Representations and Ensemble Methods for Dynamic Relational Classification
Temporal networks are ubiquitous and evolve over time by the addition, deletion, and changing of links, nodes, and attributes. Although many relational datasets contain temporal information, the majority of existing techniques in relational learning …
Authors: Ryan A. Rossi, Jennifer Neville
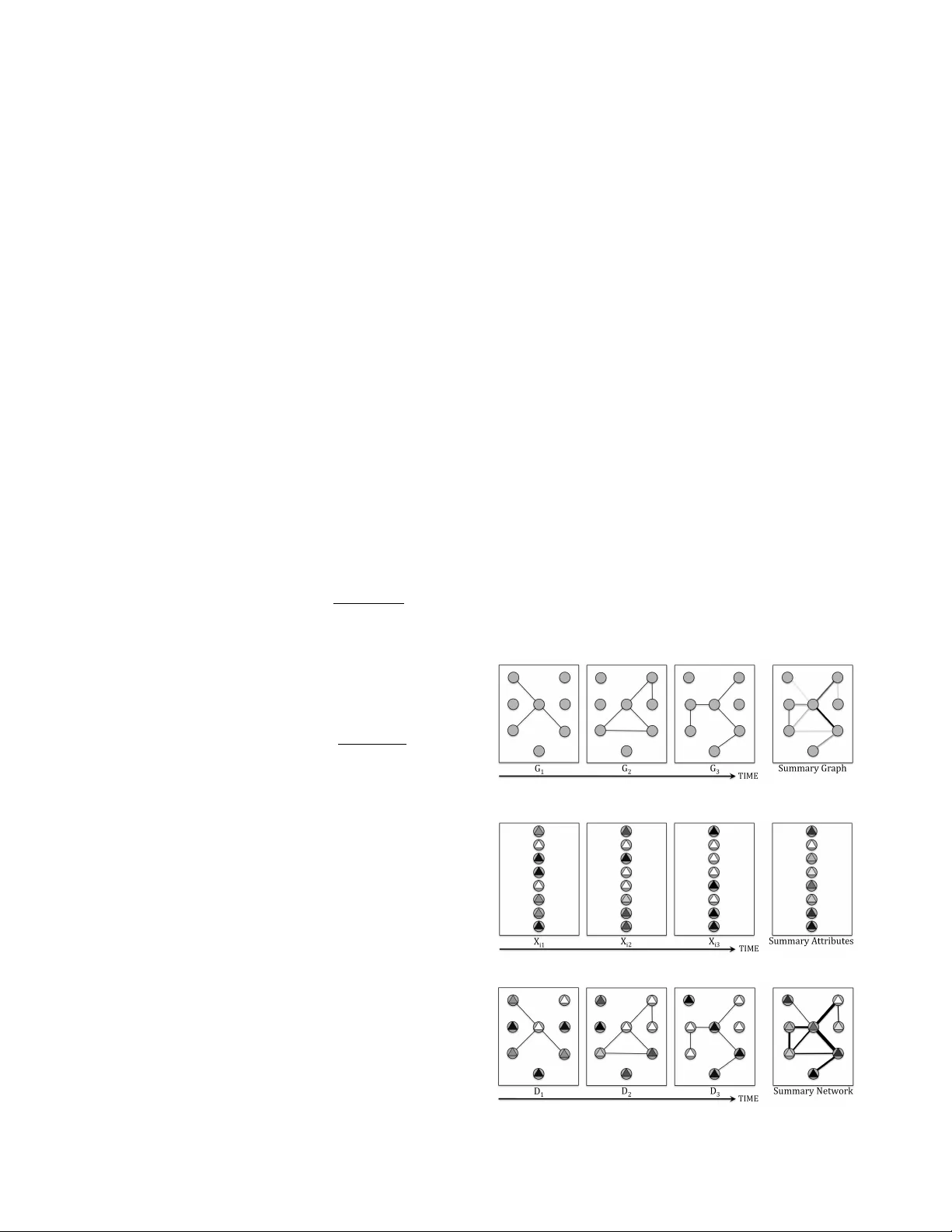
Repr esentations and Ensemble Methods f or Dynamic Relational Classification Ryan A. Rossi Department of Computer Science Pur due University rr ossi@cs.pur due.edu Jennifer Neville Department of Computer Science Pur due University neville@cs.pur due.edu Abstract —T emporal networks ar e ubiquitous and ev olve o ver time by the addition, deletion, and changing of links, nodes, and attributes. Although many r elational datasets contain temporal information, the majority of existing techniques in relational learning focus on static snapshots and ignore the temporal dynamics. W e propose a framework for discov ering temporal repr esentations of relational data to incr ease the accuracy of statistical relational lear ning algorithms. The temporal relational repr esentations serve as a basis for classification, ensembles, and pattern mining in e volving domains. The framework includes (1) selecting the time-varying relational components (links, attrib utes, nodes), (2) selecting the temporal granularity (i.e., set of timesteps), (3) predicting the temporal influence of each time-varying relational component, and (4) choosing the weighted relational classifier . Additionally , we propose temporal ensemble methods that exploit the temporal- dimension of relational data. These ensembles outperform traditional and more sophisticated relational ensembles while av oiding the issue of learning the most optimal repr esentation. Finally , the space of temporal-relational models are evaluated using a sample of classifiers. In all cases, the proposed temporal-relational classifiers outperform competing models that ignore the temporal inf ormation. The results demonstrate the capability and necessity of the temporal-relational repr esen- tations for classification, ensembles, and for mining temporal datasets. Keyw ords -Time-evolving relational classification; tempo- ral network classifiers; temporal-relational representations; temporal-relational ensembles; statistical r elational learning; graphical models; mining temporal-relational datasets I . I N T RO D U C T I O N T emporal-relational information is seemingly ubiquitous; it is present in domains such as the Internet, citation and col- laboration networks, communication/email networks, social networks, biological networks, among many others. These domains all hav e attributes, links, and/or nodes changing ov er time which are important to model. W e conjecture that discov ering an accurate temporal-r elational repr esen- tation disambiguates the true nature and strength of links, attributes, and nodes. Howe ver , the majority of research in relational learning has focused on modeling static snap- shots [1], [2], [3] and has largely ignored the utility of learning and incorporating temporal dynamics into relational representations. T emporal relational data has three main components (i.e., attributes, nodes, links) that vary in time. First, the at- tribute values might change o ver time (e.g., research area of an author). Secondly , links might be created and deleted throughout time (e.g., friendships or a paper citing a pre vious paper). Thirdly , nodes might be activ ated and deacti vated throughout time (e.g., a person might not send an email for a few days). Additionally , in a temporal pr ediction task , the attribute to predict is changing throughout time (e.g., predicting a network anomaly) whereas in a static prediction task the predictiv e attribute remains constant. Consequently , the space of temporal relational models is defined by considering the set of relational elements that might change ov er time such as the attributes, links, and nodes. Additionally , the space of temporal-relational repre- sentations depends on a temporal weighting and the temporal granularity . The temporal weighting attempts to predict the influence of the links, attributes and nodes by decaying the weights of each with respect to time whereas the temporal granularity restricts links, attributes, and nodes with respect to some window of time. The most optimal temporal- relational representation and the corresponding temporal classifier depends on the particular temporal dynamics of the links, attributes, and nodes present in the data and also on the domain and type of network (e.g., social networks, biological networks). In this work, we address the problem of selecting the most optimal temporal-relational representation to increase accuracy of predictiv e models. The space of temporal- r elational r epresentations leads us to propose the (1) temporal-relational classification framework and (2) tempo- ral ensemble methods (e.g., temporally sampling, randomiz- ing, and transforming features) that le verage time-v arying links, attributes, and nodes. W e ev aluate these temporal- relational models on a variety of classification tasks and ev aluate each under various constraints. Finally , we explore the utility of the framework for (3) mining temporal datasets and discov ering temporal patterns. The results demonstrate the importance and scalability of the temporal-relational representations for classification, ensembles, and for mining temporal datasets. I I . R E L A T E D W O R K Most previous work uses static snapshots or significantly limits the amount of temporal information used for rela- tional learning. Sharan et. al. [4] assumes a strict temporal- representation that uses kernel estimation for links and includes these into a classifier . They do not consider multiple temporal granularities (all information is used, statically) and the attributes and nodes are not weighted. In addition, they focus only on one specific temporal pattern and ig- nore the rest whereas we explore many temporal-relational representations and propose a flexible frame work capable of capturing the temporal patterns of links, attributes, and nodes. Moreover , they only ev aluate and consider static prediction tasks. Other work has focused on discov ering temporal patterns between attributes [5]. There are also temporal centrality measures that capture properties of the network structure [6]. I I I . T E M P O R A L - R E L A T I O N A L C L A S S I FI C A T I O N F R A M E W O R K The temporal-relational classification framew ork is de- fined with respect to the possible transformations of links, attributes, or nodes (as a function of time). The temporal weighting (e.g., exponential decay of past information) and temporal granularity (e.g., window of timesteps) of the links, attributes and nodes form the basis for any arbitrary transformation with respect to the temporal information (See T able I). The disco vered temporal-relational representation can be applied for mining temporal patterns, classification, and as a means for constructing temporal-ensembles. An ov ervie w of the temporal-relational representation discovery is provided below: 1) For each R E L A T I O NA L C O M P O N E N T − Links, Attributes, or Nodes 2) Select the T E M P O R A L G R A N U L A R I T Y ? T imestep t i ? W indow { t i , t i +1 ..., t j } ? Union T = { t 0 , ..., t n } 3) Select the T E M P O R A L I N FL U E N C E ? W eighted ? Uniform Repeat steps 1-3 for each relational component. 4) Select the Modified R E L A T I O N A L C L A S S I FI E R ? Relational Bayes Classifier (RBC) ? Relational Probability T rees (RPT) T able I provides an intuiti ve view of the possible temporal-relational representations. For instance, the recent TVRC model is a special case of the proposed framew ork where the links, attributes, and nodes are unioned and the links are weighted. A. Relational Components: Links, Attributes, Nodes The data is represented as an attributed graph D = ( G, X ) . The graph G = ( V , E ) represents a set of N nodes, such that v i ∈ V corresponds to node i and each edge T able I T E MP O R A L - R E L A T I O NA L R E P RE S E N T AT I ON . U N I F OR M W E I G HT I N G Timestep Windo w Union Timestep Windo w Union Edges Attributes Nodes e ij ∈ E corresponds to a link (e.g., email) between nodes i and j . The attribute set: X = X V = [ X 1 , X 2 , ..., X m v ] , X E = [ X m v +1 , X m v +2 , ..., X m v + m e ] may contain observed attributes on both the nodes ( X V ) and the edges ( X E ). Below we use X m to refer to the generic m th attribute on either nodes or edges. There are three aspects of relational data that may vary ov er time. First, the values of attribute X m may vary over time. Second, edges may vary ov er time. This results in a different data graph G t = ( V , E t ) for each time step t , where the nodes remain constant b ut the edge set may vary (i.e., E t i 6 = E t j for some i, j ). Third, a nodes existence may vary o ver time (i.e., objects may be added or deleted). This is also represented as a set of data graphs G 0 t = ( V t , E t ) , but in this case both the nodes and edge sets may vary . Let D t = ( G t , X t ) refer to the dataset set at time t , where G t = ( V , E t , W E t ) and X t = ( X V t , X E t , W X t ) . Here W t refers to a function that assigns weights on the edges and attributes that are used in the classifiers belo w . W e define W E t ( i, j ) = 1 if e ij ∈ E t and 0 otherwise. Similarly , we define W X t ( x m i ) = 1 if X m i = x m i ∈ X m t and 0 otherwise. B. T emporal Granularity T raditionally , relational classifiers ha ve attempted to use all the data [4]. Conv ersely , the appropriate temporal gran- ularity (i.e., set of timesteps) can be learned to impro ve classification accuracy . W e briefly define the three general classes ev aluated in this work for varying the temporal granularity of the links, attributes, and nodes. 1) Timestep. The timestep models only use a single timestep t i for learning. 2) Windo w . The windo w models use a sliding windo w of timesteps { t i , t i +1 ..., t j } for learning. The space of window models is by far the largest. 3) Union. The union model uses all the pre vious temporal information for learning. The timestep and union models are separated into distinct classes for clarity in ev aluation and for pattern mining. C. T emporal Influence: Links, Attributes, Nodes The influence of the relational components ov er time are predicted using temporal weighting. The temporal weights can be vie wed as probabilities that a relational component is still acti ve at the current time step t , gi ven that it was observed at time ( t − k ) . Conv ersely , the temporal influence of a relational component might be treated uniformly . Ad- ditionally , weighting functions can be chosen for different relational components with v arying temporal granularities. For instance, the temporal influence of the links might be predicted using the exponential kernel while the attributes are uniformly weighted but have a different temporal gran- ularity than the links. 1) W eighting. W e inv estigated three temporal weighting functions: • Exponential K ernel. The exponential kernel weights the recent past highly and decays the weight rapidly as time passes [7]. The kernel function K E for temporal data is defined as: K E ( D i ; t, θ ) = (1 − θ ) t − i θ W i • Linear K ernel. The linear kernel decays more gen- tly and retains the historical information longer . The linear kernel K L for the data is defined as: K L ( D i ; t, θ ) = θW i ( t ∗ − t i + 1 t ∗ − t o + 1 ) • In verse Linear K ernel. The in verse linear kernel K I L lies between the exponential and linear ker- nels when moderating the contribution of histori- cal information. The in verse linear kernel for the data is defined as: K I L ( D i ; t, θ ) = θW i ( 1 t i − t o + 1 ) 2) Uniform. The relational component(s) could be as- signed uniform weights across time for the selected temporal granularity (e.g., traditional classifiers assign uniform weights, but they do not select the appropriate temporal granularity). D. T emporal-Relational Classification Once the temporal granularity and the temporal weighting are selected for each relational component, then a temporal- relational classifier is learned. Modified versions of the RBC [8] and the RPT [9] are applied with the temporal- relational representation. Howe ver , an y relational model that has been modified for weights is suitable for this phase. W e extended RBCs and RPTs since the y are interpretable, div erse, simple, and efficient. W e use k -fold cross-validation to learn the “best” model. Both classifiers are extended for learning and inference through time. W eighted Relational Bayes Classifier . RBCs extend naiv e Bayes classifiers to relational settings by treating heterogeneous relational subgraphs as a homogenous set of attribute multisets. For example, when modeling the dependencies between the topic of a paper and the topics of its references, the topics of those references form multisets of varying size (e.g., { NN, GA } , { NN, NN, RL, NN, GA } ). The RBC models these heterogenous multisets by assuming that each v alue of the multiset is independently drawn from the same multinomial distrib ution. This approach is designed to mirror the independence assumption of the naiv e Bayesian classifier [10]. In addition to the con ventional assumption of attribute independence, the RBC also assumes attrib ute value independence within each multiset. More formally , for a class label C , attributes X , and related items R , the RBC calculates the probability of C for an item i of type G ( i ) as follows: P ( C i | X , R ) ∝ Y X m ∈ X G ( i ) P ( X i m | C ) Y j ∈ R Y X k ∈ X G ( j ) P ( X j k | C ) P ( C ) W eighted Relational Probability T rees. RPTs e xtend standard probability estimation trees to a relational setting in which data instances are heterogeneous and interdependent. The algorithm for learning the structure and parameters of a RPT searches over a space of relational features that use aggregation functions (e.g. A VERA GE, MODE, COUNT) to dynamically propositionalize relational data multisets and create binary splits within the RPT . Learning. The RBC uses standard maximum likelihood learning with Laplace correction for zero-values. More Figure 1. T emporal Link W eighting Figure 2. T emporal Attribute W eighting Figure 3. Graph and Attribute W eighting (a) Links weighting (b) Link and attribute weighting Figure 4. (a) The feature calculation that includes only the temporal link weights. (b) The feature calculation that incorporates both the temporal attribute weights and the temporal link weights. specifically , the sufficient statistics for each conditional probability distrib ution are computed as weighted sums of counts based on the link and attribute weights. The RPT uses the standard RPT learning algorithm except that the aggregate functions are computed after the appropriate links and attributes weights are included with respect to the selected temporal granularity (shown in Figure 4). Pr ediction. For prediction we compute the summary data D S t at time t − the time step for which the model is being applied. The learned model for time ( t − 1) to D S t . The weighted classifier is appropriately augmented to incorporate the weights for D S t . I V . T E M P O R A L E N S E M B L E M E T H O D S Ensemble methods hav e traditionally been used to im- prov e predictions by considering a weighted v ote from a set of classifiers [11]. W e propose temporal ensemble methods that exploit the temporal dimension of r elational data to construct more accurate predictors. This is in contrast to traditional ensembles that disregard the temporal informa- tion. The temporal-r elational classification fr amework and in particular the temporal-relational representations of the time-varying links, nodes, and attrib utes form the basis of the temporal ensembles (i.e., used as a wrapper over our framew ork). The proposed temporal ensemble techniques are assigned to one of the fiv e methodologies described below . A. T ransforming the T emporal Nodes and Links The first temporal-ensemble method learns a set of clas- sifiers where each of the classifiers are applied after the link and nodes are sampled from each discrete timestep according to some probability . This sampling strategy is performed af- ter constructing the temporal-relational representation where the temporal weighting and temporal granularity hav e been selected. Additionally , the sampling probabilities for each timestep can be chosen to be biased toward the present or the past. In contrast to applying a sampling strategy across time, we might transform the time-varying nodes and links using the methods described in the framew ork. B. Sampling or T ransforming the T emporal F eatur e Space The second type of temporal ensemble method transforms the temporal feature space by localizing randomization (for attributes at each timestep), weighting, or by varying the temporal granularity of the features. Additionally , we might use only one temporal weighting function but learn different decay parameters or resample from the temporal features. The temporal features could also be clustered (using varying decay parameter or randomizations), similar to the dynamic topic discov ery models ev aluated later in the paper . C. Adding Noise or Randomness A temporal ensemble based on adding noise along the temporal dimension of the data may significantly increase generalization and performance. Suppose, we randomly per - mute the nodes feature v alues across the timesteps (i.e., a nodes recent behavior is observed in the past and vice versa) or links between nodes are permuted across time. D. T ransforming the T ime-V arying Class Labels These temporal ensemble methods introduce v ariance in the classifiers by randomly permuting the previously learned labels at t - 1 (or more distant) with the the true labels at t . E. Multiple Classification Algorithms and W eightings A temporal ensemble may be constructed by randomly selecting from a set of classification algorithms (i.e., RPT , RBC, wvRN, RDN), while using equiv alent temporal- relational representations or by v arying the representation with respect to the temporal weighting or granularity . Notably , an ensemble using RPT and RBC significantly increases accuracy , most likely due to the di versity of these temporal classifiers (i.e., correctly predicting different instances). Additionally , the temporal-classifiers might be assigned weights based on cross-validation (or Bayesian approach). V . M E T H O D O L O G Y W e describe the datasets and define a few representativ e temporal-relational classifiers from the framew ork. A. Datasets For e valuating the framew ork, we use a range of both static (i.e., prediction attribute is constant as a function of time) and temporal prediction tasks (i.e., prediction attribute changes between timesteps). P Y C O M M Developer Communication Network. W e an- alyze email and bug communication netw orks extracted from the Python dev elopment en vironment (www .python.or g). W e use the p ython-de v mailing list archive for the period 01/01/07 − 09/30/08. The sample contains 13181 email mes- sages, among 1914 users. Bug reports were also collected and we constructed a second b ug discussion network. The sample contained 69435 bug comments among 5108 users. The size of the timesteps are three months. W e also extracted text from emails and b ug messages and use it to dynamically model the topics between individuals and teams. Additionally , we discover temporal centrality attributes (i.e., clustering coef ficient, betweenness). The pre- diction task is whether a de veloper is ef fectiv e (i.e., if a user closed a bug in that timestep). T able II G E NE R A T E D AT TR I B UT E S F RO M T H E P Y C O M M N E T WO R K Python Communication Network Attributes Con v T ool Build Demos & tools Dist Utils Documentation Doc T ools T eam Installation InterpCore Membership Regular Expr T ests Unicode W indows Ctypes Ext Modules Idle LibraryLib Tkinter XML Perf ormance Assigned T o [ H A S C L O S E D ] Communication Comm. Count Bug Comm. Attributes Email Comm. User T opics T opic Email T opic Bug T opic T emporal Eigenv ector Cluster . Coeff. Centrality Betweenness Degree Edge Count Edge T opic Link Attributes Email Count Email T opic Bug Count Bug T opic C O R A Citation Network. The C O R A database contains authorship and citation information about CS research papers extracted automatically from the web . The prediction tasks are to predict one of seven machine learning papers and to predict AI papers giv en the topic of its references. In addi- tion, these techniques are e valuated using the most prev alent topics its authors are working on through collaborations with other authors. B. T emporal Models The space of temporal-relational models are ev aluated using a representati ve sample of classifiers with varying temporal-relational weightings and granularities. For ev ery timestep t , we learn a model on D t (i.e., some set of timesteps) and apply the model to D t +1 . The utility of the temporal-relational classifiers and representation are mea- sured using the area under the ROC curv e (A UC). Below , we briefly describe a fe w classes of models that were e valuated. • TENC : The TENC models predict the temporal influ- ence of both the links and attributes. • TVRC : This model weights only the links using all previous timesteps. • Union Model : The union model uses all links and nodes up to and including t for learning. • Windo w Model : The window model uses the data D t − 1 for prediction on D t (unless otherwise specified). W e also compare simpler models such as the RPT (re- lational information only) and the DT (non-relational) that TVRC RPT Intrinsic Int+time Int+graph Int+topics AUC 0.92 0.94 0.96 0.98 1.00 Figure 5. W e compare a primitiv e temporal model (TVRC) to competing relational (RPT), and non-relational (DT) models. The A UC is averaged across the timesteps. ignore any temporal information. Additionally , we explore many other models, including the class of windo w models, various weighting functions (besides exponential kernel), and built models that v ary the set of windows in TENC and TVRC. V I . E X P E R I M E N T S W e first ev aluate temporal-relational representations for improving classification models. These models are ev aluated using different types of attributes (e.g., relational only vs. non-relational) and also by using different types of dis- cov ered attributes (e.g., temporal centrality , team attributes, communication). The results demonstrate the utility of the temporal-relational classifiers, their representation, and the discov ered temporal attributes. W e also identify the mini- mum temporal information (i.e., simplest model) required to outperform classifiers that ignore the temporal dynam- ics. Furthermore, the proposed temporal ensemble methods (i.e., temporally sampling, randomizing, and transforming features) are ev aluated and the results demonstrate signifi- cant improvements over traditional and relational ensemble methods. W e then focus on models that vary the temporal- granularity and apply these for mining temporal patterns and more generally for discov ering the nature of the time-varying links and attributes. Finally , we apply temporal te xtual analy- sis, generate topic features, and annotate the links and nodes with their corresponding topics over time. The significance of the evolutionary topic patterns are ev aluated using a classification task. The results indicate the effecti veness of the temporal textual analysis for discov ering time-v arying features and incorporating these patterns to increase the accuracy of a classification task. For bre vity , we omit many plots and comparisons. T=1 T=2 T=3 T=4 A UC 0.65 0.70 0.75 0.80 0.85 0.90 0.95 TENC TVRC TVRC+Union Window Model Union Model Figure 6. Exploring the space of temporal-relational models. W e evaluate significantly different temporal-relational representations from the proposed framew ork. This experiment uses the P Y C OM M network, but focuses on time-varying relational attributes. A. Single Models W e provide examples of temporal-relational models from the proposed framew ork and show that in all cases the performance of classification improv es when the temporal dynamics are appropriately modeled. T emporal, Relational, and Non-r elational Information. W e first assess the utility of the temporal, relational, and non-relational information. In particular , we are interested in this information as it pertains to the construction of features and their selection and pruning from the model. For these experiments, we compare the most primitiv e models such as TVRC (i.e., uses temporal-relational information), RPT (i.e., only relational information), and a decision tree that uses only non-relational information. Additionally , we learn these models using various types of attrib utes and explore the utility of each with respect to the temporal, relational or non-relational information. Figure 5 compares TVRC (i.e., a primiti ve temporal- relational classifier) with the RPT and DT models that use more features but ignore the temporal dynamics of the data. W e find the TVRC to be the simplest temporal-relational classifier that still outperforms the others. Interestingly , the discov ered topic features are the only additional features that improv e performance of the DT model. This is significant as these attributes are discovered by dynamically modeling the topics, b ut are included in the DT model as simple non- relational features (i.e., no temporal weighting or granularity , ...). W e also find that in some cases the selectiv e learner chooses a suboptimal feature when additional features are included in the basic DT model (see Figure 5). More sur- prisingly , the base RPT model does not improv e performance ov er the DT model, indicating the significance of moderating the relational information with the temporal dynamics. Exploring T emporal-Relational Models. W e focus on ex- ploring a small but representativ e set of temporal-relational models from the proposed framew ork. T o more appropriately ev aluate their temporal-representations, we chose to remove highly correlated attributes (i.e., that are not necessarily temporal patterns, or motifs), such as assignedto in the P Y C O M M prediction task. In Figure 6, we find that TENC outperforms the other models ov er all timesteps. This pro- posed class of models is significantly more complex than TVRC (and most other models) since the temporal influence of both links and attributes are learned. W e then e xplored learning the appropriate temporal gran- ularity but with respect to the TVRC model. Figure 6 shows the results from two models in the TVRC class where we attempt to tease apart the superiority of TENC (i.e., weighting or granularity). Howe ver , both models outperform one another on different timesteps, indicating the necessity for a more precise temporal-representation that optimizes the temporal granularity by selecting the appropriate decay parameters for links and attrib utes (i.e., in contrast to a more strict representation of including the links or not). The windo w and union models perform significantly worse, but are significantly more ef ficient and scalable for billion node temporal datasets while still including some temporal information based on the granularity of the links and at- tributes. Similar results were found using C O R A and other base classifiers such as RBC. W e have also experimented searching ov er many temporal weighting functions and found the exponential decay to be the most appropriate for both links and attributes in the proposed prediction tasks. The most optimal temporal- relational representation depends on the temporal dynam- ics and nature of the network under consideration (e.g., social networks, biological networks, citation networks). Nev ertheless, multiple temporal weightings and granularities are found to be useful for constructing robust temporal ensembles that significantly reduce error and variance (i.e., compared to single temporal-relational classifiers and more importantly relational and traditional ensembles). The accuracy of classification generally increases as more temporal information is included in the representation. How- ev er, this may lead to ov erfitting or other biases. On the other hand, the more complex temporal-relational representations aid in the mining of temporal patterns. For instance, the use of the evolutionary topic patterns for improving classification by moderating both the links and attrib utes over time (See Section VI-D). Selective T emporal Learning . W e also explored “selectiv e temporal learning” that uses multiple temporal weighting functions (i.e., and temporal granularities) for the links and attributes. The motivation for such an approach is that the influence of each temporal component should be modeled independently , since any two attributes (or links) are likely to decay at different rates. Howe ver , the complexity and the utility of the learned temporal-relational representation depends on the ability of the selective learner to select the best temporal features (deri ved from weighting or varying the temporal granularity of attrib utes and links) without ov er- fitting or causing other problems. W e found that the selective temporal learning performs best for simpler prediction tasks, howe ver , it still frequently outperforms classifiers that ignore the temporal information. B. T emporal-Ensemble Models Instead of directly learning the most optimal temporal- relational representation to increase the accuracy of classifi- cation, we use temporal ensembles by varying the relational representation with respect to the temporal information. These ensemble models reduce error due to variance and allow us to assess which features are the most relev ant to the domain with respect to the relational or temporal information. T emporal, Relational, and T raditional Ensembles. W e first resampled the instances (nodes, links, features) repeat- edly and then learn TVRC, RPT , and DT models. Across almost all the timesteps, we find the temporal-ensemble that uses various temporal-relational representations outperforms the relational-ensemble and the traditional ensemble (see Figure 7). The temporal-ensemble outperforms the others ev en when a the minimum amount of temporal informa- tion is used (e.g., time-varying links). More sophisticated temporal-ensembles can be constructed to further increase accuracy . For instance, we hav e in vestigated ensembles that use significantly dif ferent temporal-relational representations (i.e., from a wider range of model classes) and ensembles that use various temporal weighting parameters. In all cases, these ensembles are more robust and increase the accuracy ov er more traditional ensemble techniques (and single clas- sifiers). Additionally , the a verage improv ement of the temporal- ensembles is significant at p < 0 . 05 with a 16% reduction in error, justifying the proposed temporal ensemble method- ologies. From the individual trials, it is clear that the RPT TVRC RPT DT AUC 0.92 0.94 0.96 0.98 1.00 T=1 T=2 T=3 T=4 Avg Figure 7. Comparing T emporal, Relational, and T raditional Ensembles Communication T eam Centrality T opics AUC 0.6 0.7 0.8 0.9 1.0 TVRC RPT DT Figure 8. Comparing the utility of the discovered attribute classes and the influence of each with respect to the temporal, relational, and traditional ensembles. has a lot of variance—despite the use of ensembles, which is aimed at reducing variance, the RPT performs significantly better in one trial ( t = 3 ) and worse in another ( t = 1 ). This provides further evidence that relational information and the utility of such information increases significantly when moderated by the temporal-information. Attribute Classes: T emporal Patterns and Significance. W e again use one of the most primitiv e classes of temporal- relational representations in order to tease apart (i.e., more accurately) the most significant attribute category (commu- nication, team, centrality , topics). These primiti ve temporal- representations also help identify the minimum amount of temporal information that we must consider to outperform relational classifiers. This is important as the more temporal- relational information we exploit, the more complex and expensi ve it is to learn and search from this space. In Figure 8, we find several striking temporal patterns. First, the team attributes are localized in time and are not changing frequently . F or instance, it is unlikely that a dev el- oper changes their assigned teams and therefore modeling the temporal dynamics only increases the accuracy by a rel- ativ ely small percent. Howe ver , the temporal-ensemble still increases the accuracy over the other ensemble methods that ignore the temporal patterns. This indicates the robustness of the temporal-relational representations. Moreover , we also notice that a few dev elopers change projects frequently , which could be responsible for the increase in accuracy when the temporal information is leveraged. More importantly , the other classes of attributes are ev olving considerably and this fact is captured in the significant impro vement of the temporal ensemble models. Similar performance is also obtained by varying the temporal granularity . W e provide a few examples in the next section. Randomization. W e use randomization to identify the sig- nificant attributes in the tempor al-ensemble models . Addi- tionally , randomization provides a means to rank the features and identify redundandt features (i.e., two features may share assigned−count assigned−count−prev email−discussion−count degree−centrality−email all−communication−count bug−discussion−count bc−centrality−email−discussion eigen−centrality−all−discussion clust−coeff−email−discussion team−count hasclosed−prev clust−coeff−all−discussion bc−centrality−bug−discussion degree−centrality−all−discussion bc−centrality−all−discussion unicode−team topics−all−discussion topics−bug−discussion tkinter−team topics−email−discussion DT TVRC RPT AUC Drop 0.00 0.02 0.04 0.06 0.08 0.10 Figure 9. Identifying and ranking of the most significant features in the ensemble models. The significant features used in the temporal ensemble are compared to the relational and traditional ensembles. W e measure the change in A UC due to the randomization of attribute values. the same significant temporal pattern). Randomization is performed on an attrib ute by randomly reordering the values, thereby preserving the distribution of values but destroying any association of the attrib ute with the class label. For ev ery attribute, in ev ery time step, we randomize the giv en attribute, apply the ensemble method, and measure the drop in A UC due to that attrib ute. The resulting changes in A UC are used to assess and rank the attrib utes in terms of their impact on the temporal ensemble (and ho w it compares to more standard relational or traditional ensembles). Figure 9. The results are shown in Figure 9. W e find that the basic traditional ensemble relies more heavily on assignedto (in the current time step) while the temporal ensemble (and ev en less for the relational en- semble) relies on the pre vious assignedto attributes. This indicates that the relational information in the past is more useful than the intrinsic information in the present—which points to an interesting hypothesis that a colleagues behavior (and iteractions) precedes their o wn behavior . Or ganizations might use this to predict future behavior with less informa- tion and proactiv ely respond more quickly . Additionally , we inv estigated the attribute classes of each type of ensemble and found that topics are most useful for the temporal ensemble. This indicates that topics are useful as a way to understand the context and strength of interaction among the developers, but only when the temporal dynamics are modeled. C. Discovering T emporal P atterns W e define three temporal mining techniques based on the temporal frame work to construct models with v arying temporal granularities. These techniques are combined with relational classifiers or used separately to discov er the tem- poral nature and patterns of relational datasets. Models of T emporal Granularity . If we do not consider temporally weighting the links, nodes, and attrib utes then we restrict our focus to models based strictly on v arying the temporal granularity . In this space, there are a range of interesting models that provide insights into the temporal patterns, structure, and nature of the dataset. W e first define three classes of models based on varying the temporal granularity and then ev aluate the utility of these models. In addition to discov ering temporal patterns, these models are applied to measure the temporal stability and variance of the classifiers ov er time. • P A S T -to- P R E S E N T . These models consider the linked nodes from the distant past and successively increases the size of the window to consider more recent links, attributes, and nodes. • P R E S E N T -to- P A S T . These models initially consider only the most recent links, nodes, and attributes and successiv ely increase the size of the windo w to consid- ering more of the past. • T E M P O R A L P O I N T . These models only consider the links, nodes, and attributes at timestep k . Mining T emporal-Relational Patterns Intuitiv ely , Fig- ure 10 shows that if we consider only the past and suc- cessiv ely include more recent information, then the A UC increases as a function of the more recent attrib utes and links 0.85 0.90 0.95 1.00 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 Time AUC Time Point Present−to−Past Past−to−Present (a) AI (RBC) 0.5 0.6 0.7 0.8 0.9 1.0 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 Time AUC Time Point Present−to−Past Past−to−Present (b) ML (RBC) Figure 10. A variety of temporal granularity models (uniform weighting). A verage accuracy using RPT and RBC classifiers for ML and AI prediction tasks. (i.e., P A S T -T o- P R E S E N T model). Con versely , if we consider only the most recent temporal information and successively include more of the past then the A UC initially increases to a local maximum and then dips before increasing as additional past information is modeled. This drop in accuracy indicates a type of temporal-transition in the link structure and at- tributes. Howe ver , we might also expect the v alues to decay more quickly since papers published in the distant past are generally less similar to recent papers as shown pre viously . Overfitting may justify the slight impro vement in A UC as noisey past information is added. The noise reduces bias in training and consequently increases the models ability to generalize for predicting instances in the future. Ho wev er , this might not al ways be the case. W e expect the noise to be minor in this domain as papers are unlikely to cite other papers in the past that are not related. More interestingly , the class of T E M P O R A L - P O I N T mod- els allo w us to more accurately determine if past actions at some previous timestep are predicti ve of the future and how these beha viors transition over time. These patterns are shown in Figure 10. T emporal Anomalies. The temporal granularity models capture many temporal anomalies. One striking anomaly is seen in Figure 10(a) where the accurac y of the T E M P O R A L - P O I N T model decreases significantly in 1990, but then by 1991 the accuracy has increased back to the previous level. T emporal Stability of Relational Classifiers. W e use the temporal granularity models to compare more accurately the stability of the modified temporal RBC and RPT classifiers which leads us to identify a few striking differences between the two classifiers when modelling temporal networks. In Figure 11(b), the RBC is shown to be stable over time whereas the variance and stability of the RPT is significantly worse. This lead us to analyze the internals of the modified RPT and found that for the ML prediction task, the structure of the trees at each timestep are significantly different from one another and consequently unstable. Howe ver , we found the structure of the trees to more gradually e v olve in the AI prediction task, making the RPT relati vely more stable ov er time. In addition, we also found the RBC to perform extremely well ev en with small amounts of temporal information (low support for any hypothesis). The RPT and RBC are shown to have complementary adv antages and disadvantages, es- pecially for predicting temporal attributes. This provides further justification for the proposed temporal ensemble method that uses both RPT and RBC with each selected temporal-relational representation. T emporal Relational Statistics. The temporal granularity models can be used to compute intuitive yet informati ve simple measures to gain insights into the temporal nature of a network. The G L O B A L L I N K R E C E N C Y measures the probability of citing a paper at time t and t − 1 for the years 1993-1998 in both AI and ML prediction tasks 0.90 0.92 0.94 0.96 0.98 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 Time AUC RPT RBC (a) T emporal Stability (AI) 0.70 0.75 0.80 0.85 0.90 0.95 1.00 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 Time AUC RPT RBC (b) T emporal Stability (ML) Figure 11. A verage T emporal Stability of RPT and RBC for AI and ML prediction tasks. as shown in Figure 12(a). For instance, the link recency measure (AI) between 1993 and 1995 is approximately 60% indicating that out of all the cited papers the majority of them are published in the same year t or the previous year t − 1 . Interestingly , the papers published in the most recent years (e.g., 1998) cite fewer papers from the same year or previous year and more papers in the past (i.e., indicating a temporal-transition that could be due to papers becoming more av ailable to researchers, perhaps with digital archives or other factors). Furthermore, the temporal r elational auto- corr elation measure shows that in general the recent papers are more influential compared to the papers in the past (correlation plots omitted for brevity). The temporal link probabilities for the AI and ML pre- diction tasks are shown in Figure 12(b). For the papers in each time period, the probability of citing a paper gi ven the time-lag ` is computed. Interestingly , the link probabilities at ` = 3 for each prediction-time approximately begin to con verge. Indicating a global pattern with respect to past links that is independent of the core-nodes initial time period. Howe ver , the time-lag between 0 ≤ ` ≤ 3 captures local patterns with respect to the core-nodes prediction time. Hence, the more recent behavior of the core-nodes is significantly different than their past behavior . 0.35 0.40 0.45 0.50 0.55 0.60 0.65 1993 1994 1995 1996 1997 1998 Time Measure of Link Recency Link Recency (ML) Link Recency (AI) (a) G L OB A L L I N K R E C EN C Y 0.0 0.1 0.2 0.3 0.4 0 1 2 3 4 5 6 7 8 9 10 Time lag T emporal Link Probability 1993 1994 1995 1996 1997 1998 (b) T E M PO R A L L I NK P RO BA B I LI T Y (ML) T able III A S E T O F D I SC OV E R ED T O PI C S A N D T H E M O S T S I G NI FI C AN T W O RD S T OP I C 1 T OP I C 2 T OP I C 3 T OP I C 4 T O PI C 5 dev logged gt code test wrote patch file object lib guido issue lt class view import bugs line case svn code b ug os method trunk pep problem import type rev mail fix print list modules release fixed call set build tests days read objects amp work created socket change error people time path imple usr make docu data functions include pm module error argument home ve docs open dict file support added windows add run module check problem def main things doc traceback methods local good doesnt mailto exception src van report recent ms directory D. Dynamic T extual Analysis: Interpreting Links and Nodes In this task, we use only the communications to generate a network and then automatically annotate the links and nodes by disco vering the latent topics of these communications. There are man y moti vations for such an approach, howe ver , we are most interested in automatically learning e volu- tionary patterns between the topics and the corresponding dev elopers to increase the accurac y of temporal-relational representations and classifiers. W e first removed a standard list of stopwords and then use a version of Latent Dirichlet Allocation (LD A [12]) to model the topics over time. W e use EM to estimate the parameters and Gibbs sampling for inference. After extracting the latent topics, inference is used to label each link with it’ s most likely latent topic and each node with their most frequent topic. Instead of this simple representation, we could hav e used the link probability distributions ov er time, but found that the potential performance gain did not justify the significant increase in complexity . The latent topics are modeled in three communication networks (email, bug, and both). From these annotated temporal networks, we in vestigate the ef fects of modeling the latent topics of the communications and their e volution ov er time. W e use the disco vered ev olutionary patterns as features to explore the temporal-relational representations, classifiers, and ensembles and ev aluate and compare each of the models. T able III lists a fe w topics and the most significant words for each. W e find words with both positiv e and negativ e connotation such as ‘good’ or ‘doesnt’ (i.e., related to sentiment analysis) and also words referring to the domain such as ‘bugs’ or ‘exception’. Additionally , we find the top- ics correspond to different dev elopment and social aspects. Interestingly , the word ‘guido’ appears significant, since T=1 T=2 T=3 T=4 AV G A UC 0.65 0.70 0.75 0.80 0.85 0.90 0.95 TENC TVRC Window Model Union Model Figure 12. Evaluation of temporal-relational classifiers using only the latent topics of the communications to predict effecti veness. LD A is used to automatically discover the latent topics as well as annotating the communication links and individuals with their appropriate topic in the temporal networks. Guido van Rossum is the author of the Python programming language. E. Modeling the Evolutionary P atterns of T opics W e ev aluate these dynamic topic features using v arious temporal-relational representations for improving classifica- tion models. Figure 12 indicates the necessity of using a more optimal temporal-relational representation that models the temporal influence of links and attributes. More interest- ingly , we see that models that consider only simple temporal- relational representations perform significantly worse, in- dicating that the dynamic topics are only meaningful if appropriately modeled. Additionally , we also learned more complex models from the class of window models to exploit additional temporal granularities, but removed the plots for brevity . In all the e xperiments, we find that the temporal- relational representations that lev erage more of the temporal information outperform models that use only some of the temporal information. Evolutionary patterns between the topics, de velopers, and their effecti veness are clearly present in annotated netw orks. These results indicate that productiv e dev elopers usually communicate about similar topics or aspects of de velopment. Additionally , we find that effecti ve communications have a specific structure that consequently enables others to become more ef fective. Moreo ver , these topics and the corresponding communications ov er time are temporally correlated with a dev elopers effecti veness. V I I . C O N C L U S I O N W e proposed a framew ork for temporal-relational clas- sifiers, ensembles, and more generally , representations for mining temporal data. W e ev aluate and provide insights of each using real-world networks with different attributes and informational constraints. The results demonstrated the effecti veness, scalability , and flexibility of the temporal- relational representations for classification, ensembles, and mining temporal networks. A C K N O W L E D G M E N T S This research is supported by DARP A and NSF under contract number(s) NBCH1080005 and SES-0823313. This research was also made with Government support under and awarded by DoD, Air F orce Office of Scientific Re- search, National Defense Science and Engineering Graduate (NDSEG) Fellowship, 32 CFR 168a. The U.S. Government is authorized to reproduce and distribute reprints for go v- ernmental purposes notwithstanding any copyright notation hereon. The vie ws and conclusions contained herein are those of the authors and should not be interpreted as nec- essarily representing the official policies or endorsements either expressed or implied, of DARP A, NSF , or the U.S. Gov ernment. R E F E R E N C E S [1] S. Chakrabarti, B. Dom, and P . Indyk, “Enhanced hypertext categorization using hyperlinks, ” in SIGMOD , 1998, pp. 307– 318. [2] P . Domingos and M. Richardson, “Mining the network value of customers, ” in SIGKDD , 2001, pp. 57–66. [3] J. Ne ville, O. S ¸ ims ¸ ek, D. Jensen, J. Komorosk e, K. Palmer, and H. Goldberg, “Using relational knowledge discov ery to prev ent securities fraud, ” in SIGKDD , 2005, pp. 449–458. [4] U. Sharan and J. Ne ville, “T emporal-relational classifiers for prediction in e volving domains, ” in ICML , 2008. [5] Q. Mei and C. Zhai, “Discov ering ev olutionary theme patterns from text - an exploration of temporal text mining, ” in SIGKDD , 2005, pp. 198–207. [6] J. T ang, M. Musolesi, C. Mascolo, V . Latora, and V . Nicosia, “Analysing Information Flows and Key Mediators through T emporal Centrality Metrics, ” 2010. [7] C. Cortes, D. Pregibon, and C. V olinsky , “Communities of interest, ” in IDA , 2001, pp. 105–114. [8] J. Neville, D. Jensen, and B. Gallagher , “Simple estimators for relational Bayesian classifers, ” in ICML , 2003, pp. 609– 612. [9] J. Neville, D. Jensen, L. Friedland, and M. Hay , “Learning relational probability trees, ” in SIGKDD , 2003, pp. 625–630. [10] P . Domingos and M. Pazzani, “On the optimality of the simple bayesian classifier under zero-one loss, ” Machine Learning , vol. 29, pp. 103–130, 1997. [11] T . Dietterich, “Ensemble methods in machine learning, ” Mul- tiple classifier systems , pp. 1–15, 2000. [12] D. Blei, A. Ng, and M. Jordan, “Latent Dirichlet allocation, ” JMLR , vol. 3, pp. 993–1022, 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment