Bayesian outlier detection in Capital Asset Pricing Model
We propose a novel Bayesian optimisation procedure for outlier detection in the Capital Asset Pricing Model. We use a parametric product partition model to robustly estimate the systematic risk of an asset. We assume that the returns follow independe…
Authors: Maria Elena De Giuli (1), Mario Aless, ro Maggi (1)
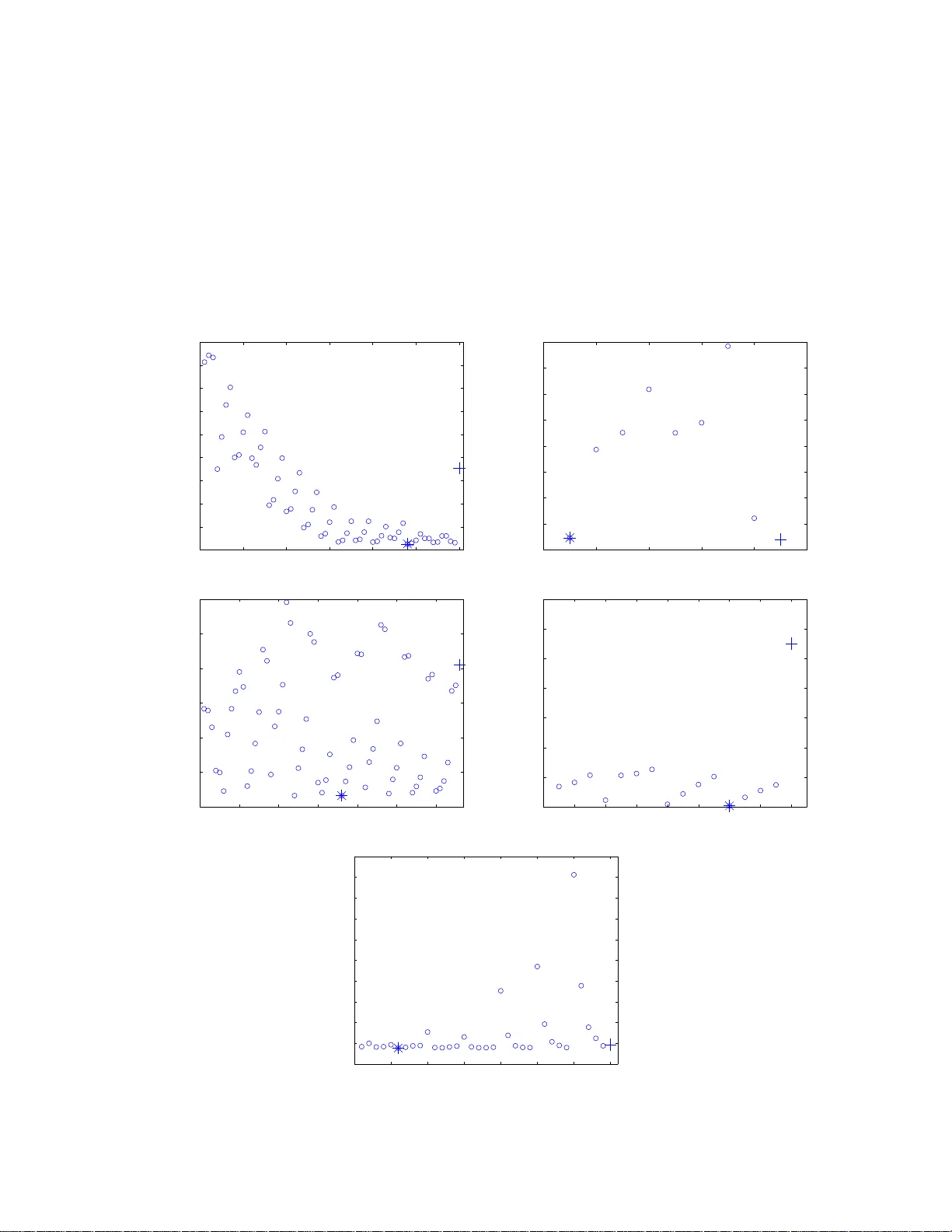
Ba y esian outlier detection in Capital Asset Pricing Mo del Maria Elena De Giuli Mario Alessandro Maggi Claudia T aran tola ∗ Departmen t of Economics and Quan titativ e Metho d s, Univ ersit y of Pa via, Italy Abstract W e prop ose a novel Bayesian optimisation pro cedure for outlier detection in the Capital Asset Pricing Mo del. W e use a par ametric pro duct partition mo del to robustly estimate the systematic r isk of an asset. W e assume tha t the returns follow indep endent nor mal distributions a nd w e impos e a pa rtition structure on the parameters o f interest. The pa rtition structure impos ed o n the parameter s induces a corres p o nding clustering o f the returns. W e iden tify v ia an optimisatio n pro cedure the partition that best separ ates standard observ a tio ns from the atypical ones. The methodo logy is illustrated with refer e nce to a real data set, for which we als o pr ovide a micro economic in terpretation of the detected outliers. Keywor ds : Capital Asset Pricing Model, Constrained optimisatio n algorithm, Mark o v Chain Mon te Carlo, Outlier iden tification, P arametric pro du ct p artition mo dels, Score function. ∗ Address for corre sp ondence: Claudia T aran tola, Department o f Economics and Quan titative Me- tho ds , Via S. F elice 7, 2 7100 P a via, Italy . E-mail: claudia.t arantola@unipv. it 1 1 In tro duction In th is pap er we prop ose a n ov el Bay esian optimisation pro cedure f or outlier identifica - tion in a Capital Asset Pricing framew ork. The Capital Asset Pr icing Mo del (CAPM), see Sharp e (19 64), Lin tner (1965), Mossin (1966) and Blac k (1972), states th at an asset exp ected retur n is equ al to the risk free rate plu s a prize for r isk. The C APM is widely used in applications to ev aluate the p erformance of assets and p ortfolios, and differ- en t p erforman ce measures are based on it, see e.g. c hap. 4 in Amenec and Le Sourd (2003 ). In particular, it is very useful for th e calculation of the cost of capital equ ities, whic h is necessary for market based firm v alue mo dels, see e.g. Ross et al. (2008). The CAPM can b e represented by a simp le linear regression where the slop e iden tifies the systematic risk of an asset, that is it measures th e return sens itivity to mo veme nt in th e mark et. The systematic risk represents the comp onen t of the risk that cannot b e eliminated simp ly via p ortfolio diversificatio n. Therefore, s ystematic risk is a k ey v ariable to b e tak en in to acco unt f or asset allo cation and p ortfolio managemen t. Almost all empirical analysis of the CAPM has b een carried out in the cla ssical framew ork, see i.e. F ama and F renc h (2004) for an exaustiv e review. The systematic risk is usually estimate d by the least squ are method which coincides with the maxim um lik eliho o d estimator und er the assumption of normalit y . It is we ll kno wn that this approac h h as at least tw o disadv an tages. Firstly , this estimation metho d is sensitiv e to the p resence of outliers, that is observ atio ns that do not follo w the same s tatistica l mo del as the main part of the d ata. Secondly , it is not p ossible to incorp orate prior b eliefs ab out b eha viour of returns in the mo del. In th is pap er, to ov ercome these p roblems, w e focus on Ba y esian robu st estima- 2 tion pro cedures for lin ear regression mod els; see e.g. Ch aturv edi (1996), F ern´ andez et al. (200 1), Qu in tana and Iglesias (20 03) and Qu in tana et al. (2005a, 2005b). In particu- lar, Quintana and I glesias (2003 ) and Qu in tana et al. (2005 a) sh o w that outlying p oin ts can b e accommod ated either by a pr o duct p artition mo del with a normal structur e on the retur ns, or b y a simple r egression mo d el with t shap e errors and small d egrees of freedom. W e follo w the fir st approac h and we app ly a norm al m o del w ith a partition structure on the parameters of interest. This approac h has at least tw o adv antag es. Firstly , the use of a n ormal distribution is consisten t with th e assu mption of mean-v ariance analysis required b y CAPM. Secondly , the use of a p artition structure sim ultaneously yields outlier identifica tion and m o del robustification. The p artition structure allo ws us to separate the main b o d y of “standard ” data p oin ts from the “at yp ical” ones. Regarding the outlier iden tification p roblem we wo rk in a Ba y esian decision theo- retical f r amew ork. The partition that b est s ep arates “standard” observ ations from the “at ypical” ones is sele cted by minimising a sp ecific score fun ction. In Quintana and Iglesias (2003 ) this p artition is identified by applying a clustering algorithm. Ho wev er, as they men tioned (see page 572 in Quintana and Iglesia s, 2003), a w eakness of their algorithm is that it could b e tr ap p ed in lo cal mo des. F urthermore, as they select out- lying p oin ts one by one, they could incur in the problem of masking. If a d ata set has m ultiple outliers, they ma y mask one another, making outlier iden tification difficult. Mask ed outliers shou ld b e remo v ed as a group, otherwise their presence could remain undetected. W e o v ercome these problems by applying a constrained optimisation al- gorithm to select the optimal partition. Our algorithm in cludes a pr eliminary step in 3 whic h the d ata are p rescreened via a robust tec hnique that allo ws us to iden tify a set of p oten tial outliers. Subsequentl y , outliers are efficien tly selected among the p oten tial ones. The pap er is structur ed as follo ws. In Section 2 we briefly int ro d uce the CAPM and parametric p ro du ct partition mo dels (PPM). In Section 3 we describ e the optimi- sation algorithm used f or outlier identificatio n. F or comparativ e pur p oses, in S ection 4 w e apply our pro cedu re to the IPS A data set, previously examined by Qu in tana et al. (2005a). Conclusions are giv en in Section 5. 2 Bac kground and preliminaries 2.1 The CAP M According to CAPM, the exp ected retur n of an y asset i is a linear fun ction of the mark et p ortfolio one E ( R i ) = R f + β i ( E ( R m ) − R f ) , i = 1 , . . . , N , (2.1) where N is the num b er of assets, R i is the return of asset i , R f is the risk-free rate of return, R m is the return on the market p ortfolio and the s lop e β i measures the systematic risk. T he market p ortfolio is the p ortfolio con taining ev ery asset a v aila ble to th e economic agen t, in amoun ts prop ortional to their tota l m arket v alues. Ma rket p ortfolio is a theoretical concept, hence it is n ecessary to use a mark et ind ex return, R M , as an observ able proxy of the mark et p ortfolio return R m . An extension of equation (2.1) is often used to estimate the systematic risk. Another 4 co efficien t denoted by α i is usu ally in tro duced, obtaining the f ollo wing expression E ( R i ) − R f = α i + β i ( E ( R M ) − R f ) , i = 1 , . . . , N , (2.2) where α i denotes wet her the asset i ov er/under-p erform s the exp ected return exp lained b y CAPM. The parameters of equ ation (2.2 ) are estimated b y using the linear regression equation R it − R f t = α i + β i ( R M t − R f t ) + ε it , y it = α i + β i x t + ε it , i = 1 , . . . , N , t = 1 , . . . , T , (2.3) where, for a t -p erio d and a generic asset i , y it is the exc ess return of the asset, R it denotes the return of the asset, R f t is the risk-free rate of return, R M t is the mark et index retur n and ε it is a normally distributed error term. The estimatio n of the systematic risk β i can b e affected b y th e pr esence of outly- ing p oin ts. An approac h that carefully tak es into account the pr esence of anomalous observ atio ns should b e applied. In this pap er we mo del outliers by a sh ift in the re- gression mean and w e handle them working with an extension of equation (2.3). More precisely , we assu me that excess returns of share i , at d ifferent time p oin ts t , can b e more appr op r iately d escrib ed by a set of parallel r egression lines (see also Qu in tana and I glesias, 2003 and Quinta na et al., 2005a ). W e allo w α i to change with t (ind icated as α it ), and we estimate the follo wing equation y it = α it + β i x t + ε it , i = 1 , . . . , N , t = 1 , . . . , T , (2.4) where α it assumes v alues in the finite set α ρ i = α ∗ i 1 , . . . , α ∗ i | ρ i | , with cardin ality | ρ i | smaller then T (mo re details w ill b e provided in Section 2.2). In fact, it can b e r e- alistical ly assumed that the num b er of regression lin es is in f erior to the num b er of 5 observ atio ns. Our aim is to group together (to cluster) time p erio ds with common v alues of th e intercepts. These group s lead to a clustering of the corresp onding excess returns y it . W e w ill end up with a main group of stand ard observ ations and one or more groups of at ypical ones. T h e n um b er and the comp osition of the group s ( th e p artition structur e ) is unkno wn, hen ce we assign a prior distribu tion to the set of all p ossible p artitions, see Section 2.2 for the details. 2.2 A parametric pro duct partition mo del F oll o win g Quintana and Iglesias (2003) and Quinta na et al. (2005a), w e use a parametric pro du ct partition mo d el (PPM) to robustly estimate the systematic risk and to iden tify outlying p oin ts. W e no w briefly review the theory on parametric pr o duct p artition mo dels with r eference to our sp ecific problem, see Ba rr y and Hartigan (1992 ) for a detailed and more general pr esen tation. Giv en the mo del describ ed by equation (2.4 ), let S 0 i = { 1 , . . . , T } b e the set of time p erio ds . A partition of the s et S 0 i , ρ i = n S 1 i , . . . , S d i , . . . , S | ρ i | i o with cardinalit y | ρ i | , is d efined by the prop erty th at S d i ∩ S d ′ i = ∅ for d 6 = d ′ and ∪ d S d i = S 0 i . T he generic elemen t of ρ i is S d i = { t : α it = α ∗ id } , where α ρ i = α ∗ i 1 , . . . , α ∗ i | ρ i | is the vec tor of the unique v alues of α i = ( α i 1 , . . . , α iT ). All α it whose sub scripts t b elong to the same set S d i ∈ ρ i are ( sto chastic al ly ) equ al; in this sense they are regarded as a single cluster . W e assign to eac h partition ρ i the follo wing prior p robabilit y P ρ i = n S 1 i , . . . , S | ρ i | i o = K | ρ i | Y d =1 C S d i , (2.5) where C S d i is a c ohesion function and K is the normalising constan t. Equation (2.5) 6 is r eferr ed to as the pr o duct distribution for partitions. Th e cohesions r epresen t prior w eigh ts on group formation and formalise our opinion on ho w tigh tly clustered the elemen ts of S d i w ould b e. The cohesions can b e sp ecified in different w ays, a usefu l c hoice is C S d i = c × S d i − 1 ! , d = 1 , . . . , | ρ i | (2.6) for some p ositiv e constan t c . F or m o derate v alues of c , e.g. c = 1, the cohesions in (2.6) yield a pr ior distribution that fa v ours the formation of partitions w ith a reduced num b er of large subsets. Th is is a desirable feature for an outlier d etection mo d el, s ince we do n ot wa nt to iden tify to o man y subsets of p oin ts as outlie rs. F or more d etails on the c hoice of c see i.e. Liu (1996), Quin tana et al. (2005b) and T aran tola et al. (200 8). Moreo v er, ther e is an inte resting connection b et w een parametric PPMs an d th e class of Ba ye sian nonparametric m o dels based on a mixture of Dirichlet Pro cesses (An toniak, 1974). Under the latter prior, the marginal distribution of the observ ables is a sp ecific P P M w ith the cohesion functions sp ecified by equation (2.6 ), see Qu in tana and Iglesias (2003). This connection allo ws us to u se efficien t Marko v Chain Mont e Carlo (MCMC) algorithms dev elop ed for Ba y esian nonp arametric problems lik e the one that w e apply here. 7 In this pap er we consid er th e follo wing Ba y esian hierarc hical mo del y it | ρ i , α ∗ i 1 , . . . , α ∗ i | ρ i | , β i , σ 2 i ind ∼ N α it + β i x t , σ 2 i α ∗ i 1 , . . . , α ∗ i | ρ i | | ρ i , σ 2 i I I D ∼ N a, τ 2 0 σ 2 i β i | σ 2 i ∼ N b, γ 2 0 σ 2 i ρ i ∼ pro d uct distribution, with C S d i = c × S d i − 1 ! σ 2 i ∼ I G ( v 0 , λ 0 ) , where a , b , τ 2 0 , γ 2 0 , v 0 and λ 0 are user-sp ecified h yp erparameters, the pro du ct dis- tribution is defined in (2 .5) and I G ( v 0 , λ 0 ) is an inv erted gamma distribution with E σ 2 i = λ 0 / ( v 0 − 1). The Gib b s algorithm applied to samp le fr om the p osterior distributions of the p arameters is describ ed in the App en d ix. 3 Optimal outlier detection T o detect outlying p oin ts w e app ly a constrained optimisation algorithm, working in a Ba ye sian d ecision th eoretic framework. Our aim is to select the partition that b est separates the main group of standard observ atio ns from one or more groups of at ypi- cal d ata. Eac h partition corresp onds to a different mo d el and the b est mo d el is the one minim isin g a giv en loss function. W e consider a loss function that com bines the estimation of the parameters and the p artition selection problems. Giv en a generic asset i , let α i , β i , σ 2 i b e the vec tor of parameters of the m o del and α ρ i , β ρ i , σ 2 ρ i b e the corresp ondin g vect or that r esults wh en fixing ρ i . W e consider the 8 loss fu nction L ρ i , α ρ i , β ρ i , σ 2 ρ i , α i , β i , σ 2 i = k 1 T k α ρ i − α i k 2 + k 2 ( β ρ i − β i ) 2 + + k 3 σ 2 ρ i − σ 2 i 2 + (1 − k 1 − k 2 − k 3 ) | ρ i | , (3.1) where k · k is the Euclidean norm, and k j ( j = 1 , 2 , 3) are p ositiv e cost-complexit y parameters with P 3 j =1 k j ≤ 1. Minimizing the exp ected v alue of (3.1) is equiv alen t to c ho osing the partition that minimises the follo wing score fu nction S C ( ρ i ) = k 1 T k ˆ α B i ( y ) − ˆ α ρ i ( y ) k 2 + k 2 h ˆ β B i ( y ) − ˆ β ρ i ( y ) i 2 + + k 3 h ˆ σ B i ( y ) 2 − ˆ σ 2 ρ i ( y ) i 2 + (1 − k 1 − k 2 − k 3 ) | ρ i | . (3.2) In (3.2), a su p erscrip t “ B ” means that w e consider the Bay esian estimates of the cor- resp ond ing parameter, whereas a subscrip t “ ρ i ” d enotes the estimate of the parameter (or ve ctor of parameters) cond itionally on the partition ρ i . F ormall y , if w e indicate with θ a generic parameter in (3.2), w e get ˆ θ B ( y ) = E ( θ | y ) and ˆ θ ρ i ( y ) = E ( θ | y , ρ i ). The estimates ˆ θ B ( y ) and ˆ θ ρ i ( y ) of θ are obtained via the MCMC m etho d d escrib ed in the Ap p endix. The n umb er of all p ossible partitions is equal to B ( a ), the Bel l numb er of ord er a , recursivel y defin ed by B ( a + 1) = P a k =0 a k B ( k ), with B (0) = 1. This quan tit y is extremely large ev en for mo d erate v alues of a , therefore we need to restrict our searc h to a tractable sub s et of all partitions. T o a v oid ev aluating and comparing the scores of an imp ossibly large n um b er of partitions, we p rop ose a tw o step algorithm. This algorithm r educes b y construction the p r obabilit y of incur ring the maskin g problem. It examines all partitions ha ving a giv en structur e, and groups of observ ations ma y b e included/excluded as blo c k in the 9 differen t clusters. In the first s tep of the algorithm we use least trimmed squares (L TS) regression, see Rousseeuw (1984) and Rousseeuw and Lero y (1987) , to prescreen the data and iden tify a large set of p oten tial outliers. A similar idea has b een successfully applied b y Ho eting et al. (1996) for simultaneous v ariable selection and outlier identificatio n in a linear regression mo d el. L TS is also used in the Ba ye sian Mo del Av eraging Pa c k age of R (Raftery et al., 2008) to prescreen the data. In th e s econd step, we constrain our searc h to partitions identifying as ou tliers only particular sub sets of those iden tified by L TS, and w e select the one that minimises the score fu n ction (3.2). Among robu st tec hniques, we ha ve c hosen L TS since it h as a very high (fi nite- sample) breakdo wn p oint (close to 1 / 2) and tends to identify a large num b er of ob- serv atio ns as abnorm al, redu cing the p ossibility of misclassifying anomalous p oin ts. Ho w ev er, it should b e n oticed that L TS can b e rather sensitiv e to small p erturbations in the cent ral part of the data (high subsamp le sens itivit y), see e.g. Ellis (1998), V ´ ı ˇ sek (1999 ), and ˇ C ´ ıˇ zek and V ´ ı ˇ sek (2000) . A tten tion should b e paid to chec k if the set of p oten tial outliers is reasonable. In the s p ecific case examined here the set of p otent ial outliers is sensible. In fact the elemen ts selected by L TS corresp ond to “small/high” v alues of the comp onen ts b α B i ( y ). The algorithm consists of the follo wing t w o steps. Let i b e a generic asset. Step 1. W e apply L TS to the excess return s of the asset i . All p oin ts with an absolute v alue of the standardized residuals greater than 2 . 5 are considered as p oten tial outliers. 10 Step 2 . Let O LT S i b e th e set of all time p oin ts corresp onding to the p oten tial outlie rs iden tified in Step 1. W e restrict our s earc h to partitions with cardinalit y 2 or 3 where the outliers are particular sub sets of O LT S i . The d ata are classified in clusters S 1 i , S 2 i and S 3 i defined as f ollo ws. Cluster S 2 i con tains “standard observ ations”, with S 0 i \ O LT S i ⊆ S 2 i . The remaining data, iden tifying “anomalous p oints”, are classified either in S 1 i (“anomalous low v alues”) or in S 3 i (“anomalous h igh v alues”) with S 1 i ∪ S 3 i ⊆ O LT S i . W e only consider partitions w ith the follo wing alternativ e structures ρ i = S 1 i , S 2 i , S 3 i or ρ i = S 2 i , S 1 i ∪ S 3 i . I f a cluster is empt y it is not considered as a comp onent of ρ i . W e do not consider the case in whic h b oth S 1 i and S 3 i are empt y . The metho dology used to construct the clusters S 1 i , S 2 i and S 3 i is describ ed b elo w. i) Given the v ector b α B i ( y ) = b α B i 1 , . . . , b α B i T of the Ba y esian estima tes of the in tercepts of mo del (2.4), we indicate with me the med ian of its elemen ts. ii) F or eac h time p oin t ℓ ∈ O LT S i w e compute the deviation from the median, d ℓ = b α B i ℓ − me . iii) W e construct th e set D contai nin g all deviatio ns from th e median and tw o instrumental extra p oints D = d ℓ , ℓ ∈ O LT S i [ min ℓ ( d ℓ ) − κ, m ax ℓ ( d ℓ ) + κ , with κ > 0 such that min ℓ ( d ℓ ) − κ < 0 and max ℓ ( d ℓ ) + κ > 0 . iiii) F or eve ry p ossible couple of v alues d L , d U ∈ ( D × D ), with d L < 0 and 0 ≤ d U , w e classify in S 1 i all ℓ ∈ O LT S i suc h that d ℓ ≤ d L and in S 3 i all 11 ℓ ∈ O LT S i that d ℓ ≥ d U , that is S 1 i = ℓ ∈ O LT S i : d ℓ ≤ d L and S 3 i = ℓ ∈ O LT S i : d ℓ ≥ d U . T he remaining p oint s are classified in S 2 i . In this wa y w e construct a list of p ossible partitions, that will then b e com- pared in terms of the v alue of the score function (3.2). The optimal partition is th e one with the minimum score function v alue. 4 Analysis of the IPSA sto ck mark et data T o test the p erformance of our pro cedu re we analysed the IPS A sto c k market data, previously examined by Qu in tana et al. (2005a). The IPSA is the main index of the “Bolsa de Comercio de S an tiago” (Sant iago Sto c k Exchange). It corresp onds to a p ortfolio conta inin g the 40 most hea vily traded stocks, the list is revised quarterly . W e considered monthly data relativ e to the p erio d J anuary 1990-June 2004. W e used the IPSA index as a pro xy of the Chilean market p ortfolio and the in terest rate of Central Bank discount b onds as the risk free rate. W e fo cu s ed our analysis only on the 5 shares listed in T able 1, for wh ic h Quintana et al. (2005a) p r o vided a detailed analysis b oth of the estimates of the p arameters and of the selected p artitions. W e us ed the follo wing v alues of the hyp er p arameters c = 1, a = 0, b = 1, τ 2 0 = γ 2 0 = 1000, v 0 = 2 . 0 001, λ 0 = 0 . 0 10001. W e set ( k 1 , k 2 , k 3 ) = 1 2012 (1000 , 1000 , 1) in (3.1) and (3.2 ), to giv e pr iorit y to the estimation of α i and β i , im p osing we ak r estriction on the num b er of clusters. These v alues lead to the same prior d istributions and the same relativ e w eigh ts for the score function comp onen ts as in Q uin tana et al. (2005a). The t wo MCMC algorithms, u sed resp ectiv ely to obtain the Ba ye sian estimates of th e p arameters and the estimate s given a sp ecific partition, are b oth based on a 12 run of 10 000 swee ps with a bur n-in of 1 000 iterations. Con v ergence of the MCMC wa s assessed u sing standard criteria, see e.g. Best et al. (1995) and Co wles and Carlin (1996). No sp ecific in d ication of abnormal b eha viour is obtained. The t w o MCMC algorithms required 16 and 2.9 minutes resp ectiv ely p er 10 000 iterations on a P en tium IV 3.4 GHz, 1 GB RAM p ersonal computer. T he p rograms w ere written in MA TLAB; it is exp ected that a lo wer lev el pr ogramming language could sp eed up the execution time b y a factor of at least 5. 4.1 Numerical results In T able 1 we rep ort the partitions selected by our al gorithm and the one p rop osed b y Quinta na et al. (2005a) , denoted by DMT and QIB resp ectiv ely . The MCMC standard err ors of the estimate s w ere calculated by splitting th e Mark o v c hain output in to batc hes, see Gey er (1992). It is also ind icated the v alue of the score fun ction S C and of the prop ortional reduction in score ( P RS ), that is P RS = (S C QIB − SC DMT ) / SC QIB ; for all shares S C D M T ≤ S C QI B . The PRS is large for 3 out of 5 cases (more than 33%), in particular it is equal to 61 . 97% for the Conc ha y T oro share. T ABLE 1 ABOUT HERE Note th at for the Concha y T oro and E n tel sh ares the outliers selected b y Quintana et al. (2005a) are a subs et of those id entified with our pr o cedure. F or the Cemento s B ´ ıo B ´ ıo S .A. and Cop ec S.A. w e select the same outlier set, but since we group th em in only one cluster w e obtain a lo wer v alue of the score fun ction. Figure 1 r ep orts the scores of all partitions explored by our algorithm and the score of the partition s elected by Q u in tana et al. (20 05a). F or the Cementos, Conc ha y T oro 13 and C op ec shares many partitions, exp lored b y our algorithm, present a low er v alue of the score function than the one selected b y Quin tana et al. (20 05a). FIGURE 1 ABOUT HERE A more detailed analysis of the Concha y T oro share is provided in Figure 2 and T able 2. In Figure 2 w e represent the Ba ye sian linear r egression lines obtained applying the algorithm b y Quin tana et al. (2005a) and the one prop osed here. T he b est partition of Quintana et al. (2005a) p r o duces a regression line for eac h detected outlier. In T able 2 w e rep ort the Ba yesian estimates of the systematic risk under the three different partition stru ctures considered in Figure 2. FIGURE 2 ABOUT HERE T ABLE 2 ABOUT HERE In T able 3 we rep ort, with reference to the Conc ha y T oro data, a sensitivit y analysis of the results for d ifferent c hoices of the constan t c in (2.6). Note that, for a wid e range of v alues of c our results are remark ably r obust. T ABLE 3 ABOUT HERE 4.2 Micro economic analysis W e p erf ormed a micro economic analysis of the companies un d er study , and w e list some ev en ts that could h a v e p r o duced the abnormal b eha viour identified by the outliers. All the in f ormation provi ded is fr eely a v ailable on the W orld Wide W eb. 14 1) CEMENTO S B ´ IO-B ´ IO S .A. The Cemen tos B ´ ıo B ´ ıo S.A. is a compan y in v olv ed in the pro duction and sale of cemen t and lime pro du cts, w o o d an d its by-prod ucts, premixed concrete and ceramics. In 1992 (outlier 27) it op ened a n ew cement plant in Copiap o. In 1998 (outlier 107) it expanded the cemen t plant in An tofagasta and started up a new cement plant in Cur ic´ o. In 1999 (outliers 112, 113) Cement os de Mexico, the world’s third -largest cemen t man- ufacturer, entered th e Chilean mark et by acquiring 12% of th e Cemen tos B ´ ıo B ´ ıo S.A. shares. 2) C MPC The group’s p rincipal activit y is man ufacturin g pulp and p ap er in Chile. It is an integrate d company that undertak es its indu strial w ork through fiv e b usiness affiliates (CMPC Celulosa, CMPC P ap eles, CMPC Pro du ctos de P ap el, CMPC T is- sue, and F orestal Mininco), and o wns industrial plants in C hile, Argen tina, P eru and Urugua y . The y ears from 1990 to 199 2 (outlier 15) w ere c haracterised by an expansion in Latin America. In 1990 CMPC entered Argen tina b y purchasing (in partnersh ip with Pro cter & Gam ble), Quimica Estrella San Luis S.A. (no w Pr o desa), a manufact ur er of sanitary napkins and pap er diap ers . In 1992 CMPC formed a strategic alliance with Pro cter & Gam ble to dev elop mark ets for the aforemen tioned pro ducts in Chile, Argentina, Bolivia, Paragua y , P eru, and Uruguay . 3) CO NCHA Y TORO Conc ha y T oro is one of the leading p ro ducers of wine in Ch ile. It pro d uces and exp orts a wide range of wines. In 1994, Conc ha y T oro b ecame the first C h ilean winery to b e listed on the New Y ork Sto c k Exc hange. 15 During the y ears 199 1-1993 (outliers 14, 18, 21, 22, 27) imp ortan t c hanges to ok place. Conc ha y T oro tripled the size of its vineya rd s to reduce dep end ence on outside grap e gro w ers and enrolled the help of F r enc h and Californian oen ologists. It mo dernized its pro du ction and tran s formed the original Conc ha y T oro mansion into the head qu arters of the firm for its exp ort op erations. In 1996 Conc ha y T oro pur c hased a viney ard in the Mendoza region in Argen tina. I n 1997 the company and th e F renc h fi rm Baron Philipp e de Rothschild S .A. endorsed a join t ve nture w ith the aim of pro d ucing a wine to th e standards of the F ren c h Grand Cr u Class. I n 1998 (outlier 97) Con cha y T oro launc hed Vin a Almaviv a int o the m ark et. I n the same y ear the company ranked second among wine exp orters to the Un ited States. 4) C OPEC S .A. Cop ec S.A. is a div ersified Chilean fi nancial holding company that participates through subsidiaries and related companies in differen t b u siness s ectors (energy , forestry , fishing, min ing and p o we r industr ies). In 199 2 (outlier 31) it united tw o fi sheries to form Igemar that b ecame the biggest fishing an d fish-pro cessing company in Chile. In 1998 (outlier 107) it b ecame C hile’s largest exp orter outside of the m ining sector. In 1999 (o utlier 111) COPEC created Air Bp Cop ec S .A. to commercialise fuels for national and in ternational air lines, in join t v en ture with BP Global Inv estments. 5) ENTEL En tel was created in 196 4 as a state compan y , an d it w as priv atised in 1986. The grou p ’s principal activities are p ro viding telecomm unication services. It also op erates in Cen tral America and P eru aside from its cen tre of m a jor op erations whic h is lo cated in Chile. In 1996 (oulier 65) T elecom I talia acquired a 19 . 99% of En tel shares. 16 5 Concluding remarks In this pap er w e presented a mo d el for robust in ference in CAPM in the presence of outliers. W orking in a Ba y esian d ecision framew ork, we dev elop ed a constrained opti- mization algorithm for outlier detection. Differently fr om the metho dology pr op osed b y Q uint ana et al. (2005a) it app eared to b e successful in the identificat ion of masked outliers and led to partitions with a lo w er v alue of the score fun ction. The outlier iden tification p ro cedure pr op osed by Quint ana and Iglesias (2003) is based on a h ierarc hical divisive metho d. Their pro cedu re w orks by d etac hing, one b y one, the most outlying comp onen t from the v ector ˆ α B i ( y ) of the Bay esian estimates. This pr o cedure is ir r ev ersible, that is once a p oin t is classified in a sp ecific cluster it is not tak en any more under consid eration. On the other hand our algorithm allo w groups of observ ations to b e considered s im ultaneously as p oten tial outliers. This could b e a p ossible explanation of why in s ome cases, as for the C onc ha y T oro share, the algorithm by Quintana and In glesias (200 3) identi fies a sm aller set of outliers, incurrin g in the the masking problem. A micro economic analysis is pro vided to confirm that the s elected outlying p oints are linked to extraordin ary ev ents in the history of th e examined companies. Ac kno wledgemen ts The authors ac kno wledge F er n ando Quintana for helpfu l discus sion regarding the com- putational algorithm and Man uel Galea-Ro jas for pro vidin g the IPS A data. W e thank Pierpaolo Ub erti f or comments on th e preliminary ve rsion of this pap er. W e are also grateful to the asso ciate editor and the referee for v aluable commen ts. T he researc h 17 of the three authors w as (partially) supp orted by Un iv ersit y of Pa via. The researc h of the first author wa s also (partially) supp orted b oth b y MUSING (con tract n umb er 02709 7); the researc h of the third author was also (partially) supp orted b y b oth MIUR, Rome (PRIN 20051 32307). App endix: A Gibbs sampling algorithm W e adapt to our problem a Gibbs sampling algorithm, pr op osed b y Bush and MacEa c h- ern (1996). Consid er a generic asset i . Giv en the starting v alues α 0 , β 0 and σ 2 0 w e iterativ ely sample fr om the follo wing distributions β i | σ 2 i , α i , y i ∼ N ( b/γ 2 0 + P T t =1 ( y i t − α i t ) x t 1 /γ 2 0 + P T t =1 x 2 t , σ 2 i 1 /γ 2 0 + P T t =1 x 2 t ) (5.1) σ 2 i | α i , β i , y i ∼ I G v 0 + T + | ρ i | + 1 2 , λ 0 + ( β i − b ) 2 2 γ 2 0 + 1 2 τ 2 0 | ρ i | X d =1 ( α ∗ i d − a ) 2 + 1 2 T X t =1 ( y i t − α i t − β x t ) 2 ) (5.2) α i t | α i − t , β i , σ 2 i , y ∝ X j 6 = t exp − 1 2 σ 2 ( y i t − α i j − β i x t ) 2 δ α i j ( α i t ) + exp − ( y i t − β x t − a ) 2 / 2 σ 2 i (1 + τ 2 0 ) p 1 + τ 2 0 N y i t − β i x t + a/τ 2 0 1 + 1 /τ 2 0 , σ 2 i 1 + 1 /τ 2 0 where α i − t = ( α i 1 , . . . , α i t − 1 , α i t +1 , . . . , α i T ) ′ and δ α j ( · ) is the K r onec k er d elta function. Note that β i and σ 2 i are sampled fr om the corresp ondin g full conditional w hereas eac h α i t is samp led from a mixtu r e of p oin t masses and a normal d istribution. In th is w a y we automatically up d ate b oth the v ector α i and the partition structure. Before pro ceeding to the next Gibbs iteration, we up date the v ector α i giv en the partition ρ i sampling from α ∗ i d ∼ N P t ∈ S d ( y i t − β i x t ) + a/τ 2 0 | S d | + 1 /τ 2 0 , σ 2 i | S d | + 1 /τ 2 0 ! d = 1 , . . . , | ρ i | . (5.3) 18 This last step w as introd u ced in Bush and MacEac h ern (1996) to av oid b eing trapp ed in stic ky patc hes in the Marko v Sp ace. If the partition s tructure ρ i is fi xed β i , σ 2 i and α i are directly sampled f r om the corresp ondin g full conditional distributions, (5.1 ), in (5.2) and (5.3) resp ectiv ely . 19 References Amenec, N. and Le Sourd , V. (2003) P ortfolio the ory and Performanc e Analysis , Wiley , Chic hester. An toniak, C.E. (1974) Mixtures of Diric hlet pro cesses with applications to Ba y esian nonparametric pr ob lems. A nnals of Statistics , 2 , 1152-11 74. Barry , D. and Hartigan, J.A. (1992) P r o duct partition mo dels for change p oin t problems. Annals of Statistics , 20 , 260 -279. Best, N.G., Co wles, M.K. and Vines, K . (1995) CODA: Conv ergence Diagnosis and Output Analysis Soft ware for Gibbs sampling output, v ersion 0.3. T e cnic al r ep ort , Medical Researc h Council, Biostatistics Unit, Cam bridge. Blac k, F. (1972) Capital market equ ilibr ium with restricted b orro wing. Journal of Business , 45 , 444 -454. Bush, C.A. and MacEac hern, S.N. (1996) A semiparametric Ba y esian mo d el for randomised blo ck designs. Biometrika , 83 , 275-285. Chaturve di, A. (1996 ) Robust Ba y esian analysis of the linear regression mo dels. Journal of Statistic al Planning and Infer enc e , 50 , 175-186. Co wles, M.K. and C arlin, B.P . (1996) Mark o v Ch ain Mon te Carlo Conv ergence Di- agnostics: A Comparativ e Review. Journal of the Americ an Statistic al Asso c iation , 91 , 883-904. ˇ C ´ ıˇ zek, P ., and V ´ ı ˇ sek, J. ` A (2000) Least trimm ed squ ares. In Xplor e A pplic ation Guide , Hardle, W., Hl´ avk a, Z., K link e, S. editors, S pringer V erlag, 46-64 20 Ellis, S.P . (1998) In stabilit y of least squares, least absolute deviation and least median of s q u ares linear regression. Statistic al Scienc e , 13 , 337 -350. F ama, E.F. and F rench, K .R. (2004) T h e Capital Asset Pricing Mo del: Theory and Evidence. Journal of E c onomic P ersp e ctives , 18 , 25-46. F ern´ andez, C., Osiew alski, J. and Steel, M.F.J. (2001) Robust Ba y esian Inference on Scale Parameters. Journal of Multivariate Ana lysis , 77 , 54-72. Gey er C. J. (1992) Practical Mark o v c hain Mon te Carlo (w ith discussion). Statistic al Scienc e , 7 , 473-511. Ho eting, J., Raftery , A.E., Madigan, D. (1996) A metho d for simulta neous v ariable selection and ou tlier id entificatio n in linear regression. Computatio nal Statistics and Data Ana lysis , 22 , 251-270 Lin tner, J. (1965 ) The V aluation of Risk Ass ets and the Selection of Risky Inv est- men ts in Sto ck Portfolio s and Capital Budgets. R evie w of Ec onomics and Statistics , 47 , 13-37. Liu, J.S. (1996) Nonparametric hierarc hical Ba y es via sequ ential im p utations. A n- nals of Statistics , 24 , 911-930. Mossin, J. (1966) Equilibrium in C apital Asset Marke t. Ec onometric a , 25 , 768-78 3. Quinta na, F.A. and Iglesias, P .L. (200 3) Ba y esian clustering and pr o duct partition mo dels. Journal of the R oyal Statistic al So c iety, Series B , 65 , 557-574. 21 Quinta na, F.A., Iglesias, P . L. and Galea -Ro jas, M. (20 05a) Ba y esian robu st estima- tion of systematic risk using p ro duct partition m o dels. Applie d Financial Ec onomics L etters , 1 , 313-320. Quinta na, F.A., Iglesias, P L. and Bolfarine, H. (200 5b) Ba y esian Id en tification of Outliers and Ch ange-P oin ts in Measuremen t Error Mo d els. A dvanc es in Complex Systems , 8 , 433 -449. Raftery , A., Ho eting, J ., V olinsky , C., P aint er, I and Y ee Y eun g, K. (2008) The BMA Pa ck age. http://cr an.r-pr oje ct.or g/w eb/p ackages/BMA/BMA.p df . Ross, S.A., W esterfiels, R.W. and Jaffe, J.F. (2008) Corp or ate Financ e , McGra w- Hill. Rousseeu w, P .J. (1984) Least median of squ are regression. J ournal of the Americ an Statistic al Asso ciation , 79 , 871-888 . Rousseeu w, P .J. and L ero y , A.M. (198 7) R obust R e gr ession and O utlier De te ction . Wiley , New Y ork. Sharp e, W.F. (1964 ) Capital Asset Prices: A Theory of Market Equilibrium u nder Conditions of Risk. Journal of Financ e , 19 , 425-4 42. T aranto la, C., Consonn i, G. and Dellap ortas, P . (2008) Ba y esian clustering f or r o w effects mo dels, Journal of Statistic al Planning and Infer enc e , 138 , 2223-2235 . V ´ ı ˇ sek, J. ` A (1999) T he least trim m ed squares-random carriers, Bul letin of the Cze ch Ec onom etric So ciety , 6 , 57-79. 22 T able 1: IPSA sto c k marke t data: comparison of the r esults obtained via L TS , QIB’s algorithm (Quinta na et al., 2005a) and DMT’s algorithm (De Giuli, Maggi and T aran tola). T he s econd, third and fourth columns displa y the clustering stru ctur e of the outliers. The last th r ee column s s ho w the s cores of the partitions selected by Quinta na et al. (2005a) and De Giuli, Maggi and T aran tola and pro du ction red uction in score (PRS). Figures in b rac k ets are Monte C arlo standard errors × 10 6 . So ciety L TS QIB DMT SC QIB SC DMT PRS CEMENTOS { 12 , 1 4 , 18 , 19 , 21 , 27 , 37 , 47 , 59 , 88 , { 12 , 18 , 27 , 37 , 112 , 121 } , { 12 , 18 , 21 , 27 , 37 , 4 7 , 59 , 0.0277 (4.79) 0.0113 (4.5 9) 0.4115 B ´ IO-B ´ IO S.A. 91 , 107 , 112 , 113 , 121 , 133 , 161 } { 21, 1 1 3 } , { 4 7 , 59 , 133 } , { 107 } 107 , 112 , 1 13 , 1 21 , 133 } CMPC { 3 , 1 5 , 49 , 50 , 54 , 5 7 , 100 , 112 } { 15 } { 15 } 0.0122 (45.09 ) 0.0122 (45.09 ) 0.0000 CONCHA Y { 12 , 14 , 18 , 21 , 22 , 23 , 27 , 29 , 32 , 83 , { 14 } , { 21 } , { 2 7 } { 14 , 18 , 21 , 22 , 27 , 9 7 } 0.0305 (5.44) 0.0116 (12.57 ) 0.6197 TORO 97 , 1 04 , 1 06 , 1 1 0 , 144 } COPEC S.A. { 31 , 105 , 1 07 , 1 08 , 109 , 111 } { 31 , 107 } , { 111 } { 3 1 , 10 7 , 11 1 } 0.0165 (13.45 ) 0.0110 (12.27 ) 0.3333 ENTEL { 14 , 27 , 29 , 48 , 59 , 63 , 65 , 106 , 111 , 112 } { 65 } { 59 , 65 } 0.0119 (41.73 ) 0.0116 (54.26 ) 0.0252 23 T able 2: Conc ha y T oro: Ba y esian Estimates of the systematic risk obtained w ith only one cluster, w ith the partition structure of QI, and with the partition strutu re of DMT resp ectiv ely . Figures in brac k ets are Monte Carlo s tandard errors × 10 5 . P artition structure ˆ β B S 0 0.9430 (9.2638) QIB 0.6486 (7.4916) DMT 0.7590 (9.0300) T able 3: Conc ha y T oro: Sensitivit y analysis c in equation (2.6) Ou tliers 0 . 01, 1 and 5 { 14 , 18 , 21 , 22 , 27 , 97 } 10 and 50 { 14 , 21 , 27 , 97 } 24 Figure 1: S core v alues for the d ifferen t partition explored by the algorithm of DMT. The optimal v alue is indicated by a star. A cross represen ts the p artition selected by QIB. 0 10 20 30 40 50 60 0.01 0.015 0.02 0.025 0.03 0.035 0.04 0.045 0.05 0.055 CEMENTOS scores 0 2 4 6 8 10 0.012 0.0125 0.013 0.0135 0.014 0.0145 0.015 0.0155 0.016 CMPC scores 0 10 20 30 40 50 60 0.01 0.015 0.02 0.025 0.03 0.035 0.04 CONCHA Y TORO scores 0 2 4 6 8 10 12 14 16 0.011 0.012 0.013 0.014 0.015 0.016 0.017 0.018 COPEC scores 0 5 10 15 20 25 30 35 0.01 0.012 0.014 0.016 0.018 0.02 0.022 0.024 0.026 0.028 0.03 ENTEL scores 25 Figure 2: Conc ha y T oro: Ba yesia n linear regression lines. Th e d ashed line represents the regression line obtained considering only one cluster. Cont inuous lines are the Ba y esian regression lines for eac h cluster iden tified b y QIB (first ro w) and DMT (second ro w). −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 −0.2 0 0.2 0.4 0.6 0.8 1 IPSA returns Concha y Toro returns QIB −0.4 −0.3 −0.2 −0.1 0 0.1 0.2 0.3 −0.2 0 0.2 0.4 0.6 0.8 1 IPSA returns Concha y Toro returns DTM 26
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment