LogMaster: Mining Event Correlations in Logs of Large scale Cluster Systems
This paper presents a methodology and a system, named LogMaster, for mining correlations of events that have multiple attributions, i.e., node ID, application ID, event type, and event severity, in logs of large-scale cluster systems. Different from …
Authors: Rui Ren, Xiaoyu Fu, Jianfeng Zhan
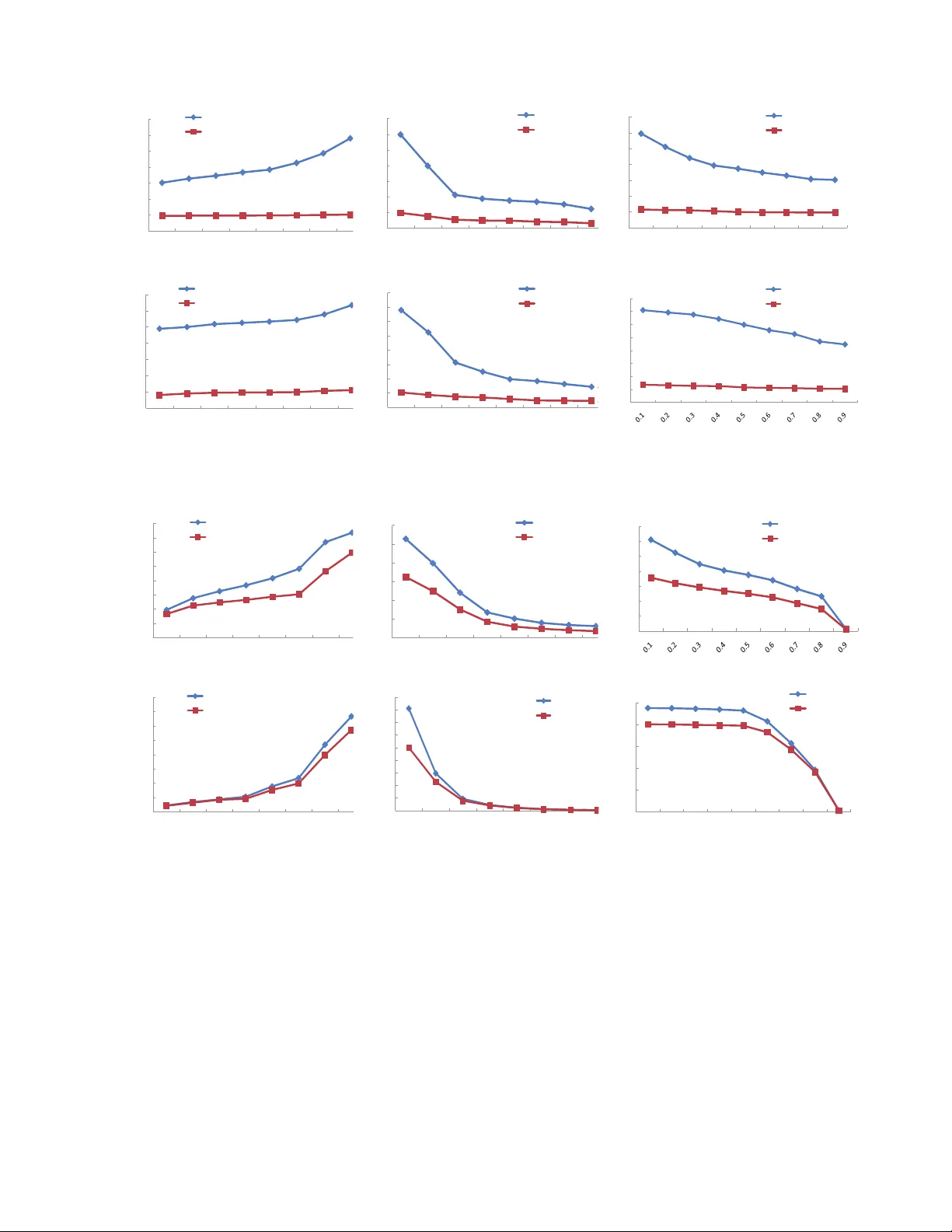
LogMaster: Mining Ev ent Correla tions in Logs of Lar ge-scal e Cluster Systems Rui Ren ∗ , Xiaoyu Fu ∗ , Jianfeng Zhan ∗ , ‡ , W ei Zhou ∗ ∗ Institute of Computing T ec hnolog y , Chinese Academy of Sciences ‡ Correspon ding a uthor: zhanjian feng@ict.ac. cn Abstract —This paper presents a method ology and a system, named LogMaster , fo r mining correlations of ev ents that hav e multiple attributions, i.e., node ID, application ID, event type, and event severity , in logs of large-scale clu ster systems. Different from traditional transactional data, e.g., supermarket pu rchases, system logs hav e their un ique characteristic, and hence we propose se veral innovati ve approaches to min e their corr elations. W e present a simpl e metrics to measure correlations of events that may happen interleav edly . On the basis of th e measurement of correla tions, we propose two approa ches to mine ev ent correla tions; meanwhile, we propose an inn ov ative abstraction— ev ent cor relation gr aphs (ECGs) to represent eve nt corr elations, and present an ECGs-based algorithm for predicting events. For two system logs of a pro ducti on Hadoop-based c loud computing system at Resear ch Institu tion of Chin a Mobile an d a production HPC cluster system at Los Alamos National L ab (LANL), we ev aluate our approaches in three scenarios: (a) predicting all ev ents on t he basis of both failure and n on-failure events; (b) predicting only failure ev ents on the b asis of b oth failure and non-failure events; (c) predicting failure events after remo ving non-failure e vents. I . I N T R O D U C T I O N Cluster systems are commo n platfo rms for both high per- forman ce com puting and cloud comp uting. As the scales of cluster sy stems increase, failures become n ormal [6]. It has been long recog nized that (failure) events ar e correlated , n ot indepen dent. In an early year as 19 92, T ang et a l. [30] con- cluded that the impac t of correlated failures on depen dability is significant. Th ough we can not inf er causalities among dif- ferent events withou t inv asi ve app roaches like r equest tracing [15], we indeed can find out corr elations among dif ferent ev ents thro ugh a data min ing approach . Th is paper focu ses o n mining r ecurring event sequences with timing orders that have corr elations , which we call event rules . As an intuition, if there is an event rule that identifies the correla tion of warning e vents and a fatal ev ent, the occurrence of warning events indica tes that a failure may happe n in a near futu re, so mining e vent rules is the ba sis f or predicting failures. Considerable work has been done in mining frequent itemset in transaction al data, e.g., sup ermarket purchases, [52] [53]. Howe ver , system log s are dif feren t from transactio nal data in fou r aspects. First, for e vent data, the timin g order play s an impo rtant role. Moreover , a p redicted ev ent seque nce without the timing constraints provid es little info rmation for a failure predictio n, so we h av e to consider time am ong ev ent occurre nces rather than just their occurrence [10]. Second, logs are tempo ral. On ly o n conditio n that events fall within a time window , we can co nsider those events may have correlation s. Third, a failure ev ent has many importan t attributions, i.e., node ID, a pplication ID, event typ e, and event sev erity . For a f ailure prediction, th ose attributions are in gredien t. For example, if you predict a failure witho ut node informatio n, an administrato r can not take an app ropriate action. Last, different events may hap pen interlea vedly , and hence it is difficult to define a metrics for ev ent co rrelation. For example, it is difficult to define the event correlation between two events A and B in an e vent sequenc e B AC B B A , since A an d B happen interleavedly . On th e basis of Apr iori-like algorithm s [52] [53], sev eral previous efforts prop ose new appro aches for freq uent itemset, ev ent bursts, per iodical events, mu tual-depe ndent events [1 0], frequen t episodes [57], sequential patterns[62] or closed se- quential pa tterns [58] [59], however mining multi-attribution ev ent rules in system logs of large-scale cluster sy stems has its unique requir ements as mentioned above. For e xamp le, in [59], in stead of m ining th e complete set of freq uent subsequen ces, Y an et a l. min e fre quent clo sed subseq uences only , i.e., those containing no super-sequence with the same occurre nce freque ncy , which is difficult to directly apply in mining event rules for the purp ose of predicting failures. Some work prop osed Apriori-like algo rithms in predicting failures [5] without providing d etails (multi-attribution) or rare events [2] [63], which are limited to the specified target events. Our effort in th is paper focuses on minin g event rules in system log s. T ak ing into accou nt the unique ch aracteristic of logs, we pro pose a simple me trics to measure event correla- tions in a sliding time wind ows. Different fr om Aprio ri that generates item set candida tes of a len gth k from all item sets of a length k − 1 [52] [5 3], we pro posed a simplified a lgorithm that gen erates a n − ar y event r ule can didate if and only if its two ( n − 1) − ar y adjacent subsets ar e frequen t, an d hence we significan tly d ecrease the time com plexity . W e validate our approa ches o n the logs of a 260 -node Had oop c luster sy stem at Research Institution of China Mobile and a pr oductio n HPC cluster system—Machine 20 of 256 nodes at Los Alamos National Lab, which we ca ll the Hadoop logs an d the HPC logs, respectiv ely . For predicting events in th e Had oop logs and the HPC log s, the precision rates are h igh as 78.20%, 81.19 %, respecti vely . W e also evaluate our approach es in three scenarios: (a) p redicting all ev ents o n the basis of both failure and non- failure events; (b ) predicting only failure events o n the b asis of bo th failure and no n-failure events; (c) pred icting 2 failure events after removin g non-failure events. Our contributions are fou r-fold. Fir st, we prop ose a simple metrics to measure event correlation s. Second , o n the basis of the mea surement me trics, we prop ose two ap proach es ( Apriori-LES and Apriori-semiLES ) to m ining ev ent correla- tions. Third, we d esign an in novati ve abstractio n– events co r- r elation g raphs (ECGs) , to represent ev ent r ules, and p resent an ECGs-based algorith m for event pre diction. Fourth, for the first time, we comp are the break down of ev ents of different types and events rules in two typica l cluster systems f or cloud and HPC, respectively . The r est of this paper is organize d as f ollows. Section II ex- plains basic con cepts. Section III presents Lo gMaster design. Section I V gives o ut Lo gMaster imp lementation . Ex perimen t results and ev aluations o n the Hadoo p logs and th e HPC log s are su mmarized in Section V. In Section VI, we describe the related work. W e d raw a conc lusion and discuss the future work in Section VII. I I . B AC K G RO U N D , A N D B A S I C C O N C E P T S A. Backgr ound of two real system logs The 260-n ode Hado op cluster system is used to run MapReduce- like cloud applicatio ns, including 10 manageme nt nodes, which are used to analyze logs or man age system , an d 250 data n odes, whic h are used to run Ha doop applica tions. W e collect the Hadoop logs by using /dev/error, / var/log, IBM Ti voli, HP ope n view , and Ne tLogger, then store them on th e mana gement node s. So these lo gs inclu de system service and kernel logs, such as crond, mountd, rpc.statd, sshd, syslogd, xin etd, and so o n. The HPC lo gs are avail able from (http://institutes.lan l.gov/data/fd ata/). T ABLE I give the summary of system log s from the Hado op a nd HPC cluster systems. Log name Days Start Date End Date Log Size No. of Recor ds Hadoop 67 2008- 10-26 2008- 12-31 130 MB 977858 HPC 1005 2003- 07-31 2006- 04-40 31.5 MB 433490 T ABLE I : The summary of logs W e u se n ine-tuples (timestamp, log ID, no de ID, event ID, severity d e gree , event type, application name, pr ocess ID, u ser ID ) to describe each e vent. For an upcoming ev ent, if a n ew 2-tu ple ( sev er ity deg r ee , ev ent ty p e ) is reported , o ur system w ill g enerate an d assign a new ev ent I D associated with this ev ent. Similarly , if a ne w 4-tuple ( node I D , ev ent I D , appl i cation name, pr ocess I D ) is re- ported, we will cr eate and assign a n ew log I D associated with this event, and hen ce a l og I D will contain rich info rmation , including severity degree, event type, n ode ID, application name, and pro cess ID. B. Basic conc epts Definition 1: An n-ary log ID sequence (LES ) : an n − ary LES is a sequences of n events that ha ve differ ent log IDs elemen t item descripti on timestamp The occurrence time associated with the e vent seve rity de gree Include five lev els: INFO, W ARNING, E RR OR, F AILURE, F A T AL eve nt type Include HARDW ARE, SYSTE M, APPLICA- TION, FILESYST EM, and NET WORK eve nt ID An e vent ID is a m apping function of a 2-tuple (se verity de gree, ev ent type). node ID The location of the ev ent applica tion name The name of the applicatio n that associate s with the ev ent pr ocess ID The ID of the proce ss that associ ated with the e vent log ID A log ID is a mapping function of a 4-tuple (node ID, ev ent ID, application name, process ID). user The user that associated the eve nt T ABLE II: Th e descrip tions about the elements of n ine-tup les in a chron ological ord er . An n − ar y LES is comp osed of an ( n − 1) − ar y LES ( n ∈ N + , n > 1 ) an d an ev ent of log ID X ( X 6∈ ( n − 1) − ar y E S ) with the presumed timing con straint that an e vent of lo g ID X follows after the ( n − 1 ) − ary LES. W e call the ( n − 1) − ary LES is the pr eceding events and the event o f log ID X is the posterior event . For example, fo r a 3 − ar y LES ( A, B , C ) , ( A, B ) ar e the precedin g events, while C is the p osterior ev ent. In this paper, we simply use an event X instead of an event of log ID X . Definition 2: A subset of LES : If the event elements o f an m − ar y LES are a sub set of the e vent elements of an n − ary LES ( m < n ) , meanwhile the timing co nstraints of the m − ary L ES do not v iolate the timing co nstraints of the n − ar y ES, we call the m − ar y LES is the subset of the n − ary LES. For example, for a 3 − ar y LES ( A, B , C ) , its 2 − ar y subsets include ( A, B ) , ( A, C ) a nd ( B , C ) . Ho wever , ( B , A ) is not its 2 − ar y subset, since it vio lated the timin g constraints of ( A, B , C ) . Definition 3: ( n − 1) − ar y adjacen t sub set of n − ary LES : For an ( n − 1) − ar y LES tha t is th e sub set of an n − ary LES, if all adjacen t events of ( n − 1) − ary LES are also adjacent in the n − ar y L ES, we call the ( n − 1 ) − ary LES the ad jacent subset o f the n − ary LES. For an n − ary LES ( a 1 , a 2 , . . . , a ( n − 1) , a ( n )) , it has two ( n − 1) − ar y adjacen t sub sets: ( a 1 , a 2 , . . . , a ( n − 1)) and ( a 2 , · · · , a ( n − 1) , a ( n )) . I I I . S Y S T E M D E S I G N A. LogMaster arc hitecture LogMaster includ es three majo r comp onents: Log agent , Log server , and Log database . On each node, Lo g agent collects, preprocesses logs, and filters repeated e vents and periodic e vents. And th en Log agent sends e vents to Log server for mining ev ent rules, which are stored in Lo g database. In Section III-C, we will propose two event correlation mining appr oaches. At the same time, Log server co nstructs 3 a set of gra phs - event corr elation g raphs (ECG) to r epresent ev ent c orrelation s. Section III-D will intr oduce the details o f ECG. LogM aster will mine event r ules and their presen tations - ECG fo r o ther systems, fo r examp le a failure pred iction or fault diag nose system. Fig . 1 summ arizes our event correlation mining approac hes. Logs Event preprocessing Event rules Other system like failure prediction systems ECG construction Event mining (Event Correlation Graph) ECG Fig. 1: The sum mary of ev ent corr elation mining ap proach es. B. An metrics for mea suring event corr elation s In th is sub section, we define a simple metr ics to measure ev ent corr elations. W e assume that time synchro nization serv ices are deployed on large-scale systems. The largest clock ske w is easy to be estimated u sing a simple cloc k syn chron ization algorithm [3 3] [34] or the ntptr ace [35] tool. W ith a time synchro nization service, like NTP , we can ign ore the effect of clock ske w in our algorith m, since a NTP service can guarantee time synchro nization to a large extent. For example, NTPv4 can achieve an accu racy of 200 microsecon ds or better in local area networks u nder ideal c ondition s. As shown in Fig . 2, we analyze th e whole log history to generate event rules. In our appr oach, we use a sliding time window to analy ze logs. For each cu rrent e vent, we sa ve ev ents within a sliding time wind ow (accord ing to timestamps) to the log buffer , an d analy ze events in th e log buffer to mine event rules. After an event log has b een analyzed , we will a dvance the sliding time wind ow accordin g to th e timestamp of the current ev ent. Prediction valid duration prediction time The whole log history Offline Analysis time for generating event rules Time Predicting point Predicted point Expiration point Sliding time windows of Log buffer Fig. 2 : T he time relation s in our event correlation min ing an d ev ent pred iction systems. Considering the events ma y happ en interleavedly , we pro- pose a confi dence metrics to measure the correlation o f a n LES as follows: we count on two im portant attr ibutes : the support count , and the posterior count . The su pport count is the recurr ing times o f the preced ing ev ents which are followed by the posterior ev ent, while th e posterio r count is the recu rring times of th e p osterior event which follows the preceding events. For example, if an e vent seque nce B AC B B A occur in a time window , for a 2 − ary LES ( A, B ) , the suppor t cou nt is one , and the posterior count is two; for a 3 − ar y LES ( A, C, B ) , the support count is one an d the p osterior count is two. The c onfidenc e metrics is c alculated to measure the event correlation acc ording to Equ ation 1. C onf idence = suppor t count ( LE S ) poster ior count ( LE S ) (1) According to Equatio n 1, in B AC B B A , the confid ence of an 2 − ary LES ( A, B ) is 1 /2. In othe r word s, if an e vent A occurs, an e vent B will occu r with the pro bability o f 50%. Based on the ab ove d efinitions, we formally define frequent LES and event rule as follows: for a n LES, if its adjacent subsets are fre quent and its su pport count exceeds a pred efined threshold, we call it a frequen t LES. For a freque nt LE S, if its confidenc e exceeds a predefine d th reshold, we call it an event rule. C. Event correlation m ining algorithms In this section, we pr opose two event cor relation min- ing algo rithms: an Apr iori-LES algo rithm and its improved version—Aprior i-simiLES. The n otations o f the Apriori- LES and Apriori-sim iLES algorithm are listed in T ABLE. I II. Notati on Descripti on T w the s ize of sliding time window Sth the threshold of the support counts of LES Cth the threshold of confidence of ev ent rules C(k) a s et of fr equent k-ary LES candidates F(k) a s et of fr equent k-ary LES R(k) a s et of k-ary event r ules T ABLE III: Notations o f the Apriori-LES and Aprio ri- simiLES 1) Apriori-LES alg orithm: In data mining appro aches, Apriori is a classic algo rithm f or learning associatio n rules in transactional d ata [5 2] [5 3]. Apr iori uses a b readth- first search and a tree structu re to co unt item set ca ndidates. Acco rding to the downward closure lemma [5 2] [5 3], a k − l eng th item set cand idate co ntains all frequ ent ( k − 1) − l eng th item sets. The Apriori algo rithm g enerates f requen t k − l eng th item set candidates f rom frequen t ( k − 1) − l eng th item sets. After that, it scans transactio n data to determine frequent item sets among the candidates. As m entioned in Section I , logs are significantly different from transaction data. W e pro pose an algor ithm to mine event rules, which we c all the Apriori- LES alg orithm. Th e Aprio ri- LES alg orithm is as follows: 4 Step 1 : Pred efine two th reshold values S th and C th fo r the support count and the confid ence, re spectiv ely . Step 2 : Add a ll events that hav e different log IDs with the support count above th e thresho ld value S th to F ( k = 1) ; Step 3 : K = k + 1 ; C ( k ) = {} ; F ( k ) = {} ; R ( k ) = {} ; Step 4 : Get all frequent k − ary LES candidates. W e gen erate the freq uent k − ary LES candidate by the LI NK operation of two fr equent ( k − 1) − ary adjacent subsets, and ad d it into C ( k ) . The L INK o peration is defined as be low: f or two frequ ent (k-1)- ary L ES, if th e last (k -2) log IDs of the one (k- 1)-ary L ES a re same like the first (k- 2) log IDs o f the other (k-1) -ary LES, th e result of the LINK operation is: LI N K (( a 1 , a 2 , · · · , a ( k − 1)) , ( a 2 , · · · , a ( k − 1) , a ( k )) = ( a 1 , a 2 , · · · , a ( k − 1 ) , a ( k )) For example, if ( A, B , C ) and ( B , C, D ) are frequen t 3 − ary LES in F (3) , then a 4 − ar y LES ( A, B , C, D ) is a frequen t 4 − ar y LES candidate, which we will ad d in to C (4) . Step 5 : Scan the log s to validate each fr equent k − ary LES candidates in C ( k ) . Th e su pport cou nt and po sterior coun t o f each k − ary LES ca ndidate in C ( k ) is coun ted. For a fr equent k − ar y LES ca ndidate ( a 1 , a 2 , · · · , a ( k − 1) , a ( k )) , if e vent a ( k − 1) o ccurs after any event in ( a 1 , a 2 , · · · , a ( k − 2)) and before the posterior event m times, an d th e posterio r event occurs after any e vent in ( a 1 , a 2 , · · · , a ( k − 2) , a ( k − 1)) n times, we inc rement the supp ort count and the po sterior coun t of the k − ary LE S candidate by m and n , respec tiv ely . Step 6 : Ge nerate frequ ent k − ar y LES an d k − ar y event rules. For a k − ar y frequen t LES candidate, if its suppor t c ount is above the thresho ld S th , add it into F ( k ) . For a k − ar y LES candid ate, if its support coun t an d confidenc e are above the thresho ld values: S th and C th , respectively , a dd it into R ( k ) . Step 7 : Loop until all f requen t LE S and event rule s are found , and save them in Log database. If R ( k ) is no t null, sa ve k − ar y event rules in R ( k ) . If F ( k ) is not null, go to step 3 ; else end the algor ithm. 2) Apriori-simiLES a lgorithm: As sh own in Section V, the Apriori-L ES algo rithm still suffers f rom inefficiency , an d g en- erates a large a mount of f requen t LE S candidate, which may lead to a long analysis time. In order to improve perfor mance and save co sts while ensuring the alg orithm’ s efficiency , we observe th e break down of ev ent rules th rough mining abou t ten d ays’ s log s of th e Had oop system (in Nov 2008 ) an d the HPC cluster system (in Jan 20 04 ), respe ctiv ely . W e set th e following config uration in the Aprior i-LES algorithm : the sliding time wind ow ( T w ), the sup port count threshold ( S th ) , an d th e confidenc e thr eshold ( C th ) are 60 minutes, 5, and 0.2 5, respe ctiv ely . W e only m ine 2 − ar y event rules so as to simp lify the experimen ts. In a ll, we get 51 7 2 − ary event rules in the Hadoop lo gs and 156 2 − ar y ev ent rules in the HPC log s. When we analy ze the break down of 2- ary event rules gener ated by the Apriori- LES algo rithm, we find that mo st of 2 − ar y event rules are composed of events that occur on the same no des or the same applications, or have the same event type s. This pheno menon is p robab ly due to: (a) err or may spread in a single node. For example: o ne ap plication o r process error can lead to another app lication or pr ocess error . (b) replicated ap plications in multiple nodes may have same err ors o r software bugs, an d same failure events may app ear in m ultiple no des. (c) n odes in an large- scale system need to transfer data and commun icate with each other, so a failure on on e no de may cause failure s of same ev ent ty pes on o ther no des. (d ) a failure on one no de may change the clu ster system environment, which may cause failures of same event types on other nodes. The analysis results are shown in T ABLE. IV and T ABLE. V. Descripti on All Same nodes Same eve nt types Same applic a- tions count 517 168 172 159 P er cent(% ) 100% 32.5% 33.3% 30.8% T ABLE IV: The break down of 2 − ary event rules in the Hadoop logs. Descripti on All Same nodes Same eve nt types Same applic a- tions count 156 10 48 52 P er cent(% ) 100% 6.4% 30.8% 33.3% T ABLE V: The breakd own of 2 − ar y event r ules in the HPC logs. On th e basis of th ese ob servations, we pr opose an improved version of the Apriori- LES algorithm: Aprior i-simiLES. The distinguished difference o f Apriori-simiLES from Apriori-LES is that the former uses an ev ent filtering policy before t he event correlation minin g. The e vent filterin g policy is described as below: to reduce the numb er of the analyzed e vents and decrease the an alysis time, we only an alyze correla tions of ev ents that occur in (a) the same nod es or (b) the sam e applicatio ns , or have ( c) th e same event types . The Ap riori-simiLES algorith m include s two rou nds of analysis: a single- node analy sis and a mu ltiple-nod e analysis. In th e single-nod e an alysis, we use the Apr iori-LES alg orithm to m ine event rules th at h av e same node I D s . An d in the multiple-no de analysis, we use the Apriori-LES algorithm to mine e vent rules that are of the same application names or the same event typ es but with different node I D s . D. ECGs construction After two roun ds of an alysis, we get a series o f ev ent ru les. Based on the event rules, we prop ose a ne w abstraction —ev ent correlation g raphs (ECGs) to represen t event rules. A ECG is a dire cted acyclic grap h (DA G). A vertex in a ECG rep resents a event. For a vertex, its ch ildren vertex es are its posterior events in e vent ru les. There are two types of vertexes: dominant and r ecessiv e. F or a 2 − ar y event ru le, such as ( A, B ) , the vertexes representing events A , B ar e do minant vertexes. An additio nal vertex A ∧ B represents the case that A and B occur red and B occurred after A . The vertex A ∧ B is a recessi ve vertex. 5 V ertexes ar e linked by edges. An ed ge rep resents the co rre- lation of two events linked by the edge. Each ed ge in ECG h as fi ve attrib utes: head verte x , ta il verte x , support count , posterior count and edge type . Similar to v ertexes, edges have two types: dominan t and recessi ve . If two vertexes lin ked by an edge are dominan t, th e edge type is d ominan t; oth erwise, th e edge ty pe is recessive. For a 2 − ar y e vent rule ( A, B ) , the head vertex is B , and th e tail vertex is A ; th e su pport count and p osterior count o f the edge is the suppor t count an d posterior count of the rule event ( A, B ) , r espectively . For a 3 − ar y event rule ( A, B , C ) , the hea d vertex is C , and the tail vertex is th e recessiv e vertex A ∧ B ; the su pport count and the po sterior count o f the edg e is the su pport count and th e posterio r cou nt of the event ru le ( A, B , C ) , respectiv ely . An example is shown in Fig. 3. There are three 2 − a ry event rules: ( A, B ) , ( B , C ) and ( C, D ) , and two 3 − ar y ( A, B , C ) and ( A, B , D ) . W e gener ate four d ominan t vertexes, which represent events A , B , C , an d D . W e also g enerate three dominan t edges wh ich rep resent the ev ent rules ( A, B ) and ( B , C ) an d ( C , D ) . I n ad ditional, we a lso generate a recessiv e vertex ( A ∧ B ). A rec essi ve edg e ( A ∧ B → C ) re presents the ev ent rule ( A, B , C ) , and a recessive edge ( A ∧ B → D ) represents the event ru le ( A, B , D ) . The add itional vertex A ∧ B is the ch ild o f both A and B . A^B A B C Dominant vertex Dominan t edge Recessive vertex Recessive edge D Fig. 3 : An example of ECG. Choosing the ECG abstractio n has three reasons: first, the visualized g raphs are easy to und erstand b y system manag ers and operator s; second, the abstraction facilitates mod eling sophisticated co rrelations of e vents, such as k − ar y ( k > 2 ) ev ent rules; third, ECGs can be easily u pdated in time since the attributes of e dges and vertexes are easily updated wh en a new ev ent comes. The constructio n of ECGs includ es thre e ma in step s: Step 1 : Construct a gr oup of ECGs based on event ru les found in the single- node analysis. Each ECG r epresent corr e- lations o f events in o ne node. Based o n event ru les gen erated in the a nalysis, the vertexes and edges of ECGs ar e created. For eac h ev ent rule, dominan t vertexes and rec essi ve vertexes are g enerated , a nd edges between vertexes are created too . Step 2 : ECGs that r epresent c orrelation s of events on multiple no des a re co nstructed based on e vent rules fo und in multiple-no des analysis. Step 3 : T he index of ECGs is created, and the po sitions o f ev ents in ECGs ar e also sav ed. W e c an locate events by using these in dexes. The ECG ID and th e E CG entrance vertex are the ind ex of the ECGs. The ECG position is the index of each event in a n ECG. So it is co n venient to locate events in the ECGs. After th ese three steps, a series of ECGs that d escribe the correlation o f events a re c onstructed . E. Event Pr edictio n For each predictio n, there are thr ee imp ortant tim ing po ints: pr edicting point , pr edicted point , and expiration point . The relations of those timing points are shown in Fig. 2. The pre diction system begins predicting events at the timing of the pred icting po int. The predicted point is the occurrence timing of the predicted e vent. The expiration point refers to the expiration time of a pr ediction, which m eans th is prediction is not valid if the actu al occurrence timing of the event passed the expir ation po int. In addition, there are two impo rtant d erived prope rties for each prediction : pr ediction time , and prediction valid duration . The pr ediction time is the time difference b etween the pre- dicting po int an d th e p redicted p oint, which is the time span left for system adm inistrators to respond with the p ossible upcomin g failures. The pred iction valid duration is the time difference b etween th e predicting po int and the expiratio n point. The e vent prediction algorithm based on ECGs is as follows : Step 1 : Define th e p rediction pro bability thresho ld P th , and the p rediction valid dura tion T p . Step 2 : Whe n an event comes, the indexes of ev ents are searched to find match ing ECGs and the correspo nding vertexes in ECGs. The searched vertexes are marked. For a recessiv e edge, if its tail vertex is marked, the recessiv e edge is m arked, too . For a recessive head vertex, if all rec essi ve edges are mar ked, the recessi ve vertex is also marked. W e mark vertexes so as to predic t e vents; and the h ead vertexes that ar e do minant vertexes are search ed accor ding to the ed ges (both do minant an d recessiv e ed ge types) linked with marked vertexes. Step 3 : The probab ilities of the head vertexes are calculated accordin g to the attributions of vertexes that are marked a nd their adjacent edges in the E CGs. For a head vertex, we calculate its p robab ility a s the p robab ility o f tail vertex tim es the confiden ce of th e edge. If a head vertex is linked with two marked vertexes with different edges, we w ill calculate two probab ilities, and we c hoose the largest one as the pro bability of the head vertex. An example is shown in Fig. 4. Wh en an e vent A occur s, the vertex A and the ed ge A → A ∧ B are ma rked. W e can calculate the probability of B acco rding to the con fidence of the edg e A → B . The prob ability of event C also can be calculated b y th e d ominan t edges A → B and B → C . If the p robab ility o f event B or event C is a bove the pred iction probab ility threshold P th , it is pred icted. So does the event D . P r obabi l ity ( B ) = conf idence ( A → B ) (2) 6 P r obabi l ity ( C ) = probab il ity ( B ) ∗ conf idence ( B → C ) = conf idence ( A → B ) ∗ conf idence ( B → C ) (3) When an event B occurs later , the vertex B and the edge B → A ∧ B are marked. Because the e dge A → A ∧ B and B → A ∧ B are b oth marked, so the vertex A ∧ B are marked too. Th e p robability of events C and D are also calculated accordin g to the new edg es. A^B A B C Dominant vertex Dominant edge Recessive vertex Recessive edge D Marked vertex A^B A B C D A^B A B C D ECG after event A occurs ECG after event B occurs ECG after event C occurs Marked edge Fig. 4 : An example of e vent pred iction. Step 4 : I f the probab ility o f a head vertex is above th e prediction prob ability thresho ld P th , then the h ead vertex is the pred icted ev ent. Step 5 : Loop Step 2 . I V . L O G M A S T E R I M P L E M E N TA T I O N W e h av e imp lemented an event correlation mining system and an e vent predictio n system. The main mod ules of Log- Master are as follows: (1) Th e co nfiguratio n file and Log datab ase. A XM L-form at configur ation file named c onfig.x ml inclu des the regular ex- pressions of impor tant definitions, fo rmats, and keywords that are u sed to p arse lo gs an d the co nfigura tion of Lo g d atabase. Log database is a My SQL databa se, including the tables of the formatted logs, the filtered logs, and th e event rules. W e define event attrib ution s in the section ”d efinitions”, and the d efinitions in clude timesta mp , node name , appl i cation , proce ss , proce ss id , use r , descr iption , and so on. The formats o f event logs are defined in the section ”fo rmat”. All keywords that a re u sed to decide the se verity degree and event type of logs are defined in the section ”keywords”. (2) The Py thon scrip ts ar e u sed to parse system log files ac- cording to the regular expressions d efined in the con figuration file. The par sed logs are sa ved to the table of the formatted logs in Log d atabase. An example of the original e vent logs and the correspon ding formatted event logs is shown as bellows: [ Original event log ] Oct 2 6 04:04:2 0 c ompute- 3-9.lo cal smartd [3 019]: Device: /dev/sdd, F AILED SMAR T self-che ck. B A CK UP D A T A NOW ! [ Formatted event log ] timestamp =”20 08102 4040 420”, node nam e =”compu te-3-9 .local”, fo rmat =”for mat1”, key- word = ”F AILED SMAR T”, application=”smartd”, pro- cess=”NULL”, p rocess id=”301 9”, user=”NULL”, descrip- tion=”Device: /d ev/sdd, F AILED SMAR T self-ch eck. B AC K UP D A T A NOW!”. (3) Log server is wr itten in Jav a. Th e simp le filterin g oper- ations are performed to r emove repeated ev ents and periodic ev ents. The filtered logs are saved in th e table o f filtered logs in Lo g database. W e implemented both Ap riori-LE S and Apriori-sem iLES algorithms. Th e attributions of each event rules, in cluding event a ttributions, support coun t, po sterior count, and co nfidence are saved to the tab le of event rules in Lo g database. (4) W e imp lement the event rule s b ased prediction system in C++. V . E V A L UAT I O N S In th is section, w e use Lo gMaster to an alyze logs o f a produ ction Had oop clu ster system and a HPC cluster system logs, th e detail o f two log s are descr ibed in Section II-A. The server we used has two I ntel Xe on Quad-Core E 5405 2.0GHZ processors, 137GB disk, and 8G mem ory . A. F iltering E vents In this step, we r emove repeated events and periodic events. After collecting logs, Log sev er will per form a simple fil- tering accor ding to two observations: first, there are two ty pes of repeated events: one kind of r epeated events are reco rded by different sub systems, and th e other kind o f repe ated events repeatedly oc cur in a sho rt time windows. Second, p eriodic ev ents. Some events perio dically occur with a fixed interval because of hardware o r sof tware bugs. Eac h type o f p eriodic ev ents may h ave two or m ore fi xed cyc les . For example, if a daemo n in a node monito rs CPU or memory systems periodically , it may prod uce large a mount of periodic ev ents. W e use a simple statistical algo rithm and a simple clustering algorithm to remove re peated events an d p eriodic ev ents, respectively . The solution to removing repeated events is as follows: for the first step, we treat events with the same log I D and the same timestamp as repeated events. For the second step, we treat events with the same l og I D occur ring in a small time windows as repeated events. In this experimen t, we set this inter val thresho ld as 10 secon ds, and the reason is that we con sider the r epeated events shou ld occur in a short time windows. The solution to rem oving periodic events is as f ollows: for each log I D, u pdate the co unts of events for different intervals. For periodic events with th e same log ID, if the count a nd the ev ent percent of the same interval, wh ich is obtained against a ll periodic e vents with the sam e log ID, is higher th an the predefined thresh old values, respectively , we consider the interval as a fixed cycle. In our experimen t, we 7 set two pred efined threshold values of the Had oop logs and the HPC logs as (20, 0.2) and (20 , 0 .1), respectively . The ef fects of different threshold values o n the number o f filtered events can be f ound at Appen dix A. L astly , we only keep o ne ev ent for p eriodic ev ents with the same fixed cycle. For p eriodic ev ents, only events deviated f rom the fixed cycle are r eserved. T ABLE VI shows the exp eriments results. I n p repro cessing, our pyth on scripts par se abou t 977 ,858 origina l H adoop event entries in 4 m inutes 24 secon ds, and inter pret tho se ev ents in to nine-tup les, which are stored into the MySQL database. W e parse 176,0 43 original H PC c luster ev ent entries in 2 m inutes 28 seconds. Please note that we o nly select the node logs from the H PC logs w ithout including oth er ev ents, e.g ., that of ” switch mo dule” , since the Ha doop logs on ly in clude no de logs. logs raw logs Pre pr o- cessing Removi ng re peated eve nts Removi ng periodic eve nts Compr ession rate Hadoop 977,858 977,858 375,369 26,538 97.29% HPC cluster 433,490 176,043 152,112 132,650 69.4% T ABLE VI: Th e r esults of prepro cessing and filtering logs. In this experimen t, the com pression ra te of the Hadoop logs can achie ves 97.29 %, but the compr ession rate of the HPC logs only ac hieves 69.4%. T he reason is prob ably that the Hadoo p logs have a large amount of repeated events, w hile the HPC logs have relatively small n umber o f events for a lo ng pe riod, and h ence hav e less repeated events. The p eriodic ev ents of HPC lo gs are small, an d the reaso n is that the HPC lo gs h ave a long time span. B. Comparison of two event co rr elation mining alg orithms In this step , we compa re two p roposed algor ithms: Apriori- LES an d Aprio ri-simiES. W e use ( a) th e average analysis time per events and (b) th e numbe r o f event rules to ev aluate th e computatio nal comp lexity and the efficiency of Apr iori-LES and Apriori- simiES algorith ms, respectively . For the Hado op logs, we analyze 43 d ays’ logs from 20 08- 10-26 04 :04:20 .0 to 2008-12- 09 23:21:28 .0. For the HPC logs, we analyze 4 8 days’ logs from 2 003- 12-26 22 :12:30 .0 to 2004- 02-13 03:02 :39.0. Before reportin g experimen t results of two algorithms, we pick the following param eters as the b aseline con figuration of LogMaster fo r c omparison s. Throug h compar isons with an large amount o f experiments, we set the baseline parameters in Lo gMaster: Hadoo p logs—[T w60/Sth5/Cth0.25] and HPC logs—[T w60 /Sth5/Cth0.25 ]. [T w x /Sth y /Cth z ] indicates that the sliding time win dow T w is x minu tes, the thre shold of suppo rt count S th is y , and the threshold o f co nfidence C th is z . The e ffect of varying parame ters ( T w , S th and C th ) on the av erag e analysis time p er event an d the number o f event ru les can be foun d in Appen dix B. The comp arison exper iments show th at: for the Hado op logs, the av erag e analysis time of Ap riori-simiLES is about 10%-20 % o f that o f Apriori- LES, wh ile Aprior i-simiLES obtains about 60%-70% e vent rules o f that of Apriori-LES; F or the HPC lo gs, th e average analysis time o f Aprior i-simiLES is abo ut 10%-20 % of that of Apriori-LES algorithm , wh ile Apriori-simiL ES obtains about 80%-90% ev ent rules of tha t of Apriori-L ES. C. The summaries o f events and event rules in two typical cluster systems In two ty pical cluster system s for Cloud and HPC, resp ec- ti vely , we giv e the summaries of the events and ev ents ru les, which are generated by the Apr iori-LES algo rithm with the baseline parameter s mentione d above. (a) I n the Hadoo p logs, the nu mber of events o f different types ranks acc ording to the order : FILE SYSTEM, HARD- W ARE, SOFTW ARE, SYST EM, ME MOR Y , NETWORK and O THER. In the HPC logs, the numbe r of events of different types rank s accordin g to the order: HARDW ARE, SYSTEM, NETWORK, FILESYSTEM, CLUSTE RSYSTEM, and KER- NEL. Please note that the event types of two lo gs are slightly different. F or th e HPC log s, the event types are rec orded in the original lo gs, while for the Hadoop log s the event types are parsed b y our self. The br eakdown of logs is shown in Fig . 5 . %UHDNGRZQRIHYHQWW\SH VLQ+DGRRSV\VWHP ),/(6<67(0 6<67(0 1(7:25. 0(025< +$5':$5( 62)7:$5( 27+(5 %UHDNGRZQRIHYH QWW\SHVLQ+3&V\VWH P ),/(6<67(0 6<67(0 1(7:25. &/867(56<67(0 +$5':$5( .(51(/ Fig. 5 : The breakd own of event types of two system logs. (b) Most of event rules a re c omposed of events with the FILESYSTEM typ e in the Hadoop log s, and the reaso n m ay be that applications runn ing o n the Had oop cluster system are data-intensive, an d n eed to access the file system f requen tly; Howe ver , most of ev ent rules in the HPC logs ar e compo sed of ev ents of HARDW ARE an d SYSTEM types, and it is pro bable that hardware an d system lev el erro rs mo re ea sily lead to failures in HPC clu ster systems. W ith the same baseline configu ration like that in V - B, we obtain 2 or 3 -ary event r ules with Apriori- LES and Ap riori- simiLES as shown in T ABLE VII . Event Rules Hadoop logs HPC cluster logs Apriori- LES Apriori- simiLES Apriori- LES Apriori- simiLES 2 − ar y 2413 1520 4726 3990 3 − ar y 1603 1603 1695 1695 T ABLE VII: T he ev ent rules obtaine d fro m two algorith ms. W e a lso analyze th e br eakdown o f event rules that lead to failure events. As shown in T ABLE VIII, with th e exceptio n of the event ru les in the HPC lo gs obtaine d with th e Ap riori- simiLES algorithm, event rules that ide ntify correlations be - tween non-failure events (inclu ding ”I NFO”, ” W ARNING”, 8 ”ERR OR”) an d failure events (”F A T AL” an d ”F A ILURE”)) dominate over the event ru les that identify the corr elations between different failure events. Fail ure Rules(No.) Hadoop logs HPC cluster logs Apriori- LES Apriori- simiLES Apriori- LES Apriori- simiLES Configur ation [T w60/St h5/Cth0.25] [T w60/St h5/Cth0.25] Non-fail ures → F ailures 377 180 97 5 F ail ures → F ailures 86 78 26 26 T ABLE VIII: Th e event rule s ob tained fr om two a lgorithms logi d1 log id2 nod eid1 type1 nodeid2 t ype2 confidence 3314 3311 249 memory 249 system 0.997487 370 359 42 har dwar e 42 filesy stem 0.993789 91 89 4 softwar e 4 system 0.961538 2034 2035 164 filesyste m 16 4 filesyste m 0.9523 81 1412 1413 120 softwar e 120 softwar e 0.947368 66 64 2 system 2 softwar e 0.947368 147 148 12 file system 12 har dware 0. 9375 3632 3628 260 system 260 softwar e 0.933333 3627 3628 270 filesyste m 27 0 softwar e 0.933333 172 169 22 har dwar e 22 filesy stem 0.928571 T ABLE IX: T op 10 2 − ar y event rules in the o rder of the descending confide nce in the Hadoo p logs logi d1 log id2 nod eid1 type1 nodeid2 t ype2 confidence 4671 4682 260 har dware 260 hardw are 0.975 2598 2580 153 har dware 153 hardw are 0.975 2601 2619 154 har dware 154 hardw are 0.928571 2193 2180 131 har dware 131 hardw are 0.923077 2774 2883 162 har dware 167 hardw are 0.923077 2796 2883 163 har dware 167 hardw are 0.923077 2819 2985 164 har dware 172 hardw are 0.923077 2556 2539 151 har dware 151 hardw are 0.916667 3195 3212 182 har dware 182 hardw are 0.916667 2661 2643 156 har dware 156 hardw are 0.909091 T ABLE X: T op 10 2 − ar y event r ules in order of c onfidence in the HPC logs. The top 10 2 − ary event rules in the order of the descendin g confidenc e in the Hadoo p logs and the HPC log s a re shown in T ABLE IX and T ABLE X, resp ectiv ely . For the top one 2 − ary event ru le in the Had oop lo gs— (3314 , 3311) , the or iginal logs a re shown in T ABLE XI. [Log id=3314] 2008-12-06 05:04:27 compute-12-9.l ocal looks like a 64bit wrap, but pre v!=ne w [Log id=3311 ] 2008-12-0 6 05:04:57 compute-12-9.local c64 32 bit check failed T ABLE XI: Th e o riginal lo gs of (3314 , 33 11) . D. Evalua tion of predication After minin g the e vent rules, w e need to consider wh ether these e vent rules are suitable for predicting e vents. W e ev aluate our algorith ms in three scenarios: (a) predictin g all ev ents on the b asis of b oth failure and non -failure events; (b ) pred icting only failure e vents on the basis o f both failure and non- failure ev ents; (c) p redicting failure events after rem oving no n-failure ev ents. On the basis of event rules obtained in Section V -C, we predict 2 1 d ays’ logs fr om 2008-1 2-10 0 0:00:3 8.0 to 2008- 12-31 15:32 :03.0 in the Hado op lo gs, and 14 day s’ log s from 2004- 02-13 03:02:4 1.0 to 2004 -02-2 7 19:0 2:00.0 , resp ectiv ely . W e use the pr ecision rate , the recall rate , and the average pr ediction time of event p r ediction to evaluate the prediction. The true positive (TP) is the cou nt of events which are correctly predicted. Th e fa lse positive (FP) is the count o f ev ents wh ich are p redicted but no t ap peared in the pred iction valid du ration. The prec ision r ate is the ratio of th e correctly predicted events (TP) to all pr edicted events, including TP and FP . T he recall r ate is the ratio o f corr ectly predicted events (TP) to all filtered events. W e calculate the average prediction time acc ording to Equ ation 4. The av erag e p rediction time = P ( the p redicted point − the predicting point ) count o f a ll predicted events (4) There are two param eters that af fect the prediction accuracy , inclu ding the predictio n probability thresho ld ( P th ) and the p rediction valid dura tion ( T p ). Befor e re- porting experimen t results, we pick the fo llowing pa- rameters as the baseline config uration for co mparison s. Throu gh compar isons with large amo unt of e xpe riments, we set the baseline par ameters of the Hadoo p logs- [T w60/Sth5 /Cth0.25/Pth 0.5/Tp6 0] and the ba seline parame- ters of the HPC logs-[T w60/Sth5/Cth0.25 /Pth0.5/Tp 60]. Please note that T w , S th , C th just keep the same baseline parameters in Sectio n V -B. [Pth u /Tp v ] indicates that the p rediction probability threshold P th is u , and the prediction v alid duration T p is v minu tes. The effects of varying P th and T p on failure prediction s can be f ound at Appen dix C. First, on the basis of events of b oth failure and no n-failure ev ents, we p redict all events, in cluding ”INFO”, ”W ARNING”, ”ERR OR”, ”F AILURE”, and ”F A T AL” events. The precision rates and recall rates o f p redicting events in the Hado op logs and the HPC lo gs are shown in Fig. 6 . From Fig. 6, w e can obser ve th at with Apriori-L ES, th e pr ecision rates of the Hadoop logs a nd the HPC logs are high as 78.20 %, 81.1 9%, respectively , while the recall r ates of th e Had oop logs and the HPC logs are 33.6 3% an d 2 0.73%, respectively . Th e reason for the lo w recall rates is that we still k eep rich log infor mation after filterin g events, including 26,538 entr ies (2.7 1% of the original Hadoop log s) a nd 1 32,65 0 entries (30.6 % of the original HPC logs), r espectively . W e also notice th at ad opting a mo re efficient algorithm—Aprio ri-semiLES, which mines fewer event rules, results in high er precision rates. This is because with Apriori-LES we can ob tain more e vent rules, which predicts more ev ents which not happ en. Second, on the basis of events of all types, we only predict failure e vents (Failure an d F A T AL types), of which 9 the precision rates and the recall ra tes of two lo gs ar e shown in Fig. 7. $SULRULVHPL/(6 $SULRUL/(6 +DGRRSV\V WHPORJV 3UHFLVLRQ 5HFDOO $SULRUL VHPL/(6 $SULRUL /(6 +3&FOXV WHU V\VW HPORJV 3UHFLVLRQ 5HFDOO Fig. 6: The precision rate an d recall ra te of predictin g events (includin g failure and non-failure e vents) o n the basis of failure and non- failure events. $SULRULVHPL/(6 $SULRUL /(6 +DGRRSV\V WHPORJV 3UHFLVLRQ 5HFDOO $SULRULVHPL/(6 $SULRUL/(6 + 3&FOXVWHU V\VW HPORJV 3UHFLVLRQ 5HFDOO Fig. 7 : Th e p recision ra te an d recall rate of predictin g failur e ev ents on the basis of bo th failure and non -failure ev ents. For predicting failure ev ents, Liang et al. [6] sug gest removing events with the typ es of INFO, W ARNING, and ERR OR in prepro cessing events. Lastly , fo llowing th eir idea, we remove non -failure ev ents, and then pr edict failure events in the subsequen t experimen ts. T ABLE XII reports the filtered events at different stages. W ith respect to T ABLE VI, T ABLE XII show after r emoving non-failure e vents, only a small fraction o f e vents are reserved: 1,993 v .s. 132,6 50 entries (not removin g non- failure events) for the HPC logs; 3 ,112 v .s. 26,5 38 entries (n ot removin g non- failure events) for the Hadoo p logs. Then we p redict failure ev ents after rem oving non-failure events, and the pr ecision rates an d recall rates o f p redicting failure events are shown in Fig. 8. From Figs.7 a nd 8, we can observe two poin ts. First, after removing non -failure events, th e pr ecision rates in pred icting failures are lower than tha t with out removing no n-failure ev ents. The reason is that in b oth logs the number s of the e vent rules that identif y correlation s between no n-failure ev ents a nd failure events are higher than that of the event rules that identify the corre lations between different failure events a s shown in T ABLE VIII in Section V -C. Second, in p redicting failures ( F AILURE an d F A T AL), the rec all rates are low (especially f or the Hado op logs). This o bservation has two reasons. (a) Some events are independ ent, and they have not correlated events. (b) Because o f th e setting of the slidin g tim e window , the support coun t and the posterior coun t threshold values, som e weak-co rrelated or long time-c orrelated ev ent rules m ay be discard ed. logs raw logs Removi ng re peated eve nts Removi ng non- failur e eve nts Removi ng periodic eve nts Compr ession rate Hadoop 977,858 375,369 53,259 3,112 99.68% HPC 433,490 152,112 5,427 1 ,993 99.54% T ABLE XII: The r esults of filtered events after r emoving n on- failure events. $SULRULVHPL/(6 $SULRUL/(6 +DGRRS V\VWHPORJV 3UHFLVLRQ 5HFDOO $SULRULVHPL/(6 $SULRUL/(6 + 3&FOXVWHU V\VW HPORJV 3UHFLVLRQ 5HFDOO Fig. 8 : Th e p recision r ate and r ecall r ate of predictin g failure ev ents after removing n on-failure events. W ith the same baseline configu rations, the a verage p redic- tion time of two logs is sho wn in T ABLE XIII , which indicates that system administrators or autonomic systems should have enoug h tim e to mon itor and hand le p redicted events. A vera ge predict ion time(minutes) Hadoop logs HPC clus- ter logs eve nt predi ction 42.78 4.01 failur e pr ediction 52.01 25.57 failur e pr ediction after remo ving non-fai lure 52.01 25.57 T ABLE XIII: Th e average pred iction time. V I . R E L AT E D W O R K W e sum marize the related work fro m fiv e perspectives: characterizin g failure ch aracteristics, log prepro cessing, event correlation mining, an omaly (failure or perfor mance bottle- neck) p rediction , and failure diagno sis. A. characterizing failure characteristics It has b een long recogn ized th at f ailure e vents are co rrelated, not indepen dent. For examp le, in the ye ar of 199 2, T ang et al. [30] con cluded that the impact of c orrelated failures on depend ability is significan t. The work in [1] has ob served th at there are strong sp atial cor relations betwe en failure e vents and most of the failure events occur on a sma ll fraction o f the nodes. The work in [ 6] presents that some failure events such as network failure e vents a nd applicatio n I /O failure e vents show more prono unced ske wness in the spatial distribution. The work of [3] and [ 6] has f ound that failure events can propag ate in th e systems. 10 Some work uses statistical analysis ap proach to find simp le temporal and sp atial laws or models o f system ev ents [13] [3] [28] in large-scale clu ster systems like Bluegene/L. When the obtained k nowledge is used in failure prediction , it ma y brin g good precision rate and recall rate, but the p rediction results are c oarse and high level with out the detail. Daniel et a l. [6 4] char acterize the av ailability prop erties of cloud stor age sy stems based on an extensive one year study o f Googles main storage infrastru cture and present statistical models that enable f urther insight into the impact of multiple design ch oices, s uch as data placement an d replication strategies. Edmun d et al. [66] p resent th e first large-scale analysis of hardware failure rates on a million consumer PCs. They found that many failures are neither tr ansient no r ind epende nt. Instead, a large p ortion o f har dware indu ced failures ar e recurren t: a machin e th at crashe s fro m a fault in har dware is up to two orders o f magn itude m ore likely to cr ash a seco nd time. B. Log P r e-pr ocessing Zheng et al. [25] pr oposes a log pre-processing metho d, and adopt a c ausality-related filtering app roach to combining correlated events for filterin g th rough ap riori association rule mining. In these r esearch efforts, the concept o f event cluster [6] is propo sed to deal with multip le redunda nt records of fatal ev ents at one locatio n f or event filtering; an aprio ri association rule minin g [10] is p resented to iden tify the sets of fatal e vents co-occu rring freq uently and filter th em to gether; an auto mated soft com petitive learn ing neural- gas method [2 8] is used fo r cluster a nalysis to red uce dep endent events. C. Even t Corr elatio n Min ing In the data mining field, [59] [58] concern about mining closed sequential pattern s, [55] [57] discusses the frequent pat- tern m ining, [54] [5 3] [52] foc us on gen eralizing association rules to correlations. Hellerstein et al. [10] present efficient algorithms to m ine three typ es of imp ortant pattern s from histor ical event d ata: ev ent bursts, periodic p atterns, and mutu ally depe ndent pat- terns, d iscuss a fra mew ork fo r efficiently m ining events that have multiple a ttributes, an d finally build a tool—Event Cor- relation Constru ctor that validates an d extends co rrelation knowledge. Lou [31] pr opose an appr oach to min e inter-comp onent depend encies fro m unstructu red logs: par se each log message into keys and p arameters; find depen dent log key pairs belong to different com ponen ts by leveraging co-occu rrence ana lysis and parameter correspo ndence; use Bayesian decision theo ry to estimate the dependen cy direction o f each depen dent log key pair . Mannila et al. [57] give efficient algo rithms fo r the discov- ery of all frequen t episod es from a given class of episodes, and present detailed experimen tal r esults. Thoug h lots of pr evious efforts have prop osed failures mining appr oaches for different pu rposes, for examp le e vent filtering [6][25], ev ent coalescin g [ 28], or failure predictio n [2], little work p roposes the event cor relation m ining system for large-scale cluster systems. D. Anoma ly (F ailur e or P erfo rmance Bo ttleneck) Pr edictio n 1) P erformance bottleneck pr edictio n: Zhan g et al. [15] propo ses a p recise request tracing algor ithm f or multi-tier ser- vices of black bo xes, which only uses applicatio n-indep enden t knowledge and constru cts a comp onent ac ti vity grap h ab strac- tion to repre sent cau sal paths of requests and facilitate e nd-to- end perfo rmance debugging. Gu et al. [37] foc us on predicting the bottleneck an omaly , the most common anoma ly in d ata stream p rocessing clus- ters. Their app roach integrates naive Bayesian classification method, which captures the d istinct symptom s of different bottleneck s cau sed by various reason s, and M arkov mod els, which captur e the ch anging pattern s of d ifferent measur ement metrics tha t are used as fea tures by the Bayesian classifiers, to ach ieve th e an omaly p rediction goal. T an et a l. [ 38] p resents the c ontext-aware ano maly pr e- diction model training algo rithm to p redict various system anomalies such as p erfor mance bottlene cks, resource h otspots, and service level objecti ve (SLO) violations. They first employ a clu stering algorith m to discover d ifferent execution c ontexts in dynamic systems, and then train a set o f prediction models, each of wh ich is respo nsible fo r pre dicting anom alies u nder a specific co ntext. Shen et a l. [47] p ropose a mo del-dr iv en an omaly chara c- terization appr oach and use it to discover operatin g sy stem perfor mance b ug s when su pportin g disk I/O-in tensiv e online servers. 2) F ailu r e pr ediction: Gu jrati et al. [5] pr esents a meta- learning m ethod ba sed on statistical analysis an d stand ard association rule a lgorithm. They not only obtain th e statistical characteristics of failures, but also gen erate association rules between n onfatal a nd fatal events for failure prediction s. Fu et al. [3][4] develops a spherica l covariance model with an adjustab le timescale param eter to qu antify the tem poral correlation and a stochastic mode l to describe spatial corre- lation. They cluster failure events based on th eir correlations and predict their futur e occu rrences. Fulp et al. [19] d escribes a spectru m-kernel Suppor t V ector Machine (SVM) appr oach to p redict failur e ev ents based o n system log files. The a pproac h described u se a sliding window (sub-sequ ence) of messages to pre dict the likelihood of failure. E. F a ilur e Diagnosis Chen et al. [40] presen ts an instance based approac h to diagnosin g failures in computin g system s. Their meth od takes advantage o f past experiences by storing h istorical failures in a database and d eveloping a novel algo rithm to efficiently retrieve failure signatures fro m the da tabase. Oliner et al. [ 42] pr opose a method for iden tifying the sources of p roblems in co mplex productio n systems wher e, 11 due to the pro hibitive c osts of instrumen tation, the d ata avail- able f or analysis may be noisy or inco mplete. John et al. [41] present a fault localization system called Spotlight that essentially uses two basic ideas. First, it com- presses a m ulti-tier depen dency grap h into a bipartite grap h with direct prob abilistic edg es betwe en r oot causes and symp- toms. Second , it runs a novel weig hted greedy minimum set cover algorithm to provide fast infer ence. Console lo gs ra rely help oper ators detect problem s in large- scale datacenter services, fo r they often consist of the volumi- nous intermixing o f mess age s from many softw are componen ts written b y inde penden t de velopers. Xu et al. [ 49] [3 6] pr opose a general meth odolo gy to mine this r ich so urce of in formatio n to automa tically detect system ru ntime pr oblems. T ucek et al. [48] propose a sy stem T riage, that automatically perfor ms on site so ftware failure diagnosis a t the very momen t of failure. It provid es a d etailed diagno sis repo rt, including the failure nature, trigger ing condition s, related co de and variables, th e fault p ropag ation chain, and potential fixes. T an et al. [60] pro pose SALSA—their approac h to au to- mated system-log analysis, wh ich inv olves exam ining the lo gs to trace control-flow and data-flow execution in a distributed system, a nd deriv e state-m achine-like views of the systems execution on each node. Based on the derived state machine views and statistics, they illustrate SALSA ’ s value by devel- oping v isualization an d failure-d iagnosis technique s for thr ee Hadoop workloads. V I I . C O N C L U S I O N A N D F U T U R E W O R K In this p aper, we d esigned and impleme nted an event correlation mining system and an event pred iction system. W e presented a simple me trics to measur e cor relations of ev ents that may happe n in terleavedly . On the ba sis o f the measuremen t of co rrelation s, we pro posed two ap proach es to mining e vent correlations; m eanwhile, we proposed an innovati ve abstractio n—event correlation gr aphs (E CGs) to represent event co rrelation s, and pre sented a n ECGs-ba sed algorithm fo r event prediction . As two typical case studies, we used Lo gMaster to analyze an d pr edict logs of a produ ction Hadoop -based cloud com puting system at Research Institutio n of China Mobile, an d a prod uction HPC cluster system at Lo s Alamos National Lab ( LANL), respectively . For th e first time, we com pared the breakdown of ev ents of different ty pes and ev ents ru les in two typ ical cluster systems f or Cloud and HPC, respectively . In the new fu ture, we w ill in vestigate two issues. a) How to use ECGs fo r fault d iagnose in large-scale pro duction cluster systems? b ) How to combine cau sal path-b ased solutions [ 15] with the log mining appr oach to diagno sis failure events and perfor mance pro blems? R E F E R E N C E S [1] R. K. Sahoo, A. Siv asubramaniam, M. S. Squillante , et al. ”Fai lure data analysi s of a large-scal e heterogene ous serve r en vironment”. In Proc . of DSN , 2004. [2] R. K. Sahoo, A. J. Oliner , et al. ”Criti cal Event Predicti on for Proacti ve Manageme nt in Large scale Computer Clusters”. In Pr oc. of SIGKDD , 2003. [3] S. Fu, C. Xu, et al. ”Explorin g Event Correla tion for Failure Prediction in Coalitions of Clusters”. In Proc. of ICS , 2007. [4] S. Fu and C. Xu, et al. ”Quantifying T emporal and S patia l Correlatio n of Failure E vent s for Proacti ve Management”. In Pr oc. of SR DS , 2007. [5] P . Gujrati, Y . L i, Z. Lan, et al. ”A Meta-Learnin g Fa ilure Predictor for Blue Gene/L Systems”. In Pr oc. of ICPP , 2007. [6] Y . Liang, et al. ”Filteri ng Failure Logs for a BlueGene/L Prototype”. In Pr oc. of DSN , 2005. [7] Z. Xue, et al. ”A Surve y on Fa ilure Predictio n of Lar ge-Scale Server Clusters” . In A CIS Conf. on SNPD, 2007. [8] C. Y uan, et al. ”Automated Known Problem Diagnosis with Even t Tra ces”. In Proc of Eurosys , 2006. [9] H. J. W ang, J. C. Platt, Y . Chen, et al. ”Automat ic Misconfigurati on Trou bleshooting with PeerPressure”. In Proc. of OSDI , 2004. [10] J. L. Hellerste in, S. Ma, and C. Perng, et al. ”Discov ering actionab le patte rns in ev ent data”. In IBM Systems Jou rnal , 41(3), 2002. [11] R Agrawal , R Srikan t, et al. ”F ast algo rithms for mining associat ion rules”. In Pr oc. of VLDB , 1994. [12] K. Y amanishi, Y . Maruyama, et al. ”Dynamic Syslog Mining for Networ k Failure Monitoring”. In Pr oc. of SIGKDD , 2004. [13] Y . Liang, Y . Zhang, et al. ”BlueGene/L Failur e Analysis and Prediction Models”. In Pr oc. of DSN , 2006. [14] T . T . Y . Lin, D. P . Sie wiorek, et al. ”Error Log Analysis: Statistic al Modelin g and Heuristic Trend Analysis”. IEE E T rans. on Reliabi lity , vol. 39, pp. 419-432, October 1990. [15] Z. Z hang, J. Zhan, Y . L i, et al. ”Precise Request Tra cing and Perfor- mance Debugg ing for Multi-ti er Services of Black Boxe s”. In Proc. of DSN , 2009. [16] W . Zhou, J. Zhan, D. Meng. ”Multidimensi onal Analysis of Logs in Large-sc ale Cluster Systems”. In F astAbstr act, P r oc. of DSN , 2008. [17] A. J. Oliner , A. Aiken, J . Stearley . ”Alert Detecti on in Logs”. In Proc. of ICDM, 2008. [18] S. Zhang, I. Cohen , M. Goldszmidt, et al. ”Ensembles of models for automate d diagnosis of system performance problems”. In Pr oc. of DSN , 2005. [19] E. W . Fulp, G. A. Fink, J. N. Haack. ”Predic ting Computer System Fail ures Using Support V ector Mac hines”. In F irst USENIX W orkshop on the Analysis of Logs (W ASL) , 2008. [20] J. C. Knight. ”An Introduct ion T o Computing System Dependabi lity”. In Proc . of ICSE , 2004. [21] L. Lamport. ”Ti me, Clocks and the Ordering of Event s in a Distri buted System”. Communications of the AC M , 21(7), 1978, pp.558-565. [22] http:// institutes.la nl.gov/data/fdata/ [23] http:// www .python.or g/ [24] J. Han, M. Kamber . ”Data mining: Concept s and T echniques”. Mor gan Kaufmann Publishers , 2000. [25] Z. Zheng, Z. Lan, B. H. Park, A. Geist . ”System L og Pre-pr ocessing to Improv e Fail ure Prediction ”. In Pr oc. of DSN , 2009. [26] R. Zhang, E. Cope, L. Heusler , F . Cheng. ”A Bayesia n Network Approach to Modeling IT Service A v ailabili ty using System Logs”. In USENIX workshop on W ASL , 2009 [27] L. W u, D. Meng, W . Gao, J. Zhan. ”A proacti ve fault-det ection mech- anism in large -scale cluster systems”. In Pr oc of IPDPS , 2006. [28] T . J. Hack er , F . Romero, and C. D. Carothe rs, ”An analysi s of clustere d fail ures on lar ge supercomputing s ystems”. J ournal of P ara llel and Distrib uted Computing . 69, 7 (Jul. 2009), 652-665. [29] L. Ching hway , N. Singh, and S. Y ajnik. ”A log mining approach to fail ure analysis of enterpri se telepho ny s ystems”. In Proc. of DSN , 2008. [30] D. T ang and R. K. Iyer , ”Analysis an d Modeling of Corr elated Failures in Multic omputer Systems”. IEEE T ransact ions on Computers . 41, 5 (May . 1992), 567-577. [31] J. Lou, Q. FU, Y . W ang, J. Li. ”Mining Depende ncy in Distrib uted Systems through Unstructure d Logs Analysis”, In USENIX workshop on W ASL , 2009. [32] W . Zhou, J. Zhan, D. Meng, and Z. Zhang. ”Online Event Correlations Analysis in System Logs of Lar ge-Scale Cluster Systems”, In Proc. NPC , 2010. [33] R. Gusella, and S. Z atti, ”The accura cy of clock synchronizati on achie ve d by TEMPO in Berke ley UNIX 4.3BSD”, IEEE T ransactions Softwar e Engineeri ng , 1989. 15: p. 847-853. [34] F . Cristian, ”Probabi listic clock synchroniz ation. Distributed Comput- ing”, 1989. 3: p. 146-158. [35] ntptrace - trac e a chain of NTP servers back to the primary source. http:/ /www .cis.udel.edu/ mills/ntp/html/ ntptrace.html. 12 [36] W . Xu, L. Huang, A. Fox, D. Patter son, and M. Jordan, ”Experience Mining Google’ s Production Console Logs”, In USENIX W orksip on SLAML , 2010. [37] X. Gu, H. W ang, ”Online Anomaly Prediction for Rob ust Cluste r Systems”, In Pr oc. ICDE , 2009. [38] Y . T an, X. Gu, and H. W ang, ”Adapti ve Runtime Anomaly Predictio n for Dynamic Hosting Infrastructures” , In Pr oc. P ODC , 2010. [39] P . Zhou, B. Gill, W . Bell uomini, and A. W ildani , ”GA UL: Gestalt Analysis of Unstructured Logs for Diagnosing Recurring Problem in Large Enterprise Storage Systems”, In Proc . SRDS , 2010. [40] H. Chen, G. Jiang, K. Y oshihira, and A. Saxena, ”Inv aria nts Based Fail ure Diagno sis in Distribute d Computing Systems”, In Proc. SRDS , 2010. [41] D. John, P . Prakash, R. R. Ko mpella, R. Chandra, ”Shedding Light on Enterprise Network Failures using Spotlight”, In Proc. SRDS , 2010 [42] A. J. Oliner , A. V . Kulkarni, A. Aiken, ”Using Correlate d Surprise to Infer Shared Influence” , In Proc. DSN , 2010. [43] M. K. Agarwa l, V . R. Madduri, ”Correla ting Failure s with Asynchronous Changes for Root Cause Analysis in Enterprise Envi ronments”, In Pr oc. DSN , 2010. [44] Y . Liang, Y . Zhang, H. Xiong, and R. Sahoo, ”Failure Predicti on in IBM BlueGen e/L Event Logs”, In Proc . of ICDM , 2007. [45] J. F . Murray , G. F . Hughes, and K. Kreutz-Delgado , ”Comparison of machine learning methods for pred icting fail ures in hard dri ves”, J ournal of Machine Learning Resear ch , 2005. [46] B. S chroede r and G. Gibson, ”Disk failures in the real world: What does an MTT F of 1,000,000 hours mean too you”, In Pr oc. of F AST , 2007. [47] K. Shen, M. Zhong, and C. Li, ”I/O system performance debugg ing using model-dri ven anomaly charac terizati on”, In Pr oc. of F A ST , 2005. [48] J. T ucek, S. Lu, C. Huang, S. Xanthos, and Y . Zhou, ”Triag e: Diagnosing Producti on Run Failures at the Users Site”, In Proc . of SOSP , 2007. [49] W . Xu, L. Huang, A. Fox, D. Patterson, and M. Jordan, ”Large-scale system problems detection by mining console logs”, In Proc. of SOSP , 2009. [50] Z. Guo, G. Jiang, H. Chen, and K. Y oshihira, ”T racking probabili stic correla tion of monitoring data for fault detecti on in complex systems”. In P r oc. of D SN , 2006. [51] W . Zhou, J. Zhan, D. Meng, D. Xu, and Z. Zhang. ”LogMast er: Mining Event Correlat ions in Logs of Large scale Cluster Systems”. T ec hnical Report . http://arxi v . org/a bs/1003.0951v1. [52] R. Agraw al, R. Srika nt, ”Fast Algorit hms for Mining Association Rules” , In P r oc. VLDB , 1994. [53] R. Agrawa l, T . Imielinski, and A. Swami, ”Mining As sociati on Rules Betwee n Sets of Items in Large Databases, ” In Proc . of SIGMODE , 1993. [54] S. Brin, R. Motiwani, and C. Silve rstein, ”Be yond Market Basket s: G en- eraliz ing Association Rules to Corre lations”, Data Mining and Knowl edge Discov ery 2 , No. 1, 39C68 (1998). [55] 15. J. Pei and J. Han, ”Can W e Push More Constraints into Frequent Patt ern Mining”, In Proc. KDD . 2000. [56] Adetokunbo Makanju , A.Nur Zincir-He ywood, E va ngelos E. Milios. ”Extract ing Message T ypes from BlueGene/ L ’ s Logs”. W ASL 2009, Big Sky Resort, B ig Sky , Montana , Octobe r 14, 2009. [57] H. Mannila, Hannu T oi vone n, and A. Inkeri V erkamo. ”Disc overy of Frequent E pisodes in Event Sequences”. Data Min. Knowl. Discov . 1, 3 (January 1997), 259-289. [58] P . Tzve tkov , X. Y an, and J. Han. ”Tsp: Mining top-k closed sequential patte rns”. In Proc. ICDM , 2003. [59] X. Y an, J. Han, and R. Afshar . ”Clospan: Mining closed s equenti al patte rns in large datasets”. In Proc . SDM , 2003. [60] J. T an, X. Pan, S. Kavul ya, R. Gandhi, and P . N arasimhan. ”SALSA: analyz ing logs as state machines”. In Proc. W ASL , 2008. [61] S. Ma and J . L. Hellerstein, ”Mining Mutually Depende nt Pattern s”, In Pr oc. ICDM , 2001. [62] R. Agrawal and R. Srikant, ”Mini ng Seque ntial Patte rns”, In Pr oc. ICDE , 1995. [63] R. V ilalta and S. Ma, ”Predict ing Rare Events in T emporal Dom ains”, In P r oc. of ICDM , 2002. [64] D. Ford, F . Labelle , F . I. Popovici , M. Stokely , V . Truon g, L. Barroso, C. Grimes, and S. Quinlan, ”A vaila bility in globally distrib uted storage systems”, In Pr oc. OSDI , 2010. [65] K. V . V ishwana th and N. Nagappan, ”Charac terizing cloud computing hardwa re reliabilit y”, In Proc . of SoCC , 2010. [66] E. B. Nighting ale, J. R. Douceur , and V . Orgov an, ”Cycle s, cell s and platt ers: an empirical anal ysisof hardware fai lures on a million consumer PCs”. In Pr oc. of EuroS ys , 2011. A P P E N D I X A C H O O S I N G T H E T H R E S H O L D V A L U E S O F T H E P E R I O D I C C O U N T A N D T H E P E R I O D I C R AT I O I N FI LT E R I N G P E R I O D I C E V E N T S L Q L Q J H Y H Q W V + D G R R S V \ V W H P O R J V 5HPDLQLQJHYHQWV 7KHWKUHVKROGRISHULRGLF FRXQ W +DGRRSV\VWHPORJV L Q L Q J H Y H Q W V + D G R R S V \ V W H P O R J V 5HPDLQLQJHYHQWV 7KHWKUHVKROGRISHULRGLFUDWLR +DGRRSV\VWHPORJV D L Q L Q J H Y H Q W V + 3 & F O X V W H U V \ V W H P O R J V 5HPDLQLQJHYHQWV 7KHWKUHVKROGRISHULRGLFFRXQW +3&FOXVWHUV\VWHPORJV Q L Q J H Y H Q W V + 3 & F O X V W H U V \ V W H P O R J V 5HPDLQLQJHYHQWV 7KHWKUHVKROGRISHULRGLFUDWLR +3&FOXVWHUV\VWHPORJV Fig. 9: Relationships betwe en remain ing events and two thresholdsłp eriodic c ount and perio dic ratio. As shown in Fig. 9, when the threshold of the periodic count is less th an 2 0, the rem aining nu mbers o f Had oop system lo gs and HPC c luster system logs ch ange little. When the th reshold of the p eriodic co unt is above 20, the remaining events chan ge significantly , so we set the thresho ld o f the pe riodic coun t as 20. When the threshold of the pe riodic r atio of Hadoop system logs is less than 0.2 and th e thresho ld of periodic ratio of HPC cluster system logs is less than 0.1 , the rem aining events change little. So we set the threshold of the periodic ratio of Hadoop system logs to 0.2 and the thresh old of p eriodic r atio of HPC cluster system logs to 0.1 , respectively . logs the thre shold of peri- odic count the threshold of peri- odic ratio Hadoop 20 0.2 HPC cluster 20 0.1 T ABLE XIV: Thresh old selection of two logs A P P E N D I X B P A R A M E T E R S E FF E C T S I N E V E N T C O R R E L A T I O N M I N I N G The effects of parameter s( T w , S th and C th ) on the average analysis time per event and the num ber of e vent rules are shown in Fig. 10 and Fig. 11, respec tiv ely . 13 151 164 173 183.45 192 213 243 289.9 47.3 47.83 47.93 48.17 48.56 49.22 50.12 51.32 0 50 100 150 200 250 300 350 10 20 30 40 50 60 90 120 Average analysis time (ms) Sliding time window(Tw) Hadoop s ystem logs Apriori-LES Apriori-semiLES 245 250.2 259.3 263.23 267.1 272.22 289.27 317.9 40.343 45.03 47.39 48.17 48.56 49.22 53.12 55.32 0 50 100 150 200 250 300 350 10 20 30 40 50 60 90 12 0 Average analysis time(ms) Sliding time window(Tw) HPC clus ter sys tem logs Apriori-LES Apriori-semiLES 599.23 399 213.34 189.13 177.23 169.43 153.2 12 3.87 98.45 77.34 55.23 49.35 48.44 42.35 39.245 3 2.12 0 100 200 300 400 500 600 700 3 4 5 6 7 8 9 10 Average analysis time(ms) The threshold of support count(Sth) Hadoop s ystem logs Apriori-LES Apriori-semiLES semi LE S 679.23 524.23 313.34 249.13 197.23 183.43 163.2 1 43.87 104.45 87.34 75.23 69.35 58.44 48.35 47.245 46.12 0 100 200 300 400 500 600 700 800 3 4 5 6 7 8 9 10 Average analysis time(ms) The threshold of support count(Sth) HPC clus ter sy stem logs Apriori-LES Apriori-semiLES 298.34 256.3 221 197.3 187.4 175.1 165.3 154.3 151.9 58.3 56.4 55.8 53.19 50.3 49.45 49.23 48.59 48.46 0 50 100 150 200 250 300 350 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Average analysis time(ms) The threshold of confidence(Cth) Hadoop s ystem logs Apriori-LES Apriori-semiLES 355.34 346.3 338.2 321.3 299.4 278.1 263.3 234.64 223.42 68.3 66.4 63.8 63.19 58.3 56.45 55.23 53.23 52.4 0 50 100 150 200 250 300 350 400 Average analysis time(ms) The threshold of confidence(Cth) HPC cluster s ystem logs Apriori-semiLES Apriori-semiLES Fig. 10: The effect of parameter s( T w , Sth and Cth ) on the average analy sis time p er event. 972 1382 1628 1836 2083 2413 3349 3 6 8 2 826 1124 1234 1322 1434 1520 2329 2 9 8 3 0 500 1000 1500 2000 2500 3000 3500 4000 10 20 30 40 50 60 90 12 0 Number of event rules Sliding time window(Tw) Hadoop s ystem logs Apriori-LES Apriori-semiLES 892 1393 1763 2126 3563 4726 9403 1 3 3 5 3 863 1297 1702 1833 3087 3990 7972 1 1 4 7 2 0 2000 4000 6000 8000 10000 12000 14000 16000 10 20 30 40 50 60 90 12 0 Number of event rules Sliding time window(Tw) HPC clust er sys tem logs Apriori-LES Apriori-semiLES 5278 3983 2413 1364 1036 806 693 6 3 0 3249 2491 1520 865 610 490 415 3 6 8 0 1000 2000 3000 4000 5000 6000 3 4 5 6 7 8 9 10 Number of event rules The threshold of support count(Sth) Hadoop s ystem logs Apriori-LES Apriori-semiLES 40553 14804 4726 2268 1164 601 364 1 7 5 25003 11475 3990 2105 1136 601 364 1 7 5 0 5000 10000 15000 20000 25000 30000 35000 40000 45000 3 4 5 6 7 8 9 10 Number of event rules The threshold of support count(Sth) HPC clust er syst em logs Apriori-LES Apriori-semiLES 3057 2622 2240 2030 1880 1700 1410 1162 77 1787 1602 1459 1345 1248 1127 933 739 61 0 500 1000 1500 2000 2500 3000 3500 Number of event rules The threshold of confidence(Cth) Hadoop s ystem logs Apriori-LES Apriori-semiLES 4749 4743 4718 4685 4636 4143 3133 1913 53 4005 3999 3982 3962 3942 3645 2847 1821 53 0 1000 2000 3000 4000 5000 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 Number of event rules The threshold of confidence(Cth) HPC clust er sys tem logs Apriori-LES Apriori-semiLES Fig. 1 1: The e ffect of paramete rs( T w , S th an d Cth ) on the numb er of event rules. A P P E N D I X C P A R A M E T E R S E FF E C T S I N E V E N T P R E D I C T I O N S The ef fects of p arameters( P th and T p ) on th e precision rates and recall rates are shown in Fig. 12, Fig. 13, r espec- ti vely . 14 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Value of Precision and Recall Pth Hadoop sys tem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Value of Precision and Recall Pth HPC clust er syst em logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Value of Presion and Recall Pth Hadoop sy stem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Value of Precision and Recall Pth HPC cluster syst em logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Value of Precision and Recall Pth Hadoop sys tem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 Value of Precision and Recall Pth HPC clust er syst em logs Apriori-semiLES:Precision Apriori-LES:Precision Apriori-semiLES:Recall Apriori-LES:Recall Fig. 12: The effects of the param eter Pth on the precision rate and the recall ra te of the Hadoo p system logs an d the HPC cluster system logs in predicting all events o n th e basis of both failure and non-failure events, predic ting only failure events on the basis of bo th failur e and non-failure events, and predicting failure events after removing non -failure ev ents (f rom left to right). 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 20 40 60 80 100 120 Value of Precision and Recall Tp (m i n ) Hadoop sys tem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 20 40 60 80 100 120 Value of Precision and Recall Tp (m i n ) HPC cluster sy stem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 20 40 60 80 100 120 Value of Precision and Recall T p (m i n ) Hadoop sys tem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 20 40 60 80 100 120 Value of Precision and Recall T p(m i n ) HPC cluster s ystem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 20 40 60 80 100 120 Value of Precision and Recall Tp(min) Hadoop sys tem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 1 20 40 60 80 100 120 Value of Precision and Recall Tp(min) HPC cluster s ystem logs Apriori-semiLES:Precision Apriori-LES:Precisiom Apriori-semiLES:Recall Apriori-LES:Recall Fig. 13: The effects of the parameter Tp on the pr ecision rate and re call rate of th e Hadoo p system logs and the HPC clu ster system logs in pr edicting all events o n the basis of bo th failure and non-failure events, pred icting only failure events on the basis of b oth failure and non -failure events, an d pr edicting failure events after removing non -failure e vents (f rom left to right).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment