Generalized Rejection Sampling Schemes and Applications in Signal Processing
Bayesian methods and their implementations by means of sophisticated Monte Carlo techniques, such as Markov chain Monte Carlo (MCMC) and particle filters, have become very popular in signal processing over the last years. However, in many problems of…
Authors: Luca Martino, Joaquin Miguez
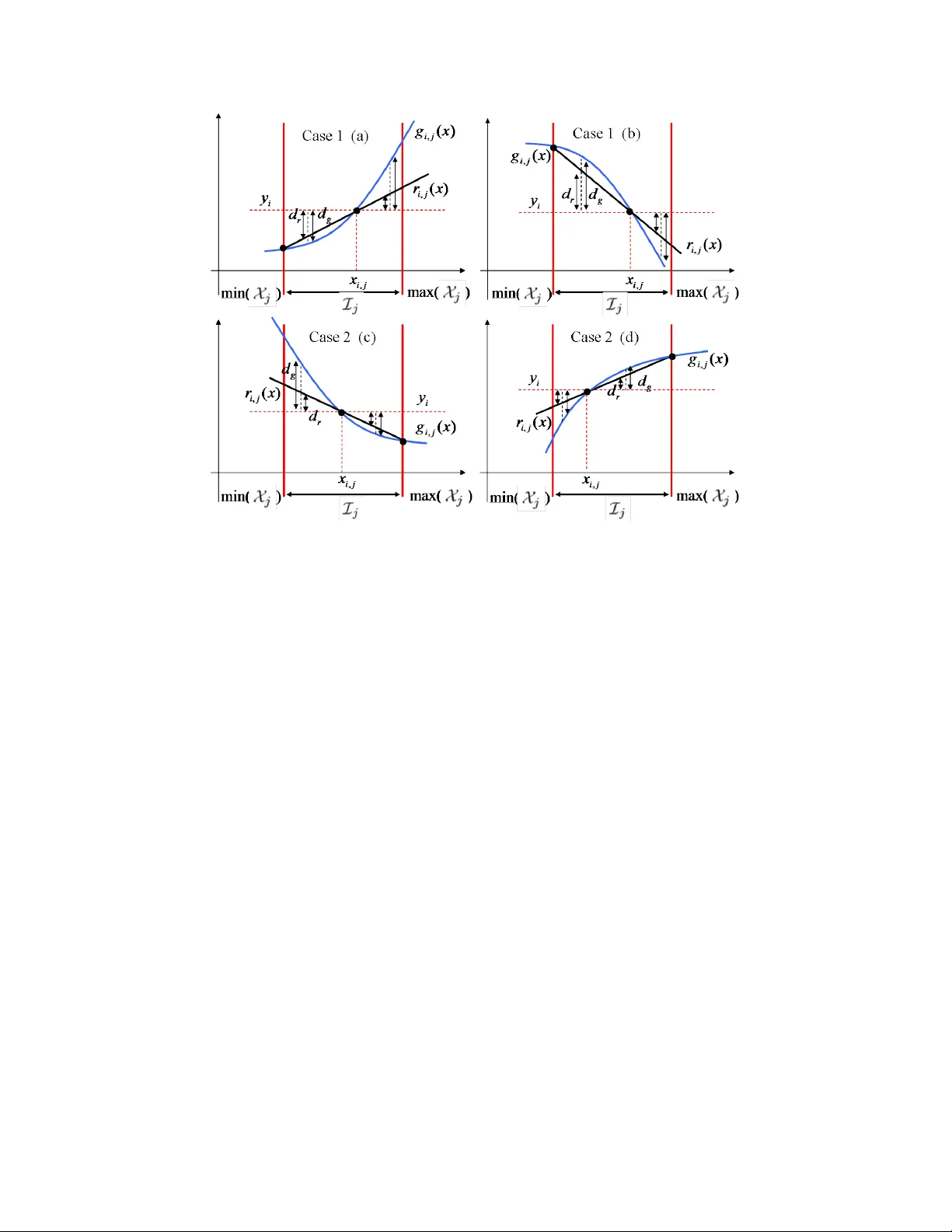
1 Generalized Rejection Sampling Schemes and Applications in Signal Processing Luca Martino and Joaqu ´ ın M ´ ıguez Department of Signal Theory and Communications, Uni versidad Carlos III de Madrid. A venida de la Uni v ersidad 30, 28911 Leg an ´ es, Madrid, Spain. E-mail: luca@tsc.uc3m.es, joaquin.miguez@uc3m.es Abstract Bayesian methods and their implementations by means of sophisticated Monte Carlo techniques, such as Markov chain Monte Carlo (MCMC) and particle filters, hav e become very popular in signal processing ov er the last years. Howe v er , in man y problems of practical interest these techniques demand procedures for sampling from probability distributions with non-standard forms, hence we are often brought back to the consideration of fundamental simulation algorithms, such as rejection sampling (RS). Unfortunately , the use of RS techniques demands the calculation of tight upper bounds for the ratio of the target probability density function (pdf) ov er the proposal density from which candidate samples are drawn. Except for the class of log-concav e target pdf ’ s, for which an efficient algorithm exists, there are no general methods to analytically determine this bound, which has to be deri ved from scratch for each specific case. In this paper, we introduce new schemes for (a) obtaining upper bounds for likelihood functions and (b) adaptiv ely computing proposal densities that approximate the target pdf closely . The former class of methods provides the tools to easily sample from a posteriori probability distributions (that appear very often in signal processing problems) by drawing candidates from the prior distribution. Ho we ver , they are e ven more useful when they are e xploited to deriv e the generalized adapti ve RS (GARS) algorithm introduced in the second part of the paper . The proposed GARS method yields a sequence of proposal densities that conv erge to wards the target pdf and enable a very ef ficient sampling of a broad class of probability distrib utions, possibly with multiple modes and non-standard forms. W e provide some simple numerical examples to illustrate the use of the proposed techniques, including an example of target localization using range measurements, often encountered in sensor network applications. Index T erms Rejection sampling; adaptiv e rejection sampling; Gibbs sampling; particle filtering; Monte Carlo integration; sensor networks; target localization. 2 I . I N T R O D U C T I O N Bayesian methods hav e become very popular in signal processing during the past decades and, with them, there has been a surge of interest in the Monte Carlo techniques that are often necessary for the implementation of optimal a posteriori estimators [6, 4, 13, 12]. Indeed, Monte Carlo statistical methods are powerful tools for numerical inference and optimization [13]. Currently , there exist several classes of MC techniques, including the popular Marko v Chain Monte Carlo (MCMC) [6, 11] and particle filtering [3, 4] families of algorithms, which enjoy numerous applications. Ho wev er, in many problems of practical interest these techniques demand procedures for sampling from probability distributions with non-standard forms, hence we are often brought back to the consideration of fundamental simulation algorithms, such as importance sampling [2], in version procedures [13] and the accept/reject method, also kno wn as r ejection sampling (RS). The RS approach [13, Chapter 2] is a classical Monte Carlo technique for “universal sampling”. It can be used to generate samples from a target probability density function (pdf) by drawing from a possibly simpler proposal density . The sample is either accepted or rejected by an adequate test of the ratio of the two pdf ’ s, and it can be proved that accepted samples are actually distributed according to the target density . RS can be applied as a tool by itself, in problems where the goal is to approximate integrals with respect to (w .r .t.) the pdf of interest, but more often it is a useful b uilding block for more sophisticated Monte Carlo procedures [8, 15, 10]. An important limitation of RS methods is the need to analytically establish a bound for the ratio of the target and proposal densities, since there is a lack of general methods for the computation of exact bounds. One exception is the so-called adaptive r ejection sampling (ARS) method [8, 7, 13] which, giv en a target density , provides a procedure to obtain both a suitable proposal pdf (easy to draw from) and the upper bound for the ratio of the target density over this proposal. Unfortunately , this procedure is only v alid when the tar get pdf is strictly log-concav e, which is not the case in most practical cases. Although an extension has been proposed [9, 5] that enables the application of the ARS algorithm with T -concav e distributions (where T is a monotonically increasing function, not necessarily the logarithm), it does not address the main limitations of the original method (e.g., the impossibility to draw from multimodal distributions) and is hard to apply , due to the difficulty to find adequate T transformations other than the logarithm. Another algorithm, called adaptive r ejection metr opolis sampling (ARMS) [14], is an attempt to extend the ARS to multimodal densities by adding Metropolis-Hastings steps. Ho wev er, the use of an MCMC procedure has two important consequences. First, the resulting samples are correlated (unlike in 3 the original ARS method), and, second, for multimodal distributions the Markov Chain often tends to get trapped in a single mode. In this paper we propose general procedures to apply RS when the tar get pdf is the posterior density of a signal of interest (SoI) giv en a collection of observations. Unlike the ARS technique, our methods can handle target pdf ’ s with several modes (hence non-log-concav e) and, unlike the ARMS algorithm, they do not in volv e MCMC steps. Hence, the resulting samples are independent and come exactly from the target pdf. W e first tackle the problem of computing an upper bound for the lik elihood of the SoI giv en fixed observ ations. The proposed solutions, that include both closed-form bounds and iterativ e procedures, are useful when we dra w the candidate samples from the prior pdf. In this second part of the paper , we extend our approach to de vise a generalization of the ARS method that can be applied to a broad class of pdf ’ s, possibly multimodal. The generalized algorithm yields an ef ficient proposal density , tailored to the target density , that can attain a much better acceptance rate than the prior distrib ution. W e remark that accepted samples from the target pdf are independent and identically distrib uted (i.i.d). The remaining of the paper is organized as follows. W e formally describe the signal model in Section II. Some useful definitions and basic assumptions are introduced in Section III. In Section IV, we propose a general procedure to compute upper bounds for a large family of likelihood functions. The ARS method is briefly re vie wed in Section V, while the main contrib ution of the paper , the generalization of the ARS algorithm, is introduced in Section VI. Section VII is de voted to simple numerical examples and we conclude with a brief summary in Section VIII. I I . M O D E L A N D P RO B L E M S TA T E M E N T A. Notation Scalar magnitudes are denoted using re gular face letters, e.g., x , X , while vectors are displayed as bold-face letters, e.g., x , X . W e indicate random variates with upper-case letters, e.g., X , X , while we use lower -case letters to denote the corresponding realizations, e.g., x , x . W e use letter p to denote the true probability density function (pdf) of a random variable or vector . This is an argument-wise notation, common in Bayesian analysis. For two random v ariables X and Y , p ( x ) is the true pdf of X and p ( y ) is the true pdf of Y , possibly dif ferent. The conditional pdf of X given Y = y is written p ( x | y ) . Sets are denoted with calligraphic upper-case letters, e.g., R . 4 B. Signal Model Many problems in science and engineering in volv e the estimation of an unobserved SoI, x ∈ R m , from a sequence of related observations. W e assume an arbitrary prior probability density function (pdf) for the SoI, X ∼ p ( x ) , and consider n scalar random observ ations, Y i ∈ R , i = 1 , . . . , n , which are obtained through nonlinear transformations of the signal X contaminated with additi ve noise. Formally , we write Y 1 = g 1 ( X ) + Θ 1 , . . . , Y n = g n ( X ) + Θ n (1) where Y = [ Y 1 , . . . , Y n ] > ∈ R n is the random observation vector , g i : R m → R , i = 1 , . . . , n , are nonlinearities and Θ i are independent noise v ariables, possibly with dif ferent distrib utions for each i . W e write y = [ y 1 , . . . , y n ] > ∈ R n for the v ector of a v ailable observ ations, i.e., a realization of Y . W e assume e xponential-type noise pdf ’ s, of the form Θ i ∼ p ( ϑ i ) = k i exp − ¯ V i ( ϑ i ) , (2) where k i > 0 is real constant and ¯ V i ( ϑ i ) is a function, subsequently referred to as marginal potential, with the follo wing properties: (P1) It is real and non neg ativ e, i.e., ¯ V i : R → [0 , + ∞ ) . (P2) It is increasing ( d ¯ V i dϑ i > 0 ) for ϑ i > 0 and decreasing ( d ¯ V i dϑ i < 0 ) for ϑ i < 0 . These conditions imply that ¯ V i ( ϑ i ) has a unique minimum at ϑ ∗ i = 0 and, as a consequence p ( ϑ i ) has only one maximum (mode) at ϑ ∗ i = 0 . Since the noise variables are independent, the joint pdf p ( ϑ 1 , ϑ 2 , . . . , ϑ n ) = Q n i =1 p ( ϑ n ) is easy to construct and we can define a joint potential function V ( n ) : R n → [0 , + ∞ ) as V ( n ) ( ϑ 1 , . . . , ϑ n ) , − log [ p ( ϑ 1 , . . . , ϑ n )] = − n X i =1 log[ p ( ϑ n )] . (3) Substituting (2) into (3) yields V ( n ) ( ϑ 1 , . . . , ϑ n ) = c n + n X i =1 ¯ V i ( ϑ i ) (4) where c n = − P n i =1 log k i is a constant. In subsequent sections we will be interested in a particular class of joint potential functions denoted as V ( n ) l ( ϑ 1 , . . . , ϑ n ) = n X i =1 | ϑ i | l , 0 < l < + ∞ , (5) where the subscript l identifies the specific member of the class. In particular , the function obtained for l = 2 , V ( n ) 2 ( ϑ 1 , . . . , ϑ n ) = P n i =1 | ϑ i | 2 is termed quadratic potential. 5 Let g = [ g 1 , . . . , g n ] > be the vector-v alued nonlinearity defined as g ( x ) , [ g 1 ( x ) , . . . , g n ( x )] > . The scalar observations are conditionally independent gi ven a realization of the SoI, X = x , hence the likelihood function ` ( x ; y , g ) , p ( y | x ) , can be factorized as ` ( x ; y , g ) = n Y i =1 p ( y i | x ) , (6) where p ( y i | x ) = k i exp − ¯ V i ( y i − g i ( x )) . The likelihood in (6) induces a system potential function V ( x ; y , g ) : R m → [0 , + ∞ ) , defined as V ( x ; y , g ) , − log[ ` ( x ; y , g )] = − n X i =1 log[ p ( y i | x )] , (7) that depends on x , the observations y , and the function g . Using (4) and (7), we can write the system potential in terms of the joint potential, V ( x ; y , g ) = c n + n X i =1 ¯ V i ( y i − g i ( x )) = V ( n ) ( y 1 − g 1 ( x ) , . . . , y n − g n ( x )) . (8) C. Rejection Sampling Assume that we wish to approximate, by sampling, some integral of the form I ( f ) = R R f ( x ) p ( x | y ) d x , where f is some measurable function of x and p ( x | y ) ∝ p ( x ) ` ( x ; y , g ) is the posterior pdf of the SoI gi ven the observations. Unfortunately , it may not be possible in general to draw directly from p ( x | y ) , so we need to apply simulation techniques to generate adequate samples. One appealing possibility is to perform RS using the prior , p ( x ) , as a proposal function. In such case, let γ be a lower bound for the system potential, γ ≤ V ( x ; y , g ) , so that L , exp {− γ } is an upper bound for the likelihood, ` ( x ; y , g ) ≤ L . W e can generate N samples according to the standard RS algorithm. 1) Set i = 1 . 2) Draw samples x 0 from p ( x ) and u 0 from U (0 , 1) , where U (0 , 1) is the uniform pdf in [0 , 1] . 3) If p ( x 0 | y ) Lp ( x 0 ) ∝ ` ( x 0 ; y , g ) L > u 0 then x ( i ) = x 0 , else discard x 0 and go back to step 2. 4) Set i = i + 1 . If i > N then stop, else go back to step 2. Then, I ( f ) can be approximated as I ( f ) ≈ ˆ I ( f ) = 1 N P N i =1 f ( x ( i ) ) . The fundamental figure of merit of a rejection sampler is the acceptance rate, i.e., the mean number of accepted samples ov er the total number of proposed candidates. In Section IV, we address the problem of analytically calculating the bound L = exp {− γ } . Note that, since the log function is monotonous, it is equiv alent to maximize ` w .r .t. x and to minimize the system potential V also w .r .t. x . As a consequence, we may focus on the calculation of a lo wer bound γ for V ( x ; y , g ) . Note that this problem is far from tri vial. Even for v ery simple marginal potentials, ¯ V i , 6 i = 1 , ..., n , the system potential can be highly multimodal w .r .t. x . See the example in the Section VII-A for an illustration. I I I . D E FI N I T I O N S A N D A S S U M P T I O N S Hereafter , we restrict our attention to the case of a scalar SoI, x ∈ R . This is done for the sake of clarity , since dealing with the general case x ∈ R m requires additional definitions and notations. The techniques to be described in Sections IV-VI can be extended to the general case, although this extension is not trivial. The example in Section VII-C illustrates how the proposal methodology is also useful in higher dimensional spaces, though. For a giv en vector of observations Y = y , we define the set of simple estimates of the SoI as X , { x i ∈ R : y i = g i ( x i ) for i = 1 , . . . , n } . (9) Each equation y i = g i ( x i ) , in general, can yield zero, one or more simple estimates. W e also introduce the maximum likelihood (ML) SoI estimator ˆ x , as ˆ x ∈ arg max x ∈ R ` ( x | y , g ) = arg min x ∈ R V ( x ; y , g ) , (10) not necessarily unique. Let us use A ⊆ R to denote the support of the vector function g , i.e., g : A ⊆ R → R n . W e assume that there exists a partition {B j } q j =1 of A (i.e., A = ∪ q j =1 B j and B i ∩ B j = ∅ , ∀ i 6 = j ) such that the subsets B j are intervals in R and we can define functions g i,j : B j → R , j = 1 , . . . , q and i = 1 , . . . , n , as g i,j ( x ) , g i ( x ) , ∀ x ∈ B j , (11) i.e., g i,j is the restriction of g i to the interval B j . W e further assume that (a) e very function g i,j is in vertible in B j and (b) ev ery function g i,j is either con ve x in B j or concave in B j . Assumptions (a) and (b) together mean that, for ev ery i and all x ∈ B j , the first deriv ativ e dg i,j dx is either strictly positiv e or strictly ne gati ve and the second deriv ati ve d 2 g i,j dx 2 is either non-negati ve or non-positiv e. As a consequence, there are exactly n simple estimates (one per observ ation) in each subset of the partition, namely x i,j = g − 1 i,j ( y i ) for i = 1 , . . . , n . W e write the set of simple estimates in B j as X j = { x 1 ,j , . . . , x n,j } . Due to the additivity of the noise in (1), if g i,j is bounded there may be a non-negligible probability that Y i > max x ∈ [ B j ] g i,j ( x ) (or Y i < min x ∈ [ B j ] g i,j ( x ) ), where [ B j ] denotes the closure of set B j , hence g − 1 i,j ( y i ) may not exist for some realization Y i = y i . In such case, we define x i,j = arg max x ∈ [ B j ] g i,j ( x ) (or x i,j = arg min x ∈ [ B j ] g i,j ( x ) , respecti vely), and admit x i,j = + ∞ (respecti vely , x i,j = −∞ ) as v alid simple estimates. 7 I V . C O M P U TA T I O N O F U P P E R B O U N D S O N T H E L I K E L I H O O D A. Basic method Let y be an arbitrary but fixed realization of the observation vector Y . Our goal is to obtain an analytical method for the computation of a scalar γ ( y ) ∈ R such that γ ( y ) ≤ inf x ∈ R V ( x ; y , g ) . Hereafter , we omit the dependence on the observation v ector and write simply γ . The main difficulty to carry out this calculation is the nonlinearity g , which renders the problem not directly tractable. T o circumvent this obstacle, we split the problem into q subproblems and address the computation of bounds for each set B j , j = 1 , . . . , q , in the partition of A . W ithin B j , we b uild adequate linear functions { r i,j } n i =1 in order to replace the nonlinearities { g i,j } n i =1 . W e require that, for ev ery r i,j , the inequalities | y i − r i,j ( x ) | ≤ | y i − g i,j ( x ) | , and (12) ( y i − r i,j ( x ))( y i − g i,j ( x )) ≥ 0 (13) hold jointly for all i = 1 , . . . , n , and all x ∈ I j ⊂ B j , where I j is any closed interval in B j such that ˆ x j ∈ arg min x ∈ [ B j ] V ( x ; y , g ) (i.e., any ML estimator of the SoI X restricted to B j , possibly non unique) is contained in I j . The latter requirement can be fulfilled if we choose I j , [min( X j ) , max( X j )] (see the Appendix for a proof). If (12) and (13) hold, we can write ¯ V i ( y i − r i,j ( x )) ≤ ¯ V i ( y i − g i,j ( x )) , ∀ x ∈ I j , (14) which follo ws easily from the properties (P1) and (P2) of the marginal potential functions ¯ V i as described in Section II-B. Moreov er , since V ( x ; y , g j ) = c n + P n i =1 ¯ V i ( y i − g i,j ( x )) and V ( x ; y , r j ) = c n + P n i =1 ¯ V i ( y i − r i,j ( x )) (this function will be subsequently referred as the modified system potential) where g j ( x ) , [ g 1 ,j ( x ) , . . . , g n,j ( x )] and r j ( x ) , [ r 1 ,j ( x ) , . . . , r n,j ( x )] , Eq. (14) implies that V ( x ; y , r j ) ≤ V ( x ; y , g j ) , ∀ x ∈ I j , and, as a consequence, γ j = inf x ∈I j V ( x ; y , r j ) ≤ inf x ∈I j V ( x ; y , g j ) = inf x ∈B j V ( x ; y , g ) . (15) Therefore, it is possible to find a lo wer bound in B j for the system potential V ( x ; y , g j ) , denoted γ j , by minimizing the modified potential V ( x ; y , r j ) in I j . All that remains is to actually build the linearities { r i,j } n i =1 . This construction is straightforward and can be described graphically by splitting the problem into two cases. Case 1 corresponds to nonlinearities g i,j such that dg i,j ( x ) dx × d 2 g i,j ( x ) dx 2 ≥ 0 (i.e., g i,j is either increasing and con vex or decreasing and concave), 8 while case 2 corresponds to functions that comply with dg i,j ( x ) dx × d 2 g i,j ( x ) dx 2 ≤ 0 (i.e., g i,j is either increasing and conca ve or decreasing and con vex), when x ∈ B j . Figure 1 (a)-(b) depicts the construction of r i,j in case 1. W e choose a linear function r i,j that connects the point (min ( X j ) , g (min ( X j ))) and the point corresponding to the simple estimate, ( x i,j , g ( x i,j )) . In the figure, d r and d g denote the distances | y i − r i,j ( x ) | and | y i − g i,j ( x ) | , respecti vely . It is apparent that d r ≤ d g for all x ∈ I j , hence inequality (12) is granted. Inequality (13) also holds for all x ∈ I j , since r i,j ( x ) and g i,j ( x ) are either simultaneously greater than (or equal to) y i , or simultaneously lesser than (or equal to) y i . Figure 1 (c)-(d) depicts the construction of r i,j in case 2. W e choose a linear function r i,j that connects the point (max ( X j ) , g (max ( X j ))) and the point corresponding to the simple estimate, ( x i,j , g ( x i,j )) . Again, d r and d g denote the distances | y i − r i,j ( x ) | and | y i − g i,j ( x ) | , respecti vely . It is apparent from the two plots that inequalities (12) and (13) hold for all x ∈ I j . A special subcase of 1 (respecti vely , of 2) occurs when x i = min ( X j ) (respectively , x i,j = max ( X j ) ). Then, r i,j ( x ) is the tangent to g i,j ( x ) at x i,j . If x i,j = ±∞ then r i,j ( x ) is a horizontal asymptote of g i,j ( x ) . It is often possible to find γ j = inf x ∈I j V ( x ; y , r j ) ≤ inf x ∈I j V ( x ; y , g j ) in closed-form. If we choose γ = min j γ j , then γ ≤ inf x ∈ R V ( x, y , g ) is a global lower bound of the system potential. T able I sho ws an outline of the proposed method, that will be subsequently referred to as bounding method 1 (BM1) for conciseness. T ABLE I B O U N D I N G M E T H O D 1 . 1. Find a partition {B j } q j =1 of the space of the SoI. 2. Compute the simple estimates X j = { x 1 ,j , . . . , x n,j } for each B j . 3. Calculate I j , [min( X j ) , max( X j )] and build r i,j ( x ) , for x ∈ I j and i = 1 , . . . , n . 4. Replace g j ( x ) with r j ( x ) , and minimize V ( x ; y , r j ) to find the lower bound γ j . 5. Find γ = min j γ j . B. Iterative Implementation The quality of the bound γ j depends, to a large e xtent, on the length of the interv al I j , denoted |I j | . This is clear if we think of r i,j ( x ) as a linear approximation on I j of the nonlinearity g i,j ( x ) . Since we 9 Fig. 1. Construction of the auxiliary linearities { r i,j } n i =1 . W e indicate d r = | y i − r i,j ( x ) | and d g = | y i − g i,j ( x ) | , respectively . It is apparent that d r ≤ d g and r i,j ( x ) and g i,j ( x ) are either simultaneously greater than (or equal to) y i , or simultaneously lesser than (or equal to) y i , for all x ∈ I j . Hence, the inequalities (12) and (13) are satisfied ∀ x ∈ I j . (a) Function g i,j is increasing and con ve x (case 1). (b) Function g i,j is decreasing and concave (case 1). (c) Function g i,j is decreasing and con ve x (case 2). (d) Function g i,j is increasing and concave (case 2). hav e assumed g i,j ( x ) is continuous and bounded in I j , the procedure to b uild r i,j ( x ) in BM1 implies that lim |I j |→ 0 | g i,j ( x ) − r i,j ( x ) | ≤ lim |I j |→ 0 | sup x ∈I j g i,j ( x ) − inf x ∈I j g i,j ( x ) | = 0 , (16) for all x ∈ I j . Therefore, if we consider intervals I j which are shorter and shorter, then the modified potential function V ( x ; y , r j ) will be closer and closer to the true potential function V ( x ; y , g j ) , and hence the bound γ j ≤ V ( x ; y , r j ) ≤ V ( x ; y , g j ) will be tighter . The latter observation suggests a procedure to improv e the bound γ j for a giv en interval I j . Indeed, let us subdi vide I j into k subintervals denoted I v ,v +1 , [ s v , s v +1 ] where v = 1 , . . . , k and s v , s v +1 ∈ I j . W e refer to the elements in the collection S j,k = { s 1 , . . . , s k +1 } , with s 1 < s 2 < . . . < s k +1 , as support points in the interv al I j . W e can b uild linear functions r ( v ) j = [ r ( v ) 1 ,j , . . . , r ( v ) n,j ] for every subinterval I v ,v +1 , using the procedure described in Section IV -A. W e recall that this procedure is graphically depicted in Fig. 1, where we simply need to 10 • substitute I j by I v ,v +1 and • when the simple estimate x i,j / ∈ I v ,v +1 , substitute x i,j by s v ( x i,j by s v +1 ) if x i,j < s v (if x i,j > s v +1 , respecti vely). Using r ( v ) j we compute a bound γ ( v ) j , v = 1 , . . . , k , and then select γ j,k = min v ∈{ 1 ,...,k } γ ( v ) j . Note that the subscript k in γ j,k indicates how many support points have been used to computed the bound in I j (which becomes tighter as k increases). Moreov er if we take a new (arbitrary) support point s ∗ from the subinterv al I v ∗ ,v ∗ +1 that contains γ j,k , and e xtend the set of support points with it, S j,k +1 = { s 1 , . . . , s ∗ , . . . , s k +2 } with s 1 < s 2 < . . . < s ∗ < . . . < s k +2 , then we can iterate the proposed procedure and obtain a refined version of the bound, denoted γ j,k +1 . The proposed iterativ e algorithm is described, with detail, in T able II. Note that k is an iteration index that mak es explicit the number of support points s v . If we plug this iterativ e procedure for the computation of γ j into BM1 (specifically , replacing steps 3 and 4 of T able I), we obtain a new technique that we will hereafter term bounding method 2 (BM2). As an illustration, Figure 2 shows four steps of the iterati ve algorithm. In Figure 2 (a) there are two support points S j, 1 = { min ( X j ) , max ( X j ) } , which yield a single interval I 1 , 2 = I j . In Figures 2 (b)- (c)-(d), we successi vely add a point s ∗ chosen in the interv al ˆ I v ∗ ,v ∗ +1 that contains the latest bound. In this example, the point s ∗ is chosen deterministically as the mean of the extremes of the interval I v ∗ ,v ∗ +1 . T ABLE II I T E R A T I V E A L G O R I T H M T O I M P R OV E γ j . 1. Start with I 1 , 2 = I j , and S j, 1 = { min ( X j ) , max ( X j ) } . Let v ∗ = 1 and k = 1 . 2. Choose an arbitrary interior point s ∗ in I v ∗ ,v ∗ +1 , and update the set of support points S j,k = S j,k − 1 ∪ { s ∗ } . 3. Sort S j,k in ascending order , so that S j,k = { s 1 , . . . , s k +1 } where s 1 = min( X j ) , s k +1 = (max X j ) , and k + 1 is the number of elements of S j,k . 4. Build r ( v ) j ( x ) for each interval I v,v +1 = [ s v , s v +1 ] with v = 1 , . . . , k . 5. Find γ ( v ) j = min V ( x ; y , r ( v ) j ) , for v = 1 , . . . , k . 6. Set the refined bound γ j,k = min v ∈{ 1 ,...,k } γ ( v ) j , and set v ∗ = arg min v γ ( v ) j . 7. T o iterate, go back to step 2. 11 Fig. 2. Four steps of the iterativ e algorithm choosing s ∗ as the middle point of the subinterval I v ∗ ,v ∗ +1 . The solid line shows the system potential V ( x ; y , g ) = ( y 1 − exp ( x )) 2 − log ( y 2 − exp ( − x ) + 1) + ( y 2 − exp ( − x )) + 1 (see the example in Section VII-A), with y 1 = 5 and y 2 = 2 , while the dashed line sho ws the modified potential V ( x ; y , r j ) . W e start in plot (a) with two points S j, 1 = { min ( X j ) , max ( X j ) } . At each iteration, we add a new point chosen in the subinterv al I v ∗ ,v ∗ +1 that contains the latest bound. It is apparent that V ( x ; y , r j ) becomes a better approximation of V ( x ; y , g j ) each time we add a new support point. C. Lower bound γ 2 for quadratic potentials Assume that the joint potential is quadratic, i.e., V ( n ) 2 ( y 1 − g 1 ,j ( x ) , . . . , y n − g n,j ( x )) = P n i =1 ( y i − g i,j ( x )) 2 for each j = 1 , . . . , q , and construct the set of linearities r i,j ( x ) = a i,j x + b i,j , for i = 1 , . . . , n and j = 1 , . . . , q . The modified system potential in B j becomes V 2 ( x ; y , r j ) = n X i =1 ( y i − r i,j ( x )) 2 = n X i =1 ( y i − a i,j x − b i,j ) 2 , (17) and it turns out straightforward to compute γ 2 ,j = min x ∈B j V ( x ; y , r j ) . Indeed, if we denote a j = [ a 1 ,j , . . . , a n,j ] > and w j = [ y 1 − b 1 ,j , . . . , y n − b n,j ] > , then we can readily obtain ˜ x j = arg min x ∈B j V ( x ; y , r j ) = a > j w j a > j a j , (18) and γ 2 ,j = V ( ˜ x j ; y , r j ) . It is apparent that γ 2 = min j γ 2 ,j ≤ V ( x ; y , g ) . Furthermore, ˜ x j is an approximation of the ML estimator ˆ x j restricted to B j . D. Adaptation of γ 2 for generic system potentials If the joint potential is not quadratic, in general it can still be difficult to minimize the modified function V ( x ; y , r ) , despite the replacement of the nonlinearities g i,j ( x ) with the linear functions r i,j ( x ) . In this section, we propose a method to transform the bound for a quadratic potential, γ 2 , into a bound for some other , non-quadratic, potential function. Consider an arbitrary joint potential V ( n ) and assume the av ailability of an in vertible increasing function R such that R ◦ V ( n ) ≥ V ( n ) 2 , where ◦ denotes the composition of functions. Then, for the system potential 12 we can write ( R ◦ V )( x ; y , g ) ≥ V ( n ) 2 ( y 1 − g 1 ( x ) , . . . , y n − g n ( x )) = n X i =1 ( y i − g i ( x )) 2 ≥ γ 2 . (19) and, as consequence, V ( x ; y , g ) ≥ R − 1 ( γ 2 ) = γ , hence γ is a lower bound for the non-quadratic system potential V ( x ; y , g ) constructed from V ( n ) . For instance, consider the family of joint potentials V ( n ) p . Using the monotonicity of L p norms, it is possible to pro ve [16] that n X i =1 | ϑ i | p ! 1 p ≥ n X i =1 ϑ 2 i ! 1 2 , for 0 ≤ p ≤ 2 , and (20) n ( p − 2 2 p ) n X i =1 | ϑ i | p ! 1 p ≥ n X i =1 ϑ 2 i ! 1 2 , for 2 ≤ p ≤ + ∞ . (21) Let R 1 ( v ) = v 2 /p . Since this function is, indeed, strictly increasing, we can transform the inequality (20) into R 1 n X i =1 | y i − g i ( x ) | p ! ≥ n X i =1 ( y i − g i ( x )) 2 , (22) which yields n X i =1 | y i − g i ( x ) | p ≥ R − 1 1 n X i =1 ( y i − g i ( x )) 2 ! = n X i =1 ( y i − g i ( x )) 2 ! p/ 2 ≥ γ p/ 2 2 , (23) hence the transformation γ p/ 2 2 of the quadratic bound γ 2 is a lower bound for V ( n ) p with 0 < p ≤ 2 . Similarly , if we let R 2 ( v ) = n “ p − 2 2 p ” v 1 /p 2 , the inequality (21) yields n X i =1 | y i − g i ( x ) | p ≥ R − 1 2 n X i =1 ( y i − g i ( x )) 2 ! = n “ − p − 2 2 p ” n X i =1 ( y i − g i ( x )) 2 ! 1 / 2 p ≥ n ( − p − 2 2 ) γ p/ 2 2 , (24) hence the transformation R − 1 2 ( γ 2 ) = n − ( p − 2) / 2 γ p/ 2 2 is a lo wer bound for V ( n ) p when 2 ≤ p < + ∞ . It is possible to devise a systematic procedure to find a suitable function R giv en an arbitrary joint potential V ( n ) ( ϑ ) , where ϑ , [ ϑ 1 , . . . , ϑ n ] T . Let us define the manifold Γ v , ϑ ∈ R n : V ( n ) ( ϑ ) = v . W e can construct R by assigning R ( v ) with the maximum of the quadratic potential P n i ϑ 2 i when ϑ ∈ Γ v , i.e., we define R ( v ) , max ϑ ∈ Γ v n X i =1 ϑ 2 i . (25) Note that (25) is a constrained optimization problem that can be solved using, e.g., Lagrangian multipliers. 13 From the definition in (25) we obtain that, ∀ ϑ ∈ Γ v , R ( v ) ≥ P n i =1 ϑ 2 i . In particular , since V ( n ) ( ϑ ) = v from the definition of Γ v , we obtain the desired relationship, R V ( n ) ( ϑ 1 , . . . , ϑ n ) ≥ n X i =1 ϑ 2 i . (26) W e additionally need to check whether R is a strictly increasing function of v . The two functions in the earlier examples of this Section, R 1 and R 2 , can be readily found using this method. E. Conve x mar ginal potentials ¯ V i Assume that A = {B j } q j =1 and that we ha ve already found r i,j ( x ) = a i,j x + b i,j , i = 1 , . . . , n and j = 1 , . . . , q , using the technique in Section IV -A. If a marginal potential ¯ V i ( ϑ i ) is con ve x, the function ¯ V i ( y i − r i,j ( x )) is also con ve x in B j . Indeed, for all x ∈ B j d 2 ¯ V i ( y i − r i,j ( x )) dx 2 = d 2 r i,j dx 2 d ¯ V i dϑ i + dr i,j dx 2 d 2 ¯ V i dϑ 2 i = 0 + a 2 i d 2 ¯ V i dϑ 2 i ≥ 0 (27) where we ha ve used that d 2 r i,j dx 2 = 0 (since r i,j is linear). As a consequence, if all marginal potentials ¯ V i ( ϑ i ) are conv ex, then the modified system potential, V ( x ; y , r j ) = c n + P n i =1 ¯ V i ( y i − r i,j ( x )) , is also con vex in B j . This is easily sho wn using (27), to obtain d 2 V ( x ; y , r j ) dx 2 = n X i =1 a 2 i d 2 ¯ V i dϑ 2 i ≥ 0 , ∀ x ∈ B j . (28) Therefore, we can use the tangents to V ( x ; y , r j ) at the limit points of I j (i.e, min( X j ) and max( X j ) ) to find a lo wer bound for the system potential V ( x ; y , g j ) . Figure 3 (left) depicts a system potential V ( x ; y , g j ) (solid line), the corresponding modified potential V ( x ; y , r j ) (dotted line) and the two tangent lines at min( X j ) and max( X j ) . It is apparent that the intersection of the two tangents yields a lower bound in B j . Specifically , if we let W ( x ) be the piecewise-linear function composed of the two tangents, then the inequality V ( x ; y , g j ) ≥ V ( x ; y , r j ) ≥ W ( x ) is satisfied for all x ∈ I j . V . A DA P T I V E R E J E C T I O N S A M P L I N G The adaptiv e rejection sampling (ARS) [8] algorithm enables the construction of a sequence of proposal densities, { π t ( x ) } t ∈ N , and bounds tailored to the target density . Its most appealing feature is that each time we draw a sample from a proposal π t and it is rejected, we can use this sample to b uild an impro ved proposal, π t +1 , with a higher mean acceptance rate. Unfortunately , this attractiv e ARS method can only be applied with tar get pdf ’ s which are log-concave (hence, unimodal), which is a very stringent constraint for may practical applications. Next, we briefly 14 re view the ARS algorithm and then proceed to introduce its extension for non-log-conca ve and multimodal target densities. Let p ( x | y ) denote the target pdf 1 . The ARS procedure can be applied when log [ p ( x | y )] is concave, i.e., when the potential function V ( x ; y , g ) , − log [ p ( x | y )] is strictly conv ex. Let S t = { s 1 , s 2 , . . . , s k t } be a set of support points in the domain D of V ( x ; y , g ) . From S t we build a piecewise-linear lo wer hull of V ( x ; y , g ) , denoted W t ( x ) , formed from segments of linear functions tangent to V ( x ; y , g ) at the support points in S t . Figure 3 (center) illustrates the construction of W t ( x ) with three support points for a generic log-conca ve potential function V ( x ; y , g ) . Once W t ( x ) is b uilt, we can use it to obtain an exponential-f amily proposal density π t ( x ) = c t exp[ − W t ( x )] , (29) where c t is the proportionality constant. Therefore π t ( x ) is piece wise-exponential and very easy to sample from. Since W t ( x ) ≤ V ( x ; y , g ) , we trivially obtain that 1 c t π ( x ) ≥ p ( x | y ) and we can apply the RS principle. When a sample x 0 from π t ( x ) is rejected we can incorporate it into the set of support points, S t +1 = S t ∪ { x 0 } (and k t +1 = k t + 1 ). Then we compute a refined lower hull, W t +1 ( x ) , and a ne w proposal density π t +1 ( x ) = c t +1 exp {− W t +1 ( x ) } . T able III summarizes the ARS algorithm. T ABLE III A D A P T I V E R E J E C T I O N S A M P L I N G A L G O R I T H M . 1. Start with t = 0 , S 0 = { s 1 , s 2 } where s 1 < s 2 , and the deriv ativ es of V ( x, y ,g ) in s 1 , s 2 ∈ D ha ving different signs. 2. Build the piecewise-linear function W t ( x ) as shown in Figure 3 (center), using the tangent lines to V ( x ; y , g ) at the support points S t . 3. Sample x 0 from π t ( x ) ∝ exp {− W t ( x ) } , and u 0 from U ([0 , 1]) . 4. If u 0 ≤ p ( x 0 | y ) exp[ − W t ( x 0 )] accept x 0 and set S t +1 = S t , k t +1 = k t . 5. Otherwise, if u 0 > p ( x 0 | y ) exp[ − W t ( x 0 )] , reject x 0 , set S t +1 = S t ∪ { x 0 } and update k t +1 = k t + 1 . 6. Sort S t +1 in ascending order , increment t and go back to step 2. V I . G E N E R A L I Z A T I O N O F T H E A R S M E T H O D In this section we introduce a generalization of the standard ARS scheme that can cope with a broader class of target pdf ’ s, including many multimodal distributions. The standard algorithm of [8], described 1 The method does not require that the target density be a posterior pdf, but we prefer to keep the same notation as in the previous section for coherence. 15 in T able III, is a special case of the method described belo w . A. Generalized adaptive r ejection sampling W e wish to dra w samples from the posterior p ( x | y ) . For this purpose, we assume that • all marginal potential functions, ¯ V i ( ϑ i ) , i = 1 , . . . , n , are strictly con vex, • the prior pdf has the form p ( x ) ∝ exp {− ¯ V n +1 ( µ − x ) } , where ¯ V n +1 is also a con vex marginal potential with its mode located at µ , and • the nonlinearities g i ( x ) are either con ve x or conca ve, not necessarily monotonic. W e incorporate the information of the prior by defining an extended observ ation v ector, ˜ y , [ y 1 , . . . , y n , y n +1 = µ ] > , and an extended vector of nonlinearities, ˜ g ( x ) , [ g 1 ( x ) , . . . , g n ( x ) , g n +1 ( x ) = x ] > . As a result, we introduce the extended system potential function V ( x ; ˜ y , ˜ g ) , V ( x ; y , g ) + ¯ V n +1 ( µ − x ) = − log[ p ( x | y )] + c 0 , (30) where c 0 accounts for the superposition of constant terms that do not depend on x . W e remark that the function V ( x ; ˜ y , ˜ g ) constructed in this way is not necessarily con ve x. It can present several minima and, as a consequence, p ( x | y ) can present sev eral maxima. Our technique is adapti ve, i.e., it is aimed at the construction of a sequence of proposals, denoted π t ( x ) , t ∈ N , but relies on the same basic arguments already exploited to de vise the BM1. T o be specific, at the t -th iteration of the algorithm we seek to replace the nonlinearities { g i } n +1 i =1 by piecewise-linear functions { r i,t } n +1 i =1 in such a w ay that the inequalities | y i − r i,t ( x ) | ≤ | y i − g i ( x ) | and (31) ( y i − r i,t ( x ))( y i − g i ( x )) ≥ 0 (32) are satisfied ∀ x ∈ R . Therefore, we repeat the same conditions as in Eqs. (12)-(13) but the deri vation of the generalized ARS (GARS) algorithm does not require the partition of the SoI space, as it was needed for the BM1. W e will sho w that it is possible to construct adequate piece wise-linear functions of the form r i,t ( x ) , max[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x )] , if g i is con vex min[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x )] , if g i is conca ve (33) where i = 1 , . . . , n and each ¯ r i,j ( x ) , j = 1 , . . . , K t , is a purely linear function. The number of linear functions in volved in the construction of r i,t ( x ) at the t -th iteration of the algorithm, denoted K t , determines ho w tightly π t ( x ) approximates the true density p ( x | y ) and, therefore, the higher K t , the 16 higher expected acceptance rate of the sampler . In Section VI-B belo w , we explicitly describe how to choose the linearities ¯ r i,j ( x ) , j = 1 , . . . , K t , in order to ensure that (31) and (32) hold. W e will also sho w that, when a proposed sample x 0 is rejected, K t can be increased ( K t +1 = K t + 1 ) to improve the acceptance rate. Let ˜ r t , [ r 1 ,t ( x ) , . . . , r n,t ( x ) , r n +1 ,t ( x ) = x ] > be the extended vector of piece wise-linear functions, that yields the modified potential V ( x ; ˜ y , ˜ r t ) . The same argument used in Section IV -A to deri ve the BM1 shows that, if (31) and (32) hold, then V ( x ; ˜ y , ˜ r t ) ≤ V ( x ; ˜ y , ˜ g ) , ∀ x ∈ R . Finally , we build a piecewise-linear lower hull W t ( x ) for the modified potential, as explained below , to obtain W t ( x ) ≤ V ( x ; ˜ y , ˜ r t ) ≤ V ( x ; ˜ y , ˜ g ) . The definition of the piecewise-linear function r i,t ( x ) in (33) can be rewritten in another form r i,t ( x ) , ¯ r i,j ( x ) for x ∈ [ a, b ] (34) where a is the abscissa of the intersection between the linear functions ¯ r i,j − 1 ( x ) and ¯ r i,j ( x ) , and b is the abscissa of the intersection between ¯ r i,j ( x ) and ¯ r i,j +1 ( x ) . Therefore, we can define the set of all abscissas of intersection points E t = { u ∈ R : ¯ r i,j ( u ) = ¯ r i,j +1 ( u ) for i = 1 , . . . , n + 1 , j = 1 , . . . , K t − 1 } , (35) and sort them in ascending order u 1 < u 2 < . . . < u Q (36) where Q is the total number of intersections. Then a) since we hav e assumed that the marginal potentials are con ve x, we can use Eq. (34) and the argument of Section IV -E to show that the modified function V ( x ; ˜ y , ˜ r t ) is con ve x in each interv al [ u q , u q +1 ] , with q = 1 , . . . , Q , and, b) as a consequence, we can to build W t ( x ) by taking the linear functions tangent to V ( x ; ˜ y , ˜ r t ) at e very intersection point u q , q = 1 , . . . , Q . Fig. 3 (right) depicts the relationship among V ( x ; ˜ y , ˜ g ) , V ( x ; ˜ y , ˜ r t ) and W t ( x ) . Since W t ( x ) is piece wise linear , the corresponding pdf π t ( x ) ∝ exp {− W t ( x ) } is piece wise exponential and can be easily used in a rejection sampler (we remark that W t ( x ) ≤ V ( x ; ˜ y , ˜ g ) , hence π t ( x ) ∝ exp {− W t ( x ) } ≥ exp {− V ( x ; ˜ y , ˜ g ) } ∝ p ( x | y ) ). Next subsection is dev oted to the deriv ation of the linear functions needed to construct ˜ r t . Then, we describe how the algorithm is iterated to obtain a sequence of improved proposal densities and provide 17 a pseudo-code. Finally , we describe a limitation of the procedure, that yields improper proposals in a specific scenario. Fig. 3. Left: The intersection of the tangents to V ( x ; y , r j ) (dashed line) at min( X j ) and max( X j ) is a lower bound for V ( x ; y , g j ) (solid line). Moreo ver , note that the resulting piecewise-linear function W ( x ) satisfies the inequality V ( x ; y , g j ) ≥ V ( x ; y , r j ) ≥ W ( x ) , for all x ∈ I j . Center: Example of construction of the piecewise-linear function W t ( x ) with 3 support points S t = { s 1 , s 2 , s 3 } , as carried out in the ARS technique. The function W t ( x ) is formed from segments of linear functions tangent to V ( x ; y , g ) at the support points in S t . Right: Construction of the piecewise linear function W t ( x ) as tangent lines to the modified potential V ( x ; ˜ y , ˜ r t ) at three intersections points u 1 , u 2 and u 3 , as carried out in the ARS technique. B. Construction of linear functions ¯ r i,j ( x ) A basic element in the description of the GARS algorithm in the pre vious section is the construction of the linear functions ¯ r i,j ( x ) . This issue is addressed belo w . For clarity , we consider two cases corresponding to non-monotonic and monotonic nonlinearities, respectiv ely . It is important to remark that the nonlinearities g i ( x ) , i = 1 , . . . , n (remember that g n +1 ( x ) = x is linear), can belong to different cases. 1) Non-monotonic nonlinearities: Assume g i ( x ) is a non-monotonic, either concav e or con ve x, function. W e hav e three possible scenarios depending on the number of simple estimates for g i ( x ) : (a) there exist two simple estimates, x i, 1 < x i, 2 , (b) there exists a single estimate, x i, 1 = x i, 2 , or (c) there is no solution for the equation y i = g i ( x ) . Let us assume that x i, 1 < x i, 2 and denote J i , [ x i, 1 , x i, 2 ] . Let us also introduce a set of support points S t , { s 1 , . . . , s k t } that contains at least the simple estimates and an arbitrary point s ∈ J i , i.e., x i, 1 , x i, 2 ∈ S t . The number of support points, k t , determines the accuracy of the approximation of the nonlinearity g i ( x ) that can be achie ved with the piecewise-linear function r i,t ( x ) . In Section VI-C we sho w how this number increases as the GARS algorithm iterates. Now , we assume it is gi ven and fixed. Figure 4 illustrates the construction of ¯ r i,j ( x ) , j = 1 , . . . , K t where K t = k t − 1 , and r i,t ( x ) for a con vex nonlinearity g i ( x ) (the procedure is completely analogous for concave g i ( x ) ). Assume that the 18 two simple estimates x i, 1 < x i, 2 exist, hence |J i | > 0 . F or each j ∈ { 1 , . . . , k t } , the linear function ¯ r i,j ( x ) is constructed in one out of two ways: (a) if [ s j , s j +1 ] ⊆ J i , then ¯ r i,j ( x ) connects the points ( s j , g i ( s j )) and ( s j +1 , g i ( s j +1 )) , else (b) if s j / ∈ J i , then ¯ r i,j ( x ) is tangent to g i ( x ) at x = s j . From Fig. 4 (left and center) it is apparent that r i,t ( x ) = max[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x )] > built in this way satisfies the inequalities (31) and (32), as required. For concav e g i ( x ) , (31) and (32) are satisfied if we choose r i,t ( x ) = min[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x )] > . When |J i | = 0 (i.e., x i, 1 = x i, 2 or there is no solution for the equation y i = g i ( x ) ), then each ¯ r i,j ( x ) is tangent to g i ( x ) at x = s j , ∀ s j ∈ S t , and in order to satisfy (31) and (32), we need to select r i,t ( x ) , max[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x ) , y i ] , if g i is con vex min[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x ) , y i ] , if g i is conca ve (37) as illustrated in Fig. 4 (right). Fig. 4. Construction of the piecewise linear function r i,t ( x ) for non-monotonic functions. The straight lines ¯ r i,j ( x ) form a piecewise linear function that is closer to the observation value y i (dashed line) than the nonlinearity g i ( x ) , i.e., | y i − r i,t ( x ) | ≤ | y i − g i ( x ) | . Moreover , r i,t ( x ) and g i ( x ) are either simultaneously greater than (or equal to) y i , or simultaneously lesser than (or equal to) y i , i.e., ( y i − r i,t ( x ))( y i − g i ( x )) ≥ 0 . Therefore, the inequalities (31) and (32) are satisfied. The point ( s j , g i ( s j )) , corresponding to support point s j , is represented either by a square or a circle, depending on whether it is a simple estimate or not, respectiv ely . Left: construction of r i,t ( x ) with k t = 4 support points when the nonlinearity g i ( x ) is con vex, therefore r i,t ( x ) = max[ ¯ r i, 1 ( x ) , . . . , ¯ r i, 3 ( x )] ( K t = k t − 1 = 3 ). W e use the tangent to g i ( x ) at x = s 4 because s 4 / ∈ J i = [ s 1 , s 3 ] , where s 1 = x i, 1 and s 3 = x i, 2 are the simple estimates (represented with squares). Center: since the nonlinearity g i ( x ) is concave, r i,t ( x ) = min[ ¯ r i, 1 ( x ) , . . . , ¯ r i, 3 ( x )] . W e use the tangent to g i ( x ) at s 4 because s 1 / ∈ J i = [ s 2 , s 4 ] , where s 2 = x i, 1 and s 4 = x i, 2 are the simple estimates (represented with squares). Right: construction of the r i,t ( x ) , with two support points, when there are not simple estimates. W e use the tangent lines, b ut we need a correction in the definition of r i,t ( x ) in order to satisfy the inequalities (31) and (32). Since g i ( x ) in the figure is con ve x, we take r i,t ( x ) = max[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x ) , y i ] . 19 2) Monotonic nonlinearities: In this case g i ( x ) is in vertible and there are two possibilities: there exists a single estimate, x i = g − 1 i ( y i ) , or there is no solution for the equation y i = g i ( x ) (where y i does not belong to the range of g i ( x ) ). Similarly to the construction in Section IV -A, we distinguish two cases: (a) if dg i ( x ) dx × d 2 g i ( x ) dx 2 ≥ 0 , then we define J i , ( −∞ , x i ] , and (b) if dg i ( x ) dx × d 2 g i ( x ) dx 2 ≤ 0 , then we define J i , [ x i , + ∞ ) . The set of support points is S t , { s 1 , . . . , s k t } , with s 1 < s 2 . . . < s k t , and includes at least the simple estimate x i and an arbitrary point s ∈ J i , i.e., x i , s ∈ S t . The procedure to build ¯ r i,j ( x ) , for j = 1 , . . . , K t , with K t = k t , is similar to Section VI-B1. Consider case (a) first. For each j ∈ { 2 , . . . , k t } , if [ s j − 1 , s j ] ⊂ J i = ( −∞ , x i ] , then ¯ r i,j ( x ) is the linear function that connects the points ( s j − 1 , g i ( s j − 1 )) and ( s j , g i ( s j )) . Otherwise, if s j / ∈ J i = ( −∞ , x i ] , ¯ r i,j ( x ) is tangent to g i ( x ) at x = s j . Finally , we set ¯ r i, 1 ( x ) = g i ( s 1 ) for all x ∈ R . The piecewise linear function r i,t is r i,t ( x ) = max[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x )] . This construction is depicted in Fig. 5 (left). Case (b) is similar . For each j ∈ { 1 , . . . , k t } , if [ s j , s j +1 ] ⊂ J i = [ x i , + ∞ ) , then ¯ r i,j ( x ) is the linear function that connects the points ( s j , g i ( s j )) and ( s j +1 , g i ( s j +1 )) . Otherwise, if s j / ∈ ˆ I i = [ x i , + ∞ ) , ¯ r i,j ( x ) is tangent to g i ( x ) at x = s j . Finally , we set ¯ r i,k t ( x ) = g i ( s k t ) (remember that, in this case, K t = k t ), for all x ∈ R . The piecewise linear function r i,t will be r i,t ( x ) = min[ ¯ r i, 1 ( x ) , . . . , ¯ r i,K t ( x )] . This construction is depicted in Fig. 5 (right). It is straightforward to check that the inequalities (31) and (32) are satisfied. Note that, in this case, the number of linear functions ¯ r i,j ( x ) coincides with the number of support points. If there is not solution for the equation y i = g i ( x ) ( y i does not belong to the range of g i ( x ) ), then (31) and (32) are satisfied if we use (37) to build r i,t ( x ) . C. Summary W e can combine the elements described in Sections VI-B1 and VI-B2 into an adaptive algorithm that improv es the proposal density π t ( x ) ∝ exp {− W t ( x ) } each time a sample is rejected. Let S t denote the set of support points after the t -th iteration. W e initialize the algorithm with S 0 , { s j } k 0 j =1 such that • all simple estimates are contained in S 0 , and • for each interval J i , i = 1 , . . . , n + 1 , with non-zero length ( |J i | > 0 ), there is at least one (arbitrary) support point contained in J i . The proposed GARS algorithm is described in T able IV. Note that ev ery time a sample x 0 drawn from π t ( x ) is rejected, x 0 is incorporated as a support point in the ne w set S t +1 = S t ∪ { x 0 } and, as a 20 Fig. 5. Examples of construction of the piecewise-linear function r i,t ( x ) with k t = 3 support points s j , for the two subcases. It is apparent that | y i − r i,t ( x ) | ≤ | y i − g i ( x ) | and that r i,t ( x ) and g i ( x ) are either simultaneously greater than (or equal to) y i , or simultaneously lesser than (or equal to) y i , i.e., ( y i − r i,t ( x ))( y i − g i ( x )) ≥ 0 . The simple estimates are represented by squares while all other support points are drawn as circles. Left: the figure corresponds to the subcase 1 where r i,t ( x ) = max[ ¯ r i, 1 ( x ) , . . . , ¯ r i, 3 ( x )] ( K t = k t = 3 ). Right: the figure corresponds to to the subcase 2 where r i,t ( x ) = min[ ¯ r i, 1 ( x ) , . . . , ¯ r i, 3 ( x )] ( K t = k t = 3 ). consequence, a refined lo wer hull W t +1 ( x ) is constructed yielding a better approximation of the system potential function. In this way , π t +1 ( x ) ∝ exp {− W t +1 ( x ) } becomes closer to p ( x | y ) and it can be expected that the acceptance rate be higher . This is specifically shown in the simulation example in Section VII-B. T ABLE IV S T E P S O F G E N E R A L I Z E D A D A P T I V E R E J E C T I O N S A M P L I N G . 1. Start with t = 0 set S 0 , { s j } k 0 j =1 . 2. Build ¯ r i,j ( x ) for i = 1 , . . . , n + 1 , j = 1 , . . . , K t , where K t = k t − 1 or K t = k t depending on whether g i ( x ) is non-monotonic or monotonic, respectively . 3. Calculate the set of intersection points E t , { u ∈ R : ¯ r i,j ( u ) = ¯ r i,j +1 ( u ) for i = 1 , . . . , n + 1 , j = 1 , . . . , K t − 1 } . Let Q = |E t | be the number of elements in E t . 4. Build W t ( x ) using the tangent lines to V ( x ; ˜ y , ˜ r t ) at the points u q ∈ E t , q = 1 , . . . , Q . 5. Draw a sample x 0 from π t ( x ) ∝ exp[ − W t ( x )] . 6. Sample u 0 from U ([0 , 1]) . 7. If u 0 ≤ p ( x 0 | y ) exp[ − W t ( x 0 )] accept x 0 and set S t +1 = S t . 8. Otherwise, if u 0 > p ( x 0 | y ) exp[ − W t ( x 0 )] reject x 0 and update S t +1 = S t ∪ { x 0 } . 9. Sort S t +1 in ascending order , set t = t + 1 and go back to step 2. 21 D. Impr oper pr oposals The GARS algorithm as described in T able IV breaks down when ev ery g i ( x ) , i = 1 , . . . , n + 1 , is nonlinear and conv ex (or concav e) monotonic. In this case, the proposed construction procedure yields a piecewise lower hull W t ( x ) which is positiv e and constant in an interval of infinite length. Thus, the resulting proposal, π t ( x ) ∝ exp {− W t ( x ) } is improper ( R + ∞ −∞ π t ( x ) dx → + ∞ ) and cannot be used for RS. One practical solution is to substitute the constant piece of W t ( x ) by a linear function with a small slope. In that case, π t ( x ) is proper but we cannot guarantee that the samples dra wn using the GARS algorithm come e xactly from the target pdf. Under the assumptions in this paper, ho we ver , g n +1 ( x ) = x is linear (due to our choice of the prior pdf), and this is enough to guarantee that π t ( x ) be proper . V I I . E X A M P L E S A. Example 1: Calculation of upper bounds for the likelihood function Let X be a scalar SoI with prior density X ∼ p ( x ) = N ( x ; 0 , 2) and the random observ ations Y 1 = exp ( X ) + Θ 1 , Y 2 = exp ( − X ) + Θ 2 , (38) where Θ 1 , Θ 2 are independent noise v ariables. Specifically , Θ 1 is Gaussian noise with N ( ϑ 1 ; 0 , 1 / 2) = k 1 exp − ( ϑ 1 ) 2 , and Θ 2 has a gamma pdf, Θ 2 ∼ Γ( ϑ 2 ; θ , λ ) = k 2 ϑ θ − 1 2 exp {− λϑ 2 } , with parameters θ = 2 , λ = 1 . The marginal potentials are ¯ V 1 ( ϑ 1 ) = ϑ 2 1 and ¯ V 2 ( ϑ 2 ) = − log( ϑ 2 ) + ϑ 2 . Since the minimum of ¯ V 2 ( ϑ 2 ) occurs in ϑ 2 = 1 , we replace Y 2 with the shifted observation Y ∗ 2 = exp ( − X ) + Θ ∗ 2 , where Y ∗ 2 = Y 2 − 1 , Θ ∗ 2 = Θ 2 − 1 . Hence, the marginal potential becomes ¯ V 2 ( ϑ ∗ 2 ) = − log ( ϑ ∗ 2 + 1) + ϑ ∗ 2 + 1 , with a minimum at ϑ ∗ 2 = 0 , the vector of observ ations is Y = [ Y 1 , Y ∗ 2 ] > and the vector of nonlinearities is g ( x ) = [exp ( x ) , exp ( − x )] > . Due to the monotonicity and conv exity of g 1 and g 2 , we can work with a partition of R consisting of just one set, B 1 ≡ R . The joint potential is V (2) ( ϑ 1 , ϑ ∗ 2 ) = P 2 i =1 ¯ V i ( ϑ i ) = ϑ 2 1 − ln( ϑ ∗ 2 + 1) + ϑ ∗ 2 + 1 and the system potential is V ( x ; y , g ) = V (2) ( y 1 − exp ( x ) , y ∗ 2 − exp ( − x )) = = ( y 1 − exp ( x )) 2 − log ( y ∗ 2 − exp ( − x ) + 1) + ( y ∗ 2 − exp ( − x )) + 1 . (39) Assume that, Y = y = [2 , 5] > . The simple estimates are X = { x 1 = log (2) , x 2 = − log (5) } , and, therefore, we can restrict the search of the bound to the interval I = [min( X ) = − log(5) , max( X ) = log(2)] (note that we omit the subscript because we have just one set, B 1 ≡ R ). Using the BM1 technique in Section IV -A, we find the linear functions r 1 ( x ) = 0 . 78 x + 1 . 45 and r 2 ( x ) = − 1 . 95 x + 1 . 85 . 22 In this case, we can analytically minimize the modified system potential, to obtain ˜ x = − 0 . 4171 = arg min x ∈I V ( x, y , r ) . The associated lo wer bound is γ = V ( ˜ x, y , r ) = 2 . 89 (the true global minimum of the system potential is 3 . 78 ). W e can also use the technique in Section IV -D with R − 1 ( v ) = − log( √ v + 1) + √ v + 1 . The lo wer bound for the quadratic potential is γ 2 = 2 . 79 and we can readily compute a lower bound γ = R − 1 ( γ 2 ) = 1 . 68 for V ( x ; y , g ) . Since the marginal potentials are both con vex, we can also use the procedure described in Section IV -E, obtaining the lower bound γ = 1 . 61 . Figure 6 (a) depicts the system potential V ( x ; y , g ) , and the lower bounds obtained with the three methods. It is the standard BM1 algorithm that yields the best bound. In order to improve the bound, we can use the iterativ e BM2 technique described in Section IV -B. W ith only 3 iterations of BM2, and minimizing analytically the modified potential V ( x, y , r ) , we find a very tight lower bound γ = min x ∈I ( V ( x, y , r )) = 3 . 77 (recall that the optimal bound is 3 . 78 ). T able V summarizes the bounds computed with the different techniques. Next, we implement a rejection sampler , using the prior pdf p ( x ) = N ( x ; 0 , 2) ∝ exp {− x 2 / 4 } as a proposal function and the upper bound for the likelihood L = exp {− 3 . 77 } . The posterior density has the form p ( x | y ) ∝ p ( y | x ) p ( x ) = exp {− V ( x ; y , g ) − x 2 / 4 } . (40) Figure 6 (b) shows the normalized histogram of N = 10 , 000 samples generated by the RS algorithm, together with the true target pdf p ( x | y ) depicted as a dashed line. The histogram follo ws closely the shape of the true posterior pdf. Figure 6 (c) shows the acceptance rates (a veraged over 10 , 000 simulations) as a function of the bound γ . W e start with the tri vial lo wer bound γ = 0 and increase it progressiv ely , up to the global minimum γ = 3 . 78 . The resulting acceptance rates are 1 . 1% for the tri vial bound γ = 0 , 18% with γ = 2 . 89 (BM1) and approximately 40% with γ = 3 . 77 (BM2). Note that the acceptance rate is ≈ 41% for the optimal bound and we cannot improve it any further . This is an intrinsic drawback of a rejection sampler with constant bound L and the principal argument that suggests the use of adaptiv e procedures. T ABLE V L O W E R B O U N D S O F T H E S Y S T E M P O T E N T I A L F U N C T I O N . Method BM1 BM1 + trasformation R BM1 + tangent lines BM2 Optimal Bound Lower Bound γ 2.89 1.68 1.61 3.77 3.78 23 Fig. 6. (a) The system potential V ( x, y , g ) (solid), the modified system potential V ( x, y , r ) (dashed), function ( R − 1 ◦ V 2 )( x, y , r ) (dot-dashed) and the piecewise-linear function W ( x ) formed by the two tangent lines to V ( x, y , r ) at min( X ) and max( X ) (dotted). The corresponding bounds are marked with dark circles. (b) The target density p ( x | y ) ∝ p ( y | x ) p ( x ) (dashed) and the normalized histogram of N = 10 , 000 samples using RS with the the calculated bound L . (c) The curve of acceptance rates (av eraged ov er 10 , 000 simulations) as a function of the lower bound γ . The acceptance rate is 1 . 1% for the trivial bound γ = 0 , 18% with γ = 2 . 89 , approximately 40% with γ = 3 . 77 and 41% with the optimal bound γ = 3 . 78 . B. Example 2: Comparison of ARMS and GARS tec hniques Consider the problem of sampling a scalar random variable X from a posterior bimodal density p ( x | y ) ∝ p ( y | x ) p ( x ) , where the likelihood function is p ( y | x ) ∝ exp {− cosh( y − x 2 ) } (note that we hav e a single observation Y = y 1 ) and prior pdf is p ( x ) ∝ exp {− α ( η − exp( | x | )) 2 } , with constant parameters α > 0 and η . Therefore, the posterior pdf is p ( x | y ) ∝ exp {− V ( x ; ˜ y , ˜ g ) } , where ˜ y = [ y , η ] > , ˜ g ( x ) = [ g 1 ( x ) , g 2 ( x )] > = [ x 2 , exp( | x | )] > and the e xtended system potential function becomes V ( x ; ˜ y , ˜ g ) = cosh( y − x 2 ) + α ( η − exp( | x | )) 2 . (41) The marginal potentials are ¯ V 1 ( ϑ 1 ) = cosh( ϑ 1 ) and ¯ V 2 ( ϑ 2 ) = αϑ 2 2 . Note that the density p ( x | y ) is an e ven function, p ( x | y ) = p ( − x | y ) , hence it has a zero mean, µ = R xp ( x | y ) dx = 0 . The constant α is a scale parameter that allows to control the v ariance of the random variable X , both a priori and a posteriori . The higher the value of α , the more skewed the modes of p ( x | y ) become. There are no standard methods to sample directly from p ( x | y ) . Moreov er, since the posterior density p ( x | y ) is bimodal, the system potential is non-log-concave and the ARS technique cannot be applied. Ho wev er, we can easily use the GARS technique. If, e.g., ˜ Y = ˜ y = [ y = 5 , η = 10] > the simple estimates corresponding to g 1 ( x ) are x 1 , 1 = − √ 5 and x 1 , 2 = √ 5 , so that J 1 = [ − √ 5 , √ 5] . In the same way , the simple estimates corresponding to g 2 ( x ) are x 2 , 1 = − log (10) and x 2 , 2 = log (10) , therefore J 2 = [ − log(10) , log (10)] . An alternativ e possibility to draw from this density is to use the ARMS method [14]. Therefore, in 24 this section we compare the two algorithms. Specifically , we look into the accuracy in the approximation of the posterior mean µ = 0 by way of the sample mean estimate, ˆ µ = 1 N P N i =1 x ( i ) , for different v alues of the scale parameter α . In particular, we ha ve considered ten equally spacial values of α in the interval [0 . 2 , 5] and then performed 10 , 000 independent simulations for each value of α , each simulation consisting of drawing 5 , 000 samples with the GARS method and the ARMS algorithm. Both techniques can be sensitiv e to their initialization. The ARMS technique starts with 5 points selected randomly in [ − 3 . 5 , 3 . 5] (with uniform distribution). The GARS starts with the set of support points S 0 = { x 2 , 1 , x 1 , 1 , s, x 1 , 2 , x 2 , 2 } sorted in ascending order , including all simple estimates and an arbitrary point s needed to enable the construction in Section VI-B. Point s is randomly chosen in each simulation, with uniform pdf in J 1 = [ x 1 , 1 , x 1 , 2 ] . The simulation results show that the two techniques attain similar performance when α ∈ [0 . 2 , 1] (the modes of p ( x | y ) are relati vely flat). When α ∈ [1 , 4] the modes become more ske wed and Marko v chain generated by the ARMS algorithm remains trapped at one of the two modes in ≈ 10% of the simulations. When α ∈ [4 , 5] the same problem occurs in ≈ 25% of the simulations. The performance of the GARS algorithm, on the other hand, is comparativ ely insensiti ve to the value of α . Figure 7 (a) shows the posterior density p ( x | y ) ∝ exp − cosh( y 1 − x 2 ) − α ( µ − exp( | x | )) 2 with α = 0 . 2 depicted as a dashed line, and the normalized histogram obtained with the GARS technique. Figure 7 (b) illustrates the acceptance rates (av eraged ov er 10 , 000 simulations) for the first 20 accepted samples drawn with the GARS algorithm. Every time a sample x 0 drawn from π t ( x ) is rejected, it is incorporated as a support point. Then, the proposal pdf π t ( x ) becomes closer to target pdf p ( x | y ) and, as a consequence, the acceptance rate becomes higher . For instance, the acceptance rate for the first sample is ≈ 16% , but for the second sample, it is already ≈ 53% . The acceptance rate for the 20 -th sample is ≈ 90% . T ABLE VI E S T I M ATE D P O S T E R I O R M E A N , ˆ µ ( F O R α = 5 ) . Simulation 1 2 3 4 5 ARMS -2.2981 0.0267 0.0635 0.0531 2.2994 GARS 0.0772 -0.0143 0.0029 0.0319 0.0709 25 Fig. 7. (a) The bimodal density p ( x | y ) ∝ exp {− V ( x ; ˜ y , ˜ g ) } (dashed line) and the normalized histogram of N = 5000 samples obtained using GARS algorithm. (b) The curve of acceptance rates (averaged over 10 , 000 simulations) as a function of the accepted samples. C. Example 3: T ar get localization with a sensor network In order to show how the proposed techniques can be used to draw samples from a multiv ariate (non-scalar) SoI, we consider the problem of positioning a target in a 2 -dimensional space using range measurements. This is a problem that appears frequently in localization applications using sensor netw orks [1]. W e use a random vector X = [ X 1 , X 2 ] > to denote the target position in the plane R 2 . The prior density of X is p ( x 1 , x 2 ) = p ( x 1 ) p ( x 2 ) , where p ( x i ) = N ( x i ; 0 , 1 / 2) = k exp − ( x i ) 2 , i = 1 , 2 , i.e., the coordinate X 1 and X 2 are i.i.d. Gaussian. The range measurements are obtained from two sensor located at h 1 = [0 , 0] > and h 2 = [2 , 2] > , respecti vely . The ef fecti ve observations are the (square) Euclidean distances from the target to the sensors, contaminated with Gaussian noise, i.e., Y 1 = X 2 1 + X 2 2 + Θ 1 , Y 2 = ( X 1 − 2) 2 + ( X 2 − 2) 2 + Θ 2 , (42) where Θ i , i = 1 , 2 , are independent Gaussian v ariables with identical pdf ’ s, N ( ϑ i ; 0 , 1 / 2) = k i exp − ϑ 2 i . Therefore, the marginal potentials are quadratic, ¯ V i ( ϑ i ) = ϑ 2 i , i = 1 , 2 . The random observ ation vector is denoted Y = [ Y 1 , Y 2 ] > . W e note that one needs three range measurements to uniquely determine the position of a target in the plane, so the posterior pdf p ( x | y ) ∝ p ( y | x ) p ( x ) is bimodal. W e apply the Gibbs sampler to draw N particles x ( i ) = [ x ( i ) 1 , x ( i ) 2 ] > , i = 1 , . . . , N , from the posterior density p ( x | y ) ∝ p ( y | x 1 , x 2 ) p ( x 1 ) p ( x 2 ) . The algorithm can be summarized as follows: 1) Set i = 1 , and draw x (1) 2 from the prior pdf p ( x 2 ) . 2) Draw a sample x ( i ) 1 from the conditional pdf p ( x 1 | y , x ( i ) 2 ) , and set x ( i ) = [ x ( i ) 1 , x ( i ) 2 ] > . 26 3) Draw a sample x ( i +1) 2 from the conditional pdf p ( x 2 | y , x ( i ) 1 ) . 4) Increment i = i + 1 . If i > N stop, else go back to step 2. The Markov chain generated by the Gibbs sampler con verges to a stationary distribution with pdf p ( x 1 , x 2 | y ) . In order to use Gibbs sampling, we ha ve to be able to dra w from the conditional densities p ( x 1 | y , x ( i ) 2 ) and p ( x 2 | y , x ( i ) 1 ) . In general, these two conditional pdf ’ s can be non-log-conca ve and can hav e se veral modes. Specifically , the density p ( x 1 | y , x ( i ) 2 ) ∝ p ( y | x 1 , x ( i ) 2 ) p ( x 1 ) can be e xpressed as p ( x 1 | y , x ( i ) 2 ) ∝ exp {− V ( x 1 ; ˜ y 1 , ˜ g 1 ) } where ˜ y 1 = [ y 1 − ( x ( i ) 2 ) 2 , y 2 − ( x ( i ) 2 − 2) 2 , 0] > , ˜ g 1 ( x ) = [ x 2 , ( x − 2) 2 , x ] > and V ( x 1 ; ˜ y 1 , ˜ g 1 ) = h y 1 − ( x ( i ) 2 ) 2 − x 2 1 i 2 + h y 2 − ( x ( i ) 2 − 2) 2 − ( x 1 − 2) 2 i 2 + x 2 1 , (43) while the pdf p ( x 2 | y , x ( i ) 1 ) ∝ p ( y | x 2 , x ( i ) 1 ) p ( x 2 ) can be expressed as p ( x 2 | y , x ( i ) 1 ) ∝ exp {− V ( x 2 ; ˜ y 2 , ˜ g 2 ) } where ˜ y 1 = [ y 1 − ( x ( i ) 1 ) 2 , y 2 − ( x ( i ) 1 − 2) 2 , 0] > , ˜ g 2 ( x ) = [ x 2 , ( x − 2) 2 , x ] > and V ( x 2 ; ˜ y 2 , ˜ g 2 ) = h y 1 − ( x ( i ) 1 ) 2 − x 2 2 i 2 + h y 2 − ( x ( i ) 1 − 2) 2 − ( x 2 − 2) 2 i 2 + x 2 2 . (44) Since the marginal potentials and the nonlinearities are conv ex, we can use the GARS technique to sample the conditional pdf ’ s. W e ha ve generated N = 10 , 000 samples from the Markov chain, with fixed observations y 1 = 5 and y 2 = 2 . The av erage acceptance rate of the GARS algorithm was ≈ 30% both for p ( x 1 | y , x 2 ) and p ( x 2 | y , x 1 ) . Note that this rate is indeed as a average because, at each step of the chain, the target pdf ’ s are dif ferent (if, e.g., x ( i ) 1 6 = x ( i − 1) 1 then p ( x 2 | y , x ( i ) 1 ) 6 = p ( x 2 | y , x ( i − 1) 1 ) ). Figure 8 (a) sho ws the shape of the true target density p ( x 1 , x 2 | y ) , while Figure 8 (b) depicts the normalized histogram with N = 10 , 000 samples. W e observe that it approximates closely the shape of target pdf. Finally , it is illustrativ e to consider the computational savings attained by using the GARS method when compared with a rejection sampler with a fixed bound. Specifically , we have run again the Gibbs sampler to generate a chain of 10 , 000 samples but, when dra wing from p ( x 1 | y , x 2 ) and p ( x 2 | y , x 1 ) , we have used RS with prior proposals ( p ( x 1 ) and p ( x 2 ) , respectively) and a fixed bound computed (analytically) with the method in Section IV -C for quadratic potentials. The average acceptance rate for the rejection sampler was ≈ 4% and the time needed to generate the chain was approximately 10 times the time needed in the simulation with the GARS algorithm. 27 Fig. 8. (a) The target density p ( x | y ) = p ( x 1 , x 2 | y ) ∝ p ( y | x 1 , x 2 ) p ( x 1 ) p ( x 2 ) . (b) The normalized histogram with N = 10 , 000 samples, using the GARS algorithm within a Gibbs sampler . V I I I . C O N C L U S I O N S W e have proposed families of generalized rejection sampling schemes that are particularly , b ut not only , useful for ef ficiently dra wing independent samples from a posteriori probability distrib utions. The problem of drawing from posterior distributions appears v ery often in signal processing, e.g., see the target localization example in this paper or virtually any application that in volves the estimation of a physical magnitude given a set of observ ations collected by a sensor network. W e hav e introduced two classes of schemes. The procedures in the first class are aimed at the computation of upper bounds for the likelihood function of the signal of interest gi ven the set of a v ailable observations. They provide the means to (quickly and easily) design sampling schemes for posterior densities using the prior pdf as a proposal function. Then, we ha ve elaborated on the bound-calculation procedures to de vise a generalized adapti ve rejection sampling (GARS) algorithm. The latter is a method to construct a sequence of proposal pdf ’ s that conv erge tow ards the target density and, therefore, can attain very high acceptance rates. It should be noted that the method introduced in this paper includes the classical adaptiv e rejection sampling scheme of [8] as a particular case. W e hav e provided some simple numerical examples to illustrate the use of the proposed techniques, including sampling from multimodal distributions (both with fixed and adapti ve proposal functions) and an example of tar get localization using range measurements. The latter problem is often encountered in positioning applications of sensor networks. I X . A C K N O W L E D G E M E N T S This work has been partially supported by the Ministry of Science and Innov ation of Spain (project MONIN, ref. TEC-2006-13514-C02-01/TCM, and program Consolider-Ingenio 2010, project CSD2008- 00010 COMONSENS) and the Autonomous Community of Madrid (project PR OMUL TIDIS-CM, ref. 28 S-0505/TIC/0233). A P P E N D I X Proposition : The state estimators ˆ x j ∈ arg max x ∈ [ B j ] ` ( x | y , g ) = arg min x ∈ [ B j ] V ( x ; y , g ) belong to the interval I j , i.e., ˆ x j ∈ I j , [min ( X j ) , max ( X j )] , (45) where X j , { x 1 ,j , . . . , x n,j } is the set of all simple estimates in B j and I j ⊆ B j . Proof : W e hav e to prov e that the deriv ativ e of the system potential function is dV dx < 0 , for all x < min ( X j ) ( x ∈ [ B j ]) , (46) and dV dx > 0 , for all x > max ( X j ) ( x ∈ [ B j ]) , (47) so that all stationary points of V stay inside I j = [min ( X j ) , max ( X j )] . Routine calculations yield the deri vati ve dV dx = − n X i =1 dg i dx d ¯ V i dϑ i ϑ i = y i − g i ( x ) (48) and we aim to ev aluate it outside the interval I j . T o do it, let us denote x min = min( X j ) and x max = max( X j ) and consider the cases dg i dx > 0 and dg i dx < 0 separately (recall that we have assumed the sign of dg i dx to remain constant in B j ). When dg i dx > 0 and since, for e very simple estimate, x i,j ≥ x min , we obtain that y i = g i ( x i,j ) ≥ g i ( x min ) > g i ( x ) ∀ x < x min . Then y i − g i ( x ) > 0 , for all x < x min , and, due to properties (P1) and (P2) of marginal potential functions, h d ¯ V i dϑ i i ϑ i = y i − g i ( x ) > 0 > 0 for all i . As a consequence, dV dx < 0 ∀ x < x min , x ∈ [ B j ] . When dg i dx < 0 and x i,j ≥ x min , we obtain that y i = g i ( x i,j ) ≤ g i ( x min ) < g i ( x ) , ∀ x < x min . Then y i − g i ( x ) < 0 for all x < x min and h d ¯ V i dϑ i i ϑ i = y i − g i ( x ) < 0 < 0 , again because of (P1) and (P2). As a consequence, dV dx < 0 ∀ x < x min , x ∈ [ B j ] . A similar ar gument for x > x max yields dV dx > 0 for all x > x max and completes the proof. 2 R E F E R E N C E S [1] A. M. Ali, K. Y ao, T . C. Collier, E. T aylor, D. Blumstein, and L. Girod. An empirical study of collaborative acoustic source localization. Pr oc. Information Pr ocessing in Sensor Networks (IPSN07), Boston , April 2007. 29 [2] M. H. DeGroot and M. J. Schervish. Pr obability and Statistics, 3r d ed. Addison-W esley , New Y ork, 2002. [3] P . M. Djuri ´ c, J. H. Kotecha, J. Zhang, Y . Huang, T . Ghirmai, M. F . Bugallo, and J. M ´ ıguez. Particle filtering. IEEE Signal Pr ocessing Magazine , 20(5):19–38, September 2003. [4] A. Doucet, N. de Freitas, and N. Gordon, editors. Sequential Monte Carlo Methods in Practice . Springer , New Y ork (USA), 2001. [5] M. Evans and T . Swartz. Random v ariate generation using concavity properties of transformed densities. Journal of Computational and Graphical Statistics , 7(4):514–528, 1998. [6] W . J. Fitzgerald. Markov chain Monte Carlo methods with applications to signal processing. Signal Pr ocessing , 81(1):3–18, January 2001. [7] W . R. Gilks. Deriv ati ve-free Adaptiv e Rejection Sampling for Gibbs Sampling. Bayesian Statistics , (4):641–649, 1992. [8] W . R. Gilks and P . W ild. Adaptive Rejection Sampling for Gibbs Sampling. Applied Statistics , 41(2):337–348, 1992. [9] W . Hoermann. A rejection technique for sampling from t-conca ve distrib utions. ACM T ransactions on Mathematical Softwar e , 21(2):182–193, 1995. [10] H. R. K ¨ unsch. Recursive Monte Carlo filters: Algorithms and theoretical bounds. The Annals of Statistics , 33(5):1983–2021, 2005. [11] J. R. Larocque and P . Reilly . Reversible jump mcmc for joint detection and estimation of sources in colored noise. IEEE T ransactions on Signal Pr ocessing , 50(2), February 1998. [12] J. S. Liu. Monte Carlo Strate gies in Scientific Computing . Springer , 2004. [13] C. P . Robert and G. Casella. Monte Carlo Statistical Methods . Springer , 2004. [14] N. G. Best W . R. Gilks and K. K. C. T an. Adapti ve Rejection Metropolis Sampling within Gibbs Sampling. Applied Statistics , 44(4):455–472, 1995. [15] N. G. O. Robert W . R. Gilks and E. I. George. Adapti ve Direction Sampling. The Statistician , 43(1):179–189, 1994. [16] D. W illiams. Pr obability with martingales. Cambridge Univ ersity Press, Cambridge, (UK), 1991.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment