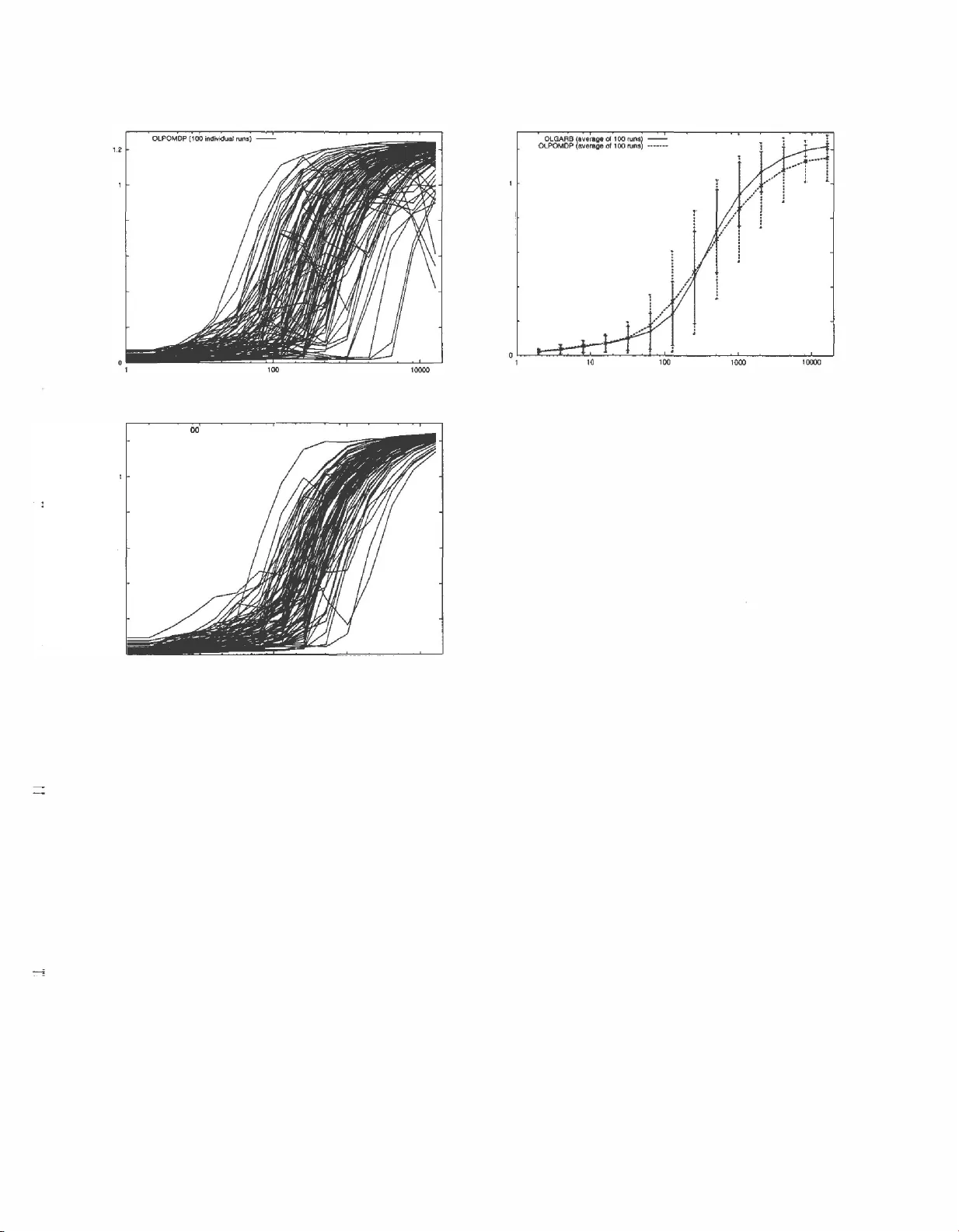
The Optimal Reward Baseline for Gradient-Based Reinforcement Learning
There exist a number of reinforcement learning algorithms which learnby climbing the gradient of expected reward. Their long-runconvergence has been proved, even in partially observableenvironments with non-deterministic actions, and without the need…
Authors: Lex Weaver, Nigel Tao
[ (;. ( l
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment