , w ( t i ) = max(6 − | t i − 11 | , 0) , v ( t i ) = max(6 − | t i − 11 | , 0) + 4 . Figure 2 denotes the true functions h ( t ) for the Cases 1 and t he Case 2, respectiv ely . W e divided the data set in to 300 training data and 300 test data with an equal prior probabilit y for eac h class . In order to impleme n t the semi-sup ervised metho d, the training data w ere randomly divided in to t wo halv es with la b eled functional data and unlab eled functional data, where the lab eled functional data we re assigned as 5%, 10%, 20%, 30%, 40%, 50% and 60% of the tra ining data, resp ective ly . W e compared the p erformances of semi-supervised f unctional logistic mo del ( SFLDA ) with those o f sup erv ised functional log istic mo del (FLDA) prop osed b y Araki et al. (2009b), supp o rt v ector machine with the RBF ke rnel (SVM), k -nearest neigh b or classifi- cation (KNN), functional supp ort v ector mac hine with the RBF k ernel (FSVM) prop osed b y Rossi and Villa (2006), and semi-sup ervised methods prop osed b y Zhou et al. (2004) (LLGC: learning with lo cal and g lobal consistency) and Y u et al. (200 4) (ILLGC: induc- 12 tiv e learning with lo cal a nd global consistency). The discrete data set w a s transformed in to a functional data set using the smo othing tec hnique describ ed in Section 2 . Semi- sup ervised and sup ervised functional mo deling strategies (i.e., SFLDA, FLD A and FSVM) w ere applied in to the functional data set. The regularizatio n parameter in the SFLDA and the F LD A was selected b y using the GIC or the GBIC. F or the GIC or the G BIC of the FLD A, w e refer to Araki et al. (2009a; 2009b). Adjusted parameters included in the SVM, the FSVM, the L L G C and the ILLGC were optimized by the five -fold cross v alidation, resp ectiv ely . The n um b er of neighbors k in the KNN was selected b y the lea v e- one-out cross v alidation. T ables 1 and 2 show comparisons of the test error rates for the simulated data . These v alues w ere a veraged o ver 5 0 r ep etitions. The a v erag e v alues of the tuning parameter λ for 50 runs of the Case 1 w ere λ = 5 . 9 6 × 1 0 − 5 for the GIC and λ = 9 . 4 8 × 1 0 − 5 for the GBIC, while those of the Case 2 w ere λ = 1 . 00 × 10 − 2 for the GIC and λ = 2 . 28 × 10 − 2 for the GBIC. F or the Case 1, w e observ e that the SFLD A metho ds ev a luated b y the GIC and the GBIC are sup erior to other metho ds except for the FLD A metho ds in almost all cases. Also, our prop osed metho ds SF L DA seem to pro vide low er misclassific ation errors than the FLDA metho ds, when the size of lab eled functional data is small (e.g., 10% of training da ta). In the case of the Case 2, the SFLDA metho ds outp erfor m the SVM, the KNN, the FSVM, the LLG C and the ILLG C in all situations with resp ect to minimizing the test errors. In addition, the pro p osed pro cedures SFLD A may b e comp etitiv e or sligh tly sup erior to the FLD A metho ds. 5.2 Microarra y data analysis W e describ e an applicatio n of the semi-supervised functional discriminan t analysis to y east g ene expression dat a giv en in Sp ellman et al . (1998) . This data set contains 77 microarra ys and consists of tw o short t ime-courses (i.e., tw o time po in ts) and four medium time-courses (18, 24, 17 and 1 4 time p oints). Ab out 800 g enes we re classified into fiv e differen t cell-cycle phases, namely , M/G1, G1, S, S/G2 a nd G2/M phases, while the o t her 5,378 genes w ere not classified. F or more details o f this data set, w e refer to Sp ellman et 13 T able 1: Comparison of test erro r s with differen t p ercen tages of labeled functional data in the training data set fo r the Case 1. F igures in pa r en theses indicate the mo del selection criteria used in the sim ulation study . Metho d \ % 5 10 20 30 40 50 60 SFLAD (GIC) 0.269 0.210 0.202 0.19 2 0 .189 0.186 0.185 FLDA (GIC) 0.248 0.21 6 0.2 04 0.193 0.187 0.185 0.184 SFLAD (GBIC) 0.271 0.210 0.202 0.19 3 0 .188 0.185 0.185 FLDA (GBIC) 0.359 0.237 0.200 0.18 8 0 .185 0.183 0.182 SVM 0.278 0.221 0.203 0.19 5 0 .194 0.183 0.185 KNN 0.268 0.244 0.236 0.22 8 0 .225 0.220 0.215 FSVM 0.322 0.266 0.253 0.23 1 0 .229 0.218 0.215 LLGC 0.313 0.255 0.227 0.20 4 0 .197 0.192 0.187 ILLGC 0.335 0.255 0.221 0.20 0 0 .193 0.189 0.185 al . (1998) . In our ana lysis, we used the “cdc15-based exp erimen t data ” sampled ov er 24 p oints after sync hronization. F or simplicit y , any genes t ha t con tain missing v alues a cross an y of the 24 time p oin ts were discarded. The se expres sion data w ere considered to b e a discretized realization of 632 expression curv es ev a luated at 24 time p o in ts. W e function- alized the data using the smo othing metho dolog y giv en in Section 2. A total of 300 genes w ere used a s t he t r aining data set, a nd the remaining 332 genes we re used as the test data set. W e compared the SFLDA , whic h is our prop osed semi-supervised functional metho d, with the FLD A, whic h is the sup ervised functional metho d. First, w e demonstrated the effectiv eness o f our semi-supervised metho dology b y set- ting functonal data with kno wn class lab els as unlab eled functional data. W e randomly split the training data set in to lab eled functional data and unlab eled functiona l data, where 15%, 20 %, 30%, 40% and 50% of training dat a are allo cated as lab eled functional data, resp ectiv ely , and w e rep eated the pro cedures 10 times. The v alues of the selecte d regularization parameter for 1 0 runs w ere λ = 2 . 80 × 10 − 5 for the GIC and λ = 7 . 78 × 10 − 4 14 T able 2: Comparison of test erro r s with differen t p ercen tages of labeled functional data in the training data set fo r the Case 2. F igures in pa r en theses indicate the mo del selection criteria used in the sim ulation study . Metho d \ % 5 10 20 30 40 50 60 SFLAD (GIC) 0.056 0.040 0.032 0.03 1 0 .029 0.028 0.027 FLDA (GIC) 0.056 0.04 3 0.0 35 0.029 0.029 0.029 0.027 SFLAD (GBIC) 0.056 0.040 0.032 0.02 9 0 .029 0.028 0.026 FLDA (GBIC) 0.056 0.043 0.035 0.02 9 0 .029 0.028 0.026 SVM 0.075 0.056 0.040 0.03 7 0 .034 0.030 0.031 KNN 0.068 0.062 0.052 0.05 1 0 .050 0.047 0.048 FSVM 0.107 0.081 0.068 0.05 7 0 .057 0.053 0.054 LLGC 0.124 0.082 0.062 0.04 9 0 .043 0.040 0.040 ILLGC 0.111 0.049 0.040 0.03 5 0 .031 0.030 0.030 for the GBIC. Figure 3 sho ws the a verage precisions of the test data set for differen t ratios of lab eled-unlab eled f unctional data in t he t r aining data set. On the x -axis, 15 means that 15% of the training data was assigned as lab ele d functional data , and the remaining 85% w as used as unlab eled functional data. F rom the left panel of Figure 3, w e observ e that the SFLDA with the GIC seems to extract useful information from unlab eled functional data, since the SFLDA p erforms b etter than the FL DA in all cases. In con trast, the righ t panel o f F igure 3 show s that the SFLDA is sup erior to the FLDA un til 30 % lab ele d functional data, where as the SF L DA is comparable to the FLDA in the r a nge from 30% to 50% la b eled functional data. Second, w e examined the p erformances o f our metho ds b y using real unlab eled func- tional data whic h we re not classified by Sp ellman et al. (1998 ) . W e prepared lab eled functional da t a whic h consist of 20%, 25%, 30%, 40%, 50% and 60% o f the training da t a , while unlab ele d f unctional data are set to 50 0 samples randomly selected from 5,378 real unlab eled examples. Our prop osed mo dels and the sup ervised functional mo dels w ere ap- plied into the data set. W e rep eated thes e procedures 10 times. W e obtained the av eraged 15 15 20 25 30 35 40 45 50 0.26 0.28 0.30 0.32 0.34 P ercentages of labeled data Prediction errors 15 20 25 30 35 40 45 50 0.25 0.30 0.35 Percentages of labeled data Prediction errors 15 20 25 30 35 40 45 50 0.25 0.30 0.35 Figure 3: Av erage prediction errors for sev eral ratios of lab eled functional da t a in the training da ta set. Solid line sho ws the result of the SF LD A while dashed line sho ws that of the FLDA. The left-hand panel indicates the results for the metho ds ev aluated by the GIC, whereas the right-hand panel indicates those b y the G BIC. optimal v alues of the regularization parameter for 10 rep etitions as λ = 1 . 00 × 10 − 5 for the GIC and λ = 7 . 85 × 10 − 5 for the GBIC. F igure 4 show s the a v erage test error rates for v arious ra tios o f lab eled functional da t a in the t raining data set. F or the left-hand panel of Figure 4, the SF LD A outp erfo r ms the FLDA without 2 0% lab eled f unctional data , while the SFLDA giv es lo w er prediction errors than the FLDA on 2 0 % lab eled functional data. Hence, these results suggest that real unlab eled functional data included in Sp ellman’s et al. (1998) data set ma y hav e a p oten tial for improvin g a prediction accuracy of our functional logistic pro cedures. 6 Conclud ing r emarks W e prop osed a semi-supervised functional logistic mo deling pro cedure for the multi-class classification problem with the help of regularization. On the step of functionalization, a smo othing metho d using Gaussian basis expansions w as applied to the observ ed discrete data set. A crucial issue for our semi-supervised mo deling pro cess is the c hoice o f the regu- larization parameter λ . In order to select the v alue of the parameter, w e intro duced mo del selection criteria f r o m the viewpoints o f info rmation-theoretic and Bay esian approac hes. 16 20 30 40 50 60 0.24 0.26 0.28 0.30 0.32 Percentages of labeled data Prediction errors 20 30 40 50 60 0.22 0.24 0.26 0.28 0.30 Percentages of labeled data Prediction errors Figure 4: Av erage prediction errors for sev eral ratios of lab eled functional da t a in the training data set, where we use real unlab eled functional data. Solid line show s the result of the SFLDA while dashed line sho ws that of the F L DA. The left- hand pa nel indicates the results for the metho ds ev aluated by the GIC, whereas the righ t-hand panel indicates those b y the GBIC. Mon te Carlo simulations and a microarray data a nalysis show ed that our mo deling strat- egy yields relat ively lo w er prediction error rates than previously dev elop ed metho ds. A further researc h should b e to construct a semi-sup ervised functional regression mo deling or clustering. Ac kno wledgemen t This work w as supp orted b y the Ministry of Education, Science, Sp o rts and Culture, Gran t-in-Aid for Y oung Scien tists (B), #247002 80, 2012 –2015. References [1] Abraham, C., Cornillon, P . A., Matzner-Lob er, E. and Molinari, N. ( 2003). Unsup er- vised curv e clustering using B -splines. Sc an d inavian Journal of Statistics , 30 , 581–595. [2] Ak aik e, H. (1974). A new lo ok at the statistical mo del iden tificatio n. IEEE T r ansac- tions o n A utomatic Con tr ol , A C-19 , 71 6–723. 17 [3] Ando, T., K onishi, S. and Imoto , S. (20 0 8). Nonlinear regression mo deling via reg- ularized radial basis function net works. Journal of Statistic a l Planning an d Infer enc e , 138 , 3616–3633 . [4] Araki, Y., Ko nishi, S., Kaw ano, S. and Matsui, H. (2009 a). F unctional regression mo deling via regularized G a ussian basis expansions. A nnals of the Institute of Statistic al Mathematics , 61 , 811 –833. [5] Araki, Y., Konishi, S., Kaw ano, S. and Matsui, H. (2009 b) . F unctional logistic dis- crimination via regularized basis expansions. Comm unic ations in Statistics - The o ry and Metho ds , 38 , 2944– 2957. [6] Basu, S., Bilenk o, M. and Mo oney , R . J. (2004). A probabilistic framew ork for semi- sup ervised clustering. Pr o c e e dings of the 1 0th ACM SIGKDD I n ternational Confe r enc e on K now le dge Disc overy and D a ta Mining , A CM Press, 59–68. [7] Chap elle, O., Sc h¨ olk opf , B. and Zien, A. (2006). Semi-Sup ervise d L e arning . Cam- bridge, MA: MIT Press. [8] Chiou, J. M. and Li, P . L. (2007). F unctional clustering and iden tifying substructures of lo ng itudinal data. Journal of the R oyal Statistic al So ciety Series B , 69 , 679–69 9 . [9] Dean, N., Murph y , T. B. and Do wney , G. (20 0 6). Using unlab elled data to up date classification rules with applications in fo o d authen ticit y studies. Journal of the R oyal Statistic al So ciety Serie s C , 55 , 1–14. [10] F erraty , F. and Vieu, P . (2003). Curv es discrimination: a nonparametric functional approac h. Computational Statistics and D ata Analysis , 44 , 161–173 . [11] F erraty , F . and Vieu, P . (2006). Nonp ar ametric F unctional Data Analysis . New Y ork: Springer. [12] James, G. M. and Silv erman, B. W. (2005). F unctional adaptiv e mo del estimation. Journal of the A meric an Statistic al Asso ciation , 100 , 565–576. [13] Kaw ano, S. and K onishi, S. (20 07). Nonlinear regression mo deling via regularized Gaussian basis functions. Bul letin of I nformatics and Cyb ernetics , 39 , 83–9 6. 18 [14] Kaw ano, S. and Ko nishi, S. ( 2 011). Semi-sup ervised logistic discrimination via regu- larized Gaussian basis expansions. Communic ations in Statistics - The ory and Metho ds , 40 , 2412–2423 [15] Konishi, S., Ando, T. and Imoto, S. (2004). Ba y esian information criteria and smo ot h- ing parameter selection in radial basis function net w o rks. Biome trika , 91 , 27–43. [16] Konishi, S. and Kita ga w a, G. (1996). Generalised information criteria in mo del se- lection. Biometrika , 83 , 87 5–890. [17] Konishi, S. and Kitagaw a, G. (2008). Inf o rmation Criteria and Statistic al Mo deling . New Y ork: Springer. [18] Kulis, B., Ba su, S., Dhillo n, I. and Mo o ney , R. (2009 ) . Semi-sup ervised graph clus- tering: a k ernel approac h. Mach ine L e arning , 74 , 1–22. [19] Lafferty , J. a nd W asserman, L. (20 0 7). Statistical analysis of semi-sup ervised regres- sion. A dvanc es in Neur al Information Pr o c essin g Systems , 21 , 801–8 08. [20] Liang, F., Mukherjee, S. and W est, M. (2 0 07). The use of unlab eled data in predictiv e mo deling. Statistic al Scienc e , 22 , 189 – 205. [21] Miller, D. and Uy ar, H. S. (199 7 ). A mixture of exp erts classifier with learning based on both lab elled and unlabelled data. A dvanc es in Neur al Information Pr o c essing Systems , 9 , 571 – 577. [22] Ng, M. K., Chan, E. Y., So, M. M. C. and Ching, W. K. (2006 ). A semi-sup ervised regression mo del for mixed nume rical and categorical v ariables. Pa ttern R e c o gnition , 40 , 1745–1752 . [23] Ramsa y , J. O. and Silv erman, B. W. (2002 ). Applie d F unctional D a ta Analysis . New Y ork: Springer. [24] Ramsa y , J. O. and Silv erman, B. W. (20 05). F unctional Data A nalysis. Second Edi- tion. New Y or k: Spring er. 19 [25] Rice, J. A. and Silv erman, B. W. (1 991). Estimating the mean and co v ariance struc- ture nonparametrically when the data are curv es. Journal of the R oyal Statistic al So ciety Series B , 53 , 233–243. [26] Rossi, F., Conan-Guez, B. and Goli, A. E. (2004). Clustering functional data with the SOM algorithm. Pr o c e e dings of XI I th Eur op e an Symp osium on Artificial Neur a l Networks , Bruges, 30 5–312. [27] Rossi, F. and Villa, N. (2006). Supp ort ve ctor mac hine for functional data classifica- tion. Neur o c om puting , 69 , 730– 742. [28] Sc h w a r z, G. (197 8 ). Estimating the dimension of a mo del. Annals of Statistics , 6 , 461–464. [29] Silv erman, B. W. (1996 ) . Smo othed functional principal comp onen ts analysis by c hoice of norm. Annals of Statistics , 24 , 1–24. [30] Sp ellman, P . T., Sherlo c k, G., Zhang, M. Q., Iy er, V. R., Anders, K., Eisen, M. B., Bro wn, P . O., Bostein, D. and F utc her, B. (1998). Comprehensiv e iden tification of cell cycle-regulated genes of the yeast Sac char omyc es c er evisiae b y microarray h ybridiza- tion. Mole cular Biolo gy of the Cel l , 9 , 327 3–3297. [31] V erb eek, J. J. and Vlassis, N. (2006 ). Gaussian fields for semi-sup ervised regression and corresp o ndence learning. Pattern R e c o g n ition , 39 , 1864–18 75. [32] Y ao, F. and Lee, T. C. M. (2006). P enalized spline mo dels for functional principal comp onen t analysis. Journal of the R oyal Statistic al So ciety Series B , 68 , 3–25. [33] Y ao, F., M ¨ uller, H. G. and W a ng, J. L. ( 2005). F unctional linear regression analysis for lo ngitudinal data. Annals of Statistics , 33 , 2873–2903 . [34] Y u, K ., T resp, V. and Zho u, D. (2004). Semi-sup ervised induction with basis func- tions. Max Planc k Institute T ec hnical Rep or t 141, Max Planc k Institute f or Biological Cybernetics, T ¨ ubingen, German y . [35] Zhong, S. (2006). Semi-sup ervised mo del- ba sed do cumen t clustering: A comparative study . Machine L e arni n g , 65 , 3–2 9 . 20 [36] Zhou, D., Bousquet, O ., Lal, T. N., W eston, J. and Sc h¨ olkopf, B. (20 04). Learning with lo cal and global consistency . A dvanc es in Neur a l Informa tion Pr o c essing Systems , 16 , 321–328. [37] Zh u, X. (2 0 08). Semi-sup ervied learning literature surv ey . Computer Sciences T ec h- nical Rep ort 1530, Unive rsit y of Wisconsin-Madison. 21
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment