Efficient Adaptive Compressive Sensing Using Sparse Hierarchical Learned Dictionaries
Recent breakthrough results in compressed sensing (CS) have established that many high dimensional objects can be accurately recovered from a relatively small number of non- adaptive linear projection observations, provided that the objects possess a…
Authors: Akshay Soni, Jarvis Haupt
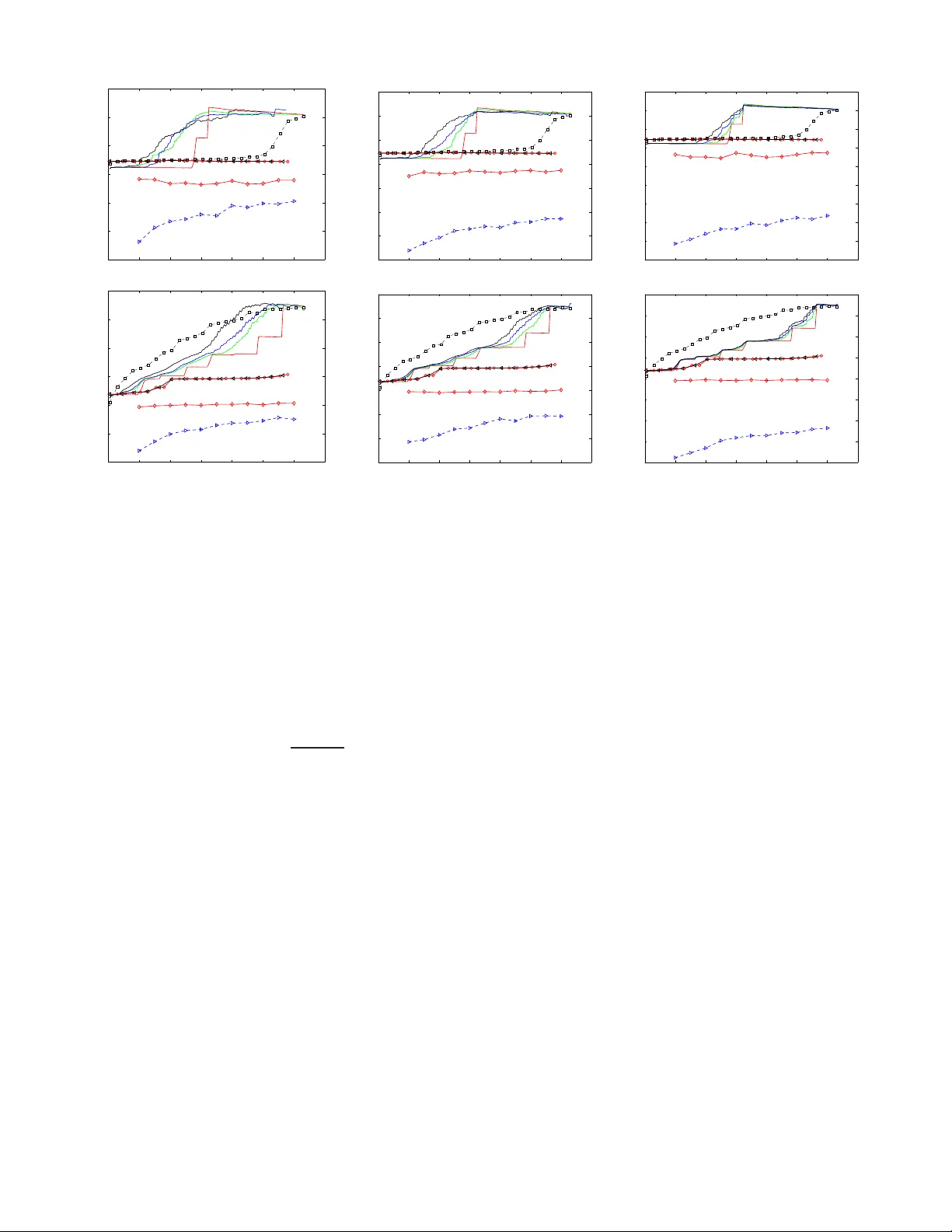
1 Ef ficient Adapti v e Compressi v e Sensing Using Sparse Hierarc hical Learned Dictionaries Akshay Soni and Jarvis Haupt Univ ersity of Mi nnes ota, T win Cities Department of Electrical and Computer Engineering Minneapolis, Minnesota USA 55455 e-mail: { sonix022,jdhaupt } @umn.edu Abstract —Recent breakthrough results in compressed sensing (CS) hav e establ ished that many high dimensional objects can be accurately reco ver ed from a relativ ely small n umber of non- adaptive lin ear p rojection observa tions, pro vided that the objects possess a sparse repr esentation in some basis. Subsequen t eff orts hav e shown th at the performance of CS ca n be improv ed b y exploiting the structure in the location of th e non-zero si gnal coefficients (structured sparsity) or using some form of online measureme nt focusing (adaptivity) in the sensing p rocess. In this paper we examine a powerful hybrid of these two techniq ues. First, we describe a simple ad aptive sensing procedure and show that it is a pr ov ably effective method f or acqui ring sparse signals that exhibit structured sparsity characterized by tree-based coefficient dependencies. Next, employing techn iques from sparse hierarchical dictionary learning, we sh ow th at representations exhibiting the appropriate fo rm of st ructured sparsity can b e learned from collections of traini ng data. The combination of these techniqu es results in an effectiv e and effici ent adaptive compressi ve acquisition procedure. I . I N T R O D U C T I O N Motiv ated in large part by br eakthro ugh results in com- pressed sensing (CS), significant a ttention ha s been focused in recent y ears on the development and analysis of samp ling and inferen ce metho ds that make efficient u se of measurem ent resources. The essential idea underly ing many directio ns of research in this area is that signals of interest often possess a parsimonio us representation in som e basis o r frame. For ex- ample, let x ∈ C n be a (p erhaps very high dimension al) vector which denotes our signal of interest. Suppo se that f or some fixed ( known) ma trix D whose columns are n -dimension al vectors d i , x may be expressed as a linear com bination of the columns of D , as x = ∑ i α i d i , (1) where the α i are th e coe fficients co rrespon ding to the relative weight of the contribution of e ach of the d i in the representa- tion. The diction ary D m ay , for example, co nsist of all of th e columns o f an orthon ormal matrix (eg., a discrete wa velet or Fourier transform matrix), tho ugh other rep resentations may be possible (eg., D may be a frame). In any case, we define the sup port set S to be the set of indices corre sponding to the nonzero values of α i in the rep resentation o f x . When S is small relativ e to the ambien t dimension n , we say that the This work was supported by DARP A/ONR under A ward N o. N66001-11- 1-4090. signal x is spar se in the dictionary D , and we call the v ector α , whose entr ies are the c oefficients α i , th e spar se rep resentation of x in the dictionar y D . The most general CS o bservation model prescr ibes collec t- ing (noisy) linear measurements of x in the form of projections of x onto a set of m ( < n ) “test vectors” φ i . Formally , these measuremen ts c an be e xpressed as y i = φ T i x + w i , i = 1 , 2 , . . . , m, (2) where w i denotes the additive m easuremen t unc ertainty asso- ciated with the i th measure ment. In “classic” CS settings, the measuremen ts are no n-ad aptive in nature, m eaning th at the { φ i } are specified indepen dently of { y i } (eg., the test vectors can be specified before an y measurem ents ar e obtained). Initial breakthr ough results in CS establish th at f or certain choices of the test vectors, or equiv a lently the matrix Φ whose rows are th e test vectors, sp arse vector s x can b e exactly r ecovered (or accu rately app roximate d) fro m m ≪ n measuremen ts. For example, if x has no mo re than k nonzero e ntries, a nd the entries of the test vectors/matrix are ch osen as iid realization s of zero -mean random variables having sub-Gaussian d istri- butions, then only m = O ( k log ( n k )) measurements of th e form ( 2) suffice to exactly r ecover (if n oise f ree) o r acc urately estimate (wh en w i ≠ 0 ) th e u nknown vector x , with high probab ility [1], [2]. Sev eral extensions to th e trad itional CS para digm have been in vestigated r ecently in the liter ature. One such extension cor- respond s to explo iting additional structu r e that may be presen t in the sp arse representation of x , wh ich can be qua ntified as follows. Suppose that α ∈ R p , the spa rse representatio n of x in an n × p orthonormal dictionary D , h as k nonzer o entries. Then, there are generally p k possible sub spaces on which x could be supp orted, and the space of all k -sp arse vectors can be u nderstoo d a s a unio n of ( k -dimension al) linear su bspaces [3]. Structur ed sparsity r efers to sparse representations th at are d rawn from a restr icted union of subspaces (wh ere only a subset of the p k subspaces are allowable). Recent works exploiting struc tured spar sity in CS reco nstruction include [4], [5]. One par ticular example of structured spar sity , which will be o ur primary focus here, is tree-sparsi ty . Let T p,d denote a balanced rooted conn ected tr ee of degree d with p nodes. Suppose that the com ponen ts of a sparse representa tion α ∈ R p can b e put into a one-to -one co rrespon dence with the no des o f the tree T p,d . W e say that the vector α ∈ R p is k -tree-sparse in 2 the tr ee T p,d if its nonzer o co mpon ents co rrespond to a r ooted connected subtree of T p,d . This type of tree structure arises, for example, in the wa velet coefficients of m any natural images [6]. Another extension to the “classic” CS obser vation mo del is to allow ad ditional flexibility in the measur ement proc ess in the form of feedback . Sequential adaptive sen sing strategies are those for which subsequent test vectors { φ i } i ≥ j may explicitly depen d on (or b e a fu nction of) p ast measure ments and test vectors { φ l , y l } l < j . Adaptive CS proced ures ha ve been shown to provide an imp roved resilience to noise relativ e to traditional CS – see, f or example, [7]–[9], as well as th e summary article [10] and th e ref erences therein. Th e essential idea of th ese sequential pro cedures is to grad ually “steer” measuremen ts towards the subspace in which signal x resides, in an effort to incre ase the signal to n oise ra tio (SNR) of each measuremen t. In this pap er we examin e a hyb rid techn ique to exploit structured sparsity and adaptivity in the con text o f n oisy com- pressed sen sing. Adaptiv e sensing techniques that exploit the hierarchica l tree-structured depen dencies present in wa velet representatio ns of images have been examined in the co ntext of n on-Fourier en coding in ma gnetic reson ance imaging [1 1], and more recen tly in the context of compressed sensing for imaging [12]. Our fir st contribution her e is to quan tify the perfo rmance of such proce dures when measureme nts are corrup ted by zero-me an ad ditive white Gaussian measureme nt noise. Our ma in theoretical results establish sufficient con- ditions (in terms of the number of m easuremen ts re quired, and th e min imum amp litude of the non zero compo nents) under which th e suppor t of tree- sparse vecto rs may be exactly recovered ( with h igh prob ability) using these adaptive sensing technique s. Our results stand in stark con trast with existing results fo r sup port recovery for ( generally un structured ) sparse vectors, highlig hting the significant improvements that can be achieved by the intellig ent exploitation of struc ture throug hout the me asurement process. Further, we demonstra te tha t tree-based adapti ve co m- pressed sensing strategies can be applied with representatio ns learned from a collection of training data using recent tech- niques in h ierarchical d ictionary lea rning. This procedu re of learning s tructu red sparse representatio ns gives rise to a power - ful general-p urpo se sensing and re construction m ethod, which we refer to as L ear ning A dapti ve Se nsing R epresen tations, or LASeR . W e demo nstrate the perform ance im provements that may be achieved v ia this approach, relative to other compressed sensing m ethods. The r emainder of this paper is organize d as follows. Sec- tion II provides a discussion o f th e top d own adapti ve com- pressed sensing pro cedure motivated by the ap proach es in [11], [12], an d contains our main theo retical results which quantify the perfo rmance of such appro aches in noisy set- tings. In Section I II we discuss the LASeR appr oach for extending this adap ti ve co mpressed sensing id ea to g eneral compressed sensing ap plications using recent techniq ues in dictionary learnin g. The per forman ce of th e LASeR pro cedure is e valuated in Section IV, and conclusion s and directions f or future work are discussed in Sectio n V. Fin ally , a sketch of the proo f of our m ain result is p rovided in Section VI . I I . A D A P T I V E C S F O R T R E E S PA R S E S I G N A L S Our analysis here pertains to a simp le ad aptive compr essed sensing p rocedu re f or tr ee sparse signals, similar to the tech- niques p roposed in [11], [1 2]. As above, let α ∈ R p denote the tree-sparse represen tation of an unknown signal x ∈ R n in a known n × p dictionary D having ortho norma l c olumns. W e assume sequential m easuremen ts of the f orm specified in (2) where the ad ditive noises w i are taken to be iid N ( 0 , 1 ) . Rather than projecting onto randomly generated test vectors, here we will obtain measu rements of x by pro jecting onto se- lectiv ely chosen, scaled versions of colum ns of the dictionary D , as follows. W ithou t loss of gene rality suppose that the index 1 correspond s to the root of th e tree T p,d . Be gin by initializing a data structure (a stack or queue) with th e index 1 , and collect a (noisy) measurement of the coeffi cient α 1 accordin g to (2) by selectin g φ 1 = β d 1 , whe re β > 0 is a fixed scaling param eter . That is, obtain a measurem ent y = β d T 1 x + w. (3) Note that our a ssumptions on the additiv e n oise imp ly th at y ∼ N ( β α 1 , 1 ) . Now , per form a significance test to determine whether th e am plitude of the measured value y exceeds a specified thresho ld τ > 0 . I f the me asurement is d eemed significant (ie, y ≥ τ ), then ad d the location s of the d ch ildren of index 1 in the tree T p,d to the stack (o r queue). If the measuremen t is not deemed sign ificant, then obtain the next index from the data structure (if the structure is nonem pty) to determine which column o f D sh ould comprise the n ext test vector , and proceed as above. If the data structur e is empty , the proced ure stops. Notice that using a stack as the data structure results in depth -first traversal of the tree, while using a queue results in br ead th-first tra versal. T he aforemen tioned algor ithm is adaptive in th e sense that the decisio n on which locations of α to measur e depends on outcom es o f the statistical tests correspo nding to the previous measurements. The perfo rmance of th is proced ure is q uantified by the following result, which com prises th e main theoretical con- tribution of this work. A sketch of the p roof of th e theo rem is given in Sec. VI. Theor em 1: Let α be k -tree-sparse in the tree T p,d with support set S , a nd suppose k < p d . F or any c 1 > 0 and c 2 ∈ ( 0 , 1 ) , ther e exists a c onstant c 3 > 0 such that if α min = min i ∈S α i ≥ c 3 log k β 2 (4) and τ = c 2 β α min , the fo llowing hold with pr o bability at least 1 − k − c 1 : th e total n umber of measur ements ob tained m = dk + 1 , a nd the support estimate S comprised of all the measur ed locations for which corresponding measur ed value exceeds τ in amplitud e is equa l to S . A brief discussion is in o rder here to p ut the results of this theo rem in context. No te that in p ractical settings, physical constrain ts (eg., power or time lim itations) effectiv ely impose a limit o n the p recision of the measurements that may 3 be obtained. This can be modeled by intro ducing a global constraint of the form ∑ i φ i 2 2 ≤ R, (5) on th e mo del (2) in order to limit th e “sensing energy” that may be e xpen ded thro ugho ut entire measurement process. In the context of Thm . 1, this corresponds to a constrain t of the form ∑ m i = 1 β 2 ≤ R . I n this case for the ch oice β = R ( d + 1 ) k , (6) Thm. 1 guarantees exact sup port r ecovery with h igh pro ba- bility fro m O ( k ) measuremen ts p rovided that α min exceeds a constant times ( d + 1 )( k R ) log k . T o assess the benefits of exploiting structure via a daptive sensing, it is illustrati ve to compare the result of Thm. 1 with r esults obtain ed in se veral recent works that examined sup port rec overy fo r unstructured sparse signals und er a Gaussian noise model. The consistent theme identified in these w orks is that exact suppo rt r ecovery is impossible unless the m inimum signal amplitude α min exceeds a constant tim es ( n R ) log n for non -adaptive measurement strategies [13], [14], or ( n R ) log k fo r adaptive sensing strategies [15]. Clearly , wh en the signal being acquire d is sparse ( k << n ), the pr ocedure analyzed in this work succeed s in recovering much weaker signa ls. Our pro of of T hm. 1 can be extended to o btain gua rantees on the accuracy of an estimate obtained via a related adaptive sensing pro cedure. Cor ollary 1: Ther e exists a two-stage (suppo rt r e covery , then estimation) ada ptive compr essed sensing pr o cedure fo r k - tr ee sparse signa ls that pr od uces an estimate fr om m = O ( k ) measur ements that ( with high pr o bability) satisfies ˆ α − α 2 2 = O k k R (7) pr ovided α min exceeds a constan t times ( k R ) log k . By com parison, non -adaptive CS estimation techniqu es that do not assume any structure in the sparse represen tation can achieve estimation er ror α − ˆ α 2 2 = O k n R log n , (8) from m = O ( k log ( n k )) measuremen ts [16]. Exp loiting structure in non- adaptive CS, as in [5], results in an estimatio n proced ure that achieves erro r α − ˆ α 2 2 = O k n R (9) from m = O ( k ) measurem ents. Ag ain, we see that the results of the corollary to Thm . 1 provid e a significant imp rovement over these existing error b ounds, especially in the case w hen k ≪ n . I I I . L E A R N I N G A DA P T I V E S E N S I N G R E P R E S E N TA T I O N S The approach outlined above ca n b e applied in g eneral settings, by employing techn iques from d ictionary learning [17], [1 8]. Let X denote an n × q matrix whose n -dime nsional columns x i comprise a collection of train ing data, and sup pose we can find a factorization o f X of the form X ≈ D A , wher e D is an n × p diction ary with or thono rmal columns, and A is a p × q m atrix wh ose colum ns a i ∈ R p each exhibit tree-sparsity in some tree T p,d . The task of find ing the diction ary D an d associated coef ficient matrix A with tree -sparse columns can be accomp lished by solving an optimization of the f orm { D , A } = arg min D ∈ R n × q , { a i }∈ R q p i = 1 x i − Da i 2 2 + λ Ω ( a i ) , (10) subject to the con straint D T D = I . Here , the regularization term is given by Ω ( a i ) = g ∈G ω g ( a i ) g , (11) where G is th e set of p grou ps, each comp rised o f a no de w ith all of its descendan ts in the tre e T p,d , th e no tation ( a i ) g refers to the subvector of a i restricted to the indices in the set g ∈ G , the ω g are non-negative weights, and the n orm can be e ither the ℓ 2 or ℓ ∞ norm. Efficient software packages hav e been developed (eg., [ 19]) for solv ing the optimization s of the form (10) via altern ating minimization over D an d A . En forcin g the a dditional constraint o f o rthogo nality of the colu mns of D can be achieved in a straightf orward mann er . I n the context of the pro cedure outline d in Sec. II, we refer to solving this form of constrained structured dictio nary learning task a s L earning A daptive Se nsing R epresentatio ns, or LASeR . Th e perfor mance of LASeR is ev aluated in the n ext section. I V . E X P E R I M E N TA L R E S U LT S W e perfor med e xperim ents o n the Psychological Image Col- lection at Stirling [20] which co ntains a set of 72 man-m ade and 91 natural im ages. The files are in JPG an d TIFF format respectively , with each image of size 25 6 × 25 6 (her e, each of the images was rescaled to 12 8 × 128 to reduce comp utational demand s on the dictionar y learning pr ocedur e). The training data were then each reshap ed to a 16384 × 1 vector and stacked together to fo rm the training matrix X ∈ R 16384 × 163 . After centerin g the training d ata by subtracting the column mean of the tr aining matrix from ea ch of the train ing vectors, we learned a b alanced binary tree structur ed or thonor mal dictionary with 7 levels (comp rising 127 o rthogo nal d ictionary elements). The LASeR sensing pro cedure was th en applied with r ows of dictionary scaled to meet the to tal sensing budget R fo r two test signals (cho sen from the orig inal trainin g set). Since, during the d ictionary learning process we specify the sparsity lev el o f the sign al in th e learned d ictionary , alloc ation of sensing energy to each mea surement can be done beforeh and (specifically β is d efined as in ( 6 ) ). W e e valuated the perfo r- mance of the procedu re for v ariou s values of τ ( the th reshold for determin ing significance o f a m easured co efficient) in a noisy setting corrup ted b y z ero-mean ad ditiv e white Gaussian measuremen t no ise. The reconstru ction fro m the LASeR pro - cedure is obtained as the column mean p lus a weighted s um of th e atom s o f the dictionary used to o btain th e pr ojections, where the weights ar e taken to be th e ac tual ob servation values ob tained by pro jecting on to the cor respond ing atom. When assessing the perfor mance of the procedure in noisy 4 0 20 40 60 80 100 120 140 −5 0 5 10 15 20 25 # Projections Reconstruction SNR(dB) 0 20 40 60 80 100 120 140 −10 −5 0 5 10 15 20 25 # Projections Reconstruction SNR(dB) 0 20 40 60 80 100 120 140 −20 −15 −10 −5 0 5 10 15 20 25 # Projections Reconstruction SNR(dB) 0 20 40 60 80 100 120 140 −5 0 5 10 15 20 25 # Projections Reconstruction SNR(dB) 0 20 40 60 80 100 120 140 −10 −5 0 5 10 15 20 25 # Projections Reconstruction SNR(dB) 0 20 40 60 80 100 120 140 −15 −10 −5 0 5 10 15 20 25 # Projections Reconstruction SNR(dB) Fig. 1: Reconstruction SNR vs. Nu mber of measurements plots ( best viewed in color) with different sensing energy R an d fixed n oise le vel σ 2 = 1 for different schemes (LASeR, PCA, d irect wa velet sen sing, model-b ased CS and L asso). Results in each row corresp onds to a different test image. Column 1 : R = 128 × 12 8 , Column 2 : R = ( 1 28 × 128 ) 8 , Column 3 : R = ( 12 8 × 128 ) 32 . Her e, is PCA, ◇ is model-based CS, ▷ is CS-Lasso, ◁ and ○ are for direct wav elet sensing with τ = 0 and τ = 0 . 5 respectiv ely . Colored solid lin es are for LASeR with red f or τ = 0 , gr een for τ = 0 . 04 , b lue f or τ = 0 . 06 and black for τ = 0 . 1 . settings, we av eraged perf ormance over a total of 500 trials correspo nding to different realization s of the random noise. Reconstruction perfo rmance is quantified by the re construc- tion signal to noise ratio (SNR), g iv en by SNR = 10 log 10 x 2 2 ˆ x − x 2 2 . (12) where x an d ˆ x are the original test an d reco nstructed signal respectively . T o provid e a performa nce comp arison for LASeR, we a lso ev alu ate the reconstruction perf ormanc e of the d irect wavelet sensing algorithm described in [12], as well as Principal com- ponen t a nalysis (PCA) based recon stuction. For PCA, the re- construction is obtain ed by taking p rojections of the test sig nal onto the princip al com ponen ts and add ing b ack the subtracted column mean to the reconstru ction. W e also compa re with “traditional” compressed sensing an d model-based compressed sensing [ 5], where measuremen ts are obtained b y pr ojecting onto ran dom vector s (in this case, vecto rs whose en tries are i.i.d. zero-m ean Gaussian distributed) and r econstructio n is obtained via the Lasso and CoSaMP respecti vely . In o rder to make a fair comparison am ong all of the dif feren t strategies, we scale so that the constraint o n the total sensing energy is met. Reconstruction SNR values vs. nu mber of m easurements for tw o of the te st images is shown in Fig. 1. The results in the top row (fo r the first test ima ge) show that for a range of th reshold values τ one can get a good reconstru ction SNR by taking only 60 − 65 me asurements u sing LASeR with very limited sensing budget R . On the other h and, reconstruc tion SNR for Lasso and model- based CS degrade as we decrease the sensing energy R . Th e results in th e bottom row (correspo nding to the second test image) demo nstrate a case wh ere th e pe rforma nce of LASeR is on p ar with PCA. In this case too , the SNR for L asso and m odel-based CS decr ease significantly as we decrease R . The advantage o f LASeR is in the low m easuremen t (high threshold ) an d low sen sing budge t scenario where we ca n g et a go od reco nstruction from few measuremen ts. V . D I S C U S S I O N / C O N C L U S I O N In th is paper , we presented a novel sensing and reco nstruc- tion pro cedure called LASeR, which uses d ictionaries learn ed from tr aining data, in conju nction with adaptive sensing, to perfor m comp ressed sensing. Bound s o n minimum f eature strength in the presence of measurement noise were explicitly proven fo r LASeR. Simulation s demon strate that the p ro- posed procedure can provide significant improvements over traditional c ompressed sensing (based on rando m projection measuremen ts), as well as other established m ethods s uch as PCA. Future w ork in th is direction will entail obtaining a complete characterizatio n of the perfor mance of the LASeR procedu re for dif f erent dictionaries, and for different learned tree struc- tures (we restricted attention here to bin ary trees, thoug h higher degrees can als o be obtained via the s ame procedure. 5 V I . P R O O F O F M A I N R E S U LT Before pr oceeding with the proof of the main theo rem, we state an interm ediate result conc erning the n umber of measuremen ts th at are obtained via the p rocedu re de scribed in Sec. II when sensing a k -tree- sparse vector . W e state the result here as a lemm a. T he proof is by inductio n on k , and is straightfor ward, so we omit it he re due to space constraints. Lemma 1: Let T p,d denote a completed r o oted con nected tr ee of degr ee d with p n odes, and let α ∈ R p be k -tree-sparse in T p,d with k ≤ q d . I f the pr o cedure described in Sec. II is used to acqu ir e α , and the ou tcome o f th e statistical test is corr ect at each step, th en the pr oce dur e halts whe n m = dk + 1 measur ements have been collected. In oth er words, suppose that for a k -tree sp arse α with support S , the outcomes of each o f the statistical tests of the proced ure described in Sec. I I are cor rect. T hen, th e set of locations that ar e measured is of the fo rm S ∪ S c , where S and S c are d isjoint, and S c = ( d − 1 ) k + 1 . A. Sketch of Pr o of of Th eor em 1 An error can occu r in two d ifferent ways, corr espondin g to missing a tru ly significant sign al component (a miss hit ) and determinin g a compon ent to be significant whe n it is no t (a false alarm ). L et y d j correspo nd to the m easurement obtained accordin g to the noisy linear mo del (2) by p rojecting onto the column d j . A false alarm co rrespon ds to the e vent y d j ≥ τ for some j ∈ S c . Since in this case, we h ave y d j ∼ N ( 0 , 1 ) , using a standa rd Gau ssian tail bo und for zero mean a nd unit variance rand om variables, the pro bability o f f alse alarm can be upp er boun ded as Pr ( false alar m ) ≤ e − τ 2 / 2 . (13) Like wise, for j ∈ S , a m iss hit corresp onds to y d j < τ . Letting α min = min j ∈S α j , we h ave Pr ( miss hit ) ≤ e −( β α min − τ ) 2 / 2 (14) for τ < β α min . Now , the pro bability of exact sup port re covery cor respond s to the prob ability of the e vent that each of the S = k statistical tests correspo nding to me asurements of nonze ro sign al com- ponen ts is co rrect, as ar e each of the S c = m − k = ( d − 1 ) k + 1 tests correspond ing to measure ments ob tained at locations where the signal ha s a zero comp onent. Thus, the pro bability of the f ailure event c an be obtained via the un ion boun d, a s Pr ( failure ) ≤ S c Pr ( false alarm ) + S Pr ( miss hit ) ≤ ( m − k ) e − τ 2 / 2 + k e −( β α min − τ ) 2 / 2 (15) Let τ = a ( β α min ) , wher e a ∈ ( 0 , 1 ) . If, for some c 1 > 0 , each of th e term s in the bound above is less th an k − c 1 2 , then the overall failure p robab ility is upper bound ed by k − c 1 . Consider the first term on the right hand side of (15), the condition ( m − k ) e − τ 2 / 2 ≤ k − c 1 2 implies that (for m = dk + 1 ), α min ≥ 2 log (( d − 1 ) k + 1 ) + 2 c 1 log k + 2 log 2 β 2 a 2 . (16) Similarly , the co ndition k e −( β α min − τ ) 2 / 2 ≤ k − c 1 2 implies α min ≥ 2 ( 1 + c 1 ) log k + 2 log 2 β 2 ( 1 − a ) 2 . (17) There exists a constant c 3 (depen ding on d and a ) such that when α min ≥ c 3 log ( k ) β 2 , bo th ( 16) an d (1 7) are satisfied. R E F E R E N C E S [1] E. J. Cand ` es and T . T ao, “Near-opti mal signal reco very from random project ions: Univ ersal encoding strate gies?, ” IEEE Tr ans. Inform. Theory , vol. 52, no. 12, pp. 5406–5425, Dec. 2006. [2] D. Donoho, “Compressed sensing, ” IEEE T ransactions on Information Theory , vol. 52, no. 4, pp. 1289–1306, Apr . 2006. [3] Y . Lu and M. Do, “ A theory for sampl ing signals from a union of subspaces, ” IEEE T rans. Signal Pr oc. , vol. 56, no. 6, pp. 2334–2345, 2008. [4] J. Huang, T . Zhang, and D. Meta xas, “Learning with structured sparsity , ” T echnica l Report , 2009, Onli ne: ar xiv.org/pdf/090 3.3002v2 . [5] R. Baraniuk, V . Cevhe r , M. Duarte, and C Hegde, “Model-b ased compressi ve sensing , ” IEEE T rans. Inform. Theory , vol. 56, no. 4, pp. 1982–2001, 2010. [6] M. Crouse, R. No wak, and R. Barani uk, “W avel et-based statistical signal processing using hid den Markov models, ” IEE E T rans. Sign al Proc. , v ol. 46, pp. 886–902, Apr . 1998. [7] S. Ji, Y . Xue , and L. C arin, “Bayesia n compressiv e sensing, ” IEEE T rans. on Sig. P r oc. , vol . 56, no. 6, pp. 2346–2356, 2008. [8] R. Castro, J. Haupt, R. Now ak, and G. Raz, “Finding needles in noisy haystac ks, ” in Pr oc. IEEE Intl. Conf. on Acoustics, Speech, and Signal Pr oc. , 2008, pp. 5133–5136. [9] J. Haupt, R. Baraniuk, R. Castro, and R. Now ak, “Compressi ve distilled sensing: Sparse rec ove ry using adapti vity in compressiv e measure- ments, ” in Proc. A silomar Conf. on Signals, Systems, and Computer s , 2009, pp. 1551–1555. [10] J. Haupt and R. No wak, “ Adapti ve sensing for sparse reco very , ” T o appear in Compr essed Sensing: Theory and applica tions , Cambridge Uni versity Press, 2011, http:/ /www .ece.umn.edu/ ∼ jdhaupt /publica tions/cs10 adapti ve sensing.pdf. [11] L. P . Panych and F . A. Jol esz, “ A dynamically ad apti ve imag ing algorit hm for wa vele t-encoded MRI, ” Magnetic Resonance in Medicine , vol. 32, pp. 738–748, 1994. [12] S. Deutsc h, A. A verbuch , and S. Dekel, “ Adaptiv e compressed image sensing based on wave let modelling and direct sampling, ” in 8th Inter- national Conferen ce on Sampling, Theory and Applicati ons. Marse ille , F rance , 2009. [13] D. Donoho and J. Jin, “Higher criticsm for dete cting sparse heterogen ous mixtures, ” Ann. Statist. , vol. 32, no. 3, pp. 962–994, 2004. [14] C. Geno vese, J. Ji n, and L. W asserman, “Re visiting marginal reg ression, ” pre print , 2009. [15] M. Malloy and R. Now ak, “On the limits of sequenti al testing in high dimensions, ” preprint , 2011. [16] E. J. Candes and T . T ao, “The Dantzig select or: Statistic al estimation when p is much larger than n , ” Ann. Statist. , vol. 35, no. 6, pp. 2313– 2351, 2007. [17] B. A. Olshausen and D. J. Field, “Sparse coding with an ove rcomplete basis set: A strate gy emplo yed by V1?, ” V ision Researc h , vol. 37, pp. 3311–3325, 1997. [18] M. Aharon, M. E lad, and A. Bruckstein, “K-SVD: An algorith m for designin g overco mplete dictionar ies for sparse representat ion, ” IEEE T rans. Signal Proc. , vol . 54, no. 11, pp. 4311–4322, 2006. [19] R. Jenatto n, J. Mairal, G. Obozinski, and F . Bach, “Proximal methods for sparse hierarchic al dicti onary learning, ” in Pr oc. ICML , 2010. [20] “Psychologic al image collect ion at stirling , ” http://www .pics.stir .ac.uk/ .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment