Exact test for Markov order
We describe an exact test of the null hypothesis that a Markov chain is nth order versus the alternate hypothesis that it is $(n+1)$-th order. The procedure does not rely on asymptotic properties, but instead builds up the test statistic distribution via surrogate data and is valid for any sample size. Surrogate data are generated using a novel algorithm that guarantees, per shot, a uniform sampling from the set of sequences that exactly match the nth order properties of the observed data.
💡 Research Summary
The paper presents an exact hypothesis‑testing framework for determining the order of a Markov chain, addressing the shortcomings of traditional asymptotic methods such as chi‑square (χ²) tests, AIC, and BIC, which become unreliable for small sample sizes. The authors focus on testing the null hypothesis that a process is an n‑th order Markov chain against the alternative that it is (n + 1)‑th order. Their key contribution is a surrogate‑generation algorithm that produces sequences which exactly preserve the n‑th order transition count matrix (the “word” counts) of the observed data while sampling uniformly from the set of all such sequences.
The algorithm relies on Whittle’s formula, which gives the number of sequences N_uv(F) that share a given transition count matrix F, start state u, and end state v. Whittle’s expression involves factorial terms and a determinant C_vu derived from a modified transition matrix. To avoid overflow, the authors compute the logarithm of the formula using Stirling’s series for factorials when arguments exceed 16.
Uniform sampling is achieved by constructing a sequence step‑by‑step. After fixing the first symbol y₁ = u, the algorithm enumerates all admissible second symbols y₂ such that the corresponding entry in F is positive. For each candidate y₂, it temporarily decrements the transition count (producing F′) and evaluates the remaining number of valid completions N_{y₂v}(F′) via Whittle’s formula. The candidate is then selected with probability proportional to N_{y₂v}(F′). This process repeats until the final symbol y_N = v is placed. Because each choice is weighted by the exact number of completions, the resulting path is a uniform draw from the full set S of admissible sequences. The computational cost grows linearly with the sequence length N, and the method scales to any order n because the transition matrix simply becomes Mⁿ × Mⁿ, which remains sparse (at most N − n non‑zero entries).
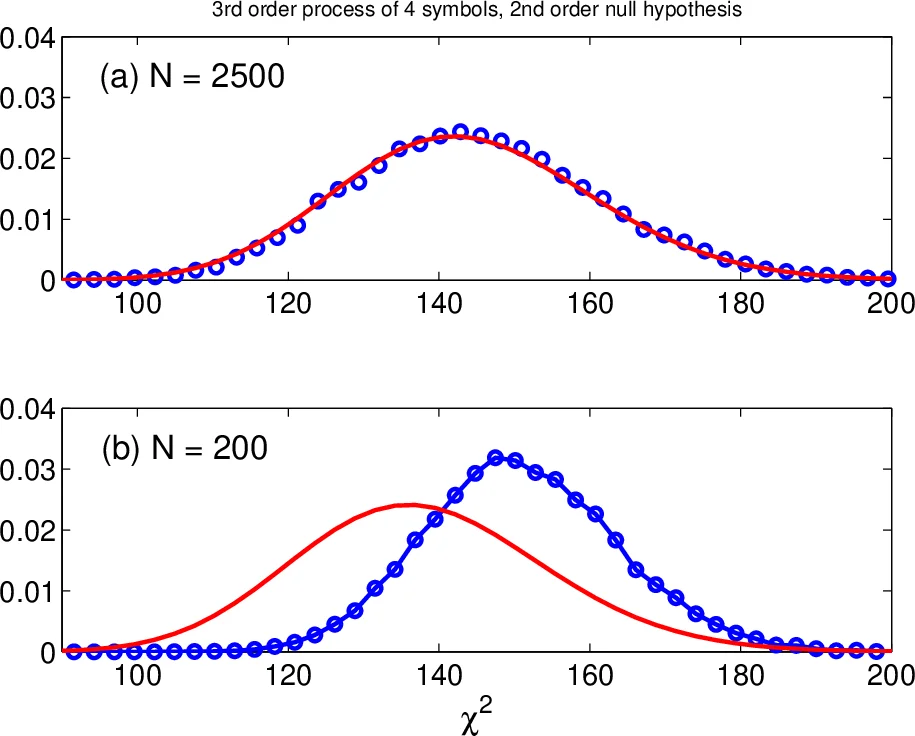
Two test statistics are examined. The first is the classic χ² statistic, which compares observed word counts O_w to expected counts E_w under the null hypothesis. The degrees of freedom d are derived from the block structure of the transition matrix: for each block of size r_k × c_k, the contribution is (r_k − 1)(c_k − 1). The second statistic is the conditional entropy rate H(x_{t+1}|x_t…x_{t‑n+1}), computed as the difference between the joint entropy of (n + 1) symbols and the entropy of the n‑symbol context. The entropy statistic does not require a degrees‑of‑freedom correction, making it attractive for small samples.
The authors conduct extensive Monte‑Carlo experiments. They generate random Markov processes with M = 4 symbols for orders 1 through 4, and for each process they create observed sequences of lengths N = 25, 50, 100, 200, 400, and 2500. For each (order, N) pair, 2500 surrogate sequences are generated using the Whittle‑based algorithm. Table I (first‑order null) and Tables II–III (second‑ and third‑order nulls) report the empirical size (type‑I error rate) and power (type‑II error complement) for three methods: the asymptotic χ² test, the exact χ² test based on surrogates (χ²_surg), and the exact entropy test (H_surg).
Results show that the asymptotic χ² test severely inflates the type‑I error for short sequences (e.g., size ≈ 0.48 for N = 25 in the first‑order case) and exhibits low power (≈ 0.03). In contrast, both exact methods quickly achieve the nominal size of 0.05 once N reaches about 50–200, and their power rises to near 1.0 for N ≥ 200. Notably, the entropy‑based exact test performs on par with the exact χ² test while being computationally simpler, and it remains reliable for higher‑order tests where χ² degrees‑of‑freedom calculations become cumbersome.
Implementation details include the use of logarithmic factorial approximations, sparse matrix representations, and the possibility of parallel surrogate generation (each surrogate is independent). The authors provide open‑source Python code (reference
Comments & Academic Discussion
Loading comments...
Leave a Comment