Two adaptive rejection sampling schemes for probability density functions log-convex tails
Monte Carlo methods are often necessary for the implementation of optimal Bayesian estimators. A fundamental technique that can be used to generate samples from virtually any target probability distribution is the so-called rejection sampling method,…
Authors: Luca Martino, Joaquin Miguez
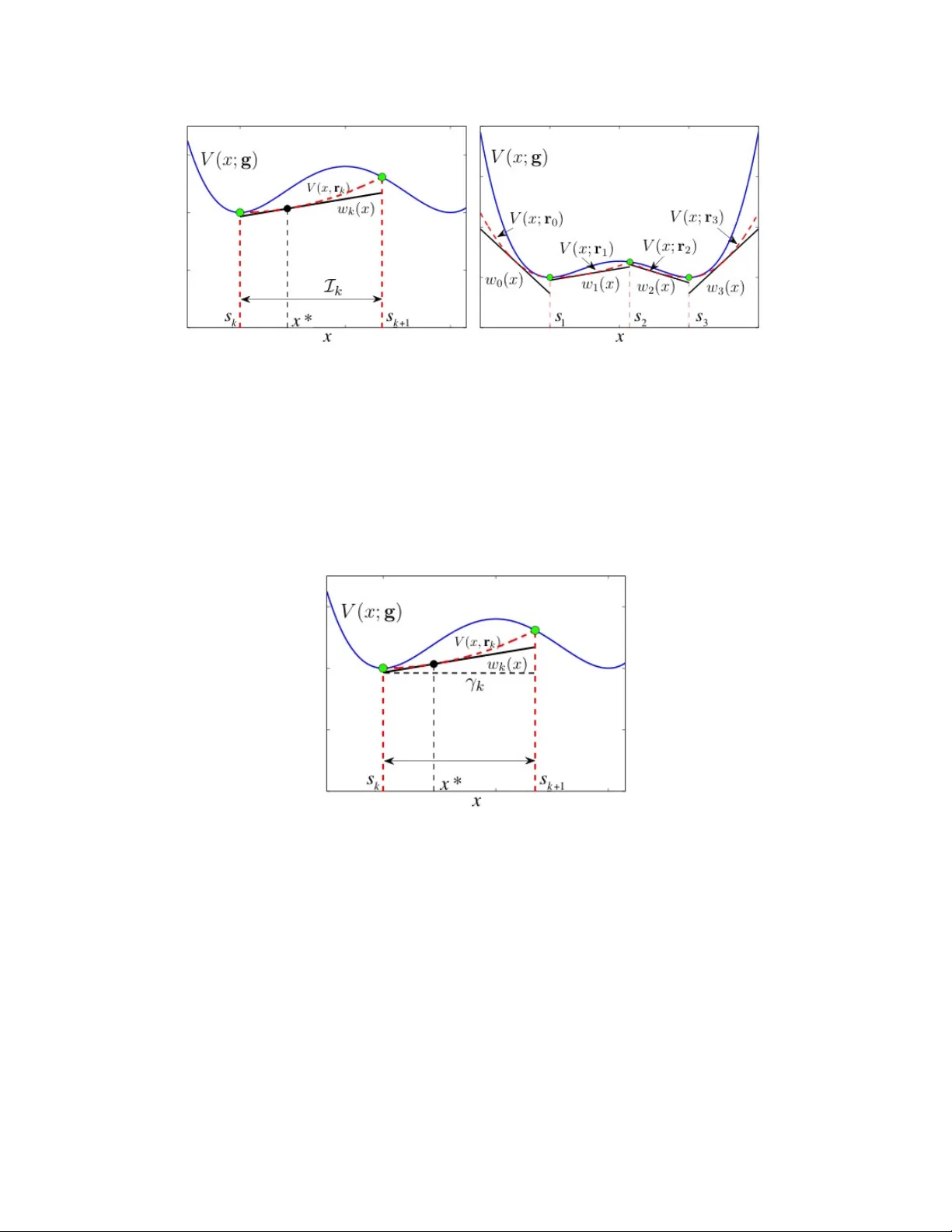
1 T wo adapti v e rejection sampling schemes for probability density functions log-con v ex tails Luca Martino and Joaqu ´ ın M ´ ıguez Department of Signal Theory and Communications, Uni versidad Carlos III de Madrid. A venida de la Uni versidad 30, 28911 Leg an ´ es, Madrid, Spain. E-mail: luca@tsc.uc3m.es, joaquin.miguez@uc3m.es Abstract Monte Carlo methods are often necessary for the implementation of optimal Bayesian estimators. A fundamental technique that can be used to generate samples from virtually any target probability distribution is the so-called rejection sampling method, which generates candidate samples from a proposal distribution and then accepts them or not by testing the ratio of the target and proposal densities. The class of adapti ve rejection sampling (ARS) algorithms is particularly interesting because they can achiev e high acceptance rates. Howe ver , the standard ARS method can only be used with log-concave target densities. For this reason, many generalizations hav e been proposed. In this work, we in vestigate two different adaptiv e schemes that can be used to draw exactly from a large family of univ ariate probability density functions (pdf ’ s), not necessarily log-concave, possibly multimodal and with tails of arbitrary concavity . These techniques are adaptiv e in the sense that ev ery time a candidate sample is rejected, the acceptance rate is improved. The two proposed algorithms can work properly when the target pdf is multimodal, with first and second deriv atives analytically intractable, and when the tails are log-con ve x in a infinite domain. Therefore, they can be applied in a number of scenarios in which the other generalizations of the standard ARS fail. T wo illustrative numerical examples are shown. Index T erms Rejection sampling; adaptive rejection sampling; ratio of uniforms method; particle filtering; Monte Carlo integration; volatility model. 2 I . I N T RO D U C T I O N Monte Carlo methods are often necessary for the implementation of optimal Bayesian estimators and, se veral families of techniques have been proposed [5, 12, 18, 1] that enjoy numerous applications. A fundamental technique that can be used to generate independent and identically distributed (i.i.d.) samples from virtually an y target probability distribution is the so-called rejection sampling method, which generates candidate samples from a proposal distribution and then accepts them or not by testing the ratio of the target and proposal densities. Se veral computationally efficiencient methods hav e been designed in which samples from a scalar random v ariable (r .v .) are accepted with high probability . The class of adaptiv e rejection sampling (ARS) algorithms [11] is particularly interesting because high acceptance rates can be achie ved. The standard ARS algorithm yields a sequence of proposal functions that actually con verge tow ards the target probability density distribution (pdf) when the procedure is iterated. As the proposal density becomes closer to the target pdf, the proportion of accepted samples grows (and, in the limit, can also con ver ge to 1). Howe ver , this algorithm can only be used with log-conca ve tar get densities. A v ariation of the standard procedure, termed adaptiv e rejection Metropolis sampling (ARMS) [10] can also be used with multimodal pdf ’ s. Howe ver , the ARMS algorithm is based on the Metropolis-Hastings algorithm, so the resulting samples form a Markov chain. As a consequence, they are correlated and, for certain multimodal densities, the chain can be easily trapped in a single mode (see, e.g., [23]). Another extension of the standard ARS technique has been proposed in [14], where the same method of [11] is applied to T -concav e densities, with T being a monotonically increasing transformation, not necessarily the logarithm. Ho we ver , in practice it is hard to find useful transformations other than the logarithm and the technique cannot be applied to multimodal densities either . The method in [6] generalizes the technique of [14] to multimodal distributions. It in volves the decomposition of the T - transformed density into pieces which are either con ve x and conca ve on disjoint intervals and can be handled separately . Unfortunately , this decomposition requires the ability to find all the inflection points of the T -transformed density , which can be something hard to do e ven for relati vely simple practical problems. More recently , it has been proposed to handle multimodal distributions by decomposing the log-density into a sum of concave and con ve x functions [13]. Then, ev ery concave/con vex element is handled using a method similar to the ARS procedure. A drawback of this technique is the need to decompose the target log-pdf into concav e and con ve x components. Although this can be natural for some examples, it can 3 also be very though for some practical problems (in general, identifying the con ve x and concav e parts of the log-density may require the computation of all its inflection points). Moreo ver , the application of this technique to distributions with an infinite support requires that the tails of the log-densities be strictly concav e. Other adaptive schemes that extend the standard ARS method for multimodal densities hav e been very recently introduced in [22, 23]. These techniques include the original ARS algorithm as a particular case and they can be relativ ely simpler than the approaches in [6] or [13] because they do not require the computation of the inflection points of the entire (transformed) target density . Howe ver , the method in [23] and the basic approach in [22] can also break down when the tails of the target pdf are log-conv ex, the same as the techniques in [11, 13, 14]. In this paper, we introduce two different ARS schemes that can be used to draw exactly from a large family of uni v ariate pdf ’ s, not necessarily log-concav e and including cases in which the pdf has log- con vex tails in an infinite domain. Therefore, the ne w methods can be applied to problems where the algorithms of, e.g., [11, 14, 13, 22] are in valid. The first adaptiv e scheme described in this work was briefly suggested in [22] as alternativ e strategy . Here, we take this suggestion and elaborate it to provide a full description of the resulting algorithm. This procedure can be easy to implement and provide good performance as shown in a numerical e xample. Ho wev er , it presents some technical requirements that can prev ent its use with certain densities, as we also illustrate in a second example. The second approach introduced here is more general and it is based on the ratio of uniforms (RoU) technique [3, 17, 25]. The RoU method enables us to obtain a two dimensional region A such that drawing from the univ ariate target density is equi valent to drawing uniformly from A . When the tails of the target density decay as 1 /x 2 (or faster), the region A is bounded and, in such case, we introduce an adaptiv e technique that generates a collection of non-ov erlapping triangular regions that cov er A completely . Then, we can efficiently use rejection sampling to draw uniformly from A (by first drawing uniformly from the triangles). Let us remark that a basic adaptive rejection sampling scheme based on the RoU technique was already introduced in [19, 20] but it only works when the region A is strictly con ve x 1 . The adapti ve scheme that we introduce can also be used with non-con vex sets. The rest of the paper is org anized as follows. The necessary background material is presented in Section II. The first adaptive procedure is described in Section III while the adaptive RoU scheme is introduced in Section IV. In Section V we present two illustrativ e examples and we conclude with a brief summary 1 It can be seen as a RoU-based counterpart of the original ARS algorithm in [11], that requires the log-density to be concav e. 4 and conclusions in Section VI. I I . B A C K G R O U N D In this Section we recall some background material needed for the remaining of the paper . First, in Sections II-A and II-B we briefly revie w the rejection sampling method and its adapti ve implementation, respecti vely . The dif ficulty of handling target densities with log-con vex tails is discussed in Section II-C. Finally , we present the ratio of uniforms (RoU) method in Section II-D. A. Rejection sampling Rejection sampling [3, Chapter 2] is a univ ersal method for drawing independent samples from a target density p o ( x ) ≥ 0 known up to a proportionality constant (hence, we can ev aluate p ( x ) ∝ p o ( x ) ). Let exp {− W ( x ) } be an ov erbounding function for p ( x ) , i.e., exp {− W ( x ) } ≥ p ( x ) . W e can generate N i.i.d. samples from p o ( x ) according to the standard rejection sampling algorithm: 1) Set i = 1 . 2) Draw samples x 0 from π ( x ) ∝ exp {− W ( x ) } and u 0 from U (0 , 1) , where U (0 , 1) is the uniform pdf in [0 , 1] . 3) If p ( x 0 ) exp {− W ( x ) } ≥ u 0 then x ( i ) = x 0 and set i = i + 1 , else discard x 0 and go back to step 2. 4) If i > N then stop, else go back to step 2. The fundamental figure of merit of a rejection sampler is the mean acceptance rate, i.e., the e xpected number of accepted samples o ver the total number of proposed candidates. In practice, finding a tight ov erbounding function is crucial for the performance of a rejection sampling algorithm. In order to improv e the mean acceptance rate many adaptiv e variants hav e been proposed [6, 11, 13, 14, 22]. B. An adaptive r ejection sampling scheme W e describe the method in [22], that contains the the standard ARS algorithm of [11] as a particular case. Let us write the target pdf as p o ( x ) ∝ p ( x ) = exp {− V ( x ; g ) } , D ⊂ R , where D ⊂ R is the support if p o ( x ) and V ( x ; g ) is termed the potential function of p o ( x ) . In order to apply the technique of [22], we assume that the potential function can be expressed ass the addition of n terms, V ( x ; g ) , n X i =1 ¯ V i ( g i ( x )) , (1) where the functions ¯ V i , i = 1 , ..., n , referred to as marginal potentials, are con ve x while e very g i ( x ) , i = 1 , ..., n , is either con vex or concav e. As a consequence, the potential V ( x ; g ) is possible non-con ve x (hence, the standard ARS algorithm cannot be applied) and can hav e rather complicated forms. 5 The sampling method is iterativ e. Assume that, after the ( t − 1) -th iteration, there is av ailable a set of m t distinct support points, S t = { s 1 , s 2 , . . . , s m t } ⊂ D , sorted in ascending order , i.e., s 1 < s 2 < . . . < s m t . From this set, we define m t + 1 intervals of the form I 0 = ( −∞ , s 1 ] , I k = [ s k , s k +1 ] , k = 1 , . . . , m t − 1 , and I m t = [ s m t , + ∞ ) . For each interval I k , it is possible to construct a vector of linear functions r k ( x ) = [ r 1 ,k ( x ) , . . . , r n,k ( x )] such that ¯ V i ( r i,k ( x )) ≤ ¯ V i ( g i ( x )) (see [22]) and, as a consequence, V ( x ; r k ) ≤ V ( x ; g ) , for all x ∈ I k (2) and k = 0 , ..., m t . Hence, it is possible to obtain exp {− V ( x ; r k ) } ≥ p ( x ) , ∀ x ∈ I k . Moreo ver , the modified potential V ( x ; r k ) is strictly con vex in the interv al I k and, therefore, it is straightforw ard to build a linear function w k ( x ) , tangent to V ( x ; r k ) , such that w k ( x ) ≤ V ( x ; r k ) and exp {− w k ( x ) } ≥ p ( x ) for all x ∈ I k . W ith these ingredients, we can outline the generalized ARS algorithm as follows. 1) Initialization. Set i = 1 , t = 0 and choose m 1 support points, S 1 = { s 1 , ..., s m 1 } . 2) Iteration. For t ≥ 1 , take the following steps. • From S t , determine the intervals I 0 , . . . , I m t . • For k = 0 , . . . , m t , construct r k , V ( x ; r k ) and w k ( x ) . • Let W t ( x ) = w k ( x ) , if x ∈ I k , k ∈ { 0 , . . . , m t } . • Build the proposal pdf π t ( x ) ∝ exp {− W t ( x ) } . • Draw x 0 from the proposal π t ( x ) and u 0 from U (0 , 1) . • If u 0 ≤ p ( x 0 ) exp {− W t ( x 0 ) } , then accept x ( i ) = x 0 and set S t +1 = S t , m t +1 = m t , i = i + 1 . • Otherwise, if u 0 > p ( x 0 ) exp {− W t ( x 0 ) } , then reject x 0 , set S t +1 = S t ∪ { x 0 } and update m t +1 = m t + 1 . • Sort S t +1 in ascending order and increment t = t + 1 . If i > N , then stop the iteration. Note that it is very easy to draw from π t ( x ) because it consists of pieces of exponential densities. Moreov er , e very time we reject a sample x 0 , it is incorporated into the set of support points and, as a consequence, the shape of the proposal π t ( x ) becomes closer to the shape of the target p o ( x ) and the acceptance rate of the candidate samples is improved [22]. C. Log-con vex tails The algorithm of Section II-B breaks down when the potential function V ( x ; g ) has both an infinite support ( x ∈ D = R ) and concave tails (i.e, the tar get pdf p o ( x ) has log-con vex tails). In this case, the function W t ( x ) becomes constant ov er an interval of infinite length and we cannot obtain a proper 6 proposal pdf π t ( x ) . T o be specific, if V ( x ; g ) is concav e in the intervals ( −∞ , s 1 ] , [ s m t , + ∞ ) or both, then w 0 ( x ) , w m t ( x ) , or both, are constant and, as a consequence, R + ∞ −∞ exp {− W t ( x ) } dx = + ∞ . This difficulty with the tails is actually shared by other adaptiv e rejection sampling techniques in the literature. A theoretical solution to the problem is to find an in vertible transformation G : D → D ∗ , where D ∗ ⊂ R is a bounded set [3, 15, 21, 26]. Then, we can define a random variable Y = G ( x ) with density q ( y ) , dra w samples y (1) , . . . , y ( N ) and then con vert them into samples x (1) = G − 1 ( y (1) ) , . . . , x ( N ) = G − 1 ( y ( N ) ) from the target pdf p o ( x ) of the r .v . X . Howe ver , in practice, it is difficult to find a suitable transformation G , since the resulting density q ( y ) may not hav e a structure that makes sampling any easier than in the original setting. A similar, albeit more sophisticated, approach is to use the method of [6]. In this case, we need to build a partition of the domain D with disjoint intervals D = ∪ m i =1 D i and then apply in vertible transformations T i : D i → R , i = 1 , ..., m , to the tar get function p ( x ) . In particular , the intervals D 1 and D m contain the tails of p ( x ) and the method works correctly if the composed functions ( T 1 ◦ p )( x ) and ( T m ◦ p )( x ) are conca ve. Howe ver , finding adequate T 1 and T m is not necessarily a simple task and, e ven if the y are obtained, applying the algorithm of [6] requires the ability to compute all the inflection points of the target function p ( x ) . D. Ratio of uniforms method The RoU method [2, 17, 25] is a sampling technique that relies on the following result. Theorem 1: Let q ( x ) ≥ 0 be a pdf kno wn only up to a proportionality constant. If ( u, v ) is a sample drawn from the uniform distribution on the set A = n ( v , u ) ∈ R 2 : 0 ≤ u ≤ p q ( v /u ) o , (3) then x = v u is a sample form q ( x ) . Proof : See [3, Theorem 7.1]. Therefore, if we are able to draw uniformly from A , then we can also draw from the pdf q o ( x ) ∝ q ( x ) . The cases of practical interest are those in which the re gion A is bounded, and A is bounded if, and only if, both p q ( x ) and x p q ( x ) are bounded. Moreover , the function p q ( x ) is bounded if, and only if, the target density q o ( x ) ∝ q ( x ) is bounded and, assuming we have a bounded target function q ( x ) , the function x p q ( x ) is bounded if, and only if, the tails of q ( x ) decay as 1 /x 2 or faster . Chung97,W akefield91 defining different region A that could be used for fatter tails. 7 Figure 1 (a) depicts a bounded set A . Note that, for e very angle α ∈ ( − π / 2 , + π / 2) rad, we can draw a straight line that passes through the origin (0 , 0) and contains points ( v i , u i ) ∈ A such that x = v i u i = tan( α ) , i.e., ev ery point ( v i , u i ) in the straight line with angle α yields the same value of x . From the definition of A , we obtain u i ≤ q ( x ) and v i = xu i ≤ x p q ( x ) , hence, if we choose the point ( v 2 , u 2 ) that lies on the boundary of A , u 2 = p q ( x ) and v 2 = x p q ( x ) . Moreov er , we can embed the set A in the rectangular region R = n ( v 0 , u 0 ) : 0 ≤ u 0 ≤ sup x p q ( x ) , inf x x p q ( x ) ≤ v 0 ≤ sup x x p q ( x ) o , (4) as depicted in Fig. 1 (b). Once R is constructed, it is straightforward to draw uniformly from A by rejection sampling: simply draw uniformly from R and then check whether the candidate point belongs to A . (a) (b) Fig. 1. (a) A bounded region A and the straight line v = xu corresponding to the sample x = tan( α ) . Every point in the intersection of the line v = xu and the set A yields the same sample x . The point on the boundary , ( v 2 , u 2 ) , has coordinates v 2 = x p q ( x ) and u 2 = p q ( x ) . (b) If the two functions p q ( x ) and x p q ( x ) are bounded, the set A is bounded and embedded in the rectangle R . I I I . A DA P T I V E R E J E C T I O N S A M P L I N G W I T H L O G - C O N V E X TA I L S In this section, we in vestigate a strategy proposed in [22] to obtain an adapti ve rejection sampling algorithm that remains valid the tails of the potential function V ( x ; g ) are concav e (i.e, the target pdf p o ( x ) has log-con ve x tails). Let us assume that for some j ∈ { 1 , . . . , n } , the pdf defined as q ( x ) ∝ exp {− ¯ V j ( g j ( x )) } (5) 8 is such that: (a) we can integrate q ( x ) ov er the interv als I 0 , I 1 , ..., I m t and (b) we can sample from the density q ( x ) restricted to every I k . T o be specific, let us introduce the reduced potential V − j ( x ; g ) , n X i =1 ,i 6 = j ¯ V i ( g i ( x )) , (6) attained by removing ¯ V j ( g j ( x )) from V ( x ; g ) . It is straightforward to obtain lo wer bounds γ k ≤ V − j ( x ; g ) by applying the procedure explained in the Appendix to the reduced potential V − j ( x ; g ) in e very interval I k , k = 0 , ..., m t . Once these bounds are a v ailable, we set L k , exp {− γ k } and build the piecewise proposal function π t ( x ) ∝ L 0 exp {− ¯ V j ( g j ( x )) } , ∀ x ∈ I 0 , . . . L k exp {− ¯ V j ( g j ( x )) } , ∀ x ∈ I k , . . . L m t exp {− ¯ V j ( g j ( x )) } , ∀ x ∈ I m t . (7) Notice that, for all x ∈ I k , we hav e L k ≥ exp {− V − j ( x ; g ) } and multiplying both sides of this inequality by the positiv e factor exp {− ¯ V j ( g j ( x )) } ≥ 0 , we obtain L k exp {− ¯ V j ( g j ( x )) } ≥ exp {− V ( x ; g ) } , ∀ x ∈ I k , hence π t ( x ) is suitable for rejection sampling. Finally , note that π t ( x ) is a mixture of truncated densities with non-overlapping supports. Indeed, let us define the mixture coefficients ¯ α k , L k Z I k q ( x ) dx (8) and normalize them as α k = ¯ α k / P m t k =0 ¯ α k . Then, π t ( x ) = m t X k =1 α k q ( x ) χ k ( x ) (9) where χ k ( x ) is an indicator function ( χ k ( x ) = 1 if x ∈ I k and χ k ( x ) = 0 if x / ∈ I k ). The complete algorithm is summarized below . 1) Initialization. Set i = 1 , t = 0 and choose m 1 support points, S 1 = { s 1 , ..., s m 1 } . 2) Iteration. For t ≥ 1 , take the following steps. • From S t , determine the intervals I 0 , . . . , I m t . • Choose a suitable pdf q ( x ) ∝ exp {− ¯ V j ( g j ( x )) } for some j ∈ { 1 , ..., n } . • For k = 0 , . . . , m t , compute the lo wer bounds γ k ≤ V − j ( x, g ) , ∀ x ∈ I k , and set L k = exp {− γ k } (see the Appendix). 9 • Build the proposal pdf π t ( x ) ∝ L k q ( x ) for x ∈ I k , k ∈ { 0 , . . . , m t } . • Draw x 0 from the proposal π t ( x ) in Eq. (9) and u 0 from U (0 , 1) . • If u 0 ≤ exp {− V − j ( x 0 ; g ) } L k , then accept x ( i ) = x 0 and set S t +1 = S t , m t +1 = m t , i = i + 1 . • Otherwise, if u 0 > exp {− V − j ( x 0 ; g ) } L k , then reject x 0 , set S t +1 = S t ∪{ x 0 } and update m t +1 = m t +1 . • Sort S t +1 in ascending order and increment t = t + 1 . If i > N , then stop the iteration. When a sample x 0 drawn from π t ( x ) is rejected, x 0 is added to the set of support points S t +1 , S t ∪{ x 0 } . Hence, we improve the piece wise constant approximation of V − j ( x ; g ) (formed by the upper bounds L k ) and proposal pdf π t +1 ( x ) ∝ L k exp {− ¯ V j ( g j ( x )) } , ∀ x ∈ I k , becomes closer to the target pdf p o ( x ) . Figure 2 (a) illustrates the reduced potential exp {− V − j ( x ; g ) } and its stepwise approximation L k = exp {− γ k } built using m t = 4 support points. Figure 2 (b) depicts the tar get pdf p o ( x ) jointly with the proposal pdf π t ( x ) , composed by weighted pieces of the function exp {− ¯ V j ( g j ( x )) } (sho wn, in dashed line). This procedure is feasible only if we can find a pair ¯ V j , g j , for some j ∈ { 1 , ..., n } , such that the pdf q ( x ) ∝ exp {− ¯ V j ( g j ( x )) } is • is analytically integrable in ev ery interv al I ⊂ D , giv en otherwise the weights α 1 ,..., α m t in Eq. (9) cannot be computed in general, and • is easy to draw from when truncated into a finite or an infinite interval, since otherwise we cannot generate samples from it. Note that in order to draw from π t ( x ) we need to be able to draw from and to integrate analytically truncated pieces of q ( x ) . This procedure is possible only if we hav e on hand a suitable pdf q ( x ) ∝ exp {− ¯ V j ( g j ( x )) } . The technique that we introduce in the next section, based on ratio of uniforms method, o vercomes these constraints. I V . A DA P T I V E R O U S C H E M E The RoU method can be a useful tool to deal with tar get pdf ’ s p o ( x ) ∝ p ( x ) = exp {− V ( x ; g ) } where V ( x ; g ) of the form in Eq. (1) in a infinite domain and with tails of arbitrary concavity . Indeed, as long as the tails of p ( x ) decay as 1 /x 2 (or faster), the region A defined by the RoU transformation is bounded and, therefore, the problem of drawing samples from the target density becomes equiv alent to that of drawing uniformly from a finite region. In order to draw uniformly from A by rejection sampling, we need to build a suitable set P ⊇ A for which we are able to generate uniform samples easily . This, in turn, requires knowledge of upper bounds 10 (a) (b) Fig. 2. (a) Example of the function exp {− V − j ( x ; g ) } and its stepwise approximation L k = exp {− γ k } , k = 0 , ..., m t = 4 , constructed with the proposed technique using four support points S t = { s 1 , s 2 , s 3 , s 4 } . (b) Our tar get pdf p o ( x ) ∝ exp {− V ( x ; g ) } = exp {− V − j ( x ; g ) − ¯ V j ( g j ( x )) } obtained by multiplying the previous function exp {− V − j ( x ; g ) } times exp {− ¯ V j ( g j ( x )) } (shown with dashed line). The picture also shows the shape of the proposal density π t ( x ) consisting of pieces of the function exp {− ¯ V j ( g j ( x )) } scaled by the constant values L k = exp {− γ k } . for the functions p p ( x ) and x p p ( x ) , as described in Section II-D. Indeed, note that to apply the RoU transformation directly to an improper proposal π t ( x ) ∝ exp { W t ( x ) } , with exp { W t ( x ) } ≥ p ( x ) and R + ∞ −∞ π t ( x ) dx → + ∞ , provides us an unbounded region A so that this strategy is useless. In the sequel, we describe how to adaptiv ely build a polygonal sets P t ( t = 1 , 2 , .... ) composed by non-ov erlapping triangular subsets that embed the region A . T o draw uniformly from P t , we randomly select one triangle (with probability proportional to its area) and then generate uniformly a sample point from it using the algorithm in the Appendix. If the sample belongs to A , it is accepted, and otherwise is rejected and the region P t is improved by adding another triangular piece. In Section IV -A below , we provide a detailed description of the proposed adaptive technique. Details of the computation of some bounds that are necessary for the algorithm are giv en in Section IV -B and in the Appendix. A. Adaptive Algorithm Gi ven a set of support points S t = { s 1 , . . . , s m t } , we assume that there always exists k 0 ∈ { 0 , ..., m t } such that s k 0 = 0 , i.e., the point zero is included in the set of support points S t . Hence, in an interv al I k = [ s k , s k +1 ] the points s k and s k +1 are both non-positi ve or both non-negati ve. 11 W e also assume that we are able to compute upper bounds L (1) k ≥ p p ( x ) , L (2) k ≥ x p p ( x ) (for x > 0 ) and L (3) k ≥ − x p p ( x ) (for x < 0 ) within e very interv al x ∈ I k = [ s k , s k +1 ] , k = 0 , ..., m t , where I 0 = ( −∞ , s 1 ] and I m t = [ s m t , + ∞ ) . 1) Construction of P t ⊇ A : Consider the construction in Figure 3 (a). For a pair of angles α k , arctan( s k ) and α k +1 , arctan( s k +1 ) , we define the subset A k , A ∩ J k , where J k is the cone with verte x at the origin (0 , 0) and delimited by the two straight lines that form angles α k and α k +1 w .r .t. the u axis. Note that, clearly , A = ∪ m t k =0 A k . For each k = 0 , ..., m t the subset A k is contained in a piece of circle C k ( A k ⊆ C k ) delimited by the angles α k , α k +1 and radius r k = r L (1) k 2 + L (2) k 2 , if s k , s k +1 ≥ 0 r L (1) k 2 + L (3) k 2 , if s k , s k +1 ≤ 0 (10) also shown (with a dashed line) in Fig. 3 (a). Unfortunately , it is not straightforward to generate samples uniformly from C k , but we can easy draw samples uniformly from a triangle in the plane R 2 , as explained in the Appendix. Hence, we can choose an arbitrarily a point in the arc of circumference that delimits C k (e.g., the point ( L (2) k , L (1) k ) in Fig. 3 (a)) and calculate the tangent line to the arc at this point. In this way , we b uild a triangular region T k such that T k ⊇ C k ⊇ A k , with a verte x at (0 , 0) . W e can repeat the procedure for ev ery k = 0 , ..., m t , with dif ferent angles α k = arctan( s k ) and α k +1 = arctan( s k +1 ) , and define the polygonal region P t , ∪ m t k =0 T k composed by non-overlapping triangular subsets. Note that, by construction, P t embeds the entire region A , i.e., A ⊆ P t . Figure 3 summarizes the procedure to build the set P t . In Figure 3 (a) we sho w the construction of a triangle T k within the angles α k = arctan( s k ) , α k +1 = arctan( s k +1 ) , using the upper bounds L (1) k and L (2) k for a single interval x ∈ I k = [ s k , s k +1 ] . Figure 3 (b) illustrates the entire region P t , ∪ 5 k =0 T k formed by m t + 1 = 6 triangular subsets that covers completely the region A , i.e., A ⊆ P t . 2) Adaptive sampling: T o generate samples uniformly in P t , we first have to select a triangle proportionally to the areas |T k | , k = 0 , ..., m t . Therefore, we define the normalized weights w k , |T k | P m t i =0 |T i | , (11) and then we choose a triangular piece by drawing an index k 0 ∈ { 0 , ..., m t } from the probability distribution P ( k ) = w k . Using the method in the Appendix, we can easily generate a point ( v 0 , u 0 ) uniformly in the selected triangular region T k 0 . If this point ( v 0 , u 0 ) belongs to A , we accept the sample 12 (a) (b) Fig. 3. (a) A region A constructed by the RoU method and a triangular region T k defining by the vertices v 1 , v 2 and v 3 built using the upper bounds L (1) k , L (2) k for the functions p p ( x ) and x p p ( x ) for all x ∈ I k = [ s k , s k +1 ] . The dashed line depicts the piece of circumference C k with radius r k = q ( L (1) k ) 2 + ( L (2) k ) 2 . The set T k embeds the subset A k = A ∩ J k where J k is the cone defined as v ∈ J k if and only if v = θ 1 v 2 + θ 2 v 3 and θ 1 , θ 2 ≥ 0 . (b) Construction of the polygonal region P t = ∪ 5 k =0 T k using m t = 5 support points, i.e., S t = { s 1 , s 2 , s 3 = 0 , s 4 , s 5 } . Observe that each triangle T k has a vertex at (0 , 0) . The set P t cov ers completely the region A obtained by the RoU method, i.e., A ⊂ P t . x 0 = v 0 /u 0 and set m t +1 = m t , S t +1 = S t and P t = P t . Otherwise, we discard the sample x 0 = v 0 /u 0 and incorporate it to the set of support points, S t +1 = S t ∪ { x 0 } , so that m t +1 = m t + 1 and the region P t is improved by adding another triangle. 3) Summary of the algorithm: The adaptiv e RS algorithm to generate N samples from p ( x ) using RoU is summarized as follows. 1) Initialization. Start with i = 1 , t = 0 and choose m 1 support points, S 1 = { s 1 , ..., s m 1 } . 2) Iteration. For t ≥ 1 , take the following steps. • From S t , determine the intervals I 0 , . . . , I m t . • Compute the upper bounds L ( j ) k , j = 1 , 2 , 3 , for each k = 0 , ..., m t (see Section IV -B and the Appendix). • Construct the triangular regions T k as described in Section IV -A1, k = 0 , ..., m t . • Calculate the area |T k | of ev ery triangle, and compute the normalized weights w k , |T k | P m t i =0 |T i | (12) with k = 0 , ..., m t . • Draw an index k 0 ∈ { 0 , ..., m t } from the probability distribution P ( k ) = w k . 13 • Generate a point ( v 0 , u 0 ) uniformly from the region T k 0 (see the Appendix). • If u 0 ≤ q p v 0 u 0 , then accept the sample x ( i ) = x 0 = v 0 u 0 , set i = i + 1 , S t +1 = S t and m t +1 = m t . • Otherwise, if u 0 > q p v 0 u 0 , then reject the sample x 0 = v 0 u 0 , set S t +1 = S t ∪ { x 0 } and m t +1 = m t + 1 . • Sort S t +1 in ascending order and increment t = t + 1 . If i > N , then stop the iteration. It is interesting to note that the region P t is equi valent, in the domain of x , to a proposal function π t ( x ) formed by pieces of reciprocal uniform distributions scaled and translated (as seen in Section II-D), i.e., π t ( x ) ∝ 1 / ( λ k x + β k ) 2 in every interv al I k , for some λ k and β k . B. Bounds for other potentials In this section we provide the details on the computation of the bounds L ( j ) k , j = 1 , 2 , 3 , needed for the implementation of the algorithm above. W e associate a potential V ( j ) to each function of interest. Specifically , since p ( x ) ∝ exp {− V ( x ; g ) } we readily obtain that p p ( x ) ∝ exp − V (1) ( x ; g ) , with V (1) ( x ; g ) , 1 2 V ( x ; g ) , x p p ( x ) ∝ exp − V (2) ( x ; g ) , with V (2) ( x ; g ) , 1 2 V ( x ; g ) − log( x ) , ( x > 0) , − x p p ( x ) ∝ exp − V (3) ( x ; g ) , with V (3) ( x ; g ) , 1 2 V ( x ; g ) − log( − x ) , ( x < 0) , (13) respecti vely . Note that it is equi valent to maximize the functions p p ( x ) , x p p ( x ) , − x p p ( x ) w .r .t. x and to minimize the corresponding potentials V ( j ) , j = 1 , 2 , 3 , also w .r .t. x . As a consequence, we may focus on the calculation of lo wer bounds γ ( j ) k ≤ V ( j ) ( x ; g ) in an interv al x ∈ I k , related to the upper bounds as L ( j ) k = exp {− γ ( j ) k } , j = 1 , 2 , 3 and k = 0 , ..., m t . This problem is far from tri vial, though. Even for very simple mar ginal potentials, ¯ V i , i = 1 , . . . , n , the potential functions, V ( j ) , j = 1 , 2 , 3 , can be highly multimodal w .r .t. x [23]. In the Appendix we describe a procedure to find a lower bound γ k for the potential V ( x ; g ) . W e can apply the same technique to the function V (1) ( x ; g ) = 1 2 V ( x ; g ) , associated to the function p p ( x ) , since V (1) is a scaled version of the generalized system potential V ( x ; g ) . Therefore, we can easily compute a lower bound γ (1) k ≤ V (1) ( x ; g ) in the interval I k . The procedure in the Appendix can also be applied to find upper bounds for x p p ( x ) , with x > 0 , and − x p p ( x ) with x < 0 . Indeed, recalling that the associated potentials are V (2) ( x ; g ) = 1 2 V ( x ; g ) − log ( x ) , 14 x > 0 , and V (3) ( x ; g ) = 1 2 V ( x ; g ) − log( − x ) , x < 0 , it is straightforward to realize that the corresponding modified potentials V (2) ( x ; r k ) , 1 2 V ( x ; r k ) − log( x ) , V (3) ( x ; r k ) , 1 2 V ( x ; r k ) − log( − x ) , (14) are con vex in I k , since the functions − log( x ) ( x > 0 ) and − log( − x ) ( x < 0 ), are also con vex. Therefore, it is always possible to compute lower bounds γ (2) k ≤ V (2) ( x ; g ) and γ (3) k ≤ V (3) ( x ; g ) . The corresponding upper bounds are L ( j ) k = exp {− γ ( j ) k } , j = 1 , 2 , 3 for all x ∈ I k . C. Heavier tails The standard RoU method can be easily generalized in this way: giv en the area A ρ = n ( v , u ) : 0 ≤ u ≤ [ p ( v /u ρ )] 1 / ( ρ +1) o , (15) if we are able to draw uniformly from it the pair ( v , u ) then x = v u ρ is a sample form p o ( x ) ∝ p ( x ) . The region A ρ is bounded if [ p ( x )] 1 / ( ρ +1) and x [ p ( x )] ρ/ ( ρ +1) are bounded. It occurs when p ( x ) is bounded and the its tails decay as 1 /x ( ρ +1) /ρ or faster . Hence, for ρ > 1 we can handle pdf ’ s with fatter tails than with the standard RoU method. In this case the potentials associated to our target pdf p o ( x ) ∝ exp {− V ( x ; g ) } are V (1) ( x ; g ) , 1 ρ + 1 V ( x ; g ) , V (2) ( x ; g ) , ρ ρ + 1 V ( x ; g ) − log( x ) , for x > 0 V (3) ( x ; g ) , ρ ρ + 1 V ( x ; g ) − log( − x ) , for x < 0 (16) Obviouly , we can use the technique in the Appendix to obtain lower bounds and to b uild an extended adapti ve RoU scheme to tackle target pdf ’ s with fatter tails. Moreov er , the constant parameter ρ affects to the shape of A ρ and, as a consequence, also the acceptance rate of a rejection sampler . Hence, in some case it is interesting to find the optimal value of ρ that maximizes the acceptance rate. V . E X A M P L E S In this section we illustrate the application of the proposed techniques. The first example is dev oted to compare the performance of the first adaptiv e technique in Section III and the adaptiv e RoU algorithm in Section IV using an artificial model. In the second example, we apply adaptiv e RoU scheme as a building block of an accept/reject particle filter [18] for inference in a financial volatility model. In this second example the first adaptiv e technique cannot implemented. Moreov er , note that the other generalizations of the standard ARS method proposed in [6, 11, 13, 14] cannot be applied in both examples. 15 A. Artificial example Let x be a positive scalar signal of interest, x ∈ R + , with exponential prior, q ( x ) ∝ exp {− λx } , λ > 0 , and consider the system with three observations, y = [ y 1 , y 2 , y 3 ] ∈ R n =3 , y 1 = a exp( − bx ) + ϑ 1 , y 2 = c log ( dx + 1) + ϑ 2 , and y 3 = ( x − e ) 2 + ϑ 3 , (17) where ϑ 1 , ϑ 2 , ϑ 3 are independent noise variables and a , b , c , d , e are constant parameters. Specifically , ϑ 1 and ϑ 2 are independent with generalized gamma pdf Γ g ( ϑ i ; α i , β i ) ∝ ϑ α i i exp {− ϑ β i i } , i = 1 , 2 , with parameters α 1 = 4 , β 1 = 2 and α 2 = 2 , β 2 = 2 , respectively . The variable ϑ 3 has a Gaussian density N ( ϑ 3 ; 0 , 1 / 2) ∝ exp {− ϑ 2 3 } . Our goal is to generate samples from the posterior pdf p ( x | y ) ∝ p ( y | x ) q ( x ) . Giv en the system (17) our target density can be written as p o ( x ) = p ( x | y ) ∝ exp {− V ( x ; g ) } , (18) where the potential is V ( x ; g ) =( y 1 − a exp( − bx )) 2 − log[ y 1 − a exp( − bx )) 4 ]+ + ( y 2 − c log( dx + 1)) 2 − log[( y 2 − c log( dx + 1)) 2 ]+ + ( y 3 − ( x − e ) 2 ) 2 + λx. (19) W e can interpreted it as V ( x ; g ) = ¯ V 1 ( g 1 ( x )) + ¯ V 2 ( g 2 ( x )) + ¯ V 3 ( g 3 ( x )) + ¯ V 4 ( g 4 ( x )) (20) where the marginal potentials are ˜ V 1 ( ϑ ) = ϑ 2 − log [ ϑ 4 ] with minimum at µ 1 = √ 2 , ˜ V 2 ( ϑ ) = ϑ 2 − log [ ϑ 2 ] with minimum at µ 2 = 1 , ˜ V 3 ( ϑ ) = ϑ 2 with minimum at µ 3 = 0 and ˜ V 4 ( ϑ ) = λ | ϑ | with minimum at µ 4 = 0 (we recall that λ > 0 and x ∈ R + ). Moreover , the vector of nonlinearities is g ( x ) = [ g 1 ( x ) = a exp( − bx ) , g 2 ( x ) = c log ( dx + 1) , g 3 ( x ) = ( x − e ) 2 , g 4 ( x ) = x ] . (21) Since all marginal potentials are con vex and all nonlinearities are con vex or concave, we can apply the proposed adaptive RoU technique. Moreover , since exp {− ¯ V 4 ( g 4 ( x )) } = exp {− λx } is easy to draw from, we can also applied the first technique described in Section III. Note, howe ver , that 1) the potential V ( x ; g ) in Eq. (19) is not con vex, 2) the target function p ( x | y ) ∝ exp {− V ( x ; g ) } can be multimodal, 3) the tails of the potential V ( x ; g ) are not con vex and 16 4) it is not possible to study analytically the first and the second deriv ativ es of the potential V ( x ; g ) . Therefore, the techniques in [11, 6, 13, 14] and the basic strategy in [22] cannot be used. The procedure in Section III can be used because of the pdf q 4 ( x ) ∝ exp {− V 4 ( g 4 ( x )) } = exp {− x } can be easily integrated and sampled, ev en if it is restricted in a interval I k . In this case, the reduced potential is V − 4 ( x ; g ) = ¯ V 1 ( g 1 ( x )) + ¯ V 2 ( g 2 ( x )) + ¯ V 3 ( g 3 ( x )) and the corresponding function exp {− V − 4 ( x ; g ) } is the likelihood, i.e., p ( y | x ) = exp {− V − 4 ( x ; g ) } , since q 4 ( x ) coincides with the prior pdf. Moreov er , in order to use the RoU method we additionally need to study the potential functions V (1) ( x ; g ) = 1 2 V ( x ; g ) and V (2) ( x ; g ) = 1 2 V ( x ; g ) − log ( x ) . Since we assume x ≥ 0 , it is not necessary to study V (3) as described in Section IV -B. W e set, e.g., a = − 2 , b = 1 . 1 , c = − 0 . 8 , d = 1 . 5 , e = 2 , λ = 0 . 2 and y = [2 . 314 , 1 . 6 , 2] , and we start with the set of support points S 0 = { 0 , 2 − √ 2 , 2 , 2 + √ 2 } (details of the initialization step are explained in [22]). Figure 4 (a) shows the posterior density p ( x | y ) and the corresponding normalized histogram obtained by the first adaptive rejection sampling scheme. Figure 4 (b) depicts, jointly , the likelihood function p ( y | x ) = exp {− V − 4 ( x ; g ) } and its stepwise approximation exp {− γ k } ∀ x ∈ I k , k = 0 , ..., m t . The computation of the lower bounds γ k ≤ V − 4 ( x ; g ) has been explained in Appendix and Section III. Figure 4 (c) depicts the set A (solid) obtained by way of the RoU method, corresponding to the posterior density p ( x | y ) and the region ∪ m t k =0 T k formed by triangular pieces, constructed as described in Section IV -A with m t = 9 support points. The simulations sho ws that both method attain very similar acceptance rates 2 . In Figure 5 (a)-(b) are sho wn the curv es of acceptance rates (av eraged ov er 10,000 independent simulation runs) versus the first 1000 accepted samples using the technique described in Section III and the adapti ve RoU algorithm explained in Section IV, respectiv ely . More specifically , ev ery point in these curves represent the probability of accepting the i -th sample. W e can see that the methods are equal ef ficient, and the rates conv erge quickly close to 1. B. Stochastic volatility model In this example, we study a stochastic volatility model where only the adaptiv e RoU scheme can be applied. Let be x k ∈ R + the volatility of a financial time series at time k , and consider the following 2 W e define the acceptance rate R i as the mean probability of accepting the i -th sample from an adaptive RS algorithm. In order to estimate it, we have run M = 10 , 000 independent simulations and recorded the numbers κ i,j , j = 1 , ..., M , of candidate samples that were needed in order to accept the i -th sample. Then, the resulting empirical acceptance rate is ˆ R i = P M j =1 κ − 1 i,j / M . 17 (a) (b) (c) Fig. 4. (a) The target function p o ( x ) = p ( x | y ) and the normalized histogram obtained by the adaptive RoU scheme. (b) The function exp {− V − 4 ( x ; g ) } obtained using the reduced potential V − 4 ( x ; g ) = V ( x ; g ) − ¯ V 4 ( g 4 ( x )) and its constant upper bounds exp {− γ k } , k = 0 , ..., m t . In this example, the function p ( y | x ) = exp {− V − 4 ( x ; g ) } coincides with the likelihood. (c) The set A corresponding to the target pdf p ( x | y ) using the RoU method and the region ∪ m t =9 k =0 T k , formed by triangles, constructed using the second adaptiv e rejection sampling scheme. 0 200 400 600 800 1000 0 0.2 0.4 0.6 0.8 1 accepted sample acceptance rate (a) 0 200 400 600 800 1000 0 0.2 0.4 0.6 0.8 1 accepted sample acceptance rate (b) Fig. 5. (a) The curve of acceptance rates (av eraged over 10,000 simulations) as a function of the first 1000 accepted samples using the first adaptive scheme described in Section III. (b) The curve of acceptance rates (av eraged over 10,000 simulations) as a function of the first 1000 accepted samples using the proposed adaptiv e RoU technique. state space system [5, Chapter 9]-[16] with scalar observation, y k ∈ R , log( x 2 k ) = β log( x 2 k − 1 ) + ϑ 2 ,k , y k = log( x 2 k ) + ϑ 1 ,k , (22) where k ∈ N denotes discrete time, β is a constant, ϑ 2 ,k ∼ N ( ϑ 2 ,k ; 0 , σ 2 ) is a Gaussian noise, i.e., p ( ϑ 2 ,k ) ∝ exp {− ϑ 2 2 ,k / 2 σ 2 } , while ϑ 1 ,k has a density p ( ϑ 1 ,k ) ∝ exp { ϑ 1 ,k / 2 − exp( ϑ 1 ,k ) / 2 } obtained from the transformation ϑ 1 ,k = log[ ϑ 2 0 ,k ] of a standard Gaussian variable ϑ 0 ,k ∼ N ( ϑ 0 ,k ; 0 , 1) . 18 Gi ven the system in Eq. (22), the transition (prior) pdf p ( x k | x k − 1 ) ∝ exp ( − log( x 2 k ) − β log ( x 2 k − 1 ) 2 σ 2 ) , (23) and the likelihood function p ( y k | x k ) ∝ exp y k − log( x 2 k ) 2 − exp( y k − log( x 2 k )) 2 = = exp y k − log( x 2 k ) 2 − exp( y k ) − 1 /x 2 k 2 , (24) W e can apply the proposed adaptiv e scheme to implement an particle filter . Specifically , let { x ( i ) k − 1 } N i =1 be a collection of samples from p ( x k − 1 | y 1: k − 1 ) . W e can approximate the predictiv e density as p ( x k | y 1: k − 1 ) = Z p ( x k | x k − 1 ) p ( x k − 1 | y 1: k − 1 ) dx k − 1 ≈ 1 N N X i =1 p ( x k | x ( i ) k − 1 ) (25) and then the filtering pdf as [4] p ( x k | y 1: k ) ∝ p ( y k | x k ) 1 N N X i =1 p ( x k | x ( i ) k − 1 ) . (26) If we can draw exact samples { x ( i ) k } N i =1 from (26) using a RS scheme, then the integrals of measurable functions I ( f ) = R f ( x k ) p ( x k | y 1: k ) dx k w .r .t. to the filtering pdf can be approximated as I ( f ) ≈ I N ( f ) = 1 N P N i =1 f ( x ( i ) k ) . T o sho w it, we first recall that the problem of drawing from the pdf in Eq. (26) can be reduced to generate an index j ∈ { 1 , ..., N } with uniform probabilities and then draw a sample from the pdf x ( i ) k ∼ p o,j ( x k ) ∝ p ( y k | x k ) p ( x k | x ( j ) k − 1 ) . (27) Note that, in order to take advantage of the adapti ve nature of the proposed technique, one can draw first N indices j 1 , ..., j r , ...j N , with j r ∈ { 1 , ..., N } , and then we sample N r particles from the same proposal, x ( m ) k ∼ p o,j r ( x k ) , m = 1 , ..., N r , where N r is the number of times the index r ∈ { 1 , ..., N } has been drawn. Obviously , N 1 + N 2 + ... + N N = N . The potential function associated with the pdf in Eq. (27) is V ( x k ; g ) = − y k − log( x 2 k ) 2 + exp { y k } 2 + 1 2 x 2 k + log( x 2 k ) − α k 2 2 σ 2 (28) where α k = β log ( x ( j ) k − 1 ) 2 is a constant and g ( x k ) = [ g 1 ( x k ) , log( x 2 k ) , g 2 ( x k ) , − log ( x 2 k ) + α k ] . The potential function in Eq. (28) can be expressed as V ( x k ; g ) = ¯ V 1 g 1 ( x k ) + ¯ V 2 g 2 ( x k ) , (29) 19 where the marginal potentials are ¯ V 1 ( ϑ 1 ) = 1 2 − ϑ 1 + exp { ϑ 1 } and ¯ V 2 ( ϑ 2 ) = 1 2 σ 2 ϑ 2 2 . Note that in this example: • Since the potential V ( x k ; g ) is in general a non-con vex function and the study of the first and the second deriv atives is not analytically tractable, the methods in [6, 11] cannot be applied. • Moreov er , since the potential function V ( x k ; g ) has concav e tails, as shown in Figure 6 (a), the method in [13] and the basic adaptiv e technique described in [22] cannot be used either . • In addition, we also cannot apply the first adapti ve procedure in Section III because there are no simple (direct) techniques to dra w from (and to integrate) the function exp {− ¯ V 1 ( g 1 ( x k )) } or exp {− ¯ V 2 ( g 2 ( x k )) } . But, since the marginal potentials ¯ V 1 and ¯ V 2 are con vex and we also know the concavity of the nonlinearities g 1 ( x k ) and g 2 ( x k ) , we can apply the proposed adaptiv e RoU scheme. Therefore, the used procedure can be summarized in this way: at each time step k , we draw N time from the set of index r ∈ { 1 , ..., N } with uniform probabilities and denote as N r the number of repetition of index r ( N 1 + ... + N N = N ). Then we apply the proposed adaptiv e RoU method, described in Section IV -A, to draw N r particles from each pdf of the form of Eq. (27) with j = r and r = 1 , ...., N . Setting the constant parameters as β = 0 . 8 and σ = 0 . 9 , we obtain an acceptance rate ≈ 42% (av eraged ov er 40 time steps in 10 , 000 independent simulation runs). It is important to remark that it is not easy to implement a standard particle filter to make inference directly about x k (not about log ( x k ) ), because it is not straightforward to draw from the prior density in Eq. (23). Indeed, there are no direct methods to sample from this prior pdf and, in general, we need to use a rejection sampling or a MCMC approach. Figure 6 (b) depicts 40 time steps of a real trajectory (solid line) of the signal of interest x k generated by the system in Eq. (22), with β = 0 . 8 and σ = 0 . 9 . In dashed line, we see the estimated trajectory obtained by the particle filter using the adaptiv e RoU scheme with N = 1000 particles. The shadowed area illustrates the standard de viation of the estimation obtained by our filter . The mean square error (MSE) achieved in the estimation of x k using N = 1000 particles is 1 . 48 . The designed particle filter is specially advantageous w .r .t. to the bootstrap filter when there is a significant discrepancy between the likelihood and prior functions. V I . C O N C L U S I O N S W e hav e proposed two adaptiv e rejection sampling schemes that can be used to draw exactly from a large family of pdfs, not necessarily log-concave. Probability distrib utions of this family appear in many 20 (a) (b) Fig. 6. (a) An example of potential function V ( x k ; g ) defined in Eq. (28), when α k = 1 , y k = 2 and σ = 0 . 8 . The right tail is concav e. (b) An example of trajectory with 40 time steps of the signal of interest x k . The solid line illustrates the real trajectory generated by the system in Eq. (22) with β = 0 . 8 and σ = 0 . 9 while the dashed line shows the estimated trajectory attained by the particle filter with N = 1000 particles. The shadowed area shows the standard deviation of the estimation. inference problems as, for example, localization in sensor networks [18, 22, 23], stochastic volatility [5, Chapter 9], [16] or hierarchical models [12, Chapter 9], [7, 8, 9]. The new method yields a sequence of proposal pdfs that con ver ge tow ards the target density and, as a consequence, can attain high acceptance rates. Moreov er , it can also be applied when the tails of the target density are log-con ve x. The new techniques are concei ved to be used within more elaborate Monte Carlo methods. It enables, for instance, a systematic implementation of the accept/reject particle filter of [18]. There is another generic application in the implementation of the Gibbs sampler for systems in which the conditional densities are complicated. Since they can be applied to multimodal densities also when the tails are log- con vex, these ne w techniques has an extended applicability compared to the related methods in literature [6, 11, 13, 20, 22], as shown in the two numerical examples. The first adapti ve approach in Section III is easier to implement. Ho wever , the proposed adapti ve RoU technique is more general than the first scheme, as sho w in our application to a stochastic volatility model. Moreo ver using the adapti ve RoU scheme to generate a candidate sample we only need to dra w tw o uniform random variates but, in exchange, we hav e to find bound for three (similar) potential functions. V I I . A C K N OW L E D G E M E N T S This work has been partially supported by the Ministry of Science and Innovation of Spain (project DEIPR O, ref. TEC-2009-14504-C02-01 and program Consolider-Ingenio 2010 CSD2008-00010 21 COMONSENS). This work was partially presented at the V alencia 9 meeting. V I I I . A P P E N D I X A. Calculation of lower bounds In some cases, it can be useful to find a lo wer bound γ k ∈ R such that γ k ≤ min x ∈I k V ( x ; g ) , (30) in some interval I k = [ s k , s k +1 ] . If we are able to minimize analytically the modified potential V ( x ; r k ) , we obtain γ k = min x ∈I k V ( x ; r k ) ≤ min x ∈I k V ( x ; g ) . (31) If the analytical minimization of the modified potential V ( x ; r k ) remains intractable, since the modified potential V ( x ; r k ) is con ve x ∀ x ∈ I k , we can use the tangent straight line w k ( x ) to V ( x ; r k ) at an arbitrary point x ∗ ∈ I k to attain a bound. Indeed, a lo wer bound ∀ x ∈ I k = [ s k , s k +1 ] can be defined as γ k , min[ w k ( s k ) , w k ( s k +1 )] ≤ min x ∈I k V ( x ; r k ) ≤ min x ∈I k V ( x ; g ) . (32) The two steps of the algorithm in Section II-B are described in the Figure 7 (a) sho ws an example of construction of the linear function w k ( x ) in a generic interv al I k ⊂ D . Figure 7 (b) illustrates the construction of the piecewise linear function W t ( x ) using three support points, m t = 3 . Function W t ( x ) consists of segments of linear functions w k ( x ) . Figure 8 (b) depicts this procedure to obtain a lower bound in an interval I k for a system potential V ( x ; g ) (solid line) using a tangent line (dotted line) to the modified potential V ( x ; r k ) (dashed line) at an arbitrary point x ∗ ∈ I k . B. Sampling uniformly in a triangular r e gion Consider a triangular set T in the plane R 2 defined by the vertices v 1 , v 2 and v 3 . W e can draw uniformly from a triangular region [24], [3, p. 570] with the following steps: 1) Sample u 1 ∼ U ([0 , 1]) and u 2 ∼ U ([0 , 1]) . 2) The resulting sample is generated by x 0 = v 1 min[ u 1 , u 2 ] + v 2 (1 − max[ u 1 , u 2 ]) + v 3 (max[ u 1 , u 2 ] − min[ u 1 , u 2 ]) . (33) The samples x 0 drawn with this conv ex linear combination are uniformly distributed within the triangle T with vertices v 1 , v 2 and v 3 . 22 (a) (b) Fig. 7. (a) Example of construction of the linear function w k ( x ) inside a generic interval I = [ s k , s k +1 ] . The picture shows a non-con ve x potential V ( x ; g ) in solid line while the modified potential V ( x ; r k ) is depicted in dashed line for ∀ x ∈ I k . The linear function w k ( x ) is tangent to V ( x ; r k ) at a arbitrary point x ∗ ∈ I k . (b) Example of construction of the piecewise linear function W t ( x ) with three support points S t = { s 1 , s 2 , s m t =3 } . The modified potential V ( x ; r k ) , for x ∈ I k , is depicted with a dashed line. The piecewise linear function W t ( x ) consists of segments of linear functions w k ( x ) tangent to the modified potential V ( x ; r k ) . Fig. 8. The picture shows the potential V ( x ; g ) , the modified potential V ( x ; r k ) an the tangent line w k ( x ) to the modified potential at an arbitrary point x ∗ in I k . The lower bound γ k is obtained as γ k = min[ w k ( s k ) , w k ( s k +1 )] . In this picture, we hav e γ k = w k ( s k ) . R E F E R E N C E S [1] J. H. Ahrens. A one-table method for sampling from continuous and discrete distributions. Computing , 54(2):127–146, June 1995. [2] Y . Chung and S. Lee. The generalized ratio-of-uniform method. Journal of Applied Mathematics 23 and Computing , 4(2):409–415, August 1997. [3] L. Devroye. Non-Uniform Random V ariate Generation . Springer , 1986. [4] A. Doucet, N. de Freitas, and N. Gordon. An introduction to sequential Monte Carlo methods. In A. Doucet, N. de Freitas, and N. Gordon, editors, Sequential Monte Carlo Methods in Practice , chapter 1, pages 4–14. Springer, 2001. [5] A. Doucet, N. de Freitas, and N. Gordon, editors. Sequential Monte Carlo Methods in Practice . Springer , New Y ork (USA), 2001. [6] M. Ev ans and T . Sw artz. Random variate generation using conca vity properties of transformed densities. J ournal of Computational and Graphical Statistics , 7(4):514–528, 1998. [7] P . H. Everson. Exact bayesian inference for normal hierarchical models. Journal of Statistical Computation and Simulation , 68(3):223 – 241, February 2001. [8] S. Fr ¨ uhwirth-Schnatter , R. Fr ¨ uhwirth, L. Held, and H. Rue. Improv ed auxiliary mixture sampling for hierarchical models of non-gaussian data. Statistics and Computing , 19(4):479–492, December 2009. [9] D. Gamerman. Sampling from the posterior distribution in generalized linear mixed models. Statistics and Computing , 7(1):57–68, 1997. [10] W . R. Gilks, N. G. Best, and K. K. C. T an. Adapti ve Rejection Metropolis Sampling within Gibbs Sampling. Applied Statistics , 44(4):455–472, 1995. [11] W . R. Gilks and P . W ild. Adaptiv e Rejection Sampling for Gibbs Sampling. Applied Statistics , 41(2):337–348, 1992. [12] W .R. Gilks, S. Richardson, and D. Spie gelhalter . Markov Chain Monte Carlo in Practice: Inter disciplinary Statistics . T aylor & Francis, Inc., UK, 1995. [13] Dilan G ¨ or ¨ ur and Y ee Whye T eh. Conc av e conv ex adaptiv e rejection sampling. J ournal of Computational and Graphical Statistics (to appear) , 2010. [14] W . H ¨ ormann. A rejection technique for sampling from t-concav e distributions. A CM T ransactions on Mathematical Softwar e , 21(2):182–193, 1995. [15] W . H ¨ ormann and G. Derflinger . The transformed rejection method for generating random variables, an alternativ e to the ratio of uniforms method. Manuskript, Institut f. Statistik, W irtschaftsuniversitat , 1994. [16] E. Jacquier, N. G. Polson, and P . E. Rossi. Bayesian analysis of stochastic volatility models. Journal of Business and Economic Statistics , 12(4):371–389, October 1994. [17] A. J. Kinderman and J. F . Monahan. Computer generation of random variables using the ratio of 24 uniform deviates. A CM T ransactions on Mathematical Softwar e , 3(3):257–260, September 1977. [18] H. R. K ¨ unsch. Recursiv e Monte Carlo filters: Algorithms and theoretical bounds. The Annals of Statistics , 33(5):1983–2021, 2005. [19] Josef Leydold. Automatic sampling with the ratio-of-uniforms method. ACM T ransactions on Mathematical Software , 26(1):78–98, 2000. [20] Josef Leydold. Short universal generators via generalized ratio-of-uniforms method. Mathematics of Computation , 72:1453–1471, 2003. [21] G. Marsaglia. The exact-approximation method for generating random v ariables in a computer . American Statistical Association , 79(385):218–221, March 1984. [22] L. Martino and J. M ´ ıguez. A generalization of the adaptiv e rejection sampling algorithm. Statistics and Computing (to appear) , July 2010. [23] L. Martino and J. M ´ ıguez. Generalized rejection sampling schemes and applications in signal processing. Signal Pr ocessing , 90(11):2981–2995, Nov ember 2010. [24] M. F . Keblis W . E. Stein. A ne w method to simulate the triangular distribution. Mathematical and Computer Modelling , 49(5):1143 1147, 2009. [25] J. C. W akefield, A. E. Gelfand, and A. F . M. Smith. Ef ficient generation of random variates via the ratio-of-uniforms method. Statistics and Computing , 1(2):129–133, August 1991. [26] C.S. W allace. T ransformed rejection generators for gamma and normal pseudo-random variables. Austr alian Computer Journal , 8:103–105, 1976.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment