Efficient Latent Variable Graphical Model Selection via Split Bregman Method
We consider the problem of covariance matrix estimation in the presence of latent variables. Under suitable conditions, it is possible to learn the marginal covariance matrix of the observed variables via a tractable convex program, where the concent…
Authors: Gui-Bo Ye, Yuanfeng Wang, Yifei Chen
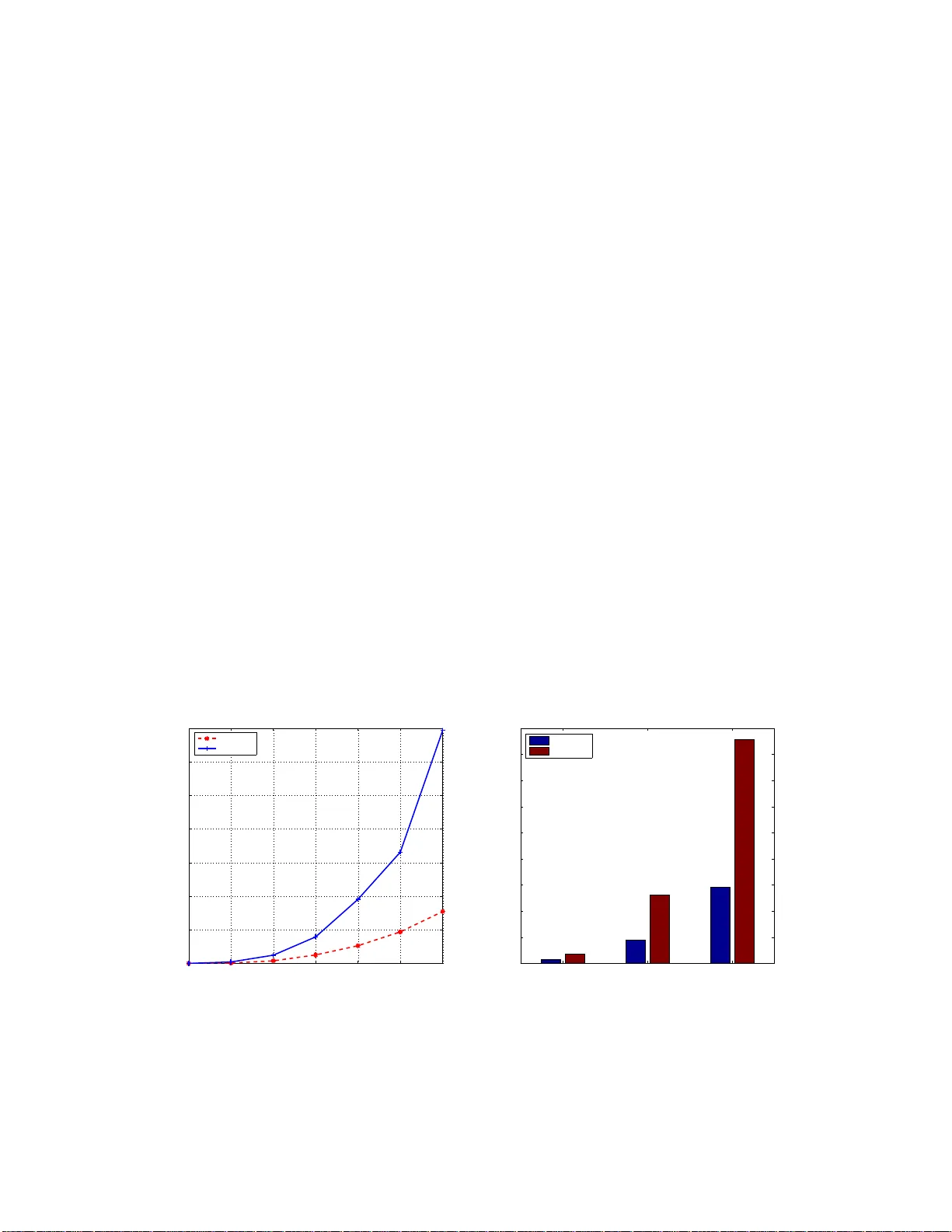
Efficien t Laten t V ariable Graphi cal Mo del Se lection via Split Breg man Meth o d Gui-Bo Y e, Y uanfeng W ang, Yifei Chen, and Xi aoh ui Xie Dep artment of Computer Scienc e, University of California, Irvine Institute for Genomics and Bioinformatics, University of California, Irvine e-mail: xhx@ics. uci.edu Abstract: W e consider the problem of co v ariance matrix estimation in the pr esence of laten t v ariables. Under suitable conditions, it i s p ossible to learn th e marginal co v ariance matrix of th e observed v ariables via a tractable conv ex program, where the concen tration matrix of the observed v ariables is decomposed into a sparse matrix (represen ting the graphical str ucture of the observed v ariables) and a low r ank matrix (represen ting the m arginalization effect of latent v ariables). W e pr esen t an efficien t first-order method based on spli t Bregman to solve the conv ex problem. The algori thm is guaran teed to conv erge under mild conditions. W e show that our algori thm is significantly faster than the state-of-the-art algorithm on both artificial and real-w orld data. Applying the algorithm to a gene expression data inv olving thousands of genes, we show th at most of the correlation betw een observed v ariables can be explained by only a few doze n latent facto rs. AMS 200 0 sub ject cl assifications: Applied statistics 97K80; Learning and adaptiv e systems 68T05; Con vex programming 90C25. Keywords and phrases: Gaussian graphical mo dels, V ariable selection, Alternative direction method of m ultipliers. 1. In tro duction Estimating cov aria nce matr ic es in the high-dimensiona l setting arise s in many applications and has drawn considerable interest recently . Because the sample cov ariance matrix is typically po orly b e hav ed in the high- dimensional regime, regular izing the sample cov ariance based on some assumptions of the underlying true cov a riance is often essential to ga in robustness and stability of the es timation. One for m of r egulariza tion that has gained p opularity recently is to require the the under lying inv erse cov a riance matrix to be sparse [ 1 – 4 ]. If the data follow a m ultiv aria te Gaus sian distribution with cov ar iance matrix Σ, the en tr ies of the inv erse cov ar iance matr ix K = Σ − 1 (also known as concentration matr ix or precision matrix) enc o de t he information of co nditio nal depe ndenc ie s b etw een v ar ia bles: K ij = 0 if the v ariable s i and j are conditio na lly independent g iven all other s. Therefore, the spar s it y regular ization is equiv alent to the a ssumption that most of the v ariable pa irs in the high-dimensional setting are conditionally independent. T o make the estimation problem computational tractable, one often adopts a conv ex r elaxation of the sparsity constraint and uses the ℓ 1 norm to promote the sparsity of the concentration matrix [ 3 – 6 ]. Denote Σ n the empirical cov ariance. Under the maximum likelihoo d fr a mework, the co v ar iance matrix estimation problem is then formulated as solving the following optimizatio n problem: min − log det K + tr(Σ n K ) + λ k K k 1 s . t . K 0 , (1) where tr denotes the trace, λ is a spar sity regulariz a tion parameter, a nd K 0 denotes that K is p os itive semidefinite. Due to the ℓ 1 pena lty term and the explicit p ositive definite constraint on K , the metho d leads to a sparse estimation of the concen tration matr ix that is guaranteed to b e p ositive definite. The problem is conv e x and many algor ithms hav e b een prop osed to s o lve the problem efficie ntly in high dimension [ 4 , 7 – 9 ]. How ever, in many real applications only a subset of the v ariables ar e directly obse r ved, a nd no additio na l information is provided on bo th the num be r of the la ten t v aria ble s and their relationship with the observed ones. F or instance, in the area of functional g enomics it is often the case that only mRNAs of the genes can be directly measure d, but not the proteins , which ar e corr elated but have no direc t corr esp ondence to the 1 imsart-g eneric ver. 2009/08 /13 file: LVGGM.tex date: September 21, 2018 mRNAs b eca us e of the pro minen t r ole o f the p ostrans criptional re gulation. Another example is the movie recommender system where the preference of a movie can be strongly influenced by la ten t factors such as advertisemen ts, so cial environmen t, etc. In these a nd other cases, the o bserved v ariables can b e densely correla ted b ecause of the ma rginalizatio n ov er the unobserved hidden v aria bles. Ther efore, the sparsity regular iz ation alo ne may fail to achiev e the desire results. W e cons ider the setting in which the hidden ( X H ) and the observed v ariables ( X O ) ar e join tly Gaussia n with co v arianc e matrix Σ ( OH ) . The marg inal statistics of the observed v aria ble X O are given by the marg ina l cov a riance matrix Σ O , which is s imply a subma trix of the full cov aria nce matrix Σ ( OH ) . Let the concen tration matrix K ( OH ) = Σ − 1 ( OH ) . The marginal concentration matrix Σ − 1 O corres p o nding to the observed v aria bles X O is given by the Schur complement [ 10 ]: ˆ K O = Σ − 1 O = K O − K O,H K − 1 H K H,O , (2) where K O , K O,H , and K H are the co r resp onding submatrices of the full co ncentration matrix. Based on the Sch ur co mplement , it is clear that the margina l conce ntration matrix of the obse rved v aria ble s can be decomp osed into tw o co mpo nent s: one is K O , which sp ecifies the conditional dep endencies of the observed v ariable s giv en b oth the obser ved and laten t v a riables, a nd the other is K O,H K − 1 H K H,O , which repre s ent s the effect of marginaliza tio n over the hidden v ariables . O ne ca n now impose as s umptions to the t wo underly ing comp onents separ ately . By assuming tha t the K O matrix is spar se and the num b er of laten t v a riables is s mall, the maximum likelihoo d estimation o f the cov ariance matrix of the o bserved v ariables at the pres e nc e of latent v ariables can then be formulated a s min S,L − lo g det( S − L ) + tr(Σ n O ( S − L )) + λ 1 k S k 1 + λ 2 tr( L ) s . t . S − L 0 , L 0 . (3) where w e decompo se Σ − 1 O = S − L with S denoting K O and L denoting K O,H K − 1 H K H,O . Beca use the n umber of the hidden v ariables is small, L is of low rank, whose conv ex relaxation is the trac e norm. There are tw o regular iz ation para meters in this mo del: λ 1 regular iz es the spars it y of S , and λ 2 regular iz es the rank of L . Under certain re g ularity co nditions, Chandrasek aran et al. show ed that this mo del ca n consistently es timate the underlying mo del structur e in the high-dimensional regime in which the num b er of obs e r ved/hidden v ariable s grow with the num b er o f samples of the observed v a riables [ 10 ]. The o b jectiv e function in ( 3 ) is strictly conv ex , so a global o ptimal solution is guaranteed to exist and b e unique. Finding the optimal so lution in the hig h- dimension setting is co mputationally c hallenging due to the log det term app ear e d in the likelihoo d function, the tra ce no r m, the nondiffere n tiability of the ℓ 1 pena lty , and the po sitive semidefinite c o nstraints. F or large-sca le problems, the sta te-of-the-art alg orithm for solving ( 3 ) is to use the spec ial purpose solver Lo gdetPP A [ 11 ] developed for log-determinant s e midefinite pro grams. How ever, the solver LogdetPP A is designed to solve s mo oth problems. In order to us e Log detPP A, o ne has to re formulate ( 3 ) to a smo oth pr oblem. As a res ult, no optimal sparse matr ix S can b e gener ated and additional heuristic steps inv olving thresholding hav e to b e applied in or de r to pro duce spar sity . In a dditio n, LogdetPP A is not esp ecially designed for ( 3 ). W e b elieve muc h more efficient algorithms can b e g e nerated by consider ing the unique structures of the mo del sp ecifically . The main con tribution o f this paper con tains t wo a sp ects. First, w e present a new a lgorithm for so lving ( 3 ) and show that the algorithm is s ignificantly faster than the state-of-the-ar t metho d, esp ecially for large -scale problems. The a lgorithm is derived by r eformulating the problem and ada pting the split Br egman metho d [ 8 , 9 ]. W e derive closed form solutions for ea ch subproblem in volv ed in the split Bregman iterations. Second, we apply the metho d to ana lyze a large-sc a le gene expre ssion data, and find that the mo del with latent v ariable s explain the data m uch better than the one without as suming la tent v aria bles. In addition, we find that most of the correla tions b etw ee n genes can be e x plained b y only a few latent factors, whic h provides a new asp ect for analyzing this type of da ta. The rest of the pap er is or ganized as follows. In Section 2 , we der ive a split Bregman method, called SBL V GG, to so lve the latent v ariable gra phical mo del selection pr oblem ( 3 ) . The co nv er gence prop erty o f the algorithm is also given. SBL V GG consists of four upda te steps and each upda te has explic it formulas to 2 calculate. In Section 3 , w e illustrate the utility of our algor ithm and compare its per formance to LogdetP P A using bo th simulated data and g ene expression data. 2. Split Bregman metho d for l aten t v ariable graphical mo del selection The split Br e g man metho d was o riginally pr op osed by O s her and coauthors to so lve total v aria tion bas ed image restor a tion problems [ 12 ]. It was later found to b e either eq uiv alent or clo sely related to a n umber of other existing optimization algo rithms, including Dougla s-Rachford splitting [ 1 3 ], the a lternating directio n metho d of multipliers (ADMM) [ 12 , 1 4 , 1 5 ] and the metho d of multipliers [ 1 6 ]. Because o f its fast convergence and the easiness o f implementation, it is increasing ly becoming a metho d o f choice for solving larg e-scale sparsity recovery problems [ 17 , 18 ]. Recently , it is also used to solve ( 1 ) and find it is very succ e ssful [ 8 , 9 ]. In this section, we fir st reformulate the problem by intro ducing an auxilia ry v ariable and then pr o ceed to der ive a split Bregman metho d to so lve the reformulated problem. Here we would like to emphas ize that, although split Br egman metho d has b een introduced to solve graphical mo del problems [ 8 , 9 ], we hav e our own contributions. Firstly , it is our first time to use split Bregman metho d to solve ( 3 ) a nd we introduce an auxiliary v a riable for a da ta fitting term instead of p enalty term whic h ha s b een adopted in [ 8 , 9 ]. Secondly , Secondly , the up da te three hasn’t b een app ear ed in [ 8 , 9 ] and we pr ovide an explicit formula for it as well. Thirdly , instead of using eig (or sch ur) decomp osition as done in pre vious work [ 8 , 9 ], we use the LAP ACK routine dsyevd.f (based o n a divide-and- c o nquer stra tegy) to compute the full eig env alue decomp osition of a symmetric matrix which is essential for up dating the fir st and third subproble ms . 2.1. Deri vation of the split br e gman metho d for latent variable gr aphic al mo del sele ction The lo g-likelihoo d term and the r e gularizatio n terms in ( 3 ) a re co upled, which makes the optimization problem difficult to solve. How ever, the three terms can b e deco upled if w e introduce an auxilia ry v a riable to trans fer the coupling fr o m the o b jectiv e function to the constraints. More sp ecia lly , the pro blem ( 3 ) is equiv alent to the following pro blem ( ˆ A, ˆ S , ˆ L ) = arg min A,S,L − lo g det A + tr (Σ n O A ) + λ 1 k S k 1 + λ 2 tr ( L ) (4) s.t. A = S − L A ≻ 0 , L 0 . The in tro duction of the new v ar iable of A is a key step of our algorithm, whic h makes the problem amenable to a s plit Bregman pro cedure to b e detailed below. Although the split Bregma n metho d originated from Bregman itera tio ns, it has been demo nstrated to be eq uiv alent to the alter nating direction metho d of multi- pliers (ADMM) [ 14 , 15 , 1 9 ]. F o r simplicity of prese ntation, next we derive the split Breg man method using the augmented Lag rangia n method [ 1 6 , 20 ]. W e firs t define a n augment ed Lagra ngian function o f ( 4 ) L ( A, S, L, U ) := − log det A + tr (Σ n O A ) + λ 1 k S k 1 + λ 2 tr ( L ) + tr ( U ( A − S + L )) + µ 2 k A − S + L k 2 F , (5) where U is a dual v aria ble matrix corr esp onding to the equa lit y constra int A = S − L , and µ > 0 is a parameter. Compar ed with the sta ndard Lagr angian function, the augmen ted Lag rangia n function has an extra term µ 2 k A − S + L k 2 F , which p enalizes the violation of the linear cons traint A = S − L . With the definition of the aug men ted Lagra ngian function ( 5 ), the primal proble m ( 4 ) is equiv alent to min A ≻ 0 ,L 0 ,S max U L ( A, S, L, U ) . (6) Exchanging the o rder of min and max in ( 6 ) leads to the formulation of the dual problem max U E ( U ) with E ( U ) = min A ≻ 0 ,L 0 ,S L ( A, S, L, U ) . (7) 3 Note that the gr adient ∇ E ( U ) can b e calcula ted b y the following [ 2 1 ] ∇ E ( U ) = A ( U ) − S ( U ) + L ( U ) , (8) where ( A ( U ) , S ( U ) , L ( U )) = arg min A ≻ 0 ,L 0 ,S L ( A, S, L, U ). Applying g radient asce n t on the dual problem ( 7 ) and using eq uation ( 8 ), we obtain the metho d o f m ultipliers [ 16 ] to s olve ( 4 ) ( ( A k +1 , S k +1 , L k +1 ) = ar g min A ≻ 0 ,L 0 ,S L ( A, S, L, U k ) , U k +1 = U k + µ ( A k +1 − S k +1 + L k +1 ) . (9) Here we hav e used µ a s the s tep s ize of the gra dient ascent. It is eas y to see that the efficiency of the iterative a lgorithm ( 9 ) lar gely hinges on whether the fir st equation of ( 9 ) can b e solved efficien tly . Note that the augmen ted Lagr angian function L ( A, S, L , U k ) still con tains A, S, L and can not eas ily b e solved directly . But we can s olve the first eq uation o f ( 9 ) through an iterative a lgorithm that alter nates b etw een the minimization of A, S a nd L . The method of m ultipliers requires that the alternative minimizatio n of A, S and L are run multiple times un til con vergence to get the so lution ( A k +1 , S k +1 , L k +1 ). Howev er , bec ause the first equation o f ( 9 ) re presents only one step of the ov e rall iteration, it is actually no t necessa ry to b e solved co mpletely . In fact, the split Breg ma n metho d (or the alternating direc tio n metho d of multipliers [ 14 ]) uses only one alternative itera tio n to get a v ery rough solution of ( 9 ), whic h leads to the following itera tive algorithm for solving ( 4 ) after some refor m ulations, A k +1 = arg min A ≻ 0 − lo g det( A ) + tr ( A Σ n O ) + µ 2 A − S k + L k + U k µ 2 F , S k +1 = a rg min S λ 1 k S k 1 + µ 2 A k +1 − S + L k + U k µ 2 F , L k +1 = a rg min L 0 λ 2 tr ( L ) + µ 2 A k +1 − S k +1 + L + U k µ 2 F , U k +1 = U k + µ ( A k +1 − S k +1 + L k +1 ) . (10) 2.1.1. Conver genc e The con vergence o f the itera tion ( 10 ) can b e derived from the convergence theor y of the a lternating direction metho d of multipliers o r the conv ergence theo ry of the split Bregma n metho d [ 14 , 17 , 22 ]. Theorem 1 . L et ( S k , L k ) b e gener ate d by ( 10 ) , and ( ˆ S , ˆ L ) b e the unique minimizer of ( 4 ) . Then, lim k →∞ k S k − ˆ S k = 0 and lim k →∞ k L k − ˆ L k = 0 . F rom Theorem 1 , the condition for the conv ergenc e o f the iteration ( 10 ) is quite mild and even irrelev ant to the choice of the parameter µ in the iteration ( 10 ). 2.1.2. Explicit formulas t o up date A, S and L W e first fo cus on the computation of the first equation of ( 10 ). T aking the deriv ative of the ob jective function and setting it to b e zer o, w e get − A − 1 + Σ n O + U k + µ ( A − S k + L k ) = 0 (11) It is a quadratic equation wher e the unknown is a matr ix. The complex ity for solving this equation is at leas t O ( p 3 ) b ecause of the in version in volv ed in ( 11 ). Note that k S k 1 = k S T k 1 and L = L T , if U k is symmetric, so is Σ n O + U k − µ ( S k − L k ). It is eas y to chec k that the explicit fo rm for the solutio n of ( 11 ) under constraint A ≻ 0, i.e., A k +1 , is A k +1 = K k + p ( K k ) 2 + 4 µI 2 µ , (12) 4 where K k = µ ( S k − L k ) − Σ n O − U k and √ C deno tes the square ro o t of a symmetric p ositive definite matrix C . Rec a ll that the s quare r o ot of a symmetric p ositive definite matrix C is defined to b e the matrix whos e eigenv ectors a re the same as tho s e of C and eigenv alues are the s quare ro ot of those of C . Therefore, to get the up date of A k +1 , can first co mpute the eigenv alues and eig env ecto r s of K k , and then get the eigen v alues of A k +1 according to ( 12 ) b y replac ing the matrices by the c orresp onding eig env alue s . W e adopt the LAP ACK routine dsyevd.f (based o n a divide-and- c o nquer stra tegy) to compute the full eig env alue decomp osition of ( K k ) 2 + 4 µI . It is ab out 1 0 times faster than eig (or sch ur) routine when n is large r tha n 500. F or the s e cond equation of ( 10 ), w e ha ve made the data fitting term µ 2 A k +1 − S + L k + U k µ 2 F separable with resp ect to the entries of A . Thus, it is very easy to get the solution and the computational complex it y would b e O ( p 2 ) for k S k 1 is als o separ a ble. Let T λ be a soft thresholding op erator defined on matrix space and satisfying T λ (Ω) = ( t λ ( ω ij )) p i,j =1 , where t λ ( ω ij ) = sgn( ω ij ) max { 0 , | ω ij | − λ } . Then the up date of S is S k +1 = T λ 1 µ ( A k +1 + L k + µ − 1 U k ) . F or the up date o f L , it can use the following Theo rem. Theorem 2 . Given a symmetric matrix X and η > 0 . Denote S η ( X ) = arg min Y 0 η tr ( Y ) + 1 2 k Y − X k 2 F . Then S η ( X ) = V diag (( λ i − η ) + ) V T , wher e λ i ( i ∈ 1 , ..., n ) ar e t he eigenvalues of X with V b eing the c orr esp onding eigenve ctor matrix and ( λ i − η ) + = max(0 , λ i − η ) . Pr o of. Note tha t tr ( Y ) = h I , Y i , where I is the identit y matrix. Thus, arg min Y 0 η tr ( Y ) + 1 2 k Y − X k 2 F = arg min Y 0 h Y − X + η I , Y − X + ηI i . Compute eig env a lue decomp osition on matrix X and get X = V Λ V T , where V V T = V T V = I a nd Λ is the diagonal matrix. Then h Y − X + η I , Y − X + η I i = h V T Y V − (Λ − η I ) , V T Y V − (Λ − η I ) i . T og ether with the fact that S η ( X ) 0, S η ( X ) s hould satisfy ( V T S η ( X ) V ) ij = ma x(0 , λ i − η ) for i = j a nd 0 otherwise. Therefor e , S η ( X ) = V diag (( λ i − η ) + ) V T . Using the op erator S η defined in Theorem 2 , it is ea sy to see that L k +1 = S λ 2 µ ( S k +1 − A k +1 − µ − 1 U k ) . (13) Here we also use the LAP A CK ro utine dsyevd.f (bas e d on a divide-and-co nquer stra tegy) to co mpute the full eigen v alue decomp osition of S k +1 − A k +1 − µ − 1 U k . Summarizing a ll to g ether, we get SBL VG G to solve the latent v ariable Gaussian Graphica l Mo del ( 3 ) as shown in Algo r ithm 1. Algorithm 1: Split Bregman metho d for solving Latent V ariable Gaussian Graphical Model (SBL V GG) Initialize S 0 , L 0 , U 0 . repea t 1) A k +1 = K k + √ ( K k ) 2 +4 µI 2 µ , where K k = µ ( S k − L k ) − Σ − U k 2) S k +1 = T λ 1 µ ( A k +1 + L k + µ − 1 U k ) 3) L k +1 = S λ 2 µ ( S k +1 − A k +1 − µ − 1 U k ) 4) U k +1 = U k + µ ( A k +1 − S k +1 + L k +1 ) un til Con vergen ce 5 3. Numerical exp eriments Next we illustrate the efficiency of the split Bregman metho d (SBL V GG) for solving ( 3 ) using time trials on artificial data a s well a s g ene ex pression da ta. All the algor ithms were implemen ted in Matlab and run on a 64-bit lin ux desktop with Intel i3 - 3.2GHz Q uadCore CPU and 8GB memory . T o ev aluate the per fo rmance of SBL VGG, we c o mpare it with logdetPP A [ 11 ] which is state- o f-art solver for ( 3 ) in lar ge-scale case. LogdetPP A was or ig inally developed for log-determinant semidefinite pr ograms with smoo th penalties. In order to solve ( 3 ) using LogdetPP A , we need to reformulate ( 3 ) as a smo oth problem as do ne in [ 1 0 ], which results in the der ived spa rse matrix ˆ S not s trictly spars e with many entries clo s e to but not exac tly 0. W e also demonstrate that la tent v aria ble Ga us sian graphical sele c tion model ( 3 ) is b etter than sparse Gaussian graphical mo del ( 1 ) in terms of genera lization abilit y using gene expre s sion data. Note that the con vergence of Algorithm ?? is guar anteed no ma tter wha t v alues of µ is used as shown in Theorem 1 . The sp eed o f the alg orithm c a n, how ever, b e influenced by the choices of µ as it would affect the n umber of iterations in volv ed. In our implementation, we c ho ose µ in [0 . 0 05 , 0 . 01] for artificial data a nd [0 . 001 , 0 . 005 ] for gene expression data. 3.1. Artificial data Let p = p o + p h with p b eing the total n umber of v ariables in the gr aph, p o the num b er of o bserved v ariables and p h the n um b er of hidden v ariables. The syn thetic data are generated in a similar wa y as the one in Section 6.1 of [ 11 ]. First, we gener a te an p × p random s pa rse matrix W with no n- zero entries dr awn from normal distribution N (0 , 1 ). Then set C = W ′ ∗ W ; C (1 : p o , p o + 1 : p ) = C (1 : p o , p o + 1 : p ) + 0 . 5 ∗ randn ( p o , p h ); C = ( C + C ′ ) / 2; d = di ag ( C ); C = max ( min ( C − diag ( d ) , 1) , − 1); K = B + max ( − 1 . 2 ∗ min ( e ig ( B )) , 0 . 0 01) ∗ ey e ( p ); K O = K (1 : p o , 1 : p o ) K OH = K (1 : p o , p o + 1 : p ); K H O = K ( p o + 1 : p, 1 : p o ); K H = K ( p o + 1 : p, p o + 1 : p ); ˜ K O = K O − K OH K − 1 H K H O . 0 500 1000 1500 2000 2500 3000 0 1000 2000 3000 4000 5000 6000 7000 Number of Observed Variables in Synthetic Data CPU Time (Secs) SBLVGG LogdetPPA (a) 1000 2000 3000 0 1000 2000 3000 4000 5000 6000 7000 8000 9000 Number of Genes in Real Data CPU Time (Secs) SBLVGG LogdetPPA (b) Fig 1: ( a) Comparison of CPU time curve w.r.t. num b er of v ariables p for artificial data; (b) Comparison of CPU time curve w.r.t. number of v ariables p for gene expression data 6 T a ble 1 Numeric al c omp arison at p o = 3000 , p h = 10 for artificial data ( λ 1 , λ 2 ) Method Ob j . V alue Rank Sparse Ratio (0.0025, 0.21) SBL VG G - 5642.6678 8 5.56% lo dgetPP A -5642.6680 8 99.97% (0.0025, 0.22) SBL VG G - 5642.4894 3 5.58% lo dgetPP A -5642.4895 3 99.97% (0.0027, 0.21) SBL VG G - 5619.2744 16 4.14% lo dgetPP A -5619.2746 16 99.97% (0.0027, 0.22) SBL VG G - 5619.0194 6 4.17% lo dgetPP A -5619.0196 6 99.97% Note that ˜ K O is mar ginal pre c ision ma trix o f observed v ariables. W e g enerate n Gaussian r andom s am- ples from ˜ K O , and c a lculates its sa mple cov a riance matrix Σ n O . In o ur nu merical ex per iments, we set sparse r atio of K O around 5%, and p h = 10 . The stopping criteria for SBL VGG is sp ecified as follows. Let Φ( A, L ) = − log det A + tr ( A Σ) + λ 1 k A + L k 1 + λ 2 tr ( L ). W e stop our alg orithm if | Φ( A k +1 , L k +1 ) − Φ( A k , L k ) | / ma x 1 , | Φ( A k +1 , L k +1 ) | < ǫ a nd k A − S + L k F < ǫ with ǫ = 1 e − 4. Figure 1 (a) shows CPU time curve of SBL VGG and Log detPP A with re s pe c t to the num b er o f v aria ble p for the artificial data. F or ea ch fixed p , the CPU time is av erag ed ov er 4 runs with four different ( λ 1 , λ 2 ) pairs. W e can see SBL V GG consistently outper form LogdetP P A. F or dimension of 25 00 or less , it is 3 .5 times fas ter on average. F or dimensio n 3000 , it is 4.5 times faster. This also shows SBL V GG s c ales b etter to problem size tha n LogdetPP A. In terms of accura c y , T able 1 summarize per formance of t wo algor ithms at p o = 3000, p h = 10 in three asp ects: o b jectiv e v alue, r ank of L , spa rsity of S (r atio of no n- zero off-diagonal elements). W e find in terms o f ob jective v alue and rank, b oth alg orithms gener ate almost identical r esults. How ever, SBL VGG outp erfo r m LogdetPP A due to its soft- thresholding opera tor in Algorithm ?? for S , while Log detPP A mis ses this kind o f op erator and result in many nonzero but clos e to ze r o entries due to numerical erro r. W e would like to emphasize that the results in lower dimensio ns a r e very similar to p o = 3 000, p h = 10. W e omit the details here due spa c e limitation. 3.2. Gene expr ession data The gene expression data [ 2 3 ] contains measurements of mRNA expressio n lev el of the 63 16 genes of S. c er evisiae (yeast) under 300 different exper imen tal conditions. First we centralize the data and choose thr ee subset of the data, 1000 , 2000 and 3000 genes with highest v ariances . Figur e 1 (b) shows CP U time of SBL VGG and LogdetPP A with different p . W e ca n see that SBL VGG consistently p erfor m b etter than Log de tP P A: in 1000 dimension case, SBL V GG is 2 . 5 times faster, while in 200 0 and 3 000 dimens io n ca se, almos t 3 times T a ble 2 Numeric al c omp arison at 3000 dimensional subset of gene expr e ssion data ( λ 1 , λ 2 ) Algorithm Ob j . V alue Rank # Non-0 En tries (0.01,0.05) SBL VG G -9793.3451 88 34 LodgetPP A -9793.3452 88 8997000 (0.01,0.1) SBL VG G -9607.8482 60 134 LodgetPP A -9607.8483 60 8997000 (0.02,0.05) SBL VG G -8096.2115 79 0 LodgetPP A -8096.2115 79 8996998 (0.02,0.1) SBL VG G -8000.9047 56 0 LodgetPP A -8000.9045 56 8997000 faster. T able 2 summarize the a ccuracy for p = 3000 dimension case in three asp ects: ob jective v alue , rank of L , sparsity of S (Num b er of non-zero off-diag onal elements) for four fixed pair of ( λ 1 , λ 2 ). Similar to artificial data, SBL V GG and Log detPP A genera te identical results in terms of ob jective v alue and num b er of hidden units. Ho wev er, logdetPP A suffers from the floating point problem of not b eing a ble to genera te exact spa rse matrix. On the other hand, SBL VGG is doing muc h b etter in this asp ect. 7 T a ble 3 Comp arison of gener alization ability on ge ne expr ession data at dimension of 1000 using latent variable Gaussian gr aphic al mo del (L VGG) and sp arse Gaussian gr aphic al mo del (SGG) Exp. Num b er L VGG SGG Rank of L Sparsi t y of S N Log l ik e Sparsity of K N Log lik e 1 48 30 -2191.3 24734 -1728.8 2 47 64 -2322.7 28438 -1994.1 3 50 58 -2669.9 35198 -2526.3 4 52 64 -2534.6 30768 -2282.5 5 48 0 -2924.0 29880 -2841.4 6 51 52 -2707.1 28754 -2642.6 7 45 0 -2873.3 30374 -2801.4 8 49 0 -2765.5 31884 -2536.7 9 48 54 -2352.0 29752 -2087.2 10 47 0 -2922.9 29760 -2843.5 W e also in vestigated generalization ability of latent v ariable Gaussian graphical selectio n model ( 3 ) versus sparse Ga ussian graphical mo del ( 1 ) using this data s et. A subset of the data, 1000 genes with hig hest v arianc e s , are used for this ex per iment . The 300 samples are randomly divided in to 20 0 for tra ining and 1 00 for testing. Denote the neg ative log likelihoo d (up to a cons tant difference) N L og l ik e = − log det A + tr ( A Σ n ) , where Σ n is the empir ical cov ariance matrix using observed sample data a nd A is the estimated cov ar ia nce matrix based on model ( 3 ) o r mo del ( 1 ). It easy to see that N Log l i k e is eq uiv alent to negative Log- likelihoo d function up to some scaling. Therefore, we use N Log lik e a s a criteria for cross- v alidation or predictio n. Regulariza tio n parameter s λ 1 , λ 2 for model ( 3 ) a nd λ for mo del ( 1 ) ar e se lected by 10- fold cross v alidation o n training set. T able 3 shows that latent v aria ble Gaussian gra phical s e lection mo del ( 3 ) co ns istent ly outp erform sparse Gauss ia n graphical mo del ( 1 ) in terms of g eneraliza tio n abilit y using criteria N Log li k e . W e also note that latent v aria ble Gauss ian g r aphical selec tion mo del ( 3 ) tend to use mo der ate num b er o f hidden units, and very sparse conditional correlatio n to explain the data. F or p = 1000, it tend to predict a bo ut 50 hidden units, and the num b er o f direct interconnections b etw een obs erved v a riables are tens, and sometimes even 0. This sugges ts that most of the correlations b etw een genes observed in the mRNA mea surement can b e explained by only a sma ll n umber of laten t factors. C ur rently we only tested the gener alization ability o f latent v aria ble Gaussian gr aphical selection mo del using N L og l ik e . The initial result with g ene express ion data is encourag ing. F urther work (mo del selection and v alidation) will b e do ne by incorp orating other prior information or by co mparing with some known gene interactions. 4. Discussion Graphical model selection in high-dimension a rises in a wide range o f applications. It is common that in many of these applications, o nly a subset o f the v ariables are directly obser v able. Under this s cenario, the marginal concentration matrix of the obs e rved v aria bles is genera lly no t spar se due to the marginaliza tion of latent v aria bles. A computatio nal attrac tive approach is to decomp ose the marg inal concentration matrix int o a spa r se matrix and a low-rank matrix, which reveals the conditio nal gra phical mode l structur e in the observed v a r iables as well a s the num b er of and effect due to the hidden v a riables. Solving the regula rized maximum likeliho o d problem is howev e r nontrivial for large- scale problems, because of the complexit y of the log-likeliho o d ter m, the trace no rm p enalty and ℓ 1 norm p enalty . In this work, w e pr op ose a new approa ch based o n the split Br egman metho d (SBL VGG) to solve it. W e show that our algo r ithm is a t lea st three times faster than the sta te- of-art solver for large-s cale pro blems. W e applied the metho d to analyze the expression of genes in yeast in a datas et consisting of thousands of genes measured ov er 300 different exp erimental conditions. It is interesting to note that the mo del considering the latent v ariables consistently o utper forms the one without consider ing laten t v ar ia bles in term of testing likelihoo d. W e also note that mos t of the cor relations observed b etw een mRNAs can b e explained b y only 8 a few dozen la ten t v ar iables. The observ ation is consis ten t with the module netw ork idea pro po sed in the genomics communit y . It also might s uggest that the postr anscriptional regulatio n might play mor e pro minent role than previously appr e ciated. References [1] A.P . Dempster. Cov ariance selection. Biometrics , 28(1):157 –175 , 1972 . ISSN 0006-3 41X. [2] J. Peng, P . W ang, N. Zhou, and J. Zh u. Partial correlation estimation by join t sparse regressio n mo dels. Journal of the Americ an Statist ic al Asso ciation , 104 (486):73 5 –746 , 20 09. ISSN 01 6 2-145 9. [3] O. Baner jee, L. El Ghao ui, and A. d’Aspremont. Mo de l selection through sparse maximum likelihoo d estimation for multiv a riate ga ussian or binary data. The Journal of Machine L e arning R ese ar ch , 9: 485–5 16, 200 8 . ISSN 1532-4 435. [4] J. F riedman, T. Hastie, and R. Tibshirani. Sparse inv erse cov ariance estimation with the g raphical lasso. Biostatistics , 9(3):4 32–44 1, 2008 . ISSN 14 65-46 44. [5] N. Meinshausen and P . B¨ uhlmann. High-dimensional graphs and v aria ble selec tion with the lasso. The Annals of St atistics , 34(3):143 6–14 62, 2006. ISSN 0090 -5364 . [6] M. Y uan and Y. Lin. Mo del selection a nd estimatio n in the g aussian g raphical mo del. Biometrika , 94 (1):19–35 , 200 7. ISSN 0006-3 444. [7] Z. Lu. Smo oth o ptimization approa ch for sparse cov a riance s election. SIAM J. Optim. , 1 9(4):1807 –182 7, 2008. ISSN 10 52-62 3 4. [8] K. Schein b e rg, S. Ma , and D. Go ldfarb. Sparse in verse cov aria nce selection via alterna ting linea rization metho ds. A dvanc es in Neu r al In formation Pr o c essing Systems (NIPS) , 2 010. [9] X. Y ua n. Alternating dire c tio n methods for sparse cov ariance selection. pr eprint , 2 009. [10] V. Chandras e k aran, P .A. Parr ilo, and A.S. Willsky . L a tent v a riable g raphical mo del selection via con- vex optimization. In Commun ic ation, Contr ol, and Computing (A l lerton), 2010 48th Annual Al lerton Confer enc e on , pa ges 1610 –1613 . IEEE, 2 010. [11] C. W a ng, D. Sun, and K.C. T oh. Solv ing log-determinant optimization problems by a newton-cg primal proximal p oint algorithm. SIAM J. Optimization , pages 29 94–3 0 13, 2010. [12] T. Goldstein a nd S. Osher. The split Bregman metho d for L 1- regular iz e d problems. S IAM J. Imaging Sci. , 2(2):323– 343, 200 9. ISSN 1936- 4 954. [13] C. W u a nd X.C. T ai. Augmented L a grang ia n metho d, dual metho ds, and split Br egman itera tion for R OF, vectorial TV, and hig h order mo dels. S IAM Journ al on Im aging Scienc es , 3:300 , 2 010. [14] D. Ga bay and B. Mercier. A dual algorithm for the solution of nonlinear v ariatio nal problems via finite element approximation. Computers and Mathematics with Applic ations , 2(1):17– 40, 1 976. [15] R. Glowinski and A. Ma rro co. Sur l’appr oximation, pa r ´ el´ ements finis d’ordre un, et la r´ esolution, pa r pena lisation-dualit´ e, d’une classe de probl` emes de dirichlet non lin ´ eaires. R ev. F r anc. A utomat. Inform. R e ch. O p er at. [16] R. T. Ro ck afellar. A dual appr oach to so lving nonlinea r pro gramming pro blems by unconstra ined optimization. Math. Pr o gr amming , 5:35 4–373 , 1973. ISSN 002 5-561 0. [17] J. F. Cai, S. Osher, and Z. Shen. Split bregman metho ds and frame based image resto ration. Multisc ale Mo del. Simul. , 8(2):33 7–36 9 , 2009. [18] E.J . Candes, X. Li, Y. Ma, a nd J. W right. Robust principal comp onent analysis? Arxiv pr eprint arXiv:091 2.3599 , 20 09. [19] S. Setzer. Split bregman algo r ithm, dougla s -rachford splitting and fr ame shr ink age. Sc ale sp ac e and variational metho ds in c omputer vision , pages 464 – 476, 20 09. [20] M. R. Hestenes. Multiplier and g r adient metho ds . J. O ptimization The ory Appl. , 4 :303– 3 20, 1 969. ISSN 0022- 3239. [21] D.P . Bertsek as. C o nstrained optimization and lagr a nge m ultiplier methods . 198 2. [22] J. E ckstein and D.P . Be r tsek as. On the douglas rachford s plitting method and the proximal p oint algorithm for maxima l mo notone oper a tors. Mathematic al Pr o gr amming , 55 (1 ):293–3 18, 19 92. ISSN 0025- 5610. [23] T.R. Hughes, M.J . Ma rton, A.R. Jones, C.J. Rob erts, R. Sto ughton, C.D. Armour, H.A. Bennett, 9 E. Co ffey , H. Dai, Y.D. He, et a l. F unctional dis cov e ry via a co mpe ndium o f expressio n pro files. Cel l , 102(1):10 9–12 6 , 2000. ISSN 0092- 8674. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment