Matrix probing and its conditioning
When a matrix A with n columns is known to be well approximated by a linear combination of basis matrices B_1,..., B_p, we can apply A to a random vector and solve a linear system to recover this linear combination. The same technique can be used to …
Authors: Jiawei Chiu, Laurent Demanet
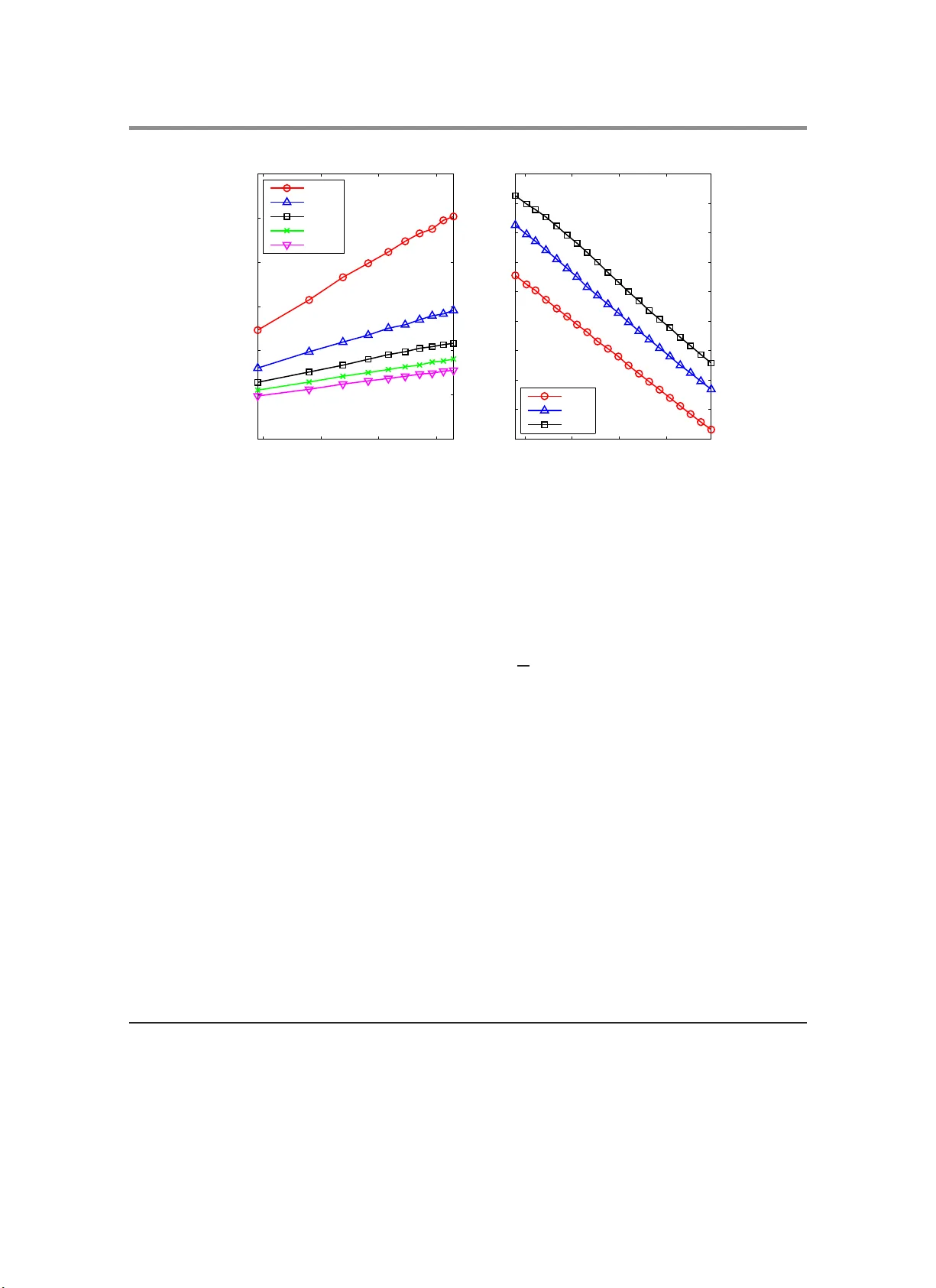
Matrix p robing and its conditioning ∗ Jia w ei Chiu † and Laurent Demanet ‡ Abstract. When a matrix A with n c olumns is known to be w ell approximated b y a linear co mbination of basis matrices B 1 , . . . , B p , w e can apply A to a random v ector and solv e a linear system to reco ver this linear com bination. The same technique can be used t o obtain an appro ximation to A − 1 . A basic qu estion is whether this linear system is well-conditioned. This is important for t wo reasons: a well-conditioned system means (1) we can invert it and (2) the error in the reconstruction can b e con trolled. In this paper, w e sho w that if the Gram matrix of the B j ’s is sufficien tly w ell- conditioned and each B j has a high numerical rank, then n ∝ p log 2 n will ensure that the linear system is w ell-conditioned with high probabilit y . Our main application is probing linear op erators with smooth pseudo differential sym bols such as the w av e equation Hessian in seismic imag ing [ 9 ]. W e also demonstrate numerically that matrix probing can pro duce go o d preconditioners for inv erting elliptic operators in v ariable media. Acknowledgments. JC is supp orted b y the A*ST AR fellow ship from Singap ore. LD is sup p orted in p art by a gran t from the N ational Science F oundation and t h e Alfred P . Sloan foundation. W e thank Holge r Rauhut for the interesting discussions, and the anon ymous referees for sugges ting several impro v ements to the pap er. 1. Intro duction. The earliest randomized algorithms include Mon te Carlo in tegration and Mon te Carlo Marko v c hains [ 1 ]. These are standard techniques in numerical computing with widespread app lications from p h ysics, e conometrics to mac hine lea rning. Ho w ev er, they a re often seen as the metho d s of last resort, b ecause they are e asy to imp lemen t but pro d uce solutions of uncertain accuracy . In the last few decades, a new breed of randomized alg orithms has b een d evelo p ed by the computer science communit y . These algorithms remain ea sy to implemen t, and in addition, ha v e failure p robabilities that are pro v ably negligible. In other w ords, w e ha v e rigorous th eory to ensure that these algorithms p erform consisten tly well . Moreo v er, th eir time complexit y can b e as go o d as the most sophisticated dete rministic alg orithms, e.g., Karp -Rabin’s pattern matc hing algorithm [ 17 ] and Karger’s min-cut algorithm [ 16 ]. In r ecent yea rs, equally attractiv e randomized algorithms are b eing develo p ed in the n u- merical comm unit y . F or example, in compressed sensin g [ 4 ], we can reco v er sparse v ectors with random measurement matrices and ℓ 1 minimization. Another in teresting example is that w e can build a go o d lo w rank approxima tion of a matrix b y applying it to r andom ve ctors [ 14 ]. Our w ork carries a similar fla v or: o ften, the matrix A can b e appro ximated as a linea r com bination of a small n um b er of matrices and the idea is to obtai n these co efficients b y applying A to a random vec tor or just a few of them. W e call this “forw ard matrix p robing.” What is ev en more in teresting is that we can also prob e for A − 1 b y applying A to a r andom v ector. W e call this “bac kwa rd matrix pr obing” for a reason that will b e clear in Section 1.5 . Due to appro ximation errors, the outpu t of “bac kward probing” denoted as C , is only an app ro ximate in v erse. Nev ertheless, as we will see in Section 4 , C serve s v ery w ell as ∗ Dated F ebrua ry 201 1. † Co rrespond ing author. jia w ei@mit.edu . Depar tment of Ma thematics, MIT, Camb ridge, MA 021 39, US A. ‡ Department of Mathematics, MIT, Cambr idge, MA 02139, USA. 1 2 a p reconditioner for in v erting A , and w e b eliev e that its p erf ormance could m atc h that of m ultigrid metho ds for elliptic op erators in smo oth media. W e lik e to add that the idea of “matrix probing” is not new. F or example, Chan [ 6 , 5 ] et. al. use the tec h nique t o app ro ximate A with a sparse matrix. Another example is the work b y Pfander e t. al. [ 21 ] wher e the same idea is used in a w a y t ypical in compressed sensing. In the next section, we will see that their set-up is fundamental ly different from ours. 1.1. F o rw a rd mat rix p robing. Let B = { B 1 , . . . , B p } w h ere eac h B j ∈ C m × n is c alled a basis matrix. Note that B is sp ecified in adv ance. Let u b e a Gaussian or a Rademac her sequence, that is eac h comp onen t of u is indep endent and is either a standard normal v ariable or ± 1 with equal probability . Define the matrix L ∈ C m × p suc h th at its j -th column is B j u . Let A ∈ C m × n b e the matrix w e wa nt to prob e and sup p ose A lies in the span of B . Sa y A = p X i =1 c i B i for some c 1 , . . . , c p ∈ C . Observe that Au = P p i =1 c i ( B i u ) = Lc . Giv en the v ector Au , we can obtain the co efficien t v ector c = ( c 1 , . . . , c p ) T b y solving the linear system Lc = Au. (1.1) In practice , A is not exactly in the span of a small B and E q u ation ( 1.1 ) has to b e solved in a least squares sense, that is c = L + ( Au ) wh er e L + is the pseud oin v erse of L . W e will assume that p ≤ n . Otherw ise there are more unknowns than equations and th ere is n o unique solution if there is any . This differs fr om the set-up in [ 21 ] where n ≫ p b ut A is assumed to b e a s p arse linear com bination of B 1 , . . . , B p . 1.2. Conditioning of L . Whether Equ ation ( 1.1 ) can b e solv ed accurately dep end s on cond( L ), the condition n um b er of L . Th is is the ratio b et w een th e largest and the smallest singular v alues of L and can b e understo o d as h o w differen t L can stretc h or shrink a v ector. In tuitiv ely , whether cond( L ) is small d ep ends on the follo wing tw o prop erties of B . 1. T he B i ’s “act different ly” in the sense that h B j , B k i ≃ δ j k for an y 1 ≤ j, k ≤ p . 1 2. E ac h B i has a high rank so that B 1 u, . . . , B p u ∈ C n exist in a high d imensional sp ace. When B p ossesses these t w o p rop erties and p is sufficien tly small compared to n , it make s sense that L ’s columns , B 1 u, . . . , B p u , are lik ely to b e indep enden t, th u s guaran teeing that L is in v ertible, at least. W e now mak e the ab o v e tw o prop erties more precise. Let M = L ∗ L ∈ C p × p and N = E M . (1.2) Clearly , cond( M ) = co nd( L ) 2 . If E M is ill-conditioned, there is little c hance th at M or L is w ell-conditioned. This can b e relate d to Prop erty 1 b y observing that N j k = E M j k = T r( B j ∗ B k ) = h B j , B k i . (1.3) 1 Note that h· , ·i is the F roben ius inner product and δ j k is the Kronec k er delta. 3 If h B j , B k i ≃ δ j k , then the Gram matrix N is appro ximately the iden tit y matrix whic h is w ell-conditioned. Hence, a m ore quan titativ e wa y of putting Pr op ert y 1 is that we ha v e con trol o v er κ ( B ) defin ed as follo ws. Definition 1.1. L et B = { B 1 , . . . , B p } b e a set of matric es. Define its c ondition numb er κ ( B ) as the c ondition numb er of the matrix N ∈ C p × p wher e N j k = h B j , B k i . On th e other h and, Prop erty 2 can b e made precise b y sa ying that we hav e con trol o ver λ ( B ) as defin ed b elo w. Definition 1.2. L et A ∈ C m × n . Define its we ak c ondition numb er 2 as λ ( A ) = k A k n 1 / 2 k A k F . L et B b e a set of matric es. Define its (u niform) we ak c ondition numb er as λ ( B ) = max A ∈B λ ( A ) . W e j u stify the n omenclature as follo ws. Supp ose A ∈ C n × n has condition n um b er k , then k A k 2 F = P n i =1 σ 2 i ≥ nσ 2 min ≥ n k A k 2 /k 2 . T aking square ro ot, w e o btain λ ( A ) ≤ k . In other wo rds, an y well-co nditioned matrix is also weakly wel l-conditioned. And like the u sual condition num b er, λ ( A ) ≥ 1 b ecause w e alw a ys hav e k A k F ≤ n 1 / 2 k A k . The numerical r ank of a matrix A is k A k 2 F / k A k 2 = nλ ( A ) − 2 , thus ha ving a small λ ( A ) is the same as ha ving a h igh numerical r ank. W e also wan t to caution the reader that λ ( B ) is defined v ery different ly from κ ( B ) and is not a weak er ve rsion of κ ( B ). Using classical concen tratio n inequalties, it w as sho wn [ 9 ] that when λ ( B ) and κ ( B ) are fixed, p = ˜ O ( n 1 / 2 ) 3 will ensur e that L is w ell-conditioned with h igh probabilit y . In this pap er, w e establish a stronger result, namely that p = ˜ O ( n ) suffices. The implica- tion is that we can exp ect to reco v er ˜ O ( n ) in stead of ˜ O ( n 1 / 2 ) co efficien ts. Th e exact stat emen t is present ed b elow. Theo rem 1.3 (Main result). L et C 1 , C 2 > 0 b e numb ers given by R emark B.1 in the Ap- p endix. L et B = { B 1 , . . . , B p } wher e e ach B j ∈ C m × n . De fine L ∈ C n × p such that i ts j -th c olumn is B j u wher e u is either a Gaussian or R ademacher se quenc e. L et M = L ∗ L , N = E M κ = κ ( B ) and λ = λ ( B ) . Supp ose n ≥ p ( C κλ log n ) 2 for some C ≥ 1 . Then P k M − N k ≥ t k N k κ ≤ 2 C 2 pn 1 − α wher e α = tC eC 1 . The num b er C 1 is small . C 2 ma y b e large but i t p oses no problem b ecause n − α deca ys v ery fast with larger n an d C . With t = 1 / 2, we deduce that with high p robabilit y , cond( M ) ≤ 2 κ + 1 . 2 Throughout the paper, k·k and k·k F denote the spectral and F rob enius norms resp ectivel y . 3 Note that ˜ O ( n ) den otes O ( n log c n ) for some c > 0. In other words, ignore log factors. 4 In general, w e let 0 < t < 1 a nd for the p r obabilit y b ound to b e useful, w e need α > 2, whic h im p lies C > 2 eC 1 > 1. T herefore the assumption that C ≥ 1 in the theorem can be considered redun dan t. W e remark that Rauh ut and T ropp h a v e a n ew result ( a Bernstein-like tail boun d) that ma y b e used to refine the theorem. Th is will b e briefly discu s sed in Section 4.1 where we conduct a numerical exp er im ent. Note that when u is a Gaussian sequence, M resembles a W ishart mat rix for which the distribution of the s m allest eigen v alue is we ll-studied [ 11 ]. Ho w ev er, eac h ro w of L is not indep end en t, so results from random matrix theory cannot b e used in this wa y . An in termediate result in the pro of of Theorem 1.3 is the follo win g. It con v eys the essence of Theorem 1.3 and ma y b e easie r to remem b er. Theo rem 1.4. Assume the same set-up as in The or e m 1.3 . Supp ose n = ˜ O ( p ) . Then E k M − N k ≤ C (log n ) k N k ( p/n ) 1 / 2 λ f or some C > 0 . A numerical exp eriment in S ection 4.1 suggests th at the relationship b etw een p and n is not tigh t in the log factor. Our exp erimen t sh o w that for E k M − N k / k N k to v anish as p → ∞ , n jus t n eeds to increase faster than p log ( np ), w hereas Theorem 1.4 r equires n to gro w faster than p log 2 n . Next, we see that when L is w ell-c onditioned, the error in the reconstruction is also sm all. Prop osition 1.5. Assume the same set-up as in The or em 1.3 . Supp ose A = P p j =1 d j B j + E wher e k E k ≤ ε and assume whp, k M − N k ≤ t k N k κ for some 0 < t < 1 . L et c = L + Au b e the r e c over e d c o efficients. Then whp, A − p X j =1 c j B j ≤ O ελ κp 1 − t 1 / 2 ! . If ε = o ( p − 1 / 2 ), then th e prop ositio n guaran tees that the ov erall err or go es to zero as p → ∞ . Of course, a larger n and more computational effort are required. 1.3. Multiple probes. Fix n and supp ose p > n . L is not going to b e w ell- conditioned or ev en in v ertible. One wa y around this is to pr ob e A with m u ltiple random ve ctors u 1 , . . . , u q ∈ C n at one go, that is to solve L ′ c = A ′ u, where the j -th column of L ′ and A ′ u are resp ect iv ely B j u 1 . . . B j u q and Au 1 . . . Au q . 5 F or this to make sense, A ′ = I q ⊗ A where I q is th e identit y matrix of size q . Also define B ′ j = I q ⊗ B j and treat the ab o v e as probing A ′ assuming that it lies in the sp an o f B ′ = { B ′ 1 , . . . , B ′ p } . Regarding the conditioning of L ′ , we can apply Theorem 1.3 to A ′ and B ′ . It is an easy exercise (cf. P rop osition A.1 ) to see th at the condition n umber s are un c hanged, that is κ ( B ) = κ ( B ′ ) and λ ( B ) = λ ( B ′ ). Applying T heorem 1.3 to A ′ and B ′ , we deduce that cond( L ) ≤ 2 κ + 1 w ith high probabilit y p ro vided that nq ∝ p ( κλ log n ) 2 . Remem b er that A has only mn degrees of freedom; wh ile we can increase q as m uc h as we lik e to improv e the conditioning of L , the problem set-up d o es not al lo w p > mn co efficien ts. In general, when A has r ank ˜ n , its degrees of freedom is ˜ n ( m + n − ˜ n ) by considering its SVD. 1.4. When to p rob e. Matrix p robing is an esp ecially useful tec hnique when the follo wing holds. 1. W e kn o w that the prob ed m atrix A can b e approximat ed b y a s m all n umber of basis matrices that are sp ecified in adv ance. Th is holds for op erators with smo oth pseudo d - ifferen tial symbols, wh ich will b e studied in Section 3 . 2. E ac h mat rix B i can be applied to a v ector in ˜ O (max( m, n )) time u s ing only ˜ O (max( m, n )) memory . The second cond ition confers t w o b enefits. First, the co efficien ts c can b e r eco v ered fast, assuming that u and Au are already pro vided. Th is is b ecause L can be computed in ˜ O (max ( m, n ) p ) time and Equation ( 1.1 ) can b e solv ed in O ( mp 2 + p 3 ) time b y QR factoriza tion or ot her metho ds. I n the case wh er e increasing m, n do es not require a b igger B to appro ximate A , p can b e treated as a constan t and the r eco v ery of c tak es only ˜ O (max( m, n )) time. Second, giv en the co efficient v ector c , A can b e applied to any vect or v by summing o v er B i v ’s in ˜ O (max( m, n ) p ) time . This sp eeds up iterativ e methods suc h as GMRES and Arnoldi. 1.5. Backw a rd matrix p robing. A co mp elling application of mat rix probin g is computing the pseudoinv ers e A + of a matrix A ∈ C m × n when A + is kno wn to b e well -approxima ted in the space of some B = { B 1 , . . . , B p } . This time, w e pr ob e A + b y applying it to a rand om v ector v = Au where u is a Gaussian or Rademacher sequence that we generate . Lik e in Section 1.1 , define L ∈ C n × p suc h that its j -th column is B j v = B j Au . Supp ose A + = P p i =1 c i B i for some c 1 , . . . , c p ∈ C . Then the co efficient v ector c can b e obtained b y solving Lc = A + v = A + Au. (1.4) The right h and side is u pro jected on to n ull( A ) ⊥ where null( A ) is th e nullspace of A . When A is in v ertible, A + Au is simply u . W e call this “bac kw ard matrix pr ob in g” because the generate d rand om v ector u app ears on the opp osite side of the matrix b eing prob ed in Equation ( 1.4 ). The equation suggests the follo wing framew ork for p robing A + . Algo rithm 1 (Backw a rd matrix p robing). Supp ose A + = P p i =1 c i B i . The go al is to r etrieve the c o efficients c 1 , . . . , c p . 1. Gener ate u ∼ N (0 , 1) n iid. 2. Compute v = Au . 6 3. Filter away u ’s c omp onents in nul l ( A ) . Cal l this ˜ u . 4. Compute L by setting its j -c olumn to B j v . 5. Solve for c the system Lc = ˜ u in a le ast squar es sense. In order to p erform th e filtering in Step 3 efficientl y , pr ior kno wledge of A may b e needed. F or example, if A is the Laplacian with p erio d ic bou n dary conditions, its n ullspace is the set of constant fun ctions and Step 3 amounts to subtr acting the m ean fr om u . A m ore inv olv ed example can b e foun d in [ 9 ]. In this pap er, we in v ert the wa ve equation Hessian, and Step 3 en tails building an illumination mask. F urth er comments on [ 9 ] are lo cated in S ection 4.5 of this pap er. F or the co nditioning of L , w e ma y app ly T h eorem 1.3 with B replaced w ith B A := { B 1 A, . . . , B p A } sin ce the j -th column of L is no w B j Au . Of course, κ ( B A ) and λ ( B A ) can b e v ery differen t from κ ( B ) and λ ( B ); in fact, κ ( B A ) and λ ( B A ) seem m uc h harder to con trol b ecause it dep end s on A . F ortunately , as w e s hall see in S ection 3.5 , kn o wing the “order” of A + as a pseudo d ifferen tial op erator helps in k eeping these condition num b ers small. When A has a h igh dimensional nullspace but has comparable nonzero singular v alues, λ ( B A ) may b e m u c h larger than is necessary . By a c hange of basis, we can obtain the follo wing tigh ter result. Co rolla ry 1.6. L et C 1 , C 2 > 0 b e numb ers given by R emark B.1 in the App endix. L et A ∈ C m × n , ˜ n = rank( A ) and B A = { B 1 A, . . . , B p A } wher e e ach B j ∈ C n × m . Define L ∈ C n × p such tha t its j - th c olumn is B j Au wh er e u ∼ N (0 , 1) n iid. L et M = L ∗ L , N = E M , κ = κ ( B A ) and λ = ( ˜ n/n ) 1 / 2 λ ( B A ) . Supp ose ˜ n ≥ p ( C κλ log ˜ n ) 2 for some C ≥ 1 . Then P k M − N k ≥ t k N k κ ≤ (2 C 2 p ) ˜ n 1 − α wher e α = tC eC 1 . Notice that ˜ n = rank ( A ) has tak en the role of n , and our λ is no w max 1 ≤ j ≤ p ˜ n 1 / 2 k B j A k k B j A k F , whic h ig nores the n − ˜ n ze ro singular v alues of eac h B j A and can b e m uc h smaller than λ ( B A ). 2. Pro ofs. 2.1. Pro of of Theo rem 1.3 . Ou r pro of is d ecoupled into t w o comp onents: one linear algebraic and one probabilistic. The plan is to collect all th e results that are lin ear al gebraic, deterministic in nature, then app eal to a probabilistic resu lt dev elop ed in the App endix. T o facilitate the exp osition, w e use a differen t notation for this section. W e use lo w er ca se letters as sup e rscripts th at run from 1 to p and Greek symb ols as subscripts that r un from 1 to n or m . F or example, th e set of basis matrices is no w B = { B 1 , . . . , B p } . Our linear algebraic resu lts concern the follo wing v ariables. 1. L et T j k = B j ∗ B k ∈ C n × n and T ξ η ∈ C p × p suc h th at the ( j, k )-th en try o f T ξ η is the ( ξ , η )-th ent ry of T j k . 2. L et Q = P 1 ≤ ξ ,η ≤ n T ∗ ξ η T ξ η . 3. L et S = P p j =1 B j B j ∗ ∈ C m × m . 4. L et F and G b e blo c k matrices ( T ξ η ) 1 ≤ ξ ,η ≤ n and ( T ∗ ξ η ) 1 ≤ ξ ,η ≤ n resp ectiv ely . 7 The r eason for in tro d ucing T is that M can b e wr itten as a quadratic form in T ξ η with input u : M = X 1 ≤ ξ ,η ≤ n u ξ u η T ξ η . Since u ξ has unit v ariance and zero mean, N = E M = P n ξ =1 T ξ ξ . Probabilistic inequalties applied to M w ill inv olv e T ξ η , whic h m ust b e r elated to B . The connection b et we en these n b y n matrices and p by p matrices lies in th e iden tit y T j k ξ η = m X ζ =1 B j ζ ξ B k ζ η . (2.1) The linear algebraic results are conta ined in the follo wing p rop ositions. Prop osition 2.1. F or any 1 ≤ ξ , η ≤ n , T ξ η = T ∗ ηξ . Henc e, T ξ ξ , N ar e al l He rmitian. Mor e over, they ar e p ositive semidefinite. Pr o of . Sh o wing that T ξ η = T ∗ ηξ is straigh tforw ard from Equation ( 2.1 ). W e no w c hec k that T ξ ξ is p ositiv e semidefinite. Let v ∈ C p . By Equation ( 2.1 ), v ∗ T ξ ξ v = P ζ P j k v j v k B j ζ ξ B k ζ ξ = P ζ P k v k B k ζ ξ 2 ≥ 0. It follo ws that N = P ξ T ξ ξ is also p ositiv e s emid efinite. Prop osition 2.2. Q j k = T r ( B j ∗ S B k ) and Q = X 1 ≤ ξ ,η ≤ n T ξ η T ∗ ξ η . Pr o of . By Equation ( 2.1 ), Q j k = P l T lj , T lk = P l T r( B j ∗ B l B l ∗ B k ). Th e s u mmation and trace co mmute to give us the first iden tit y . S imilarly , the ( j, k )-th ent ry of P ξ η T ξ η T ∗ ξ η is P l T k l , T j l = P l T r( B l ∗ B k B j ∗ B l ). Cycle the terms in the trace to obtain Q j k . Prop osition 2.3. L e t u ∈ C p b e a unit ve ctor. D efine U = P p k =1 u k B k ∈ C m × n . Then k U k 2 F ≤ k N k . Pr o of . k U k 2 F = T r( U ∗ U ) = T r( P j k u j u k B j ∗ B k ). The su m and trace comm ute an d due to Equation ( 1.3 ), k U k 2 F = P j k u j u k N j k ≤ k N k . Prop osition 2.4. k Q k ≤ k S k k N k . Pr o of . Q is Hermitian, so k Q k = max u u ∗ Qu where u ∈ C p has un it n orm . No w let u b e an arbitrary unit ve ctor and defin e U = P p k =1 u k B k . By Prop osition 2.2 , u ∗ Qu = P j k u j u k Q j k = T r( P j k u j u k B j ∗ S B k ) = T r( U ∗ S U ). Since S is p ositiv e definite, it follo ws from “ k AB k F ≤ k A k k B k F ” that u ∗ Qu = S 1 / 2 U 2 F ≤ k S k k U k 2 F . By Prop osition 2.3 , u ∗ Qu ≤ k S k k N k . 8 Prop osition 2.5. F or any 1 ≤ j ≤ p , B j ≤ λn − 1 / 2 k N k 1 / 2 . It fol lows that k Q k = X ξ η T ξ η T ∗ ξ η ≤ pλ 2 k N k 2 /n. Pr o of . W e b egin b y noting that k N k ≥ max j | N j j | = max j B j , B j = max j B j 2 F . F rom Definition 1.2 , B j ≤ λn − 1 / 2 B j F ≤ λn − 1 / 2 k N k 1 / 2 for an y 1 ≤ j ≤ p , whic h is our fi rst inequalit y . It follo ws that k S k ≤ P p j =1 B j 2 ≤ pλ 2 k N k /n . Apply Pr op ositions 2.4 and 2.2 to obtain the second in equalit y . Prop osition 2.6. F , G ar e Hermitian, and max( k F k , k G k ) ≤ λ 2 k N k ( p/n ) . Pr o of . T hat F , G a re Hermitian follo w from Prop osition 2 .1 . Define F ′ = ( T j k ) another blo c k matrix. Since reindexin g the r ows and columns of F do es not c hange its n orm, k F k = k F ′ k . By Prop osition 2.5 , k F ′ k 2 ≤ P p j,k =1 T j k 2 ≤ P p j,k =1 B j 2 B k 2 ≤ λ 4 k N k 2 ( p/n ) 2 . The same argumen t works for G . W e no w combine the ab o v e linear algebraic r esu lts with a probabilistic result in App endix B . Pr epare to apply Pr op osition B.6 with A ij replaced with T ξ η . Note that R = P ξ η T ξ η T ∗ ξ η = Q b y Prop ositi on 2.2 . Bound σ using Prop ositio ns 2.5 and 2.6 : σ = C 1 max( k Q k 1 / 2 , k R k 1 / 2 , k F k , k G k ) ≤ C 1 k N k max(( p/n ) 1 / 2 λ, ( p/n ) λ 2 ) ≤ C 1 k N k ( p/n ) 1 / 2 λ. The last step go es th r ough b ecause our assumption on n guaran tees that ( p/n ) 1 / 2 λ ≤ 1. Finally , app ly Prop osition B.6 with t k N k /κ = eσ u . The pro of is complete. 2.2. Sk etch of the proof f o r Theore m 1.4 . F ollo w the pro of of Prop osition B.6 . Letting s = log n , w e obtain E k M − N k ≤ ( E k M − N k s ) 1 /s ≤ C 1 (2 C 2 np ) 1 /s s max( k Q k 1 / 2 , k R k 1 / 2 , k F k , k G k ) ≤ C (log n ) k N k ( p/n ) 1 / 2 λ. 2.3. Pro of of Prop osition 1.5 . Recall that A is approximate ly the linear com bination P p j =1 d j B j , wh ile P p j =1 c j B j is the reco v ered linear com bination. W e s h all first sho w that the 9 reco v ered co efficien ts c is close to d : k d − c k = L + Au − c = L + ( Lc + E u ) − c = L + E u ≤ ε k u k κ (1 − t ) k N k 1 / 2 . Let v b e a unit n -v ector. L et L ′ b e a n × p matrix su c h that its j -th column is B j v . Now, Av − p X j =1 c j B j v = ( L ′ d + E v ) − L ′ c = E v + L ′ ( d − c ) . Com bining the t w o equations, w e ha v e A − p X j =1 c j B j ≤ ε + ε L ′ k u k κ (1 − t ) k N k 1 / 2 . (2.2) With o v erwhelming probabilit y , k u k = O ( √ n ). T he only term left that needs to b e b oun ded is k L ′ k . Th is turns out to b e easy b ecause B j ≤ λn − 1 / 2 k N k 1 / 2 b y Pr op osition 2.5 and L ′ 2 ≤ p X j =1 B j v 2 ≤ λ 2 k N k p/n. Substitute this into Equation ( 2.2 ) to finish the pro of. 2.4. Pro of of Co rolla ry 1.6 . Let u ∼ N (0 , 1) n iid. Sa y A has a singular v alue decomp o- sition E Λ F ∗ where Λ is diagonal. Do a change of b asis by letting u ′ = F ∗ u ∼ N (0 , 1) n iid, B ′ j = F ∗ B j E an d B ′ Λ = { B ′ 1 Λ , . . . , B ′ p Λ } . Equation ( 1.1 ) is reduced to L ′ c = Λ u ′ where the j -th column of L ′ is B ′ j Λ u ′ . Since F rob en iu s inner pro ducts, k·k and k·k F are all preserv ed und er u nitary transforma- tions, it is clear that κ ( B ′ Λ ) = κ ( B A ) and λ ( B ′ Λ ) = λ ( B A ). Essent ially , for our p urp ose here, w e ma y pretend that A = Λ. Let ˜ n = r an k ( A ). If A has a large n ullspace, i.e., ˜ n ≪ min ( m, n ), then B ′ j Λ has n − ˜ n columns of zeros a nd many comp onents of u ′ are nev er transmitted to the B ′ j ’s an yw a y . W e ma y therefore truncate the length of u ′ to ˜ n , let ˜ B j ∈ C n × ˜ n b e B ′ j Λ with its column s of zeros c hopp ed a w a y and apply Theorem 1.3 with B replaced with ˜ B := { ˜ B 1 , . . . , ˜ B p } . Ob serv e that κ ( ˜ B ) = κ ( B ′ Λ ), whereas λ ( ˜ B ) = ( ˜ n/n ) 1 / 2 λ ( B ′ Λ ) b ecause ˜ B j F = B ′ j Λ F and ˜ B j = B ′ j Λ but ˜ B j has ˜ n instead of n columns. The pro of is co mplete. 3. Probing op erators with smo oth symb ols. 10 3.1. Basics and a ssumptions. W e b egin by defining what a pseud o different ial sym b ol is. Definition 3.1. Every line ar op er ator A is asso ci ate d with a ps eudo differ ential symb ol a ( x, ξ ) such that for any u : R d → R , Au ( x ) = Z ξ ∈ R d e 2 π iξ · x a ( x, ξ ) ˆ u ( ξ ) dξ (3.1) wher e ˆ u is the F ourier tr ansform o f u , that is ˆ u ( ξ ) = R x ∈ R d u ( x ) e − 2 π iξ · x dx . W e r efrain from calling A a “pseudo differen tial op erator” at this p oint because its sym b ol has to satisfy some additional constrain ts that will b e co v ered in Section 3.5 . What is worth noting here is the Sc hw artz k ern el theorem w h ic h sho ws that ev ery linear o p erator A : S ( R d ) → S ′ ( R d ) has a symb ol repr esen tation as in Equation ( 3.1 ) and in that in tegral , a ( x, ξ ) ∈ S ′ ( R d × R d ) acts as a distr ib ution. Recall that S is the Sch wartz space and S ′ is its dual or the space of temp ered distributions. The in terested reader ma y refer to [ 12 ] or [ 25 ] for a deep er discourse. The term “ps eudo differentia l” arises from the fact that differenti al op er ators ha v e v ery simple sym b ols. F or example, the Laplacian has the symbol a ( x, ξ ) = − 4 π 2 k ξ k 2 . Another example is Au ( x ) = u ( x ) − ∇ · α ( x ) grad u ( x ) for some α ( x ) ∈ C 1 ( R d ) . Its sym b ol is a ( x, ξ ) = 1 + α ( x )(4 π 2 k ξ k 2 ) − d X k =1 (2 π iξ k ) ∂ x k α ( x ) . (3.2) Clearly , if the media α ( x ) is s m o oth, so is th e symbol a ( x, ξ ) sm o oth in b oth x and ξ , an imp ortant p rop erty w hic h will b e u s ed in Section 3.3 . F or practical reasons, we mak e the f ollo wing assumptions ab out u : R d → R on w hic h sym b ols are applied. 1. u is p erio dic with p erio d 1, so only ξ ∈ Z d will b e considered in the F ourier d omain. 2. u is bandlimited, sa y ˆ u is supp orted on Ξ := [ − ξ 0 , ξ 0 ] d ⊆ Z d . Any summation o v er the F ourier domain is b y default o v er Ξ. 4 3. a ( x, ξ ) and u ( x ) are only ev aluated at x ∈ X ⊂ [0 , 1] d whic h are p oin ts uniformly spaced apart. Any summation o v er x is b y default o v er X . Subsequ ently , Equation ( 3.1 ) reduces to a d iscrete and finite form: Au ( x ) = X ξ ∈ Ξ e 2 π iξ · x a ( x, ξ ) ˆ u ( ξ ) . (3.3) W e lik e to ca ll a ( x, ξ ) a “discrete symb ol.” Some tools are already a v ailable for manipulating suc h symbols [ 10 ]. 3.2. User friendly rep resentations of symb ols. Giv en a linear op erator A , it is useful to relate its sym b ol a ( x, ξ ) to its matrix repr esen tation in the F ourier basis. Th is helps us understand the symb ol as a matrix and also exp oses easy w a ys of computing the symbols of A − 1 , A ∗ and AB using standard linear algebra soft wa re. 4 T o ha ve an ev en number of p oints p er dimension, one can u se Ξ = [ − ξ 0 , ξ 0 − 1] d for ex ample. W e leav e this general ization to the reader and contin ue to assume ξ ∈ [ − ξ 0 , ξ 0 ] d . 11 By a matrix repr esentati on ( A ηξ ) in F ourier b asis, we mean of course that c Au ( η ) = P ξ A ηξ ˆ u ( ξ ) for an y η . W e also introd uce a more compact form of the symb ol: ˆ a ( j, ξ ) = R x a ( x, ξ ) e − 2 π ij · x dx . Th e next few results are p edagog ical and listed for futu r e reference. Prop osition 3.2. L et A b e a line ar op er ator with symb ol a ( x, ξ ) . L et ( A ηξ ) and ˆ a ( j , ξ ) b e as define d ab ove. Then A ηξ = Z x a ( x, ξ ) e − 2 π i ( η − ξ ) x dx ; a ( x, ξ ) = e − 2 π iξ x X η e 2 π iηx A ηξ ; A ηξ = ˆ a ( η − ξ , ξ ); ˆ a ( j, ξ ) = A j + ξ, ξ . Pr o of . Let η = ξ + j and app ly the defin itions. Prop osition 3.3 (T race). L et A b e a line ar o p er ator with symb ol a ( x, ξ ) . Then T r ( A ) = X ξ ˆ a (0 , ξ ) = X ξ Z x a ( x, ξ ) dx. Prop osition 3.4 (Adjoint). L et A and C = A ∗ b e line ar op er ators with symb ols a ( x, ξ ) , c ( x, ξ ) . Then ˆ c ( j, ξ ) = ˆ a ( − j, j + ξ ); c ( x, ξ ) = X η Z y a ( y , η ) e 2 π i ( η − ξ )( x − y ) dy . Prop osition 3.5 (Comp osition). L et A, B and C = AB b e line ar op er ato rs with symb ols a ( x, ξ ) , b ( x, ξ ) , c ( x, ξ ) . Then ˆ c ( j, ξ ) = X ζ ˆ a ( j + ξ − ζ , ζ ) ˆ b ( ζ − ξ , ξ ); c ( x, ξ ) = X ζ Z y e 2 π i ( ζ − ξ )( x − y ) a ( x, ζ ) b ( y , ξ ) dy . W e lea v e it to the reader to verify the ab o v e r esults. 3.3. Symb ol expansions. Th e idea is that wh en a linea r op erator A h as a smooth symbol a ( x, ξ ), only a few basis f unctions are needed to approximate a , and corresp ondingly only a small B is needed to represen t A . Th is is n ot new, see for example [ 10 ]. In this pap er, w e consider the separable expansion a ( x, ξ ) = X j k c j k e j ( x ) g k ( ξ ) . This is the same a s expanding A a s P j k c j k B j k where th e sym b ol for B j k is e j ( x ) g k ( ξ ). With an abu se of notation, let B j k also denote its matrix repr esen tation in F ourier b asis . Giv en our assumption that ξ ∈ [ − ξ 0 , ξ 0 ] d , w e ha v e B j k ∈ C n × n where n = (2 ξ 0 + 1) d . As its sym b ol is separable, B j k can b e factorized as B j k = F diag ( e j ( x )) F − 1 diag( g k ( ξ )) (3.4) 12 where F is the unitary F ourier matrix. An alternative wa y of viewing B j k is that it tak es its in put ˆ u ( ξ ), m ultiply by g k ( ξ ) and conv olve it with ˆ e j ( η ), the F ourier transform of e j ( x ). There is also an ob vious algorithm to apply B j k to u ( x ) in ˜ O ( n ) time as outlined b elo w. As men tioned in Section 1.4 , this sp eeds up the r eco v ery o f the co efficien ts c and make s m atrix probing a c heap op eratio n. Algo rithm 2. Given ve ctor u ( x ) , apply the symb ol e j ( x ) g k ( ξ ) . 1. Perform FFT on u to obtain ˆ u ( ξ ) . 2. Mu ltiply ˆ u ( ξ ) by g k ( ξ ) elementwise. 3. Perform IFFT on the pr evious r esu lt, o btaining P ξ e 2 π iξ · x g k ( ξ ) ˆ u ( ξ ) . 4. Mu ltiply the pr evious r esult by e j ( x ) elementwise. Recall that for L to be well -conditioned w ith high probabilit y , we need to c hec k whether N , as defined in Equation ( 1.3 ), is w ell-conditioned, or in a r ou gh sense wh ether h B j , B k i ≃ δ j k . F or separable symb ols, this inner p ro duct is easy to compute. Prop osition 3.6. L et B j k , B j ′ k ′ ∈ C n × n b e matrix r epr e sentations (in F ourier b asis) of line ar op er ators with symb ols e j ( x ) g k ( ξ ) and e j ′ ( x ) g k ′ ( ξ ) . Then B j k , B j ′ k ′ = e j , e j ′ h g k , g k ′ i wher e e j , e j ′ = 1 n P n i =1 e j ( x i ) e j ′ ( x i ) and x 1 , . . . , x n ar e p oints in [0 , 1] d uniformly sp ac e d, and h g k , g k ′ i = P ξ g k ( ξ ) g k ( ξ ) . Pr o of . Apply Pr op ositions 3.3 , 3.4 and 3.5 with th e sym b ols in the ˆ a ( η, ξ ) form. T o compute λ ( B ) as in De finition 1 .2 , we examine the sp ectrum of B j k for ev ery j, k . A simple and relev ant result is as follo ws. Prop osition 3.7. Assume the same set-up as in Pr op osition 3.6 . Then σ min ( B j k ) ≥ min x | e j ( x ) | min ξ | g k ( ξ ) | ; σ max ( B j k ) ≤ max x | e j ( x ) | max ξ | g k ( ξ ) | . Pr o of . In Equation ( 3.4 ), F diag( e j ( x )) F − 1 has s ingular v alues | e j ( x ) | a s x v aries o v er X , defined at the end of S ection 3.1 . T h e result follo ws from the m in-max theorem. As an examp le, supp ose a ( x, ξ ) is smo oth and p er io dic in b oth x and ξ . It is w ell-kno wn that a F ourier series is goo d expansion scheme b ecause the smo other a ( x, ξ ) is as a perio d ic function in x , the faster its F ou r ier coefficien ts deca y , and less is lost wh en we trun cate the F ourier series. Hence, we pic k 5 e j ( x ) = e 2 π ij · x ; g k ( ξ ) = e 2 π ik · ϕ ( ξ ) , (3.5) where ϕ ( ξ ) = ( ξ + ξ 0 ) / (2 ξ 0 + 1) maps ξ in to [0 , 1] d . Due to Prop ositio n 3.6 , N = E M is a multiple of the iden tit y matrix and κ ( B ) = 1 where B = { B j k } . It is also immediate from Pr op osition 3.7 that λ ( B j k ) = 1 f or eve ry j, k , and λ ( B ) = 1. T he optimal condition num b ers of this B make it suitable for matrix pr obing. 5 Actually , exp(2 πik ξ 0 / (2 ξ 0 + 1)) do es n ot v ary with ξ , and we can use ϕ ( ξ ) = ξ / (2 ξ 0 + 1). 13 3.4. Cheb yshe v expansion of symb ols. The symbols of differential op erators are p oly- nomials in ξ and n onp erio d ic. When p robing these op erators, a Cheb yshev expansion in ξ is in principle fa v ored o v er a F ourier expansion, wh ic h ma y suffer from the Gibbs phenomenon. Ho w ev er, as we shall see, κ ( B ) gro ws w ith p and can lead to ill-conditioning. F or simplicit y , assume that the sym b ol is p erio dic in x and that e j ( x ) = e 2 π ij · x . Applying Prop osition 3.2 , w e see that B j k is a matrix with a d isplaced diagonal and its s in gular v alues are ( g k ( ξ )) ξ ∈ Ξ . (Recall that w e denote the matrix representat ion (in F ourier basis) of B j k as B j k as we ll.) Let T k b e the k -th Cheb yshev p olynomial. In 1D, we ca n pic k g k ( ξ ) = T k ( ξ /ξ 0 ) for k = 1 , . . . , K . (3.6 ) Define k T k k 2 = ( R 1 z = − 1 T k ( z ) 2 dz ) 1 / 2 . By appr o ximating sums w ith in tegrals, λ ( B j k ) ≃ √ 2 k T k k − 1 2 = 4 k 2 − 1 2 k 2 − 1 1 / 2 . Notice that there is n o (1 − z 2 ) − 1 / 2 w eigh t factor in the definition of k T k k 2 b ecause e j ( x ) T k ( ξ ) is trea ted as a pseudo differential sym b ol and has to b e ev aluated on the uniform grid. In practice, this app r o ximation b ecomes v ery accurate with larger n and w e see n o need to b e rigorous here. As k in creases, λ ( B j k ) app r oac hes √ 2. More imp ortan tly , λ ( B j k ) ≤ λ ( B j 1 ) for an y j, k , so λ ( B ) = √ 3 . Applying the same tec hnique to appr o ximate the sum h g k , g k ′ i , we find that h g k , g k ′ i ∝ (1 − ( k + k ′ ) 2 ) − 1 + (1 − ( k − k ′ ) 2 ) − 1 when k + k ′ is ev en, a nd zero otherwise. W e then compute N = E M for v arious K and p lot κ ( B ) versus K , the num b er of Cheb yshev p olynomials. As sho wn in Figure 3.1 (a), κ ( B ) ≃ 1 . 3 K. This m eans that if we exp ect to reco v er p = ˜ O ( n ) co efficien ts, w e m ust ke ep K fixed. Otherwise, if p = K 2 , only p = ˜ O ( n 1 / 2 ) are guarante ed to b e reco v ered by Theorem 1.3 . In 2D, a plausible expans ion is g k ( ξ ) = e ik 1 arg ξ T k 2 ( ϕ ( k ξ k )) for 1 ≤ k 2 ≤ K (3.7) where k = ( k 1 , k 2 ) and ϕ ( r ) = ( √ 2 r /ξ 0 ) − 1 maps k ξ k in to [ − 1 , 1]. W e call this the “Chebyshev on a disk” expansion. The quantit y λ ( B j k ) is appro ximately 2 R 1 x = − 1 R 1 y = − 1 T k ( ψ ( x, y )) 2 dx dy − 1 / 2 where ψ ( x, y ) = (2 x 2 + 2 y 2 ) 1 / 2 − 1. Th e in teg ral is ev aluated numerically and app ears to con v erge 6 to √ 2 for large k 2 . Also, k 2 = 1 again pro duces the worst λ ( B j k ) and λ ( B ) ≤ 2 . 43 . 7 6 This is b ecause when we trun cate the disk of radius ξ 0 √ 2 to a square of length 2 ξ 0 , mos t is lost along the vertica l axis and a w ay fro m the diagonals. H o wev er, for large k , T k oscillates very muc h and the tru ncation does not matter. If we pretend t h at th e square is a disk, then we are back in the 1D case where the answ er approac hes √ 2 for la rge k . 7 The exact v alue is 2(4 − 8 3 √ 2 sinh − 1 (1)) − 1 / 2 . 14 0 10 20 30 40 0 10 20 30 40 50 60 K κ (B) (a) 1D 10 0 10 1 10 2 10 0 10 1 10 2 10 3 10 4 10 5 10 6 K κ (b) 2D B B’ Figure 3.1. L et K b e the numb er of Chebyshev p olynomials use d in the exp ansion of the symb ol, se e Equation ( 3.6 ) and ( 3.7 ). Observe that i n 1D, κ ( B ) = O ( K ) while in 2D, κ ( B ) = O ( K 3 ) . These c ondition numb ers me an that we c annot exp e ct to r etrieve p = ˜ O ( n ) p ar ameters unless K is fixe d and indep endent of p, n . As f or κ ( B ), o bserve that when k 1 6 = k ′ 1 , D g k 1 k 2 , g k ′ 1 k ′ 2 E = ± 1 due to symm etry 8 , w h ereas when k 1 = k ′ 1 , the inner prod uct is prop ortional to n and is m u c h la rger. As a result, the g k ’s with different k 1 ’s hard ly in teract and in studying κ ( B ), one may assume that k 1 = k ′ 1 = 0. T o impro v e κ ( B ), we can norm alize g k suc h that the d iagonal en tries of N are all ones, that is g ′ k ( ξ ) = g k ( ξ ) / k g k ( ξ ) k . This yields another set of basis matrices B ′ . Figure 3.1 (b) rev eals that κ ( B ) = O ( K 3 ) and κ ( B ′ ) ≃ κ ( B ) . The latter can b e explained as follo ws: w e sa w earlier that h B j k , B j k i con v erges as k 2 increases, so the d iagonal entries of N are ab ou t th e same and the normalizatio n is only a minor correction. If a ( x, ξ ) is expanded using the same num b er of basis functions in eac h d ir ection of x and ξ , i.e., K = p 1 / 4 , then Theorem 1.3 suggests th at only p = ˜ O ( n 2 / 5 ) coefficien ts can b e reco v ered. T o recap, for b oth 1D and 2D, λ ( B ) is a small num b er but κ ( B ) increases with K . F or- tunately , if w e kno w that the op erator b eing prob ed is a second order deriv ativ e for example, w e can fix K = 2. Numerically , we hav e observe d that t he Chebyshev expansion can p r o duce dramatic ally b etter results than the F our ier expansion o f the sym b ol. More details can b e found in Section 4.3 . 8 The ξ and − ξ terms cancel eac h other. Only ξ = 0 contributes to the sum. 15 3.5. Order of an operator. In standard texts, A is said to b e a pseudo differen tial op erator of order w if its symb ol a ( x, ξ ) is in C ∞ ( R d × R d ) and for an y m ulti-indices α, β , there exists a constan t C αβ suc h that | ∂ α ξ ∂ β x a ( x, ξ ) | ≤ C αβ h ξ i w −| α | for all ξ , where h ξ i = 1 + k ξ k . Letting α = β = 0, w e see th at such op erators ha v e sym b ols that gro w or deca y as (1 + k ξ k ) w . As an example, the Laplacian is of order 2. The factor 1 p rev en ts h ξ i from blo wing up wh en ξ = 0. T here is nothing sp ecial ab out it and if w e take extra care when ev aluating the s ym b ol at ξ = 0, w e can use h ξ i = k ξ k . F or forw ard matrix probing, if it is kno wn a priori that a ( x, ξ ) b eha v es like h ξ i w , it mak es sense to expand a ( x, ξ ) h ξ i − w instead. Another wa y of v iewin g this is th at the sym b ol of the op erator B j k is mo dified from e j ( x ) g k ( ξ ) to e j ( x ) g k ( ξ ) h ξ i w to suit A b etter. F or bac kw ard mat rix probing, if A is of order z , then A − 1 is of order − z and w e sh ould replace th e symb ol of B j k with e j ( x ) g k ( ξ ) h ξ i − w . W e b eliev e that this small correction has an impact on th e accuracy of matrix pr ob in g, as well as the condition n umb er s κ ( B A ) and λ ( B A ). Recall that an eleme nt of B A is B j k A . If A is of order w and B j k is of order 0, then B j k A is of order w a nd λ ( B j k A ) will grow with n w , whic h will adversely affect the conditioning of matrix pr ob in g. Ho wev er, by m ultiplying t he sym b ol of B j k b y h ξ i − w , w e can exp ect B j k A to b e order 0 and th at λ ( B j k A ) is indep endent of the size of th e problem n . The argumen t is heuristical but w e will supp ort it with some numerical evidence in Section 4.3 . 4. Numerical examples. W e carry out four d ifferen t exp erimen ts. T h e fir st exp eriment suggests that Th eorem 1.4 is not tigh t. T he second exp erimen t pr esents the outp u t of bac k- w ard probing in a visual w a y . In the th ird exp eriment , w e explore th e limita tions of b ac kw ard probing and a lso tests the Chebyshev expansion of sym b ols. The last exp erimen t inv olve s the forw ard probing of the fov eation op erator, w hic h is related to human vision. 4.1. 1D statistical study . W e are intereste d in whether the probabilit y b ound in Th eorem 1.3 is tight with r esp ect to p and n , but as the tail probabilities are small and hard to estimate, w e opt to study the first moment instead. In particular, if Theorem 1.4 captures exactl y the dep end ence of E k M − N k / k N k on p and n , then w e would need n to grow faster than p log 2 n for E k M − N k / k N k to v anish, assuming λ ( B ) is fixed. F or simplicit y , w e use the F ourier expansion of the sym b ol in 1D so that λ ( B ) = κ ( B ) = 1. Let J b e the num b er of basis functions in b oth x and ξ and p = J 2 . Figure 4. 1 (a) suggests that E k M − N k / k N k deca ys to zero wh en n = p log c p and c > 1. It follo ws from the previous paragraph that Theorem 1.4 cannot b e tigh t. Nev ertheless, Theorem 1.4 is optimal in the foll o wing sense. Imagine a more general b ound E k M − N k k N k ≤ (log α n ) p n β for some α, β > 0 . (4.1) In Figure 4.2 (a), we see th at for v arious v alues of p/n , α = 1 since the graphs are linear. On the other hand, if we fix p and v ary n , th e log-log graph of Figure 4.2 (b) s h o ws that β = 1 / 2. Therefore, any b ound in the form of Equation ( 4.1 ) is n o b etter than Theorem 1.4 . 16 4 6 8 10 12 14 10 −0.2 10 −0.1 10 0 10 0.1 10 0.2 J E[|M−N|/|N|] (a) c=1.0 c=1.1 c=1.2 c=1.5 c=2.0 0 0.5 1 1.5 2 10 −3 10 −2 10 −1 10 0 P(|M−N|>t|N|) t (b) Figure 4.1. Consider the F ourier exp ansion of the symb ol. J i s the numb er of b asis functions i n x and ξ , so p = J 2 . L et n = p log c p . Figur e ( a) shows that the estimate d E k M − N k / k N k de c ays for c ≥ 1 . 1 which sugge sts that The or em 1.4 is not tight . In Figur e (b), we estimate P ( k M − N k / k N k > t ) by sampling k M − N k / k N k 1 0 5 times. The tail pr ob ability app e ars to b e sub gaussian for smal l t and sub exp onential for lar ger t . Next, w e fix p = 25 , n = 51 and sample k M − N k / k N k man y times to estimate the tail probabilities. In Figure 4.1 (b), w e see that the tail probabilit y of P ( k M − N k / k N k > t ) deca ys as exp( − c 1 t ) when t is big, and as exp( − c 2 t 2 ) when t is small, for some p ositive n um b ers c 1 , c 2 . This b eha vior ma y b e explained by Rauh ut and T ropp’s y et pu blished result. 4.2. Elliptic equation in 1D. W e find it instructiv e to consider a 1D example of matrix probing b ecause it is easy to visualize the symbol a ( x, ξ ). Consider the op erator Au ( x ) = − d dx α ( x ) du ( x ) dx where α ( x ) = 1 + 0 . 4 cos(4 π x ) + 0 . 2 cos(6 π x ) . (4.2) Note that we use p erio dic b oundaries and A is p ositiv e semidefinite with a on e dimensional n ullspace consisting of constant functions. W e prob e f or A + using Algorithm 1 and the F ourier exp an s ion of its sym b ol or Equ ation ( 3.5 ). Sin ce A is of order 2, we prem ultiply g k ( ξ ) b y h ξ i − 2 as explained in Section 3.5 . In the exp eriment, n = 20 1 and there are tw o other parameters J , K which are the n umber of e j ’s and g k ’s used in Equation ( 3.5 ). T o b e clear, − J − 1 2 ≤ j ≤ J − 1 2 and − K − 1 2 ≤ k ≤ K − 1 2 . Let C b e the output of mat rix probing. In Figure 4.3 (b), we see that J = K = 5 is not enough to rep resen t A + prop erly . This is exp ected b ecause our media α ( x ) has a bandwidth of 7. W e exp ect J = K = 13 to do b etter, but the m u c h larger p leads to o verfitting and a p o or result, as is evident from the w obbles in th e symbol of C i n Figure 4.3 (c). Pr obing w ith four random v ectors, we obtain a m uc h b etter result as sho wn in Figure 4.3 (d). 17 1 1.5 2 2.5 0 0.5 1 1.5 2 2.5 3 log 10 p |M−N|/|N| (a) Fixed p/n n=3p n=7p n=11p n=15p n=19p 1.5 2 2.5 3 −1 −0.8 −0.6 −0.4 −0.2 0 0.2 0.4 0.6 0.8 log 10 n log 10 |M−N|/|N| (b) Fixed p p=9 p=25 p=49 Figure 4. 2. Consider b ounding E k M − N k / k N k by (log α n )( p/n ) β . Ther e is little loss in r eplacing log n with log p i n the simulation. In Figur e (a), the estimate d E k M − N k / k N k dep ends li ne arly on log p , so α ≥ 1 . In Figur e (b), we fix p and find that for l ar ge n , β = 1 / 2 . The c onclusion is that the b ound in The or em 1.4 has the b est α, β . 4.3. Elliptic Equation in 2D. In this section, we extend the previous set-up to 2D and address a different set of questions. Consid er the op erator A defin ed as Au ( x ) = − ∇ · α ( x ) ∇ u ( x ) where α ( x ) = 1 T + cos 2 ( π γ x 1 ) s in 2 ( π γ x 2 ) . (4.3) The p ositiv e v alue T is calle d the con trast while t he p ositiv e in teger γ is the r oughness of the media, since the band w idth of α ( x ) is 2 γ + 1. Again, we a ssume p erio dic b oundary conditions suc h that A ’s nullspace is exactly the set of constan t functions. Let C b e the output of the bac kward probing of A . As w e shall see, the qualit y of C drops as w e increase the contrast T or th e roughness γ . Fix n = 101 2 and expand the sym b ol u sing Equation ( 3.5 ). Let J = K b e the num b er of basis functions used to expand th e symbol in eac h of its four dimensions, that is p = J 4 . In Figure 4.4 (b), we see that b etw een J = 2 γ − 1 and J = 2 γ + 1, the ban d width of the media, th er e is a marke d impr o v emen t in the preconditioner, as measured b y the ratio cond( C A ) / cond( A ). 9 On the other hand, Figure 4.4 (a) sh o ws that as the con tr ast increases, the preconditioner C degrades in p erformance, but the impro v emen t b etw een J = 2 γ − 1 and 2 γ + 1 b eco mes more pronounced. The error bars in Fig ure 4.4 are not err or margins but ˆ σ where ˆ σ 2 is the unbiased estimator of th e v ariance. T hey indicate that cond ( C A ) / cond( A ) is tightl y concentrat ed around its 9 Since A has one zero singular v alue, cond( A ) actually refers to the ratio b etw een its largest singular v alue and its seco nd smallest singular v alue. The same applies to C A . 18 ξ x (a) Symbol of A + −100 0 100 0 0.2 0.4 0.6 0.8 0 1 2 3 4 ξ x (b) Symbol of C, J=K=5, q=1 −100 0 100 0 0.2 0.4 0.6 0.8 0 1 2 3 4 ξ x (c) Symbol of C, J=K=13, q=1 −100 0 100 0 0.2 0.4 0.6 0.8 0 1 2 3 4 ξ x (d) Symbol of C, J=K=13, q=4 −100 0 100 0 0.2 0.4 0.6 0.8 0 1 2 3 4 Figure 4.3. L et A b e the 1D el liptic op er ator in Equation ( 4.2 ) and A + b e its pseudoinvers e. L et C b e the output of b ackwar d matrix pr obing with the fol lowing p ar ameters: q is the numb er of r andom ve ctors applie d to A + ; J, K ar e the numb er of e j ’s and g k ’s use d to exp and the symb ol of A + in Equation ( 3.5 ). Figur e (a) is the symb ol of A + . Figur e (b) i s the symb ol of C wi th J = K = 5 . It lacks the shar p fe atur es of Figur e (a) b e c ause B is to o smal l to r epr esent A + wel l . With J = K = 13 , pr obing with only one r andom ve ctor le ads to il l-c onditioni ng and an inac cur ate r esult in Figur e (b). In Figur e (c), four r andom ve ctors ar e use d and a much b ette r r esult is obtaine d. Note that the symb ols ar e multiple d by h ξ i 3 for b etter visual c ontr ast. mean, pro vided J is not to o m uc h larger than is n ecessary . F or instance, for γ = 1, J = 3 already wo rks wel l b u t pushin g to J = 9 leads to greater uncertain t y . Next, w e consider forwar d pr obing of A u sing the “Chebyshev on a disk” exp ansion or Equation ( 3.7 ). L et m b e the order correction, th at is we m ultiply g k ( ξ ) b y h ξ i m = k ξ k m . Let C b e the output of the probing and K b e the num b er of Chebyshev p olynomials used. Fix n = 55 2 , T = 10, γ = 2 a nd J = 5. F or m = 0 and K = 3, i.e., no ord er correction and using up to qu adratic p olynomials in ξ , we obtain a r elativ e error k C − A k / k A k that is less than 10 − 14 . On the other hand , using F ourier expansion, with K = 5 in the sense that − K − 1 2 ≤ k 1 , k 2 ≤ K − 1 2 , the relativ e error is on the order of 1 0 − 1 . The p oin t is that in this case, A has an exact “Ch eb yshev on a disk” repr esen tation and pr ob in g u sing th e correct B enables us to retriev e the coefficient s with negligible errors. Finally , we consider bac kw ard p robing w ith the Chebyshev expansion. W e use J = 5, 19 0 2 4 6 8 10 10 −4 10 −3 10 −2 10 −1 J=K cond(CA)/cond(A) (a) γ =2 T=10 2 T=10 3 T=10 4 0 2 4 6 8 10 10 −4 10 −3 10 −2 10 −1 J=K cond(CA)/cond(A) (b) T=10 4 γ =1 γ =2 γ =3 Figure 4.4. L et A b e the op er ator define d in Equation ( 4.3 ) and C b e the output of b ackwar d pr obing. In Figur e (b), we fix T = 10 4 and find that as J go es fr om 2 γ − 1 to 2 γ + 1 , the b andwidth of the me dia, the quality of the pr e c ondi ti oner C impr oves by a factor b etwe en 10 0 . 5 and 10 . In Figur e (a), we fix γ = 2 and find that incr e asing the c ontr ast worsens c ond ( C A ) / c ond ( A ) . Nevertheless, the impr ovement b etwe en J = 3 and J = 5 b e c omes mor e distinct. The err or b ars c orr esp ond to ˆ σ wher e ˆ σ 2 is the estimate d varianc e. They indic ate that C is not just go o d on aver age, but go o d with high pr ob ability. γ = 2 an d T = 10. Figure 4.5 shows th at when m = − 2, the co ndition n um b ers λ ( B A ) and κ ( B A ) are minimized and hardly increase s with n . This emphasizes the imp ortance of knowing the order of the op erator b eing prob ed. 4.4. F oveation. In this s ection, we forward-prob e f or th e fov eation op erator, a space- v ariant ima ging op erator [ 7 ], wh ic h is particula rly in teresting as a mo del for human vision. F ormally , w e ma y treat the fo vea tion op erator A as a Gaussian blur w ith a width or standard deviation that v aries o v er space, that is Au ( x ) = Z R 2 K ( x, y ) u ( y ) dy where K ( x, y ) = 1 w ( x ) √ 2 π exp − k x − y k 2 2 w 2 ( x ) ! , (4.4) where w ( x ) is the width function whic h return s only p ositiv e real num b ers. The r esolution of the output image is h ighest at the point where w ( x ) is minim al. Call this p oin t x 0 . It is the p oint of fi xation, corresp onding t o the cen ter of the fo v ea. F or our exp eriment, the width fu nction t ak es the form of w ( x ) = ( α k x − x 0 k 2 + β ) 1 / 2 . Our ima ges are 201 × 201 and treated as f unctions on the unit squ are. W e c ho ose x 0 = (0 . 5 , 0 . 5) and α, β > 0 suc h that w ( x 0 ) = 0 . 0 03 and w (1 , 1) = 0 . 012. The sym b ol of A is a ( x, ξ ) = exp( − 2 π 2 w ( x ) 2 k ξ k 2 ), an d w e c ho ose to use a F ourier series or Equation ( 3.5 ) for exp an d ing it. Let C b e the output of matrix p robing and z b e a standard test image. Figure 4.6 (c) sh o ws that the relativ e ℓ 2 error k C z − Az k ℓ 2 / k Az k ℓ 2 decreases exp onenti ally as p increases. In ge neral, forwa rd probing yiel ds great results lik e this b ecause w e kno w its s y mb ol w ell and can c ho ose an appropriate B . 20 −10 −5 0 5 10 10 0 10 5 10 10 10 15 10 20 κ (B A ) q (a) n=15 2 n=29 2 n=57 2 −10 −5 0 5 10 10 0 10 1 10 2 λ (B A ) q (b) n=15 2 n=29 2 n=57 2 Figure 4.5. Consider th e b ackwar d pr obing of A in Equation ( 4.3 ), a pseudo differ ential o epr ator of or der 2. Perform or der c orr e ction by multiplying g k ( ξ ) by h ξ i q in the exp ansion of the symb ol. Se e Se ction 3.5 . Observ e that at q = − 2 , the c ondition numb ers λ ( B A ) and κ ( B A ) ar e mini m ize d and har d ly gr ow with n . 4.5. Inverting t he w ave equation Hessian. In seismology , it is common to reco v er the mo del parameters m , whic h describ e the subsurface, b y minimizing th e least squares misfit b et we en the observed data and F ( m ) where F , the forw ard mo del, pr ed icts data from m . Metho ds to so lv e this problem can b e broadly categ orized into t wo cl asses: steep est descen t or Newton’s metho d. The former tak es more iteratio ns to con v erge but eac h iteration is computationally c heap er. The latter requires the inv er s ion of the Hessian of the ob jectiv e function, but ac hiev es q u adratic con v ergence near the optimal p oint. In another pap er , we use matrix p robing to precondition the inv ers ion of the Hessian. Remo ving the nullspace comp onent from the n oise v ector is more tric ky (see Algorithm 1 ) and in v olv es c hec king wh ether “a cur velet is visible to any r eceiv er” via ra ytracing. F or details on this more elab orate application, please refer to [ 9 ]. 5. Conclusion and futur e w o rk. When a matrix A with n columns b elongs to a sp ecified p -dimensional subspace, sa y A = P p i =1 c i B i , we c an prob e it with a few rand om vecto rs to reco v er the co efficien t v ector c . Let q b e the num b er of ran d om vec tors u s ed, κ b e the cond ition num b er of the Gram matrix o f B 1 , . . . , B p and λ b e t he “w eak condition n umb er ” of eac h B i (cf. Definition 1 .2 ) whic h is relate d to th e numerica l rank. F rom Theorem 1.3 and Sectio n 1.3 , w e learn that when nq ∝ p ( κλ log n ) 2 , then the linear system that has to b e solv ed to reco v er c (cf. Eq u ation ( 1.1 )) will b e well-co nditioned with high p robabilit y . Consequently , the reconstru ction error is small by P r op osition 1.5 . The same tec hnique can b e used to compute an appr o ximate A − 1 , or a preconditioner for in v erting A . In [ 9 ], w e us ed it to inv ert th e wa v e equati on Hessian — here we d emonstrate that it can also b e used to in v ert elliptic op erators in smooth media (cf. Sections 4.2 and 4.3 ). Some p ossible futur e w ork include the follo wing. 21 (a) (b) 4 6 8 10 12 10 −3 10 −2 10 −1 10 0 Relative l 2 error J=K (c) Figure 4. 6. L et A b e the fove ation op er ator in Equation ( 4.4 ) and C b e the output of the forwar d pr obing of A . Figur e (a) is the test image z . Figur e (b) is C z and it shows that C b ehave s li ke the fove ation op er ator as exp e cte d. Figur e (c) shows that the r elative ℓ 2 err or (se e text) de cr e ases exp onential ly with the numb er of p ar ameters p = J 4 . 1. E xtend the w ork of Pfander, Rau hut et. al. [ 21 , 20 , 22 ]. Th ese pap ers are concerned with sparse signal reco v ery . Th ey consider the sp ecial case where B cont ains n 2 matri- ces eac h repr esen ting a ti me-frequency shift, b ut A is an unkno wn l inear com bination of only p of them. The task is to iden tify these p matrices and the associated coefficients b y applying A to noise vecto rs. Our p ro ofs ma y b e used to establish similar r eco v ery results for a more general B . Ho w ev er, note that in [ 20 ], Pfander a nd Rauh ut sho w that n ∝ p log n suffices, wh ereas our main result requ ir es an additional log factor. 2. Bu ild a framewo rk for pr obing f ( A ) in terpreted as a Cauch y in tegral f ( A ) = 1 2 π i I Γ f ( z )( z I − A ) − 1 dz , where Γ is a closed curve enclosing the eigen v alues of A . F or more on appr o ximating matrix functions, see [ 13 , 15 ]. 3. C onsider expansion schemes for sym b ols that highly oscillate or ha v e singularities that are w ell-understo o d. App endix A. Linear algeb ra. 22 Recall the defin itions of κ ( B ) and λ ( B ) at the b eginning of th e pap er. The follo wing concerns probing with multiple v ectors (cf. Section 1.3 ). Prop osition A.1. L et I q ∈ C q × q b e the identity. L e t B = { B 1 , . . . , B p } . L et B ′ j = I q ⊗ B j and B ′ = { B ′ 1 , . . . , B ′ p } . Then κ ( B ) = κ ( B ′ ) and λ ( B ) = λ ( B ′ ) . Pr o of . Define N ∈ C p × p suc h that N j k = h B j , B k i . Define N ′ ∈ C p × p suc h that N ′ j k = D B ′ j , B ′ k E . C learly , N ′ = q N , so their condition num b ers are the same and κ ( B ) = κ ( B ′ ). F or an y A = B j ∈ C m × n and A ′ = B ′ j , we ha v e k A ′ k ( nq ) 1 / 2 k A ′ k F = k A k ( nq ) 1 / 2 k A k F q 1 / 2 = k A k n 1 / 2 k A k F . Hence, λ ( B ) = λ ( B ′ ). App endix B. Probabilistic to ols. In this section, we presen t some probabilistic results used in our pro ofs. The fir st theorem is used to decouple homogeneous R ad emacher c haos of order 2 and can b e fou n d in [ 8 , 23 ] for example. Theo rem B.1. L e t ( u i ) and ( ˜ u i ) b e two iid se quenc es of r e al-value d r andom variables and A ij b e in a Banach sp ac e wher e 1 ≤ i, j ≤ n . Ther e exists universal c onstants C 1 , C 2 > 0 such that for a ny s ≥ 1 , E X 1 ≤ i 6 = j ≤ n u i u j A ij s 1 /s ≤ C 1 C 1 /s 2 E X 1 ≤ i,j ≤ n u i ˜ u j A ij s 1 /s . (B.1) A homoge neous Gaussian c haos is one that in volv es only pr o ducts of Hermite p olynomials with the same total degree. F or instance, a homogeneous Gaussian c haos of order 2 tak es the form P 1 ≤ i 6 = j ≤ n g i g j A ij + P n i =1 ( g 2 i − 1) A ii . I t can b e decoupled acc ording to Arcones and Gin ´ e [ 2 ]. Theo rem B.2. L et ( u i ) and ( ˜ u i ) b e two i i d Gaussian se qu enc es and A ij b e in a Banach sp ac e wher e 1 ≤ i, j ≤ n . Ther e exists universal c onstants C 1 , C 2 > 0 such that for any s ≥ 1 , E X 1 ≤ i 6 = j ≤ n u i u j A ij + n X i =1 ( u 2 i − 1) A ii s 1 /s ≤ C 1 C 1 /s 2 E X 1 ≤ i,j ≤ s u i ˜ u j A ij s 1 /s . Rema rk B.1. F or R ademacher chaos, C 1 = 4 and C 2 = 1 . F or Gaussian chaos, we c an inte gr ate Eq uation (2.6) of [ 2 ] (with m = 2 ) to obtain C 1 = 2 1 / 2 and C 2 = 2 14 . Better c onstants may b e available. W e no w p r o ceed to the Khintc hin e inequalties. Let k·k C s denote the s -Sc hatten n orm. Recall that k A k C s = ( P i | σ i | s ) 1 /s where σ i is a singular v alue of A . Th e follo wing is du e to Lust-Piquard and Pisier [ 18 , 19 ]. Theo rem B.3. L e t s ≥ 2 and ( u i ) b e a R ademacher or Gaussian se quenc e. Then for a ny set of matric es { A i } 1 ≤ i ≤ n , E n X i =1 u i A i s C s 1 /s ≤ s 1 / 2 max ( n X i =1 A ∗ i A i ) 1 / 2 C s , ( n X i =1 A i A ∗ i ) 1 / 2 C s . 23 The factor s 1 / 2 ab o v e is n ot optimal. See for example [ 3 ] by Buc hholz, or [ 24 , 26 ]. In [ 23 ], Th eorem B.3 is app lied t wice in a clev er wa y to obtain a Khin tc hine inequalit y for a decoupled c haos of ord er 2. Theo rem B.4. L et s ≥ 2 and ( u i ) and ( ˜ u i ) b e two indep endent R ademacher or Gaussian se que nc es. F or any set of matric es { A ij } 1 ≤ i,j ≤ n , E X 1 ≤ i,j ≤ n u i ˜ u j A ij s C s 1 /s ≤ 2 1 /s s max( Q 1 / 2 C s , R 1 / 2 C s , k F k C s , k G k C s ) wher e Q = P 1 ≤ i,j ≤ n A ∗ ij A ij and R = P 1 ≤ i,j ≤ n A ij A ∗ ij and F , G ar e the blo ck matric es ( A ij ) 1 ≤ i,j ≤ n , ( A ∗ ij ) 1 ≤ i,j ≤ n r esp e ctively. F or Rademacher and Gaussian chaos, higher momen ts are con trolled by lo w er moment s, a prop ert y kno wn as “h yp ercontrac tivit y” [ 2 , 8 ]. This leads to exp onential tail b ound s b y Mark o v’s inequalit y as we illustrate b elo w. Th e same resu lt app ears as Prop ositio n 6.5 of [ 24 ]. Prop osition B.5. L et X b e a nonne g ative r andom variable. L et σ , c, α > 0 . Supp ose ( E X s ) 1 /s ≤ σ c 1 /s s 1 /α for al l s 0 ≤ s < ∞ . Then for any k > 0 and u ≥ s 1 /α 0 , P X ≥ e k σ u ≤ c exp ( − k u α ) . Pr o of . By Mark o v’s inequalit y , for any s > 0, P X ≥ e k σ u ≤ E X s ( e k σu ) s ≤ c σs 1 /α e k σu s . Pic k s = u α ≥ s 0 to complete the pro of. Prop osition B.6. L et ( u i ) b e a R ademacher or Gaussian se quenc e and C 1 , C 2 b e c onstants obtaine d fr om Th e or em B.1 or B.2 . L et { A ij } 1 ≤ i,j ≤ n b e a set of p b y p matric e s, a nd assume that the diagonal entries A ii ar e p ositive semidefinite. Define M = P i u i u j A ij and σ = C 1 max( k Q k 1 / 2 , k R k 1 / 2 , k F k , k G k ) wher e Q, R, F , G ar e as define d in The or em B.4 . Then P ( k M − E M k ≥ eσu ) ≤ (2 C 2 np ) exp( − u ) . Pr o of . W e will p ro v e the Gaussian case fir st. Recall that th e s -Sc hatten and s p ectral norms are equ iv alen t: for an y A ∈ C r × r , k A k ≤ k A k C s ≤ r 1 /s k A k . App ly the decoupling inequalit y , th at is Theorem B.2 , and ded u ce that for an y s ≥ 2, ( E k M − N k s ) 1 /s ≤ C 1 C 1 /s 2 E X 1 ≤ i,j ≤ n u i ˜ u j A ij s C s 1 /s . In v ok e Khintc h ine’s inequalit y , that is T h eorem B.4 , and obtain ( E k M − N k s ) 1 /s ≤ C 1 (2 C 2 ) 1 /s s max( Q 1 / 2 C s , R 1 / 2 C s , k F k C s , k G k C s ) ≤ C 1 (2 C 2 np ) 1 /s s max( k Q k 1 / 2 , k R k 1 / 2 , k F k , k G k ) ≤ σ (2 C 2 np ) 1 /s s. 24 Apply Prop osition B.5 with c = 2 C 2 np and k = α = 1 to co mplete the p r o of for the Gaus- sian case. F or th e Rademac her case, w e tak e similar steps. First, decouple ( E k M − N k s ) 1 /s using Theorem B.1 . T his lea ves us a s u m that excl udes the A ii ’s. Ap ply Khin tc hine’s inequal- it y with th e A ii ’s zero ed. O f course, Q, R , F , G in Prop osition B.4 will n ot con tain any A ii ’s, but th is do es not matter b ecause A ∗ ii A ii and A ii A ∗ ii and A ii are all p ositiv e semidefi n ite for an y 1 ≤ i ≤ n and w e can add them b ack. F or example, k ( A ij ) 1 ≤ i 6 = j ≤ n k ≤ k ( A ij ) 1 ≤ i,j ≤ n k as blo c k matrices. An alternativ e w a y to pro v e the Gaussian case of Prop osition B.6 is to split ( E k M − N k s ) 1 /s in to t wo te rms ( E P i ( u 2 i − 1) A ii ) 1 /s and ( E k P i u i u j A ij k ) 1 /s . F or the second term , we can insert Rademac h er v ariables, condition on the Gaussians, decouple the Rademac h er sum and apply Th eorem B.4 . After that, w e can pull out the maxim um of all the Gaussians from Q, R, F , G . Nevertheless, as this ma y introdu ce extra log n facto rs, w e p refer to simply app eal to [ 2 ] to decouple the Gaussian sum righ t a w a y . REFERENCES [1] C. Andrieu, N. De Freit as, A. D oucet, a nd M.I. Jord an , An intr o duction to MCMC for machine le arning , Mac hine learning, 50 ( 2003), pp. 5–43. [2] M.A. Arc ones and E. Gin ´ e , On de c oupling, series ex p ansions, and tail b ehavior of chao s pr o c esses , Journal of Theoretica l Pro bability , 6 (1993), pp. 101–122. [3] A. Buchholz , Op er ator khintchine ine quali ty in non-c ommutative pr ob ability , Mathematisc he Annalen, 319 (2001), pp. 1–16. [4] E.J. Cand es, J.K. Romber g, and T. T ao , Stable signal r e c overy fr om inc omplete and inac cur ate me asur ements , Communications on pure and app lied mathematics, 59 (200 6), pp. 1207–1223. [5] T.F.C. Ch a n and T.P. Ma the w , The interfac e pr obing te chnique i n domain de c om p osition , SI A M Journal on Matrix Analysis and A pplications, 13 (1992), p. 212 . [6] T.F. Chan and D.C. Resasco , A survey of pr e c onditioners f or domain de c omp osition. , tec h. rep ort, DTIC Document, 1985. [7] E.C. Chang, S. Ma lla t, and C. Y ap , Wavelet f ove ation , Applied and Computational Harmonic Anal- ysis, 9 (2000), pp. 312–335. [8] V. De la Pe ˜ na and E. Gin ´ e , De c oupling: fr om dep endenc e to indep endenc e , Springer V erlag, 19 99. [9] L. De manet, P.D. L ´ etourneau, N. Bouma l, H. Calandra, J. C hiu, and S . Snelson , Matrix pr obing: a r andomize d pr e c onditioner for the wave-e quation Hessian , Ap plied and Computational Harmonic Analysis, (2011). [10] L. Demanet and L. Ying , Di scr ete symb ol c alculus , SIAM Review, 53 (2011), pp. 71–104. [11] A. Edelman , Eigenvalues and c ondition numb ers of r andom matric es , PhD th esis, Massac husetts Insti- tute of T echnology , 1989 . [12] G.B. F olland , Intr o duction t o p artial differ ential e quations , Princeton U niv Pr, 199 5. [13] N. Hale, N .J. Higham , L.N. Trefethen, et al. , Computing a α , lo g (a), and r elate d matrix functions by c ontour inte gr als , SIAM Journal on N umerical Analysis, 46 (200 8), pp. 2505–2523. [14] N. Halk o, P. Mar tin sson, and J. Tropp , Finding structur e with r andomness: Pr ob abil istic algorithms for c onstructing appr oximate matr ix de c omp ositions , SIAM Review, 53 ( 2011), p. 217. [15] N.J. Hi g ham , F unct ions of matric es: the ory and c omputation , Society for Industrial Mathematics, 2008. [16] D.R. Kar ger and C . Stei n , A new appr o ach to the minim um cut pr oblem , Journal of the ACM, 43 (1996), pp. 601–64 0. [17] R.M. Karp and M. O. Rabin , Effici ent r andomize d p att ern-matching algor ithms , IBM Journal of Re- searc h and Developmen t, 31 (1987), p p. 249– 260. [18] F. Lust-Piquard , In ´ egalit ´ es de Khintchine dans Cp , CR Acad. Sci. Pa ris, 303 (1986), pp. 289– 292. [19] F. Lust-Piquard and G . Pisier , Non-c ommutative Khintchine and Paley ine quali ties , Arkiv f¨ or Matem- atik, 29 (1991), pp. 24 1–260. 25 [20] G.E. Pf ander and H. Rauhut , Sp arsity in time-fr e quency r epr esentat ions , Journal of F ourier Analysis and Applications, 16 (2010), pp. 23 3–260. [21] G.E. Pf ande r, H . R auhut, and J. T anner , Identific ation of matr ic es having a sp arse r epr esen tation , Signal Processing, IEEE T ransactions on, 56 (2008), pp. 5376–5 388. [22] G.E. Pf a nder, H. Rauhut, and J.A. Tropp , The r estricte d i sometry pr op erty f or ti m e-fr e quency structur e d r andom matric es , Arxiv preprint arXiv:110 6.3184, (20 11). [23] H. Ra uhut , Cir culant and To eplitz m atric es in c ompr esse d sensing , Proc. SP AR S, 9 (2009). [24] , Com pr essive sensing and structur e d r andom matric es , Theoretical F oundations and Numerical Method s for Sparse Reco very , 9 (201 0), p p. 1–9 2. [25] M.A. Shubin , Pseud o differ ential op er ators and sp e ctr al the ory , S p ringer V erlag, 200 1. [26] J.A. Tropp , On the c onditioning of r andom sub dictionaries , App lied and Computational Harmonic Anal- ysis, 25 (2008), pp. 1–24 .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment