Multi and Independent Block Approach in Public Cluster
We present extended multi block approach in the LIPI Public Cluster. The multi block approach enables a cluster to be divided into several independent blocks which run jobs owned by different users simultaneously. Previously, we have maintained the b…
Authors: ** Z. Akbar, L.T. H, oko *Group for Theoretical
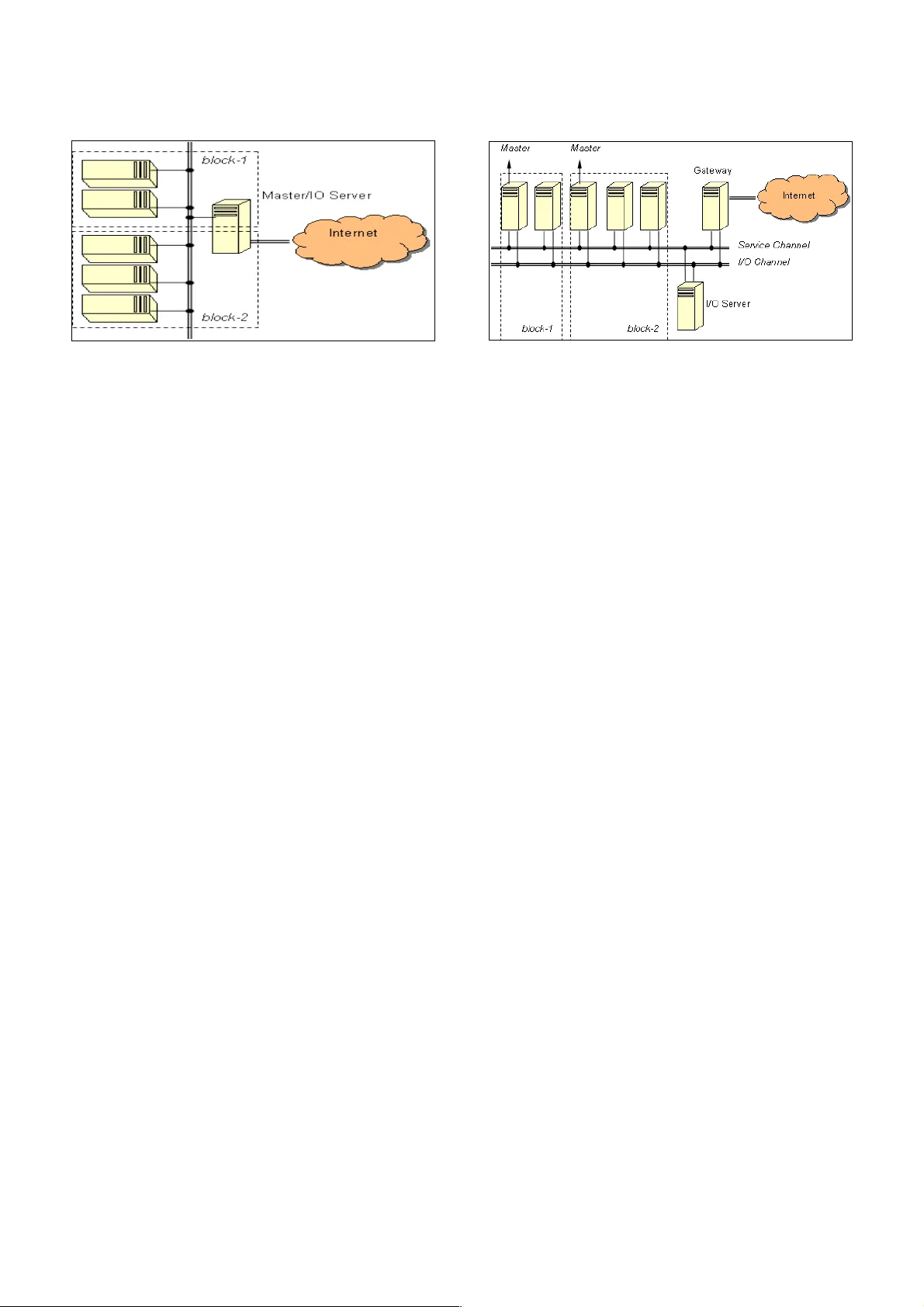
MUL TI AND INDEPENDENT BLOCK APPROACH IN PUBLIC CLUSTER Z. Akb ar and L .T . Handoko Group for Theo retical a nd Computational Physi c, Rese arch Cente r for P hysics, Indon esian Institute o f S ciences , Kompleks Puspiptek Serpong, T anger ang 15310 , Indonesia zae nal@teori .fisika.lipi.go.id ABSTRACT W e p resent extended multi blo ck appro ach in the LIPI Public Clu ster . The multi block appro ach enables a cluster to be divided into sever al ind epend ent blo cks which run jobs owned by diff erent use rs simu ltan eously . Previously , we h ave maintained the blocks using single master node fo r all blocks due to ef ficiency and resour ce limitations. Following recent advanc ements and expansion of nod e's numbe r , we have modified the multi block approa ch with multip le maste r nodes, each of them is responsib le fo r a single block . W e argu e that this approa ch improves the ov erall per forman ce significantly , for espe cially dat a intensive computational works. Keywo rds : cluste r computer , resour ce alloc ation, multi block app roach 1 INTRODUCTION LIP I Public Cluster (LPC) is glob ally a unique inf rastru cture due to its openn ess [1,2 ,3]. This nature leads to some innovations on cluster architectur e, especially so called multi block appro ach to enable multiple blocks of small cluster running simul tan eously without any inte rruption among each other [4]. In multi block appro ach, all running blocks have a common single maste r node as shown in Fig. 1. T his is actually motivated by resour ce (e specially hardwa re) limi tations. For instanc e all nodes we re not equipped with stor age media . So, the initial runtime environment contains sever al daemons called MPD's in each block were boot ed disklessly through network using embedded boot ROM in network cards attach ed in eac h node. The master nod e further works as a gateway for use rs, and all blo cks have only one MPD in it. Ther efore this maste r nod e is the last point for users acce ssing the cluster . Some benefits in this appro ach are : It avoids possible overl apping or interruption a mong the nod es own ed by dif ferent users . Numb er of nodes in an allocated block can be changed easily . It prevents a nonymous ac cesses to anothe r blocks own ed by anoth er users . V ery ef ficient in initial constru ction and furthe r mainten ance w orks. As ar gued in previous paper [4 ], this technique is quite reliable and the over all pe rform ances are af fected slightly . How ever , we con cern that the result is valid as long as the node 's number is small, nam ely at the order of few nodes . Mor eove r , the a ppro ach is suitable for som e computational w orks th at are processor (including memory ) intensive, but not for th e othe rs which are dat a intensive . In some proc essor intensive jobs, the data traffi c through netwo rk among the nodes during computation period is relatively small. Bec ause on ce all sub-jobs pr edefined in a parallel programming wer e sent to and initiated at the alloc ated nod es, each of them is executed ind epend ently in a node almost without any communic ation with the others. In contrar y , th e case in some data intensive jobs like image mapping are quite dif ferent. This type of computational works usually requir e very intensiv e data exchang e among the nodes during computation period . It is clear that th en perfo rmanc e of cluste r with conv entional multi block approa ch would be dec reased dr astically in this case , sinc e the maste r nod e is soon ov erlo aded. In LPC cur rently the allocated nodes in a block is usually few , and the d ata intensive job is extremely rar e. Bec ause the facility is mor eless used f or edu cational and training field for beginn ers in p arallel progr amming. How eve r, we anticip ate furthe r advan cements of our use rs and the incr easing level of their jobs in the near futur e. Also, recently we have upgraded the ha rdwa re environment to be mor e sophist icated , i. e. all nod es are curr ently equipped with storage medias. So , regardless with some ben efits in the conventional multi block appro ach, we are now involved in expanding th e multi block appro ach with an independ ent mast er nod e in each block. In this paper , we first discuss the n ew approa ch, followed with the analysis performan ce before ending with con clusion. 2 MUL TI BLOCK CLUSTER WITH INDEPENDENT MASTER NODES Now we are ready to discuss the extended multi block app roach with an indep endent master nod e in each block . The most common archite ctures fo r cluster computer are the symmetric and asymmetric clusters [5]. In the symmetric cluster all nodes ar e treated equ ally and acce ssible by extern al users. In contr ast, the re is only on e node that is acce ssible by external users and performs as mediator betwe en users and the rest nod es in the asymmetric cluster . In this case , ther e should be a public interf ace f or user and anothe r private interf aces fo r nod es. In the LPC with indep endent m aster nodes, we extend it by a dding some dedic ated serv ers for specifi c jobs b eside Fig ure 1. M ulti blo ck app roach. computational jobs owned by users . The architectur e is shown in Fig . 2. In this app roach, p revious master node is transform ed to be the gatew ay server mainly for users' acc ess through intern et. W e also split the IO rel ated jobs of f to be handled by diff erent dedic ated server . Bo th se rvers are conn ected to all nod es through ind epend ent networks betwe en them, n amely the service and IO chann els. The servic e serv er serves the web , ssh, monitoring servic es, and also stor es all common binary prog rammes including libr aries and compilers. On the oth er h and, the IO server is us ed for computational dat a commun ication, and s erves the us ers' home directori es, NIS and NFS se rvices . Ther efore we h ave implemented the I O ch annel on a gigabit loc al are a network , while the servic e chann el sits on regula r fast eth ernet b ased n etwork . This physi cal sep aration is ur gent in the case of data intensive , or let us call it IO intensive , computational works as mentioned be fore. M any rese arch works related to clust er's archite ctures are mainly intend ed for these IO intensive jobs. Th ere are also anothe r appro ach es to deal with, for example : making us e of cache [6] , or spr eading of the IO processes from satur ated nodes to oth er und erload ed nod es [7 ]. Although the IO and servi ce channels are separ ated physic ally , the blocks are separ ated logic ally as usual but with an ind epend ent maste r node in each o f them . Th ese mast er nodes function as inter faces between the gateway and the blocks . This me ans all commands sent by use rs ov er web in the gateway are forward ed to the maste r node of rel evant block , and vice versa through the servic e chann el. Un fortunat ely , du e to its natu re in LPC there is no way to kno w in advan ced the types of computational works being run by users , and actu ally we do not put any limi tation on that. The refore we are forc ed to accommodate both types easily and ef ficiently . He re ef ficient is in the sense th at we should provide a blo ck of cluste r as close as to the us er needs. For instanc e, IO intensive resour ces must not be provided to users who actually need only processor intensive ones . This is the main reason w e still keep the conventional multi block app roach in LPC. So during the initial resourc e allocation proc edur e don e by adminis trator on ce a new registration has been p rocessed [8] , the admin istrator should d etermine the typ e of propos ed Fig ure 2. M ulti an d inde pendent block approa ch. computational w orks. At time b eing, we hav e not yet implement ed dyn amical change o f the cluster arc hitectur e partially , eith er conv entional or indep endent multi block approa ches. This means the whole LPC has used on e of them, and not both of them at the same time. Now let us proce ed with the case that LPC deploys the independ ent multi block appro ach. All use rs' data ar e stor ed in the IO serve r , and then exported to all alloc ated nodes through Network File System (NFS ) [9]. This solves the problem due to centraliz ed d ata storag e whi ch could burd ened the IO chann el, and also enhan ces the fl exibility of a block a s w ell. In the next se ction, we provide a performan ce analysis for typical IO intensive c omputational wo rks. 3 PERFORMANCE ANAL YSIS In the present analysis, we are not using the same ben chmarking progr amme mpptes as alre ady don e for the conv entional multi block app roach [4]. This programme has been developed by the Ar gonn e Nation al Labor atory [10] , and runs und er par allel prog ramming environm ent Messag e Passing Int erfac e (M PI) [1 1]. The reason is this time th e an alysis is focus ed on compa ring th e pe rforman ces of the modified cluster archite cture and the n etwork being used . Inste ad w e perform a ping -pong test based on the LAM-M PI [12] . M easurement is done by using twin indep endent blocks with exactly same spe cifications. Ea ch consists of 4 nodes. W e perfo rm typical IO intensive computation by sending data with various size from 2 nodes in a block to the r est 2 nodes in the same block. First , this is execut ed only for one block, and further the same proc edure is don e for both blocks. Through this perform ance test, w e could me asure the reliabili ty of indep endent multi block a rchitectur e against the growing number of blocks that could happ en dynamic ally in the re al daily ope ration. First of all w e compa re the r unning time in f ast-eth ernet (FE) and gigabit networks (GE) . T he result for one blo ck is depict ed in Fig. 3 with time axis shows the round-trip time in mic rosecond. Th e messag e size is limited to around 33 Mb since the cas e in FE is not reliabl e anymor e beyond it. In contr ast with this, th e GE is stil l reliable up to messag e Fig ure 3. Comp arison of roun d-trip time s betw een FE (gree n lin e) and GE (red line). siz e close to 1 Gb . Further we test fo r simultaneous twin blocks r un in F E and GE as shown in Fig . 4. It is trivial that the perform ance in GE is signific antly improved , and it is much bette r th an in F E. 4 CONCLUSION Thes e results prov e our argument that, esp ecially in multi-block cluster th at is urg ent for a public cluster , splitt ing of f the networks and implem enting gigabit network is very cruci al to improve the whole performan ce. W e have shown th at the independ ent multi block appro ach is much better esp ecially for I O intensive computational works. This approa ch would complem ent the conventional multi block appro ach. Both of them should be c ombined tog ether and imp lemented dyn amically for nod e allocations acc ording to the us ers' requests and types of parallel p rogrammings being ex ecuted . This study is very import ant for the administrator in acc ommodating the us ers' requests a nd allo cating the resour ces for them. In the future we are going to develop simultaneous conventional multi block and indep endent multi block architectur es in LPC to accommodate user's needs on IO intensive and proc essor intensive computational works at the s ame time . Fig ure 4. Round -trip times for twi n blocks in FE (gree n line) and GE (red line ). ACKNOWLEDGMENT This wo rk is financially suppo rted by the Riset Kompetitif LIPI in fiscal yea r 2007 under Contra ct no. 1 1.04/SK/K PP I/II/2007 and the Indon esia T oray Sci ence Found ation Rese arch G rant 2007 . REFERENCE [1] LIPI Public Cluste r , http:// www .cluster .lipi.go .id . [2] L.T . Handoko ,, Indon esian Copyright, No . B 268487 (2006). [3] Z . Akbar , Sl amet, B. I. Ajinagoro , G.J . Oh ara, I. Firmansyah , B. Hermanto and L.T . Handoko , “Op en and Fre e Cluster for Public” , Proc eeding of the Intern ational Conf erence on Rural In formation and Communication T echnology 2007 , Bandung, Indonesia ,2007. [4] Z . Akbar , Slamet, B. I. Ajinagoro , G.J . Oh ara, I. Firmansyah , B. Hermanto and L. T . Handoko, “Public Cluster : parallel machine with multi-block appro ach”, Pro ceeding of the Inte rnational Conf eren ce on El ectrical Engine ering and Informatics , Bandung, Indonesia , 2007 . [5] I. Firmansyah , B. Hermanto , Slamet, Hadiyanto and L.T . Handoko , “Real-time control and moni toring system for LIPI’ s public cluster ”, Proc eeding o f the Intern ational Conf erence on Instrumentation, Communication, and Info rmation T echnology , Bandung , Indonesia , 2007 . [5] J. Sloan , "High Performan ce Linux Clusters with OSCAR, Rocks , openMosix, and MPI" , O’Reilly (2005) 0 -596-00570-9 . [6] Murali V il ayannur , Anand Siv asubr amaniam, Mahmut Kandemir , Rajeev Thaku r and Robe rt Ross, “Discr etionary Caching for I/O on Clusters” , Cluster Computing 9, 29–44, 2006. [7] Xiao Qin, Hong Jiang, Y ifeng Zhu, David R. Swanson , “Imp roving the Perfo rmanc e of IO-Intensive Applications on Cluste rs of W orkst ations” , Cluster Compu ting (2006 ) 9:297–31 1. [8] Z. Akba r and L.T . Handoko, “Resourc e Allo cation in Public Cluster with Extend ed Optimization Algo rithm” , Proce eding of the Intern ational Conf erenc e on Instrumentation, Com munic ation, and Information T echnolog y , Bandung, Indon esia, 2007. [9] N FS , http://nfs.sour cefor ge.net. [10] W illiam Gr opp and Ewing Lusk, “Rep roducible M easurements of MPI Perfo rmanc e Char acterist ics ”,in the Proc eedings o f PVMMPI '99, 1999. [1 1] Messag e Passing Int erface Forum, “MPI2: A Mess age Passing Int erface stand ard”. International Jou rnal of High Performan ce Computing Applic ations, 12 (1– 2):1–299, 1998 . [12] LAM-M PI, http:/ /ww w .lam-mpi.or g/linux/.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment